Интервалы прогноза по линейному уравнению регрессии
Прогнозирование по уравнению регрессии представляет собой подстановку в уравнение регрессии соответственного значения х. Такой прогноз ух называется точечным. Он не является точным, поэтому дополняется расчетом его стандартной ошибки, в результате чего получается интервальная оценка прогнозного значения:
Преобразуем уравнение регрессии:
Ошибка т. зависит от ошибки у и ошибки коэффициента ре-
грессии Ь, т.е.
Из теории выборки известно, что
Используя в качестве оценки а 2 остаточную дисперсию на одну степень свободы S 2 , получаем:
Ошибка коэффициента регрессии из формулы (1.20):
Таким образом, при х = хр получаем:
Как видно из формулы (1.31), величина т- достигает минимума при хр = х и возрастает по мере удаления хр от х в любом направлении (рис. 1.3). Для нашего примера эта величина составит:
Рис. 1.3. Доверительные границы прогноза при парной линейной регрессии При При хр = 4.
Для прогнозируемого значения у 95 %-ные доверительные интервалы при заданном хр определены выражением
т.е. прил:р = 4 у + 2,57х3,34 или у±8,58. Прихр = 4 прогнозное значение составит у* = —5,79 + 36,84 х 4 = 141,57. Это точечный прогноз.
Прогноз линии регрессии (1.32) лежит в интервале
ИНТЕРВАЛЫ ПРОГНОЗА ПО УРАВНЕНИЮ РЕГРЕССИИ
Одной из центральных задач эконометрического моделирования является предсказание (прогнозирование) значений зависимой переменной при определенных значениях объясняющих переменных при определенных значениях объясняющих переменных. Здесь возможен двоякий подход: либо предсказать условное математическое ожидание зависимой переменной (предсказание среднего значения), либо прогнозировать некоторое конкретное значение зависимой переменной (предсказание конкретного значения).
Замечание. Некоторые авторы различают такие понятия, как прогнозирование и предсказание. Если значение объясняющей переменной X известно точно, то оценивание зависимой переменной Y называется предсказанием. Если же значение объясняющей переменной X неизвестно точно, то говорят, что делается прогноз значения Y. Такая ситуация характерна для временных рядов. В данном случае мы не будем различать предсказание и прогноз.
Различают точечное и интервальное прогнозирование. В первом случае оценка – некоторое число, во втором – интервал, в котором находится истинное значение зависимой переменной с заданным уровнем значимости.
а) Предсказание среднего значения. Пусть построено уравнение парной регрессии , на основе которого необходимо предсказать условное математическое ожидание . В данном случае значение является точечной оценкой . Тогда естественно возникает вопрос, как сильно может отклониться модельное значение , рассчитанное по эмпирическому уравнению, от соответствующего условного математического ожидания. Ответ на этот вопрос даётся на основе интервальных оценок, построенных с заданным уровнем значимости a при любом конкретном значении xp объясняющей переменной.
Запишем эмпирическое уравнение регрессии в виде
.
Здесь выделены две независимые составляющие: средняя и приращение . Отсюда вытекает, что дисперсия будет равна
. (5.53)
Из теории выборки известно, что
.
Используя в качестве оценки s 2 остаточную дисперсию S 2 , получим
. (5.54)
Дисперсия коэффициента регрессии, как уже было показано
. (5.55)
Подставляя найденные дисперсии в (5.41), получим
. (5.56)
Таким образом, формула расчета стандартной ошибки предсказываемого по линии регрессии среднего значения Y имеет вид
. (5.57)
Величина стандартной ошибки , как видно из формулы, достигает минимума при , и возрастает по мере удаления от в любом направлении. Иными словами, больше разность между и , тем больше ошибка с которой предсказывается среднее значение y для заданного значения xp. Можно ожидать наилучшие результаты прогноза, если значения xp находятся в центре области наблюдений X и нельзя ожидать хороших результатов прогноза по мере удаления от .
Случайная величина
(5.58)
имеет распределение Стьюдента с числом степеней свободы n=n–2 (в рамках нормальной классической модели). Следовательно, по таблице критических точек распределения Стьюдента по требуемому уровню значимости a и числу степеней свободы n=n–2 можно определить критическую точку , удовлетворяющую условию
.
С учетом (5.46) имеем:
.
