
Уровень сложности
Средний
Время на прочтение
8 мин
Количество просмотров 6.8K

Люди, которые пишут код, часто воспринимают работу с исключениями как необходимое зло. Но освоение системы обработки исключений в Python способно повысить профессиональный уровень программиста, сделать его эффективнее. В этом материале я разберу следующие темы, изучение которых поможет всем желающим раскрыть потенциал Python через разумный подход к обработке исключений:
-
Что такое обработка исключений?
-
Разница между оператором
ifи обработкой исключений. -
Использование разделов
elseиfinallyблокаtry-exceptдля организации правильного обращения с ошибками. -
Определение пользовательских исключений.
-
Рекомендации по обработке исключений.
Что такое обработка исключений?
Обработка исключений — это процесс написания кода для перехвата и обработки ошибок или исключений, которые могут возникать при выполнении программы. Это позволяет разработчикам создавать надёжные программы, которые продолжают работать даже при возникновении неожиданных событий или ошибок. Без системы обработки исключений подобное обычно приводит к фатальным сбоям.
Когда возникают исключения — Python выполняет поиск подходящего обработчика исключений. После этого, если обработчик будет найден, выполняется его код, в котором предпринимаются уместные действия. Это может быть логирование данных, вывод сообщения, попытка восстановить работу программы после возникновения ошибки. В целом можно сказать, что обработка исключения помогает повысить надёжность Python-приложений, улучшает возможности по их поддержке, облегчает их отладку.
Различия между оператором if и обработкой исключений
Главные различия между оператором if и обработкой исключений в Python произрастают из их целей и сценариев использования.
Оператор if — это базовый строительный элемент структурного программирования. Этот оператор проверяет условие и выполняет различные блоки кода, основываясь на том, истинно проверяемое условие или ложно. Вот пример:
temperature = int(input("Please enter temperature in Fahrenheit: "))
if temperature > 100:
print("Hot weather alert! Temperature exceeded 100°F.")
elif temperature >= 70:
print("Warm day ahead, enjoy sunny skies.")
else:
print("Bundle up for chilly temperatures.")Обработка исключений, с другой стороны, играет важную роль в написании надёжных и отказоустойчивых программ. Эта роль раскрывается через работу с неожиданными событиями и ошибками, которые могут возникать во время выполнения программы.
Исключения используются для подачи сигналов о проблемах и для выявления участков кода, которые нуждаются в улучшении, отладке, или в оснащении их дополнительными механизмами для проверки ошибок. Исключения позволяют Python достойно справляться с ситуациями, в которых возникают ошибки. В таких ситуациях исключения дают возможность продолжать выполнение скрипта вместо того, чтобы резко его останавливать.
Рассмотрим следующий код, демонстрирующий пример того, как можно реализовать обработку исключений и улучшить ситуацию с потенциальными отказами, связанными с делением на ноль:
# Определение функции, которая пытается поделить число на ноль
def divide(x, y):
result = x / y
return result
# Вызов функции divide с передачей ей x=5 и y=0
result = divide(5, 0)
print(f"Result of dividing {x} by {y}: {result}")Вывод:
Traceback (most recent call last):
File "<stdin>", line 8, in <module>
ZeroDivisionError: division by zero attemptedПосле того, как было сгенерировано исключение, программа, не дойдя до инструкции print, сразу же прекращает выполняться.
Вышеописанное исключение можно обработать, обернув вызов функции divide в блок try-except:
# Определение функции, которая пытается поделить число на ноль
def divide(x, y):
result = x / y
return result
# Вызов функции divide с передачей ей x=5 и y=0
try:
result = divide(5, 0)
print(f"Result of dividing {x} by {y}: {result}")
except ZeroDivisionError:
print("Cannot divide by zero.")Вывод:
Cannot divide by zero.Сделав это, мы аккуратно обработали исключение ZeroDivisionError, предотвратили аварийное завершение остального кода из-за необработанного исключения.
Подробности о других встроенных Python-исключениях можно найти здесь.
Использование разделов else и finally блока try-except для организации правильного обращения с ошибками
При работе с исключениями в Python рекомендуется включать в состав блоков try-except и раздел else, и раздел finally. Раздел else позволяет программисту настроить действия, производимые в том случае, если при выполнении кода, который защищают от проблем, не было вызвано исключений. А раздел finally позволяет обеспечить обязательное выполнение неких заключительных операций, вроде освобождения ресурсов, независимо от факта возникновения исключений (вот и вот — полезные материалы об этом).
Например — рассмотрим ситуацию, когда нужно прочитать данные из файла и выполнить какие-то действия с этими данными. Если при чтении файла возникнет исключение — программист может решить, что надо залогировать ошибку и остановить выполнение дальнейших операций. Но в любом случае файл нужно правильно закрыть.
Использование разделов else и finally позволяет поступить именно так — обработать данные обычным образом в том случае, если исключений не возникло, либо обработать любые исключения, но, как бы ни развивались события, в итоге закрыть файл. Без этих разделов код страдал бы уязвимостями в виде утечки ресурсов или неполной обработки ошибок. В результате оказывается, что else и finally играют важнейшую роль в создании устойчивых к ошибкам и надёжных программ.
try:
# Открытие файла в режиме чтения
file = open("file.txt", "r")
print("Successful opened the file")
except FileNotFoundError:
# Обработка ошибки, возникающей в том случае, если файл не найден
print("File Not Found Error: No such file or directory")
exit()
except PermissionError:
# Обработка ошибок, связанных с разрешением на доступ к файлу
print("Permission Denied Error: Access is denied")
else:
# Всё хорошо - сделать что-то с данными, прочитанными из файла
content = file.read().decode('utf-8')
processed_data = process_content(content)
# Прибираемся после себя даже в том случае, если выше возникло исключение
finally:
file.close()В этом примере мы сначала пытаемся открыть файл file.txt для чтения (в подобной ситуации можно использовать выражение with, которое гарантирует правильное автоматическое закрытие объекта файла после завершения работы). Если в процессе выполнения операций файлового ввода/вывода возникают ошибки FileNotFoundError или PermissionError — выполняются соответствующие разделы except. Здесь, ради простоты, мы лишь выводим на экран сообщения об ошибках и выходим из программы в том случае, если файл не найден.
В противном случае, если в блоке try исключений не возникло, мы продолжаем работу, обрабатывая содержимое файла в ветви else. И наконец — выполняется «уборка» — файл закрывается независимо от возникновения исключения. Это обеспечивает блок finally (подробности смотрите здесь).
Применяя структурированный подход к обработке исключений, напоминающий вышеописанный, можно поддерживать свой код в хорошо организованном состоянии и обеспечивать его читабельность. При этом код будет рассчитан на борьбу с потенциальными ошибками, которые могут возникнуть при взаимодействии с внешними системами или входными данными.
Определение пользовательских исключений
В Python можно определять пользовательские исключения путём создания подклассов встроенного класса Exception или любых других классов, являющихся прямыми наследниками Exception.
Для того чтобы определить собственное исключение — нужно создать новый класс, являющийся наследником одного из подходящих классов, и оснастить этот класс атрибутами, соответствующими нуждам программиста. Затем новый класс можно использовать в собственном коде, работая с ним так же, как работают со встроенными классами исключений.
Вот пример определения пользовательского исключения, названного InvalidEmailAddress:
class InvalidEmailAddress(ValueError):
def __init__(self, message):
super().__init__(message)
self.msgfmt = messageЭто исключение является наследником ValueError. Его конструктор принимает необязательный аргумент message (по умолчанию он устанавливается в значение invalid email address).
Вызвать это исключение можно в том случае, если в программе встретился адрес электронной почты, имеющий некорректный формат:
def send_email(address):
if isinstance(address, str) == False:
raise InvalidEmailAddress("Invalid email address")
# Отправка электронного письмаТеперь, если функции send_email() будет передана строка, содержащая неправильно оформленный адрес, то, вместо сообщения стандартной ошибки TypeError, будет выдано настроенное заранее сообщение об ошибке, которое чётко указывает на возникшую проблему. Например, это может выглядеть так:
>>> send_email(None)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/path/to/project/main.py", line 8, in send_email
raise InvalidEmailAddress("Invalid email address")
InvalidEmailAddress: Invalid email addressРекомендации по обработке исключений
Вот несколько рекомендаций, относящихся к обработке ошибок в Python:
-
Проектируйте код в расчёте на возможное возникновение ошибок. Заранее планируйте устройство кода с учётом возможных сбоев и проектируйте программы так, чтобы они могли бы достойно обрабатывать эти сбои. Это означает — предугадывать возможные пограничные случаи и реализовывать подходящие обработчики ошибок.
-
Используйте содержательные сообщения об ошибках. Сделайте так, чтобы программа выводила бы, на экран, или в файл журнала, подробные сообщения об ошибках, которые помогут пользователям понять — что и почему пошло не так. Старайтесь не применять обобщённые сообщения об ошибках, наподобие
Error occurredилиSomething bad happened. Вместо этого подумайте об удобстве пользователя и покажите сообщение, в котором будет дан совет по решению проблемы или будет приведена ссылка на документацию. Постарайтесь соблюсти баланс между выводом подробных сообщений и перегрузкой пользовательского интерфейса избыточными данными. -
Минимизируйте побочные эффекты. Постарайтесь свести к минимуму последствия сбойных операций, изолируя проблемные разделы кода посредством конструкции
try-finallyилиtryс использованиемwith. Сделайте так, чтобы после выполнения кода, было ли оно удачным или нет, обязательно выполнялись бы «очистительные» операции. -
Тщательно тестируйте код. Обеспечьте корректное поведение обработчиков ошибок в различных сценариях использования программы, подвергнув код всеобъемлющему тестированию.
-
Регулярно выполняйте рефакторинг кода. Выполняйте рефакторинг фрагментов кода, подверженных ошибкам, чтобы улучшить их надёжность и производительность. Постарайтесь, чтобы ваша кодовая база была бы устроена по модульному принципу, чтобы её отдельные части слабо зависели бы друг от друга. Это позволяет независимым частям код самостоятельно эволюционировать, не оказывая негативного воздействия на другие его части.
-
Логируйте важные события. Следите за интересными событиями своего приложения, записывая сведения о них в файл журнала или выводя в консоль. Это поможет вам выявлять проблемы на ранних стадиях их возникновения, не тратя время на длительный анализ большого количества неструктурированных логов.
