
Ошибки и исключения. Обработка исключений
В любой, особенно большой, программе могут возникать ошибки, приводящие к ее неработоспособности или к тому, что программа делает не то, что должна. Причин возникновения ошибок много.
Программист может сделать ошибку в употреблении самого языка программирования. Другими словами, выразиться так, как выражаться не положено. Например, начать имя переменной с цифры или забыть поставить двоеточие в заголовке сложной инструкции. Подобные ошибки называют синтаксическими, они нарушают синтаксис и пунктуацию языка. Интерпретатор Питона, встретив ошибочное выражение, не знает как его интерпретировать. Поэтому останавливает выполнение программы и выводит соответствующее сообщение, указав на место возникновения ошибки:
SyntaxError: invalid syntax
В терминологии языка Python здесь возникло исключение, принадлежащее классу SyntaxError. Согласно документации Python синтаксические ошибки все-таки принято относить к ошибкам, а все остальные – к исключениям. В некоторых языках программирования не используется слово «исключение», а ошибки делят на синтаксические и семантические. Нарушение семантики обычно означает, что, хотя выражения написаны верно с точки зрения синтаксиса языка, программа не работает так, как от нее ожидалось. Для сравнения. Вы можете грамотным русским языком сказать несколько предложений, но по смыслу это будет белиберда, или вас поймут не так, как хотелось бы.
В Python не говорят о семантических ошибках, говорят об исключениях. Их множество. В этом уроке мы рассмотрим некоторые из них, в последующих встретимся с еще несколькими.
Если вы попытаетесь обратиться к переменной, которой не было присвоено значение, что в случае Python означает, что переменная вообще не была объявлена, она не существует, то возникнет исключение NameError.
Traceback (most recent call last):
File «<stdin>», line 1, in <module>
NameError: name ‘b’ is not defined
Последнюю строку сообщения можно перевести как «Ошибка имени: имя ‘b’ не определено».
Если исключение возникает при выполнении кода из файла, то вместо «line 1» будет указана строка, в которой оно возникло, например, «line 24». Вместо «<stdin>» будет указано имя файла, например, «test.py». В данном же случае stdin обозначает стандартный поток ввода. По-умолчанию это поток ввода с клавиатуры. Строка 1 – потому что в интерактивном режиме каждое выражение интерпретируется отдельно, как обособленная программка. Если написать выражение, состоящее из нескольких строк, то линия возникновения ошибки может быть другой:
Traceback (most recent call last):
File «<stdin>», line 3, in <module>
NameError: name ‘b’ is not defined
Следующие два исключения, о которых следует упомянуть, и с которыми вы уже могли встретиться в предыдущих уроках, это ValueError и TypeError – ошибка значения и ошибка типа.
Traceback (most recent call last):
File «<stdin>», line 1, in <module>
ValueError: invalid literal for int()
Traceback (most recent call last):
File «<stdin>», line 1, in <module>
TypeError: unsupported operand type(s)
В примере строку «Hi» нельзя преобразовать к целому числу. Возникает исключение ValueError, потому что функция int() не может преобразовать такое значение.
Число 8 и строка «3» принадлежат разным типам, операнд сложения между которыми не поддерживается. При попытке их сложить возникает исключение TypeError.
Деление на ноль вызывает исключение ZeroDivisionError:
Traceback (most recent call last):
File «<stdin>», line 1, in <module>
ZeroDivisionError: division by zero
Обработка исключений. Оператор try-except
Обработка исключений. Оператор try-except
Когда ошибки в программе возникают в процессе написания кода или его тестирования, то код исправляется программистом так, чтобы ошибок не возникало. Однако нередко действия пользователя приводят к тому, что в программе возникает исключение. Например, программа ожидает ввод числа, но человек ввел букву. Попытка преобразовать ее к числу приведет к возбуждению исключения ValueError, и программа аварийно завершится.
На этот случай в языках программирования, в том числе Python, существует специальный оператор, позволяющий перехватывать возникающие исключения и обрабатывать их так, чтобы программа продолжала работать или корректно завершала свою работу.
В Питоне такой перехват выполняет оператор try-except. «Try» переводится как «попытаться», «except» – как исключение. Словами описать его работу можно так: «Попытаться сделать то-то и то-то, если при этом возникло исключение, то сделать вот это и это.» Его конструкция похожа на условный оператор с веткой else. Рассмотрим пример:
n = input(«Введите целое число: «)
print(«Что-то пошло не так»)
Исключительная ситуация может возникнуть в третьей строчке кода, когда значение переменной n преобразуется к целому числу. Если это невозможно, то дальнейшее выполнение выражений в теле try прекращается. В данном случае выражение print("Удачно") выполнено не будет. При этом поток выполнения программы перейдет на ветку except и выполнит ее тело.
Если в теле try исключения не возникает, то тело ветки except не выполняется.
Вот пример вывода программы, когда пользователь вводит целое число:
А здесь – когда вводит не то, что ожидалось:
Есть одна проблема. Код выше обработает любое исключение. Однако в теле try могут возникать разные исключения, и у каждого из них должен быть свой обработчик. Поэтому более правильным является указание типа исключения после ключевого слова except.
n = input(‘Введите целое число: ‘)
print(«Все нормально. Вы ввели число», n)
print(«Вы ввели не целое число»)
Теперь если сработает тело except мы точно знаем, из-за чего возникла ошибка. Но если в теле try возникнет еще какое-нибудь исключение, то оно не будет обработано. Для него надо написать отдельную ветку except. Рассмотрим программу:
a = float(input(«Введите делимое: «))
b = float(input(«Введите делитель: «))
print(«Частное: %.2f» % c)
print(«Нельзя вводить строки»)
except ZeroDivisionError:
print(«Нельзя делить на ноль»)
При ее выполнении исключения могут возникнуть в трех строчках кода: где происходит преобразование введенных значений к вещественным числам и в месте, где происходит деление. В первом случае может возникнуть ValueError, во втором – ZeroDivisionError. Каждый тип исключения обрабатывается своей веткой except.
Несколько исключений можно сгруппировать в одну ветку и обработать совместно:
a = float(input(«Введите делимое: «))
b = float(input(«Введите делитель: «))
print(«Частное: %.2f» % c)
except (ValueError, ZeroDivisionError):
print(«Нельзя вводить строки»)
print(«или делить на ноль»)
У оператора обработки исключений, кроме except, могут быть еще ветки finally и else (не обязательно обе сразу). Тело finally выполняется всегда, независимо от того, выполнялись ли блоки except в ответ на возникшие исключения или нет. Тело else сработает, если исключений в try не было, то есть не было переходов на блоки except.
n = input(‘Введите целое число: ‘)
print(«Вы что-то попутали с вводом»)
else: # когда в блоке try не возникло исключения
print(«Все нормально. Вы ввели число», n)
finally: # выполняется в любом случае
Примечание. В данном коде используются комментарии. В языке Python перед ними ставится знак решетки #. Комментарии в программном коде пишутся исключительно для человека и игнорируются интерпретатором или компилятором.
Посмотрите, как выполняется программа в случае возникновения исключения и без этого:
Вы что—то попутали с вводом
Все нормально. Вы ввели число 4
В данном уроке изложены не все особенности обработки исключений. Так в более крупных программах, содержащих несколько уровней вложенности кода, функции, модули и классы, исключения могут обрабатываться не по месту их возникновения, а передаваться дальше по иерархии вызовов.
Также исключение может возникнуть в блоке except, else или finally, и тогда им нужен собственный обработчик. Модифицируем немного предыдущую программу и специально сгенерируем исключение в теле except:
n = input(‘Введите целое число: ‘)
print(«Вы что-то попутали с вводом»)
except ZeroDivisionError:
print(«Все нормально. Вы ввели число», n)
По началу может показаться, что все нормально. Исключение, генерируемое выражением 3 / 0 будет обработано веткой except ZeroDivisionError. Однако это не так. Эта ветка обрабатывает только исключения, возникающие в блоке try, к которому она сама относится. Вот вывод программы, если ввести не целое число:
Вы что—то попутали с вводом
Traceback (most recent call last):
File «test.py», line 15, in <module>
ValueError: invalid literal for
During handling of the above exception,
another exception occurred:
Traceback (most recent call last):
File «test.py», line 18, in <module>
ZeroDivisionError: division by zero
Мало того, что не было обработано деление на ноль, поскольку тело except ValueError неудачно завершилось, само исключение ValueError посчиталось необработанным. Решение проблемы может быть, например, таким:
print(«Вы что-то попутали с вводом»)
except ZeroDivisionError:
Здесь в тело except вложен свой внутренний обработчик исключений.
Напишите программу, которая запрашивает ввод двух значений. Если хотя бы одно из них не является числом, то должна выполняться конкатенация, то есть соединение, строк. В остальных случаях введенные числа суммируются.
Примеры выполнения программы:
Поговорим об исключениях в C++, начиная определением и заканчивая грамотной обработкой.
- Инструмент программирования для исключительных ситуаций
- Исключения: панацея или нет
- Синтаксис исключений в C++
- Базовые исключения стандартной библиотеки
- Заключение

Георгий Осипов
Один из авторов курса «Разработчик C++» в Яндекс Практикуме, разработчик в Лаборатории компьютерной графики и мультимедиа ВМК МГУ
Исключения — важный инструмент в современном программировании. В большинстве источников тема исключений раскрывается не полностью: не описана механика их работы, производительность или особенности языка C++.
В статье я постарался раскрыть тему исключений достаточно подробно. Она будет полезна новичкам, чтобы узнать об исключениях, и программистам с опытом, чтобы углубиться в явление и достичь его полного понимания.
Статья поделена на две части. Первая перед вами и содержит базовые, но важные сведения. Вторая выйдет чуть позже. В ней — информация для более продвинутых разработчиков.
В первой части разберёмся:
- для чего нужны исключения;
- особенности C++;
- синтаксис выбрасывания и обработки исключений;
- особые случаи, связанные с исключениями.
Также рассмотрим основные стандартные типы исключений, где и для чего они применяются.
Мы опираемся на современные компиляторы и Стандарт C++20. Немного затронем C++23 и даже C++03.
Если вы только осваиваете C++, возможно, вам будет интересен курс «Разработчик C++» в Яндекс Практикуме. У курса есть бесплатная вводная часть. Именно она может стать вашим первым шагом в мир C++. Для тех, кто знаком с программированием, есть внушительная ознакомительная часть, тоже бесплатная.
Инструмент программирования для исключительных ситуаций
В жизни любой программы бывают моменты, когда всё идёт не совсем так, как задумывал разработчик. Например:
- в системе закончилась оперативная память;
- соединение с сервером внезапно прервалось;
- пользователь выдернул флешку во время чтения или записи файла;
- понадобилось получить первый элемент списка, который оказался пустым;
- формат файла не такой, как ожидалось.
Примеры объединяет одно: возникшая ситуация достаточно редка, и при нормальной работе программы, всех устройств, сети и адекватном поведении пользователя она не возникает.
Хороший программист старается предусмотреть подобные ситуации. Однако это бывает сложно: перечисленные проблемы обладают неприятным свойством — они могут возникнуть практически в любой момент.
На помощь программисту приходят исключения (exception). Так называют объекты, которые хранят данные о возникшей проблеме. Механизмы исключений в разных языках программирования очень похожи. В зависимости от терминологии языка исключения либо выбрасывают (throw), либо генерируют (raise). Это происходит в тот момент, когда программа не может продолжать выполнять запрошенную операцию.
