
Необходимо включить JavaScript
Для корректной работы этого сайта
включите JavaScript.
Войдите с Яндекс ID
Номер мобильного телефона
Создать ID
Войти с помощью
Яндекс ID — ключ от всех сервисов Узнать больше
Что такое валидатор файла robots.txt?
Инструмент проверки Robots.txt создан для того, чтобы показать, правильно ли составлен ваш файл robots.txt, нет ли в нем ошибок. Robots.txt — этот файл, который является частью вашего веб-сайта и описывает правила индексации для роботов поисковых машин, чтобы веб-сайт индексировался правильно, и первыми на сайте индексировались самые важные данные (без каких-либо скрытых платежей).Это очень простой инструмент, который создает отчет уже через несколько секунд сканирования: вам просто ввести в поле URL своего веб-сайта, через слэш /robots.txt (например, yourwebsite.com/robots.txt), а затем нажать на кнопку “проверить”. Наш инструмент для тестирования файлов robots.txt находит все ошибки (опечатки, синтаксические и “логические”) и выдает советы по оптимизации файла robots.txt.
Зачем нужно проверять файл robots.txt?
Проблемы с файлом robots.txt или его отсутствие могут негативно отразиться на SEO-оптимизации сайта: ваш сайт может не выдаваться на странице результатов выдачи поисковых машин (SERP). Это происходит из-за того, что нерелевантный контент может обходиться до или вместо важного контента.Проверить свой файл перед тем, как обходить контент важно, чтобы вы смогли избежать проблем, когда весь контент на сайте индексируется, а не только самый релевантный. Например, вы хотите, чтобы доступ к основному контенту вашего веб-сайта пользователи получали только после того, как заполнят форму подписки или войдут в свою учетную запись, но вы не исключаете ее в правилах файла robot.txt, и поэтому она может проиндексироваться.
Что означают ошибки и предупреждения?
Есть определенный список ошибок, которые могут повлиять на эффективность файла robots.txt, а также вы можете увидеть при проверке файла список определенных рекомендаций. Это вещи, которые могут повлиять на SEO-оптимизацию сайта, и которые нужно исправить. Предупреждения менее критичны, и это просто советы о том, как улучшить ваш сайт robots.txt.Ошибки, которые вы можете увидеть:Invalid URL: эта ошибка сообщает о том, что файл robots.txt на сайте отсутствует.Potential wildcard error: технически это больше предупреждение, чем сообщение об ошибке. Это сообщение обычно означает, что в вашем файле robots.txt содержится символ (*) в поле Disallow (например, Disallow: /*.rss). Это проблема приемлемого использования синтаксиса: Google не запрещает использование символов в поле Disallow, но это не рекомендуется.Generic and specific user-agents in the same block of code: это синтаксическая ошибка в файле robots.txt, которую нужно исправить, чтобы избежать проблем с индексацией контента на вашем веб-сайте.Предупреждения, которые вы можете увидеть:Allow: / : порядок разрешения не повредит и не повлияет на ваш веб-сайт, но это не стандартная практика. Самые крупные поисковые машины, включая Google и Bing, примут эту директиву, но не все программы-кроулеры будут такими же неразборчивыми. Если говорить начистоту, то всегда лучше сделать файл robots.txt совместимым со всеми программами-индексаторами, а не только с самыми популярными.Field name capitalization: несмотря на то, что имена полей не чувствительны к регистру, некоторые индексаторы могут требовать писать их заглавными буквами, так что хорошей идеей будет делать это по умолчанию — специально для самых привередливых программ.Sitemap support: во многих файлах robots.txt содержатся данные о карте сайта, но это не считается хорошим решением. Однако, Google и Bing поддерживают эту возможность.
Как исправить ошибки в файле Robots.txt?
Насколько просто будет исправить ошибки в файле robots.txt? Зависит от платформы, которую вы используете. Если это WordPress, то лучше воспользоваться плагином типа WordPress Robots.txt Optimization или Robots.txt Editor. Если вы подключили свой веб-сайт к веб-службе Google Search Console, вы сможете редактировать свой файл robots.txt прямо в ней.Некоторые конструкторы веб-сайтов типа Wix не дают возможности редактировать файл robots.txt напрямую, но позволяют добавлять неиндексируемые теги для определенных страниц.
С помощью этого инструмента вы можете узнать, запрещает ли файл robots.txt поисковым роботам Google сканировать определенные URL на вашем сайте. Предположим, у вас есть изображение, которое не должно появляться в результатах поиска Google Картинок. Наш инструмент позволит вам проверить, закрыт ли роботу Googlebot-Image доступ к этому файлу.
Попробовать
Вам потребуется только указать нужный URL. После этого инструмент проверки обработает файл robots.txt так, как это сделал бы робот Googlebot, и определит, закрыт ли доступ к этому адресу.
Процедура проверки
- В Search Console выберите ваш сайт, перейдите к инструменту проверки и изучите код в файле
robots.txt. Синтаксические и логические ошибки в нем будут выделены, а их количество – указано под окном редактирования. - Внизу на странице интерфейса укажите нужный URL в специальном текстовом поле.
- В раскрывающемся меню справа выберите робота.
- Нажмите кнопку ПРОВЕРИТЬ.
- Отобразится статус ДОСТУПЕН или НЕДОСТУПЕН. В первом случае роботы Google могут переходить по указанному вами адресу, а во втором – нет.
- При необходимости внесите изменения в код, указанный в Search Console, и выполните проверку заново. Внимание! Эти исправления не будут автоматически внесены в файл robots.txt на вашем сайте.
- Скопируйте измененный код и добавьте его в файл robots.txt на вашем веб-сервере.
На что следует обратить внимание
- Инструмент работает только с ресурсами с префиксом в URL и несовместим с доменными ресурсами.
- Изменения, внесенные в редакторе, не сохраняются на веб-сервере. Необходимо скопировать полученный код и вставить его в файл