Итоги
Написание кода обработки ошибок — это неотъемлемая часть индустрии разработки ПО, и, в частности — разработки на Python. Это позволяет разработчикам создавать более надёжные и стабильные программы. Следуя индустриальным стандартам и рекомендациям по обработке исключений, разработчик может сократить время, необходимое на отладку кода, способен обеспечить написание качественных программ и сделать так, чтобы пользователям было бы приятно работать с этими программами.
О, а приходите к нам работать? 🤗 💰
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
Присоединяйтесь к нашей команде.
Обработка ошибок увеличивает отказоустойчивость кода, защищая его от потенциальных сбоев, которые могут привести к преждевременному завершению работы.

Прежде чем переходить к обсуждению того, почему обработка исключений так важна, и рассматривать встроенные в Python исключения, важно понять, что есть тонкая грань между понятиями ошибки и исключения.
Ошибку нельзя обработать, а исключения Python обрабатываются при выполнении программы. Ошибка может быть синтаксической, но существует и много видов исключений, которые возникают при выполнении и не останавливают программу сразу же. Ошибка может указывать на критические проблемы, которые приложение и не должно перехватывать, а исключения — состояния, которые стоит попробовать перехватить. Ошибки — вид непроверяемых и невозвратимых ошибок, таких как OutOfMemoryError, которые не стоит пытаться обработать.
Обработка исключений делает код более отказоустойчивым и помогает предотвращать потенциальные проблемы, которые могут привести к преждевременной остановке выполнения. Представьте код, который готов к развертыванию, но все равно прекращает работу из-за исключения. Клиент такой не примет, поэтому стоит заранее обработать конкретные исключения, чтобы избежать неразберихи.
Ошибки могут быть разных видов:
- Синтаксические
- Недостаточно памяти
- Ошибки рекурсии
- Исключения
Разберем их по очереди.
Синтаксические ошибки (SyntaxError)
Синтаксические ошибки часто называют ошибками разбора. Они возникают, когда интерпретатор обнаруживает синтаксическую проблему в коде.
Рассмотрим на примере.
a = 8
b = 10
c = a b
File "", line 3
c = a b
^
SyntaxError: invalid syntax
Стрелка вверху указывает на место, где интерпретатор получил ошибку при попытке исполнения. Знак перед стрелкой указывает на причину проблемы. Для устранения таких фундаментальных ошибок Python будет делать большую часть работы за программиста, выводя название файла и номер строки, где была обнаружена ошибка.
Недостаточно памяти (OutofMemoryError)
Ошибки памяти чаще всего связаны с оперативной памятью компьютера и относятся к структуре данных под названием “Куча” (heap). Если есть крупные объекты (или) ссылки на подобные, то с большой долей вероятности возникнет ошибка OutofMemory. Она может появиться по нескольким причинам:
- Использование 32-битной архитектуры Python (максимальный объем выделенной памяти невысокий, между 2 и 4 ГБ);
- Загрузка файла большого размера;
- Запуск модели машинного обучения/глубокого обучения и много другое;
Обработать ошибку памяти можно с помощью обработки исключений — резервного исключения. Оно используется, когда у интерпретатора заканчивается память и он должен немедленно остановить текущее исполнение. В редких случаях Python вызывает OutofMemoryError, позволяя скрипту каким-то образом перехватить самого себя, остановить ошибку памяти и восстановиться.
Но поскольку Python использует архитектуру управления памятью из языка C (функция malloc()), не факт, что все процессы восстановятся — в некоторых случаях MemoryError приведет к остановке. Следовательно, обрабатывать такие ошибки не рекомендуется, и это не считается хорошей практикой.
Ошибка рекурсии (RecursionError)
Эта ошибка связана со стеком и происходит при вызове функций. Как и предполагает название, ошибка рекурсии возникает, когда внутри друг друга исполняется много методов (один из которых — с бесконечной рекурсией), но это ограничено размером стека.
Все локальные переменные и методы размещаются в стеке. Для каждого вызова метода создается стековый кадр (фрейм), внутрь которого помещаются данные переменной или результат вызова метода. Когда исполнение метода завершается, его элемент удаляется.
Чтобы воспроизвести эту ошибку, определим функцию recursion, которая будет рекурсивной — вызывать сама себя в бесконечном цикле. В результате появится ошибка StackOverflow или ошибка рекурсии, потому что стековый кадр будет заполняться данными метода из каждого вызова, но они не будут освобождаться.
def recursion():
return recursion()
recursion()
---------------------------------------------------------------------------
RecursionError Traceback (most recent call last)
in
----> 1 recursion()
in recursion()
1 def recursion():
----> 2 return recursion()
... last 1 frames repeated, from the frame below ...
in recursion()
1 def recursion():
----> 2 return recursion()
RecursionError: maximum recursion depth exceeded
Ошибка отступа (IndentationError)
Эта ошибка похожа по духу на синтаксическую и является ее подвидом. Тем не менее она возникает только в случае проблем с отступами.
Пример:
for i in range(10):
print('Привет Мир!')
File "", line 2
print('Привет Мир!')
^
IndentationError: expected an indented block
Исключения
Даже если синтаксис в инструкции или само выражение верны, они все равно могут вызывать ошибки при исполнении. Исключения Python — это ошибки, обнаруживаемые при исполнении, но не являющиеся критическими. Скоро вы узнаете, как справляться с ними в программах Python. Объект исключения создается при вызове исключения Python. Если скрипт не обрабатывает исключение явно, программа будет остановлена принудительно.
Программы обычно не обрабатывают исключения, что приводит к подобным сообщениям об ошибке:
Ошибка типа (TypeError)
a = 2
b = 'PythonRu'
a + b
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in
1 a = 2
2 b = 'PythonRu'
----> 3 a + b
TypeError: unsupported operand type(s) for +: 'int' and 'str'
Ошибка деления на ноль (ZeroDivisionError)
10 / 0
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
in
----> 1 10 / 0
ZeroDivisionError: division by zero
Есть разные типы исключений в Python и их тип выводится в сообщении: вверху примеры TypeError и ZeroDivisionError. Обе строки в сообщениях об ошибке представляют собой имена встроенных исключений Python.
Оставшаяся часть строки с ошибкой предлагает подробности о причине ошибки на основе ее типа.
Теперь рассмотрим встроенные исключения Python.
Встроенные исключения
BaseException
+-- SystemExit
+-- KeyboardInterrupt
+-- GeneratorExit
+-- Exception
+-- StopIteration
+-- StopAsyncIteration
+-- ArithmeticError
| +-- FloatingPointError
| +-- OverflowError
| +-- ZeroDivisionError
+-- AssertionError
+-- AttributeError
+-- BufferError
+-- EOFError
+-- ImportError
| +-- ModuleNotFoundError
+-- LookupError
| +-- IndexError
| +-- KeyError
+-- MemoryError
+-- NameError
| +-- UnboundLocalError
+-- OSError
| +-- BlockingIOError
| +-- ChildProcessError
| +-- ConnectionError
| | +-- BrokenPipeError
| | +-- ConnectionAbortedError
| | +-- ConnectionRefusedError
| | +-- ConnectionResetError
| +-- FileExistsError
| +-- FileNotFoundError
| +-- InterruptedError
| +-- IsADirectoryError
| +-- NotADirectoryError
| +-- PermissionError
| +-- ProcessLookupError
| +-- TimeoutError
+-- ReferenceError
+-- RuntimeError
| +-- NotImplementedError
| +-- RecursionError
+-- SyntaxError
| +-- IndentationError
| +-- TabError
+-- SystemError
+-- TypeError
+-- ValueError
| +-- UnicodeError
| +-- UnicodeDecodeError
| +-- UnicodeEncodeError
| +-- UnicodeTranslateError
+-- Warning
+-- DeprecationWarning
+-- PendingDeprecationWarning
+-- RuntimeWarning
+-- SyntaxWarning
+-- UserWarning
+-- FutureWarning
+-- ImportWarning
+-- UnicodeWarning
+-- BytesWarning
+-- ResourceWarning
Прежде чем переходить к разбору встроенных исключений быстро вспомним 4 основных компонента обработки исключения, как показано на этой схеме.
Try: он запускает блок кода, в котором ожидается ошибка.Except: здесь определяется тип исключения, который ожидается в блокеtry(встроенный или созданный).Else: если исключений нет, тогда исполняется этот блок (его можно воспринимать как средство для запуска кода в том случае, если ожидается, что часть кода приведет к исключению).Finally: вне зависимости от того, будет ли исключение или нет, этот блок кода исполняется всегда.
В следующем разделе руководства больше узнаете об общих типах исключений и научитесь обрабатывать их с помощью инструмента обработки исключения.
Ошибка прерывания с клавиатуры (KeyboardInterrupt)
Исключение KeyboardInterrupt вызывается при попытке остановить программу с помощью сочетания Ctrl + C или Ctrl + Z в командной строке или ядре в Jupyter Notebook. Иногда это происходит неумышленно и подобная обработка поможет избежать подобных ситуаций.
В примере ниже если запустить ячейку и прервать ядро, программа вызовет исключение KeyboardInterrupt. Теперь обработаем исключение KeyboardInterrupt.
try:
inp = input()
print('Нажмите Ctrl+C и прервите Kernel:')
except KeyboardInterrupt:
print('Исключение KeyboardInterrupt')
else:
print('Исключений не произошло')
Исключение KeyboardInterrupt
Стандартные ошибки (StandardError)
Рассмотрим некоторые базовые ошибки в программировании.
Арифметические ошибки (ArithmeticError)
- Ошибка деления на ноль (Zero Division);
- Ошибка переполнения (OverFlow);
- Ошибка плавающей точки (Floating Point);
Все перечисленные выше исключения относятся к классу Arithmetic и вызываются при ошибках в арифметических операциях.
Деление на ноль (ZeroDivisionError)
Когда делитель (второй аргумент операции деления) или знаменатель равны нулю, тогда результатом будет ошибка деления на ноль.
try:
a = 100 / 0
print(a)
except ZeroDivisionError:
print("Исключение ZeroDivisionError." )
else:
print("Успех, нет ошибок!")
Исключение ZeroDivisionError.
Переполнение (OverflowError)
Ошибка переполнение вызывается, когда результат операции выходил за пределы диапазона. Она характерна для целых чисел вне диапазона.
try:
import math
print(math.exp(1000))
except OverflowError:
print("Исключение OverFlow.")
else:
print("Успех, нет ошибок!")
