
Очень часто при работе в Excel необходимо использовать вычисления вероятности появления некоторого события. Для этого используется статистическая функция ВЕРОЯТНОСТЬ.
Примеры использования функции вероятность для расчетов в Excel
Стоит отметить, что используются часто в Excel и другие статистические функции, к примеру:
- ДИСП;
- ГИПЕРГЕОМ.РАСП;
- СРЗНАЧ и другие.
Функция выполняет вычисление вероятности того, что значения с интервала находятся в заданных пределах. В случае, если верхний предел не будет задан, то будет возвращена вероятность того, что значения аргумента x_интервал будет равно значению аргумента под названием нижний_предел.
Вычисление процента вероятности события в Excel
Пример 1. Дана таблица диапазона числовых значений, а также вероятностей, которые им соответствуют:
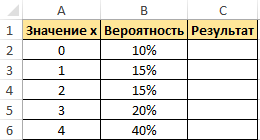
Необходимо при использовании данной статистической функции вычислить вероятность события, что значение с указанного интервала входит в интервал [1;4].
Для этого введем функцию со следующими аргументами:
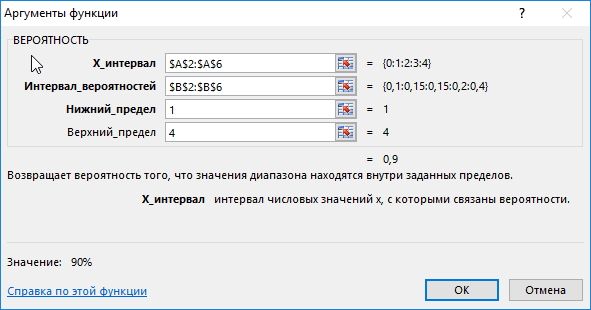
тут:
- х_интервал – это начальные данные (0, …, 4);
- интервал вероятностей является множеством вероятностей для начальных данных (0,15; 0,1; 0,15; 0,2; 0,4);
- нижний предел равен значению 1;
- верхний предел равен 4.
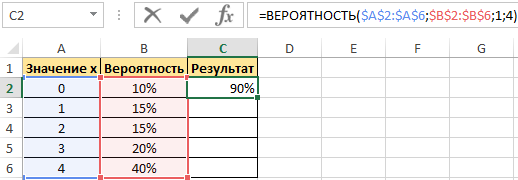
В результате выполненных вычислений получим:
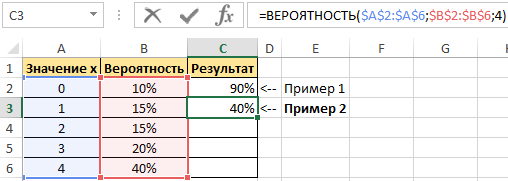
Пример 2. В условии предыдущего примера нужно вычислить вероятность события «значение х равно 4».
Введем в ячейку С3 введем функцию с такими аргументами:
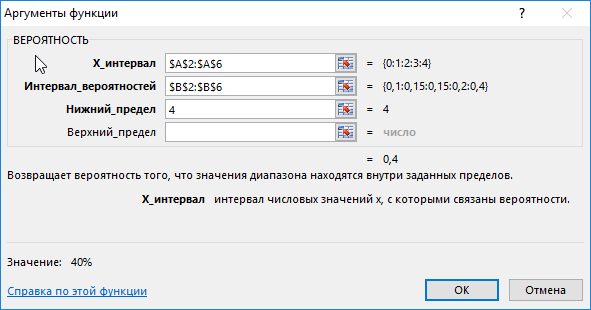
тут:
- х_интервал – начальные параметры (0, …, 4);
- интервал вероятностей – совокупность вероятностей для параметров (0,1; 0,15; 0,2; 0,15; 0,4);
- нижний предел – 4;
В данном примере верхний предел не указан, поскольку необходимо конкретное значение вероятности, а именно для значения 4.
