
Систематическая погрешность измерения— это составляющая погрешности измерения,
остающаяся постоянной или закономерно
изменяющаяся при повторных измерениях
одной и той же величины. Систематические
погрешности разделяются на постоянные
(например, погрешность из-за смещения
нуля прибора) и переменные (например,
погрешность, обусловленная изменением
температуры окружающей среды). Рассмотрим
основные методы уменьшения систематических
погрешностей измерения.
3.2.1. Уменьшение постоянных систематических погрешностей
Для уменьшения постоянной систематической
погрешности наибольшее распространение
получили следующие методы: введение
поправок, метод замещения, метод
компенсации погрешности по знаку.
Введение поправок является широко
используемым методом исключения
систематических погрешностей. Поправкой
называют величину, которую надо прибавить
к результату измерения с целью
исключения систематической погрешности.
Рассмотрим введение поправки, если
результат измерения содержит аддитивную
0, мультипликативнуюSи обе составляющие погрешности.
В случае наличия аддитивной погрешности
она устраняется алгебраическим сложением
результата измерения Y и поправки а =
-0,
то есть
X = Y + а = Y —
0.
(3.4)
Если систематическая погрешность
является мультипликативной, то она
может быть исключена умножением
результата измерения Y на поправочный
коэффициент, который равен b= S/(S +S) [7]. В
этом случае имеем
Х = Y b = Y[S/(S +
S)],
(3.5)
где S — чувствительность средства
измерения; S —
абсолютная мультипликативная погрешность
(погрешность чувствительности).
При наличии обеих составляющих
погрешности результат измерения может
быть исправлен с помощью поправки и
поправочного коэффициента
Х = (Y
+ a)b. (3.6)
Поправки могут быть определены различными
способами: расчетным путем (например,
поправки на погрешность от собственного
потребления мощности средством
измерения); по результатам поверки
средств измерений в рабочих условиях,
что дает возможность учесть все
систематические погрешности без
выяснения причин их возникновения.
 Метод
Метод
замещения (метод разновременного
сравнения) является одним из наиболее
распространенных методов устранения
большинства систематических погрешностей
и заключается в том, что воздействие на
измерительный прибор измеряемой величины
заменяется эквивалентным, известным
воздействием на прибор регулируемой
меры. Измерение осуществляется в два
этапа. При сохранении условий эксперимента
неизменными за результат измерения
принимается значение известной величины,
определяемое по указателю переменной
меры. Погрешность измерения при этом
будет определяться погрешностью меры
и случайной погрешностью измерительного
прибора, умноженной на2.
Метод замещения широко используется
для повышения точности измерения
величин, для которых существуют точные
регулируемые меры (например, при
измерении сопротивлений, емкостей и
др.) [4].
Метод компенсации погрешности по
знакуприменяется для исключения
известных по природе, но неизвестных
по значению погрешностей, источники
которых имеют направленное действие
(погрешности от влияния магнитных
полей, термоЭДС и др.). Для устранения
таких погрешностей измерения проводят
дважды (или четное число раз) так, чтобы
систематическая погрешность входила
в результаты измерений с противоположными
знаками. Среднее значение из двух
полученных результатов является
окончательным результатом измерения
[4].
Реализация этого метода может
осуществляться двумя способами:
1) Изменением знака систематической
погрешностипри неизменном значении
измеряемой величины (например, для
исключения влияния внешнего магнитного
поля на показания магнитоэлектрического
прибора изменение знака погрешности
достигают поворотом прибора на 1800).
Х = (Y1+
Y2)/2 = (Х +С+Х -С),
(3.7)
где Y1= Х +С;
Y2= Х -С— результаты двух измерений величины
Х, содержащие систематическую погрешностьС, природа
которой известна.
2) Инвертированием входного сигналапри сохранении знака и значения
систематической погрешности (например,
при измерении постоянного напряжения
для исключения погрешности от термоЭДС
производится повторное измерение при
одновременном изменении полярности
измеряемого напряжения). При этом
результаты двух измерений Y1 и
-Y2, содержащих систематическую
погрешность, могут быть представлены
в виде
Y1= Х +С;
-Y2= -Х +С,
(3.8)
где Х и (-Х) — значение измеряемой
величины.
Окончательный результат измерения
определяется по формуле 3.7.
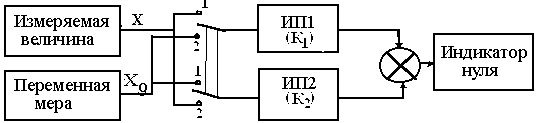 Метод
Метод
противопоставленияпозволяет
исключить мультипликативную составляющую
систематической погрешности. Для этого
проводят два измерения. В первом —
измеряемую величину Х подают на вход
измерительного преобразователя ИП1
(рис. 3.1) с коэффициентом преобразования
К1, а на вход второго преобразователя
ИП2 с коэффициентом преобразования
К2(К1К2) подают величину, воспроизводимую
мерой Х0. Затем изменением Х0производят уравновешивание. При этом
Х.К1, = Х01.К2.
При втором измерении объект измерения
и меру меняют местами и вновь производят
уравновешивание Х.К2=
ХО2.К1, (ХО1и ХО2— значения величин, воспроизводимых
мерой, которым соответствует нулевое
показание индикатора нуля).
Рис. 3.1
Если отношение коэффициентов преобразования
К1/К2остается постоянным,
то результат измерения Х не содержит
мультипликативной погрешности и его
можно определить как [7]
 Х =ХО1ХО2. (3.9)
Х =ХО1ХО2. (3.9)
При незначительном отличии
коэффициентов преобразования К1и К2друг от друга для определения
измеряемой величины Х можно использовать
приближенное выражение
Х (ХО1+ХО2)/2.
(3.10)
Примером метода противопоставления
является взвешивание на равноплечих
весах, при котором уравновешивание
весов осуществляется дважды. Во втором
случае взвешиваемое тело и гири меняются
местами. При этом устраняется погрешность,
обусловленная неравноплечестью весов.
Методы исключения систематических погрешностей
Результаты
измерений, содержащие систематическую
погрешность, относятся к неисправленным.
При проведении измерений стремятся
исключить, уменьшить или учесть влияние
систематических погрешностей. Однако
вначале их надо обнаружить.
Постоянные
систематические погрешности можно
обнаружить только путем сравнения
результатов измерений с другими,
полученными с использованием более
точных методов и средств измерения. В
ряде случаев такие погрешности можно
устранить, используя специальные методы
измерений.
Рассмотрим
наиболее известные методы исключения
(существенного уменьшения) постоянных
систематических погрешностей.
Метод замещения
обеспечивает наиболее полное решение
задачи компенсации постоянной
систематической погрешности. Суть
метода состоит в такой замене измеряемой
величины Хи известной величиной А,
получаемой с помощью регулируемой меры,
чтобы показание измерительного прибора
сохранилось неизменным. Значение
измеряемой величины считывается в этом
случае по указателю меры.
При использовании
данного метода погрешность неточного
измерительного прибора устраняется, а
погрешность измерения определяется
только погрешностью самой меры и
погрешностью отсчета измеряемой величины
по указателю меры.
Пример. Измерялось
сопротивление резистора Rx
омметром малой точности. Результат
измерения равен Х = Rx
+ Δс, где Х и Δс — соответственно показание
омметра и систематическая погрешность
измерения. Заменив Rx
магазином сопротивлений и отрегулировав
его так, чтобы сохранилось показание
омметра, получим Х = Rм
+ Δс. Из приведенных двух выражений для
х следует, что Rx
= Rм.
Метод компенсации
погрешности
по знаку
(метод двух отсчетов или изменения знака
систематической погрешности) используется
для устранения постоянной систематической
погрешности, у которой в зависимости
от условий измерения изменяется только
знак. При этом методе выполняют два
измерения, результаты которых должны
быть равны
Х1
= Хи + Δс
и
Х2
= Хи — Δс.
где Хи — измеряемая
величина. Среднее значение из полученных
результатов
(Х1
+ Х2)/2
= Хи
представляет собой
окончательный результат измерения, не
содержащий погрешности ±Δс. Данный
метод часто используется при измерении
экстремальных значений (максимума и
нуля) неизвестной величины.
Пример. Измерить
значение ЭДС потенциометром постоянного
тока, который обладает паразитной
термоЭДС.
Решение.
Уравновесив потенциометр и выполнив
первое измерение, получаем ЭДС U1.
Затем меняем полярность измеряемой
ЭДС, а значит и направление тока в
потенциометре. Снова проводим его
уравновешивание и в результате второго
измерения получаем значение U2.
Если термоЭДС дает погрешность ΔU
и напряжение
U1
= Ux
+ ΔU,
то U2
= Uх
— ΔU.
Отсюда напряжение
Ux
= (U1
+ U2)/2.
Итак, систематическая
погрешность, обусловленная действием
термоЭДС потенциометра, устранена.
Метод
противопоставления
применяется в радиоизмерениях для
уменьшения постоянных систематических
погрешностей при сравнении измеряемой
величины с известной величиной примерно
равного значения, воспроизводимой
соответствующей образцовой мерой. Этот
метод является разновидностью метода
сравнения, при котором измерение
выполняется дважды и проводится так,
чтобы в обоих случаях причина постоянной
погрешности оказывала разные, но
известные по закономерности воздействия
на результаты наблюдений.
Пример. Измерить
сопротивление резистора с помощью
одинарного моста методом противопоставления.
Решение. Сначала
измеряемое сопротивление Rx
уравновешивают образцовой мерой —
известным сопротивлением R1
включенным в плечо сравнения моста. При
этом
Rx
= R1R3/R4,
где R3,
R4
— сопротивления плеч моста. Затем
резисторы Rx
и R1
меняют местами и вновь уравновешивают
мост, регулируя сопротивление образцового
резистора R1
= R’1
В этом случае
Rx
= R’1R3/R4.
Из двух уравнений
для Rx
исключается отношение R3/R4.
Тогда
![]()
.
Метод рандомизации
(от англ. random
— случайный, беспорядочный; в переводе
на русский означает: перемешивание,
создание беспорядка, хаоса) основан на
принципе перевода систематических
погрешностей в случайные.
Этот метод
позволяет эффективно уменьшать постоянную
систематическую погрешность (методическую
и инструментальную) путем измерения
некоторой величины рядом однотипных
приборов с последующей оценкой результата
измерений в виде математического
ожидания (среднего арифметического
значения) выполненного ряда наблюдений.
В данном методе при обработке результатов
измерений используются случайные
изменения погрешности от прибора к
прибору. Уменьшение систематической
погрешности достигается и при изменении
случайным образом методики и условий
проведения измерений.
Поясним действие
метода рандомизации простым примером.
Пусть некоторая физическая величина
измеряется n
(число n
достаточно велико) однотипными приборами,
имеющими систематические погрешности
одинакового происхождения. Для одного
прибора эта погрешность — величина
постоянная, но от прибора к прибору она
изменяется случайным образом. Поэтому,
если измерить неизвестную величину n
приборами и затем вычислить математическое
ожидание всех результатов, то значение
погрешности существенно уменьшится
(как и в случае усреднения случайной
погрешности).
Метод введения
поправок.
Довольно часто систематические
погрешности могут быть вычислены и
исключены из результата измерения с
помощью поправки. Поправка С — величина,
одноименная с измеряемой Хи, которая
вводится в результат измерения Х = Хи +
Δс + С с целью исключения систематической
погрешности Δс,.. В случае С = -Δс,
систематическая погрешность полностью
исключается из результата измерения.
Поправки определяются экспериментально
или путем специальных теоретических
исследований и задаются в виде формул,
таблиц или графиков.
Наиболее просто
методом введения поправок исключают
постоянные инструментальные систематические
погрешности, которые обычно выявляют
посредством поверки средства измерения.
Пример. При
измерении напряжения в сети переменного
тока показания вольтметра составили
218 В. В свидетельстве о поверке прибора
указано, что на этой отметке его шкалы
систематическая погрешность вольтметра
составляет -2 В. С учетом поправки
напряжение в сети равно 218 + 2 = 220 В.
Пример. Напряжение
источника ЭДС Ux
измерено вольтметром, сопротивление
которого RV
= 5 кОм
определено с погрешностью ± 0,5 %. Внутреннее
сопротивление источника ЭДС Ri
= 60 ±10 Ом. Показание вольтметра Uv
= 12,50 В. Найти поправку, которую нужно
внести, и показание прибора для определения
действительного значения напряжения
источника.
