
ыЙТПЛБС ØàÞÚÐï ╒┌тр╪ф╪┌ПрЎ.ТруНЬ_аЭШЩ ФРбв ЬЮ!…
Нет, мы не сошли с ума. Просто сегодня будем разбираться, как устранить ошибки кодировки и вернуть на сайт читаемый текст. Узнаем, как кодировка влияет на SEO-оптимизацию, и познакомимся с полезными сервисами, которые позволят вовремя идентифицировать ошибки.
Что такое кодировка, и когда возникают ошибки с отображением текста
Если вместо нормального текста на вашем сайте отображается странный набор символов, значит, есть проблемы с кодировкой. Впрочем, иногда кодировка на сайте является стандартизированной и выбрана корректно, но вместо текста все равно отображаются иероглифы.
Кодировка – это набор символов и система их передачи для последующего вывода на экран. Кроме алфавита при помощи кодировки передаются также специальные символы и цифры.
Сегодня массово используются 2 вида кодировки: Windows-1251 и UTF-8. Чаще всего «кракозябра» появляется, когда на одном сайте используется сразу несколько видов кодировки (да, такое бывает чаще, чем может показаться на первый взгляд).
Можно выделить и другие причины неполадок:
- Используется устаревший браузер.
- В браузере / программе установлена одна кодировка, на сайте – другая. В таком случае нужно поменять кодировку в программе.
- В БД и других файлах сайта указаны несовпадающие кодировки. В этом случае нужно выбрать одну кодировку для всего сайта.

Как поменять кодировку в браузере
Проблему с кодировкой на стороне браузера исправить легко.
Internet Explorer
- Открываем проблемную веб-страницу.
- Вызываем контекстное меню, кликнув правой кнопкой мыши по любому месту на странице.
- Выбираем «Кодировка».
- Кликаем Unicode (UTF-8).
Chrome
Chrome современный и модный браузер, но вот кодировку стандартными средствами поменять в нем нельзя (сюрприз!). Будем делать это через расширение.
- Открываем магазин Chrome.
- Кликаем «Расширения» в левой части экрана.
- Указываем слово «кодировка».
- Устанавливаем любое подходящее расширение.
Safari
- Выбираем пункт «Вид».
- Кликаем по разделу «Кодировка текста».
- Выбраем вариант Unicode (UTF-8).
Firefox
- Выбираем пункт «Вид».
- Кликаем по раздел «Кодировка текста».
- Нужно выбрать вариант Unicode (UTF-8).
Как выбрать кодировку
Если в качестве CMS вы используете WordPress, Joomla, Drupal, OpenCart или TYPO3, то дополнительно настраивать ничего не нужно. Эти движки по умолчанию работает именно с UTF-8. Все должно работать из коробки. Просто убедитесь, что везде прописана UTF-8.
В самых сложных случаях придется отдельно скачивать шаблоны под конкретную кодировку, предварительно создав MySQL. Последнее актуально, например, для DLE. Если же ваш cайт полностью самописный, просто проследите за тем, чтобы везде была установлена идентичная кодировка, желательно – UTF-8.
Какую кодировку выбрать
Сегодня большинство экспертов солидарны в том, что наиболее удобной кодировкой является UTF-8. Этот стандарт поддерживает большинство браузеров, баз данных, серверов и языков. Еще одно преимущество – она изначально была кроссплатформенной.
UTF-8 может закодировать любой unicode-символ. Пожалуй, именно это достоинство позволило кодировке стать одной из самых популярных в мире.
Windows-1251 известна в меньшей степени, но Windows-1251 и не отличается такой универсальностью и распространенностью как UTF-8. Проблемы с кодировкой могут встречаться на всех сайтах, даже на отлаженных площадках, которые работают в течение многих лет. Чтобы предотвратить проблемы с «кракозябрами» на своем сайте в будущем, необходимо с самого начала выбирать единую кодировку. Как вы уже догадались, лучший кандидат на эту роль – UTF-8.
Как узнать, какая кодировка используется на моем сайте
Узнать, какая кодировка используется на всем сайте или на конкретной странице, можно за несколько секунд. Для этого нужно просмотреть исходник HTML-страницы. Чтобы увидеть его, используем одновременное нажатие горячих клавиш Сtrl + U (на «Маке» активируем шорткатом Option/Alt + Command + U). Появится такое окно:

Теперь используем сочетание горячих клавиш Ctrl + F (Command + F) – откроется окно поиска. Вводим в поисковую строку атрибут charset (он же character set, кодировка документа). После этого атрибута мы увидим знак равенства. За ним и будет указана кодировка страницы.

Если атрибут charset не задан, его придется задать. Предварительно нужно проверить сайт при помощи сторонних сервисов. Один из них – Browserstack. Платформа платная, но, чтобы проверить кодировку, платить необязательно. Достаточно открыть сайт и выбрать пункт Get started free, создать аккаунт (можно просто залогиниться при помощи «Google-аккаунта»). После авторизации появится такое окно:

Выбираем интересующую нас операционную систему / устройство и вводим сайт, который нужно протестировать:

Если с кодировкой на сайте что-то не так, все ошибки будут представлены в результатах теста.
Для проверки и определения ошибок кодировки можно использовать не только Browserstack. Альтернатива – бесплатный сервис Validator. Он позволит идентифицировать кодировку сразу по нескольким данным, включая заголовки. Пример ошибки кодировки в результатах анализа Validator:

Также неплохие возможности для проверки технических ошибок сайта дает pr-cy.ru. Не забудьте выбрать пункт «Аудит страниц»:

Хорошие инструменты для проверки кодировки предоставляют сервисы NetPeak и SeoFrog. Последний удобен еще тем, что позволяет проверить кодировку сразу по всем страницам сайта, а не только по одной.
Кодировка и оптимизация
Даже если кодировка на сайте не совсем обычная или отличается на разных страницах, Google и «Яндекс» все равно проиндексируют такой сайт, но при условии, что контент уникален и не переспамлен ключами. Одна из самых неприятных ошибок здесь – несовместимость кодировки веб-ресурса с той, которая используется на сервере. Даже в таком случае Google, например, способен корректно идентифицировать ошибку. Сайт будет в выдаче, если соответствующие условия были соблюдены.
Ошибки кодировки сами по себе не влияют на оптимизацию сайта прямым образом. Они сказываются на отказах и времени, проведенном на сайте, а также на иных поведенческих показателях аудитории.
Если на вашем сайте возникают ошибки кодировки, и контент отображается некорректно, то посетитель ни при каких обстоятельствах не будет тратить свое время, пытаясь настроить правильную кодировку и, тем более, пытаться ее преобразовать в читаемую. Большинство посетителей просто не знают, как это сделать, но даже если знают, не будут тратить время и точно уйдут к конкурентам на тот сайт, где содержимое изначально отображается корректно.
Устранить проблемы кодировки сложно: мало поменять ее на одной или нескольких страницах. Обычно приходится исправлять ее также в мете (одноименных тегах), БД MySQL, файле htaccess и других системных файлах сайта.
Как исправить ошибки кодировки на своем сайте
Инструкция предназначена только для опытных пользователей и не является призывом к действию. Код и настройки я привожу исключительно в качестве примера. Если вы решитесь вносить изменения в БД и системные файлы, особенно в root, обязательно сделайте резервную копию всех данных сайта!
Документы / HTML-файлы
Если возникают проблемы с документами, необходимо удостовериться в том, что они имеют одинаковую кодировку, и в том, что она вообще задана. Для этого открываем HTML-файл при помощи любого редактора, который позволяет работать с кодом. Например, через Notepad++. Открываем проблемный документ и выполняем следующую последовательность действий:

Htaccess
«Кракозябра» может появляться даже в тех случаях, когда ошибки в документах уже исправлены. В таком случае нужно проверить файл htaccess. Открываем его при помощи редактора кода, затем, используя одновременное сочетание горячих клавиш Ctrl + F, открываем окно «Поиск по странице» и вводим уже знакомый нам атрибут Charset. Если атрибут найден, его необходимо исправить на тот, который является стандартным для вашего сайта. Если его нет вообще, добавляем атрибут AddDefaultCharset UTF-8 в любом месте в самом начале документа.
Теги типа meta
Именно мета-тег используется для установки требуемой кодировки. Кроме этого, в нем прописываются и другие мета-теги, которые задействованы для хранения информации, используемой браузерами. Прописываются теги типа meta в head-разделе. Выглядит следующим образом:
<!DOCTYPE HTML>
<html>
<head>
<title>Тег META</title>
<meta charset="utf-8">
</head>
<body>
<p>...</p>
</body>
</html>
Этот код приводится в качестве примера. Не исключено появление ошибок.
Базы данных
Если «кракозябры» при открытии страниц так и не исчезают, придется проверять MySQL. Нас интересуют значения, прописанные в таблицах баз данных. Чтобы устранить эту проблему, необходимо подключиться к серверу через mysql root. Для этого выполняем следующие шаги:

Так мы приведем кодировку БД к единому стандарту UTF-8.
Онлайн-декодеры
Онлайн-декодеры и другие инструменты с аналогичным функционалом позволяют преобразовать «кракозябру» в читаемый текст. Foxtools – приятный и удобный декодер, который работает в автоматическом режиме. У Foxtools вообще много полезных инструментов:

2cyr – еще более функциональный инструмент, который не только преобразует «кракозябры» в читаемый текст, но и выводит множество возможных вариантов. Бывает и такое, что все варианты «расшифровки» являются некорректными:

Итоги
Чтобы вовремя идентифицировать проблемы с кодировкой на своем сайте, используйте перечисленные выше инструменты. Не забывайте и об онлайн-декодерах: они эффективно расшифровывают нечитаемый текст в случаях, когда необходимо быстро преобразовать «кракозябру». Помните, что иероглифы на сайте недопустимы, и устранять такие ошибки нужно как можно скорее. В противном случае ухудшатся поведенческие факторы, и сайт может навсегда выпасть из поисковой выдачи.
Всех приветствую на портале WiFiGiD.RU. Сегодня мы рассмотрим еще одну достаточно популярную проблему, когда в Windows вместо букв отображаются кракозябры, иероглифы, знаки вопроса и какие-то непонятные символы. Проблема встречается на всех версиях Windows 10, 11, 7 и 8, и решается она одинаково. Причем кракозябры могут быть как в отдельных программах (например, в блокноте или Word) или системных окнах (в проводнике, компьютере или панели управления). В статье я расскажу вам, как можно исправить кодировку и вернуть все на свои места.
Содержание
- Способ 1: Изменение системного языка
- Способ 2: Изменение кодовой таблицы
- Способ 3: Подмена файлов
- Способ 4: Дополнительные советы
- Задать вопрос автору статьи
Способ 1: Изменение системного языка
Итак, у нас вместо русских букв отображаются знаки вопроса или другие непонятные символы в Windows – давайте разбираться вместе. После установки английской или любой другой версии, есть вероятность, что язык, который установлен в системе, установился неправильно. Второй вариант – когда региональные стандарты языка были сбиты или установлены не так как нужно. Давайте это исправим.
- Зажимаем на клавиатуре две клавиши:
+ R
- Теперь используем команду:
control
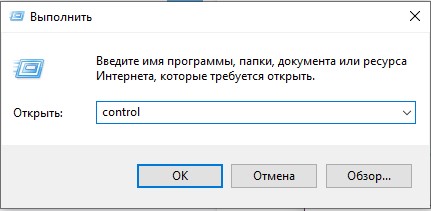
- В панели управления найдите пункт «Региональные стандарты» – ориентируйтесь на значок. Если вы видите, что пунктов не так много как у меня, измените режим «Просмотра».
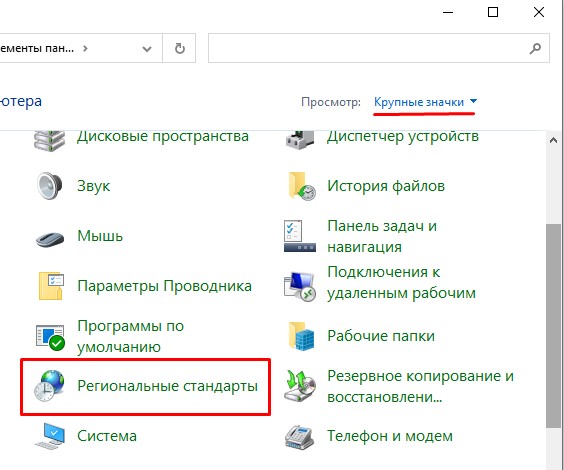
- На второй вкладке нажмите по кнопке «Изменить язык…».
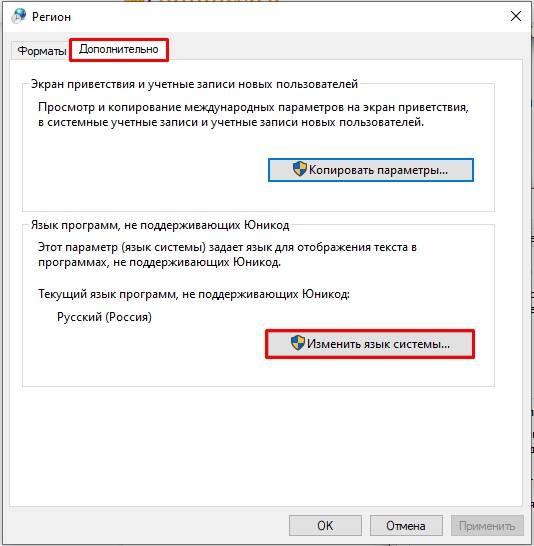
- Сначала в первом пункте установите «Русский» язык. Ниже есть настройка использования Юникода (UTF-8). Если эта галочка стоит, значит попробуйте её убрать. Если эта конфигурация, наоборот, выключена – активируйте. Нажмите «ОК».
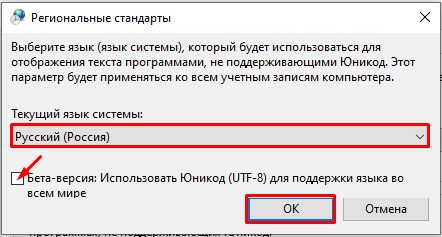
- Вас попросят перезагрузиться – сделайте это.
Способ 2: Изменение кодовой таблицы
Смотрите, каждому символу кириллицы соответствует свое отображение. Также у каждого такого символа есть специальный байтовый код. Чтобы все это работало нормально, для каждого символа и байта есть таблица соответствия. Если таблица выбрана неправильно, код байта будет показывать иероглифы – вопросительные знаки или еще какие кракозябры.
Мы просто подставим для нашей кириллицы правильную таблицу отображения символов, и после этого проблема должна решиться. Мы будем использовать редактор реестра. Сам способ не должен поломать систему, но перед этим я настоятельно рекомендую создать точку восстановления (на всякий случай!).
Читаем – как создать точку восстановления.
После этого переходим к описанным ниже шагам:
- Используем наши любимые волшебные кнопки:
+ R
- Вводим команду:
regedit
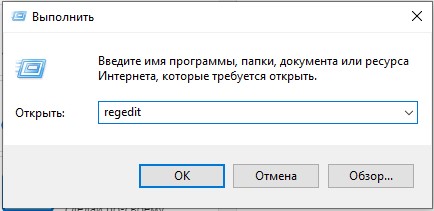
- Можете скопировать путь, который я укажу ниже, и вставить в адресную строку. Или просто пройтись по папкам и разделам вручную.
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsCodePage
- В правом блоке, где находится список файлов с конфигурациями, в самом низу найдите:
ACP
- Именно этот файл отвечает за настройку соответствия таблицы символов. Два раза кликните левой кнопкой мыши и установите значение:
1251
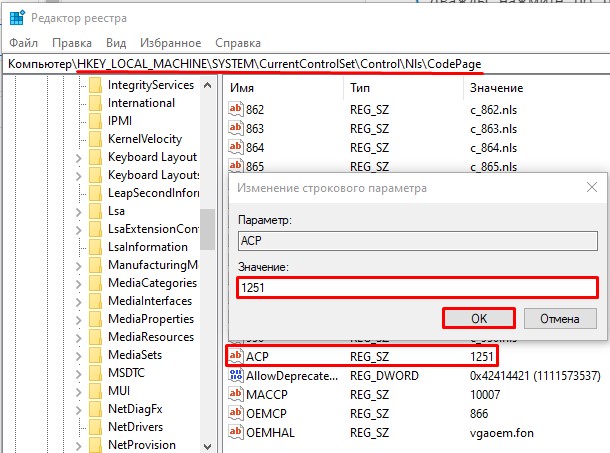
- Нажмите «ОК», закройте окно редактора реестра и перезагрузите компьютер.
Способ 3: Подмена файлов
Третий способ чуть сложнее, мы просто возьмем файл, который используется для английского языка и подменим его на русский. Я все же рекомендую использовать прошлый вариант с реестром (он все же проще). Но, на всякий пожарный, опишу и этот способ.
- Откройте проводник и пройдите по пути:
C:/Windows/System32
- Найдите файл:
C_1252.NLS
- Он используется для английского языка. Через правую кнопку заходим в «Свойства».
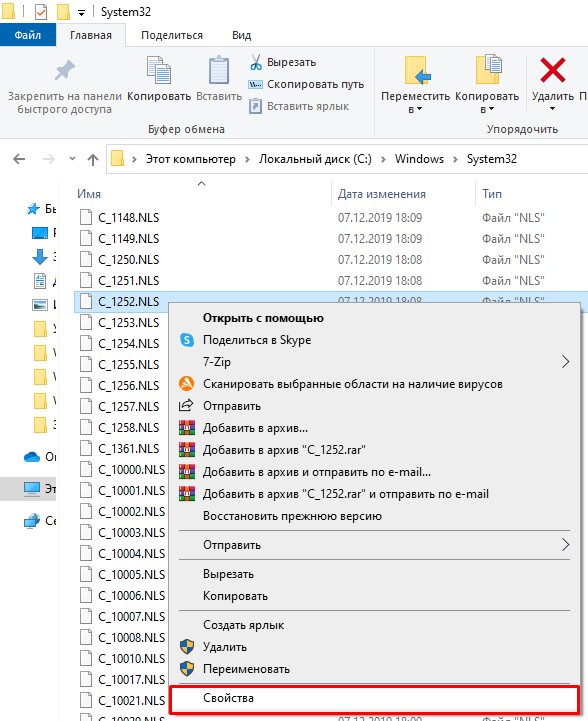
- Во вкладке «Безопасность» выбираем кнопку «Дополнительно». Нам нужно дать вам полные права. В противном случае вы ничего с этим файлом не сделаете.
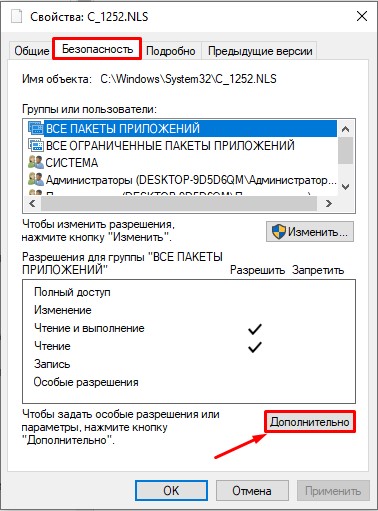
- В строке «Владелец» жмем по ссылке «Изменить».
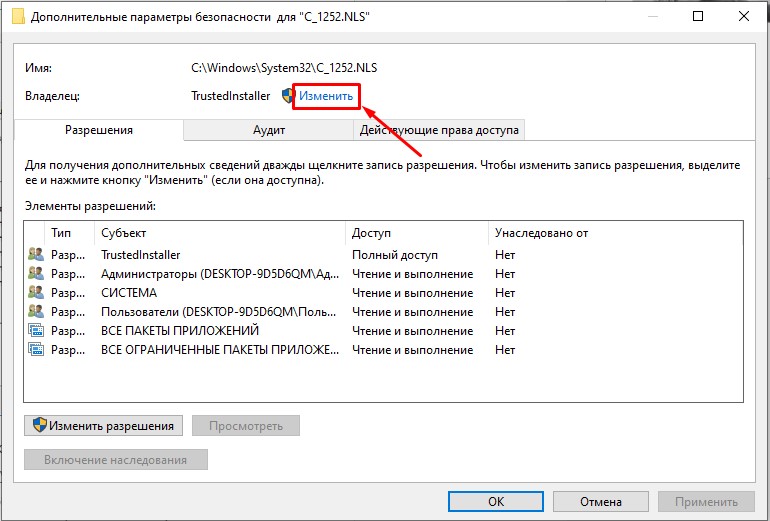
- «Дополнительно».
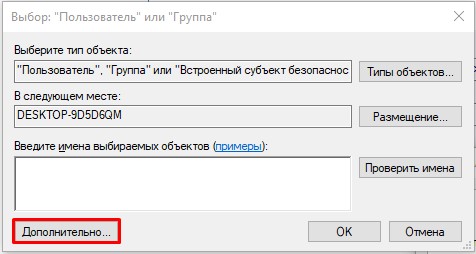
- Нажмите «Поиск». Ниже в списке кликните по той учетной записи, через которую вы сейчас сидите. Если у вас авторизация через учётку Microsoft, то указываем почту. Как только пользователь будет выбран, жмем «ОК».
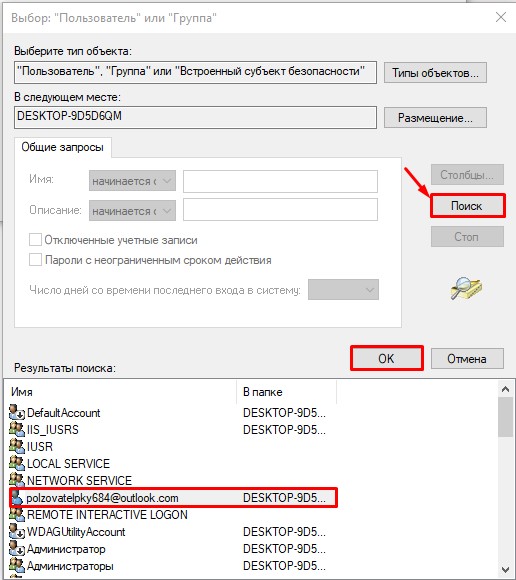
- В этом и следующем окне жмем на кнопку «ОК», чтобы применить параметры.
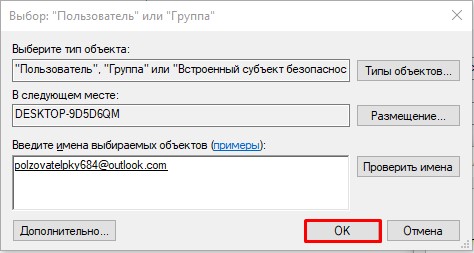
- В окне «Свойства» нажмите «Изменить».
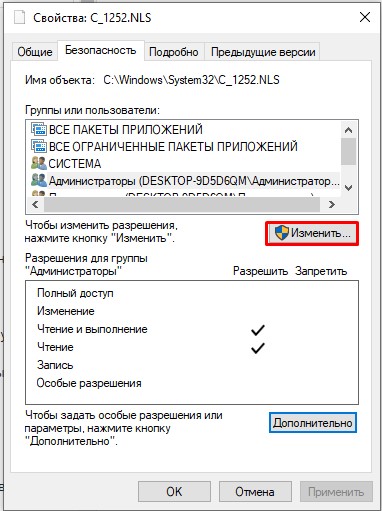
- Выберите «Администраторов» и установите «Полный доступ». Применяем настройки и закрываем оба окошка.
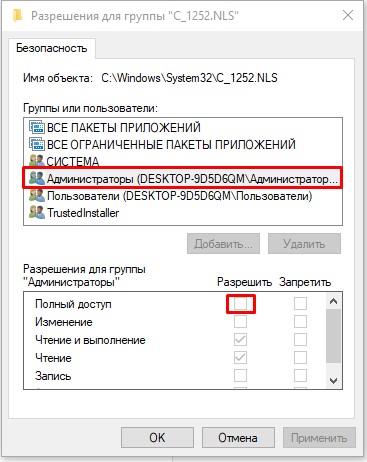
- Теперь установите другой формат для файла (через ПКМ и команду «Переименовать»):
c_1252.NLS
- Например:
c_1252.txt
- На клавиатуре, зажмите Ctrl и, не отпуская, перетащите в любое место в папке файл:
c_1251.NLS
- Мы создали копию файла. Теперь оригинал NLS переименуйте в:
c_1252.NLS
- Перезагрузите систему.
В случае чего у вас есть оригинал c_1251.NLS и сам файл c_1252, у которого мы изменили формат.
Способ 4: Дополнительные советы
Если вы видите иероглифы вместо русских букв в Windows 10, 11, 7 или 8, то есть вероятность, что произошла более серьезная поломка в системных файлах. Поэтому вот ряд советов:
- Если вы делали какие-то глобальные обновления в ОС, то попробуйте выполнить откат системы до самой ранней точки восстановления.
- Если вы устанавливали какую-то кривую и стороннюю сборку Windows, то советую выполнить установку оригинальной версии «Окон».
- Проверьте системные файлы на наличие ошибок.
- Можно попробовать выполнить чистку системы.
На этом все, дорогие друзья. Пишите свои вопросы в комментариях. Всем добра и берегите себя.
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.

Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
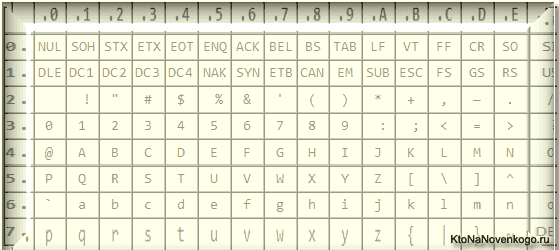
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
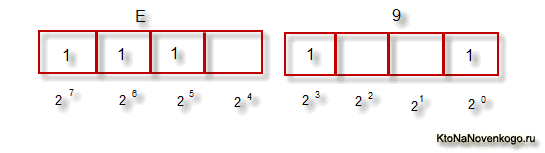
Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII.
Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика):

Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:

Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
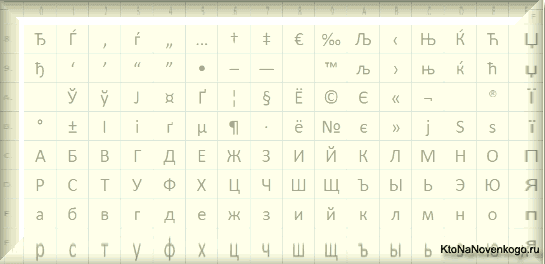
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.

Аналогичная ситуация очень часто возникает при создании сайтов на WordPress и Joomla, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
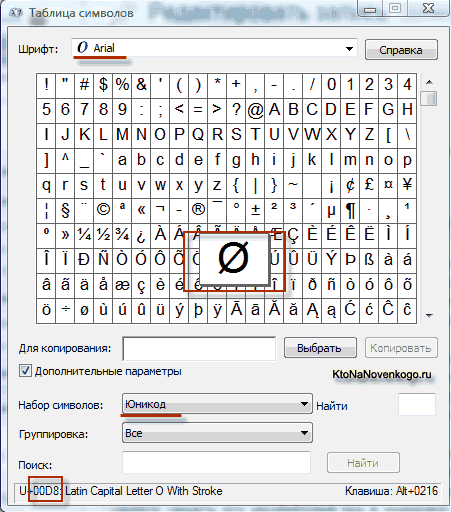
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
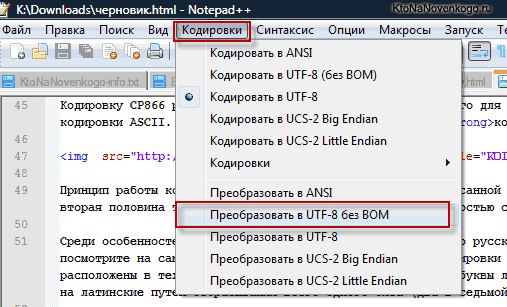
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
![]()
Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.
![]()
Автор:
Обновлено: 09.10.2022
Когда человек работает с программой «MS Word», у него редко возникает потребность вникать в нюансы кодировки. Но как только появляется необходимость поделиться документом с коллегами, существует вероятность того, что отправленный пользователем файл может просто-напросто не быть прочитан получателем. Это случается из-за несовпадения настроек, а конкретно кодировок в разных версиях программы.