После выбрасывания в дело вступает системный код, который ищет подходящий обработчик. Особенность в том, что тот, кто выбрасывает исключение, не знает, кто будет его обрабатывать. Может быть, что и вовсе никто — такое исключение останется сиротой и приведёт к падению программы.
Если обработчик всё же найден, то он ловит (catch) исключение и программа продолжает работать как обычно. В некоторых языках вместо catch используется глагол except (исключить).
Обработчик ловит не все исключения, а только некоторые — те, что возникли в конкретной части определённой функции. Эту часть нужно явно обозначить, для чего используют конструкцию try (попробовать). Также обработчик не поймает исключение, которое ранее попало в другой обработчик. После обработки исключения программа продолжает выполнение как ни в чём не бывало.
Исключения: панацея или нет
Перед тем как совершить операцию, нужно убедиться, что она корректна. Если да — совершить эту операцию, а если нет — выбросить исключение. Так делается в некоторых языках, но не в C++. Проверка корректности — это время, а время, как известно, деньги. В C++ считается, что программист знает, что делает, и не нуждается в дополнительных проверках. Это одна из причин, почему программы на C++ такие быстрые.
Но за всё нужно платить. Если вы не уследили и сделали недопустимую операцию, то в менее производительных языках вы получите исключение, а в C++ — неопределённое поведение. Исключение можно обработать и продолжить выполнение программы. Неопределённое поведение гарантированно обработать нельзя.
Но некоторые виды неопределённого поведения вполне понятны и даже могут быть обработаны. Это зависит от операционной системы:
- сигналы POSIX — низкоуровневые уведомления, которые отправляются программе при совершении некорректных операций и в некоторых других случаях;
- структурированные исключения Windows (SEH) — специальные исключения, которые нельзя обработать средствами языка.
Особенность C++ в том, что не любая ошибка влечёт исключение, и не любую ошибку можно обработать. Но если для операции производительность не так критична, почему бы не сделать проверку?
У ряда операций в C++ есть две реализации. Одна супербыстрая, но вы будете отвечать за корректность, а вторая делает проверку и выбрасывает исключение в случае ошибки. Например, к элементу класса std::vector можно обратиться двумя способами:
vec[15]— ничего не проверяет. Если в векторе нет элемента с индексом 15, вы получаете неопределённое поведение. Это может быть сигнал SIGSEGV, некорректное значение или взрыв компьютера.vec.at(15)— то же самое, но в случае ошибки выбрасывается исключение, которое можно обработать.
В C++ вам даётся выбор: делать быстро или делать безопасно. Часто безопасность важнее, но в определённых местах программы любое промедление критично.
Ловим исключения
Начнём с примера:
void SomeFunction() {
DoSomething0();
try {
SomeClass var;
DoSomething1();
DoSomething2();
// ещё код
cout << "Если возникло исключение, то этот текст не будет напечатан" << std::endl;
}
catch(ExceptionType e) {
std::cout << "Поймано исключение: " << e.what() << std::endl;
// ещё код
}
std::cout << "Это сообщение не будет выведено, если возникло исключение в DoSomething0 или "
"непойманное исключение внутри блока try." << std::endl;
}
В примере есть один try-блок и один catch-блок. Если в блоке try возникает исключение типа ExceptionType, то выполнение блока заканчивается. При этом корректно удаляются созданные объекты — в данном случае переменная var. Затем управление переходит в конструкцию catch. Сам объект исключения передаётся в переменную e. Выводя e.what(), мы предполагаем, что у типа ExceptionType есть метод what.
Если в блоке try возникло исключение другого типа, то управление также прервётся, но поиск обработчика будет выполняться за пределами функции SomeFunction — выше по стеку вызовов. Это также касается любых исключений, возникших вне try-блока.
Во всех случаях объект var будет корректно удалён.
Исключение не обязано возникнуть непосредственно внутри DoSomething*(). Будут обработаны исключения, возникшие в функциях, вызванных из DoSomething*, или в функциях, вызванных из тех функций, да и вообще на любом уровне вложенности. Главное, чтобы исключение не было обработано ранее.
Ловим исключения нескольких типов
Можно указать несколько блоков catch, чтобы обработать исключения разных типов:
void SomeFunction() {
DoSomething0();
try {
DoSomething1();
DoSomething2();
// ещё код
}
catch(ExceptionType1 e) {
std::cout << "Some exception of type ExceptionType1: " << e.what() << std::endl;
// ещё код
}
catch(ExceptionType2 e) {
std::cout << "Some exception of type ExceptionType2: " << e.what() << std::endl;
// ещё код
}
// ещё код
}Ловим все исключения
void SomeFunction() {
DoSomething0();
try {
DoSomething1();
DoSomething2();
// ещё код
}
catch(...) {
std::cout << "An exception any type" << std::endl;
// ещё код
}
// ещё код
}Если перед catch(...) есть другие блоки, то он означает «поймать все остальные исключения». Ставить другие catch-блоки после catch(...) не имеет смысла.
Перебрасываем исключение
Внутри catch(...) нельзя напрямую обратиться к объекту-исключению. Но можно перебросить тот же объект, чтобы его поймал другой обработчик:
void SomeFunction() {
DoSomething0();
try {
DoSomething1();
DoSomething2();
// ещё код
}
catch(...) {
std::cout << "Какое-то исключение неизвестного типа. Сейчас не можем его обработать" << std::endl;
throw; // перебрасываем исключение
}
// ещё код
}Можно использовать throw в catch-блоках с указанным типом исключения. Но если поместить throw вне блока catch, то программа тут же аварийно завершит работу через вызов std::terminate().
Перебросить исключение можно другим способом:
std::rethrow_exception(std::current_exception())Этот способ обладает дополнительным преимуществом: можно сохранить исключение и перебросить его в другом месте. Однако результат std::current_exception() — это не объект исключения, поэтому его можно использовать только со специализированными функциями.
Принимаем исключение по ссылке
Чтобы избежать лишних копирований, можно ловить исключение по ссылке или константной ссылке:
void SomeFunction() {
DoSomething0();
try {
DoSomething1();
DoSomething2();
// ещё код
}
catch(ExceptionType& e) {
std::cout << "Some exception of type ExceptionType: " << e.what() << std::endl;
// ещё код
}
catch(const OtherExceptionType& e) {
std::cout << "Some exception of type OtherExceptionType: " << e.what() << std::endl;
// ещё код
}
}Это особенно полезно, когда мы ловим исключение по базовому типу.
Выбрасываем исключения
Чтобы поймать исключение, нужно его вначале выбросить. Для этого применяется throw.
Если throw используется с параметром, то он не перебрасывает исключение, а выбрасывает новое. Параметр может быть любого типа, даже примитивного. Использовать такую конструкцию разрешается в любом месте программы:
void ThrowIfNegative(int x) {
if (x < 0) {
// выбрасываем исключение типа int
throw x;
}
}
int main() {
try {
ThrowIfNegative(10);
ThrowIfNegative(-15);
ThrowIfNegative(0);
cout << "Этот текст никогда не будет напечатан" << std::endl;
}
// ловим выброшенное исключение
catch(int x) {
cout << "Поймано исключение типа int, содержащее число " << x << std::endl;
}
}Вывод: «Поймано исключение типа int, содержащее число –15».
Создаём типы для исключений
Выбрасывать int или другой примитивный тип можно, но это считается дурным тоном. Куда лучше создать специальный тип, который будет использоваться только для исключений. Причём удобно для каждого вида ошибок сделать отдельный класс. Он даже не обязан содержать какие-то данные или методы: отличать исключения друг от друга можно по названию типа.
class IsZeroException{};
struct IsNegativeException{};
void ThrowIfNegative(int x) {
if (x < 0) {
// Выбрасывается не тип, а объект.
// Не забываем скобки, чтобы создать объект заданного типа:
throw IsNegativeException();
}
}
void ThrowIfZero(int x) {
if (x == 0) {
throw IsZeroException();
}
}
void ThrowIfNegativeOrZero(int x) {
ThrowIfNegative(x);
ThrowIfZero(x);
}
int main() {
try {
ThrowIfNegativeOrZero(10);
ThrowIfNegativeOrZero(-15);
ThrowIfNegativeOrZero(0);
}
catch(IsNegativeException x) {
cout << "Найдено отрицательное число" << std::endl;
}
catch(IsZeroException x) {
cout << "Найдено нулевое число" << std::endl;
}
}В итоге будет напечатана только фраза: «Найдено отрицательное число», поскольку –15 проверено раньше нуля.
Ловим исключение по базовому типу
Чтобы поймать исключение, тип обработчика должен в точности совпадать с типом исключения. Например, нельзя поймать исключение типа int обработчиком типа unsigned int.
Но есть ситуации, в которых типы могут не совпадать. Про одну уже сказано выше: можно ловить исключение по ссылке. Есть ещё одна возможность — ловить исключение по базовому типу.
Например, чтобы не писать много catch-блоков, можно сделать все используемые типы исключений наследниками одного. В этом случае рекомендуется принимать исключение по ссылке.
class NumericException {
public:
virtual std::string_view what() const = 0;
}
// Класс — наследник NumericException.
class IsZeroException : public NumericException {
public:
std::string_view what() const override {
return "Обнаружен ноль";
}
}
// Ещё один наследник NumericException.
class IsNegativeException : public NumericException {
public:
std::string_view what() const override {
return "Обнаружено отрицательное число";
}
}
void ThrowIfNegative(int x) {
if (x < 0) {
// Выбрасывается не тип, а объект.
// Не забываем скобки, чтобы создать объект заданного типа:
throw IsNegativeException();
}
}
void ThrowIfZero(int x) {
if (x == 0) {
throw IsZeroException();
}
}
void ThrowIfNegativeOrZero(int x) {
ThrowIfNegative(x);
ThrowIfZero(x);
}
int main() {
try {
ThrowIfNegativeOrZero(10);
ThrowIfNegativeOrZero(-15);
ThrowIfNegativeOrZero(0);
}
// Принимаем исключение базового типа по константной ссылке (&):
catch(const NumericException& e) {
std::cout << e.what() << std::endl;
}
}Выбрасываем исключение в тернарной операции ?:
Напомню, что тернарная операция ?: позволяет выбрать из двух альтернатив в зависимости от условия:
std::cout << (age >= 18 ? "Проходите" : "Извините, вход в бар с 18 лет") << std::endl;Оператор throw можно использовать внутри тернарной операции в качестве одного из альтернативных значений. Например, так можно реализовать безопасное деление:
int result = y != 0 ? x / y : throw IsZeroException();Это эквивалентно такой записи:
int result;
if (y != 0) {
result = x / y;
}
else {
throw IsZeroException();
}Согласитесь, первый вариант лаконичнее. Так можно выбрасывать несколько исключений в одном выражении:
// Вычислим корень отношения чисел:
int result = y == 0 ? throw IsZeroException() : x / y < 0 ? throw IsNegativeException() : sqrt(x / y);Вся функция — try-блок
Блок try может быть всем телом функции:
int SomeFunction(int x) try {
return DoSomething(x);
}
catch(ExceptionType e) {
std::cout << "Some exception of type ExceptionType: " << e.what() << std::endl;
// ещё код
// Для того, кто вызвал функцию, всё прошло штатно: исключение поймано.