Решение. Показания
вольтметра соответствуют падению
напряжения на нем:
![]()
Относительная
систематическая методическая погрешность,
обусловленная ограниченным значением
сопротивления RV,
![]()
Поправка измерения
напряжения равна абсолютной систематической
погрешности, взятой с обратным знаком:
Δс= 12,50-0,012 = 0,15В.
Погрешность
полученного значения поправки определяется
погрешностью, с которой известно
сопротивление Ri
а это Δ = ± 10 Ом. Ее предельное значение
составит
ΔсRi
= 10/60 = 0,167.
Погрешностью
ΔRV
= 0,005 неточности оценки RV
можно пренебречь. Следовательно,
погрешность определения поправки
Δ = ± 0,167 · 0,15 = 0,0251
≈ 0,03 В.
Итак, в показания
вольтметра необходимо ввести поправку:
ΔU=
+ 0,15 В.
Тогда исправленное
значение
![]()
= 12,5 + 0,15 = 12,65 В.
Этот результат
имеет определенную погрешность, в том
числе неисключенный остаток систематической
погрешности
Δ = ± 0,03 В
или
δ = ± 0,24 %
из-за потребления
некоторой мощности вольтметром.
Ввод одной
поправки позволяет исключить влияние
только одной составляющей систематической
погрешности. Для устранения всех
составляющих, в результат измерения
приходится вводить ряд поправок.
Рассмотрим далее
некоторые методы, применяющиеся для
обнаружения и уменьшения переменных и
монотонно изменяющихся во времени
систематических погрешностей.
Метод симметричных
наблюдений
весьма эффективен при выявлении и
исключении погрешности, являющейся
линейной функцией соответствующего
аргумента (амплитуды, напряжения,
времени, температуры и т. д.).
Предположим,
что измеряется величина Хи, а результаты
наблюдений Хi
зависят от времени t.
Для выявления характера изменения
погрешности выполняют несколько
наблюдений через равные промежутки
времени Δt.
Пусть выполнено пять наблюдений Х1
… Х5
в моменты времени t1
… t5.
Далее вычисляют средние арифметические
значения двух пар наблюдений
(Х1
+ Х5)/2
и (Х2
+ Х4)/2.
Наблюдения в
этих парах проведены в моменты t1,
t5
и t2,
t4,
симметричные относительно момента t3.
При линейном характере изменения
погрешности, полученные средние значения
должны быть одинаковы. Убедившись в
этом, результаты наблюдений можно
записать в виде
Хi
= Хи + kti
где k
— некоторая постоянная.
Пусть
Х1 = Хи + kt1
и Х2 = Хи + kt2.
Решение системы
этих уравнений дает значение Хи свободное
от переменной систематической погрешности:
Хи = (Х2t1
– X1t2)/(t2
– t1).
Подобным образом
удается исключить погрешности,
обусловленные, например, постепенным
падением уровня напряжения источника
питания (аккумулятора, батареи).
Метод анализа
знаков неисправленных случайных
погрешностей.
Когда знаки неисправленных случайных
погрешностей чередуются с некоторой
закономерностью, имеет место переменная
систематическая погрешность. Если у
случайных погрешностей последовательность
знаков «+» сменяется последовательностью
знаков «-» или наоборот, то присутствует
монотонно изменяющаяся систематическая
погрешность. Если же у случайных
погрешностей группы знаков «+» и «-»
чередуются, то имеет место периодическая
систематическая погрешность.
Графический
метод является
наиболее простым для обнаружения
переменной систематической погрешности
в ряде результатов наблюдений. При этом
методе рекомендуется построить график,
на который нанесены результаты наблюдений
в той последовательности, в какой они
были получены. На графике через точки
наблюдений проводят плавную линию,
которая выражает тенденцию результата
измерения, если она существует. Если
тенденция не прослеживается, то переменную
систематическую погрешность считают
практически отсутствующей.
В заключение
отметим, что при измерениях всегда
остаются неисключенные остатки
систематических погрешностей (НСП).
Вопрос №4
Случайные
погрешности (ошибки)
Случайными
являются такие ошибки, которые меняются
непредсказуемо от одного измерения к
другому при определении одной и той же
физической величины с помощью одной и
той же измерительной системы при
неизменных условиях. Обычно они
обусловлены большим числом факторов,
которые влияют на результат измерения
независимо. Мы не можем скорректировать
случайные ошибки, так как нам неизвестны
их причины и следствием их являются
случайные (непредсказуемые) колебания
результата измерения.
Примерами
случайных ошибок служат:
ошибки наблюдателя;
ошибки регулировки
и настройки Ипри;
ошибки округления
и т. д.
Все, о чем мы
можем говорить, имея дело со случайными
ошибками, это вероятность того, что
ошибка будет той или иной величины.
Теория вероятностей и мат. статистика
дают возможность делать определенные
утверждения при наличии случайных
ошибок.
Можно считать,
что как систематические, так и случайные
ошибки вызываются сигналом помехи,
который накладывается на истинный
сигнал при его измерении. Флюктуация
помехи вызывает случайную ошибку, а
постоянный сигнал помехи является
причиной систематической погрешности.
К сожалению, постоянный характер помехи
делает задачу обнаружения систематических
ошибок более трудной.
Влияние случайных
ошибок можно уменьшить, осуществляя
измерения несколько раз и принимая в
качестве конечного результата среднее
значение результатов отдельных измерений.
Возможно это тогда, когда измеряемая
величина не изменяется на протяжении
всех этих измерений и измерения
выполняются быстро. Среднее значение
![]()
результатов
![]()
измерений
![]()
имеет вид:
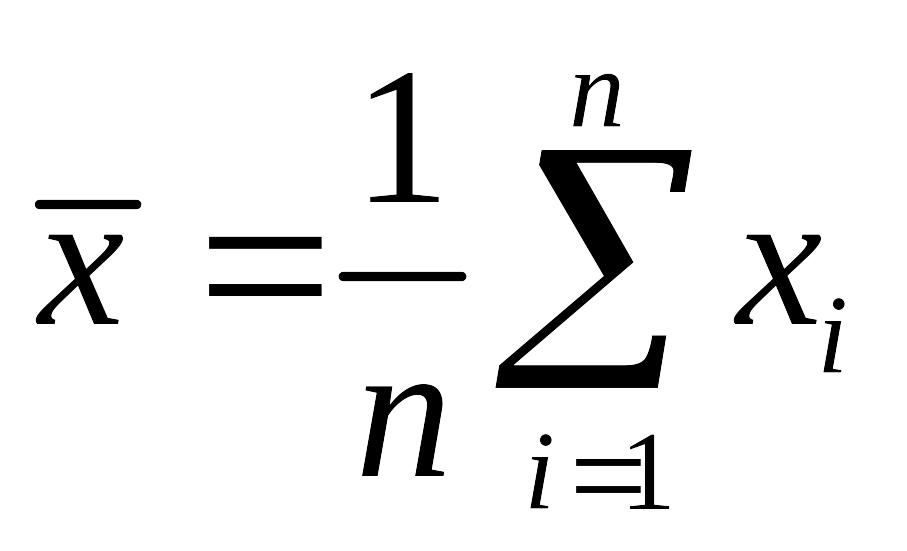
.
Среднее
![]()
представляет собой лучшую возможную
оценку значения
![]()
постоянной ФВ по
результатам измерений. Такой вывод
можно сделать из того факта, что

Таким образом,
сумма всех отклонений
![]()
равна нулю. Кроме того, величина
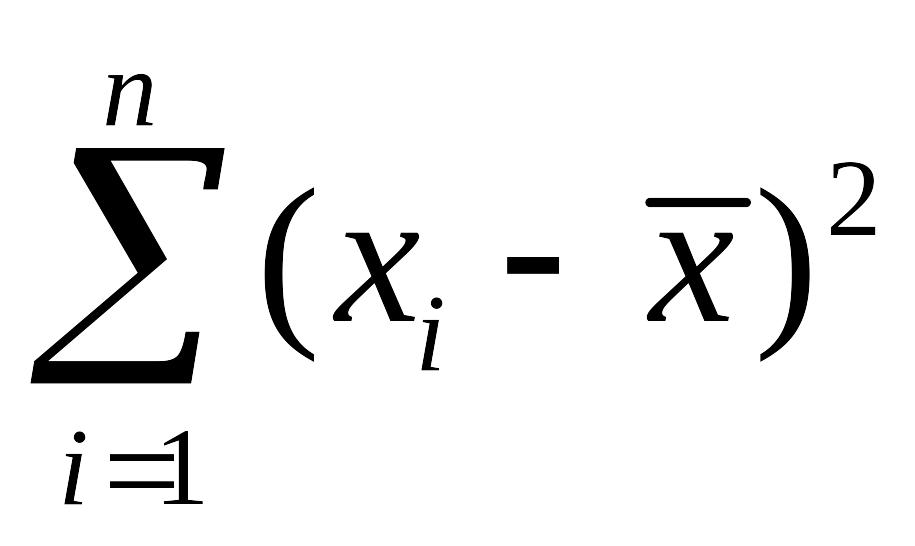
минимальна.
Другими словами,
минимальными являются рассеяние
или разброс выборочных значений
![]()
относительно среднего
.
Мерой рассеяния
в окрестности среднего
является дисперсия
![]()
(мера концентрированности распределения),
равная по определению,
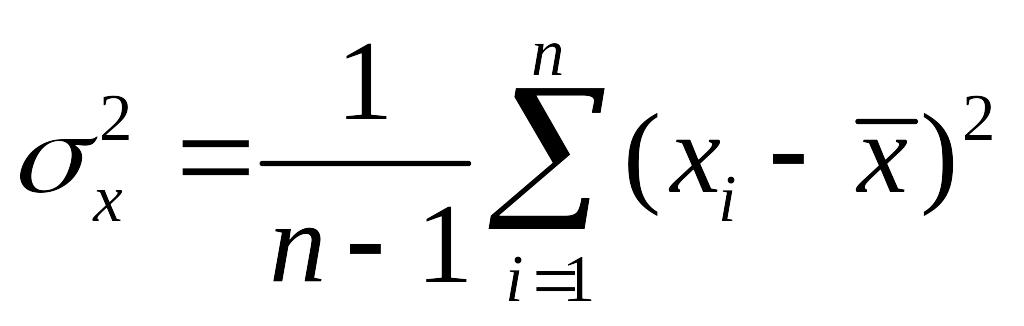
.
Обычно указывается
квадратный корень из дисперсии; эта
величина называется среднеквадратическим
отклонением
![]()
.
Выборки
,
полученные в отдельных измерениях
величины
,
при наличии случайный ошибок, можно
представить на диаграмме в виде столбцов.
Чтобы построить такую диаграмму, нам
следует разбить диапазон всех возможных
значений
![]()
,
включающий все выборки
полученные в измерениях, на небольшие
интервалы ширины
![]()
,
а затем отложить число выборок
![]()
,
попавших в эти небольшие интервалы
![]()
,
как функцию от
(см рис.1). Обычно размер мелких интервалов
выбирается по правилу
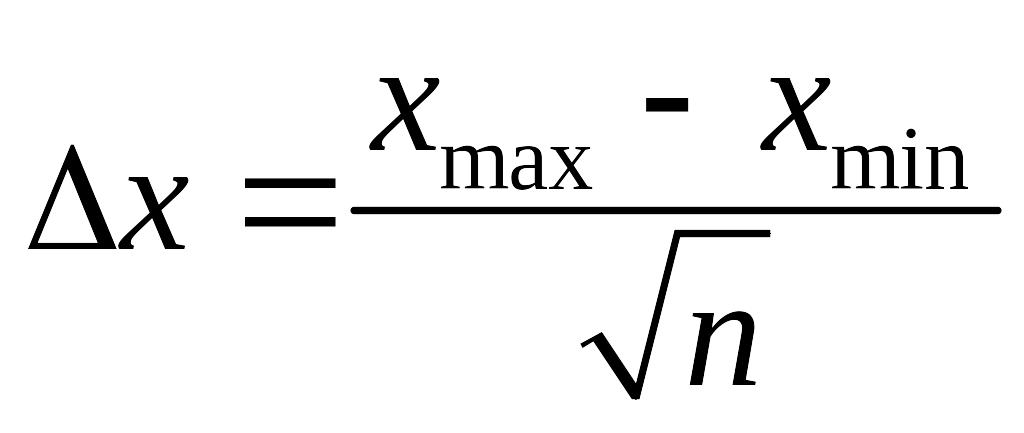
.
