
Новогодние праздники — прекрасный повод попрокрастинировать в уютной домашней обстановке и вспомнить дорогие сердцу мемы из 2k17, уходящие навсегда, как совесть Electronic Arts.
Однако даже обильно сдобренная салатами совесть иногда просыпалась и требовала хоть немного взять себя в руки и заняться полезной деятельностью. Поэтому мы совместили приятное с полезным и на примере любимых мемов посмотрели, как можно спарсить себе небольшую базу
данных, попутно обходя всевозможные блокировки, ловушки и ограничения, расставленные сервером на нашем пути. Всех заинтересованных любезно приглашаем под кат.
Машинное обучение, эконометрика, статистика и многие другие науки о данных занимаются поиском закономерностей. Каждый день доблестные аналитики-инквизиторы пытают природу разными методами и вытаскивают из неё сведенья о том, как именно устроен великий процесс порождения данных, создавший нашу вселенную. Испанские инквизиторы в своей повседневной деятельности использовали непосредственно физическое тело своей жертвы. Природа же вездесуща и не имеет однозначного физического облика. Из-за этого профессия современного инквизитора имеет странную специфику — пытки природы происходят через анализ данных, которые надо откуда-то брать. Обычно данные инквизиторам приносят мирные собиратели. Эта статейка призвана немного приоткрыть завесу тайны насчет того, откуда данные берутся и как их можно немножечко пособирать.
Нашим девизом стала знаменитая фраза капитана Джека Воробья: «Бери всё и не отдавай ничего». Иногда для сбора мемов придется использовать довольно бандитские методы. Тем не менее, мы будем оставаться мирными собирателями данных, и ни в коей мере не будем становиться бандитами. Брать мемы мы будем из главного мемохранилища.

1. Вламываемся в мемохранилище
1.1. Что мы хотим получить
Итак, мы хотим распарсить knowyourmeme.com и получить кучу разных переменных:
- Name – название мема,
- Origin_year – год его создания,
- Views – число просмотров,
- About – текстовое описание мема,
- и многие другие
Более того, мы хотим сделать это без вот этого всего:
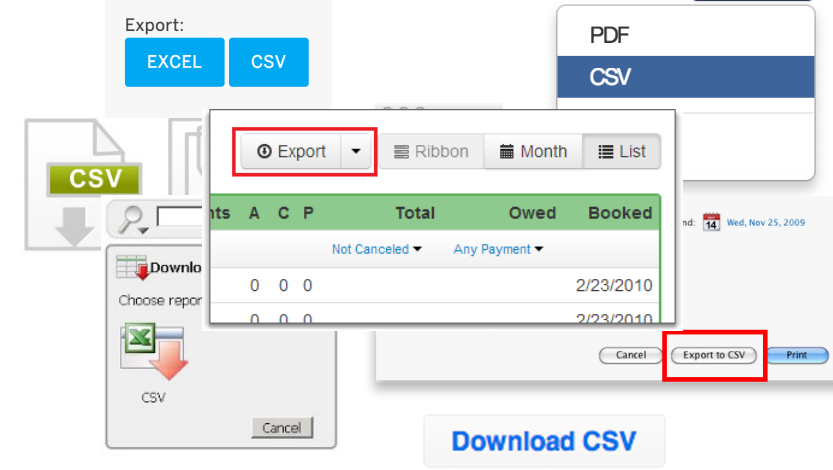
После скачивания и чистки данных от мусора можно будет заняться строительством моделей. Например, попытаться предсказать популярность мема по его параметрам. Но это все позже, а сейчас познакомимся с парой определений:
- Парсер — это скрипт, который грабит информацию с сайта
- Краулер — это часть парсера, которая бродит по ссылкам
- Краулинг — это переход по страницам и ссылкам
- Скрапинг — это сбор данных со страниц
- Парсинг — это сразу и краулинг и скрапинг!
1.2. Что такое HTML
HTML (HyperText Markup Language) — это такой же язык разметки как Markdown или LaTeX. Он является стандартным для написания различных сайтов. Команды в таком языке называются тегами. Если открыть абсолютно любой сайт, нажать на правую кнопку мышки, а после нажать View page source, то перед вами предстанет HTML скелет этого сайта.
Можно увидеть, что HTML-страница это ни что иное как набор вложенных тегов. Можно заметить, например, следующие теги:
<title>– заголовок страницы<h1>…<h6>– заголовки разных уровней<p>– абзац (paragraph)<div>– выделения фрагмента документа с целью изменения вида содержимого<table>– прорисовка таблицы<tr>– разделитель для строк в таблице<td>– разделитель для столбцов в таблице<b>– устанавливает жирное начертание шрифта
Обычно команда <...> открывает тег, а </...> закрывает его. Все, что находится между этими двумя командами, подчиняется правилу, которое диктует тег. Например, все, что находится между <p> и </p> — это отдельный абзац.
Теги образуют своеобразное дерево с корнем в теге <html> и разбивают страницу на разные логические кусочки. У каждого тега могут быть свои потомки (дети) — те теги, которые вложены в него, и свои родители.
Например, HTML-древо страницы может выглядеть вот так:
<html>
<head> Заголовок </head>
<body>
<div>
Первый кусок текста со своими свойствами
</div>
<div>
Второй кусок текста
<b>
Третий, жирный кусок
</b>
</div>
Четвёртый кусок текста
</body>
</html>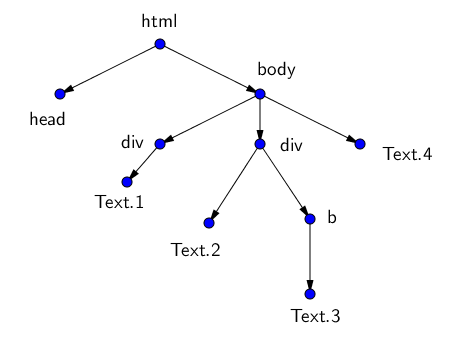
Можно работать с этим html как с текстом, а можно как с деревом. Обход этого дерева и есть парсинг веб-страницы. Мы всего лишь будем находить нужные нам узлы среди всего этого разнообразия и забирать из них информацию!
Вручную обходить эти деревья не очень приятно, поэтому есть специальные языки для обхода деревьев.
- CSS-селектор (это когда мы ищем элемент страницы по паре ключ, значение)
- XPath (это когда мы прописываем путь по дереву вот так: /html/body/div[1]/div[3]/div/div[2]/div)
- Всякие разные библиотеки для всяких разных языков, например, BeautifulSoup для питона. Именно эту библиотеку мы и будем использовать.
1.3. Наш первый запрос
Доступ к веб-станицам позволяет получать модуль requests. Подгрузим его. За компанию подгрузим ещё парочку дельных пакетов.
import requests # Библиотека для отправки запросов
import numpy as np # Библиотека для матриц, векторов и линала
import pandas as pd # Библиотека для табличек
import time # Библиотека для тайм-менеджментаДля наших благородных исследовательских целей нужно собрать данные по каждому мему с соответствующей ему страницы. Но для начала нужно получить адреса этих страниц. Поэтому открываем основную страницу со всеми выложенными мемами. Выглядит она следующим образом:
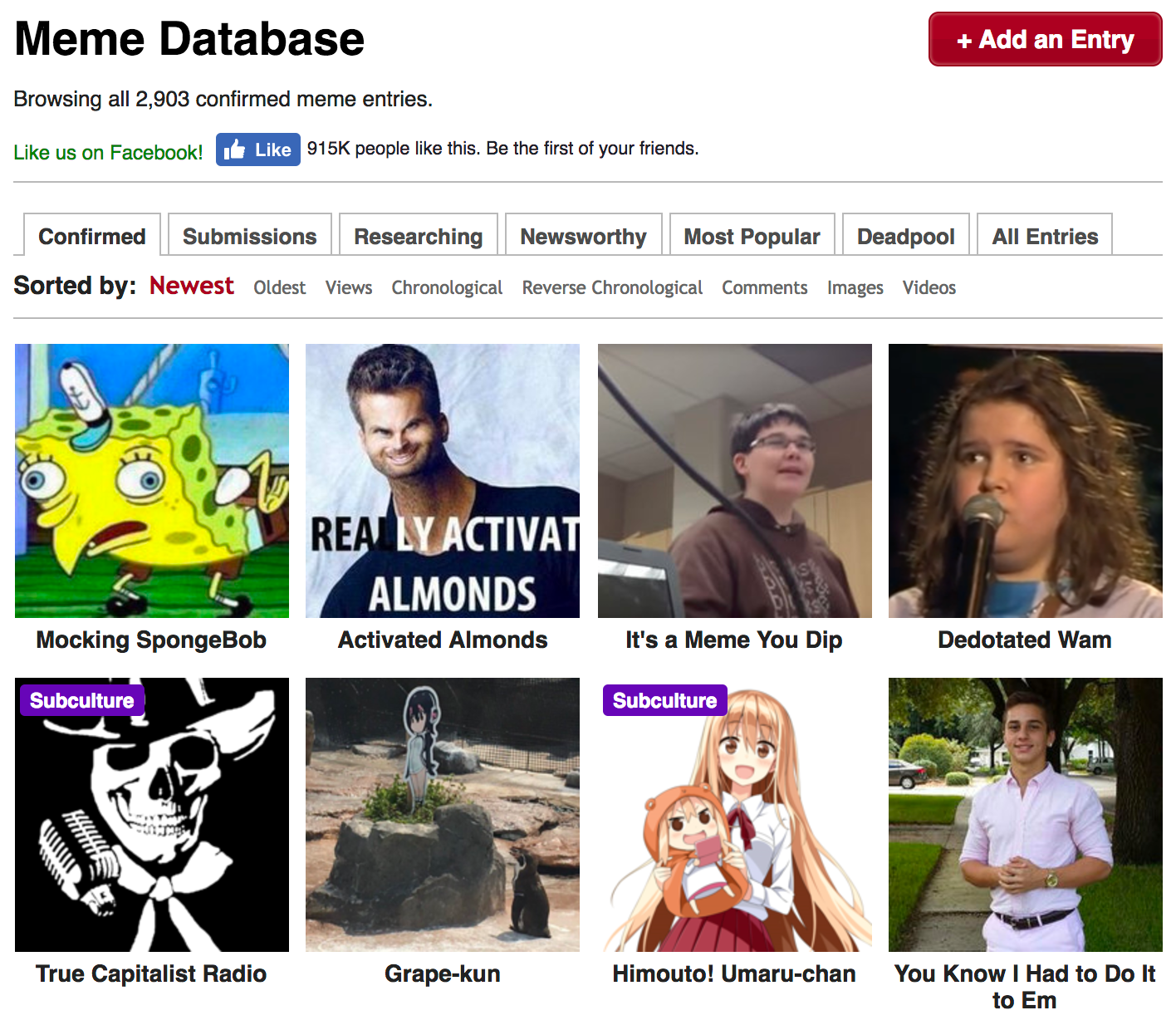
Отсюда мы и будем тащить ссылки на каждый из перечисленных мемов. Сохраним в переменную page_link адрес основной страницы и откроем её при помощи библиотеки requests.
page_link = 'http://knowyourmeme.com/memes/all/page/1'
response = requests.get(page_link)
responseOut: <Response [403]>А вот и первая проблема! Обращаемся к  главному источнику знаний и выясняем, что 403-я ошибка выдается сервером, если он доступен и способен обрабатывать запросы, но по некоторым личным причинам отказывается это делать.
главному источнику знаний и выясняем, что 403-я ошибка выдается сервером, если он доступен и способен обрабатывать запросы, но по некоторым личным причинам отказывается это делать.
Попробуем выяснить, почему. Для этого проверим, как выглядел финальный запрос, отправленный нами на сервер, а конкретнее — как выглядел наш User-Agent в глазах сервера.
for key, value in response.request.headers.items():
print(key+": "+value)Out:
User-Agent: python-requests/2.14.2
Accept-Encoding: gzip, deflate
Accept: */*
Connection: keep-aliveПохоже, мы недвусмысленно дали понять серверу, что мы сидим на питоне и используем библиотеку requests под версией 2.14.2. Скорее всего, это вызвало у сервера некоторые подозрения относительно наших благих намерений и он решил нас безжалостно отвергнуть. Для сравнения, можно посмотреть, как выглядят request-headers у здорового человека:

Очевидно, что нашему скромному запросу не тягаться с таким обилием мета-информации, которое передается при запросе из обычного браузера. К счастью, никто нам не мешает притвориться человечными и пустить пыль в глаза сервера при помощи генерации фейкового юзер-агента. Библиотек, которые справляются с такой задачей, существует очень и очень много, лично мне больше всего нравится fake-useragent. При вызове метода из различных кусочков будет генерироваться рандомное сочетание операционной системы, спецификаций и версии браузера, которые можно передавать в запрос:
# подгрузим один из методов этой библиотеки
from fake_useragent import UserAgent
UserAgent().chromeOut: 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36'Попробуем прогнать наш запрос еще раз, уже со сгенерированным агентом
response = requests.get(page_link, headers={'User-Agent': UserAgent().chrome})
responseOut: <Response [200]>Замечательно, наша небольшая маскировка  сработала и обманутый сервер покорно выдал благословенный 200 ответ — соединение установлено и данные получены, всё чудесно! Посмотрим, что же все-таки мы получили.
сработала и обманутый сервер покорно выдал благословенный 200 ответ — соединение установлено и данные получены, всё чудесно! Посмотрим, что же все-таки мы получили.
html = response.content
html[:1000]Out: b'<!DOCTYPE html>n<html xmlns:fb='http://www.facebook.com/2008/fbml' xmlns='http://www.w3.org/1999/xhtml'>n<head>n<meta content='text/html; charset=utf-8' http-equiv='Content-Type'>n<script type="text/javascript">window.NREUM||(NREUM={});NREUM.info={"beacon":"bam.nr-data.net","errorBeacon":"bam.nr-data.net","licenseKey":"c1a6d52f38","applicationID":"31165848","transactionName":"dFdfRUpeWglTQB8GDUNKWFRLHlcJWg==","queueTime":0,"applicationTime":59,"agent":""}</script>n<script type="text/javascript">window.NREUM||(NREUM={}),__nr_require=function(e,t,n){function r(n){if(!t[n]){var o=t[n]={exports:{}};e[n][0].call(o.exports,function(t){var o=e[n][1][t];return r(o||t)},o,o.exports)}return t[n].exports}if("function"==typeof __nr_require)return __nr_require;for(var o=0;o<n.length;o++)r(n[o]);return r}({1:[function(e,t,n){function r(){}function o(e,t,n){return function(){return i(e,[f.now()].concat(u(arguments)),t?null:this,n),t?void 0:this}}var i=e("handle"),a=e(2),u=e(3),c=e("ee").get("tracer")'Выглядит неудобоваримо, как насчет сварить из этого дела что-то покрасивее? Например, прекрасный суп.
