
Отладка, или debugging, — это поиск (локализация), анализ и устранение ошибок в программном обеспечении, которые были найдены во время тестирования.
Виды ошибок
Ошибки компиляции
Это простые ошибки, которые в компилируемых языках программирования выявляет компилятор (программа, которая преобразует текст на языке программирования в набор машинных кодов). Если компилятор показывает несколько ошибок, отладку кода начинают с исправления самой первой, так как она может быть причиной других.
В интерпретируемых языках (например Python) текст программы команда за командой переводится в машинный код и сразу исполняется. К моменту обнаружения ошибки часть программы уже может исполниться.
Ошибки компоновки
Ошибки связаны с разрешением внешних ссылок. Выявляет компоновщик (редактор связей) при объединении модулей программы. Простой пример — ситуация, когда требуется обращение к подпрограмме другого модуля, но при компоновке она не найдена. Ошибки также просто найти и устранить.
Ошибки выполнения (RUNTIME Error)
Ошибки, которые обнаруживают операционная система, аппаратные средства или пользователи при выполнении программы. Они считаются непредсказуемыми и проявляются после успешной компиляции и компоновки. Можно выделить четыре вида проявления таких ошибок:
- сообщение об ошибке, которую зафиксировали схемы контроля машинных команд. Это может быть переполнение разрядной сетки (когда старшие разряды результата операции не помещаются в выделенной области памяти), «деление на ноль», нарушение адресации и другие;
- сообщение об ошибке, которую зафиксировала операционная система. Она же, как правило, и документирует ошибку. Это нарушение защиты памяти, отсутствие файла с заданным именем, попытка записи на устройство, защищенное от записи;
- прекращение работы компьютера или зависание. Это и простые ошибки, которые не требуют перезагрузки компьютера, и более сложные, когда нужно выключать ПК;
- получение результатов, которые отличаются от ожидаемых. Программа работает стабильно, но выдает некорректный результат, который пользователь воспринимает за истину.
Ошибки выполнения можно разделить на три большие группы.
Ошибки определения данных или неверное определение исходных данных. Они могут появиться во время выполнения операций ввода-вывода.
К ним относятся:
- ошибки преобразования;
- ошибки данных;
- ошибки перезаписи.
Как правило, использование специальных технических средств для отладки (API-логгеров, логов операционной системы, профилировщиков и пр.) и программирование с защитой от ошибок помогает обнаружить и решить лишь часть из них.
Логические ошибки. Они могут возникать из ошибок, которые были допущены при выборе методов, разработке алгоритмов, определении структуры данных, кодировании модуля.
В эту группу входят:
- ошибки некорректного использования переменных. Сюда относятся неправильный выбор типов данных, использование индексов, выходящих за пределы определения массивов, использование переменных до присвоения переменной начального значения, нарушения соответствия типов данных;
- ошибки вычислений. Это некорректная работа с переменными, неправильное преобразование типов данных в процессе вычислений;
- ошибки взаимодействия модулей или межмодульного интерфейса. Это нарушение типов и последовательности при передаче параметров, области действия локальных и глобальных переменных, несоблюдение единства единиц измерения формальных и фактических параметров;
- неправильная реализация логики при программировании.
Ошибки накопления погрешностей. Могут возникать при неправильном округлении, игнорировании ограничений разрядной сетки, использовании приближенных методов вычислений и т.д.
Методы отладки программного обеспечения
Метод ручного тестирования
Отладка программы заключается в тестировании вручную с помощью тестового набора, при работе с которым была допущена ошибка. Несмотря на эффективность, метод не получится использовать для больших программ или программ со сложными вычислениями. Ручное тестирование применяется как составная часть других методов отладки.
Метод индукции
В основе отладки системы — тщательный анализ проявлений ошибки. Это могут быть сообщения об ошибке или неверные результаты вычислений. Например, если во время выполнения программы завис компьютер, то, чтобы найти фрагмент проявления ошибки, нужно проанализировать последние действия пользователя. На этапе отладки программы строятся гипотезы, каждая из них проверяется. Если гипотеза подтвердилась, информация об ошибке детализируется, если нет — выдвигаются новые.
Вот как выглядит процесс:
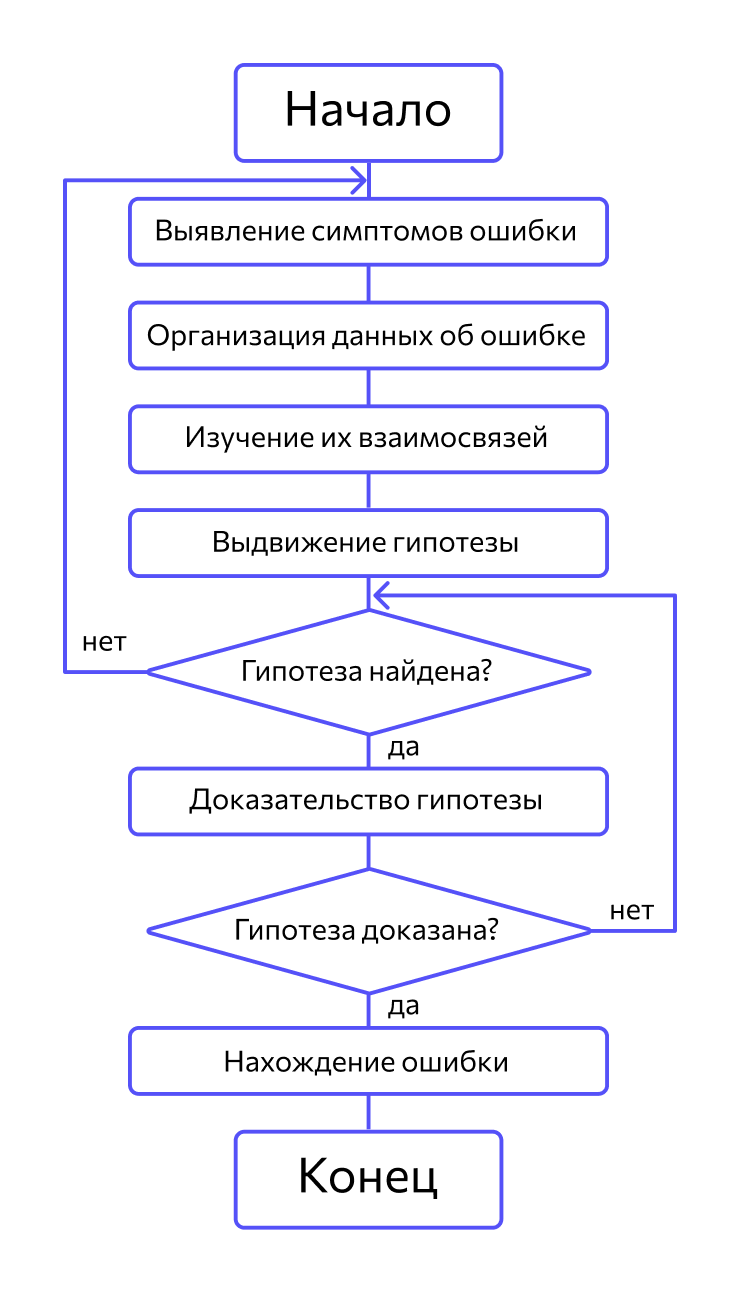
Важно, чтобы выдвинутая гипотеза объясняла все проявления ошибки. Если объясняется только их часть, то либо гипотеза неверна, либо ошибок несколько.
Метод дедукции
Сначала специалисты предлагают множество причин, по которым могла возникнуть ошибка. Затем анализируют их, исключают противоречащие имеющимся данным. Если все причины были исключены, проводят дополнительное тестирование. В обратном случае наиболее вероятную причину пытаются доказать.
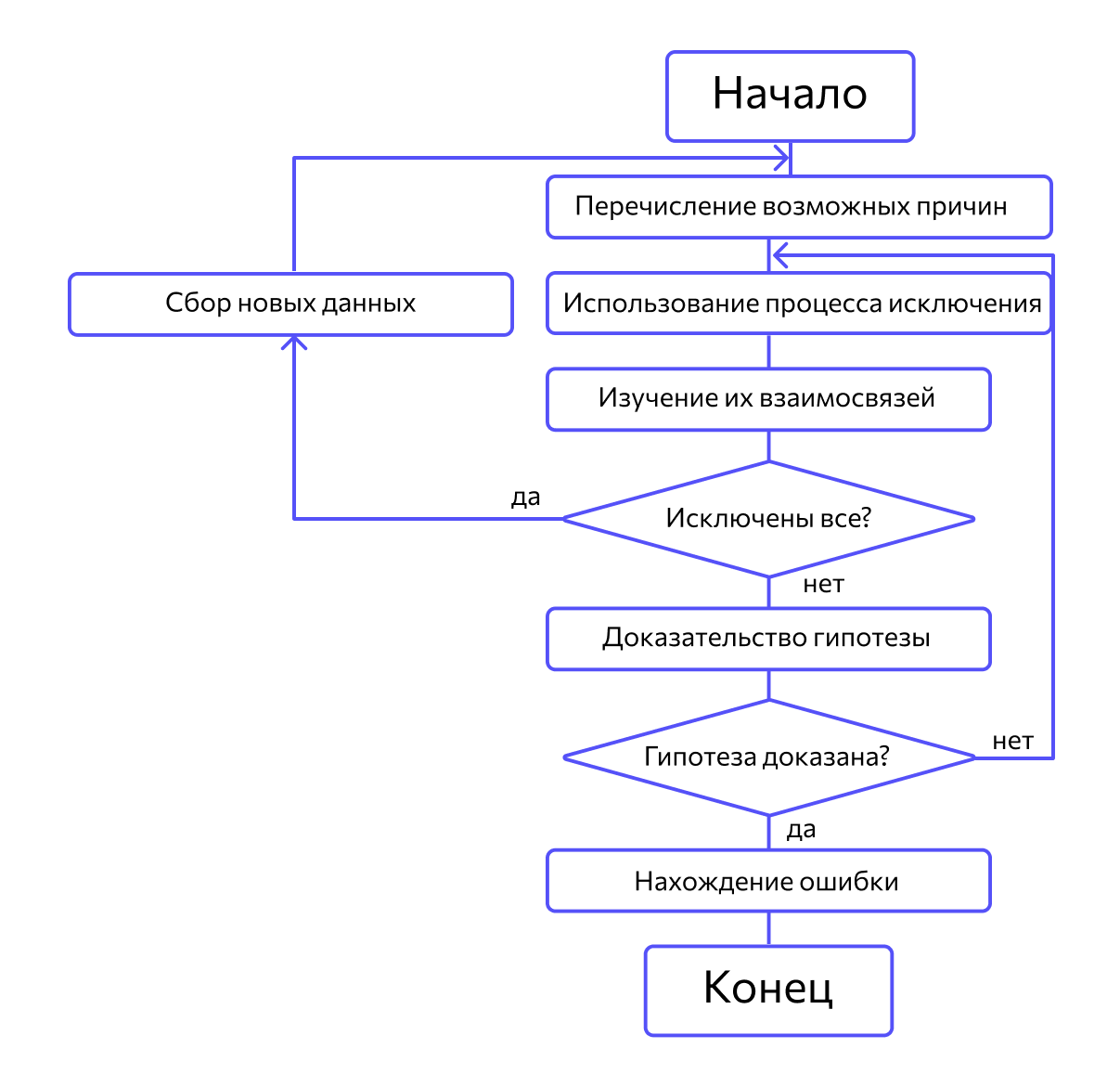
Метод обратного прослеживания
Эффективен для небольших программ. Начинается с точки вывода неправильного результата. Для точки выдвигается гипотеза о значениях основных переменных, которые могли привести к ошибке. Далее на основании этой гипотезы строятся предположения о значениях переменных в предыдущей точке. Процесс продолжается до момента, пока не найдут ошибку.
Как выполняется отладка в современных IDE
Ранние отладчики, например gdb, представляли собой отдельные программы с интерфейсами командной строки. Более поздние, например первые версии Turbo Debugger, были автономными, но имели собственный графический интерфейс для облегчения работы. Сейчас большинство IDE имеют встроенный отладчик. Он использует такой же интерфейс, как и редактор кода, поэтому можно выполнять отладку в той же среде, которая используется для написания кода.
Отладчик позволяет разработчику контролировать выполнение и проверять (или изменять) состояние программ. Например, можно использовать отладчик для построчного выполнения программы, проверяя по ходу значения переменных. Сравнение фактических и ожидаемых значений переменных или наблюдение за ходом выполнения кода может помочь в отслеживании логических (семантических) ошибок.
Пошаговое выполнение — это набор связанных функций отладчика, позволяющих поэтапно выполнять код.
Шаг с заходом (step into)
Команда выполняет очередную инструкцию, а потом приостанавливает процесс, чтобы с помощью отладчика было можно проверить состояние программы. Если в выполняемом операторе есть вызов функции, step into заставляет программу переходить в начало вызываемой функции, где она приостанавливается.
Шаг с обходом (step over)
Команда также выполняет очередную инструкцию. Однако когда step into будет входить в вызовы функций и выполнять их строка за строкой, step over выполнит всю функцию, не останавливаясь, и вернет управление после ее выполнения. Команда step over позволяет пропустить функции, если разработчик уверен, что они уже исправлены, или не заинтересован в их отладке в данный момент.
Шаг с выходом (step out)
В отличие от step into и step over, step out выполняет не следующую строку кода, а весь оставшийся код функции, исполняемой в настоящее время. После возврата из функции он возвращает управление разработчику. Эта команда полезна, когда специалист случайно вошел в функцию, которую не нужно отлаживать.
Как правило, при пошаговом выполнении можно идти только вперед. Поэтому легко перешагнуть место, которое нужно проверить. Если это произошло, необходимо перезапустить отладку.
У некоторых отладчиков (таких как GDB 7.0, Visual Studio Enterprise Edition 15.5 и более поздних версий) есть возможность вернуться на шаг назад. Это полезно, если пропущена цель либо нужно повторно проверить выполненную инструкцию.
Здесь вы не увидите ни строчки кода. Мы поговорим об обычных людях — о наших пользователях, точнее о том, как сообщать им, если в системе возникла какая-то непредвиденная ситуация.
В основе статьи доклад Антонины Хисаметдиновой с Heisenbug 2017 Moscow, которая занимается проектировкой пользовательских интерфейсов в компании Собака Павлова.
Кроме того, на Медиуме есть цикл статей «Руководство по проектированию ошибок». Цикл еще не дописан до конца, но дает более полную и цельную картину по теме статьи.
Ошибочный сценарий
Раз за разом мы проектируем основные сценарии самых разнообразных сервисов. В случае интернет-магазина основной будет таким:

Человек заходит на сайт, выбирает товар, заказывает его доставку; оплачивает и получает заказ.
Мы так концентрируемся на основных сценариях, что забываем одну очень важную вещь: есть альтернативные сценарии и тысячи способов того, как основной сценарий может прерваться.
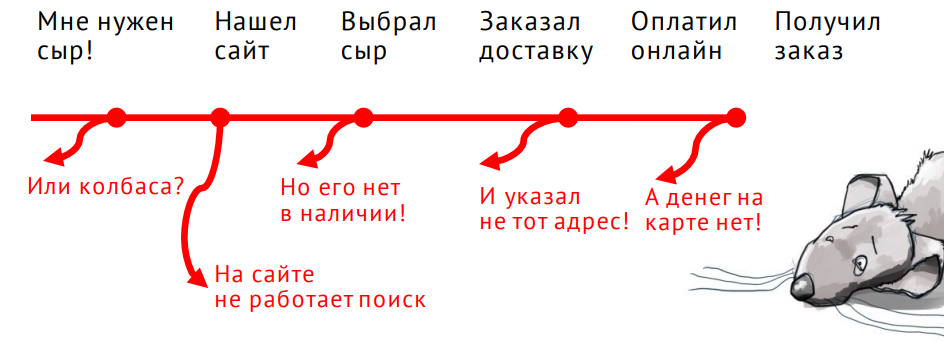
Всё это — ошибочные сценарии, возникающие, когда что-то идет не так.

Продуктовые команды часто не уделяют достаточно внимания таким сценариям. Например, очень типичная история: «Что-то пошло не так. У нас проблемы, поэтому просто закройте это сообщение».

Еще пример: «У нас ошибка. Повторите вашу попытку позже»:

И еще одна категория ошибок — моя любимая: неизвестные ошибки.

Зачем работать над ошибочными сценариями?
Обосновать бизнесу необходимость проработки ошибочных сценариев бывает очень сложно. Зачем нам возвращаться назад и что-то исправлять, когда впереди у нас новые фичи? Но у меня есть четыре железных аргумента, которые помогут продемонстрировать вашему product owner’у или бизнесу необходимость такой работы.
Хорошее сообщение об ошибке снижает нагрузку на техническую поддержку и персонал
На слайде представлены некоторые цифры одного из наших клиентов. Это количество звонков пользователей в техподдержку в месяц. Звонки связаны с проблемами определенного рода:

Обратите внимание, 400 человек в месяц звонят просто из-за того, что не могут войти или корректно ввести логин / пароль в соответствующей форме на сайте.
Хорошее сообщение об ошибке помогает пользователю не потеряться в воронке конверсии
Если сообщение об ошибке составлено грамотно, оно возвращает его к основному сценарию, даже если произошел разрыв сессии.

Хорошее сообщение об ошибке обучает работе с сервисом
Возможно, вам даже не потребуется создавать onboarding или какие-то обучающие видео, разработка которых, кстати говоря, тоже стоит приличных денег.

Хорошее сообщение об ошибке позволяет сохранить доверие к сервису в трудную минуту
Это последний, но немаловажный аргумент.

Вообще тема доверия «человек-технология» исследуется довольно давно. Сейчас мы уже достаточно доверяем технологиям. Например, мы никогда не будем перепроверять, отправил ли мессенджер сообщение адресату, или как калькулятор сложил или умножил трехзначные числа (к сожалению, правда, не все сервисы могут похвастаться таким уровнем доверия, как калькуляторы).
Мы доверяем свою жизнь десяткам видов разного программного обеспечения, летая в самолетах. Но это доверие очень легко разрушить. Сделать это может даже самая маленькая ошибка. И такие ошибки случаются как в маленьких, так и в очень больших компаниях.
Из-за чего возникают ошибки
Я несколько раз упомянула «хорошее сообщение об ошибке». Настала пора поговорить о том, что это значит. И для начала разберемся, из-за чего в принципе возникают ошибки.
- первое, что приходит в голову, это какие-то глобальные сбои или технические работы на сервисе;
- специфические баги;
- ошибки пользователя.
Но это далеко не всё. Еще есть:
- проблемы на стороне подключенных сервисов;
- внешние проблемы;
- крайне необычное поведение пользователей или сервиса.
Это не попытка классификации. На самом деле видов ошибок далеко не шесть, их может быть сотня или даже больше. Но в контексте проектирования интерфейсов эти ошибки самые значимые.
Глобальные сбои
Давайте начнем с ситуации, когда ваш сервис полностью недоступен.

К сожалению, такие ошибки могут возникнуть в любых сервисах, от онлайн игр до сложных биржевых профессиональных инструментов.
Хороший вопрос: что в такой ситуации делать?
Пока разработчики спешно чинят какие-то инструменты, несчастные пользователи получают странные сообщения об ошибках и достают вашу техподдержку, пишут неприятные посты в твиттере:

Давайте посмотрим на сообщения, которые в этот момент выводятся:

Они достаточно простые и некоторые из них даже честно извиняются. Но пользователи все равно чувствуют себя некомфортно и пытаются понять, в чем же дело; повторяют вход далеко не через 15 минут; тыкают, куда попало.
Как им помочь?
Подумайте о последствиях
Если вы не знаете, каковы последствия глобального сбоя, просто сходите в техподдержку. Потому что в этот момент ребята там огребают по полной. И они с удовольствием с вами этой болью поделятся.
Многие в таких ситуациях ограничиваются сообщением: да, у нас есть проблема и мы скоро ее поправим:

Но «скоро» — это когда?
Пользователю не нужно знать, когда вы всё поправите, с точностью до минуты. Но им нужно понимать какие-то значимые временные ориентиры, например, 15 минут, один час, пять часов или даже сутки. Это поможет им сориентироваться в пространстве и спланировать управление своими деньгами.
Еще один резонный вопрос (в ракурсе финансового сервиса): работают ли карточки?

