
Для
совокупности факторов С, С, С (приложение
Б) объем выборки будет равен 24 элементам.
[3]
ЗАДАЧА № 7
Аудитор оценивает
уровень допустимой ошибки в размере
6% общей
суммы генеральной совокупности, а
ожидаемой ошибки – 4%. При этом аудитор
устанавливает риск выборки на уровне
5%. Объем генеральной совокупности
составляет 505
элементов.
Определите количество элементов
генеральной совокупности, подлежащих
отбору в выборку. Скорректируйте, при
необходимости, полученное значение
объема выборки.
Решение:
Количество элементов
генеральной совокупности, подлежащих
отбору в выборку будем определять
методом определения объема выборки по
оценке риска выборки, ожидаемой и
допустимой степени отклонений.
Данный подход был
разработан американским исследователем
Р. Монтгомери (1872–1953). Суть метода
заключается в следующем: чтобы
рассчитать объем выборки, аудитору
необходимо оценить некоторые критерии:
а) уровень надежности
(100% минус риск выборки);
б) ожидаемая ошибка
(% генеральной совокупности);
в) допустимая ошибка
(% генеральной совокупности).
По данным условиям
задачи определим:
Уровень надежности
= 100% — 5% = 95%,
ожидаемая ошибка
составляет 4% генеральной совокупности,
допустимая ошибка
составляет 6% генеральной совокупности.
Далее, объем выборки
определяем с применением таблицы,
составленной для соответствующего
уровня надежности. Расчет объема выборки
для уровня надежности 95% осуществляется
исходя из данных таблицы 1.
Таблица 1 –
Объем выборки
в зависимости от ожидаемого и допустимого
уровней ошибок
(для уровня надежности 95%)
|
Ожидаемая ошибка, |
Допустимая ошибка, |
|||||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
12 |
14 |
|
|
0 |
300 |
150 |
100 |
75 |
60 |
50 |
45 |
40 |
35 |
30 |
25 |
20 |
|
0,50 |
* |
320 |
160 |
120 |
95 |
80 |
70 |
60 |
55 |
50 |
40 |
35 |
|
1,0 |
* |
* |
260 |
160 |
95 |
80 |
70 |
60 |
55 |
50 |
40 |
35 |
|
2,0 |
* |
* |
* |
300 |
190 |
130 |
90 |
80 |
70 |
50 |
40 |
35 |
|
3,0 |
* |
* |
* |
* |
370 |
200 |
130 |
95 |
85 |
65 |
55 |
35 |
|
4,0 |
* |
* |
* |
* |
* |
430 |
230 |
150 |
100 |
90 |
65 |
45 |
|
5,0 |
* |
* |
* |
* |
* |
* |
480 |
240 |
160 |
120 |
75 |
55 |
|
6,0 |
* |
* |
* |
* |
* |
* |
* |
* |
270 |
180 |
100 |
65 |
|
7,0 |
* |
* |
* |
* |
* |
* |
* |
* |
* |
300 |
130 |
85 |
|
8,0 |
* |
* |
* |
* |
* |
* |
* |
* |
* |
* |
200 |
100 |
|
* Объем выборки |
Исходя их условий
задачи, при уровне допустимой ошибки в
размере 6% общей суммы генеральной
совокупности, ожидаемой ошибки – 4%, при
установленном уровне надежности, равном
95% (аудитор должен быть на 95% уверен, что
реальная ошибка, содержащаяся в
генеральной совокупности, не превысит
установленную им допустимую ошибку),
объем выборки будет определен на
пересечении соответствующей графы и
строки таблицы и составит 430 элементов.
Отметим, что если отбирается более 10%
элементов генеральной совокупности,
то данный фактор позволяет пересмотреть
объем выборки.
Скорректируем
полученное значение объема выборки на
объем генеральной совокупности по
формуле:
 , (1)
, (1)
где ОВ1
и ОВ2
– объем выборки соответственно до и
после учета влияния
фактора объема
генеральной совокупности;
ГС – объем генеральной
совокупности.