1.4. Прекрасный суп

Пакет bs4, a.k.a BeautifulSoup (тут есть гиперссылка на лучшего друга человека — документацию) был назван в честь стишка про прекрасный суп из Алисы в стране чудес.
Прекрасный суп — это совершенно волшебная библиотека, которая из сырого и необработанного HTML кода страницы выдаст вам структурированный массив данных, по которому очень удобно искать необходимые теги, классы, атрибуты, тексты и прочие элементы веб страниц.
Пакет под названием
BeautifulSoup— скорее всего, не то, что нам нужно. Это третья версия (Beautiful Soup 3), а мы будем использовать четвертую. Нужно будет установить пакетbeautifulsoup4. Чтобы было совсем весело, при импорте нужно указывать другое название пакета —bs4, а импортировать функцию под названиемBeautifulSoup. В общем, сначала легко запутаться, но эти трудности нужно преодолеть.
С необработанным XML кодом страницы пакет также работает (XML — это исковерканый и превращённый в диалект, с помощью своих команд, HTML). Для того, чтобы пакет корректно работал с XML разметкой, придётся в довесок ко всему нашему арсеналу установить пакет xml.
from bs4 import BeautifulSoupПередадим функции BeautifulSoup текст веб-страницы, которую мы недавно получили.
soup = BeautifulSoup(html,'html.parser') # В опции также можно указать lxml,
# если предварительно установить одноименный пакетПолучим что-то вот такое:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>
<script type="text/javascript">window.NREUM||(NREUM={});NREUM.info={"beacon":"bam.nr-data.net","errorBeacon":"bam.nr-data.net","licenseKey":"c1a6d52f38","applicationID":"31165848","transactionName":"dFdfRUpeWglTQB8GDUNKWFRLHkUNWUU=","queueTime":0,"applicationTime":24,"agent":""}</script>
<script type="text/javascript">window.NREUM||(NREUM={}),__nr_require=function(e,n,t){function r(t){if(!n[t]){var o=n[t]={exports:{}};e[t][0].call(o.exports,function(n){var o=e[t][1][n];return r(o||n)},o,o.exports)}return n[t].exports}if("function"==typeof __nr_require)return __nr_require;for(var o=0;o<t.length;o++)r(t[o]);return r}({1:[function(e,n,t){function r(){}function o(e,n,t){return function(){return i(e,[c.now()].concat(u(arguments)),n?null:this,t),n?void 0:this}}var i=e("handle"),a=e(2),u=e(3),f=e("ee").get("tracer"),c=e("loader"),s=NREUM;"undefined"==typeof window.newrelic&&(newrelic=s);var p=Стало намного лучше, не правда ли? Что же лежит в переменной soup? Невнимательный пользователь, скорее всего, скажет, что ничего вообще не изменилось. Тем не менее, это не так. Теперь мы можем свободно бродить по HTML-дереву страницы, искать детей, родителей и вытаскивать их!
Например, можно бродить по вершинам, указывая путь из тегов.
soup.html.head.titleOut: <title>All Entries | Know Your Meme</title>Можно вытащить из того места, куда мы забрели, текст с помощью метода text.
soup.html.head.title.textOut: 'All Entries | Know Your Meme'Более того, зная адрес элемента, мы сразу можем найти его. Например, можно сделать это по классу. Следующая команда должна найти элемент, который лежит внутри тега a и имеет класс photo.
obj = soup.find('a', attrs = {'class':'photo'})
objOut: <a class="photo left" href="/memes/nu-male-smile" target="_self"><img alt='The "Nu-Male Smile" Is Duck Face for Men' data-src="http://i0.kym-cdn.com/featured_items/icons/wide/000/007/585/7a2.jpg" height="112" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title='The "Nu-Male Smile" Is Duck Face for Men' width="198"/> <div class="info abs"> <div class="c"> The "Nu-Male Smile" Is Duck Face for Men </div> </div> </a>Однако даже обильно сдобренная салатами совесть иногда просыпалась и требовала хоть немного взять себя в руки и заняться полезной деятельностью. Поэтому мы совместили приятное с полезным и на примере любимых мемов посмотрели, как можно спарсить себе небольшую базу
данных, попутно обходя всевозможные блокировки, ловушки и ограничения, расставленные сервером на нашем пути. Всех заинтересованных любезно приглашаем под кат.Машинное обучение, эконометрика, статистика и многие другие науки о данных занимаются поиском закономерностей. Каждый день доблестные аналитики-инквизиторы пытают природу разными методами и вытаскивают из неё сведенья о том, как именно устроен великий процесс порождения данных, создавший нашу вселенную. Испанские инквизиторы в своей повседневной деятельности использовали непосредственно физическое тело своей жертвы. Природа же вездесуща и не имеет однозначного физического облика. Из-за этого профессия современного инквизитора имеет странную специфику — пытки природы происходят через анализ данных, которые надо откуда-то брать. Обычно данные инквизиторам приносят мирные собиратели. Эта статейка призвана немного приоткрыть завесу тайны насчет того, откуда данные берутся и как их можно немножечко пособирать.
Нашим девизом стала знаменитая фраза капитана Джека Воробья: «Бери всё и не отдавай ничего». Иногда для сбора мемов придется использовать довольно бандитские методы. Тем не менее, мы будем оставаться мирными собирателями данных, и ни в коей мере не будем становиться бандитами. Брать мемы мы будем из главного мемохранилища.
1. Вламываемся в мемохранилище
1.1. Что мы хотим получить
Итак, мы хотим распарсить knowyourmeme.com и получить кучу разных переменных:
- Name – название мема,
- Origin_year – год его создания,
- Views – число просмотров,
- About – текстовое описание мема,
- и многие другие
Более того, мы хотим сделать это без вот этого всего:
После скачивания и чистки данных от мусора можно будет заняться строительством моделей. Например, попытаться предсказать популярность мема по его параметрам. Но это все позже, а сейчас познакомимся с парой определений:
- Парсер — это скрипт, который грабит информацию с сайта
- Краулер — это часть парсера, которая бродит по ссылкам
- Краулинг — это переход по страницам и ссылкам
- Скрапинг — это сбор данных со страниц
- Парсинг — это сразу и краулинг и скрапинг!
1.2. Что такое HTML
HTML (HyperText Markup Language) — это такой же язык разметки как Markdown или LaTeX. Он является стандартным для написания различных сайтов. Команды в таком языке называются тегами. Если открыть абсолютно любой сайт, нажать на правую кнопку мышки, а после нажать View page source, то перед вами предстанет HTML скелет этого сайта.
Можно увидеть, что HTML-страница это ни что иное как набор вложенных тегов. Можно заметить, например, следующие теги:
<title>– заголовок страницы<h1>…<h6>– заголовки разных уровней<p>– абзац (paragraph)<div>– выделения фрагмента документа с целью изменения вида содержимого<table>– прорисовка таблицы<tr>– разделитель для строк в таблице<td>– разделитель для столбцов в таблице<b>– устанавливает жирное начертание шрифта
Обычно команда <...> открывает тег, а </...> закрывает его. Все, что находится между этими двумя командами, подчиняется правилу, которое диктует тег. Например, все, что находится между <p> и </p> — это отдельный абзац.
Теги образуют своеобразное дерево с корнем в теге <html> и разбивают страницу на разные логические кусочки. У каждого тега могут быть свои потомки (дети) — те теги, которые вложены в него, и свои родители.
Например, HTML-древо страницы может выглядеть вот так:
<html>
<head> Заголовок </head>
<body>
<div>
Первый кусок текста со своими свойствами
</div>
<div>
Второй кусок текста
<b>
Третий, жирный кусок
</b>
</div>
Четвёртый кусок текста
</body>
</html>
Можно работать с этим html как с текстом, а можно как с деревом. Обход этого дерева и есть парсинг веб-страницы. Мы всего лишь будем находить нужные нам узлы среди всего этого разнообразия и забирать из них информацию!
Вручную обходить эти деревья не очень приятно, поэтому есть специальные языки для обхода деревьев.
- CSS-селектор (это когда мы ищем элемент страницы по паре ключ, значение)
- XPath (это когда мы прописываем путь по дереву вот так: /html/body/div[1]/div[3]/div/div[2]/div)
- Всякие разные библиотеки для всяких разных языков, например, BeautifulSoup для питона. Именно эту библиотеку мы и будем использовать.
1.3. Наш первый запрос
Доступ к веб-станицам позволяет получать модуль requests. Подгрузим его. За компанию подгрузим ещё парочку дельных пакетов.
import requests # Библиотека для отправки запросов
import numpy as np # Библиотека для матриц, векторов и линала
import pandas as pd # Библиотека для табличек
import time # Библиотека для тайм-менеджментаДля наших благородных исследовательских целей нужно собрать данные по каждому мему с соответствующей ему страницы. Но для начала нужно получить адреса этих страниц. Поэтому открываем основную страницу со всеми выложенными мемами. Выглядит она следующим образом:
Отсюда мы и будем тащить ссылки на каждый из перечисленных мемов. Сохраним в переменную page_link адрес основной страницы и откроем её при помощи библиотеки requests.
page_link = 'http://knowyourmeme.com/memes/all/page/1'
response = requests.get(page_link)
responseOut: <Response [403]>А вот и первая проблема! Обращаемся к главному источнику знаний и выясняем, что 403-я ошибка выдается сервером, если он доступен и способен обрабатывать запросы, но по некоторым личным причинам отказывается это делать.
Попробуем выяснить, почему. Для этого проверим, как выглядел финальный запрос, отправленный нами на сервер, а конкретнее — как выглядел наш User-Agent в глазах сервера.
for key, value in response.request.headers.items():
print(key+": "+value)Out:
User-Agent: python-requests/2.14.2
Accept-Encoding: gzip, deflate
Accept: */*
Connection: keep-aliveПохоже, мы недвусмысленно дали понять серверу, что мы сидим на питоне и используем библиотеку requests под версией 2.14.2. Скорее всего, это вызвало у сервера некоторые подозрения относительно наших благих намерений и он решил нас безжалостно отвергнуть. Для сравнения, можно посмотреть, как выглядят request-headers у здорового человека:
Очевидно, что нашему скромному запросу не тягаться с таким обилием мета-информации, которое передается при запросе из обычного браузера. К счастью, никто нам не мешает притвориться человечными и пустить пыль в глаза сервера при помощи генерации фейкового юзер-агента. Библиотек, которые справляются с такой задачей, существует очень и очень много, лично мне больше всего нравится fake-useragent. При вызове метода из различных кусочков будет генерироваться рандомное сочетание операционной системы, спецификаций и версии браузера, которые можно передавать в запрос:
# подгрузим один из методов этой библиотеки
from fake_useragent import UserAgent
UserAgent().chromeOut: 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36'Попробуем прогнать наш запрос еще раз, уже со сгенерированным агентом
response = requests.get(page_link, headers={'User-Agent': UserAgent().chrome})
responseOut: <Response [200]>Замечательно, наша небольшая маскировка сработала и обманутый сервер покорно выдал благословенный 200 ответ — соединение установлено и данные получены, всё чудесно! Посмотрим, что же все-таки мы получили.
html = response.content
html[:1000]Out: b'<!DOCTYPE html>n<html xmlns:fb='http://www.facebook.com/2008/fbml' xmlns='http://www.w3.org/1999/xhtml'>n<head>n<meta content='text/html; charset=utf-8' http-equiv='Content-Type'>n<script type="text/javascript">window.NREUM||(NREUM={});NREUM.info={"beacon":"bam.nr-data.net","errorBeacon":"bam.nr-data.net","licenseKey":"c1a6d52f38","applicationID":"31165848","transactionName":"dFdfRUpeWglTQB8GDUNKWFRLHlcJWg==","queueTime":0,"applicationTime":59,"agent":""}</script>n<script type="text/javascript">window.NREUM||(NREUM={}),__nr_require=function(e,t,n){function r(n){if(!t[n]){var o=t[n]={exports:{}};e[n][0].call(o.exports,function(t){var o=e[n][1][t];return r(o||t)},o,o.exports)}return t[n].exports}if("function"==typeof __nr_require)return __nr_require;for(var o=0;o<n.length;o++)r(n[o]);return r}({1:[function(e,t,n){function r(){}function o(e,t,n){return function(){return i(e,[f.now()].concat(u(arguments)),t?null:this,n),t?void 0:this}}var i=e("handle"),a=e(2),u=e(3),c=e("ee").get("tracer")'Выглядит неудобоваримо, как насчет сварить из этого дела что-то покрасивее? Например, прекрасный суп.
1.4. Прекрасный суп
Пакет bs4, a.k.a BeautifulSoup (тут есть гиперссылка на лучшего друга человека — документацию) был назван в честь стишка про прекрасный суп из Алисы в стране чудес.
Прекрасный суп — это совершенно волшебная библиотека, которая из сырого и необработанного HTML кода страницы выдаст вам структурированный массив данных, по которому очень удобно искать необходимые теги, классы, атрибуты, тексты и прочие элементы веб страниц.
Пакет под названием
BeautifulSoup— скорее всего, не то, что нам нужно. Это третья версия (Beautiful Soup 3), а мы будем использовать четвертую. Нужно будет установить пакетbeautifulsoup4. Чтобы было совсем весело, при импорте нужно указывать другое название пакета —bs4, а импортировать функцию под названиемBeautifulSoup. В общем, сначала легко запутаться, но эти трудности нужно преодолеть.
С необработанным XML кодом страницы пакет также работает (XML — это исковерканый и превращённый в диалект, с помощью своих команд, HTML). Для того, чтобы пакет корректно работал с XML разметкой, придётся в довесок ко всему нашему арсеналу установить пакет xml.
from bs4 import BeautifulSoupПередадим функции BeautifulSoup текст веб-страницы, которую мы недавно получили.
soup = BeautifulSoup(html,'html.parser') # В опции также можно указать lxml,
# если предварительно установить одноименный пакетПолучим что-то вот такое:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>
<script type="text/javascript">window.NREUM||(NREUM={});NREUM.info={"beacon":"bam.nr-data.net","errorBeacon":"bam.nr-data.net","licenseKey":"c1a6d52f38","applicationID":"31165848","transactionName":"dFdfRUpeWglTQB8GDUNKWFRLHkUNWUU=","queueTime":0,"applicationTime":24,"agent":""}</script>
<script type="text/javascript">window.NREUM||(NREUM={}),__nr_require=function(e,n,t){function r(t){if(!n[t]){var o=n[t]={exports:{}};e[t][0].call(o.exports,function(n){var o=e[t][1][n];return r(o||n)},o,o.exports)}return n[t].exports}if("function"==typeof __nr_require)return __nr_require;for(var o=0;o<t.length;o++)r(t[o]);return r}({1:[function(e,n,t){function r(){}function o(e,n,t){return function(){return i(e,[c.now()].concat(u(arguments)),n?null:this,t),n?void 0:this}}var i=e("handle"),a=e(2),u=e(3),f=e("ee").get("tracer"),c=e("loader"),s=NREUM;"undefined"==typeof window.newrelic&&(newrelic=s);var p=Стало намного лучше, не правда ли? Что же лежит в переменной soup? Невнимательный пользователь, скорее всего, скажет, что ничего вообще не изменилось. Тем не менее, это не так. Теперь мы можем свободно бродить по HTML-дереву страницы, искать детей, родителей и вытаскивать их!
