
From Wikipedia, the free encyclopedia
«Invalid proof» redirects here. For any type of invalid proof besides mathematics, see Fallacy.
«0 = 1» redirects here. For the algebraic structure where this equality holds, see Null ring.
In mathematics, certain kinds of mistaken proof are often exhibited, and sometimes collected, as illustrations of a concept called mathematical fallacy. There is a distinction between a simple mistake and a mathematical fallacy in a proof, in that a mistake in a proof leads to an invalid proof while in the best-known examples of mathematical fallacies there is some element of concealment or deception in the presentation of the proof.
For example, the reason why validity fails may be attributed to a division by zero that is hidden by algebraic notation. There is a certain quality of the mathematical fallacy: as typically presented, it leads not only to an absurd result, but does so in a crafty or clever way.[1] Therefore, these fallacies, for pedagogic reasons, usually take the form of spurious proofs of obvious contradictions. Although the proofs are flawed, the errors, usually by design, are comparatively subtle, or designed to show that certain steps are conditional, and are not applicable in the cases that are the exceptions to the rules.
The traditional way of presenting a mathematical fallacy is to give an invalid step of deduction mixed in with valid steps, so that the meaning of fallacy is here slightly different from the logical fallacy. The latter usually applies to a form of argument that does not comply with the valid inference rules of logic, whereas the problematic mathematical step is typically a correct rule applied with a tacit wrong assumption. Beyond pedagogy, the resolution of a fallacy can lead to deeper insights into a subject (e.g., the introduction of Pasch’s axiom of Euclidean geometry,[2] the five colour theorem of graph theory). Pseudaria, an ancient lost book of false proofs, is attributed to Euclid.[3]
Mathematical fallacies exist in many branches of mathematics. In elementary algebra, typical examples may involve a step where division by zero is performed, where a root is incorrectly extracted or, more generally, where different values of a multiple valued function are equated. Well-known fallacies also exist in elementary Euclidean geometry and calculus.[4][5]
Howlers[edit]

Anomalous cancellation in calculus
Examples exist of mathematically correct results derived by incorrect lines of reasoning. Such an argument, however true the conclusion appears to be, is mathematically invalid and is commonly known as a howler. The following is an example of a howler involving anomalous cancellation:

Here, although the conclusion 16/64 = 1/4 is correct, there is a fallacious, invalid cancellation in the middle step.[note 1] Another classical example of a howler is proving the Cayley–Hamilton theorem by simply substituting the scalar variables of the characteristic polynomial by the matrix.
Bogus proofs, calculations, or derivations constructed to produce a correct result in spite of incorrect logic or operations were termed «howlers» by Maxwell.[2] Outside the field of mathematics the term howler has various meanings, generally less specific.
Division by zero[edit]
The division-by-zero fallacy has many variants. The following example uses a disguised division by zero to «prove» that 2 = 1, but can be modified to prove that any number equals any other number.
- Let a and b be equal, nonzero quantities
- Multiply by a
- Subtract b2
- Factor both sides: the left factors as a difference of squares, the right is factored by extracting b from both terms
- Divide out (a − b)
- Use the fact that a = b
- Combine like terms on the left
- Divide by the non-zero b








- Q.E.D.[6]
The fallacy is in line 5: the progression from line 4 to line 5 involves division by a − b, which is zero since a = b. Since division by zero is undefined, the argument is invalid.
Analysis[edit]
Mathematical analysis as the mathematical study of change and limits can lead to mathematical fallacies — if the properties of integrals and differentials are ignored. For instance, a naive use of integration by parts can be used to give a false proof that 0 = 1.[7] Letting u = 1/log x and dv = dx/x, we may write:

after which the antiderivatives may be cancelled yielding 0 = 1. The problem is that antiderivatives are only defined up to a constant and shifting them by 1 or indeed any number is allowed. The error really comes to light when we introduce arbitrary integration limits a and b.

Since the difference between two values of a constant function vanishes, the same definite integral appears on both sides of the equation.
Multivalued functions[edit]
Many functions do not have a unique inverse. For instance, while squaring a number gives a unique value, there are two possible square roots of a positive number. The square root is multivalued. One value can be chosen by convention as the principal value; in the case of the square root the non-negative value is the principal value, but there is no guarantee that the square root given as the principal value of the square of a number will be equal to the original number (e.g. the principal square root of the square of −2 is 2). This remains true for nth roots.
Positive and negative roots[edit]
Care must be taken when taking the square root of both sides of an equality. Failing to do so results in a «proof» of[8] 5 = 4.
Proof:
- Start from
- Write this as
- Rewrite as
- Add 81/4 on both sides:
- These are perfect squares:
- Take the square root of both sides:
- Add 9/2 on both sides:
- Q.E.D.







The fallacy is in the second to last line, where the square root of both sides is taken: a2 = b2 only implies a = b if a and b have the same sign, which is not the case here. In this case, it implies that a = –b, so the equation should read

which, by adding 9/2 on both sides, correctly reduces to 5 = 5.
Another example illustrating the danger of taking the square root of both sides of an equation involves the following fundamental identity[9]

which holds as a consequence of the Pythagorean theorem. Then, by taking a square root,

Evaluating this when x = π , we get that

or

which is incorrect.
The error in each of these examples fundamentally lies in the fact that any equation of the form

where  , has two solutions:
, has two solutions:

and it is essential to check which of these solutions is relevant to the problem at hand.[10] In the above fallacy, the square root that allowed the second equation to be deduced from the first is valid only when cos x is positive. In particular, when x is set to π, the second equation is rendered invalid.
Square roots of negative numbers[edit]
Invalid proofs utilizing powers and roots are often of the following kind:

The fallacy is that the rule  is generally valid only if at least one of
is generally valid only if at least one of  and
and  is non-negative (when dealing with real numbers), which is not the case here.[11]
is non-negative (when dealing with real numbers), which is not the case here.[11]
Alternatively, imaginary roots are obfuscated in the following:

The error here lies in the third equality, as the rule  only holds for positive real a and real b, c.
only holds for positive real a and real b, c.
Complex exponents[edit]
When a number is raised to a complex power, the result is not uniquely defined (see Exponentiation § Failure of power and logarithm identities). If this property is not recognized, then errors such as the following can result:

The error here is that the rule of multiplying exponents as when going to the third line does not apply unmodified with complex exponents, even if when putting both sides to the power i only the principal value is chosen. When treated as multivalued functions, both sides produce the same set of values, being {e2πn | n ∈ ℤ}.
Geometry[edit]
Many mathematical fallacies in geometry arise from using an additive equality involving oriented quantities (such as adding vectors along a given line or adding oriented angles in the plane) to a valid identity, but which fixes only the absolute value of (one of) these quantities. This quantity is then incorporated into the equation with the wrong orientation, so as to produce an absurd conclusion. This wrong orientation is usually suggested implicitly by supplying an imprecise diagram of the situation, where relative positions of points or lines are chosen in a way that is actually impossible under the hypotheses of the argument, but non-obviously so.
In general, such a fallacy is easy to expose by drawing a precise picture of the situation, in which some relative positions will be different from those in the provided diagram. In order to avoid such fallacies, a correct geometric argument using addition or subtraction of distances or angles should always prove that quantities are being incorporated with their correct orientation.
Fallacy of the isosceles triangle[edit]

The fallacy of the isosceles triangle, from (Maxwell 1959, Chapter II, § 1), purports to show that every triangle is isosceles, meaning that two sides of the triangle are congruent. This fallacy was known to Lewis Carroll and may have been discovered by him. It was published in 1899.[12][13]
Given a triangle △ABC, prove that AB = AC:
- Draw a line bisecting ∠A.
- Draw the perpendicular bisector of segment BC, which bisects BC at a point D.
- Let these two lines meet at a point O.
- Draw line OR perpendicular to AB, line OQ perpendicular to AC.
- Draw lines OB and OC.
- By AAS, △RAO ≅ △QAO (∠ORA = ∠OQA = 90°; ∠RAO = ∠QAO; AO = AO (common side)).
- By RHS,[note 2] △ROB ≅ △QOC (∠BRO = ∠CQO = 90°; BO = OC (hypotenuse); RO = OQ (leg)).
- Thus, AR = AQ, RB = QC, and AB = AR + RB = AQ + QC = AC.
Q.E.D.
As a corollary, one can show that all triangles are equilateral, by showing that AB = BC and AC = BC in the same way.
The error in the proof is the assumption in the diagram that the point O is inside the triangle. In fact, O always lies on the circumcircle of the △ABC (except for isosceles and equilateral triangles where AO and OD coincide). Furthermore, it can be shown that, if AB is longer than AC, then R will lie within AB, while Q will lie outside of AC, and vice versa (in fact, any diagram drawn with sufficiently accurate instruments will verify the above two facts). Because of this, AB is still AR + RB, but AC is actually AQ − QC; and thus the lengths are not necessarily the same.
Proof by induction[edit]
There exist several fallacious proofs by induction in which one of the components, basis case or inductive step, is incorrect. Intuitively, proofs by induction work by arguing that if a statement is true in one case, it is true in the next case, and hence by repeatedly applying this, it can be shown to be true for all cases. The following «proof» shows that all horses are the same colour.[14][note 3]
- Let us say that any group of N horses is all of the same colour.
- If we remove a horse from the group, we have a group of N − 1 horses of the same colour. If we add another horse, we have another group of N horses. By our previous assumption, all the horses are of the same colour in this new group, since it is a group of N horses.
- Thus we have constructed two groups of N horses all of the same colour, with N − 1 horses in common. Since these two groups have some horses in common, the two groups must be of the same colour as each other.
- Therefore, combining all the horses used, we have a group of N + 1 horses of the same colour.
- Thus if any N horses are all the same colour, any N + 1 horses are the same colour.
- This is clearly true for N = 1 (i.e., one horse is a group where all the horses are the same colour). Thus, by induction, N horses are the same colour for any positive integer N, and so all horses are the same colour.
The fallacy in this proof arises in line 3. For N = 1, the two groups of horses have N − 1 = 0 horses in common, and thus are not necessarily the same colour as each other, so the group of N + 1 = 2 horses is not necessarily all of the same colour. The implication «every N horses are of the same colour, then N + 1 horses are of the same colour» works for any N > 1, but fails to be true when N = 1. The basis case is correct, but the induction step has a fundamental flaw.
See also[edit]
- Anomalous cancellation – Kind of arithmetic error
- Division by zero – Class of mathematical expression
- List of incomplete proofs
- Mathematical coincidence – Coincidence in mathematics
- Paradox – Statement that apparently contradicts itself
- Proof by intimidation – Marking an argument as obvious or trivial
Notes[edit]
- ^ The same fallacy also applies to the following:

- ^ Hypotenuse–leg congruence
- ^ George Pólya’s original «proof» was that any n girls have the same colour eyes.

References[edit]
- ^ Maxwell 1959, p. 9
- ^ a b Maxwell 1959
- ^ Heath & Heiberg 1908, Chapter II, §I
- ^ Barbeau, Ed (1991). «Fallacies, Flaws, and Flimflam» (PDF). The College Mathematics Journal. 22 (5). ISSN 0746-8342.
- ^ «soft question – Best Fake Proofs? (A M.SE April Fools Day collection)». Mathematics Stack Exchange. Retrieved 2019-10-24.
- ^ Heuser, Harro (1989), Lehrbuch der Analysis – Teil 1 (6th ed.), Teubner, p. 51, ISBN 978-3-8351-0131-9
- ^ Barbeau, Ed (1990), «Fallacies, Flaws and Flimflam #19: Dolt’s Theorem», The College Mathematics Journal, 21 (3): 216–218, doi:10.1080/07468342.1990.11973308
- ^ Frohlichstein, Jack (1967). Mathematical Fun, Games and Puzzles (illustrated ed.). Courier Corporation. p. 207. ISBN 0-486-20789-7. Extract of page 207
- ^ Maxwell 1959, Chapter VI, §I.1
- ^ Maxwell 1959, Chapter VI, §II
- ^ Nahin, Paul J. (2010). An Imaginary Tale: The Story of «i«. Princeton University Press. p. 12. ISBN 978-1-4008-3029-9. Extract of page 12
- ^ S.D.Collingwood, ed. (1899), The Lewis Carroll Picture Book, Collins, pp. 190–191
- ^ Robin Wilson (2008), Lewis Carroll in Numberland, Penguin Books, pp. 169–170, ISBN 978-0-14-101610-8
- ^ Pólya, George (1954). Induction and Analogy in Mathematics. Mathematics and plausible reasoning. Vol. 1. Princeton. p. 120.
- Barbeau, Edward J. (2000), Mathematical fallacies, flaws, and flimflam, MAA Spectrum, Mathematical Association of America, ISBN 978-0-88385-529-4, MR 1725831.
- Bunch, Bryan (1997), Mathematical fallacies and paradoxes, New York: Dover Publications, ISBN 978-0-486-29664-7, MR 1461270.
- Heath, Sir Thomas Little; Heiberg, Johan Ludvig (1908), The thirteen books of Euclid’s Elements, Volume 1, The University Press.
- Maxwell, E. A. (1959), Fallacies in mathematics, Cambridge University Press, ISBN 0-521-05700-0, MR 0099907.
External links[edit]
- Invalid proofs at Cut-the-knot (including literature references)
- Classic fallacies with some discussion
- More invalid proofs from AhaJokes.com
- Math jokes including an invalid proof
![]()
Загрузить PDF
![]()
Загрузить PDF
Стандартной ошибкой называется величина, которая характеризует стандартное (среднеквадратическое) отклонение выборочного среднего. Другими словами, эту величину можно использовать для оценки точности выборочного среднего. Множество областей применения стандартной ошибки по умолчанию предполагают нормальное распределение. Если вам нужно рассчитать стандартную ошибку, перейдите к шагу 1.
-
1
Запомните определение среднеквадратического отклонения. Среднеквадратическое отклонение выборки – это мера рассеянности значения. Среднеквадратическое отклонение выборки обычно обозначается буквой s. Математическая формула среднеквадратического отклонения приведена выше.
-
2
Узнайте, что такое истинное среднее значение. Истинное среднее является средним группы чисел, включающим все числа всей группы – другими словами, это среднее всей группы чисел, а не выборки.
-
3
Научитесь рассчитывать среднеарифметическое значение. Среднеаримфетическое означает попросту среднее: сумму значений собранных данных, разделенную на количество значений этих данных.
-
4
Узнайте, что такое выборочное среднее. Когда среднеарифметическое значение основано на серии наблюдений, полученных в результате выборок из статистической совокупности, оно называется “выборочным средним”. Это среднее выборки чисел, которое описывает среднее значение лишь части чисел из всей группы. Его обозначают как:
-
5
Усвойте понятие нормального распределения. Нормальные распределения, которые используются чаще других распределений, являются симметричными, с единичным максимумом в центре – на среднем значении данных. Форма кривой подобна очертаниям колокола, при этом график равномерно опускается по обе стороны от среднего. Пятьдесят процентов распределения лежит слева от среднего, а другие пятьдесят процентов – справа от него. Рассеянность значений нормального распределения описывается стандартным отклонением.
-
6
Запомните основную формулу. Формула для вычисления стандартной ошибки приведена выше.
Реклама






-
1
Рассчитайте выборочное среднее. Чтобы найти стандартную ошибку, сначала нужно определить среднеквадратическое отклонение (поскольку среднеквадратическое отклонение s входит в формулу для вычисления стандартной ошибки). Начните с нахождения средних значений. Выборочное среднее выражается как среднее арифметическое измерений x1, x2, . . . , xn. Его рассчитывают по формуле, приведенной выше.
- Допустим, например, что вам нужно рассчитать стандартную ошибку выборочного среднего результатов измерения массы пяти монет, указанных в таблице:
Вы сможете рассчитать выборочное среднее, подставив значения массы в формулу:
- Допустим, например, что вам нужно рассчитать стандартную ошибку выборочного среднего результатов измерения массы пяти монет, указанных в таблице:
-
2
Вычтите выборочное среднее из каждого измерения и возведите полученное значение в квадрат. Как только вы получите выборочное среднее, вы можете расширить вашу таблицу, вычтя его из каждого измерения и возведя результат в квадрат.
- Для нашего примера расширенная таблица будет иметь следующий вид:
-
3
Найдите суммарное отклонение ваших измерений от выборочного среднего. Общее отклонение – это сумма возведенных в квадрат разностей от выборочного среднего. Чтобы определить его, сложите ваши новые значения.
- В нашем примере нужно будет выполнить следующий расчет:
Это уравнение дает сумму квадратов отклонений измерений от выборочного среднего.
- В нашем примере нужно будет выполнить следующий расчет:
-
4
Рассчитайте среднеквадратическое отклонение ваших измерений от выборочного среднего. Как только вы будете знать суммарное отклонение, вы сможете найти среднее отклонение, разделив ответ на n -1. Обратите внимание, что n равно числу измерений.
- В нашем примере было сделано 5 измерений, следовательно n – 1 будет равно 4. Расчет нужно вести следующим образом:
-
5
Найдите среднеквадратичное отклонение. Сейчас у вас есть все необходимые значения для того, чтобы воспользоваться формулой для нахождения среднеквадратичного отклонения s.
- В нашем примере вы будете рассчитывать среднеквадратичное отклонение следующим образом:
Следовательно, среднеквадратичное отклонение равно 0,0071624.
Реклама
- В нашем примере вы будете рассчитывать среднеквадратичное отклонение следующим образом:





-
1
Чтобы вычислить стандартную ошибку, воспользуйтесь базовой формулой со среднеквадратическим отклонением.
- В нашем примере вы сможете рассчитать стандартную ошибку следующим образом:
Таким образом в нашем примере стандартная ошибка (среднеквадратическое отклонение выборочного среднего) составляет 0,0032031 грамма.
- В нашем примере вы сможете рассчитать стандартную ошибку следующим образом:

Советы
- Стандартную ошибку и среднеквадратическое отклонение часто путают. Обратите внимание, что стандартная ошибка описывает среднеквадратическое отклонение выборочного распределения статистических данных, а не распределения отдельных значений
- В научных журналах понятия стандартной ошибки и среднеквадратического отклонения несколько размыты. Для объединения двух величин используется знак ±.
Реклама
Об этой статье
Эту страницу просматривали 47 997 раз.
Была ли эта статья полезной?
Стандартное отклонение (англ. Standard Deviation) — простыми словами это мера того, насколько разбросан набор данных.
Вычисляя его, можно узнать, являются ли числа близкими к среднему значению или далеки от него. Если точки данных находятся далеко от среднего значения, то в наборе данных имеется большое отклонение; таким образом, чем больше разброс данных, тем выше стандартное отклонение.
Стандартное отклонение обозначается буквой σ (греческая буква сигма).
Стандартное отклонение также называется:
- среднеквадратическое отклонение,
- среднее квадратическое отклонение,
- среднеквадратичное отклонение,
- квадратичное отклонение,
- стандартный разброс.
Использование и интерпретация величины среднеквадратического отклонения
Стандартное отклонение используется:
- в финансах в качестве меры волатильности,
- в социологии в опросах общественного мнения — оно помогает в расчёте погрешности.
Пример:
Рассмотрим два малых предприятия, у нас есть данные о запасе какого-то товара на их складах.
| День 1 | День 2 | День 3 | День 4 | |
|---|---|---|---|---|
| Пред.А | 19 | 21 | 19 | 21 |
| Пред.Б | 15 | 26 | 15 | 24 |
В обеих компаниях среднее количество товара составляет 20 единиц:
- А -> (19 + 21 + 19+ 21) / 4 = 20
- Б -> (15 + 26 + 15+ 24) / 4 = 20
Однако, глядя на цифры, можно заметить:
- в компании A количество товара всех четырёх дней очень близко находится к этому среднему значению 20 (колеблется лишь между 19 ед. и 21 ед.),
- в компании Б существует большая разница со средним количеством товара (колеблется между 15 ед. и 26 ед.).
Если рассчитать стандартное отклонение каждой компании, оно покажет, что
- стандартное отклонение компании A = 1,
- стандартное отклонение компании Б ≈ 5.
Стандартное отклонение показывает эту волатильность данных — то, с каким размахом они меняются; т.е. как сильно этот запас товара на складах компаний колеблется (поднимается и опускается).
Расчет среднеквадратичного (стандартного) отклонения
Формулы вычисления стандартного отклонения

σ — стандартное отклонение,
xi — величина отдельного значения выборки,
μ — среднее арифметическое выборки,
n — размер выборки.
Эта формула применяется, когда анализируются все значения выборки.