элемента
Корректируемое
количество элементов генеральной
совокупности, подлежащих отбору в
выборку, составляет 232 элемента.
ЗАДАЧА
№ 7
Аудитор
оценивает уровень допустимой ошибки в
размере 6%
общей
суммы генеральной совокупности, а
ожидаемой ошибки – 4%. При этом аудитор
устанавливает риск выборки на уровне
5%. Объем генеральной совокупности
составляет 505
элементов.
Определите количество элементов
генеральной совокупности, подлежащих
отбору в выборку. Скорректируйте, при
необходимости, полученное значение
объема выборки.
Решение:
 ,
,
где
ОВ, и ОВ2
– объем выборки соответственно до и
после учета влияния
фактора
объема генеральной совокупности;
ГС
– объем генеральной совокупности.
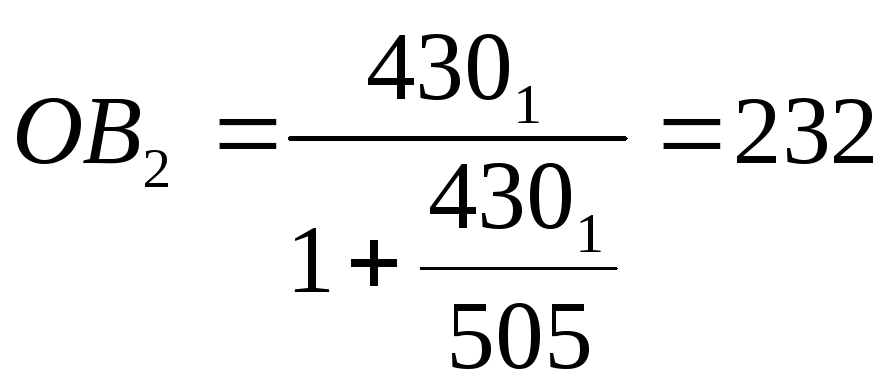
документа
ЗАДАЧА
№ 8
Аудитору
требуется провести проверку некоторой
совокупности, элементы которой в сумме
составляют 106,5 млн руб.; элементы
наибольшей стоимости и «ключевые»
элементы 11,5 млн руб.; уровень существенности
– 7,5 млн руб.; оценка рисков сальдо
счета: неотъемлемый (внутрихозяйственный)
– средний; риск средств контроля –
средний; риск, связанный с пересекающимися
процедурами, – средний. Определите
число элементов выборки, имеющих:
а) сальдо;
б) обороты
по счетам бухгалтерского учета.
Укажите
возможные ситуации, когда риск средств
контроля аудитором оценивается высоким.
Метод
определения числа элементов выборки,
имеющих сальдо:
Данный
метод применяется для определения
объема выборки из элементов генеральной
совокупности, составляющих сальдо
бухгалтерского счета в аудируемой
финансовой отчетности. Считается, что
элементы наибольшей стоимости и
«ключевые» элементы были уже отобраны
в отдельную группу и подлежат сплошной
проверке.
Согласно
данной методике, число элементов,
подлежащих отбору для выборки, исчисляется
по формуле
![]() ,
,
где
ОВ – объем выборки;
ГС
– объем генеральной совокупности в
стоимостном выражении;
ЭН
– сумма элементов наибольшей стоимости;
ЭК
– сумма «ключевых» элементов;
КП
– коэффициент проверки;
УС
– уровень существенности.
![]() элементов.
элементов.
Метод
определения числа элементов выборки,
основанных на оборотах по счетам
бухгалтерского учета:
В
случае если проверке подлежат счета
бухгалтерского учета, не имеющие сальдо
на дату составления финансовой отчетности,
применяется отличный следующий порядок.
Здесь
проводится оценка аудитором уровней
рисков: неотъемлемого (внутрихозяйственного),
средств контроля и пересекающихся
процедур по той же шкале. Значения для
вариантов, связанных с низкой степенью
риска средств контроля, отсутствуют; в
случае необходимости могут быть применены
значения, соответствующие среднему
уровню указанного риска. В результате
комбинации различных оценок также
получают варианты значений, но уже не
условных коэффициентов, а конкретных
объемов выборки.
Так
как уровень неотъемлемого
(внутрихозяйственного) риска – средний,
риска средств контроля – средний и
риск, связанный с пересекающимися
процедурами, – средний, то число элементов
выборки будет равно 24.
ЗАДАЧА
9
Аудитор
выборочным методом проверяет вопрос
приобретения объектов основных средств.
Данные о стоимости поступивших в
организацию за проверяемый период
объектов основных средств представлены
в таблице 1:
Таблица
1 – Данные о стоимости поступивших в
организацию основных средств
|
Инвентарный |
Наименование |
Сумма, |
|
1001 |
Автомобиль |
255,0 |
|
1002 |
Автомобиль |
220,2 |
|
1003 |
Портативный |
112,0 |
|
1004 |
Стационарный |
22,6 |
|
1005 |
Набор |
110,0 |
|
1006 |
Музыкальный |
33,2 |
|
1007 |
Домашний |
98,2 |
|
1008 |
Холодильник |
15,8 |
Число
элементов, которые необходимо проверить
(объем выборки), равно 4. Для упрощения,
из совокупности исключены элементы
наибольшей стоимости и ключевые элементы.
Определить, какие объекты основных
средств следует проверить. Решите задачу
методом случайного бесповторного
отбора.
Решение:
Из
выборки исключаются автомобиль «Волга
3110» стоимостью 255,0 рублей, автомобиль
«Вольво» стоимостью 220,2 рублей. В таблице
случайных чисел определим случайное
число приходящееся для каждого
инвентарного номера.
Табл
2 – Порядок нахожд-я элем-в выборки при
использ-ии метода случайн бесповторного
отбора
|
№ пп |
Инвентарный |
Случайное |
Произведение |
Порядковый
Н |
|
1 |
1003 |
0,2695 |
1 |
1004 |
|
2 |
1004 |
0,4260 |
2 |
1005 |
|
3 |
1005 |
0,9295 |
4 |
1007 |
|
4 |
1006 |
0,8160 |
4 |
1007 |
|
5 |
1007 |
0,2651 |
1 |
1004 |
|
6 |
1008 |
0,5821 |
3 |
1006 |
ЗК
– ЗН = 1008 – 1003 = 5
-
СЧ·(ЗК–ЗН)
= 0,2695 ∙ 5 = 1 -
СЧ·(ЗК–ЗН)
= 0,4260 ∙ 5 = 2 -
СЧ·(ЗК–ЗН)
= 0,9295 ∙ 5 = 4 -
СЧ·(ЗК–ЗН)
= 0,8160 ∙ 5 = 4 -
СЧ·(ЗК–ЗН)
= 0,2651 ∙ 5 = 1 -
СЧ·(ЗК–ЗН)
= 0,5821 ∙ 5 = 3
Н
= ЗН + (ЗК–ЗН)·СЧ,
где
Н – номер отбираемого документа;
ЗН
– начальное значение интервала;
ЗК
– конечное значение интервала;
СЧ
– случайное число.
1)
Н = ЗН + (ЗК–ЗН)·СЧ =1003 + 1 = 1004
2)
Н = ЗН + (ЗК–ЗН)·СЧ =1003 + 2 = 1005
3)
Н = ЗН + (ЗК–ЗН)·СЧ =1003 + 4 = 1007
4)
Н = ЗН + (ЗК–ЗН)·СЧ =1003 + 4 = 1007
5)
Н = ЗН + (ЗК–ЗН)·СЧ =1003 + 1 = 1004
6)
Н = ЗН + (ЗК–ЗН)·СЧ =1003 + 3 = 1006
Задача
№ 10
В
соответствии с программой аудиторской
проверки аудитор А. Петров должен
провести в ОАО «Техносбыт» формальную
проверку расходных кассовых ордеров с
№ 545 по 874 выборочно. Для упрощения, число
элементов, которые необходимо выбрать,
равно пяти, а из генеральной совокупности
исключены элементы наибольшей стоимости
и «ключевые» элементы. Решите задачу
методом случайного бесповторного
отбора.
Решение:
Для
определения случайного числа воспользуемся
таблицей случайных чисел. Случайным
образом, ничем не руководствуясь, выберем
из таблицы пять случайных чисел: 0,8626;
0,5043; 0,9385; 0,3365; 0,7530. Порядок нахождения
элементов выборки приведен в таблице
1.
Начальное
значение интервала ЗН = 545, а конечное
ЗК = 874. Таким образом, разница между
конечным и начальным значениями интервала
генеральной совокупности составляет
329. Умножая последовательно полученное
значение на случайное число и добавляя
в каждом случае к полученному результату
начальное значение интервала, равное
545, получим элементы, подлежащие проверке
аудитором (см. последнюю графу таблице
1).
Таблица
1 –
Порядок
нахождения элементов выборки при
использовании метода случайного
бесповторного отбора
|
Порядковый |
Случайное СЧ |
Произведение СЧ·(ЗК–ЗН) |
Порядковый
Н |
|
1 |
0,8626 |
284 |
829 |
|
2 |
0,5043 |
166 |
711 |
|
3 |
0,9385 |
309 |
854 |
|
4 |
0,3365 |
111 |
656 |
|
5 |
0,7530 |
248 |
793 |
ЗАДАЧА
№10
В
соответствии с программой аудиторской
проверки аудитор А. Петров должен
провести в ОАО «Техносбыт» формальную
проверку расходных кассовых ордеров с
№545 по 874 выборочно. Для упрощения, число
элементов, которые необходимо выбрать,
равно пяти, а из генеральной совокупности
исключены элементы наибольшей стоимости
и «ключевые» элементы. Решить задачу
необходимо методом случайного
бесповторного отбора.
РЕШЕНИЕ:
Зная
случайное число, начальное и конечное
значение интервала генеральной
совокупности, то номер документа, который
необходимо выбрать можно рассчитать
по формуле (1):
Н=(ЗК-ЗН)
СЧ+ЗН,
Где
Н- номер отбираемого документа,
ЗН
– начальное значение интервала,
ЗК
– конечное значение интервала,
СЧ
– случайное число.
Для
определения случайного числа воспользуемся
таблицей случайных чисел. Выберем пять
случайных чисел, используя первые три
цифры четырехзначных чисел, начиная с
номера, находящегося на пересечении
второй строки (2) с колонкой №2. маршрут
движения вертикальный. Случайные числа:
0,812; 0,150; 0,730; 0,877; 0,723.
В
данной задаче начальное значение
интервала ЗН=545, а конечное ЗК=874. Таким
образом, разница между конечным и
начальным значениями интервала
генеральной совокупности составляет
329. Умножая последовательно полученное
значение на случайное число и добавляя
в каждом случае к полученному результату
начальное значение интервала, равное
545, получим элементы, подлежащие проверке
аудитором. Порядок нахождения элементов
выборки приведен в таблице 1.
Таблица
1 – Порядок нахождения элементов выборки
при использовании метода
случайного
бесповторного отбора
|
Порядковый |
Случайное |
Произведение |
Порядковый |
|
1 |
0,812 |
267 |
812 |
|
2 |
0,150 |
49 |
594 |
|
3 |
0,730 |
240 |
785 |
|
4 |
0,877 |
289 |
834 |
|
5 |
0,723 |
238 |
783 |
Таким
образом, аудитору А. Петрову необходимо
проверить расходные кассовые ордера с
№594, №783, №785, №812, №834.
ЗАДАЧА
№ 11
Для
проведения аудиторской проверки был
привлечен эксперт (юрисконсульт) с целью
проверки соответствия требованиям
действующего законодательства заключенных
и исполненных в отчетном периоде
договоров в аудируемой организации с
регистрационного № 674 по 774 выборочно.
Для упрощения, число договоров, которые
необходимо проверить, равно пяти, а из
совокупности исключены элементы
наибольшей стоимости и «ключевые»
элементы. Какие договоры необходимо
проверить эксперту? Решите задачу
методом систематического отбора
(количественной выборки по интервалам).
Решение:
-
Определяем
интервал выборки: ИВ = (ЗК-ЗН)/5 = (774-674)/5
= 20 -
Находим
случайное число: (см. Прил. В) = 0,9895 -
Рассчитываем
стартовую точку выборки:
СТВ
= ИВ*СЧ = 20*0,9895+674 = 694
-
Определяем
номера договоров, подлежащих проверке:
694
+ 20 = 714; 714 + 20 = 734 и т.д.
Таким
образом, договоры, которые необходимо
представить эксперту на проверку, должны
иметь регистрационные номера: 694; 714;
734; 754; 774;
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ( ).
).
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
 — при оценивании среднего значения признака;
— при оценивании среднего значения признака;
 — если признак альтернативный, и оценивается доля.
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
 — для среднего значения признака;
— для среднего значения признака;
 — для доли.
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки ( ) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
 .
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
Таблица
11.2.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:

Итак, определение границ генеральной средней и доли состоит из следующих этапов:
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
Таблица
11.3.
Формулы для расчета средней ошибки собственно случайной и механической выборки ()
 |
|
где |
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
Таблица
11.4.
| Уровень фондоотдачи, руб. | До 1,4 | 1,4-1,6 | 1,6-1,8 | 1,8-2,0 | 2,0-2,2 | 2,2 и выше | Итого |
|---|---|---|---|---|---|---|---|
| Количество предприятий | 13 | 15 | 17 | 15 | 16 | 14 | 90 |
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
Таблица
11.5.
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xixb4 | xixb4fi | xixb42fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная средняя

Выборочная дисперсия изучаемого признака

- Определяем среднюю ошибку повторной случайной выборки

- Зададим вероятность, на уровне которой будем говорить о величине предельной ошибки выборки. Чаще всего она принимается равной 0,999; 0,997; 0,954.

Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
- Предельная ошибка выборки с вероятностью 0,954 равна
- Найдем доверительные границы для среднего значения уровня фондоотдачи в генеральной совокупности


Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле

Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:

Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:

Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
 ;
;
- средняя ошибка выборки при использовании повторной схемы отбора составит

Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит

- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):

- установим границы для генеральной доли с вероятностью 0,997:

Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N1 + N2 + … + Ni + … + Nk = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n1 + n2 + … + ni + … + nk = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = ni · Ni/N
где ni — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.
Таблица
11.6.
Формулы для расчета средней ошибки выборки ( ) при использовании типического отбора, пропорционального объему типических групп
) при использовании типического отбора, пропорционального объему типических групп

Здесь  — средняя из групповых дисперсий типических групп.
— средняя из групповых дисперсий типических групп.
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
Таблица
11.7.
| Номер курса | Всего студентов, чел., Ni | Обследовано в результате выборочного наблюдения, чел., ni | Среднее число посещений библиотеки одним студентом за семестр, xi | Внутригрупповая выборочная дисперсия,  |
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности:
n = 2550/130*5 =128 (чел.);
- количество единиц, отобранных из каждой типической группы:

аналогично для других групп:
n2 = 31 (чел.);
n3 = 29 (чел.);
n4 = 18 (чел.);
n5 = 17 (чел.).
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:
- Средняя из внутригрупповых дисперсий
- Средняя ошибка выборки:
С вероятностью 0,954 находим предельную ошибку выборки:
- Доверительные границы для среднего значения признака в генеральной совокупности:





Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
- Малая выборка. В связи с небольшим объемом выборочной совокупности те формулы для определения ошибок выборки, которые использовались нами ранее при «больших» выборках, становятся неподходящими и требуют корректировки.
Среднюю ошибку малой выборки определяют по формуле

Предельная ошибка малой выборки:

Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
- Среднее значение признака в выборке равно
- Значение среднего квадратического отклонения составляет
- Средняя ошибка выборки:
- Значение коэффициента доверия t = 2,365 для п = 8 и Р = 0,95 .
- Предельная ошибка выборки:
- Доверительный интервал для среднего значения признака в генеральной совокупности:





То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч.
11.2.2. Определение численности выборочной совокупности
Перед непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
- вид предполагаемой выборки;
- способ отбора (повторный или бесповторный);
- выбор оцениваемого параметра (среднего значения признака или доли).
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
Таблица
11.8.
Формулы для определения численности выборочной совокупности

Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить

При бесповторном случайном отборе потребуется проверить

Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.

Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
ШПАРГАЛКА (скопируйте ссылку или текст)
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!
Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:
где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).
Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:
Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)
где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.
Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).
Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.
Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.
При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
Ошибка выборки — расхождение между характеристиками выборочной и генеральной совокупности. Различают два вида ошибок выборки: случайную ошибку и систематическую ошибку, возникающую вследствие нарушения правил отбора (или из-за смещений при отборе). При определении случайной ошибки предполагается, что ошибка регистрации равна нулю. Систематическую ошибку часто называют ошибкой, вызванной смещением. Общая ошибка выборки складывается из случайной ошибки (вследствие случайных различий между элементами совокупности, включенными в выборку и не попавшими в нее) и из смещения (систематической ошибки), если оно существует.
Ошибка выборки (sample error) – значение ошибки при проведении выборочной аудиторской проверки. Ошибка выборки возникает, если при проверке обнаруживается то, что в действительности отсутствует (например, в процессе наблюдения экономических явлений, при решении задач поиска).
При определении объема выборки устанавливается риск выборки, допустимая и ожидаемая ошибки. Риск выборки заключается в том, что мнения исследователя по определенному вопросу, составленные на основе выборочных данных и на основании изучения генеральной совокупности, могут различаться. Риск выборки имеет место как при тестировании средств системы контроля, так и при проведении детальной проверки. В контексте проверки на соответствие термин «ошибка» означает, что результаты проверки свидетельствуют либо о неправильном функционировании внутреннего контроля, либо о его неэффективности. В контексте проверки по существу – наличие ложных заявлений, возникающих как случайно, так и преднамеренно (см. Аудиторский риск).
Допустимая ошибка выборки – максимальное значение ошибки, обнаруженной в ходе выборки, в пределах которой исследователь все еще может сделать вывод о достоверности в целом данных, подлежащих проверке. Допустимая ошибка выборки определяется на стадии планирования аудита. Чем меньше размер допустимой ошибки выборки, тем больше должен быть объем выборки. Результатом высокой степени допустимой ошибки при малом объеме выборки могут быть данные, слишком приблизительные для подкрепления вывода о том, что совокупность в целом не имеет существенных искажений. Большая выборка помогает также обнаружить как частые, так и редкие отклонения или искажения, содержащиеся в денежной сумме.
Ожидаемая ошибка выборки – примерное, субъективно оцениваемое значение ошибки, которое до начала проведения выборки аудитор предполагает получить в ходе ее проведения. Если ошибка превышает ожидаемую ошибку выборки, то объем выборки, необходимой для получения определения риска выборочной проверки на заданной допустимой степени отклонения, следует увеличить. Для определения ожидаемой ошибки выборки обычно используют результаты проверок за предшествующие годы; если их невозможно получить, то пользуются небольшой выборкой из генеральной совокупности за текущий год или прибегают к опыту и интуиции аудитора.
Значение ожидаемой ошибки выборки не должно быть точным, т.к. оно влияет только на определение объема выборки, а не на оценку ее результатов. Исследователь обязан анализировать каждую ошибку, попавшую в выборку, экстраполировать полученные при выборке результаты на всю проверяемую совокупность (см. Экстраполяция результатов выборки) и оценить риски выборки.
Аудиторская выборка
- Основные принципы выборочных проверок в аудите
- Методы определения объема выборки
- Метод определения объема выборки по оценке влияния определенных факторов
- Метод определения объема выборки по оценке риска выборки, ожидаемой и допустимой степени отклонений
- Метод определения числа элементов выборки, имеющих сальдо
- Метод определения числа элементов выборки, основанных на оборотах по счетам бухгалтерского учета
- Стратификация (понятие, применение при планировании выборочного исследования). Правило «90-10»
- Характеристика методов отбора элементов выборки
- Анализ результатов выборочного исследования. Риск аудиторской выборки
Основные принципы выборочных проверок в аудите
Согласно МСА № 530, под аудиторской выборкой (Audit sampling) понимается применение аудиторских процедур менее чем к 100% статей в пределах сальдо счета или класса хозяйственных операций с целью предоставить возможность аудитору получить и оценить аудиторские доказательства о ряде характеристик статей, отобранных для того, чтобы помочь в формулировании заключения, связанного с генеральной совокупностью.
Проще говоря, «выборочный метод аудита» можно определить как применение аудиторских процедур менее чем к 100% совокупности проверяемых элементов.
Каждый процесс проведения выборочного метода в аудите состоит из следующих этапов:
- определение метода отбора;
- нахождение объема и получение выборки;
- выполнение аудиторских процедур по отношению к отобранным элементам выборки;
- анализ полученных результатов и распространение их на генеральную совокупность.
Рассмотрим каждый этап выборочного метода в отдельности. В международном стандарте отмечается, что при определении метода отбора элементов выборки аудитор должен оценить поставленные перед аудиторской проверкой цели, генеральную совокупность и размер (объем) выборки.
Первое, с чего аудитору необходимо начинать подготовку к аудиту конкретного участка учета, — это определение «специфических» (конкретных) целей и задач, которые необходимо решить при проведении проверки на данном участке. Как правило, такими задачами является выявление возможных ошибок и нарушений, способных оказать существенное влияние на достоверность финансовой отчетности (так называемых критериев проверки, соблюдение которых должно быть подтверждено или опровергнуто доказательствами в ходе проведения аудита).
Например, при осуществлении тестов контроля процесса заготовления и приобретения материалов аудитор проверяет обязательное выполнение следующих процедур контроля: предварительный и текущий контроль правильности составления первичных и иных документов — договоров, счетов-фактур, накладных и т.д. — со стороны ответственных должностных лиц аудируемого предприятия; санкционирование — согласование с руководителем — каждой хозяйственной операции по расходованию средств предприятия на приобретение указанных ценностей. При проведении процедур по существу аудитор устанавливает степень полноты и своевременности отражения всех хозяйственных операций, связанных с заготовлением материалов, в бухгалтерском учете и финансовой отчетности.
Генеральная совокупность (population) представляет собой полную совокупность документов или хозяйственных операций, которые проверяет аудитор посредством выборки и изучения выборочной совокупности для того, чтобы в дальнейшем сформировать заключение.
Правильное определение генеральной совокупности является важной задачей для аудитора, так как мнение аудитора формируется о всей (генеральной) совокупности. К примеру, если аудитор выбрал для проведения проверки документы только за первое полугодие, то и выводы правомерно распространять лишь на совокупность документов за этот период, но никак не за весь финансовый год.
Существенное влияние на определение метода и величины выборки оказывает прием стратификации, речь о котором пойдет ниже.
При определении размера (объема) выборки аудитор должен оценить:
- риск выборки;
- уровень допустимой ошибки;
- уровень ожидаемой ошибки.
Риск выборки (sampling risk) означает вероятность того, что заключение аудитора, основанное на выборке, будет отличаться от заключения, которое было бы сделано, если бы генеральная совокупность была подвергнута той же аудиторской процедуре.
Риск выборки следует отличать от иной разновидности аудиторского риска, не связанного с применением выборочного метода (non-sampling risk). Так, на качество проведенной аудиторской проверки, степень выявленных нарушений оказывает влияние уровень компетентности и квалификации аудитора в тех или иных вопросах.