Например, можно бродить по вершинам, указывая путь из тегов.
soup.html.head.titleOut: <title>All Entries | Know Your Meme</title>Можно вытащить из того места, куда мы забрели, текст с помощью метода text.
soup.html.head.title.textOut: 'All Entries | Know Your Meme'Более того, зная адрес элемента, мы сразу можем найти его. Например, можно сделать это по классу. Следующая команда должна найти элемент, который лежит внутри тега a и имеет класс photo.
obj = soup.find('a', attrs = {'class':'photo'})
objOut: <a class="photo left" href="/memes/nu-male-smile" target="_self"><img alt='The "Nu-Male Smile" Is Duck Face for Men' data-src="http://i0.kym-cdn.com/featured_items/icons/wide/000/007/585/7a2.jpg">Однако, вопреки нашим ожиданиям, вытащенный объект имеет класс "photo left". Оказывается, BeautifulSoup4 расценивает аттрибуты class как набор отдельных значений, поэтому "photo left" для библиотеки равносильно ["photo", "left"], а указанное нами значение этого класса "photo" входит в этот список. Чтобы избежать такой неприятной ситуации и проходов по ненужным нам ссылкам, придется воспользоваться собственной функцией и задать строгое соответствие:
obj = soup.find(lambda tag: tag.name == 'a' and tag.get('class') == ['photo'])
objOut: <a class="photo" href="/memes/people/mf-doom"><img alt="MF DOOM" data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/149/1489698959244.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="MF DOOM"/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> <span class="label" style="background: #d32f2e; color: white;">Person</span> </div> </a>Полученный после поиска объект также обладает структурой bs4. Поэтому можно продолжить искать нужные нам объекты уже в нём! Вытащим ссылку на этот мем. Сделать это можно по атрибуту href, в котором лежит наша ссылка.
obj.attrs['href']Out: '/memes/people/mf-doom'Обратите внимание, что после всех этих безумных преобразований у данных поменялся тип. Теперь они str. Это означет, что с ними можно работать как с текстом и пускать в ход для отсеивания лишней информации регулярные выражения.
print("Тип данных до вытаскивания ссылки:", type(obj))
print("Тип данных после вытаскивания ссылки:", type(obj.attrs['href']))Out:
Тип данных до вытаскивания ссылки: <class 'bs4.element.Tag'>
Тип данных после вытаскивания ссылки: <class 'str'>Если несколько элементов на странице обладают указанным адресом, то метод find вернёт только самый первый. Чтобы найти все элементы с таким адресом, нужно использовать метод findAll, и на выход будет выдан список. Таким образом, мы можем получить одним поиском сразу все объекты, содержащие ссылки на страницы с мемами.
meme_links = soup.findAll(lambda tag: tag.name == 'a' and tag.get('class') == ['photo'])
meme_links[:3]Out: [<a class="photo" href="/memes/people/mf-doom"><img alt="MF DOOM" data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/149/1489698959244.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="MF DOOM"/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> <span class="label" style="background: #d32f2e; color: white;">Person</span> </div> </a>,
<a class="photo" href="/memes/here-lies-beavis-he-never-scored"><img alt="Here Lies Beavis. He Never Scored." data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/148/maxresdefault.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="Here Lies Beavis. He Never Scored."/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> </div> </a>,
<a class="photo" href="/memes/people/vanossgaming"><img alt="VanossGaming" data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/147/Evan-Fong-e1501621844732.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="VanossGaming"/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> <span class="label" style="background: #d32f2e; color: white;">Person</span> </div> </a>]Осталось очистить полученный список от мусора:
meme_links = [link.attrs['href'] for link in meme_links]
meme_links[:10]Out: ['/memes/people/mf-doom',
'/memes/here-lies-beavis-he-never-scored',
'/memes/people/vanossgaming',
'/memes/stream-sniping',
'/memes/kids-describe-god-to-an-illustrator',
'/memes/bad-teacher',
'/memes/people/adam-the-creator',
'/memes/but-can-you-do-this',
'/memes/people/ken-ashcorp',
'/memes/heartbroken-cowboy']Готово, получили ровно 16 ссылок по числу мемов на одной странице поиска.
Хорошо, то, что можно искать элемент по его адресу, конечно же, круто, но откуда взять этот адрес? Можно установить для своего браузера какую-нибудь утилиту, позволяющую вытаскивать со страницы нужные теги, например, selectorgadget.
Тем не менее, этот путь не подходит для истинного самурая. Для последователей бусидо есть другой способ — искать теги для каждого нужного нам элемента вручную. Для этого придётся жать правой кнопкой мышки по окну браузера и тыкать кнопку Inspect. После всех этих манипуляций браузер будет выглядеть как-то вот так:
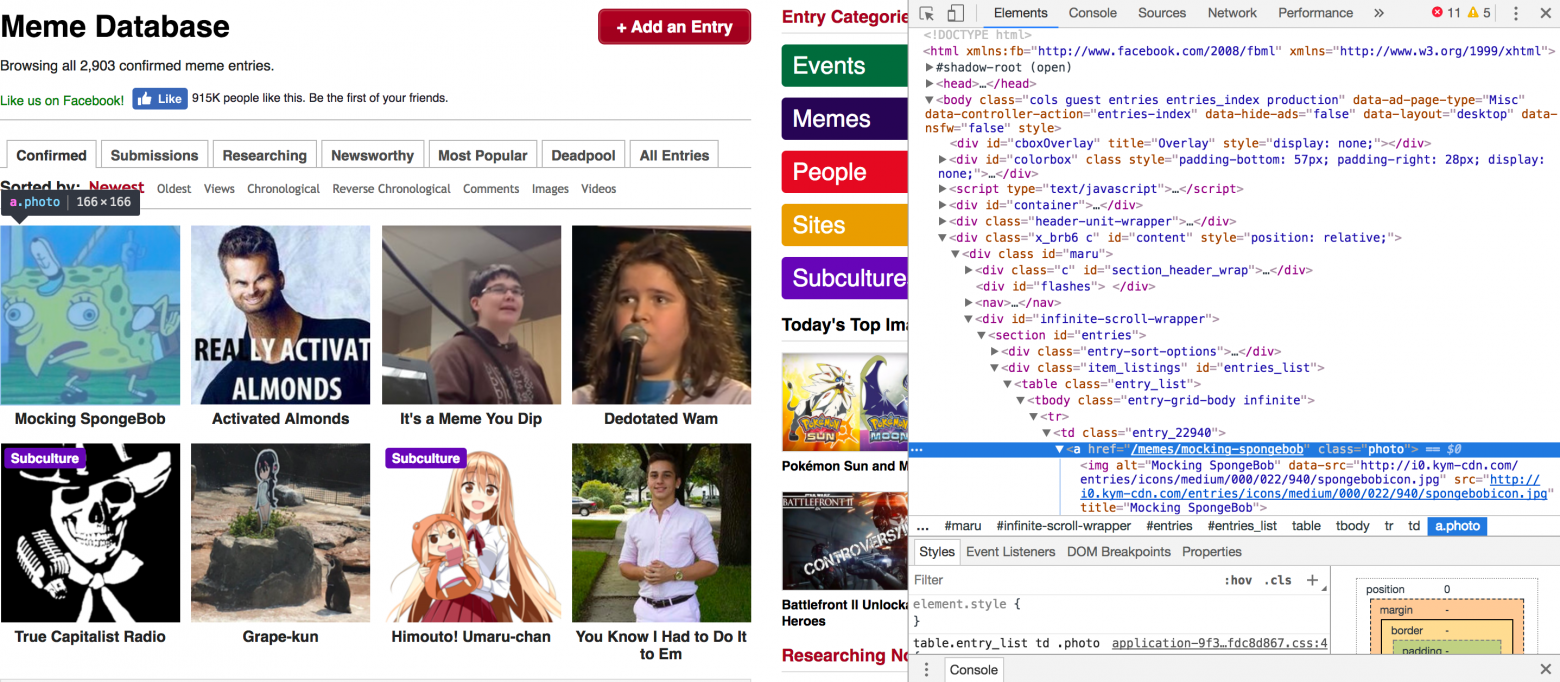
Выскочивший кусок html, в котором находится адрес выбранного вами объекта, можно смело копировать в код и наслаждаться своей брутальностью.
Остался последний момент. Когда мы скачаем все мемы с текущей страницы, нам нужно будет каким-то образом забраться на соседнюю. На сайте это можно делать просто пролистывая страницу с мемами вниз, javascript-функции подтянут новые мемы на текущее окно, но сейчас трогать эти функции не хочется.
Обычно, все параметры, которые мы устанавливаем на сайте для поиска, отображаются на структуре хрефа. Мемы не являются исключением. Если мы хотим получить первую порцию мемов, мы должны будем обратиться к сайту по ссылке
http://knowyourmeme.com/memes/all/page/1
Если мы захотим получить вторую поцию с шестнадцатью мемами, нам придётся немного видоизменить ссылку, а именно заменить номер страницы на 2.
http://knowyourmeme.com/memes/all/page/2
Таким незатейливым образом мы сможем пройтись по всем страницам и ограбить мемохранилище. Наконец, обернем в красивую функцию все-все манипуляции, проделанные выше:
Функция для скачивания ссылок на мемы
def getPageLinks(page_number):
"""
Возвращает список ссылок на мемы, полученный с текущей страницы
page_number: int/string
номер страницы для парсинга
"""
# составляем ссылку на страницу поиска
page_link = 'http://knowyourmeme.com/memes/all/page/{}'.format(page_number)
# запрашиваем данные по ней
response = requests.get(page_link, headers={'User-Agent': UserAgent().chrome})
if not response.ok:
# если сервер нам отказал, вернем пустой лист для текущей страницы
return []
# получаем содержимое страницы и переводим в суп
html = response.content
soup = BeautifulSoup(html,'html.parser')
# наконец, ищем ссылки на мемы и очищаем их от ненужных тэгов
meme_links = soup.findAll(lambda tag: tag.name == 'a' and tag.get('class') == ['photo'])
meme_links = ['http://knowyourmeme.com' + link.attrs['href'] for link in meme_links]
return meme_linksПротестируем функцию и убедимся, что всё хорошо
meme_links = getPageLinks(1)
meme_links[:2]Out: ['http://knowyourmeme.com/memes/people/mf-doom',
'http://knowyourmeme.com/memes/here-lies-beavis-he-never-scored']Отлично, функция работает и теперь мы теоретически можем достать ссылки на все 17171 мем, для чего нам придется пройтись по 17171/16 ~ 1074 страницам. Прежде чем расстраивать сервер таким количеством запросов, посмотрим, как доставать всю необходимую информацию о конкретном меме.
1.5 Финальная подготовка к грабежу
По аналогии со ссылками можно вытащить что угодно. Для этого надо сделать несколько шагов:
- Открываем страничку с мемом
- Находим любым способом тег для нужной нам информации
- Пихаем всё это в прекрасный суп
- ……
- Profit
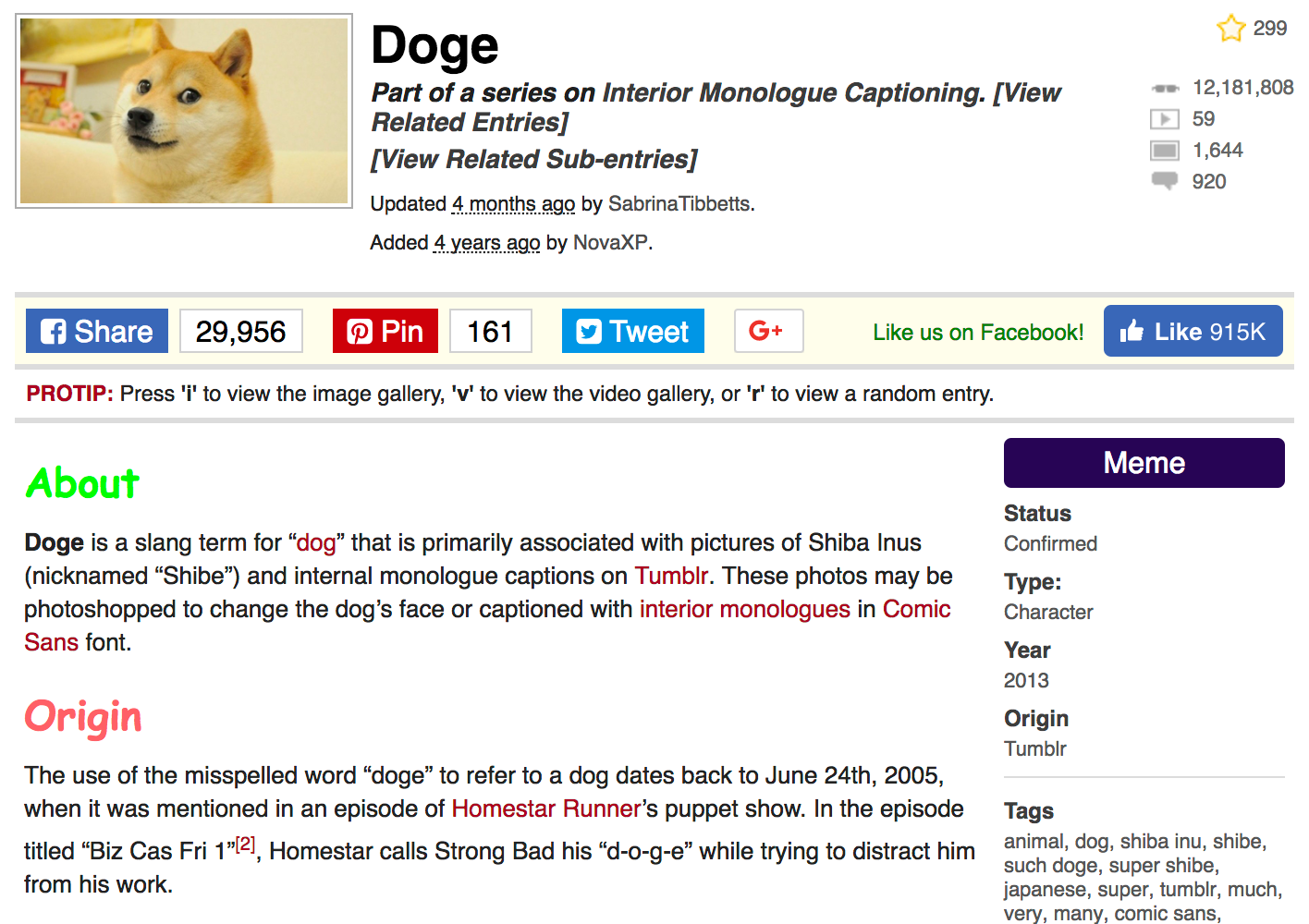
Для закрепления информации в голове любознательного читателя, вытащим число просмотров мема.
