
4.3.1. Коды, исправляющие ошибки
Помехоустойчивое
кодирование передаваемой информации
позволяет в приемной части системы
обнаруживать и исправлять ошибки. Коды,
применяемые при помехоустойчивом
кодировании, называются корректирующими
кодамиили кодами, исправляющими
ошибки.
Если применяемый
способ кодирования позволяет обнаружить
ошибочные кодовые комбинации, то в
случае приема изображения можно заменить
принятый с ошибкой элемент изображения
на предыдущий принятый элемент или на
соответствующий элемент предыдущей
строки или предыдущего кадра. При этом
заметность искажений на экране
телевизионного приемника существенно
уменьшается. Такой способ называется
маскировкой ошибки.
Более совершенные
корректирующие коды позволяют не только
обнаруживать, но и исправлять ошибки.
Как правило, корректирующий код может
исправлять меньше ошибок, чем
обнаруживать. Количество ошибок, которые
корректирующий код может исправить
в определенном интервале последовательности
двоичных символов, например, в одной
кодовой комбинации, называется
исправляющей способностью кода.
Основной принцип
построения корректирующих кодов
заключается в том, что в каждую
передаваемую кодовую комбинацию,
содержащую kинформационных двоичных символов,
вводятрдополнительных двоичных
символов. В результате получается новая
кодовая комбинация, содержащая![]() двоичных символов. Такой код будем
двоичных символов. Такой код будем
обозначать![]() .
.
Доля информационных символов в нем
характеризуетсяотносительной
скоростью кода, определяемой
соотношением
 .
.
Количество
возможных кодовых комбинаций кода
![]() равно
равно![]() .
.
Из них передаваться могут![]() кодовых комбинаций, называемых
кодовых комбинаций, называемых
разрешенными. Остальные![]() кодовые комбинации являются запрещенными.
кодовые комбинации являются запрещенными.
Появление одной из этих запрещенных
комбинаций в приемной части означает,
что имеется ошибка.
Для оценки
способности кода обнаруживать и
исправлять ошибки используется
понятие кодового расстояния(расстояния Хемминга). Кодовое расстояние![]() между кодовыми комбинациями
между кодовыми комбинациями![]() и
и![]() определяется как число двоичных
определяется как число двоичных
разрядов, в которых эти комбинации
различаются. Например, кодовое расстояние
между кодовыми комбинациями 0001 и 0011
равно 1, а между комбинациями 0000 и
1111 равно 4.
Если разрешенные
кодовые комбинации выбраны таким
образом, что при изменении любого
двоичного символа разрешенная кодовая
комбинация переходит в запрещенную,
то корректирующий код позволяет
обнаруживать одиночные ошибки в
отдельных кодовых комбинациях.
Одиночная ошибка
переводит исходную кодовую комбинацию
в кодовую комбинацию, отстоящую от нее
на d= 1.
Следовательно, для обнаружения одиночных
ошибок необходимо, чтобы кодовое
расстояние между любыми двумя разрешенными
кодовыми комбинациями корректирующего
кода было не менее 2. Для обнаруженияr1ошибок в
кодовой комбинации необходимо, чтобы
кодовое расстояние между двумя
разрешенными кодовыми комбинациями
удовлетворяло неравенству![]() .
.
Один
из самых простых и известных примеров
помехоустойчивого кодирования –
проверка на четность. В каждую кодовую
комбинацию вводится один дополнительный
двоичный символ хр,
называемый
контрольным или проверочным битом.
Этот бит устанавливается равным 1, если
сумма единиц в исходной кодовой
комбинации равна нечетному числу, и
равным 0 в противоположном случае.
Данное правило выражается соотношением
![]() ,
,
где
![]() – двоичные символы исходной кодовой
– двоичные символы исходной кодовой
комбинации.
Если в приемной
части системы один из двоичных символов
кодовой комбинации принят с ошибкой,
значение контрольного бита не будет
удовлетворять равенству . Это
несоответствие будет обнаружено
специальной схемой и явится признаком
того, что произошла ошибка. Таким
образом, проверка на четность позволяет
обнаруживать одиночные ошибки, но не
позволяет их исправлять (рис. 4.3). Код
с одной проверкой на четность,
обнаруживающий только одиночные ошибки,
применяется в тех случаях, когда
необходимо лишь контролировать качество
передачи, например, в каналах связи с
достаточно малой вероятностью ошибки.
Д
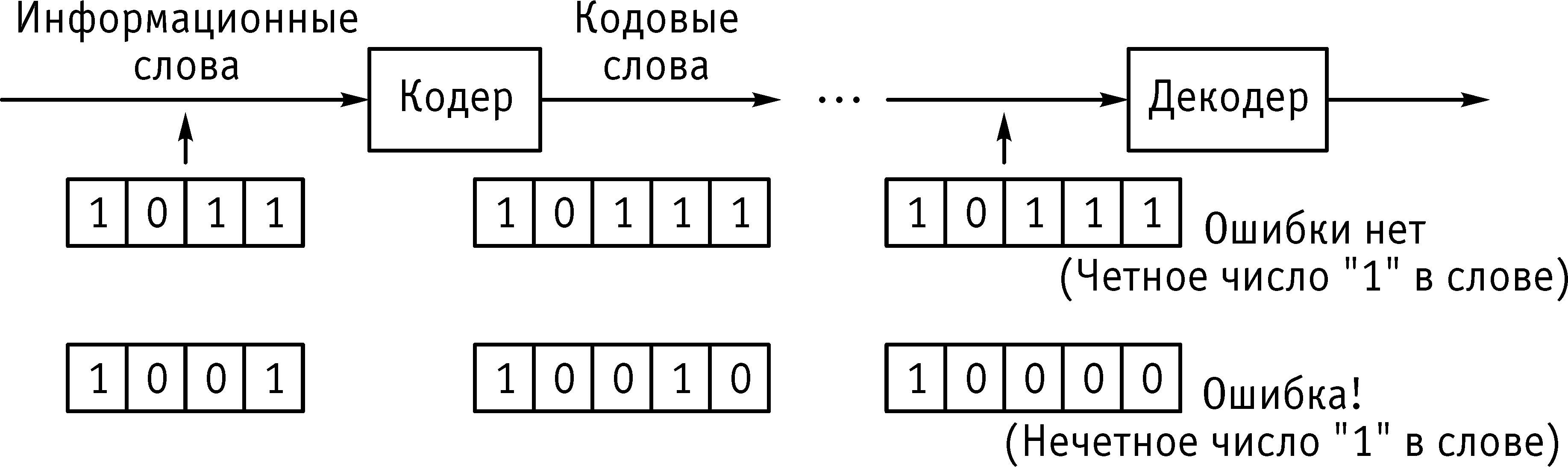
Рис. 4.3.Схема
обнаружения одной ошибки в кодовом
слове
ля исправления одиночных ошибок
необходимо, чтобы кодовое расстояние
между любыми двумя разрешенными кодовыми
комбинациями корректирующего кода
было не менее 3. В этом случае принятая
запрещенная кодовая комбинация
заменяется ближайшей к ней разрешенной
кодовой комбинацией. Так как ошибки
одиночные, то переданная разрешенная
кодовая комбинация отстоит от
принятой запрещенной кодовой комбинации
на 1, а остальные разрешенные кодовые
комбинации – не менее чем на 2. В этом
случае ошибка надежно исправляется.
В общем случае для коррекцииr2ошибок в кодовой комбинации кодовое
расстояниеdмежду
любыми двумя разрешенными кодовыми
комбинациями должно удовлетворять
неравенству![]() .
.
Для увеличения
кодового расстояния между разрешенными
кодовыми комбинациями необходимо
увеличивать число рконтрольных
символов в передаваемых кодовых
комбинациях. Известно соотношение
![]() ,
,
где
![]() – минимальное кодовое расстояние между
– минимальное кодовое расстояние между
двумя разрешенными кодовыми
комбинациями. Чтобы при этом относительная
скорость кода не стала чрезмерно малой,
необходимо в соответствии с увеличивать
и числоkинформационных
символов в кодовой комбинации.
Построение кода
с заданными nиkможет осуществляться разными способами.
Есть хорошо разработанные математические
методы решения этой задачи и обширная
литература. Для цифровых телевизионных
систем большое значение имеет возможность
коррекции пакетных ошибок, искажающих
сразу несколько соседних двоичных
символов. Кроме того, при выборе кода
для системы цифрового телевидения
необходимо обеспечить по возможности
простой метод декодирования, так как
декодер должен быть в каждом телевизионном
приемнике.
Видеоурок: Коды Хэмминга
Лекция: Кодирование с исправлением ошибок
Многие программисты имеют желание себя обезопасить. Именно поэтому в программу внедряется код, который самостоятельно производит её проверку. Такие коды называются самоконтролирующимися.