Риск выборки имеет место в случае применения как тестов контроля, так и процедур по существу. При этом как в международном, так и в отечественном1 стандартах различают риски первого и второго рода.
Так, при применении тестов контроля различают следующие риски выборки:
- риск ниже уровня доверия — риск того, что после выборочно проведенных тестов контроля аудитором будет сделан вывод о ненадежности системы контроля клиента, в то время как в действительности такая система надежна;
- риск выше уровня доверия — риск, обратный предыдущему.
При использовании процедур по существу выделяют следующие риски выборки:
- риск неверного отклонения — риск того, что результаты проведенного выборочного исследования будут свидетельствовать о том, что отраженные в учете сальдо счета или класс хозяйственных операций содержат существенную ошибку, в то время как в действительности такой ошибки нет;
- риск неверного принятия (одобрения) — риск, обратный предыдущему.
Риски первого рода приводят к необходимости выполнения аудитором дополнительных и излишних аудиторских процедур либо дополнительной работы самим клиентом для того, чтобы установить, что первоначальный, сделанный аудитором, вывод о наличии ошибки или ненадежности системы контроля был необоснованным. Тем не менее риски первого рода вызывают меньшие опасения, чем риски второго рода, поскольку в результате наличия последних мнение аудитора о финансовой отчетности может оказаться неправильным, а существенные нарушения и недостатки системы контроля клиента не будут вскрыты.
Очевидно, что риск выборки находится в обратном отношении к объему выборки: чем больше последний, тем меньше риск, связанный с применением выборочного метода, и наоборот.
Правило (стандарт) аудиторской деятельности «Аудиторская выборка». Одобрено Комиссией по аудиторской деятельности при Президенте РФ 25 декабря 1996 г., протокол № 6, п. 3.6, 3.7.
Допустимая ошибка (tolerable error) — это максимальное искажение в денежном выражении в генеральной совокупности данных — сальдо счета или классе хозяйственных операций, — наличие которого не ведет к существенному искажению финансовой отчетности. Размер допустимой ошибки определяется на стадии планирования аудита и, применительно к процедурам по существу, связан с субъективной оценкой аудитора уровня существенности. Чем меньше значение допустимой ошибки, тем больше размер выборочной совокупности, подлежащий проверке аудитором, и наоборот.
Ожидаемая ошибка (expected error) — ошибка, которая по прогнозам аудитора будет присутствовать в генеральной совокупности.
В случае если аудитор ожидает наличие ошибок в генеральной совокупности, по сравнению с иной ситуацией, когда, по его мнению, наличие возможных ошибок исключено, требуется увеличить объем выборки и, соответственно, количество применяемых аудиторских процедур для того, чтобы сделать вывод о том, что действительное наличие ошибок и искажений в первом случае не превышает уровня допустимой ошибки. Для определения величины ожидаемой ошибки в генеральной совокупности аудитору следует принимать во внимание такие факторы, как уровни риска, полученные в результате предыдущих аудиторских проверок, изменения, произошедшие в хозяйственной деятельности клиента, и др.
Согласно требованиям МСА № 530 «Аудиторская выборка», выборка должна быть репрезентативной (или представительной), т.е. каждый элемент генеральной совокупности должен иметь возможность (точнее, равную вероятность) попасть в выборку.
В научной литературе встречается и иное определение указанного понятия. Так, представительная выборка — это выборка, обладающая теми же свойствами, что и генеральная совокупность.
Если, например, количество документов в проверяемой совокупности за январь и сентябрь одинаково, то и вероятность для них попасть в выборку должна быть одинакова (это не означает, что количество документов в выборке за январь и сентябрь будет равным; вероятнее всего, эти числа будут близкими). Однако и в настоящее время на практике встречаются случаи, когда аудиторы проверяют, например, накладные на поступление материалов за один месяц, после чего считают, что получили ясное представление о правильности их документального оформления за весь проверяемый период (например, за год). Такие действия противоречат принципу репрезентативности аудиторской выборки.
В международном стандарте упоминаются три основных метода аудиторской выборки:
- случайного отбора;
- систематического отбора;
- бессистемного отбора.
Подробнее на методах выборки и их применении в аудите мы остановимся в Характеристика методов отбора элементов выборки.
В ходе анализа полученных результатов и распространения их на генеральную совокупность аудитору необходимо:
- определить, действительно ли полученные отклонения являтся ошибкой;
- рассмотреть качественные аспекты выявленных ошибок (их характер — умышленные или непреднамеренные, систематические или случайные; причину и воздействие на дальнейший ход аудиторской проверки);
- распространить полученные в ходе аудита выборочной совокупности результаты на генеральную совокупность, обращая внимание на качественные аспекты выявленных ошибок (при этом может быть проведена статистическая или нестатистическая оценка результатов);
- заново оценить риск выборки (если значение выявленной ошибки в генеральной совокупности превышает уровень допустимой ошибки, то необходимо переоценить риск выборки, и если определенный уровень риска окажется неприемлемым, то рассмотреть возможность увеличения объема выборки или применения альтернативных аудиторских процедур).
Методы определения объема выборки
В мировой практике применяются различные подходы к определению совокупности данных, которая в дальнейшем подвергается выборочной проверке:
- оценка влияния таких факторов, как фактор уверенности, общая стоимость генеральной совокупности; допустимая и ожидаемая сумма ошибок;
- оценка риска выборки, ожидаемой и допустимой степени отклонений;
- определение числа элементов выборки, имеющих сальдо;
- нахождение числа элементов выборки, основанных на оборотах по счетам бухгалтерского учета.
Рассмотрим каждый, подход подробнее.
Метод определения объема выборки по оценке влияния определенных факторов
В рамках применения данного подхода возможны варианты: методика расчета объема выборки для генеральных совокупностей, в которых ожидается незначительное количество или совсем не ожидается ошибок, отличается от той, когда такие ошибки с большой степенью вероятности могут существовать.
В первом случае объем выборки (ОВ) находят умножением фактора надежности (ФН) на общую сумму всей генеральной совокупности (ГС) и делением на допустимую сумму ошибок (ДСО), или Объем генеральной совокупности оценивается по балансовой стоимости на дату составления финансовой отчетности. Значения фактора надежности в зависимости от уровня надежности приведены ниже:
| Уровень надежности, % | 80,0 | 90,0 | 95,0 | 97,5 | 99,0 | 99,5 |
| Риск,% (1-уровень надежности) | 20,0 | 10,0 | 5,0 | 2,5 | 1,0 | 0,5 |
| Фактор надежности | 1,61 | 2,31 | 3,0 | 3,69 | 4,61 | 5,3 |
Пример. Предположим, что генеральная совокупность имеет балансовую стоимость 4,0 млн руб. Аудитор хочет быть на 95% уверен, что обнаружит ошибки в генеральной совокупности, если они превышают 100 тыс. руб.
Подставляя значения факторов в формулу (8), получим объем выборки т.е. необходимый объем выборки составляет 120 элементов.
Во втором случае (когда ожидается наличие ошибок) в дополнение к вышеизложенным факторам аудитор должен оценить ожидаемую сумму искажения (ОСО) и применить следующую формулу:
Фактор надежности определяется выше. Однако для уровней надежности 97,5% и выше рекомендуется использовать следующие значения:
| Уровень надежности | Фактор надежности |
| 97,5 | 3,84 |
| 99,0 | 5,43 |
| 99,5 | 6,63 |
Предположим, в предыдущем примере аудитор ожидает, что искажение в совокупности достигнет 10 тыс. руб. В этом случае т.е. объем выборки возрастет до 148 элементов.
Метод определения объема выборки по оценке риска выборки, ожидаемой и допустимой степени отклонений
Данный подход был разработан американским исследователем Р. Монтгомери (1872-1953). Суть метода заключается в следующем: чтобы рассчитать объем выборки, аудитору необходимо оценить некоторые критерии:
- уровень надежности (100% минус риск выборки);
- ожидаемая ошибка (% генеральной совокупности);