robots.txt. - Инструмент проверки файла robots.txt предоставляет результаты только для агентов пользователя Google и роботов, относящихся к Google (например, для робота Googlebot)
. Мы не можем гарантировать, что другие поисковые роботы будут обрабатывать код в вашем файлеrobots.txtаналогичным образом.
Эта информация оказалась полезной?
Как можно улучшить эту статью?
Файл robots.txt — это инструкция для поисковых роботов. В ней указывается, какие разделы и страницы сайта могут посещать роботы, а какие должны пропускать. В фокусе этой статьи — проверка robots.txt. Мы рассмотрим советы по созданию файла для начинающих веб-разработчиков, а также разберем, как делать анализ robots.txt с помощью стандартных инструментов Яндекс и Google.
Зачем нужен robots.txt
Поисковые роботы — это программы, которые сканируют содержимое сайтов и заносят их в базы поисковиков Яндекс, Google и других систем. Этот процесс называется индексацией.
robots.txt содержит информацию о том, какие разделы нельзя посещать поисковым роботам. Это нужно для того, чтобы в выдачу не попадало лишнее: служебные и временные файлы, формы авторизации и т. п. В поисковой выдаче должен быть только уникальный контент и элементы, необходимые для корректного отображения страниц (изображения, CSS- и JS-код).
Если на сайте нет robots.txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
Если же файл есть в корневой папке сайта на хостинге, роботы сначала обращаются к прописанным в нём правилам. Они узнают, куда нельзя заходить, а какие страницы/разделы обязательно нужно посетить. И только после этого начинают обход сайта по инструкции.
Веб-разработчикам следует создать файл, если его нет, и наполнить его правильными директивами (командами) для поисковых роботов. Ниже кратко рассмотрим основные директивы для robots.txt.
Основные директивы robots.txt
Структура файла robots.txt выглядит так:
- Директива User-agent. Обозначает, для каких поисковых роботов предназначены правила в документе. Здесь можно указать все поисковые системы (для этого используется символ «*») или конкретных роботов (Yandex, Googlebot и другие).
- Директива Disallow (запрет индексации). Указывает, какие разделы не должны сканировать роботы. Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.
- Директива Allow (разрешение). Указывает, какие разделы или файлы должны просканировать поисковые роботы. Здесь не нужно указывать все разделы сайта: все, что не запрещено к обходу, индексируется автоматически. Поэтому следует задавать только исключения из правила Disallow.
- Sitemap (карта сайта). Полная ссылка на файл в формате .xml. Sitemap содержит список всех страниц, доступных для индексации, а также время и частоту их обновления.
Пример простого файла robots.txt (после # указаны пояснительные комментарии к директивам):
User-agent: * # правила ниже предназначены для всех поисковых роботов
Disallow: /wp-admin # запрет индексации служебной папки со всеми вложениями
Disallow: /*? # запрет индексации результатов поиска на сайте
Allow: /wp-admin/admin-ajax.php # разрешение индексации JS-скрипты темы WordPress
Allow: /*.jpg # разрешение индексации всех файлов формата .jpg
Sitemap: http://site.ru/sitemap.xml # адрес карты сайта, где вместо site.ru — домен сайтаСоветы по созданию robots.txt
Для того чтобы файл читался поисковыми программами корректно, он должен быть составлен по определенным правилам. Даже детали (регистр, абзацы, написание) играют важную роль. Рассмотрим несколько основных советов по оформлению текстового документа.
Группируйте директивы
Если требуется задать различные правила для отдельных поисковых роботов, в файле нужно сделать несколько блоков (групп) с правилами и разделить их пустой строкой. Это необходимо, чтобы не возникало путаницы и каждому роботу не нужно было сканировать весь документ в поисках подходящих инструкций. Если правила сгруппированы и разделены пустой строкой, робот находит нужную строку User-agent и следует директивам. Пример:
User-agent: Yandex # правила только для ПС Яндекс
Disallow: # раздел, файл или формат файлов
Allow: # раздел, файл или формат файлов
# пустая строка
User-agent: Googlebot # правила только для ПС Google
Disallow: # раздел, файл или формат файлов
Allow: # раздел, файл или формат файлов
Sitemap: # адрес файлаУчитывайте регистр в названии файла
Для некоторых поисковых систем не имеет значение, какими буквами (прописными или строчными) будет обозначено название файла robots.txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
Не указывайте несколько каталогов в одной директиве
Для каждого раздела/файла нужно указывать отдельную директиву Disallow. Это значит, что нельзя писать Disallow: /cgi-bin/ /authors/ /css/ (указаны три папки в одной строке). Для каждой нужно прописывать свою директиву Disallow:
Disallow: /cgi-bin/
Disallow: /authors/
Disallow: /css/Убирайте лишние директивы
Часть директив robots.txt считается устаревшими и необязательными: Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующегося контента). Вы можете удалить эти директивы, чтобы не «засорять» файл.
Как проверить robots.txt онлайн
Чтобы убедиться в том, что файл составлен грамотно, можно использовать веб-инструменты Яндекс, Google или онлайн-сервисы (PR-CY, Website Planet и т. п.). В Яндекс и Google есть собственные правила для проверки robots.txt. Поэтому файл необходимо проверять дважды: и в Яндекс, и в Google.
Яндекс.Вебмастер
Если вы впервые пользуетесь сервисом Яндекс.Вебмастер, сначала добавьте свой сайт и подтвердите права на него. После этого вы получите доступ к инструментам для анализа SEO-показателей сайта и продвижения в ПС Яндекс.
Чтобы проверить robots.txt с помощью валидатора Яндекс:
-
1.
Зайдите в личный кабинет Яндекс.Вебмастер.
-
2.
Выберите в левом меню раздел Инструменты → Анализ robots.txt.
-
3.
Содержимое нужного файла подставиться автоматически. Если по какой-то причине этого не произошло, скопируйте код, вставьте его в поле и нажмите Проверить:

-
4.
Ниже будут указаны результаты проверки. Если в директивах есть ошибки, сервис покажет, какую строку нужно поправить, и опишет проблему:


Google Search Console
Чтобы сделать проверку с помощью Google:
-
1.
Перейдите на страницу инструмента проверки.
-
2.
Если на открывшейся странице отображается неактуальная версия robots.txt, нажмите кнопку Отправить и следуйте инструкциям Google:
-
3.
Через несколько минут вы можете обновить страницу. В поле будут отображаться актуальные директивы. Предупреждения/ошибки (если система найдет их) будут перечислены под кодом.
Проверка robots.txt Google не выявила ошибок
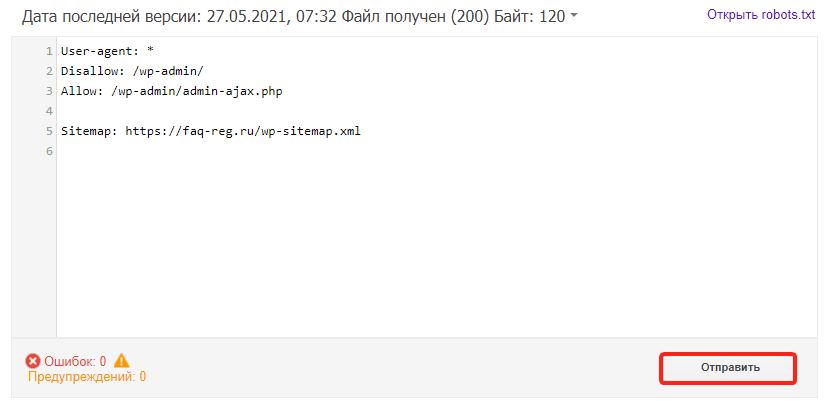

Обратите внимание: правки, которые вы вносите в сервисе проверки, не будут автоматически применяться в robots.txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
В этой статье мы рассмотрим:
- Что такое robots.txt?
- Все директивы файла:
- Disallow и Allow
- Sitemap
- Host
- Crawl-delay
- Clean-param
- Использование спецсимволов
- Как проверить корректную работу файла
- Часто допускаемые ошибки
- Примеры robots.txt для различных CMS:
- WordPress
- Joomla
- Bitrix
Что такое robots.txt?
Robots.txt — это текстовый файл, который содержит в себе рекомендации для действий поисковых роботов. В этом файле находятся инструкции (директивы), с помощью которых можно ограничить доступ поисковых роботов к определённым папкам, страницам и файлам, задать скорость сканирования сайта, указать главное зеркало или адрес карты сайта.
Обход сайта поисковыми роботами начинается с поиска файла роботс. Отсутствие файла не является критической ошибкой. В таком случае роботы считают, что ограничений для них нет и они полностью могут сканировать сайт.
Файл должен быть размещён в корневом каталоге сайта и быть доступен по адресу https://mysite.com/robots.txt.
Инструкции стандарта исключения для роботов носят рекомендательный характер, а не являются прямыми командами для роботов. То есть существует вероятность, что даже закрыв страницу в robots.txt, она всё равно попадёт в индекс.
Указывать директивы в файле нужно только латиницей, использовать кириллицу запрещено. Русские доменные имена можно преобразовать с помощью кодировки Punycode.