Автор:
Обновлено: 09.10.2022
Когда человек работает с программой «MS Word», у него редко возникает потребность вникать в нюансы кодировки. Но как только появляется необходимость поделиться документом с коллегами, существует вероятность того, что отправленный пользователем файл может просто-напросто не быть прочитан получателем. Это случается из-за несовпадения настроек, а конкретно кодировок в разных версиях программы.
Как поменять кодировку в Word
Содержание
- Что представляет собой кодировка и от чего она зависит?
- Изменение кодировки текста в «Word 2013»
- Первый способ изменения кодировки в «Word»
- Второй способ изменения кодировки в «Word»
- Изменение кодировки в программе «Notepad ++»
- Корректировка кодировки веб-страниц
- Как поменять кодировку в «Mozilla Firefox»
- Установка кодировки в интерфейсе Блокнота
- Видео — Как изменить кодировку в Word
Что представляет собой кодировка и от чего она зависит?
Для каждого региона кодировка может в значительной степени разниться. Для понимания кодировки необходимо знать то, что информация в текстовом документе сохраняется в виде некоторых числовых значений. Персональный компьютер самостоятельно преобразует числа в текст, используя при этом алгоритм отдельно взятой кодировки. Для стран СНГ используется кодировка файлов с названием «Кириллица», а для других регионов, таких как Западная Европа, применяется «Западноевропейская (Windows)». Если текстовый документ был сохранен в кодировке кириллицы, а открыт с использованием западноевропейского формата, то символы будут отображаться совершенно неправильно, представляя собой бессмысленный набор знаков.

При открытии документа, сохраненного одним типом кодировки, в другом формате кодировки невозможно будет прочитать
Во избежание недоразумений и облегчения работы разработчики внедрили специальную единую кодировку для всех алфавитов – «Юникод». Этот общепринятый стандарт кодировки содержит в себе практически все знаки большинства письменных языков нашей планеты. К тому же он преобладает в интернете, где так необходима подобная унификация для охвата большего количества пользователей и удовлетворения их потребностей.

Тип кодировок, которые используются, как стандартные для всех языков
«Word 2013» работает как раз на основе Юникода, что позволяет обмениваться текстовыми файлами без применения сторонних программ и исправления кодировок в настройках. Но нередко пользователи сталкиваются с ситуацией, когда при открытии вроде бы простого файла вместо текста отображаются только знаки. В таком случае программа «Word» неправильно определила существующую первоначальную кодировку текста.
Справка! Некоторые кодировки применяются к определенным языкам. Для японского языка специально была разработана кодировка «Shift JIS», для корейского – «EUC-KR», а для китайского «ISO-2022» и «EUC».
Изменение кодировки текста в «Word 2013»
Первый способ изменения кодировки в «Word»
Для исправления текстового документа, которому была неправильно определена изначальная кодировка, необходимо:
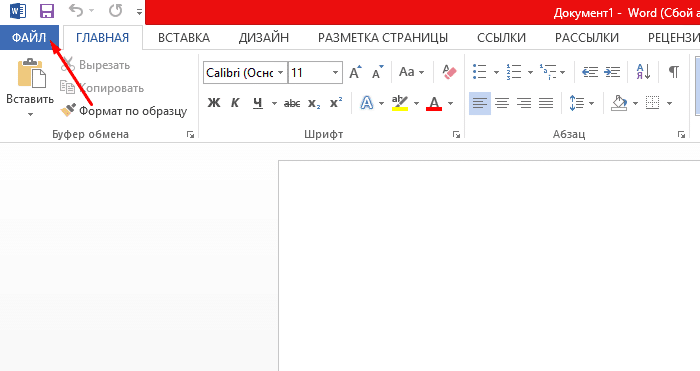
Шаг 1. Запустить текстовый документ и открыть вкладку «Файл».

Открываем вкладку «Файл»
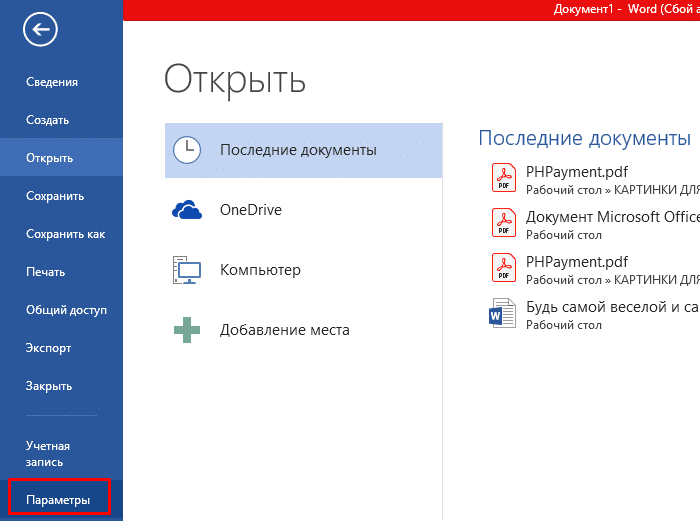
Шаг 2. Перейти в меню настроек «Параметры».

Переходим в меню настроек «Параметры»
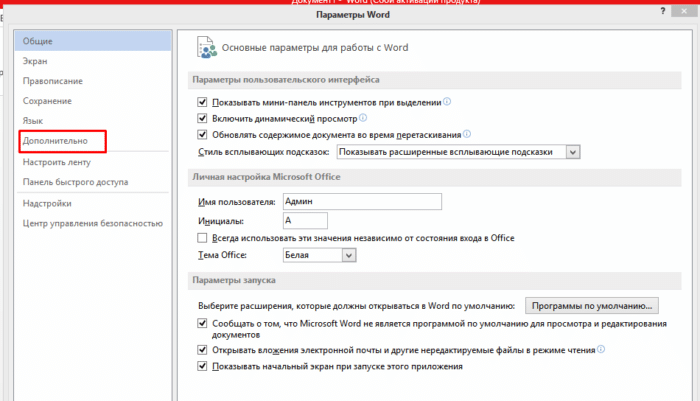
Шаг 3. Выбрать пункт «Дополнительно» и перейти к разделу «Общие».

