
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
 .
.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости  .
.
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.

Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН.
Для этого:
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;

Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК;

Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу <F2>, а затем на комбинацию клавиш <Ctrl>+<Shift>+<Enter>.
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов
|
Остаточная сумма квадратов
|



Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:

Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
3. Коэффициент детерминации  означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции:  .
.
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент

Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки.
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
• Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
• Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал X – диапазон, содержащий данные факторного признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист – можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК.

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:


Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:

Качество построенной модели оценивается как хорошее, так как  не превышает 8 – 10%.
не превышает 8 – 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: 

Поскольку  при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля:
 .
.
 для числа степеней свободы
для числа степеней свободы 
На рисунке 7 имеются фактические значения t-статистики:

t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ: 
где  – случайная ошибка коэффициента корреляции.
– случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.

II способ: 
Фактические значения t-статистики превосходят табличные значения:


Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как

Для параметра a 95%-ные границы как показано на рисунке 7 составили:

Доверительный интервал для коэффициента регрессии определяется как

Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:

Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью  параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:

Тогда прогнозное значение прожиточного минимума составит:

Ошибку прогноза рассчитаем по формуле:

где 
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК.

Рисунок 10 Расчёт дисперсии
Получили значение дисперсии 
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.


Доверительные интервалы прогноза индивидуальных значений у при  с вероятностью 0,95 определяются выражением:
с вероятностью 0,95 определяются выражением:



Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил.



Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:
Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
Означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х — среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции:  .
.
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее , и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент
Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа . В главном меню последовательно выберите: Файл/Параметры/Надстройки .
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа , а затем нажмите кнопку ОК .
Если Пакет анализа отсутствует в списке поля Доступные надстройки , нажмите кнопку Обзор , чтобы выполнить поиск.
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да , чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия , а затем нажмите кнопку ОК .
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y — диапазон, содержащий данные результативного признака;
Входной интервал X — диапазон, содержащий данные факторного признака;
Метки — флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа — ноль — флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал — достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист — можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК .

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:


Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:

Качество построенной модели оценивается как хорошее, так как не превышает 8 — 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: 
Поскольку  при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н 0 о статистически незначимом отличии показателей от нуля:
 .
.
 для числа степеней свободы
для числа степеней свободы
На рисунке 7 имеются фактические значения t-статистики:
t-критерий для коэффициента корреляции можно рассчитать двумя способами:
где  — случайная ошибка коэффициента корреляции.
— случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.

Фактические значения t-статистики превосходят табличные значения:
Поэтому гипотеза Н 0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как

Для параметра a 95%-ные границы как показано на рисунке 7 составили:
Доверительный интервал для коэффициента регрессии определяется как

Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:

Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью  параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:
Тогда прогнозное значение прожиточного минимума составит:
Ошибку прогноза рассчитаем по формуле:

где 
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций : в главном меню выберете Формулы / Вставить функцию .
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК .

Рисунок 10 Расчёт дисперсии
Получили значение дисперсии 
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.

Доверительные интервалы прогноза индивидуальных значений у при с вероятностью 0,95 определяются выражением:

Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. — М.: Финансы и статистика, 2003. — 192 с.: ил.
Для общей оценки качества построенной эконометрической определяются такие характеристики как коэффициент детерминации, индекс корреляции, средняя относительная ошибка аппроксимации, а также проверяется значимость уравнения регрессии с помощью F -критерия Фишера. Перечисленные характеристики являются достаточно универсальными и могут применяться как для линейных, так и для нелинейных моделей, а также моделей с двумя и более факторными переменными. Определяющее значение при вычислении всех перечисленных характеристик качества играет ряд остатков ε i , который вычисляется путем вычитания из фактических (полученных по наблюдениям) значений исследуемого признака y i значений, рассчитанных по уравнению модели y рi .
показывает, какая доля изменения исследуемого признака учтена в модели. Другими словами коэффициент детерминации показывает, какая часть изменения исследуемой переменной может быть вычислена, исходя из изменений включённых в модель факторных переменных с помощью выбранного типа функции, связывающей факторные переменные и исследуемый признак в уравнении модели.
Коэффициент детерминации R 2 может принимать значения от 0 до 1. Чем ближе коэффициент детерминации R 2 к единице, тем лучше качество модели.
Индекс корреляции можно легко вычислить, зная коэффициент детерминации:
Индекс корреляции R характеризует тесноту выбранного при построении модели типа связи между учтёнными в модели факторами и исследуемой переменной. В случае линейной парной регрессии его значение по абсолютной величине совпадает с коэффициентом парной корреляции r (x, y) , который мы рассмотрели ранее, и характеризует тесноту линейной связи между x и y . Значения индекса корреляции, очевидно, также лежат в интервале от 0 до 1. Чем ближе величина R к единице, тем теснее выбранный вид функции связывает между собой факторные переменные и исследуемый признак, тем лучше качество модели.
 (2.11)
(2.11)
выражается в процентах и характеризует точность модели. Приемлимая точность модели при решении практических задач может определяться, исходя из соображений экономической целесообразности с учётом конкретной ситуации. Широко применяется критерий, в соответствии с которым точность считается удовлетворительной, если средняя относительная погрешность меньше 15%. Если E отн.ср. меньше 5%, то говорят, что модель имеет высокую точность. Не рекомендуется применять для анализа и прогноза модели с неудовлетворительной точностью, то есть, когда E отн.ср. больше 15%.
F-критерий Фишера используется для оценки значимости уравнения регрессии. Расчётное значение F-критерия определяется из соотношения:
 . (2.12)
. (2.12)
Критическое значение F -критерия определяется по таблицам при заданном уровне значимости α и степенях свободы (можно использовать функцию FРАСПОБР в Excel). Здесь, по-прежнему, m – число факторов, учтённых в модели, n – количество наблюдений. Если расчётное значение больше критического, то уравнение модели признаётся значимым. Чем больше расчётное значение F -критерия, тем лучше качество модели.
Определим характеристики качества построенной нами линейной модели для Примера 1 . Воспользуемся данными Таблицы 2. Коэффициент детерминации :
Следовательно, в рамках линейной модели изменение объёма продаж на 90,1% объясняется изменением температуры воздуха.
 .
.
Значение индекса корреляции в случае парной линейной модели как мы видим, действительно по модулю равно коэффициенту корреляции между соответствующими переменными (объём продаж и температура). Поскольку полученное значение достаточно близко к единице, то можно сделать вывод о наличии тесной линейной связи между исследуемой переменной (объём продаж) и факторной переменноё (температура).

Критическое значение F кр при α = 0,1; ν 1 =1; ν 2 =7-1-1=5 равно 4,06. Расчётное значение F -критерия больше табличного, следовательно, уравнение модели является значимым.
Средняя относительная ошибка аппроксимации
Построенная линейная модель парной регрессии имеет неудовлетворительную точность (>15%), и её не рекомендуется использовать для анализа и прогнозирования.
В итоге, несмотря на то, что большинство статистических характеристик удовлетворяют предъявляемым к ним критериям, линейная модель парной регрессии непригодна для прогнозирования объёма продаж в зависимости от температуры воздуха. Нелинейный характер зависимости между указанными переменными по данным наблюдений достаточно хорошо виден на Рис.1. Проведённый анализ это подтвердил.
Среди различных методов прогнозирования нельзя не выделить аппроксимацию. С её помощью можно производить приблизительные подсчеты и вычислять планируемые показатели, путем замены исходных объектов на более простые. В Экселе тоже существует возможность использования данного метода для прогнозирования и анализа. Давайте рассмотрим, как этот метод можно применить в указанной программе встроенными инструментами.
Наименование данного метода происходит от латинского слова proxima – «ближайшая» Именно приближение путем упрощения и сглаживания известных показателей, выстраивание их в тенденцию и является его основой. Но данный метод можно использовать не только для прогнозирования, но и для исследования уже имеющихся результатов. Ведь аппроксимация является, по сути, упрощением исходных данных, а упрощенный вариант исследовать легче.
Главный инструмент, с помощью которого проводится сглаживания в Excel – это построение линии тренда. Суть состоит в том, что на основе уже имеющихся показателей достраивается график функции на будущие периоды. Основное предназначение линии тренда, как не трудно догадаться, это составление прогнозов или выявление общей тенденции.
Но она может быть построена с применением одного из пяти видов аппроксимации:
- Линейной;
- Экспоненциальной;
- Логарифмической;
- Полиномиальной;
- Степенной.
Рассмотрим каждый из вариантов более подробно в отдельности.
Способ 1: линейное сглаживание
Прежде всего, давайте рассмотрим самый простой вариант аппроксимации, а именно с помощью линейной функции. На нем мы остановимся подробнее всего, так как изложим общие моменты характерные и для других способов, а именно построение графика и некоторые другие нюансы, на которых при рассмотрении последующих вариантов уже останавливаться не будем.
Прежде всего, построим график, на основании которого будем проводить процедуру сглаживания. Для построения графика возьмем таблицу, в которой помесячно указана себестоимость единицы продукции, производимой предприятием, и соответствующая прибыль в данном периоде. Графическая функция, которую мы построим, будет отображать зависимость увеличения прибыли от уменьшения себестоимости продукции.


Сглаживание, которое используется в данном случае, описывается следующей формулой:
В конкретно нашем случае формула принимает такой вид:
Величина достоверности аппроксимации у нас равна 0,9418 , что является довольно приемлемым итогом, характеризующим сглаживание, как достоверное.
Способ 2: экспоненциальная аппроксимация
Теперь давайте рассмотрим экспоненциальный тип аппроксимации в Эксель.


Общий вид функции сглаживания при этом такой:
где e – это основание натурального логарифма.
В конкретно нашем случае формула приняла следующую форму:
Способ 3: логарифмическое сглаживание
Теперь настала очередь рассмотреть метод логарифмической аппроксимации.


В общем виде формула сглаживания выглядит так:
где ln – это величина натурального логарифма. Отсюда и наименование метода.
В нашем случае формула принимает следующий вид:
Способ 4: полиномиальное сглаживание
Настал черед рассмотреть метод полиномиального сглаживания.


Формула, которая описывает данный тип сглаживания, приняла следующий вид:
Способ 5: степенное сглаживание
В завершении рассмотрим метод степенной аппроксимации в Excel.


