
#статьи
- 21 ноя 2019
-

15
В данном руководстве я расскажу, где искать причину возникновения ошибки сканирования сайта и как вернуть страницы в индекс Google.
vlada_maestro / shutterstock

SEO-специалист компании Adindex.ua

Googlebot не всегда должным образом обрабатывает директивы в тегах <meta name=»robots»>. Одной из причин может быть неверное расположение этих элементов в структуре кода страницы. Из-за этого нужные страницы выпадают из поиска, а нежелательные, наоборот, попадают.
На сайте нашего клиента были реализованы метатеги noindex (для закрытия страниц от индексации поисковым роботом) и canonical (для указания основной версии страницы для Googlebot). Эти теги размещались в секции <head> и были действительны, однако поисковый робот не мог их распознать.
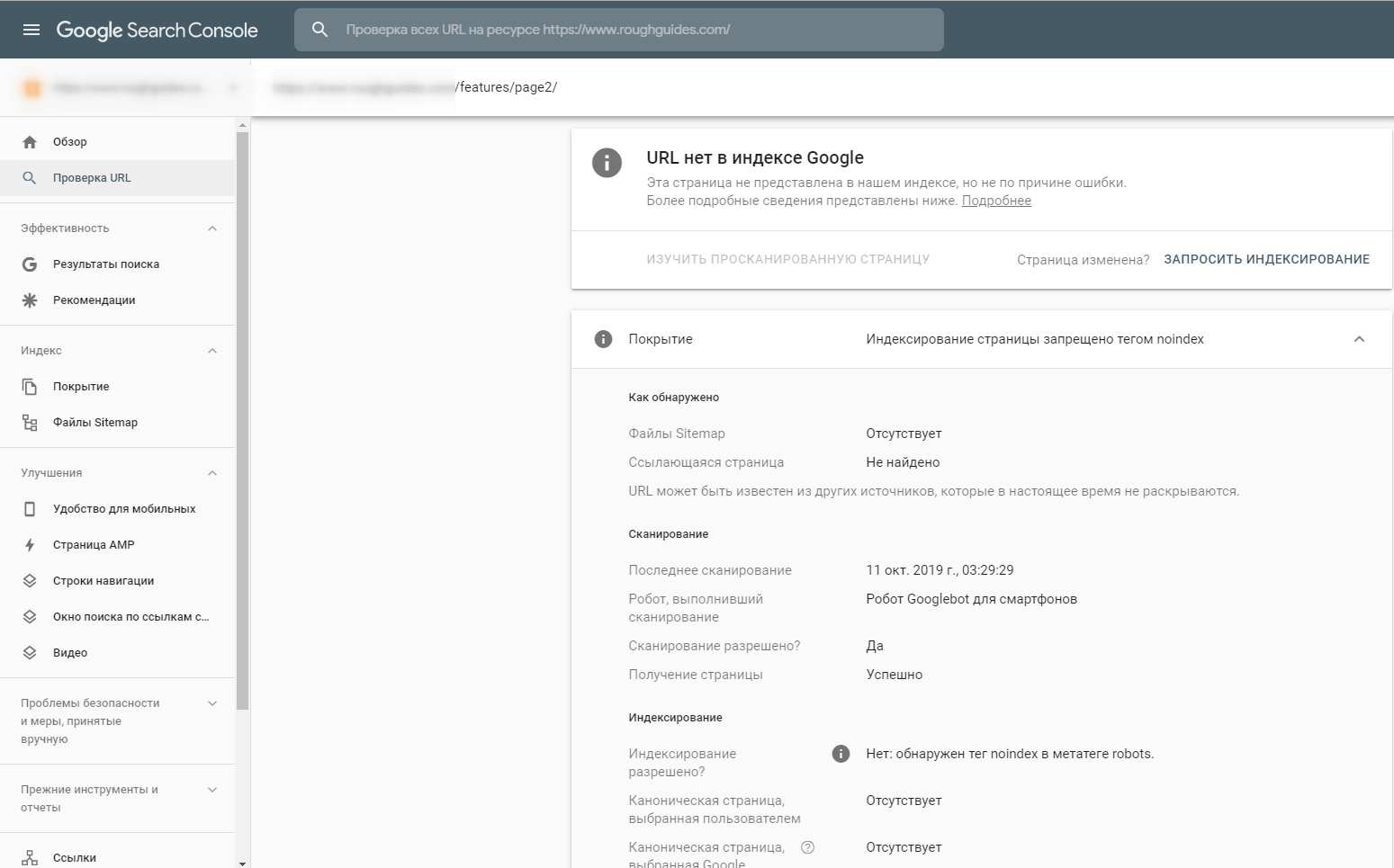
Как следствие, в индекс Google попадали страницы, ненужные с точки зрения поискового продвижения. Проверка страниц в консоли поиска показала, что Googlebot не видит установленные директивы <meta name=»robots»>:
Для поиска решения проблемы сравнили исходный HTML-код страницы с готовым DOM. Первое — это код, который браузер выдаёт в режиме просмотра кода страницы, а второе — то, что браузер использует для показа страницы конечным пользователям, когда весь код выполнен на стороне клиента (например, JavaScript-сценарии).