И хорошее сообщение об ошибке сможет на него ответить. Даже если карточки не работают, лучше всё равно об этом сказать, потому что это очень важная информация.
Еще одна история — тут зарплата или перевод должны быть; а когда придут эти деньги?

Вроде бы ничего критичного, но когда человек не может проверить баланс, он начинает сильно паниковать. Поэтому предложите проверить баланс альтернативными методами, если это, конечно, возможно.
И последняя, очень серьезная ситуация, когда действительно человеку срочно нужны его деньги. Если это возможно, сообщите, как снять деньги или найти ближайший офис, если у вас есть такой сервис:

Важно понимать, что глобальный сбой — это проблема ваша, а не пользователя. Не нужно перекладывать на него мыслительные процессы. Предложите сразу готовые варианты.
Предупредите заранее
Не все пользователи готовы зайти в личный кабинет прямо сейчас, и далеко не все пользователи в принципе зайдут и заметят ошибку. Но если вы предупредите их заранее (например, постом в Twitter, SMS-сообщением или по электронной почте), то когда они столкнутся с сообщением об ошибке, будут готовы.

Отдельно стоит сказать про профессиональные сервисы, от которых ежедневно зависит работа пользователей. Например, сервис Антиплагиат иногда выводит такое сообщение о проведении технических работ:

Обратите внимание, что указана точная дата и точный диапазон времени — это поможет пользователю спланировать свою работу в вашем сервисе.
Тема предупреждений об ошибках косвенно связана с сохранением доверия. Может показаться, что очередное предупреждение об ошибке заставит часть пользователей усомниться в надежности сервиса (возможно, они бы в этот момент и не воспользовались сервисом, т.е. в принципе не узнали бы об ошибке). Но восприятие предупреждения как заботы или как лишнего камня в огород сервиса зависит в том числе и от того, как часто вы говорите, что у вас проблемы. Плюс есть совершенно разные сервисы. Интернет-банк — это одно. Но, к примеру, если у вас интернет-магазин, не нужно каждый раз писать пользователю о проблемах, потому что он заходит к вам не так часто.
Однако если же мы говорим о профессиональных инструментах, от которых пользователь реально зависит каждый день с утра и до вечера, очень странно не предупредить о проблеме (а частота, с которой допустимо сообщать пользователю о проблемах, при этом сильно зависит от отрасли).
Специфические баги
Тестировщики и продуктовые команды в целом вовремя отлавливают и не допускают вывода на пользователя очень большой доли багов. Но, к сожалению, ошибки случаются везде, и не всегда возможно их избежать.

Для нас баги — это знакомая история. Мы четко классифицируем их по разным параметрам: степени опасности, необходимости исправления и т.п.

Но пользователи когда замечают баг, в принципе не понимают, с чем они столкнулись. Многие даже не знают этого термина. Для них баги на самом деле выглядят вот так:

Мы предполагаем, что если пользователь вдруг заметил что-то странное, он конечно же нам об этом сообщит. У него есть для этого пять или даже больше способов:
- раздел «Контакты» и обратная связь;
- онлайн-консультант и звонок в техподдержку;
- социальные сети и чаты компании;
- отзывы (App Store и Play Market)!!!
- блоги и форумы.
Мы предполагаем, что пользователь когда-нибудь проскролит страницу вниз до подвала, найдет там вкладку «Контакты». В разделе контактов найдет среди карт, отделов, офисов продаж и прочего маленькую кнопочку «Обратная связь», нажмет на нее, выберет тему обращения. Напишет подробное письмо о том, как воспроизвести эту ошибку, приложит скриншоты и отправит.
Да, действительно, такие письма приходят. Но если ошибка очень плохая, человек может сразу оставить отзыв с низкой оценкой на App Store, где также подробно распишет, чем ему ваш сервис не нравится.
У всех перечисленных каналов обращений есть одна очень большая проблема: они вырывают пользователя из контекста, заставляют его отвлекаться на то, чтобы, по сути, помочь вам. Поэтому большинство пользователей предпочитают подождать, пока проблема исчезнет сама (пока вы сами ее заметите):

Или могут вообще перестать пользоваться вашим сервисом, как неработающим.
Поэтому в багтрекере ВКонтакте висит такой вот тикет, который называется «отсутствие кнопки «Сообщить о баге»»:

Действительно, это проблема очень многих сервисов.
Создайте специальные окна для сбора обратной связи
Но есть и позитивные примеры, например, Semrush. Почти по всему сервису размещены специальные окна, которые нацелены на то, чтобы забирать фидбэк от человека.

В такой ситуации пользователю стоит меньших усилий написать вам о какой-то ошибке или о фидбеке. Особенно это актуально для бета-тестирования.
Если нельзя исправить баг быстро, предупредите о нем
К сожалению, бывают такие ситуации, когда вы не можете исправить баг быстро. Можно просто предупредить об этом пользователя — как и в предыдущей части доклада.
В качестве примера здесь приведен скриншот, когда с помощью совершенно обычных окошек разработчики иконочного шрифта material design предупреждают пользователей, что есть проблема совместимости, и приносят свои извинения:

Обратите внимание, что они приводят ссылку для тех, у кого возникли эти проблемы. По ссылке инструкция, как всё исправить.
Самое главное, что нужно запомнить про специфические баги, — это необходимость качественного фидбэка. Поэтому создавайте специальные окна, чтобы как можно быстрее получать от пользователей эту информацию. Ну и второе — конечно, предупреждайте, если вам какой-то баг известен, но вы не можете его поправить.
Ошибки пользователей
К сожалению, многие разработчики считают, что ошибки пользователей — это дело пользователя. Но на самом деле, чем больше пользователи ошибаются в определенной точке продукта, тем сильнее в этой точке виноват сам сервис. В контексте проектирования ошибок я могу предложить пять фишек, которые помогут вам улучшить пользовательский опыт в подобных местах.
Первый пример узкого места многих сервисов — это, конечно, вход / регистрация:

Например, поле входа в InVision. Маленькая красная полосочка — это, в принципе, всё сообщение об ошибке. Наверное, когда дизайнер его рисовал, думал, что пользователь без труда прочитает сообщение: «Упс, комбинация email и пароля не верна». Проверит сначала email, затем пароль, и снова нажмет кнопочку войти. Но статистика подсказывает, что пользователь делает несколько попыток входа и ввода пароля, прежде чем догадывается, что проблема в email-адресе.
Это происходит, потому что внимание пользователя в момент входа сосредоточено в одной очень узкой области — она называется фокусом внимания:

Как вы видите, сообщение об ошибке, достаточно высоко и пользователь может его просто не заметить при обновлении страницы. К тому же InVision стирает пароль (надо же помочь пользователю…). И шевеление в области пароля еще больше фокусирует внимание пользователя; он думает, что ошибка именно там.
Фишка 1. Разместите сообщение в фокусе внимания
Те же ребята из InVision в другой части продукта предоставили информацию об ошибке немного по-другому. Во-первых, они подсветили оба поля. Во-вторых, не стирают пароль, потому что он может быть правильный (они предполагают, что пользователь заметит, где именно ошибка, и сам примет решение):

Фишка 2. Показывайте, где именно ошибка
Подсвечивание обоих полей — это и есть вторая фишка.
Но и это не всегда помогает.
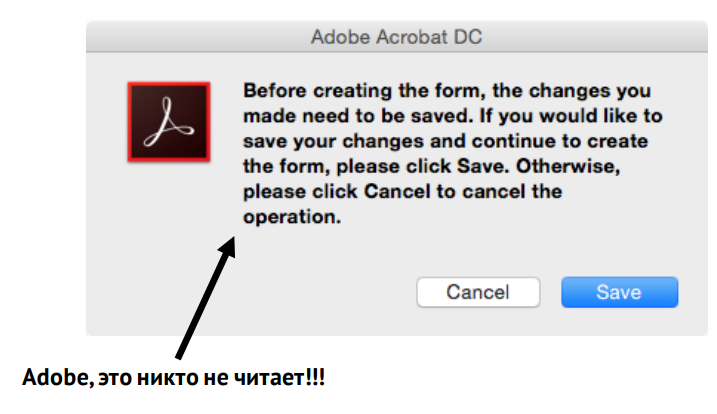
Например, дизайнеры компании Adobe считают, что пользователи действительно это всё читают:
Еще один классический пример предлагает Xiaomi:

Или, например, сайт Госуслуги (как и многие другие) просто дублирует название поля заголовка в ошибку:

Фишка 3. Используйте понятные и короткие формулировки
В примерах выше вся проблема в буквах. Поэтому нужно подумать над тем, как сделать формулировки короче и понятнее. Мы можем легко прочитать это сообщение, когда видим его на огромном экране и фокусируемся на чтении:

Но в окружении интерфейса и текущих задач у пользователей это выглядит вот так:

И они не дочитывают до конца. Когда пользователь читает строку, он фокусируется на начале строки. А чтобы прочитать дальше, ему надо приложить усилия:

Ему неохота читать ваши тексты, он хочет дальше решать свои задачи.
Поэтому, сокращая формулировку и размещая сообщение в зоне фокусировки, мы можем быстрее донести смысл.

Фишка 4. Подскажите, как исправить ошибку
Кто сталкивался с кассами самообслуживания?

Современные кассы самообслуживания, конечно, построены по-разному. Но самые первые из них были построены по такому сценарию: я кладу корзинку на одну сторону, беру по очереди товары, сканирую штрих-код и кладу их на другую сторону, чтобы система знала, что я действительно всю корзину просканировала (по весу). В тот момент, когда я складываю товар на левую сторону, система понимает, что я его отсканировала, и добавляет его в чек. Разработчики касс обратили внимание на очень интересную проблему: люди берут маленький товар (например, бутылку воды), сканируют его, затем сразу берут второй товар и пытаются его провести. При этом система никак не реагирует, сканер не работает, а пользователи ищут глазами помощников и напрягают персонал ритейлера.
В чем была проблема? Пользователи забывают положить маленькие товары на другую сторону. Поэтому разработчики добавили звуковой сигнал, после чего в 90% таких ситуаций покупатели стали обходиться без помощника. Сигнал заставлял человека поднимать глаза на экран кассы и выходить из состояния, когда он сканирует свою огромную корзину покупок: «Точно, я не положил воду».