Отсюда, после некоторых алгебраических преобразований, получим, что доверительный интервал для имеет вид:
, (5.59)
где предельная ошибка Dp имеет вид
. (5.60)
Из формул (5.57) и (5.60) видно, что величина (длина) доверительного интервала зависит от значения объясняющей переменной xp: при она минимальна, а по мере удаления xp от величина доверительного интервала увеличивается (рис. 5.4). Таким образом, прогноз значений зависимой переменной Y по уравнению регрессии оправдан, если значение xp объясняющей переменной X не выходит за диапазон ее значений по выборке (причем более точный, чем ближе xp к ). Другими словами, экстраполяция кривой регрессии, т.е. её использование вне пределов обследованного диапазона значений объясняющей переменной (даже если она оправдана для рассматриваемой переменной исходя из смысла решаемой задачи) может привести к значительным погрешностям.
б) Предсказание индивидуальных значений зависимой переменной. На практике иногда более важно знать дисперсию Y, чем ее средние значения или доверительные интервалы для условных математических ожиданий. Это связано с тем, что фактические значения Y варьируют около среднего значения . Индивидуальные значения Y могут отклоняться от на величину случайной ошибки e, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы S 2 . Поэтому ошибка предсказываемого индивидуального значения Y должны включать не только стандартную ошибку , но и случайную ошибку S. Это позволяет определять допустимые границы для конкретного значения Y.
Пусть нас интересует некоторое возможное значение y0 переменной Y при определенном значении xp объясняющей переменной X. Предсказанное по уравнению регрессии значение Y при X=xp составляет yp. Если рассматривать значение y0 как случайную величину Y0, а yp – как случайную величину Yp, то можно отметить, что
,
.
Случайные величины Y0 и Yp являются независимыми, а следовательно, случайная величина U= Y0–Yp имеет нормальное распределение с
и . (5.61)
Используя в качестве s 2 остаточную дисперсию S 2 , получим формулу расчета стандартной ошибки предсказываемого по линии регрессии индивидуального значения Y:
. (5.63)
(5.64)
имеет распределение Стьюдента с числом степеней свободы k=n–2. На основании этого можно построить доверительный интервал для индивидуальных значений Yp:
, (5.65)
где предельная ошибка Du имеет вид
. (5.66)
Заметим, что данный интервал шире доверительного интервала для условного математического ожидания (см. рис. 5.4).
Пример 5.5. По данным примеров 5.1-5.3 рассчитать 95%-ый доверительный интервал для условного математического ожидания и индивидуального значения при xp=160.
Решение. В примере 5.1 было найдено . Воспользовавшись формулой (5.48), найдем предельную ошибку для условного математического ожидания
.
Тогда доверительный интервал для среднего значения на уровне значимости a=0,05 будет иметь вид
Другими словами, среднее потребление при доходе 160 с вероятностью 0,95 будет находиться в интервале (149,8; 156,6).
Рассчитаем границы интервала, в котором будет сосредоточено не менее 95% возможных объёмов потребления при уровне дохода xp=160, т.е. доверительный интервал для индивидуального значения . Найдем предельную ошибку для индивидуального значения
.
Тогда интервал, в котором будут находиться , по крайней мере, 95% индивидуальных объёмов потребления при доходе xp=160, имеет вид
Нетрудно заметить, что он включает в себя доверительный интервал для условного среднего потребления. â
ПРИМЕРЫ
Пример 5.65.По территориям региона приводятся данные за 199X г. (таб. 1.1).
| Номер региона |
Среднедушевой прожиточный минимум в день одного трудоспособного, руб., x |
Среднедневная заработная плата, руб., y |
1. Рассчитать линейный коэффициент парной корреляции, оценить его статистическую значимость и построить для него доверительный интервал с уровнем значимости a=0,05.