Данный способ эффективно используется в случаях интенсивного изменения данных функции. Важно учесть, что этот вариант применим только при условии, что функция и аргумент не принимают отрицательных или нулевых значений.
Общая формула, описывающая данный метод имеет такой вид:
В конкретно нашем случае она выглядит так:
Как видим, при использовании конкретных данных, которые мы применяли для примера, наибольший уровень достоверности показал метод полиномиальной аппроксимации с полиномом в шестой степени (0,9844 ), наименьший уровень достоверности у линейного метода (0,9418 ). Но это совсем не значит, что такая же тенденция будет при использовании других примеров. Нет, уровень эффективности у приведенных выше методов может значительно отличаться, в зависимости от конкретного вида функции, для которой будет строиться линия тренда. Поэтому, если для этой функции выбранный метод наиболее эффективен, то это совсем не означает, что он также будет оптимальным и в другой ситуации.
Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. После построения линии тренда и просмотра её уровня достоверности можно будет выбрать оптимальный вариант.
Контрольная работа: Парная регрессия
Смысл регрессионного анализа – построение функциональных зависимостей между двумя группами переменных величин Х1 , Х2 , … Хр и Y. При этом речь идет о влиянии переменных Х (это будут аргументы функций) на значения переменной Y (значение функции). Переменные Х мы будем называть факторами, а Y – откликом.
Наиболее простой случай – установление зависимости одного отклика y от одного фактора х. Такой случай называется парной (простой) регрессией.
Парная регрессия – уравнение связи двух переменных у иx :
,
где у – зависимая переменная (результативный признак);
х – независимая, объясняющая переменная (признак-фактор).
Различают линейные и нелинейные регрессии.
Линейная регрессия:.
Нелинейные регрессии делятся на два класса: регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам, и регрессии, нелинейные по оцениваемым параметрам.
Регрессии, нелинейные по объясняющим переменным:
• полиномы разных степеней
•равносторонняя гипербола
Регрессии, нелинейные по оцениваемым параметрам:
• степенная ;
• показательная
• экспоненциальная
Построение уравнения регрессии сводится к оценке ее параметров. Для оценки параметров регрессий, линейных по параметрам, используют метод наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака у от теоретических минимальна, т.е.
Для линейных и нелинейных уравнений, приводимых к линейным, решается следующая система относительно а и b :
Можно воспользоваться готовыми формулами, которые вытекают из этой системы:
Тесноту связи изучаемых явлений оценивает линейный коэффициент парной корреляции для линейной регрессии
и индекс корреляции — для нелинейной регрессии ():
Оценку качества построенной модели даст коэффициент (индекс) детерминации, а также средняя ошибка аппроксимации.
Средняя ошибка аппроксимации – среднее отклонение расчетных значений от фактических:
Допустимый предел значений – не более 8 – 10%.
Средний коэффициент эластичности показывает, на сколько процентов в среднем по совокупности изменится результат у от своей средней величины при изменении фактора x на 1% от своего среднего значения:
Задача дисперсионного анализа состоит в анализе дисперсии зависимой переменной:
где – общая сумма квадратов отклонений;
– сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);
–остаточная сумма квадратов отклонений.
Долю дисперсии, объясняемую регрессией, в общей дисперсии результативного признака у характеризует коэффициент (индекс) детерминации R 2 :
Коэффициент детерминации – квадрат коэффициента или индекса корреляции.
F -тест – оценивание качества уравнения регрессии – состоит в проверке гипотезы Но о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F -критерия Фишера. F факт определяется из соотношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:
п – число единиц совокупности;
т – число параметров при переменных х.
Fтабл – это максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости а. Уровень значимости а – вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно а принимается равной 0,05 или 0,01.
Если Fтабл Fфакт , то гипотеза Н0 не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитываются t -критерий Стьюдента и доверительные интервалы каждого из показателей. Выдвигается гипотеза Н0 о случайной природе показателей, т.е. о незначимом их отличии от нуля. Оценка значимости коэффициентов регрессии и корреляции с помощью f-критерия Стьюдента проводится путем сопоставления их значений с величиной случайной ошибки:
Случайные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам:
Сравнивая фактическое и критическое (табличное) значения t-статистики – tтабл и tфакт – принимаем или отвергаем гипотезу Hо .
Связь между F-критерием Фишера и t-статистикой Стьюдента выражается равенством
Если tтабл tфакт , то гипотеза Но не отклоняется и признается случайная природа формирования a , b или .
Для расчета доверительного интервала определяем предельную ошибку ∆ для каждого показателя:
Формулы для расчета доверительных интервалов имеют следующий вид:
Если в границы доверительного интервала попадает ноль, т.е. нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается нулевым, так как он не может одновременно принимать и положительное, и отрицательное значения.
Прогнозное значение определяется путем подстановки в уравнение регрессии соответствующего (прогнозного) значения . Вычисляется средняя стандартная ошибка прогноза :
где
и строится доверительный интервал прогноза:
где
По 22 регионам страны изучается зависимость розничной продажи телевизоров, y от среднедушевых денежных доходов в месяц, x (табл. 1):
| Название: Парная регрессия Раздел: Рефераты по математике Тип: контрольная работа Добавлен 13:41:57 15 апреля 2011 Похожие работы Просмотров: 3780 Комментариев: 22 Оценило: 4 человек Средний балл: 4.5 Оценка: неизвестно Скачать |
| № региона | X | Y |
| 1,000 | 2,800 | 28,000 |
| 2,000 | 2,400 | 21,300 |
| 3,000 | 2,100 | 21,000 |
| 4,000 | 2,600 | 23,300 |
| 5,000 | 1,700 | 15,800 |
| 6,000 | 2,500 | 21,900 |
| 7,000 | 2,400 | 20,000 |
| 8,000 | 2,600 | 22,000 |
| 9,000 | 2,800 | 23,900 |
| 10,000 | 2,600 | 26,000 |
| 11,000 | 2,600 | 24,600 |
| 12,000 | 2,500 | 21,000 |
| 13,000 | 2,900 | 27,000 |
| 14,000 | 2,600 | 21,000 |
| 15,000 | 2,200 | 24,000 |
| 16,000 | 2,600 | 34,000 |
| 17,000 | 3,300 | 31,900 |
| 19,000 | 3,900 | 33,000 |
| 20,000 | 4,600 | 35,400 |
| 21,000 | 3,700 | 34,000 |
| 22,000 | 3,400 | 31,000 |
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессий.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. С помощью среднего (общего) коэффициента эластичности дайте сравнительную оценку силы связи фактора с результатом.
5. Качество уравнений оцените с помощью средней ошибки аппроксимации.
6. С помощью F-критерия Фишера определите статистическую надежность результатов регрессионного моделирования. Выберите лучшее уравнение регрессии и дайте его обоснование.
7. Рассчитайте прогнозное значение результата по линейному уравнению регрессии, если прогнозное значение фактора увеличится на 7% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости α=0,05.
8. Оцените полученные результаты, выводы оформите в аналитической записке.
1. Поле корреляции для:
· Линейной регрессии y=a+b*x:
Гипотеза о форме связи: чем больше размер среднедушевого денежного дохода в месяц (факторный признак), тем больше при прочих равных условиях розничная продажа телевизоров (результативный признак). В данной модели параметр b называется коэффициентом регрессии и показывает, насколько в среднем отклоняется величина результативного признака у при отклонении величины факторного признаках на одну единицу.
· Степенной регрессии :
Гипотеза о форме связи : степенная функция имеет вид Y=ax b .
Параметр b степенного уравнения называется показателем эластичности и указывает, на сколько процентов изменится у при возрастании х на 1%. При х = 1 a = Y.
· Экспоненциальная регрессия :
· Равносторонняя гипербола :
Гипотеза о форме связи: В ряде случаев обратная связь между факторным и результативным признаками может быть выражена уравнением гиперболы: Y=a+b/x.
· Обратная гипербола :
· Полулогарифмическая регрессия :
2. Рассчитайте параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессий.
· Рассчитаем параметры уравнений линейной парной регрессии. Для расчета параметров a и b линейной регрессии y=a+b*x решаем систему нормальных уравнений относительно a и b:
По исходным данным рассчитываем ∑y, ∑x, ∑yx, ∑x 2 , ∑y 2 (табл. 2):
| № региона | X | Y | XY | X^2 | Y^2 | Y^cp | Y-Y^cp | Ai |
| 1 | 2,800 | 28,000 | 78,400 | 7,840 | 784,000 | 25,719 | 2,281 | 0,081 |
| 2 | 2,400 | 21,300 | 51,120 | 5,760 | 453,690 | 22,870 | -1,570 | 0,074 |
| 3 | 2,100 | 21,000 | 44,100 | 4,410 | 441,000 | 20,734 | 0,266 | 0,013 |
| 4 | 2,600 | 23,300 | 60,580 | 6,760 | 542,890 | 24,295 | -0,995 | 0,043 |
| 5 | 1,700 | 15,800 | 26,860 | 2,890 | 249,640 | 17,885 | -2,085 | 0,132 |
| 6 | 2,500 | 21,900 | 54,750 | 6,250 | 479,610 | 23,582 | -1,682 | 0,077 |
| 7 | 2,400 | 20,000 | 48,000 | 5,760 | 400,000 | 22,870 | -2,870 | 0,144 |
| 8 | 2,600 | 22,000 | 57,200 | 6,760 | 484,000 | 24,295 | -2,295 | 0,104 |
| 9 | 2,800 | 23,900 | 66,920 | 7,840 | 571,210 | 25,719 | -1,819 | 0,076 |
| 10 | 2,600 | 26,000 | 67,600 | 6,760 | 676,000 | 24,295 | 1,705 | 0,066 |
| 11 | 2,600 | 24,600 | 63,960 | 6,760 | 605,160 | 24,295 | 0,305 | 0,012 |
| 12 | 2,500 | 21,000 | 52,500 | 6,250 | 441,000 | 23,582 | -2,582 | 0,123 |
| 13 | 2,900 | 27,000 | 78,300 | 8,410 | 729,000 | 26,431 | 0,569 | 0,021 |
| 14 | 2,600 | 21,000 | 54,600 | 6,760 | 441,000 | 24,295 | -3,295 | 0,157 |
| 15 | 2,200 | 24,000 | 52,800 | 4,840 | 576,000 | 21,446 | 2,554 | 0,106 |
| 16 | 2,600 | 34,000 | 88,400 | 6,760 | 1156,000 | 24,295 | 9,705 | 0,285 |
| 17 | 3,300 | 31,900 | 105,270 | 10,890 | 1017,610 | 29,280 | 2,620 | 0,082 |
| 19 | 3,900 | 33,000 | 128,700 | 15,210 | 1089,000 | 33,553 | -0,553 | 0,017 |
| 20 | 4,600 | 35,400 | 162,840 | 21,160 | 1253,160 | 38,539 | -3,139 | 0,089 |
| 21 | 3,700 | 34,000 | 125,800 | 13,690 | 1156,000 | 32,129 | 1,871 | 0,055 |
| 22 | 3,400 | 31,000 | 105,400 | 11,560 | 961,000 | 29,992 | 1,008 | 0,033 |
| Итого | 58,800 | 540,100 | 1574,100 | 173,320 | 14506,970 | 540,100 | 0,000 | |
| сред значение | 2,800 | 25,719 | 74,957 | 8,253 | 690,808 | 0,085 | ||
| станд. откл | 0,643 | 5,417 |
Система нормальных уравнений составит:
Ур-ие регрессии: = 5,777+7,122∙x. Данное уравнение показывает, что с увеличением среднедушевого денежного дохода в месяц на 1 тыс. руб. доля розничных продаж телевизоров повышается в среднем на 7,12%.
· Рассчитаем параметры уравнений степенной парной регрессии. Построению степенной модели предшествует процедура линеаризации переменных. В примере линеаризация производится путем логарифмирования обеих частей уравнения:
где
Для расчетов используем данные табл. 3:
| № рег | X | Y | XY | X^2 | Y^2 | Yp^cp | y^cp |
| 1 | 1,030 | 3,332 | 3,431 | 1,060 | 11,104 | 3,245 | 25,67072 |
| 2 | 0,875 | 3,059 | 2,678 | 0,766 | 9,356 | 3,116 | 22,56102 |
| 3 | 0,742 | 3,045 | 2,259 | 0,550 | 9,269 | 3,004 | 20,17348 |
| 4 | 0,956 | 3,148 | 3,008 | 0,913 | 9,913 | 3,183 | 24,12559 |
| 5 | 0,531 | 2,760 | 1,465 | 0,282 | 7,618 | 2,827 | 16,90081 |
| 6 | 0,916 | 3,086 | 2,828 | 0,840 | 9,526 | 3,150 | 23,34585 |
| 7 | 0,875 | 2,996 | 2,623 | 0,766 | 8,974 | 3,116 | 22,56102 |
| 8 | 0,956 | 3,091 | 2,954 | 0,913 | 9,555 | 3,183 | 24,12559 |
| 9 | 1,030 | 3,174 | 3,268 | 1,060 | 10,074 | 3,245 | 25,67072 |
| 10 | 0,956 | 3,258 | 3,113 | 0,913 | 10,615 | 3,183 | 24,12559 |
| 11 | 0,956 | 3,203 | 3,060 | 0,913 | 10,258 | 3,183 | 24,12559 |
| 12 | 0,916 | 3,045 | 2,790 | 0,840 | 9,269 | 3,150 | 23,34585 |
| 13 | 1,065 | 3,296 | 3,509 | 1,134 | 10,863 | 3,275 | 26,4365 |
| 14 | 0,956 | 3,045 | 2,909 | 0,913 | 9,269 | 3,183 | 24,12559 |
| 15 | 0,788 | 3,178 | 2,506 | 0,622 | 10,100 | 3,043 | 20,97512 |
| 16 | 0,956 | 3,526 | 3,369 | 0,913 | 12,435 | 3,183 | 24,12559 |
| 17 | 1,194 | 3,463 | 4,134 | 1,425 | 11,990 | 3,383 | 29,4585 |
| 19 | 1,361 | 3,497 | 4,759 | 1,852 | 12,226 | 3,523 | 33,88317 |
| 20 | 1,526 | 3,567 | 5,443 | 2,329 | 12,721 | 3,661 | 38,90802 |
| 21 | 1,308 | 3,526 | 4,614 | 1,712 | 12,435 | 3,479 | 32,42145 |
| 22 | 1,224 | 3,434 | 4,202 | 1,498 | 11,792 | 3,408 | 30,20445 |
| итого | 21,115 | 67,727 | 68,921 | 22,214 | 219,361 | 67,727 | 537,270 |
| сред зн | 1,005 | 3,225 | 3,282 | 1,058 | 10,446 | 3,225 | |