σ — стандартное отклонение,
xi — величина отдельного значения выборки,
μ — среднее арифметическое выборки,
n — размер выборки.
Эта формула применяется, когда анализируются все значения выборки.
S — стандартное отклонение,
n — размер выборки,
xi — величина отдельного значения выборки,
xср — среднее арифметическое выборки.
Эта формула применяется, когда присутствует очень большой размер выборки, поэтому на анализ обычно берётся только её часть.
Единственная разница с предыдущей формулой: “n — 1” вместо “n”, и обозначение «xср» вместо «μ».
Разница между формулами S и σ («n» и «n–1»)
Состоит в том, что мы анализируем — всю выборку или только её часть:
- только её часть – используется формула S (с «n–1»),
- полностью все данные – используется формула σ (с «n»).
Как рассчитать стандартное отклонение?
Пример 1 (с σ)
Рассмотрим данные о запасе какого-то товара на складах Предприятия Б.
| День 1 | День 2 | День 3 | День 4 | |
| Пред.Б | 15 | 26 | 15 | 24 |
Если значений выборки немного (небольшое n, здесь он равен 4) и анализируются все значения, то применяется эта формула:

Применяем эти шаги:
1. Найти среднее арифметическое выборки:
μ = (15 + 26 + 15+ 24) / 4 = 20
2. От каждого значения выборки отнять среднее арифметическое:
x1 — μ = 15 — 20 = -5
x2 — μ = 26 — 20 = 6
x3 — μ = 15 — 20 = -5
x4 — μ = 24 — 20 = 4
3. Каждую полученную разницу возвести в квадрат:
(x1 — μ)² = (-5)² = 25
(x2 — μ)² = 6² = 36
(x3 — μ)² = (-5)² = 25
(x4 — μ)² = 4² = 16
4. Сделать сумму полученных значений:
Σ (xi — μ)² = 25 + 36+ 25+ 16 = 102
5. Поделить на размер выборки (т.е. на n):
(Σ (xi — μ)²)/n = 102 / 4 = 25,5
6. Найти квадратный корень:
√((Σ (xi — μ)²)/n) = √ 25,5 ≈ 5,0498
Пример 2 (с S)
Задача усложняется, когда существуют сотни, тысячи или даже миллионы данных. В этом случае берётся только часть этих данных и анализируется методом выборки.
У Андрея 20 яблонь, но он посчитал яблоки только на 6 из них.
Популяция — это все 20 яблонь, а выборка — 6 яблонь, это деревья, которые Андрей посчитал.
| Яблоня 1 | Яблоня 2 | Яблоня 3 | Яблоня 4 | Яблоня 5 | Яблоня 6 |
| 9 | 2 | 5 | 4 | 12 | 7 |
Так как мы используем только выборку в качестве оценки всей популяции, то нужно применить эту формулу:

Применяем эти шаги:
1. Найти среднее арифметическое выборки:
μ = (15 + 26 + 15+ 24) / 4 = 20
2. От каждого значения выборки отнять среднее арифметическое:
x1 — μ = 15 — 20 = -5
x2 — μ = 26 — 20 = 6
x3 — μ = 15 — 20 = -5
x4 — μ = 24 — 20 = 4
3. Каждую полученную разницу возвести в квадрат:
(x1 — μ)² = (-5)² = 25
(x2 — μ)² = 6² = 36
(x3 — μ)² = (-5)² = 25
(x4 — μ)² = 4² = 16
4. Сделать сумму полученных значений:
Σ (xi — μ)² = 25 + 36+ 25+ 16 = 102
5. Поделить на размер выборки (т.е. на n):
(Σ (xi — μ)²)/n = 102 / 4 = 25,5
6. Найти квадратный корень:
√((Σ (xi — μ)²)/n) = √ 25,5 ≈ 5,0498
Пример 2 (с S)
Задача усложняется, когда существуют сотни, тысячи или даже миллионы данных. В этом случае берётся только часть этих данных и анализируется методом выборки.
У Андрея 20 яблонь, но он посчитал яблоки только на 6 из них.
Популяция — это все 20 яблонь, а выборка — 6 яблонь, это деревья, которые Андрей посчитал.
| Яблоня 1 | Яблоня 2 | Яблоня 3 | Яблоня 4 | Яблоня 5 | Яблоня 6 |
| 9 | 2 | 5 | 4 | 12 | 7 |
Так как мы используем только выборку в качестве оценки всей популяции, то нужно применить эту формулу:
Математически она отличается от предыдущей формулы только тем, что от n нужно будет вычесть 1. Формально нужно будет также вместо μ (среднее арифметическое) написать X ср.
Применяем практически те же шаги:
1. Найти среднее арифметическое выборки:
Xср = (9 + 2 + 5 + 4 + 12 + 7) / 6 = 39 / 6 = 6,5
2. От каждого значения выборки отнять среднее арифметическое:
X1 – Xср = 9 – 6,5 = 2,5
X2 – Xср = 2 – 6,5 = –4,5
X3 – Xср = 5 – 6,5 = –1,5
X4 – Xср = 4 – 6,5 = –2,5
X5 – Xср = 12 – 6,5 = 5,5
X6 – Xср = 7 – 6,5 = 0,5
3. Каждую полученную разницу возвести в квадрат:
(X1 – Xср)² = (2,5)² = 6,25
(X2 – Xср)² = (–4,5)² = 20,25
(X3 – Xср)² = (–1,5)² = 2,25
(X4 – Xср)² = (–2,5)² = 6,25
(X5 – Xср)² = 5,5² = 30,25
(X6 – Xср)² = 0,5² = 0,25
4. Сделать сумму полученных значений:
Σ (Xi – Xср)² = 6,25 + 20,25+ 2,25+ 6,25 + 30,25 + 0,25 = 65,5
5. Поделить на размер выборки, вычитав перед этим 1 (т.е. на n–1):
(Σ (Xi – Xср)²)/(n-1) = 65,5 / (6 – 1) = 13,1
6. Найти квадратный корень:
S = √((Σ (Xi – Xср)²)/(n–1)) = √ 13,1 ≈ 3,6193
Дисперсия и стандартное отклонение
Стандартное отклонение равно квадратному корню из дисперсии (S = √D). То есть, если у вас уже есть стандартное отклонение и нужно рассчитать дисперсию, нужно лишь возвести стандартное отклонение в квадрат (S² = D).
Дисперсия — в статистике это «среднее квадратов отклонений от среднего». Чтобы её вычислить нужно:
- Вычесть среднее значение из каждого числа
- Возвести каждый результат в квадрат (так получатся квадраты разностей)
- Найти среднее значение квадратов разностей.
Ещё расчёт дисперсии можно сделать по этой формуле:

S² — выборочная дисперсия,
Xi — величина отдельного значения выборки,
Xср (может появляться как X̅) — среднее арифметическое выборки,
n — размер выборки.
Правило трёх сигм
Это правило гласит: вероятность того, что случайная величина отклонится от своего математического ожидания более чем на три стандартных отклонения (на три сигмы), почти равна нулю.

S² — выборочная дисперсия,
Xi — величина отдельного значения выборки,
Xср (может появляться как X̅) — среднее арифметическое выборки,
n — размер выборки.
Правило трёх сигм
Это правило гласит: вероятность того, что случайная величина отклонится от своего математического ожидания более чем на три стандартных отклонения (на три сигмы), почти равна нулю.
Глядя на рисунок нормального распределения случайной величины, можно понять, что в пределах:
- одного среднеквадратического отклонения заключаются 68,26% значений (Xср ± 1σ или μ ± 1σ),
- двух стандартных отклонений — 95,44% (Xср ± 2σ или μ ± 2σ),
- трёх стандартных отклонений — 99,72% (Xср ± 3σ или μ ± 3σ).
Это означает, что за пределами остаются лишь 0,28% — это вероятность того, что случайная величина примет значение, которое отклоняется от среднего более чем на 3 сигмы.
Стандартное отклонение в excel
Вычисление стандартного отклонения с «n – 1» в знаменателе (случай выборки из генеральной совокупности):
1. Занесите все данные в документ Excel.

2. Выберите поле, в котором вы хотите отобразить результат.
3. Введите в этом поле «=СТАНДОТКЛОНА(«
4. Выделите поля, где находятся данные, потом закройте скобки.

2. Выберите поле, в котором вы хотите отобразить результат.
3. Введите в этом поле «=СТАНДОТКЛОНА(«
4. Выделите поля, где находятся данные, потом закройте скобки.
5. Нажмите Ввод (Enter).

В случае если данные представляют всю генеральную совокупность (n в знаменателе), то нужно использовать функцию СТАНДОТКЛОНПА.

В случае если данные представляют всю генеральную совокупность (n в знаменателе), то нужно использовать функцию СТАНДОТКЛОНПА.

Коэффициент вариации
Коэффициент вариации — отношение стандартного отклонения к среднему значению, т.е. Cv = (S/μ) × 100% или V = (σ/X̅) × 100%.
Стандартное отклонение делится на среднее и умножается на 100%.
Можно классифицировать вариабельность выборки по коэффициенту вариации:
- при <10% выборка слабо вариабельна,
- при 10% – 20 % — средне вариабельна,
- при >20 % — выборка сильно вариабельна.
Узнайте также про:
- Корреляции,
- Метод Крамера,
- Метод наименьших квадратов,
- Теорию вероятностей
- Интегралы.
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.

Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:

Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:

Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:

Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:

Стандартное отклонение этих средних значений известно как стандартная ошибка.

Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.

Коэффициент вариации
Коэффициент вариации — отношение стандартного отклонения к среднему значению, т.е. Cv = (S/μ) × 100% или V = (σ/X̅) × 100%.
Стандартное отклонение делится на среднее и умножается на 100%.
Можно классифицировать вариабельность выборки по коэффициенту вариации:
- при <10% выборка слабо вариабельна,
- при 10% – 20 % — средне вариабельна,
- при >20 % — выборка сильно вариабельна.
Узнайте также про:
- Корреляции,
- Метод Крамера,
- Метод наименьших квадратов,
- Теорию вероятностей
- Интегралы.
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.
Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:
Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:
Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:
Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:
Стандартное отклонение этих средних значений известно как стандартная ошибка.
Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
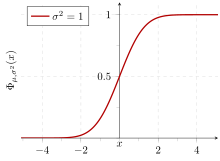
Cumulative probability of a normal distribution with expected value 0 and standard deviation 1
In statistics, the standard deviation is a measure of the amount of variation or dispersion of a set of values.[1] A low standard deviation indicates that the values tend to be close to the mean (also called the expected value) of the set, while a high standard deviation indicates that the values are spread out over a wider range.
Standard deviation may be abbreviated SD, and is most commonly represented in mathematical texts and equations by the lower case Greek letter σ (sigma), for the population standard deviation, or the Latin letter s, for the sample standard deviation.
The standard deviation of a random variable, sample, statistical population, data set, or probability distribution is the square root of its variance. It is algebraically simpler, though in practice less robust, than the average absolute deviation.[2][3] A useful property of the standard deviation is that, unlike the variance, it is expressed in the same unit as the data.
The standard deviation of a population or sample and the standard error of a statistic (e.g., of the sample mean) are quite different, but related. The sample mean’s standard error is the standard deviation of the set of means that would be found by drawing an infinite number of repeated samples from the population and computing a mean for each sample. The mean’s standard error turns out to equal the population standard deviation divided by the square root of the sample size, and is estimated by using the sample standard deviation divided by the square root of the sample size. For example, a poll’s standard error (what is reported as the margin of error of the poll), is the expected standard deviation of the estimated mean if the same poll were to be conducted multiple times. Thus, the standard error estimates the standard deviation of an estimate, which itself measures how much the estimate depends on the particular sample that was taken from the population.
In science, it is common to report both the standard deviation of the data (as a summary statistic) and the standard error of the estimate (as a measure of potential error in the findings). By convention, only effects more than two standard errors away from a null expectation are considered «statistically significant», a safeguard against spurious conclusion that is really due to random sampling error.
When only a sample of data from a population is available, the term standard deviation of the sample or sample standard deviation can refer to either the above-mentioned quantity as applied to those data, or to a modified quantity that is an unbiased estimate of the population standard deviation (the standard deviation of the entire population).
Basic examples[edit]
Population standard deviation of grades of eight students[edit]
Suppose that the entire population of interest is eight students in a particular class. For a finite set of numbers, the population standard deviation is found by taking the square root of the average of the squared deviations of the values subtracted from their average value. The marks of a class of eight students (that is, a statistical population) are the following eight values:

These eight data points have the mean (average) of 5:

First, calculate the deviations of each data point from the mean, and square the result of each:

The variance is the mean of these values:

and the population standard deviation is equal to the square root of the variance:

This formula is valid only if the eight values with which we began form the complete population. If the values instead were a random sample drawn from some large parent population (for example, they were 8 students randomly and independently chosen from a class of 2 million), then one divides by 7 (which is n − 1) instead of 8 (which is n) in the denominator of the last formula, and the result is  In that case, the result of the original formula would be called the sample standard deviation and denoted by s instead of
In that case, the result of the original formula would be called the sample standard deviation and denoted by s instead of  Dividing by n − 1 rather than by n gives an unbiased estimate of the variance of the larger parent population. This is known as Bessel’s correction.[4][5] Roughly, the reason for it is that the formula for the sample variance relies on computing differences of observations from the sample mean, and the sample mean itself was constructed to be as close as possible to the observations, so just dividing by n would underestimate the variability.
Dividing by n − 1 rather than by n gives an unbiased estimate of the variance of the larger parent population. This is known as Bessel’s correction.[4][5] Roughly, the reason for it is that the formula for the sample variance relies on computing differences of observations from the sample mean, and the sample mean itself was constructed to be as close as possible to the observations, so just dividing by n would underestimate the variability.
Standard deviation of average height for adult men[edit]
If the population of interest is approximately normally distributed, the standard deviation provides information on the proportion of observations above or below certain values. For example, the average height for adult men in the United States is about 70 inches, with a standard deviation of around 3 inches. This means that most men (about 68%, assuming a normal distribution) have a height within 3 inches of the mean (67–73 inches) – one standard deviation – and almost all men (about 95%) have a height within 6 inches of the mean (64–76 inches) – two standard deviations. If the standard deviation were zero, then all men would be exactly 70 inches tall. If the standard deviation were 20 inches, then men would have much more variable heights, with a typical range of about 50–90 inches. Three standard deviations account for 99.73% of the sample population being studied, assuming the distribution is normal or bell-shaped (see the 68–95–99.7 rule, or the empirical rule, for more information).
Definition of population values[edit]
Let μ be the expected value (the average) of random variable X with density f(x):
![{displaystyle mu equiv operatorname {E} [X]=int _{-infty }^{+infty }xf(x),mathrm {d} x}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fb2a61843da0d05619c0dd691dbf3fe315b395ad)
The standard deviation σ of X is defined as
![{displaystyle sigma equiv {sqrt {operatorname {E} left[(X-mu )^{2}right]}}={sqrt {int _{-infty }^{+infty }(x-mu )^{2}f(x),mathrm {d} x}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e3a1cfef8ad100fbcae387d9581763f0b389bbc3)
which can be shown to equal ![{textstyle {sqrt {operatorname {E} left[X^{2}right]-(operatorname {E} [X])^{2}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e2dd8d466c3ecb05713377fefcb7e7f787b29ce7)
Using words, the standard deviation is the square root of the variance of X.
The standard deviation of a probability distribution is the same as that of a random variable having that distribution.
Not all random variables have a standard deviation. If the distribution has fat tails going out to infinity, the standard deviation might not exist, because the integral might not converge. The normal distribution has tails going out to infinity, but its mean and standard deviation do exist, because the tails diminish quickly enough. The Pareto distribution with parameter ![{displaystyle alpha in (1,2]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/782b1d598278b0238ee817c658744e8a7ed3a06e) has a mean, but not a standard deviation (loosely speaking, the standard deviation is infinite). The Cauchy distribution has neither a mean nor a standard deviation.
has a mean, but not a standard deviation (loosely speaking, the standard deviation is infinite). The Cauchy distribution has neither a mean nor a standard deviation.
Discrete random variable[edit]
In the case where X takes random values from a finite data set x1, x2, …, xN, with each value having the same probability, the standard deviation is
![{displaystyle sigma ={sqrt {{frac {1}{N}}left[(x_{1}-mu )^{2}+(x_{2}-mu )^{2}+cdots +(x_{N}-mu )^{2}right]}},{text{ where }}mu ={frac {1}{N}}(x_{1}+cdots +x_{N}),}](https://wikimedia.org/api/rest_v1/media/math/render/svg/827beb1be760eed3cb07b20d29f01d326f728071)
or, by using summation notation,