Получим:
Функция ВЕРОЯТНОСТЬ при нескольких условиях интервалов
Пример 3. В условии примера 1 нужно вычислить вероятность того, что значения интервала [0; 4] будут находится находятся внутри интервалов [0;1] и [3;4].
Введем формулу:
Описание формул аналогичные предыдущим примерам.
В результате выполненных вычислений получим:

Скачать примеры функции ВЕРОЯТНОСТЬ в Excel
Таким образом составив формулу можно с помощью данной функции вычислить процент вероятности при нескольких условиях.
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование proB
Функция Microsoft Excel.
Описание
Возвращает вероятность того, что значение из интервала находится внутри заданных пределов. Если верхний_предел не задан, то возвращается вероятность того, что значения в аргументе x_интервал равняются значению аргумента нижний_предел.
Синтаксис
ВЕРОЯТНОСТЬ(x_интервал;интервал_вероятностей;[нижний_предел];[верхний_предел])
Аргументы функции ВЕРОЯТНОСТЬ описаны ниже.
-
x_интервал Обязательный. Диапазон числовых значений x, с которыми связаны вероятности.
-
Интервал_вероятностей Обязательный. Множество вероятностей, соответствующих значениям в аргументе «x_интервал».
-
Нижний_предел Необязательный. Нижняя граница значения, для которого вычисляется вероятность.
-
Верхний_предел Необязательный. Верхняя граница значения, для которого вычисляется вероятность.
Замечания
-
Если значение в prob_range ≤ 0 или любое значение в prob_range > 1, функция PROB возвращает #NUM! (значение ошибки).
-
Если сумма значений в prob_range не равна 1, функция PROB возвращает #NUM! (значение ошибки).
-
Если верхний_предел опущен, то функция ВЕРОЯТНОСТЬ возвращает вероятность равенства значению аргумента нижний_предел.
-
Если x_интервал и интервал_вероятностей содержат различное количество точек данных, то функция ВЕРОЯТНОСТЬ возвращает значение ошибки #Н/Д.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу Enter. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|---|---|---|
|
Значение x |
Вероятность |
|
|
0 |
0,2 |
|
|
1 |
0,3 |
|
|
2 |
0,1 |
|
|
3 |
0,4 |
|
|
Формула |
Описание |
Результат |
|
=ВЕРОЯТНОСТЬ(A3:A6;B3:B6;2) |
Вероятность того, что x является числом 2. |
0,1 |
|
=ВЕРОЯТНОСТЬ(A3:A6;B3:B6;1;3) |
Вероятность того, что x находится в интервале от 1 до 3. |
0,8 |
Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
17 авг. 2022 г.
читать 2 мин
Вероятность описывает вероятность того, что некоторое событие произойдет.
Мы можем рассчитать вероятности в Excel, используя функцию PROB , которая использует следующий синтаксис:
ПРОБ(x_диапазон, вероятностный_диапазон, нижний_предел, [верхний_предел])
куда:
- x_range: диапазон числовых значений x.
- prob_range: диапазон вероятностей, связанных с каждым значением x.
- нижний_предел: нижний предел значения, для которого вы хотите получить вероятность.
- upper_limit: Верхний предел значения, для которого вы хотите получить вероятность. По желанию.
В этом руководстве представлено несколько примеров использования этой функции на практике.
Пример 1: Вероятность игры в кости
На следующем изображении показана вероятность выпадения кубика с определенным значением при данном броске:

Поскольку кости с одинаковой вероятностью выпадут на каждом значении, вероятность одинакова для каждого значения.
На следующем рисунке показано, как найти вероятность того, что кубик выпадет на число от 3 до 6:

Вероятность оказывается равной 0,5 .