// Мы должны возвратить значение:
return –1;
}Тут мы просто опустили фигурные скобки функции. По-другому можно записать так:
int SomeFunction(int x) {
try {
return DoSomething(x);
}
catch(ExceptionType e) {
std::cout << "Some exception of type ExceptionType: " << e.what() << std::endl;
// ещё код
// Для того, кто вызвал функцию, всё прошло штатно: исключение поймано.
// Мы должны возвратить значение:
return –1;
}
}Исключения в конструкторе
Есть как минимум два случая возникновения исключений в конструкторе объекта:
- Внутри тела конструктора.
- При конструировании данных объекта.
В первом случае исключение ещё можно поймать внутри тела конструктора и сделать вид, как будто ничего не было.
Во втором случае исключение тоже можно поймать, если использовать try-блок в качестве тела конструктора. Однако тут есть особенность: сделать вид, что ничего не было, не получится. Объект всё равно будет считаться недоконструированным:
class IsZeroException{};
// Функция выбросит исключение типа IsZeroException
// если аргумент равен нулю.
void ThrowIf0(int x) {
if (x == 0) {
throw IsZeroException();
}
}
// Класс содержит только одно число.
// Он выбрасывает исключение в конструкторе, если число нулевое.
class NotNullInt {
public:
NotNullInt(int x) : x_(x) {
ThrowIf0(x_);
}
private:
int x_;
}
class Ratio {
public:
// Инициализаторы пишем после try:
Ratio(int x, int y) try : x_(x), y_(y) {
}
catch(IsZeroException e) {
std::cout << "Знаменатель дроби не может быть нулём" << std::endl;
// Тут неявный throw; — конструктор прерван
}
private:
int x_;
NotNullInt y_;
};
int main() {
Ratio(10, 15);
try {
Ratio(15, 0);
}
catch(...) {
std::cout << "Дробь не построена" << std::endl;
}
}Тут мы увидим оба сообщения: «Знаменатель дроби не может быть нулём» и «Дробь не построена».
Если объект недоконструирован, то его деструктор не вызывается. Это логичная, но неочевидная особенность языка. Однако все полностью построенные члены – данные объекта будут корректно удалены:
#include
class A{
public:
A() {
std::cout << "A constructed" << std::endl;
}
~A() {
std::cout << "A destructed" << std::endl;
}
private:
}
class B{
public:
B() {
std::cout << "B constructed" << std::endl;
throw 1;
}
~B() {
// Этой надписи мы не увидим:
std::cout << "B destructed" << std::endl;
}
private:
A a;
};
int main() {
try {
B b;
}
catch (...) {
}
}Запустим код и увидим такой вывод:
A constructed
B constructed
A destructedОбъект типа A создался и удалился, а объект типа B создался не до конца и поэтому не удалился.
Не все исключения в конструкторах можно обработать. Например, нельзя поймать исключения, выброшенные при конструировании глобальных и thread_local объектов, — в этом случае будет вызван std::terminate.
Исключения в деструкторе
В этом разделе примера не будет, потому что исключения в деструкторе — нежелательная практика. Бывает, что язык удаляет объекты вынужденно, например, при поиске обработчика выброшенного исключения. Если во время этого возникнет другое исключение в деструкторе какого-то объекта, то это приведёт к вызову std::terminate.
Более того, по умолчанию исключения в деструкторе запрещены и всегда приводят к вызову std::terminate. Выможете разрешить их для конкретного конструктора — об этом я расскажу в следующей части — но нужно много раз подумать, прежде чем сделать это.
Обрабатываем непойманные исключения
Поговорка «не пойман — не вор» для исключений не работает. Непойманные исключения приводят к завершению программы через std::terminate. Это нештатная ситуация, но можно предотвратить немедленное завершение, добавив обработчик для std::terminate:
int main() {
// Запишем обработчик в переменную terminate_handler
auto terminate_handler = []() {
auto e_ptr = std::current_exception();
if (e_ptr) {
try {
// Перебросим исключение:
std::rethrow_exception(e_ptr);
} catch (const SomeType& e) {
std::cerr << "Непойманное исключение типа SomeType: " << e.what() << std::endl;
}
catch (...) {
std::cerr << "Непойманное исключение неизвестного типа" << std::endl;
}
}
else {
std::cerr << "Неизвестная ошибка" << std::endl;
}
// Всё равно завершим программу.
std::abort();
};
// Установим обработчик для функции terminate
std::set_terminate(terminate_handler);
// …..
}Однако не стоит надеяться, что программа после обработки такой неприятной ситуации продолжит работу как ни в чём не бывало. std::terminate — часть завершающего процесса программы. Внутри него доступен только ограниченный набор операций, зависящий от операционной системы.
Остаётся только сохранить всё, что можно, и извиниться перед пользователем за неполадку. А затем выйти из программы окончательно вызовом std::abort().
Базовые исключения стандартной библиотеки
Далеко не всегда есть смысл создавать новый тип исключений, ведь в стандартной библиотеке их и так немало. А если вы всё же создаёте свои исключения, то сделайте их наследниками одного из базовых. Рекомендуется делать все типы исключений прямыми или косвенными наследниками std::exception.
Обратим внимание на одну важную вещь. Все описываемые далее классы не содержат никакой магии. Это обычные и очень простые классы, которые вы могли бы реализовать и самостоятельно. Использовать их можно и без throw, однако смысла в этом немного.
Их особенность в том, что разработчики договорились использовать эти классы для описания исключений, генерируемых в программе. Например, этот код абсолютно корректен, но совершенно бессмысленен:
#include
#include
int main() {
// Используем std::runtime_error вместо std::string.
// Но зачем?
std::runtime_error err("Буря мглою небо кроет");
std::cout << err.what() << std::endl;
}Разберём основные типы исключений, описанные в стандартной библиотеке C++.
std::exception
Базовый класс всех исключений стандартной библиотеки. Конструктор не принимает параметров. Имеет метод what(), возвращающий описание исключения. Как правило, используются производные классы, переопределяющие метод what().
std::logic_error : public std::exception
Исключение типа logic_error выбрасывается, когда нарушены условия, сформулированные на этапе написания программы. Например, мы передали в функцию извлечения квадратного корня отрицательное число или попытались извлечь элемент из пустого списка.
Конструктор принимает сообщение в виде std::string, которое будет возвращаться методом what().
// класс копилка
class Moneybox {
public:
void WithdrawCoin() {
if (coins_ == 0) {
throw std::logic_error("В копилке нет денег");
}
--coins_;
}
void PutCoin() {
++coins_;
}
private:
int coins_ = 0;
}Перечислим некоторые производные классы std::logic_error. У всех них похожий интерфейс.
- std::invalid_argument. Исключение этого типа показывает, что функции передан некорректный аргумент, не соответствующий условиям.
double GetSqrt(double x) {
return x >= 0 ? sqrt(x) :
throw std::invalid_argument("Попытка извлечь квадратный корень из отрицательного числа");
}Это исключение выбрасывают функции преобразования строки в число, такие как stol, stof, stoul, а также конструктор класса std::bitset:
try {
int f = std::stoi("abracadabra");
} catch (std::invalid_argument& ex) {
std::cout << ex.what() << 'n';
}- std::length_error. Исключение говорит о том, что превышен лимит вместимости контейнера. Может выбрасываться из методов, меняющих размер контейнеров
stringиvector. Напримерresize,reserve,push_back.
- std::out_of_range. Исключение говорит о том, что некоторое значение находится за пределами допустимого диапазона. Возникает при использовании метода
atпрактически всех контейнеров. Также возникает при использовании функций конвертации в строки в число, таких какstol,stof,stoul. В стандартной библиотеке есть исключение с похожим смыслом —std::range_error.
std::runtime_error : public std::exception
std::runtime_error — ещё один базовый тип для нескольких видов исключений. Он говорит о том, что исключение относится скорее не к предусмотренной ошибке, а к выявленной в процессе выполнения.
При этом, если std::logic_error подразумевает конкретную причину ошибки — нарушение конкретного условия, — то std::runtime_error говорит о том, что что-то идёт не так, но первопричина может быть не вполне очевидна.
Интерфейс такой же, как и у logic_error: класс принимает описание ошибки в конструкторе и переопределяет метод what() базового класса std::exception.
class CommandLineParsingError : public std::runtime_error {
public:
// этой строкой импортируем конструктор из базового класса:
using runtime_error::runtime_error;
};
class ZeroDenominatorError : public std::runtime_error {
public:
// используем готовое сообщение:
ZeroDenominatorError() : std::runtime_error("Знаменатель не может быть нулём") {
}
}Рассмотрим некоторые важные производные классы:
std::regex_error.Исключение, возникшее в процессе работы с регулярными выражениями. Например, при неверном синтаксисе регулярного выражения.std::system_error.Широкий класс исключений, связанных с потоками, вводом-выводом или файловой системой.std::format_error.Исключение, возникшее при работе функцииstd::format.
std::bad_alloc : public std::exception
У std::exception есть и другие наследники. Самый важный — std::bad_alloc. Его может выбрасывать операция new. Это исключение — слабое место многих программ и головная боль многих разработчиков, ведь оно может возникать практически везде — в любом месте, где есть динамическая аллокация. То есть при:
- вставке в любой контейнер;
- копировании любого контейнера, например, обычной строки;
- создании умного указателя unique_ptr или shared_ptr;
- копировании объекта, содержащего контейнер;
- прямом вызове new (надеемся, что вы так не делаете);
- работе с потоками ввода-вывода;
- работе алгоритмов;
- вызове корутин;
- в пользовательских классах и библиотеках — практически при любых операциях.
При обработке bad_alloc нужно соблюдать осторожность и избегать других динамических аллокаций.
#include
#include
#include
#include
int main() {
std::vector vec;
try {
while (true) {
vec.push_back(std::string(10000000, 'a'));
}
}
catch (const std::bad_alloc& e) {
std::cout << "Место закончилось после вставки " << vec.size() << " элементов" << std::endl;
}
}Возможный вывод: «Место закончилось после вставки 2640 элементов».
При аллокациях возможна также ошибка std::bad_array_new_length, производная от bad_alloc. Она возникает при попытке выделить слишком большое, слишком маленькое (меньше, чем задано элементов для инициализации) либо отрицательное количество памяти.
Также при аллокации можно запретить new выбрасывать исключение. Для этого пишем (std::nothrow) после new:
int main()
{
int* m = new (std::nothrow) int [0xFFFFFFFFFFFFFFULL];
std::cout << m; // выведет 0
delete[] m;
}В случае ошибки операция будет возвращать нулевой указатель.
bad_alloc настолько сложно учитывать, что многие даже не пытаются это делать. Мотивация такая: если память закончилась, то всё равно программе делать уже нечего. Лучше поскорей вызвать std::terminate и завершиться.
Заключение
В этой части мы разобрали, как создавать исключения C++, какие они бывают и как с ними работать. Разобрали ключевые слова try, catch и throw.
В следующей части запустим бенчмарк, разберём гарантии безопасности, спецификации исключений, а также узнаем, когда нужны исключения, а когда можно обойтись без них. И главное — узнаем, как они работают.
Исключения не так просты, как кажутся на первый взгляд. Они нарушают естественный ход программы и кратно увеличивают количество возможных путей исполнения. Но без них ещё сложнее.
C++ позволяет выразительно обрабатывать исключения, он аккуратен при удалении всех объектов и освобождении ресурсов. Будьте аккуратны и вы, и тогда всё получится. Каждому исключению — по обработчику.
Исключения — это лишь одна из многих возможностей C++. Глубже погрузиться в язык и узнать больше о нём, его экосистеме и принципах программирования поможет курс «Разработчик C++».