Если
![]()
,
то лучшее определить значение
по правилу Старджеса
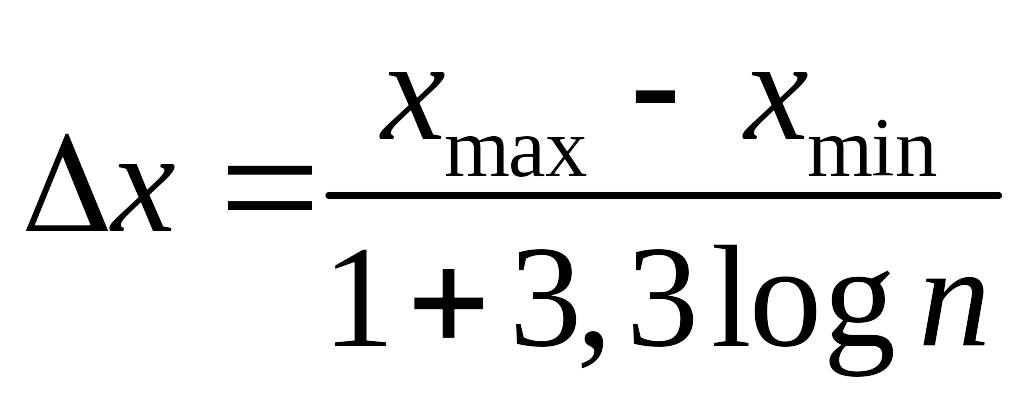
.
Если ширину
интервала
выбрать слишком малой, то «огибающая»
диаграммы будет сильно изрезанной. При
слишком большом значении
«огибающая» оказывается квантованной
слишком грубо, и форма распределения
проступает не так явно.
Можно построить
нормализованную диаграмму, откладывая
![]()
,
а не
![]()
.
Тогда по вертикали указывается
относительное число измерений, результаты
которых лежат в данном интервале. В этом
случае можно утверждать, что теперь по
оси ординат отложена вероятность
попадания результата измерения в данный
интервал. Кроме того, можно произвести
нормализацию также и по ширине интервала
,
откладывая
![]()
вместо
.
Диаграмму, получающуюся в результате
нормализации, обычно называют
гистограммой.

Рис.1 Гистограммы:
а.
при правильном выборе ширины интервалов
Δх,
на которые разбивается весь диапазон
возможных значений х;
-
при слишком малых
значениях Δх; -
при слишком больших
значениях Δх.
Если число
выборок растет, а диапазон
![]()
остается в ограниченных пределах, как
это бывает на практике при измерении
всех физических величин, то число
интервалов, на которые разбивается этот
диапазон, и число столбцов в гистограмме,
увеличиваются, тогда как ширина одного
интервала
уменьшается. При
![]()
огибающая гистограммы переходит в
гладкую кривую. Такая (дважды)
нормализованная гистограмма носит
название плотности
распределения вероятностей
![]()
.
По определению,
.
Это соотношение
можно также записать в виде:

.
Это означает,
что
![]()
есть вероятность того, что значение
выборки попадает в интервал между
и
![]()
;
отсюда и следует название: плотность
распределения вероятности.
Из последнего равенства следует, что
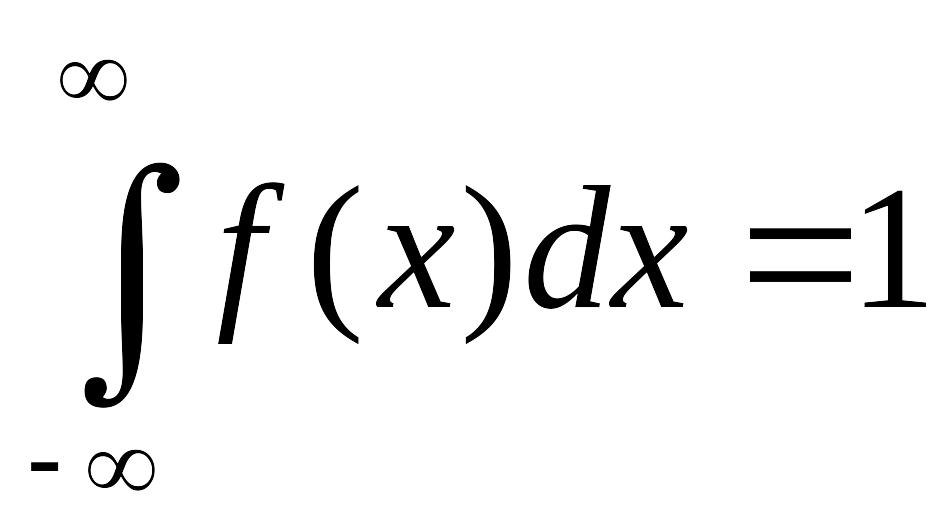
.
Интеграл в этом
выражении представляет собой сумму
всех вероятностей
.
Он равен вероятности того, что очередная
выборка попадет в первый интервал ширины
![]()
,
или во второй, или в третий и т.д. Так как
результат измерения должен принадлежать
одному из этих интервалов, сумма должна
равняться 1. Последнее соотношение
показывает, что единице равна площадь
под плотностью распределения вероятностей
(что и достигается, главным образом,
путем двукратной нормализации). Зная
плотность распределения вероятностей,
легко найти вероятность того, что
результат очередного измерения окажется
меньше определенного значения а
(см. рис.2).
Обозначая эту вероятность
![]()
,
получим
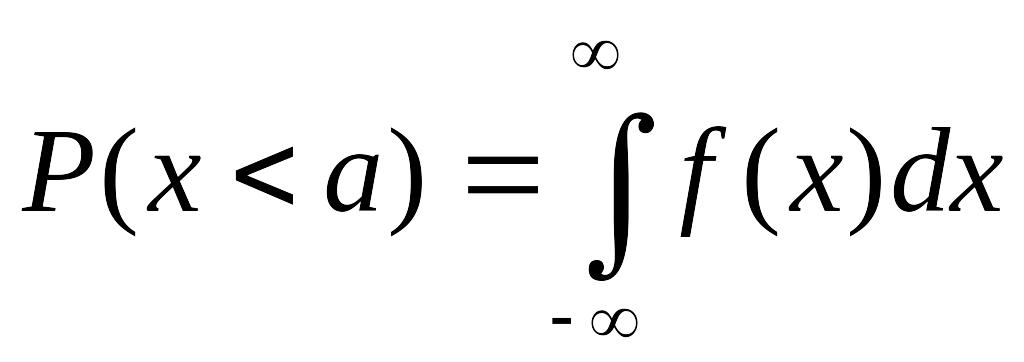
Эта величина в
точности равна площади под
слева от линии х
= а (см. рис.2).

Рис.2 Плотность
распределения вероятностей.
Точно так же при
заданной плотности распределения
можно найти среднее
набора выборочных значений
:
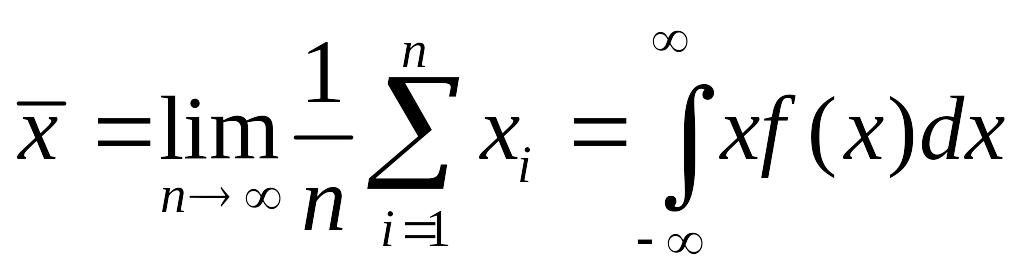
.
Эта величина
получила название
МОЖ случайной
величины и равна сумме бесконечно
большого числа произведений всех
возможных значений случайной величины
на бесконечно малые площади f(x)dx.
Дисперсию, как
меру рассеяния случайной величины,
можно представить в виде:
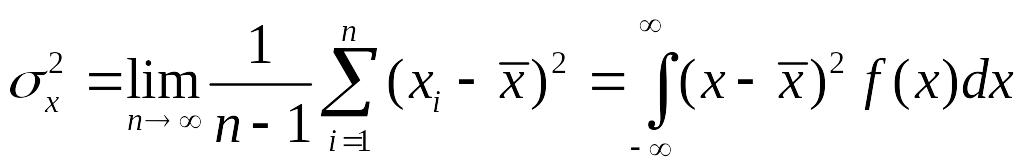
.
Отметим ещё раз,
что СКО
– это квадратный корень из дисперсии:
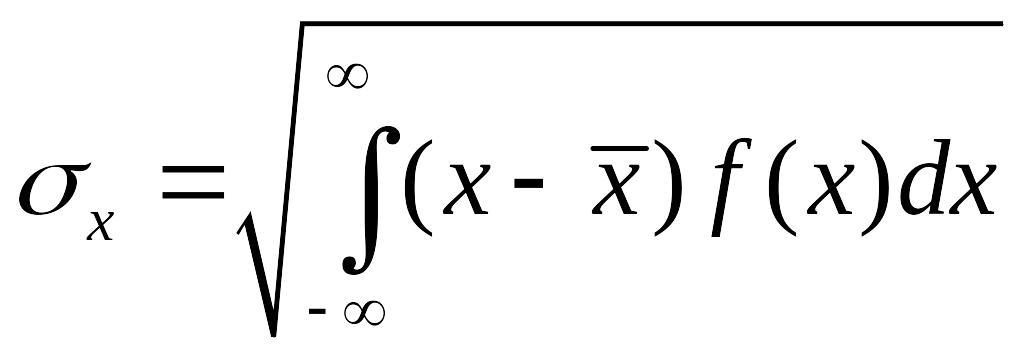
СКО
чаще всего используется для характеристики
рассеяния (степени разбросанности)
случайной величины и имеет ту же
размерность, что и сама случайная
величина.
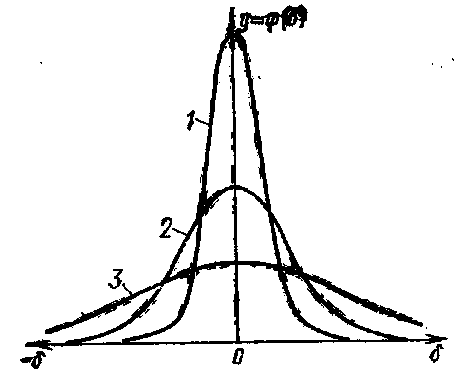
Рис. 3. Кривые
нормального распределения случайных
погрешностей: 1—σ = 0,5а; 2—σ = 1а; 3—σ = 2а,
где а — исходное значение

Рис. 4. Кривая
нормального распределения случайных
погрешностей и среднее квадратическое
отклонение ± σ
На рис.3 указаны
относительные значения среднего
квадратического отклонения σ. Как видим,
чем меньше σ, тем больше вероятность
появления малых погрешностей и меньше
вероятность появления больших
погрешностей. Другими словами, тем
больше сходимость результатов наблюдений.
Среднее
квадратическое отклонение соответствует
характерной точке кривой нормального
распределения. Абсциссам +σ, -σ соответствуют
точки перегиба кривой. Вероятность
того, что случайные погрешности измерения
не выйдут за пределы ±σ составляет
0,6826, приближенно 2/3. На рис.4 это
соответствует попаданию в заштрихованную
площадь, примерно в два раза большую,
чем в незаштрихованную.
Если ошибки,
содержащиеся в результатах измерений,
обусловлены большим числом взаимно
независимых событий, то можно доказать,
что они распределены по вполне
определенному закону: в этом случае
распределение вероятностей является
нормальным
или
гауссовым.
Доказательство
содержится в центральной
предельной теореме теории вероятностей.