Если в некоторой программе происходит получения информации частично, то код для этой программы называют блочным.
Если код называют самокорректирующим, то подразумевают, что он не только находит допущенную ошибку, но и пытается её исправить.
Самым распространенным самокорректирующим и самоконтролирующим кодом считают код Хэмминга.

In coding theory, burst error-correcting codes employ methods of correcting burst errors, which are errors that occur in many consecutive bits rather than occurring in bits independently of each other.
Many codes have been designed to correct random errors. Sometimes, however, channels may introduce errors which are localized in a short interval. Such errors occur in a burst (called burst errors) because they occur in many consecutive bits. Examples of burst errors can be found extensively in storage mediums. These errors may be due to physical damage such as scratch on a disc or a stroke of lightning in case of wireless channels. They are not independent; they tend to be spatially concentrated. If one bit has an error, it is likely that the adjacent bits could also be corrupted. The methods used to correct random errors are inefficient to correct burst errors.
Definitions[edit]

A burst of length ℓ[1]
Say a codeword  is transmitted, and it is received as
is transmitted, and it is received as  Then, the error vector
Then, the error vector  is called a burst of length
is called a burst of length  if the nonzero components of are confined to consecutive components. For example,
if the nonzero components of are confined to consecutive components. For example,  is a burst of length
is a burst of length 
Although this definition is sufficient to describe what a burst error is, the majority of the tools developed for burst error correction rely on cyclic codes. This motivates our next definition.
A cyclic burst of length ℓ[1]
An error vector is called a cyclic burst error of length if its nonzero components are confined to cyclically consecutive components. For example, the previously considered error vector  , is a cyclic burst of length
, is a cyclic burst of length  , since we consider the error starting at position
, since we consider the error starting at position  and ending at position
and ending at position  . Notice the indices are
. Notice the indices are  -based, that is, the first element is at position .
-based, that is, the first element is at position .
For the remainder of this article, we will use the term burst to refer to a cyclic burst, unless noted otherwise.
Burst description[edit]
It is often useful to have a compact definition of a burst error, that encompasses not only its length, but also the pattern, and location of such error. We define a burst description to be a tuple  where
where  is the pattern of the error (that is the string of symbols beginning with the first nonzero entry in the error pattern, and ending with the last nonzero symbol), and
is the pattern of the error (that is the string of symbols beginning with the first nonzero entry in the error pattern, and ending with the last nonzero symbol), and  is the location, on the codeword, where the burst can be found.[1]
is the location, on the codeword, where the burst can be found.[1]
For example, the burst description of the error pattern is  . Notice that such description is not unique, because
. Notice that such description is not unique, because  describes the same burst error. In general, if the number of nonzero components in is
describes the same burst error. In general, if the number of nonzero components in is  , then will have different burst descriptions each starting at a different nonzero entry of . To remedy the issues that arise by the ambiguity of burst descriptions with the theorem below, however before doing so we need a definition first.
, then will have different burst descriptions each starting at a different nonzero entry of . To remedy the issues that arise by the ambiguity of burst descriptions with the theorem below, however before doing so we need a definition first.
Definition. The number of symbols in a given error pattern  is denoted by
is denoted by 
A corollary of the above theorem is that we cannot have two distinct burst descriptions for bursts of length 
Cyclic codes for burst error correction[edit]
Cyclic codes are defined as follows: think of the  symbols as elements in
symbols as elements in  . Now, we can think of words as polynomials over
. Now, we can think of words as polynomials over  where the individual symbols of a word correspond to the different coefficients of the polynomial. To define a cyclic code, we pick a fixed polynomial, called generator polynomial. The codewords of this cyclic code are all the polynomials that are divisible by this generator polynomial.
where the individual symbols of a word correspond to the different coefficients of the polynomial. To define a cyclic code, we pick a fixed polynomial, called generator polynomial. The codewords of this cyclic code are all the polynomials that are divisible by this generator polynomial.
Codewords are polynomials of degree  . Suppose that the generator polynomial
. Suppose that the generator polynomial  has degree
has degree  . Polynomials of degree that are divisible by result from multiplying by polynomials of degree
. Polynomials of degree that are divisible by result from multiplying by polynomials of degree  . We have
. We have  such polynomials. Each one of them corresponds to a codeword. Therefore,
such polynomials. Each one of them corresponds to a codeword. Therefore,  for cyclic codes.
for cyclic codes.
Cyclic codes can detect all bursts of length up to  . We will see later that the burst error detection ability of any
. We will see later that the burst error detection ability of any  code is bounded from above by
code is bounded from above by  . Cyclic codes are considered optimal for burst error detection since they meet this upper bound:
. Cyclic codes are considered optimal for burst error detection since they meet this upper bound:
Theorem (Cyclic burst correction capability) — Every cyclic code with generator polynomial of degree can detect all bursts of length 
The above proof suggests a simple algorithm for burst error detection/correction in cyclic codes: given a transmitted word (i.e. a polynomial of degree ), compute the remainder of this word when divided by . If the remainder is zero (i.e. if the word is divisible by ), then it is a valid codeword. Otherwise, report an error. To correct this error, subtract this remainder from the transmitted word. The subtraction result is going to be divisible by (i.e. it is going to be a valid codeword).
By the upper bound on burst error detection ( ), we know that a cyclic code can not detect all bursts of length
), we know that a cyclic code can not detect all bursts of length  . However cyclic codes can indeed detect most bursts of length
. However cyclic codes can indeed detect most bursts of length  . The reason is that detection fails only when the burst is divisible by . Over binary alphabets, there exist
. The reason is that detection fails only when the burst is divisible by . Over binary alphabets, there exist  bursts of length . Out of those, only
bursts of length . Out of those, only  are divisible by . Therefore, the detection failure probability is very small (
are divisible by . Therefore, the detection failure probability is very small ( ) assuming a uniform distribution over all bursts of length .
) assuming a uniform distribution over all bursts of length .
We now consider a fundamental theorem about cyclic codes that will aid in designing efficient burst-error correcting codes, by categorizing bursts into different cosets.
Burst error correction bounds[edit]
Upper bounds on burst error detection and correction[edit]
By upper bound, we mean a limit on our error detection ability that we can never go beyond. Suppose that we want to design an code that can detect all burst errors of length  A natural question to ask is: given
A natural question to ask is: given  and
and  , what is the maximum that we can never achieve beyond? In other words, what is the upper bound on the length of bursts that we can detect using any code? The following theorem provides an answer to this question.
, what is the maximum that we can never achieve beyond? In other words, what is the upper bound on the length of bursts that we can detect using any code? The following theorem provides an answer to this question.
Theorem (Burst error detection ability) — The burst error detection ability of any code is 
Now, we repeat the same question but for error correction: given and , what is the upper bound on the length of bursts that we can correct using any code? The following theorem provides a preliminary answer to this question:
Theorem (Burst error correction ability) — The burst error correction ability of any code satisfies 
A stronger result is given by the Rieger bound:
Definition. A linear burst-error-correcting code achieving the above Rieger bound is called an optimal burst-error-correcting code.
Further bounds on burst error correction[edit]
There is more than one upper bound on the achievable code rate of linear block codes for multiple phased-burst correction (MPBC). One such bound is constrained to a maximum correctable cyclic burst length within every subblock, or equivalently a constraint on the minimum error free length or gap within every phased-burst. This bound, when reduced to the special case of a bound for single burst correction, is the Abramson bound (a corollary of the Hamming bound for burst-error correction) when the cyclic burst length is less than half the block length.[3]
Theorem (Abramson’s bounds) — If  is a binary linear
is a binary linear  -burst error correcting code, its block-length must satisfy:
-burst error correcting code, its block-length must satisfy:

Proof
For a linear code, there are  codewords. By our previous result, we know that
codewords. By our previous result, we know that

Isolating , we get  . Since
. Since  and must be an integer, we have
and must be an integer, we have  .
.
Remark.  is called the redundancy of the code and in an alternative formulation for the Abramson’s bounds is
is called the redundancy of the code and in an alternative formulation for the Abramson’s bounds is 
Fire codes[3][4][5][edit]
While cyclic codes in general are powerful tools for detecting burst errors, we now consider a family of binary cyclic codes named Fire Codes, which possess good single burst error correction capabilities. By single burst, say of length , we mean that all errors that a received codeword possess lie within a fixed span of digits.
Let  be an irreducible polynomial of degree
be an irreducible polynomial of degree  over
over  , and let
, and let  be the period of . The period of , and indeed of any polynomial, is defined to be the least positive integer such that
be the period of . The period of , and indeed of any polynomial, is defined to be the least positive integer such that  Let be a positive integer satisfying
Let be a positive integer satisfying  and
and  not divisible by , where is the period of . Define the Fire Code
not divisible by , where is the period of . Define the Fire Code  by the following generator polynomial:
by the following generator polynomial:

We will show that is an -burst-error correcting code.
Lemma 1 — 
Lemma 2 — If is a polynomial of period , then  if and only if
if and only if 
Proof
If  , then
, then  . Thus,
. Thus, 
Now suppose . Then,  . We show that is divisible by by induction on . The base case
. We show that is divisible by by induction on . The base case  follows. Therefore, assume
follows. Therefore, assume  . We know that divides both (since it has period )
. We know that divides both (since it has period )

But is irreducible, therefore it must divide both  and
and  ; thus, it also divides the difference of the last two polynomials,
; thus, it also divides the difference of the last two polynomials,  . Then, it follows that divides
. Then, it follows that divides  . Finally, it also divides:
. Finally, it also divides:  . By the induction hypothesis,
. By the induction hypothesis,  , then .
, then .
A corollary to Lemma 2 is that since  has period , then divides
has period , then divides  if and only if .
if and only if .
Theorem — The Fire Code is -burst error correcting[4][5]
If we can show that all bursts of length or less occur in different cosets, we can use them as coset leaders that form correctable error patterns. The reason is simple: we know that each coset has a unique syndrome decoding associated with it, and if all bursts of different lengths occur in different cosets, then all have unique syndromes, facilitating error correction.
Proof of Theorem[edit]
Let  and
and  be polynomials with degrees
be polynomials with degrees  and
and  , representing bursts of length
, representing bursts of length  and
and  respectively with
respectively with  The integers
The integers  represent the starting positions of the bursts, and are less than the block length of the code. For contradiction sake, assume that and are in the same coset. Then,
represent the starting positions of the bursts, and are less than the block length of the code. For contradiction sake, assume that and are in the same coset. Then,  is a valid codeword (since both terms are in the same coset). Without loss of generality, pick
is a valid codeword (since both terms are in the same coset). Without loss of generality, pick  . By the division theorem we can write:
. By the division theorem we can write:  for integers
for integers  and
and  . We rewrite the polynomial
. We rewrite the polynomial  as follows:
as follows:

Notice that at the second manipulation, we introduced the term  . We are allowed to do so, since Fire Codes operate on . By our assumption, is a valid codeword, and thus, must be a multiple of . As mentioned earlier, since the factors of are relatively prime, has to be divisible by
. We are allowed to do so, since Fire Codes operate on . By our assumption, is a valid codeword, and thus, must be a multiple of . As mentioned earlier, since the factors of are relatively prime, has to be divisible by  . Looking closely at the last expression derived for we notice that
. Looking closely at the last expression derived for we notice that  is divisible by (by the corollary of Lemma 2). Therefore,
is divisible by (by the corollary of Lemma 2). Therefore,  is either divisible by or is . Applying the division theorem again, we see that there exists a polynomial
is either divisible by or is . Applying the division theorem again, we see that there exists a polynomial  with degree
with degree  such that:
such that:

Then we may write:

Equating the degree of both sides, gives us  Since
Since  we can conclude
we can conclude  which implies
which implies  and
and  . Notice that in the expansion:
. Notice that in the expansion:

The term  appears, but since
appears, but since  , the resulting expression
, the resulting expression  does not contain , therefore
does not contain , therefore  and subsequently
and subsequently  This requires that
This requires that  , and
, and  . We can further revise our division of
. We can further revise our division of  by
by  to reflect
to reflect  that is
that is  . Substituting back into gives us,
. Substituting back into gives us,

Since  , we have
, we have  . But is irreducible, therefore
. But is irreducible, therefore  and must be relatively prime. Since is a codeword,
and must be relatively prime. Since is a codeword,  must be divisible by , as it cannot be divisible by . Therefore, must be a multiple of . But it must also be a multiple of , which implies it must be a multiple of
must be divisible by , as it cannot be divisible by . Therefore, must be a multiple of . But it must also be a multiple of , which implies it must be a multiple of  but that is precisely the block-length of the code. Therefore, cannot be a multiple of since they are both less than . Thus, our assumption of being a codeword is incorrect, and therefore and are in different cosets, with unique syndromes, and therefore correctable.
but that is precisely the block-length of the code. Therefore, cannot be a multiple of since they are both less than . Thus, our assumption of being a codeword is incorrect, and therefore and are in different cosets, with unique syndromes, and therefore correctable.
Example: 5-burst error correcting fire code[edit]
With the theory presented in the above section, consider the construction of a  -burst error correcting Fire Code. Remember that to construct a Fire Code, we need an irreducible polynomial , an integer , representing the burst error correction capability of our code, and we need to satisfy the property that
-burst error correcting Fire Code. Remember that to construct a Fire Code, we need an irreducible polynomial , an integer , representing the burst error correction capability of our code, and we need to satisfy the property that
is not divisible by the period of . With these requirements in mind, consider the irreducible polynomial  , and let . Since is a primitive polynomial, its period is
, and let . Since is a primitive polynomial, its period is  . We confirm that
. We confirm that  is not divisible by
is not divisible by  . Thus,
. Thus,

is a Fire Code generator. We can calculate the block-length of the code by evaluating the least common multiple of and . In other words,  . Thus, the Fire Code above is a cyclic code capable of correcting any burst of length or less.
. Thus, the Fire Code above is a cyclic code capable of correcting any burst of length or less.
Binary Reed–Solomon codes[edit]
Certain families of codes, such as Reed–Solomon, operate on alphabet sizes larger than binary. This property awards such codes powerful burst error correction capabilities. Consider a code operating on  . Each symbol of the alphabet can be represented by bits. If is an Reed–Solomon code over , we can think of as an
. Each symbol of the alphabet can be represented by bits. If is an Reed–Solomon code over , we can think of as an ![{displaystyle [mn,mk]_{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/479cc66e2a601a8f28c80c0d3136e9d45f84728d) code over .
code over .
The reason such codes are powerful for burst error correction is that each symbol is represented by bits, and in general, it is irrelevant how many of those bits are erroneous; whether a single bit, or all of the bits contain errors, from a decoding perspective it is still a single symbol error. In other words, since burst errors tend to occur in clusters, there is a strong possibility of several binary errors contributing to a single symbol error.
Notice that a burst of  errors can affect at most
errors can affect at most  symbols, and a burst of
symbols, and a burst of  can affect at most
can affect at most  symbols. Then, a burst of
symbols. Then, a burst of  can affect at most
can affect at most  symbols; this implies that a
symbols; this implies that a  -symbols-error correcting code can correct a burst of length at most
-symbols-error correcting code can correct a burst of length at most  .
.
In general, a -error correcting Reed–Solomon code over can correct any combination of