В результате заметили интересную особенность: в необработанном HTML-коде стоял блок JavaScript, он находился над метатегами robots. Когда страница была полностью обработана и весь код на стороне клиента выполнен, JavaScript вставлял на страницу дополнительный блок <iframe>, который размещался над метатегами.
Этот блок кода оказался проблематичным в связи с двухэтапным процессом индексации Google:
- Первый этап индексации основан на исходном коде HTML веб-страницы, когда никакие клиентские скриптовые сценарии не выполняются как часть процесса индексации.
- На втором этапе Google выполняет индексацию той же страницы, но с загрузкой клиентских сценариев, и страница отображается в том виде, как это сделал бы веб-браузер.
Проблема была как раз на втором этапе индексации. JavaScript-сценарий вставлял блок скриптов над метатегами robots в финальном коде страницы. Но по официальному стандарту W3C блок не принадлежит разделу <head> кода страницы и должен находиться в <body>.
Когда Google видит данный блок в разделе <head>, он предполагает, что <head> завершился и начался раздел <body> страницы. Судя по всему, Google обрабатывает метатеги как часть второго этапа индексации. Это и стало причиной ошибки, так как Google преждевременно обработал остальной код скриптового блока как часть <body> и проигнорировал наличие тегов robots.
Решение проблемы оказалось довольно простым — переместить метатеги robots над блоком скриптов в разделе <head>. В течение нескольких дней бот распознал изменения и начал сообщать о них в Google Search Console:
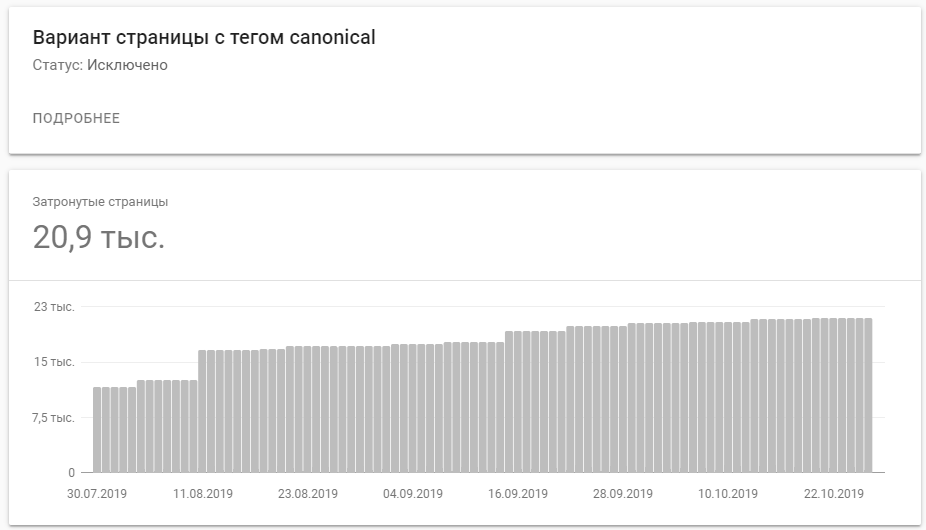
Количество проиндексированных страниц с тегом canonical заметно увеличилось. Вот такую динамику показывает Google Search Console:

Научитесь: Интернет-маркетолог с нуля
Узнать больше

Богдан Василенко
SEO-специалист SE Ranking
По каждому запросу поисковая система подбирает релевантные результаты — страницы, подходящие по тематике, и ранжирует их, отображая в виде списка. Согласно исследованиям, 99 % пользователей находят информацию, отвечающую запросу, уже на первой странице выдачи и не пролистывают дальше. И чем выше позиция сайта в топ-10, тем больше посетителей она привлекает.
Перед тем, как распределить ресурсы в определенном порядке, поисковики оценивают их по ряду параметров. Это позволяет улучшить выдачу для пользователя, предоставляя наиболее полезные, удобные и авторитетные варианты.
В чём заключается оптимизация сайта?
Оптимизация сайта или SEO (Search Engine Optimization) представляет собой комплекс действий, цель которых — улучшить качество ресурса и адаптировать его с учётом рекомендаций поисковых систем.
SEO помогает попасть содержимому сайта в индекс, улучшить позиции его страниц при ранжировании и увеличить органический, то есть бесплатный трафик. Техническая оптимизация сайта — это важный этап SEO, направленный на работу с его внутренней частью, которая обычно скрыта от пользователей, но доступна для поисковых роботов.
Страницы представляют собой HTML-документы, и их отображение на экране — это результат воспроизведения браузером HTML-кода, от которого зависит не только внешний вид сайта, но и его производительность. Серверные файлы и внутренние настройки ресурса могут влиять на его сканирование и индексацию поисковиком.