Выбираем пункт «Дополнительно»

Прокрутив список вниз, переходим к разделу «Общие»
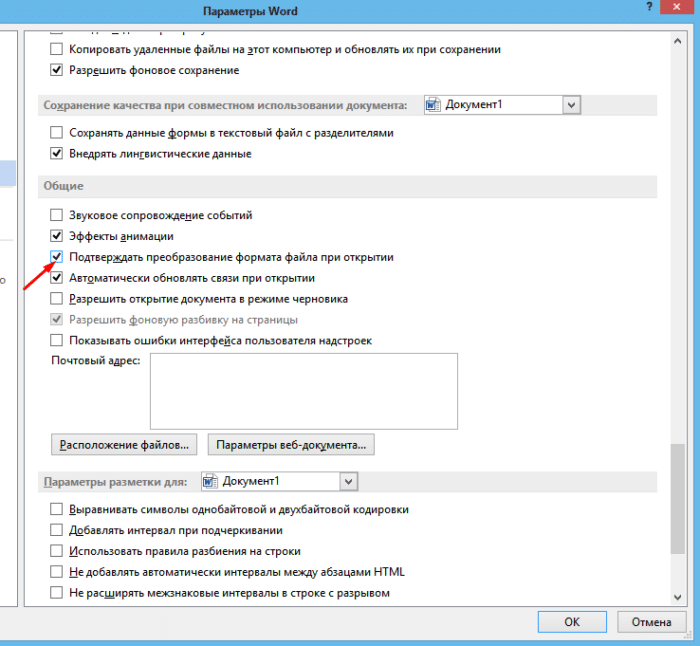
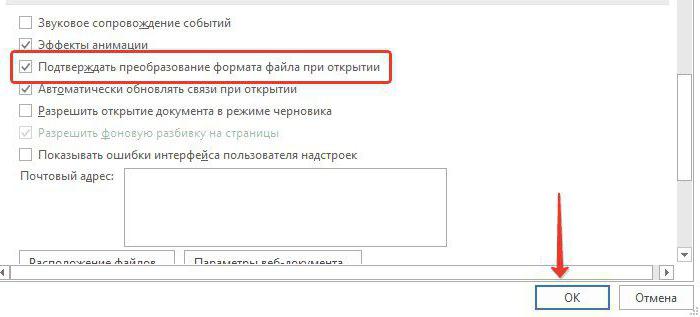
Шаг 4. Активируем нажатием по соответствующей области настройку в графе «Подтверждать преобразование формата файла при открытии».

Отмечаем галочкой графу «Подтверждать преобразование формата файла при открытии», нажимаем «ОК»
Шаг 5. Сохраняем изменения и закрываем текстовый документ.
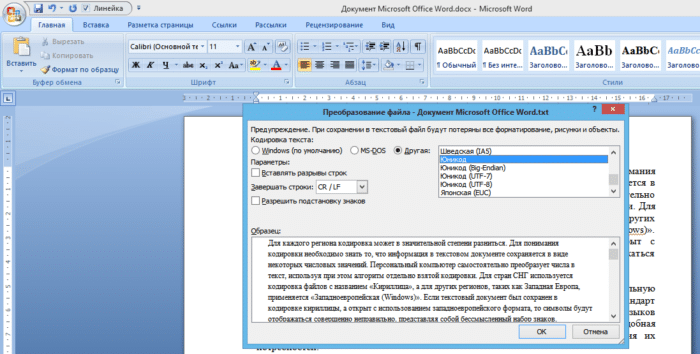
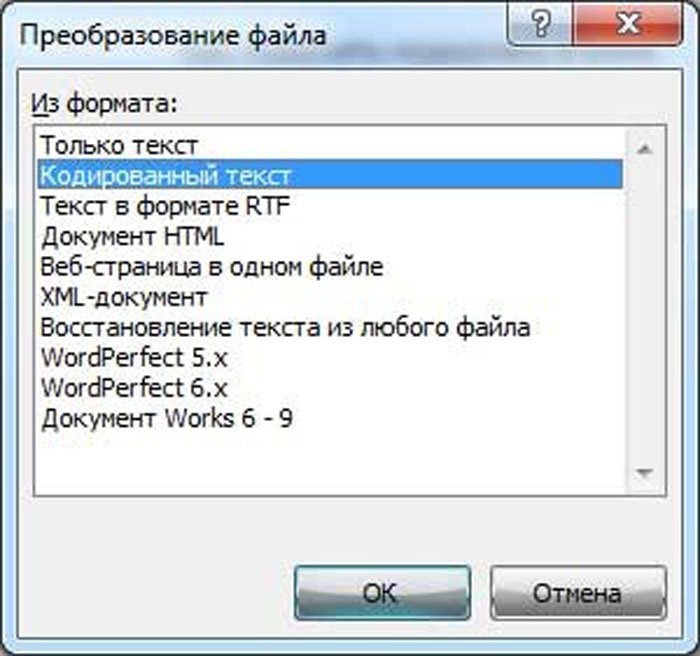
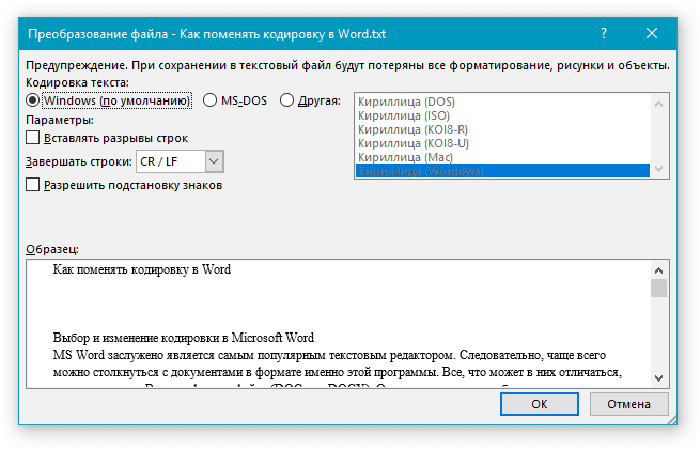
Шаг 6. Повторно запускаем необходимый файл. Перед пользователем появится окно «Преобразование файла», в котором необходимо выбрать пункт «Кодированный текст», и сохранить изменения нажатием «ОК».

Выбираем пункт «Кодированный текст», сохраняем изменения нажатием «ОК»
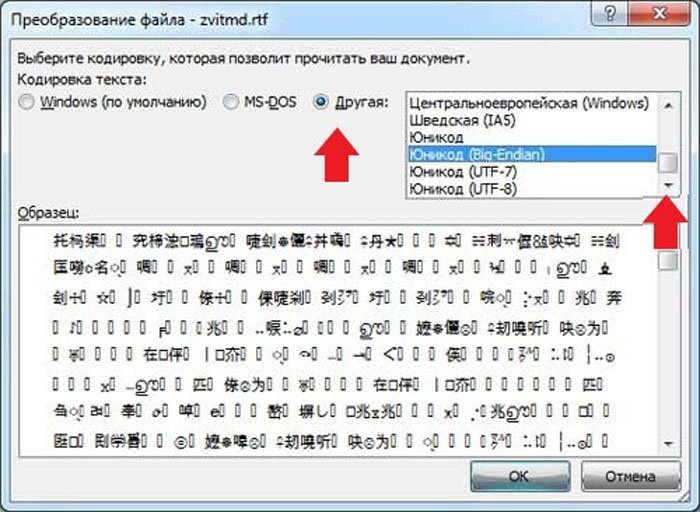
Шаг 7. Всплывет еще одна область, в которой необходимо выбрать пункт кодировки «Другая» и выбрать в списке подходящую. Поле «Образец» поможет пользователю подобрать необходимую кодировку, отображаемую изменения в тексте. После выбора подходящей сохраняем изменения кнопкой «ОК».