#Руководства
- 30 июн 2020
-

14
Что такое баги, ворнинги и исключения в программировании
Разбираемся, какие бывают типы ошибок в программировании и как с ними справляться.
vlada_maestro / shutterstock

Пишет о программировании, в свободное время создаёт игры. Мечтает открыть свою студию и выпускать ламповые RPG.
Многим известно слово баг (англ. bug — жук), которым называют ошибки в программах. Однако баг — это не совсем ошибка, а скорее неожиданный результат работы. Также есть и другие термины: ворнинг, исключение, утечка.
В этой статье мы на примере C++ разберём, что же значат все эти слова и как эти проблемы влияют на эффективность программы.
Словом «ошибка» (англ. error) можно описать любую проблему, но чаще всего под ним подразумевают синтаксическую ошибку — некорректно написанный код, который даже не скомпилируется:
//В конце команды забыли поставить точку с запятой (;)
int a = 5
Компилятор тут же скажет, что в коде ошибка и скорее всего не хватает запятой или точки с запятой.
Также существуют ворнинги (англ. warning — предупреждение). Они не являются ошибками, поэтому программа всё равно будет собрана. Вот пример:
int main()
{
//Мы создаём две переменные, которые просто занимают память и никак не используются
int a, b;
}
Мы можем попросить компилятор показать нам все предупреждения с помощью флага -Wall:
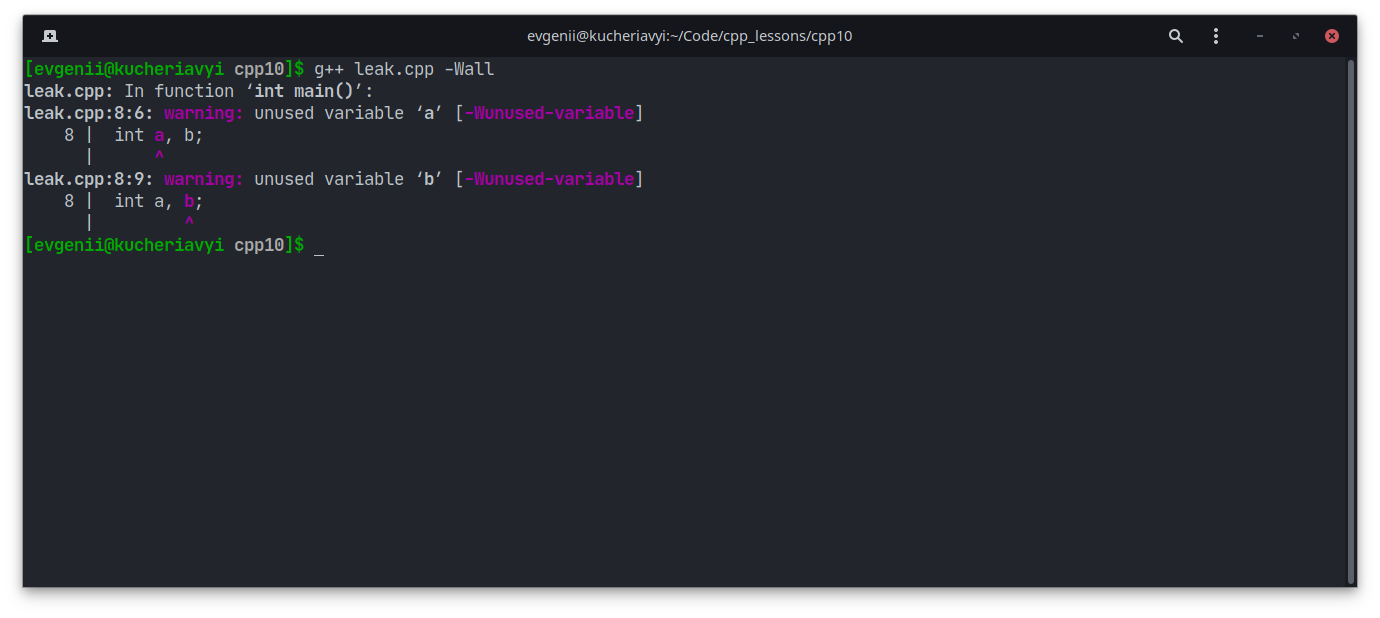
Предупреждения не являются чем-то критичным, но могут иметь негативные последствия. Например, ваша программа будет использовать больше памяти, чем должна. Так как C++ нужен в том числе и для разработки высоконагруженных систем, этого допускать нельзя.

После восклицательного знака в треугольнике — количество предупреждений
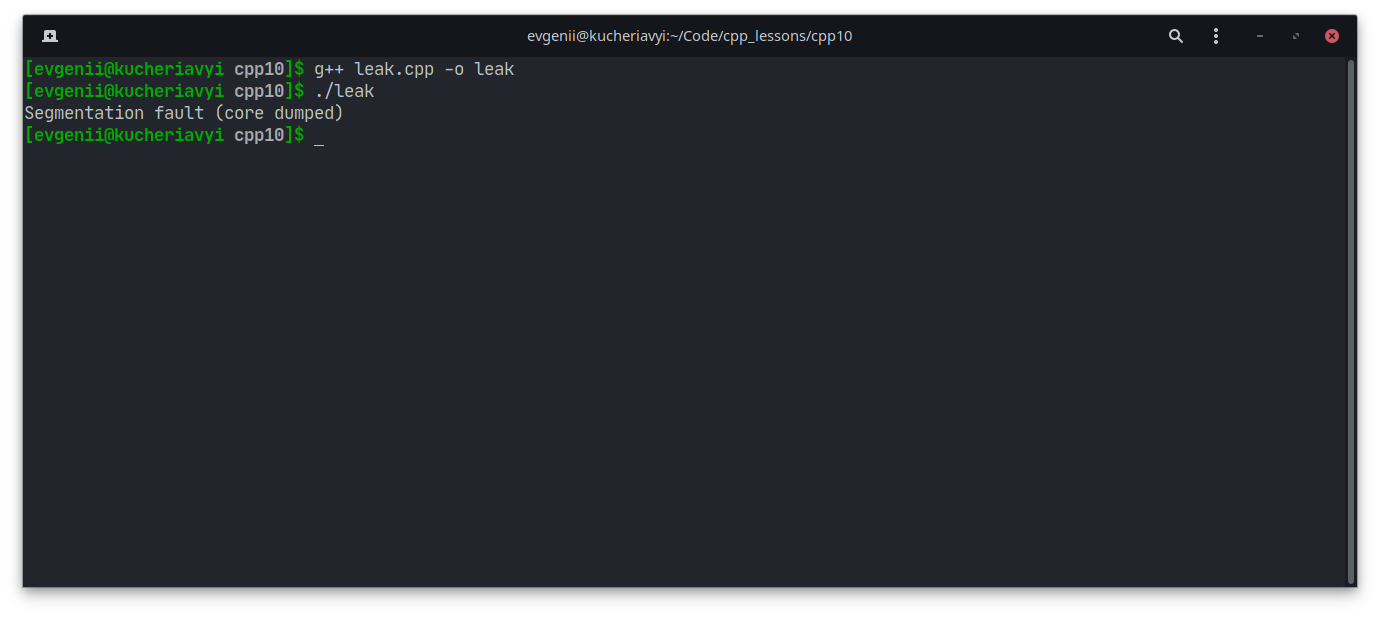
Третий вид ошибок — ошибки сегментации (англ. segmentation fault, сокр. segfault, жарг. сегфолт). Они возникают, если программа пытается записать что-то в ячейку, недоступную для записи. Например:
//Создаём константный массив символов
const char * s = "Hello World";
//Если мы попытаемся перезаписать значение константы, компилятор выдаст ошибку
//Но с помощью указателей мы можем обойти её, поэтому программа успешно скомпилируется
//Однако во время работы она будет выдавать ошибку сегментации
* (char *) s = 'H';
Вот результат работы такого кода:
Мы выяснили, что баг — это не совсем ошибка, а скорее неожиданное поведение программы или результат такого поведения. Баги могут быть чем-то забавным или неприятным. Например, как в играх:
Но они могут привести и к более серьёзным последствиям. Если неправильно спроектировать работу многопоточного приложения, то потоки будут постоянно опережать друг друга. Например, сообщение об ошибке из одного потока может опоздать на миллисекунду, из-за чего второй поток подумает, что никакой ошибки не было, и продолжит работу.
Если ваш код приводит в действие какое-нибудь потенциально опасное устройство, то ценой такой ошибки может быть чья-нибудь жизнь. Такое случилось с кодом для аппарата лучевой терапии Therac-25 — как минимум два человека умерло и ещё больше пострадали из-за превышения дозы радиации.
Также во время работы программы могут возникать ситуации, которые мешают корректной работе программы. Например, если вы просите пользователя ввести число, а он вводит строку.
Конвертировать введённое значение не всегда возможно, поэтому функция, которая занимается преобразованием, «выбрасывает» исключение (англ. exception). Это специальное сообщение говорит о том, что что-то идёт не так.
Если разработчик не описывает логику работы программы при вы выбрасывании исключения, то программа аварийно закрывается. Подробнее мы рассказали об этом в статье про ввод и конвертацию в C++.
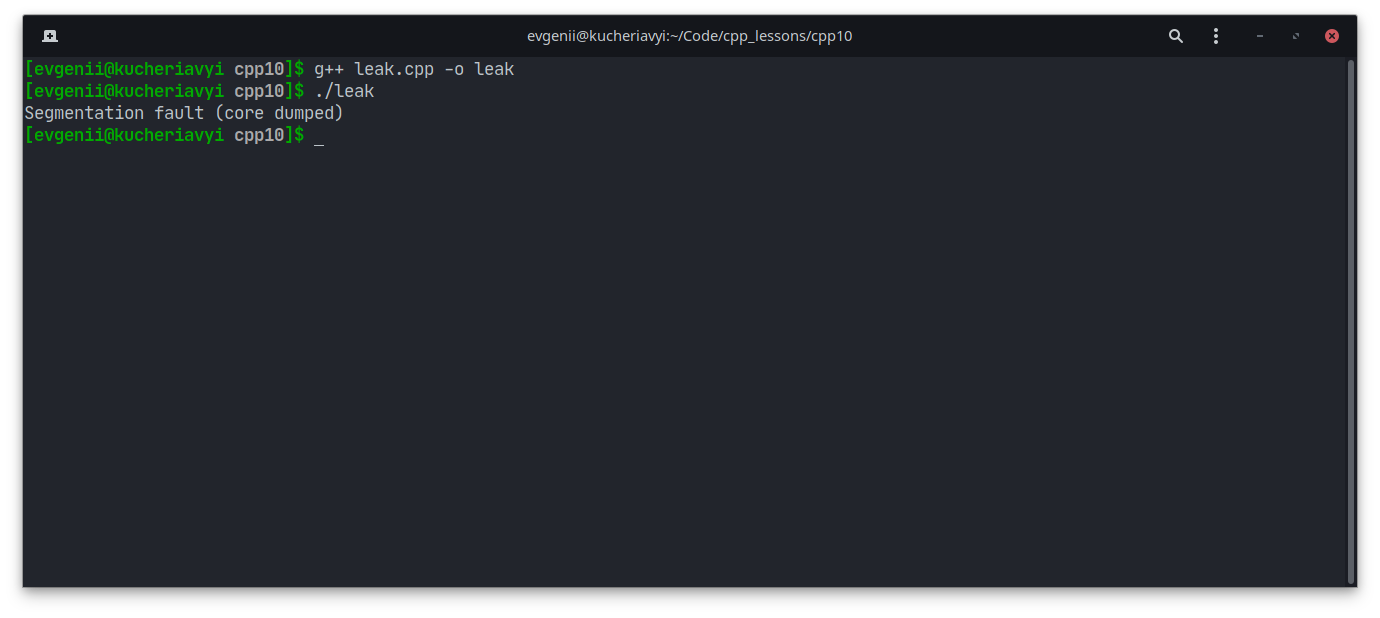
Одно из самых известных исключений — переполнение стека (англ. stack overflow). В честь него даже назвали сайт, на котором программисты ищут помощь в решении своих проблем.