If, instead of having equal probabilities, the values have different probabilities, let x1 have probability p1, x2 have probability p2, …, xN have probability pN. In this case, the standard deviation will be

Continuous random variable[edit]
The standard deviation of a continuous real-valued random variable X with probability density function p(x) is

and where the integrals are definite integrals taken for x ranging over the set of possible values of the random variable X.
In the case of a parametric family of distributions, the standard deviation can be expressed in terms of the parameters. For example, in the case of the log-normal distribution with parameters μ and σ2, the standard deviation is

Estimation[edit]
One can find the standard deviation of an entire population in cases (such as standardized testing) where every member of a population is sampled. In cases where that cannot be done, the standard deviation σ is estimated by examining a random sample taken from the population and computing a statistic of the sample, which is used as an estimate of the population standard deviation. Such a statistic is called an estimator, and the estimator (or the value of the estimator, namely the estimate) is called a sample standard deviation, and is denoted by s (possibly with modifiers).
Unlike in the case of estimating the population mean, for which the sample mean is a simple estimator with many desirable properties (unbiased, efficient, maximum likelihood), there is no single estimator for the standard deviation with all these properties, and unbiased estimation of standard deviation is a very technically involved problem. Most often, the standard deviation is estimated using the corrected sample standard deviation (using N − 1), defined below, and this is often referred to as the «sample standard deviation», without qualifiers. However, other estimators are better in other respects: the uncorrected estimator (using N) yields lower mean squared error, while using N − 1.5 (for the normal distribution) almost completely eliminates bias.
Uncorrected sample standard deviation[edit]
The formula for the population standard deviation (of a finite population) can be applied to the sample, using the size of the sample as the size of the population (though the actual population size from which the sample is drawn may be much larger). This estimator, denoted by sN, is known as the uncorrected sample standard deviation, or sometimes the standard deviation of the sample (considered as the entire population), and is defined as follows:[6]

where  are the observed values of the sample items, and
are the observed values of the sample items, and  is the mean value of these observations, while the denominator N stands for the size of the sample: this is the square root of the sample variance, which is the average of the squared deviations about the sample mean.
is the mean value of these observations, while the denominator N stands for the size of the sample: this is the square root of the sample variance, which is the average of the squared deviations about the sample mean.
This is a consistent estimator (it converges in probability to the population value as the number of samples goes to infinity), and is the maximum-likelihood estimate when the population is normally distributed.[7] However, this is a biased estimator, as the estimates are generally too low. The bias decreases as sample size grows, dropping off as 1/N, and thus is most significant for small or moderate sample sizes; for  the bias is below 1%. Thus for very large sample sizes, the uncorrected sample standard deviation is generally acceptable. This estimator also has a uniformly smaller mean squared error than the corrected sample standard deviation.
the bias is below 1%. Thus for very large sample sizes, the uncorrected sample standard deviation is generally acceptable. This estimator also has a uniformly smaller mean squared error than the corrected sample standard deviation.
Corrected sample standard deviation[edit]
If the biased sample variance (the second central moment of the sample, which is a downward-biased estimate of the population variance) is used to compute an estimate of the population’s standard deviation, the result is

Here taking the square root introduces further downward bias, by Jensen’s inequality, due to the square root’s being a concave function. The bias in the variance is easily corrected, but the bias from the square root is more difficult to correct, and depends on the distribution in question.
An unbiased estimator for the variance is given by applying Bessel’s correction, using N − 1 instead of N to yield the unbiased sample variance, denoted s2:

This estimator is unbiased if the variance exists and the sample values are drawn independently with replacement. N − 1 corresponds to the number of degrees of freedom in the vector of deviations from the mean, 
Taking square roots reintroduces bias (because the square root is a nonlinear function which does not commute with the expectation, i.e. often ![{displaystyle E[{sqrt {X}}]neq {sqrt {E[X]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/79fa5d2ba8891a41598ddeadc10ba844a20cdfa0) ), yielding the corrected sample standard deviation, denoted by s:
), yielding the corrected sample standard deviation, denoted by s:

As explained above, while s2 is an unbiased estimator for the population variance, s is still a biased estimator for the population standard deviation, though markedly less biased than the uncorrected sample standard deviation. This estimator is commonly used and generally known simply as the «sample standard deviation». The bias may still be large for small samples (N less than 10). As sample size increases, the amount of bias decreases. We obtain more information and the difference between  and
and  becomes smaller.
becomes smaller.
Unbiased sample standard deviation[edit]
For unbiased estimation of standard deviation, there is no formula that works across all distributions, unlike for mean and variance. Instead, s is used as a basis, and is scaled by a correction factor to produce an unbiased estimate. For the normal distribution, an unbiased estimator is given by s/c4, where the correction factor (which depends on N) is given in terms of the Gamma function, and equals:

This arises because the sampling distribution of the sample standard deviation follows a (scaled) chi distribution, and the correction factor is the mean of the chi distribution.
An approximation can be given by replacing N − 1 with N − 1.5, yielding:

The error in this approximation decays quadratically (as 1/N2), and it is suited for all but the smallest samples or highest precision: for N = 3 the bias is equal to 1.3%, and for N = 9 the bias is already less than 0.1%.
A more accurate approximation is to replace  above with
above with  .[8]
.[8]
For other distributions, the correct formula depends on the distribution, but a rule of thumb is to use the further refinement of the approximation:

where γ2 denotes the population excess kurtosis. The excess kurtosis may be either known beforehand for certain distributions, or estimated from the data.[9]
Confidence interval of a sampled standard deviation[edit]
The standard deviation we obtain by sampling a distribution is itself not absolutely accurate, both for mathematical reasons (explained here by the confidence interval) and for practical reasons of measurement (measurement error). The mathematical effect can be described by the confidence interval or CI.
To show how a larger sample will make the confidence interval narrower, consider the following examples:
A small population of N = 2 has only 1 degree of freedom for estimating the standard deviation. The result is that a 95% CI of the SD runs from 0.45 × SD to 31.9 × SD; the factors here are as follows:

where  is the p-th quantile of the chi-square distribution with k degrees of freedom, and
is the p-th quantile of the chi-square distribution with k degrees of freedom, and  is the confidence level. This is equivalent to the following:
is the confidence level. This is equivalent to the following:

With k = 1,  and
and  . The reciprocals of the square roots of these two numbers give us the factors 0.45 and 31.9 given above.
. The reciprocals of the square roots of these two numbers give us the factors 0.45 and 31.9 given above.
A larger population of N = 10 has 9 degrees of freedom for estimating the standard deviation. The same computations as above give us in this case a 95% CI running from 0.69 × SD to 1.83 × SD. So even with a sample population of 10, the actual SD can still be almost a factor 2 higher than the sampled SD. For a sample population N=100, this is down to 0.88 × SD to 1.16 × SD. To be more certain that the sampled SD is close to the actual SD we need to sample a large number of points.
These same formulae can be used to obtain confidence intervals on the variance of residuals from a least squares fit under standard normal theory, where k is now the number of degrees of freedom for error.
Bounds on standard deviation[edit]
For a set of N > 4 data spanning a range of values R, an upper bound on the standard deviation s is given by s = 0.6R.[10]
An estimate of the standard deviation for N > 100 data taken to be approximately normal follows from the heuristic that 95% of the area under the normal curve lies roughly two standard deviations to either side of the mean, so that, with 95% probability the total range of values R represents four standard deviations so that s ≈ R/4. This so-called range rule is useful in sample size estimation, as the range of possible values is easier to estimate than the standard deviation. Other divisors K(N) of the range such that s ≈ R/K(N) are available for other values of N and for non-normal distributions.[11]
Identities and mathematical properties[edit]
The standard deviation is invariant under changes in location, and scales directly with the scale of the random variable. Thus, for a constant c and random variables X and Y:

The standard deviation of the sum of two random variables can be related to their individual standard deviations and the covariance between them:

where  and
and  stand for variance and covariance, respectively.
stand for variance and covariance, respectively.
The calculation of the sum of squared deviations can be related to moments calculated directly from the data. In the following formula, the letter E is interpreted to mean expected value, i.e., mean.
![{displaystyle sigma (X)={sqrt {operatorname {E} left[(X-operatorname {E} [X])^{2}right]}}={sqrt {operatorname {E} left[X^{2}right]-(operatorname {E} [X])^{2}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d3ab12089bd2027790ef060ff7cc2ec05ae2021f)
The sample standard deviation can be computed as:
![{displaystyle s(X)={sqrt {frac {N}{N-1}}}{sqrt {operatorname {E} left[(X-operatorname {E} [X])^{2}right]}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/702e9da21c721697e6e81932bf8b7443028f7d6d)
For a finite population with equal probabilities at all points, we have

which means that the standard deviation is equal to the square root of the difference between the average of the squares of the values and the square of the average value.
See computational formula for the variance for proof, and for an analogous result for the sample standard deviation.
Interpretation and application[edit]

Example of samples from two populations with the same mean but different standard deviations. Red population has mean 100 and SD 10; blue population has mean 100 and SD 50.
A large standard deviation indicates that the data points can spread far from the mean and a small standard deviation indicates that they are clustered closely around the mean.
For example, each of the three populations {0, 0, 14, 14}, {0, 6, 8, 14} and {6, 6, 8, 8} has a mean of 7. Their standard deviations are 7, 5, and 1, respectively. The third population has a much smaller standard deviation than the other two because its values are all close to 7. These standard deviations have the same units as the data points themselves. If, for instance, the data set {0, 6, 8, 14} represents the ages of a population of four siblings in years, the standard deviation is 5 years. As another example, the population {1000, 1006, 1008, 1014} may represent the distances traveled by four athletes, measured in meters. It has a mean of 1007 meters, and a standard deviation of 5 meters.
Standard deviation may serve as a measure of uncertainty. In physical science, for example, the reported standard deviation of a group of repeated measurements gives the precision of those measurements. When deciding whether measurements agree with a theoretical prediction, the standard deviation of those measurements is of crucial importance: if the mean of the measurements is too far away from the prediction (with the distance measured in standard deviations), then the theory being tested probably needs to be revised. This makes sense since they fall outside the range of values that could reasonably be expected to occur, if the prediction were correct and the standard deviation appropriately quantified. See prediction interval.
While the standard deviation does measure how far typical values tend to be from the mean, other measures are available. An example is the mean absolute deviation, which might be considered a more direct measure of average distance, compared to the root mean square distance inherent in the standard deviation.
Application examples[edit]
The practical value of understanding the standard deviation of a set of values is in appreciating how much variation there is from the average (mean).
Experiment, industrial and hypothesis testing[edit]
Standard deviation is often used to compare real-world data against a model to test the model.
For example, in industrial applications the weight of products coming off a production line may need to comply with a legally required value. By weighing some fraction of the products an average weight can be found, which will always be slightly different from the long-term average. By using standard deviations, a minimum and maximum value can be calculated that the averaged weight will be within some very high percentage of the time (99.9% or more). If it falls outside the range then the production process may need to be corrected. Statistical tests such as these are particularly important when the testing is relatively expensive. For example, if the product needs to be opened and drained and weighed, or if the product was otherwise used up by the test.
In experimental science, a theoretical model of reality is used. Particle physics conventionally uses a standard of «5 sigma» for the declaration of a discovery. A five-sigma level translates to one chance in 3.5 million that a random fluctuation would yield the result. This level of certainty was required in order to assert that a particle consistent with the Higgs boson had been discovered in two independent experiments at CERN,[12] also leading to the declaration of the first observation of gravitational waves.[13]
Weather[edit]
As a simple example, consider the average daily maximum temperatures for two cities, one inland and one on the coast. It is helpful to understand that the range of daily maximum temperatures for cities near the coast is smaller than for cities inland. Thus, while these two cities may each have the same average maximum temperature, the standard deviation of the daily maximum temperature for the coastal city will be less than that of the inland city as, on any particular day, the actual maximum temperature is more likely to be farther from the average maximum temperature for the inland city than for the coastal one.
Finance[edit]
In finance, standard deviation is often used as a measure of the risk associated with price-fluctuations of a given asset (stocks, bonds, property, etc.), or the risk of a portfolio of assets[14] (actively managed mutual funds, index mutual funds, or ETFs). Risk is an important factor in determining how to efficiently manage a portfolio of investments because it determines the variation in returns on the asset and/or portfolio and gives investors a mathematical basis for investment decisions (known as mean-variance optimization). The fundamental concept of risk is that as it increases, the expected return on an investment should increase as well, an increase known as the risk premium. In other words, investors should expect a higher return on an investment when that investment carries a higher level of risk or uncertainty. When evaluating investments, investors should estimate both the expected return and the uncertainty of future returns. Standard deviation provides a quantified estimate of the uncertainty of future returns.
For example, assume an investor had to choose between two stocks. Stock A over the past 20 years had an average return of 10 percent, with a standard deviation of 20 percentage points (pp) and Stock B, over the same period, had average returns of 12 percent but a higher standard deviation of 30 pp. On the basis of risk and return, an investor may decide that Stock A is the safer choice, because Stock B’s additional two percentage points of return is not worth the additional 10 pp standard deviation (greater risk or uncertainty of the expected return). Stock B is likely to fall short of the initial investment (but also to exceed the initial investment) more often than Stock A under the same circumstances, and is estimated to return only two percent more on average. In this example, Stock A is expected to earn about 10 percent, plus or minus 20 pp (a range of 30 percent to −10 percent), about two-thirds of the future year returns. When considering more extreme possible returns or outcomes in future, an investor should expect results of as much as 10 percent plus or minus 60 pp, or a range from 70 percent to −50 percent, which includes outcomes for three standard deviations from the average return (about 99.7 percent of probable returns).
Calculating the average (or arithmetic mean) of the return of a security over a given period will generate the expected return of the asset. For each period, subtracting the expected return from the actual return results in the difference from the mean. Squaring the difference in each period and taking the average gives the overall variance of the return of the asset. The larger the variance, the greater risk the security carries. Finding the square root of this variance will give the standard deviation of the investment tool in question.
Population standard deviation is used to set the width of Bollinger Bands, a technical analysis tool. For example, the upper Bollinger Band is given as  The most commonly used value for n is 2; there is about a five percent chance of going outside, assuming a normal distribution of returns.
The most commonly used value for n is 2; there is about a five percent chance of going outside, assuming a normal distribution of returns.
Financial time series are known to be non-stationary series, whereas the statistical calculations above, such as standard deviation, apply only to stationary series. To apply the above statistical tools to non-stationary series, the series first must be transformed to a stationary series, enabling use of statistical tools that now have a valid basis from which to work.
Geometric interpretation[edit]
To gain some geometric insights and clarification, we will start with a population of three values, x1, x2, x3. This defines a point P = (x1, x2, x3) in R3. Consider the line L = {(r, r, r) : r ∈ R}. This is the «main diagonal» going through the origin. If our three given values were all equal, then the standard deviation would be zero and P would lie on L. So it is not unreasonable to assume that the standard deviation is related to the distance of P to L. That is indeed the case. To move orthogonally from L to the point P, one begins at the point:

whose coordinates are the mean of the values we started out with.
A little algebra shows that the distance between P and M (which is the same as the orthogonal distance between P and the line L)  is equal to the standard deviation of the vector (x1, x2, x3), multiplied by the square root of the number of dimensions of the vector (3 in this case).
is equal to the standard deviation of the vector (x1, x2, x3), multiplied by the square root of the number of dimensions of the vector (3 in this case).
Chebyshev’s inequality[edit]
An observation is rarely more than a few standard deviations away from the mean. Chebyshev’s inequality ensures that, for all distributions for which the standard deviation is defined, the amount of data within a number of standard deviations of the mean is at least as much as given in the following table.
| Distance from mean | Minimum population |
|---|---|
 |
50% |
| 2σ | 75% |
| 3σ | 89% |
| 4σ | 94% |
| 5σ | 96% |
| 6σ | 97% |
 |
 [15] [15]
|
 |

|
Rules for normally distributed data[edit]
Dark blue is one standard deviation on either side of the mean. For the normal distribution, this accounts for 68.27 percent of the set; while two standard deviations from the mean (medium and dark blue) account for 95.45 percent; three standard deviations (light, medium, and dark blue) account for 99.73 percent; and four standard deviations account for 99.994 percent. The two points of the curve that are one standard deviation from the mean are also the inflection points.
The central limit theorem states that the distribution of an average of many independent, identically distributed random variables tends toward the famous bell-shaped normal distribution with a probability density function of

where μ is the expected value of the random variables, σ equals their distribution’s standard deviation divided by n1/2, and n is the number of random variables. The standard deviation therefore is simply a scaling variable that adjusts how broad the curve will be, though it also appears in the normalizing constant.
If a data distribution is approximately normal, then the proportion of data values within z standard deviations of the mean is defined by:

where  is the error function. The proportion that is less than or equal to a number, x, is given by the cumulative distribution function:
is the error function. The proportion that is less than or equal to a number, x, is given by the cumulative distribution function:
- .[16]
![{displaystyle {text{Proportion}}leq x={frac {1}{2}}left[1+operatorname {erf} left({frac {x-mu }{sigma {sqrt {2}}}}right)right]={frac {1}{2}}left[1+operatorname {erf} left({frac {z}{sqrt {2}}}right)right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3907d1b0502235fa3fd00f261b290406a02e7b21)
If a data distribution is approximately normal then about 68 percent of the data values are within one standard deviation of the mean (mathematically, μ ± σ, where μ is the arithmetic mean), about 95 percent are within two standard deviations (μ ± 2σ), and about 99.7 percent lie within three standard deviations (μ ± 3σ). This is known as the 68–95–99.7 rule, or the empirical rule.
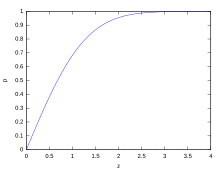
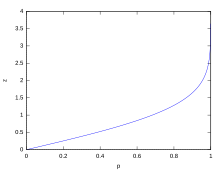
For various values of z, the percentage of values expected to lie in and outside the symmetric interval, CI = (−zσ, zσ), are as follows:
| Confidence interval |
Proportion within | Proportion without | |
|---|---|---|---|
| Percentage | Percentage | Fraction | |
| 0.318639σ | 25% | 75% | 3 / 4 |
| 0.674490σ | 50% | 50% | 1 / 2 |
| 0.977925σ | 66.6667% | 33.3333% | 1 / 3 |
| 0.994458σ | 68% | 32% | 1 / 3.125 |
| 1σ | 68.2689492% | 31.7310508% | 1 / 3.1514872 |
| 1.281552σ | 80% | 20% | 1 / 5 |
| 1.644854σ | 90% | 10% | 1 / 10 |
| 1.959964σ | 95% | 5% | 1 / 20 |
| 2σ | 95.4499736% | 4.5500264% | 1 / 21.977895 |
| 2.575829σ | 99% | 1% | 1 / 100 |
| 3σ | 99.7300204% | 0.2699796% | 1 / 370.398 |
| 3.290527σ | 99.9% | 0.1% | 1 / 1000 |
| 3.890592σ | 99.99% | 0.01% | 1 / 10000 |
| 4σ | 99.993666% | 0.006334% | 1 / 15787 |
| 4.417173σ | 99.999% | 0.001% | 1 / 100000 |
| 4.5σ | 99.9993204653751% | 0.0006795346249% | 1 / 147159.5358 6.8 / 1000000 |
| 4.891638σ | 99.9999% | 0.0001% | 1 / 1000000 |
| 5σ | 99.9999426697% | 0.0000573303% | 1 / 1744278 |
| 5.326724σ | 99.99999% | 0.00001% | 1 / 10000000 |
| 5.730729σ | 99.999999% | 0.000001% | 1 / 100000000 |
| 6σ | 99.9999998027% | 0.0000001973% | 1 / 506797346 |
| 6.109410σ | 99.9999999% | 0.0000001% | 1 / 1000000000 |
| 6.466951σ | 99.99999999% | 0.00000001% | 1 / 10000000000 |
| 6.806502σ | 99.999999999% | 0.000000001% | 1 / 100000000000 |
| 7σ | 99.9999999997440% | 0.000000000256% | 1 / 390682215445 |
Relationship between standard deviation and mean[edit]
The mean and the standard deviation of a set of data are descriptive statistics usually reported together. In a certain sense, the standard deviation is a «natural» measure of statistical dispersion if the center of the data is measured about the mean. This is because the standard deviation from the mean is smaller than from any other point. The precise statement is the following: suppose x1, …, xn are real numbers and define the function:

Using calculus or by completing the square, it is possible to show that σ(r) has a unique minimum at the mean:

Variability can also be measured by the coefficient of variation, which is the ratio of the standard deviation to the mean. It is a dimensionless number.
Standard deviation of the mean[edit]
Often, we want some information about the precision of the mean we obtained. We can obtain this by determining the standard deviation of the sampled mean. Assuming statistical independence of the values in the sample, the standard deviation of the mean is related to the standard deviation of the distribution by:

where N is the number of observations in the sample used to estimate the mean. This can easily be proven with (see basic properties of the variance):

(Statistical independence is assumed.)

hence

Resulting in:

In order to estimate the standard deviation of the mean  it is necessary to know the standard deviation of the entire population
it is necessary to know the standard deviation of the entire population  beforehand. However, in most applications this parameter is unknown. For example, if a series of 10 measurements of a previously unknown quantity is performed in a laboratory, it is possible to calculate the resulting sample mean and sample standard deviation, but it is impossible to calculate the standard deviation of the mean. However, one can estimate the standard deviation of the entire population from the sample, and thus obtain an estimate for the standard error of the mean.
beforehand. However, in most applications this parameter is unknown. For example, if a series of 10 measurements of a previously unknown quantity is performed in a laboratory, it is possible to calculate the resulting sample mean and sample standard deviation, but it is impossible to calculate the standard deviation of the mean. However, one can estimate the standard deviation of the entire population from the sample, and thus obtain an estimate for the standard error of the mean.
Rapid calculation methods[edit]
The following two formulas can represent a running (repeatedly updated) standard deviation. A set of two power sums s1 and s2 are computed over a set of N values of x, denoted as x1, …, xN:

Given the results of these running summations, the values N, s1, s2 can be used at any time to compute the current value of the running standard deviation:

Where N, as mentioned above, is the size of the set of values (or can also be regarded as s0).
Similarly for sample standard deviation,

In a computer implementation, as the two sj sums become large, we need to consider round-off error, arithmetic overflow, and arithmetic underflow. The method below calculates the running sums method with reduced rounding errors.[17] This is a «one pass» algorithm for calculating variance of n samples without the need to store prior data during the calculation. Applying this method to a time series will result in successive values of standard deviation corresponding to n data points as n grows larger with each new sample, rather than a constant-width sliding window calculation.
For k = 1, …, n:

where A is the mean value.

Note:  since
since  or
or 
Sample variance:

Population variance:

Weighted calculation[edit]
When the values xi are weighted with unequal weights wi, the power sums s0, s1, s2 are each computed as:

And the standard deviation equations remain unchanged. s0 is now the sum of the weights and not the number of samples N.
The incremental method with reduced rounding errors can also be applied, with some additional complexity.
A running sum of weights must be computed for each k from 1 to n:

and places where 1/n is used above must be replaced by wi/Wn:

In the final division,

and

or

where n is the total number of elements, and n’ is the number of elements with non-zero weights.
The above formulas become equal to the simpler formulas given above if weights are taken as equal to one.
History[edit]
The term standard deviation was first used in writing by Karl Pearson in 1894, following his use of it in lectures.[18][19] This was as a replacement for earlier alternative names for the same idea: for example, Gauss used mean error.[20]
Higher dimensions[edit]
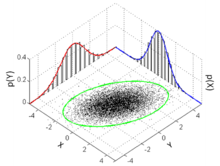
The standard deviation ellipse (green) of a two-dimensional normal distribution
In two dimensions, the standard deviation can be illustrated with the standard deviation ellipse (see Multivariate normal distribution § Geometric interpretation).
See also[edit]
- 68–95–99.7 rule
- Accuracy and precision
- Chebyshev’s inequality An inequality on location and scale parameters
- Coefficient of variation
- Cumulant
- Deviation (statistics)
- Distance correlation Distance standard deviation
- Error bar
- Geometric standard deviation
- Mahalanobis distance generalizing number of standard deviations to the mean
- Mean absolute error
- Pooled variance
- Propagation of uncertainty
- Percentile
- Raw data
- Robust standard deviation
- Root mean square
- Sample size
- Samuelson’s inequality
- Six Sigma
- Standard error
- Standard score
- Yamartino method for calculating standard deviation of wind direction
References[edit]
- ^ Bland, J.M.; Altman, D.G. (1996). «Statistics notes: measurement error». BMJ. 312 (7047): 1654. doi:10.1136/bmj.312.7047.1654. PMC 2351401. PMID 8664723.
- ^ Gauss, Carl Friedrich (1816). «Bestimmung der Genauigkeit der Beobachtungen». Zeitschrift für Astronomie und Verwandte Wissenschaften. 1: 187–197.
- ^ Walker, Helen (1931). Studies in the History of the Statistical Method. Baltimore, MD: Williams & Wilkins Co. pp. 24–25.
- ^ Weisstein, Eric W. «Bessel’s Correction». MathWorld.
- ^ «Standard Deviation Formulas». www.mathsisfun.com. Retrieved 21 August 2020.
- ^ Weisstein, Eric W. «Standard Deviation». mathworld.wolfram.com. Retrieved 21 August 2020.
- ^ «Consistent estimator». www.statlect.com. Retrieved 10 October 2022.
- ^ Gurland, John; Tripathi, Ram C. (1971), «A Simple Approximation for Unbiased Estimation of the Standard Deviation», The American Statistician, 25 (4): 30–32, doi:10.2307/2682923, JSTOR 2682923
- ^ «Standard Deviation Calculator». PureCalculators. 11 July 2021. Retrieved 14 September 2021.
- ^ Shiffler, Ronald E.; Harsha, Phillip D. (1980). «Upper and Lower Bounds for the Sample Standard Deviation». Teaching Statistics. 2 (3): 84–86. doi:10.1111/j.1467-9639.1980.tb00398.x.
- ^ Browne, Richard H. (2001). «Using the Sample Range as a Basis for Calculating Sample Size in Power Calculations». The American Statistician. 55 (4): 293–298. doi:10.1198/000313001753272420. JSTOR 2685690. S2CID 122328846.
- ^ «CERN experiments observe particle consistent with long-sought Higgs boson | CERN press office». Press.web.cern.ch. 4 July 2012. Archived from the original on 25 March 2016. Retrieved 30 May 2015.
- ^ LIGO Scientific Collaboration, Virgo Collaboration (2016), «Observation of Gravitational Waves from a Binary Black Hole Merger», Physical Review Letters, 116 (6): 061102, arXiv:1602.03837, Bibcode:2016PhRvL.116f1102A, doi:10.1103/PhysRevLett.116.061102, PMID 26918975, S2CID 124959784
- ^ «What is Standard Deviation». Pristine. Retrieved 29 October 2011.
- ^ Ghahramani, Saeed (2000). Fundamentals of Probability (2nd ed.). New Jersey: Prentice Hall. p. 438. ISBN 9780130113290.
- ^ Eric W. Weisstein. «Distribution Function». MathWorld—A Wolfram Web Resource. Retrieved 30 September 2014.
- ^ Welford, BP (August 1962). «Note on a Method for Calculating Corrected Sums of Squares and Products». Technometrics. 4 (3): 419–420. CiteSeerX 10.1.1.302.7503. doi:10.1080/00401706.1962.10490022.
- ^ Dodge, Yadolah (2003). The Oxford Dictionary of Statistical Terms. Oxford University Press. ISBN 978-0-19-920613-1.
- ^ Pearson, Karl (1894). «On the dissection of asymmetrical frequency curves». Philosophical Transactions of the Royal Society A. 185: 71–110. Bibcode:1894RSPTA.185…71P. doi:10.1098/rsta.1894.0003.
- ^ Miller, Jeff. «Earliest Known Uses of Some of the Words of Mathematics».
External links[edit]
- «Quadratic deviation», Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- «Standard Deviation Calculator»
Cumulative probability of a normal distribution with expected value 0 and standard deviation 1
In statistics, the standard deviation is a measure of the amount of variation or dispersion of a set of values.[1] A low standard deviation indicates that the values tend to be close to the mean (also called the expected value) of the set, while a high standard deviation indicates that the values are spread out over a wider range.
Standard deviation may be abbreviated SD, and is most commonly represented in mathematical texts and equations by the lower case Greek letter σ (sigma), for the population standard deviation, or the Latin letter s, for the sample standard deviation.
The standard deviation of a random variable, sample, statistical population, data set, or probability distribution is the square root of its variance. It is algebraically simpler, though in practice less robust, than the average absolute deviation.[2][3] A useful property of the standard deviation is that, unlike the variance, it is expressed in the same unit as the data.
The standard deviation of a population or sample and the standard error of a statistic (e.g., of the sample mean) are quite different, but related. The sample mean’s standard error is the standard deviation of the set of means that would be found by drawing an infinite number of repeated samples from the population and computing a mean for each sample. The mean’s standard error turns out to equal the population standard deviation divided by the square root of the sample size, and is estimated by using the sample standard deviation divided by the square root of the sample size. For example, a poll’s standard error (what is reported as the margin of error of the poll), is the expected standard deviation of the estimated mean if the same poll were to be conducted multiple times. Thus, the standard error estimates the standard deviation of an estimate, which itself measures how much the estimate depends on the particular sample that was taken from the population.
In science, it is common to report both the standard deviation of the data (as a summary statistic) and the standard error of the estimate (as a measure of potential error in the findings). By convention, only effects more than two standard errors away from a null expectation are considered «statistically significant», a safeguard against spurious conclusion that is really due to random sampling error.
When only a sample of data from a population is available, the term standard deviation of the sample or sample standard deviation can refer to either the above-mentioned quantity as applied to those data, or to a modified quantity that is an unbiased estimate of the population standard deviation (the standard deviation of the entire population).
Basic examples[edit]
Population standard deviation of grades of eight students[edit]
Suppose that the entire population of interest is eight students in a particular class. For a finite set of numbers, the population standard deviation is found by taking the square root of the average of the squared deviations of the values subtracted from their average value. The marks of a class of eight students (that is, a statistical population) are the following eight values:
These eight data points have the mean (average) of 5:
First, calculate the deviations of each data point from the mean, and square the result of each:
The variance is the mean of these values:
and the population standard deviation is equal to the square root of the variance:
This formula is valid only if the eight values with which we began form the complete population. If the values instead were a random sample drawn from some large parent population (for example, they were 8 students randomly and independently chosen from a class of 2 million), then one divides by 7 (which is n − 1) instead of 8 (which is n) in the denominator of the last formula, and the result is In that case, the result of the original formula would be called the sample standard deviation and denoted by s instead of Dividing by n − 1 rather than by n gives an unbiased estimate of the variance of the larger parent population. This is known as Bessel’s correction.[4][5] Roughly, the reason for it is that the formula for the sample variance relies on computing differences of observations from the sample mean, and the sample mean itself was constructed to be as close as possible to the observations, so just dividing by n would underestimate the variability.
Standard deviation of average height for adult men[edit]
If the population of interest is approximately normally distributed, the standard deviation provides information on the proportion of observations above or below certain values. For example, the average height for adult men in the United States is about 70 inches, with a standard deviation of around 3 inches. This means that most men (about 68%, assuming a normal distribution) have a height within 3 inches of the mean (67–73 inches) – one standard deviation – and almost all men (about 95%) have a height within 6 inches of the mean (64–76 inches) – two standard deviations. If the standard deviation were zero, then all men would be exactly 70 inches tall. If the standard deviation were 20 inches, then men would have much more variable heights, with a typical range of about 50–90 inches. Three standard deviations account for 99.73% of the sample population being studied, assuming the distribution is normal or bell-shaped (see the 68–95–99.7 rule, or the empirical rule, for more information).
Definition of population values[edit]
Let μ be the expected value (the average) of random variable X with density f(x):
The standard deviation σ of X is defined as
which can be shown to equal
Using words, the standard deviation is the square root of the variance of X.
The standard deviation of a probability distribution is the same as that of a random variable having that distribution.
Not all random variables have a standard deviation. If the distribution has fat tails going out to infinity, the standard deviation might not exist, because the integral might not converge. The normal distribution has tails going out to infinity, but its mean and standard deviation do exist, because the tails diminish quickly enough. The Pareto distribution with parameter has a mean, but not a standard deviation (loosely speaking, the standard deviation is infinite). The Cauchy distribution has neither a mean nor a standard deviation.
Discrete random variable[edit]
In the case where X takes random values from a finite data set x1, x2, …, xN, with each value having the same probability, the standard deviation is
or, by using summation notation,
If, instead of having equal probabilities, the values have different probabilities, let x1 have probability p1, x2 have probability p2, …, xN have probability pN. In this case, the standard deviation will be
Continuous random variable[edit]
The standard deviation of a continuous real-valued random variable X with probability density function p(x) is
and where the integrals are definite integrals taken for x ranging over the set of possible values of the random variable X.
In the case of a parametric family of distributions, the standard deviation can be expressed in terms of the parameters. For example, in the case of the log-normal distribution with parameters μ and σ2, the standard deviation is
Estimation[edit]
One can find the standard deviation of an entire population in cases (such as standardized testing) where every member of a population is sampled. In cases where that cannot be done, the standard deviation σ is estimated by examining a random sample taken from the population and computing a statistic of the sample, which is used as an estimate of the population standard deviation. Such a statistic is called an estimator, and the estimator (or the value of the estimator, namely the estimate) is called a sample standard deviation, and is denoted by s (possibly with modifiers).
Unlike in the case of estimating the population mean, for which the sample mean is a simple estimator with many desirable properties (unbiased, efficient, maximum likelihood), there is no single estimator for the standard deviation with all these properties, and unbiased estimation of standard deviation is a very technically involved problem. Most often, the standard deviation is estimated using the corrected sample standard deviation (using N − 1), defined below, and this is often referred to as the «sample standard deviation», without qualifiers. However, other estimators are better in other respects: the uncorrected estimator (using N) yields lower mean squared error, while using N − 1.5 (for the normal distribution) almost completely eliminates bias.
Uncorrected sample standard deviation[edit]
The formula for the population standard deviation (of a finite population) can be applied to the sample, using the size of the sample as the size of the population (though the actual population size from which the sample is drawn may be much larger). This estimator, denoted by sN, is known as the uncorrected sample standard deviation, or sometimes the standard deviation of the sample (considered as the entire population), and is defined as follows:[6]
where are the observed values of the sample items, and is the mean value of these observations, while the denominator N stands for the size of the sample: this is the square root of the sample variance, which is the average of the squared deviations about the sample mean.
This is a consistent estimator (it converges in probability to the population value as the number of samples goes to infinity), and is the maximum-likelihood estimate when the population is normally distributed.[7] However, this is a biased estimator, as the estimates are generally too low. The bias decreases as sample size grows, dropping off as 1/N, and thus is most significant for small or moderate sample sizes; for the bias is below 1%. Thus for very large sample sizes, the uncorrected sample standard deviation is generally acceptable. This estimator also has a uniformly smaller mean squared error than the corrected sample standard deviation.
Corrected sample standard deviation[edit]
If the biased sample variance (the second central moment of the sample, which is a downward-biased estimate of the population variance) is used to compute an estimate of the population’s standard deviation, the result is
Here taking the square root introduces further downward bias, by Jensen’s inequality, due to the square root’s being a concave function. The bias in the variance is easily corrected, but the bias from the square root is more difficult to correct, and depends on the distribution in question.
An unbiased estimator for the variance is given by applying Bessel’s correction, using N − 1 instead of N to yield the unbiased sample variance, denoted s2:
This estimator is unbiased if the variance exists and the sample values are drawn independently with replacement. N − 1 corresponds to the number of degrees of freedom in the vector of deviations from the mean,
Taking square roots reintroduces bias (because the square root is a nonlinear function which does not commute with the expectation, i.e. often ), yielding the corrected sample standard deviation, denoted by s:
As explained above, while s2 is an unbiased estimator for the population variance, s is still a biased estimator for the population standard deviation, though markedly less biased than the uncorrected sample standard deviation. This estimator is commonly used and generally known simply as the «sample standard deviation». The bias may still be large for small samples (N less than 10). As sample size increases, the amount of bias decreases. We obtain more information and the difference between and becomes smaller.
Unbiased sample standard deviation[edit]
For unbiased estimation of standard deviation, there is no formula that works across all distributions, unlike for mean and variance. Instead, s is used as a basis, and is scaled by a correction factor to produce an unbiased estimate. For the normal distribution, an unbiased estimator is given by s/c4, where the correction factor (which depends on N) is given in terms of the Gamma function, and equals:
This arises because the sampling distribution of the sample standard deviation follows a (scaled) chi distribution, and the correction factor is the mean of the chi distribution.
An approximation can be given by replacing N − 1 with N − 1.5, yielding:
The error in this approximation decays quadratically (as 1/N2), and it is suited for all but the smallest samples or highest precision: for N = 3 the bias is equal to 1.3%, and for N = 9 the bias is already less than 0.1%.
A more accurate approximation is to replace above with .[8]
For other distributions, the correct formula depends on the distribution, but a rule of thumb is to use the further refinement of the approximation:
where γ2 denotes the population excess kurtosis. The excess kurtosis may be either known beforehand for certain distributions, or estimated from the data.[9]
Confidence interval of a sampled standard deviation[edit]
The standard deviation we obtain by sampling a distribution is itself not absolutely accurate, both for mathematical reasons (explained here by the confidence interval) and for practical reasons of measurement (measurement error). The mathematical effect can be described by the confidence interval or CI.
To show how a larger sample will make the confidence interval narrower, consider the following examples:
A small population of N = 2 has only 1 degree of freedom for estimating the standard deviation. The result is that a 95% CI of the SD runs from 0.45 × SD to 31.9 × SD; the factors here are as follows:
where is the p-th quantile of the chi-square distribution with k degrees of freedom, and is the confidence level. This is equivalent to the following:
With k = 1, and . The reciprocals of the square roots of these two numbers give us the factors 0.45 and 31.9 given above.
A larger population of N = 10 has 9 degrees of freedom for estimating the standard deviation. The same computations as above give us in this case a 95% CI running from 0.69 × SD to 1.83 × SD. So even with a sample population of 10, the actual SD can still be almost a factor 2 higher than the sampled SD. For a sample population N=100, this is down to 0.88 × SD to 1.16 × SD. To be more certain that the sampled SD is close to the actual SD we need to sample a large number of points.
These same formulae can be used to obtain confidence intervals on the variance of residuals from a least squares fit under standard normal theory, where k is now the number of degrees of freedom for error.
Bounds on standard deviation[edit]
For a set of N > 4 data spanning a range of values R, an upper bound on the standard deviation s is given by s = 0.6R.[10]
An estimate of the standard deviation for N > 100 data taken to be approximately normal follows from the heuristic that 95% of the area under the normal curve lies roughly two standard deviations to either side of the mean, so that, with 95% probability the total range of values R represents four standard deviations so that s ≈ R/4. This so-called range rule is useful in sample size estimation, as the range of possible values is easier to estimate than the standard deviation. Other divisors K(N) of the range such that s ≈ R/K(N) are available for other values of N and for non-normal distributions.[11]
Identities and mathematical properties[edit]
The standard deviation is invariant under changes in location, and scales directly with the scale of the random variable. Thus, for a constant c and random variables X and Y:
The standard deviation of the sum of two random variables can be related to their individual standard deviations and the covariance between them:
where and stand for variance and covariance, respectively.
The calculation of the sum of squared deviations can be related to moments calculated directly from the data. In the following formula, the letter E is interpreted to mean expected value, i.e., mean.
The sample standard deviation can be computed as:
For a finite population with equal probabilities at all points, we have
which means that the standard deviation is equal to the square root of the difference between the average of the squares of the values and the square of the average value.
See computational formula for the variance for proof, and for an analogous result for the sample standard deviation.
Interpretation and application[edit]
Example of samples from two populations with the same mean but different standard deviations. Red population has mean 100 and SD 10; blue population has mean 100 and SD 50.
A large standard deviation indicates that the data points can spread far from the mean and a small standard deviation indicates that they are clustered closely around the mean.
For example, each of the three populations {0, 0, 14, 14}, {0, 6, 8, 14} and {6, 6, 8, 8} has a mean of 7. Their standard deviations are 7, 5, and 1, respectively. The third population has a much smaller standard deviation than the other two because its values are all close to 7. These standard deviations have the same units as the data points themselves. If, for instance, the data set {0, 6, 8, 14} represents the ages of a population of four siblings in years, the standard deviation is 5 years. As another example, the population {1000, 1006, 1008, 1014} may represent the distances traveled by four athletes, measured in meters. It has a mean of 1007 meters, and a standard deviation of 5 meters.
Standard deviation may serve as a measure of uncertainty. In physical science, for example, the reported standard deviation of a group of repeated measurements gives the precision of those measurements. When deciding whether measurements agree with a theoretical prediction, the standard deviation of those measurements is of crucial importance: if the mean of the measurements is too far away from the prediction (with the distance measured in standard deviations), then the theory being tested probably needs to be revised. This makes sense since they fall outside the range of values that could reasonably be expected to occur, if the prediction were correct and the standard deviation appropriately quantified. See prediction interval.
While the standard deviation does measure how far typical values tend to be from the mean, other measures are available. An example is the mean absolute deviation, which might be considered a more direct measure of average distance, compared to the root mean square distance inherent in the standard deviation.
Application examples[edit]
The practical value of understanding the standard deviation of a set of values is in appreciating how much variation there is from the average (mean).
Experiment, industrial and hypothesis testing[edit]
Standard deviation is often used to compare real-world data against a model to test the model.
For example, in industrial applications the weight of products coming off a production line may need to comply with a legally required value. By weighing some fraction of the products an average weight can be found, which will always be slightly different from the long-term average. By using standard deviations, a minimum and maximum value can be calculated that the averaged weight will be within some very high percentage of the time (99.9% or more). If it falls outside the range then the production process may need to be corrected. Statistical tests such as these are particularly important when the testing is relatively expensive. For example, if the product needs to be opened and drained and weighed, or if the product was otherwise used up by the test.
In experimental science, a theoretical model of reality is used. Particle physics conventionally uses a standard of «5 sigma» for the declaration of a discovery. A five-sigma level translates to one chance in 3.5 million that a random fluctuation would yield the result. This level of certainty was required in order to assert that a particle consistent with the Higgs boson had been discovered in two independent experiments at CERN,[12] also leading to the declaration of the first observation of gravitational waves.[13]
Weather[edit]
As a simple example, consider the average daily maximum temperatures for two cities, one inland and one on the coast. It is helpful to understand that the range of daily maximum temperatures for cities near the coast is smaller than for cities inland. Thus, while these two cities may each have the same average maximum temperature, the standard deviation of the daily maximum temperature for the coastal city will be less than that of the inland city as, on any particular day, the actual maximum temperature is more likely to be farther from the average maximum temperature for the inland city than for the coastal one.
Finance[edit]
In finance, standard deviation is often used as a measure of the risk associated with price-fluctuations of a given asset (stocks, bonds, property, etc.), or the risk of a portfolio of assets[14] (actively managed mutual funds, index mutual funds, or ETFs). Risk is an important factor in determining how to efficiently manage a portfolio of investments because it determines the variation in returns on the asset and/or portfolio and gives investors a mathematical basis for investment decisions (known as mean-variance optimization). The fundamental concept of risk is that as it increases, the expected return on an investment should increase as well, an increase known as the risk premium. In other words, investors should expect a higher return on an investment when that investment carries a higher level of risk or uncertainty. When evaluating investments, investors should estimate both the expected return and the uncertainty of future returns. Standard deviation provides a quantified estimate of the uncertainty of future returns.
For example, assume an investor had to choose between two stocks. Stock A over the past 20 years had an average return of 10 percent, with a standard deviation of 20 percentage points (pp) and Stock B, over the same period, had average returns of 12 percent but a higher standard deviation of 30 pp. On the basis of risk and return, an investor may decide that Stock A is the safer choice, because Stock B’s additional two percentage points of return is not worth the additional 10 pp standard deviation (greater risk or uncertainty of the expected return). Stock B is likely to fall short of the initial investment (but also to exceed the initial investment) more often than Stock A under the same circumstances, and is estimated to return only two percent more on average. In this example, Stock A is expected to earn about 10 percent, plus or minus 20 pp (a range of 30 percent to −10 percent), about two-thirds of the future year returns. When considering more extreme possible returns or outcomes in future, an investor should expect results of as much as 10 percent plus or minus 60 pp, or a range from 70 percent to −50 percent, which includes outcomes for three standard deviations from the average return (about 99.7 percent of probable returns).
Calculating the average (or arithmetic mean) of the return of a security over a given period will generate the expected return of the asset. For each period, subtracting the expected return from the actual return results in the difference from the mean. Squaring the difference in each period and taking the average gives the overall variance of the return of the asset. The larger the variance, the greater risk the security carries. Finding the square root of this variance will give the standard deviation of the investment tool in question.
Population standard deviation is used to set the width of Bollinger Bands, a technical analysis tool. For example, the upper Bollinger Band is given as The most commonly used value for n is 2; there is about a five percent chance of going outside, assuming a normal distribution of returns.
Financial time series are known to be non-stationary series, whereas the statistical calculations above, such as standard deviation, apply only to stationary series. To apply the above statistical tools to non-stationary series, the series first must be transformed to a stationary series, enabling use of statistical tools that now have a valid basis from which to work.
Geometric interpretation[edit]
To gain some geometric insights and clarification, we will start with a population of three values, x1, x2, x3. This defines a point P = (x1, x2, x3) in R3. Consider the line L = {(r, r, r) : r ∈ R}. This is the «main diagonal» going through the origin. If our three given values were all equal, then the standard deviation would be zero and P would lie on L. So it is not unreasonable to assume that the standard deviation is related to the distance of P to L. That is indeed the case. To move orthogonally from L to the point P, one begins at the point:
whose coordinates are the mean of the values we started out with.
A little algebra shows that the distance between P and M (which is the same as the orthogonal distance between P and the line L) is equal to the standard deviation of the vector (x1, x2, x3), multiplied by the square root of the number of dimensions of the vector (3 in this case).
Chebyshev’s inequality[edit]
An observation is rarely more than a few standard deviations away from the mean. Chebyshev’s inequality ensures that, for all distributions for which the standard deviation is defined, the amount of data within a number of standard deviations of the mean is at least as much as given in the following table.
| Distance from mean | Minimum population |
|---|---|
|
50% |
| 2σ | 75% |
| 3σ | 89% |
| 4σ | 94% |
| 5σ | 96% |
| 6σ | 97% |
|
[15]
|
|
|
Rules for normally distributed data[edit]
Dark blue is one standard deviation on either side of the mean. For the normal distribution, this accounts for 68.27 percent of the set; while two standard deviations from the mean (medium and dark blue) account for 95.45 percent; three standard deviations (light, medium, and dark blue) account for 99.73 percent; and four standard deviations account for 99.994 percent. The two points of the curve that are one standard deviation from the mean are also the inflection points.
The central limit theorem states that the distribution of an average of many independent, identically distributed random variables tends toward the famous bell-shaped normal distribution with a probability density function of
where μ is the expected value of the random variables, σ equals their distribution’s standard deviation divided by n1/2, and n is the number of random variables. The standard deviation therefore is simply a scaling variable that adjusts how broad the curve will be, though it also appears in the normalizing constant.
If a data distribution is approximately normal, then the proportion of data values within z standard deviations of the mean is defined by:
where is the error function. The proportion that is less than or equal to a number, x, is given by the cumulative distribution function:
- .[16]
If a data distribution is approximately normal then about 68 percent of the data values are within one standard deviation of the mean (mathematically, μ ± σ, where μ is the arithmetic mean), about 95 percent are within two standard deviations (μ ± 2σ), and about 99.7 percent lie within three standard deviations (μ ± 3σ). This is known as the 68–95–99.7 rule, or the empirical rule.
For various values of z, the percentage of values expected to lie in and outside the symmetric interval, CI = (−zσ, zσ), are as follows:
| Confidence interval |
Proportion within | Proportion without | |
|---|---|---|---|
| Percentage | Percentage | Fraction | |
| 0.318639σ | 25% | 75% | 3 / 4 |
| 0.674490σ | 50% | 50% | 1 / 2 |
| 0.977925σ | 66.6667% | 33.3333% | 1 / 3 |
| 0.994458σ | 68% | 32% | 1 / 3.125 |
| 1σ | 68.2689492% | 31.7310508% | 1 / 3.1514872 |
| 1.281552σ | 80% | 20% | 1 / 5 |
| 1.644854σ | 90% | 10% | 1 / 10 |
| 1.959964σ | 95% | 5% | 1 / 20 |
| 2σ | 95.4499736% | 4.5500264% | 1 / 21.977895 |
| 2.575829σ | 99% | 1% | 1 / 100 |
| 3σ | 99.7300204% | 0.2699796% | 1 / 370.398 |
| 3.290527σ | 99.9% | 0.1% | 1 / 1000 |
| 3.890592σ | 99.99% | 0.01% | 1 / 10000 |
| 4σ | 99.993666% | 0.006334% | 1 / 15787 |
| 4.417173σ | 99.999% | 0.001% | 1 / 100000 |
| 4.5σ | 99.9993204653751% | 0.0006795346249% | 1 / 147159.5358 6.8 / 1000000 |
| 4.891638σ | 99.9999% | 0.0001% | 1 / 1000000 |
| 5σ | 99.9999426697% | 0.0000573303% | 1 / 1744278 |
| 5.326724σ | 99.99999% | 0.00001% | 1 / 10000000 |
| 5.730729σ | 99.999999% | 0.000001% | 1 / 100000000 |
| 6σ | 99.9999998027% | 0.0000001973% | 1 / 506797346 |
| 6.109410σ | 99.9999999% | 0.0000001% | 1 / 1000000000 |
| 6.466951σ | 99.99999999% | 0.00000001% | 1 / 10000000000 |
| 6.806502σ | 99.999999999% | 0.000000001% | 1 / 100000000000 |
| 7σ | 99.9999999997440% | 0.000000000256% | 1 / 390682215445 |
Relationship between standard deviation and mean[edit]
The mean and the standard deviation of a set of data are descriptive statistics usually reported together. In a certain sense, the standard deviation is a «natural» measure of statistical dispersion if the center of the data is measured about the mean. This is because the standard deviation from the mean is smaller than from any other point. The precise statement is the following: suppose x1, …, xn are real numbers and define the function:
Using calculus or by completing the square, it is possible to show that σ(r) has a unique minimum at the mean:
Variability can also be measured by the coefficient of variation, which is the ratio of the standard deviation to the mean. It is a dimensionless number.
Standard deviation of the mean[edit]
Often, we want some information about the precision of the mean we obtained. We can obtain this by determining the standard deviation of the sampled mean. Assuming statistical independence of the values in the sample, the standard deviation of the mean is related to the standard deviation of the distribution by:
where N is the number of observations in the sample used to estimate the mean. This can easily be proven with (see basic properties of the variance):
(Statistical independence is assumed.)
hence
Resulting in:
In order to estimate the standard deviation of the mean it is necessary to know the standard deviation of the entire population beforehand. However, in most applications this parameter is unknown. For example, if a series of 10 measurements of a previously unknown quantity is performed in a laboratory, it is possible to calculate the resulting sample mean and sample standard deviation, but it is impossible to calculate the standard deviation of the mean. However, one can estimate the standard deviation of the entire population from the sample, and thus obtain an estimate for the standard error of the mean.
Rapid calculation methods[edit]
The following two formulas can represent a running (repeatedly updated) standard deviation. A set of two power sums s1 and s2 are computed over a set of N values of x, denoted as x1, …, xN:
Given the results of these running summations, the values N, s1, s2 can be used at any time to compute the current value of the running standard deviation:
Where N, as mentioned above, is the size of the set of values (or can also be regarded as s0).
Similarly for sample standard deviation,
In a computer implementation, as the two sj sums become large, we need to consider round-off error, arithmetic overflow, and arithmetic underflow. The method below calculates the running sums method with reduced rounding errors.[17] This is a «one pass» algorithm for calculating variance of n samples without the need to store prior data during the calculation. Applying this method to a time series will result in successive values of standard deviation corresponding to n data points as n grows larger with each new sample, rather than a constant-width sliding window calculation.
For k = 1, …, n:
where A is the mean value.
Note: since or
Sample variance:
Population variance:
Weighted calculation[edit]
When the values xi are weighted with unequal weights wi, the power sums s0, s1, s2 are each computed as:
And the standard deviation equations remain unchanged. s0 is now the sum of the weights and not the number of samples N.
The incremental method with reduced rounding errors can also be applied, with some additional complexity.
A running sum of weights must be computed for each k from 1 to n:
and places where 1/n is used above must be replaced by wi/Wn:
In the final division,
and
or
where n is the total number of elements, and n’ is the number of elements with non-zero weights.
The above formulas become equal to the simpler formulas given above if weights are taken as equal to one.
History[edit]
The term standard deviation was first used in writing by Karl Pearson in 1894, following his use of it in lectures.[18][19] This was as a replacement for earlier alternative names for the same idea: for example, Gauss used mean error.[20]
Higher dimensions[edit]
The standard deviation ellipse (green) of a two-dimensional normal distribution
In two dimensions, the standard deviation can be illustrated with the standard deviation ellipse (see Multivariate normal distribution § Geometric interpretation).
See also[edit]
- 68–95–99.7 rule
- Accuracy and precision
- Chebyshev’s inequality An inequality on location and scale parameters
- Coefficient of variation
- Cumulant
- Deviation (statistics)
- Distance correlation Distance standard deviation
- Error bar
- Geometric standard deviation
- Mahalanobis distance generalizing number of standard deviations to the mean
- Mean absolute error
- Pooled variance
- Propagation of uncertainty
- Percentile
- Raw data
- Robust standard deviation
- Root mean square
- Sample size
- Samuelson’s inequality
- Six Sigma
- Standard error
- Standard score
- Yamartino method for calculating standard deviation of wind direction
References[edit]
- ^ Bland, J.M.; Altman, D.G. (1996). «Statistics notes: measurement error». BMJ. 312 (7047): 1654. doi:10.1136/bmj.312.7047.1654. PMC 2351401. PMID 8664723.
- ^ Gauss, Carl Friedrich (1816). «Bestimmung der Genauigkeit der Beobachtungen». Zeitschrift für Astronomie und Verwandte Wissenschaften. 1: 187–197.
- ^ Walker, Helen (1931). Studies in the History of the Statistical Method. Baltimore, MD: Williams & Wilkins Co. pp. 24–25.
- ^ Weisstein, Eric W. «Bessel’s Correction». MathWorld.
- ^ «Standard Deviation Formulas». www.mathsisfun.com. Retrieved 21 August 2020.
- ^ Weisstein, Eric W. «Standard Deviation». mathworld.wolfram.com. Retrieved 21 August 2020.
- ^ «Consistent estimator». www.statlect.com. Retrieved 10 October 2022.
- ^ Gurland, John; Tripathi, Ram C. (1971), «A Simple Approximation for Unbiased Estimation of the Standard Deviation», The American Statistician, 25 (4): 30–32, doi:10.2307/2682923, JSTOR 2682923
- ^ «Standard Deviation Calculator». PureCalculators. 11 July 2021. Retrieved 14 September 2021.
- ^ Shiffler, Ronald E.; Harsha, Phillip D. (1980). «Upper and Lower Bounds for the Sample Standard Deviation». Teaching Statistics. 2 (3): 84–86. doi:10.1111/j.1467-9639.1980.tb00398.x.
- ^ Browne, Richard H. (2001). «Using the Sample Range as a Basis for Calculating Sample Size in Power Calculations». The American Statistician. 55 (4): 293–298. doi:10.1198/000313001753272420. JSTOR 2685690. S2CID 122328846.
- ^ «CERN experiments observe particle consistent with long-sought Higgs boson | CERN press office». Press.web.cern.ch. 4 July 2012. Archived from the original on 25 March 2016. Retrieved 30 May 2015.
- ^ LIGO Scientific Collaboration, Virgo Collaboration (2016), «Observation of Gravitational Waves from a Binary Black Hole Merger», Physical Review Letters, 116 (6): 061102, arXiv:1602.03837, Bibcode:2016PhRvL.116f1102A, doi:10.1103/PhysRevLett.116.061102, PMID 26918975, S2CID 124959784
- ^ «What is Standard Deviation». Pristine. Retrieved 29 October 2011.
- ^ Ghahramani, Saeed (2000). Fundamentals of Probability (2nd ed.). New Jersey: Prentice Hall. p. 438. ISBN 9780130113290.
- ^ Eric W. Weisstein. «Distribution Function». MathWorld—A Wolfram Web Resource. Retrieved 30 September 2014.
- ^ Welford, BP (August 1962). «Note on a Method for Calculating Corrected Sums of Squares and Products». Technometrics. 4 (3): 419–420. CiteSeerX 10.1.1.302.7503. doi:10.1080/00401706.1962.10490022.
- ^ Dodge, Yadolah (2003). The Oxford Dictionary of Statistical Terms. Oxford University Press. ISBN 978-0-19-920613-1.
- ^ Pearson, Karl (1894). «On the dissection of asymmetrical frequency curves». Philosophical Transactions of the Royal Society A. 185: 71–110. Bibcode:1894RSPTA.185…71P. doi:10.1098/rsta.1894.0003.
- ^ Miller, Jeff. «Earliest Known Uses of Some of the Words of Mathematics».
External links[edit]
- «Quadratic deviation», Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- «Standard Deviation Calculator»
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:
![]()
То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:
![]()
где
s2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.