| стан откл | 0,216 | 0,211 |
Рассчитаем С и b:
Получим линейное уравнение: . Выполнив его потенцирование, получим:
Подставляя в данное уравнение фактические значения х, получаем теоретические значения результата y .
· Рассчитаем параметры уравнений экспоненциальной парной регрессии. Построению экспоненциальной модели предшествует процедура линеаризации переменных. В примере линеаризация производится путем логарифмирования обеих частей уравнения:
где
Для расчетов используем данные табл. 4:
| № региона | X | Y | XY | X^2 | Y^2 | Yp | y^cp |
| 1 | 2,800 | 3,332 | 9,330 | 7,840 | 11,104 | 3,225 | 25,156 |
| 2 | 2,400 | 3,059 | 7,341 | 5,760 | 9,356 | 3,116 | 22,552 |
| 3 | 2,100 | 3,045 | 6,393 | 4,410 | 9,269 | 3,034 | 20,777 |
| 4 | 2,600 | 3,148 | 8,186 | 6,760 | 9,913 | 3,170 | 23,818 |
| 5 | 1,700 | 2,760 | 4,692 | 2,890 | 7,618 | 2,925 | 18,625 |
| 6 | 2,500 | 3,086 | 7,716 | 6,250 | 9,526 | 3,143 | 23,176 |
| 7 | 2,400 | 2,996 | 7,190 | 5,760 | 8,974 | 3,116 | 22,552 |
| 8 | 2,600 | 3,091 | 8,037 | 6,760 | 9,555 | 3,170 | 23,818 |
| 9 | 2,800 | 3,174 | 8,887 | 7,840 | 10,074 | 3,225 | 25,156 |
| 10 | 2,600 | 3,258 | 8,471 | 6,760 | 10,615 | 3,170 | 23,818 |
| 11 | 2,600 | 3,203 | 8,327 | 6,760 | 10,258 | 3,170 | 23,818 |
| 12 | 2,500 | 3,045 | 7,611 | 6,250 | 9,269 | 3,143 | 23,176 |
| 13 | 2,900 | 3,296 | 9,558 | 8,410 | 10,863 | 3,252 | 25,853 |
| 14 | 2,600 | 3,045 | 7,916 | 6,760 | 9,269 | 3,170 | 23,818 |
| 15 | 2,200 | 3,178 | 6,992 | 4,840 | 10,100 | 3,061 | 21,352 |
| 16 | 2,600 | 3,526 | 9,169 | 6,760 | 12,435 | 3,170 | 23,818 |
| 17 | 3,300 | 3,463 | 11,427 | 10,890 | 11,990 | 3,362 | 28,839 |
| 19 | 3,900 | 3,497 | 13,636 | 15,210 | 12,226 | 3,526 | 33,978 |
| 20 | 4,600 | 3,567 | 16,407 | 21,160 | 12,721 | 3,717 | 41,140 |
| 21 | 3,700 | 3,526 | 13,048 | 13,690 | 12,435 | 3,471 | 32,170 |
| 22 | 3,400 | 3,434 | 11,676 | 11,560 | 11,792 | 3,389 | 29,638 |
| Итого | 58,800 | 67,727 | 192,008 | 173,320 | 219,361 | 67,727 | 537,053 |
| сред зн | 2,800 | 3,225 | 9,143 | 8,253 | 10,446 | ||
| стан откл | 0,643 | 0,211 |
Рассчитаем С и b:
Получим линейное уравнение: . Выполнив его потенцирование, получим:
Для расчета теоретических значений y подставим в уравнение значения x .
· Рассчитаем параметры уравнений полулогарифмической парной регрессии. Построению полулогарифмической модели предшествует процедура линеаризации переменных. В примере линеаризация производится путем замены:
где
Для расчетов используем данные табл. 5:
| № региона | X | Y | XY | X^2 | Y^2 | y^cp |
| 1 | 1,030 | 28,000 | 28,829 | 1,060 | 784,000 | 26,238 |
| 2 | 0,875 | 21,300 | 18,647 | 0,766 | 453,690 | 22,928 |
| 3 | 0,742 | 21,000 | 15,581 | 0,550 | 441,000 | 20,062 |
| 4 | 0,956 | 23,300 | 22,263 | 0,913 | 542,890 | 24,647 |
| 5 | 0,531 | 15,800 | 8,384 | 0,282 | 249,640 | 15,525 |
| 6 | 0,916 | 21,900 | 20,067 | 0,840 | 479,610 | 23,805 |
| 7 | 0,875 | 20,000 | 17,509 | 0,766 | 400,000 | 22,928 |
| 8 | 0,956 | 22,000 | 21,021 | 0,913 | 484,000 | 24,647 |
| 9 | 1,030 | 23,900 | 24,608 | 1,060 | 571,210 | 26,238 |
| 10 | 0,956 | 26,000 | 24,843 | 0,913 | 676,000 | 24,647 |
| 11 | 0,956 | 24,600 | 23,506 | 0,913 | 605,160 | 24,647 |
| 12 | 0,916 | 21,000 | 19,242 | 0,840 | 441,000 | 23,805 |
| 13 | 1,065 | 27,000 | 28,747 | 1,134 | 729,000 | 26,991 |
| 14 | 0,956 | 21,000 | 20,066 | 0,913 | 441,000 | 24,647 |
| 15 | 0,788 | 24,000 | 18,923 | 0,622 | 576,000 | 21,060 |
| 16 | 0,956 | 34,000 | 32,487 | 0,913 | 1156,000 | 24,647 |
| 17 | 1,194 | 31,900 | 38,086 | 1,425 | 1017,610 | 29,765 |
| 19 | 1,361 | 33,000 | 44,912 | 1,852 | 1089,000 | 33,351 |
| 20 | 1,526 | 35,400 | 54,022 | 2,329 | 1253,160 | 36,895 |
| 21 | 1,308 | 34,000 | 44,483 | 1,712 | 1156,000 | 32,221 |
| 22 | 1,224 | 31,000 | 37,937 | 1,498 | 961,000 | 30,406 |
| Итого | 21,115 | 540,100 | 564,166 | 22,214 | 14506,970 | 540,100 |
| сред зн | 1,005 | 25,719 | 26,865 | 1,058 | 690,808 | |
| стан откл | 0,216 | 5,417 |
Рассчитаем a и b:
Получим линейное уравнение: .
· Рассчитаем параметры уравнений обратной парной регрессии. Для оценки параметров приведем обратную модель к линейному виду, заменив , тогда
Для расчетов используем данные табл. 6:
| № региона | X | Y | XY | X^2 | Y^2 | Y^cp |
| 1 | 2,800 | 0,036 | 0,100 | 7,840 | 0,001 | 24,605 |
| 2 | 2,400 | 0,047 | 0,113 | 5,760 | 0,002 | 22,230 |
| 3 | 2,100 | 0,048 | 0,100 | 4,410 | 0,002 | 20,729 |
| 4 | 2,600 | 0,043 | 0,112 | 6,760 | 0,002 | 23,357 |
| 5 | 1,700 | 0,063 | 0,108 | 2,890 | 0,004 | 19,017 |
| 6 | 2,500 | 0,046 | 0,114 | 6,250 | 0,002 | 22,780 |
| 7 | 2,400 | 0,050 | 0,120 | 5,760 | 0,003 | 22,230 |
| 8 | 2,600 | 0,045 | 0,118 | 6,760 | 0,002 | 23,357 |
| 9 | 2,800 | 0,042 | 0,117 | 7,840 | 0,002 | 24,605 |
| 10 | 2,600 | 0,038 | 0,100 | 6,760 | 0,001 | 23,357 |
| 11 | 2,600 | 0,041 | 0,106 | 6,760 | 0,002 | 23,357 |
| 12 | 2,500 | 0,048 | 0,119 | 6,250 | 0,002 | 22,780 |
| 13 | 2,900 | 0,037 | 0,107 | 8,410 | 0,001 | 25,280 |
| 14 | 2,600 | 0,048 | 0,124 | 6,760 | 0,002 | 23,357 |
| 15 | 2,200 | 0,042 | 0,092 | 4,840 | 0,002 | 21,206 |
| 16 | 2,600 | 0,029 | 0,076 | 6,760 | 0,001 | 23,357 |
| 17 | 3,300 | 0,031 | 0,103 | 10,890 | 0,001 | 28,398 |
| 19 | 3,900 | 0,030 | 0,118 | 15,210 | 0,001 | 34,844 |
| 20 | 4,600 | 0,028 | 0,130 | 21,160 | 0,001 | 47,393 |
| 21 | 3,700 | 0,029 | 0,109 | 13,690 | 0,001 | 32,393 |
| 22 | 3,400 | 0,032 | 0,110 | 11,560 | 0,001 | 29,301 |
| Итого | 58,800 | 0,853 | 2,296 | 173,320 | 0,036 | 537,933 |
| сред знач | 2,800 | 0,041 | 0,109 | 8,253 | 0,002 | |
| стан отклон | 0,643 | 0,009 |
Рассчитаем a и b:
Получим линейное уравнение: . Выполнив его потенцирование, получим:
Для расчета теоретических значений y подставим в уравнение значения x .
· Рассчитаем параметры уравнений равносторонней гиперболы парной регрессии. Для оценки параметров приведем модель равносторонней гиперболы к линейному виду, заменив , тогда
Для расчетов используем данные табл. 7:
| № региона | X=1/z | Y | XY | X^2 | Y^2 | Y^cp |
| 1 | 0,357 | 28,000 | 10,000 | 0,128 | 784,000 | 26,715 |
| 2 | 0,417 | 21,300 | 8,875 | 0,174 | 453,690 | 23,259 |
| 3 | 0,476 | 21,000 | 10,000 | 0,227 | 441,000 | 19,804 |
| 4 | 0,385 | 23,300 | 8,962 | 0,148 | 542,890 | 25,120 |
| 5 | 0,588 | 15,800 | 9,294 | 0,346 | 249,640 | 13,298 |
| 6 | 0,400 | 21,900 | 8,760 | 0,160 | 479,610 | 24,227 |
| 7 | 0,417 | 20,000 | 8,333 | 0,174 | 400,000 | 23,259 |
| 8 | 0,385 | 22,000 | 8,462 | 0,148 | 484,000 | 25,120 |
| 9 | 0,357 | 23,900 | 8,536 | 0,128 | 571,210 | 26,715 |
| 10 | 0,385 | 26,000 | 10,000 | 0,148 | 676,000 | 25,120 |
| 11 | 0,385 | 24,600 | 9,462 | 0,148 | 605,160 | 25,120 |
| 12 | 0,400 | 21,000 | 8,400 | 0,160 | 441,000 | 24,227 |
| 13 | 0,345 | 27,000 | 9,310 | 0,119 | 729,000 | 27,430 |
| 14 | 0,385 | 21,000 | 8,077 | 0,148 | 441,000 | 25,120 |
| 15 | 0,455 | 24,000 | 10,909 | 0,207 | 576,000 | 21,060 |
| 16 | 0,385 | 34,000 | 13,077 | 0,148 | 1156,000 | 25,120 |
| 17 | 0,303 | 31,900 | 9,667 | 0,092 | 1017,610 | 29,857 |
| 19 | 0,256 | 33,000 | 8,462 | 0,066 | 1089,000 | 32,564 |
| 20 | 0,217 | 35,400 | 7,696 | 0,047 | 1253,160 | 34,829 |
| 21 | 0,270 | 34,000 | 9,189 | 0,073 | 1156,000 | 31,759 |
| 22 | 0,294 | 31,000 | 9,118 | 0,087 | 961,000 | 30,374 |
| Итого | 7,860 | 540,100 | 194,587 | 3,073 | 14506,970 | 540,100 |
| сред знач | 0,374 | 25,719 | 9,266 | 0,146 | 1318,815 | |
| стан отклон | 0,079 | 25,639 |
Рассчитаем a и b:
Получим линейное уравнение: . Получим уравнение регрессии: .
3. Оценка тесноты связи с помощью показателей корреляции и детерминации :
· Линейная модель. Тесноту линейной связи оценит коэффициент корреляции. Был получен следующий коэффициент корреляции rxy =b=7,122*, что говорит о прямой сильной связи фактора и результата. Коэффициент детерминации r²xy =(0,845)²=0,715. Это означает, что 71,5% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц.
· Степенная модель. Тесноту нелинейной связи оценит индекс корреляции. Был получен следующий индекс корреляции =, что говорит о очень сильной тесной связи, но немного больше чем в линейной модели. Коэффициент детерминации r²xy =0,7175. Это означает, что 71,75% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц.
· Экспоненциальная модель. Был получен следующий индекс корреляции ρxy =0,8124, что говорит о том, что связь прямая и очень сильная, но немного слабее, чем в линейной и степенной моделях. Коэффициент детерминации r²xy =0,66. Это означает, что 66% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц.
· Полулогарифмическая модель. Был получен следующий индекс корреляции ρxy =0,8578, что говорит о том, что связь прямая и очень сильная, но немного больше чем в предыдущих моделях. Коэффициент детерминации r²xy =0,7358. Это означает, что 73,58% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц.
· Гиперболическая модель. Был получен следующий индекс корреляции ρxy =0,8448 и коэффициент корреляции rxy =-0,1784 что говорит о том, что связь обратная очень сильная. Коэффициент детерминации r²xy =0,7358. Это означает, что 73,5% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц.
· Обратная модель. Был получен следующий индекс корреляции ρxy =0,8114 и коэффициент корреляции rxy =-0,8120, что говорит о том, что связь обратная очень сильная. Коэффициент детерминации r²xy =0,6584. Это означает, что 65,84% вариации результативного признака (розничнаяпродажа телевизоров, у) объясняется вариацией фактора х – среднедушевой денежный доход в месяц.
Вывод: по полулогарифмическому уравнению получена наибольшая оценка тесноты связи: ρxy =0,8578 (по сравнению с линейной, степенной, экспоненциальной, гиперболической, обратной регрессиями).
4. С помощью среднего (общего) коэффициента эластичности дайте сравнительную оценку силы связи фактора с результатом.
Рассчитаем коэффициент эластичности для линейной модели:
· Для уравнения прямой:y = 5,777+7,122∙x
· Для уравнениястепенноймодели :
· Для уравненияэкспоненциальноймодели :
Для уравненияполулогарифмическоймодели :
· Для уравнения обратной гиперболической модели :
· Для уравнения равносторонней гиперболической модели :
Сравнивая значения , характеризуем оценку силы связи фактора с результатом:
·
·
·
·
·
·
Известно, что коэффициент эластичности показывает связь между фактором и результатом, т.е. на сколько% изменится результат y от своей средней величины при изменении фактора х на 1% от своего среднего значения. В данном примере получилось, что самая большая сила связи между фактором и результатом в полулогарифмической модели, слабая сила связи в обратной гиперболической модели.
5. Оценка качества уравнений с помощью средней ошибки аппроксимации.
Подставляя в уравнение регрессии фактические значения х, определим теоретические (расчетные) значения . Найдем величину средней ошибки аппроксимации :
В среднем расчетные значения отклоняются от фактических на:
· Линейная регрессия. =*100%= 8,5%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
Качество построенной модели оценивается как хорошее, так как не превышает 8 -10%.
· Степенная регрессия. =*100%= 8,2%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
Качество построенной модели оценивается как хорошее, так как не превышает 8 -10%.
· Экспоненциальная регрессия. =*100%= 9%, что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
Качество построенной модели оценивается как хорошее, так как не превышает 8 -10%.
· Полулогарифмическая регрессия. =*100%= 7,9 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
Качество построенной модели оценивается как хорошее, так как не превышает 8 -10%.
· Гиперболическая регрессия. =*100%= 9,3 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
Качество построенной модели оценивается как хорошее, так как не превышает 8 -10%.
· Обратная регрессия. =*100%= 9,9 3 что говорит о повышенной ошибке аппроксимации, но в допустимых пределах.
Качество построенной модели оценивается как хорошее, так как не превышает 8 -10%.
6. Рассчитаем F-критерий:
· Линейная регрессия. = *19= 47,579
http://welom.ru/srednyaya-oshibka-approksimacii-v-excel-ocenka-kachestva-uravneniya/
http://www.bestreferat.ru/referat-268496.html
Вариант
5
1
задание
-
Постройте
поле корреляции и сформулируйте гипотезу
о форме связи.
-
Введу
значения Y
и X
в таблицу, отсортирую их по возрастанию
по X:Y
X
68,77
70,5
64,19
70,64
65,78
70,93
63,35
71,61
67,67
73,37
60,95
75,93
61,21
76,31
65,96
76,37
67,47
76,72
61,13
77,18
65,55
77,43
62,47
77,79
64,53
78,38
66,67
78,5
64,81
78,75
69,68
79,3
61,5
79,38
61,57
79,69
-
Построю
поле корреляции по данным из таблицы:

-
Сказать
о форме связи достаточно тяжело, потому
что точки располагаются неравномерно.
Возможно, здесь линейная форма связи.
-
Рассчитайте
параметры уравнения линейной регрессии.
-
Чтобы
рассчитать параметры уравнения линейной
регрессии, необходимо написать само
уравнение: y=ax+b,
а также нужно записать формулу для
коэффициентов а и b.



-
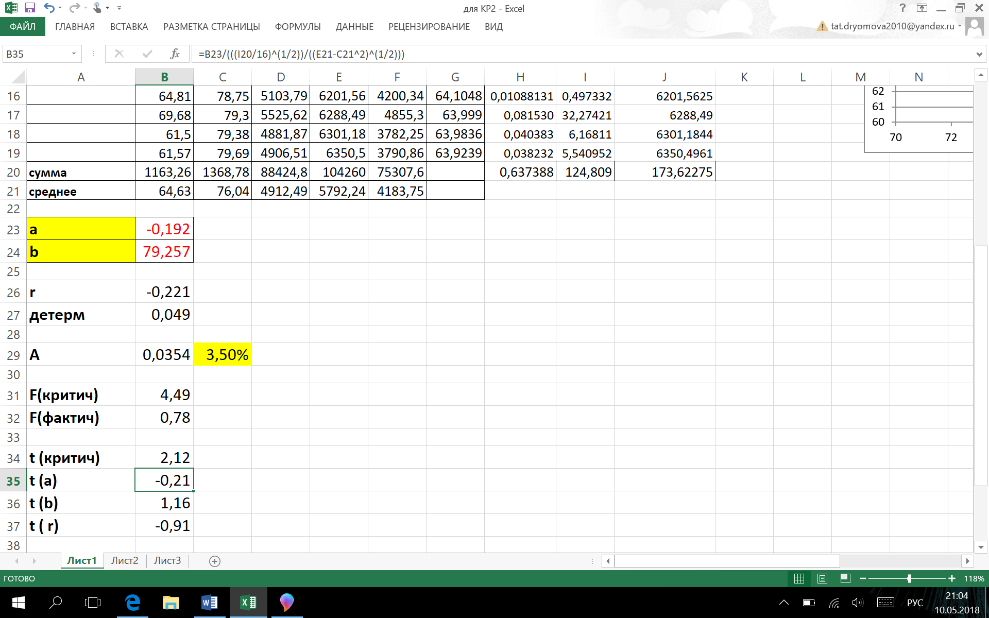
Введу
в таблицу новые показатели: x*y,
x^2,
сумму, среднее значение и рассчитаю
их, а затем по формулам рассчитаю
коэффициенты а и b.
|
|
||||
|
|
||||