int main()
{
//Бесконечная рекурсия - одна из причин переполнения стека вызовов
main();
}
Компилятор C++ при этом может выдать ошибку сегментации, а не сообщение о переполнении стека:
Вот аналогичный код на языке C#:
class Program
{
static void Main(string[] args)
{
Main(args);
}
}
Однако сообщение в этот раз более конкретное:
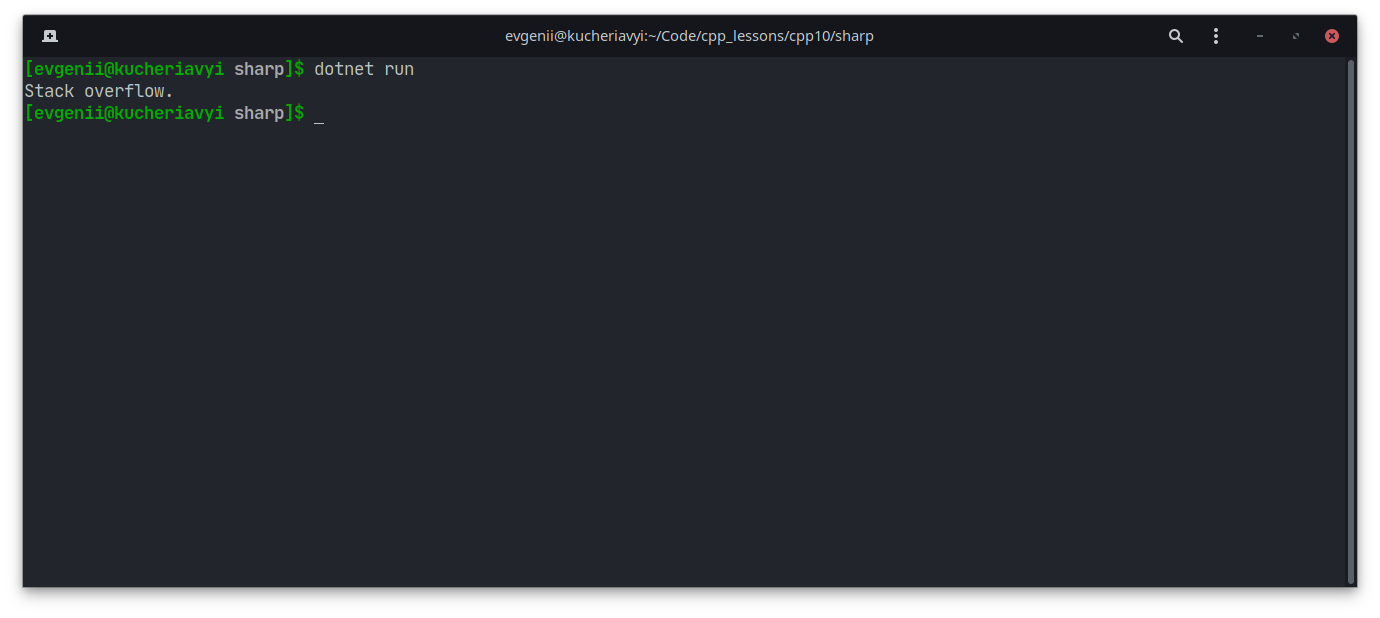
В обоих случаях программа завершается, потому что не может дальше корректно работать.
Похожая ситуация — переполнение буфера (англ. buffer overflow). Она происходит, когда записываемое значение больше выделенной области в памяти.
//Пробуем записать в переменную типа int значение, которое превышает лимит
//Константа INT_MAX находится в библиотеке climits
int a = INT_MAX + 1;
Обратите внимание, что мы получили предупреждение об арифметическом переполнении (англ. integer overflow):
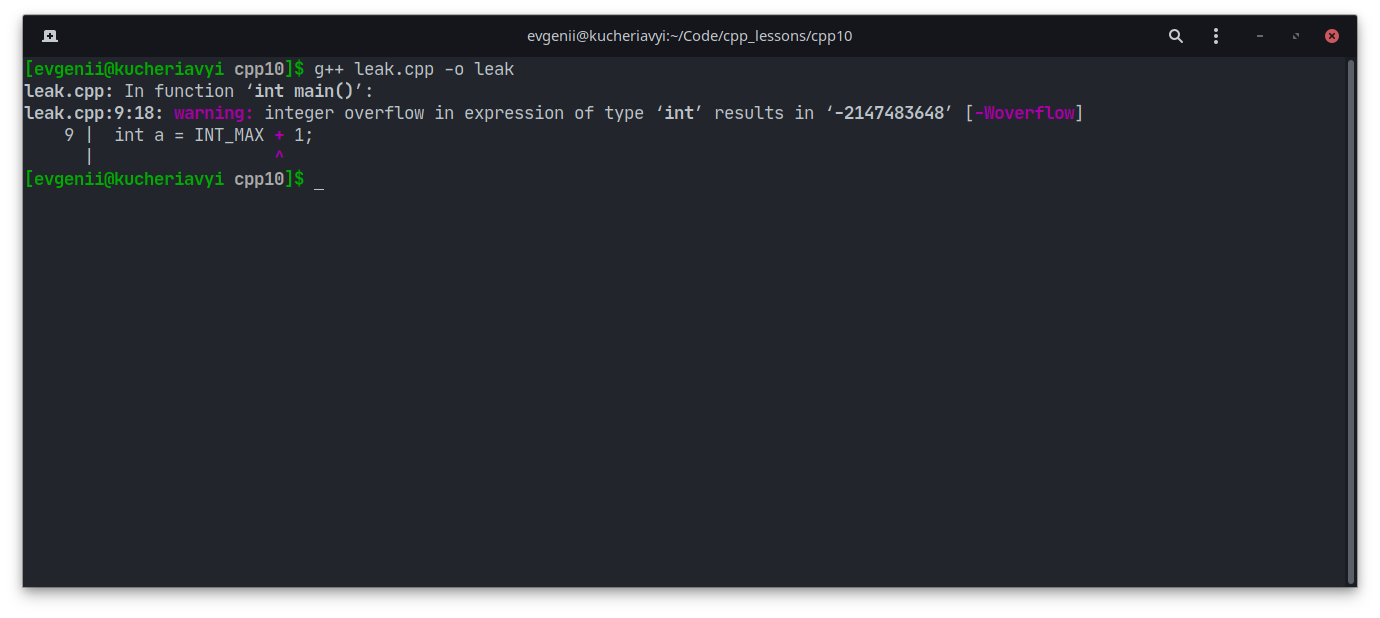
Тем не менее программа скомпилировалась. Если же такая ситуация возникнет во время вычислений, то мы можем не получить предупреждения.
Арифметическое переполнение стало причиной одной из самых дорогих аварий, произошедших из-за ошибки в коде. В 1996 году ракета-носитель «Ариан-5» взорвалась на 40-й секунде полёта — потери оценивают в 360–500 миллионов долларов.
К сожалению, вручную всё это заметить и исправить не получится. Однако существуют различные инструменты и технологии, которые могут помочь.
Один из таких инструментов — отладчик. Он помогает контролировать ход работы программы, чтобы отслеживать разные показатели.
Второй, более эффективный метод — unit-тесты. Они представляют из себя набор описанных ситуаций для каждого компонента программы с указанием ожидаемого поведения.
Например, у вас есть функция sum (int a, int b), которая возвращает сумму двух чисел. Вы можете написать unit-тесты, чтобы проверять следующие ситуации:
| Входные данные | Ожидаемый результат |
|---|---|
| 5, 10 | 15 |
| 99, 99 | 198 |
| 8, -9 | -1 |
| -1, -1 | -2 |
| fff, 8 | IllegalArgumentException |
Если какой-то из этих тестов не пройден, вы узнаете об этом и сможете всё исправить. Это намного быстрее, чем проверять всё вручную.
Ошибок существует слишком много. При этом самые опасные тяжелее обнаружить, что только усугубляет ситуацию.

Научитесь: Профессия Разработчик на C++ с нуля
Узнать больше
В C++ различают ошибки времени компиляции и ошибки времени выполнения. Ошибки первого типа обнаруживает компилятор до запуска программы. К ним относятся, например, синтаксические ошибки в коде. Ошибки второго типа проявляются при запуске программы. Примеры ошибок времени выполнения: ввод некорректных данных, некорректная работа с памятью, недостаток места на диске и т. д. Часто такие ошибки могут привести к неопределённому поведению программы.
Некоторые ошибки времени выполнения можно обнаружить заранее с помощью проверок в коде. Например, такими могут быть ошибки, нарушающие инвариант класса в конструкторе. Обычно, если ошибка обнаружена, то дальнейшее выполение функции не имеет смысла, и нужно сообщить об ошибке в то место кода, откуда эта функция была вызвана. Для этого предназначен механизм исключений.
Коды возврата и исключения
Рассмотрим функцию, которая считывает со стандартного потока возраст и возвращает его вызывающей стороне. Добавим в функцию проверку корректности возраста: он должен находиться в диапазоне от 0 до 128 лет. Предположим, что повторный ввод возраста в случае ошибки не предусмотрен.
int ReadAge() {
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
// Что вернуть в этом случае?
}
return age;
}
Что вернуть в случае некорректного возраста? Можно было бы, например, договориться, что в этом случае функция возвращает ноль. Но тогда похожая проверка должна быть и в месте вызова функции:
int main() {
if (int age = ReadAge(); age == 0) {
// Произошла ошибка
} else {
// Работаем с возрастом age
}
}
Такая проверка неудобна. Более того, нет никакой гарантии, что в вызывающей функции программист вообще её напишет. Фактически мы тут выбрали некоторое значение функции (ноль), обозначающее ошибку. Это пример подхода к обработке ошибок через коды возврата. Другим примером такого подхода является хорошо знакомая нам функция main. Только она должна возвращать ноль при успешном завершении и что-либо ненулевое в случае ошибки.
Другим способом сообщить об обнаруженной ошибке являются исключения. С каждым сгенерированным исключением связан некоторый объект, который как-то описывает ошибку. Таким объектом может быть что угодно — даже целое число или строка. Но обычно для описания ошибки заводят специальный класс и генерируют объект этого класса:
#include <iostream>
struct WrongAgeException {
int age;
};
int ReadAge() {
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
throw WrongAgeException(age);
}
return age;
}
Здесь в случае ошибки оператор throw генерирует исключение, которое представлено временным объектом типа WrongAgeException. В этом объекте сохранён для контекста текущий неправильный возраст age. Функция досрочно завершает работу: у неё нет возможности обработать эту ошибку, и она должна сообщить о ней наружу. Поток управления возвращается в то место, откуда функция была вызвана. Там исключение может быть перехвачено и обработано.
