Как искать и исправлять ошибки в коде
Искать ошибки в программах — непростая задача. Здесь нет никаких готовых методик или рецептов успеха. Можно даже сказать, что это — искусство. Тем не менее есть общие советы, которые помогут вам при поиске. В статье описаны основные шаги, которые стоит предпринять, если ваша программа работает некорректно.
Шаг 1: Занесите ошибку в трекер
После выполнения всех описанных ниже шагов может так случиться, что вы будете рвать на себе волосы от безысходности, все еще сидя на работе, когда поймете, что:
- Вы забыли какую-то важную деталь об ошибке, например, в чем она заключалась.
- Вы могли делегировать ее кому-то более опытному.
Трекер поможет вам не потерять нить размышлений и о текущей проблеме, и о той, которую вы временно отложили. А если вы работаете в команде, это поможет делегировать исправление коллеге и держать все обсуждение в одном месте.
Вы должны записать в трекер следующую информацию:
- Что делал пользователь.
- Что он ожидал увидеть.
- Что случилось на самом деле.
Это должно подсказать, как воспроизвести ошибку. Если вы не сможете воспроизвести ее в любое время, ваши шансы исправить ошибку стремятся к нулю.
Шаг 2: Поищите сообщение об ошибке в сети
Если у вас есть сообщение об ошибке, то вам повезло. Или оно будет достаточно информативным, чтобы вы поняли, где и в чем заключается ошибка, или у вас будет готовый запрос для поиска в сети. Не повезло? Тогда переходите к следующему шагу.
Шаг 3: Найдите строку, в которой проявляется ошибка
Если ошибка вызывает падение программы, попробуйте запустить её в IDE под отладчиком и посмотрите, на какой строчке кода она остановится. Совершенно необязательно, что ошибка будет именно в этой строке (см. следующий шаг), но, по крайней мере, это может дать вам информацию о природе бага.
Шаг 4: Найдите точную строку, в которой появилась ошибка
Как только вы найдете строку, в которой проявляется ошибка, вы можете пройти назад по коду, чтобы найти, где она содержится. Иногда это может быть одна и та же строка. Но чаще всего вы обнаружите, что строка, на которой упала программа, ни при чем, а причина ошибки — в неправильных данных, которые появились ранее.
Если вы отслеживаете выполнение программы в отладчике, то вы можете пройтись назад по стектрейсу, чтобы найти ошибку. Если вы находитесь внутри функции, вызванной внутри другой функции, вызванной внутри другой функции, то стектрейс покажет список функций до самой точки входа в программу (функции main() ). Если ошибка случилась где-то в подключаемой библиотеке, предположите, что ошибка все-таки в вашей программе — это случается гораздо чаще. Найдите по стектрейсу, откуда в вашем коде вызывается библиотечная функция, и продолжайте искать.
Шаг 5: Выясните природу ошибки
Ошибки могут проявлять себя по-разному, но большинство из них можно отнести к той или иной категории. Вот наиболее частые.
- Вы начали цикл for с единицы вместо нуля или наоборот. Или, например, подумали, что метод .count() или .length() вернул индекс последнего элемента. Проверьте документацию к языку, чтобы убедиться, что нумерация массивов начинается с нуля или с единицы. Эта ошибка иногда проявляется в виде исключения Index out of range .
- Неправильные настройки или константы
Проверьте ваши конфигурационные файлы и константы. Я однажды потратил ужасные 16 часов, пытаясь понять, почему корзина на сайте с покупками виснет на стадии отправки заказа. Причина оказалась в неправильном значении в /etc/hosts , которое не позволяло приложению найти ip-адрес почтового сервера, что вызывало бесконечный цикл в попытке отправить счет заказчику. - Неожиданный null
Бьюсь об заклад, вы не раз получали ошибку с неинициализированной переменной. Убедитесь, что вы проверяете ссылки на null , особенно при обращении к свойствам по цепочке. Также проверьте случаи, когда возвращаемое из базы данных значение NULL представлено особым типом. - Некорректные входные данные
Вы проверяете вводимые данные? Вы точно не пытаетесь провести арифметические операции с введенными пользователем строками? - Присваивание вместо сравнения
Убедитесь, что вы не написали = вместо == , особенно в C-подобных языках. - Ошибка округления
Это случается, когда вы используете целое вместо Decimal , или float для денежных сумм, или слишком короткое целое (например, пытаетесь записать число большее, чем 2147483647, в 32-битное целое). Кроме того, может случиться так, что ошибка округления проявляется не сразу, а накапливается со временем (т. н. Эффект бабочки). - Переполнение буфера и выход за пределы массива
Проблема номер один в компьютерной безопасности. Вы выделяете память меньшего объема, чем записываемые туда данные. Или пытаетесь обратиться к элементу за пределами массива. - Программисты не умеют считать
Вы используете некорректную формулу. Проверьте, что вы не используете целочисленное деление вместо взятия остатка, или знаете, как перевести рациональную дробь в десятичную и т. д. - Конкатенация строки и числа
Вы ожидаете конкатенации двух строк, но одно из значений — число, и компилятор пытается произвести арифметические вычисления. Попробуйте явно приводить каждое значение к строке. - 33 символа в varchar(32)
Проверяйте данные, передаваемые в INSERT , на совпадение типов. Некоторые БД выбрасывают исключения (как и должны делать), некоторые просто обрезают строку (как MySQL). Недавно я столкнулся с такой ошибкой: программист забыл убрать кавычки из строки перед вставкой в базу данных, и длина строки превысила допустимую как раз на два символа. На поиск бага ушло много времени, потому что заметить две маленькие кавычки было сложно. - Некорректное состояние
Вы пытаетесь выполнить запрос при закрытом соединении или пытаетесь вставить запись в таблицу прежде, чем обновили таблицы, от которых она зависит. - Особенности вашей системы, которых нет у пользователя
Например: в тестовой БД между ID заказа и адресом отношение 1:1, и вы программировали, исходя из этого предположения. Но в работе выясняется, что заказы могут отправляться на один и тот же адрес, и, таким образом, у вас отношение 1:многим.