Отмечаем пункт кодировки «Другая», выбираем в списке подходящую, нажимаем «ОК»
Второй способ изменения кодировки в «Word»
- Производим запуск файла, кодировку текста которого необходимо произвести.
- Переходим во вкладку «Файл».

Открываем вкладку «Файл»
- Кликаем «Сохранить как».

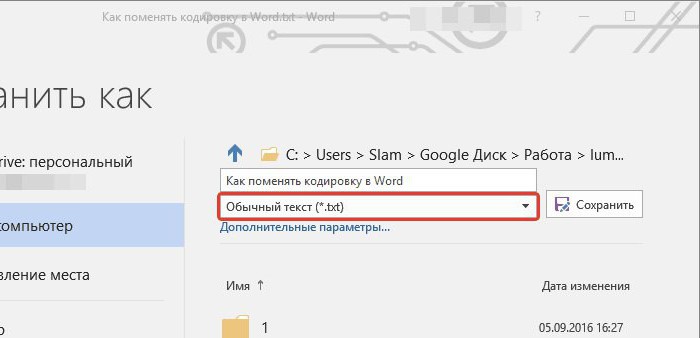
Кликаем «Сохранить как»
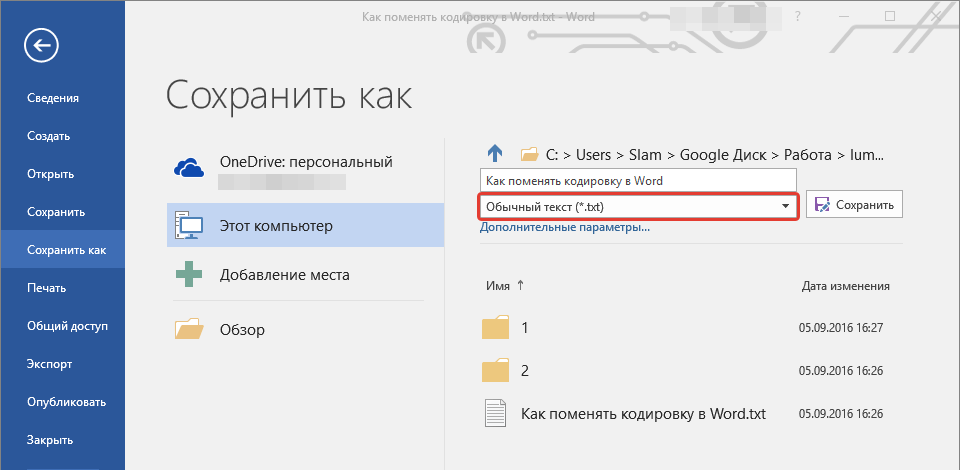
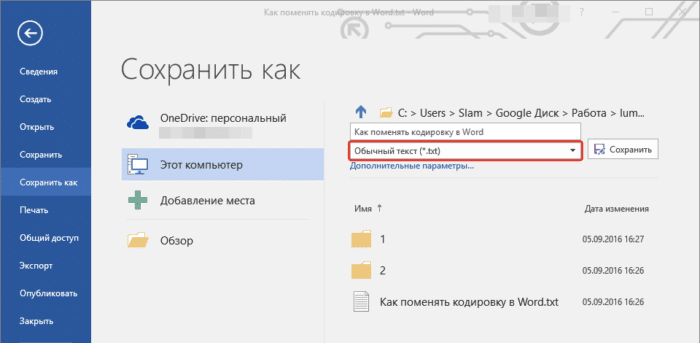
- В области «Тип файла» необходимо выбрать «Обычный текст» и нажать «Сохранить».

В области «Тип файла» выбираем «Обычный текст», нажимаем «Сохранить»
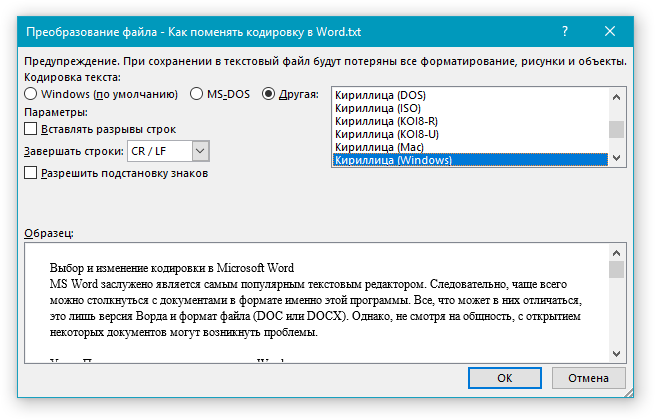
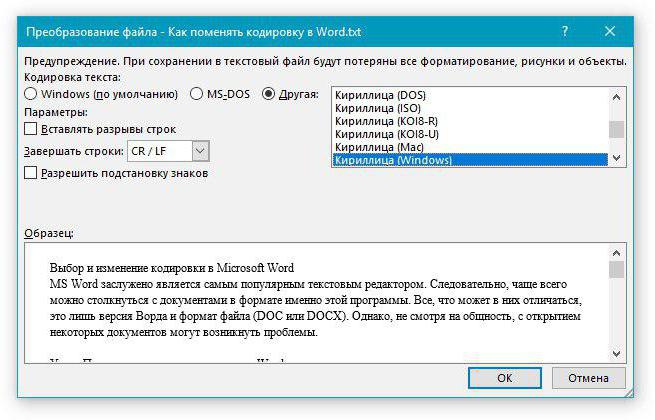
- В появившемся «Преобразование файла» выбираем кодировку «Другая» и в списке активируем нужную.

Отмечаем опцию «Другая», в списке активируем нужную, нажимаем «ОК»



Читайте полезную информацию, как работать в ворде
для чайников, в новой статье на нашем портале.
Изменение кодировки в программе «Notepad ++»
Подобное приложение используется многими программистами для создания сайтов, различных приложений и многого другого. Поэтому очень важно сохранять и создавать файлы, используя необходимую кодировку. Для того, чтобы настроить нужный вариант для пользователя, следует:
Шаг 1. Запустить программу и в верхнем контекстном меню выбрать вкладку «Кодировки».

Выбираем вкладку «Кодировки»
Шаг 2. В выпадающем списке пользователю требуется выбрать из списка необходимую для него кодировку и щелкнуть на нее.

Выбираем из списка необходимую кодировку, щелкаем на ней
Шаг 3. Правильность проведения процедуры легко проверить, обратив внимание на нижнюю панель программы, которая будет отображать только что измененную кодировку.