Перехват исключения
Мы вызывали нашу функцию ReadAge из функции main. Обработать ошибку в месте вызова можно с помощью блока try/catch:
int main() {
try {
age = ReadAge(); // может сгенерировать исключение
// Работаем с возрастом age
} catch (const WrongAgeException& ex) { // ловим объект исключения
std::cerr << "Age is not correct: " << ex.age << "n";
return 1; // выходим из функции main с ненулевым кодом возврата
}
// ...
}
Мы знаем заранее, что функция ReadAge может сгенерировать исключение типа WrongAgeException. Поэтому мы оборачиваем вызов этой функции в блок try. Если происходит исключение, для него подбирается подходящий catch-обработчик. Таких обработчиков может быть несколько. Можно смотреть на них как на набор перегруженных функций от одного аргумента — объекта исключения. Выбирается первый подходящий по типу обработчик и выполняется его код. Если же ни один обработчик не подходит по типу, то исключение считается необработанным. В этом случае оно пробрасывается дальше по стеку — туда, откуда была вызвана текущая функция. А если обработчик не найдётся даже в функции main, то программа аварийно завершается.
Усложним немного наш пример, чтобы из функции ReadAge могли вылетать исключения разных типов. Сейчас мы проверяем только значение возраста, считая, что на вход поступило число. Но предположим, что поток ввода досрочно оборвался, или на входе была строка вместо числа. В таком случае конструкция std::cin >> age никак не изменит переменную age, а лишь возведёт специальный флаг ошибки в объекте std::cin. Наша переменная age останется непроинициализированной: в ней будет лежать неопределённый мусор. Можно было бы явно проверить этот флаг в объекте std::cin, но мы вместо этого включим режим генерации исключений при таких ошибках ввода:
int ReadAge() {
std::cin.exceptions(std::istream::failbit);
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
throw WrongAgeException(age);
}
return age;
}
Теперь ошибка чтения в операторе >> у потока ввода будет приводить к исключению типа std::istream::failure. Функция ReadAge его не обрабатывает. Поэтому такое исключение покинет пределы этой функции. Поймаем его в функции main:
int main() {
try {
age = ReadAge(); // может сгенерировать исключения разных типов
// Работаем с возрастом age
} catch (const WrongAgeException& ex) {
std::cerr << "Age is not correct: " << ex.age << "n";
return 1;
} catch (const std::istream::failure& ex) {
std::cerr << "Failed to read age: " << ex.what() << "n";
return 1;
} catch (...) {
std::cerr << "Some other exceptionn";
return 1;
}
// ...
}
При обработке мы воспользовались функцией ex.what у исключения типа std::istream::failure. Такие функции есть у всех исключений стандартной библиотеки: они возвращают текстовое описание ошибки.
Обратите внимание на третий catch с многоточием. Такой блок, если он присутствует, будет перехватывать любые исключения, не перехваченные ранее.
Исключения стандартной библиотеки
Функции и классы стандартной библиотеки в некоторых ситуациях генерируют исключения особых типов. Все такие типы выстроены в иерархию наследования от базового класса std::exception. Иерархия классов позволяет писать обработчик catch сразу на группу ошибок, которые представлены базовым классом: std::logic_error, std::runtime_error и т. д.
Вот несколько примеров:
-
Функция
atу контейнеровstd::array,std::vectorиstd::dequeгенерирует исключениеstd::out_of_rangeпри некорректном индексе. -
Аналогично, функция
atуstd::map,std::unordered_mapи у соответствующих мультиконтейнеров генерирует исключениеstd::out_of_rangeпри отсутствующем ключе. -
Обращение к значению у пустого объекта
std::optionalприводит к исключениюstd::bad_optional_access. -
Потоки ввода-вывода могут генерировать исключение
std::ios_base::failure.
Исключения в конструкторах
В главе 3.1 мы написали класс Time. Этот класс должен был соблюдать инвариант на значение часов, минут и секунд: они должны были быть корректными. Если на вход конструктору класса Time передавались некорректные значения, мы приводили их к корректным, используя деление с остатком.
Более правильным было бы сгенерировать в конструкторе исключение. Таким образом мы бы явно передали сообщение об ошибке во внешнюю функцию, которая пыталась создать объект.
class Time {
private:
int hours, minutes, seconds;
public:
// Заведём класс для исключения и поместим его внутрь класса Time как в пространство имён
class IncorrectTimeException {
};
Time::Time(int h, int m, int s) {
if (s < 0 || s > 59 || m < 0 || m > 59 || h < 0 || h > 23) {
throw IncorrectTimeException();
}
hours = h;
minutes = m;
seconds = s;
}
// ...
};
Генерировать исключения в конструкторах — совершенно нормальная практика. Однако не следует допускать, чтобы исключения покидали пределы деструкторов. Чтобы понять причины, посмотрим подробнее, что происходит при генерации исключения.
Свёртка стека
Вспомним класс Logger из предыдущей главы. Посмотрим, как он ведёт себя при возникновении исключения. Воспользуемся в этом примере стандартным базовым классом std::exception, чтобы не писать свой класс исключения.
#include <exception>
#include <iostream>
void f() {
std::cout << "Welcome to f()!n";
Logger x;
// ...
throw std::exception(); // в какой-то момент происходит исключение
}
int main() {
try {
Logger y;
f();
} catch (const std::exception&) {
std::cout << "Something happened...n";
return 1;
}
}
Мы увидим такой вывод:
Logger(): 1 Welcome to f()! Logger(): 2 ~Logger(): 2 ~Logger(): 1 Something happened...
Сначала создаётся объект y в блоке try. Затем мы входим в функцию f. В ней создаётся объект x. После этого происходит исключение. Мы должны досрочно покинуть функцию. В этот момент начинается свёртка стека (stack unwinding): вызываются деструкторы для всех созданных объектов в самой функции и в блоке try, как если бы они вышли из своей области видимости. Поэтому перед обработчиком исключения мы видим вызов деструктора объекта x, а затем — объекта y.
Аналогично, свёртка стека происходит и при генерации исключения в конструкторе. Напишем класс с полем Logger и сгенерируем нарочно исключение в его конструкторе:
#include <exception>
#include <iostream>
class C {
private:
Logger x;
public:
C() {
std::cout << "C()n";
Logger y;
// ...
throw std::exception();
}
~C() {
std::cout << "~C()n";
}
};
int main() {
try {
C c;
} catch (const std::exception&) {
std::cout << "Something happened...n";
}
}
Вывод программы:
Logger(): 1 // конструктор поля x C() Logger(): 2 // конструктор локальной переменной y ~Logger(): 2 // свёртка стека: деструктор y ~Logger(): 1 // свёртка стека: деструктор поля x Something happened...
Заметим, что деструктор самого класса C не вызывается, так как объект в конструкторе не был создан.
Механизм свёртки стека гарантирует, что деструкторы для всех созданных автоматических объектов или полей класса в любом случае будут вызваны. Однако он полагается на важное свойство: деструкторы самих классов не должны генерировать исключений. Если исключение в деструкторе произойдёт в момент свёртки стека при обработке другого исключения, то программа аварийно завершится.
Пример с динамической памятью
Подчеркнём, что свёртка стека работает только с автоматическими объектами. В этом нет ничего удивительного: ведь за временем жизни объектов, созданных в динамической памяти, программист должен следить самостоятельно. Исключения вносят дополнительные сложности в ручное управление динамическими объектами:
void f() {
Logger* ptr = new Logger(); // конструируем объект класса Logger в динамической памяти
// ...
g(); // вызываем какую-то функцию
// ...
delete ptr; // вызываем деструктор и очищаем динамическую память
}
На первый взгляд кажется, что в этом коде нет ничего опасного: delete вызывается в конце функции. Однако функция g может сгенерировать исключение. Мы не перехватываем его в нашей функции f. Механизм свёртки уберёт со стека лишь сам указатель ptr, который является автоматической переменной примитивного типа. Однако он ничего не сможет сделать с объектом в памяти, на которую ссылается этот указатель. В логе мы увидим только вызов конструктора класса Logger, но не увидим вызова деструктора. Нам придётся обработать исключение вручную:
void f() {
Logger* ptr = new Logger();
// ...
try {
g();
} catch (...) { // ловим любое исключение
delete ptr; // вручную удаляем объект
throw; // перекидываем объект исключения дальше
}
// ...
delete ptr;
}
Здесь мы перехватываем любое исключение и частично обрабатываем его, удаляя объект в динамической памяти. Затем мы прокидываем текущий объект исключения дальше с помощью оператора throw без аргументов.
Согласитесь, этот код очень далёк от совершенства. При непосредственной работе с объектами в динамической памяти нам приходится оборачивать в try/catch любую конструкцию, из которой может вылететь исключение. Понятно, что такой код чреват ошибками. В главе 3.6 мы узнаем, как с точки зрения C++ следует работать с такими ресурсами, как память.
Гарантии безопасности исключений
Предположим, что мы пишем свой класс-контейнер, похожий на двусвязный список. Наш контейнер позволяет добавлять элементы в хранилище и отдельно хранит количество элементов в некотором поле elementsCount. Один из инвариантов этого класса такой: значение elementsCount равно реальному числу элементов в хранилище.
Не вдаваясь в детали, давайте посмотрим, как могла бы выглядеть функция добавления элемента.
template <typename T>
class List {
private:
struct Node { // узел двусвязного списка
T element;
Node* prev = nullptr; // предыдущий узел
Node* next = nullptr; // следующий узел
};
Node* first = nullptr; // первый узел списка
Node* last = nullptr; // последний узел списка
int elementsCount = 0;
public:
// ...
size_t Size() const {
return elementsCount;
}
void PushBack(const T& elem) {
++elementsCount;
// Конструируем в динамической памяти новой узел списка
Node* node = new Node(elem, last, nullptr);
// Связываем новый узел с остальными узлами
if (last != nullptr) {
last->next = node;
} else {
first = node;
}
last = node;
}
};
Не будем здесь рассматривать другие функции класса — конструкторы, деструктор, оператор присваивания… Рассмотрим функцию PushBack. В ней могут произойти такие исключения:
-
Выражение
newможет сгенерировать исключениеstd::bad_allocиз-за нехватки памяти. -
Конструктор копирования класса
Tможет сгенерировать произвольное исключение. Этот конструктор вызывается при инициализации поляelementсоздаваемого узла в конструкторе классаNode. В этом случаеnewведёт себя как транзакция: выделенная перед этим динамическая память корректно вернётся системе.
Эти исключения не перехватываются в функции PushBack. Их может перехватить код, из которого PushBack вызывался:
#include <iostream>
class C; // какой-то класс
int main() {
List<C> data;
C element;
try {
data.PushBack(element);
} catch (...) { // не получилось добавить элемент
std::cout << data.Size() << "n"; // внезапно 1, а не 0
}
// работаем дальше с data
}
Наша функция PushBack сначала увеличивает счётчик элементов, а затем выполняет опасные операции. Если происходит исключение, то в классе List нарушается инвариант: значение счётчика elementsCount перестаёт соответствовать реальности. Можно сказать, что функция PushBack не даёт гарантий безопасности.
Всего выделяют четыре уровня гарантий безопасности исключений (exception safety guarantees):
-
Гарантия отсутствия сбоев. Функции с такими гарантиями вообще не выбрасывают исключений. Примерами могут служить правильно написанные деструктор и конструктор перемещения, а также константные функции вида
Size. -
Строгая гарантия безопасности. Исключение может возникнуть, но от этого объект нашего класса не поменяет состояние: количество элементов останется прежним, итераторы и ссылки не будут инвалидированы и т. д.