Ваш процесс или поток пытается использовать результат выполнения дочернего до того, как тот завершил свою работу. Ищите использование sleep() в коде. Возможно, на мощной машине дочерний поток выполняется за миллисекунду, а на менее производительной системе происходят задержки. Используйте правильные способы синхронизации многопоточного кода: мьютексы, семафоры, события и т. д.
Если ваша ошибка не похожа на описанные выше, или вы не можете найти строку, в которой она появилась, переходите к следующему шагу.
Шаг 6: Метод исключения
Если вы не можете найти строку с ошибкой, попробуйте или отключать (комментировать) блоки кода до тех пор, пока ошибка не пропадет, или, используя фреймворк для юнит-тестов, изолируйте отдельные методы и вызывайте их с теми же параметрами, что и в реальном коде.
Попробуйте отключать компоненты системы один за другим, пока не найдете минимальную конфигурацию, которая будет работать. Затем подключайте их обратно по одному, пока ошибка не вернется. Таким образом вы вернетесь на шаг 3.
Шаг 7: Логгируйте все подряд и анализируйте журнал
Пройдитесь по каждому модулю или компоненту и добавьте больше сообщений. Начинайте постепенно, по одному модулю. Анализируйте лог до тех пор, пока не проявится неисправность. Если этого не случилось, добавьте еще сообщений.
Ваша задача состоит в том, чтобы вернуться к шагу 3, обнаружив, где проявляется ошибка. Также это именно тот случай, когда стоит использовать сторонние библиотеки для более тщательного логгирования.
Шаг 8: Исключите влияние железа или платформы
Замените оперативную память, жесткие диски, поменяйте сервер или рабочую станцию. Установите обновления, удалите обновления. Если ошибка пропадет, то причиной было железо, ОС или среда. Вы можете по желанию попробовать этот шаг раньше, так как неполадки в железе часто маскируют ошибки в ПО.
Если ваша программа работает по сети, проверьте свитч, замените кабель или запустите программу в другой сети.
Ради интереса, переключите кабель питания в другую розетку или к другому ИБП. Безумно? Почему бы не попробовать?
Если у вас возникает одна и та же ошибка вне зависимости от среды, то она в вашем коде.
Шаг 9: Обратите внимание на совпадения
- Ошибка появляется всегда в одно и то же время? Проверьте задачи, выполняющиеся по расписанию.
- Ошибка всегда проявляется вместе с чем-то еще, насколько абсурдной ни была бы эта связь? Обращайте внимание на каждую деталь. На каждую. Например, проявляется ли ошибка, когда включен кондиционер? Возможно, из-за этого падает напряжение в сети, что вызывает странные эффекты в железе.
- Есть ли что-то общее у пользователей программы, даже не связанное с ПО? Например, географическое положение (так был найден легендарный баг с письмом за 500 миль).
- Ошибка проявляется, когда другой процесс забирает достаточно большое количество памяти или ресурсов процессора? (Я однажды нашел в этом причину раздражающей проблемы «no trusted connection» с SQL-сервером).
Шаг 10: Обратитесь в техподдержку
Наконец, пора попросить помощи у того, кто знает больше, чем вы. Для этого у вас должно быть хотя бы примерное понимание того, где находится ошибка — в железе, базе данных, компиляторе. Прежде чем писать письмо разработчикам, попробуйте задать вопрос на профильном форуме.
Ошибки есть в операционных системах, компиляторах, фреймворках и библиотеках, и ваша программа может быть действительно корректна. Но шансы привлечь внимание разработчика к этим ошибкам невелики, если вы не сможете предоставить подробный алгоритм их воспроизведения. Дружелюбный разработчик может помочь вам в этом, но чаще всего, если проблему сложно воспроизвести вас просто проигнорируют. К сожалению, это значит, что нужно приложить больше усилий при составлении багрепорта.
Полезные советы (когда ничего не помогает)
- Позовите кого-нибудь еще.
Попросите коллегу поискать ошибку вместе с вами. Возможно, он заметит что-то, что вы упустили. Это можно сделать на любом этапе. - Внимательно просмотрите код.
Я часто нахожу ошибку, просто спокойно просматривая код с начала и прокручивая его в голове. - Рассмотрите случаи, когда код работает, и сравните их с неработающими.
Недавно я обнаружил ошибку, заключавшуюся в том, что когда вводимые данные в XML-формате содержали строку xsi:type=’xs:string’ , все ломалось, но если этой строки не было, все работало корректно. Оказалось, что дополнительный атрибут ломал механизм десериализации. - Идите спать.
Не бойтесь идти домой до того, как исправите ошибку. Ваши способности обратно пропорциональны вашей усталости. Вы просто потратите время и измотаете себя. - Сделайте творческий перерыв.
Творческий перерыв — это когда вы отвлекаетесь от задачи и переключаете внимание на другие вещи. Вы, возможно, замечали, что лучшие идеи приходят в голову в душе или по пути домой. Смена контекста иногда помогает. Сходите пообедать, посмотрите фильм, полистайте интернет или займитесь другой проблемой. - Закройте глаза на некоторые симптомы и сообщения и попробуйте сначала.