А в качестве примера возьмем самый популярный на этом сайте мем — Doge, набравший более 12 миллионов просмотров по состоянию на 1 января 2018 года.
Сама страница, с которой мы будем доставать дорогую нашему исследовательскому сердцу информацию выглядит следуюшим образом:
Как и прежде, для начала сохраним ссылку на страницу в переменную и вытащим по ней контент.
meme_page = 'http://knowyourmeme.com/memes/doge'
response = requests.get(meme_page, headers={'User-Agent': UserAgent().chrome})
html = response.content
soup = BeautifulSoup(html,'html.parser')Посмотрим, как можно вытащить статистику просмотров, комментариев, а также числа загруженных видео и фото, связанных с нашим мемов. Всё это добро хранится справа вверху под тэгами "dd" и с классами "views", "videos", "photos" и "comments"
views = soup.find('dd', attrs={'class':'views'})
print(views)Out:
<dd class="views" title="12,318,185 Views">
<a href="/memes/doge" rel="nofollow">12,318,185</a>
</dd>Очистим от тэгов и пунктуации
views = views.find('a').text
views = int(views.replace(',', ''))
print(views)Out:
12318185Снова запихнём всё это в небольшую функцию.
Функция, возвращающая статистику по мему
def getStats(soup, stats):
"""
Возвращает очищенное число просмотров/коментариев/...
soup: объект bs4.BeautifulSoup
суп текущей страницы
stats: string
views/videos/photos/comments
"""
obj = soup.find('dd', attrs={'class':stats})
obj = obj.find('a').text
obj = int(obj.replace(',', ''))
return objВсё готово!
views = getStats(soup, stats='views')
videos = getStats(soup, stats='videos')
photos = getStats(soup, stats='photos')
comments = getStats(soup, stats='comments')
print("Просмотры: {}nВидео: {}nФото: {}nКомментарии: {}".format(views, videos, photos, comments))Out:
Просмотры: 12318185
Видео: 59
Фото: 1645
Комментарии: 918Еще из интересного и исследовательского — достанем дату и время добавления мема. Если посмотреть на страницу в браузере, можно подумать, что максимум информации, который мы можем вытащить — это число лет, прошедших с момента публикации — Added 4 years ago by NovaXP. Однако мы так просто сдаваться не будем, полезем в кишки html и откопаем там кусок, ответственный за эту надпись:
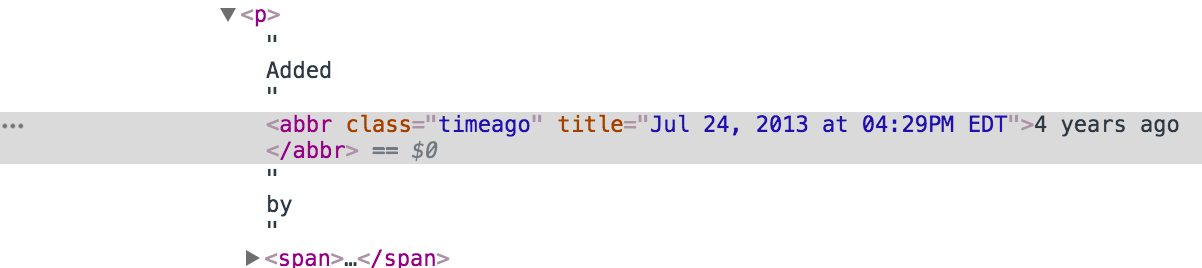
Ага! Вот и подробности по дате добавления, с точностью до минуты. Элементарно

date = soup.find('abbr', attrs={'class':'timeago'}).attrs['title']
dateOut: '2017-12-31T01:59:14-05:00'На самом деле, парсеры — дело непредсказуемое. Часто страницы, которые мы парсим, имеют очень неоднородну структуру. Например, если мы парсим мемы, на части страниц может быть указано описание, а на части нет. Как только код впервые натыкается на отсутствие описания, он выдаёт ошибку и останавливается. Чтобы нормально собрать все данные, приходится прописывать исключения. Вроде бы, хранилище мемов хорошо оборудовано и никаких внештатных ситуаций происходить не должно.
Тем не менее, очень не хочется проснуться утром и увидеть, что код сделал 20 итераций, нарвался на ошибку и отрубился. Чтобы такого не произошло, можно, например, использовать конструкцию try - except и просто обрабатывать неугодные нам ошибки. Про исключения можно почитать на просторах интернета. В нашем же случае до ошибки можно и не доводить, а предварительно проверять, есть ли необходимый элемент на странице или нет при помощи обычного if - else, и уже после этого пытаться его распарсить.
Например, мы хотим вытащить статус мема, для этого найдем окружающие его тэги:
properties = soup.find('aside', attrs={'class':'left'})
meme_status = properties.find("dd")
meme_statusOut:
<dd>
Confirmed
</dd>Дальше нужно вытащить из тэгов текст, а после обрубить все лишние пробелы.
meme_status.text.strip()Out: 'Confirmed'Однако, если неожиданно выяснится, что у мема нет статуса, метод find вернёт пустоту. Метод text, в свою очередь, не сможет найти в тэгах текст и выдаст ошибку. Чтобы обезопасить себя от таких пустот, можно прописать исключение или if - else. Так как в текущем меме статус все-таки есть, нарочно зададим его как пустой объект, чтобы проверить, что ошибка поймается в обоих случаях
# Делай раз! Ищем статус мема, но не находим его
meme_status = None
# Делай два! Пытаемся вытащить его...
# ... с исключениями
try:
print(meme_status.text.strip())
# Ежели возникает ошибка, статус не найден, выдаём пустоту.
except:
print("Exception")
# ... с проверкой на пустой элемент
if meme_status:
print(meme_status.text.strip())
else:
print("Empty")Out:
Exception
EmptyТакой код позволяет обезопасить себя от ошибок. В данном случае, мы можем переписать всю конструкцию с if - else в виде одной удобной строки. Эта строка проверит, полон ли респонса meme_status и ежели нет, то выдаст пустоту.
# снова найдем настоящий статус
properties = soup.find('aside', attrs={'class':'left'})
meme_status = properties.find("dd")
meme_status = "" if not meme_status else meme_status.text.strip()
print(meme_status)Out: ConfirmedПо аналогии можно вытащить всю остальную информацию со страницы, для чего вновь напишем функцию
Функция для парсинга свойств мема
def getProperties(soup):
"""
Возвращает список (tuple) с названием, статусом, типом,
годом и местом происхождения и тэгами
soup: объект bs4.BeautifulSoup
суп текущей страницы
"""
# название - идёт с самым большим заголовком h1, легко найти
meme_name = soup.find('section', attrs={'class':'info'}).find('h1').text.strip()
# достаём все данные справа от картинки
properties = soup.find('aside', attrs={'class':'left'})
# статус идет первым - можно не уточнять класс
meme_status = properties.find("dd")
# oneliner, заменяющий try-except: если тэга нет в properties, вернётся объект NoneType,
# у которого аттрибут text отсутствует, и в этом случае он заменится на пустую строку
meme_status = "" if not meme_status else meme_status.text.strip()
# тип мема - обладает уникальным классом
meme_type = properties.find('a', attrs={'class':'entry-type-link'})
meme_type = "" if not meme_type else meme_type.text
# год происхождения первоисточника можно найти после заголовка Year,
# находим заголовок, определяем родителя и ищем следущего ребенка - наш раздел
meme_origin_year = properties.find(text='nYearn')
meme_origin_year = "" if not meme_origin_year else meme_origin_year.parent.find_next()
meme_origin_year = meme_origin_year.text.strip()
# сам первоисточник
meme_origin_place = properties.find('dd', attrs={'class':'entry_origin_link'})
meme_origin_place = "" if not meme_origin_place else meme_origin_place.text.strip()
# тэги, связанные с мемом
meme_tags = properties.find('dl', attrs={'id':'entry_tags'}).find('dd')
meme_tags = "" if not meme_tags else meme_tags.text.strip()
return meme_name, meme_status, meme_type, meme_origin_year, meme_origin_place, meme_tagsgetProperties(soup)Out:
('Doge',
'Confirmed',
'Animal',
'2013',
'Tumblr',
'animal, dog, shiba inu, shibe, such doge, super shibe, japanese, super, tumblr, much, very, many, comic sans, photoshop meme, such, shiba, shibe doge, doges, dogges, reddit, comic sans ms, tumblr meme, hacked, bitcoin, dogecoin, shitposting, stare, canine')Свойства мема собрали. Теперь собираем по аналогии его текстовое описание.
Функция для парсинга текстового описания мема
def getText(soup):
"""
Возвращает текстовые описания мема
soup: объект bs4.BeautifulSoup
суп текущей страницы
"""
# достаём все тексты под картинкой
body = soup.find('section', attrs={'class':'bodycopy'})
# раздел about (если он есть), должен идти первым, берем его без уточнения класса
meme_about = body.find('p')
meme_about = "" if not meme_about else meme_about.text
# раздел origin можно найти после заголовка Origin или History,
# находим заголовок, определяем родителя и ищем следущего ребенка - наш раздел
meme_origin = body.find(text='Origin') or body.find(text='History')
meme_origin = "" if not meme_origin else meme_origin.parent.find_next().text
# весь остальной текст (если он есть) можно запихнуть в одно текстовое поле
if body.text:
other_text = body.text.strip().split('n')[4:]
other_text = " ".join(other_text).strip()
else:
other_text = ""
return meme_about, meme_origin, other_textmeme_about, meme_origin, other_text = getText(soup)
print("О чем мем:n{}nnПроисхождение:n{}nnОстальной текст:n{}...n"
.format(meme_about, meme_origin, other_text[:200]))Out:
О чем мем:
Doge is a slang term for “dog” that is primarily associated with pictures of Shiba Inus (nicknamed “Shibe”) and internal monologue captions on Tumblr. These photos may be photoshopped to change the dog’s face or captioned with interior monologues in Comic Sans font.
Происхождение:
The use of the misspelled word “doge” to refer to a dog dates back to June 24th, 2005, when it was mentioned in an episode of Homestar Runner’s puppet show. In the episode titled “Biz Cas Fri 1”[2], Homestar calls Strong Bad his “d-o-g-e” while trying to distract him from his work.
Остальной текст:
Identity On February 23rd, 2010, Japanese kindergarten teacher Atsuko Sato posted several photos of her rescue-adopted Shiba Inu dog Kabosu to her personal blog.[38] Among the photos included a peculi...Наконец, создадим функцию, возвращающую всю информацию по текущему мему
Функция, возвращающая все данные по мему
def getMemeData(meme_page):
"""
Запрашивает данные по странице, возвращает обработанный словарь с данными
meme_page: string
ссылка на страницу с мемом
"""
# запрашиваем данные по ссылке
response = requests.get(meme_page, headers={'User-Agent': UserAgent().chrome})
if not response.ok:
# если сервер нам отказал, вернем статус ошибки
return response.status_code
# получаем содержимое страницы и переводим в суп
html = response.content
soup = BeautifulSoup(html,'html.parser')
# используя ранее написанные функции парсим информацию
views = getStats(soup=soup, stats='views')
videos = getStats(soup=soup, stats='videos')
photos = getStats(soup=soup, stats='photos')
comments = getStats(soup=soup, stats='comments')
# дата
date = soup.find('abbr', attrs={'class':'timeago'}).attrs['title']
# имя, статус, и т.д.
meme_name, meme_status, meme_type, meme_origin_year, meme_origin_place, meme_tags =
getProperties(soup=soup)
# текстовые поля
meme_about, meme_origin, other_text = getText(soup=soup)
# составляем словарь, в котором будут хранится все полученные и обработанные данные
data_row = {"name":meme_name, "status":meme_status,
"type":meme_type, "origin_year":meme_origin_year,
"origin_place":meme_origin_place,
"date_added":date, "views":views,
"videos":videos, "photos":photos, "comments":comments, "tags":meme_tags,
"about":meme_about, "origin":meme_origin, "other_text":other_text}
return data_rowА теперь подготовим табличку, чтобы в неё записывать всё награбленные честно полученные данные, добавим в неё первую полученную строку и полюбуемся на результат
final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place',
'date_added', 'views', 'videos', 'photos', 'comments',
'tags', 'about', 'origin', 'other_text'])
data_row = getMemeData('http://knowyourmeme.com/memes/doge')
final_df = final_df.append(data_row, ignore_index=True)
final_dfOut:| name | status | type | origin_year | … |
|---|---|---|---|---|
| Doge | Confirmed | Animal | 2013 | … |
Первый мем оказался в наших рукак. Еще раз убедимся что всё работает — пройдемся по списку из ссылок на мемы, полученных ранее в перменной meme_links.
for meme_link in meme_links:
data_row = getMemeData(meme_link)
final_df = final_df.append(data_row, ignore_index=True)Out:| name | status | type | origin_year | … |
|---|---|---|---|---|
| Doge | Confirmed | Animal | 2013 | … |
| Charles C. Johnson | Submission | Activist | 2013 | … |
| Bat- (Prefix) | Submission | Snowclone | 2018 | … |
| The Eric Andre Show | Deadpool | TV Show | 2012 | … |
| Hopsin | Submission | Musician | 2003 | … |
Отлично! Всё работает, мемы качаются, данные наполняются и всё было бы хорошо, если бы не одно но — количество запросов, которое нам придётся сделать, чтобы всё получить.
2. Прячемся от стражников
2.1 Когда работающий код больше не работает
Вот он! Тот самый момент абсолютного триумфа, когда код дописан и всё, что нам, мирным собирателям, остаётся — запустить наш код на одну ночку. Кажется, что через страсть мы преобрели силу. Запускаем наш код по всем  страницам с мемами. На всякий случай обернём наш цикл в
страницам с мемами. На всякий случай обернём наш цикл в try-except. Мало ли что там с этими мемами бывает.
Цикл на ночь
# Немного красивых циклов. При желании пакет можно отключить и
# удалить команду tqdm_notebook из всех циклов
from tqdm import tqdm_notebook
final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place',
'date_added', 'views', 'videos', 'photos', 'comments',
'tags', 'about', 'origin', 'other_text'])
for page_number in tqdm_notebook(range(1075), desc='Pages'):
# собрали хрефы с текущей страницы
meme_links = getPageLinks(page_number)
for meme_link in tqdm_notebook(meme_links, desc='Memes', leave=False):
# иногда с первого раза страничка не парсится
for i in range(5):
try:
# пытаемся собрать по мему немного даты
data_row = getMemeData(meme_link)
# и закидываем её в таблицу
final_df = final_df.append(data_row, ignore_index=True)
# если всё получилось - выходим из внутреннего цикла
break
except:
# Иначе, пробуем еще несколько раз, пока не закончатся попытки
print('AHTUNG! parsing once again:', meme_link)
continueСон был прекрасным! Солнце только-только взошло из-за горизонта, мы уже бежим за компьютер смотреть мемы и видим, что огромное число мемов не скачалось.