Обратите внимание, что аргумент верхнего предела является необязательным. Таким образом, мы могли бы использовать следующий синтаксис, чтобы найти вероятность того, что кости приземлятся только на 4:
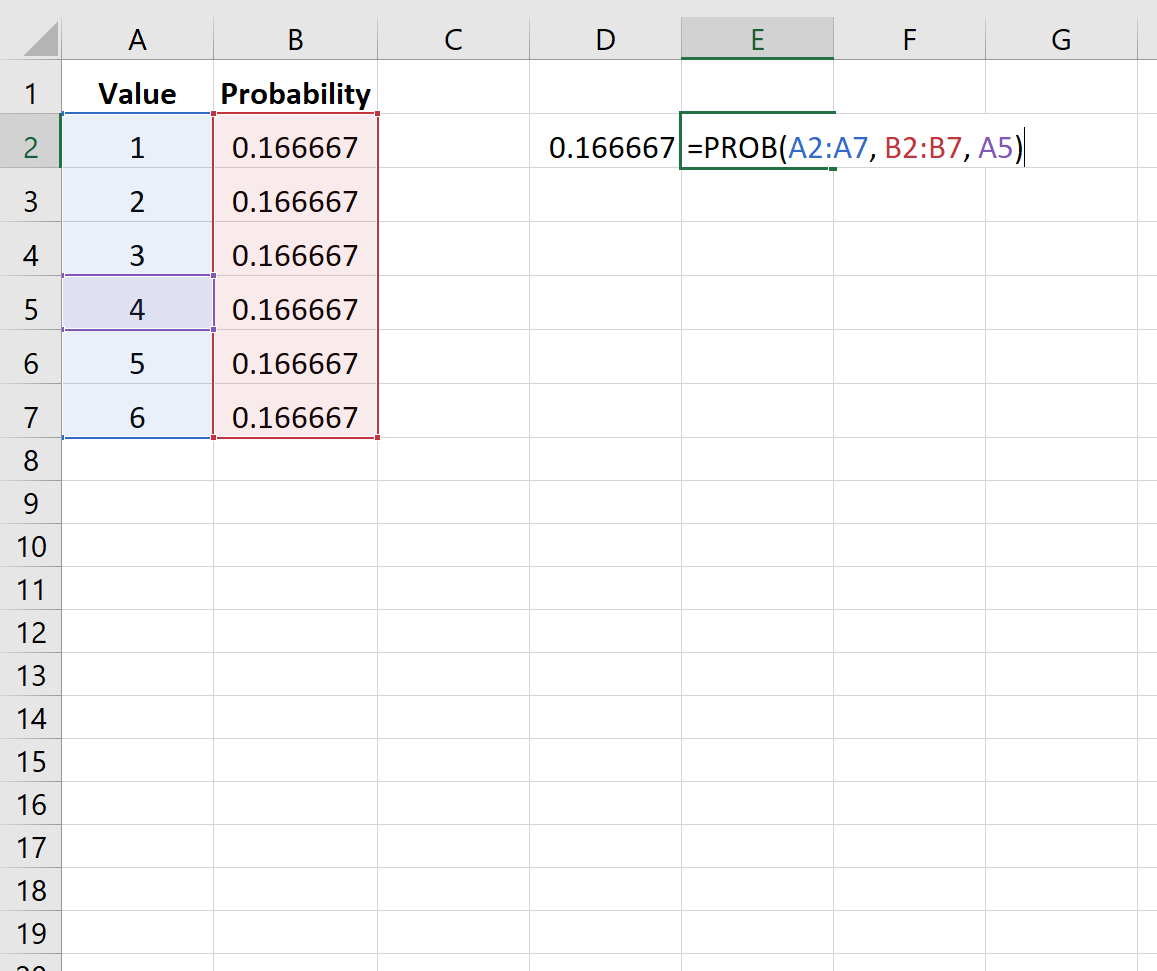
Вероятность оказывается равной 0,166667 .