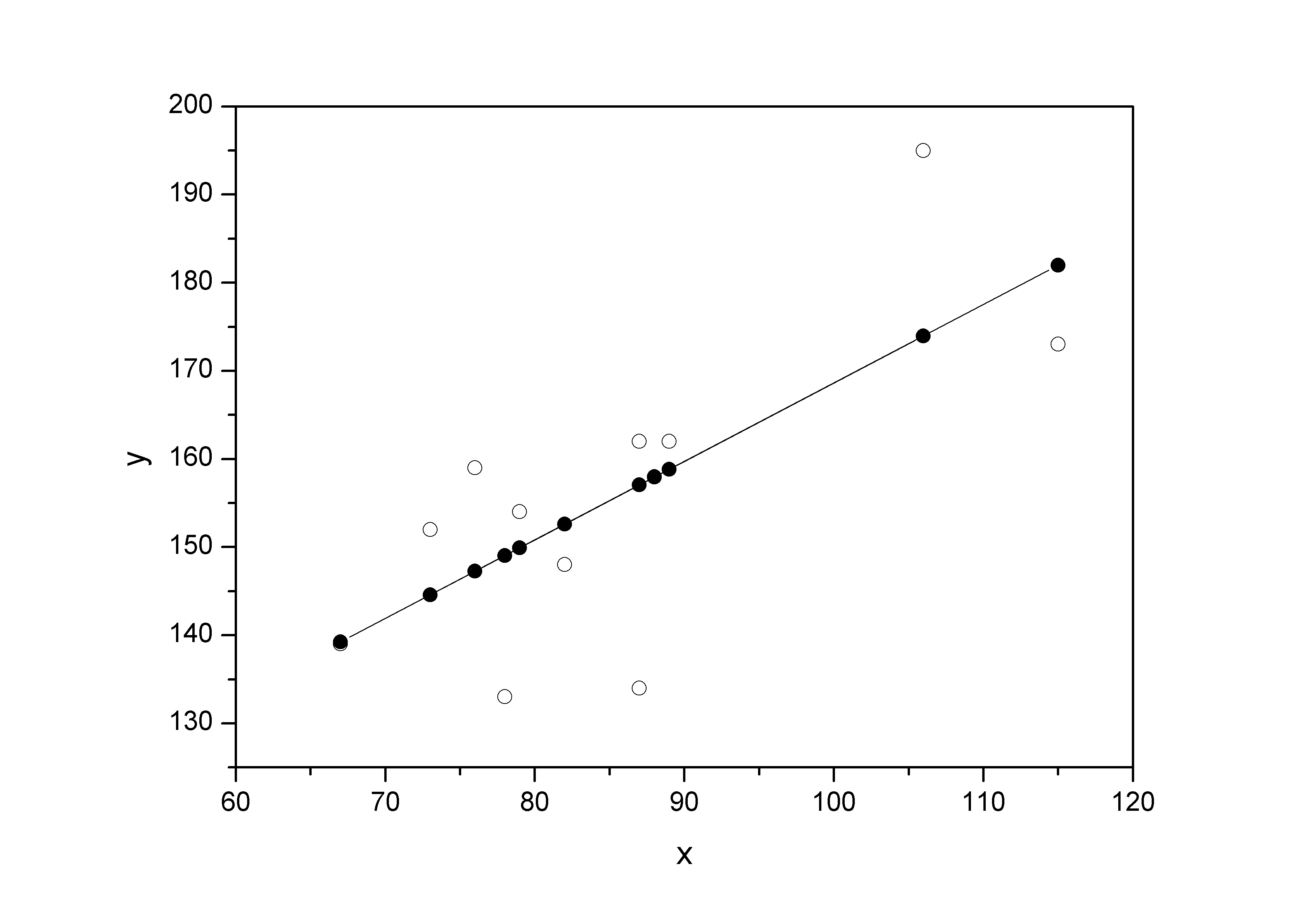
2. Построить линейное уравнение парной регрессии y на x и оценить статистическую значимость параметров регрессии. Сделать рисунок.
3. Оценить качество уравнения регрессии при помощи коэффициента детерминации. Проверить качество уравнения регрессии при помощи F-критерия Фишера.
4. Выполнить прогноз заработной платы y при прогнозном значении среднедушевого прожиточного минимума x, составляющем 107% от среднего уровня. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал для уровня значимости a=0,05. Сделать выводы.