or fewer bursts of length  , on top of being able to correct -random worst case errors.
, on top of being able to correct -random worst case errors.
An example of a binary RS code[edit]
Let be a ![{displaystyle [255,223,33]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bc05fee57b496252bf9064f1e35606fae8d805dc) RS code over
RS code over  . This code was employed by NASA in their Cassini-Huygens spacecraft.[6] It is capable of correcting
. This code was employed by NASA in their Cassini-Huygens spacecraft.[6] It is capable of correcting  symbol errors. We now construct a Binary RS Code
symbol errors. We now construct a Binary RS Code  from . Each symbol will be written using
from . Each symbol will be written using  bits. Therefore, the Binary RS code will have
bits. Therefore, the Binary RS code will have ![{displaystyle [2040,1784,33]_{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e0de5be730230c649eac90e01bb084dbcd81319a) as its parameters. It is capable of correcting any single burst of length
as its parameters. It is capable of correcting any single burst of length  .
.
Interleaved codes[edit]
Interleaving is used to convert convolutional codes from random error correctors to burst error correctors. The basic idea behind the use of interleaved codes is to jumble symbols at the transmitter. This leads to randomization of bursts of received errors which are closely located and we can then apply the analysis for random channel. Thus, the main function performed by the interleaver at transmitter is to alter the input symbol sequence. At the receiver, the deinterleaver will alter the received sequence to get back the original unaltered sequence at the transmitter.
Burst error correcting capacity of interleaver[edit]

Illustration of row- and column-major order
Block interleaver[edit]
The figure below shows a 4 by 3 interleaver.

An example of a block interleaver
The above interleaver is called as a block interleaver. Here, the input symbols are written sequentially in the rows and the output symbols are obtained by reading the columns sequentially. Thus, this is in the form of  array. Generally,
array. Generally,  is length of the codeword.
is length of the codeword.
Capacity of block interleaver: For an block interleaver and burst of length  the upper limit on number of errors is
the upper limit on number of errors is  This is obvious from the fact that we are reading the output column wise and the number of rows is
This is obvious from the fact that we are reading the output column wise and the number of rows is  . By the theorem above for error correction capacity up to
. By the theorem above for error correction capacity up to  the maximum burst length allowed is
the maximum burst length allowed is  For burst length of
For burst length of  , the decoder may fail.
, the decoder may fail.
Efficiency of block interleaver ( ): It is found by taking ratio of burst length where decoder may fail to the interleaver memory. Thus, we can formulate as
): It is found by taking ratio of burst length where decoder may fail to the interleaver memory. Thus, we can formulate as

Drawbacks of block interleaver : As it is clear from the figure, the columns are read sequentially, the receiver can interpret single row only after it receives complete message and not before that. Also, the receiver requires a considerable amount of memory in order to store the received symbols and has to store the complete message. Thus, these factors give rise to two drawbacks, one is the latency and other is the storage (fairly large amount of memory). These drawbacks can be avoided by using the convolutional interleaver described below.
Convolutional interleaver[edit]
Cross interleaver is a kind of multiplexer-demultiplexer system. In this system, delay lines are used to progressively increase length. Delay line is basically an electronic circuit used to delay the signal by certain time duration. Let be the number of delay lines and  be the number of symbols introduced by each delay line. Thus, the separation between consecutive inputs =
be the number of symbols introduced by each delay line. Thus, the separation between consecutive inputs =  symbols. Let the length of codeword
symbols. Let the length of codeword  Thus, each symbol in the input codeword will be on distinct delay line. Let a burst error of length occur. Since the separation between consecutive symbols is
Thus, each symbol in the input codeword will be on distinct delay line. Let a burst error of length occur. Since the separation between consecutive symbols is  the number of errors that the deinterleaved output may contain is
the number of errors that the deinterleaved output may contain is  By the theorem above, for error correction capacity up to , maximum burst length allowed is
By the theorem above, for error correction capacity up to , maximum burst length allowed is  For burst length of
For burst length of  decoder may fail.
decoder may fail.
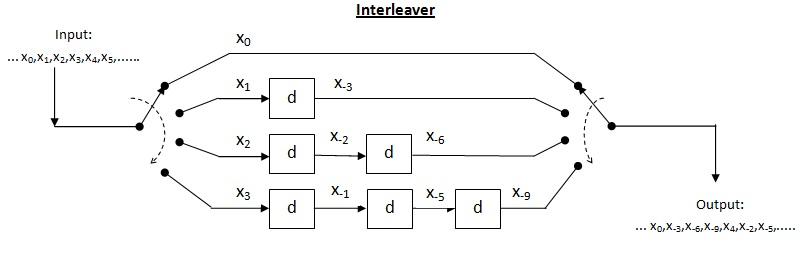
An example of a convolutional interleaver
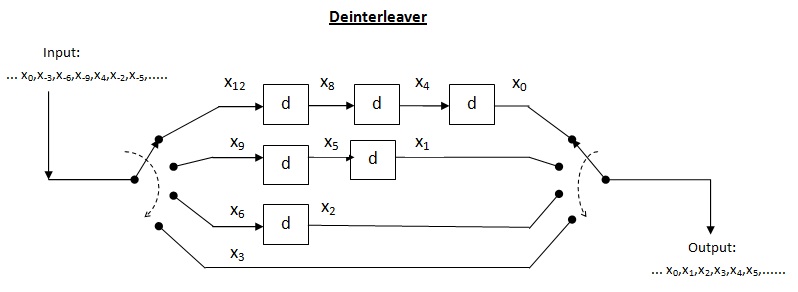
An example of a deinterleaver
Efficiency of cross interleaver (): It is found by taking the ratio of burst length where decoder may fail to the interleaver memory. In this case, the memory of interleaver can be calculated as

Thus, we can formulate as follows:

Performance of cross interleaver : As shown in the above interleaver figure, the output is nothing but the diagonal symbols generated at the end of each delay line. In this case, when the input multiplexer switch completes around half switching, we can read first row at the receiver. Thus, we need to store maximum of around half message at receiver in order to read first row. This drastically brings down the storage requirement by half. Since just half message is now required to read first row, the latency is also reduced by half which is good improvement over the block interleaver. Thus, the total interleaver memory is split between transmitter and receiver.
Applications[edit]
Compact disc[edit]
Without error correcting codes, digital audio would not be technically feasible.[7] The Reed–Solomon codes can correct a corrupted symbol with a single bit error just as easily as it can correct a symbol with all bits wrong. This makes the RS codes particularly suitable for correcting burst errors.[5] By far, the most common application of RS codes is in compact discs. In addition to basic error correction provided by RS codes, protection against burst errors due to scratches on the disc is provided by a cross interleaver.[3]
Current compact disc digital audio system was developed by N. V. Philips of The Netherlands and Sony Corporation of Japan (agreement signed in 1979).
A compact disc comprises a 120 mm aluminized disc coated with a clear plastic coating, with spiral track, approximately 5 km in length, which is optically scanned by a laser of wavelength ~0.8 μm, at a constant speed of ~1.25 m/s. For achieving this constant speed, rotation of the disc is varied from ~8 rev/s while scanning at the inner portion of the track to ~3.5 rev/s at the outer portion. Pits and lands are the depressions (0.12 μm deep) and flat segments constituting the binary data along the track (0.6 μm width).[8]
The CD process can be abstracted as a sequence of the following sub-processes:
- Channel encoding of source of signals
- Mechanical sub-processes of preparing a master disc, producing user discs and sensing the signals embedded on user discs while playing – the channel
- Decoding the signals sensed from user discs
The process is subject to both burst errors and random errors.[7] Burst errors include those due to disc material (defects of aluminum reflecting film, poor reflective index of transparent disc material), disc production (faults during disc forming and disc cutting etc.), disc handling (scratches – generally thin, radial and orthogonal to direction of recording) and variations in play-back mechanism. Random errors include those due to jitter of reconstructed signal wave and interference in signal. CIRC (Cross-Interleaved Reed–Solomon code) is the basis for error detection and correction in the CD process. It corrects error bursts up to 3,500 bits in sequence (2.4 mm in length as seen on CD surface) and compensates for error bursts up to 12,000 bits (8.5 mm) that may be caused by minor scratches.
Encoding: Sound-waves are sampled and converted to digital form by an A/D converter. The sound wave is sampled for amplitude (at 44.1 kHz or 44,100 pairs, one each for the left and right channels of the stereo sound). The amplitude at an instance is assigned a binary string of length 16. Thus, each sample produces two binary vectors from  or 4
or 4  bytes of data. Every second of sound recorded results in 44,100 × 32 = 1,411,200 bits (176,400 bytes) of data.[5] The 1.41 Mbit/s sampled data stream passes through the error correction system eventually getting converted to a stream of 1.88 Mbit/s.
bytes of data. Every second of sound recorded results in 44,100 × 32 = 1,411,200 bits (176,400 bytes) of data.[5] The 1.41 Mbit/s sampled data stream passes through the error correction system eventually getting converted to a stream of 1.88 Mbit/s.
Input for the encoder consists of input frames each of 24 8-bit symbols (12 16-bit samples from the A/D converter, 6 each from left and right data (sound) sources). A frame can be represented by  where
where  and
and  are bytes from the left and right channels from the
are bytes from the left and right channels from the  sample of the frame.
sample of the frame.
Initially, the bytes are permuted to form new frames represented by  where
where  represent
represent  -th left and right samples from the frame after 2 intervening frames.
-th left and right samples from the frame after 2 intervening frames.
Next, these 24 message symbols are encoded using C2 (28,24,5) Reed–Solomon code which is a shortened RS code over  . This is two-error-correcting, being of minimum distance 5. This adds 4 bytes of redundancy,
. This is two-error-correcting, being of minimum distance 5. This adds 4 bytes of redundancy,  forming a new frame:
forming a new frame:  . The resulting 28-symbol codeword is passed through a (28.4) cross interleaver leading to 28 interleaved symbols. These are then passed through C1 (32,28,5) RS code, resulting in codewords of 32 coded output symbols. Further regrouping of odd numbered symbols of a codeword with even numbered symbols of the next codeword is done to break up any short bursts that may still be present after the above 4-frame delay interleaving. Thus, for every 24 input symbols there will be 32 output symbols giving
. The resulting 28-symbol codeword is passed through a (28.4) cross interleaver leading to 28 interleaved symbols. These are then passed through C1 (32,28,5) RS code, resulting in codewords of 32 coded output symbols. Further regrouping of odd numbered symbols of a codeword with even numbered symbols of the next codeword is done to break up any short bursts that may still be present after the above 4-frame delay interleaving. Thus, for every 24 input symbols there will be 32 output symbols giving  . Finally one byte of control and display information is added.[5] Each of the 33 bytes is then converted to 17 bits through EFM (eight to fourteen modulation) and addition of 3 merge bits. Therefore, the frame of six samples results in 33 bytes × 17 bits (561 bits) to which are added 24 synchronization bits and 3 merging bits yielding a total of 588 bits.
. Finally one byte of control and display information is added.[5] Each of the 33 bytes is then converted to 17 bits through EFM (eight to fourteen modulation) and addition of 3 merge bits. Therefore, the frame of six samples results in 33 bytes × 17 bits (561 bits) to which are added 24 synchronization bits and 3 merging bits yielding a total of 588 bits.
Decoding: The CD player (CIRC decoder) receives the 32 output symbol data stream. This stream passes through the decoder D1 first. It is up to individual designers of CD systems to decide on decoding methods and optimize their product performance. Being of minimum distance 5 The D1, D2 decoders can each correct a combination of  errors and
errors and  erasures such that
erasures such that  .[5] In most decoding solutions, D1 is designed to correct single error. And in case of more than 1 error, this decoder outputs 28 erasures. The deinterleaver at the succeeding stage distributes these erasures across 28 D2 codewords. Again in most solutions, D2 is set to deal with erasures only (a simpler and less expensive solution). If more than 4 erasures were to be encountered, 24 erasures are output by D2. Thereafter, an error concealment system attempts to interpolate (from neighboring symbols) in case of uncorrectable symbols, failing which sounds corresponding to such erroneous symbols get muted.
.[5] In most decoding solutions, D1 is designed to correct single error. And in case of more than 1 error, this decoder outputs 28 erasures. The deinterleaver at the succeeding stage distributes these erasures across 28 D2 codewords. Again in most solutions, D2 is set to deal with erasures only (a simpler and less expensive solution). If more than 4 erasures were to be encountered, 24 erasures are output by D2. Thereafter, an error concealment system attempts to interpolate (from neighboring symbols) in case of uncorrectable symbols, failing which sounds corresponding to such erroneous symbols get muted.
Performance of CIRC:[7] CIRC conceals long bust errors by simple linear interpolation. 2.5 mm of track length (4000 bits) is the maximum completely correctable burst length. 7.7 mm track length (12,300 bits) is the maximum burst length that can be interpolated. Sample interpolation rate is one every 10 hours at Bit Error Rate (BER)  and 1000 samples per minute at BER =
and 1000 samples per minute at BER =  Undetectable error samples (clicks): less than one every 750 hours at BER = and negligible at BER =
Undetectable error samples (clicks): less than one every 750 hours at BER = and negligible at BER =  .
.
See also[edit]
- Error detection and correction
- Error-correcting codes with feedback
- Code rate
- Reed–Solomon error correction
References[edit]
- ^ a b c d Coding Bounds for Multiple Phased-Burst Correction and Single Burst Correction Codes
- ^ The Theory of Information and Coding: Student Edition, by R. J. McEliece
- ^ a b c Ling, San, and Chaoping Xing. Coding Theory: A First Course. Cambridge, UK: Cambridge UP, 2004. Print
- ^ a b Moon, Todd K. Error Correction Coding: Mathematical Methods and Algorithms. Hoboken, NJ: Wiley-Interscience, 2005. Print
- ^ a b c d e f Lin, Shu, and Daniel J. Costello. Error Control Coding: Fundamentals and Applications. Upper Saddle River, NJ: Pearson-Prentice Hall, 2004. Print
- ^ quest.arc.nasa.gov https://web.archive.org/web/20120627022807/http://quest.arc.nasa.gov/saturn/qa/cassini/Error_correction.txt. Archived from the original on 2012-06-27.
- ^ a b c Algebraic Error Control Codes (Autumn 2012) – Handouts from Stanford University
- ^ McEliece, Robert J. The Theory of Information and Coding: A Mathematical Framework for Communication. Reading, MA: Addison-Wesley Pub., Advanced Book Program, 1977. Print
Корректирующие коды «на пальцах»
Время на прочтение
11 мин
Количество просмотров 63K
 Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Как нетрудно догадаться, ко всему этому причастны корректирующие коды. Собственно, ECC так и расшифровывается — «error-correcting code», то есть «код, исправляющий ошибки». А CRC — это один из алгоритмов, обнаруживающих ошибки в данных. Исправить он их не может, но часто это и не требуется.
Давайте же разберёмся, что это такое.
Для понимания статьи не нужны никакие специальные знания. Достаточно лишь понимать, что такое вектор и матрица, как они перемножаются и как с их помощью записать систему линейных уравнений.
Внимание! Много текста и мало картинок. Я постарался всё объяснить, но без карандаша и бумаги текст может показаться немного запутанным.
Каналы с ошибкой
Разберёмся сперва, откуда вообще берутся ошибки, которые мы собираемся исправлять. Перед нами стоит следующая задача. Нужно передать несколько блоков данных, каждый из которых кодируется цепочкой двоичных цифр. Получившаяся последовательность нулей и единиц передаётся через канал связи. Но так сложилось, что реальные каналы связи часто подвержены ошибкам. Вообще говоря, ошибки могут быть разных видов — может появиться лишняя цифра или какая-то пропасть. Но мы будем рассматривать только ситуации, когда в канале возможны лишь замены нуля на единицу и наоборот. Причём опять же для простоты будем считать такие замены равновероятными.
Ошибка — это маловероятное событие (а иначе зачем нам такой канал вообще, где одни ошибки?), а значит, вероятность двух ошибок меньше, а трёх уже совсем мала. Мы можем выбрать для себя некоторую приемлемую величину вероятности, очертив границу «это уж точно невозможно». Это позволит нам сказать, что в канале возможно не более, чем  ошибок. Это будет характеристикой канала связи.
ошибок. Это будет характеристикой канала связи.
Для простоты введём следующие обозначения. Пусть данные, которые мы хотим передавать, — это двоичные последовательности фиксированной длины. Чтобы не запутаться в нулях и единицах, будем иногда обозначать их заглавными латинскими буквами ( ,
,  ,
,  , …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
, …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
Кодирование и декодирование будем обозначать прямой стрелкой ( ), а передачу по каналу связи — волнистой стрелкой (
), а передачу по каналу связи — волнистой стрелкой ( ). Ошибки при передаче будем подчёркивать.
). Ошибки при передаче будем подчёркивать.
Например, пусть мы хотим передавать только сообщения  и
и  . В простейшем случае их можно закодировать нулём и единицей (сюрприз!):
. В простейшем случае их можно закодировать нулём и единицей (сюрприз!):