У этого сообщения об ошибке есть две из перечисленных «фишек»: оно подсказывает, где именно ошибка, и обучает работе с сервисом.
Фишка 5. Сохраняйте работу пользователя
Последнее, но самое интересное.
Давайте сразу на примере. Это кусочек пути регистрации (в очередной раз напоминаю, что регистрация — достаточно слабое место у очень многих сервисов):

Чтобы вообще начать пользоваться финансовым сервисом Revolut, я должна сначала подтвердить свой номер телефона. Обратите внимание, они уже автоматически определили и подставили код страны. Спасибо ребятам.
Дальше я должна ввести свое имя и фамилию. Ну раз они определили мою страну, то я начинаю вводить автоматически по-русски, и когда я уже нажимаю «Далее», заполнив всю форму, сервис мне говорит: «Пожалуйста, используйте латинские буквы». Автоматическая валидация уже давно всем известна, и ее нужно обязательно применять! Но на этом дело не заканчивается. Мне нужно заполнить адресную информацию, причем, обратите внимание, страна уже подставлена автоматически и написана кириллицей.

Но меня не обманешь — я ввожу адрес латиницей, нажимаю Continue. И, как вы думаете, что происходит?

В такие моменты действительно хочется выкинуть телефон куда-нибудь. Но это, конечно, исключительный случай. Однако этот пример также показывает, что лишние и любые повторные действия очень сильно напрягают пользователя, заставляют его нервничать и негативно сказываются на имидже вашего продукта.
Поэтому не заставляйте пользователя вводить какие-то поля заново, используйте как можно больше автоматизации.
Проблемы подключенного сервиса
Тестируйте API подключенных сервисов
На днях мне попался интересный отчет на сайте APIFortress. Там был рассказ про компанию, которая поставляла стоковые изображение своим партнерам. Одним из них было агентство, которое занималось сувениркой с мопсами.
Однажды этот мопс-партнер позвонил в стоковую компанию и пожаловался на поломку сервиса.
Оказалось, что стоковая компания в тот день выпустила с утра минорное обновление API, которое не затронуло большую часть клиентов, но очень сильно ударило по мопс-компании. Сайт у них был построен таким образом, что обновление вызвало какой-то критический сбой работы поиска. Конечные пользователи видели, что ничего не найдено или какую-то неизвестную ошибку. Поэтому на подключенные сервисы надо обращать пристальное внимание.
Учите их различать проблемы
Иногда недостаточно просто знать, что где-то там у вас проблема, потому что пользователи будут видеть странные окна, которые не будут им помогать:

И в интерфейсе эту проблему не решить.
Поэтому очень важно потратить усилия, чтобы научить ваш сервис различать причины проблем с API.
Предусмотрите в интерфейсе оповещение о проблемах
Очень хороший пример — сервис-автоматизатор ifthisthenthat. С помощью связок API различных сервисов (например, умного дома или социальных сетей) они заставляют сторонние сервисы делать определенные вещи. Например, если я опубликовала пост в Instagram, он автоматически уходит в мой Facebook. Или, если я вышла из дома, сервис определяет по моей геопозиции, что я нахожусь в офисе, и проверяет, выключила ли я все свои смарт-утюги. А если не выключила, то выключает.
Эти ребята проделали очень большую работу, и не только в интерфейсе.
Во-первых, они выделяют отдельную вкладку для ошибок. Все неудавшиеся операции собираются в этот лог.
Они определяют разные типы ошибок:
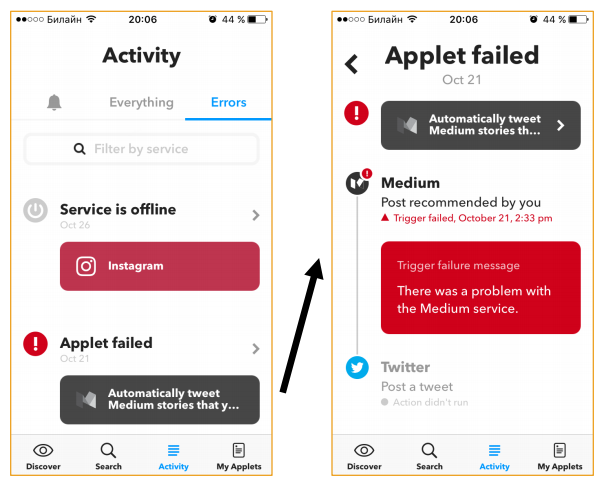
В первом случае — сервис Instagram офлайн, и мы понимаем, в чем проблема. Возможно, мы временно вышли из зоны действия сети.
В случае, если пользователь никак не может поспособствовать решению проблемы, выводится просто оповещение.
Внешние проблемы
Что такое внешние проблемы в моем пользовательском понимании?

Весь software завязан на аппаратуру, на датчики и т.п. Всё это тоже создано людьми и может не работать. Поэтому очень важно сообщать об этом пользователю. Хороший сервис может сообщать о таких ошибках, как о своих.
Дайте понять, какие действия в вашем сервисе недоступны из-за внешних проблем
Хороший пример — отсутствие интернет-соединения в коммуникаторе Slack. Если во время работы у меня отвалился интернет, я вижу вот такое сообщение сверху:
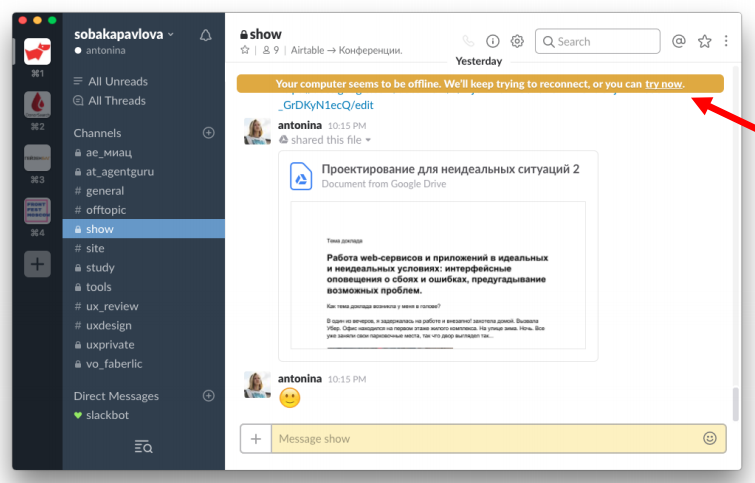
Как мы помним про сообщения об ошибках пользователей, в момент ввода какого-то текста пользователь сконцентрирован в этой области:

Slack об этом не забывает и подсвечивает поле желтеньким.
При этом он не блокирует мне набор сообщения. Я могу продолжить писать его дальше, но при попытке отправить Slack-бот отправляет мне вот такое сообщение:

И в принципе очень доступно объясняет, с чем именно проблема. Такую ошибку я замечу достаточно быстро.
Большая проблема с внешними ошибками, которая пришла к нам еще из «древних» времен, когда продукты создавались инженерами для инженеров, — это содержание текстов об ошибках:

Они написаны таким языком, как будто мы сейчас до сих пор подразумеваем, что пользователь знает, что такое firewall, ftp, dll, ядро, kernel и так далее.
Четко разделите уровни компетенции
Техническому специалисту мы показываем одну информацию, а пользователю — другую.
Наверное, стоит отдельно сказать про то, как люди в принципе общаются с техподдержкой.

Для многих это действительно большой стресс. Большая часть сообщений об ошибках совершенно не подразумевает, что они должны быть поняты. Человек, который даже не знает английского языка, пытается как-то объяснить: у меня там что-то сломалось. Он испытывает очень сильный дискомфорт. И всё это влияет в целом на его опыт общения с вашим сервисом. Поэтому старайтесь создавать такие сообщения, которые пользователь сможет осознать и своими словами передать техподдержке.
Например, это фото 3D-принтера, который четко и ясно (с помощью маленького экранчика) говорит, что температурный сенсор испортился — произошла ошибка, поэтому он остановился. Свяжитесь с техподдержкой. Пользователь легко может понять, в чем дело, и для него не сложно описать эту проблему своими словами без технических терминов:

Помогите пользователю оценить приоритет проблемы
Что это значит?
Рассмотрим такой пример: большая часть машин уже имеет экранчики, где мы можем выводить текст (не то, что раньше). Но такое ощущение, будто разработчики копипастят текст описания ошибок из старых инструкций, которые совершенно непонятны и требуют долгого вчитывания:

В такой ситуации пользователь не понимает, что делать. Некоторые водители-новички вместо того, чтобы прочитать инструкцию, просто продолжают ездить, думая, что всё в порядке. А у других, наоборот, начинается паника — они пытаются вызвать эвакуатор.
А есть еще такая категория: «У меня там до зарплаты неделька… ничего же не случится?»
Поэтому очень важно дать возможность пользователю оценить опасность этой проблемы. Пользователь в этот момент не хочет лезть в какие-то сложные инструкции. Если действительно произошло что-то страшное, важно указать одно — серьезность проблемы. Иногда «эксплуатацию продолжать нельзя», а иногда и правда можно подождать до зарплаты.
Крайне необычное поведение пользователей или сервисов.

