
Абсолютная и относительная погрешности (ошибки).
Пусть некоторая
величина x
измерена n
раз. В результате получен ряд значений
этой величины: x1,
x2,
x3,
…, xn
Величиной, наиболее
близкой к действительному значению,
является среднее арифметическое этих
результатов:
![]()
Отсюда следует,
что каждое физическое измерение должно
быть повторено несколько раз.
Разность между
средним значением
![]() измеряемой
измеряемой
величины и значением отдельного измерения
называется абсолютной
погрешностью отдельного измерения:
![]()
(13)
Абсолютная
погрешность может быть как положительной,
так и отрицательной и измеряется в тех
же единицах, что и измеряемая величина.
Средняя абсолютная
ошибка результата — это среднее
арифметическое значений абсолютных
погрешностей отдельных измерений,
взятых по абсолютной величине (модулю):
![]()
(14)
Отношения
![]()
называются относительными погрешностями
(ошибками) отдельных измерений.
Отношение средней
абсолютной погрешности результата
![]()
к среднему арифметическому значению
![]()
измеряемой величины называют относительной
ошибкой результата и выражают в процентах:
![]()
Относительная
ошибка характеризует точность измерения.
Законы распределения случайных величин.
Результат измерения
физической величины зависит от многих
факторов, влияние которых заранее учесть
невозможно. Поэтому значения, полученные
в результате прямых измерений какого
— либо параметра, являются случайными,
обычно не совпадающие между собой.
Следовательно, случайные
величины —
это такие величины, которые в зависимости
от обстоятельств могут принимать те
или иные значения. Если случайная
величина принимает только определенные
числовые значения, то она называется
дискретной.
Например,
количество заболеваний в данном регионе
за год, оценка, полученная студентом на
экзамене, энергия электрона в атоме и
т.д.
Непрерывная
случайная величина принимает любые
значения в данном интервале.
Например: температура
тела человека, мгновенные скорости
теплового движения молекул, содержание
кислорода в воздухе и т.д.
Под событием
понимается всякий результат или исход
испытания. В теории вероятностей
рассматриваются события, которые при
выполнение некоторых условий могут
произойти, а могут не произойти. Такие
события называются
случайными.
Например, событие, состоящее в появлении
цифры 1 при выполнении условия — бросания
игральной кости, может произойти, а
может не произойти.
Если событие
неизбежно происходит в результате
каждого испытания, то оно называется
достоверным.
Событие называется невозможным,
если оно вообще не происходит ни при
каких условиях.
Два события,
одновременное появление которых
невозможно, называются несовместными.
Пусть случайное
событие А в серии из n
независимых испытаний произошло m
раз, тогда отношение:
![]()
называется
относительной частотой события А. Для
каждой относительной частоты выполняется
неравенство:
![]()
При небольшом
числе опытов относительная частота
событий в значительной мере имеет
случайный характер и может заметно
изменяться от одной группы опытов к
другой. Однако при увеличении числа
опытов частота событий все более теряет
свой случайный характер и приближается
к некоторому постоянному положительному
числу, которое является количественной
мерой возможности реализации случайного
события А. Предел, к которому стремится
относительная частота событий при
неограниченном увеличении числа
испытаний, называется статистической
вероятностью события:
![]()
Например, при
многократном бросании монеты частота
выпадения герба будет лишь незначительно
отличаться от ½. Для достоверного события
вероятность Р(А) равна единице. Если
Р=0, то событие невозможно.
Математическим
ожиданием
дискретной случайной величины называется
сумма произведений всех ее возможных
значений хi
на вероятность этих значений рi:
![]()
Статистическим
аналогом математического ожидания
является среднее арифметическое значений
![]() :
:
![]() ,
,
где mi
— число дискретных случайных величин,
имеющих значение хi.
Для непрерывной
случайной величины математическим
ожиданием служит интеграл:
![]() ,
,
где р(х) — плотность
вероятности.
Отдельные значения
случайной величины группируются около
математического ожидания. Отклонение
случайной величины от ее математического
ожидания (среднего значения) характеризуется
дисперсией,
которая для дискретной случайной
величины определяется формулой:
![]()
(15)

(16)
Дисперсия имеет
размерность случайной величины. Для
того, чтобы оценивать рассеяние
(отклонение) случайной величины в
единицах той же размерности, введено
понятие среднего
квадратичного отклонения
σ(Х), которое
равно корню квадратному из дисперсии:
![]()
(17)
Вместо среднего
квадратичного отклонения иногда
используется термин «стандартное
отклонение».
Всякое отношение,
устанавливающее связь между всеми
возможными значениями случайной величины
и соответствующими им вероятностями,
называется законом
распределения случайной величины.
Формы задания закона распределения
могут быть разными:
а) ряд распределения
(для дискретных величин);
б) функция
распределения;
в) кривая распределения
(для непрерывных величин).
Существует
относительно много законов распределения
случайных величин.
Нормальный
закон распределения случайных
величин (закон
Гаусса).
Случайная величина
![]()
распределена по
нормальному закону, если ее плотность
вероятности f(x)
определяется формулой:

(18),
где <x>
— математическое ожидание (среднее
значение) случайной величины <x>
= M
(X);
![]() —
—
среднее квадратичное отклонение;
![]() —
—
основание натурального логарифма
(неперово число);
f
(x)
– плотность вероятности (функция
распределения вероятностей).
Многие случайные
величины (в том числе все случайные
погрешности) подчиняются нормальному
закону распределения (закону Гаусса).
Для этого распределения наиболее
вероятным значением
измеряемой
величины
является
её среднее
арифметическое
значение.
График нормального
закона распределения изображен на
рисунке (колоколообразная кривая).

Кривая симметрична
относительно прямой х=<x>=α,
следовательно, отклонения случайной
величины вправо и влево от <x>=α
равновероятны. При х=<x>±
кривая асимптотически приближается к
оси абсцисс. Если х=<x>,
то функция распределения вероятностей
f(x)
максимальна и принимает вид:
![]()
(19)
Таким образом,
максимальное значение функции fmax(x)
зависит от величины среднего квадратичного
отклонения. На рисунке изображены 3
кривые распределения. Для кривых 1 и 2
<x>
= α = 0 соответствующие значения среднего
квадратичного отклонения различны, при
этом 2>1.
(При увеличении
кривая распределения становится более
пологой, а при уменьшении
– вытягивается вверх). Для кривой 3 <x>
= α ≠ 0 и 3
= 2.
Закон
распределения
молекул в газах по скоростям называется
распределением
Максвелла.
Функция плотности вероятности попадания
скоростей молекул в определенный
интервал
![]()
теоретически была определена в 1860 году
английским физиком Максвеллом

. На рисунке
распределение Максвелла представлено
графически. Распределение движется
вправо или влево в зависимости от
температуры газа (на рисунке Т1
< Т2).
Закон распределения Максвелла определяется
формулой:
![]()
(20),
где mо
– масса молекулы, k
– постоянная Больцмана, Т – абсолютная
температура газа,
![]() —
—
скорость молекулы.
Распределение
концентрации молекул газа в атмосфере
Земли (т.е.
в силовом поле) в зависимости от высоты
было дано австрийским физиком Больцманом
и называется
распределением
Больцмана:

(21)
Где n(h)
– концентрация молекул газа на высоте
h,
n0
– концентрация у поверхности Земли, g
– ускорение свободного падения, m
– масса молекулы.