Нормальное
распределение плотности вероятности
характерно тем, что, согласно центральной
предельной теореме теории вероятностей,
такое распределение имеет сумма
бесконечно большого числа бесконечно
малых случайных возмущений с любыми
распределениями. Применительно к
измерениям это означает, что нормальное
распределение случайных погрешностей
возникает тогда, когда на результат
измерения действует множество случайных
возмущений, ни одно из которых не является
преобладающим. Практически, суммарное
воздействие даже сравнительно небольшого
числа возмущений приводит к закону
распределения результатов и погрешностей
измерений, близкому к нормальному.
Плотность
вероятности нормального распределения
имеет вид:
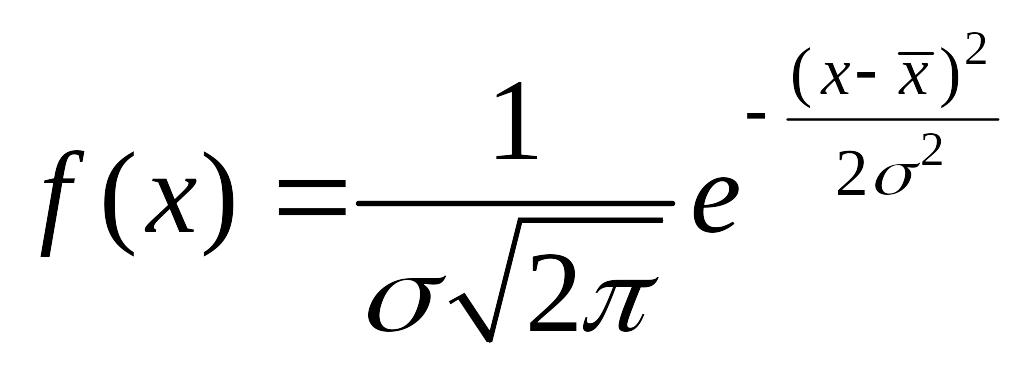
;
график такого
распределения показан на рис.5. Вероятности
того, что
![]()
или х >![]()
+ а, выражаются
следующими интегралами, соответственно:

и
![]()
;
эти интегралы
нельзя представить с помощью элементарных
функций.

Рис.5 Нормальное
или гауссово распределение
Примеры найденных
численно приближенных значений этих
интегралов представлены в табл.1.
«Вероятность того,
что результат измерения, имеющий
нормальное распределение со средним
значением и СКО, лежит вне интервалов
шириной 1![]()
,
2
и 3
с центром в точке
»
Табл.1
|
находится |
Вероятность |
|
|
0,32 |
|
|
0,045 |
|
|
0,0026 |
На рис.6 показан
случай, когда результаты измерений
содержат как случайные, так и систематические
ошибки. Здесь случайные ошибки распределены
по нормальному закону.
Истинное значение
измеряемой величины равно
а.
Систематическая ошибка вызывает сдвиг
среднего значения выборок, которое
равно b.
Полная ошибка (при верояности больших
уклонений 0,14%) равна сумме систематической
ошибки а-b
и
«максимальной случайной ошибки». Этой
полной ошибкой определяется погрешность
измерения. Неопределенность результата
измерения является мера разброса между
выборками, обусловленного только
случайными ошибками. Строго говоря,
неопределенность результата измерения
задается интервалом, в пределах которого
истинное значение измеряемой величины
находится с заданной доверительной
вероятностью.

Рис.6 Случайные и
систематические ошибки
Оценка результата
измерения.
Задача состоит в том, чтобы по полученным
экспериментальным путем результатам
наблюдений, содержащим случайные
погрешности, найти оценку истинного
значения измеряемой величины — результат
измерения. Будем полагать, что
систематические погрешности в результатах
наблюдений отсутствуют или исключены.
К оценкам,
получаемым по статистическим данным,
предъявляются требования состоятельности,
несмещенности и
эффективности.
Оценка называется
состоятельной,
если при увеличении числа наблюдений
она стремится к истинному значению
оцениваемой величины.
Оценка называется
несмещенной,
если ее математическое ожидание равно
истинному значению оцениваемой величины.
В том случае, когда можно найти несколько
несмещенных оценок, лучшей из них
считается та, которая имеет наименьшую
дисперсию. Чем меньше дисперсия оценки,
тем более эффективной считают эту
оценку.
Способы нахождения
оценок результата зависят от вида
функции распределения и от имеющихся
соглашений по этому вопросу, регламентируемых
в рамках законодательной метрологии.
Общие соображения по выбору оценок
заключаются в следующем.
Распределения
погрешностей результатов наблюдений,
как правило, являются симметричными
относительно центра распределения,
поэтому истинное значение измеряемой
величины может быть определено как
координата центра рассеивания Хц, т.е.
центра симметрии распределения случайной
погрешности (при условии, что систематическая
погрешность исключена). Отсюда следует
принятое в метрологии правило оценивания
случайной погрешности в виде интервала,
симметричного относительно результата
измерения (Хц ± Δх). Координата Хц может
быть найдена несколькими способами.
Наиболее общим является определение
центра симметрии из принципа симметрии
вероятностей, т.е. нахождение такой
точки на оси х, слева и справа от которой
вероятности появления различных значений
случайных погрешностей равны между
собой и составляют P1
= Р2
= 0,5. Такое значение Хц называется
медианой.
Координата Хц
может быть определена и как центр тяжести
распределения, т.е. как математическое
ожидание случайной величины.
При ассиметричной
кривой плотности распределения
вероятностей оценкой центра распределения
может служить абсцисса моды распределения,
т.е. координата максимума плотности.
Однако есть распределения, у которых
не существует моды (например, равномерное),
и распределения, у которых не существует
математического ожидания.
В практике
измерений встречаются различные формы
кривой закона распределения, однако
чаще всего имеют дело с нормальным и
равномерным распределением плотности
вероятностей.
Учитывая
многовариантность подходов к выбору
оценок и в целях обеспечения единства
измерений, правила обработки результатов
наблюдений обычно регламентируются
нормативно-техническими документами
(стандартами, методическими указаниями,
инструкциями). Так, в стандарте на методы
обработки результатов прямых измерений
с многократными наблюдениями указывается,
что приведенные в нем методы обработки
установлены для результатов наблюдений,
принадлежащих нормальному распределению.
Если вы устраняете систематическую ошибку модели, то уже слишком поздно

Введение
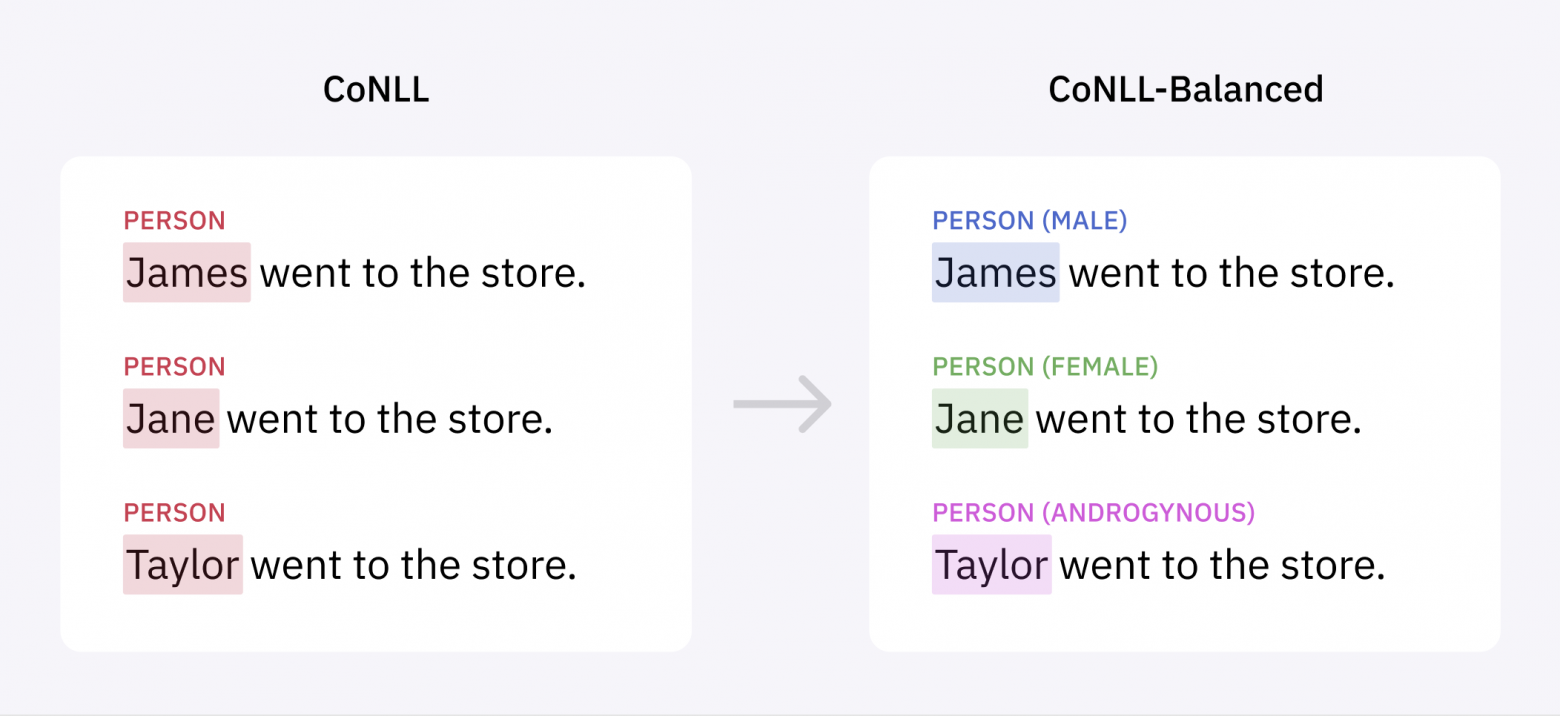
Машинное обучение — это технологический прорыв, случающийся раз в поколение. Однако с ростом его популярности основной проблемой становятся систематические ошибки алгоритма. Если модели ML не обучаются на репрезентативных данных, у них могут развиться серьёзные систематические ошибки, оказывающие существенный вред недостаточно представленным группам и приводящие к созданию неэффективных продуктов. Мы изучили массив данных CoNLL-2003, являющийся стандартом для создания алгоритмов распознавания именованных сущностей в тексте, и выяснили, что в данных присутствует серьёзный перекос в сторону мужских имён. При помощи наших технологии мы смогли компенсировать эту систематическую ошибку:
- Мы обогатили данные, чтобы выявить сокрытые систематические ошибки
- Дополнили массив данных недостаточно представленными примерами, чтобы компенсировать гендерный перекос
Модель, обученная на нашем расширенном массиве данных CoNLL-2003, характеризуется снижением систематической ошибки и повышенной точностью, и это показывает, что систематическую ошибку можно устранить без каких-либо изменений в модели. Мы выложили в open source наши аннотации Named Entity Recognition для исходного массива данных CoNLL-2003, а также его улучшенную версию, скачать их можно здесь.
Систематическая ошибка алгоритма: слабое место ИИ
Сегодня тысячи инженеров и исследователей создают системы, самостоятельно обучающиеся тому, как достигать существенных прорывов — повышать безопасность на дорогах при помощи беспилотных автомобилей, лечить болезни оптимизированными ИИ процедурами, бороться с изменением климата при помощи управления энергопотреблением.
Однако сила самообучающихся систем является и их слабостью. Так как фундаментом всех процессов машинного обучения являются данные, обучение на несовершенных данных может привести к искажённым результатам.
ИИ-системы имеют большие полномочия, поэтому они могут наносить существенный ущерб. Недавние протесты против полицейской жестокости, приведшей к смертям Джорджа Флойда, Бреонны Тейлор, Филандо Кастиле, Сандры Блэнд и многих других, является важным напоминанием о систематическом неравенстве в нашем обществе, которое не должны усугублять ИИ-системы. Но нам известны многочисленные примеры (закрепляющие гендерные стереотипы результаты поиска картинок, дискриминация чёрных подсудимых в системах управления данными нарушителей и ошибочная идентификация цветных людей системами распознавания лиц), показывающие, что предстоит пройти долгий путь, прежде чем проблема систематических ошибок ИИ будет решена.