Бывает ситуация, как на графике. Что вызвало такой резкий скачок? К примеру, это температура в двигателе повысилась? Или это просто датчик какой-то забарахлил?
В таких ситуациях лучше всего пользователю дать возможность самому принять решение о том, что же это было.
В качестве примера — хорошая длинная история. В сентябре этого года видеоблогер PewDiePie во время стрима на несколько сотен тыс. человек обозвал своего чернокожего противника словом, которое в англоязычном мире называть в принципе не стоит. Он, конечно, потом извинился, но все равно произошел скандал. Производители разных игр, в том числе, Шон Ванаман, подали жалобу в YouTube с просьбой удалить все видеозаписи того, как PewDiePie играл в их игры.
Но за PewDiePie тоже стояла большая армия поддержки. И на игры Шона Ванамана в Steam (сервис, который продает эти игры) посыпались сотни негативных отзывов. Эти отзывы не отражали качество игры, но могли негативно сказаться на ее продажах. И Steam проделал просто потрясающую работу: они обратили внимание пользователя, что произошло, что замечен нетипичный объем отрицательных отзывов с 11 сентября:

При этом они позволяют пользователю самому решить, исключать эти отзывы или учитывать. Пользователь может сам принять решение, насколько эти отзывы для него важны в контексте покупки игры. Такая работа над ошибками восхищает меня и как usabilist’а, и как пользователя этого сервиса.
Дополнительные возможности — скрытый потенциал
Не все ошибки — просто баги. У многих есть скрытый потенциал. Давайте про это немного поговорим.
Обучайте через ошибки
Во-первых, как я уже говорила ранее, через ошибки можно и нужно обучать.
Например, сервис Skyeng — это онлайн школа английского языка, которая работает только через браузер Google Chrome. Этот браузер автоматически (по дефолту) иногда блокирует входящие видеозвонки или аудиозаписи. И в такой ситуации Skyeng вешает кнопочку, которая ведет на вполне подробную инструкцию:

У этого решения тоже есть некоторые проблемы. Если таких кнопочек в вашем сервисе будет очень много, все эти инструкции будет просто невыносимо, дорого и сложно поддерживать в актуальном виде. А пользователь на самом деле не сильно любит читать какие-то инструкции.
Еще один пример — SEMrush. Это окно входа в сервис:

Оно отображается в том случае, если я пошла по ссылке, которая требует от меня авторизации. Большая часть сервисов в такой ситуации выдает ошибку 404, пользователь уходит и больше не возвращается по этой ссылке. Но в SEMrush не ограничиваются просто формой входа. Они показывают дополнительные картинки и описание работы в той части сервиса, куда ведет эта ссылка. Таким образом пользователь входит в контекст. Он понимает, куда пойдет, если сервис ему знаком. А если сервис не знаком, получит беглое представление о том, что его ждет после входа.
Выводите из тупика
Еще один потенциал сообщений об ошибках — это вывод из тупика.
Часто ошибки являются абсолютно тупиковыми сценариями. Пользователю нужно вспоминать контекст и возвращаться по сценарию выше.
Например, возьмем сервис Avito. Там есть вкладка «Сохраненные поиски»:

Если там ничего нет, пользователь вынужден возвращаться обратно к строке поиска. В соответствии с представленной здесь инструкцией, которую он должен каким-то образом запомнить, он должен выполнить сохранение поиска где-то там на странице.
А можно было сделать вот так:

Мы знаем (сохраняем) историю и выводим ее здесь, чтобы пользователь, не отрываясь от контекста, нажал звездочку и сохранил какой-то нужный ему поиск. Таким образом мы превращаем тупиковый сценарий в возврат к основному пути.
Доступность
Есть еще одна важная тема, которую я хотела обсудить, это доступность интерфейсов.

Меня очень радует, что в последнее время об этом стали много говорить, и много в этом направлении стали делать. Например, недавно UsabilityLab проводили тестирование доступности интернет-банков для людей с нарушениями зрения и слуха.
Но в контексте ошибок мы иногда забываем про разницу восприятия и делаем некоторые вещи, которых делать нельзя.
Например, многие используют только цветовую индикацию ошибки. Так делать не стоит, потому что есть дальтоники:

Многие дизайнеры скажут: «Я всё проверил в специальном сервисе, который показывает, как видит дальтоник». Но на самом деле эти сервисы никогда не покажут точной картины, потому что все дальтоники видят по-разному. И даже если вы подберете яркость / контрастность, всё равно существует риск, что пользователь-дальтоник эту ошибку не распознает.
Например, поле регистрации во Wrike содержит как раз такую ошибку:

У них реализована чисто цветовая дифференциация — при ошибке красным подсвечивается обводка и текст внутри поля. Лучше всего добавить какое-то текстовое сообщение или символ.
Еще одна проблема — это серые или слишком мелкие надписи. Если вы увидите в своем интерфейсе мелкий серый курсивный шрифт на сером фоне, можете смело идти к дизайнеру и заставлять его переделывать, потому что существуют разные мониторы и на дешевых такие вещи иногда не видны:

Человек просто сломает глаза при попытке прочитать такой текст.
Проводите Accessibility testing для сценариев с ошибками
Бизнес-ценность
Когда я показала этот доклад своему коллеге-менеджеру, он сказал: «Не убедила». Потому что для бизнеса долго, дорого и совсем не выгодно делать такую большую работу над ошибками. В контексте проектирования интерфейсов я бы хотела сказать, что я не призываю вас так прорабатывать вообще все ошибочные ситуации.
Что нужно делать? Мой коллега выстроил работу в своем коллективе следующим образом. Все ошибки, которые возникают, сначала собираются в какой-то один большой мешок (log). Оттуда вычленяются только те ошибки, которые повторяются.
Повторяющиеся ошибки уже имеют бизнес-ценность. Это те ошибки, на которые стоит потратить время.
Но далеко не всегда нужно торопиться и сразу лепить ошибку на интерфейс, потому что очень часто возникновение таких ошибок вообще можно предотвратить, переписав немножко код, сходив к фронтенду и поправив что-то. И только если не получается избежать выхода ошибки на пользователя, действительно стоит задуматься о каких-то интерфейсных сообщениях.
Я понимаю, что интерфейс — это не всегда часть вашей работы. И даже далеко не все product owner’ы горят желанием выстраивать работу с ошибками в своей команде, потому что это не всегда выгодно (выгода, если и есть, иногда не видна сразу). Но моя цель — немного расширить ваш образ мышления и задать вопрос: вы делаете только свою работу или вы делаете классный продукт?
Потому что классный продукт умеет сообщать об ошибках. Он заботится о пользователе, даже когда что-то идет не так.
Резюме
Что я предлагаю вам делать со всей этой информацией?
- Когда вы придете на работу, обсудите доклад с командой и владельцем продукта. Особенно полезно зайти к UX’ерам или к дизайнерам.
- Проверьте, насколько ваши сообщения об ошибках полезны пользователям.
- После этого вы сможете комплексно посмотреть на свой продукт, найти его слабые места, которых раньше, возможно, не замечали, и улучшить ошибочные сценарии.
- И еще один очень важный пункт в контексте тестирования — ошибочные сценарии тоже нужно тестировать и часто на равных правах с остальными.
Что почитать?
Здесь есть несколько ссылок:
- «Release It!: Design and Deploy Production-Ready Software», Michael T. Nygard
- «How to write a great error message», Thomas Fuchs, https://goo.gl/4L8YWo
- Architecting Your Software Errors For Better Error Reporting, Nick Harley, https://goo.gl/7em6cQ
В заключение я хочу сказать, наверное, только одну вещь: ошибки — это тоже опыт. Проектируйте его.
Если тема тестирования и обработки ошибок вам так же близка, как и нам, наверняка вас заинтересуют вот эти доклады на нашей майской конференции Heisenbug 2018 Piter:
- Пишем UI тесты для Web, iOS и Android одновременно # python (Игорь Балагуров, Uptick)
- Web Security Testing Starter Kit (Андрей Леонов, SEMrush)
- Бета-тестирование ВКонтакте (Анастасия Семенюк, ВКонтакте)
Готовая программа не всегда работает как надо. Бывает, возникают баги, предупреждения, исключения. В итоге программа зависает, дает сбой или вылетает. Но это не конец света. Любую ошибку в коде можно исправить, если знать, почему она возникла.
Программная ошибка: что это и почему возникает
Программная ошибка — это дефект в коде. Из-за него программа сбоит или выдает неверные результаты. Некоторые ошибки серьезные — например, блокируют логин и пароль, из-за чего пользователь не может попасть в личный кабинет. А другие незаметны. Некоторое время программа работает как будто бы исправно — и только потом начинает глючить.
Ошибка в программировании — это зачастую ошибки разработчиков, которые находят тестировщики. Запускают разные тесты и отладку, чтобы определить источники проблемы.
Научитесь находить ошибки в приложениях и на сайтах до того, как ими начнут пользоваться клиенты. Для этого освойте профессию «Инженер по тестированию». Изучать язык программирования необязательно. Тестировщик работает с готовыми сайтами, приложениями, сервисами, а не с кодом. В программе от Skypro: четыре проекта для портфолио, практика с обратной связью, все основные инструменты тестировщика.
Ошибки часто называют багами, но подразумевают под ними разное, например:
❗ Ворнинги, или предупреждения. Возникают, когда программа начинает вести себя не так, как задумывалось. Не являются критичными ошибками. Программа с ворнингами работает, но с аномалиями.
❗ Исключения. Это не ошибки, а особые ситуации, которые нужно обработать.
❗ Синтаксические ошибки. Это ошибка в программе, связанная с написанием кода. Пример: программист забыл поставить точку или неверно написал название оператора. Если не исправить, код программы не запустится, а останется просто текстом.
Классификация багов
У багов есть два атрибута — серьезности (Severity) и приоритета (Priority). Серьезность касается технической стороны, а приоритет — организационной.
🚨 По серьезности. Атрибут показывает, как сильно ошибка влияет на общую функциональность программы. Чем выше значение атрибута, тем хуже.
По серьезности баги классифицируют так:
- Blocker — блокирующий баг. Программа запускается, но спустя время баг останавливает ее выполнение. Чтобы снова пользоваться программой, блокирующую ошибку в коде устраняют.
- Critical — критический баг. Нарушает функциональность программы. Появляется в разных частях кода, из-за этого основные функции не выполняются.
- Major — существенный баг. Не нарушает, но затрудняет работу основного функционала программы либо не дает функциям выполняться так, как задумано.
- Minor — незначительный баг. Слабо влияет на функционал программы, но может нарушать работу некоторых дополнительных функций.
- Trivial — тривиальный баг. На работу программы не влияет, но ухудшает общее впечатление. Например, на экране появляются посторонние символы или всё рябит.
🚦 По приоритету. Атрибут показывает, как быстро баг необходимо исправить, пока он не нанес программе приличный ущерб. Бывает таким:
- Top — наивысший. Такой баг — суперсерьезный, потому что может обвалить всю программу. Его устраняют в первую очередь.
- High — высокий. Может затруднить работу программы или ее функций, устраняют как можно скорее.
- Normal — обычный. Баг программу не ломает, просто где-то что-то будет работать не совсем верно. Устраняют в штатном порядке.
- Low — низкий. Баг не влияет на программу. Исправляют, только если у команды есть на это время.
Типы ошибок в программе
🧨 Логические. Приводят к тому, что программа зависает, работает не так, как надо, или выдает неожиданные результаты — например, не записывает файл, а стирает.
Логические ошибки коварны: их трудно обнаружить. Программа выглядит так, будто в ней всё правильно, но при этом работает некорректно. Чтобы победить логические ошибки, специалист должен хорошо ориентироваться в коде программы.
🧨 Синтаксические. Это опечатки в названиях операторов, пропущенные запятые или кавычки. Безобидные ошибки: их обнаруживают и подсвечивают в коде компиляторы, а программисту остается исправить.
🧨 Взаимодействия. Это ошибка в участке кода, который отвечает за взаимодействие с аппаратным или программным окружением. Такая ошибка возникает, например, если неправильно использовать веб-протоколы. Исправляется элементарно: разработчик переписывает нужный кусок кода.
🧨 Компиляционные. Любая программа — это текст. Чтобы он заработал как программа, используют компилятор. Он преобразует программный код в машинный, но одновременно может вызывать ошибки.
Компиляционные баги появляются, если что-то не так с компилятором или в коде есть синтаксические ошибки. Компилятор будто ругается: «Не понимаю, что тут написано. Не знаю, как обработать».
🧨 Ошибки среды выполнения. Возникают, когда программа скомпилирована и уже выглядит как файл — жми и работай. Юзер запускает файл, а программа тормозит и виснет. Причина — нехватка ресурсов, например памяти или буфера.
Такой баг — ошибка разработчика. Он не предвидел реальные условия развертывания программы. Теперь ему надо вернуться в исходный код и поправить фрагмент.
🧨 Арифметические. Бывает, в коде есть числовые переменные и математические формулы. Если где-то проблема — не указаны константы или округление сработало не так, возникает баг. Надо лезть в код и проверять математику.