Распределение
Больцмана.
Совокупность всех
значений случайной величины называется
простым
статистическим рядом.
Так как простой статистический ряд
оказывается большим, то его преобразуют
в вариационный
статистический
ряд или интервальный
статистический ряд. По интервальному
статистическому ряду для оценки вида
функции распределения вероятностей по
экспериментальным данным строят
гистограмму
– столбчатую
диаграмму. (Гистограмма – от греческих
слов “histos”–
столб и “gramma”–
запись).
n

-
h
Гистограмма
распределения Больцмана.
Для построения
гистограммы интервал, содержащий
полученные значения случайной величины
делят на несколько интервалов xi
одинаковой ширины. Для каждого интервала
подсчитывают число mi
значений случайной величины, попавших
в этот интервал. После этого вычисляют
плотность частоты случайной величины
![]()
для каждого интервала xi
и среднее значение случайной величины
<xi
> в каждом интервале.
Затем по оси абсцисс
откладывают интервалы xi,
являющиеся основаниями прямоугольников,
высота которых равна
![]() (или
(или
высотой
![]()
– плотностью относительной частоты
![]() ).
).
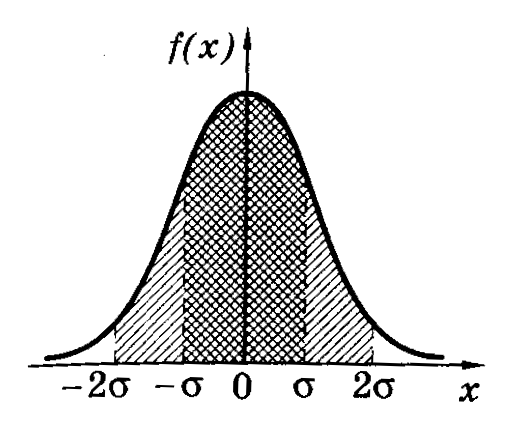
Расчетами показано,
что вероятность попадания нормально
распределенной случайной величины в
интервале значений от <x>–
до <x>+
в среднем равна 68%. В границах вдвое
более широких (<x>–2;
<x>+2)
размещается в среднем 95% всех значений
измерений, а в интервале (<x>–3;<x>+3)
– уже 99,7%. Таким образом, вероятность
того, что отклонение значений нормально
распределенной случайной величины
превысит 3
(
– среднее квадратичное отклонение)
чрезвычайно мала (~0,003). Такое событие
можно считать практически невозможным.
Поэтому границы <x>–3
и <x>+3
принимаются за границы практически
возможных значений нормально распределенной
случайной величины («правило трех
сигм»).
Если число измерений
(объем выборки) невелико (n<30),
дисперсия вычисляется по формуле:
![]()
(22)
Уточненное среднее
квадратичное отклонение отдельного
измерения вычисляется по формуле:

(23)
Напомним, что для
эмпирического распределения по выборке
аналогом математического ожидания
является среднее арифметическое значение
<x>
измеряемой величины.
Чтобы дать
представление о точности и надежности
оценки измеряемой величины, используют
понятия доверительного интервала и
доверительной вероятности.
Доверительным
интервалом
называется интервал (<x>–x,
<x>+x),
в который по определению попадает с
заданной вероятностью действительное
(истинное) значение измеряемой величины.
Доверительный интервал характеризует
точность полученного результата: чем
уже доверительный интервал, тем меньше
погрешность.
Доверительной
вероятностью
(надежностью)
результата серии измерений называется
вероятность того, что истинное значение
измеряемой величины попадает в данный
доверительный интервал (<x>±x).
Чем больше величина доверительного
интервала, т.е. чем больше x,
тем с большей надежностью величина <x>
попадает в этот интервал. Надежность
выбирается самим исследователем
самостоятельно, например, =0,95;
0,98. В медицинских и биологических
исследованиях, как правило, доверительную
вероятность (надежность) принимают
равной 0,95.
Если величина х
подчиняется нормальному закону
распределения Гаусса, а <x>
и <>
оцениваются по выборке (числу измерений)
и если объем выборки невелик (n<30),
то интервал (<x>
– t,n<>,
<x>
+ t,n<>)
будет доверительным интервалом для
известного параметра х с доверительной
вероятностью .
Коэффициент t,n
называется коэффициентом
Стьюдента
(этот коэффициент был предложен в 1908 г.
английским математиком и химиком В.С.
Госсетом, публиковавшим свои работы
под псевдонимом «Стьюдент» – студент).
Значении коэффициента
Стьюдента t,n
зависит от доверительной вероятности
и числа измерений n
(объема выборки). Некоторые значения
коэффициента Стьюдента приведены в
таблице 1.
Таблица 1
|
n |
|
||||||
|
0,6 |
0,7 |
0,8 |
0,9 |
0,95 |
0,98 |
0,99 |
|
|
2 |
1,38 |
2,0 |
3,1 |
6,3 |
12,7 |
31,8 |
63,7 |
|
3 |
1,06 |
1,3 |
1,9 |
2,9 |
4,3 |
7,0 |
9,9 |
|
4 |
0,98 |
1,3 |
1,6 |
2,4 |
3,2 |
4,5 |
5,8 |
|
5 |
0,94 |
1,2 |
1,5 |
2,1 |
2,8 |
3,7 |
4,6 |
|
6 |
0,92 |
1,2 |
1,5 |
2,0 |
2,6 |
3,4 |
4,0 |
|
7 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,1 |
3,7 |
|
8 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,0 |
3,5 |
|
9 |
0,90 |
1,1 |
1,4 |
1,9 |
2,3 |
2,9 |
3,4 |
|
10 |
0,88 |
1,1 |
1,4 |
1,9 |
2,3 |
2,8 |
3,3 |
В таблице 1 в верхней
строке заданы значения доверительной
вероятности
от 0,6 до 0,99, в левом столбце – значение
n.
Коэффициент Стьюдента следует искать
на пересечении соответствующих строки
и столбца.
Окончательный
результат измерений записывается в
виде:
![]()
(25)
Где
![]()
– полуширина доверительного интервала.
Результат серии
измерений оценивается относительной
погрешностью:

(26)
Как рассчитать экспериментальную ошибку в химии
На чтение 1 мин. Просмотров 387 Опубликовано 05.06.2021
Ошибка – это мера точности значений в вашем эксперименте. Важно уметь вычислить экспериментальную ошибку, но есть несколько способов ее вычислить и выразить. Вот наиболее распространенные способы вычисления экспериментальной ошибки:
Содержание
- Формула ошибки
- Формула относительной ошибки
- Формула процента ошибки
- Пример расчета ошибки
Формула ошибки
В общем, ошибка – это разница между принятым или теоретическое значение и экспериментальное значение.
Ошибка = экспериментальное значение – известное значение
Формула относительной ошибки
Относительная ошибка = ошибка/известное значение
Формула процента ошибки
% Error = относительная ошибка x 100%
Пример расчета ошибки
Допустим, исследователь измеряет массу образца, который должен быть 5,51 грамм. Известно, что фактическая масса образца составляет 5,80 грамма. Рассчитайте погрешность измерения.
Экспериментальное значение = 5,51 грамма
Известное значение = 5,80 грамма
Ошибка = экспериментальное значение – известное значение
Ошибка = 5,51 г – 5,80 грамма
Ошибка = – 0,29 грамма
Относительная ошибка = ошибка/известное значение
Относительная ошибка = – 0,29 г/5,80 г
Относительная ошибка = – 0,050
% Error = относительная ошибка x 100%
% Error = – 0,050 x 100%
% Error = – 5,0%
Погрешности измерений, представление результатов эксперимента
- Шкала измерительного прибора
- Цена деления
- Виды измерений
- Погрешность измерений, абсолютная и относительная погрешность
- Абсолютная погрешность серии измерений
- Представление результатов эксперимента
- Задачи
п.1. Шкала измерительного прибора
Шкала – это показывающая часть измерительного прибора, состоящая из упорядоченного ряда отметок со связанной с ними нумерацией. Шкала может располагаться по окружности, дуге или прямой линии.
Примеры шкал различных приборов:
п.2. Цена деления
Цена деления измерительного прибора равна числу единиц измеряемой величины между двумя ближайшими делениями шкалы. Как правило, цена деления указана на маркировке прибора.
Алгоритм определения цены деления
Шаг 1. Найти два ближайшие пронумерованные крупные деления шкалы. Пусть первое значение равно a, второе равно b, b > a.
Шаг 2. Посчитать количество мелких делений шкалы между ними. Пусть это количество равно n.
Шаг 3. Разделить разницу значений крупных делений шкалы на количество отрезков, которые образуются мелкими делениями: $$ triangle=frac{b-a}{n+1} $$ Найденное значение (triangle) и есть цена деления данного прибора.
Пример определения цены деления:
 |
Определим цену деления основной шкалы секундомера. Два ближайших пронумерованных деления на основной шкале:a = 5 c b = 10 cМежду ними находится 4 средних деления, а между каждыми средними делениями еще 4 мелких. Итого: 4+4·5=24 деления. Цена деления: begin{gather*} triangle=frac{b-a}{n+1}\ triangle=frac{10-5}{24+1}=frac15=0,2 c end{gather*} |
п.3. Виды измерений
Вид измерений
Определение
Пример
Прямое измерение
Физическую величину измеряют с помощью прибора
Измерение длины бруска линейкой
Косвенное измерение
Физическую величину рассчитывают по формуле, куда подставляют значения величин, полученных с помощью прямых измерений
Определение площади столешницы при измеренной длине и ширине
п.4. Погрешность измерений, абсолютная и относительная погрешность
Погрешность измерений – это отклонение измеренного значения величины от её истинного значения.
Составляющие погрешности измерений
Причины
Инструментальная погрешность
Определяется погрешностью инструментов и приборов, используемых для измерений (принципом действия, точностью шкалы и т.п.)
Погрешность метода
Определяется несовершенством методов и допущениями в методике.
Погрешность теории (модели)
Определяется теоретическими упрощениями, степенью соответствия теоретической модели и реальности.
Погрешность оператора
Определяется субъективным фактором, ошибками экспериментатора.
Инструментальная погрешность измерений принимается равной половине цены деления прибора: $$ d=frac{triangle}{2} $$
Если величина (a_0) — это истинное значение, а (triangle a) — погрешность измерения, результат измерений физической величины записывают в виде (a=a_0pmtriangle a).
Абсолютная погрешность измерения – это модуль разности между измеренным и истинным значением измеряемой величины: $$ triangle a=|a-a_0| $$
Отношение абсолютной погрешности измерения к истинному значению, выраженное в процентах, называют относительной погрешностью измерения: $$ delta=frac{triangle a}{a_0}cdot 100text{%} $$
Относительная погрешность является мерой точности измерения: чем меньше относительная погрешность, тем измерение точнее. По абсолютной погрешности о точности измерения судить нельзя.
На практике абсолютную и относительную погрешности округляют до двух значащих цифр с избытком, т.е. всегда в сторону увеличения.
Значащие цифры – это все верные цифры числа, кроме нулей слева. Результаты измерений записывают только значащими цифрами.
Примеры значащих цифр:
0,403 – три значащих цифры, величина определена с точностью до тысячных.
40,3 – три значащих цифры, величина определена с точностью до десятых.
40,300 – пять значащих цифр, величина определена с точностью до тысячных.
В простейших измерениях инструментальная погрешность прибора является основной.
В таких случаях физическую величину измеряют один раз, полученное значение берут в качестве истинного, а абсолютную погрешность считают равной инструментальной погрешности прибора.
Примеры измерений с абсолютной погрешностью равной инструментальной:
- определение длины с помощью линейки или мерной ленты;
- определение объема с помощью мензурки.
Пример получения результатов прямых измерений с помощью линейки:
 |
Измерим длину бруска линейкой, у которой пронумерованы сантиметры и есть только одно деление между пронумерованными делениями. Цена деления такой линейки: begin{gather*} triangle=frac{b-a}{n+1}= frac{1 text{см}}{1+1}=0,5 text{см} end{gather*} Инструментальная погрешность: begin{gather*} d=frac{triangle}{2}=frac{0,5}{2}=0,25 text{см} end{gather*} Истинное значение: (L_0=4 text{см}) Результат измерений: $$ L=L_0pm d=(4,00pm 0,25) text{см} $$ Относительная погрешность: $$ delta=frac{0,25}{4,00}cdot 100text{%}=6,25text{%}approx 6,3text{%} $$ |
 |
Теперь возьмем линейку с n=9 мелкими делениями между пронумерованными делениями. Цена деления такой линейки: begin{gather*} triangle=frac{b-a}{n+1}= frac{1 text{см}}{9+1}=0,1 text{см} end{gather*} Инструментальная погрешность: begin{gather*} d=frac{triangle}{2}=frac{0,1}{2}=0,05 text{см} end{gather*} Истинное значение: (L_0=4,15 text{см}) Результат измерений: $$ L=L_0pm d=(4,15pm 0,05) text{см} $$ Относительная погрешность: $$ delta=frac{0,05}{4,15}cdot 100text{%}approx 1,2text{%} $$ |
Второе измерение точнее, т.к. его относительная погрешность меньше.
п.5. Абсолютная погрешность серии измерений
Измерение длины с помощью линейки (или объема с помощью мензурки) являются теми редкими случаями, когда для определения истинного значения достаточно одного измерения, а абсолютная погрешность сразу берется равной инструментальной погрешности, т.е. половине цены деления линейки (или мензурки).
Гораздо чаще погрешность метода или погрешность оператора оказываются заметно больше инструментальной погрешности. В таких случаях значение измеренной физической величины каждый раз немного меняется, и для оценки истинного значения и абсолютной погрешности нужна серия измерений и вычисление средних значений.
Алгоритм определения истинного значения и абсолютной погрешности в серии измерений
Шаг 1. Проводим серию из (N) измерений, в каждом из которых получаем значение величины (x_1,x_2,…,x_N)
Шаг 2. Истинное значение величины принимаем равным среднему арифметическому всех измерений: $$ x_0=x_{cp}=frac{x_1+x_2+…+x_N}{N} $$ Шаг 3. Находим абсолютные отклонения от истинного значения для каждого измерения: $$ triangle_1=|x_0-x_1|, triangle_2=|x_0-x_2|, …, triangle_N=|x_0-x_N| $$ Шаг 4. Находим среднее арифметическое всех абсолютных отклонений: $$ triangle_{cp}=frac{triangle_1+triangle_2+…+triangle_N}{N} $$ Шаг 5. Сравниваем полученную величину (triangle_{cp}) c инструментальной погрешностью прибора d (половина цены деления). Большую из этих двух величин принимаем за абсолютную погрешность: $$ triangle x=maxleft{triangle_{cp}; dright} $$ Шаг 6. Записываем результат серии измерений: (x=x_0pmtriangle x).
Пример расчета истинного значения и погрешности для серии прямых измерений:
Пусть при измерении массы шарика с помощью рычажных весов мы получили в трех опытах следующие значения: 99,8 г; 101,2 г; 100,3 г.
Инструментальная погрешность весов d = 0,05 г.
Найдем истинное значение массы и абсолютную погрешность.
Составим расчетную таблицу:
| № опыта | 1 | 2 | 3 | Сумма |
| Масса, г | 99,8 | 101,2 | 100,3 | 301,3 |
| Абсолютное отклонение, г | 0,6 | 0,8 | 0,1 | 1,5 |
Сначала находим среднее значение всех измерений: begin{gather*} m_0=frac{99,8+101,2+100,3}{3}=frac{301,3}{3}approx 100,4 text{г} end{gather*} Это среднее значение принимаем за истинное значение массы.
Затем считаем абсолютное отклонение каждого опыта как модуль разности (m_0) и измерения. begin{gather*} triangle_1=|100,4-99,8|=0,6\ triangle_2=|100,4-101,2|=0,8\ triangle_3=|100,4-100,3|=0,1 end{gather*} Находим среднее абсолютное отклонение: begin{gather*} triangle_{cp}=frac{0,6+0,8+0,1}{3}=frac{1,5}{3}=0,5 text{(г)} end{gather*} Мы видим, что полученное значение (triangle_{cp}) больше инструментальной погрешности d.