SEO включает анализ технических параметров сайта, выявление проблем и их устранение. Это помогает повысить позиции при ранжировании, обойти конкурентов, увеличить посещаемость и прибыль.
Как обнаружить проблемы SEO на сайте?
Процесс оптимизации стоит начать с SEO-аудита — анализа сайта по самым разным критериям. Есть инструменты, выполняющие оценку определенных показателей, например, статус страниц, скорость загрузки, адаптивность для мобильных устройств и так далее. Альтернативный вариант — аудит сайта на платформе для SEO-специалистов.
Один из примеров — сервис SE Ranking, объединяющий в себе разные аналитические инструменты. Результатом SEO-анализа будет комплексный отчёт. Для запуска анализа сайта онлайн нужно создать проект, указать в настройках домен своего ресурса, и перейти в раздел «Анализ сайта». Одна из вкладок — «Отчёт об ошибках», где отображаются выявленные проблемы оптимизации.
Все параметры сайта разделены на блоки: «Безопасность», «Дублирование контента», «Скорость загрузки» и другие. При нажатии на любую из проблем появится её описание и рекомендации по исправлению. После технической SEO оптимизации и внесения корректировок следует повторно запустить аудит сайта. Увидеть, были ли устранены ошибки, можно колонке «Исправленные».
Ошибки технической оптимизации и способы их устранения
Фрагменты кода страниц, внутренние файлы и настройки сайта могут негативно влиять на его эффективность. Давайте разберём частые проблемы SEO и узнаем, как их исправить.
Отсутствие протокола HTTPS
Расширение HTTPS (HyperText Transfer Protocol Secure), которое является частью доменного имени, — это более надежная альтернатива протоколу соединения HTTP. Оно обеспечивает шифрование и сохранность данных пользователей. Сегодня многие браузеры блокируют переход по ссылке, начинающейся на HTTP, и отображают предупреждение на экране.
Поисковые системы учитывают безопасность соединения при ранжировании, и если сайт использует версию HTTP, это будет минусом не только для посетителей, но и для его позиций в выдаче.
Как исправить
Чтобы перевести ресурс на HTTPS, необходимо приобрести специальный сертификат и затем своевременно продлевать срок его действия. Настроить автоматическое перенаправление с HTTP-версии (редирект) можно в файле конфигурации .htaccess.
После перехода на безопасный протокол будет полезно выполнить аудит сайта и убедиться, что всё сделано правильно, а также при необходимости заменить неактуальные URL с HTTP среди внутренних ссылок (смешанный контент).
У сайта нет файла robots.txt
Документ robots размещают в корневой папке сайта. Его содержимое доступно по ссылке website.com/robots.txt. Этот файл представляет собой инструкцию для поисковых систем, какое содержимое ресурса следует сканировать, а какое нет. К нему роботы обращаются в первую очередь и затем начинают обход сайта.
Ограничение сканирования файлов и папок особенно актуально для экономии краулингового бюджета — общего количества URL, которое может просканировать робот на данном сайте. Если инструкция для краулеров отсутствует или составлена неправильно, это может привести к проблемам с отображением страниц в выдаче.
Как исправить
Создайте текстовый документ с названием robots в корневой папке сайта и с помощью директив пропишите внутри рекомендации по сканированию содержимого страниц и каталогов. В файле могут быть указаны виды роботов (user-agent), для которых действуют правила; ограничивающие и разрешающие команды (disallow, allow), а также ссылка на карту сайта (sitemap).
Проблемы с файлом Sitemap.xml
Карта сайта — это файл, содержащий список всех URL ресурса, которые должен обойти поисковый робот. Наличие sitemap.xml не является обязательным условием, для попадания страниц в индекс, но во многих случаях файл помогает поисковику их обнаружить.
Обработка XML Sitemap может быть затруднительна, если ее размер превышает 50 МБ или 50000 URL. Другая проблема — присутствие в карте страниц, закрытых для индексации метатегом noindex. При использовании канонических ссылок на сайте, выделяющих их похожих страниц основную, в файле sitemap должны быть указаны только приоритетные для индексации URL.
Как исправить
Если в карте сайта очень много URL и её объем превышает лимит, разделите файл на несколько меньших по размеру. XML Sitemap можно создавать не только для страниц, но и для изображений или видео. В файле robots.txt укажите ссылки на все карты сайта.
В случае, когда SEO-аудит выявил противоречия, — страницы в карте сайта, имеющие запрет индексации noindex в коде, их необходимо устранить. Также проследите, чтобы в Sitemap были указаны только канонические URL.
Дубли контента
Один из важных факторов, влияющих на ранжирование, — уникальность контента. Недопустимо не только копирование текстов у конкурентов, но и дублирование их внутри своего сайта. Это проблема особенно актуальна для больших ресурсов, например, интернет-магазинов, где описания к товарам имеют минимальные отличия.