-
Оцените
тесноту связи с помощью показателей
корреляции и детерминации.
-
С
помощью формулы линейного коэффициента
парной корреляции определю тесноту
связи
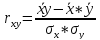
R=-0,221
-
Коэффициент
детерминации – это коэффициент
корреляции в квадрате.
Он
равен = 0,049

Вывод:
связь слабая.
-
Оцените
с помощью средней ошибки аппроксимации
качество уравнений.
Средняя
ошибка аппроксимации – среднее отклонение
расчетных значений от фактических:

Для
данных расчётов мне необходимо значение
 ,
,
которое в Excel
назову y(t).
По формуле рассчитала показатель А.

Средняя
ошибка аппроксимации равна 3,5%. Величина
ошибки аппроксимации говорит о высоком
качестве модели.
-
Оцените
с помощью F -критерия Фишера и t -критерия
Стьюдента статистическую значимость
результатов регрессионного моделирования.
-
Рассчитаю
F-критерий
Фишера по формулам
Критическое
значение рассчитала по специальной
статистической формуле в Excel
F.ОБР.ПХ.
(вероятность 0,05; степени свободы1 =1;
степени свободы2 = 16). F(критич)
= 4,49

Фактическое
значение рассчитала по формуле:
 ,
,
где n-
количество исследуемых точек.
F
(фактич) = 0,78

Так
как F
(критич) больше F
(фактич), то можно сделать вывод, что
уравнение связи является статистически
незначимым.
-
Рассчитаю
критический t-критерий
Стьюдента по статистической формуле
в Excel
СТЬЮДЕНТ.ОБР.2Х (вероятность = 0,05; степени
свободы (18-2) =16). t (критич) = 2,12.

Фактическое
значение считаю для каждого параметра:
Параметр
а:

,
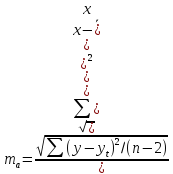
Параметр
b:


Параметр
r:
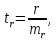

t(a)
= -0,01
t(b)
= 1,16
t(r
) = -0,91
Так
как все фактические критерии параметров
меньше критического t-критерия,
значит все параметры статистически не
значимые.
-
По
значениям характеристик, рассчитанным
в пп. 3-5, выберите лучшее уравнение
регрессии и дайте его обоснование.
Наше
уравнение линейной регрессии обладает
такими свойствами:
-
Связь
слабая (по коэффициенту парной корреляции) -
Высокое
качество модели (по средней ошибке
аппроксимации) -
Уравнение
связи и все его параметры являются
статистически незначимыми (на основании
F-критерия
Фишера и t-критерия
Стьюдента)
-
Рассчитайте
прогнозное значение результата, если
значение фактора увеличится на 10% от
его среднего уровня. Определите
доверительный интервал прогноза для
уровня значимости α= 0,05
Прогнозное
значение
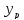
определяется путём подстановки в
уравнение регрессии

соответствующего (прогнозного) значения
 .
.
Вычисляется средняя стандартная ошибка
прогноза

:

где

и
строится доверительный интервал
прогноза:

-
Найду
прогнозное значение результативного
фактора

при значении признака-фактора,
составляющем 110% от среднего уровня

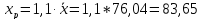


-
Найду
доверительный интервал прогноза. Ошибка
прогноза


Доверительный
интервал рассчитывается:
 )
)
Здесь:
(двухстороннее значение t-критерия
Стьюдента): t
(0,05; 18-2) = 2,12
Доверительный
интервал: (63,16- 9,81*2,12; 63,16+ 9,81*2,12) = (42,38;
83,95)
Истинное
значение прогноза (63,16) попадает в этот
интервал.
2
задание
Разработайте
план погашения кредита, полученного на
следующих условиях: Сумма кредита – Р
тысяч рублей, срок кредита – n лет,
процентная ставка по кредиту – i% годовых,
количество платежей в год –m раз. Данные
для каждого варианта приводятся в
таблице ниже:
|
Сумма |
Срок |
Процентная |
Количество |
|
675 |
5 |
28 |
1 |
-
Составлю
таблицу «План погашения кредита»
|
№ п/п |
Сумма |
Годовая |
Процентные |
Осталось |
-
Для
начала рассчитаю сумму ежегодного
платежа (тыс. руб.). Для этого выберу
финансовую функцию ПЛТ в Excel:
ПЛТ(28%; В3; А3; 0; 0)
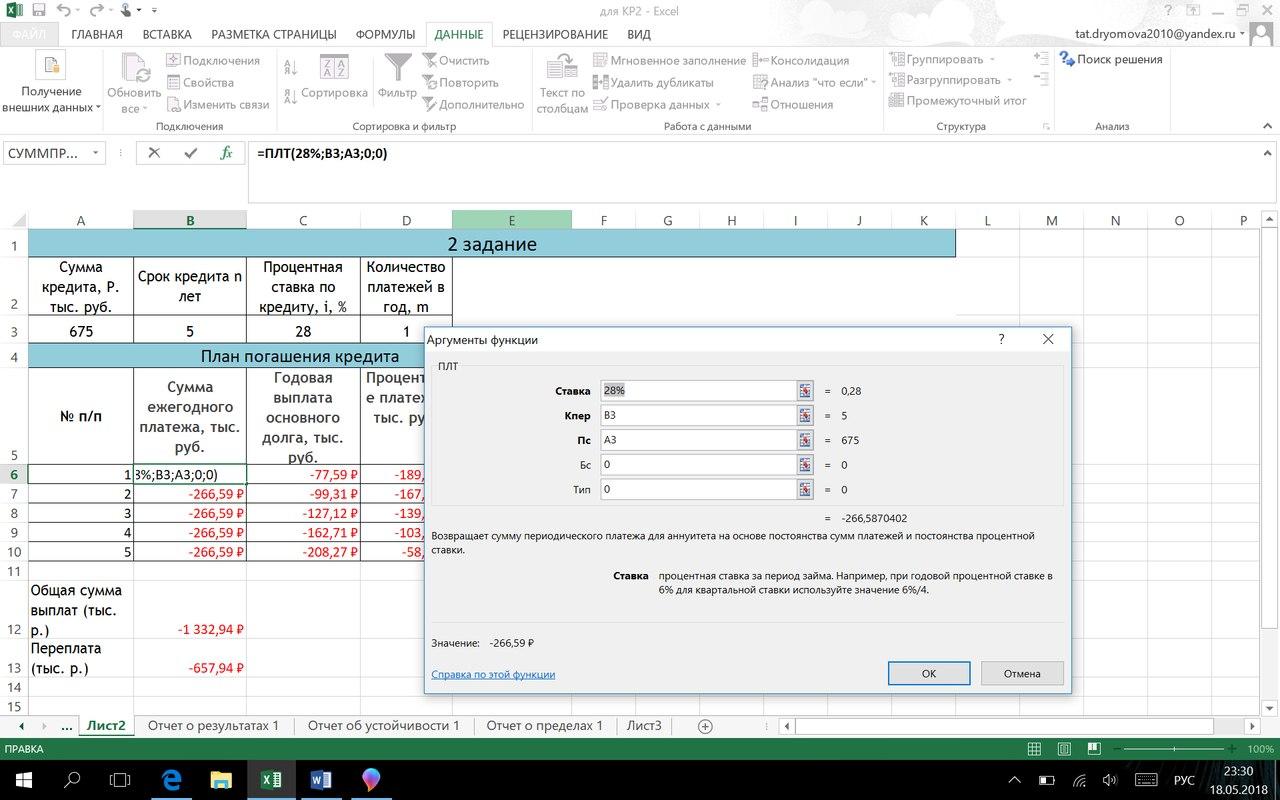
Ежегодный
платёж на протяжении 5-ти лет будет
равным. Поэтому можно рассчитать общую
сумму выплат (долг + проценты) и переплату:
-
Общая
сумма выплат = сумма ежегодного платежа
* срок кредита = 266, 59 тыс. р. * 5 лет = 1332,94
тыс. р. -
Переплата
составит = общая сумма выплат – сумма
кредита = 1332,59 тыс. р. – 675 тыс. р. = 657, 94
тыс. р.
-
Рассчитаю
годовую выплату основного долга:
Для
этого использую функцию ОСПЛТ в Excel:
ОСПЛТ (28%; период; $B$3;
$A$3;
0) – период соответственно каждой строке
(1-5)

Годовая
выплата по кредиту для каждого года
составила:

-
Далее
рассчитаю сколько процентных платежей
уплачивается за каждый период. Для
этого из суммы ежегодного платежа вычту
годовую выплату основного долга
(результаты этих вычислений на фото
таблицы Excel
выше). -
Чтобы
посчитать последний столбец «осталось
выплатить» проделаю следующую операцию:
-
для
первого периода: =$A$3+СУММ($C$6:C6), где $A$3
– первоначальная сумма кредита, $C$6:C6
– годовая выплата основного долга в
рассматриваемый период; -
для
второго периода: =$E$6+СУММ($C$7:C7), где $E$6
– осталось выплатить в предыдущем
периоде; -
для
остальных периодов первое слагаемое
будет равно «осталось выплатить» в
предыдущем периоде, а второе слагаемое
– годовая выплата основного долга в
рассматриваемом периоде.
В
конце последнего периода «осталось
выплатить» становится равным 0, так как
мы полностью погасили долг.
План
погашения кредита разработан.