Поэтому абсолютная погрешность измерения массы: begin{gather*} triangle m=maxleft{triangle_{cp}; dright}=maxleft{0,5; 0,05right} text{(г)} end{gather*} Записываем результат: begin{gather*} m=m_0pmtriangle m\ m=(100,4pm 0,5) text{(г)} end{gather*} Относительная погрешность (с двумя значащими цифрами): begin{gather*} delta_m=frac{0,5}{100,4}cdot 100text{%}approx 0,050text{%} end{gather*}
п.6. Представление результатов эксперимента
Результат измерения представляется в виде $$ a=a_0pmtriangle a $$ где (a_0) – истинное значение, (triangle a) – абсолютная погрешность измерения.
Как найти результат прямого измерения, мы рассмотрели выше.
Результат косвенного измерения зависит от действий, которые производятся при подстановке в формулу величин, полученных с помощью прямых измерений.
Погрешность суммы и разности
Если (a=a_0+triangle a) и (b=b_0+triangle b) – результаты двух прямых измерений, то
- абсолютная погрешность их суммы равна сумме абсолютных погрешностей
$$ triangle (a+b)=triangle a+triangle b $$
- абсолютная погрешность их разности также равна сумме абсолютных погрешностей
$$ triangle (a-b)=triangle a+triangle b $$
Погрешность произведения и частного
Если (a=a_0+triangle a) и (b=b_0+triangle b) – результаты двух прямых измерений, с относительными погрешностями (delta_a=frac{triangle a}{a_0}cdot 100text{%}) и (delta_b=frac{triangle b}{b_0}cdot 100text{%}) соответственно, то:
- относительная погрешность их произведения равна сумме относительных погрешностей
$$ delta_{acdot b}=delta_a+delta_b $$
- относительная погрешность их частного также равна сумме относительных погрешностей
$$ delta_{a/b}=delta_a+delta_b $$
Погрешность степени
Если (a=a_0+triangle a) результат прямого измерения, с относительной погрешностью (delta_a=frac{triangle a}{a_0}cdot 100text{%}), то:
- относительная погрешность квадрата (a^2) равна удвоенной относительной погрешности
$$ delta_{a^2}=2delta_a $$
- относительная погрешность куба (a^3) равна утроенной относительной погрешности
$$ delta_{a^3}=3delta_a $$
- относительная погрешность произвольной натуральной степени (a^n) равна
$$ delta_{a^n}=ndelta_a $$
Вывод этих формул достаточно сложен, но если интересно, его можно найти в Главе 7 справочника по алгебре для 8 класса.
п.7. Задачи
Задача 1. Определите цену деления и объем налитой жидкости для каждой из мензурок. В каком случае измерение наиболее точно; наименее точно? 
Составим таблицу для расчета цены деления:
| № мензурки | a, мл | b, мл | n | (triangle=frac{b-a}{n+1}), мл |
| 1 | 20 | 40 | 4 | (frac{40-20}{4+1}=4) |
| 2 | 100 | 200 | 4 | (frac{200-100}{4+1}=20) |
| 3 | 15 | 30 | 4 | (frac{30-15}{4+1}=3) |
| 4 | 200 | 400 | 4 | (frac{400-200}{4+1}=40) |
Инструментальная точность мензурки равна половине цены деления.
Принимаем инструментальную точность за абсолютную погрешность и измеренное значение объема за истинное.
Составим таблицу для расчета относительной погрешности (оставляем две значащих цифры и округляем с избытком):
| № мензурки | Объем (V_0), мл | Абсолютная погрешность (triangle V=frac{triangle}{2}), мл |
Относительная погрешность (delta_V=frac{triangle V}{V_0}cdot 100text{%}) |
| 1 | 68 | 2 | 3,0% |
| 2 | 280 | 10 | 3,6% |
| 3 | 27 | 1,5 | 5,6% |
| 4 | 480 | 20 | 4,2% |
Наиболее точное измерение в 1-й мензурке, наименее точное – в 3-й мензурке.
Ответ:
Цена деления 4; 20; 3; 40 мл
Объем 68; 280; 27; 480 мл
Самое точное – 1-я мензурка; самое неточное – 3-я мензурка
Задача 2. В двух научных работах указаны два значения измерений одной и той же величины: $$ x_1=(4,0pm 0,1) text{м}, x_2=(4,0pm 0,03) text{м} $$ Какое из этих измерений точней и почему?
Мерой точности является относительная погрешность измерений. Получаем: begin{gather*} delta_1=frac{0,1}{4,0}cdot 100text{%}=2,5text{%}\ delta_2=frac{0,03}{4,0}cdot 100text{%}=0,75text{%} end{gather*} Относительная погрешность второго измерения меньше. Значит, второе измерение точней.
Ответ: (delta_2lt delta_1), второе измерение точней.
Задача 3. Две машины движутся навстречу друг другу со скоростями 54 км/ч и 72 км/ч.
Цена деления спидометра первой машины 10 км/ч, второй машины – 1 км/ч.
Найдите скорость их сближения, абсолютную и относительную погрешность этой величины.
Абсолютная погрешность скорости каждой машины равна инструментальной, т.е. половине деления спидометра: $$ triangle v_1=frac{10}{2}=5 (text{км/ч}), triangle v_2=frac{1}{2}=0,5 (text{км/ч}) $$ Показания каждого из спидометров: $$ v_1=(54pm 5) text{км/ч}, v_2=(72pm 0,5) text{км/ч} $$ Скорость сближения равна сумме скоростей: $$ v_0=v_{10}+v_{20}, v_0=54+72=125 text{км/ч} $$ Для суммы абсолютная погрешность равна сумме абсолютных погрешностей слагаемых. $$ triangle v=triangle v_1+triangle v_2, triangle v=5+0,5=5,5 text{км/ч} $$ Скорость сближения с учетом погрешности равна: $$ v=(126,0pm 5,5) text{км/ч} $$ Относительная погрешность: $$ delta_v=frac{5,5}{126,0}cdot 100text{%}approx 4,4text{%} $$ Ответ: (v=(126,0pm 5,5) text{км/ч}, delta_vapprox 4,4text{%})
Задача 4. Измеренная длина столешницы равна 90,2 см, ширина 60,1 см. Измерения проводились с помощью линейки с ценой деления 0,1 см. Найдите площадь столешницы, абсолютную и относительную погрешность этой величины.
Инструментальная погрешность линейки (d=frac{0,1}{2}=0,05 text{см})
Результаты прямых измерений длины и ширины: $$ a=(90,20pm 0,05) text{см}, b=(60,10pm 0,05) text{см} $$ Относительные погрешности (не забываем про правила округления): begin{gather*} delta_1=frac{0,05}{90,20}cdot 100text{%}approx 0,0554text{%}approx uparrow 0,056text{%}\ delta_2=frac{0,05}{60,10}cdot 100text{%}approx 0,0832text{%}approx uparrow 0,084text{%} end{gather*} Площадь столешницы: $$ S=ab, S=90,2cdot 60,1 = 5421,01 text{см}^2 $$ Для произведения относительная погрешность равна сумме относительных погрешностей слагаемых: $$ delta_S=delta_a+delta_b=0,056text{%}+0,084text{%}=0,140text{%}=0,14text{%} $$ Абсолютная погрешность: begin{gather*} triangle S=Scdot delta_S=5421,01cdot 0,0014=7,59approx 7,6 text{см}^2\ S=(5421,0pm 7,6) text{см}^2 end{gather*} Ответ: (S=(5421,0pm 7,6) text{см}^2, delta_Sapprox 0,14text{%})
Абсолютная и относительная погрешности (ошибки).
Пусть некоторая
величина x
измерена n
раз. В результате получен ряд значений
этой величины: x1,
x2,
x3,
…, xn
Величиной, наиболее
близкой к действительному значению,
является среднее арифметическое этих
результатов:
![]()
Отсюда следует,
что каждое физическое измерение должно
быть повторено несколько раз.
Разность между
средним значением
![]() измеряемой
измеряемой
величины и значением отдельного измерения
называется абсолютной
погрешностью отдельного измерения:
![]()
(13)
Абсолютная
погрешность может быть как положительной,
так и отрицательной и измеряется в тех
же единицах, что и измеряемая величина.
Средняя абсолютная
ошибка результата — это среднее
арифметическое значений абсолютных
погрешностей отдельных измерений,
взятых по абсолютной величине (модулю):
![]()
(14)
Отношения
![]()
называются относительными погрешностями
(ошибками) отдельных измерений.
Отношение средней
абсолютной погрешности результата
![]()
к среднему арифметическому значению
![]()
измеряемой величины называют относительной
ошибкой результата и выражают в процентах:
![]()
Относительная
ошибка характеризует точность измерения.
Законы распределения случайных величин.
Результат измерения
физической величины зависит от многих
факторов, влияние которых заранее учесть
невозможно. Поэтому значения, полученные
в результате прямых измерений какого
— либо параметра, являются случайными,
обычно не совпадающие между собой.
Следовательно, случайные
величины —
это такие величины, которые в зависимости
от обстоятельств могут принимать те
или иные значения. Если случайная
величина принимает только определенные
числовые значения, то она называется
дискретной.
Например,
количество заболеваний в данном регионе
за год, оценка, полученная студентом на
экзамене, энергия электрона в атоме и
т.д.
Непрерывная
случайная величина принимает любые
значения в данном интервале.
Например: температура
тела человека, мгновенные скорости
теплового движения молекул, содержание
кислорода в воздухе и т.д.
Под событием
понимается всякий результат или исход
испытания. В теории вероятностей
рассматриваются события, которые при
выполнение некоторых условий могут
произойти, а могут не произойти. Такие
события называются
случайными.
Например, событие, состоящее в появлении
цифры 1 при выполнении условия — бросания
игральной кости, может произойти, а
может не произойти.
Если событие
неизбежно происходит в результате
каждого испытания, то оно называется
достоверным.
Событие называется невозможным,
если оно вообще не происходит ни при
каких условиях.
Два события,
одновременное появление которых
невозможно, называются несовместными.
Пусть случайное
событие А в серии из n
независимых испытаний произошло m
раз, тогда отношение:
![]()
называется
относительной частотой события А. Для
каждой относительной частоты выполняется
неравенство:
![]()
При небольшом
числе опытов относительная частота
событий в значительной мере имеет
случайный характер и может заметно
изменяться от одной группы опытов к
другой. Однако при увеличении числа
опытов частота событий все более теряет
свой случайный характер и приближается
к некоторому постоянному положительному
числу, которое является количественной
мерой возможности реализации случайного
события А. Предел, к которому стремится
относительная частота событий при
неограниченном увеличении числа
испытаний, называется статистической
вероятностью события:
![]()
Например, при
многократном бросании монеты частота
выпадения герба будет лишь незначительно
отличаться от ½. Для достоверного события
вероятность Р(А) равна единице. Если
Р=0, то событие невозможно.
Математическим
ожиданием
дискретной случайной величины называется