Причиной, почему дубли страниц попадают в индекс, может быть отсутствие или неправильная настройка «зеркала» — редиректа между именем сайта с www и без. В этом случае поисковая система индексирует две идентичные страницы, например, www.website.com и website.com.
Также к проблеме дублей приводит копирование контента внутри сайта без настройки канонических ссылок, определяющих приоритетную для индексации страницу из похожих.
Как исправить
Настройте www-редиректы и проверьте с помощью SEO-аудита, не осталось ли на сайте дублей. При создании страниц с минимальными отличиями используйте канонические ссылки, чтобы указать роботу, какие из них индексировать. Чтобы не ввести в заблуждение поисковые системы, неканоническая страница должна содержать тег rel=”canonical” только для одного URL.
Страницы, отдающие код ошибки
Перед тем, как отобразить страницу на экране, браузер отправляет запрос серверу. Если URL доступен, у него будет успешный статус HTTP-состояния — 200 ОК. При возникновении проблем, когда сервер не может выполнить задачу, страница возвращает код ошибки 4ХХ или 5ХХ. Это приводит к таким негативным последствиям для сайта, как:
- Ухудшение поведенческих факторов. Если вместо запрошенной страницы пользователь видит сообщение об ошибке, например, «Page Not Found» или «Internal Server Error», он не может получить нужную информацию или завершить целевое действие.
- Исключение контента из индекса. Когда роботу долго не удается просканировать страницу, она может быть удалена из индекса поисковой системы.
- Расход краулингового бюджета. Роботы делают попытку просканировать URL, независимо от его статуса. Если на сайте много страниц с ошибками, происходит бессмысленный расход краулингового лимита.
Как исправить
После анализа сайта найдите страницы в статусе 4ХХ и 5ХХ и установите, в чём причина ошибки. Если страница была удалена, поисковая система через время исключит её из индекса. Ускорить этот процесс поможет инструмент удаления URL. Чтобы своевременно находить проблемные страницы, периодически повторяйте поиск проблем на сайте.
Некорректная настройка редиректов
Редирект — это переадресация в браузере с запрошенного URL на другой. Обычно его настраивают при смене адреса страницы и её удалении, перенаправляя пользователя на актуальную версию.
Преимущества редиректов в том, что они происходят автоматически и быстро. Их использование может быть полезно для SEO, когда нужно передать наработанный авторитет от исходной страницы к новой.
Но при настройке переадресаций нередко возникают такие проблемы, как:
- слишком длинная цепочка редиректов — чем больше в ней URL, тем позже отображается конечная страница;
- зацикленная (циклическая) переадресация, когда страница ссылается на себя или конечный URL содержит редирект на одно из предыдущих звеньев цепочки;
- в цепочке переадресаций есть неработающий, отдающий код ошибки URL;
- страниц с редиректами слишком много — это уменьшает краулинговый бюджет.
Как исправить
Проведите SEO-аудит сайта и найдите страницы со статусом 3ХХ. Если среди них есть цепочки редиректов, состоящие из трех и более URL, их нужно сократить до двух адресов — исходного и актуального. При выявлении зацикленных переадресаций необходимо откорректировать их последовательность. Страницы, имеющие статус ошибки 4ХХ или 5ХХ, нужно сделать доступными или удалить из цепочки.
Низкая скорость загрузки
Скорость отображения страниц — важный критерий удобства сайта, который поисковые системы учитывают при ранжировании. Если контент загружается слишком долго, пользователь может не дождаться и покинуть ресурс.
Google использует специальные показатели Core Web Vitals для оценки сайта, где о скорости говорят значения LCP (Largest Contentful Paint) и FID (First Input Delay). Рекомендуемая скорость загрузки основного контента (LCP) — до 2,5 секунд. Время отклика на взаимодействие с элементами страницы (FID) не должно превышать 0,1.
К распространённым факторам, негативно влияющим на скорость загрузки, относятся:
- объёмные по весу и размеру изображения;
- несжатый текстовый контент;
- большой вес HTML-кода и файлов, которые добавлены в него в виде ссылок.
Как исправить
Стремитесь к тому, чтобы вес HTML-страниц не превышал 2 МБ. Особое внимание стоит уделить изображениям сайта: выбирать правильное расширение файлов, сжимать их вес без потери качества с помощью специальных инструментов, уменьшать слишком крупные по размеру фотографии в графическом редакторе или через панель управления сайтом.
Также будет полезно настроить сжатие текстов. Благодаря заголовку Content-Encoding, сервер будет уменьшать размер передаваемых данных, и контент будет загружаться в браузере быстрее. Также полезно оптимизировать объем страницы, используя архивирование GZIP.
Не оптимизированы элементы JavaScript и CSS
Код JavaScript и CSS отвечает за внешний сайта. С помощью стилей CSS (Cascading Style Sheets) задают фон, размер и цвета блоков страницы, шрифты текста. Сценарии на языке JavaScript делают дизайн сайта динамичным.