Исключение OverFlow.
Ошибка утверждения (AssertionError)
Когда инструкция утверждения не верна, вызывается ошибка утверждения.
Рассмотрим пример. Предположим, есть две переменные: a и b. Их нужно сравнить. Чтобы проверить, равны ли они, необходимо использовать ключевое слово assert, что приведет к вызову исключения Assertion в том случае, если выражение будет ложным.
try:
a = 100
b = "PythonRu"
assert a == b
except AssertionError:
print("Исключение AssertionError.")
else:
print("Успех, нет ошибок!")
Исключение AssertionError.
Ошибка атрибута (AttributeError)
При попытке сослаться на несуществующий атрибут программа вернет ошибку атрибута. В следующем примере можно увидеть, что у объекта класса Attributes нет атрибута с именем attribute.
class Attributes(obj):
a = 2
print(a)
try:
obj = Attributes()
print(obj.attribute)
except AttributeError:
print("Исключение AttributeError.")
2
Исключение AttributeError.
Ошибка импорта (ModuleNotFoundError)
Ошибка импорта вызывается при попытке импортировать несуществующий (или неспособный загрузиться) модуль в стандартном пути или даже при допущенной ошибке в имени.
import nibabel
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
in
----> 1 import nibabel
ModuleNotFoundError: No module named 'nibabel'
Ошибка поиска (LookupError)
LockupError выступает базовым классом для исключений, которые происходят, когда key или index используются для связывания или последовательность списка/словаря неверна или не существует.
Здесь есть два вида исключений:
- Ошибка индекса (
IndexError); - Ошибка ключа (
KeyError);
Ошибка ключа
Если ключа, к которому нужно получить доступ, не оказывается в словаре, вызывается исключение KeyError.
try:
a = {1:'a', 2:'b', 3:'c'}
print(a[4])
except LookupError:
print("Исключение KeyError.")
else:
print("Успех, нет ошибок!")
Исключение KeyError.
Ошибка индекса
Если пытаться получить доступ к индексу (последовательности) списка, которого не существует в этом списке или находится вне его диапазона, будет вызвана ошибка индекса (IndexError: list index out of range python).
try:
a = ['a', 'b', 'c']
print(a[4])
except LookupError:
print("Исключение IndexError, индекс списка вне диапазона.")
else:
print("Успех, нет ошибок!")
Исключение IndexError, индекс списка вне диапазона.
Ошибка памяти (MemoryError)
Как уже упоминалось, ошибка памяти вызывается, когда операции не хватает памяти для выполнения.
Ошибка имени (NameError)
Ошибка имени возникает, когда локальное или глобальное имя не находится.
В следующем примере переменная ans не определена. Результатом будет ошибка NameError.
try:
print(ans)
except NameError:
print("NameError: переменная 'ans' не определена")
else:
print("Успех, нет ошибок!")
NameError: переменная 'ans' не определена
Ошибка выполнения (Runtime Error)
Ошибка «NotImplementedError»
Ошибка выполнения служит базовым классом для ошибки NotImplemented. Абстрактные методы определенного пользователем класса вызывают это исключение, когда производные методы перезаписывают оригинальный.
class BaseClass(object):
"""Опередляем класс"""
def __init__(self):
super(BaseClass, self).__init__()
def do_something(self):
# функция ничего не делает
raise NotImplementedError(self.__class__.__name__ + '.do_something')
class SubClass(BaseClass):
"""Реализует функцию"""
def do_something(self):
# действительно что-то делает
print(self.__class__.__name__ + ' что-то делает!')
SubClass().do_something()
BaseClass().do_something()
SubClass что-то делает!
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
in
14
15 SubClass().do_something()
---> 16 BaseClass().do_something()
in do_something(self)
5 def do_something(self):
6 # функция ничего не делает
----> 7 raise NotImplementedError(self.__class__.__name__ + '.do_something')
8
9 class SubClass(BaseClass):
NotImplementedError: BaseClass.do_something
Ошибка типа (TypeError)
Ошибка типа вызывается при попытке объединить два несовместимых операнда или объекта.
В примере ниже целое число пытаются добавить к строке, что приводит к ошибке типа.
try:
a = 5
b = "PythonRu"
c = a + b
except TypeError:
print('Исключение TypeError')
else:
print('Успех, нет ошибок!')
Исключение TypeError
Ошибка значения (ValueError)
Ошибка значения вызывается, когда встроенная операция или функция получают аргумент с корректным типом, но недопустимым значением.
В этом примере встроенная операция float получат аргумент, представляющий собой последовательность символов (значение), что является недопустимым значением для типа: число с плавающей точкой.
try:
print(float('PythonRu'))
except ValueError:
print('ValueError: не удалось преобразовать строку в float: 'PythonRu'')
else:
print('Успех, нет ошибок!')
ValueError: не удалось преобразовать строку в float: 'PythonRu'
Пользовательские исключения в Python
В Python есть много встроенных исключений для использования в программе. Но иногда нужно создавать собственные со своими сообщениями для конкретных целей.
Это можно сделать, создав новый класс, который будет наследовать из класса Exception в Python.
class UnAcceptedValueError(Exception):
def __init__(self, data):
self.data = data
def __str__(self):
return repr(self.data)
Total_Marks = int(input("Введите общее количество баллов: "))
try:
Num_of_Sections = int(input("Введите количество разделов: "))
if(Num_of_Sections < 1):
raise UnAcceptedValueError("Количество секций не может быть меньше 1")
except UnAcceptedValueError as e:
print("Полученная ошибка:", e.data)
Введите общее количество баллов: 10
Введите количество разделов: 0
Полученная ошибка: Количество секций не может быть меньше 1
В предыдущем примере если ввести что-либо меньше 1, будет вызвано исключение. Многие стандартные исключения имеют собственные исключения, которые вызываются при возникновении проблем в работе их функций.
Недостатки обработки исключений в Python
У использования исключений есть свои побочные эффекты, как, например, то, что программы с блоками try-except работают медленнее, а количество кода возрастает.
Дальше пример, где модуль Python timeit используется для проверки времени исполнения 2 разных инструкций. В stmt1 для обработки ZeroDivisionError используется try-except, а в stmt2 — if. Затем они выполняются 10000 раз с переменной a=0. Суть в том, чтобы показать разницу во времени исполнения инструкций. Так, stmt1 с обработкой исключений занимает больше времени чем stmt2, который просто проверяет значение и не делает ничего, если условие не выполнено.
Поэтому стоит ограничить использование обработки исключений в Python и применять его в редких случаях. Например, когда вы не уверены, что будет вводом: целое или число с плавающей точкой, или не уверены, существует ли файл, который нужно открыть.
import timeit
setup="a=0"
stmt1 = '''
try:
b=10/a
except ZeroDivisionError:
pass'''
stmt2 = '''
if a!=0:
b=10/a'''
print("time=",timeit.timeit(stmt1,setup,number=10000))
print("time=",timeit.timeit(stmt2,setup,number=10000))
time= 0.003897680000136461
time= 0.0002797570000439009
Выводы!
Как вы могли увидеть, обработка исключений помогает прервать типичный поток программы с помощью специального механизма, который делает код более отказоустойчивым.
Обработка исключений — один из основных факторов, который делает код готовым к развертыванию. Это простая концепция, построенная всего на 4 блоках: try выискивает исключения, а except их обрабатывает.
Очень важно поупражняться в их использовании, чтобы сделать свой код более отказоустойчивым.
Перевод публикуется с сокращениями, автор оригинальной статьи David
Amos.
Выявление ошибок называется
дебаггингом, а дебаггер – помогающий понять причину их появления инструмент. Умение находить
и исправлять ошибки в коде – важный навык в работе программиста, не
пренебрегайте им.
IDLE (Integrated Development and Learning Environment) – кроссплатформенная интегрированная среда разработки и обучения для Python, созданная Гвидо ван Россумом.
Используйте окно управления отладкой
Основным интерфейсом отладки в IDLE является специальное окно управления (Debug Control window). Открыть его
можно, выбрав в меню интерактивного окна пункт Debug→Debugger.
Примечание: если отладка отсутствует в строке меню, убедитесь, что интерактивное окно находится
в фокусе.
Всякий раз, когда окно отладки
открыто, интерактивное окно отображает [DEBUG ON].
Обзор окна управления отладкой
Чтобы увидеть работу отладчика, напишем простую
программу без ошибок. Введите в редактор следующий код:
for i in range(1, 4):
j = i * 2
print(f"i is {i} and j is {j}")
Сохраните все, откройте окно отладки и нажмите клавишу F5 –
выполнение не завершилось.
Окно отладки будет выглядеть следующим образом:
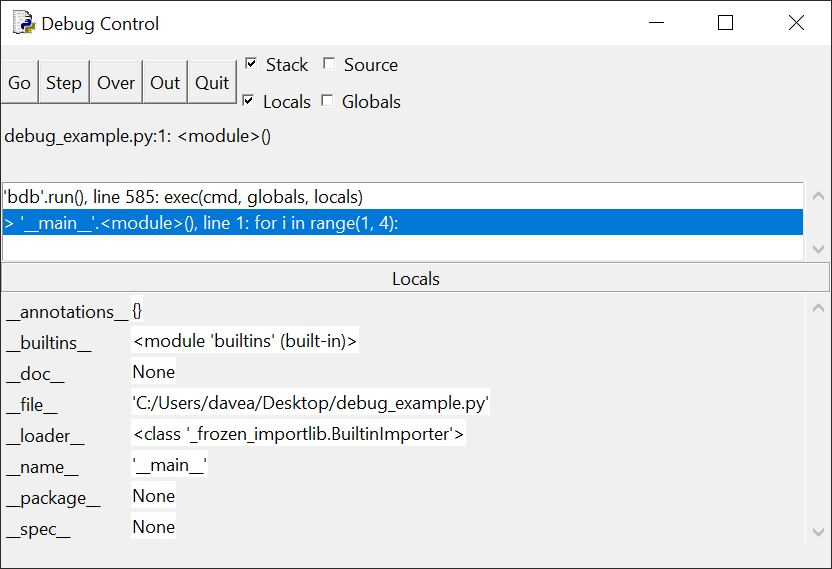
Обратите внимание, что панель в верхней части окна содержит сообщение:
> '__main__'.<module>(), line 1: for i in range(1, 4):
Расшифруем: код for i in range(1, 4): еще не запущен, а '__main__'.module() сообщает, что в данный момент мы находимся в
основном разделе программы, а не в определении функции.