сумма произведений всех ее возможных
значений хi
на вероятность этих значений рi:
![]()
Статистическим
аналогом математического ожидания
является среднее арифметическое значений
![]() :
:
![]() ,
,
где mi
— число дискретных случайных величин,
имеющих значение хi.
Для непрерывной
случайной величины математическим
ожиданием служит интеграл:
![]() ,
,
где р(х) — плотность
вероятности.
Отдельные значения
случайной величины группируются около
математического ожидания. Отклонение
случайной величины от ее математического
ожидания (среднего значения) характеризуется
дисперсией,
которая для дискретной случайной
величины определяется формулой:
![]()
(15)
(16)
Дисперсия имеет
размерность случайной величины. Для
того, чтобы оценивать рассеяние
(отклонение) случайной величины в
единицах той же размерности, введено
понятие среднего
квадратичного отклонения
σ(Х), которое
равно корню квадратному из дисперсии:
![]()
(17)
Вместо среднего
квадратичного отклонения иногда
используется термин «стандартное
отклонение».
Всякое отношение,
устанавливающее связь между всеми
возможными значениями случайной величины
и соответствующими им вероятностями,
называется законом
распределения случайной величины.
Формы задания закона распределения
могут быть разными:
а) ряд распределения
(для дискретных величин);
б) функция
распределения;
в) кривая распределения
(для непрерывных величин).
Существует
относительно много законов распределения
случайных величин.
Нормальный
закон распределения случайных
величин (закон
Гаусса).
Случайная величина
![]()
распределена по
нормальному закону, если ее плотность
вероятности f(x)
определяется формулой:
(18),
где <x>
— математическое ожидание (среднее
значение) случайной величины <x>
= M
(X);
![]() —
—
среднее квадратичное отклонение;
![]() —
—
основание натурального логарифма
(неперово число);
f
(x)
– плотность вероятности (функция
распределения вероятностей).
Многие случайные
величины (в том числе все случайные
погрешности) подчиняются нормальному
закону распределения (закону Гаусса).
Для этого распределения наиболее
вероятным значением
измеряемой
величины
является
её среднее
арифметическое
значение.
График нормального
закона распределения изображен на
рисунке (колоколообразная кривая).
Кривая симметрична
относительно прямой х=<x>=α,
следовательно, отклонения случайной
величины вправо и влево от <x>=α
равновероятны. При х=<x>±
кривая асимптотически приближается к
оси абсцисс. Если х=<x>,
то функция распределения вероятностей
f(x)
максимальна и принимает вид:
![]()
(19)
Таким образом,
максимальное значение функции fmax(x)
зависит от величины среднего квадратичного
отклонения. На рисунке изображены 3
кривые распределения. Для кривых 1 и 2
<x>
= α = 0 соответствующие значения среднего
квадратичного отклонения различны, при
этом 2>1.
(При увеличении
кривая распределения становится более
пологой, а при уменьшении
– вытягивается вверх). Для кривой 3 <x>
= α ≠ 0 и 3
= 2.
Закон
распределения
молекул в газах по скоростям называется
распределением
Максвелла.
Функция плотности вероятности попадания
скоростей молекул в определенный
интервал
![]()
теоретически была определена в 1860 году
английским физиком Максвеллом
. На рисунке
распределение Максвелла представлено
графически. Распределение движется
вправо или влево в зависимости от
температуры газа (на рисунке Т1
< Т2).
Закон распределения Максвелла определяется
формулой:
![]()
(20),
где mо
– масса молекулы, k
– постоянная Больцмана, Т – абсолютная
температура газа,
![]() —
—
скорость молекулы.
Распределение
концентрации молекул газа в атмосфере
Земли (т.е.
в силовом поле) в зависимости от высоты
было дано австрийским физиком Больцманом
и называется
распределением
Больцмана:
(21)
Где n(h)
– концентрация молекул газа на высоте
h,
n0
– концентрация у поверхности Земли, g
– ускорение свободного падения, m
– масса молекулы.
Распределение
Больцмана.
Совокупность всех
значений случайной величины называется
простым
статистическим рядом.
Так как простой статистический ряд
оказывается большим, то его преобразуют
в вариационный
статистический
ряд или интервальный
статистический ряд. По интервальному
статистическому ряду для оценки вида
функции распределения вероятностей по
экспериментальным данным строят
гистограмму
– столбчатую
диаграмму. (Гистограмма – от греческих
слов “histos”–
столб и “gramma”–
запись).
n
-
h
Гистограмма
распределения Больцмана.
Для построения
гистограммы интервал, содержащий
полученные значения случайной величины
делят на несколько интервалов xi
одинаковой ширины. Для каждого интервала
подсчитывают число mi
значений случайной величины, попавших
в этот интервал. После этого вычисляют
плотность частоты случайной величины
![]()
для каждого интервала xi
и среднее значение случайной величины
<xi
> в каждом интервале.
Затем по оси абсцисс
откладывают интервалы xi,
являющиеся основаниями прямоугольников,
высота которых равна
![]() (или
(или
высотой
![]()
– плотностью относительной частоты
![]() ).
).
Расчетами показано,
что вероятность попадания нормально
распределенной случайной величины в
интервале значений от <x>–
до <x>+
в среднем равна 68%. В границах вдвое
более широких (<x>–2;
<x>+2)
размещается в среднем 95% всех значений
измерений, а в интервале (<x>–3;<x>+3)
– уже 99,7%. Таким образом, вероятность
того, что отклонение значений нормально
распределенной случайной величины
превысит 3
(
– среднее квадратичное отклонение)
чрезвычайно мала (~0,003). Такое событие
можно считать практически невозможным.
Поэтому границы <x>–3
и <x>+3
принимаются за границы практически
возможных значений нормально распределенной
случайной величины («правило трех
сигм»).
Если число измерений
(объем выборки) невелико (n<30),
дисперсия вычисляется по формуле:
![]()
(22)
Уточненное среднее
квадратичное отклонение отдельного
измерения вычисляется по формуле:
(23)
Напомним, что для
эмпирического распределения по выборке
аналогом математического ожидания
является среднее арифметическое значение
<x>
измеряемой величины.
Чтобы дать
представление о точности и надежности
оценки измеряемой величины, используют
понятия доверительного интервала и
доверительной вероятности.
Доверительным
интервалом
называется интервал (<x>–x,
<x>+x),
в который по определению попадает с
заданной вероятностью действительное
(истинное) значение измеряемой величины.
Доверительный интервал характеризует
точность полученного результата: чем
уже доверительный интервал, тем меньше
погрешность.
Доверительной
вероятностью
(надежностью)
результата серии измерений называется
вероятность того, что истинное значение
измеряемой величины попадает в данный
доверительный интервал (<x>±x).
Чем больше величина доверительного
интервала, т.е. чем больше x,
тем с большей надежностью величина <x>
попадает в этот интервал. Надежность
выбирается самим исследователем
самостоятельно, например, =0,95;
0,98. В медицинских и биологических
исследованиях, как правило, доверительную
вероятность (надежность) принимают
равной 0,95.
Если величина х
подчиняется нормальному закону
распределения Гаусса, а <x>
и <>
оцениваются по выборке (числу измерений)
и если объем выборки невелик (n<30),
то интервал (<x>
– t,n<>,
<x>
+ t,n<>)
будет доверительным интервалом для
известного параметра х с доверительной
вероятностью .
Коэффициент t,n
называется коэффициентом
Стьюдента
(этот коэффициент был предложен в 1908 г.
английским математиком и химиком В.С.
Госсетом, публиковавшим свои работы
под псевдонимом «Стьюдент» – студент).
Значении коэффициента
Стьюдента t,n
зависит от доверительной вероятности
и числа измерений n
(объема выборки). Некоторые значения
коэффициента Стьюдента приведены в
таблице 1.
Таблица 1
|
n |
|
||||||
|
0,6 |
0,7 |
0,8 |
0,9 |
0,95 |
0,98 |
0,99 |
|
|
2 |
1,38 |
2,0 |
3,1 |
6,3 |
12,7 |
31,8 |
63,7 |
|
3 |
1,06 |
1,3 |
1,9 |
2,9 |
4,3 |
7,0 |
9,9 |
|
4 |
0,98 |
1,3 |
1,6 |
2,4 |
3,2 |
4,5 |
5,8 |
|
5 |
0,94 |
1,2 |
1,5 |
2,1 |
2,8 |
3,7 |
4,6 |
|
6 |
0,92 |
1,2 |
1,5 |
2,0 |
2,6 |
3,4 |
4,0 |
|
7 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,1 |
3,7 |
|
8 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,0 |
3,5 |
|
9 |
0,90 |
1,1 |
1,4 |
1,9 |
2,3 |
2,9 |
3,4 |
|
10 |
0,88 |
1,1 |
1,4 |
1,9 |
2,3 |
2,8 |
3,3 |
В таблице 1 в верхней
строке заданы значения доверительной
вероятности
от 0,6 до 0,99, в левом столбце – значение
n.
Коэффициент Стьюдента следует искать
на пересечении соответствующих строки
и столбца.
Окончательный
результат измерений записывается в
виде:
![]()
(25)
Где
![]()
– полуширина доверительного интервала.
Результат серии
измерений оценивается относительной
погрешностью:
(26)
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Статьи
Главная страница
 Из графика
Из графика
видно, что существует вероятность, пусть и очень маленькая, что наше единичное
измерение покажет результат, сколь угодно далеко отстоящий от истинного
значения. Выходом из положения является проведение серии измерений. Если на
разброс данных действительно влияет случай, то в результате нескольких
измерений мы скорее всего получим следующее (рис 2):
Будет ли
рассчитанное среднее значение нескольких измерений совпадать с истинным? Как
правило – нет. Но по теории вероятности, чем больше сделано измерений, тем
ближе найденное среднее значение к истинному. На языке математики это можно
записать так:
![]()
Но с бесконечностью у всех дело обстоит неважно. Поэтому на практике мы имеем дело
не со всеми возможными результатами измерений, а с некоторой выборкой из этого
бесконечного множества. Сколько же реально следует делать измерений? Наверное,
до тех пор, пока полученное среднее значение не будет отличаться от истинного
меньше чем точность отдельного измерения.