Распространённость ошибок вызвана лёгкостью их внесения. Например, они проникают в «золотые стандарты» моделей и массивов данных в open source, ставшие фундаментом огромного объёма работы в сфере ML. Массив данных для определения эмоционального настроя текста word2vec, используемый в построении моделей других языков, искажён по этнической принадлежности, а word embeddings — способ сопоставления слов и значений алгоритмом ML — содержит сильно искажённые допущения о занятиях, с которыми ассоциируются женщины.
Проблема (и, как минимум, часть её решения) лежит в данных. Чтобы проиллюстрировать это, мы провели эксперимент с одним из самых популярных массивов данных для построения систем распознавания именованных сущностей в тексте: CoNLL-2003.
Что такое «распознавание именованных сущностей»?
Распознавание именованных сущностей (Named-Entity Recognition, NER) — один из фундаментальных камней моделей естественных языков, без него были бы невозможны онлайн-поиск, извлечение информации и анализ эмоционального настроя текста.
Миссия нашей компании заключается в ускорении разработки ИИ. Естественный язык — одна из основных сфер наших интересов. Наш продукт Scale Text содержит NER, заключающееся в аннотировании текста согласно заданному списку меток. На практике, среди прочего, это может помочь крупным розничным сетям анализировать онлайн-обсуждение их продуктов.
Многие модели NER обучаются и подвергаются бенчмаркам на CoNLL-2003 — массиве данных из примерно 20 тысяч предложений новостных статей Reuters, аннотированных такими атрибутами, как «PERSON», «LOCATION» и «ORGANIZATION».
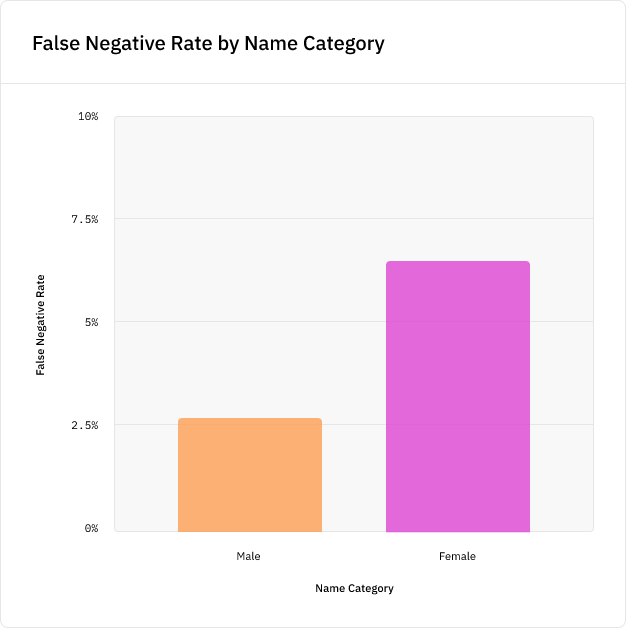
Нам захотелось изучить эти данные на наличие систематических ошибок. Для этого мы воспользовались своим конвейером разметки, чтобы категоризировать все имена в массиве данных, размечая их как мужские, женские или гендерно-нейтральные, исходя из традиционного использования имён.
При этом мы выявили существенную разницу. Мужские имена упоминались почти в пять раз чаще женских, и менее 2% имён были гендерно-нейтральными:

Это вызвано тем, что по социальным причинам новостные статьи в основном содержат мужские имена. Однако из-за этого модель NER, обученная на таких данных, лучше будет справляться с выбором мужских имён, чем женских. Например, поисковые движки используют модели NER для классификации имён в поисковых запросах, чтобы выдавать более точные результаты. Но если внедрить модель NER с перекосом, то поисковый движок хуже будет идентифицировать женские имена по сравнению с мужскими, и именно подобная малозаметная распространённая систематическая ошибка может проникнуть во многие системы реального мира.
Новый эксперимент по снижению систематической ошибки
Чтобы проиллюстрировать это, мы обучили модель NER для изучения того, как этот гендерный перекос повлияет на её точность. Был создан алгоритм извлечения имён, выбирающий метки PERSON при помощи популярной NLP-библиотеки spaCy, и на подмножестве данных CoNLL была обучена модель. Затем мы протестировали модель на новых именах из тестовых данных, не присутствовавших в данных обучения, и обнаружили, что модель с вероятностью на 5% больше пропустит новое женское имя, чем новое мужское имя, а это серьёзное расхождение в точности:
Мы наблюдали схожие результаты, когда применили модель к шаблону «NAME is a person», подставив 100 самых популярных мужских и женских имён на каждый год переписи населения США. Результаты работы модели оказались значительно хуже для женских имён во все года переписи:
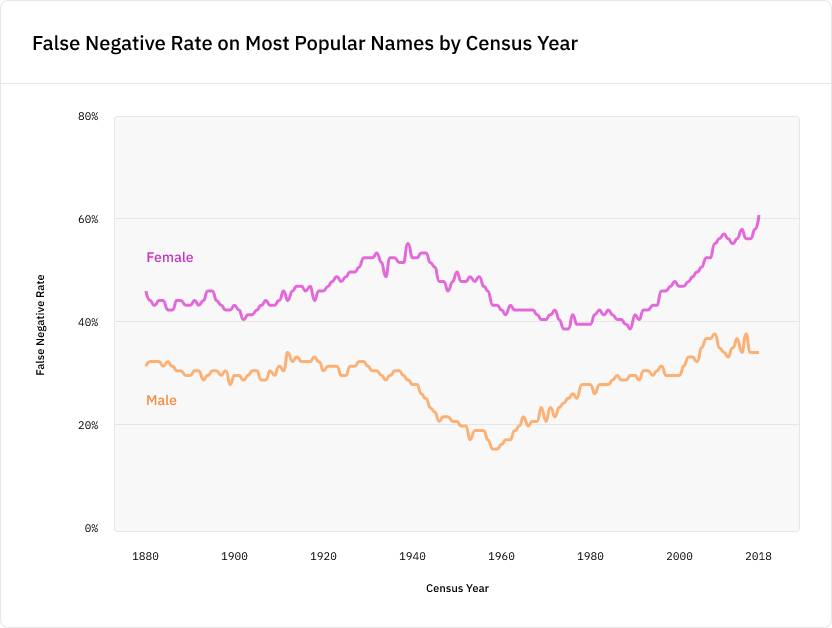
Критически важно то, что наличие перекоса в данных обучения приводит к смещению ошибок в сторону недостаточно представленных категорий. Эксперимент с переписями демонстрирует это и другим образом: точность модели существенно деградирует после 1997 года (точки отсечения статей Reuters в массиве данных CoNLL), потому что массив данных больше не является репрезентативным отображением популярности имён каждого последующего года.
Модели обучаются соответствовать трендам данных, на которых они обучены. Нельзя ожидать их хорошей точности в случаях, когда они видели лишь малое количество примеров.
Если вы исправляете систематическую ошибку модели, то уже слишком поздно
Как же это исправить?
Один из способов — попробовать устранить систематическую ошибку модели, например, выполнив постобработку модели или добавив целевую функцию для смягчения перекоса, оставив определение подробностей самой модели.
Но это не лучший подход по множеству причин:
- Справедливость — это очень сложная проблема, и мы не можем ждать, что алгоритм решит её сам. Исследование показало, что обучение алгоритма на одинаковый уровень точности для всех подмножеств населения не обеспечит справедливости и нанесёт вред обучению модели.
- Добавление новых целевых функций может навредить точности модели, приводя к негативному побочному эффекту. Вместо этого лучше обеспечить простоту алгоритма и сбалансированность данных, что повысит точность модели и позволит избежать негативных эффектов.
- Неразумно ожидать, что модель покажет хорошие результаты в случаях, примеров которых она видела очень мало. Наилучший способ обеспечения хороших результатов заключается в повышении разнообразия данных.
- Попытки устранения систематической ошибки при помощи инженерных техник — это дорогой и длительный процесс. Гораздо дешевле и проще изначально обучать модели на данных без перекосов, освободив ресурсы инженеров для работы над реализацией.
Данные — это лишь одна часть проблемы систематических ошибок. Однако эта часть фундаментальна и влияет на всё, что идёт после неё. Именно поэтому мы считаем, что данные содержат ключ к частичному решению, обеспечивая потенциальные систематические улучшения в исходных материалах. Если вы не размечаете критические классы (например, гендер или этническую принадлежность) явным образом, то невозможно сделать так, чтобы эти классы не были источником систематической ошибки.
Такая ситуация контринтуитивна. Кажется, что если нам нужно построить модель, не зависящую от чувствительных характеристик наподобие гендера, возраста или этнической принадлежности, то лучше исключить эти свойства из данных обучения, чтобы модель не могла их учитывать.
Однако принцип «справедливости, реализуемой через неведение» на самом деле усугубляет проблему. Модели ML превосходно справляются с выводом заключений из признаков, они не прекращают делать этого, если мы не разметили эти признаки явным образом. Систематические ошибки просто остаются невыявленными, из-за чего их сложнее устранить.
Единственный надёжный способ решения проблемы заключается в разметке большего количества данных, чтобы сбалансировать распределение имён. Мы использовали отдельную модель ML для идентификации предложений в корпусах Reuters и Brown, с большой вероятностью содержащих женские имена, а затем разметили эти предложения в нашем конвейере NER, чтобы дополнить CoNLL.
Получившийся массив данных, который мы назвали CoNLL-Balanced, содержит на 400 с лишним больше женских имён. После повторного обучения на нём модели NER мы обнаружили, что алгоритм больше не имеет систематической ошибки, приводящей к снижению показателей при распознавании женских имён:

Кроме того, модель улучшила показатели и при распознавании мужских имён.
Это стало впечатляющей демонстрацией важности данных. Благодаря устранению перекоса в исходном материале нам не пришлось вносить никаких изменений в нашу модель ML, что позволило сэкономить на времени разработки. И мы достигли этого без негативного влияния на точность модели; на самом деле, она даже слегка увеличилась.
Чтобы позволить сообществу разработчиков развивать нашу работу и устранять гендерный перекос в моделях, построенных на основе CoNLL-2003, мы выложили на наш веб-сайте дополненный массив данных в open source, в том числе и добавив гендерную информацию.
Сообщество разработчиков ИИ/ML имеет проблемы с культурными различиями, но мы испытываем умеренный оптимизм от этих результатов. Они намекают на то, что мы, возможно, сможем предложить техническое решение насущной социальной проблемы, если займёмся проблемой сразу же, выявим сокрытые систематические ошибки и улучшим точность модели для всех.
Сейчас мы изучаем, как этот подход можно применить к ещё одному критичному атрибуту — этнической принадлежности — чтобы придумать, как создать надёжную систему для устранения перекоса в массивах данных, распространяющегося и на другие охраняемые от дискриминации категории населения.
Кроме того, это показывает, почему наша компания уделяет так много внимания качеству данных. Если нельзя доказать, что данные точны, сбалансированы и лишены систематических ошибок, то нет гарантии того, что создаваемые на их основе модели будут безопасными и точными. А без этого мы не сможем создавать качественно новых ИИ-технологий, идущих на пользу всем людям.
Благодарности
Упоминаемый в этом посте массив данных CoNLL 2003 — это тестовый набор Reuters-21578, Distribution 1.0, доступный для скачивания на странице проекта исходного эксперимента 2003 года: https://www.clips.uantwerpen.be/conll2003/ner/.
From Wikipedia, the free encyclopedia
«Systematic bias» redirects here. For the sociological and organizational phenomenon, see Systemic bias.
Observational error (or measurement error) is the difference between a measured value of a quantity and its true value.[1] In statistics, an error is not necessarily a «mistake». Variability is an inherent part of the results of measurements and of the measurement process.
Measurement errors can be divided into two components: random and systematic.[2]
Random errors are errors in measurement that lead to measurable values being inconsistent when repeated measurements of a constant attribute or quantity are taken. Systematic errors are errors that are not determined by chance but are introduced by repeatable processes inherent to the system.[3] Systematic error may also refer to an error with a non-zero mean, the effect of which is not reduced when observations are averaged.[citation needed]
Measurement errors can be summarized in terms of accuracy and precision.
Measurement error should not be confused with measurement uncertainty.
Science and experiments[edit]
When either randomness or uncertainty modeled by probability theory is attributed to such errors, they are «errors» in the sense in which that term is used in statistics; see errors and residuals in statistics.
Every time we repeat a measurement with a sensitive instrument, we obtain slightly different results. The common statistical model used is that the error has two additive parts:
- Systematic error which always occurs, with the same value, when we use the instrument in the same way and in the same case.