Инженер-тестировщик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT
Узнать больше
Что такое исключения в программах
Это механизм, который помогает программе обрабатывать нестандартную ситуацию и при этом не вылетать. Идеально, если программист предусмотрел все возможные ситуации. Но так бывает редко, поэтому лучше использовать специальный обработчик. Он обработает исключения так, что программа продолжит работать.
Как это происходит:
- Когда программист кодит, то продумывает, в какой части программы может вылезти ошибка.
- В этой части пишет специальный фрагмент, который предупредит компьютер, что ошибка — вполне ожидаемое явление и резко обрывать программу не нужно.
- Когда юзер запустит программу и появится ошибка, компьютер увидит заранее подготовленное предупреждение программиста. Продолжит выполнять алгоритм так, словно никакого бага и не было.
Исключения бывают программными и аппаратными:
- Аппаратные создает процессор. К ним относят деление на ноль, выход за границы массива, обращение к невыделенной памяти.
- Программные создает операционка и приложения. Возникают, когда программа их инициирует: аномальная ситуация возникла — программа создала исключение.
Как контролировать баги в программе
🔧 Следите за компилятором. Когда компилятор преобразует текст программы в машинный код, то подсвечивает в нём сомнительные участки, которые способны вызывать баги. Некоторые предупреждения не обозначают баг как таковой, а только говорят: «Тут что-то подозрительное». Всё подозрительное надо изучать и прорабатывать, чтобы не было проблемы в будущем.
🔧 Используйте отладчик. Это программа, которая без участия айтишника проверяет, исправно ли работает алгоритм. В случае чего сообщает об ошибках. Например, отладчик используют для построчного выполнения программы. Вместе с тем проверяют значения переменных: фактические сравнивают с ожидаемыми. Если что-то не сходится, ищут баги и исправляют.
🔧 Проводите юнит-тесты. Это когда разработчик или тестировщик описывает ситуации для каждого компонента и указывает, к какому результату должна привести программа. Потом запускает проверку. Если результат не совпадает с ожидаемым, появляется предупреждение. Дальше программисты находят и устраняют проблему.
Ключевое: что такое ошибки в программировании
- Ошибка в программировании — это дефект кода, баг, который может вызывать в программе сбои и неожиданное поведение.
- По серьезности баги делятся на блокирующие, критические, существенные, незначительные, тривиальные. По приоритету — на наивысший, высокий, обычный, низкий.
- Ошибки в коде могут быть разными, например связанные с логикой программы. Или с математическими вычислениями — логические. Еще бывают синтаксические, ошибки взаимодействия, компиляционные и ошибки среды выполнения.
- Некоторые ошибки помогают ловить обработчики исключений.
- Чтобы находить ошибки в коде, тестировщики используют компиляторы, отладчики и пишут юнит-тесты.
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
 Рис Пример отладки приложения
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
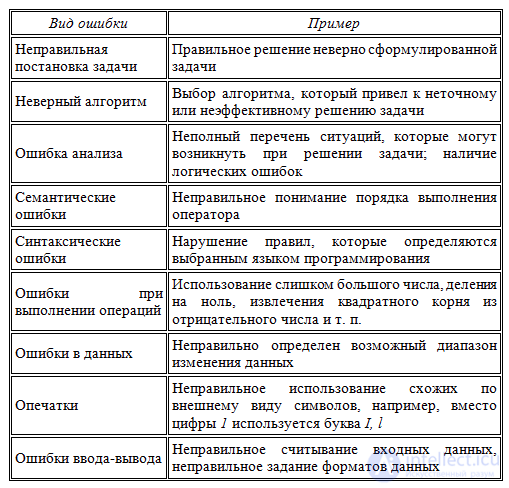
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
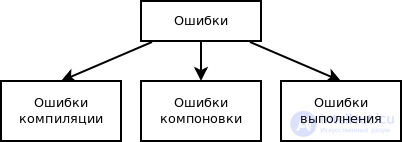
Классификация ошибок по этапу обработки программы
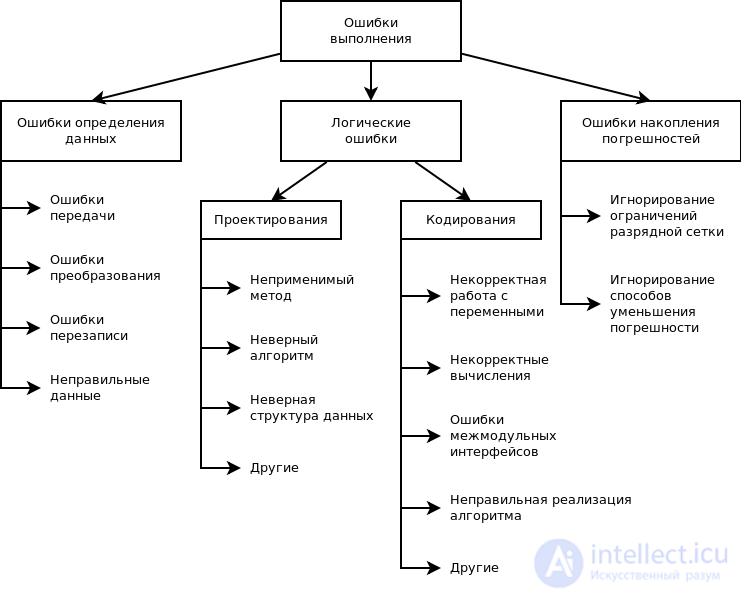
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
 Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
Вау!! 😲 Ты еще не читал? Это зря!
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
#Руководства
- 30 июн 2020
-

14
Что такое баги, ворнинги и исключения в программировании
Разбираемся, какие бывают типы ошибок в программировании и как с ними справляться.
vlada_maestro / shutterstock