Следовательно,
когда наше среднее значение (рис. 2) отличается от истинного меньше чем
погрешность измерений, дальнейшее увеличение числа опытов бессмысленно. Однако
на практике мы не знаем истинного значения! Значит, получив среднее по
результатам серии опытов, мы должны определить, какова вероятность того, что
истинное значение находится внутри заданного интервала ошибки. Или каков тот
доверительный интервал, в который с заданной надежностью попадет истинное
значение (рис 3).
Рассмотрим
некоторый условный эксперимент, где в серии измерений получены некоторые
значения величины Х (см. табл. 1). Рассчитаем среднее значение и, чтобы оценить
разброс данных найдем величины DХ = Х –
Хср
|
Таблица |
||||||
|
№ |
Х |
Х ср |
DХ |
DХ2 |
s2 |
s |
|
1 |
130 |
143,5 » 144 |
-13,5 |
182,3 |
420 |
20,5 |
|
2 |
162 |
18,5 |
342,3 |
|||
|
3 |
160 |
16,5 |
272,3 |
s2ср |
sср |
|
|
4 |
122 |
-21,5 |
462,3 |
105 |
10,2 |
Ясно, что
величины DХ как-то характеризуют
разброс данных. На практике для усредненной характеристики разброса серии измерений используется
дисперсия выборки:

и среднеквадратичное или стандартное отклонение выборки:

Последнее
показывает, что каждое измерение в данной серии (в данной выборке) отличается
от другого в среднем на ± s.
Понятно, что каждое отдельное
значение оказывает влияние на средний результат. Но это влияние тем меньше, чем
больше измерений в нашей выборке. Поэтому дисперсия и стандартное отклонение
среднего значения, будет определяться по формулам:

Можем ли мы теперь определить вероятность того, что
истинное значение попадет в указанный интервал среднего? Или наоборот,
рассчитать тот доверительный интервал в который истинное значение
попадет с заданной вероятностью (95%)? Поскольку кривая на наших графиках это
распределение вероятностей, то площадь под кривой, попадающая в указанный
интервал и будет равна этой вероятности (доля площади, в процентах). А площади
математики научились рассчитывать хорошо, знать бы только уравнение этой
кривой.

И здесь мы сталкиваемся еще с одной сложностью. Кривая, которая описывает распределение
вероятности для выборки, для ограниченного числа измерений, уже не будет кривой нормального
распределения. Ее форма будет зависеть
не только от дисперсии (разброса данных) но и от степени свободы для выборки
(от числа независимых измерений) (рис 4):
Уравнения этих кривых впервые были предложены в 1908
году английским математиком и химиком Госсетом, который опубликовал их под
псевдонимом Student (студент), откуда пошло хорошо известные термины
«коэффициент Стьюдента» и аналогичные. Коэффициенты Стьюдента получены на
основе обсчета этих кривых для разных степеней свободы (f = n-1) и уровней
надежности (Р) и сведены в специальные таблицы. Для получения доверительного интервала необходимо
умножить уже найденное стандартное отклонение среднего на соответствующий
коэффициент Стьюдента. ДИ = sср*tf, P
Проанализируем, как меняется доверительный интервал
при изменении требований к надежности результата и числа измерений в серии.
Данные в таблице 2 показывают, что чем больше требование к надежности, тем
больше будет коэффициент Стьюдента и, следовательно, доверительный интервал. В большинстве случаев, приемлемым считают значение Р=95%
|
Таблица |
||||
|
P |
0,9 |
0,95 |
0,99 |
0,999 |
|
t5, |
2,02 |
2,57 |
4,03 |
6,87 |
|
Таблица |
|||||||
|
f= |
1 |
2 |
3 |
4 |
5 |
16 |
30 |
|
tf, |
12,7 |
4,3 |
3,18 |
2,78 |
2,57 |
2,23 |
2,04 |