Конечно же, вполне естественной реакцией будет нажать на первую же ссылку, перейти в мемохранилище и увидеть, что нас забанили. Все наши реквесты остались без респонсов.
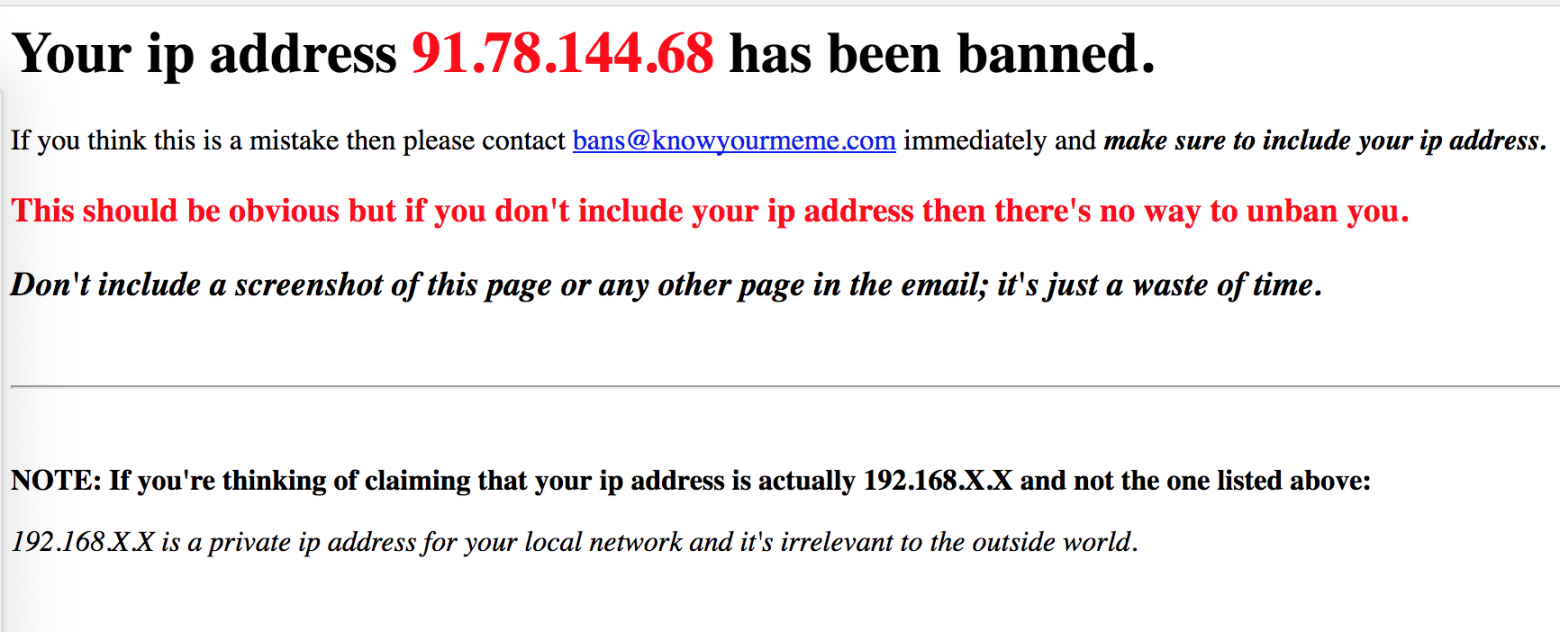
2.2 Тор — сын Одина
Иногда серверу надоедает общаться с одним и тем же человеком, делающим кучу запросов и сервер банит его. К сожалению, не только у людей запас терпения ограничен.
Приходится маскироваться. Для такой маскировки можно использовать разные способы, более того, один из них мы уже использовали, когда притворились человеком в нашем request-header. Для текущей же задачи, когда нас вероломно заблокировали по IP, нужно искать способы помощнее, чтобы иметь возможность этот IP менять. Конечно, как вариант можно было бы использовать прокси-сервера, тогда мы бы имели в запасе некоторое количество разных IP адресов, которые можно подставлять по мере «забанивания». Однако в этом подходе есть пара проблем: первая — нужно где-то раздобыть эти прокси, вторая — а что если ограниченного числа адресов нам не хватит и нужно больше?
В таком случае лучше всего нам подойдёт Tor. Вопреки пропагандируемому мнению, Tor используется не только преступниками, педофилами и прочими нехорошими террористами. Это, мягко говоря, далеко не так, и мы, мирные собиратели данных, являемся тому подтверждением. Всем прелестям, связанным с работой Tor, можно было бы посвятить несколько больших статеек, что собственно говоря уже и сделано. Подробнее про это можно почитатать по следующим ссылкам:
- Как работает Tor
- Методы анонимности в сети
- Прокси-сервер с помощью Tor
Мы же ограничимся только функциональной частью, а именно без углубления в детали опишем шаги, которые нужно предпринять для того, чтобы использовать возможности Tor для обхода блокировки. Для начала полюбуемся на свой ip-адрес. Для этого сделаем get-запрос к сайту, который возвращяет наш IP
def checkIP():
ip = requests.get('http://checkip.dyndns.org').content
soup = BeautifulSoup(ip, 'html.parser')
print(soup.find('body').text)
checkIP()Out: Current IP Address: 82.198.191.130Заменить свой ip через Tor можно двумя путями. Простой — через браузер, а сложный — через небольшие махинации с настройками.
Скачаем браузерный tor, чтобы лёгкий путь был совсем прост. Для сложного пути в довесок к браузеру поставим tor через консоль.
- Linux — нам поможет команда
apt-get install tor, - Mac — сделаем это в рамках brew,
brew install tor. - Windows — нам поможет установка другой операционной системы.
2.3 Путь первый
Теперь запускаем свежескачанный браузер и оставляем его открытым. Менять ip нам поможет библиотека PySocks. Конечно же, её нужно установить, скопировав в терминал pip3 install PySocks.
Браузер тора по умолчанию использует порт номер 9150. В питоне при помощи библиотек socks и socket можно задать дефолтный порт для подключения. В результате текущая сессия будет использовать именно этот порт при отправке любого запроса, а значит – запросы будут посылаться из-под запущенного тора.
import socks
import socket
socks.set_default_proxy(socks.SOCKS5, "localhost", 9150)
socket.socket = socks.socksocketПосмотрим на свой новый ip-aдрес.
checkIP()Out: Current IP Address: 51.15.92.24При сопутствующем желании, можно выяснить из какой страны в данный момент мы сидим в интернете.
Ого… бывший член Европейского союза!
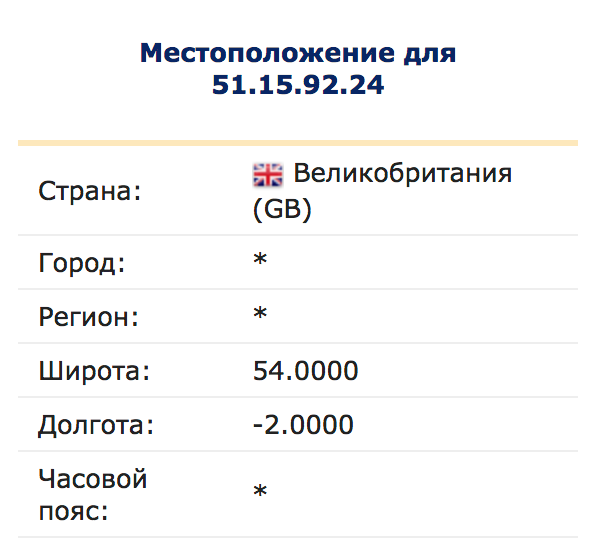
Попробуем обратиться к мемохранилищу с нового ip-адреса.
data_row = getMemeData('http://knowyourmeme.com/memes/doge')
for key, value in data_row.items():
print(key.capitalize()+":", str(value)[:200], end='nn')Out:
Name: Doge
Status: Confirmed
Type: Animal
Origin_year: 2013
Origin_place: Tumblr
Date_added: 2017-12-31T01:59:14-05:00
Views: 12318185
Videos: 59
Photos: 1645
Comments: 918
Tags: animal, dog, shiba inu, shibe, such doge, super shibe, japanese, super, tumblr, much, very, many, comic sans, photoshop meme, such, shiba, shibe doge, doges, dogges, reddit, comic sans ms, tumblr meme
About: Doge is a slang term for “dog” that is primarily associated with pictures of Shiba Inus (nicknamed “Shibe”) and internal monologue captions on Tumblr...Бан снят. Стражники мемов ничего не заподозрили и пустили нас в сокровищницу. Чашу нашего респонса снова переполняет контент. Через силу мы обрели мощь.
При желании, можно выяснить одну занимательную вещь: при базовых настройках, Тор-браузер меняет ip каждые 10 минут. Но что делать, если сервер банит нас быстрее? Всё просто, в папке, куда был установлен Tor найдём файлик с настройками под названием torrc (на маке он лежит по адресу ~/Library/Application Support/TorBrowser-Data/torrc, если не получится найти — добро пожаловать сюда) и отредактируем его. Добавим строки:
CircuitBuildTimeout 10
LearnCircuitBuildTimeout 0
MaxCircuitDirtiness 10Минимально возможный период для обновления ip составляет 10 секунд. Установим туда эту цифру и попробуем поиграться.
for i in range(10):
checkIP()
time.sleep(5)Out:
Current IP Address: 89.31.57.5
Current IP Address: 93.174.93.71
Current IP Address: 62.210.207.52
Current IP Address: 209.141.43.42
Current IP Address: 209.141.43.42
Current IP Address: 162.247.72.216
Current IP Address: 185.220.101.17
Current IP Address: 193.171.202.150
Current IP Address: 128.31.0.13
Current IP Address: 185.163.1.11Действительно, смена ip происходит примерно раз в 10 секунд. Для наших целей по скачке мемов было достаточно и базовых настроек. Бан наступал примерно через 20 минут после начала работы кода.
- Открываем браузер;
- Запускаем кусок кода с подгрузкой библиотек;
- Запускаем цикл по мемам
- …..
- Profit
Еще один цикл на ночь
final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place',
'date_added', 'views', 'videos', 'photos', 'comments',
'tags', 'about', 'origin', 'other_text'])
for page_number in tqdm_notebook(range(1075), desc='Pages'):
# собрали хрефы с текущей страницы
meme_links = getPageLinks(page_number)
for meme_link in tqdm_notebook(meme_links, desc='Memes', leave=False):
# иногда с первого раза страничка не парсится
for i in range(5):
try:
# пытаемся собрать по мему немного даты
data_row = getMemeData(meme_link)
# и закидываем её в таблицу
final_df = final_df.append(data_row, ignore_index=True)
# если всё получилось - выходим из внутреннего цикла
break
except:
# Иначе, пробуем еще несколько раз, пока не закончатся попытки
continue
final_df.to_csv('MEMES.csv')Все мемы в наших руках. Можно приступать к варке фичей и моделированию. Через мощь мы познали победу. Остался только один вопрос: Что, если мы хотим менять ip каждый реквест?
2.4 Путь второй
Второй путь помогает извращаться со сменой ip как угодно. Зайдём на Github каких-то ребят и скачаем себе их скрипт под названием TorCrawler.py. Все недостающие библиотеки, используемые в этом скрипте, придётся доставить. Поставим парням на репозиторий за их код звёздочку. Закинем этот скрипт либо в папку со своими библиотеками либо в папку к этому блокноту. Обратите внимание, что скрипт работает только с третьим питоном.
Перед использованием библиотечки, нужно подкрутить настройки в torrc файлике. На маке он будет лежать в папке /usr/local/etc/tor/, на линуксе в папке /etc/tor/. Проследуем по инструкции авторов скрипта.
- Генерируем в консоли пароль
tor --hash-password mypassword - Открываем torrc файл в редакторе вроде vim, nano или atom
- Сохраняем пароль в наш torrc-файл в строку, которая начинается с HashedControlPassword
- Раскоментируем строку, начинающуюся с HashedControlPassword
- Раскоментируем (если она закоментирована) строку ControlPort 9051
- Сохраним изменения.
Запускаем tor в терминале. Линукс: service tor start, мак: tor.
Теперь мы готовы парсить.
from TorCrawler import TorCrawler
# Создаём свой краулер, в опциях вводим пароль
crawler = TorCrawler(ctrl_pass='mypassword') Мы можем сделать get-запрос по аналогии с тем как делали раньше, причем ответ получим сразу в формате bs4.
meme_page = 'http://knowyourmeme.com/memes/doge'
response = crawler.get(meme_page, headers={'User-Agent': UserAgent().chrome})
type(response)Out: bs4.BeautifulSoupНаходим внутри что-нибудь нужное.
views = response.find('dd', attrs={'class':'views'})
viewsOut:
<dd class="views" title="12,318,185 Views">
<a href="/memes/doge" rel="nofollow">12,318,185</a>
</dd>Проверим IP адрес краулера
crawler.ipOut: '51.15.40.23'По дефолту краулер меняет ip каждые 25 запросов. За это отвечает параметр n_requests. При создании нового краулера, его можно настроить по собственному желанию.
crawler.n_requestsOut: 25Более того, ip можно при желании поменять вручную.
crawler.rotate()IP successfully rotated. New IP: 62.176.4.1Теперь весь код для парсинга можно перевести на рельсы этого небольшого скрипта, заменив все реквесты на торовские, и менять IP адрес с каждым новым запросом. На бедный сервер внезапно обрушится огромное число запросов из всех уголков света.
Победа порвала наши оковы. Великая Сила освободила нас.
Заключение
Напоследок, хотелось бы сказать пару слов о парсинге вообще и при помощи Тора в частности. Добывать себе данные — это стильно, модно и в принципе интересно, можно получить датасеты, которых еще никто никогда не обрабатывал, сделать что-то новое, посмотреть, наконец, на все мемы мира сразу. Однако не стоит забывать, что ограничения, введенные сервером, в том числе баны, появились не просто так, а в целях защиты сайта от недоброжелательных ковровых бомбардировок запросами и DDoS-атак. К чужому труду стоит относится с уважением, и даже если у сервера никакой защиты нет, — это еще не повод неограниченно забрасывать его реквестами, особенно если это может привести к его отключению — уголовное наказание никто не отменял.
К тому же Тор — это всё-таки не первое решение, к которому стоит прибегать в случае проблем с парсингом. Иногда достаточно будет просто поставить в нужных местах time.sleep() и заполнить request-header информацией об операционной системе — в большинстве случаев этого должно быть достаточно для аккуратного сбора интересующей вас информации.
Успешных и безопасных вам исследований и да прибудет с вами Сила!
Авторы: Ульянкин Филипп filfonul, Сергеев Дмитрий Skolopendriy
Почиташки
- Годная книга про парсинг на английском языке.
- Неплохая инструкция о самостоятельном парсинге через Tor без использования чужих готовых классов.