Некоторые баги могут влиять друг на друга. Драйвер для dial-up соединения в Windows 95 мог сообщать, что канал занят, при том что вы могли отчетливо слышать звук соединяющегося модема. Если вам приходится держать в голове слишком много симптомов, попробуйте сконцентрироваться только на одном. Исправьте или найдите его причину и переходите к следующему. - Поиграйте в доктора Хауса (только без Викодина).
Соберите всех коллег, ходите по кабинету с тростью, пишите симптомы на доске и бросайте язвительные комментарии. Раз это работает в сериалах, почему бы не попробовать?
Что вам точно не поможет
- Паника
Не надо сразу палить из пушки по воробьям. Некоторые менеджеры начинают паниковать и сразу откатываться, перезагружать сервера и т. п. в надежде, что что-нибудь из этого исправит проблему. Это никогда не работает. Кроме того, это создает еще больше хаоса и увеличивает время, необходимое для поиска ошибки. Делайте только один шаг за раз. Изучите результат. Обдумайте его, а затем переходите к следующей гипотезе. - «Хелп, плиииз!»
Когда вы обращаетесь на форум за советом, вы как минимум должны уже выполнить шаг 3. Никто не захочет или не сможет вам помочь, если вы не предоставите подробное описание проблемы, включая информацию об ОС, железе и участок проблемного кода. Создавайте тему только тогда, когда можете все подробно описать, и придумайте информативное название для нее. - Переход на личности
Если вы думаете, что в ошибке виноват кто-то другой, постарайтесь по крайней мере говорить с ним вежливо. Оскорбления, крики и паника не помогут человеку решить проблему. Даже если у вас в команде не в почете демократия, крики и применение грубой силы не заставят исправления магическим образом появиться.
Ошибка, которую я недавно исправил
Это была загадочная проблема с дублирующимися именами генерируемых файлов. Дальнейшая проверка показала, что у файлов различное содержание. Это было странно, поскольку имена файлов включали дату и время создания в формате yyMMddhhmmss . Шаг 9, совпадения: первый файл был создан в полпятого утра, дубликат генерировался в полпятого вечера того же дня. Совпадение? Нет, поскольку hh в строке формата — это 12-часовой формат времени. Вот оно что! Поменял формат на yyMMddHHmmss , и ошибка исчезла.
Отладка
Отладка, или debugging, — это поиск (локализация), анализ и устранение ошибок в программном обеспечении, которые были найдены во время тестирования.
Виды ошибок
Ошибки компиляции
Это простые ошибки, которые в компилируемых языках программирования выявляет компилятор (программа, которая преобразует текст на языке программирования в набор машинных кодов). Если компилятор показывает несколько ошибок, отладку кода начинают с исправления самой первой, так как она может быть причиной других.
В интерпретируемых языках (например Python) текст программы команда за командой переводится в машинный код и сразу исполняется. К моменту обнаружения ошибки часть программы уже может исполниться.
Ошибки компоновки
Ошибки связаны с разрешением внешних ссылок. Выявляет компоновщик (редактор связей) при объединении модулей программы. Простой пример — ситуация, когда требуется обращение к подпрограмме другого модуля, но при компоновке она не найдена. Ошибки также просто найти и устранить.
Ошибки выполнения (RUNTIME Error)
Ошибки, которые обнаруживают операционная система, аппаратные средства или пользователи при выполнении программы. Они считаются непредсказуемыми и проявляются после успешной компиляции и компоновки. Можно выделить четыре вида проявления таких ошибок:
- сообщение об ошибке, которую зафиксировали схемы контроля машинных команд. Это может быть переполнение разрядной сетки (когда старшие разряды результата операции не помещаются в выделенной области памяти), «деление на ноль», нарушение адресации и другие;
- сообщение об ошибке, которую зафиксировала операционная система. Она же, как правило, и документирует ошибку. Это нарушение защиты памяти, отсутствие файла с заданным именем, попытка записи на устройство, защищенное от записи;
- прекращение работы компьютера или зависание. Это и простые ошибки, которые не требуют перезагрузки компьютера, и более сложные, когда нужно выключать ПК;
- получение результатов, которые отличаются от ожидаемых. Программа работает стабильно, но выдает некорректный результат, который пользователь воспринимает за истину.
Ошибки выполнения можно разделить на три большие группы.
Ошибки определения данных или неверное определение исходных данных. Они могут появиться во время выполнения операций ввода-вывода.
К ним относятся:
- ошибки преобразования;
- ошибки данных;
- ошибки перезаписи.
Как правило, использование специальных технических средств для отладки (API-логгеров, логов операционной системы, профилировщиков и пр.) и программирование с защитой от ошибок помогает обнаружить и решить лишь часть из них.
Логические ошибки. Они могут возникать из ошибок, которые были допущены при выборе методов, разработке алгоритмов, определении структуры данных, кодировании модуля.
В эту группу входят:
- ошибки некорректного использования переменных. Сюда относятся неправильный выбор типов данных, использование индексов, выходящих за пределы определения массивов, использование переменных до присвоения переменной начального значения, нарушения соответствия типов данных;
- ошибки вычислений. Это некорректная работа с переменными, неправильное преобразование типов данных в процессе вычислений;
- ошибки взаимодействия модулей или межмодульного интерфейса. Это нарушение типов и последовательности при передаче параметров, области действия локальных и глобальных переменных, несоблюдение единства единиц измерения формальных и фактических параметров;
- неправильная реализация логики при программировании.
Ошибки накопления погрешностей. Могут возникать при неправильном округлении, игнорировании ограничений разрядной сетки, использовании приближенных методов вычислений и т.д.
Веб-разработчик с нуля
Освойте веб-разработку за 12 месяце и делайте сайты и приложения любой сложности.