Ниже панели стека находится панель Locals, в которой
перечислены непонятные вещи: __annotations__, __builtins__, __doc__ и т. д. – это
внутренние системные переменные, которые пока можно игнорировать. По мере
выполнения программы переменные, объявленные в коде и отображаемые в этом окне,
помогут в отслеживании их значений.
В левом верхнем углу окна расположены пять кнопок:
Go, Step, Over, Out и Quit – они управляют перемещением отладчика по коду.
В следующих разделах вы узнаете, что делает каждая из
этих кнопок.
Кнопка Step
Нажмите Step и окно отладки будет выглядеть
следующим образом:
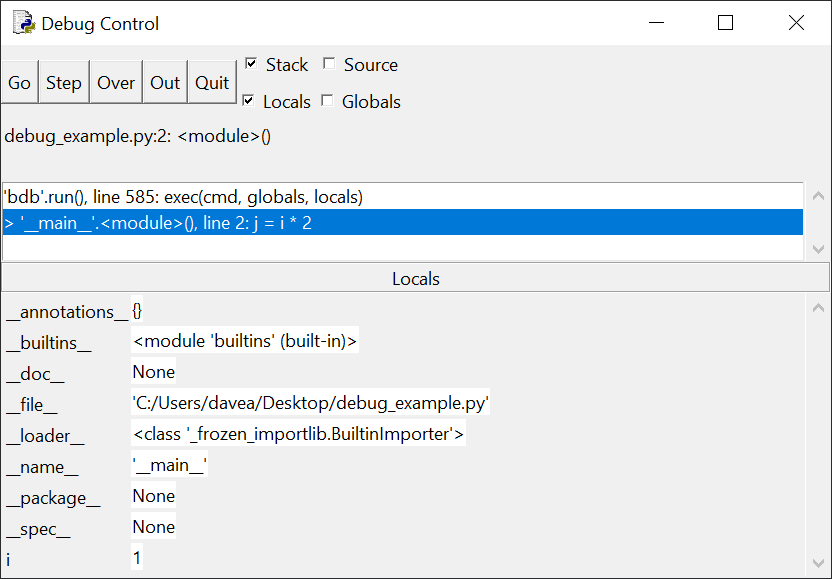
Обратите внимание на два отличия. Во-первых, сообщение на
панели стека изменилось:
> '__main__'.<module>(), line 2: j = i * 2:
На этом этапе выполняется line 1 и отладчик останавливается перед
выполнением line 2.
Во-вторых – новая переменная i со значением 1 на панели Locals. Цикл for в line 1
создал переменную и присвоил ей это значение.
Продолжайте нажимать кнопку Step, чтобы пройтись по коду
строка за строкой, и наблюдайте, что происходит в окне отладчика. Когда
доберетесь до строки print(f"i is {i} and j is {j}"), сможете увидеть
вывод, отображаемый в интерактивном окне по одному фрагменту за раз.
Здесь важно, что можно отслеживать растущие значения i и j по
мере прохождения цикла for. Это полезная фича поиска источника ошибок в коде.
Знание значения каждой переменной в каждой строке кода может помочь точно
определить проблемную зону.
Точки останова и кнопка Go
Часто вам известно, что ошибка должна всплыть в определенном куске
кода, но неизвестно, где именно. Чтобы не нажимать кнопку Step весь
день, установите точку останова, которая скажет отладчику запускать весь код,
пока он ее не достигнет.
Точки останова сообщают отладчику, когда следует
приостановить выполнение кода, чтобы вы могли взглянуть на текущее состояние
программы.
Чтобы установить точку останова, щелкните правой кнопкой мыши
(Ctrl для Mac) по строке кода, на которой хотите сделать паузу, и выберите
пункт Set Breakpoint – IDLE выделит линию желтым. Чтобы удалить ее, выберите Clear
Breakpoint.
Установите точку останова в строке с оператором print(). Окно
редактора должно выглядеть так:
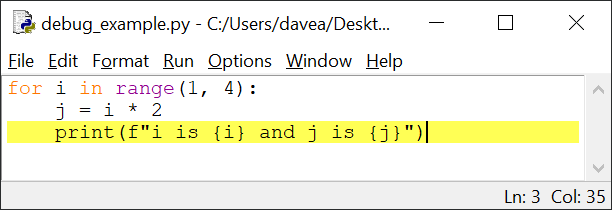
Сохраните и запустите. Как и раньше, панель стека указывает, что отладчик запущен и ожидает выполнения line 1. Нажмите
кнопку Go и посмотрите, что произойдет:
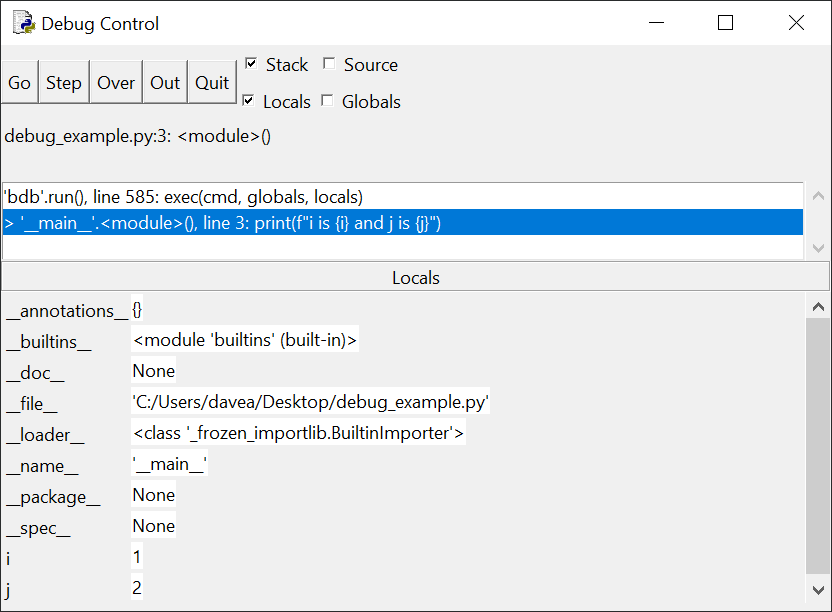
Теперь на панели стека информация о выполнении line 3:
> '__main__'.<module>(), line 3: print(f"i is {i} and j is {j}")
На панели Locals мы видим, что переменные i и j имеют значения 1
и 2 соответственно. Нажмем кнопку Go и попросим отладчик запускать код до точки
останова или до конца программы. Снова нажмите Go – окно отладки теперь выглядит так:
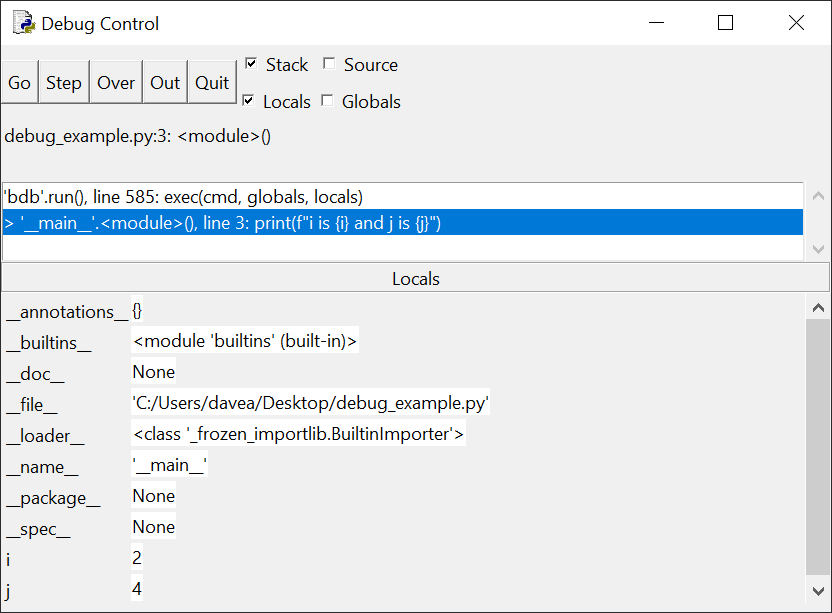
На панели стека отображается то же сообщение, что и раньше –
отладчик ожидает выполнения line 3. Однако значения переменных i и j теперь
равны 2 и 4. Интерактивное окно также отображает выходные данные после первого
запуска строки с помощью функции print() через цикл.
Нажмите кнопку в третий раз. Теперь i и j равны 3 и 6. Если
нажать Go еще раз, программа завершит работу.
Over и Out
Кнопка Over работает, как сочетание Step и Go – она
перешагивает через функцию или цикл. Другими словами, если вы собираетесь попасть
в функцию с помощью отладчика, можно и не запускать код этой функции – кнопка
Over приведет непосредственно к результату ее выполнения.
Аналогично если вы уже находитесь внутри функции или цикла –
кнопка Out выполняет оставшийся код внутри тела функции или цикла, а затем
останавливается.
В следующем разделе мы изучим некоторые ошибки и узнаем, как
их исправить с помощью IDLE.
Борьба с багами
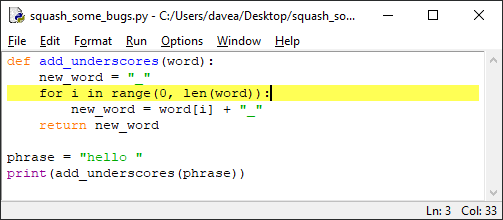
Взглянем на «глючную» программу.
Следующий код определяет функцию add_underscores(), принимающую
в качестве аргумента строковый объект и возвращающую новую строку – копию слова с каждым символом, окруженным подчеркиванием. Например,
add_underscores("python") вернет «_p_y_t_h_o_n_».
Вот неработающий код:
def add_underscores(word):
new_word = "_"
for i in range(len(word)):
new_word = word[i] + "_"
return new_word
phrase = "hello"
print(add_underscores(phrase))
Введите этот код в редактор, сохраните и нажмите F5.
Ожидаемый результат – _h_e_l_l_o_, но вместо этого выведется o_.
Если вы нашли, в чем проблема, не исправляйте ее. Наша цель – научиться
использовать для этого IDLE.
Рассмотрим 4 этапа поиска бага:
- предположите, где может быть ошибка;
- установите точку останова и проверьте код по строке за раз;
- определите строку и внесите изменения;
- повторяйте шаги 1-3, пока код не заработает.