Что нужно закрыть от индексации в robots.txt?
- страницы с личной информацией пользователей;
- корзину и сравнение товаров;
- переписку пользователей;
- административную часть сайта;
- скрипты.
Как создать robots.txt?
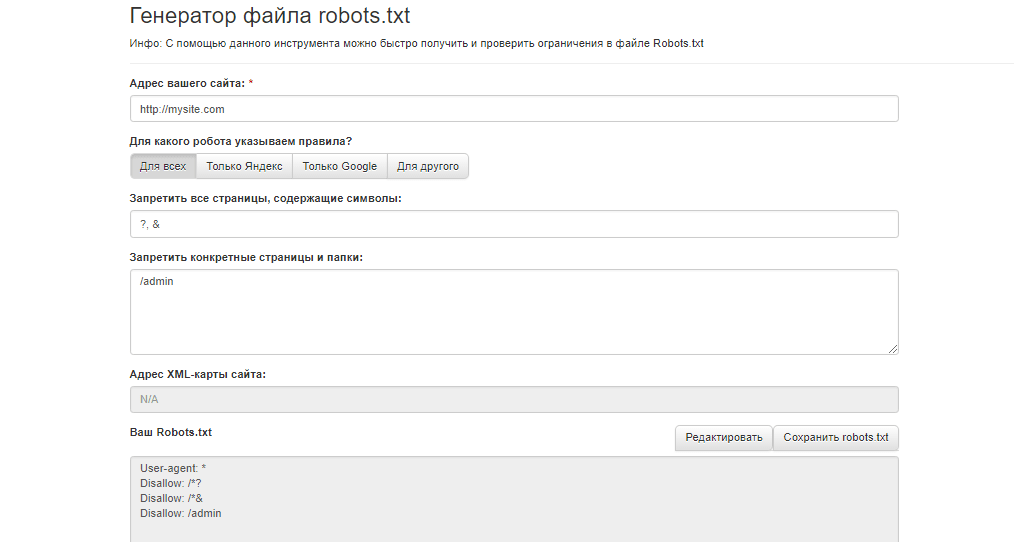
Составить файл можно в любом текстовом редакторе (блокнот, TextEdit и др.). Можно создать файл robots.txt для сайта онлайн, воспользовавшись генератором файла, например, инструментом сервиса Seolib.
Нужен ли robots.txt?
Прописав правильные инструкции, боты не будут тратить краулинговый бюджет (количество URL, которое может обойти поисковый робот за один обход) на сканирование бесполезных страниц, а проиндексируют только нужные для поиска страницы. В дополнение, не будет перегружаться работа сервера.
Директивы robots.txt
Файл роботс состоит из основных директив: User-agent и Disallow и дополнительных: Allow, Sitemap, Host, Crawl-delay, Clean-param. Ниже мы разберём все правила, для чего они нужны и как их правильно прописать.
User-agent — приветствие с роботом
Существует множество роботов, которые могут сканировать сайт. Наиболее популярными являются боты поисковых систем Google и Яндекса.
Роботы Google:
- Googlebot;
- Googlebot-Video;
- Googlebot-News;
- Googlebot-Image.
Роботы Яндекса:
- YandexBot;
- YandexDirect;
- YandexDirectDyn;
- YandexMedia;
- YandexImages;
- YaDirectFetcher;
- YandexBlogs;
- YandexNews;
- YandexPagechecker;
- YandexMetrika;
- YandexMarket;
- YandexCalendar.
В директиве User-agent указывают, к какому роботу обращены инструкции.
Для обращения ко всем роботам достаточно прописать следующую строку в файле:

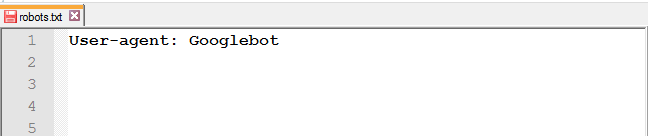
Для обращения к определённому роботу, например, к Google, нужно прописать в этой строке его имя:
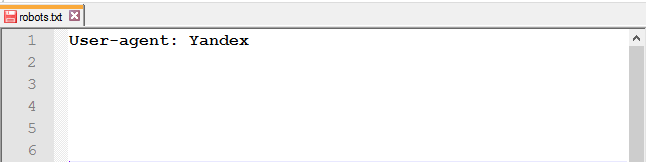
В отличие от Google, дабы не прописывать правила для каждого робота Яндекса, в User-agent можно указать следующее:
В Рунете принято прописывать инструкции для двух User-agent: для всех и отдельно для Яндекса.
Директивы Disallow и Allow
Чтобы запретить роботу доступ к сайту, каталогу или странице, используйте Disallow.
Как применять правило Disallow в различных ситуациях
Закрыть от индексации весь сайт: используйте слеш (/), чтобы заблокировать доступ ко всему сайту.
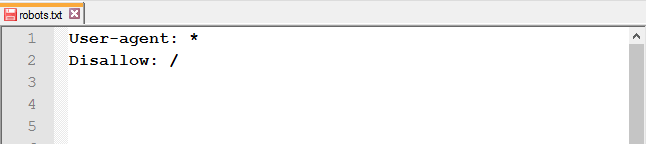
Полностью закрывать доступ роботам стоит на ранних этапах работы с сайтом, чтобы в поисковой выдачи он появился уже готовым.
Закрыть доступ к папке и её содержимому: используйте слеш после названия папки.
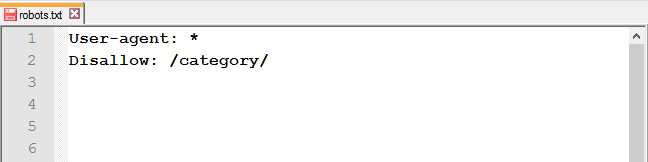
Закрыть определённую страницу или файл: укажите URL без хоста.
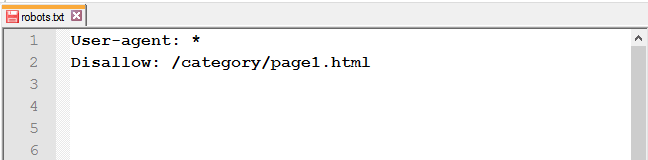
Открыть доступ к странице из закрытой папки: после Disallow используйте правило Allow.
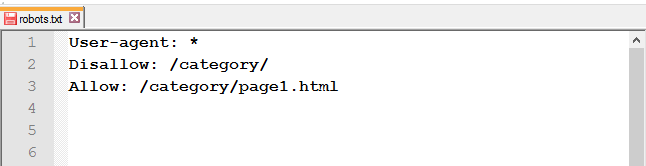
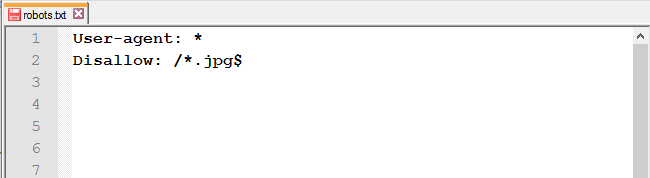
Запретить доступ к файлам одного типа: чтобы запретить к обходу однотипные файлы, воспользуйтесь специальными символами * и $.
Адрес Sitemap в robots.txt
Если на сайте есть файл Sitemap, укажите в соответствующей директиве адрес к нему. Если же карт сайта несколько, пропишите все.