- Димин репозиторий с собранным датасетом из более чем 16k мемов, а также с их исследованием и ноутбуком с парсером.
- Филин репозиторий с ещё парой хорошо расписаных блокнотов с парсерами. Репозиторий изначально делался как страничка факультатива для студентов.
- Оригинальный кодекс адепта тёмной стороны силы.
I was trying to scrape a website for practice, but I kept on getting the HTTP Error 403 (does it think I’m a bot)?
Here is my code:
#import requests
import urllib.request
from bs4 import BeautifulSoup
#from urllib import urlopen
import re
webpage = urllib.request.urlopen('http://www.cmegroup.com/trading/products/#sortField=oi&sortAsc=false&venues=3&page=1&cleared=1&group=1').read
findrows = re.compile('<tr class="- banding(?:On|Off)>(.*?)</tr>')
findlink = re.compile('<a href =">(.*)</a>')
row_array = re.findall(findrows, webpage)
links = re.finall(findlink, webpate)
print(len(row_array))
iterator = []
The error I get is:
File "C:Python33liburllibrequest.py", line 160, in urlopen
return opener.open(url, data, timeout)
File "C:Python33liburllibrequest.py", line 479, in open
response = meth(req, response)
File "C:Python33liburllibrequest.py", line 591, in http_response
'http', request, response, code, msg, hdrs)
File "C:Python33liburllibrequest.py", line 517, in error
return self._call_chain(*args)
File "C:Python33liburllibrequest.py", line 451, in _call_chain
result = func(*args)
File "C:Python33liburllibrequest.py", line 599, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 403: Forbidden

Страница 1 из 2
-

Выскочивший кусок html, в котором находится адрес выбранного вами объекта, можно смело копировать в код и наслаждаться своей брутальностью.
Остался последний момент. Когда мы скачаем все мемы с текущей страницы, нам нужно будет каким-то образом забраться на соседнюю. На сайте это можно делать просто пролистывая страницу с мемами вниз, javascript-функции подтянут новые мемы на текущее окно, но сейчас трогать эти функции не хочется.
Обычно, все параметры, которые мы устанавливаем на сайте для поиска, отображаются на структуре хрефа. Мемы не являются исключением. Если мы хотим получить первую порцию мемов, мы должны будем обратиться к сайту по ссылке
http://knowyourmeme.com/memes/all/page/1
Если мы захотим получить вторую поцию с шестнадцатью мемами, нам придётся немного видоизменить ссылку, а именно заменить номер страницы на 2.
http://knowyourmeme.com/memes/all/page/2
Таким незатейливым образом мы сможем пройтись по всем страницам и ограбить мемохранилище. Наконец, обернем в красивую функцию все-все манипуляции, проделанные выше:
Функция для скачивания ссылок на мемы
def getPageLinks(page_number): """ Возвращает список ссылок на мемы, полученный с текущей страницы page_number: int/string номер страницы для парсинга """ # составляем ссылку на страницу поиска page_link = 'http://knowyourmeme.com/memes/all/page/{}'.format(page_number) # запрашиваем данные по ней response = requests.get(page_link, headers={'User-Agent': UserAgent().chrome}) if not response.ok: # если сервер нам отказал, вернем пустой лист для текущей страницы return [] # получаем содержимое страницы и переводим в суп html = response.content soup = BeautifulSoup(html,'html.parser') # наконец, ищем ссылки на мемы и очищаем их от ненужных тэгов meme_links = soup.findAll(lambda tag: tag.name == 'a' and tag.get('class') == ['photo']) meme_links = ['http://knowyourmeme.com' + link.attrs['href'] for link in meme_links] return meme_linksПротестируем функцию и убедимся, что всё хорошо
meme_links = getPageLinks(1) meme_links[:2]Out: ['http://knowyourmeme.com/memes/people/mf-doom', 'http://knowyourmeme.com/memes/here-lies-beavis-he-never-scored']Отлично, функция работает и теперь мы теоретически можем достать ссылки на все 17171 мем, для чего нам придется пройтись по 17171/16 ~ 1074 страницам. Прежде чем расстраивать сервер таким количеством запросов, посмотрим, как доставать всю необходимую информацию о конкретном меме.
1.5 Финальная подготовка к грабежу
По аналогии со ссылками можно вытащить что угодно. Для этого надо сделать несколько шагов:
- Открываем страничку с мемом
- Находим любым способом тег для нужной нам информации
- Пихаем всё это в прекрасный суп
- ……
- Profit
Для закрепления информации в голове любознательного читателя, вытащим число просмотров мема.
А в качестве примера возьмем самый популярный на этом сайте мем — Doge, набравший более 12 миллионов просмотров по состоянию на 1 января 2018 года.
Сама страница, с которой мы будем доставать дорогую нашему исследовательскому сердцу информацию выглядит следуюшим образом:
Как и прежде, для начала сохраним ссылку на страницу в переменную и вытащим по ней контент.
meme_page = 'http://knowyourmeme.com/memes/doge' response = requests.get(meme_page, headers={'User-Agent': UserAgent().chrome}) html = response.content soup = BeautifulSoup(html,'html.parser')Посмотрим, как можно вытащить статистику просмотров, комментариев, а также числа загруженных видео и фото, связанных с нашим мемов. Всё это добро хранится справа вверху под тэгами
"dd"и с классами"views","videos","photos"и"comments"views = soup.find('dd', attrs={'class':'views'}) print(views)Out: <dd class="views" title="12,318,185 Views"> <a href="/memes/doge" rel="nofollow">12,318,185</a> </dd>Очистим от тэгов и пунктуации
views = views.find('a').text views = int(views.replace(',', '')) print(views)Out: 12318185Снова запихнём всё это в небольшую функцию.
Функция, возвращающая статистику по мему
def getStats(soup, stats): """ Возвращает очищенное число просмотров/коментариев/... soup: объект bs4.BeautifulSoup суп текущей страницы stats: string views/videos/photos/comments """ obj = soup.find('dd', attrs={'class':stats}) obj = obj.find('a').text obj = int(obj.replace(',', '')) return objВсё готово!
views = getStats(soup, stats='views') videos = getStats(soup, stats='videos') photos = getStats(soup, stats='photos') comments = getStats(soup, stats='comments') print("Просмотры: {}nВидео: {}nФото: {}nКомментарии: {}".format(views, videos, photos, comments))Out: Просмотры: 12318185 Видео: 59 Фото: 1645 Комментарии: 918Еще из интересного и исследовательского — достанем дату и время добавления мема. Если посмотреть на страницу в браузере, можно подумать, что максимум информации, который мы можем вытащить — это число лет, прошедших с момента публикации —
Added 4 years ago by NovaXP. Однако мы так просто сдаваться не будем, полезем в кишки html и откопаем там кусок, ответственный за эту надпись:
Ага! Вот и подробности по дате добавления, с точностью до минуты. Элементарно

date = soup.find('abbr', attrs={'class':'timeago'}).attrs['title'] dateOut: '2017-12-31T01:59:14-05:00'На самом деле, парсеры — дело непредсказуемое. Часто страницы, которые мы парсим, имеют очень неоднородну структуру. Например, если мы парсим мемы, на части страниц может быть указано описание, а на части нет. Как только код впервые натыкается на отсутствие описания, он выдаёт ошибку и останавливается. Чтобы нормально собрать все данные, приходится прописывать исключения. Вроде бы, хранилище мемов хорошо оборудовано и никаких внештатных ситуаций происходить не должно.
Тем не менее, очень не хочется проснуться утром и увидеть, что код сделал 20 итераций, нарвался на ошибку и отрубился. Чтобы такого не произошло, можно, например, использовать конструкциюtry - exceptи просто обрабатывать неугодные нам ошибки. Про исключения можно почитать на просторах интернета. В нашем же случае до ошибки можно и не доводить, а предварительно проверять, есть ли необходимый элемент на странице или нет при помощи обычногоif - else, и уже после этого пытаться его распарсить.Например, мы хотим вытащить статус мема, для этого найдем окружающие его тэги:
properties = soup.find('aside', attrs={'class':'left'}) meme_status = properties.find("dd") meme_statusOut: <dd> Confirmed </dd>Дальше нужно вытащить из тэгов текст, а после обрубить все лишние пробелы.
meme_status.text.strip()Out: 'Confirmed'Однако, если неожиданно выяснится, что у мема нет статуса, метод
findвернёт пустоту. Методtext, в свою очередь, не сможет найти в тэгах текст и выдаст ошибку. Чтобы обезопасить себя от таких пустот, можно прописать исключение илиif - else. Так как в текущем меме статус все-таки есть, нарочно зададим его как пустой объект, чтобы проверить, что ошибка поймается в обоих случаях# Делай раз! Ищем статус мема, но не находим его meme_status = None # Делай два! Пытаемся вытащить его... # ... с исключениями try: print(meme_status.text.strip()) # Ежели возникает ошибка, статус не найден, выдаём пустоту. except: print("Exception") # ... с проверкой на пустой элемент if meme_status: print(meme_status.text.strip()) else: print("Empty")Out: Exception EmptyТакой код позволяет обезопасить себя от ошибок. В данном случае, мы можем переписать всю конструкцию с
if - elseв виде одной удобной строки. Эта строка проверит, полон ли респонсаmeme_statusи ежели нет, то выдаст пустоту.# снова найдем настоящий статус properties = soup.find('aside', attrs={'class':'left'}) meme_status = properties.find("dd") meme_status = "" if not meme_status else meme_status.text.strip() print(meme_status)Out: ConfirmedПо аналогии можно вытащить всю остальную информацию со страницы, для чего вновь напишем функцию
Функция для парсинга свойств мема
def getProperties(soup): """ Возвращает список (tuple) с названием, статусом, типом, годом и местом происхождения и тэгами soup: объект bs4.BeautifulSoup суп текущей страницы """ # название - идёт с самым большим заголовком h1, легко найти meme_name = soup.find('section', attrs={'class':'info'}).find('h1').text.strip() # достаём все данные справа от картинки properties = soup.find('aside', attrs={'class':'left'}) # статус идет первым - можно не уточнять класс meme_status = properties.find("dd") # oneliner, заменяющий try-except: если тэга нет в properties, вернётся объект NoneType, # у которого аттрибут text отсутствует, и в этом случае он заменится на пустую строку meme_status = "" if not meme_status else meme_status.text.strip() # тип мема - обладает уникальным классом meme_type = properties.find('a', attrs={'class':'entry-type-link'}) meme_type = "" if not meme_type else meme_type.text # год происхождения первоисточника можно найти после заголовка Year, # находим заголовок, определяем родителя и ищем следущего ребенка - наш раздел meme_origin_year = properties.find(text='nYearn') meme_origin_year = "" if not meme_origin_year else meme_origin_year.parent.find_next() meme_origin_year = meme_origin_year.text.strip() # сам первоисточник meme_origin_place = properties.find('dd', attrs={'class':'entry_origin_link'}) meme_origin_place = "" if not meme_origin_place else meme_origin_place.text.strip() # тэги, связанные с мемом meme_tags = properties.find('dl', attrs={'id':'entry_tags'}).find('dd') meme_tags = "" if not meme_tags else meme_tags.text.strip() return meme_name, meme_status, meme_type, meme_origin_year, meme_origin_place, meme_tagsgetProperties(soup)Out: ('Doge', 'Confirmed', 'Animal', '2013', 'Tumblr', 'animal, dog, shiba inu, shibe, such doge, super shibe, japanese, super, tumblr, much, very, many, comic sans, photoshop meme, such, shiba, shibe doge, doges, dogges, reddit, comic sans ms, tumblr meme, hacked, bitcoin, dogecoin, shitposting, stare, canine')Свойства мема собрали. Теперь собираем по аналогии его текстовое описание.
Функция для парсинга текстового описания мема
def getText(soup): """ Возвращает текстовые описания мема soup: объект bs4.BeautifulSoup суп текущей страницы """ # достаём все тексты под картинкой body = soup.find('section', attrs={'class':'bodycopy'}) # раздел about (если он есть), должен идти первым, берем его без уточнения класса meme_about = body.find('p') meme_about = "" if not meme_about else meme_about.text # раздел origin можно найти после заголовка Origin или History, # находим заголовок, определяем родителя и ищем следущего ребенка - наш раздел meme_origin = body.find(text='Origin') or body.find(text='History') meme_origin = "" if not meme_origin else meme_origin.parent.find_next().text # весь остальной текст (если он есть) можно запихнуть в одно текстовое поле if body.text: other_text = body.text.strip().split('n')[4:] other_text = " ".join(other_text).strip() else: other_text = "" return meme_about, meme_origin, other_textmeme_about, meme_origin, other_text = getText(soup) print("О чем мем:n{}nnПроисхождение:n{}nnОстальной текст:n{}...n" .format(meme_about, meme_origin, other_text[:200]))Out: О чем мем: Doge is a slang term for “dog” that is primarily associated with pictures of Shiba Inus (nicknamed “Shibe”) and internal monologue captions on Tumblr. These photos may be photoshopped to change the dog’s face or captioned with interior monologues in Comic Sans font. Происхождение: The use of the misspelled word “doge” to refer to a dog dates back to June 24th, 2005, when it was mentioned in an episode of Homestar Runner’s puppet show. In the episode titled “Biz Cas Fri 1”[2], Homestar calls Strong Bad his “d-o-g-e” while trying to distract him from his work. Остальной текст: Identity On February 23rd, 2010, Japanese kindergarten teacher Atsuko Sato posted several photos of her rescue-adopted Shiba Inu dog Kabosu to her personal blog.[38] Among the photos included a peculi...Наконец, создадим функцию, возвращающую всю информацию по текущему мему
Функция, возвращающая все данные по мему
def getMemeData(meme_page): """ Запрашивает данные по странице, возвращает обработанный словарь с данными meme_page: string ссылка на страницу с мемом """ # запрашиваем данные по ссылке response = requests.get(meme_page, headers={'User-Agent': UserAgent().chrome}) if not response.ok: # если сервер нам отказал, вернем статус ошибки return response.status_code # получаем содержимое страницы и переводим в суп html = response.content soup = BeautifulSoup(html,'html.parser') # используя ранее написанные функции парсим информацию views = getStats(soup=soup, stats='views') videos = getStats(soup=soup, stats='videos') photos = getStats(soup=soup, stats='photos') comments = getStats(soup=soup, stats='comments') # дата date = soup.find('abbr', attrs={'class':'timeago'}).attrs['title'] # имя, статус, и т.д. meme_name, meme_status, meme_type, meme_origin_year, meme_origin_place, meme_tags = getProperties(soup=soup) # текстовые поля meme_about, meme_origin, other_text = getText(soup=soup) # составляем словарь, в котором будут хранится все полученные и обработанные данные data_row = {"name":meme_name, "status":meme_status, "type":meme_type, "origin_year":meme_origin_year, "origin_place":meme_origin_place, "date_added":date, "views":views, "videos":videos, "photos":photos, "comments":comments, "tags":meme_tags, "about":meme_about, "origin":meme_origin, "other_text":other_text} return data_rowА теперь подготовим табличку, чтобы в неё записывать всё награбленные честно полученные данные, добавим в неё первую полученную строку и полюбуемся на результат
final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place', 'date_added', 'views', 'videos', 'photos', 'comments', 'tags', 'about', 'origin', 'other_text']) data_row = getMemeData('http://knowyourmeme.com/memes/doge') final_df = final_df.append(data_row, ignore_index=True) final_dfOut:name status type origin_year … Doge Confirmed Animal 2013 … Первый мем оказался в наших рукак. Еще раз убедимся что всё работает — пройдемся по списку из ссылок на мемы, полученных ранее в перменной
meme_links.for meme_link in meme_links: data_row = getMemeData(meme_link) final_df = final_df.append(data_row, ignore_index=True)Out:name status type origin_year … Doge Confirmed Animal 2013 … Charles C. Johnson Submission Activist 2013 … Bat- (Prefix) Submission Snowclone 2018 … The Eric Andre Show Deadpool TV Show 2012 … Hopsin Submission Musician 2003 … Отлично! Всё работает, мемы качаются, данные наполняются и всё было бы хорошо, если бы не одно но — количество запросов, которое нам придётся сделать, чтобы всё получить.