Пишет о программировании, в свободное время создаёт игры. Мечтает открыть свою студию и выпускать ламповые RPG.
Многим известно слово баг (англ. bug — жук), которым называют ошибки в программах. Однако баг — это не совсем ошибка, а скорее неожиданный результат работы. Также есть и другие термины: ворнинг, исключение, утечка.
В этой статье мы на примере C++ разберём, что же значат все эти слова и как эти проблемы влияют на эффективность программы.
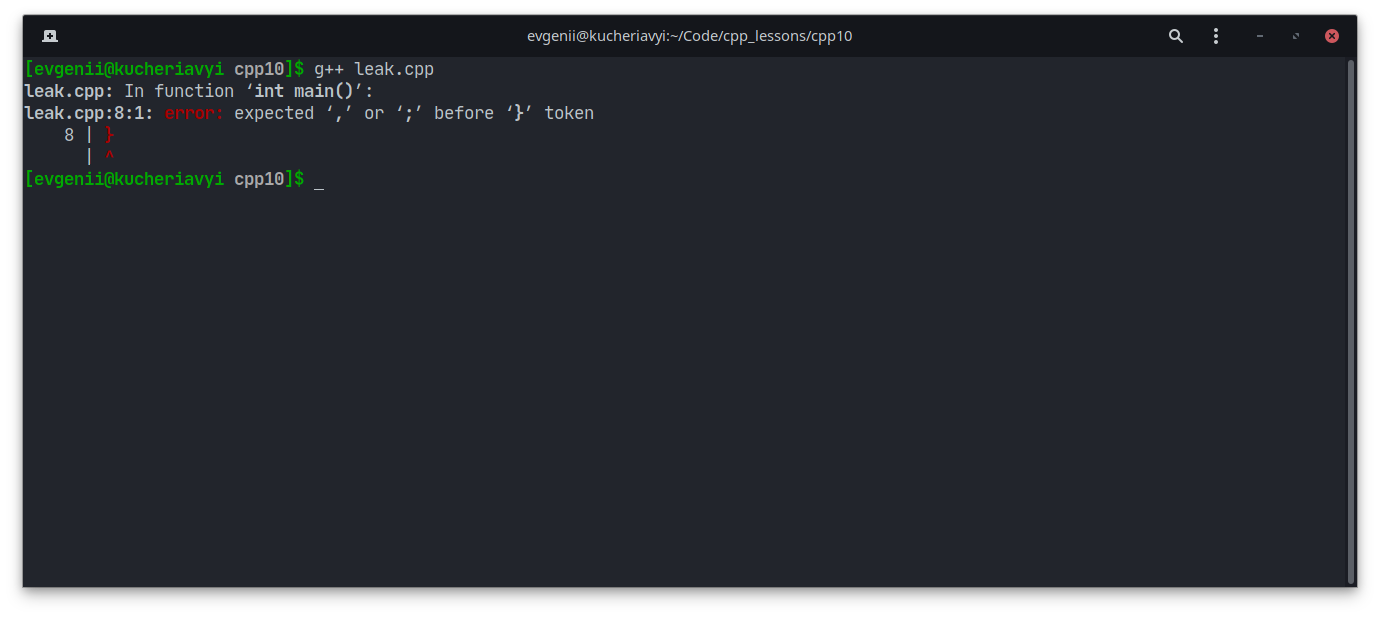
Словом «ошибка» (англ. error) можно описать любую проблему, но чаще всего под ним подразумевают синтаксическую ошибку — некорректно написанный код, который даже не скомпилируется:
//В конце команды забыли поставить точку с запятой (;)
int a = 5
Компилятор тут же скажет, что в коде ошибка и скорее всего не хватает запятой или точки с запятой.
Также существуют ворнинги (англ. warning — предупреждение). Они не являются ошибками, поэтому программа всё равно будет собрана. Вот пример:
int main()
{
//Мы создаём две переменные, которые просто занимают память и никак не используются
int a, b;
}
Мы можем попросить компилятор показать нам все предупреждения с помощью флага -Wall:
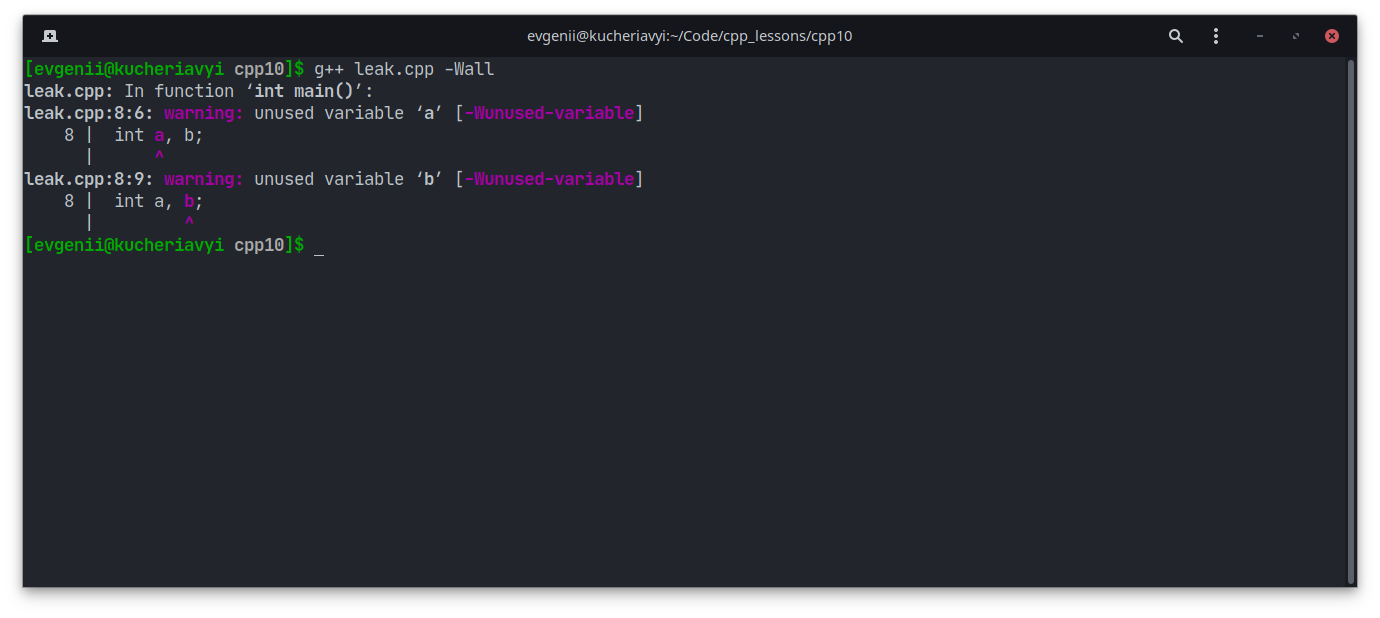
Предупреждения не являются чем-то критичным, но могут иметь негативные последствия. Например, ваша программа будет использовать больше памяти, чем должна. Так как C++ нужен в том числе и для разработки высоконагруженных систем, этого допускать нельзя.