Методы отладки программного обеспечения
Метод ручного тестирования
Отладка программы заключается в тестировании вручную с помощью тестового набора, при работе с которым была допущена ошибка. Несмотря на эффективность, метод не получится использовать для больших программ или программ со сложными вычислениями. Ручное тестирование применяется как составная часть других методов отладки.
Метод индукции
В основе отладки системы — тщательный анализ проявлений ошибки. Это могут быть сообщения об ошибке или неверные результаты вычислений. Например, если во время выполнения программы завис компьютер, то, чтобы найти фрагмент проявления ошибки, нужно проанализировать последние действия пользователя. На этапе отладки программы строятся гипотезы, каждая из них проверяется. Если гипотеза подтвердилась, информация об ошибке детализируется, если нет — выдвигаются новые.
Вот как выглядит процесс:

Важно, чтобы выдвинутая гипотеза объясняла все проявления ошибки. Если объясняется только их часть, то либо гипотеза неверна, либо ошибок несколько.
Метод дедукции
Сначала специалисты предлагают множество причин, по которым могла возникнуть ошибка. Затем анализируют их, исключают противоречащие имеющимся данным. Если все причины были исключены, проводят дополнительное тестирование. В обратном случае наиболее вероятную причину пытаются доказать.

Метод обратного прослеживания
Эффективен для небольших программ. Начинается с точки вывода неправильного результата. Для точки выдвигается гипотеза о значениях основных переменных, которые могли привести к ошибке. Далее на основании этой гипотезы строятся предположения о значениях переменных в предыдущей точке. Процесс продолжается до момента, пока не найдут ошибку.
Как выполняется отладка в современных IDE
Ранние отладчики, например gdb, представляли собой отдельные программы с интерфейсами командной строки. Более поздние, например первые версии Turbo Debugger, были автономными, но имели собственный графический интерфейс для облегчения работы. Сейчас большинство IDE имеют встроенный отладчик. Он использует такой же интерфейс, как и редактор кода, поэтому можно выполнять отладку в той же среде, которая используется для написания кода.
Отладчик позволяет разработчику контролировать выполнение и проверять (или изменять) состояние программ. Например, можно использовать отладчик для построчного выполнения программы, проверяя по ходу значения переменных. Сравнение фактических и ожидаемых значений переменных или наблюдение за ходом выполнения кода может помочь в отслеживании логических (семантических) ошибок.
Пошаговое выполнение — это набор связанных функций отладчика, позволяющих поэтапно выполнять код.
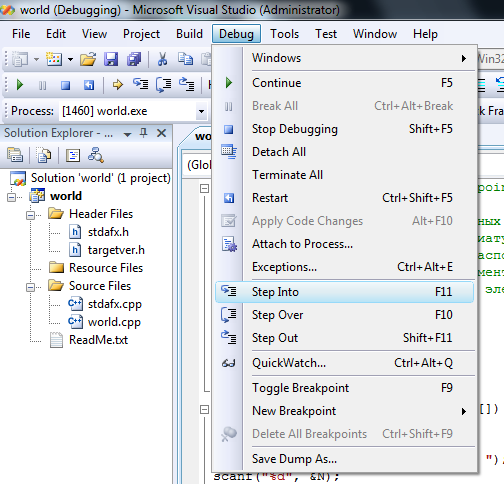
Шаг с заходом (step into)
Команда выполняет очередную инструкцию, а потом приостанавливает процесс, чтобы с помощью отладчика было можно проверить состояние программы. Если в выполняемом операторе есть вызов функции, step into заставляет программу переходить в начало вызываемой функции, где она приостанавливается.
Шаг с обходом (step over)
Команда также выполняет очередную инструкцию. Однако когда step into будет входить в вызовы функций и выполнять их строка за строкой, step over выполнит всю функцию, не останавливаясь, и вернет управление после ее выполнения. Команда step over позволяет пропустить функции, если разработчик уверен, что они уже исправлены, или не заинтересован в их отладке в данный момент.
Шаг с выходом (step out)
В отличие от step into и step over, step out выполняет не следующую строку кода, а весь оставшийся код функции, исполняемой в настоящее время. После возврата из функции он возвращает управление разработчику. Эта команда полезна, когда специалист случайно вошел в функцию, которую не нужно отлаживать.
Как правило, при пошаговом выполнении можно идти только вперед. Поэтому легко перешагнуть место, которое нужно проверить. Если это произошло, необходимо перезапустить отладку.
У некоторых отладчиков (таких как GDB 7.0, Visual Studio Enterprise Edition 15.5 и более поздних версий) есть возможность вернуться на шаг назад. Это полезно, если пропущена цель либо нужно повторно проверить выполненную инструкцию.
Веб-разработчик с нуля
За 12 месяцев вы освоите базовую верстку, frontend и backend. В конце обучения у вас будет готовое портфолио из проектов.
Виды ошибок в программах
Я учусь на своих ошибках. Ругаю себя за это, но продолжаю ошибаться. С другой стороны — это всё-таки лучше, чем не учиться совсем, и наступать на одни и те же грабли бесконечно.
При создании программ, даже простых, ошибки неизбежны. Поэтому для поиска ошибок во всех средствах разработки имеются особые инструменты для отладки. Но сегодня не об отладке и не о поиске ошибок. Сегодня о видах ошибок, которые встречаются в программах.
Итак, основных вида всего три:
Синтаксические ошибки в программах
Эти ошибки довольно распространены, особенно среди начинающих. Но эти ошибки — самые безобидные. Потому что компиляторы легко находят ошибки синтаксиса и указывают место в исходном коде, где обнаружена такая ошибка. Программисту остаётся только исправить её.
Синтаксические ошибки — это ошибки синтаксиса (а то бы вы не догадались))). То есть ошибки правил языка. Например, для Паскаля это будет синтаксической ошибкой:
Потому что после первой строки нет точки с запятой.