Это правило учитывается роботами независимо от его месторасположения.
Директива Host для Яндекса
UPD: 20 марта Яндекс официально объявил об отмене директивы Host. Подробнее об этом можно прочитать в блоге Яндекса для вебмастеров.Что теперь делать с директивой Host:
- удалить из robots.txt;
- оставить — робот будет игнорировать её.
В обоих случаях нужно настроить 301 редирект.
Роботы Яндекса поддерживают robots.txt с расширенными возможностями. Инструкция Host является одной из них. Она указывает главное зеркало сайта.
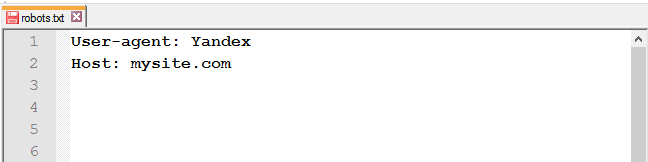
Важно:
- 1. использовать www (если так начинается адрес сайта);
- 2. использовать HTTPS (если сайт на защищённом протоколе, если нет — HTTP можно не прописывать).
Как и с Sitemap, месторасположение правила не влияет на работу робота, оно может быть указано как в начале файла, так и в конце.
Некорректно прописанная директива Host игнорируется роботом.
Crawl-delay
Директива Crawl-delay указывает время, которое роботы должны выдерживать между загрузкой двух страниц. Эта инструкция значительно снизит нагрузку на сервер, если у него есть проблемы с обработкой запросов.
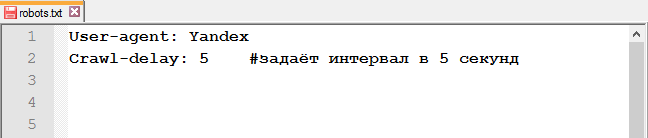
Строка с Crawl-delay должна находиться после всех директив с Allow и Disallow.
Так как Google это правило не учитывает, для гуглбота есть другой метод изменения скорости сканирования.
Clean-param
Для исключения страниц сайта, которые содержат динамические (GET) параметры (например, сортировка товара или идентификаторы сессий), используйте директиву Clean-param.
Например, есть следующие страницы:
https://mysite.com/shop/all/good1?partner_fid=3
https://mysite.com/shop/all/good1?partner_fid=4
https://mysite.com/shop/all/good1?partner_fid=1
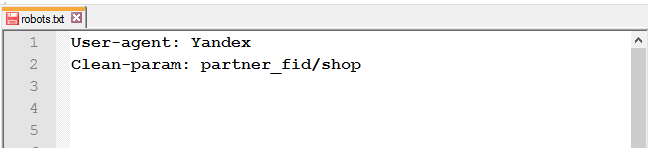
Используя данные из Clean-param, робот не будет перезагружать дублирующуюся информацию.
Спецсимволы $, *, /, #
Спецсимвол * (звёздочка) означает любую последовательность символов. То есть, используя звёздочку, вы запретите доступ ко всем URL, содержащим слово «obmanki».

Этот спецсимвол проставляется по умолчанию в конце каждой строки.

Чтобы отменить *, в конце правила нужно указать спецсимвол $ (знак доллара).

Спецсимвол / (слеш) используется в каждой директиве Allow и Disallow. С помощью слеша можно запретить доступ к папке и её содержимому /category/ или ко всем страницам, которые начинаются с /category.