После восклицательного знака в треугольнике — количество предупреждений
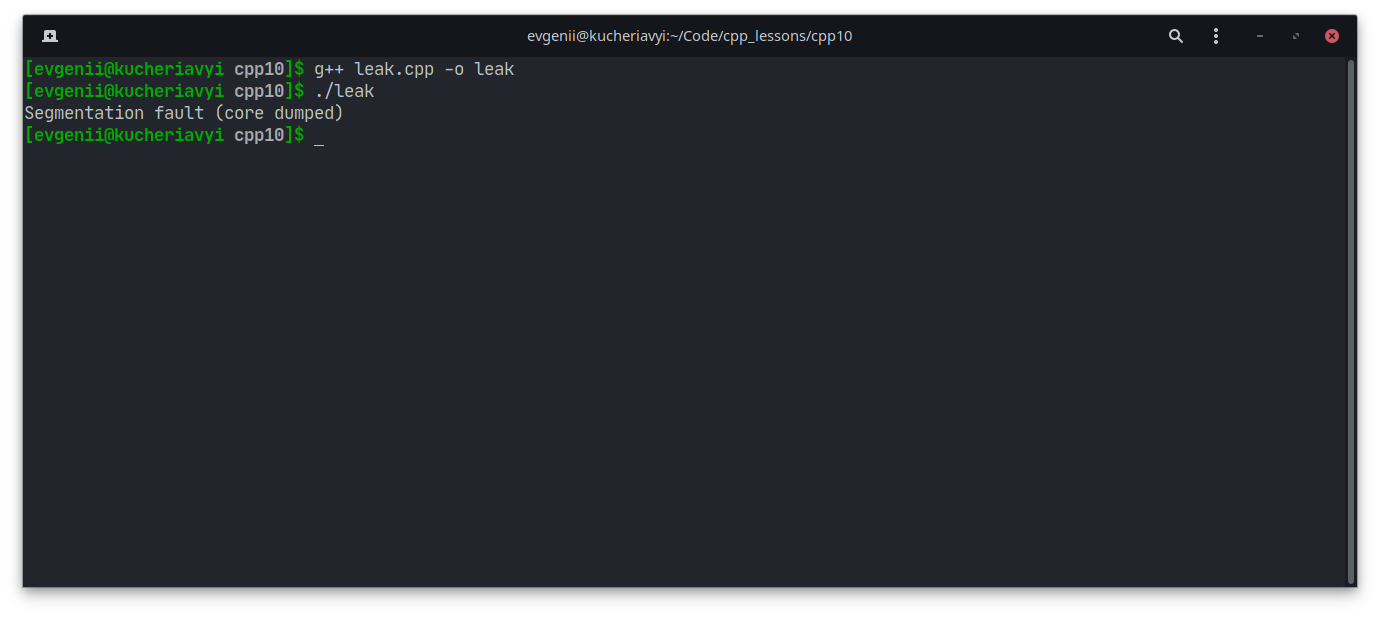
Третий вид ошибок — ошибки сегментации (англ. segmentation fault, сокр. segfault, жарг. сегфолт). Они возникают, если программа пытается записать что-то в ячейку, недоступную для записи. Например:
//Создаём константный массив символов
const char * s = "Hello World";
//Если мы попытаемся перезаписать значение константы, компилятор выдаст ошибку
//Но с помощью указателей мы можем обойти её, поэтому программа успешно скомпилируется
//Однако во время работы она будет выдавать ошибку сегментации
* (char *) s = 'H';
Вот результат работы такого кода:
Мы выяснили, что баг — это не совсем ошибка, а скорее неожиданное поведение программы или результат такого поведения. Баги могут быть чем-то забавным или неприятным. Например, как в играх:
Но они могут привести и к более серьёзным последствиям. Если неправильно спроектировать работу многопоточного приложения, то потоки будут постоянно опережать друг друга. Например, сообщение об ошибке из одного потока может опоздать на миллисекунду, из-за чего второй поток подумает, что никакой ошибки не было, и продолжит работу.
Если ваш код приводит в действие какое-нибудь потенциально опасное устройство, то ценой такой ошибки может быть чья-нибудь жизнь. Такое случилось с кодом для аппарата лучевой терапии Therac-25 — как минимум два человека умерло и ещё больше пострадали из-за превышения дозы радиации.
Также во время работы программы могут возникать ситуации, которые мешают корректной работе программы. Например, если вы просите пользователя ввести число, а он вводит строку.
Конвертировать введённое значение не всегда возможно, поэтому функция, которая занимается преобразованием, «выбрасывает» исключение (англ. exception). Это специальное сообщение говорит о том, что что-то идёт не так.
Если разработчик не описывает логику работы программы при вы выбрасывании исключения, то программа аварийно закрывается. Подробнее мы рассказали об этом в статье про ввод и конвертацию в C++.
Одно из самых известных исключений — переполнение стека (англ. stack overflow). В честь него даже назвали сайт, на котором программисты ищут помощь в решении своих проблем.
int main()
{
//Бесконечная рекурсия - одна из причин переполнения стека вызовов
main();
}
Компилятор C++ при этом может выдать ошибку сегментации, а не сообщение о переполнении стека:
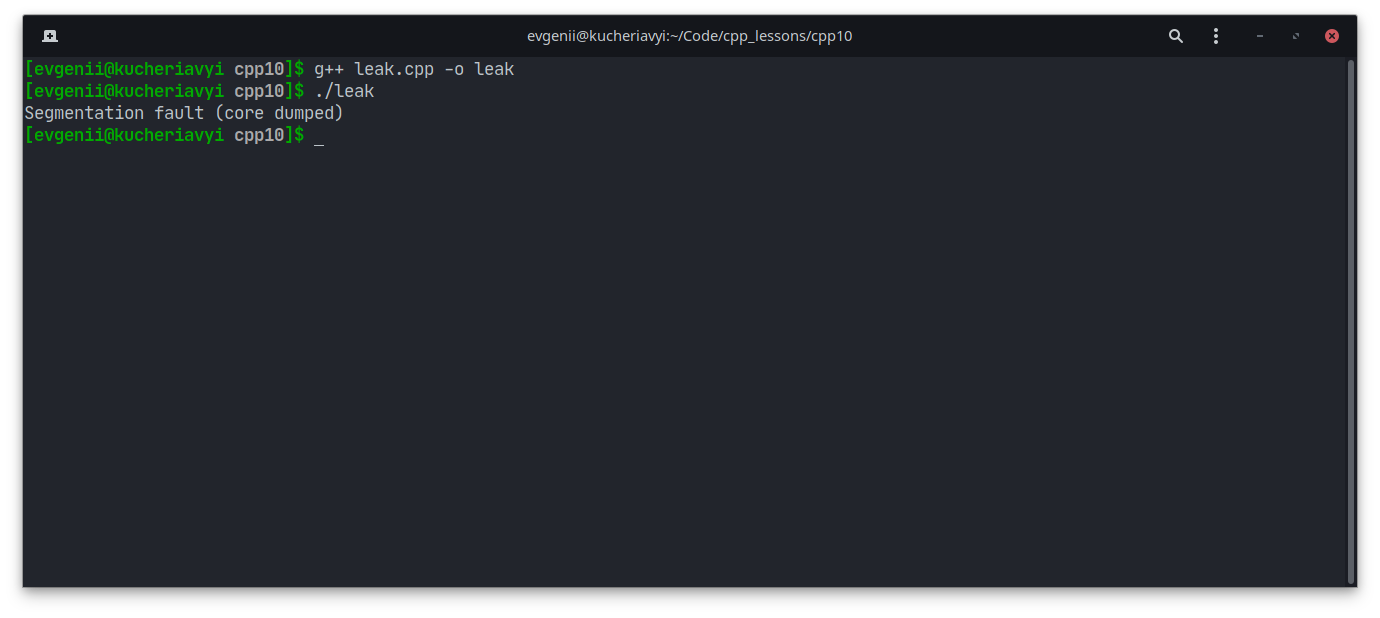
Вот аналогичный код на языке C#:
class Program
{
static void Main(string[] args)
{
Main(args);
}
}
Однако сообщение в этот раз более конкретное:
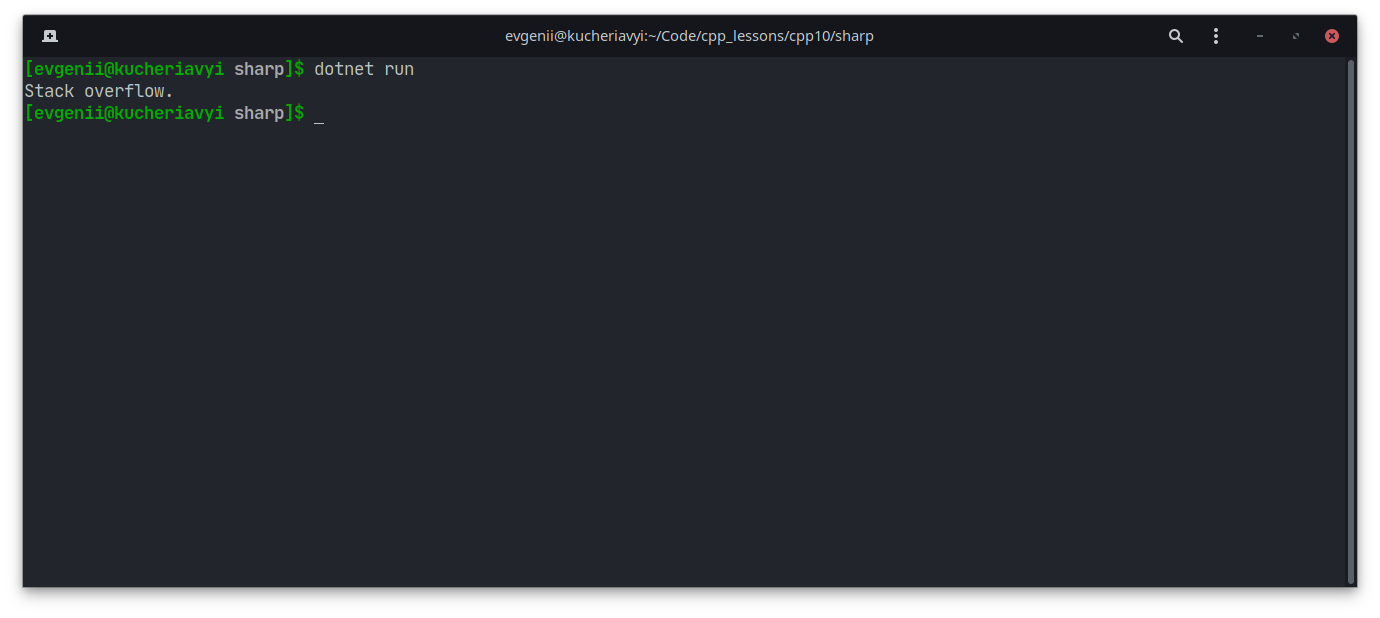
В обоих случаях программа завершается, потому что не может дальше корректно работать.
Похожая ситуация — переполнение буфера (англ. buffer overflow). Она происходит, когда записываемое значение больше выделенной области в памяти.
//Пробуем записать в переменную типа int значение, которое превышает лимит
//Константа INT_MAX находится в библиотеке climits
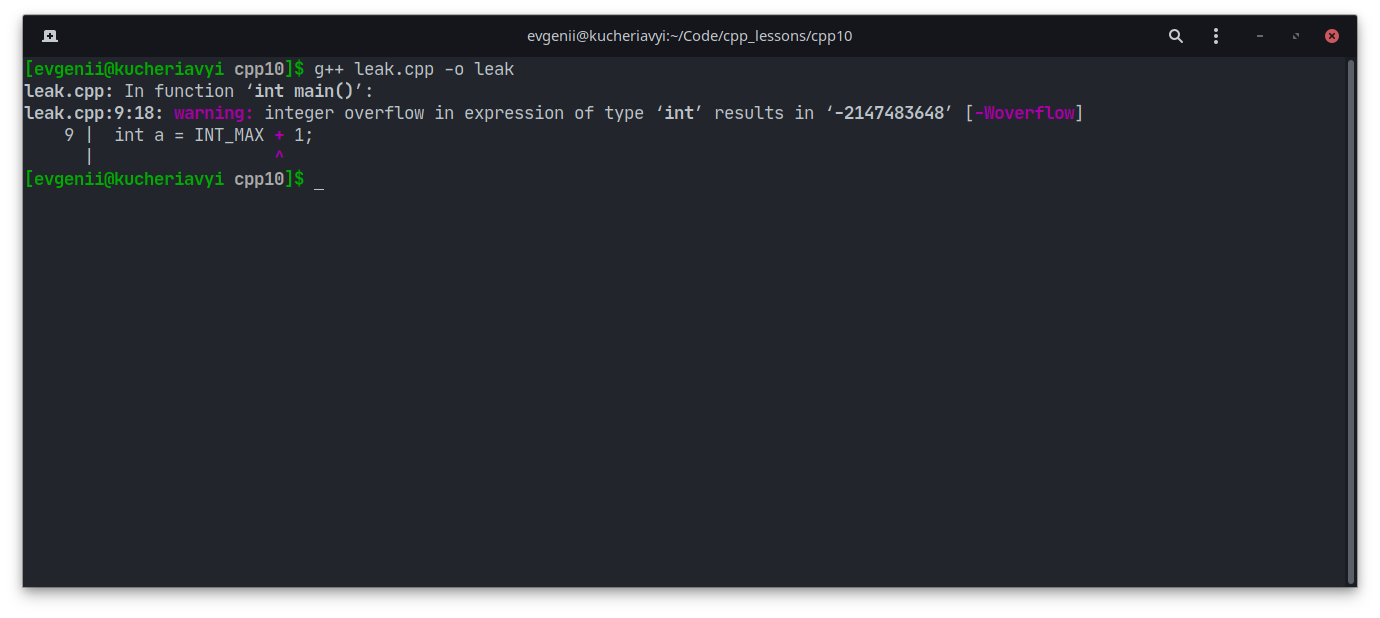
int a = INT_MAX + 1;
Обратите внимание, что мы получили предупреждение об арифметическом переполнении (англ. integer overflow):
Тем не менее программа скомпилировалась. Если же такая ситуация возникнет во время вычислений, то мы можем не получить предупреждения.
Арифметическое переполнение стало причиной одной из самых дорогих аварий, произошедших из-за ошибки в коде. В 1996 году ракета-носитель «Ариан-5» взорвалась на 40-й секунде полёта — потери оценивают в 360–500 миллионов долларов.
К сожалению, вручную всё это заметить и исправить не получится. Однако существуют различные инструменты и технологии, которые могут помочь.
Один из таких инструментов — отладчик. Он помогает контролировать ход работы программы, чтобы отслеживать разные показатели.
Второй, более эффективный метод — unit-тесты. Они представляют из себя набор описанных ситуаций для каждого компонента программы с указанием ожидаемого поведения.
Например, у вас есть функция sum (int a, int b), которая возвращает сумму двух чисел. Вы можете написать unit-тесты, чтобы проверять следующие ситуации:
| Входные данные | Ожидаемый результат |
|---|---|
| 5, 10 | 15 |
| 99, 99 | 198 |
| 8, -9 | -1 |
| -1, -1 | -2 |
| fff, 8 | IllegalArgumentException |
Если какой-то из этих тестов не пройден, вы узнаете об этом и сможете всё исправить. Это намного быстрее, чем проверять всё вручную.
Ошибок существует слишком много. При этом самые опасные тяжелее обнаружить, что только усугубляет ситуацию.

Научитесь: Профессия Разработчик на C++ с нуля
Узнать больше