В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
D(A) = 0
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А2 D(X)
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A + X) = D(X)
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y)
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
D(X-Y) = D(X) + D(Y)
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:
![]()
На практике формула стандартного отклонения следующая:
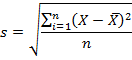
Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
 отклонение в Excel")
Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:
![]()
По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
=СТАНДОТКЛОН.В()/СРЗНАЧ()
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:

Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
Поделиться в социальных сетях:
From Wikipedia, the free encyclopedia

For a value that is sampled with an unbiased normally distributed error, the above depicts the proportion of samples that would fall between 0, 1, 2, and 3 standard deviations above and below the actual value.
The standard error (SE)[1] of a statistic (usually an estimate of a parameter) is the standard deviation of its sampling distribution[2] or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM).[1]
The sampling distribution of a mean is generated by repeated sampling from the same population and recording of the sample means obtained. This forms a distribution of different means, and this distribution has its own mean and variance. Mathematically, the variance of the sampling mean distribution obtained is equal to the variance of the population divided by the sample size. This is because as the sample size increases, sample means cluster more closely around the population mean.
Therefore, the relationship between the standard error of the mean and the standard deviation is such that, for a given sample size, the standard error of the mean equals the standard deviation divided by the square root of the sample size.[1] In other words, the standard error of the mean is a measure of the dispersion of sample means around the population mean.
In regression analysis, the term «standard error» refers either to the square root of the reduced chi-squared statistic or the standard error for a particular regression coefficient (as used in, say, confidence intervals).
Standard error of the sample mean[edit]
Exact value[edit]
Suppose a statistically independent sample of  observations
observations  is taken from a statistical population with a standard deviation of . The mean value calculated from the sample, , will have an associated standard error on the mean,
is taken from a statistical population with a standard deviation of . The mean value calculated from the sample, , will have an associated standard error on the mean,  , given by:[1]
, given by:[1]
- .

Practically this tells us that when trying to estimate the value of a population mean, due to the factor  , reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
, reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
Estimate[edit]
The standard deviation of the population being sampled is seldom known. Therefore, the standard error of the mean is usually estimated by replacing with the sample standard deviation  instead:
instead:
- .

As this is only an estimator for the true «standard error», it is common to see other notations here such as:
- or alternately .


A common source of confusion occurs when failing to distinguish clearly between:
Accuracy of the estimator[edit]
When the sample size is small, using the standard deviation of the sample instead of the true standard deviation of the population will tend to systematically underestimate the population standard deviation, and therefore also the standard error. With n = 2, the underestimate is about 25%, but for n = 6, the underestimate is only 5%. Gurland and Tripathi (1971) provide a correction and equation for this effect.[3] Sokal and Rohlf (1981) give an equation of the correction factor for small samples of n < 20.[4] See unbiased estimation of standard deviation for further discussion.
Derivation[edit]
The standard error on the mean may be derived from the variance of a sum of independent random variables,[5] given the definition of variance and some simple properties thereof. If are independent samples from a population with mean and standard deviation , then we can define the total

which due to the Bienaymé formula, will have variance

where we’ve approximated the standard deviations, i.e., the uncertainties, of the measurements themselves with the best value for the standard deviation of the population. The mean of these measurements is simply given by
- .

The variance of the mean is then

The standard error is, by definition, the standard deviation of which is simply the square root of the variance:
- .

For correlated random variables the sample variance needs to be computed according to the Markov chain central limit theorem.
Independent and identically distributed random variables with random sample size[edit]
There are cases when a sample is taken without knowing, in advance, how many observations will be acceptable according to some criterion. In such cases, the sample size  is a random variable whose variation adds to the variation of
is a random variable whose variation adds to the variation of  such that,
such that,
- [6]

If has a Poisson distribution, then  with estimator
with estimator  . Hence the estimator of
. Hence the estimator of  becomes
becomes  , leading the following formula for standard error:
, leading the following formula for standard error:

(since the standard deviation is the square root of the variance)
Student approximation when σ value is unknown[edit]
In many practical applications, the true value of σ is unknown. As a result, we need to use a distribution that takes into account that spread of possible σ’s.
When the true underlying distribution is known to be Gaussian, although with unknown σ, then the resulting estimated distribution follows the Student t-distribution. The standard error is the standard deviation of the Student t-distribution. T-distributions are slightly different from Gaussian, and vary depending on the size of the sample. Small samples are somewhat more likely to underestimate the population standard deviation and have a mean that differs from the true population mean, and the Student t-distribution accounts for the probability of these events with somewhat heavier tails compared to a Gaussian. To estimate the standard error of a Student t-distribution it is sufficient to use the sample standard deviation «s» instead of σ, and we could use this value to calculate confidence intervals.
Note: The Student’s probability distribution is approximated well by the Gaussian distribution when the sample size is over 100. For such samples one can use the latter distribution, which is much simpler.
Assumptions and usage[edit]
An example of how  is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
- Upper 95% limit and
- Lower 95% limit


In particular, the standard error of a sample statistic (such as sample mean) is the actual or estimated standard deviation of the sample mean in the process by which it was generated. In other words, it is the actual or estimated standard deviation of the sampling distribution of the sample statistic. The notation for standard error can be any one of SE, SEM (for standard error of measurement or mean), or SE.
Standard errors provide simple measures of uncertainty in a value and are often used because:
- in many cases, if the standard error of several individual quantities is known then the standard error of some function of the quantities can be easily calculated;
- when the probability distribution of the value is known, it can be used to calculate an exact confidence interval;
- when the probability distribution is unknown, Chebyshev’s or the Vysochanskiï–Petunin inequalities can be used to calculate a conservative confidence interval; and
- as the sample size tends to infinity the central limit theorem guarantees that the sampling distribution of the mean is asymptotically normal.
Standard error of mean versus standard deviation[edit]
In scientific and technical literature, experimental data are often summarized either using the mean and standard deviation of the sample data or the mean with the standard error. This often leads to confusion about their interchangeability. However, the mean and standard deviation are descriptive statistics, whereas the standard error of the mean is descriptive of the random sampling process. The standard deviation of the sample data is a description of the variation in measurements, while the standard error of the mean is a probabilistic statement about how the sample size will provide a better bound on estimates of the population mean, in light of the central limit theorem.[7]
Put simply, the standard error of the sample mean is an estimate of how far the sample mean is likely to be from the population mean, whereas the standard deviation of the sample is the degree to which individuals within the sample differ from the sample mean.[8] If the population standard deviation is finite, the standard error of the mean of the sample will tend to zero with increasing sample size, because the estimate of the population mean will improve, while the standard deviation of the sample will tend to approximate the population standard deviation as the sample size increases.
Extensions[edit]
Finite population correction (FPC)[edit]
The formula given above for the standard error assumes that the population is infinite. Nonetheless, it is often used for finite populations when people are interested in measuring the process that created the existing finite population (this is called an analytic study). Though the above formula is not exactly correct when the population is finite, the difference between the finite- and infinite-population versions will be small when sampling fraction is small (e.g. a small proportion of a finite population is studied). In this case people often do not correct for the finite population, essentially treating it as an «approximately infinite» population.
If one is interested in measuring an existing finite population that will not change over time, then it is necessary to adjust for the population size (called an enumerative study). When the sampling fraction (often termed f) is large (approximately at 5% or more) in an enumerative study, the estimate of the standard error must be corrected by multiplying by a »finite population correction» (a.k.a.: FPC):[9]
[10]

which, for large N:

to account for the added precision gained by sampling close to a larger percentage of the population. The effect of the FPC is that the error becomes zero when the sample size n is equal to the population size N.
This happens in survey methodology when sampling without replacement. If sampling with replacement, then FPC does not come into play.
Correction for correlation in the sample[edit]

Expected error in the mean of A for a sample of n data points with sample bias coefficient ρ. The unbiased standard error plots as the ρ = 0 diagonal line with log-log slope −½.
If values of the measured quantity A are not statistically independent but have been obtained from known locations in parameter space x, an unbiased estimate of the true standard error of the mean (actually a correction on the standard deviation part) may be obtained by multiplying the calculated standard error of the sample by the factor f:

where the sample bias coefficient ρ is the widely used Prais–Winsten estimate of the autocorrelation-coefficient (a quantity between −1 and +1) for all sample point pairs. This approximate formula is for moderate to large sample sizes; the reference gives the exact formulas for any sample size, and can be applied to heavily autocorrelated time series like Wall Street stock quotes. Moreover, this formula works for positive and negative ρ alike.[11] See also unbiased estimation of standard deviation for more discussion.
See also[edit]
- Illustration of the central limit theorem
- Margin of error
- Probable error
- Standard error of the weighted mean
- Sample mean and sample covariance
- Standard error of the median
- Variance
References[edit]
- ^ a b c d Altman, Douglas G; Bland, J Martin (2005-10-15). «Standard deviations and standard errors». BMJ: British Medical Journal. 331 (7521): 903. doi:10.1136/bmj.331.7521.903. ISSN 0959-8138. PMC 1255808. PMID 16223828.
- ^ Everitt, B. S. (2003). The Cambridge Dictionary of Statistics. CUP. ISBN 978-0-521-81099-9.
- ^ Gurland, J; Tripathi RC (1971). «A simple approximation for unbiased estimation of the standard deviation». American Statistician. 25 (4): 30–32. doi:10.2307/2682923. JSTOR 2682923.
- ^ Sokal; Rohlf (1981). Biometry: Principles and Practice of Statistics in Biological Research (2nd ed.). p. 53. ISBN 978-0-7167-1254-1.
- ^ Hutchinson, T. P. (1993). Essentials of Statistical Methods, in 41 pages. Adelaide: Rumsby. ISBN 978-0-646-12621-0.
- ^ Cornell, J R, and Benjamin, C A, Probability, Statistics, and Decisions for Civil Engineers, McGraw-Hill, NY, 1970, ISBN 0486796094, pp. 178–9.
- ^ Barde, M. (2012). «What to use to express the variability of data: Standard deviation or standard error of mean?». Perspect. Clin. Res. 3 (3): 113–116. doi:10.4103/2229-3485.100662. PMC 3487226. PMID 23125963.
- ^ Wassertheil-Smoller, Sylvia (1995). Biostatistics and Epidemiology : A Primer for Health Professionals (Second ed.). New York: Springer. pp. 40–43. ISBN 0-387-94388-9.
- ^ Isserlis, L. (1918). «On the value of a mean as calculated from a sample». Journal of the Royal Statistical Society. 81 (1): 75–81. doi:10.2307/2340569. JSTOR 2340569. (Equation 1)
- ^ Bondy, Warren; Zlot, William (1976). «The Standard Error of the Mean and the Difference Between Means for Finite Populations». The American Statistician. 30 (2): 96–97. doi:10.1080/00031305.1976.10479149. JSTOR 2683803. (Equation 2)
- ^ Bence, James R. (1995). «Analysis of Short Time Series: Correcting for Autocorrelation». Ecology. 76 (2): 628–639. doi:10.2307/1941218. JSTOR 1941218.
From Wikipedia, the free encyclopedia
For a value that is sampled with an unbiased normally distributed error, the above depicts the proportion of samples that would fall between 0, 1, 2, and 3 standard deviations above and below the actual value.
The standard error (SE)[1] of a statistic (usually an estimate of a parameter) is the standard deviation of its sampling distribution[2] or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM).[1]
The sampling distribution of a mean is generated by repeated sampling from the same population and recording of the sample means obtained. This forms a distribution of different means, and this distribution has its own mean and variance. Mathematically, the variance of the sampling mean distribution obtained is equal to the variance of the population divided by the sample size. This is because as the sample size increases, sample means cluster more closely around the population mean.
Therefore, the relationship between the standard error of the mean and the standard deviation is such that, for a given sample size, the standard error of the mean equals the standard deviation divided by the square root of the sample size.[1] In other words, the standard error of the mean is a measure of the dispersion of sample means around the population mean.
In regression analysis, the term «standard error» refers either to the square root of the reduced chi-squared statistic or the standard error for a particular regression coefficient (as used in, say, confidence intervals).
Standard error of the sample mean[edit]
Exact value[edit]
Suppose a statistically independent sample of observations is taken from a statistical population with a standard deviation of . The mean value calculated from the sample, , will have an associated standard error on the mean, , given by:[1]
- .
Practically this tells us that when trying to estimate the value of a population mean, due to the factor , reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
Estimate[edit]
The standard deviation of the population being sampled is seldom known. Therefore, the standard error of the mean is usually estimated by replacing with the sample standard deviation instead:
- .
As this is only an estimator for the true «standard error», it is common to see other notations here such as:
- or alternately .
A common source of confusion occurs when failing to distinguish clearly between:
Accuracy of the estimator[edit]
When the sample size is small, using the standard deviation of the sample instead of the true standard deviation of the population will tend to systematically underestimate the population standard deviation, and therefore also the standard error. With n = 2, the underestimate is about 25%, but for n = 6, the underestimate is only 5%. Gurland and Tripathi (1971) provide a correction and equation for this effect.[3] Sokal and Rohlf (1981) give an equation of the correction factor for small samples of n < 20.[4] See unbiased estimation of standard deviation for further discussion.
Derivation[edit]
The standard error on the mean may be derived from the variance of a sum of independent random variables,[5] given the definition of variance and some simple properties thereof. If are independent samples from a population with mean and standard deviation , then we can define the total
which due to the Bienaymé formula, will have variance
where we’ve approximated the standard deviations, i.e., the uncertainties, of the measurements themselves with the best value for the standard deviation of the population. The mean of these measurements is simply given by
- .
The variance of the mean is then
The standard error is, by definition, the standard deviation of which is simply the square root of the variance:
- .
For correlated random variables the sample variance needs to be computed according to the Markov chain central limit theorem.
Independent and identically distributed random variables with random sample size[edit]
There are cases when a sample is taken without knowing, in advance, how many observations will be acceptable according to some criterion. In such cases, the sample size is a random variable whose variation adds to the variation of such that,
- [6]
If has a Poisson distribution, then with estimator . Hence the estimator of becomes , leading the following formula for standard error:
(since the standard deviation is the square root of the variance)
Student approximation when σ value is unknown[edit]
In many practical applications, the true value of σ is unknown. As a result, we need to use a distribution that takes into account that spread of possible σ’s.
When the true underlying distribution is known to be Gaussian, although with unknown σ, then the resulting estimated distribution follows the Student t-distribution. The standard error is the standard deviation of the Student t-distribution. T-distributions are slightly different from Gaussian, and vary depending on the size of the sample. Small samples are somewhat more likely to underestimate the population standard deviation and have a mean that differs from the true population mean, and the Student t-distribution accounts for the probability of these events with somewhat heavier tails compared to a Gaussian. To estimate the standard error of a Student t-distribution it is sufficient to use the sample standard deviation «s» instead of σ, and we could use this value to calculate confidence intervals.
Note: The Student’s probability distribution is approximated well by the Gaussian distribution when the sample size is over 100. For such samples one can use the latter distribution, which is much simpler.
Assumptions and usage[edit]
An example of how is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
- Upper 95% limit and
- Lower 95% limit
In particular, the standard error of a sample statistic (such as sample mean) is the actual or estimated standard deviation of the sample mean in the process by which it was generated. In other words, it is the actual or estimated standard deviation of the sampling distribution of the sample statistic. The notation for standard error can be any one of SE, SEM (for standard error of measurement or mean), or SE.
Standard errors provide simple measures of uncertainty in a value and are often used because:
- in many cases, if the standard error of several individual quantities is known then the standard error of some function of the quantities can be easily calculated;
- when the probability distribution of the value is known, it can be used to calculate an exact confidence interval;
- when the probability distribution is unknown, Chebyshev’s or the Vysochanskiï–Petunin inequalities can be used to calculate a conservative confidence interval; and
- as the sample size tends to infinity the central limit theorem guarantees that the sampling distribution of the mean is asymptotically normal.
Standard error of mean versus standard deviation[edit]
In scientific and technical literature, experimental data are often summarized either using the mean and standard deviation of the sample data or the mean with the standard error. This often leads to confusion about their interchangeability. However, the mean and standard deviation are descriptive statistics, whereas the standard error of the mean is descriptive of the random sampling process. The standard deviation of the sample data is a description of the variation in measurements, while the standard error of the mean is a probabilistic statement about how the sample size will provide a better bound on estimates of the population mean, in light of the central limit theorem.[7]
Put simply, the standard error of the sample mean is an estimate of how far the sample mean is likely to be from the population mean, whereas the standard deviation of the sample is the degree to which individuals within the sample differ from the sample mean.[8] If the population standard deviation is finite, the standard error of the mean of the sample will tend to zero with increasing sample size, because the estimate of the population mean will improve, while the standard deviation of the sample will tend to approximate the population standard deviation as the sample size increases.
Extensions[edit]
Finite population correction (FPC)[edit]
The formula given above for the standard error assumes that the population is infinite. Nonetheless, it is often used for finite populations when people are interested in measuring the process that created the existing finite population (this is called an analytic study). Though the above formula is not exactly correct when the population is finite, the difference between the finite- and infinite-population versions will be small when sampling fraction is small (e.g. a small proportion of a finite population is studied). In this case people often do not correct for the finite population, essentially treating it as an «approximately infinite» population.
If one is interested in measuring an existing finite population that will not change over time, then it is necessary to adjust for the population size (called an enumerative study). When the sampling fraction (often termed f) is large (approximately at 5% or more) in an enumerative study, the estimate of the standard error must be corrected by multiplying by a »finite population correction» (a.k.a.: FPC):[9]
[10]
which, for large N:
to account for the added precision gained by sampling close to a larger percentage of the population. The effect of the FPC is that the error becomes zero when the sample size n is equal to the population size N.
This happens in survey methodology when sampling without replacement. If sampling with replacement, then FPC does not come into play.
Correction for correlation in the sample[edit]
Expected error in the mean of A for a sample of n data points with sample bias coefficient ρ. The unbiased standard error plots as the ρ = 0 diagonal line with log-log slope −½.
If values of the measured quantity A are not statistically independent but have been obtained from known locations in parameter space x, an unbiased estimate of the true standard error of the mean (actually a correction on the standard deviation part) may be obtained by multiplying the calculated standard error of the sample by the factor f:
where the sample bias coefficient ρ is the widely used Prais–Winsten estimate of the autocorrelation-coefficient (a quantity between −1 and +1) for all sample point pairs. This approximate formula is for moderate to large sample sizes; the reference gives the exact formulas for any sample size, and can be applied to heavily autocorrelated time series like Wall Street stock quotes. Moreover, this formula works for positive and negative ρ alike.[11] See also unbiased estimation of standard deviation for more discussion.
See also[edit]
- Illustration of the central limit theorem
- Margin of error
- Probable error
- Standard error of the weighted mean
- Sample mean and sample covariance
- Standard error of the median
- Variance
References[edit]
- ^ a b c d Altman, Douglas G; Bland, J Martin (2005-10-15). «Standard deviations and standard errors». BMJ: British Medical Journal. 331 (7521): 903. doi:10.1136/bmj.331.7521.903. ISSN 0959-8138. PMC 1255808. PMID 16223828.
- ^ Everitt, B. S. (2003). The Cambridge Dictionary of Statistics. CUP. ISBN 978-0-521-81099-9.
- ^ Gurland, J; Tripathi RC (1971). «A simple approximation for unbiased estimation of the standard deviation». American Statistician. 25 (4): 30–32. doi:10.2307/2682923. JSTOR 2682923.
- ^ Sokal; Rohlf (1981). Biometry: Principles and Practice of Statistics in Biological Research (2nd ed.). p. 53. ISBN 978-0-7167-1254-1.
- ^ Hutchinson, T. P. (1993). Essentials of Statistical Methods, in 41 pages. Adelaide: Rumsby. ISBN 978-0-646-12621-0.
- ^ Cornell, J R, and Benjamin, C A, Probability, Statistics, and Decisions for Civil Engineers, McGraw-Hill, NY, 1970, ISBN 0486796094, pp. 178–9.
- ^ Barde, M. (2012). «What to use to express the variability of data: Standard deviation or standard error of mean?». Perspect. Clin. Res. 3 (3): 113–116. doi:10.4103/2229-3485.100662. PMC 3487226. PMID 23125963.
- ^ Wassertheil-Smoller, Sylvia (1995). Biostatistics and Epidemiology : A Primer for Health Professionals (Second ed.). New York: Springer. pp. 40–43. ISBN 0-387-94388-9.
- ^ Isserlis, L. (1918). «On the value of a mean as calculated from a sample». Journal of the Royal Statistical Society. 81 (1): 75–81. doi:10.2307/2340569. JSTOR 2340569. (Equation 1)
- ^ Bondy, Warren; Zlot, William (1976). «The Standard Error of the Mean and the Difference Between Means for Finite Populations». The American Statistician. 30 (2): 96–97. doi:10.1080/00031305.1976.10479149. JSTOR 2683803. (Equation 2)
- ^ Bence, James R. (1995). «Analysis of Short Time Series: Correcting for Autocorrelation». Ecology. 76 (2): 628–639. doi:10.2307/1941218. JSTOR 1941218.
Я читаю курс статистического мышления магистрам, и одна тема вызывает у них явные затруднения – чем стандартное отклонение отличается от стандартной ошибки, и в каких случаях, применять ту или иную статистику. А недавно в книге Искусство статистики Дэвида Шпигельхалтера я узнал про бутстрэппинг, и понял, как объяснить различия стандартного отклонения и стандартной ошибки.
Для начала зададим 100 значений стандартной нормально распределенной случайной величины. В этом контексте стандартная означает, что ее матожидание μ = 0, а среднеквадратичное отклонение σ = 1. Поскольку значения в Excel получены с помощью волатильной функции СЛМАССИВ(), после любого действия они пересчитываются. Поэтому диаграммы в заметке и в файле будут отличаться.
Рис. 1. Нормально распределенная случайная величина
Скачать заметку в формате Word или pdf, примеры в формате Excel
Стандартное отклонение
… является наиболее распространенным показателем рассеивания значений случайной величины относительно её среднего арифметического.
Стандартное отклонение вычисляют по формуле:
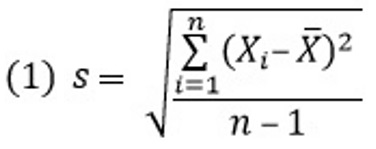
где X̅ – среднее арифметическое значений случайной величины (далее я буду называть его просто средним), Хi – отдельные значения случайной величины, n – число значений случайной величины.
Вообще термины разными авторами используются немного по-разному. Мне нравится следующий подход. Генеральную совокупность описывают параметрами, обозначаемыми греческими буквами: математическое ожидание μ и среднеквадратичное отклонение σ. Выборки описывают статистиками, обозначаемыми латинскими буквами: среднее арифметическое X̅ и стандартное отклонение s. Стандартное отклонение иначе называют оценкой среднеквадратичного отклонения. Как правило, есть генеральная совокупность с неизвестным нам среднеквадратичным отклонением σ. Извлекая выборку, и вычисляя стандартное отклонение s, мы кое-что узнаем о среднеквадратичном отклонении генеральной совокупности σ. Поэтому и говорят, что s является оценкой сигмы.
На самом деле за термином стандартное отклонение стоят две немного отличающиеся статистики. Но эта заметка о другом)) Подробнее см. СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г: в чем различие?
Нанесем на диаграмму линию среднего и границы, отстоящие от среднего на расстоянии ±2s.

Рис. 2. Линия среднего и границы ±2s
Для стандартного нормального распределения за границы ±2s попадают 4,6% значений.
=(1-НОРМ.СТ.РАСП(2;ИСТИНА))*2 = 4,6%
И действительно 5 точек на рис. 2 лежат вне границ. Совпадение не обязано быть таким точным. Если вы откроете файл Excel на листе «Рис. 2» и понажимаете F9, принудительно изменяя случайные значения, то увидите, что вне границ может лежать от 2 до 8 точек. А если нажимать F9 достаточно долго, то вы получите более экстремальные числа точек вне границ. Для стандартного нормального распределения в пределах ±2s лежат приблизительно 95% значений. Поскольку s – оценка среднеквадратичного отклонения σ, которое в свою очередь равно 1, то 95% всех значений попадают в диапазон ≈ ±2.
Чем меньше s, тем кучнее значения случайной величины располагаются вокруг среднего. Итак
стандартное отклонение – мера разброса случайной величины
Среднее арифметическое выборки
Напомню, что мы задаем наши 100 значений с помощью генератора случайных чисел формулой в Excel
=НОРМ.СТ.ОБР(СЛМАССИВ(100;;0;1;ЛОЖЬ))
Хотя мы установили для генератора случайных чисел μ = 0 и σ = 1, значения X̅ и s будут немного отличаться для каждой выборки.
Рис. 3. Среднее и стандартное отклонение для 15 выборок размером n = 100
Теперь мы хотим узнать, что можно сказать о неизвестном математическом ожидании генеральной совокупности μ, подсчитав среднее арифметическое конкретной выборки, например, первой X̅ = 0,119?
Бутстрэп
Как пишет Евгения Поникарова, переводчик книги Дэвида Шпигельхалтера «Искусство статистики», слово bootstraps означает ремешки в виде ушка, которые прикрепляются к верхней части обуви, чтобы ее было проще натягивать. В английском языке есть выражение To pull oneself over a fence by one’s bootstraps (буквально — перетащить себя через ограду за ушки своей обуви), которое означает «выпутаться из своих проблем самому». Еще можно вспомнить барона Мюнхгаузена, который вытащил себя за волосы из болота.
Бутстрэп – компьютерный метод исследования распределения статистик, основанный на многократной генерации выборок методом Монте-Карло на базе имеющейся одной выборки. Термин ввел в 1977 году Брэдли Эфрон.
Итак, возьмем одну выборку из 100 случайных чисел и зафиксируем значения. Это наша исходная выборка (столбец А на рис. 4). Её среднее X̅(100) = 0,121, а стандартное отклонение s(100) = 0,995. 95% значений попадают в диапазон ≈ 0,121 ± 1,990.
С помощью генератора случайных чисел будем формировать из исходной выборки бутстрэп-выборки разного размера. Хитрость заключается в том, что выбирать значения мы будем с возвращением. Т.е., все значения любой бутстрэп-выборки взяты из исходной, а вот уникальность значений будет потеряна. Например, выборка в столбце С содержит два значения 0,7394. Я подсветил их с помощью условного форматирования. Опять же, если вы откроете Excel-файл, то дублей может не быть, так как бутстрэп-выборка сформирована волатильной функцией СЛМАССИВ().
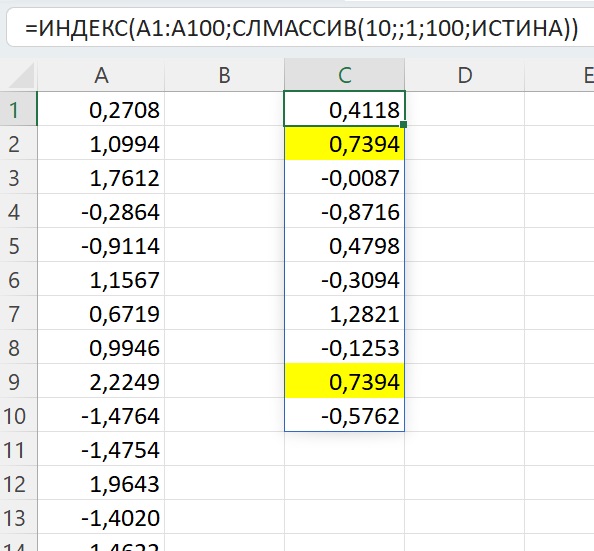
Рис. 4. Бутстрэп-выборка может содержать повторения
Для удобства последующей обработки расположим значения бутстрэп-выборки по горизонтали. Начнем со значения n = 3. Извлечем 1000 бутстрэп-выборок (рис. 5). В столбце А исходная выборка, n = 100. Столбец С содержит номер бутстрэп-выборки. В столбцах D, E и F извлеченные значения, в G – средние значения по выборкам. В ячейке G1 среднее D1:F1, в ячейке G2 – среднее D2:F2 и т.д. На диаграмме показано распределение средних значений бутстрэп-выборок для n = 3.
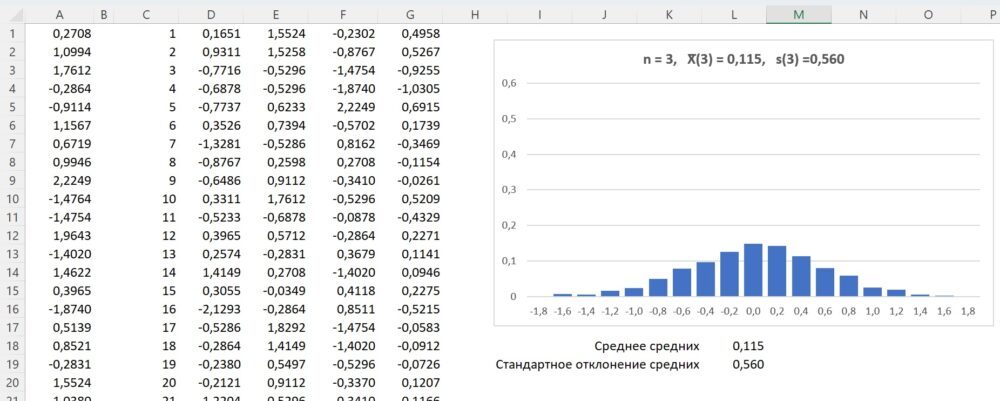
Рис. 5. Распределений средних значений 1000 бутстрэп-выборок, n = 3
Среднее средних 1000 бутстрэп-выборок = 0,115, стандартное отклонение средних значений 1000 бутстрэп-выборок = 0,560. Напоминаю, что 95% исходных значений выборки попадают в диапазон 0,12 ± 1,99. Для бутстрэп-выборок n = 3 мы только что нашли, что 95% средних попадают в диапазон 0,115 ± 1,120 (0,560*2 = 1,120). Кажется естественным, что разброс средних меньше, чем разброс отдельных значений.
Повторим моделирование для n = 5, 20, 50.
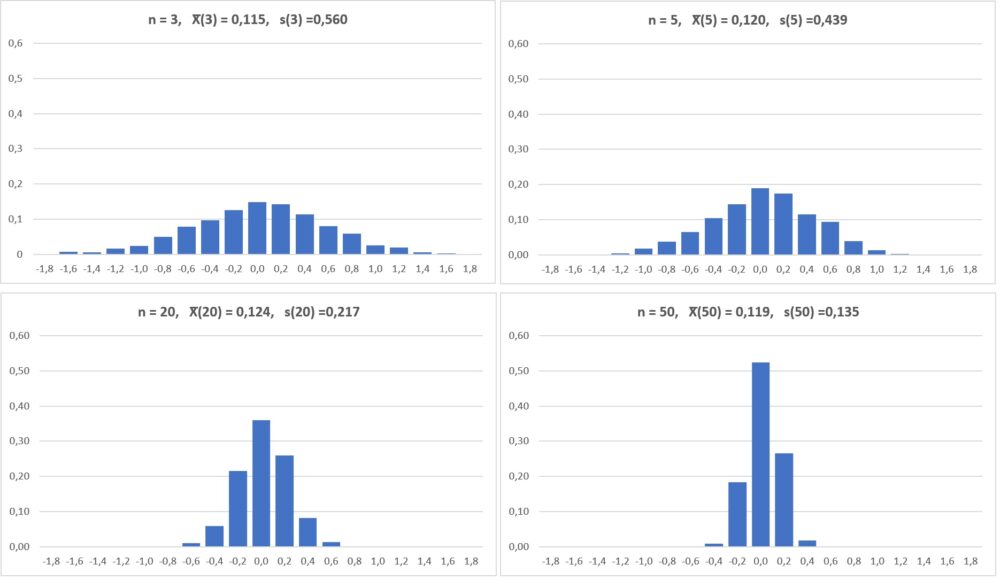
Рис. 6. С увеличением n стандартное отклонение средних значений бутстрэп-выборок уменьшается
Осмыслим, что мы получили. На рис. 6 представлены распределения средних значений бутстрэп-выборок разного размера из исходной выборки 100 случайных нормально распределенных чисел. Среднее каждого распределения близко к нулю (в нашей конкретной выборке из 100 чисел это среднее равно 0,121). А вот стандартное отклонение s(n) уменьшается по мере роста размера бутстрэп-выборок: s(3) = 0,560, s(5) = 0,439, s(20) = 0,217, s(50) = 0,135.
Стандартна ошибка
…или стандартная ошибка среднего – статистика, характеризующая стандартное отклонение выборочного среднего, рассчитанное по выборке размера n из генеральной совокупности.
Ничего не напоминает!? А что за статистику s(n) мы рассчитали выше в бутстрэп-анализе!? Да, это было стандартное отклонение выборочного среднего X̅(n).
Величина стандартной ошибки зависит от дисперсии генеральной совокупности σ2 и объёма выборки n. Стандартная ошибка среднего вычисляется по формуле
![]()
где σ – величина среднеквадратического отклонения генеральной совокупности, и n – объём выборки. Поскольку дисперсия генеральной совокупности, как правило, неизвестна, то оценка стандартной ошибки вычисляется по формуле:
![]()
где s — стандартное отклонение случайной величины.
Сведем в одной таблице рассмотренные статистики:

Рис. 7. Рассмотренные статистики
Здесь в столбцах J:L приведены статистики для одной выборки размера n, а в столбце M – статистики для бутстрэп-выборок соответствующего размера с рис. 6. Если в Excel-файле на листе «Рис. 7» понажимать F9, вы увидите, что не всегда совпадение между столбцами L и M будет таким хорошим, но тенденция будет прослеживаться.
Выше я писал, что мы исследуем неизвестное математическое ожидание генеральной совокупности μ на основе среднего арифметического выборки X̅(100) = 0,119.
Мы можем использовать статистику, именуемую стандартной ошибкой. Для нас она черный ящик – формула, выведенная на основе теории вероятностей. С другой стороны мы можем построить множество бутстрэп-выборок размера n = 100, и подсчитать стандартное отклонение средних этих бутстрэп-выборок. И мы показали, что стандартная ошибка для одной выборки и стандартное отклонение средних бутстрэп-выборок, это одно и то же! В нашем примере, получив X̅(100) = 0,119, мы можем сказать, что с вероятностью 95% математическое ожидание генеральной совокупности μ лежит в диапазоне 0,119 ± 0,212 (0,106*2=0,212). Итак
стандартная ошибка – мера оценки математического ожидания генеральной совокупности μ на основании статистик выборки
Например, 95%-ный доверительный интервал для μ
Понятно, что с увеличением размера выборки n доверительный интервал будет сужаться. В пределе при n → ∞, X̅ → μ и SE → 0.
Имея
прямую регрессии, необходимо оценить
насколько сильно точки исходных данных
отклоняются от прямой регрессии. Можно
выполнить оценку разброса, аналогичную
стандартному отклонению выборки. Этот
показатель, называемый стандартной
ошибкой оценки, демонстрирует величину
отклонения точек исходных данных от
прямой регрессии в направлении оси Y.
Стандартная ошибка оценки (![]() )
)
вычисляется по следующей формуле.
![]()
Стандартная
ошибка оценки измеряет степень отличия
реальных значений Y от оцененной величины.
Для сравнительно больших выборок следует
ожидать, что около 67% разностей по модулю
не будет превышать
![]()
и около 95% модулей разностей будет не
больше 2![]() .
.
Стандартная
ошибка оценки подобна стандартному
отклонению. Ее можно использовать для
оценки стандартного отклонения
совокупности. Фактически
![]()
оценивает стандартное отклонение
![]()
слагаемого ошибки
![]()
в статистической модели простой линейной
регрессии. Другими словами,
![]()
оценивает общее стандартное отклонение
![]()
нормального распределения значений Y,
имеющих математические ожидания
![]()
для каждого X.
Малая
стандартная ошибка оценки, полученная
при регрессионном анализе, свидетельствует,
что все точки данных находятся очень
близко к прямой регрессии. Если стандартная
ошибка оценки велика, точки данных могут
значительно удаляться от прямой.
2.3 Прогнозирование величины y
Регрессионную
прямую можно использовать для оценки
величины переменной Y
при данных значениях переменной X. Чтобы
получить точечный прогноз, или предсказание
для данного значения X, просто вычисляется
значение найденной функции регрессии
в точке X.
Конечно
реальные значения величины Y,
соответствующие рассматриваемым
значениям величины X, к сожалению, не
лежат в точности на регрессионной
прямой. Фактически они разбросаны
относительно прямой в соответствии с
величиной
![]() .
.
Более того, выборочная регрессионная
прямая является оценкой регрессионной
прямой генеральной совокупности,
основанной на выборке из определенных
пар данных. Другая случайная выборка
даст иную выборочную прямую регрессии;
это аналогично ситуации, когда различные
выборки из одной и той же генеральной
совокупности дают различные значения
выборочного среднего.
Есть
два источника неопределенности в
точечном прогнозе, использующем уравнение
регрессии.
-
Неопределенность,
обусловленная отклонением точек данных
от выборочной прямой регрессии. -
Неопределенность,
обусловленная отклонением выборочной
прямой регрессии от регрессионной
прямой генеральной совокупности.
Интервальный
прогноз значений переменной Y
можно построить так, что при этом будут
учтены оба источника неопределенности.
Стандартная
ошибка прогноза
![]()
дает меру вариативности предсказанного
значения Y
около истинной величины Y
для данного значения X.
Стандартная ошибка прогноза равна:

Стандартная
ошибка прогноза зависит от значения X,
для которого прогнозируется величина
Y.
![]()
минимально, когда
![]() ,
,
поскольку тогда числитель в третьем
слагаемом под корнем в уравнении будет
0. При прочих неизменных величинах
большему отличию соответствует большее
значение стандартной ошибки прогноза.
Если
статистическая модель простой линейной
регрессии соответствует действительности,
границы интервала прогноза величины Y
равны:
![]()
где
![]()
— квантиль распределения Стьюдента с
n-2 степенями свободы (![]() ).
).
Если выборка велика (![]() ),
),
этот квантиль можно заменить соответствующим
квантилем нормального распределения.
Например, для большой выборки 95%-ный
интервал прогноза задается следующими
значениями:
![]()
Завершим
раздел обзором предположений, положенных
в основу статистической модели линейной
регрессии.
-
Для
заданного значения X генеральная
совокупность значений Y имеет нормальное
распределение относительно регрессионной
прямой совокупности. На практике
приемлемые результаты получаются
и
тогда, когда значения Y имеют
нормальное распределение лишь
приблизительно. -
Разброс
генеральной совокупности точек данных
относительно регрессионной прямой
совокупности остается постоянным всюду
вдоль этой прямой. Иными словами, при
возрастании значений X в точках данных
дисперсия генеральной совокупности
не увеличивается и не уменьшается.
Нарушение этого предположения называется
гетероскедастичностью. -
Слагаемые
ошибок

независимы между собой. Это предположение
определяет случайность выборки точек
Х-Y.
Если точки данных X-Y
записывались в течение некоторого
времени, данное предположение часто
нарушается. Вместо независимых данных,
такие последовательные наблюдения
будут давать серийно коррелированные
значения. -
В
генеральной совокупности существует
линейная зависимость между X и Y.
По аналогии с простой линейной регрессией
может рассматриваться и нелинейная
зависимость между X и У. Некоторые такие
случаи будут обсуждаться ниже.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #



 График функции
График функции 



 и q { displaystyle q}
и q { displaystyle q} как:
как:
 — это вероятность того, что ошибка единичного измерения находится между −a и + a, для положительного a. Это полезно, например, при определении коэффициента битовых ошибок цифровой системы связи.
— это вероятность того, что ошибка единичного измерения находится между −a и + a, для положительного a. Это полезно, например, при определении коэффициента битовых ошибок цифровой системы связи.![X sim operatorname {Norm} [ му, sigma]](https://wikimedia.org/api/rest_v1/media/math/render/svg/84024bc6827355ec6d23a062283a26d54b29698d) и константа L < μ {displaystyle L<mu }
и константа L < μ {displaystyle L<mu } :
:![{ displaystyle Pr [X leq L ] = { frac {1} {2}} + { frac {1} {2}} operatorname {erf} left ({ frac {L- mu} {{ sqrt {2}} sigma }} right) приблизительно A exp left (-B left ({ frac {L- mu} { sigma}} right) ^ {2} right)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a72302c46832449e128a4d4e1adb28b514131270)
 , то:
, то:![{ displaystyle Pr [X leq L] leq A exp (-B ln {k}) = { frac {A} {k ^ {B}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2baadea015e20a45d1034fd88eed861e7fcce178)
 .
. Интегрируем exp (-z)
Интегрируем exp (-z)  erf (z)
erf (z)  означает, что функция является ошибкой нечетной функции. Это связано с тем, что подынтегральное выражение e — t 2 { displaystyle e ^ {- t ^ {2}}}
означает, что функция является ошибкой нечетной функции. Это связано с тем, что подынтегральное выражение e — t 2 { displaystyle e ^ {- t ^ {2}}} является четной функцией.
является четной функцией.
 — комплексное сопряжение число z.
— комплексное сопряжение число z.

 выражает множитель для превращения члена k в член (k + 1) (рассматривая z как первый член).
выражает множитель для превращения члена k в член (k + 1) (рассматривая z как первый член).





 — физики многочлены Эрмита.
— физики многочлены Эрмита.![{ displaystyle { begin {align} operatorname {erf} (x) = { frac {2} { sqrt { pi}}} operatorname {sgn} (x) { sqrt {1-e ^ {- x ^ {2}}}} left (1 - { frac {1} {12}} left (1 -e ^ {- x ^ {2}} right) - { frac {7} {480}} left (1-e ^ {- x ^ {2}} right) ^ {2} - { frac {5} {896}} left (1-e ^ {- x ^ {2}} right) ^ {3} - { frac {787} {276480}} left (1-e ^ {- x ^ {2 }} right) ^ {4} - cdots right) \ [10pt] = { frac {2} { sqrt { pi}}} operatorname {sgn} (x) { sqrt {1 -e ^ {- x ^ {2}}}} left ({ frac { sqrt { pi}} {2}} + sum _ {k = 1} ^ { infty} c_ {k} e ^ {- kx ^ {2}} right). end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/24ddba05e595a553fee25644a3542188281bd844)
 и c 2 = — 341 8000, { displaystyle c_ {2} = — { frac {341} {8000}},}
и c 2 = — 341 8000, { displaystyle c_ {2} = — { frac {341} {8000}},} результирующая аппроксимация дает наибольшую относительную ошибку при x = ± 1,3796, { displaystyle x = pm 1,3796,}
результирующая аппроксимация дает наибольшую относительную ошибку при x = ± 1,3796, { displaystyle x = pm 1,3796,} , где оно меньше 3,6127 ⋅ 10 — 3 { displaystyle 3.6127 cdot 10 ^ {- 3}}
, где оно меньше 3,6127 ⋅ 10 — 3 { displaystyle 3.6127 cdot 10 ^ {- 3}} :
:
 Обратная функция
Обратная функция  , поэтому истинная обратная функция будет многозначной. Однако для −1 < x < 1, there is a unique real number denoted erf — 1 (x) { displaystyle operatorname {erf} ^ {- 1} (x)}
, поэтому истинная обратная функция будет многозначной. Однако для −1 < x < 1, there is a unique real number denoted erf — 1 (x) { displaystyle operatorname {erf} ^ {- 1} (x)} , удовлетворяющего
, удовлетворяющего



 .
.
 удовлетворяет erfi (erfi — 1 (x)) = x { displaystyle operatorname { erfi} left ( operatorname {erfi} ^ {- 1} (x) right) = x}
удовлетворяет erfi (erfi — 1 (x)) = x { displaystyle operatorname { erfi} left ( operatorname {erfi} ^ {- 1} (x) right) = x} . функция обратной мнимой ошибки определяется как erfi — 1 (x) { displaystyle operatorname {erfi} ^ {- 1} (x)}
. функция обратной мнимой ошибки определяется как erfi — 1 (x) { displaystyle operatorname {erfi} ^ {- 1} (x)} , сходится следующий ряд Маклорена:
, сходится следующий ряд Маклорена:
![{ displaystyle operatorname {erfc} (x) = { frac {e ^ {- x ^ {2}}} {x { sqrt { pi}}}} left [1+ sum _ {n = 1} ^ { infty} (-1) ^ {n} { frac {1 cdot 3 cdot 5 cdots (2n-1)} {(2x ^ {2}) ^ { n}}} right] = { frac {e ^ {-x ^ {2}}} {x { sqrt { pi}}}} sum _ {n = 0} ^ { infty} (- 1) ^ {n} { frac {(2n-1) !!} {(2x ^ {2}) ^ {n}}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7fc8c3aefff3ba787b080c5186dd3aec8ec76ef9)
 имеется
имеется





![{ displaystyle int _ {- infty} ^ { infty} operatorname {erf} left (ax + b right) { frac {1} { sqrt {2 pi sigma ^ {2}}}} e ^ {- { frac {(x- mu) ^ {2}} {2 sigma ^ {2}}}} , dx = operatorname {erf} left [{ frac {a mu + b} { sqrt {1 + 2a ^ {2} sigma ^ {2}}} right], qquad a, b, му, sigma in mathbb {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9b6adc2c661b24b44dc1e3d7e16be70023daacd8)


 обозначает возрастающий факториал, а s (n, k) { displaystyle s (n, k)}
обозначает возрастающий факториал, а s (n, k) { displaystyle s (n, k)} обозначает знаковое число Стирлинга первого рода.
обозначает знаковое число Стирлинга первого рода.

 (максимальная ошибка: 2,5 × 10)
(максимальная ошибка: 2,5 × 10) (максимальная ошибка: 3 × 10)
(максимальная ошибка: 3 × 10) (максимальная ошибка: 1,5 × 10)
(максимальная ошибка: 1,5 × 10)

 , что дает хорошее приближение для всех x ≥ 0. { displaystyle x geq 0.}
, что дает хорошее приближение для всех x ≥ 0. { displaystyle x geq 0.}




 для любого действительного аргумента:
для любого действительного аргумента:


 , определяется как
, определяется как![{ displaystyle { begin {align} operatorname {erfc} (x) = 1- operatorname {erf} (x) \ [5pt ] = { frac {2} { sqrt { pi}}} int _ {x} ^ { infty} e ^ {- t ^ {2}} , dt \ [5pt] = e ^ {- x ^ {2}} operatorname {erfcx} (x), end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8808e6f3ad9aab23f14d55db707a39388d256788)
 , масштабированная дополнительная функция ошибок (которую можно использовать вместо erfc, чтобы избежать арифметического переполнения ). Известна другая форма erfc (x) { displaystyle operatorname {erfc} (x)}
, масштабированная дополнительная функция ошибок (которую можно использовать вместо erfc, чтобы избежать арифметического переполнения ). Известна другая форма erfc (x) { displaystyle operatorname {erfc} (x)} для неотрицательного x { displaystyle x}
для неотрицательного x { displaystyle x}

![{ displaystyle { begin {align} operatorname {erfi} (x) = - i operatorname {erf} (ix) \ [5pt] = { frac {2} { sqrt { pi}}} int _ {0} ^ {x} e ^ {t ^ {2 }} , dt \ [5pt] = { frac {2} { sqrt { pi}}} e ^ {x ^ {2}} D (x), end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4480a8ec17e274a7ad6b8ef25cc76234d48c0433)
 реально, когда x действительно.
реально, когда x действительно.
![{ displaystyle Phi (x) = { frac {1} { sqrt {2 pi}}} int _ {- infty} ^ {x } e ^ { tfrac {-t ^ {2}} {2}} , dt = { frac {1} {2}} left [1+ operatorname {erf} left ({ frac {x } { sqrt {2}}} right) right] = { frac {1} {2}} operatorname {erfc} left (- { frac {x} { sqrt {2}}} справа)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e19dc7206f8b3b571e81153816c478abd91a679e)


 известен как функция нормальной квантиля или функция пробит и может быть выражена в терминах обратная функция ошибок как
известен как функция нормальной квантиля или функция пробит и может быть выражена в терминах обратная функция ошибок как


 — знаковая функция .
— знаковая функция . График обобщенных функций ошибок E n (x):. серая кривая: E 1 (x) = (1 — e) /
График обобщенных функций ошибок E n (x):. серая кривая: E 1 (x) = (1 — e) /  . красная кривая: E 2 (x) = erf (x). зеленая кривая: E 3 (x). синяя кривая: E 4 (x). золотая кривая: E 5 (x).
. красная кривая: E 2 (x) = erf (x). зеленая кривая: E 3 (x). синяя кривая: E 4 (x). золотая кривая: E 5 (x). 



![{ displaystyle { begin {align} operatorname { i ^ {n} erfc} (z) = int _ {z} ^ { infty} operatorname {i ^ {n-1} erfc} ( zeta) , d zeta \ имя оператора {i ^ {0} erfc} (z) = operatorname {erfc} (z) \ operatorname {i ^ {1} erfc} (z) = operatorname {ierfc} (z) = { frac {1} { sqrt { pi}}} e ^ {- z ^ {2}} - z operatorname {erfc} (z) \ operatorname {i ^ {2} erfc} (z) = { frac { 1} {4}} left [ operatorname {erfc} (z) -2z operatorname {ierfc} (z) right] \ конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/66b57abb0a01139b31a14f5a8d651e4aa2e5f4f2)