Подобные ошибки очень часто совершают новички. И это вгоняет их в ступор — они пугаются и не могут понять, что же не так с их кодом. Хотя если бы они внимательно его посмотрели и прочитали сообщение об ошибке, то легко могли бы исправить её:
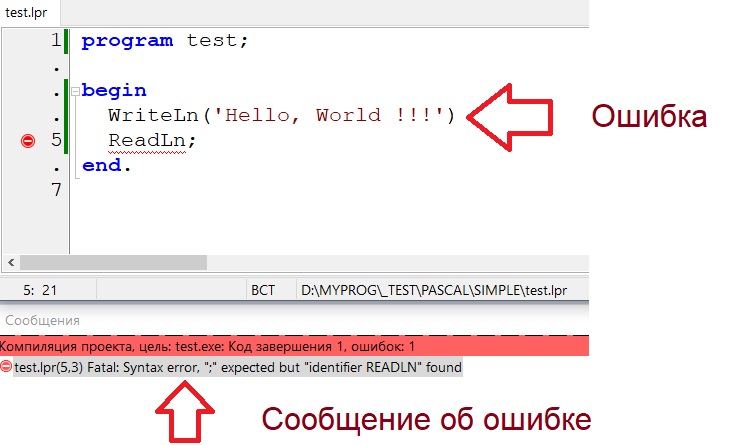
Потому что в сообщении чётко сказано:
что можно перевести как
То есть компилятор говорит нам: я ожидал увидеть точку с запятой, а нашёл идентификатор READLN .
Логические ошибки в программах
Это самые противные и самые труднонаходимые ошибки. Программа может быть написана совершенно правильно с точки зрения синтаксиса языка, и при этом она будет неправильно работать. Потому что программист допустил где-то логическую ошибку.
И компилятор вам ничего об этой ошибке не расскажет, потому что правила языка не нарушены.
Поиски таких ошибок могут занять много времени и отнять у вас немало здоровья. Поэтому при разработке программ лучше не торопиться и стараться не допускать логических ошибок.
Пример логической ошибки:
Здесь мы сравниваем значение i с числом 15, и выводим сообщение, если i = 15 . Но фишка в том, что в данном цикле i не будет равно 15 НИКОГДА, потому что в цикле переменной i присваиваются значения от 1 до 10.
Эта ошибка довольно безобидная. Здесь мы имеем просто бессмысленный код, который не причинит никакого вреда. Однако представьте, что программа должна выдавать какой-то сигнал тревоги, если i = 15 . Тогда получится, что никакого сигнала пользователь никогда не услышит, даже если случилось что-то страшное. А всё потому, что программист немного ошибся. Вот так вот и падают ракеты и самолёты…
Распространённые логические ошибки в С++ вы можете посмотреть здесь.
Ошибки времени выполнения программы
Даже если исходный код не содержит ни логических, не синтаксических ошибок, это ещё не означает, что ваша программа безупречна. Потому что ошибки могут возникнуть в ходе выполнения программы. Например, случайно будет удалён файл, который должна читать программа, и она не сможет его найти. Если не принять мер, то программа может завершиться аварийно. А пользователям такое поведение программ очень не нравится.
Одна из самых рапространённых ошибок времени выполнения — это неожиданное деление на ноль. Пример:
Что здесь такого? Всё правильно и с точки зрения логики, и с точки зрения синтаксиса. И в большинстве случаев программа отработает без каких-либо неожиданностей.
Но представьте, что пользователь введёт ноль. Что тогда будет? Правильно — попытка деления на ноль. А на ноль делить нельзя. Поэтому во время выполнения этой программы произойдёт ошибка, которая очень расстроит пользователя. Потому что в случае, например, с консольным приложением программа просто закроется, и пользователь не поймёт, что это было. Но зато поймёт, что программа — говно, и программы от этого разработчика лучше больше никогда не использовать.
В данном случае, если вы не уверены на 100%, что y будет отличаться от нуля, надо всегда делать проверку на ноль. И хороший код должен быть хотя бы таким:
Ну что же. На этом с видами ошибок пока всё. Изучайте программирование и поменьше ошибайтесь.
Поиск и исправление ошибок в программе — это интересная и необычная задача. Некоторые ошибки найти и исправить несложно. А для других до сих пор конкретных алгоритмов не придумали, поэтому приходится ограничиться лишь обобщенными решениями, следование которым облегчит ваш поиск и сделает вашу программу функциональной и эффективной.
Поиск и исправление ошибок в программе
Для того, чтобы правильно найти и исправить ошибку в коде программы, нужно понимать, что существует всего 2 вида таких ошибок:
Синтаксические — ошибки, которые допускаются в результате невнимательности программистов: неправильно выбран оператор, пропущена буква или символ, лишние буква, символ, оператор и т. п.
Логические — ошибки, которые возникают от неправильного выполнения скрипта или части кода. Такие ошибки могут привести к критическим ситуациям, когда становится невозможной дальнейшая работа или модернизация программы. Как правило, эта категория ошибок очень трудно обнаруживается.
Синтаксические ошибки
Данный вид ошибок также иногда очень критично влияет на работу программы и может привести к тому, что программа не сможет запуститься. Но такие ошибки найти и исправить довольно просто. Для этого используют специальные сервисы или программы — валидаторы.
Очень часто такой вид ошибок связан с кодом HTML. Потому что очень важно, чтобы код HTML вашего ресурса был валидным, так как от этого напрямую зависит качество его индексации. Об этом неоднократно заявляли представители компании Гугл.