Из таблицы 3 и графика
видно, что чем больше число измерений, тем меньше коэффициент и доверительный
интервал для данного уровня надежности. Особенно значительное падение
происходит при переходе от степени свободы 1 (два измерения) к 2 (три
измерения). Отсюда следует, что имеет смысл ставить не менее трех параллельных
опытов, проводить не менее трех измерений.
Окончательно
для измеряемой величины Х получаем значение Хсред±sср*tf,P. В
нашем случае получаем: f=3; t=3,18;
ДИ = 3,18*10,2 = 32,6; X = 143,5 ±32,6
Как правило,
значение доверительного интервала округляется до одной значащей цифры, а
значение измеряемой величины – в соответствии с округлением доверительного
интервала. Поэтому для нашей серии окончательно имеем: X = 140 ±30
Найденная
нами погрешность является абсолютной погрешностью и ничего не говорит еще о
точности измерений. Она свидетельствует о точности измерений только в сравнении
с измеряемой величиной. Отсюда представление об относительной ошибке:
![]()
Косвенные определения.
Исследуемая величина рассчитывается в этом случае с помощью
математических формул по другим величинам, которые были измерены
непосредственно. В этом случае для расчета ошибок можно использовать
соотношения, приведенные в таблице 4.
|
Таблица |
||
|
Формула |
Абсолютная |
Относительная |
|
x = a ± b |
Dx = Da+Db |
e = |
|
x = a* b; x = a* k |
Dx = bDa+aDb; Dx = kDa |
e = Da/a+Db/b = ea + e b |
|
x = a / b |
Dx = (bDa+aDb) / b2 |
e = Da/a+Db/b = ea + e b |
|
x = a*k; (x = a / k) |
Dx = Da*k; (Dx = Da/k ) |
e = ea |
|
x = a2 |
Dx = 2aDa |
e = 2Da/a = 2ea |
|
x = Öa |
Dx = Da/(2Öa) |
e = Da/2a = ea/2 |
Из таблицы видно, что относительная ошибка и точность определения не изменяются при умножении (делении) на некоторый постоянный коэффициент. Особенно сильно относительная ошибка может возрасти при вычитании
близких величин, так как при этом абсолютные ошибки суммируются, а значение Х
может уменьшиться на порядки.
Пусть например, нам необходимо определить
объем проволочки.
Если диаметр проволочки измерен с погрешностью 0,01 мм (микрометром) и равен 4 мм, то относительная погрешность составит 0,25% (приборная). Если
длину проволочки (200 мм) мы измерим линейкой с погрешностью 0,5 мм, то относительная погрешность также составит 0,25%. Объем можно рассчитать по формуле: V=(pd2/4)*L. Посмотрим, как будут меняться ошибки
по мере проведения расчетов (табл. 5):
|
Таблица 5. Расчет абсолютных и относительных ошибок. |
|||
|
Величина |
Значение |
Абсолютная |
Относительная |
|
d2 |
16 |
Dx = 2*4*0,01=0,08 |
e = 0,5% |
|
pd2 *) |
50,27 |
Dx = 0,08*3,14+0,0016*16 |
e = 0,55% |
|
pd2/4 |
12,57 |
Dx = 0,28/4 = 0,07 |
e = 0,55% |
|
(pd2/4)*L |
2513 |
Dx = 12,57*0,5+200*0,07=20 |
e = 0,8% |
|
*) Если мы возьмем привычное p=3,14, то Dp=0,0016 |
Окончательный
результат V=2510±20 (мм3) e
=0,8%. Чтобы повысить точность косвенного определения, нужно в первую очередь
повышать точность измерения той величины, которая вносит больший вклад в ошибку
(в данном случае – точность измерения диаметра проволочки).
План проведения измерений:
[1]
1. Знакомство
с методикой, подготовка прибора, оценка приборной погрешности d. Оценка возможных причин
систематических ошибок, их исключение.
2.
Проведение серии измерений. Если получены совпадающие результаты, можно
считать что случайная ошибка равна 0, DХ
= d. Переходим к пункту 7.
3.
Исключение промахов – результатов значительно отличающихся по своей
величине от остальных.
4.
Расчет
среднего значения Хср, и стандартного отклонение среднего
значения scp
5.
Задание значения уровня надежности P,
определение коэффициента Стьюдента t и
нахождение доверительного интервала ДИ= t*scp
6.
Сравнение случайной и приборной погрешности, при этом возможны варианты:
—
ДИ << d, можно
считать, что DХ = d, повысить точность измерения
можно, применив более точный прибор
—
ДИ >> d, можно
считать, что DХ = ДИ,
повысить точность можно, уменьшая случайную ошибку, повышая число измерений в
серии, снижая требования к надежности.
—
ДИ » d, в этом
случае расчитываем ошибку по формуле DХ
= ![]()
7.
Записывается окончательный результат Х = Хср ± DХ.
Оценивается относительная ошибка
измерения e = DХ/Хср
Если
проводится несколько однотипных измерений (один прибор, исследователь, порядок
измеряемой величины, условия) то подобную работу можно проводить один раз. В
дальнейшем можно считать DХ
постоянной и ограничиться минимальным числом измерений (два-три измерения
должны отличаться не более, чем на DХ)
Для косвенных
измерений необходимо провести обработку данных измерения каждой величины. При
этом желательно использовать приборы, имеющие близкие относительные погрешности
и задавать одинаковую надежность для расчета доверительного интервала. На
основании полученных значений Da, Db, определяется DХ
для результирующей величины (см табл. 4). Для повышения точности надо
совершенствовать измерение той величины, вклад ошибки которой в DХ наиболее существенен.
Изучение зависимостей.
Частым вариантом экспериментальной работы является
измерение различных величин с целью установления зависимостей. Характер этих
зависимостей может быть различен: линейный, квадратичный, экспоненциальный,
логарифмический, гиперболический. Для выявления зависимостей широко
используется построение графиков.
При построении графиков вручную важно правильно
выбрать оси, величины, масштаб, шкалы. Следует предупредить школьников, что
шкалы должны иметь равномерный характер, нежелательна как слишком детальная,
так и слишком грубая их разметка. Точки должны заполнять всю площадь графика,
их расположение в одном углу, или «прижатыми» к одной из осей, говорит о
неправильно выбранном масштабе и затрудняет определение характера зависимости.
При проведении линии по точкам надо использовать теоретические представление о
характере зависимости: является она непрерывной или прерывистой, возможно ли ее
прохождение через начало координат, отрицательные значения, максимумы и
минимумы.
Наиболее легко проводится и анализируется прямая
линия. Поэтому часто при изучении более сложных зависимостей часто используется
линеаризация зависимостей, которая достигается подходящей заменой переменных.
Например:
Зависимость ![]() . Вводя новую переменную
. Вводя новую переменную
![]() , получаем уравнение
, получаем уравнение
a = bx, которое
будет изображаться на графике прямой линией. Наклон этой прямой позволяет
рассчитать константу диссоциации.
Разумеется и в этом случае полученные в эксперименте данные включают в себя различные ошибки, и точки редко лежат строго на прямой. Возникает
вопрос, как с наибольшей точностью провести прямую по экспериментальным точкам, каковы ошибки в определении
параметров.
Математическая статистика показывает, что наилучшим
приближением будет такая линия, для которой дисперсия (разброс) точек
относительно ее будет минимальным. А дисперсия определяется как средний квадрат
отклонений наблюдаемого положения точки от расчитанного:

Отсюда название этого метода – метод наименьших
квадратов. Задавая условие, чтобы величина s2
принимала минимальное значение, получают формулы для коэффициентов а и b в уравнении прямой у = а + bx:

и формулы для расчета соответствующих ошибок
[2].

Если
делать расчеты, используя калькулятор, то лучше оформлять их в виде таблицы:
|
x |
x2 |
y |
y2 |
xy |
|
… |
… |
… |
… |
… |
|
… |
… |
… |
… |
… |
|
Sx = |
Sx2 |
Sy = |
Sy2 |
Sxy = |
Подводя
итог, следует сказать, что обработка данных эксперимента достаточно сложный
этап работы ученого. Необходимость проведения большого числа измерений требует
большой затраты времени и материальных ресурсов. Громоздкость формул, необходимость
использования большого числа значащих цифр затрудняют вычисления. Поэтому, возможно,
не все рекомендации этой статьи применимы в рамках школьного исследования. Но
понимать их сущность, значимость, необходимость, и в соответствии с этим
адекватно оценивать свои результаты, должен любой исследователь.
В настоящее время обработку экспериментальных данных
существенно облегчают современные компьютерные технологии, современное
программное обеспечение. Об том, как их можно использовать – в следующей
статье.
Литература:
[1]
Кассандрова О.Н., Лебедев В.В. Обработка результатов наблюдений, М., «Наука»,
1970, 194 с.
[2]
Петерс Д., Хайес Дж., Хифтье Г. Химическое разделение и измерение – М.,: Химия,
1978, 816 с.