Решение
1. Для определения степени тесноты связи обычно используют коэффициент корреляции:
,
где , – выборочные дисперсии переменных x и y. Для расчета коэффициента корреляции строим расчетную таблицу (табл. 5.4):
| x |
y |
xy |
x 2 |
y 2 |
|
|
e 2 |
| 148,77 |
-15,77 |
248,70 |
| 152,45 |
-4,45 |
19,82 |
| 157,05 |
-23,05 |
531,48 |
| 149,69 |
4,31 |
18,57 |
| 158,89 |
3,11 |
9,64 |
| 174,54 |
20,46 |
418,52 |
| 138,65 |
0,35 |
0,13 |
| 157,97 |
0,03 |
0,00 |
| 144,17 |
7,83 |
61,34 |
| 157,05 |
4,95 |
24,46 |
| 146,93 |
12,07 |
145,70 |
| 182,83 |
-9,83 |
96,55 |
| Итого |
– |
1574,92 |
| Среднее значение |
85,58 |
155,75 |
13484,00 |
7492,25 |
24531,42 |
– |
– |
– |
По данным таблицы находим:
, , , ,
, , , ,
, .
Таким образом, между заработной платой (y) и среднедушевым прожиточным минимумом (x) существует прямая достаточно сильная корреляционная зависимость.
Для оценки статистической значимости коэффициента корреляции рассчитаем двухсторонний t-критерий Стьюдента:
,
который имеет распределение Стьюдента с k=n–2 и уровнем значимости a. В нашем случае
и .
Поскольку , то коэффициент корреляции существенно отличается от нуля.
Для значимого коэффициента можно построить доверительный интервал, который с заданной вероятностью содержит неизвестный генеральный коэффициент корреляции. Для построения интервальной оценки (для малых выборок n
Контрольные вопросы по эконометрике
Контрольные вопросы по эконометрике.
Каковы основные цели эконометрики?
прогноз экономических и соц-экономических показателей, характеризующих состояние и развитие анализируемой системы. имитация различных возможных сценариев социально-экономического развития
Что понимают под спецификацией модели?
Это построение экономических моделей, т.е. представление экономических моделей в математической форме удобной для проведения эмпирического анализа
Что называется параметризацией?
Оценка параметров построенной модели, делающих выбранную модель наиболее адекватной реальным данным.
Проверка качества найденных параметров модели и самой модели в целом.
Что означает простая и множественная регрессии?
Простая регрессия представляет собой регрессию между двумя переменными – y и x, т. е. модель вида y=f(x).
Множественная регрессия представляет собой регрессию результативного признака с двумя и большим числом факторов, т. е. модель вида f=(x1,x2. xk)
Когда предпочтительна парная регрессия?
Парная регрессия достаточна, если имеется доминирующий фактор, который и используется в качестве объясняющей переменной.
Что понимается под ошибкой спецификации?
Это неправильно выбранная форма модели, недоучет какого-либо существенного фактора в уравнении регрессии, т. е. использование парной регрессии вместо множественной.
Какие основные источники ошибок эконометрических моделей?
Ошибки спецификации, ошибки выборки и ошибки измерения.
Какой вид имеет уравнение парной линейной регрессии?
МНК позволяет получить такие оценки параметров а и b, при которых сумма квадратов отклонений фактических значений от теоретических минимальна:
или.
Какой экономический смысл имеет коэффициент парной линейной регрессии?
Показывает среднее изменение результата с изменением фактора на одну единицу.
Что такое регрессор?
Регрессор – (признак — фактор) – независимая, или объясняющая переменная (х).
Что такое результативный признак?
Результативный признак – зависимая переменная (у)
Какой смысл может иметь свободный член в парной линейной регрессии?
Формально a – значение y при x=0. Если x не имеет и не может иметь нулевого значения, то такая трактовка свободного члена a не имеет смысла. Параметр a может не иметь экономического содержания. Попытки экономически интерпретировать его могут привести к абсурду, особенно при a 0. Интерпретировать можно лишь знак при параметре a. Если a> 0, то относительное изменение результата происходит медленнее, чем изменение фактора.
Чему равен свободный член, если все переменные в линейной модели взяты в отклонениях от средних значений?
Иногда линейное уравнение парной регрессии записывают для отклонений от средних значений: , где , . При этом свободный член равен нулю.
Какова связь между линейным коэффициентом корреляции и коэффициентом парной линейной регрессии?