Вопрос: «Как найти ошибки кода HTML?» решается за пять минут. В сети очень много валидаторов кода HTML — найдите себе подходящий и используйте. К примеру, самым известным из них является «Валидатор от W3C». Данный ресурс предоставит список ошибок HTML с инструкциями и описанием. Вам останется только их исправить — и все будет хорошо.
Таким же образом проверяются синтаксические ошибки CSS и JavaScript:
находите нужный валидатор,
находите при помощи него синтаксические ошибки,
исправляете ошибки.
Логические ошибки
С логическим ошибками все куда сложнее. Специальных сервисов для этого нет, поэтому приходится ограничиваться лишь общими советами, которые помогут провести поиск и исправление логических ошибок в программе.
Советы:
Всегда записывайте ошибку в блокнот или трекер. Как только заметили логическую ошибку в программе, нужно записать ее в трекер. Потому что вы не знаете, сколько уйдет времени и сил на поиск такой ошибки. А в процессе поиска может произойти все что угодно и вы просто можете забыть какие-то важные детали о самой ошибке.
«Ок, Google!». Если вы нашли ошибку, то есть шанс, что она не уникальна и кто-то с ней уже сталкивался. А это значит, что вполне вероятно, что у кого-то уже есть решение этой проблемы. Поэтому попробуйте найти ее решение в сети.
Ищите строку! Если поиск в сети не дал результатов, то запустите программу в отладчике и попробуйте найти строку кода, где возникает ошибка. Это, скорее всего, не решит проблему, но даст вам хоть какое-то представление о ней и позволит продолжить дальнейшие поиски.
Найдите точную строку! Отладчик вам выдаст строку с багом, но, скорее всего, причина будет не в этой строке. Чаще всего причина возникает в данных, которые получила эта строка с багом. Поэтому нужно провести более тщательный анализ и найти причину и природу возникновения ошибки. Ошибки могут происходить по-разным причинам, поэтому этот процесс будет не самым простым и легким.
Исключайте. Может так случиться, что сразу найти нужную строку кода не получится. В таком случае нужно выявить «проблемный» блок кода. Для этого нужно постепенно отключать компоненты программы, пока не будет выявлен «проблемный» компонент.
Нужно исключить проблему в аппаратном обеспечении. Редкий случай, но бывает так, что проблема с «железом» вызывает ошибки с исследуемой программой. Можно обновить операционную систему, среду разработки, заменить оперативную память и т. д.
Ищите совпадения. Когда возникают ошибки в программе? В одно и то же время? В одном и том же месте? Что общего у пользователей, у которых возникают ошибки? Задавайте подобные вопросы и ищите взаимосвязь. Это может натолкнуть вас на поиск самой проблемы.
Обратитесь за помощью. Не стесняйтесь спрашивать у более опытных коллег, что может быть не так с вашей программой? Как найти ошибки в коде и как их исправить? Ведь проблема может быть в чем угодно, а поиски решения могут занять долгое время. А с вами рядом всегда могут оказаться те, кто сможет помочь.
Заключение
Поиск и исправление логических ошибок в программе иногда становится очень стрессовой задачей. Поэтому в первую очередь никогда не нужно паниковать, если ваша программа работает не так, как надо. Не нужно сразу обвинять всех подряд или себя в том, что такая ошибка возникла.
Иногда логические ошибки действительно возникают по стечению обстоятельств и чисто случайно, поэтому только ваши спокойствие и размеренность помогут их обнаружить.
Как было показано
в предыдущем разделе на примере программы,
преобразующей
массив целых чисел,
приложение может
собираться и работать,
но не выполнять
полностью того,
что ему полагается
делать. Это
означает, что
текст программы не соответствует
спецификации поставленной задачи и
содержит логическую ошибку,
а возможно,
сразу и несколько
логических ошибок.
Из всех категорий
ошибок логические ошибки найти наиболее
трудно, так
как они берут свое начало в ошибочном
рассуждении при поиске решения задачи.
Такие ошибки
обнаруживаются на этапе выполнения
программы и приводят к неверным
результатам, к
остановке или «зависанию»
приложения.
Это делает
необходимым тестирование приложения
с различными наборами данных.
Только тщательное
тестирование на самых разнообразных
значениях данных может дать на практике
гарантию того,
что приложение
не содержит логических ошибок.