Элементы CSS/JS важны для ресурса, но в то же время они увеличивают общий объём страниц. Файлы CSS, превышающие по размеру 150 KB, а JavaScript — 2 MB, могут негативно влиять на скорость загрузки.
Как исправить
Чтобы уменьшить размер и вес кода CSS и JavaScript, используют такие технологии, как сжатие, кэширование, минификация. SEO-аудит помогает определить, влияют ли CSS/JS-файлы на скорость сайта и какие методы оптимизации использованы.
Кэширование CSS/JS-элементов снижает нагрузку на сервер, поскольку в этом случае браузер загружает сохранённые в кэше копии контента и не воспроизводит страницы с нуля. Минификация кода, то есть удаление из него ненужных символов и комментариев, уменьшает исходный размер. Ещё один способ оптимизации таблиц стилей и скриптов — объединение нескольких файлов CSS и JavaScript в один.
Отсутствие мобильной оптимизации
Когда сайт подходит только для больших экранов и не оптимизирован для смартфонов, у посетителей возникают проблемы с его использованием. Это негативно отражается на поведенческих факторах и, как следствие, позициях при ранжировании.
Шрифт может оказаться слишком мелким для чтения. Если элементы интерфейса размещены слишком близко друг к другу, нажать на кнопку и ссылку проще только после увеличения фрагмента экрана. Нередко загруженная на смартфоне страница выходит за пределы экрана, и для просмотра контента приходится использовать нижнюю прокрутку.
О проблемах с настройками мобильной версии говорит отсутствие метатега viewport, отвечающего за адаптивность страницы под экраны разного формата, или его неправильное заполнение. Также о нестабильности элементов страницы во время загрузки информирует еще показатель производительности сайта Core Web Vitals — CLS (Cumulative Layout Shift). Его норма: 0,1.
Как исправить
В качестве альтернативы отдельной версии для мобильных устройств можно создать сайт с адаптивным дизайном. В этом случае его внешний вид, компоновка и величина блоков будет зависеть от размера экрана конкретного пользователя.
Обратите внимание, чтобы в HTML-коде страниц были метатеги viewport. При этом значение device-width не должно быть фиксированным, чтобы ширина страницы адаптировалась под размер ПК, планшета, смартфона.
Отсутствие alt-текста к изображениям
В HTML-коде страницы за визуальный контент отвечают теги <img>. Кроме ссылки на сам файл, тег может содержать альтернативный текст с описанием изображения и ключевыми словами.
Если атрибут alt — пустой, поисковику сложнее определить тематику фото. В итоге сайт не сможет привлекать дополнительный трафик из раздела «Картинки», где поисковая система отображает релевантные запросу изображения. Также текст alt отображается вместо фото, когда браузер не может его загрузить. Это особенно актуально для пользователей голосовыми помощниками и программами для чтения экрана.
Как исправить
Пропишите альтернативный текст к изображениям сайта. Это можно сделать после установки SEO-плагина к CMS, после чего в настройках к изображениям появятся специальные поля. Рекомендуем заполнить атрибут alt, используя несколько слов. Добавление ключевых фраз допустимо, но не стоит перегружать описание ими.
Заключение
Технические ошибки негативно влияют как на восприятие сайта пользователями, так и на позиции его страниц при ранжировании. Чтобы оптимизировать ресурс с учётом рекомендаций поисковых систем, нужно сначала провести SEO-аудит и определить внутренние проблемы. С этой задачей справляются платформы, выполняющие комплексный анализ сайта.
К частым проблемам оптимизации можно отнести:
- имя сайта с HTTP вместо безопасного расширения HTTPS;
- отсутствие или неправильное содержимое файлов robots.txt и sitemap.xml;
- медленная загрузка страниц;
- некорректное отображение сайта на смартфонах;
- большой вес файлов HTML, CSS, JS;
- дублированный контент;
- страницы с кодом ошибки 4ХХ, 5ХХ;
- неправильно настроенные редиректы;
- изображения без alt-текста.
Если вовремя находить и исправлять проблемы технической оптимизации сайта, это поможет в продвижении — его страницы будут занимать и сохранять высокие позиции при ранжировании.
Всем доброго времени суток! Совсем недавно столкнулся с ошибкой 404 именно в поисковике «Яндекс». Как понимаю многих тяготит данная проблема, поэтому я решил написать более подробную статью по данной теме. Начнем с того, что ошибка 404 может возникнуть и появится не только в поисковике.
Богдан Василенко
SEO-специалист SE Ranking
По каждому запросу поисковая система подбирает релевантные результаты — страницы, подходящие по тематике, и ранжирует их, отображая в виде списка. Согласно исследованиям, 99 % пользователей находят информацию, отвечающую запросу, уже на первой странице выдачи и не пролистывают дальше. И чем выше позиция сайта в топ-10, тем больше посетителей она привлекает.
Перед тем, как распределить ресурсы в определенном порядке, поисковики оценивают их по ряду параметров. Это позволяет улучшить выдачу для пользователя, предоставляя наиболее полезные, удобные и авторитетные варианты.