- допустимая ошибка (% генеральной совокупности).
Далее, объем выборки определяется с применением таблицы, составленной для соответствующего уровня надежности. Расчет объема выборки для уровня надежности 95% осуществляется исходя из данных табл. 6.
Таблица 6
Объем выборки в зависимости от ожидаемого и допустимого уровней ошибок (для уровня надежности 95%)
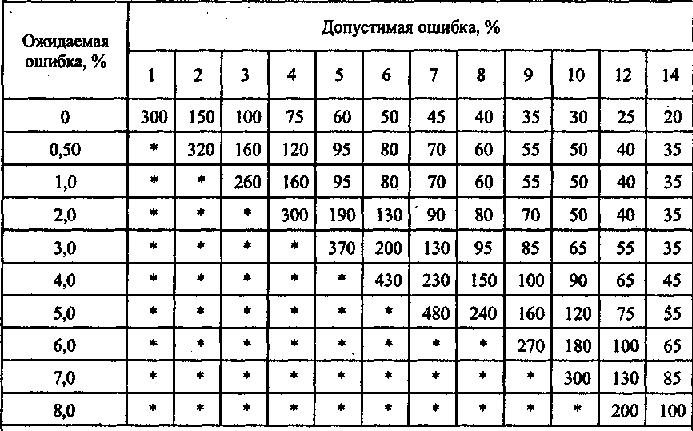
К примеру, аудитор оценивает уровень допустимой ошибки в размере 7% общей суммы генеральной совокупности, а ожидаемой ошибки — 2%. При этом аудитор устанавливает уровень надежности, равный 95%, т.е. должен быть на 95% уверен, что реальная ошибка, содержащаяся в генеральной совокупности, не превысит установленную им допустимую ошибку. Объем выборки будет определен на пересечении соответствующей графы и строки таблицы и составит 90 элементов.
Можно заметить, что объем генеральной совокупности в данном подходе не является фактором, влияющим на объем выборки. Однако при необходимости можно скорректировать полученное значение объема выборки на объем генеральной совокупности по формуле
где ОВ, и ОВ2 — объем выборки соответственно до и после учета влияния фактора объема генеральной совокупности;
Г С — объем генеральной совокупности.
Исходя из формулы (10) можно отметить, что данный фактор позволяет пересмотреть объем выборки, если отбирается более 10% элементов генеральной совокупности.
Метод определения числа элементов выборки, имеющих сальдо
Данный метод применяется для определения объема выборки из элементов генеральной совокупности, составляющих сальдо бухгалтерского счета в аудируемой финансовой отчетности.
Считается, что элементы наибольшей стоимости и «ключевые» элементы были уже отобраны в отдельную группу и подлежат сплошной проверке.
Согласно данной методике, число элементов, подлежащих отбору для выборки, исчисляется по формуле
OB = (ГС — ЭН — ЭК) x КП : (УС x 0,75), (11)
где ОВ — объем выборки;
ГС — объем генеральной совокупности в стоимостном выражении;
ЭН — сумма элементов наибольшей стоимости;
ЭК — сумма «ключевых» элементов;
КП — коэффициент проверки;
УС — уровень существенности.
Коэффициент проверки зависит от уровня аудиторского риска. Ранее нами неоднократно отмечалось, что аудиторский риск состоит из трех составных частей: неотъемлемый (внутрихозяйственный) риск; риск системы контроля; риск необнаружения.
Последнюю составляющую аудиторского риска нельзя использовать при исчислении объема аудиторской выборки, так как этот риск не оказывает влияния, а напротив, зависит от того, сколько элементов будет отобрано для проведения проверки.
Кроме риска средств контроля и неотъемлемого (внутрихозяйственного) риска, в расчетах рекомендуется использовать показатель степени риска, связанного с наличием «пересекающихся процедур». Так, отдельную совокупность первичных окументов изучают не саму по себе, а во взаимосвязи с документами, относящимися к другому разделу бухгалтерского учета.
Таким образом, аудиторский риск может снижаться, если достоверность бухгалтерских данных из одной области учета подтверждается проверенными бухгалтерскими данными из другой области учета. И, наоборот, недостатки одной из подсистем бухгалтерского учета могут оказать существенное негативное влияние на иные его подсистемы, а также на достоверность финансовой отчетности в целом. (Данное положение следует из принципа двойной записи, поскольку любая хозяйственная операция отражается в бухгалтерском учете как по дебету одного счета, так и по кредиту другого. Поэтому ошибка, связанная с неправильным отражением какой-либо хозяйственной операции, всегда затронет, как минимум, два сальдо счета.)
Каждая из степеней риска оценивается по следующей шкале: высокий, средний, низкий. Если аудитор не смог достоверно оценить какое-либо значение риска, то для целей определения объема выборки необходимо принять это значение высоким. Таким образом, можно получить 27 комбинаций рисков, каждой из которых соответствует определенное значение коэффициента проверки (приложение 1).
К формуле (11) необходимо дать следующие пояснения:
- если в полученном объеме выборки оказывается менее 10 элементов, то такая ситуация считается нецелесообразной с математической точки зрения. Тогда формула (11) принимает вид ОВ = КП 10, т.е. объем выборки рассчитывается как произведение коэффициента проверки на число 10;
- в противоположном случае, если количество элементов выборки превысит значение 40 — 50, то следует ограничиться 35 элементами, тогда формула (11) запишется как ОВ = КП 35, т.е. объем выборки будет равен произведению коэффициента проверки на 35.
Покажем применение данного подхода на примере.
Пример. Требуется провести проверку некоторой совокупности, элементы которой в сумме обеспечивают значение ГС = 105 822 тыс. руб.; элементы наибольшей стоимости и «ключевые» элементы составляют ЭН + ЭК = 10 554 тыс. руб.; уровень существенности УС — 6000 тыс. руб.; оценка рисков сальдо счета:
Для данной совокупности значений факторов (С; Н; С) получаем коэффициент проверки КП = 0,66 (см. приложение 1).
Далее определяем объем выборки:
ОВ = (105 822 — 10 554) x 0,66 : (6000 x 0,75) «14,
т.е. в дополнение к элементам наибольшей стоимости и «ключевым» элементам следует отобрать 14 элементов представительной выборки.
Метод определения числа элементов выборки, основанных на оборотах по счетам бухгалтерского учета
В случае если проверке подлежат счета бухгалтерского учета, не имеющие сальдо на дату составления финансовой отчетности, применяется отличный от рассмотренного в Метод определения числа элементов выборки, имеющих сальдо порядок.
Здесь проводится оценка аудитором уровней рисков: неотъемлемого (внутрихозяйственного), средств контроля и пересекающихся процедур по той же шкале1. В результате комбинации различных оценок также получают варианты значений, но уже не условных коэффициентов, а конкретных объемов выборки (приложение 2).
Пример. Оценка, проведенная аудитором, показала, что уровень неотъемлемого (внутрихозяйственного) риска — средний, риска средств контроля — средний, а риска, связанного с пересекающимися процедурами, — высокий. В приложении 2 для совокупности факторов С; С; В находим объем выборки, который будет равен 28 элементам.
Стратификация (понятие, применение при планировании выборочного исследования).Правило «90-10»
Под стратификацией (stratification) понимается процесс деления генеральной совокупности на подсовокупности, каждая из которых состоит из элементов, обладающих сходными характеристиками, т.е. свойством однородности.
Стратификация является действенным приемом повышения эффективности выборочного метода. Она позволяет использовать меньший объем выборки (в рамках каждой подгруппы, или страты), не ухудшая качества самой аудиторской проверки. Это связано с тем, что показатель вариации, рассчитанный для элементов внутри отдельной страты, будет иметь небольшое значение.
Зачастую используется критерий суммовой оценки, т.е. выделяют элементы наибольшей стоимости и иные элементы. Как правило, первые из них подлежат сплошной (100%-ной) проверке (поскольку для них справедливо утверждение о том, что небольшая в процентном значении ошибка может иметь большое абсолютное значение и оказать существенное влияние на финансовую отчетность).
В связи с этим можно сформулировать правило «90 -10», суть которого заключается в следующем.
Нельзя оценить степень достоверности финансовой отчетности аудируемой организации, применив аудиторские процедуры в отношении документов, на основе которых получены сальдо счетов или отражены хозяйственные операции, составляющие в совокупности 10% общей суммы в денежном выражении. Для получения 90%-ной выборки достаточно отобрать лишь 10% общего их количества.
Рассмотрим данное правило на примере проверки документов по существу. Действительно, чаще всего документов со значительными суммами встречается немного. Однако при этом они занимают наибольший удельный вес в структуре всех документов в суммовом выражении. Поэтому для формирования мнения о генеральной совокупности, как правило, нет необходимости проводить детальную проверку документов с незначительными суммами, которых в наличии имеется много, но они составляют небольшой удельный вес в суммовом выражении. И наоборот, как отмечалось выше, большее внимание аудитор должен уделять тем документам и отраженным в них хозяйственным операциям, в которых сумма значительна и возможная ошибка может оказать существенное влияние на финансовую отчетность.