Самым простым
способом локализации логической ошибки
является пошаговое прослеживание
результатов выполнения всех операторов
программы. При
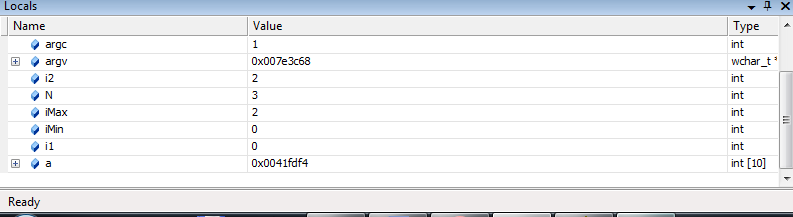
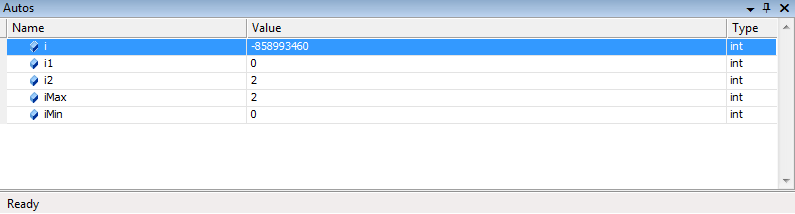
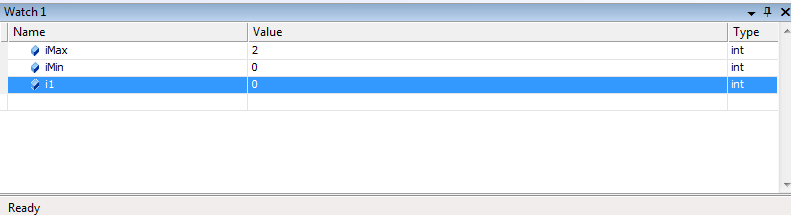
отладке приложения в VS
можно отображать
значения указанных переменных или
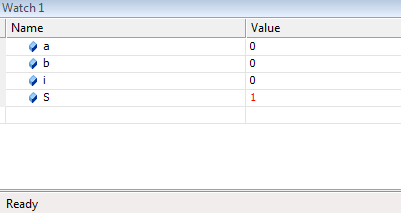
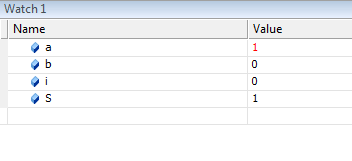
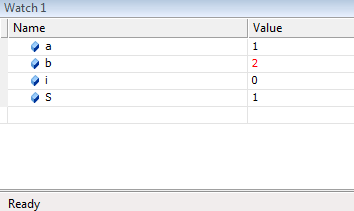
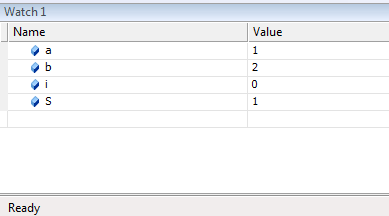
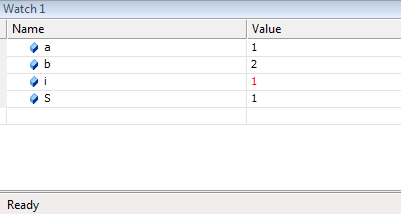
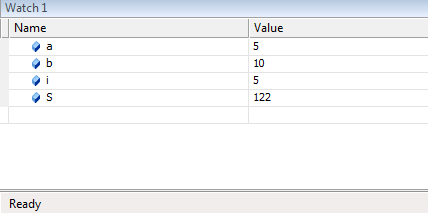
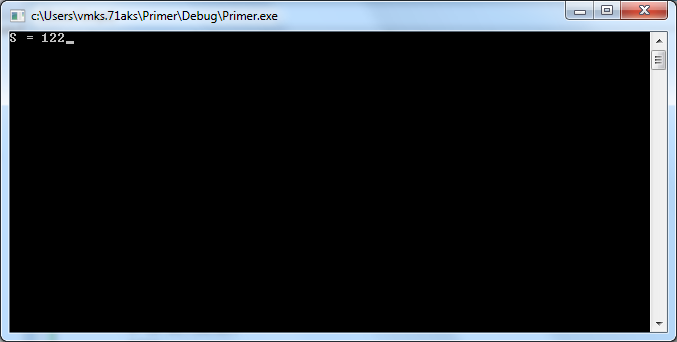
выражений в любой точке программы.
Вычисленные значения
можно, сравнивать с теми, что должны
быть, и если обнаруживается несоответствие,
то, логическая ошибка локализована.
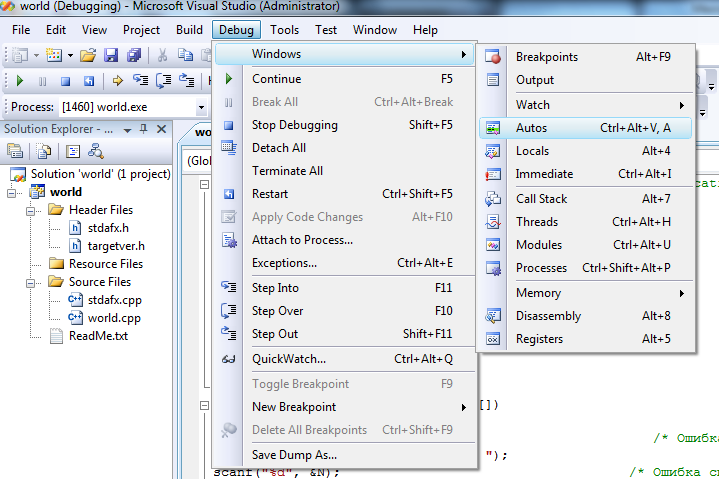
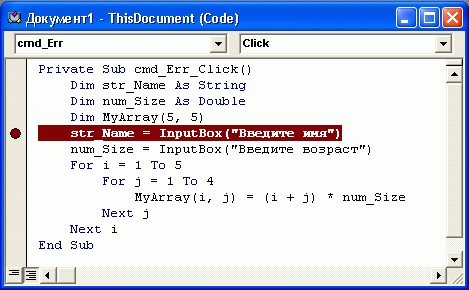
Начало
сеанса отладки
Первый шаг отладки
приложения – это выбор команды Start
Debugging
(F5) на стандартной
панели инструментов или в меню Debug,
после чего приложение запускается в
режиме отладки.
Перед началом отладки
целесообразно определить то место в
программе, где возможна ошибка. Это, как
правило, позволяет существенно сократить
время, затрачиваемое на поиски ошибки.