Шаг 1: Предположение
Сначала вы не сможете точно определить местонахождение ошибки,
но обычно проще логически представить, в какой раздел кода смотреть.
Обратите внимание, что программа разделена на два раздела:
определение функции add_underscores() и основной блок, определяющий переменную
со значением «hello» и выводящий результат.
Посмотрим на основной раздел:
phrase = "hello"
print(add_underscores(phrase))
Очевидно, что здесь все хорошо и проблема должна быть в
определении функции:
def add_underscores(word):
new_word = "_"
for i in range(len(word)):
new_word = word[i] + "_"
return new_word
Первая строка создает переменную new_word со значением «_». Промах,
проблема находится где-то в теле цикла for.
Шаг 2: точка останова
Определив, где может быть ошибка, установите точку
останова в начале цикла for, чтобы проследить за происходящим внутри кода:
Запустим. Выполнение останавливается на строке с определением
функции.
Нажмите кнопку Go, чтобы выполнить код до точки останова:
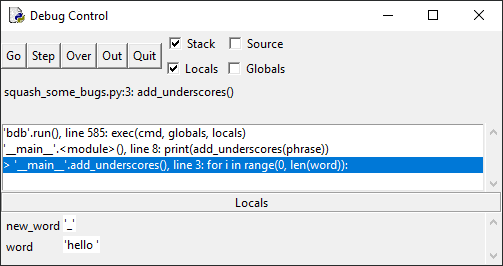
Код останавливается перед циклом for в функции
add_underscores(). Обратите внимание, что на панели Locals отображаются две
локальные переменные – word со значением «hello», и new_word со значением «_»,
Нажмите кнопку Step, чтобы войти в цикл for. Окно отладки
изменится, и новая переменная i со значением 0 отобразится на панели Locals:
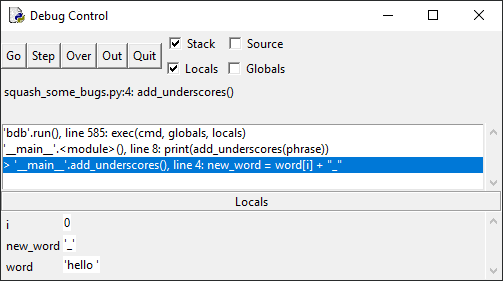
Переменная i – это счетчик для цикла for, который можно
использовать, чтобы отслеживать активную на данный момент итерацию.
Нажмите кнопку Step еще раз и посмотрите на панель Locals –
переменная new_word приняла значение «h_»:
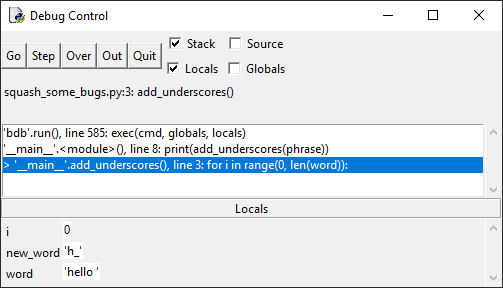
Это неправильно т. к. сначала в new_word было значение «_», на
второй итерации цикла for в ней должно быть «_h_». Если нажать Step еще
несколько раз, то увидим, что в new_word попадает значение e_, затем l_ и так
далее.
Шаг 3: Определение ошибки и исправление
Как мы уже выяснили – на каждой итерации цикла new_word
перезаписывается следующим символом в строке «hello» и подчеркиванием.
Поскольку внутри цикла есть только одна строка кода, проблема должна быть именно
там:
new_word = word[i] + "_"
Код указывает Python получить следующий символ word,
прикрепить подчеркивание и назначить новую строку переменной new_word. Это
именно то неверное поведение, которое мы наблюдали.
Чтобы все починить, нужно объединить word[i] + "_"
с существующим значением new_word. Нажмите кнопку Quit в окне отладки, но не
закрывайте его. Откройте окно редактора и измените строку внутри цикла for на
следующую:
new_word = new_word + word[i] + "_"
Примечание: Если бы вы закрыли
отладчик, не нажав кнопку Quit, при повторном открытии окна отладки могла
появиться ошибка:
You can only toggle the debugger when
idle
Всегда нажимайте кнопку Go или Quit, когда заканчиваете отладку,
иначе могут возникнуть проблемы с ее повторным запуском.
Шаг 4: повторение шагов 1-3, пока ошибка не исчезнет
Сохраните изменения в программе и запустите ее снова. В окне
отладки нажмите кнопку Go, чтобы выполнить код до точки останова. Понажимайте
Step несколько раз и смотрите, что происходит с переменной new_word на каждой
итерации – все работает, как положено. Иногда необходимо повторять этот процесс
несколько раз, прежде чем исправится ошибка.
Альтернативные способы поиска ошибок
Использование отладчика может быть сложным и трудоемким, но
это самый надежный способ найти ошибки в коде. Однако отладчики не всегда есть в наличии. В подобных ситуациях можно использовать print debugging для поиска
ошибок в коде. PD задействует функцию print() для отображения в консоли текста, указывающего место выполнения программы и состояние
переменных.
Например, вместо отладки предыдущего примера можно добавить
следующую строку в конец цикла for:
print(f"i = {i}; new_word = {new_word}")
Измененный код будет выглядеть следующим образом:
def add_underscores(word):
new_word = "_"
for i in range(len(word)):
new_word = word[i] + "_"
print(f"i = {i}; new_word = {new_word}")
return new_word
phrase = "hello"
print(add_underscores(phrase))
Вывод должен выглядеть так:
i = 0; new_word = h_
i = 1; new_word = e_
i = 2; new_word = l_
i = 3; new_word = l_
i = 4; new_word = o_
o_
PD работает, но имеет
несколько недостатков по сравнению с отладкой дебаггером. Вы должны запускать
всю программу каждый раз, когда хотите проверить значения переменных, а также помнить про удаление вызовов функций print().
Один из способов улучшить наш цикл – перебирать символы в
word:
def add_underscores(word):
new_word = "_"
for letter in word:
new_word = new_word + letter + "_"
return new_word
Заключение
Теперь вы знаете все об отладке с помощью DLE.
Вы можете использовать этот принцип с
различными дебагерами.
В статье мы разобрали следующие темы:
- использование окна управления отладкой;
- установку точки останова для глубокого понимания работы кода;
- применение кнопок Step, Go, Over и Out;
- четырехэтапный процессом выявления и удаления ошибок.
Не останавливайтесь в обучении и практикуйте дебаггинг – это
весело!
Дополнительные материалы:
- ТОП-10 книг по Python: эффективно, емко, доходчиво
- Парсинг сайтов на Python: подробный видеокурс и программный код
- Python + Visual Studio Code = успешная разработка
- 29 Python-проектов, оказавших огромное влияние на разработку
- 15 вопросов по Python: как джуниору пройти собеседование
SyntaxError — это ошибка, которая легко может ввести в ступор начинающего программиста. Стоит забыть одну запятую или не там поставить кавычку и Python наотрез откажется запускать программу. Что ещё хуже, по выводу в консоль сложно сообразить в чём дело. Выглядят сообщения страшно и непонятно. Что с этим делать — не ясно. Вот неполный список того, что можно встретить:
SyntaxError: invalid syntaxSyntaxError: EOL while scanning string literalSyntaxError: unexpected EOF while parsing
Эта статья о том, как справиться с синтаксической ошибкой SyntaxError. Дочитайте её до конца и получите безотказный простой алгоритм действий, что поможет вам в трудную минуту — ваш спасательный круг.
Работать будем с программой, которая выводит на экран список учеников. Её код выглядит немного громоздко и, возможно, непривычно. Если не всё написанное вам понятно, то не отчаивайтесь, чтению статьи это не помешает.
students = [
['Егор', 'Кузьмин'],
['Денис', 'Давыдов'],
]
for first_name, last_name in students:
label = 'Имя ученика: {first_name} {last_name}'.format(
first_name = first_name
last_name = last_name
)
print(label)
Ожидается примерно такой результат в консоли:
$ python script.py
Имя ученика: Егор Кузьмин
Имя ученика: Денис Давыдов
Но запуск программы приводит к совсем другому результату. Скрипт сломан:
$ python script.py
File "script.py", line 9
last_name = last_name
^
SyntaxError: invalid syntax
Ошибки в программе бывают разные и каждой нужен свой особый подход. Первым делом внимательно посмотрите на вывод программы в консоль. На последней строчке написано SyntaxError: invalid syntax. Если эти слова вам не знакомы, то обратитесь за переводом к Яндекс.Переводчику:
SyntaxError: недопустимый синтаксис
SyntaxError: неверный синтаксис
Первое слово SyntaxError Яндекс не понял. Помогите ему и разделите слова пробелом:
Syntax Error: invalid syntax
Синтаксическая ошибка: неверный синтаксис
Теория. Синтаксические ошибки
Программирование — это не магия, а Python — не волшебный шар. Он не умеет предсказывать будущее, у него нет доступа к секретным знаниями, это просто автомат, это программа. Узнайте как она работает, как ищет ошибки в коде, и тогда легко найдете эффективный способ отладки. Вся необходимая теория собрана в этом разделе, дочитайте до конца.
SyntaxError — это синтаксическая ошибка. Она случается очень рано, еще до того, как Python запустит программу. Вот что делает компьютер, когда вы запускаете скрипт командой python script.py:
- запускает программу
python pythonсчитывает текст из файлаscript.pypythonпревращает текст программы в инструкцииpythonисполняет инструкции
Синтаксическая ошибка SyntaxError возникает на четвёртом этапе в момент, когда Python разбирает текст программы на понятные ему компоненты. Сложные выражения в коде он разбирает на простейшие инструкции. Вот пример кода и инструкции для него:
person = {'name': 'Евгений'}
Инструкции:
- создать строку
'Евгений' - создать словарь
- в словарь добавить ключ
'name'со значением'Евгений' - присвоить результат переменной
person
SyntaxError случается когда Python не смог разбить сложный код на простые инструкции. Зная это, вы можете вручную разбить код на инструкции, чтобы затем проверить каждую из них по отдельности. Ошибка прячется в одной из инструкций.