- Random error which may vary from observation to another.
Systematic error is sometimes called statistical bias. It may often be reduced with standardized procedures. Part of the learning process in the various sciences is learning how to use standard instruments and protocols so as to minimize systematic error.
Random error (or random variation) is due to factors that cannot or will not be controlled. One possible reason to forgo controlling for these random errors is that it may be too expensive to control them each time the experiment is conducted or the measurements are made. Other reasons may be that whatever we are trying to measure is changing in time (see dynamic models), or is fundamentally probabilistic (as is the case in quantum mechanics — see Measurement in quantum mechanics). Random error often occurs when instruments are pushed to the extremes of their operating limits. For example, it is common for digital balances to exhibit random error in their least significant digit. Three measurements of a single object might read something like 0.9111g, 0.9110g, and 0.9112g.
Characterization[edit]
Measurement errors can be divided into two components: random error and systematic error.[2]
Random error is always present in a measurement. It is caused by inherently unpredictable fluctuations in the readings of a measurement apparatus or in the experimenter’s interpretation of the instrumental reading. Random errors show up as different results for ostensibly the same repeated measurement. They can be estimated by comparing multiple measurements and reduced by averaging multiple measurements.
Systematic error is predictable and typically constant or proportional to the true value. If the cause of the systematic error can be identified, then it usually can be eliminated. Systematic errors are caused by imperfect calibration of measurement instruments or imperfect methods of observation, or interference of the environment with the measurement process, and always affect the results of an experiment in a predictable direction. Incorrect zeroing of an instrument leading to a zero error is an example of systematic error in instrumentation.
The Performance Test Standard PTC 19.1-2005 “Test Uncertainty”, published by the American Society of Mechanical Engineers (ASME), discusses systematic and random errors in considerable detail. In fact, it conceptualizes its basic uncertainty categories in these terms.
Random error can be caused by unpredictable fluctuations in the readings of a measurement apparatus, or in the experimenter’s interpretation of the instrumental reading; these fluctuations may be in part due to interference of the environment with the measurement process. The concept of random error is closely related to the concept of precision. The higher the precision of a measurement instrument, the smaller the variability (standard deviation) of the fluctuations in its readings.
Sources[edit]
Sources of systematic error[edit]
Imperfect calibration[edit]
Sources of systematic error may be imperfect calibration of measurement instruments (zero error), changes in the environment which interfere with the measurement process and sometimes imperfect methods of observation can be either zero error or percentage error. If you consider an experimenter taking a reading of the time period of a pendulum swinging past a fiducial marker: If their stop-watch or timer starts with 1 second on the clock then all of their results will be off by 1 second (zero error). If the experimenter repeats this experiment twenty times (starting at 1 second each time), then there will be a percentage error in the calculated average of their results; the final result will be slightly larger than the true period.
Distance measured by radar will be systematically overestimated if the slight slowing down of the waves in air is not accounted for. Incorrect zeroing of an instrument leading to a zero error is an example of systematic error in instrumentation.
Systematic errors may also be present in the result of an estimate based upon a mathematical model or physical law. For instance, the estimated oscillation frequency of a pendulum will be systematically in error if slight movement of the support is not accounted for.
Quantity[edit]
Systematic errors can be either constant, or related (e.g. proportional or a percentage) to the actual value of the measured quantity, or even to the value of a different quantity (the reading of a ruler can be affected by environmental temperature). When it is constant, it is simply due to incorrect zeroing of the instrument. When it is not constant, it can change its sign. For instance, if a thermometer is affected by a proportional systematic error equal to 2% of the actual temperature, and the actual temperature is 200°, 0°, or −100°, the measured temperature will be 204° (systematic error = +4°), 0° (null systematic error) or −102° (systematic error = −2°), respectively. Thus the temperature will be overestimated when it will be above zero and underestimated when it will be below zero.
Drift[edit]
Systematic errors which change during an experiment (drift) are easier to detect. Measurements indicate trends with time rather than varying randomly about a mean. Drift is evident if a measurement of a constant quantity is repeated several times and the measurements drift one way during the experiment. If the next measurement is higher than the previous measurement as may occur if an instrument becomes warmer during the experiment then the measured quantity is variable and it is possible to detect a drift by checking the zero reading during the experiment as well as at the start of the experiment (indeed, the zero reading is a measurement of a constant quantity). If the zero reading is consistently above or below zero, a systematic error is present. If this cannot be eliminated, potentially by resetting the instrument immediately before the experiment then it needs to be allowed by subtracting its (possibly time-varying) value from the readings, and by taking it into account while assessing the accuracy of the measurement.
If no pattern in a series of repeated measurements is evident, the presence of fixed systematic errors can only be found if the measurements are checked, either by measuring a known quantity or by comparing the readings with readings made using a different apparatus, known to be more accurate. For example, if you think of the timing of a pendulum using an accurate stopwatch several times you are given readings randomly distributed about the mean. Hopings systematic error is present if the stopwatch is checked against the ‘speaking clock’ of the telephone system and found to be running slow or fast. Clearly, the pendulum timings need to be corrected according to how fast or slow the stopwatch was found to be running.
Measuring instruments such as ammeters and voltmeters need to be checked periodically against known standards.
Systematic errors can also be detected by measuring already known quantities. For example, a spectrometer fitted with a diffraction grating may be checked by using it to measure the wavelength of the D-lines of the sodium electromagnetic spectrum which are at 600 nm and 589.6 nm. The measurements may be used to determine the number of lines per millimetre of the diffraction grating, which can then be used to measure the wavelength of any other spectral line.
Constant systematic errors are very difficult to deal with as their effects are only observable if they can be removed. Such errors cannot be removed by repeating measurements or averaging large numbers of results. A common method to remove systematic error is through calibration of the measurement instrument.
Sources of random error[edit]
The random or stochastic error in a measurement is the error that is random from one measurement to the next. Stochastic errors tend to be normally distributed when the stochastic error is the sum of many independent random errors because of the central limit theorem. Stochastic errors added to a regression equation account for the variation in Y that cannot be explained by the included Xs.
Surveys[edit]
The term «observational error» is also sometimes used to refer to response errors and some other types of non-sampling error.[1] In survey-type situations, these errors can be mistakes in the collection of data, including both the incorrect recording of a response and the correct recording of a respondent’s inaccurate response. These sources of non-sampling error are discussed in Salant and Dillman (1994) and Bland and Altman (1996).[4][5]
These errors can be random or systematic. Random errors are caused by unintended mistakes by respondents, interviewers and/or coders. Systematic error can occur if there is a systematic reaction of the respondents to the method used to formulate the survey question. Thus, the exact formulation of a survey question is crucial, since it affects the level of measurement error.[6] Different tools are available for the researchers to help them decide about this exact formulation of their questions, for instance estimating the quality of a question using MTMM experiments. This information about the quality can also be used in order to correct for measurement error.[7][8]
Effect on regression analysis[edit]
If the dependent variable in a regression is measured with error, regression analysis and associated hypothesis testing are unaffected, except that the R2 will be lower than it would be with perfect measurement.
However, if one or more independent variables is measured with error, then the regression coefficients and standard hypothesis tests are invalid.[9]: p. 187 This is known as attenuation bias.[10]
See also[edit]
- Bias (statistics)
- Cognitive bias
- Correction for measurement error (for Pearson correlations)
- Errors and residuals in statistics
- Error
- Replication (statistics)
- Statistical theory
- Metrology
- Regression dilution
- Test method
- Propagation of uncertainty
- Instrument error
- Measurement uncertainty
- Errors-in-variables models
- Systemic bias
References[edit]
- ^ a b Dodge, Y. (2003) The Oxford Dictionary of Statistical Terms, OUP. ISBN 978-0-19-920613-1
- ^ a b John Robert Taylor (1999). An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements. University Science Books. p. 94, §4.1. ISBN 978-0-935702-75-0.
- ^ «Systematic error». Merriam-webster.com. Retrieved 2016-09-10.
- ^ Salant, P.; Dillman, D. A. (1994). How to conduct your survey. New York: John Wiley & Sons. ISBN 0-471-01273-4.
- ^ Bland, J. Martin; Altman, Douglas G. (1996). «Statistics Notes: Measurement Error». BMJ. 313 (7059): 744. doi:10.1136/bmj.313.7059.744. PMC 2352101. PMID 8819450.
- ^ Saris, W. E.; Gallhofer, I. N. (2014). Design, Evaluation and Analysis of Questionnaires for Survey Research (Second ed.). Hoboken: Wiley. ISBN 978-1-118-63461-5.
- ^ DeCastellarnau, A. and Saris, W. E. (2014). A simple procedure to correct for measurement errors in survey research. European Social Survey Education Net (ESS EduNet). Available at: http://essedunet.nsd.uib.no/cms/topics/measurement Archived 2019-09-15 at the Wayback Machine
- ^ Saris, W. E.; Revilla, M. (2015). «Correction for measurement errors in survey research: necessary and possible» (PDF). Social Indicators Research. 127 (3): 1005–1020. doi:10.1007/s11205-015-1002-x. hdl:10230/28341. S2CID 146550566.
- ^ Hayashi, Fumio (2000). Econometrics. Princeton University Press. ISBN 978-0-691-01018-2.
- ^ Angrist, Joshua David; Pischke, Jörn-Steffen (2015). Mastering ‘metrics : the path from cause to effect. Princeton, New Jersey. p. 221. ISBN 978-0-691-15283-7. OCLC 877846199.
The bias generated by this sort of measurement error in regressors is called attenuation bias.
Further reading[edit]
- Cochran, W. G. (1968). «Errors of Measurement in Statistics». Technometrics. 10 (4): 637–666. doi:10.2307/1267450. JSTOR 1267450.
From Wikipedia, the free encyclopedia
«Systematic bias» redirects here. For the sociological and organizational phenomenon, see Systemic bias.
Observational error (or measurement error) is the difference between a measured value of a quantity and its true value.[1] In statistics, an error is not necessarily a «mistake». Variability is an inherent part of the results of measurements and of the measurement process.
Measurement errors can be divided into two components: random and systematic.[2]
Random errors are errors in measurement that lead to measurable values being inconsistent when repeated measurements of a constant attribute or quantity are taken. Systematic errors are errors that are not determined by chance but are introduced by repeatable processes inherent to the system.[3] Systematic error may also refer to an error with a non-zero mean, the effect of which is not reduced when observations are averaged.[citation needed]
Measurement errors can be summarized in terms of accuracy and precision.
Measurement error should not be confused with measurement uncertainty.
Science and experiments[edit]
When either randomness or uncertainty modeled by probability theory is attributed to such errors, they are «errors» in the sense in which that term is used in statistics; see errors and residuals in statistics.
Every time we repeat a measurement with a sensitive instrument, we obtain slightly different results. The common statistical model used is that the error has two additive parts:
- Systematic error which always occurs, with the same value, when we use the instrument in the same way and in the same case.
- Random error which may vary from observation to another.
Systematic error is sometimes called statistical bias. It may often be reduced with standardized procedures. Part of the learning process in the various sciences is learning how to use standard instruments and protocols so as to minimize systematic error.
Random error (or random variation) is due to factors that cannot or will not be controlled. One possible reason to forgo controlling for these random errors is that it may be too expensive to control them each time the experiment is conducted or the measurements are made. Other reasons may be that whatever we are trying to measure is changing in time (see dynamic models), or is fundamentally probabilistic (as is the case in quantum mechanics — see Measurement in quantum mechanics). Random error often occurs when instruments are pushed to the extremes of their operating limits. For example, it is common for digital balances to exhibit random error in their least significant digit. Three measurements of a single object might read something like 0.9111g, 0.9110g, and 0.9112g.
Characterization[edit]
Measurement errors can be divided into two components: random error and systematic error.[2]
Random error is always present in a measurement. It is caused by inherently unpredictable fluctuations in the readings of a measurement apparatus or in the experimenter’s interpretation of the instrumental reading. Random errors show up as different results for ostensibly the same repeated measurement. They can be estimated by comparing multiple measurements and reduced by averaging multiple measurements.