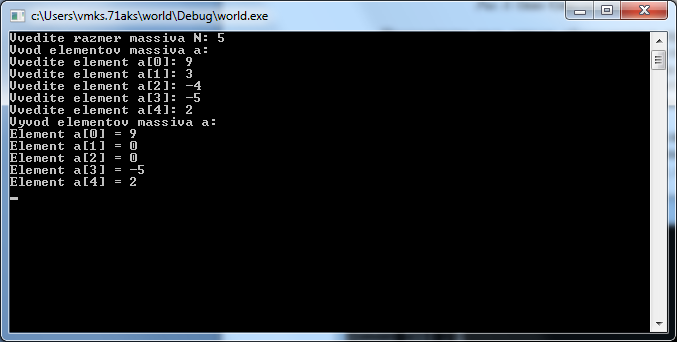
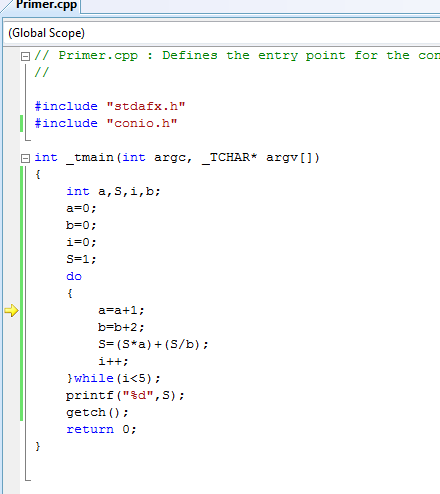
В примере 2 ошибка может содержаться в
том фрагменте программы, который изменяет
значения элементов массива после их
ввода с клавиатуры.
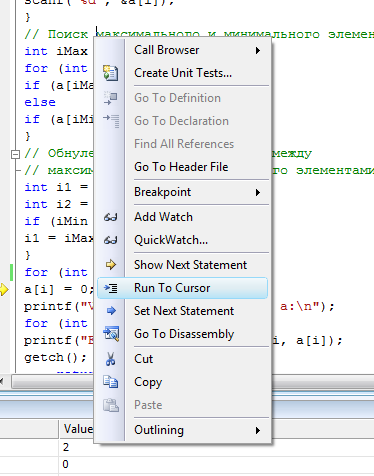
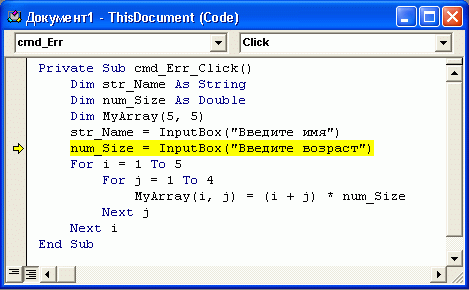
Установка
точек останова
Для того чтобы
отладчик прерывал выполнение программы
на определенной строке, необходимо
установить на этой строке точку
останова.
Точка останова
– это просто
место (например, строка с оператором
программы), которое помечено для отладчика
и отображается красным кружком в поле
индикаторов (узкое
поле серого цвета с левого края окна
редактора кода). Когда отладчик встречает
точку останова, то выполняющаяся
программа моментально останавливается
(до выполнения данной строки кода).
Установить точку
останова на какой-либо строке кода можно
при помощи щелчка по полю индикаторов
данной строки (рис. 16). Либо можно
установить курсор на нужной строке и
нажать клавишу F9.

Потому что в сообщении чётко сказано:
что можно перевести как
То есть компилятор говорит нам: я ожидал увидеть точку с запятой, а нашёл идентификатор READLN .
Логические ошибки в программах
Это самые противные и самые труднонаходимые ошибки. Программа может быть написана совершенно правильно с точки зрения синтаксиса языка, и при этом она будет неправильно работать. Потому что программист допустил где-то логическую ошибку.
И компилятор вам ничего об этой ошибке не расскажет, потому что правила языка не нарушены.
Поиски таких ошибок могут занять много времени и отнять у вас немало здоровья. Поэтому при разработке программ лучше не торопиться и стараться не допускать логических ошибок.
Пример логической ошибки:
Здесь мы сравниваем значение i с числом 15, и выводим сообщение, если i = 15 . Но фишка в том, что в данном цикле i не будет равно 15 НИКОГДА, потому что в цикле переменной i присваиваются значения от 1 до 10.
Эта ошибка довольно безобидная. Здесь мы имеем просто бессмысленный код, который не причинит никакого вреда. Однако представьте, что программа должна выдавать какой-то сигнал тревоги, если i = 15 . Тогда получится, что никакого сигнала пользователь никогда не услышит, даже если случилось что-то страшное. А всё потому, что программист немного ошибся. Вот так вот и падают ракеты и самолёты…
Распространённые логические ошибки в С++ вы можете посмотреть здесь.
Ошибки времени выполнения программы
Даже если исходный код не содержит ни логических, не синтаксических ошибок, это ещё не означает, что ваша программа безупречна. Потому что ошибки могут возникнуть в ходе выполнения программы. Например, случайно будет удалён файл, который должна читать программа, и она не сможет его найти. Если не принять мер, то программа может завершиться аварийно. А пользователям такое поведение программ очень не нравится.
Одна из самых рапространённых ошибок времени выполнения — это неожиданное деление на ноль. Пример:
Что здесь такого? Всё правильно и с точки зрения логики, и с точки зрения синтаксиса. И в большинстве случаев программа отработает без каких-либо неожиданностей.
Но представьте, что пользователь введёт ноль. Что тогда будет? Правильно — попытка деления на ноль. А на ноль делить нельзя. Поэтому во время выполнения этой программы произойдёт ошибка, которая очень расстроит пользователя. Потому что в случае, например, с консольным приложением программа просто закроется, и пользователь не поймёт, что это было. Но зато поймёт, что программа — говно, и программы от этого разработчика лучше больше никогда не использовать.
В данном случае, если вы не уверены на 100%, что y будет отличаться от нуля, надо всегда делать проверку на ноль. И хороший код должен быть хотя бы таким:
Ну что же. На этом с видами ошибок пока всё. Изучайте программирование и поменьше ошибайтесь.