1. Найдите поломанное выражение
Этот шаг сэкономит вам кучу сил. Найдите в программе сломанный участок кода. Его вам предстоит разобрать на отдельные инструкции. Посмотрите на вывод программы в консоль:
$ python script.py
File "script.py", line 9
last_name = last_name
^
SyntaxError: invalid syntax
Вторая строчка сообщает: File "script.py", line 9 — ошибка в файле script.py на девятой строчке. Но эта строка является частью более сложного выражения, посмотрите на него целиком:
label = 'Имя ученика: {first_name} {last_name}'.format(
first_name = first_name
last_name = last_name
)
«Девман» — авторская методика обучения программированию. Готовим к работе крутых программистов на Python. Станьте программистом, пройдите продвинутый курс Python.
2. Разбейте выражение на инструкции
В прошлых шагах вы узнали что сломан этот фрагмент кода:
label = 'Имя ученика: {first_name} {last_name}'.format(
first_name = first_name
last_name = last_name
)
Разберите его на инструкции:
- создать строку
'Имя ученика: {first_name} {last_name}' - получить у строки метод
format - вызвать функцию с двумя аргументами
- результат присвоить переменной
label
Так выделил бы инструкции программист, но вот Python сделать так не смог и сломался. Пора выяснить на какой инструкции нашла коса на камень.
Теперь ваша задача переписать код так, чтобы в каждой строке программы исполнялось не более одной инструкции из списка выше. Так вы сможете тестировать их по отдельности и облегчите себе задачу. Так выглядит отделение инструкции по созданию строки:
# 1. создать строку
template = 'Имя ученика: {first_name} {last_name}'
label = template.format(
first_name = first_name
last_name = last_name
)
Сразу запустите код, проверьте что ошибка осталась на прежнему месте. Приступайте ко второй инструкции:
# 1. создать строку
template = 'Имя ученика: {first_name} {last_name}'
# 2. получить у строки метод
format = template.format
label = format(
first_name = first_name
last_name = last_name
)
Строка format = template.format создает новую переменную format и кладёт в неё функцию. Да, да, это не ошибка! Python разрешает класть в переменные всё что угодно, в том числе и функции. Новая переменная переменная format теперь работает как обычная функция, и её можно вызвать: format(...).
Снова запустите код. Ошибка появится внутри format. Под сомнением остались две инструкции:
- вызвать функцию с двумя аргументами
- результат присвоить переменной
label
Скорее всего, Python не распознал вызов функции. Проверьте это, избавьтесь от последней инструкции — от создания переменной label:
# 1. создать строку
template = 'Имя ученика: {first_name} {last_name}'
# 2. получить у строки метод
format = template.format
# 3. вызвать функцию
format(
first_name = first_name
last_name = last_name
)
Запустите код. Ошибка снова там же — внутри format. Выходит, код вызова функции написан с ошибкой, Python не смог его превратить в инструкцию.
3. Проверьте синтаксис вызова функции
Теперь вы знаете что проблема в коде, вызывающем функцию. Можно помедитировать еще немного над кодом программы, пройтись по нему зорким взглядом еще разок в надежде на лучшее. А можно поискать в сети примеры кода для сравнения.
Запросите у Яндекса статьи по фразе “Python синтаксис функции”, а в них поищите код, похожий на вызов format и сравните. Вот одна из первых статей в поисковой выдаче:
- Функции в Python
Уверен, теперь вы нашли ошибку. Победа!
Python выводит трассировку (далее traceback), когда в вашем коде появляется ошибка. Вывод traceback может быть немного пугающим, если вы видите его впервые, или не понимаете, чего от вас хотят. Однако traceback Python содержит много информации, которая может помочь вам определить и исправить причину, из-за которой в вашем коде возникла ошибка.
Содержание статьи
- Traceback — Что это такое и почему оно появляется?
- Как правильно читать трассировку?
- Обзор трассировка Python
- Подробный обзор трассировки в Python
- Обзор основных Traceback исключений в Python
- AttributeError
- ImportError
- IndexError
- KeyError
- NameError
- SyntaxError
- TypeError
- ValueError
- Логирование ошибок из Traceback
- Вывод
Понимание того, какую информацию предоставляет traceback Python является основополагающим критерием того, как стать лучшим Python программистом.
К концу данной статьи вы сможете:
- Понимать, что несет за собой traceback
- Различать основные виды traceback
- Успешно вести журнал traceback, при этом исправить ошибку
Python Traceback — Как правильно читать трассировку?
Traceback (трассировка) — это отчет, который содержит вызовы выполненных функций в вашем коде в определенный момент.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Traceback называют по разному, иногда они упоминаются как трассировка стэка, обратная трассировка, и так далее. В Python используется определение “трассировка”.
Когда ваша программа выдает ошибку, Python выводит текущую трассировку, чтобы подсказать вам, что именно пошло не так. Ниже вы увидите пример, демонстрирующий данную ситуацию:
|
def say_hello(man): print(‘Привет, ‘ + wrong_variable) say_hello(‘Иван’) |
Здесь say_hello() вызывается с параметром man. Однако, в say_hello() это имя переменной не используется. Это связано с тем, что оно написано по другому: wrong_variable в вызове print().
Обратите внимание: в данной статье подразумевается, что вы уже имеете представление об ошибках Python. Если это вам не знакомо, или вы хотите освежить память, можете ознакомиться с нашей статьей: Обработка ошибок в Python
Когда вы запускаете эту программу, вы получите следующую трассировку:
|
Traceback (most recent call last): File «/home/test.py», line 4, in <module> say_hello(‘Иван’) File «/home/test.py», line 2, in say_hello print(‘Привет, ‘ + wrong_variable) NameError: name ‘wrong_variable’ is not defined Process finished with exit code 1 |
Эта выдача из traceback содержит массу информации, которая вам понадобится для определения проблемы. Последняя строка трассировки говорит нам, какой тип ошибки возник, а также дополнительная релевантная информация об ошибке. Предыдущие строки из traceback указывают на код, из-за которого возникла ошибка.
В traceback выше, ошибкой является NameError, она означает, что есть отсылка к какому-то имени (переменной, функции, класса), которое не было определено. В данном случае, ссылаются на имя wrong_variable.
Последняя строка содержит достаточно информации для того, чтобы вы могли решить эту проблему. Поиск переменной wrong_variable, и заменит её атрибутом из функции на man. Однако, скорее всего в реальном случае вы будете иметь дело с более сложным кодом.
Python Traceback — Как правильно понять в чем ошибка?
Трассировка Python содержит массу полезной информации, когда вам нужно определить причину ошибки, возникшей в вашем коде. В данном разделе, мы рассмотрим различные виды traceback, чтобы понять ключевые отличия информации, содержащейся в traceback.
Существует несколько секций для каждой трассировки Python, которые являются крайне важными. Диаграмма ниже описывает несколько частей:

В Python лучше всего читать трассировку снизу вверх.
- Синее поле: последняя строка из traceback — это строка уведомления об ошибке. Синий фрагмент содержит название возникшей ошибки.
- Зеленое поле: после названия ошибки идет описание ошибки. Это описание обычно содержит полезную информацию для понимания причины возникновения ошибки.
- Желтое поле: чуть выше в трассировке содержатся различные вызовы функций. Снизу вверх — от самых последних, до самых первых. Эти вызовы представлены двухстрочными вводами для каждого вызова. Первая строка каждого вызова содержит такую информацию, как название файла, номер строки и название модуля. Все они указывают на то, где может быть найден код.
- Красное подчеркивание: вторая строка этих вызовов содержит непосредственный код, который был выполнен с ошибкой.
Есть ряд отличий между выдачей трассировок, когда вы запускает код в командной строке, и между запуском кода в REPL. Ниже вы можете видеть тот же код из предыдущего раздела, запущенного в REPL и итоговой выдачей трассировки:
|
Python 3.7.4 (default, Jul 16 2019, 07:12:58) [GCC 9.1.0] on linux Type «help», «copyright», «credits» or «license» for more information. >>> >>> >>> def say_hello(man): ... print(‘Привет, ‘ + wrong_variable) ... >>> say_hello(‘Иван’) Traceback (most recent call last): File «<stdin>», line 1, in <module> File «<stdin>», line 2, in say_hello NameError: name ‘wrong_variable’ is not defined |
Обратите внимание на то, что на месте названия файла вы увидите <stdin>. Это логично, так как вы выполнили код через стандартный ввод. Кроме этого, выполненные строки кода не отображаются в traceback.
Важно помнить: если вы привыкли видеть трассировки стэка в других языках программирования, то вы обратите внимание на явное различие с тем, как выглядит traceback в Python. Большая часть других языков программирования выводят ошибку в начале, и затем ведут сверху вниз, от недавних к последним вызовам.
Это уже обсуждалось, но все же: трассировки Python читаются снизу вверх. Это очень помогает, так как трассировка выводится в вашем терминале (или любым другим способом, которым вы читаете трассировку) и заканчивается в конце выдачи, что помогает последовательно структурировать прочтение из traceback и понять в чем ошибка.
Traceback в Python на примерах кода
Изучение отдельно взятой трассировки поможет вам лучше понять и увидеть, какая информация в ней вам дана и как её применить.
Код ниже используется в примерах для иллюстрации информации, данной в трассировке Python:
Мы запустили ниже предоставленный код в качестве примера и покажем какую информацию мы получили от трассировки.
Сохраняем данный код в файле greetings.py
|
def who_to_greet(person): return person if person else input(‘Кого приветствовать? ‘) def greet(someone, greeting=‘Здравствуйте’): print(greeting + ‘, ‘ + who_to_greet(someone)) def greet_many(people): for person in people: try: greet(person) except Exception: print(‘Привет, ‘ + person) |
Функция who_to_greet() принимает значение person и либо возвращает данное значение если оно не пустое, либо запрашивает значение от пользовательского ввода через input().
Далее, greet() берет имя для приветствия из someone, необязательное значение из greeting и вызывает print(). Также с переданным значением из someone вызывается who_to_greet().
Наконец, greet_many() выполнит итерацию по списку людей и вызовет greet(). Если при вызове greet() возникает ошибка, то выводится резервное приветствие print('hi, ' + person).
Этот код написан правильно, так что никаких ошибок быть не может при наличии правильного ввода.
Если вы добавите вызов функции greet() в конце нашего кода (которого сохранили в файл greetings.py) и дадите аргумент который он не ожидает (например, greet('Chad', greting='Хай')), то вы получите следующую трассировку:
|
$ python greetings.py Traceback (most recent call last): File «/home/greetings.py», line 19, in <module> greet(‘Chad’, greting=‘Yo’) TypeError: greet() got an unexpected keyword argument ‘greting’ |
Еще раз, в случае с трассировкой Python, лучше анализировать снизу вверх. Начиная с последней строки трассировки, вы увидите, что ошибкой является TypeError. Сообщения, которые следуют за типом ошибки, дают вам полезную информацию. Трассировка сообщает, что greet() вызван с аргументом, который не ожидался. Неизвестное название аргумента предоставляется в том числе, в нашем случае это greting.