При линейной регрессии в качестве показателя тесноты связи выступает линейный коэффициент корреляции . Коэффициент регрессии показывает, на сколько единиц в среднем изменится У, когда Х увеличивается на одну единицу. Однако он зависит от единиц измерения переменных. Для исправления Кр. Как показателя тесноты связи нужна такая стандартная система единиц измерения, в которой данные по различным характеристикам оказались бы сравнимы между собой. Эта система использует в качестве единицы измерения переменной её среднее квадратическое отклонение s
Для оценки качества подбора линейной функции рассчитывается коэффициент детерминации как квадрат линейного коэффициента корреляции r2. Он характеризует долю дисперсии результативного признака y, объясняемую регрессией, в общей дисперсии результативного признака:
Величина коэффициента детерминации служит одним из критериев оценки качества линейной модели. Чем больше доля объясненной вариации, тем соответственно меньше роль прочих факторов, и, следовательно, линейная модель хорошо аппроксимирует исходные данные и ею можно воспользоваться для прогноза значений результативного признака.
Каково среднее значение случайного отклонения при выполнении предпосылок МНК?
Выполнение предпосылок МНК – условие необходимое для получения несмещенных, состоятельных и эффективных оценок. И при их выполнении среднее значение случайного отклонения равняется нулю.
Что такое гомоскедастичность и гетероскедастичность?
Дисперсия случайных отклонений постоянна: .
Выполнимость данной предпосылки называется гомоскедастичностью (постоянством дисперсии отклонений). Невыполнимость данной предпосылки называется гетероскедастичностью (непостоянством дисперсии отклонений)
Что такое автокорреляция случайных отклонений?
Отсутствие независимости случайных отклонений друг от друга.
Что означает несмещенность оценок параметров уравнения регрессии и их эффективность?
Несмещенность оценки означает, что математическое ожидание остатков равно нулю.
Баланс для сумм квадратов отклонений результативного признака. или Q = Qr + Qe, где Q – общая сумма квадратов отклонений зависимой переменной от средней, Qr и Qe – соответственно, сумма квадратов, обусловленная регрессией, и остаточная сумма квадратов, характеризующая влияние неучтённых факторов.
Что происходит, когда общая СКО равна остаточной?
Когда общая СКО в точности равна остаточной, сумма квадратов, обусловленная регрессией равняется нулю. Фактор х не оказывает влияния на результат, вся дисперсия y обусловлена воздействием прочих факторов, линия регрессии параллельна оси Ох и
В каком случае общая СКО равна факторной?
Общая СКО равна факторной, когда прочие факторы не влияют на результат, y связан с x функционально, и остаточная СКО равна нулю.
Что такое число степеней свободы?
Число степеней свободы (df-degrees of freedom)- это число независимо варьируемых значений признака.
Чему равны числа степеней свободы для различных СКО в парной регрессии?
Для общей СКО требуется (n-1) независимых отклонений, т. к. что позволяет свободно варьировать (n-1) значений, а последнее n-е отклонение определяется из общей суммы, равной нулю. Поэтому
Факторную СКО можно выразить так:
Эта СКО зависит только от одного параметра b,-поскольку выражение под знаком суммы к значениям результативного признака не относится. Следовательно, факторная СКО имеет одну степень свободы, и
Для определения воспользуемся аналогией с балансовым равенством (11). Так же, как и в равенстве (11), можно записать равенство и между числами степеней свободы:
Таким образом, можем записать:
Из этого баланса определяем, что = n–2.
Как определяется статистика по Фишеру?
Оценка значимости уравнения регрессии в целом дается с помощью F-критерия Фишера. При этом выдвигается нулевая гипотеза H0:b=0 о том, что коэффициент регрессии равен нулю и следовательно, фактор Х не оказывает влияния на результат У.
Как записываются основная и альтернативная гипотезы при проверке адекватности уравнения регрессии в целом?
, эта гипотеза говорит о том что уравнение регрессии не вносит существенного вклада в объяснение дисперсии зависимой переменой.
Как проверяются гипотезы при использовании статистики по Фишеру в парной регрессии?
Разделив каждую СКО на свое число степеней свободы, получим средний квадрат отклонений, или дисперсию на одну степень свободы:
Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим — критерий для проверки нулевой гипотезы, которая в данном случае записывается как
(18)
Если справедлива, то дисперсии не отличаются друг от друга. Для необходимо опровержение, чтобы факторная дисперсия превышала остаточную в несколько раз. Английским статистиком Снедекором разработаны таблицы критических значений F при разных уровнях существенности и различных числах степеней свободы. Табличное значение F — критерия – это максимальная величина отношения дисперсий, которая может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы. При нахождении табличного значения F — критерия задается уровень значимости (обычно 0,05 или 0,01) и две степени свободы – числителя (она равна единице) и знаменателя, равная n-2.