Systematic error is predictable and typically constant or proportional to the true value. If the cause of the systematic error can be identified, then it usually can be eliminated. Systematic errors are caused by imperfect calibration of measurement instruments or imperfect methods of observation, or interference of the environment with the measurement process, and always affect the results of an experiment in a predictable direction. Incorrect zeroing of an instrument leading to a zero error is an example of systematic error in instrumentation.
The Performance Test Standard PTC 19.1-2005 “Test Uncertainty”, published by the American Society of Mechanical Engineers (ASME), discusses systematic and random errors in considerable detail. In fact, it conceptualizes its basic uncertainty categories in these terms.
Random error can be caused by unpredictable fluctuations in the readings of a measurement apparatus, or in the experimenter’s interpretation of the instrumental reading; these fluctuations may be in part due to interference of the environment with the measurement process. The concept of random error is closely related to the concept of precision. The higher the precision of a measurement instrument, the smaller the variability (standard deviation) of the fluctuations in its readings.
Sources[edit]
Sources of systematic error[edit]
Imperfect calibration[edit]
Sources of systematic error may be imperfect calibration of measurement instruments (zero error), changes in the environment which interfere with the measurement process and sometimes imperfect methods of observation can be either zero error or percentage error. If you consider an experimenter taking a reading of the time period of a pendulum swinging past a fiducial marker: If their stop-watch or timer starts with 1 second on the clock then all of their results will be off by 1 second (zero error). If the experimenter repeats this experiment twenty times (starting at 1 second each time), then there will be a percentage error in the calculated average of their results; the final result will be slightly larger than the true period.
Distance measured by radar will be systematically overestimated if the slight slowing down of the waves in air is not accounted for. Incorrect zeroing of an instrument leading to a zero error is an example of systematic error in instrumentation.
Systematic errors may also be present in the result of an estimate based upon a mathematical model or physical law. For instance, the estimated oscillation frequency of a pendulum will be systematically in error if slight movement of the support is not accounted for.
Quantity[edit]
Systematic errors can be either constant, or related (e.g. proportional or a percentage) to the actual value of the measured quantity, or even to the value of a different quantity (the reading of a ruler can be affected by environmental temperature). When it is constant, it is simply due to incorrect zeroing of the instrument. When it is not constant, it can change its sign. For instance, if a thermometer is affected by a proportional systematic error equal to 2% of the actual temperature, and the actual temperature is 200°, 0°, or −100°, the measured temperature will be 204° (systematic error = +4°), 0° (null systematic error) or −102° (systematic error = −2°), respectively. Thus the temperature will be overestimated when it will be above zero and underestimated when it will be below zero.
Drift[edit]
Systematic errors which change during an experiment (drift) are easier to detect. Measurements indicate trends with time rather than varying randomly about a mean. Drift is evident if a measurement of a constant quantity is repeated several times and the measurements drift one way during the experiment. If the next measurement is higher than the previous measurement as may occur if an instrument becomes warmer during the experiment then the measured quantity is variable and it is possible to detect a drift by checking the zero reading during the experiment as well as at the start of the experiment (indeed, the zero reading is a measurement of a constant quantity). If the zero reading is consistently above or below zero, a systematic error is present. If this cannot be eliminated, potentially by resetting the instrument immediately before the experiment then it needs to be allowed by subtracting its (possibly time-varying) value from the readings, and by taking it into account while assessing the accuracy of the measurement.
If no pattern in a series of repeated measurements is evident, the presence of fixed systematic errors can only be found if the measurements are checked, either by measuring a known quantity or by comparing the readings with readings made using a different apparatus, known to be more accurate. For example, if you think of the timing of a pendulum using an accurate stopwatch several times you are given readings randomly distributed about the mean. Hopings systematic error is present if the stopwatch is checked against the ‘speaking clock’ of the telephone system and found to be running slow or fast. Clearly, the pendulum timings need to be corrected according to how fast or slow the stopwatch was found to be running.
Measuring instruments such as ammeters and voltmeters need to be checked periodically against known standards.
Systematic errors can also be detected by measuring already known quantities. For example, a spectrometer fitted with a diffraction grating may be checked by using it to measure the wavelength of the D-lines of the sodium electromagnetic spectrum which are at 600 nm and 589.6 nm. The measurements may be used to determine the number of lines per millimetre of the diffraction grating, which can then be used to measure the wavelength of any other spectral line.
Constant systematic errors are very difficult to deal with as their effects are only observable if they can be removed. Such errors cannot be removed by repeating measurements or averaging large numbers of results. A common method to remove systematic error is through calibration of the measurement instrument.
Sources of random error[edit]
The random or stochastic error in a measurement is the error that is random from one measurement to the next. Stochastic errors tend to be normally distributed when the stochastic error is the sum of many independent random errors because of the central limit theorem. Stochastic errors added to a regression equation account for the variation in Y that cannot be explained by the included Xs.
Surveys[edit]
The term «observational error» is also sometimes used to refer to response errors and some other types of non-sampling error.[1] In survey-type situations, these errors can be mistakes in the collection of data, including both the incorrect recording of a response and the correct recording of a respondent’s inaccurate response. These sources of non-sampling error are discussed in Salant and Dillman (1994) and Bland and Altman (1996).[4][5]
These errors can be random or systematic. Random errors are caused by unintended mistakes by respondents, interviewers and/or coders. Systematic error can occur if there is a systematic reaction of the respondents to the method used to formulate the survey question. Thus, the exact formulation of a survey question is crucial, since it affects the level of measurement error.[6] Different tools are available for the researchers to help them decide about this exact formulation of their questions, for instance estimating the quality of a question using MTMM experiments. This information about the quality can also be used in order to correct for measurement error.[7][8]
Effect on regression analysis[edit]
If the dependent variable in a regression is measured with error, regression analysis and associated hypothesis testing are unaffected, except that the R2 will be lower than it would be with perfect measurement.
However, if one or more independent variables is measured with error, then the regression coefficients and standard hypothesis tests are invalid.[9]: p. 187 This is known as attenuation bias.[10]
See also[edit]
- Bias (statistics)
- Cognitive bias
- Correction for measurement error (for Pearson correlations)
- Errors and residuals in statistics
- Error
- Replication (statistics)
- Statistical theory
- Metrology
- Regression dilution
- Test method
- Propagation of uncertainty
- Instrument error
- Measurement uncertainty
- Errors-in-variables models
- Systemic bias
References[edit]
- ^ a b Dodge, Y. (2003) The Oxford Dictionary of Statistical Terms, OUP. ISBN 978-0-19-920613-1
- ^ a b John Robert Taylor (1999). An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements. University Science Books. p. 94, §4.1. ISBN 978-0-935702-75-0.
- ^ «Systematic error». Merriam-webster.com. Retrieved 2016-09-10.
- ^ Salant, P.; Dillman, D. A. (1994). How to conduct your survey. New York: John Wiley & Sons. ISBN 0-471-01273-4.
- ^ Bland, J. Martin; Altman, Douglas G. (1996). «Statistics Notes: Measurement Error». BMJ. 313 (7059): 744. doi:10.1136/bmj.313.7059.744. PMC 2352101. PMID 8819450.
- ^ Saris, W. E.; Gallhofer, I. N. (2014). Design, Evaluation and Analysis of Questionnaires for Survey Research (Second ed.). Hoboken: Wiley. ISBN 978-1-118-63461-5.
- ^ DeCastellarnau, A. and Saris, W. E. (2014). A simple procedure to correct for measurement errors in survey research. European Social Survey Education Net (ESS EduNet). Available at: http://essedunet.nsd.uib.no/cms/topics/measurement Archived 2019-09-15 at the Wayback Machine
- ^ Saris, W. E.; Revilla, M. (2015). «Correction for measurement errors in survey research: necessary and possible» (PDF). Social Indicators Research. 127 (3): 1005–1020. doi:10.1007/s11205-015-1002-x. hdl:10230/28341. S2CID 146550566.
- ^ Hayashi, Fumio (2000). Econometrics. Princeton University Press. ISBN 978-0-691-01018-2.
- ^ Angrist, Joshua David; Pischke, Jörn-Steffen (2015). Mastering ‘metrics : the path from cause to effect. Princeton, New Jersey. p. 221. ISBN 978-0-691-15283-7. OCLC 877846199.
The bias generated by this sort of measurement error in regressors is called attenuation bias.
Further reading[edit]
- Cochran, W. G. (1968). «Errors of Measurement in Statistics». Technometrics. 10 (4): 637–666. doi:10.2307/1267450. JSTOR 1267450.
Содержание
- Методы уменьшения систематических погрешностей.
- СПОСОБЫ УМЕНЬШЕНИЯ СИСТЕМАТИЧЕСКИХ ПОГРЕШНОСТЕЙ
- 1.5. Способы уменьшения систематических погрешностей
Методы уменьшения систематических погрешностей.
Для уменьшения постоянной систематической погрешности наибольшее распространение получили следующие методы: введение поправок, метод замещения, метод компенсации погрешности по знаку.
Введение поправок является широко используемым методом исключения систематических погрешностей. Поправкой называют величину, которую надо прибавить к результату измерения с целью исключения систематической погрешности.
Метод замещения (метод разновременного сравнения) является одним из наиболее распространенных методов устранения большинства систематических погрешностей и заключается в том, что воздействие на измерительный прибор измеряемой величины заменяется эквивалентным, известным воздействием на прибор регулируемой меры. Измерение осуществляется в два этапа. При сохранении условий эксперимента неизменными за результат измерения принимается значение известной величины, определяемое по указателю переменной меры. Погрешность измерения при этом будет определяться погрешностью меры и случайной погрешностью измерительного прибора, умноженной на Ö2. Метод замещения широко используется для повышения точности измерения величин, для которых существуют точные регулируемые меры (например, при измерении сопротивлений, емкостей и др.).
Метод компенсации погрешности по знаку применяется для исключения известных по природе, но неизвестных по значению погрешностей, источники которых имеют направленное действие (погрешности от влияния магнитных полей, термоЭДС и др.). Для устранения таких погрешностей измерения проводят дважды (или четное число раз) так, чтобы систематическая погрешность входила в результаты измерений с противоположными знаками. Среднее значение из двух полученных результатов является окончательным результатом измерения.
Реализация этого метода может осуществляться двумя способами:
1) Изменением знака систематической погрешности при неизменном значении измеряемой величины (например, для исключения влияния внешнего магнитного поля на показания магнитоэлектрического прибора изменение знака погрешности достигают поворотом прибора на 180 0 ).
где Y1 = Х + DС; Y2 = Х — DС — результаты двух измерений величины Х, содержащие систематическую погрешность DС, природа которой известна.
2) Инвертированием входного сигнала при сохранении знака и значения систематической погрешности (например, при измерении постоянного напряжения для исключения погрешности от термоЭДС производится повторное измерение при одновременном изменении полярности измеряемого напряжения). При этом результаты двух измерений Y1 и -Y2, содержащих систематическую погрешность, могут быть представлены в виде
где Х и (-Х) — значение измеряемой величины.
Окончательный результат измерения определяется по формуле 3.7.
5. Логометры: принцип действия, примеры конструкции приборов, основные соотношения, области применения.
Логометр — механизм приборов для измерения отношения сил двух электрических токов. Принцип действия Л. основан на том, что направленные встречно вращающие моменты, возникающие вследствие воздействия на подвижную часть Л. величин, входящих в измеряемое отношение, уравновешиваются при отклонении подвижной части на некоторый угол. Например, подвижную часть магнитоэлектрического Л. образуют две скрепленные под углом рамки, токи к которым подводятся через безмоментные спирали (рис.,а). Находясь в поле постоянного магнита, рамки стремятся повернуться в направлении действия большего момента, и подвижная часть отклоняется до тех пор, пока моменты не уравновесятся. Л. широко применяются в различных схемах для измерения электрических величин: ёмкости, индуктивности, сопротивления. Например, при использовании Л. в Омметре(рис., б) угол α, на который отклоняется подвижная часть Л., зависит только от отношения сил токов I1 и I2,
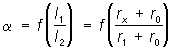 ;
;
т. e. при постоянных r0 и r1 отклонение подвижной части пропорционально измеряемому сопротивлению; шкала Л. градуируется непосредственно в омах (ом). Широко распространены также Л. электродинамических и ферродинамических систем.