3
задание
-
определить
оптимальный план выпуска, максимизирующий
прибыль; -
насколько
изменится оптимальное решение, если
продукция будет измеряться в шт.
(целочисленное). -
насколько
изменится оптимальное решение, если
задана нижняя граница плана выпуска
по каждому изделию (договорные
обязательства) -
Провести
анализ чувствительности оптимального
решения.
|
Нормы |
Запасы |
||||
|
Изделие |
Изделие |
Изделие |
Изделие |
||
|
Сырьё |
5 |
1 |
8 |
7 |
745 |
|
Сырьё |
1 |
5 |
5 |
6 |
610 |
|
Сырьё |
7 |
5 |
7 |
4 |
768 |
|
Цена |
7 |
6 |
9 |
14 |

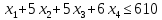


-
Составлю
таблицу в Excel:
создала сроку «коэф. цф», где написала
коэффициенты переменных из первого
уравнения и столбец «знач. цф». Через
функцию СУММПРОИЗВ посчитала «знач.
цф». Затем, нажав ячейку «знач. цф»,
нажму «поиск решения» и введу ограничения,
а также выберу метод поиска решений.
Таким образом определила оптимальный
план выпуска, максимизирующий прибыль.

-
Для
ответа на второй вопрос задачи оставлю
эту же таблицу. В графе поиска решений
добавлю ограничение на значения
переменных – они должны быть целыми.
Значение переменных изменится
незначительно (округлится до целых
чисел), а в столбце на пересечении стоки
«огранич» и столбца «знач. цф» произойдут
изменения с 745 до 741 (на 4 ед.) и с 768 до 764
(на 4 ед.)

-
Задам
произвольную нижнюю границу: 1 и добавлю
это условие в ограничения на поиск
решений. При этом значения переменных
изменятся следующим образом:
Х1
уменьшится на 3 ед., Х2 уменьшится на 3
ед., Х3 увеличится на 1 ед., Х4 увеличится
на 2 ед.

-
Отчёты:



Согласно
отчёту о результатах все ресурсы являются
дефицитными (состояние – привязка).
Согласно
отчёту об устойчивости:
Х1: допустимое
увеличение =6,741, допустимое уменьшение
= 0,172
Х2: допустимое увеличение =6,894,
допустимое уменьшение = 0,217
Х3:
допустимое увеличение =5,306, допустимое
уменьшение = 1Е+30
Х4: допустимое увеличение
=0,208, допустимое уменьшение = 7,271.
F10:
допустимое увеличение =348, 774, допустимое
уменьшение = 242,896
F11:
допустимое увеличение =620,75, допустимое
уменьшение = 306,26
F9:
допустимое увеличение =185,368, допустимое
уменьшение = 496,6
Соседние файлы в предмете Компьютерный практикум
- #
20.03.201819.8 Кб2711 курс КП 11.xlsx
- #
20.03.201836.24 Кб1611 курс КП 6.xlsx
- #
20.03.201821.95 Кб1111 курс КП 8.xlsx
- #
20.03.201822.76 Кб1361 курс КП 9.xlsx
- #
Средняя ошибка аппроксимации
Решение проводим при помощь онлайн калькулятора Линейное уравнение регрессии.
а) линейное уравнение регрессии;
Использование графического метода.
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
Для наших данных система уравнений имеет вид
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = -0.35, a = 76.88
Уравнение регрессии:
y = -0.35 x + 76.88
| x | y | x 2 | y 2 | x • y | y(x) | (y i -y cp ) 2 | (y-y(x)) 2 | |y — y x |:y |
| 45,1 | 68,8 | 2034,01 | 4733,44 | 3102,88 | 61,28 | 119,12 | 56,61 | 0,1094 |
| 59 | 61,2 | 3481 | 3745,44 | 3610,8 | 56,47 | 10,98 | 22,4 | 0,0773 |
| 57,2 | 59,9 | 3271,84 | 3588,01 | 3426,28 | 57,09 | 4,06 | 7,9 | 0,0469 |
| 61,8 | 56,7 | 3819,24 | 3214,89 | 3504,06 | 55,5 | 1,41 | 1,44 | 0,0212 |
| 58,8 | 55 | 3457,44 | 3025 | 3234 | 56,54 | 8,33 | 2,36 | 0,0279 |
| 47,2 | 54,3 | 2227,84 | 2948,49 | 2562,96 | 60,55 | 12,86 | 39,05 | 0,1151 |
| 55,2 | 49,3 | 3047,04 | 2430,49 | 2721,36 | 57,78 | 73,71 | 71,94 | 0,172 |
| 384,3 | 405,2 | 21338,41 | 23685,76 | 22162,34 | 405,2 | 230,47 | 201,71 | 0,5699 |
Примечание: значения y(x) находятся из полученного уравнения регрессии:
y(45.1) = -0.35*45.1 + 76.88 = 61.28
y(59) = -0.35*59 + 76.88 = 56.47
. . .
Ошибка аппроксимации
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации. Средняя ошибка аппроксимации — среднее отклонение расчетных значений от фактических:
F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=5, Fkp = 6.61
Поскольку фактическое значение F b
в) показательная регрессия;
г) модель равносторонней гиперболы.
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
7a + 0.1291b = 405.2
0.1291a + 0.0024b = 7.51
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 1054.67, a = 38.44
Уравнение регрессии:
y = 1054.67 / x + 38.44
Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Метод аппроксимации в Microsoft Excel

Среди различных методов прогнозирования нельзя не выделить аппроксимацию. С её помощью можно производить приблизительные подсчеты и вычислять планируемые показатели, путем замены исходных объектов на более простые. В Экселе тоже существует возможность использования данного метода для прогнозирования и анализа. Давайте рассмотрим, как этот метод можно применить в указанной программе встроенными инструментами.
Выполнение аппроксимации
Наименование данного метода происходит от латинского слова proxima – «ближайшая» Именно приближение путем упрощения и сглаживания известных показателей, выстраивание их в тенденцию и является его основой. Но данный метод можно использовать не только для прогнозирования, но и для исследования уже имеющихся результатов. Ведь аппроксимация является, по сути, упрощением исходных данных, а упрощенный вариант исследовать легче.
Главный инструмент, с помощью которого проводится сглаживания в Excel – это построение линии тренда. Суть состоит в том, что на основе уже имеющихся показателей достраивается график функции на будущие периоды. Основное предназначение линии тренда, как не трудно догадаться, это составление прогнозов или выявление общей тенденции.
Но она может быть построена с применением одного из пяти видов аппроксимации:
- Линейной;
- Экспоненциальной;
- Логарифмической;
- Полиномиальной;
- Степенной.
Рассмотрим каждый из вариантов более подробно в отдельности.
Способ 1: линейное сглаживание
Прежде всего, давайте рассмотрим самый простой вариант аппроксимации, а именно с помощью линейной функции. На нем мы остановимся подробнее всего, так как изложим общие моменты характерные и для других способов, а именно построение графика и некоторые другие нюансы, на которых при рассмотрении последующих вариантов уже останавливаться не будем.
Прежде всего, построим график, на основании которого будем проводить процедуру сглаживания. Для построения графика возьмем таблицу, в которой помесячно указана себестоимость единицы продукции, производимой предприятием, и соответствующая прибыль в данном периоде. Графическая функция, которую мы построим, будет отображать зависимость увеличения прибыли от уменьшения себестоимости продукции.
- Для построения графика, прежде всего, выделяем столбцы «Себестоимость единицы продукции» и «Прибыль». После этого перемещаемся во вкладку «Вставка». Далее на ленте в блоке инструментов «Диаграммы» щелкаем по кнопке «Точечная». В открывшемся списке выбираем наименование «Точечная с гладкими кривыми и маркерами». Именно данный вид диаграмм наиболее подходит для работы с линией тренда, а значит, и для применения метода аппроксимации в Excel.



Существует ещё один вариант её добавления. В дополнительной группе вкладок на ленте «Работа с диаграммами» перемещаемся во вкладку «Макет». Далее в блоке инструментов «Анализ» щелкаем по кнопке «Линия тренда». Открывается список. Так как нам нужно применить линейную аппроксимацию, то из представленных позиций выбираем «Линейное приближение».

Если же вы выбрали все-таки первый вариант действий с добавлением через контекстное меню, то откроется окно формата.
В блоке параметров «Построение линии тренда (аппроксимация и сглаживание)» устанавливаем переключатель в позицию «Линейная».
При желании можно установить галочку около позиции «Показывать уравнение на диаграмме». После этого на диаграмме будет отображаться уравнение сглаживающей функции.
Также в нашем случае для сравнения различных вариантов аппроксимации важно установить галочку около пункта «Поместить на диаграмму величину достоверной аппроксимации (R^2)». Данный показатель может варьироваться от 0 до 1. Чем он выше, тем аппроксимация качественнее (достовернее). Считается, что при величине данного показателя 0,85 и выше сглаживание можно считать достоверным, а если показатель ниже, то – нет.
После того, как провели все вышеуказанные настройки. Жмем на кнопку «Закрыть», размещенную в нижней части окна.


Сглаживание, которое используется в данном случае, описывается следующей формулой:
В конкретно нашем случае формула принимает такой вид:
Величина достоверности аппроксимации у нас равна 0,9418, что является довольно приемлемым итогом, характеризующим сглаживание, как достоверное.
Способ 2: экспоненциальная аппроксимация
Теперь давайте рассмотрим экспоненциальный тип аппроксимации в Эксель.
- Для того, чтобы изменить тип линии тренда, выделяем её кликом правой кнопки мыши и в раскрывшемся меню выбираем пункт «Формат линии тренда…».

После этого запускается уже знакомое нам окно формата. В блоке выбора типа аппроксимации устанавливаем переключатель в положение «Экспоненциальная». Остальные настройки оставим такими же, как и в первом случае. Щелкаем по кнопке «Закрыть».


Общий вид функции сглаживания при этом такой:
где e – это основание натурального логарифма.
В конкретно нашем случае формула приняла следующую форму:
Способ 3: логарифмическое сглаживание
Теперь настала очередь рассмотреть метод логарифмической аппроксимации.
- Тем же способом, что и в предыдущий раз через контекстное меню запускаем окно формата линии тренда. Устанавливаем переключатель в позицию «Логарифмическая» и жмем на кнопку «Закрыть».