-
Базовая гарантия безопасности. При исключении состояние объекта может поменяться, но оно останется внутренне согласованным, то есть, инварианты будут соблюдаться.
-
Отсутсвие гарантий. Это довольно опасная категория: при возникновении исключений могут нарушаться инварианты.
Всегда стоит разрабатывать классы, обеспечивающие хотя бы базовую гарантию безопасности. При этом не всегда возможно эффективно обеспечить строгую гарантию.
Переместим в нашей функции PushBack изменение счётчика в конец:
void PushBack(const T& elem) {
Node* node = new Node(elem, last, nullptr);
if (last != nullptr) {
last->next = node;
} else {
first = node;
}
last = node;
++elementsCount; // выполнится только если раньше не было исключений
}
Теперь такая функция соответствует строгой гарантии безопасности.
В документации функций из классов стандартной библиотеки обычно указано, какой уровень гарантии они обеспечивают. Рассмотрим, например, гарантии безопасности класса std::vector.
-
Деструктор, функции
empty,size,capacity, а такжеclearпредоставляют гарантию отсутствия сбоев. -
Функции
push_backиresizeпредоставляют строгую гарантию. -
Функция
insertпредоставляет лишь базовую гарантию. Можно было бы сделать так, чтобы она предоставляла строгую гарантию, но за это пришлось бы заплатить её эффективностью: при вставке в середину вектора пришлось бы делать реаллокацию.
Функции класса, которые гарантируют отсутсвие сбоев, следует помечать ключевым словом noexcept:
class C {
public:
void f() noexcept {
// ...
}
};
С одной стороны, эта подсказка позволяет компилятору генерировать более эффективный код. С другой — эффективно обрабатывать объекты таких классов в стандартных контейнерах. Например, std::vector<C> при реаллокации будет использовать конструктор перемещения класса C, если он помечен как noexcept. В противном случае будет использован конструктор копирования, который может быть менее эффективен, но зато позволит обеспечить строгую гарантию безопасности при реаллокации.
Время на прочтение
13 мин
Количество просмотров 75K

Введение
Ошибки, увы, неизбежны, поэтому их обработка занимает очень важное место в программировании. И если алгоритмические ошибки можно выявить и исправить во время написания и тестирования программы, то ошибок времени выполнения избежать нельзя в принципе. Сегодня мы рассмотрим функции стандартной библиотеки (C Standard Library) и POSIX, используемые в обработке ошибок.
Переменная errno и коды ошибок
<errno.h>
errno – переменная, хранящая целочисленный код последней ошибки. В каждом потоке существует своя локальная версия errno, чем и обусловливается её безопасность в многопоточной среде. Обычно errno реализуется в виде макроса, разворачивающегося в вызов функции, возвращающей указатель на целочисленный буфер. При запуске программы значение errno равно нулю.
Все коды ошибок имеют положительные значения, и могут использоваться в директивах препроцессора #if. В целях удобства и переносимости заголовочный файл <errno.h> определяет макросы, соответствующие кодам ошибок.
Стандарт ISO C определяет следующие коды:
- EDOM – (Error domain) ошибка области определения.
- EILSEQ – (Error invalid sequence) ошибочная последовательность байтов.
- ERANGE – (Error range) результат слишком велик.
Прочие коды ошибок (несколько десятков) и их описания определены в стандарте POSIX. Кроме того, в спецификациях стандартных функций обычно указываются используемые ими коды ошибок и их описания.
Нехитрый скрипт печатает в консоль коды ошибок, их символические имена и описания:
#!/usr/bin/perl
use strict;
use warnings;
use Errno;
foreach my $err (sort keys (%!)) {
$! = eval "Errno::$err";
printf "%20s %4d %sn", $err, $! + 0, $!
}
Если вызов функции завершился ошибкой, то она устанавливает переменную errno в ненулевое значение. Если же вызов прошёл успешно, функция обычно не проверяет и не меняет переменную errno. Поэтому перед вызовом функции её нужно установить в 0.
Пример:
/* convert from UTF16 to UTF8 */
errno = 0;
n_ret = iconv(icd, (char **) &p_src, &n_src, &p_dst, &n_dst);
if (n_ret == (size_t) -1) {
VJ_PERROR();
if (errno == E2BIG)
fprintf(stderr, " Error : input conversion stopped due to lack of space in the output buffern");
else if (errno == EILSEQ)
fprintf(stderr, " Error : input conversion stopped due to an input byte that does not belong to the input codesetn");
else if (errno == EINVAL)
fprintf(stderr, " Error : input conversion stopped due to an incomplete character or shift sequence at the end of the input buffern");
/* clean the memory */
free(p_out_buf);
errno = 0;
n_ret = iconv_close(icd);
if (n_ret == (size_t) -1)
VJ_PERROR();
return (size_t) -1;
}
Как видите, описания ошибок в спецификации функции iconv() более информативны, чем в <errno.h>.
Функции работы с errno
Получив код ошибки, хочется сразу получить по нему её описание. К счастью, ISO C предлагает целый набор полезных функций.
<stdio.h>
void perror(const char *s);
Печатает в stderr содержимое строки s, за которой следует двоеточие, пробел и сообщение об ошибке. После чего печатает символ новой строки 'n'.
Пример:
/*
// main.c
// perror example
//
// Created by Ariel Feinerman on 23/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
int main(int argc, const char * argv[])
{
// Generate unique filename.
char *file_name = tmpnam((char[L_tmpnam]){0});
errno = 0;
FILE *file = fopen(file_name, "rb");
if (file) {
// Do something useful.
fclose(file);
}
else {
perror("fopen() ");
}
return EXIT_SUCCESS;
}<string.h>
char* strerror(int errnum);
Возвращает строку, содержащую описание ошибки errnum. Язык сообщения зависит от локали (немецкий, иврит и даже японский), но обычно поддерживается лишь английский.
/*
// main.c
// strerror example
//
// Created by Ariel Feinerman on 23/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
int main(int argc, const char * argv[])
{
// Generate unique filename.
char *file_name = tmpnam((char[L_tmpnam]){0});
errno = 0;
FILE *file = fopen(file_name, "rb");
// Save error number.
errno_t error_num = errno;
if (file) {
// Do something useful.
fclose(file);
}
else {
char *errorbuf = strerror(error_num);
fprintf(stderr, "Error message : %sn", errorbuf);
}
return EXIT_SUCCESS;
}strerror() не безопасная функция. Во-первых, возвращаемая ею строка не является константной. При этом она может храниться в статической или в динамической памяти в зависимости от реализации. В первом случае её изменение приведёт к ошибке времени выполнения. Во-вторых, если вы решите сохранить указатель на строку, и после вызовите функцию с новым кодом, все прежние указатели будут указывать уже на новую строку, ибо она использует один буфер для всех строк. В-третьих, её поведение в многопоточной среде не определено в стандарте. Впрочем, в QNX она объявлена как thread safe.
Поэтому в новом стандарте ISO C11 были предложены две очень полезные функции.
size_t strerrorlen_s(errno_t errnum);
Возвращает длину строки с описанием ошибки errnum.
errno_t strerror_s(char *buf, rsize_t buflen, errno_t errnum);
Копирует строку с описание ошибки errnum в буфер buf длиной buflen.
Пример:
/*
// main.c
// strerror_s example
//
// Created by Ariel Feinerman on 23/02/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#define __STDC_WANT_LIB_EXT1__ 1
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
int main(int argc, const char * argv[])
{
// Generate unique filename.
char *file_name = tmpnam((char[L_tmpnam]){0});
errno = 0;
FILE *file = fopen(file_name, "rb");
// Save error number.
errno_t error_num = errno;
if (file) {
// Do something useful.
fclose(file);
}
else {
#ifdef __STDC_LIB_EXT1__
size_t error_len = strerrorlen_s(errno) + 1;
char error_buf[error_len];
strerror_s(error_buf, error_len, errno);
fprintf(stderr, "Error message : %sn", error_buf);
#endif
}
return EXIT_SUCCESS;
}Функции входят в Annex K (Bounds-checking interfaces), вызвавший много споров. Он не обязателен к выполнению и целиком не реализован ни в одной из свободных библиотек. Open Watcom C/C++ (Windows), Slibc (GNU libc) и Safe C Library (POSIX), в последней, к сожалению, именно эти две функции не реализованы. Тем не менее, их можно найти в коммерческих средах разработки и системах реального времени, Embarcadero RAD Studio, INtime RTOS, QNX.
Стандарт POSIX.1-2008 определяет следующие функции:
char *strerror_l(int errnum, locale_t locale);
Возвращает строку, содержащую локализованное описание ошибки errnum, используя locale. Безопасна в многопоточной среде. Не реализована в Mac OS X, FreeBSD, NetBSD, OpenBSD, Solaris и прочих коммерческих UNIX. Реализована в Linux, MINIX 3 и Illumos (OpenSolaris).
Пример:
/*
// main.c
// strerror_l example – works on Linux, MINIX 3, Illumos
//
// Created by Ariel Feinerman on 23/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <locale.h>
int main(int argc, const char * argv[])
{
locale_t locale = newlocale(LC_ALL_MASK, "fr_FR.UTF-8", (locale_t) 0);
if (!locale) {
fprintf(stderr, "Error: cannot create locale.");
exit(EXIT_FAILURE);
}
// Generate unique filename.
char *file_name = tmpnam((char[L_tmpnam]){0});
errno = 0;
FILE *file = fopen(tmpnam(file_name, "rb");
// Save error number.
errno_t error_num = errno;
if (file) {
// Do something useful.
fclose(file);
}
else {
char *error_buf = strerror_l(errno, locale);
fprintf(stderr, "Error message : %sn", error_buf);
}
freelocale(locale);
return EXIT_SUCCESS;
}Вывод:
Error message : Aucun fichier ou dossier de ce typeint strerror_r(int errnum, char *buf, size_t buflen);
Копирует строку с описание ошибки errnum в буфер buf длиной buflen. Если buflen меньше длины строки, лишнее обрезается. Безопасна в многоготочной среде. Реализована во всех UNIX.
Пример:
/*
// main.c
// strerror_r POSIX example
//
// Created by Ariel Feinerman on 25/02/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#define MSG_LEN 1024
int main(int argc, const char * argv[])
{
// Generate unique filename.
char *file_name = tmpnam((char[L_tmpnam]){0});
errno = 0;
FILE *file = fopen(file_name, "rb");
// Save error number.
errno_t error_num = errno;
if (file) {
// Do something useful.
fclose(file);
}
else {
char error_buf[MSG_LEN];
errno_t error = strerror_r (error_num, error_buf, MSG_LEN);
switch (error) {
case EINVAL:
fprintf (stderr, "strerror_r() failed: invalid error code, %dn", error);
break;
case ERANGE:
fprintf (stderr, "strerror_r() failed: buffer too small: %dn", MSG_LEN);
case 0:
fprintf(stderr, "Error message : %sn", error_buf);
break;
default:
fprintf (stderr, "strerror_r() failed: unknown error, %dn", error);
break;
}
}
return EXIT_SUCCESS;
}
Увы, никакого аналога strerrorlen_s() в POSIX не определили, поэтому длину строки можно выяснить лишь экспериментальным путём. Обычно 300 символов хватает за глаза. GNU C Library в реализации strerror() использует буфер длиной в 1024 символа. Но мало ли, а вдруг?