2. Прячемся от стражников
2.1 Когда работающий код больше не работает
Вот он! Тот самый момент абсолютного триумфа, когда код дописан и всё, что нам, мирным собирателям, остаётся — запустить наш код на одну ночку. Кажется, что через страсть мы преобрели силу. Запускаем наш код по всем
страницам с мемами. На всякий случай обернём наш цикл в try-except. Мало ли что там с этими мемами бывает.Цикл на ночь
# Немного красивых циклов. При желании пакет можно отключить и # удалить команду tqdm_notebook из всех циклов from tqdm import tqdm_notebook final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place', 'date_added', 'views', 'videos', 'photos', 'comments', 'tags', 'about', 'origin', 'other_text']) for page_number in tqdm_notebook(range(1075), desc='Pages'): # собрали хрефы с текущей страницы meme_links = getPageLinks(page_number) for meme_link in tqdm_notebook(meme_links, desc='Memes', leave=False): # иногда с первого раза страничка не парсится for i in range(5): try: # пытаемся собрать по мему немного даты data_row = getMemeData(meme_link) # и закидываем её в таблицу final_df = final_df.append(data_row, ignore_index=True) # если всё получилось - выходим из внутреннего цикла break except: # Иначе, пробуем еще несколько раз, пока не закончатся попытки print('AHTUNG! parsing once again:', meme_link) continueСон был прекрасным! Солнце только-только взошло из-за горизонта, мы уже бежим за компьютер смотреть мемы и видим, что огромное число мемов не скачалось.
Конечно же, вполне естественной реакцией будет нажать на первую же ссылку, перейти в мемохранилище и увидеть, что нас забанили. Все наши реквесты остались без респонсов.
2.2 Тор — сын Одина
Иногда серверу надоедает общаться с одним и тем же человеком, делающим кучу запросов и сервер банит его. К сожалению, не только у людей запас терпения ограничен.
Приходится маскироваться. Для такой маскировки можно использовать разные способы, более того, один из них мы уже использовали, когда притворились человеком в нашем
request-header. Для текущей же задачи, когда нас вероломно заблокировали по IP, нужно искать способы помощнее, чтобы иметь возможность этот IP менять. Конечно, как вариант можно было бы использовать прокси-сервера, тогда мы бы имели в запасе некоторое количество разных IP адресов, которые можно подставлять по мере «забанивания». Однако в этом подходе есть пара проблем: первая — нужно где-то раздобыть эти прокси, вторая — а что если ограниченного числа адресов нам не хватит и нужно больше?В таком случае лучше всего нам подойдёт Tor. Вопреки пропагандируемому мнению, Tor используется не только преступниками, педофилами и прочими нехорошими террористами. Это, мягко говоря, далеко не так, и мы, мирные собиратели данных, являемся тому подтверждением. Всем прелестям, связанным с работой Tor, можно было бы посвятить несколько больших статеек, что собственно говоря уже и сделано. Подробнее про это можно почитатать по следующим ссылкам:
- Как работает Tor
- Методы анонимности в сети
- Прокси-сервер с помощью Tor
Мы же ограничимся только функциональной частью, а именно без углубления в детали опишем шаги, которые нужно предпринять для того, чтобы использовать возможности Tor для обхода блокировки. Для начала полюбуемся на свой ip-адрес. Для этого сделаем get-запрос к сайту, который возвращяет наш IP
def checkIP(): ip = requests.get('http://checkip.dyndns.org').content soup = BeautifulSoup(ip, 'html.parser') print(soup.find('body').text) checkIP()Out: Current IP Address: 82.198.191.130Заменить свой ip через Tor можно двумя путями. Простой — через браузер, а сложный — через небольшие махинации с настройками.
Скачаем браузерный tor, чтобы лёгкий путь был совсем прост. Для сложного пути в довесок к браузеру поставим tor через консоль.
- Linux — нам поможет команда
apt-get install tor, - Mac — сделаем это в рамках brew,
brew install tor. - Windows — нам поможет установка другой операционной системы.
2.3 Путь первый
Теперь запускаем свежескачанный браузер и оставляем его открытым. Менять ip нам поможет библиотека
PySocks. Конечно же, её нужно установить, скопировав в терминалpip3 install PySocks.Браузер тора по умолчанию использует порт номер 9150. В питоне при помощи библиотек socks и socket можно задать дефолтный порт для подключения. В результате текущая сессия будет использовать именно этот порт при отправке любого запроса, а значит – запросы будут посылаться из-под запущенного тора.
import socks import socket socks.set_default_proxy(socks.SOCKS5, "localhost", 9150) socket.socket = socks.socksocketПосмотрим на свой новый ip-aдрес.
checkIP()Out: Current IP Address: 51.15.92.24При сопутствующем желании, можно выяснить из какой страны в данный момент мы сидим в интернете.
Ого… бывший член Европейского союза!

Попробуем обратиться к мемохранилищу с нового ip-адреса.
data_row = getMemeData('http://knowyourmeme.com/memes/doge') for key, value in data_row.items(): print(key.capitalize()+":", str(value)[:200], end='nn')Out: Name: Doge Status: Confirmed Type: Animal Origin_year: 2013 Origin_place: Tumblr Date_added: 2017-12-31T01:59:14-05:00 Views: 12318185 Videos: 59 Photos: 1645 Comments: 918 Tags: animal, dog, shiba inu, shibe, such doge, super shibe, japanese, super, tumblr, much, very, many, comic sans, photoshop meme, such, shiba, shibe doge, doges, dogges, reddit, comic sans ms, tumblr meme About: Doge is a slang term for “dog” that is primarily associated with pictures of Shiba Inus (nicknamed “Shibe”) and internal monologue captions on Tumblr...Бан снят. Стражники мемов ничего не заподозрили и пустили нас в сокровищницу. Чашу нашего респонса снова переполняет контент. Через силу мы обрели мощь.
При желании, можно выяснить одну занимательную вещь: при базовых настройках, Тор-браузер меняет ip каждые 10 минут. Но что делать, если сервер банит нас быстрее? Всё просто, в папке, куда был установлен Tor найдём файлик с настройками под названием torrc (на маке он лежит по адресу
~/Library/Application Support/TorBrowser-Data/torrc, если не получится найти — добро пожаловать сюда) и отредактируем его. Добавим строки:CircuitBuildTimeout 10 LearnCircuitBuildTimeout 0 MaxCircuitDirtiness 10Минимально возможный период для обновления ip составляет 10 секунд. Установим туда эту цифру и попробуем поиграться.
for i in range(10): checkIP() time.sleep(5)Out: Current IP Address: 89.31.57.5 Current IP Address: 93.174.93.71 Current IP Address: 62.210.207.52 Current IP Address: 209.141.43.42 Current IP Address: 209.141.43.42 Current IP Address: 162.247.72.216 Current IP Address: 185.220.101.17 Current IP Address: 193.171.202.150 Current IP Address: 128.31.0.13 Current IP Address: 185.163.1.11Действительно, смена ip происходит примерно раз в 10 секунд. Для наших целей по скачке мемов было достаточно и базовых настроек. Бан наступал примерно через 20 минут после начала работы кода.
- Открываем браузер;
- Запускаем кусок кода с подгрузкой библиотек;
- Запускаем цикл по мемам
- …..
- Profit
Еще один цикл на ночь
final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place', 'date_added', 'views', 'videos', 'photos', 'comments', 'tags', 'about', 'origin', 'other_text']) for page_number in tqdm_notebook(range(1075), desc='Pages'): # собрали хрефы с текущей страницы meme_links = getPageLinks(page_number) for meme_link in tqdm_notebook(meme_links, desc='Memes', leave=False): # иногда с первого раза страничка не парсится for i in range(5): try: # пытаемся собрать по мему немного даты data_row = getMemeData(meme_link) # и закидываем её в таблицу final_df = final_df.append(data_row, ignore_index=True) # если всё получилось - выходим из внутреннего цикла break except: # Иначе, пробуем еще несколько раз, пока не закончатся попытки continue final_df.to_csv('MEMES.csv')Все мемы в наших руках. Можно приступать к варке фичей и моделированию. Через мощь мы познали победу. Остался только один вопрос: Что, если мы хотим менять ip каждый реквест?
2.4 Путь второй
Второй путь помогает извращаться со сменой ip как угодно. Зайдём на Github каких-то ребят и скачаем себе их скрипт под названием
TorCrawler.py. Все недостающие библиотеки, используемые в этом скрипте, придётся доставить. Поставим парням на репозиторий за их код звёздочку. Закинем этот скрипт либо в папку со своими библиотеками либо в папку к этому блокноту. Обратите внимание, что скрипт работает только с третьим питоном.Перед использованием библиотечки, нужно подкрутить настройки в torrc файлике. На маке он будет лежать в папке
/usr/local/etc/tor/, на линуксе в папке/etc/tor/. Проследуем по инструкции авторов скрипта.- Генерируем в консоли пароль
tor --hash-password mypassword - Открываем torrc файл в редакторе вроде vim, nano или atom
- Сохраняем пароль в наш torrc-файл в строку, которая начинается с HashedControlPassword
- Раскоментируем строку, начинающуюся с HashedControlPassword
- Раскоментируем (если она закоментирована) строку ControlPort 9051
- Сохраним изменения.
Запускаем tor в терминале. Линукс:
service tor start, мак:tor.Теперь мы готовы парсить.
from TorCrawler import TorCrawler # Создаём свой краулер, в опциях вводим пароль crawler = TorCrawler(ctrl_pass='mypassword')Мы можем сделать get-запрос по аналогии с тем как делали раньше, причем ответ получим сразу в формате bs4.
meme_page = 'http://knowyourmeme.com/memes/doge' response = crawler.get(meme_page, headers={'User-Agent': UserAgent().chrome}) type(response)Out: bs4.BeautifulSoupНаходим внутри что-нибудь нужное.
views = response.find('dd', attrs={'class':'views'}) viewsOut: <dd class="views" title="12,318,185 Views"> <a href="/memes/doge" rel="nofollow">12,318,185</a> </dd>Проверим IP адрес краулера
crawler.ipOut: '51.15.40.23'По дефолту краулер меняет ip каждые 25 запросов. За это отвечает параметр
n_requests. При создании нового краулера, его можно настроить по собственному желанию.crawler.n_requestsOut: 25Более того, ip можно при желании поменять вручную.
crawler.rotate()IP successfully rotated. New IP: 62.176.4.1Теперь весь код для парсинга можно перевести на рельсы этого небольшого скрипта, заменив все реквесты на торовские, и менять IP адрес с каждым новым запросом. На бедный сервер внезапно обрушится огромное число запросов из всех уголков света.
Победа порвала наши оковы. Великая Сила освободила нас.
Заключение
Напоследок, хотелось бы сказать пару слов о парсинге вообще и при помощи Тора в частности. Добывать себе данные — это стильно, модно и в принципе интересно, можно получить датасеты, которых еще никто никогда не обрабатывал, сделать что-то новое, посмотреть, наконец, на все мемы мира сразу. Однако не стоит забывать, что ограничения, введенные сервером, в том числе баны, появились не просто так, а в целях защиты сайта от недоброжелательных ковровых бомбардировок запросами и DDoS-атак. К чужому труду стоит относится с уважением, и даже если у сервера никакой защиты нет, — это еще не повод неограниченно забрасывать его реквестами, особенно если это может привести к его отключению — уголовное наказание никто не отменял.
К тому же Тор — это всё-таки не первое решение, к которому стоит прибегать в случае проблем с парсингом. Иногда достаточно будет просто поставить в нужных местах
time.sleep()и заполнитьrequest-headerинформацией об операционной системе — в большинстве случаев этого должно быть достаточно для аккуратного сбора интересующей вас информации.Успешных и безопасных вам исследований и да прибудет с вами Сила!
Авторы: Ульянкин Филипп filfonul, Сергеев Дмитрий Skolopendriy
Почиташки
- Годная книга про парсинг на английском языке.
- Неплохая инструкция о самостоятельном парсинге через Tor без использования чужих готовых классов.
- Димин репозиторий с собранным датасетом из более чем 16k мемов, а также с их исследованием и ноутбуком с парсером.
- Филин репозиторий с ещё парой хорошо расписаных блокнотов с парсерами. Репозиторий изначально делался как страничка факультатива для студентов.
- Оригинальный кодекс адепта тёмной стороны силы.
I was trying to scrape a website for practice, but I kept on getting the HTTP Error 403 (does it think I’m a bot)?
Here is my code:
#import requests import urllib.request from bs4 import BeautifulSoup #from urllib import urlopen import re webpage = urllib.request.urlopen('http://www.cmegroup.com/trading/products/#sortField=oi&sortAsc=false&venues=3&page=1&cleared=1&group=1').read findrows = re.compile('<tr class="- banding(?:On|Off)>(.*?)</tr>') findlink = re.compile('<a href =">(.*)</a>') row_array = re.findall(findrows, webpage) links = re.finall(findlink, webpate) print(len(row_array)) iterator = []The error I get is:
File "C:Python33liburllibrequest.py", line 160, in urlopen return opener.open(url, data, timeout) File "C:Python33liburllibrequest.py", line 479, in open response = meth(req, response) File "C:Python33liburllibrequest.py", line 591, in http_response 'http', request, response, code, msg, hdrs) File "C:Python33liburllibrequest.py", line 517, in error return self._call_chain(*args) File "C:Python33liburllibrequest.py", line 451, in _call_chain result = func(*args) File "C:Python33liburllibrequest.py", line 599, in http_error_default raise HTTPError(req.full_url, code, msg, hdrs, fp) urllib.error.HTTPError: HTTP Error 403: ForbiddenСтраница 1 из 2
-

dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
Здравствуйте, парсил Ссылки недоступны для гостей и получил бан практически сразу, роутер перезагружал ip не меняется, подскажите что делать?)