Передача по каналу, в котором возникла ошибка будет записана так:

Цепочки нулей и единиц, которыми мы кодируем буквы, будем называть кодовыми словами. В данном простом случае кодовые слова — это  и
и  .
.
Код с утроением
Давайте попробуем построить какой-то корректирующий код. Что мы обычно делаем, когда кто-то нас не расслышал? Повторяем дважды:

Правда, это нам не очень поможет. В самом деле, рассмотрим канал с одной возможной ошибкой:

Какие выводы мы можем сделать, когда получили  ? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
То есть, получившийся код обнаруживает, но не исправляет ошибки. Ну, тоже неплохо, в общем-то. Но мы пойдём дальше и будем теперь утраивать цифры.

Проверим в деле:

Получили  . Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
. Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
Если в канале связи возможна максимум одна ошибка, то первое предположение о двух ошибках становится невозможным и остаётся только один вариант — передавалась буква .
Про такой код говорят, что он исправляет одну ошибку. Две он тоже обнаружит, но исправит уже неверно.
Это, конечно, самый простой код. Кодировать легко, да и декодировать тоже. Ноликов больше — значит передавался ноль, единичек — значит единица.
Если немного подумать, то можно предложить код исправляющий две ошибки. Это будет код, в котором мы повторяем одиночный бит 5 раз.
Расстояния между кодами
Рассмотрим поподробнее код с утроением. Итак, мы получили работающий код, который исправляет одиночную ошибку. Но за всё хорошее надо платить: он кодирует один бит тремя. Не очень-то и эффективно.
И вообще, почему этот код работает? Почему нужно именно утраивать для устранения одной ошибки? Наверняка это всё неспроста.
Давайте подумаем, как этот код работает. Интуитивно всё понятно. Нолики и единички — это две непохожие последовательности. Так как они достаточно длинные, то одиночная ошибка не сильно портит их вид.
Пусть мы передавали  , а получили
, а получили  . Видно, что эта цепочка больше похожа на исходные , чем на
. Видно, что эта цепочка больше похожа на исходные , чем на  . А так как других кодовых слов у нас нет, то и выбор очевиден.
. А так как других кодовых слов у нас нет, то и выбор очевиден.
Но что значит «больше похоже»? А всё просто! Чем больше символов у двух цепочек совпадает, тем больше их схожесть. Если почти все символы отличаются, то цепочки «далеки» друг от друга.
Можно ввести некоторую величину  , равную количеству различающихся цифр в соответствующих разрядах цепочек
, равную количеству различающихся цифр в соответствующих разрядах цепочек  и
и  . Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
. Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
Например,  , так как все цифры в соответствующих позициях равны, а вот
, так как все цифры в соответствующих позициях равны, а вот  .
.
Расстояние Хэмминга называют расстоянием неспроста. Ведь в самом деле, что такое расстояние? Это какая-то характеристика, указывающая на близость двух точек, и для которой верны утверждения:
- Расстояние между точками неотрицательно и равно нулю только, если точки совпадают.
- Расстояние в обе стороны одинаково.
- Путь через третью точку не короче, чем прямой путь.
Достаточно разумные требования.
Математически это можно записать так (нам это не пригодится, просто ради интереса посмотрим):

- .


 .
.Предлагаю читателю самому убедиться, что для расстояния Хэмминга эти свойства выполняются.
Окрестности
Таким образом, разные цепочки мы считаем точками в каком-то воображаемом пространстве, и теперь мы умеем находить расстояния между ними. Правда, если попытаться сколько нибудь длинные цепочки расставить на листе бумаги так, чтобы расстояния Хэмминга совпадали с расстояниями на плоскости, мы можем потерпеть неудачу. Но не нужно переживать. Всё же это особое пространство со своими законами. А слова вроде «расстояния» лишь помогают нам рассуждать.
Пойдём дальше. Раз мы заговорили о расстоянии, то можно ввести такое понятие как окрестность. Как известно, окрестность какой-то точки — это шар определённого радиуса с центром в ней. Шар? Какие ещё шары! Мы же о кодах говорим.
Но всё просто. Ведь что такое шар? Это множество всех точек, которые находятся от данной не дальше, чем некоторое расстояние, называемое радиусом. Точки у нас есть, расстояние у нас есть, теперь есть и шары.
Так, скажем, окрестность кодового слова радиуса 1 — это все коды, находящиеся на расстоянии не больше, чем 1 от него, то есть отличающиеся не больше, чем в одном разряде. То есть это коды:

Да, вот так странно выглядят шары в пространстве кодов.
А теперь посмотрите. Это же все возможные коды, которые мы получим в канале в одной ошибкой, если отправим ! Это следует прямо из определения окрестности. Ведь каждая ошибка заставляет цепочку измениться только в одном разряде, а значит удаляет её на расстояние 1 от исходного сообщения.
Аналогично, если в канале возможны две ошибки, то отправив некоторое сообщение  , мы получим один из кодов, который принадлежит окрестности радиусом 2.
, мы получим один из кодов, который принадлежит окрестности радиусом 2.
Тогда всю нашу систему декодирования можно построить так. Мы получаем какую-то цепочку нулей и единиц (точку в нашей новой терминологии) и смотрим, в окрестность какого кодового слова она попадает.
Сколько ошибок может исправить код?
Чтобы код мог исправлять больше ошибок, окрестности должны быть как можно шире. С другой стороны, они не должны пересекаться. Иначе если точка попадёт в область пересечения, непонятно будет, к какой окрестности её отнести.
В коде с удвоением между кодовыми словами  и
и  расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
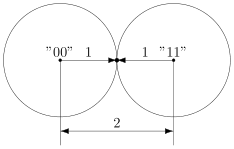
Именно это мы и получали. Мы видели, что есть ошибка, но не могли её исправить.
Что интересно, точек касания в нашем странном пространстве у шаров две — это коды и  . Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
. Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
В случае кода с утроением, между шарами будет зазор.

Минимальный зазор между шарами равен 1, так как у нас расстояния всегда целые (ну не могут же две цепочки отличаться в полутора разрядах).
В общем случае получаем следующее.
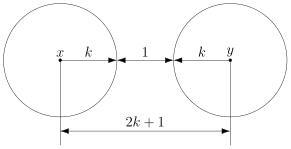
Этот очевидный результат на самом деле очень важен. Он означает, что код с минимальным кодовым расстоянием  будет успешно работать в канале с ошибками, если выполняется соотношение
будет успешно работать в канале с ошибками, если выполняется соотношение

Полученное равенство позволяет легко определить, сколько ошибок будет исправлять тот или иной код. А сколько код ошибок может обнаружить? Рассуждения такие же. Код обнаруживает ошибок, если в результате не получится другое кодовое слово. То есть, кодовые слова не должны находиться в окрестностях радиуса других кодовых слов. Математически это записывается так:

Рассмотрим пример. Пусть мы кодируем 4 буквы следующим образом.