Вычисленное значение F признается достоверным (отличным от единицы), если оно больше табличного, т. е. Fфактич>Fтабл(б;1;n-2). В этом случае отклоняется и делается вывод о существенности превышения Dфакт над Dостат., т. е. о существенности статистической связи между y и x.
Если , то вероятность выше заданного уровня (например, 0,05), и эта гипотеза не может быть отклонена без серьезного риска сделать неправильный вывод о наличии связи между y и x. Уравнение регрессии считается статистически незначимым, не отклоняется.
Как F — статистика связана с коэффициентом детерминации в парной регрессии?
Величина F-критерия связана с коэффициентом детерминации
Индекс детерминации используется для проверки существенности в целом уравнения нелинейной регрессии по F-критерию Фишера:
Как рассчитать критерий Стьюдента коэффициента парной линейной регрессии?
Чем больше кривизна линии регрессии, тем больше разница между R2 и r2. Близость этих показателей означает, что усложнять форму уравнения регрессии не следует и можно использовать линейную функцию. Практически, если величина (R2-r2) не превышает 0,1, то линейная зависимость считается оправданной. В противном случае проводится оценка существенности различия показателей детерминации, вычисленных по одним и тем же данным, через t-критерий Стьюдента:
. (56)
Здесь в знаменателе находится ошибка разности (R2-r2), определяемая по формуле:
. (57)
Если , то различия между показателями корреляции существенны и замена нелинейной регрессии линейной нецелесообразна.
33Какая связь между tb — и F – статистиками в парной линейной регрессии?
Существует связь между и :
Отсюда следует, что
33Как построить доверительный интервал для коэффициента парной линейной регрессии?
Доверительный интервал для b определяется как
,
где – рассчитанное (оцененное) по МНК значение коэффициента регрессии,
Стандартная ошибка коэффициента регрессии определяется по формуле:
, (20)
— остаточная дисперсия на одну степень свободы (то же, что и Dостат).
Интервалы прогноза по линейному уравнению регрессии
Чтобы обойти это затруднение, используется так называемое z-преобразование Фишера:
которое дает нормально распределенную величину z, значения которой при изменении r от –1 до +1 изменяются от -∞ до +∞.
В каком месте доверительный интервал прогноза по парной модели является наименьшим?
. (31)
Как видно из формулы, величина достигает минимума при и возрастает по мере удаления от в любом направлении.
Как классический МНК применяется к нелинейным моделям регрессии?
При анализе нелинейных регрессионных зависимостей наиболее важным вопросом применения классического МНК является способ их линеаризации. В случае линеаризации нелинейной зависимости получаем линейное регрессионное уравнение типа (3), параметры которого оцениваются обычным МНК, после чего можно записать исходное нелинейное соотношение.
Несколько особняком в этом смысле стоит полиномиальная модель произвольной степени:
, (34)
к которой обычный МНК можно применять без всякой предварительной линеаризации.
Как преобразуется уравнение гиперболического типа для использования МНК?
Линеаризация уравнения (37) сводится к замене фактора z=1/x, и уравнение регрессии имеет вид (3), в котором вместо фактора х используем фактор z:
Как преобразуется уравнение экспоненциального типа, чтобы использовать МНК?
зависимости показательного (экспоненциального) типа, которые записываются в виде:
(40)
. (41)
Возможна и такая зависимость:
. (42)
В регрессиях типа (40) – (42) применяется один и тот же способ линеаризации – логарифмирование. Уравнение (40) приводится к виду:
. (43)
Замена переменной сводит его к линейному виду:
, (44)
где .
Как преобразуется степенная зависимость при использовании МНК?
Они используются для построения и анализа производственных функций. В функциях вида:
(48)
особенно ценным является то обстоятельство, что параметр b равен коэффициенту эластичности результативного признака по фактору х. Преобразуя (48) путем логарифмирования, получаем линейную регрессию:
, (49)
где .
41Как преобразуется логистическая зависимость для применения МНК?
зависимость логистического типа:
. (52)
Графиком функции (52) является так называемая «кривая насыщения», которая имеет две горизонтальные асимптоты y=0 и y=1/a и точку перегиба , а также точку пересечения с осью ординат y=1/(a+b):
Уравнение (52) приводится к линейному виду заменами переменных .