Поднимаясь выше, вы можете видеть строку, которая привела к исключению. В данном случае, это вызов greet(), который мы добавили в конце greetings.py.
Следующая строка дает нам путь к файлу, в котором лежит код, номер строки этого файла, где вы можете найти код, и то, какой в нем модуль. В нашем случае, так как наш код не содержит никаких модулей Python, мы увидим только надпись , означающую, что этот файл является выполняемым.
С другим файлом и другим вводом, вы можете увидеть, что трассировка явно указывает вам на правильное направление, чтобы найти проблему. Следуя этой информации, мы удаляем злополучный вызов greet() в конце greetings.py, и добавляем следующий файл под названием example.py в папку:
|
from greetings import greet greet(1) |
Здесь вы настраиваете еще один файл Python, который импортирует ваш предыдущий модуль greetings.py, и используете его greet(). Вот что произойдете, если вы запустите example.py:
|
$ python example.py Traceback (most recent call last): File «/path/to/example.py», line 3, in <module> greet(1) File «/path/to/greetings.py», line 5, in greet print(greeting + ‘, ‘ + who_to_greet(someone)) TypeError: must be str, not int |
В данном случае снова возникает ошибка TypeError, но на этот раз уведомление об ошибки не очень помогает. Оно говорит о том, что где-то в коде ожидается работа со строкой, но было дано целое число.
Идя выше, вы увидите строку кода, которая выполняется. Затем файл и номер строки кода. На этот раз мы получаем имя функции, которая была выполнена — greet().
Поднимаясь к следующей выполняемой строке кода, мы видим наш проблемный вызов greet(), передающий целое число.
Иногда, после появления ошибки, другой кусок кода берет эту ошибку и также её выдает. В таких случаях, Python выдает все трассировки ошибки в том порядке, в котором они были получены, и все по тому же принципу, заканчивая на самой последней трассировке.
Так как это может сбивать с толку, рассмотрим пример. Добавим вызов greet_many() в конце greetings.py:
|
# greetings.py ... greet_many([‘Chad’, ‘Dan’, 1]) |
Это должно привести к выводу приветствия всем трем людям. Однако, если вы запустите этот код, вы увидите несколько трассировок в выдаче:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
$ python greetings.py Hello, Chad Hello, Dan Traceback (most recent call last): File «greetings.py», line 10, in greet_many greet(person) File «greetings.py», line 5, in greet print(greeting + ‘, ‘ + who_to_greet(someone)) TypeError: must be str, not int During handling of the above exception, another exception occurred: Traceback (most recent call last): File «greetings.py», line 14, in <module> greet_many([‘Chad’, ‘Dan’, 1]) File «greetings.py», line 12, in greet_many print(‘hi, ‘ + person) TypeError: must be str, not int |
Обратите внимание на выделенную строку, начинающуюся с “During handling in the output above”. Между всеми трассировками, вы ее увидите.
Это достаточно ясное уведомление: Пока ваш код пытался обработать предыдущую ошибку, возникла новая.
Обратите внимание: функция отображения предыдущих трассировок была добавлена в Python 3. В Python 2 вы можете получать только трассировку последней ошибки.
Вы могли видеть предыдущую ошибку, когда вызывали greet() с целым числом. Так как мы добавили 1 в список людей для приветствия, мы можем ожидать тот же результат. Однако, функция greet_many() оборачивает вызов greet() и пытается в блоке try и except. На случай, если greet() приведет к ошибке, greet_many() захочет вывести приветствие по-умолчанию.
Соответствующая часть greetings.py повторяется здесь:
|
def greet_many(people): for person in people: try: greet(person) except Exception: print(‘hi, ‘ + person) |
Когда greet() приводит к TypeError из-за неправильного ввода числа, greet_many() обрабатывает эту ошибку и пытается вывести простое приветствие. Здесь код приводит к другой, аналогичной ошибке. Он все еще пытается добавить строку и целое число.
Просмотр всей трассировки может помочь вам увидеть, что стало причиной ошибки. Иногда, когда вы получаете последнюю ошибку с последующей трассировкой, вы можете не увидеть, что пошло не так. В этих случаях, изучение предыдущих ошибок даст лучшее представление о корне проблемы.
Обзор основных Traceback исключений в Python 3
Понимание того, как читаются трассировки Python, когда ваша программа выдает ошибку, может быть очень полезным навыком, однако умение различать отдельные трассировки может заметно ускорить вашу работу.
Рассмотрим основные ошибки, с которыми вы можете сталкиваться, причины их появления и что они значат, а также информацию, которую вы можете найти в их трассировках.
Ошибка AttributeError object has no attribute [Решено]
AttributeError возникает тогда, когда вы пытаетесь получить доступ к атрибуту объекта, который не содержит определенного атрибута. Документация Python определяет, когда эта ошибка возникнет:
Возникает при вызове несуществующего атрибута или присвоение значения несуществующему атрибуту.
Пример ошибки AttributeError:
|
>>> an_int = 1 >>> an_int.an_attribute Traceback (most recent call last): File «<stdin>», line 1, in <module> AttributeError: ‘int’ object has no attribute ‘an_attribute’ |
Строка уведомления об ошибке для AttributeError говорит вам, что определенный тип объекта, в данном случае int, не имеет доступа к атрибуту, в нашем случае an_attribute. Увидев AttributeError в строке уведомления об ошибке, вы можете быстро определить, к какому атрибуту вы пытались получить доступ, и куда перейти, чтобы это исправить.
Большую часть времени, получение этой ошибки определяет, что вы возможно работаете с объектом, тип которого не является ожидаемым:
|
>>> a_list = (1, 2) >>> a_list.append(3) Traceback (most recent call last): File «<stdin>», line 1, in <module> AttributeError: ‘tuple’ object has no attribute ‘append’ |
В примере выше, вы можете ожидать, что a_list будет типом списка, который содержит метод .append(). Когда вы получаете ошибку AttributeError, и видите, что она возникла при попытке вызова .append(), это говорит о том, что вы, возможно, не работаете с типом объекта, который ожидаете.
Часто это происходит тогда, когда вы ожидаете, что объект вернется из вызова функции или метода и будет принадлежать к определенному типу, но вы получаете тип объекта None. В данном случае, строка уведомления об ошибке будет выглядеть так:
AttributeError: ‘NoneType’ object has no attribute ‘append’
Python Ошибка ImportError: No module named [Решено]
ImportError возникает, когда что-то идет не так с оператором import. Вы получите эту ошибку, или ее подкласс ModuleNotFoundError, если модуль, который вы хотите импортировать, не может быть найден, или если вы пытаетесь импортировать что-то, чего не существует во взятом модуле. Документация Python определяет, когда возникает эта ошибка:
Ошибка появляется, когда в операторе импорта возникают проблемы при попытке загрузить модуль. Также вызывается, при конструкции импорта
from listвfrom ... importимеет имя, которое невозможно найти.
Вот пример появления ImportError и ModuleNotFoundError:
|
>>> import asdf Traceback (most recent call last): File «<stdin>», line 1, in <module> ModuleNotFoundError: No module named ‘asdf’ >>> from collections import asdf Traceback (most recent call last): File «<stdin>», line 1, in <module> ImportError: cannot import name ‘asdf’ |
В примере выше, вы можете видеть, что попытка импорта модуля asdf, который не существует, приводит к ModuleNotFoundError. При попытке импорта того, что не существует (в нашем случае — asdf) из модуля, который существует (в нашем случае — collections), приводит к ImportError. Строки сообщения об ошибке трассировок указывают на то, какая вещь не может быть импортирована, в обоих случаях это asdf.
Ошибка IndexError: list index out of range [Решено]
IndexError возникает тогда, когда вы пытаетесь вернуть индекс из последовательности, такой как список или кортеж, и при этом индекс не может быть найден в последовательности. Документация Python определяет, где эта ошибка появляется:
Возникает, когда индекс последовательности находится вне диапазона.
Вот пример, который приводит к IndexError:
|
>>> a_list = [‘a’, ‘b’] >>> a_list[3] Traceback (most recent call last): File «<stdin>», line 1, in <module> IndexError: list index out of range |
Строка сообщения об ошибке для IndexError не дает вам полную информацию. Вы можете видеть, что у вас есть отсылка к последовательности, которая не доступна и то, какой тип последовательности рассматривается, в данном случае это список.
Иными словами, в списке a_list нет значения с ключом
3. Есть только значение с ключами0и1, этоaиbсоответственно.
Эта информация, в сочетании с остальной трассировкой, обычно является исчерпывающей для помощи программисту в быстром решении проблемы.
Возникает ошибка KeyError в Python 3 [Решено]
Как и в случае с IndexError, KeyError возникает, когда вы пытаетесь получить доступ к ключу, который отсутствует в отображении, как правило, это dict. Вы можете рассматривать его как IndexError, но для словарей. Из документации:
Возникает, когда ключ словаря не найден в наборе существующих ключей.
Вот пример появления ошибки KeyError:
|
>>> a_dict = [‘a’: 1, ‘w’: ‘2’] >>> a_dict[‘b’] Traceback (most recent call last): File «<stdin>», line 1, in <module> KeyError: ‘b’ |
Строка уведомления об ошибки KeyError говорит о ключе, который не может быть найден. Этого не то чтобы достаточно, но, если взять остальную часть трассировки, то у вас будет достаточно информации для решения проблемы.
Ошибка NameError: name is not defined в Python [Решено]
NameError возникает, когда вы ссылаетесь на название переменной, модуля, класса, функции, и прочего, которое не определено в вашем коде.
Документация Python дает понять, когда возникает эта ошибка NameError:
Возникает, когда локальное или глобальное название не было найдено.
В коде ниже, greet() берет параметр person. Но в самой функции, этот параметр был назван с ошибкой, persn:
|
>>> def greet(person): ... print(f‘Hello, {persn}’) >>> greet(‘World’) Traceback (most recent call last): File «<stdin>», line 1, in <module> File «<stdin>», line 2, in greet NameError: name ‘persn’ is not defined |
Строка уведомления об ошибке трассировки NameError указывает вам на название, которое мы ищем. В примере выше, это названная с ошибкой переменная или параметр функции, которые были ей переданы.