-
Achronis
Well-Known Member
Пользователи- Регистрация:
- 30 июл 2020
- Сообщения:
- 64
- Город:
- Барнаул
Здравствуйте.
Как правило сайты банят временно, подождите 15, 30, 60 минут и ваш ip должны разбанить.
При парсинге данного сайта необходимо использовать прокси, либо уменьшать количество потоков парсинга, увеличивать задержки между запросами.
Ссылки недоступны для гостейИспользование прокси Ссылки недоступны для гостей
-
kagorec
Администратор
Команда форума
АдминистраторПробуте через прокси или через vpn
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
что то ничего не выходит, некоторые ссылки норм, а по некоторым Программе не удалось загрузить WEB-страницу (HTTP/1.1 403 Forbidden) и это я еще не парсил, только предпросмотр и задание границ парсинга
посмотрите пожалуйстаВложения:
-
Root
Администратор
Администратор- Регистрация:
- 10 мар 2010
- Сообщения:
- 14.818
- Город:
- Барнаул
Здравствуйте.
Передайте Cookie из браузера в окне задания границ парсинга вот так
Тогда этот сайт должен парситься.
Также послеживайте за развитием WBApp2 Ссылки недоступны для гостей
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
в общем что то все равно не выходит и прокси подключил и wbapp и куки, но парсится вначале через 1 товар, потом вообще не парсится
Вложения:
-
kagorec
Администратор
Команда форума
АдминистраторПарситься все вполне хорошо без банов через прокси.
В Ctrl+h выберите CIS -
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
а у меня вот такая тема в задании границ и при парсинге Ссылки недоступны для гостей
-
kagorec
Администратор
Команда форума
АдминистраторВстроенный броузер работает без поддержки прокси в режиму указания границ.
На панеле в самом верху, нажмите кнопку «CODE -> WEB» для отображения страницы как видит парсер. -
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
все облазил не могу найти эту кнопку)
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
если у вас все работает, может спарсите?)
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
я спарсил в итоге файл пустой
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
видимо у меня прокси не рабочие, подскажите где приобрести нормальные и какое количество нужно для парсинга этого сайта?
-
Root
Администратор
Администратор- Регистрация:
- 10 мар 2010
- Сообщения:
- 14.818
- Город:
- Барнаул
Если не подберете прокси, подождите пару дней. Отпишусь тут.
-
kagorec
Администратор
Команда форума
Администратор -
kagorec
Администратор
Команда форума
Администратор -
Root
Администратор
Администратор- Регистрация:
- 10 мар 2010
- Сообщения:
- 14.818
- Город:
- Барнаул
Вот так можно выкачать WEB страницы на диск, а затем спарсить локальные документы в Content Downloader -> Ссылки недоступны для гостей
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
а что с этими файлами дальше делать? есть инструкция?
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
блин столько гемора, первый раз с таким сайтом сталкиваюсь и надеюсь последний, может кто нибудь спарсит через нормальные прокси и скинет мне файл, готов заплатить. файл исправленного проекта прикрепил
Вложения:
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
благодарю этот способ помог
сначала не дошло что и как, благодарю за помощь
Всем спасибо кто откликнулся!
Страница 1 из 2
Поделиться этой страницей
Python is a rather easy-to-learn but powerful language enough to be used in a variety of applications ranging from AI and Machine Learning all the way to something as simple as creating web scraping bots.
That said, random bugs and glitches are still the order of the day in a Python programmer’s life. In this article, we’re talking about the “urllib.error.httperror: HTTP error 403: Forbidden” when trying to scrape sites with Python and what you can to do fix the problem.
Also read: Is Python case sensitive when dealing with identifiers?
Why does this happen?
While the error can be triggered by anything from a simple runtime error in the script to server issues on the website, the most likely reason is the presence of some sort of server security feature to prevent bots or spiders from crawling the site. In this case, the security feature might be blocking urllib, a library used to send requests to websites.
How to fix this?
Here are two fixes you can try out.
Disable mod_security or equivalent security features
As mentioned before, server-side security features can cause problems with web scrapers. Try setting your browser agent as follows to see if you can avoid the issue.
from urllib.request import Request, urlopen req = Request( url='enter request URL here', headers={'User-Agent': 'Mozilla/5.0'} ) webpage = urlopen(req).read()A correctly defined browser agent should be able to scrape data from any site.
Set a timeout
If you aren’t getting a response, try setting a timeout to prevent the server from mistaking your bot for a DDoS attacking and hence blocking all requests altogether.
from urllib.request import Request, urlopen req = Request('enter request URL here', headers={'User-Agent': 'Mozilla/5.0'}) webpage = urlopen(req,timeout=10).read()The aforementioned example sets a 10-second timeout between requests to not overload the server while maintaining good request frequency.
Also read: How to fix Javascript error: ipython is not defined?
helhel20
0 / 0 / 1
Регистрация: 21.04.2019
Сообщений: 29
1
15.06.2021, 10:41. Показов 7647. Ответов 9
Метки нет (Все метки)
Здравствуйте, нужно написать парсер сайта. Хочу получить html страницы, но запрос выдает ошибку 403, я так понимаю на сайте какая-то защита стоит. Как ее обойти?
Python 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
import requests from bs4 import BeautifulSoup URL = '***' HEADERS = { 'Host': '***', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Accept-Language': 'en-US,en;q=0.5', 'Accept-Encoding': 'gzip, deflate, br', 'Connection': 'keep-alive', 'Upgrade-Insecure-Requests': '1', 'Cache-Control': 'max-age=0'} def get_html(url, params=None): r = requests.get(url, headers=HEADERS, params=params) return r def parse(): html = get_html(URL) print(html) parse()
0
Автоматизируй это!
7112 / 4410 / 1182
Регистрация: 30.03.2015
Сообщений: 12,864
Записей в блоге: 29
15.06.2021, 10:50
2
helhel20, почти все эти заголовки не нужны (не обязательны), 403 это
возможно
отсутствие авторизации, залогиниться не надо сначала на сайте?
0
0 / 0 / 1
Регистрация: 21.04.2019
Сообщений: 29
15.06.2021, 11:47
[ТС]
3
Нет, не нужно логиниться
0
Автоматизируй это!
7112 / 4410 / 1182
Регистрация: 30.03.2015
Сообщений: 12,864
Записей в блоге: 29
15.06.2021, 14:06
4
helhel20, я достаю хрустальный шар. Так, или ты не верно формируешь запрос, или не туда его шлешь, или добавляешь не те хедеры, или не добавляешь нужные куки. Вот.
0
0 / 0 / 1
Регистрация: 21.04.2019
Сообщений: 29
15.06.2021, 17:43
[ТС]
5
А какие хедеры еще могут быть нужны? И какие куки надо добавить?
0
Автоматизируй это!
7112 / 4410 / 1182
Регистрация: 30.03.2015
Сообщений: 12,864
Записей в блоге: 29
15.06.2021, 17:45
6
helhel20, те, которые нужны для этого запроса конечно, смотрим в браузере что и куда уходит, повторяем запрос как там.
0
helhel20
0 / 0 / 1
Регистрация: 21.04.2019
Сообщений: 29
15.06.2021, 20:00
[ТС]
7
Я правильно куки отправляю? Что-то не работает, все уже перепробовал
Python 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
import requests from bs4 import BeautifulSoup import cfscrape URL = 'https://www.computeruniverse.net/en' HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'en-US,en;q=0.5', 'Alt-Used': 'www.computeruniverse.net', 'Cache-Control': 'max-age=0', 'Connection': 'keep-alive', 'Host': 'www.computeruniverse.net', 'TE': 'Trailers', 'Upgrade-Insecure-Requests': '1', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', } response = requests.get('https://www.computeruniverse.net/en') cookies = response.cookies.get_dict() print(cookies) def get_html(url, params=None): r = requests.get(url, headers=HEADERS, params=params, cookies=cookies) return r def parse(): html = get_html(URL) print(html) parse()
0
Автоматизируй это!
7112 / 4410 / 1182
Регистрация: 30.03.2015
Сообщений: 12,864
Записей в блоге: 29
16.06.2021, 12:09
8
helhel20, сайтик не простой, очень сильно заколдовано) Если ты хочешь его содержимое парсить, то сразу рекомендую на селениум переходить, тут очень много динамики и подгрузок.
0
АмигоСП
295 / 108 / 57
Регистрация: 07.12.2016
Сообщений: 209
16.06.2021, 15:10
9
Сообщение было отмечено Welemir1 как решение
Решение
helhel20, как написал Уважаемый Welemir1, сайт действительно непростой. И, если вы только пытаетесь изучить парсинг, то сложно будет. И вдогонку такой вопрос ещё — а нужна ли вам главная страница? Информативности в ней не то, чтобы очень. Обычно вытягивают по разделам информацию о продукте конечную.
Поковыряйтесь в инструментах разработчика в браузере, посмотрите куда запросы уходят при переходе по той или иной ссылке. Вот для примера вам — отсюда только что вытащил данные по ноутбукам(1 или нулевая страница)Python 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
import requests url = 'https://s94rts9o9n-dsn.algolia.net/1/indexes/*/queries' params = { 'x-algolia-agent': 'Algolia for JavaScript (4.8.3); Browser (lite); JS Helper (3.3.4); react (16.14.0); react-instantsearch (6.8.2)', 'x-algolia-api-key': '68254877d0fccdeaa3e9b24d2814a827', 'x-algolia-application-id': 'S94RTS9O9N' } dataset = {"requests": [{"indexName": "Prod-ComputerUniverse", "params": "highlightPreTag=%3Cais-highlight-0000000000%3E&highlightPostTag=%3C%2Fais-highlight-0000000000%3E&filters=(categoryid%3A38%20OR%20categoryids%3A38)%20%20AND%20(parentproductid%3A0%20OR%20isparenteol%3Atrue)%20AND%20(productchannel.1.published%3Atrue)&ruleContexts=%5B%22facet_category_38%22%5D&distinct=true&maxValuesPerFacet=1000&clickAnalytics=true&query=&hitsPerPage=20&page=0&facets=%5B%22price_ag_floored%22%2C%22isnew%22%2C%22deliverydatepreorder%22%2C%22deliverydatenow%22%2C%22manufacturer%22%2C%22facets.Ger%25c3%25a4tetyp.values%22%2C%22facets.Displaygr%25c3%25b6sse.valuesDisplayOrder%22%2C%22facets.Aufl%25c3%25b6sung.valuesDisplayOrder%22%2C%22facets.Touchscreen.values%22%2C%22facets.Displayoberfl%25c3%25a4che.values%22%2C%22facets.DisplayFeatures.values%22%2C%22facets.Betriebssystem.values%22%2C%22facets.BetriebssystemArchitektur.values%22%2C%22facets.SSDSpeicher.valuesDisplayOrder%22%2C%22facets.Festplattenspeicher.valuesDisplayOrder%22%2C%22facets.optischesLaufwerk.values%22%2C%22facets.Arbeitsspeicher%2528RAM%2529.valuesDisplayOrder%22%2C%22facets.ProzessorHersteller.values%22%2C%22facets.ProzessorModell.values%22%2C%22facets.ProzessorKerne.valuesDisplayOrder%22%2C%22facets.ProzessorGeschwindigkeit.valuesDisplayOrder%22%2C%22facets.TurboGeschwindigkeit.valuesDisplayOrder%22%2C%22facets.LeistungsstufeCPU.values%22%2C%22facets.Grafikchip.values%22%2C%22facets.Grafikspeicher.valuesDisplayOrder%22%2C%22facets.LeistungsstufeGrafikkarte.values%22%2C%22facets.WirelessLAN.values%22%2C%22facets.USBTypCAnschl%25c3%25bcsse.values%22%2C%22facets.USB31Gen2Anschl%25c3%25bcsse%2528USB31TypA%2529.valuesDisplayOrder%22%2C%22facets.USB31Gen1Anschl%25c3%25bcsse%2528USB30TypA%2529.valuesDisplayOrder%22%2C%22facets.USB20Anschl%25c3%25bcsse%2528TypA%2529.valuesDisplayOrder%22%2C%22facets.Monitoranschluss%2528extern%2529.values%22%2C%22facets.ThunderboltAnschl%25c3%25bcsse.valuesDisplayOrder%22%2C%22facets.Bluetooth.values%22%2C%22facets.MobilesInternet.values%22%2C%22facets.Webcam.values%22%2C%22facets.Tastaturbeleuchtung.values%22%2C%22facets.Dockinganschluss.values%22%2C%22facets.Gewicht%2528ca%2529.valuesDisplayOrder%22%2C%22facets.Farbe.values%22%2C%22facets.Besonderheiten.values%22%2C%22facets.maxAkkulaufzeit%2528ca%2529.valuesDisplayOrder%22%2C%22facets.Arbeitsspeichertyp.values%22%2C%22facets.RAMSteckpl%25c3%25a4tzefrei.values%22%2C%22facets.RAMSteckpl%25c3%25a4tzegesamt.values%22%2C%22facets.maxRAM.values%22%5D&tagFilters="}]} headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0', 'Referer': 'https://www.computeruniverse.net/' } response = requests.post(url, params=params, json=dataset, headers=headers) products = response.json() for product in products['results'][0]['hits']: print(product)
0
0 / 0 / 1
Регистрация: 21.04.2019
Сообщений: 29
16.06.2021, 19:46
[ТС]
10
Благодарю за помощь, селениум выручил.
0
IT_Exp
Эксперт
87844 / 49110 / 22898
Регистрация: 17.06.2006
Сообщений: 92,604
16.06.2021, 19:46 Помогаю со студенческими работами здесь
Django Ошибка доступа (403) Ошибка проверки CSRF. Запрос отклонён
На хостинге разместил сайт и не могу войти в админку, т.к. возникает 403 ошибка "Ошибка доступа…При создании класса в проекте, после сборки появляется ошибка Ошибка HTTP 403.14 — Forbidden.
Сайт только начинаю делать. БД подключена, данные выводятся. При создании класса в проекте, после…ошибка Ошибка HTTP 403.14 — Forbidden Веб-сервер настроен таким образом, чтобы не формировать списка содержимого каталога
вообщем создаю тупо пустой веб сайт ничего в нем не меняю и не трогаю запускаю,получаю такую…Ошибка 403
Здравствуйте, выполняю запрос через модуль Axios, программа прекращает работу при ошибке 403, как…Ошибка 403
Добрый день! Подскажите, пожалуйста, может кто сталкивался, что делать? Кароче, первый раз загружаю…Ошибка 403
Недаёт зайти в admin панель
Forbidden
You don’t have permission to access /admin/ on this…Искать еще темы с ответами
Или воспользуйтесь поиском по форуму:
10





![[IMG]](https://i.imgur.com/vXcLz2D.png)
![[IMG]](https://i.imgur.com/AYaujb0.png)

 Сообщение было отмечено Welemir1 как решение
Сообщение было отмечено Welemir1 как решение