В общем виде формула сглаживания выглядит так:
где ln – это величина натурального логарифма. Отсюда и наименование метода.
В нашем случае формула принимает следующий вид:
Способ 4: полиномиальное сглаживание
Настал черед рассмотреть метод полиномиального сглаживания.
- Переходим в окно формата линии тренда, как уже делали не раз. В блоке «Построение линии тренда» устанавливаем переключатель в позицию «Полиномиальная». Справа от данного пункта расположено поле «Степень». При выборе значения «Полиномиальная» оно становится активным. Здесь можно указать любое степенное значение от 2 (установлено по умолчанию) до 6. Данный показатель определяет число максимумов и минимумов функции. При установке полинома второй степени описывается только один максимум, а при установке полинома шестой степени может быть описано до пяти максимумов. Для начала оставим настройки по умолчанию, то есть, укажем вторую степень. Остальные настройки оставляем такими же, какими мы выставляли их в предыдущих способах. Жмем на кнопку «Закрыть».

Линия тренда с использованием данного метода построена. Как видим, она ещё более изогнута, чем при использовании экспоненциальной аппроксимации. Уровень достоверности выше, чем при любом из использованных ранее способов, и составляет 0,9724.

Данный метод наиболее успешно можно применять в том случае, если данные носят постоянно изменчивый характер. Функция, описывающая данный вид сглаживания, выглядит таким образом:
В нашем случае формула приняла такой вид:
y=0,0015*x^2-1,7202*x+507,01
Теперь давайте изменим степень полиномов, чтобы увидеть, будет ли отличаться результат. Возвращаемся в окно формата. Тип аппроксимации оставляем полиномиальным, но напротив него в окне степени устанавливаем максимально возможное значение – 6.


Формула, которая описывает данный тип сглаживания, приняла следующий вид:
Способ 5: степенное сглаживание
В завершении рассмотрим метод степенной аппроксимации в Excel.
- Перемещаемся в окно «Формат линии тренда». Устанавливаем переключатель вида сглаживания в позицию «Степенная». Показ уравнения и уровня достоверности, как всегда, оставляем включенными. Жмем на кнопку «Закрыть».