NameError также возникнет, если берется параметр, который мы назвали неправильно:
|
>>> def greet(persn): ... print(f‘Hello, {person}’) >>> greet(‘World’) Traceback (most recent call last): File «<stdin>», line 1, in <module> File «<stdin>», line 2, in greet NameError: name ‘person’ is not defined |
Здесь все выглядит так, будто вы сделали все правильно. Последняя строка, которая была выполнена, и на которую ссылается трассировка выглядит хорошо.
Если вы окажетесь в такой ситуации, то стоит пройтись по коду и найти, где переменная person была использована и определена. Так вы быстро увидите, что название параметра введено с ошибкой.
Ошибка SyntaxError: invalid syntax в Python [Решено]
Возникает, когда синтаксический анализатор обнаруживает синтаксическую ошибку.
Ниже, проблема заключается в отсутствии двоеточия, которое должно находиться в конце строки определения функции. В REPL Python, эта ошибка синтаксиса возникает сразу после нажатия Enter:
|
>>> def greet(person) File «<stdin>», line 1 def greet(person) ^ SyntaxError: invalid syntax |
Строка уведомления об ошибке SyntaxError говорит вам только, что есть проблема с синтаксисом вашего кода. Просмотр строк выше укажет вам на строку с проблемой. Каретка ^ обычно указывает на проблемное место. В нашем случае, это отсутствие двоеточия в операторе def нашей функции.
Стоит отметить, что в случае с трассировками SyntaxError, привычная первая строка Tracebak (самый последний вызов) отсутствует. Это происходит из-за того, что SyntaxError возникает, когда Python пытается парсить ваш код, но строки фактически не выполняются.
Ошибка TypeError в Python 3 [Решено]
TypeError возникает, когда ваш код пытается сделать что-либо с объектом, который не может этого выполнить, например, попытка добавить строку в целое число, или вызвать len() для объекта, в котором не определена длина.
Ошибка возникает, когда операция или функция применяется к объекту неподходящего типа.
Рассмотрим несколько примеров того, когда возникает TypeError:
|
>>> 1 + ‘1’ Traceback (most recent call last): File «<stdin>», line 1, in <module> TypeError: unsupported operand type(s) for +: ‘int’ and ‘str’ >>> ‘1’ + 1 Traceback (most recent call last): File «<stdin>», line 1, in <module> TypeError: must be str, not int >>> len(1) Traceback (most recent call last): File «<stdin>», line 1, in <module> TypeError: object of type ‘int’ has no len() |
Указанные выше примеры возникновения TypeError приводят к строке уведомления об ошибке с разными сообщениями. Каждое из них весьма точно информирует вас о том, что пошло не так.
В первых двух примерах мы пытаемся внести строки и целые числа вместе. Однако, они немного отличаются:
- В первом примере мы пытаемся добавить
strкint. - Во втором примере мы пытаемся добавить
intкstr.
Уведомления об ошибке указывают на эти различия.
Последний пример пытается вызвать len() для int. Сообщение об ошибке говорит нам, что мы не можем сделать это с int.
Возникла ошибка ValueError в Python 3 [Решено]
ValueError возникает тогда, когда значение объекта не является корректным. Мы можем рассматривать это как IndexError, которая возникает из-за того, что значение индекса находится вне рамок последовательности, только ValueError является более обобщенным случаем.
Возникает, когда операция или функция получает аргумент, который имеет правильный тип, но неправильное значение, и ситуация не описывается более детальной ошибкой, такой как IndexError.
Вот два примера возникновения ошибки ValueError:
|
>>> a, b, c = [1, 2] Traceback (most recent call last): File «<stdin>», line 1, in <module> ValueError: not enough values to unpack (expected 3, got 2) >>> a, b = [1, 2, 3] Traceback (most recent call last): File «<stdin>», line 1, in <module> ValueError: too many values to unpack (expected 2) |
Строка уведомления об ошибке ValueError в данных примерах говорит нам в точности, в чем заключается проблема со значениями:
- В первом примере, мы пытаемся распаковать слишком много значений. Строка уведомления об ошибке даже говорит нам, где именно ожидается распаковка трех значений, но получаются только два.
- Во втором примере, проблема в том, что мы получаем слишком много значений, при этом получаем недостаточно значений для распаковки.
Логирование ошибок из Traceback в Python 3
Получение ошибки, и ее итоговой трассировки указывает на то, что вам нужно предпринять для решения проблемы. Обычно, отладка кода — это первый шаг, но иногда проблема заключается в неожиданном, или некорректном вводе. Хотя важно предусматривать такие ситуации, иногда есть смысл скрывать или игнорировать ошибку путем логирования traceback.
Рассмотрим жизненный пример кода, в котором нужно заглушить трассировки Python. В этом примере используется библиотека requests.
Файл urlcaller.py:
|
import sys import requests response = requests.get(sys.argv[1]) print(response.status_code, response.content) |
Этот код работает исправно. Когда вы запускаете этот скрипт, задавая ему URL в качестве аргумента командной строки, он откроет данный URL, и затем выведет HTTP статус кода и содержимое страницы (content) из response. Это работает даже в случае, если ответом является статус ошибки HTTP:
|
$ python urlcaller.py https://httpbin.org/status/200 200 b» $ python urlcaller.py https://httpbin.org/status/500 500 b» |
Однако, иногда данный URL не существует (ошибка 404 — страница не найдена), или сервер не работает. В таких случаях, этот скрипт приводит к ошибке ConnectionError и выводит трассировку:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
$ python urlcaller.py http://thisurlprobablydoesntexist.com ... During handling of the above exception, another exception occurred: Traceback (most recent call last): File «urlcaller.py», line 5, in <module> response = requests.get(sys.argv[1]) File «/path/to/requests/api.py», line 75, in get return request(‘get’, url, params=params, **kwargs) File «/path/to/requests/api.py», line 60, in request return session.request(method=method, url=url, **kwargs) File «/path/to/requests/sessions.py», line 533, in request resp = self.send(prep, **send_kwargs) File «/path/to/requests/sessions.py», line 646, in send r = adapter.send(request, **kwargs) File «/path/to/requests/adapters.py», line 516, in send raise ConnectionError(e, request=request) requests.exceptions.ConnectionError: HTTPConnectionPool(host=‘thisurlprobablydoesntexist.com’, port=80): Max retries exceeded with url: / (Caused by NewConnectionError(‘<urllib3.connection.HTTPConnection object at 0x7faf9d671860>: Failed to establish a new connection: [Errno -2] Name or service not known’,)) |
Трассировка Python в данном случае может быть очень длинной, и включать в себя множество других ошибок, которые в итоге приводят к ошибке ConnectionError. Если вы перейдете к трассировке последних ошибок, вы заметите, что все проблемы в коде начались на пятой строке файла urlcaller.py.
Если вы обернёте неправильную строку в блоке try и except, вы сможете найти нужную ошибку, которая позволит вашему скрипту работать с большим числом вводов:
Файл urlcaller.py:
|
try: response = requests.get(sys.argv[1]) except requests.exceptions.ConnectionError: print(—1, ‘Connection Error’) else: print(response.status_code, response.content) |
Код выше использует предложение else с блоком except.
Теперь, когда вы запускаете скрипт на URL, который приводит к ошибке ConnectionError, вы получите -1 в статусе кода и содержимое ошибки подключения:
|
$ python urlcaller.py http://thisurlprobablydoesntexist.com —1 Connection Error |
Это работает отлично. Однако, в более реалистичных системах, вам не захочется просто игнорировать ошибку и итоговую трассировку, вам скорее понадобиться внести в журнал. Ведение журнала трассировок позволит вам лучше понять, что идет не так в ваших программах.
Обратите внимание: Для более лучшего представления о системе логирования в Python вы можете ознакомиться с данным руководством тут: Логирование в Python
Вы можете вести журнал трассировки в скрипте, импортировав пакет logging, получить logger, вызвать .exception() для этого логгера в куске except блока try и except. Конечный скрипт будет выглядеть примерно так:
|
# urlcaller.py import logging import sys import requests logger = logging.getLogger(__name__) try: response = requests.get(sys.argv[1]) except requests.exceptions.ConnectionError as e: logger.exception() print(—1, ‘Connection Error’) else: print(response.status_code, response.content) |
Теперь, когда вы запускаете скрипт с проблемным URL, он будет выводить исключенные -1 и ConnectionError, но также будет вести журнал трассировки:
|
$ python urlcaller.py http://thisurlprobablydoesntexist.com ... File «/path/to/requests/adapters.py», line 516, in send raise ConnectionError(e, request=request) requests.exceptions.ConnectionError: HTTPConnectionPool(host=‘thisurlprobablydoesntexist.com’, port=80): Max retries exceeded with url: / (Caused by NewConnectionError(‘<urllib3.connection.HTTPConnection object at 0x7faf9d671860>: Failed to establish a new connection: [Errno -2] Name or service not known’,)) —1 Connection Error |
По умолчанию, Python будет выводить ошибки в стандартный stderr. Выглядит так, будто мы совсем не подавили вывод трассировки. Однако, если вы выполните еще один вызов при перенаправлении stderr, вы увидите, что система ведения журналов работает, и мы можем изучать логи программы без необходимости личного присутствия во время появления ошибок:
|
$ python urlcaller.py http://thisurlprobablydoesntexist.com 2> my—logs.log —1 Connection Error |
Подведем итоги данного обучающего материала
Трассировка Python содержит замечательную информацию, которая может помочь вам понять, что идет не так с вашим кодом Python. Эти трассировки могут выглядеть немного запутанно, но как только вы поймете что к чему, и увидите, что они в себе несут, они могут быть предельно полезными. Изучив несколько трассировок, строку за строкой, вы получите лучшее представление о предоставляемой информации.
Понимание содержимого трассировки Python, когда вы запускаете ваш код может быть ключом к улучшению вашего кода. Это способ, которым Python пытается вам помочь.
Теперь, когда вы знаете как читать трассировку Python, вы можете выиграть от изучения ряда инструментов и техник для диагностики проблемы, о которой вам сообщает трассировка. Модуль traceback может быть полезным, если вам нужно узнать больше из выдачи трассировки.
- Текст является переводом статьи: Understanding the Python Traceback
- Изображение из шапки статьи принадлежит сайту © Real Python

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»