Пример 2: Вероятность продаж
На следующем изображении показана вероятность того, что компания продаст определенное количество товаров в предстоящем квартале:

На следующем рисунке показано, как найти вероятность того, что компания совершит 3 или 4 продажи:
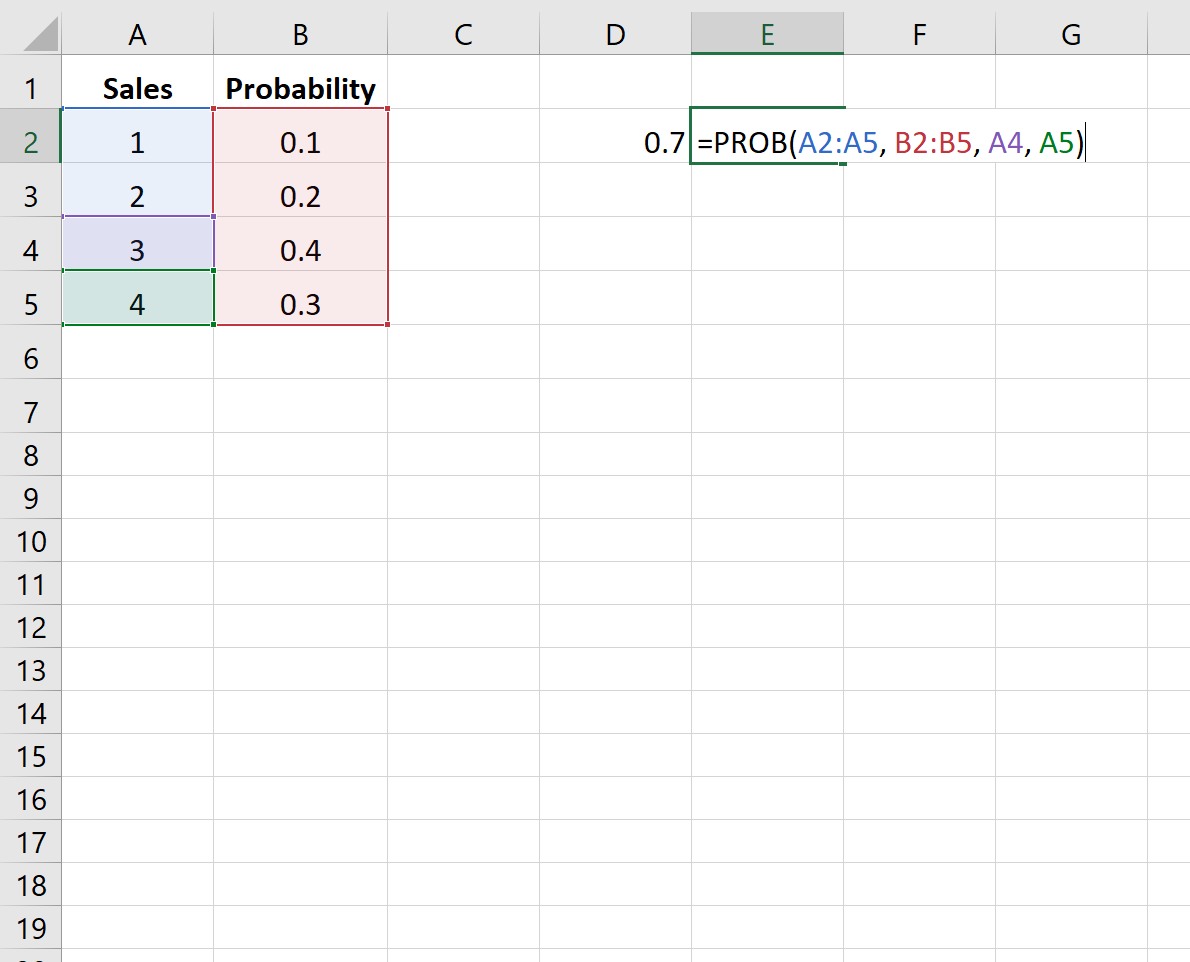
Вероятность оказывается равной 0,7 .
Дополнительные ресурсы
Как рассчитать относительную частоту в Excel
Как рассчитать кумулятивную частоту в Excel
Как создать частотное распределение в Excel
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.
Определим выражение для вычисления ошибки второго рода и мощности теста, построим в
MS
EXCEL
кривые оперативной характеристики (Operating-characteristic curves).
Тема этой статьи – вычисление
ошибки второго рода
(type II error) при
проверке гипотез
. Основная статья про
проверку гипотез
находится здесь
.