42Где применяется квадратичная парабола в уравнениях регрессии и при каких условиях?
Такая зависимость целесообразна в случае, если для некоторого интервала значений фактора возрастающая зависимость меняется на убывающую или наоборот. В этом случае можно определить значение фактора, при котором достигается максимальное или минимальное значение результативного признака. Если исходные данные не обнаруживают изменение направленности связи, параметры параболы становятся трудно интерпретируемыми, и форму связи лучше заменить другими нелинейными моделями.
43Какие зависимости используются для кривых Филипса и кривых Энгеля?
Зависимости гиперболического типа имеют вид:
. (37)
Примером такой зависимости является кривая Филлипса, констатирующая обратную зависимость процента прироста заработной платы от уровня безработицы. В этом случае значение параметра b будет больше нуля. Другим примером зависимости (37) являются кривые Энгеля, формулирующие следующую закономерность: с ростом дохода доля доходов, расходуемых на продовольствие, уменьшается, а доля доходов, расходуемых на непродовольственные товары, будет возрастать. В этом случае b 0, то при b 0 . По данным примера , что означает очень тесную зависимость затрат на производство от величины объема выпускаемой продукции.
Величина R находится в границах , и чем ближе она к единице, тем теснее связь рассматриваемых признаков, тем более надежно найденное уравнение регрессии
45В чем особенность вычисления статистики Фишера для полиноминальных регрессии?
Индекс детерминации используется для проверки существенности в целом уравнения нелинейной регрессии по F-критерию Фишера:
, (55)
где n-число наблюдений, m-число параметров при переменных х. Во всех рассмотренных нами случаях, кроме полиномиальной регрессии, m=1, для полиномов (34) m=k, т. е. степени полинома. Величина m характеризует число степеней свободы для факторной СКО, а (n-m-1) – число степеней свободы для остаточной СКО.
источники:
http://megaobuchalka.ru/9/33835.html
http://pandia.ru/text/80/498/1346.php









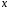
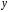
 от
от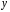 от
от .
.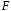 -критерия
-критерия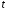 -критерия
-критерия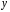 при прогнозном значении среднедушевого
при прогнозном значении среднедушевого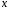 ,
,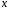
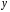
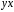
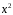
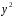
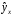
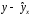
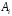
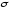
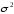
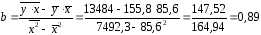 ;
;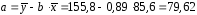 .
.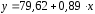 .
.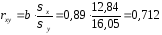 ;
; 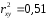 .
. )
) – среднедушевого прожиточного минимума.
– среднедушевого прожиточного минимума.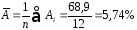 .
.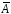 не превышает 8-10%.
не превышает 8-10%. -критерия
-критерия -критерия:
-критерия: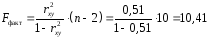 .
.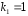 и
и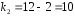 составляет
составляет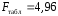 .
.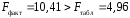 ,
, -статистики
-статистики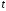 -критерия
-критерия и
и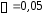 составит
составит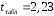 .
. ,
,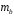 ,
,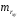 :
: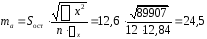 ;
;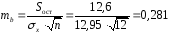 ;
; .
.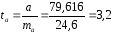 ;
;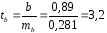 ;
; .
.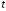 -статистики
-статистики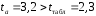 ;
; 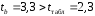 ;
;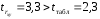 ,
,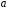 ,
,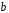 и
и не случайно отличаются от нуля, а
не случайно отличаются от нуля, а и
и .
.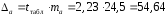 ;
;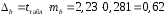 .
.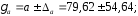
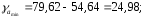
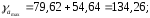

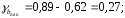

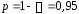 параметры
параметры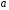 и
и ,
,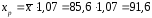 руб., тогда прогнозное значение заработной
руб., тогда прогнозное значение заработной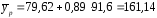 руб.
руб.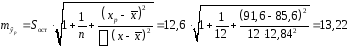 .
.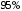 случаев не будет превышена, составит:
случаев не будет превышена, составит: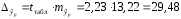 .
.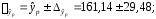
 руб.;
руб.;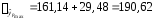 руб.
руб.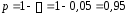 )
)


 – прогнозное.
– прогнозное. .
.
 .
. .
.