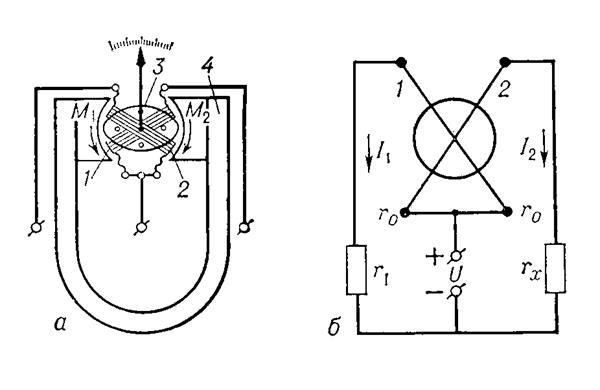
Устройство магнитоэлектрического логометра (а) и схема омметра с магнитоэлектрическим логометром (б): M1, M2 — вращающие моменты; l1, I2 — токи в цепях омметра; U — источник питания; r0 — сопротивление рамок логометра; r1 — омическое сопротивление; rx — измеряемое сопротивление; 1, 2 — рамки логометра; 3 — сердечник; 4 — постоянный магнит.
6. Цифровой вольтметр частотно-импульсного преобразования: принцип действия, структурная схема, основные соотношения, источник погрешности.
В этих вольтметрах измеряемая величина 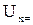 предварительно преобразуется в пропорциональное ей значение частоты
предварительно преобразуется в пропорциональное ей значение частоты 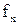 . Затем частота непосредственно преобразуется в цифровой код. Таким образом, эти ЦВ относятся к вольтметрам прямого преобразования. Однако поскольку измерение частоты всегда производится за определенный интервал времени (
. Затем частота непосредственно преобразуется в цифровой код. Таким образом, эти ЦВ относятся к вольтметрам прямого преобразования. Однако поскольку измерение частоты всегда производится за определенный интервал времени ( 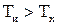 ), эти вольтметры всегда являются интегрирующими. Интегрирование в них является аналоговым, а при необходимости аналоговый интегрирующий ЦВ может быть дополнен устройством усреднения.
), эти вольтметры всегда являются интегрирующими. Интегрирование в них является аналоговым, а при необходимости аналоговый интегрирующий ЦВ может быть дополнен устройством усреднения.
Обобщенная структурная схема ИЦВ реализующего частотно-импульсный метод преобразования имеет следующий вид:

Как видно из этой схемы, основными функциональными узлами ИЦВ являются преобразователь напряжение-частота (ПН-Ч) и цифровой частотомер. В ПН-Ч измеряемое напряжение преобразуется в частоту, причем
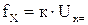 ,
,
где 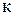 – коэффициент преобразования. Затем измеряется цифровым частотомером за время
– коэффициент преобразования. Затем измеряется цифровым частотомером за время 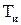 и его показания будут
и его показания будут
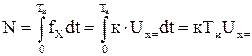 .
.
При  показания частотомера N пропорциональны и получаем прямоотсчетный вольтметр.
показания частотомера N пропорциональны и получаем прямоотсчетный вольтметр.
В настоящее время известно большое число схем ПН-Ч. В зависимости от метода преобразования в все схемы подразделяются на две группы: с непосредственным преобразованием и с косвенным преобразованием. В пределах каждой группы могут быть реализованы схемы с разомкнутым и замкнутым контурами, а при необходимости расширения диапазона может быть применено преобразование частоты.
В ПН-Ч первой группы само непосредственно используется для формирования выходного сигнала частоты . Характерными представителями таких ПН-Ч являются преобразователи с циклическим интегрированием. В ПН-Ч второй группы влияет на параметр, определяющий частоту генератора с самовозбуждением (гармонического или релаксационного). Эти ПН-Ч имеют относительно невысокие метрологические характеристики. Поэтому основное применение получили ПН-Ч на основе интегрирующих звеньев с замкнутым контуром.
Источник
СПОСОБЫ УМЕНЬШЕНИЯ СИСТЕМАТИЧЕСКИХ ПОГРЕШНОСТЕЙ
Так как систематические погрешности являются детерминированными величинами, уменьшение или даже полное исключение их возможно на всех этапах измерительного эксперимента: при планировании и подготовке эксперимента, в процессе измерений и при обработке их результатов.
На этапе планирования и подготовки эксперимента принципиальным является выбор метода и средства измерений, определение источников и номенклатуры систематических погрешностей, составление плана эксперимента и такая постановка его, которая уменьшала или позволяла бы оценить максимальное число выявленных погрешностей. Для этого, в частности, рекомендуется тщательно устанавливать нулевое показание и калибровать СИ, прогревать их в течение времени, указанного в инструкции по эксплуатации, применять при сборке короткие соединительные провода, а на высоких частотах — коаксиальные кабели, прибегать в необходимых случаях к экранированию и термостатированию, правильно размещать СИ (устанавливать в рабочее положение, размещать вдали от источников тепла и электромагнитных полей и т. п.), применять только предварительно поверенные СИ и т. д.
В процессе измерений систематические погрешности могут быть исключены с помощью одного из следующих способов.
Способ замещения, при котором измеряемый объект заменяется образцовой мерой, находящейся в тех же условиях, что и сам объект. Способ замещения является, кроме того, одной из модификаций метода сравнения (см. § 1.1.2). Поэтому он широко применяется в практике электрорадиоизмерений и будет проиллюстрирован на большом количестве конкретных примеров.
Способ компенсации по знаку, при котором измерение проводят дважды так, чтобы неизвестная по абсолютному значению, но известная по своей природе систематическая погрешность входила в результаты наблюдений с противоположными знаками. Тогда полусумма их результатов будет свободна от этой погрешности. Так можно, например, исключать погрешности из-за трения, люфта механизма перестройки и др. Разновидностью этого способа является способ противопоставления, применяемый для исключения погрешностей при сравнении измеряемой величины с известной величиной примерно равного значения, воспроизводимой соответствующей образцовой мерой.
Способ симметричных наблюдений, который оказывается весьма эффективным при исключении прогрессивной погрешности, являющейся линейной функцией соответствующего аргумента (например, времени, температуры и т. д.). Измерения проводят последовательно через одинаковые интервалы изменения аргумента, а обработку полученных результатов осуществляют с учетом равенства среднего значения погрешности любой пары симметричных наблюдений погрешности, соответствующей средней точке данного интервала.
Эффективным способом уменьшения систематических погрешностей является их рандомизация, т. е. перевод в случайные. Пусть, например, имеется n однотипных приборов с систематической погрешностью одинакового происхождения. Если для данного прибора эта погрешность постоянна, то от прибора к прибору она изменяется случайным образом. Поэтому измерение одной и той же величины всеми приборами и усреднение результатов полученных наблюдений позволяет значительно уменьшить эту погрешность. Того же эффекта можно добиться, изменяя методику и условия эксперимента или те параметры, от которых не зависит значение измеряемой величины, но зависят систематические погрешности ее измерения.
Систематические погрешности с известными значениями и знаками могут быть исключены и после проведения измерений при обработке их результатов. С этой целью в неисправленные результаты наблюдений вводятся поправки (q) или эти результаты умножаются на поправочные множители (η):
X=X΄+ q или X=X΄η (1.5)
Числовые значения q и η определяются по данным оценок соответствующих систематических погрешностей. Результаты наблюдений, получаемые по формулам (1.5), называются исправленными
Источник
1.5. Способы уменьшения систематических погрешностей
Имеются несколько стандартных приемов уменьшения систематических погрешностей. К ним относятся следующие.
Соблюдение и поддержание постоянными внешних условий измерений, включая уменьшение внешних воздействующих факторов: нагрева, электрических и магнитных полей, радиопомех и других непреднамеренных излучений, влажности, статических, механических напряжений и т.п.
Если в качестве средства измерений применяется измерительный прибор, то бывает полезно произвести сравнение измеряемой ФВ с более точной мерой этой же величины, используя измерительный прибор в качестве компаратора.
Индивидуальная градуировка измерительного прибора — по существу это сравнение с более точной мерой, однако в приборе «запоминаются» более точные значения меры на более длительный срок. В области радиоизмерений, имеющих дело с измерениями физических величин в широком диапазоне частот, индивидуальная градуировка является наиболее распространенным способом уменьшения систематической погрешности, возникающей из-за неопределенности частотных свойств измерительного прибора. Результатом индивидуальной градуировки может быть составление таблицы или графика поправок, введением которых в результат измерения уменьшают систематическую погрешность.
Метод противоположного влияния или компенсации погрешности по знаку. При этом выполняют два измерения, изменяя процедуру таким образом, чтобы предполагаемая погрешность имела другой знак. Так, например, оператор предполагает наличие термоЭДС в цепи измерений малых напряжений. В этом случае изменение полярности подключения микровольтметра позволяет ввести эту неизвестную термоЭДС в результат измерения с разными знаками. Усредняя затем результаты, можно исключить предполагаемую составляющую систематической погрешности.
Введение поправки, значение которой получено расчетом. Для реализации этого метода необходимо разработать физическую модель измерительного эксперимента, выполняемого методом косвенных измерений, или измерительного прибора. На основе физической модели составляется математическая модель, часто эта модель называется уравнением измерения (формулой измерения) y = y(x1, x2, . xn). Это уравнение связывает значение искомой ФВ (функцию y) с результатами прямых измерений величин xi — аргументов, получаемых при прямых измерениях. Значение систематической погрешности и, следовательно, поправки определяют как полный дифференциал функции y на основе известных дифференциалов аргументов, то есть на основе систематических погрешностей прямых измерений
 . (1.2)
. (1.2)
Если известны абсолютные значения и знаки Δxi, то можно определить знак и численное значение Δy и ввести соответствующую поправку. Производные 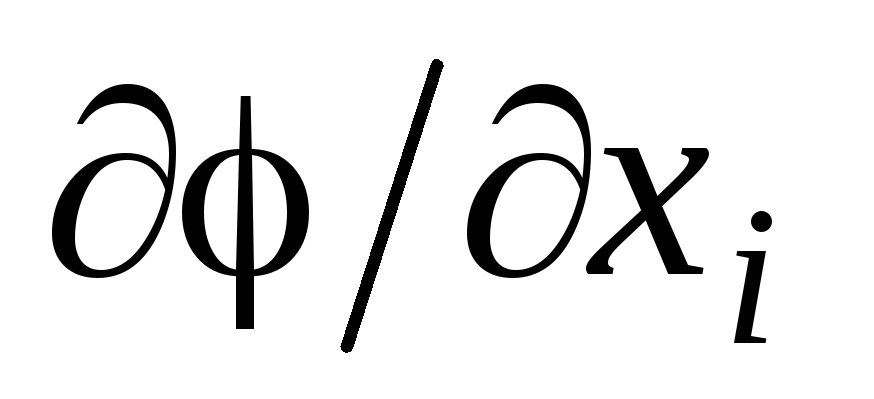 называют коэффициентами влияния, а величины
называют коэффициентами влияния, а величины — частными составляющими погрешности.
— частными составляющими погрешности.
Иногда неизвестны ни численные значения Δxi, ни их знаки, а известны только границы неисключенных систематических погрешностей прямых измерений. В этом случае границы систематической погрешности результата косвенного измерения Δс определяются формулой:
 . (1.3)
. (1.3)
Однако поправка в результат измерений не может быть введена.
Еще один способ уменьшения систематической погрешности — перевод систематической погрешности в случайную (метод рандомизации, от английского слова «random»). Этот метод применим, когда имеется источник систематической погрешности, значение которой может изменяться случайным образом при повторении измерений. Так, например, при наличии люфта, зоны нечувствительности и трения в измерительном механизме весов их показания могут устанавливаться случайным образом в определенных пределах. Повторяя от начала до конца всю процедуру взвешивания несколько раз подряд, можно перевести систематическую погрешность, имеющую место в каждом отдельном измерении, в случайную погрешность. Другой пример, характерный для радиоизмерений при сверхвысоких частотах, это погрешность, вызываемая неопределенностью коаксиальных соединителей. Эти соединители вносят потери и отражения, которые влияют на результат измерений. Для измерений при данном конкретном присоединении измерительного прибора погрешность из-за потерь и отражений является систематической. Однако, при повторных соединениях она может принимать различные значения в определенных границах. Поэтому, повторяя присоединение и измерение несколько раз, можно перевести данную систематическую погрешность в случайную, определить среднее значение и, благодаря этому, снизить границы неисключенной систематической погрешности, возникающей за счет неидеальности соединителя.
Источник