В основу деления генеральной совокупности на страты также может быть положен не только количественный, но и качественный признак, а именно: тип хозяйственной операции, группа активов и т.д. Например, при проведении аудита основных средств предприятия может оказаться целесообразным разделить весь их массив на группы и провести пров фку в рамках каждой группы (здания, сооружения, рабочие и силовые машины и оборудование, транспортные средства и др.), поскольку учет каждой группы имеет свои особенности.
Необходимо отметить, что качественный и количественный признаки деления могут встречаться одновременно. К примеру, здания и сооружения на крупных промышленных предприятиях, как правило, занимают наибольший удельный вес в структуре всех основных фондов, и выделение по качественному признаку данной группы основных средств с целью проведения в дальнейшем их проверки будет отвечать тем же принципам, что и отмеченные выше для элементов наибольшей стоимости.
Исходя из опыта работы международных аудиторских фирм рекомендуется выделять из проверяемой генеральной совокупности и подвергать сплошной проверке следующие группы (страты):
- наиболее крупные элементы (элементы с наибольшей стоимостью — сальдо счета или классы хозяйственных операций);
- элементы, в которых по профессиональному суждению аудитора наиболее высока вероятность наличия ошибки или искажения («ключевые» элементы).
Характеристика методов отбора элементов выборки
Все методы отбора элементов выборки из генеральной совокупности можно разделить на две группы: вероятностные и невероятностные. Согласно первым, существует равная вероятность того, что каждая единица генеральной совокупности может оказаться в выборке. Используя невероятностные методы, аудитор сам решает, какой элемент выбрать.
Поскольку невероятностные методы не дают возможности оценивать результаты выборки статистическими способами, то их применение требует особой осторожности.
Далее, среди вероятностных методов различают:
- случайный отбор;
- систематический отбор (метод количественной или стоимостной выборки по интервалам).
Случайный отбор обеспечивает равную вероятность быть отобранным для каждого элемента генеральной совокупности. Встречаются следующие разновидности данного метода:
- повторный случайный отбор, при котором один и тот же элемент генеральной совокупности может попасть в выборку более одного раза;
- бесповторный (наиболее часто используют в ходе аудита).
Случайный отбор основан на использовании в расчетах случайных чисел. Последние могут быть получены:
- при помощи таблиц случайных чисел;
- с использованием специальных компьютерных программ.
Таблица случайных чисел представляет собой список случайных чисел в табличной форме для удобства их выбора (приложение 3).
Рекомендуется случайное число в данной таблице находить случайным же образом (например, задумать два числа: первое — от 1 до 10, второе — от 1 до 40, На пересечении соответствующих графы и строки с такими координатами и находится искомое случайное число). При этом индивидуально могут быть разработаны разные системы нахождения координат случайным образом (например, с использованием даты чьего-либо дня рождения, времени и т.д.).
Случайные числа можно получить также при помощи генераторов случайных чисел, разработанных на базе компьютерных программ. Так, функция генерации случайных чисел предусмотрена в программе Microsoft Excel. Для нахождения случайного числа при работе с программой необходимо в соответствующей ячейке с помощью клавиатуры набрать следующие символы: «=слчисо».
Необходимое условие применения данного метода — совокупность элементов, подлежащих проверке, должна быть пронумерована. Если обозначить случайное число — СЧ, начальное и конечное значения интервала генеральной совокупности — ЗН и ЗК, то номер документа, который необходимо выбрать (Н), запишем как Н = (ЗК-ЗН)- СЧ + ЗН. (12)
Рассмотрим применение данного метода на примере.
В настоящем учебном пособии рассматривается только метод бесповторного случайного отбора.
Пример. Аудитору требуется провести формальную проверку кассовых документов (приходных кассовых ордеров) с № 1159 по 1422 выборочно. Для упрощения число элементов, которое необходимо выбрать, равно шести, а из генеральной совокупности исключены элементы наибольшей стоимости и «ключевые» элементы.
Решение. Для определения случайного числа воспользуемся таблицей, приведенной в приложении 3. Пусть с помощью методов, описанных выше, мы выбрали шесть случайных чисел: 0,5569; 0,9813; 0,5643; 0,8777; 0,3401; 0,0050. Порядок нахождения элементов выборки приведен в табл. 7.
В нашем примере начальное значение интервала ЗН = 1159, а конечное ЗК = 1422. Таким образом, разница между конечным и начальным значениями интервала генеральной совокупности составляет 263. Умножая последовательно полученное значение на случайное число и добавляя в каждом случае к полученному результату начальное значение интервала, равное 1159, получим элементы, подлежащие проверке аудитором (см. последнюю графу табл. 7).
Таблица 7
| Порядковый номер элемента выборки | Случайное число СЧ | Произведение разницы между конечным и начальным значением интервала на случайное число СЧ(ЗК-ЗН) | Порядковый номер документа, подлежащего отбору в выборочную совокупность Н = ЗН + (ЗК-ЗН)СЧ |
|---|---|---|---|
| 1 | 0,5569 | 146 | 1305 |
| 2 | 0,9813 | 258 | 1417 |
| 3 | 0,5643 | 148 | 1307 |
| 4 | 0,8777 | 231 | 1390 |
| 5 | 0,3401 | 89 | 1248 |
| 6 | 0,0050 | 1 | 1160 |
Метод количественной выборки по интервалам. Предполагается выполнение следующих процедур:
- нахождение интервала выборки (ИВ);
- определение стартовой (начальной) точки выборки (СТВ);
- вычисление номеров элементов, подлежащих включению в выборочную совокупность, путем последовательного (кратного) прибавления к стартовой точке значения интервала выборки.
При этом интервал выборки находится по формуле
ИВ = (ЗК-ЗН):ЭВ, (13)
где ЭВ — количество элементов выборки.
Стартовая точка выборки (СТВ) исчисляется следующим образом:
СТВ = ИВ СЧ + ЗН. (14)
Рассмотрим данный метод на примере.
Пример. Для проведения аудиторской проверки привлечен эксперт по правовым вопросам. Ему необходимо провести проверку соответствия заключенных в отчетном периоде договоров в аудируемой организации требованиям действующего законодательства, включая наличие необходимого перечня условий и реквизитов с № 550 по 650 выборочно. Для упрощения число элементов, которое следует выбрать, равно шести, а из совокупности исключены элементы наибольшей стоимости и «ключевые» элементы.
Решение.
Шаг 1. Определяем интервал выборки: ИВ = (650 — 550): 6 x 16,67.
Шаг 2. Находим случайное число. Предположим, что из таблицы оно равно 0,5569.
Шаг 3. Рассчитываем стартовую точку выборки: СТВ = 16,67 х 0,5569 + 550 « 559.
Шаг 4. Определяем номера договоров, подлежащих проверке, прибавляя к стартовому значению одинарное, двукратное и т.д. значение интервала выборки (559 + 16,67 « 576; 576 + 16,67 ««593 и т.д.).
Таким образом, договоры, которые необходимо представить эксперту на проверку, должны иметь регистрационные номера 559; 576; 593; 609; 626; 643.
Методы случайного отбора и количественной выборки по интервалам применяются, как правило, в случае, если генеральная совокупность однородна, а стоимостные значения ее элементов отличаются друг от друга незначительно (т.е. данные методы предпочтительнее использовать при выборочной проверке элементов внутри отдельных страт).
Метод стоимостной выборки по интервалам. В отличие от рассмотренных выше, он используется в случае, если элементы генеральной совокупности имеют стоимостные значения со значительной вариацией.
Необходимым условием применения данного метода является наличие стоимостного значения у элементов генеральной совокупности. Алгоритм указанного метода также состоит в расчете показателей интервала, стартовой точки и элементов выборки. Однако он отличается от предьвдущего тем, что вместо порядкового номера документов в вычислениях «участвуют» их стоимостные эквиваленты (отсюда и название метода).
Согласно рассматриваемому методу, интервал выборки находят по формуле
ИВ = ОС:ЭВ, (15)
где ОС — общий объем генеральной совокупности в денежном выражении.
Стартовую точку выборки (ее первый порядковый элемент) определяют следующим образом:
СТВ = ИВ x СЧ. (16)