В чём заключается оптимизация сайта?
Оптимизация сайта или SEO (Search Engine Optimization) представляет собой комплекс действий, цель которых — улучшить качество ресурса и адаптировать его с учётом рекомендаций поисковых систем.
SEO помогает попасть содержимому сайта в индекс, улучшить позиции его страниц при ранжировании и увеличить органический, то есть бесплатный трафик. Техническая оптимизация сайта — это важный этап SEO, направленный на работу с его внутренней частью, которая обычно скрыта от пользователей, но доступна для поисковых роботов.
Страницы представляют собой HTML-документы, и их отображение на экране — это результат воспроизведения браузером HTML-кода, от которого зависит не только внешний вид сайта, но и его производительность. Серверные файлы и внутренние настройки ресурса могут влиять на его сканирование и индексацию поисковиком.
SEO включает анализ технических параметров сайта, выявление проблем и их устранение. Это помогает повысить позиции при ранжировании, обойти конкурентов, увеличить посещаемость и прибыль.
Как обнаружить проблемы SEO на сайте?
Процесс оптимизации стоит начать с SEO-аудита — анализа сайта по самым разным критериям. Есть инструменты, выполняющие оценку определенных показателей, например, статус страниц, скорость загрузки, адаптивность для мобильных устройств и так далее. Альтернативный вариант — аудит сайта на платформе для SEO-специалистов.
Один из примеров — сервис SE Ranking, объединяющий в себе разные аналитические инструменты. Результатом SEO-анализа будет комплексный отчёт. Для запуска анализа сайта онлайн нужно создать проект, указать в настройках домен своего ресурса, и перейти в раздел «Анализ сайта». Одна из вкладок — «Отчёт об ошибках», где отображаются выявленные проблемы оптимизации.
Все параметры сайта разделены на блоки: «Безопасность», «Дублирование контента», «Скорость загрузки» и другие. При нажатии на любую из проблем появится её описание и рекомендации по исправлению. После технической SEO оптимизации и внесения корректировок следует повторно запустить аудит сайта. Увидеть, были ли устранены ошибки, можно колонке «Исправленные».
Ошибки технической оптимизации и способы их устранения
Фрагменты кода страниц, внутренние файлы и настройки сайта могут негативно влиять на его эффективность. Давайте разберём частые проблемы SEO и узнаем, как их исправить.
Отсутствие протокола HTTPS
Расширение HTTPS (HyperText Transfer Protocol Secure), которое является частью доменного имени, — это более надежная альтернатива протоколу соединения HTTP. Оно обеспечивает шифрование и сохранность данных пользователей. Сегодня многие браузеры блокируют переход по ссылке, начинающейся на HTTP, и отображают предупреждение на экране.
Поисковые системы учитывают безопасность соединения при ранжировании, и если сайт использует версию HTTP, это будет минусом не только для посетителей, но и для его позиций в выдаче.
Как исправить
Чтобы перевести ресурс на HTTPS, необходимо приобрести специальный сертификат и затем своевременно продлевать срок его действия. Настроить автоматическое перенаправление с HTTP-версии (редирект) можно в файле конфигурации .htaccess.
После перехода на безопасный протокол будет полезно выполнить аудит сайта и убедиться, что всё сделано правильно, а также при необходимости заменить неактуальные URL с HTTP среди внутренних ссылок (смешанный контент).
У сайта нет файла robots.txt
Документ robots размещают в корневой папке сайта. Его содержимое доступно по ссылке website.com/robots.txt. Этот файл представляет собой инструкцию для поисковых систем, какое содержимое ресурса следует сканировать, а какое нет. К нему роботы обращаются в первую очередь и затем начинают обход сайта.
Ограничение сканирования файлов и папок особенно актуально для экономии краулингового бюджета — общего количества URL, которое может просканировать робот на данном сайте. Если инструкция для краулеров отсутствует или составлена неправильно, это может привести к проблемам с отображением страниц в выдаче.
Как исправить
Создайте текстовый документ с названием robots в корневой папке сайта и с помощью директив пропишите внутри рекомендации по сканированию содержимого страниц и каталогов. В файле могут быть указаны виды роботов (user-agent), для которых действуют правила; ограничивающие и разрешающие команды (disallow, allow), а также ссылка на карту сайта (sitemap).
Проблемы с файлом Sitemap.xml
Карта сайта — это файл, содержащий список всех URL ресурса, которые должен обойти поисковый робот. Наличие sitemap.xml не является обязательным условием, для попадания страниц в индекс, но во многих случаях файл помогает поисковику их обнаружить.
Обработка XML Sitemap может быть затруднительна, если ее размер превышает 50 МБ или 50000 URL. Другая проблема — присутствие в карте страниц, закрытых для индексации метатегом noindex. При использовании канонических ссылок на сайте, выделяющих их похожих страниц основную, в файле sitemap должны быть указаны только приоритетные для индексации URL.