Напомним, что процедура
проверки гипотез
состоит из следующих шагов:
-
из исследуемого распределения берется
выборка
; -
на основании значений
выборки
вычисляется
тестовая статистика
; -
значение
тестовой статистики
сравнивается со значениями, соответствующим заданномууровню значимости (ошибке первого рода)
;
-
по результату сравнения делается вывод об отклонении (или не отклонении)
нулевой гипотезы
.
Обычно с
проверкой гипотез
связывают 2 типа ошибок. Если
нулевая гипотеза
отклоняется, когда она верна – это
ошибка первого рода
(обозначается α,
альфа
). Если нулевая гипотеза не отклоняется, когда она неверна, то это
ошибка второго рода
(обозначается β,
бета
).
Ошибка первого рода
часто называется риском производителя. Это осознанный риск, на который идет производитель продукции, т.к. он определяет вероятность того, что годная продукция может быть забракована, хотя на самом деле она таковой не является. Величина
ошибки первого рода
задается перед
проверкой гипотезы
, таким образом, она контролируется исследователем напрямую и может быть задана в соответствии с условиями решаемой задачи. После этого, процедура проверки гипотезы составляется таким образом, чтобы вероятность
ошибки второго рода
была как можно меньше.
Ошибка второго рода
β
зависит от размера
выборки
n и
уровня значимости α
, и поэтому контролируется косвенно. Чем больше размер
выборки
, тем меньше
ошибка второго рода
(при прочих равных).
Часто также используют величину
1-β
, которая называется
мощностью статистического критерия
(мощностью теста, мощностью исследования, англ. power of a statistical test).
Мощность статистического критерия
— это вероятность правильно отклонить нулевую гипотезу. Чем ближе эта величина к единице, тем меньше у нас шансов ошибиться при проверке гипотезы (тем лучше критерий различает гипотезы Н
0
и Н
1
).
Ошибку второго рода
вычисляют для каждого вида
проверки гипотез
по-разному. Получим выражение для вычисления
ошибки второго рода
для
проверки двусторонней гипотезы о равенстве среднего значения распределения некоторой величине (стандартное отклонение известно)
.
Для
проверки гипотезы
этого типа используется
тестовая статистика
Z
0
:
![]()
которая имеет
стандартное нормальное распределение
.
Чтобы найти
Ошибку второго рода
необходимо предположить, что гипотеза Н
0
: μ=μ
0
не верна, и соответственно истинное
среднее значение распределения
μ=μ
0
+Δ, где Δ>0. В этом случае,
тестовая статистика
Z
0
будет иметь
нормальное распределение
N(Δ√n/σ;1), т.е. будет смещено вправо на Δ√n/σ (см.
файл примера на листе Бета
).
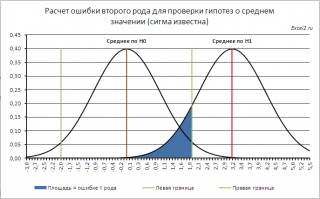
Согласно определения,
ошибка второго рода
равна вероятности, принять нулевую гипотезу, если на самом деле справедлива Н
1
. Эта вероятность соответствует выделенной на рисунке области.
Статистика
Z
0
, в этом случае, примет значение между -Z
α/2
и Z
α/2
(эти значения соответствуют границам
доверительного интервала
). Z
α/2
– это
верхний α/2-квантиль стандартного нормального распределения
.
Определим
ошибку второго рода
в терминах
стандартного нормального распределения
:
![]()
Это выражение будет работать и для Δ<0. Как видно из выражения,
ошибка второго рода
является функцией от α, Δ и n. В
файле примера на листе Бета
можно быстро рассчитать β и
мощность теста
в зависимости от этих параметров. Диаграмма, приведенная выше, будет автоматически перестроена.
Для заданного значения α часто строят семейство кривых, которые иллюстрируют зависимость
ошибки второго рода
от Δ и n. Такие кривые называются
операционными характеристиками
(Operating-characteristic curves).