Спецсимвол # (решётка).
Используется для комментариев в файле для себя, пользователей, или других веб-мастеров. Поисковые роботы эту информацию не учитывают.
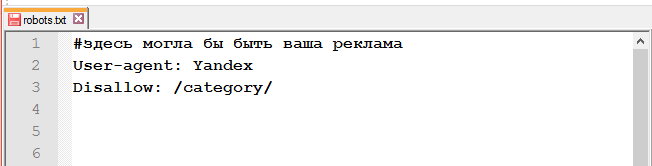
Проверка работы файла
Чтобы проверить файл robots.txt на наличие ошибок, можно воспользоваться инструментами от Google и/или Яндекса.
Как проверить robots.txt в Google Search Console?
Перейдите к инструменту проверки файла. Ошибки и предупреждения будут выделены в содержании роботс.тхт, а общее количество указано под окном редактирования.
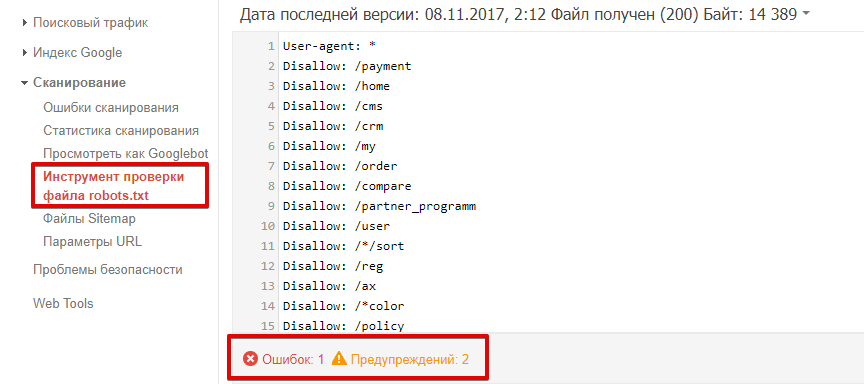
Чтобы проверить, доступна ли страница роботу, в соответствующем окне введите URL страницы и нажмите кнопку «проверить». После проверки инструмент покажет статус страницы: доступен или недоступен.

Как проверить robots.txt в Яндекс.Вебмастер?
Для проверки файла нужно перейти в «Инструменты» — «Анализ robots.txt».
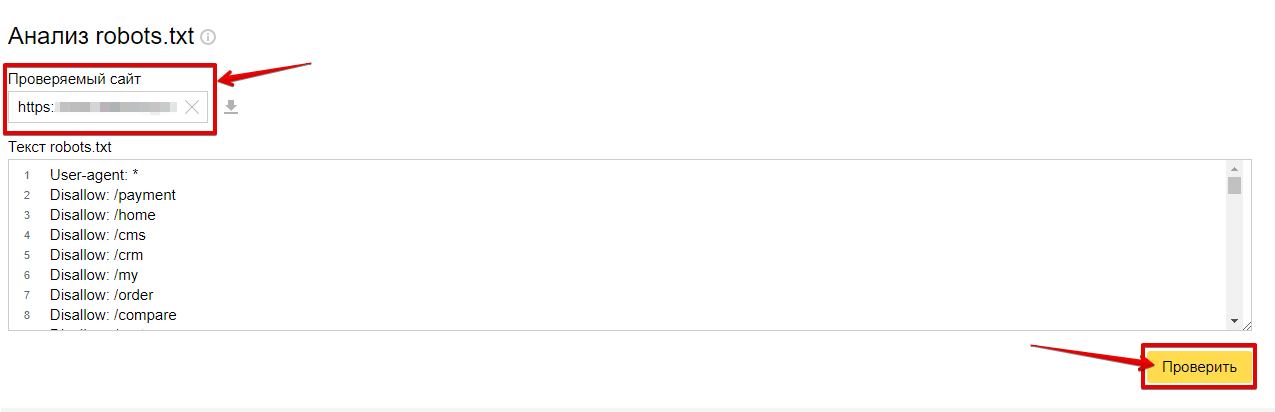
Список ошибок, возникающих при анализе роботс.
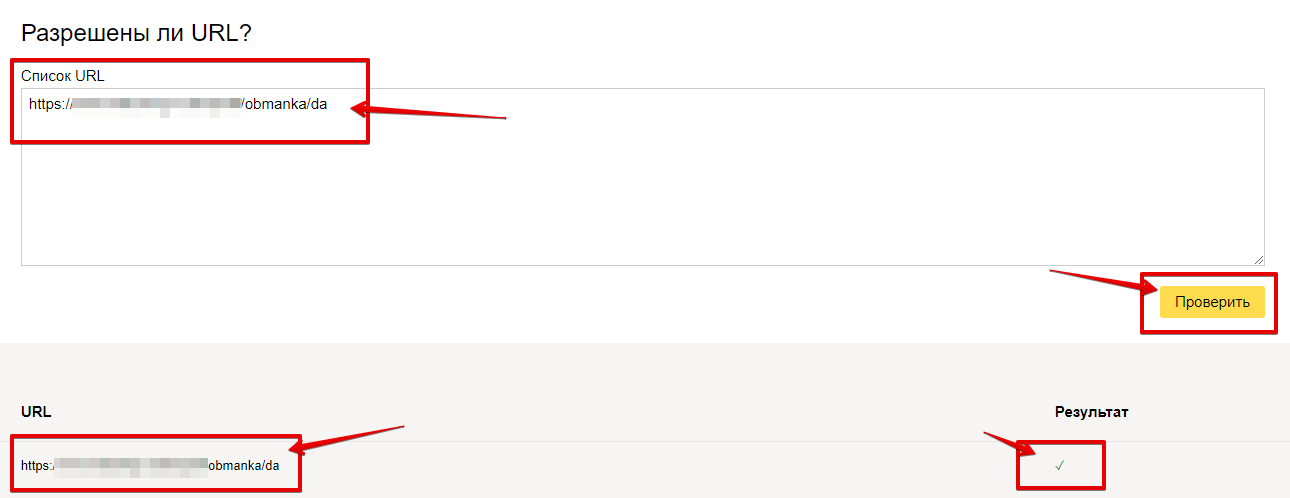
Чтобы проверить, разрешён ли доступ к странице, в соответствующем окне введите URL страницы и нажмите кнопку «проверить». После проверки инструмент покажет статус страницы: знак галочки (разрешён) или будет выведена директива, запрещающая доступ.
Распространённые ошибки
-
- неправильное имя файла;
Файл должен называться robots.txt. Ошибки, допускаемые в названии файла: robot.txt, Robots.txt, ROBOTS.TXT. - незаполненная строка в User-agent;
- неправильное имя файла;
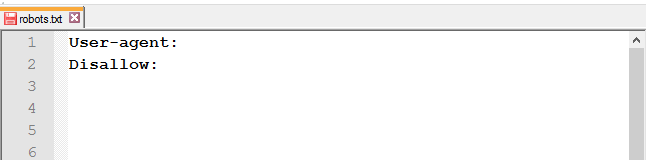
-
- перепутанные инструкции или неправильный порядок директив;