Как исправить
Если в карте сайта очень много URL и её объем превышает лимит, разделите файл на несколько меньших по размеру. XML Sitemap можно создавать не только для страниц, но и для изображений или видео. В файле robots.txt укажите ссылки на все карты сайта.
В случае, когда SEO-аудит выявил противоречия, — страницы в карте сайта, имеющие запрет индексации noindex в коде, их необходимо устранить. Также проследите, чтобы в Sitemap были указаны только канонические URL.
Дубли контента
Один из важных факторов, влияющих на ранжирование, — уникальность контента. Недопустимо не только копирование текстов у конкурентов, но и дублирование их внутри своего сайта. Это проблема особенно актуальна для больших ресурсов, например, интернет-магазинов, где описания к товарам имеют минимальные отличия.
Причиной, почему дубли страниц попадают в индекс, может быть отсутствие или неправильная настройка «зеркала» — редиректа между именем сайта с www и без. В этом случае поисковая система индексирует две идентичные страницы, например, www.website.com и website.com.
Также к проблеме дублей приводит копирование контента внутри сайта без настройки канонических ссылок, определяющих приоритетную для индексации страницу из похожих.
Как исправить
Настройте www-редиректы и проверьте с помощью SEO-аудита, не осталось ли на сайте дублей. При создании страниц с минимальными отличиями используйте канонические ссылки, чтобы указать роботу, какие из них индексировать. Чтобы не ввести в заблуждение поисковые системы, неканоническая страница должна содержать тег rel=”canonical” только для одного URL.
Страницы, отдающие код ошибки
Перед тем, как отобразить страницу на экране, браузер отправляет запрос серверу. Если URL доступен, у него будет успешный статус HTTP-состояния — 200 ОК. При возникновении проблем, когда сервер не может выполнить задачу, страница возвращает код ошибки 4ХХ или 5ХХ. Это приводит к таким негативным последствиям для сайта, как:
- Ухудшение поведенческих факторов. Если вместо запрошенной страницы пользователь видит сообщение об ошибке, например, «Page Not Found» или «Internal Server Error», он не может получить нужную информацию или завершить целевое действие.
- Исключение контента из индекса. Когда роботу долго не удается просканировать страницу, она может быть удалена из индекса поисковой системы.
- Расход краулингового бюджета. Роботы делают попытку просканировать URL, независимо от его статуса. Если на сайте много страниц с ошибками, происходит бессмысленный расход краулингового лимита.
Как исправить
После анализа сайта найдите страницы в статусе 4ХХ и 5ХХ и установите, в чём причина ошибки. Если страница была удалена, поисковая система через время исключит её из индекса. Ускорить этот процесс поможет инструмент удаления URL. Чтобы своевременно находить проблемные страницы, периодически повторяйте поиск проблем на сайте.
Некорректная настройка редиректов
Редирект — это переадресация в браузере с запрошенного URL на другой. Обычно его настраивают при смене адреса страницы и её удалении, перенаправляя пользователя на актуальную версию.
Преимущества редиректов в том, что они происходят автоматически и быстро. Их использование может быть полезно для SEO, когда нужно передать наработанный авторитет от исходной страницы к новой.
Но при настройке переадресаций нередко возникают такие проблемы, как:
- слишком длинная цепочка редиректов — чем больше в ней URL, тем позже отображается конечная страница;
- зацикленная (циклическая) переадресация, когда страница ссылается на себя или конечный URL содержит редирект на одно из предыдущих звеньев цепочки;
- в цепочке переадресаций есть неработающий, отдающий код ошибки URL;
- страниц с редиректами слишком много — это уменьшает краулинговый бюджет.
Как исправить
Проведите SEO-аудит сайта и найдите страницы со статусом 3ХХ. Если среди них есть цепочки редиректов, состоящие из трех и более URL, их нужно сократить до двух адресов — исходного и актуального. При выявлении зацикленных переадресаций необходимо откорректировать их последовательность. Страницы, имеющие статус ошибки 4ХХ или 5ХХ, нужно сделать доступными или удалить из цепочки.
Низкая скорость загрузки
Скорость отображения страниц — важный критерий удобства сайта, который поисковые системы учитывают при ранжировании. Если контент загружается слишком долго, пользователь может не дождаться и покинуть ресурс.
Google использует специальные показатели Core Web Vitals для оценки сайта, где о скорости говорят значения LCP (Largest Contentful Paint) и FID (First Input Delay). Рекомендуемая скорость загрузки основного контента (LCP) — до 2,5 секунд. Время отклика на взаимодействие с элементами страницы (FID) не должно превышать 0,1.
К распространённым факторам, негативно влияющим на скорость загрузки, относятся:
- объёмные по весу и размеру изображения;
- несжатый текстовый контент;
- большой вес HTML-кода и файлов, которые добавлены в него в виде ссылок.