Чтобы найти минимальное расстояние между различными кодовыми словами, построим таблицу попарных расстояний.
| A | B | C | D | |
|---|---|---|---|---|
| A | — | 3 | 3 | 4 |
| B | 3 | — | 4 | 3 |
| C | 3 | 4 | — | 3 |
| D | 4 | 3 | 3 | — |
Минимальное расстояние  , а значит
, а значит  , откуда получаем, что такой код может исправить до
, откуда получаем, что такой код может исправить до  ошибок. Обнаруживает же он две ошибки.
ошибок. Обнаруживает же он две ошибки.
Рассмотрим пример:

Чтобы декодировать полученное сообщение, посмотрим, к какому символу оно ближе всего.

Минимальное расстояние получилось для символа , значит вероятнее всего передавался именно он:

Итак, этот код исправляет одну ошибку, как и код с утроением. Но он более эффективен, так как в отличие от кода с утроением здесь кодируется уже 4 символа.
Таким образом, основная проблема при построении такого рода кодов — так расположить кодовые слова, чтобы они были как можно дальше друг от друга, и их было побольше.
Для декодирования можно было бы использовать таблицу, в которой указывались бы все возможные принимаемые сообщения, и кодовые слова, которым они соответствуют. Но такая таблица получилась бы очень большой. Даже для нашего маленького кода, который выдаёт 5 двоичных цифр, получилось бы  варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
Попробуем придумать способ коррекции сообщения без таблиц. Мы всегда сможем найти полезное применение освободившейся памяти.
Интерлюдия: поле GF(2)
Для изложения дальнейшего материала нам потребуются матрицы. А при умножении матриц, как известно мы складываем и перемножаем числа. И тут есть проблема. Если с умножением всё более-менее хорошо, то как быть со сложением? Из-за того, что мы работаем только с одиночными двоичными цифрами, непонятно, как сложить 1 и 1, чтобы снова получилась одна двоичная цифра. Значит вместо классического сложения нужно использовать какое-то другое.
Введём операцию сложения как сложение по модулю 2 (хорошо известный программистам XOR):

Умножение будем выполнять как обычно. Эти операции на самом деле введены не абы как, а чтобы получилась система, которая в математике называется полем. Поле — это просто множество (в нашем случае из 0 и 1), на котором так определены сложение и умножение, чтобы основные алгебраические законы сохранялись. Например, чтобы основные идеи, касающиеся матриц и систем уравнений по-прежнему были верны. А вычитание и деление мы можем ввести как обратные операции.
Множество из двух элементов  с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
У сложения есть несколько очень полезных свойств, которыми мы будем пользоваться в дальнейшем.

Это свойство прямо следует из определения.

А в этом можно убедиться, прибавив  к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
Проверяем корректность
Вернёмся к коду с утроением.
Для начала просто решим задачу проверки, были ли вообще ошибки при передаче. Как видно, из самого кода, принятое сообщение будет кодовым словом только тогда, когда все три цифры равны между собой.
Пусть мы приняли вектор-строку из трёх цифр. (Стрелочки над векторами рисовать не будем, так как у нас почти всё — это вектора или матрицы.)

Математически равенство всех трёх цифр можно записать как систему:

Или, если воспользоваться свойствами сложения в GF(2), получаем

Или

В матричном виде эта система будет иметь вид

где

Транспонирование здесь нужно потому, что — это вектор-строка, а не вектор-столбец. Иначе мы не могли бы умножать его справа на матрицу.
Будем называть матрицу  проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
Умножение на матрицу — это гораздо более эффективно, чем поиск в таблице, но у нас на самом деле есть ещё одна таблица — это таблица кодирования. Попробуем от неё избавиться.
Кодирование
Итак, у нас есть система для проверки
Её решения — это кодовые слова. Собственно, мы систему и строили на основе кодовых слов. Попробуем теперь решить обратную задачу. По системе (или, что то же самое, по матрице ) найдём кодовые слова.
Правда, для нашей системы мы уже знаем ответ, поэтому, чтобы было интересно, возьмём другую матрицу:

Соответствующая система имеет вид:

Чтобы найти кодовые слова соответствующего кода нужно её решить.
В силу линейности сумма двух решений системы тоже будет решением системы. Это легко доказать. Если  и
и  — решения системы, то для их суммы верно
— решения системы, то для их суммы верно

что означает, что она тоже — решение.
Поэтому если мы найдём все линейно независимые решения, то с их помощью можно получить вообще все решения системы. Для этого просто нужно найти их всевозможные суммы.
Выразим сперва все зависимые слагаемые. Их столько же, сколько и уравнений. Выражать надо так, чтобы справа были только независимые. Проще всего выразить  .
.
Если бы нам не так повезло с системой, то нужно было бы складывая уравнения между собой получить такую систему, чтобы какие-то три переменные встречались по одному разу. Ну, или воспользоваться методом Гаусса. Для GF(2) он тоже работает.
Итак, получаем:

Чтобы получить все линейно независимые решения, приравниваем каждую из зависимых переменных к единице по очереди.

Всевозможные суммы этих независимых решений (а именно они и будут кодовыми векторами) можно получить так:

где  равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно
равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно  сочетания.
сочетания.
Но посмотрите! Формула, которую мы только что получили — это же снова умножение матрицы на вектор.

Строчки здесь — линейно независимые решения, которые мы получили. Матрица  называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:
называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:

Найдём кодовые слова для этого кода. (Не забываем, что длина исходных сообщений должна быть равна 2 — это количество найденных решений.)

Итак, у нас есть готовый код, обнаруживающий ошибки. Проверим его в деле. Пусть мы хотим отправить 01 и у нас произошла ошибка при передаче. Обнаружит ли её код?

А раз в результате не нулевой вектор, значит код заподозрил неладное. Провести его не удалось. Ура, код работает!
Для кода с утроением, кстати, порождающая матрица выглядит очень просто:

Подобные коды, которые можно порождать и проверять матрицей называются линейными (бывают и нелинейные), и они очень широко применяются на практике. Реализовать их довольно легко, так как тут требуется только умножение на константную матрицу.
Ошибка по синдрому
Ну хорошо, мы построили код обнаруживающий ошибки. Но мы же хотим их исправлять!
Для начала введём такое понятие, как вектор ошибки. Это вектор, на который отличается принятое сообщение от кодового слова. Пусть мы получили сообщение , а было отправлено кодовое слово  . Тогда вектор ошибки по определению
. Тогда вектор ошибки по определению

Но в странном мире GF(2), где сложение и вычитание одинаковы, будут верны и соотношения:

В силу особенностей сложения, как читатель сам может легко убедиться, в векторе ошибки на позициях, где произошла ошибка будет единица, а на остальных ноль.
Как мы уже говорили раньше, если мы получили сообщение с ошибкой, то  . Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
. Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
Назовём результат умножения на проверочную матрицу синдромом:

И заметим следующее

Это означает, что для ошибки синдром будет таким же, как и для полученного сообщения.
Разложим все возможные сообщения, которые мы можем получить из канала связи, по кучкам в зависимости от синдрома. Тогда из последнего соотношения следует, что в каждой кучке будут вектора с одной и той же ошибкой. Причём вектор этой ошибки тоже будет в кучке. Вот только как его узнать?
А очень просто! Помните, мы говорили, что у нескольких ошибок вероятность ниже, чем у одной ошибки? Руководствуясь этим соображением, наиболее правдоподобным будет считать вектором ошибки тот вектор, у которого меньше всего единиц. Будем называть его лидером.
Давайте посмотрим, какие синдромы дают всевозможные 5-элементные векторы. Сразу сгруппируем их и подчеркнём лидеров — векторы с наименьшим числом единиц.
 |
|
|---|---|
|
 |
|
 |
|
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
 |
В принципе, для корректирования ошибки достаточно было бы хранить таблицу соответствия синдрома лидеру.
Обратите внимание, что в некоторых строчках два лидера. Это значит для для данного синдрома два паттерна ошибки равновероятны. Иными словами, код обнаружил две ошибки, но исправить их не может.
Лидеры для всех возможных одиночных ошибок находятся в отдельных строках, а значит код может исправить любую одиночную ошибку. Ну, что же… Попробуем в этом убедиться.