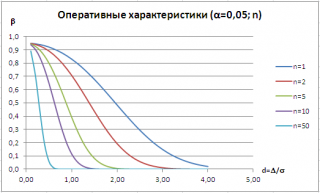
Как видно из рисунка, чем дальше истинное значение
среднего
от μ
0
, т.е. чем больше Δ, тем меньше
ошибка второго рода.
Таким образом, для заданных α и n, тест легче определит большие отклонения от
среднего
, чем малые (тест обладает, в данном случае, большей
мощностью
). При росте n
мощность теста
также растет.
Кривые
операционных характеристик
используются для оценки размера
выборки
, достаточного для определения заданной разницы между истинным значением
среднего
μ
от μ
0
с требуемой вероятностью.
В
файле примера на листе ОХ
создана форма для определения размера
выборки
, достаточного для обеспечения заданной
мощности теста
.
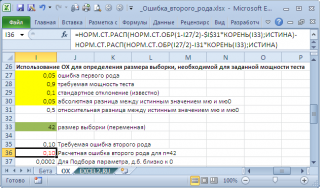
Например, Н
0
: μ
0
=20, истинное значение μ=20,05,
стандартное отклонение
=0,1, α=0,05. Чтобы вероятность правильно отклонить гипотезу H
0
была равна 0,9 (
мощность теста
), размер
выборки
должен быть 42 или более.
Примечание
:
Для нахождения размера
выборки
потребуется использование инструмента MS EXCEL
Подбор параметра
.
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

которая имеет
стандартное нормальное распределение
.
Чтобы найти
Ошибку второго рода
необходимо предположить, что гипотеза Н
0
: μ=μ
0
не верна, и соответственно истинное
среднее значение распределения
μ=μ
0
+Δ, где Δ>0. В этом случае,
тестовая статистика
Z
0
будет иметь
нормальное распределение
N(Δ√n/σ;1), т.е. будет смещено вправо на Δ√n/σ (см.
файл примера на листе Бета
).
Согласно определения,
ошибка второго рода
равна вероятности, принять нулевую гипотезу, если на самом деле справедлива Н
1
. Эта вероятность соответствует выделенной на рисунке области.
Статистика
Z
0
, в этом случае, примет значение между -Z
α/2
и Z
α/2
(эти значения соответствуют границам
доверительного интервала
). Z
α/2
– это
верхний α/2-квантиль стандартного нормального распределения
.
Определим
ошибку второго рода
в терминах
стандартного нормального распределения
:
![]()
Это выражение будет работать и для Δ<0. Как видно из выражения,
ошибка второго рода
является функцией от α, Δ и n. В
файле примера на листе Бета
можно быстро рассчитать β и
мощность теста
в зависимости от этих параметров. Диаграмма, приведенная выше, будет автоматически перестроена.
Для заданного значения α часто строят семейство кривых, которые иллюстрируют зависимость
ошибки второго рода
от Δ и n. Такие кривые называются
операционными характеристиками
(Operating-characteristic curves).
Как видно из рисунка, чем дальше истинное значение
среднего
от μ
0
, т.е. чем больше Δ, тем меньше
ошибка второго рода.
Таким образом, для заданных α и n, тест легче определит большие отклонения от
среднего
, чем малые (тест обладает, в данном случае, большей
мощностью
). При росте n
мощность теста
также растет.
Кривые
операционных характеристик
используются для оценки размера
выборки
, достаточного для определения заданной разницы между истинным значением
среднего
μ
от μ
0
с требуемой вероятностью.
В
файле примера на листе ОХ
создана форма для определения размера
выборки
, достаточного для обеспечения заданной
мощности теста
.
Например, Н
0
: μ
0
=20, истинное значение μ=20,05,
стандартное отклонение
=0,1, α=0,05. Чтобы вероятность правильно отклонить гипотезу H
0
была равна 0,9 (
мощность теста
), размер
выборки
должен быть 42 или более.
Примечание
:
Для нахождения размера
выборки
потребуется использование инструмента MS EXCEL
Подбор параметра
.
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы
Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.









Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.