Как исправить
Стремитесь к тому, чтобы вес HTML-страниц не превышал 2 МБ. Особое внимание стоит уделить изображениям сайта: выбирать правильное расширение файлов, сжимать их вес без потери качества с помощью специальных инструментов, уменьшать слишком крупные по размеру фотографии в графическом редакторе или через панель управления сайтом.
Также будет полезно настроить сжатие текстов. Благодаря заголовку Content-Encoding, сервер будет уменьшать размер передаваемых данных, и контент будет загружаться в браузере быстрее. Также полезно оптимизировать объем страницы, используя архивирование GZIP.
Не оптимизированы элементы JavaScript и CSS
Код JavaScript и CSS отвечает за внешний сайта. С помощью стилей CSS (Cascading Style Sheets) задают фон, размер и цвета блоков страницы, шрифты текста. Сценарии на языке JavaScript делают дизайн сайта динамичным.
Элементы CSS/JS важны для ресурса, но в то же время они увеличивают общий объём страниц. Файлы CSS, превышающие по размеру 150 KB, а JavaScript — 2 MB, могут негативно влиять на скорость загрузки.
Как исправить
Чтобы уменьшить размер и вес кода CSS и JavaScript, используют такие технологии, как сжатие, кэширование, минификация. SEO-аудит помогает определить, влияют ли CSS/JS-файлы на скорость сайта и какие методы оптимизации использованы.
Кэширование CSS/JS-элементов снижает нагрузку на сервер, поскольку в этом случае браузер загружает сохранённые в кэше копии контента и не воспроизводит страницы с нуля. Минификация кода, то есть удаление из него ненужных символов и комментариев, уменьшает исходный размер. Ещё один способ оптимизации таблиц стилей и скриптов — объединение нескольких файлов CSS и JavaScript в один.
Отсутствие мобильной оптимизации
Когда сайт подходит только для больших экранов и не оптимизирован для смартфонов, у посетителей возникают проблемы с его использованием. Это негативно отражается на поведенческих факторах и, как следствие, позициях при ранжировании.
Шрифт может оказаться слишком мелким для чтения. Если элементы интерфейса размещены слишком близко друг к другу, нажать на кнопку и ссылку проще только после увеличения фрагмента экрана. Нередко загруженная на смартфоне страница выходит за пределы экрана, и для просмотра контента приходится использовать нижнюю прокрутку.
О проблемах с настройками мобильной версии говорит отсутствие метатега viewport, отвечающего за адаптивность страницы под экраны разного формата, или его неправильное заполнение. Также о нестабильности элементов страницы во время загрузки информирует еще показатель производительности сайта Core Web Vitals — CLS (Cumulative Layout Shift). Его норма: 0,1.
Как исправить
В качестве альтернативы отдельной версии для мобильных устройств можно создать сайт с адаптивным дизайном. В этом случае его внешний вид, компоновка и величина блоков будет зависеть от размера экрана конкретного пользователя.
Обратите внимание, чтобы в HTML-коде страниц были метатеги viewport. При этом значение device-width не должно быть фиксированным, чтобы ширина страницы адаптировалась под размер ПК, планшета, смартфона.
Отсутствие alt-текста к изображениям
В HTML-коде страницы за визуальный контент отвечают теги <img>. Кроме ссылки на сам файл, тег может содержать альтернативный текст с описанием изображения и ключевыми словами.
Если атрибут alt — пустой, поисковику сложнее определить тематику фото. В итоге сайт не сможет привлекать дополнительный трафик из раздела «Картинки», где поисковая система отображает релевантные запросу изображения. Также текст alt отображается вместо фото, когда браузер не может его загрузить. Это особенно актуально для пользователей голосовыми помощниками и программами для чтения экрана.
Как исправить
Пропишите альтернативный текст к изображениям сайта. Это можно сделать после установки SEO-плагина к CMS, после чего в настройках к изображениям появятся специальные поля. Рекомендуем заполнить атрибут alt, используя несколько слов. Добавление ключевых фраз допустимо, но не стоит перегружать описание ими.
Заключение
Технические ошибки негативно влияют как на восприятие сайта пользователями, так и на позиции его страниц при ранжировании. Чтобы оптимизировать ресурс с учётом рекомендаций поисковых систем, нужно сначала провести SEO-аудит и определить внутренние проблемы. С этой задачей справляются платформы, выполняющие комплексный анализ сайта.
К частым проблемам оптимизации можно отнести:
- имя сайта с HTTP вместо безопасного расширения HTTPS;
- отсутствие или неправильное содержимое файлов robots.txt и sitemap.xml;
- медленная загрузка страниц;
- некорректное отображение сайта на смартфонах;
- большой вес файлов HTML, CSS, JS;
- дублированный контент;
- страницы с кодом ошибки 4ХХ, 5ХХ;
- неправильно настроенные редиректы;
- изображения без alt-текста.
Если вовремя находить и исправлять проблемы технической оптимизации сайта, это поможет в продвижении — его страницы будут занимать и сохранять высокие позиции при ранжировании.






")






")