или
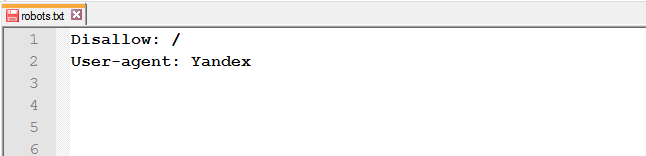
-
- пробелы, расставленные в разных местах;
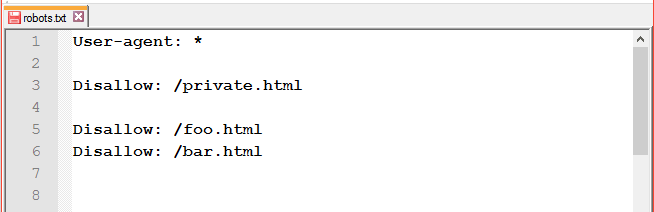
-
- использование больших букв;
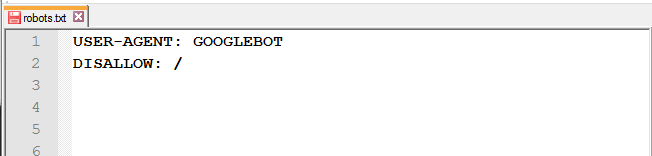
-
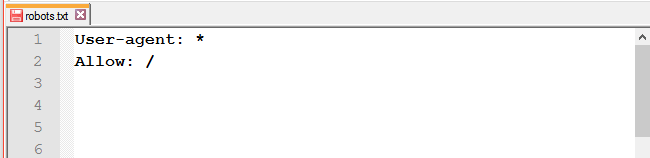
- Allow для индексации;
 Она нужна только для переопределения директивы Disallow в том же файле robots.txt.
Она нужна только для переопределения директивы Disallow в том же файле robots.txt. - после доработок весь сайт остаётся закрытым от индексации;
- Allow для индексации;
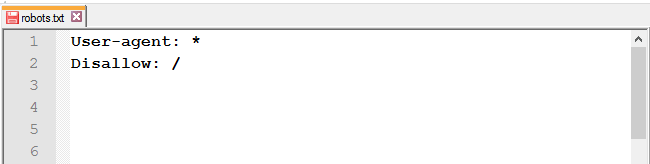
-
- закрыты от индексации CSS и JavaScript.
Часто встречаются сайты, у которых в robots.txt закрыты стили. По итогу роботы видят страницу следующим образом:
- закрыты от индексации CSS и JavaScript.
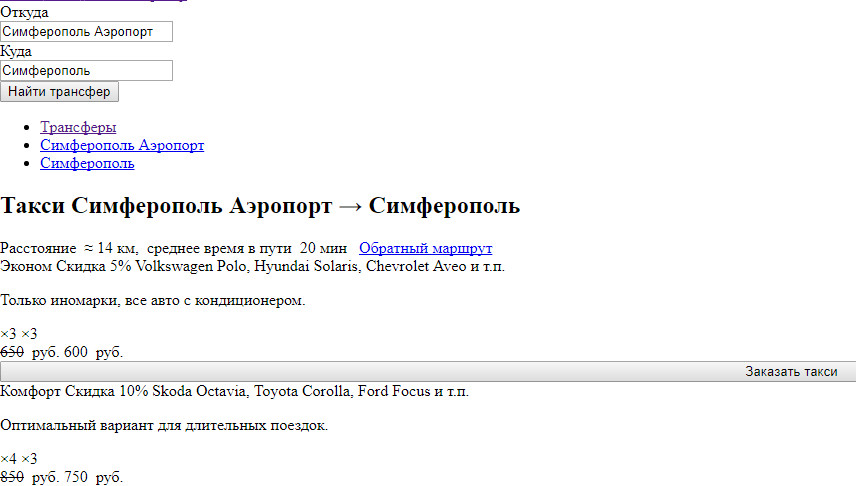
Поисковые системы не рекомендуют закрывать эти файлы от роботов.
Рекомендации Яндекса:

Рекомендации Google:

Robots.txt для различных CMS
Ниже мы предлагаем рассмотреть часто используемые директивы для различных CMS. Это не конечный вариант файла robots.txt. Этот набор правил редактируется под каждый сайт отдельно и зависит от того, что нужно закрыть, а что — оставить открытым.
Robots.txt для WordPress
Пример файла под Вордпресс:
User-Agent: * Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Allow: /wp-content/uploads/ Disallow: /tag Disallow: /category Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Allow: /wp-content/*.css* Allow: /wp-content/*.jpg Allow: /wp-content/*.gif Allow: /wp-content/*.png Allow: /wp-content/*.js* Allow: /wp-includes/js/ Host: mysite.com Sitemap: http://mysite.com/sitemap.xml
Robots.txt для Joomla
Пример роботс для Джумла:
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /components/ Disallow: /images/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Allow: /templates/*.css Allow: /templates/*.js Allow: /media/*.png Allow: /media/*.js Allow: /modules/*.css Allow: /modules/*.js Host: mysite.com Sitemap: http://mysite.com/sitemap.xml
Robots.txt для Bitrix
Пример файла для Битрикса:
User-agent: * Disallow: /*index.php$ Disallow: /bitrix/ Disallow: /auth/ Disallow: /personal/ Disallow: /upload/ Disallow: /search/ Disallow: /*/search/ Disallow: /*/slide_show/ Disallow: /*/gallery/*order=* Disallow: /*?* Disallow: /*&print= Disallow: /*register= Disallow: /*forgot_password= Disallow: /*change_password= Disallow: /*login= Disallow: /*logout= Disallow: /*auth= Disallow: /*action=* Disallow: /*bitrix_*= Disallow: /*backurl=* Disallow: /*BACKURL=* Disallow: /*back_url=* Disallow: /*BACK_URL=* Disallow: /*back_url_admin=* Disallow: /*print_course=Y Disallow: /*COURSE_ID= Allow: /bitrix/*.css Allow: /bitrix/*.js Host: mysite.com Sitemap: http://mysite.com/sitemap.xml
Заключение
Файл Robots.txt — полезный инструмент в формировании взаимоотношений между поисковыми роботами и вашим сайтом. При правильном использовании он может оказать положительное влияние на ранжирование и сделать сайт более удобным для сканирования. Используйте это руководство, чтобы понять, как работает robots.txt, как он устроен и как его использовать.
P.S. В знак благодарности, что дочитали статью до конца, мы подготовили подборку неожиданных находок в файлах robots.txt.
Интернет-магазин косметики
Площадка для обмена знаниями, учебниками и ГДЗ

Приглашение на работу от известного SEO-сервиса
Ещё одно приглашение, но уже в файле humans.txt
После 2166 запрещающих, направляющих и разрешающих директив, в конце файла можно обнаружить рисуночек
Хотите узнать, нет ли ошибок в robots.txt на вашем сайте, — мы можем провести технический аудит, в котором проанализируем файл и напишем инструкции по исправлению недоработок!
Отправить заявку
Еще по теме:
- HTTP-заголовки, которые влияют на SEO
- Как и зачем обновлять CMS вашего сайта
- Мобильная адаптация сайта – ответы на вопросы
- Инструменты для анализа отображения сайта на разных устройствах
- Безопасный переезд сайта с http на https в Яндексе и Google
Скорее всего, вы знаете, что при открытии страницы любого сайта происходят действия на сервере, которые не видны пользователям. Однако эти данные обрабатывают поисковые системы. И…
Почему нужно обновлять CMS вашего сайта, насколько часто, как правильно это сделать и как проверить результаты обновления. Читайте в статье нашего программиста. К нам обращаются…
В этой статье мы рассмотрим: Как влияет адаптивность сайта на ранжирование в ПС Как оптимизировать сайт под мобильные устройства Какие инструменты можно использовать для проверки…
Поисковые системы учитывают поведенческие факторы как в десктопной версии, так и на мобильных устройствах, поэтому необходимо учитывать этот факт при разработке сайта (или при его…
В последние время всё больше владельцев проектов задумываются о переводе сайтов на защищённый протокол. Не перестают напоминать об этом и представители поисковых систем. Яндекс пока…

SEO-TeamLead
За два года от стажера до тимлида.
Google меня любит.
Множко катаю на сапборде.
Девиз: Либо делай качественно, либо делай качественно.
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.