Данный способ эффективно используется в случаях интенсивного изменения данных функции. Важно учесть, что этот вариант применим только при условии, что функция и аргумент не принимают отрицательных или нулевых значений.
Общая формула, описывающая данный метод имеет такой вид:
В конкретно нашем случае она выглядит так:
Как видим, при использовании конкретных данных, которые мы применяли для примера, наибольший уровень достоверности показал метод полиномиальной аппроксимации с полиномом в шестой степени (0,9844), наименьший уровень достоверности у линейного метода (0,9418). Но это совсем не значит, что такая же тенденция будет при использовании других примеров. Нет, уровень эффективности у приведенных выше методов может значительно отличаться, в зависимости от конкретного вида функции, для которой будет строиться линия тренда. Поэтому, если для этой функции выбранный метод наиболее эффективен, то это совсем не означает, что он также будет оптимальным и в другой ситуации.
Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. После построения линии тренда и просмотра её уровня достоверности можно будет выбрать оптимальный вариант.
Мы рады, что смогли помочь Вам в решении проблемы.
Помимо этой статьи, на сайте еще 11905 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Ниже приведены условия задач, и текстовый отчет о решении. Закачка полного решения(документы doc и xlsx в архиве zip) начнется автоматически через 10 секунд.
Задача 1. По данным приведенным в таблице 1 провести регрессионный анализ, используя следующие зависимости: линейную, квадратическую, гиперболическую, показательную, степенную, логарифмическую. Выбрать лучшую модель.
Таблица 1 – Исходные данные
|
№ п/п |
X |
Y |
|
1 |
1 |
12 |
|
2 |
2 |
18 |
|
3 |
3 |
15 |
|
4 |
4 |
25 |
|
5 |
5 |
26 |
|
6 |
6 |
34 |
|
7 |
7 |
37 |
|
8 |
8 |
47 |
Решение.
Для решения поставленной задачи и упрощения расчетов воспользуемся средствами табличного процессора MS Excel.
Первым этапом будет ввод исходных данных и построение линейной модели регрессии.
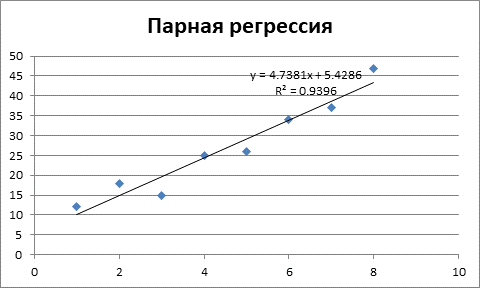
Рисунок 1 – Получение параметров линейной модели регрессии.
Таким образом, получили следующее линейное уравнение регрессии:
![]()
На рисунке 1 показано значение коэффициента детерминации R2 = 0,94. То есть 94% значений переменной Y объясняется значениями переменной X. Таким образом, можно говорить о высоком качестве уравнения регрессии.
Следующим этапом будет построение квадратического уравнения регрессии.
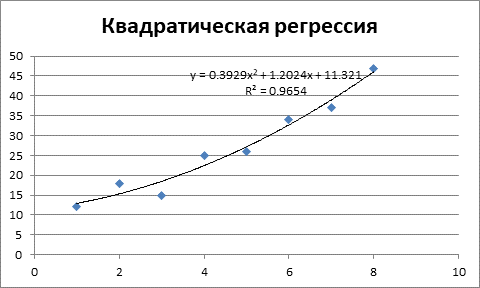
Рисунок 2 – Квадратическое уравнение регрессии и коэффициент детерминации.
Как видим из рисунка 2, коэффициент детерминации составляет R2 = 0,9654, то есть качество уравнения несколько выше линейного уравнения.
Следующим этапом будет получение показательного уравнения регрессии.
Рисунок 3 – Показательная регрессия и коэффициент детерминации.
Уравнение показательной регрессии объясняет 94,06% значений зависимой переменной Y от факторной переменной X.
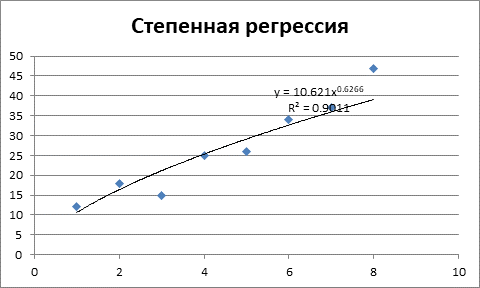
Рисунок 4 – Степенная регрессия и коэффициент детерминации.
Согласно рис. 4 полученное уравнение регрессии объясняет 87,7% значений зависимой переменной Y. Данное уравнение достаточно хуже по качеству, чем предыдущие.
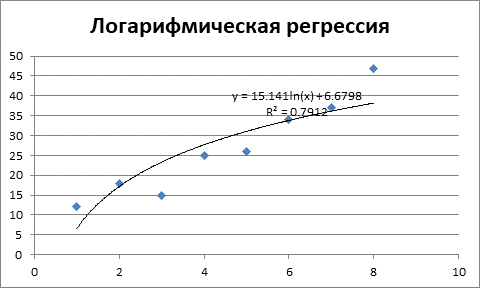
Рисунок 5 – Логарифмическая регрессия и коэффициент детерминации
Коэффициент детерминации логарифмического уравнения регрессии говорит о достаточно хорошем качестве уравнения регрессии, однако оно уступает по качеству предыдущим уравнениям.
В заключении строим график гиперболической регрессии.
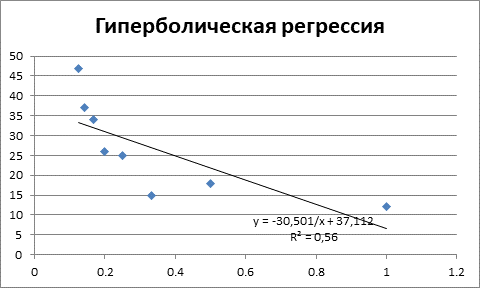
Рисунок 6 – Гиперболическая регрессия и коэффициент детерминации
Как видим данное уравнение регрессии является наихудшим по качеству, поскольку объясняет только 56% значений зависимой переменной Y.
Наилучшим по качеству уравнением регрессии в данной задаче является уравнение квадратической регрессии. Данное уравнение объясняет 96,54% значений зависимой переменной Y.
Задача 2. По данным приведенным в таблице 2 требуется:
1. Построить линейное уравнение регрессии Y по X.
2. Рассчитать линейный коэффициент корреляции, коэффициент детерминации и среднюю ошибку аппроксимации.
3. Рассчитать коэффициент эластичности.
Таблица 2 – Исходные данные
|
№ п / п |
X |
Y |
|
1 |
10 |
33 |
|
2 |
9 |
40 |
|
3 |
9 |
20 |
|
4 |
7 |
34 |
|
5 |
9 |
35 |
|
6 |
12 |
44 |
|
7 |
10 |
37 |
|
8 |
6 |
30 |
Решение.
Для решения поставленной задачи воспользуемся средствами табличного процессора MS Excel.
Для этого создаем новый лист и вводим исходные данные
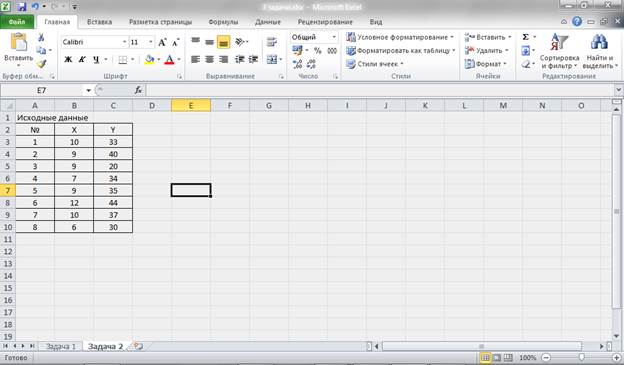
Рисунок 7 – Исходные данные.
Уравнение парной регрессии имеет вид:
![]()
— x, y – факторная и зависимые переменные;
— a, b – коэффициенты уравнения.
Коэффициенты уравнения парной линейной регрессии будем искать с помощью метода наименьших квадратов и табличного процессора MS Excel. Согласно МНК коэффициенты уравнения находятся по следующим формулам:
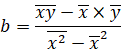
![]()
Составим дополнительную таблицу и произведем промежуточные расчеты в табличном процессоре:
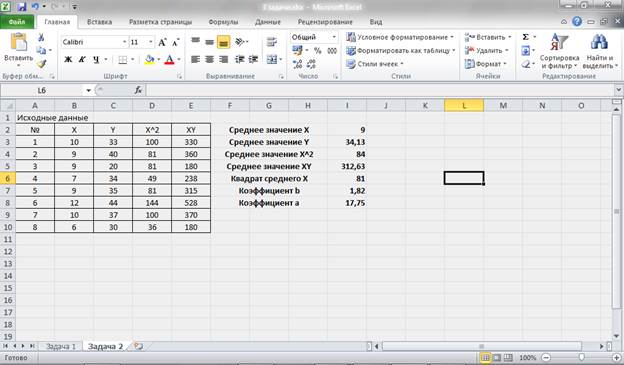
Рисунок 8 – Промежуточные расчеты и расчет коэффициентов уравнения.
В результате мы получили уравнение парной линейной регрессии:
![]()
Коэффициент корреляции, как правило используется для оценки направления и тесноты связи между зависимой и факторной переменными. Однако уже сейчас мы можем предположить направление связи между X и Y по знаку в уравнении регрессии.
Поскольку в уравнении стоит знак «+», то можно предположить наличие прямой связи между X и Y, т.е. значения Y напрямую зависят от значений X.
С помощью средств табличного процессора оценим тесноту этой связи:
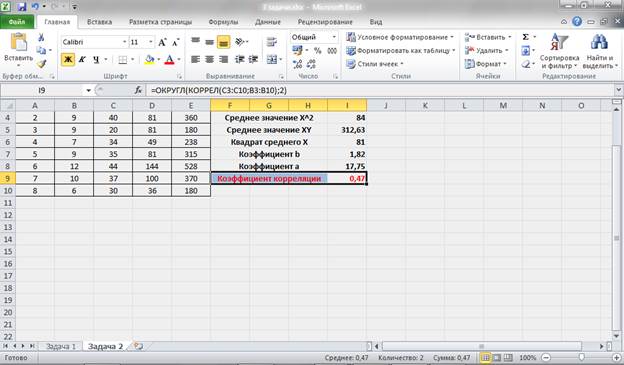
Рисунок 9 – Оценка тесноты связи с помощью коэффициента корреляции.
Коэффициент корреляции ryx = 0,47. Отсюда можно сделать вывод, что между переменными X и Y существует умеренная связь. Положительное значение коэффициента корреляции подтверждает наше предположение о направлении связи – Y зависит от X.
Между коэффициентом корреляции и коэффициентом детерминации существует взаимосвязь:
![]()
Отсюда получаем значение коэффициента детерминации: R2 = 0,22. То есть уравнение регрессии объясняет 22% значений зависимой переменной. Можно говорить о невысоком качестве уравнения регрессии.
Для подтверждения наших выводов о качестве уравнения рассчитаем показатель средней ошибки аппроксимации:
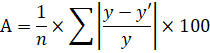
Проведем дополнительные расчеты:
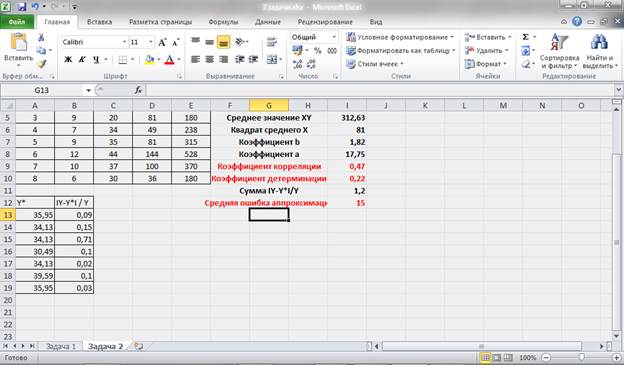
Рисунок 10 – Промежуточные расчеты и расчет средней ошибки аппроксимации.
Получаем, что средняя ошибка аппроксимации не попадает в предел до 5 – 8% (А = 15%), что подтверждает наш вывод о невысоком качестве уравнения регрессии.
Коэффициент эластичности определим по следующей формуле:
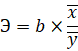
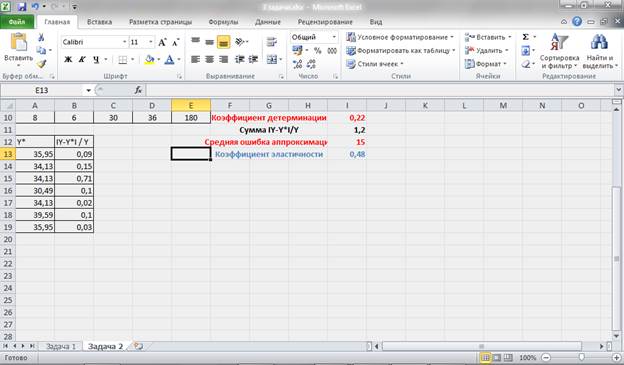
Рисунок 11 – Расчет коэффициента эластичности.
Таким образом, при изменении значения Х на 1% значение Y изменится на 0,48%.
Задача 3. По данным приведенным в таблице 3 требуется:
1. Построить линейную модель множественной регрессии.
2. Записать стандартизированное уравнение множественной регрессии.
3. Рассчитать коэффициенты парной, частной и множественной корреляции. Проанализировать их.
Таблица 3 – Исходные данные
|
№ п / п |
Х1 |
X2 |
Y |
|
1 |
12 |
12 |
133 |
|
2 |
8 |
22 |
135 |
|
3 |
8 |
15 |
120 |
|
4 |
7 |
19 |
125 |
|
5 |
9 |
17 |
130 |
|
6 |
10 |
11 |
144 |
|
7 |
7 |
10 |
137 |
|
8 |
9 |
28 |
121 |
Решение.
Для решения поставленной задачи используем возможности и средства табличного процессора MS Excel. Вводим исходные данные.
Для построения модели множественной регрессии проведем дополнительные расчеты:
Рисунок 12 – Промежуточные расчеты.
Параметры уравнения множественной регрессии для двухфакторной модели можно определить из системы уравнений:
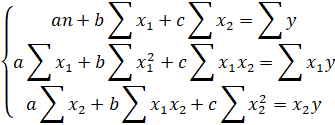
Запишем действующую систему уравнений:
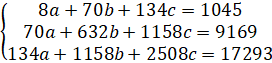
Данную систему можно решить методом Крамера при условии, что матрица, составленная из коэффициентов при неизвестных, не являтся вырожденной, т.е. Δ ≠ 0.
Для упрощения вычислений рассчитываем определитель матрицы, составленной из коэффициентов при неизвестных:
Δ = 39 424
Поскольку исходная матрица не является вырожденной система уравнений имеет решение.
Δ1 = 5 399 564
Δ2 = 28 780
Δ3 = -29 948
Отсюда находим коэффициенты при неизвестных в уравнении регрессии:
— a = 136,96
— b = 0,73
— c = -0,76.
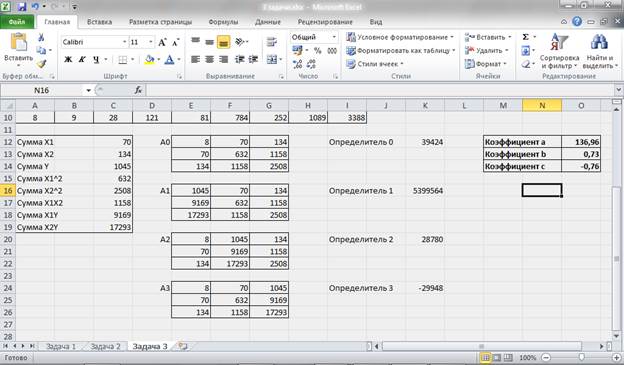
Рисунок 13 – Расчет параметров уравнения множественной регрессии.
Таким образом, мы получаем следующее уравнение множественной регрессии:
![]()
Для построения уравнения множественной регрессии в стандартизированной форме проведем расчет стандартных ошибок и коэффициентов стандартизированного уравнения:
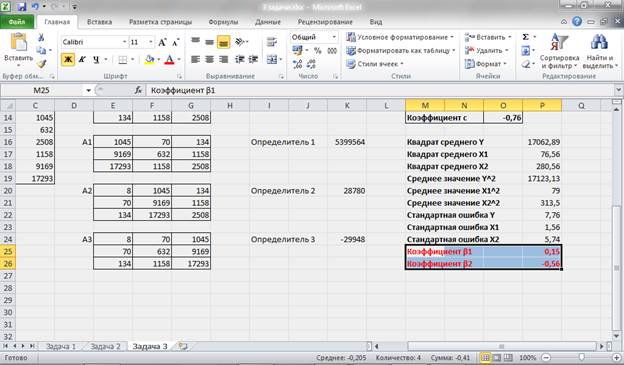
Рисунок 14 – Расчет коэффициентов стандартизированного уравнения.
Таким образом, стандартизированное уравнение множественной регрессии примет вид: ty = 0,15tx1 – 0,56tx2
Для расчета парной, частной и множественной корреляции воспользуемся таким инструментом табличного процессора, как пакет анализа, для построения корреляционной матрицы:
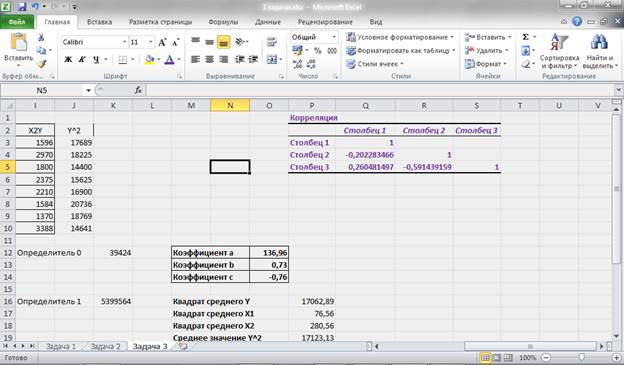
Рисунок 15 – Расчет корреляционной матрицы.
Как видим из рис. 15. Наибольшая связь обратного направления присутствует между переменными Y и X2, т.е. по сути Х2 зависит от значений Y. Прямая же связь между Y и X1 хоть и присутствует, но она достаточно слабая.
Также присутствует слабая обратная связь между переменными X1 и X2.
Список литературы
Список литературы
1. Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. Учебник для вузов. – М.ЮНИТИ, 1998. – с. 621 – 632; 751 – 766.
2. Бородич С.А. Эконометрика: Учебное пособие. – Мн.: Новое знание, 2001. – с. 98 – 115; 121 – 147; 200 – 222
3. Доугерти К. Введение в эконометрику: Пер. с англ. – М.: ИНФРА-М, 1999. – XIV, с. 53 – 111
4. Кремер Н.Ш., Путко Б.А. Эконометрика: Учебник для вузов / Под ред. Проф. Н.Ш. Кремера. – М.: ЮНИТИ-ДАНА, 2002. – с. 50 – 80
5. Кулинич Е.И. Эконометрия. – М.: Финансы и статистика, 2001. с. 43 – 83
6. Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. Учебное пособие. 2-е изд. – М.: Дело, 1998. – с. 17 – 42
7. Практикум по эконометрике: Учебное пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2002. – с. 5 – 48