Вектор ошибки равен  , а значит ошибка в третьем разряде. Как мы и загадали.
, а значит ошибка в третьем разряде. Как мы и загадали.
Ура, всё работает!
Что же дальше?
Чтобы попрактиковаться, попробуйте повторить рассуждения для разных проверочных матриц. Например, для кода с утроением.
Логическим продолжением изложенного был бы рассказ о циклических кодах — чрезвычайно интересном подклассе линейных кодов, обладающим замечательными свойствами. Но тогда, боюсь, статья уж очень бы разрослась.
Если вас заинтересовали подробности, то можете почитать замечательную книжку Аршинова и Садовского «Коды и математика». Там изложено гораздо больше, чем представлено в этой статье. Если интересует математика кодирования — то поищите «Теория и практика кодов, контролирующих ошибки» Блейхута. А вообще, материалов по этой теме довольно много.
Надеюсь, когда снова будет свободное время, напишу продолжение, в котором расскажу про циклические коды и покажу пример программы для кодирования и декодирования. Если, конечно, почтенной публике это интересно.

Проверка четности. Контрольная сумма. Блочные и древовидные коды. Вес и расстояние Хэмминга между двоичными словами.

Коды делятся на два больших класса
Коды с исправлением ошибок
Цель восстановить с вероятностью, близкой к единице, посланное сообщение.
Коды с обнаружением ошибок
Цель выявить с вероятностью, близкой к единице, наличие ошибок.

Коды с обнаружением ошибок в передаче
Введение в передаваемые кодовые комбинации избыточных разрядов все множество кодовых комбинаций разбивает на два подмножества, что снижает мощность и информационную скорость кода, но позволяет, при принятой запрещенной кодовой комбинации, обнаружить ошибку в передаче.
Например,
введение дополнительного бита контроля по четности делает четным число единиц в каждой кодовой комбинации равнодоступного кода и одновременно увеличивает их отличия не менее чем до двух разрядов.
Разрешенные кодовые комбинации
Запрещенные кодовые комбинации
Коды с обнаружением ошибок в передаче
В результате контроля четности оди-ночная ошибка в любом разряде, изменившая число единиц в комбинации кода на нечетное, будет обнаружена.
Минимально возможное число позиций кода, на которых символы одной комбинации кода отличаются от любой другой его комбинации, называется его кодовым (хэмминговым) расстоянием .
Оно находится путем сложения по модулю 2 всех комбинаций кода:
d ij
Разрешенные кодовые комбинации
Запрещенные кодовые комбинации

Виды корректирующих кодов

Коды с исправлением ошибок в передаче
Коды, которые позволяют не только обнаружить ошибку, но и определить номер искаженного символа (позиции), называются кодами с исправлением ошибок .
Для исправления одиночной ошибки придется увеличить кодовое расстояние минимум до 3, двухкратной до 4 и т. п.
В блоковых (блочных) кодах входная непрерывная последовательность информационных символов разбивается на блоки, содержащие k сим — волов.
 k . Этот набор, называемый кодовым словом , передается по каналу связи, искажается шумами и помехами, а затем декодируется независимо от всех других кодовых слов. Величина n называется длиной канального кода или длиной канального блока . Каждое сообщение в этом случае передаётся собственным кодовым словом. Кодовые слова могут объединяться в группы – кодовые предложения или фразы, объединённые некоторой общностью, например, способом защиты от помех кодовых слов, входящих в блок, и т. п. » width=»640″
k . Этот набор, называемый кодовым словом , передается по каналу связи, искажается шумами и помехами, а затем декодируется независимо от всех других кодовых слов. Величина n называется длиной канального кода или длиной канального блока . Каждое сообщение в этом случае передаётся собственным кодовым словом. Кодовые слова могут объединяться в группы – кодовые предложения или фразы, объединённые некоторой общностью, например, способом защиты от помех кодовых слов, входящих в блок, и т. п. » width=»640″
Все дальнейшие операции в кодере производятся над каждым блоком отдельно и независимо от других блоков.
Каждому информационному блоку из k символов ставится в соответствие набор из n символов кода канала передачи сообщений, где n k . Этот набор, называемый кодовым словом , передается по каналу связи, искажается шумами и помехами, а затем декодируется независимо от всех других кодовых слов.
Величина n называется длиной канального кода или длиной канального блока . Каждое сообщение в этом случае передаётся собственным кодовым словом.
Кодовые слова могут объединяться в группы – кодовые предложения или фразы, объединённые некоторой общностью, например, способом защиты от помех кодовых слов, входящих в блок, и т. п.

К онтрольная сумма — это некоторое значение, вычисленное по определённой схеме на основе кодируемого сообщения.
Проверочная информация при систематическом кодировании приписывается к передаваемым данным.
На принимающей стороне абонент знает алгоритм вычисления контрольной суммы: соответственно, программа имеет возможность проверить корректность принятых данных.

Без контрольной суммы, передавать данные опасно, так как помехи присутствуют везде и всегда, весь вопрос только в их вероятности возникновения и вызываемых ими побочных эффектах.
В зависимости от условий и выбирается алгоритм выявления ошибок и количество данных в контрольной сумме.
Чем сложнее алгоритм, и больше контрольная сумма, тем меньше не распознанных ошибок.

Все алгебраические коды можно разделить на два больших класса:
Блочные (блоковые)
Непрерывные
(древовидные)

Блочные коды представляют собой совокупность кодовых символов, состоящих из отдельных комбинаций (блоков) элементов символов кода, которые кодируются и декодируются независимо.

Непрерывные (древовидные) коды представляют собой непрерывную последовательность кодовых символов, причем введение проверочных элементов производится непрерывно, без разделения ее на независимые блоки.

В древовидных (непрерывных) кодах информационная последовательность подвергается обработке без предварительного разбиения на независимые блоки. Длинной, полубесконечной информационной последовательности ставится в соответствие кодовая последовательность, состоящая из большего числа символов.
Непрерывными эти коды называются потому, что операции кодирования и декодирования в них совершаются непрерывно. Они способны исправлять пакетные ошибки при сравнительно простых алгоритмах кодирования и декодирования .

Свойства кодов с исправлением ошибок в передаче
Кодированный цифровой сигнал приобретает свойства обнаружения, а иногда и исправления ошибок, возникающих в процессе передачи и приёма сообщений, т. е. свойство помехозащищенности .
Применение специальных криптографических кодов, известных только соответствующим абонентам, обеспечивает секретность передачи, а зашифрованное сообщение приобретает свойство криптографической стойкости .
Первыми появились блоковые коды, они же также лучше теоретически исследованы. Из древовидных кодов проще всего с точки зрения реализации свёрточные и цепные коды .
Возможности блоковых и древовидных кодов по исправлению ошибок передачи примерно одинаковы. Наибольшее распространение в существующих системах передачи получили разделимые систематические коды , а из них – коды Хэмминга и циклические коды.

Расстоя́ние и вес Хэ́мминга

Пусть u =( u 1 , u 2 , … , u n ) – двоичная последовательность длиной n .
Число единиц в этой последовательности называется весом Хэмминга вектор а u и обозначается как w(u).
Например: u =( 1 0 0 1 0 1 1 ), тогда w ( u )= 4 .
Пусть u и v – двоичные слова длиной n .
Число разрядов, в которых эти слова различаются, называется расстоянием Хэмминга между u и v и обозначается как d(u, v) .
Например: u =( 1 0 0 1 0 1 1 ), v =( 0 1 0 0 0 1 1 ), тогда d ( u , v )= 3 .

Самостоятельно
Найти вес и кодовое расстояние для двоичных слов
- a=011011100
- b=100111001
Решение: Вес для двоичных слов w(a)=5 ; w(b)= 5 .
Кодовое расстояние d(A,B) = 6.