Пример:
/*
// main.c
// strerror_r safe POSIX example
//
// Created by Ariel Feinerman on 23/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#define MSG_LEN 1024
#define MUL_FACTOR 2
int main(int argc, const char * argv[])
{
// Generate unique filename.
char *file_name = tmpnam((char[L_tmpnam]){0});
errno = 0;
FILE *file = fopen(file_name, "rb");
// Save error number.
errno_t error_num = errno;
if (file) {
// Do something useful.
fclose(file);
}
else {
errno_t error = 0;
size_t error_len = MSG_LEN;
do {
char error_buf[error_len];
error = strerror_r (error_num, error_buf, error_len);
switch (error) {
case 0:
fprintf(stderr, "File : %snLine : %dnCurrent function : %s()nFailed function : %s()nError message : %sn", __FILE__, __LINE__, __func__, "fopen", error_buf);
break;
case ERANGE:
error_len *= MUL_FACTOR;
break;
case EINVAL:
fprintf (stderr, "strerror_r() failed: invalid error code, %dn", error_num);
break;
default:
fprintf (stderr, "strerror_r() failed: unknown error, %dn", error);
break;
}
} while (error == ERANGE);
}
return EXIT_SUCCESS;
}Вывод:
File : /Users/ariel/main.c
Line : 47
Current function : main()
Failed function : fopen()
Error message : No such file or directoryМакрос assert()
<assert.h>
void assert(expression)
Макрос, проверяющий условие expression (его результат должен быть числом) во время выполнения. Если условие не выполняется (expression равно нулю), он печатает в stderr значения __FILE__, __LINE__, __func__ и expression в виде строки, после чего вызывает функцию abort().
/*
// main.c
// assert example
//
// Created by Ariel Feinerman on 23/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <math.h>
int main(int argc, const char * argv[]) {
double x = -1.0;
assert(x >= 0.0);
printf("sqrt(x) = %fn", sqrt(x));
return EXIT_SUCCESS;
}Вывод:
Assertion failed: (x >= 0.0), function main, file /Users/ariel/main.c, line 17.
Если макрос NDEBUG определён перед включением <assert.h>, то assert() разворачивается в ((void) 0) и не делает ничего. Используется в отладочных целях.
Пример:
/*
// main.c
// assert_example
//
// Created by Ariel Feinerman on 23/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#NDEBUG
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <math.h>
int main(int argc, const char * argv[]) {
double x = -1.0;
assert(x >= 0.0);
printf("sqrt(x) = %fn", sqrt(x));
return EXIT_SUCCESS;
}Вывод:
sqrt(x) = nanФункции atexit(), exit() и abort()
<stdlib.h>
int atexit(void (*func)(void));
Регистрирует функции, вызываемые при нормальном завершении работы программы в порядке, обратном их регистрации. Можно зарегистрировать до 32 функций.
_Noreturn void exit(int exit_code);
Вызывает нормальное завершение программы, возвращает в среду число exit_code. ISO C стандарт определяет всего три возможных значения: 0, EXIT_SUCCESS и EXIT_FAILURE. При этом вызываются функции, зарегистрированные через atexit(), сбрасываются и закрываются потоки ввода — вывода, уничтожаются временные файлы, после чего управление передаётся в среду. Функция exit() вызывается в main() при выполнении return или достижении конца программы.
Главное преимущество exit() в том, что она позволяет завершить программу не только из main(), но и из любой вложенной функции. К примеру, если в глубоко вложенной функции выполнилось (или не выполнилось) некоторое условие, после чего дальнейшее выполнение программы теряет всякий смысл. Подобный приём (early exit) широко используется при написании демонов, системных утилит и парсеров. В интерактивных программах с бесконечным главным циклом exit() можно использовать для выхода из программы при выборе нужного пункта меню.
Пример:
/*
// main.c
// exit example
//
// Created by Ariel Feinerman on 17/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
void third_2(void)
{
printf("third #2n"); // Does not print.
}
void third_1(void)
{
printf("third #1n"); // Does not print.
}
void second(double num)
{
printf("second : before exit()n"); // Prints.
if ((num < 1.0f) && (num > -1.0f)) {
printf("asin(%.1f) = %.3fn", num, asin(num));
exit(EXIT_SUCCESS);
}
else {
fprintf(stderr, "Error: %.1f is beyond the range [-1.0; 1.0]n", num);
exit(EXIT_FAILURE);
}
printf("second : after exit()n"); // Does not print.
}
void first(double num)
{
printf("first : before second()n")
second(num);
printf("first : after second()n"); // Does not print.
}
int main(int argc, const char * argv[])
{
atexit(third_1); // Register first handler.
atexit(third_2); // Register second handler.
first(-3.0f);
return EXIT_SUCCESS;
}Вывод:
first : before second()
second : before exit()
Error: -3.0 is beyond the range [-1.0; 1.0]
third #2
third #1_Noreturn void abort(void);
Вызывает аварийное завершение программы, если сигнал не был перехвачен обработчиком сигналов. Временные файлы не уничтожаются, закрытие потоков определяется реализацией. Самое главное отличие вызовов abort() и exit(EXIT_FAILURE) в том, что первый посылает программе сигнал SIGABRT, его можно перехватить и произвести нужные действия перед завершением программы. Записывается дамп памяти программы (core dump file), если они разрешены. При запуске в отладчике он перехватывает сигнал SIGABRT и останавливает выполнение программы, что очень удобно в отладке.
Пример:
/*
// main.c
// abort example
//
// Created by Ariel Feinerman on 17/02/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
void third_2(void)
{
printf("third #2n"); // Does not print.
}
void third_1(void)
{
printf("third #1n"); // Does not print.
}
void second(double num)
{
printf("second : before exit()n"); // Prints.
if ((num < 1.0f) && (num > -1.0f)) {
printf("asin(%.1f) = %.3fn", num, asin(num));
exit(EXIT_SUCCESS);
}
else {
fprintf(stderr, "Error: %.1f is beyond the range [-1.0; 1.0]n", num);
abort();
}
printf("second : after exit()n"); // Does not print.
}
void first(double num)
{
printf("first : before second()n");
second(num);
printf("first : after second()n"); // Does not print.
}
int main(int argc, const char * argv[])
{
atexit(third_1); // register first handler
atexit(third_2); // register second handler
first(-3.0f);
return EXIT_SUCCESS;
}Вывод:
first : before second()
second : before exit()
Error: -3.0 is beyond the range [-1.0; 1.0]
Abort trap: 6Вывод в отладчике:
$ lldb abort_example
(lldb) target create "abort_example"
Current executable set to 'abort_example' (x86_64).
(lldb) run
Process 22570 launched: '/Users/ariel/abort_example' (x86_64)
first : before second()
second : before exit()
Error: -3.0 is beyond the range [-1.0; 1.0]
Process 22570 stopped
* thread #1: tid = 0x113a8, 0x00007fff89c01286 libsystem_kernel.dylib`__pthread_kill + 10, queue = 'com.apple.main-thread', stop reason = signal SIGABRT
frame #0: 0x00007fff89c01286 libsystem_kernel.dylib`__pthread_kill + 10
libsystem_kernel.dylib`__pthread_kill:
-> 0x7fff89c01286 <+10>: jae 0x7fff89c01290 ; <+20>
0x7fff89c01288 <+12>: movq %rax, %rdi
0x7fff89c0128b <+15>: jmp 0x7fff89bfcc53 ; cerror_nocancel
0x7fff89c01290 <+20>: retq
(lldb)
В случае критической ошибки нужно использовать функцию abort(). К примеру, если при выделении памяти или записи файла произошла ошибка. Любые дальнейшие действия могут усугубить ситуацию. Если завершить выполнение обычным способом, при котором производится сброс потоков ввода — вывода, можно потерять ещё неповрежденные данные и временные файлы, поэтому самым лучшим решением будет записать дамп и мгновенно завершить программу.
В случае же некритической ошибки, например, вы не смогли открыть файл, можно безопасно выйти через exit().
Функции setjmp() и longjmp()
Вот мы и подошли к самому интересному – функциям нелокальных переходов. setjmp() и longjmp() работают по принципу goto, но в отличие от него позволяют перепрыгивать из одного места в другое в пределах всей программы, а не одной функции.
<setjmp.h>
int setjmp(jmp_buf env);
Сохраняет информацию о контексте выполнения программы (регистры микропроцессора и прочее) в env. Возвращает 0, если была вызвана напрямую или value, если из longjmp().
void longjmp(jmp_buf env, int value);
Восстанавливает контекст выполнения программы из env, возвращает управление setjmp() и передаёт ей value.
Пример:
/*
// main.c
// setjmp simple
//
// Created by Ariel Feinerman on 18/02/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <setjmp.h>
static jmp_buf buf;
void second(void)
{
printf("second : before longjmp()n"); // prints
longjmp(buf, 1); // jumps back to where setjmp was called – making setjmp now return 1
printf("second : after longjmp()n"); // does not prints
// <- Here is the point that is never reached. All impossible cases like your own house in Miami, your million dollars, your nice girl, etc.
}
void first(void)
{
printf("first : before second()n");
second();
printf("first : after second()n"); // does not print
}
int main(int argc, const char * argv[])
{
if (!setjmp(buf))
first(); // when executed, setjmp returned 0
else // when longjmp jumps back, setjmp returns 1
printf("mainn"); // prints
return EXIT_SUCCESS;
}Вывод:
first : before second()
second : before longjmp()
main
Используя setjmp() и longjmp() можно реализовать механизм исключений. Во многих языках высокого уровня (например, в Perl) исключения реализованы через них.
Пример:
/*
// main.c
// exception simple
//
// Created by Ariel Feinerman on 18/02/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <setjmp.h>
#define str(s) #s
static jmp_buf buf;
typedef enum {
NO_EXCEPTION = 0,
RANGE_EXCEPTION = 1,
NUM_EXCEPTIONS
} exception_t;
static char *exception_name[NUM_EXCEPTIONS] = {
str(NO_EXCEPTION),
str(RANGE_EXCEPTION)
};
float asin_e(float num)
{
if ((num < 1.0f) && (num > -1.0f)) {
return asinf(num);
}
else {
longjmp(buf, RANGE_EXCEPTION); // | @throw
}
}
void do_work(float num)
{
float res = asin_e(num);
printf("asin(%f) = %fn", num, res);
}
int main(int argc, const char * argv[])
{
exception_t exc = NO_EXCEPTION;
if (!(exc = setjmp(buf))) { // |
do_work(-3.0f); // | @try
} // |
else { // |
fprintf(stderr, "%s was hadled in %s()n", exception_name[exc], __func__); // | @catch
} // |
return EXIT_SUCCESS;
}Вывод:
RANGE_EXCEPTION was hadled in main()
Внимание! Функции setjmp() и longjmp() в первую очередь применяются в системном программировании, и их использование в клиентском коде не рекомендуется. Их применение ухудшает читаемость программы и может привести к непредсказуемым ошибкам. Например, что произойдёт, если вы прыгните не вверх по стеку – в вызывающую функцию, а в параллельную, уже завершившую выполнение?
Информация
- стандарт ISO/IEC C (89/99/11)
- Single UNIX Specifcation, Version 4, 2016 Edition
- The Open Group Base Specifcations Issue 7, 2016 Edition (POSIX.1-2008)
- SEI CERT C Coding Standard
- cправочная информация среды программирования
- справочная информация операционной системы (man pages)
- заголовочные файлы (/usr/include)
- исходные тексты библиотеки (C Standard Library)