Значение каждого последующего элемента равно предыдущему значению, увеличенному на значение интервала выборки. При этом выбираются элементы, в диапазон стоимости которых, рассчитанной нарастающим итогом, входит полученное значение в стоимостном выражении.
Поясним содержание данного метода на примере.
Пример. Аудитор выборочным методом проверяет обоснованность первичными документами показателя выручки от реализации продукции, выпускаемой аудируемой организацией. Данные о выручке от реализации продукции приведены в табл. 8.
Таблица 8
| Дата | Выручка с НДС, тыс. руб. | Дата | Выручка с НДС, тыс. руб. |
|---|---|---|---|
| 15.03 | 22,6 | 20.03 | 63,4 |
| 16.03 | 66,3 | 21.03 | 15,9 |
| 17.03 | 5,5 | 22.03 | 21,8 |
| 18.03 | 40,0 | Ито го | 293,3 |
| 19.03 | 57,8 |
Для упрощения число элементов, которые необходимо проверить (объем выборки), равно четырем, а из совокупности исключены элементы наибольшей стоимости и «ключевые» элементы.
Решение.
Шаг 1. Определяем интервал выборки ИВ = 293,3 : 4 « 73,3.
Шаг 2. Находим случайное число. Предположим, что из таблицы оно равно 0,5569.
Шаг 3. Рассчитываем стартовую точку выборки СТВ = 73,3 х 0,5569 « 40,8.
Шаг 4. Определяем остальные элементы выборочной совокупности: 40,8 + 73,3 = 114,1; 114,1 + 73,3 = 187,4; 187,4 + 73,3 = 260,7.
Аналогично проверим документы по состоянию на 16, 18, 19 и 21 марта 200_ г. (табл. 9).
Таблица 9
| Дата | Значение элемента генеральной совокупности (выручка с НДС, тыс. руб.) | Суммарное значение элемента совокупности нарастающим итогом, тыс. руб. | Элемент выборки, тыс. руб. |
|---|---|---|---|
| 15.03 | 22,6 | 22,6 | |
| 16.03 | 66,3 | 88,9 | 40,8 |
| 17.03 | 5,5 | 94,4 | |
| 18.03 | 40,0 | 134,4 | 114,1 |
| 19.03 | 57,8 | 192,2 | 187,4 |
| 20.03 | 63,4 | 255,6 | |
| 21.03 | 15,9 | 271,5 | 260,7 |
| 22.03 | 21,8 | 293,3 | |
| Итого | 293,3 | X | X |
Среди невероятностных методов выборки выделяют:
- блочный отбор — отбор последовательности нескольких элементов. Как только выбирается начальный элемент, остальные элементы выборки выделяются автоматически (например, отбор для проверки последовательности из тридцати кассовых ордеров за июнь 200_г.);
- беспорядочный отбор — исследование генеральной совокупности и выделение элементов выборки безотносительно к ее объему, источнику или другим характеристикам;
- оценочные методы — определение элементов выборки на основе профессиональных суждений самих аудиторов; при этом их выбор падает на элементы, с вероятностью содержащие ошибку («узкие» места), разного рода нетипичные операции, базирующиеся на личном опыте, проведенных аудиторских процедурах и выводах относительно системы бухгалтерского учета и внутреннего контроля клиента.
Несмотря на простоту применения, невероятностные методы не лишены существенного недостатка — высокой степени вероятности получения непредставительной выборки, в результате чего значительно возрастает аудиторский риск выборки.
Анализ результатов выборочного исследования. Риск аудиторской выборки
Как отмечалось выше, выборка в аудите проводится в целях формирования мнения и выводов о свойствах всей проверяемой генеральной совокупности. Поэтому важным этапом выборочного исследования является проведение анализа выявленных отклонений и экстраполяции их на генеральную совокупность.
Основным правилом2 является то, что ошибки и искажения, выявленные аудитором по элементам представительной выборки, подлежат распространению на всю проверенную совокупность (путем умножения общей суммы отклонения на отношение объемов генеральной и выборочной совокупностей). Ошибки и искажения, содержащиеся в элементах наибольшей стоимости и «ключевых» элементах, учитываются в фактически выявленной сумме и экстраполяции на генеральную совокупность не подлежат. Таким образом, ОПП = ОВ x (ГС — ЭН — ЭК): СЭВ + ОЭН + ОЭК, (17)
где ОПП — полная прогнозная величина ошибок;
О В — фактическая величина ошибок, выявленна при проверке представительной выборки;
СЭВ — суммарная величина элементов представительной выборки;
ОЭН — ошибки, выявленные в ходе проверки элементов наибольшей стоимости;
ОЭК — ошибки, выявленные в ходе проверки «ключевых» элементов.
(Все показатели в формуле должны быть рассчитаны в денежном выражении.)
Рассмотрим данные положения на примере.
В этом заключается еще одно отличие аудита от ревизии: выводы ревизии строятся исключительно на фактах, подтвержденных документально (т.е. на 100%), поэтому в ней, как правило, нет места экстраполяции и иным вероятностным суждениям, поскольку выводы ревизии в последнем случае можно оспорить. Для аудитора, напротив, важным будет получение результата не с максимальной, а с достаточной степенью точности для выражения мнения о финансовой отчетности, поэтому перечисленные выше методы теории вероятностей и математической статистики широко используются в его инструментарии.
Данный подход может показаться упрощенным. В курсе математической статистики рассматриваются иные, более сложные (статистические), методы распространения результатов выборочного исследования на генеральную совокупность.
Пример. Объем генеральной совокупности ГС = 105 822 тыс. руб., элементы наибольшей стоимости и «ключевые» элементы в сумме равны ЭН + ЭК = 10 554 тыс. руб.; уровень существенности УС = 6000 тыс. руб.
Предположим, что в результате проверки удалось установить наличие ошибок и искажений: в выборочной совокупности объемом 1022 тыс. руб. на сумму 31 тыс. руб., в элементах наибольшей стоимости и «ключевых» элементах — на общую сумму 415 тыс. руб.
Рассчитаем полную прогнозную величину ошибок ОПП = 31 x (105 822 — 10 554): 1022 + 415 « 3305 (тыс. руб.).
Поскольку уровень существенности составляет 6000 тыс. руб., полная прогнозная ошибка равна 55% уровня существенности.
В общем случае в результате экстраполяции результатов выборочной проверки на всю проверяемую совокупность возможны следующие варианты:
- если общая прогнозная ошибка больше уровня существенности, то у аудитора нет достаточных оснований для подтверждения достоверности проверяемой совокупности;
- если общая прогнозная ошибка меньше уровня существенности, то с учетом иных аудиторских доказательств достоверность проверяемой совокупности может быть подтверждена;
- если указанные величины незначительно отличаются друг от друга, то аудитору рекомендуется предпринять следующие меры:
- увеличить объем выборки либо применить иные аудиторские процедуры;
- провести более детальный анализ причин возникновения ошибок и искажений;
- потребовать от клиента устранения установленных проверкой нарушений до ее окончания;
- потребовать от клиента исправления не только выборочно выявленных, но и всех остальных возможных нарушений, после этого провести повторную проверку иных (ранее не проверенных) элементов генеральной совокупности.
Тем не менее необходимо помнить, что абсолютно представительная выборка на практике не встречается. Всегда существует вероятность того, что на основе результатов выборочно проведенной проверки аудитором будет сформировано неправильное мнение (из-за наличия аудиторского риска), что может иметь для самого аудитора негативные правовые и экономические последствия.
Контрольные вопросы и задания
- Каковы основные принципы выборочных проверок в аудите?
- Что понимается под аудиторской выборкой, генеральной и выборочной совокупностью?
- Дайте характеристику основных этапов проведения выборочной проверки.
- Какие способы используются для определения объема выборки?
- В чем сущность стратификации? Поясните на примерах применение правила «90 -10».
- Что понимается под экстраполяцией результатов выборочного наблюдения?
- Какая выборка имеет свойство репрезентативности? В чем заключается риск аудиторской выборки?
Сущность контроля и аудита Цель и основные принципы, регулирующие аудит финансовой отчетности Условия аудиторских заданий (обязательств) Основные этапы процесса аудиторской проверки и приемы аудита Существенность в аудите Оценки риска и внутренний контроль Планирование аудита Аудит в среде компьютерных информационных систем Аудиторское доказательство Аудиторская выборка Заключение аудитора по финансовой отчетности Развитие международной теории и практики аудита Обязательный аудит как инструмент обеспечения экономической безопасности государства Качество аудита и ответственность аудиторов
Стандарты аудиторской деятельности | Шеремет А.Д. Аудит | Ерофеева В.А. Аудит. Конспект лекций | Шешукова Т.Г. Аудит: теория и практика применения международных стандартов | Налетова И.А. Аудит | Соколова Е.С. Основы аудита | Камзолов В.А. Аудит | Лукьянчук У.Р. Аудит