В нижней панели программы можно увидеть измененную кодировку
Важно! Перед началом работы в «Notepad ++» в первую очередь рекомендуется проверить установленную кодировку. При необходимости ее нужно изменить при помощи инструкции, приведенной ранее.
Корректировка кодировки веб-страниц
Кодировка символов – неотъемлемая часть работы браузеров для серфинга в интернете. Поэтому каждому из пользователей просто необходимо уметь ее настраивать. Чтобы быстро изменить кодировку «Google Chrome», необходимо будет установить дополнительное расширение, так как разработчики убрали возможность изменения данного параметра.
Для того, чтобы сменить кодировку на необходимую, нужно:
- Запустить браузер.
- Перейти по ссылке chrome://extensions/.

В адресную строку вводим указанный адрес, нажимаем «Enter»
- Затем кликнуть в левом верхнем углу по опции «Расширения».

Нажимаем по опции «Расширения» в левом верхнем углу страницы
- Внизу найти и открыть интернет-магазин браузера Хром.

В левом нижнем углу щелкаем по ссылке «Открыть Интернет-магазин Chrome»
- В поиске найти расширение и установить «Set Character Encoding», нажать «Enter».

В поле для поиска вводим Set Character Encodin, нажимаем «Enter»
- Рядом с приложением нажать «Установить».

Нажимаем по кнопке «Установить»
- Для того, чтобы с легкостью поменять значение кодировки, необходимо убедится в работоспособности расширения, после чего на любом сайте на пустой области правой кнопкой мыши вызвать контекстное меню. В нем следует перейти в «Set Character Encoding» и выбрать необходимое значение.

На пустой области нажимаем правой кнопкой мышки, левой кнопкой по пункту «Set Character Encoding», выбираем необходимое значение






Как поменять кодировку в «Mozilla Firefox»
Для этого пользователю потребуется:
Шаг 1. Запустить браузер и открыть меню, нажав по иконке трех линий левой клавишей мыши в правом верхнем углу страницы.

Нажимаем по иконке из трех линий в правом верхнем углу
Шаг 2. В контекстном меню запустить «Настройки».

Открываем «Настройки»
Шаг 3. Перейти во вкладку «Содержимое».

Переходим во вкладку «Содержимое»
Шаг 4. В разделе «Шрифты и цвета» нажать на блок «Дополнительные».

В разделе «Шрифты и цвета» нажимаем по блоку «Дополнительно»
Шаг 5. Перед пользователем отобразится специальная панель, на которой будет указана использующаяся кодировка. Для ее изменения потребуется нажать на название кодировки и выбрать нужную.

Нажимаем на название кодировки

Выбираем подходящую кодировку, нажимаем «ОК»
Установка кодировки в интерфейсе Блокнота
Тем юзерам, кому необходимо пользоваться стандартным приложением «Блокнот» ![]() , будет полезно знать о том, что изменить кодировку можно следующим образом:
, будет полезно знать о том, что изменить кодировку можно следующим образом:
- Открыть текстовый документ и повторно сохранить его, нажав «Файл» и затем «Сохранить как».

Нажимаем по вкладке «Файл», затем по опции «Сохранить как»
- В появившемся окне помимо директории следует выбрать и кодировку, найдя необходимый формат, нажать «Сохранить».

В параметре «Кодировка» выбираем подходящий формат, нажимаем «Сохранить»


После этого без труда можно открывать необходимый текст в нужной кодировке.
Благодаря правильно подобранной и установленной кодировке пользователь может избежать неприятностей при отправке файла другим юзерам. Все, что для этого требуется, – это выставлять перед началом работы необходимое значение.
Видео — Как изменить кодировку в Word
Рекомендуем похожие статьи
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
-
Общие сведения о кодировке текста
-
Выбор кодировки при открытии файла
-
Выбор кодировки при сохранении файла
-
Поиск кодировок, доступных в Word
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
К началу страницы
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
-
Откройте вкладку Файл.
-
Нажмите кнопку Параметры.
-
Нажмите кнопку Дополнительно.
-
Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
-
Закройте, а затем снова откройте файл.
-
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
-
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
-
Нажмите кнопку Пуск и выберите пункт Панель управления.
-
Выполните одно из указанных ниже действий.
В Windows 7
-
На панели управления выберите раздел Удаление программы.
-
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
-
На панели управления выберите раздел Удаление программы.
-
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows XP
-
На панели управления щелкните элемент Установка и удаление программ.
-
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
-
-
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
-
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
-
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
К началу страницы
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
-
Откройте вкладку Файл.
-
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
-
В поле Имя файла введите имя нового файла.
-
В поле Тип файла выберите Обычный текст.
-
Нажмите кнопку Сохранить.
-
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
-
В диалоговом окне Преобразование файла выберите подходящую кодировку.
-
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
-
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
-
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
-
-
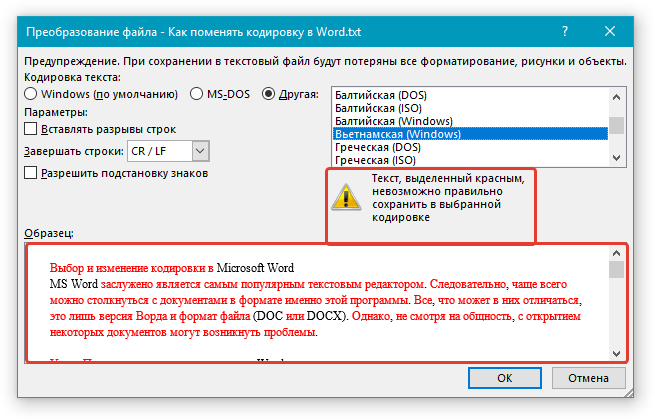
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
-
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
К началу страницы
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
|
Система письменности |
Кодировки |
Используемый шрифт |
|---|---|---|
|
Многоязычная |
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7) |
Стандартный шрифт для стиля «Обычный» локализованной версии Word |
|
Арабская |
Windows 1256, ASMO 708 |
Courier New |
|
Китайская (упрощенное письмо) |
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ |
SimSun |
|
Китайская (традиционное письмо) |
BIG5, EUC-TW, ISO-2022-TW |
MingLiU |
|
Кириллица |
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866 |
Courier New |
|
Английская, западноевропейская и другие, основанные на латинице |
Windows 1250, 1252-1254, 1257, ISO8859-x |
Courier New |
|
Греческая |
Windows 1253 |
Courier New |
|
Иврит |
Windows 1255 |
Courier New |
|
Японская |
Shift-JIS, ISO-2022-JP (JIS), EUC-JP |
MS Mincho |
|
Корейская |
Wansung, Johab, ISO-2022-KR, EUC-KR |
Malgun Gothic |
|
Тайская |
Windows 874 |
Tahoma |
|
Вьетнамская |
Windows 1258 |
Courier New |
|
Индийские: тамильская |
ISCII 57004 |
Latha |
|
Индийские: непальская |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: конкани |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: хинди |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: ассамская |
ISCII 57006 |
|
|
Индийские: бенгальская |
ISCII 57003 |
|
|
Индийские: гуджарати |
ISCII 57010 |
|
|
Индийские: каннада |
ISCII 57008 |
|
|
Индийские: малаялам |
ISCII 57009 |
|
|
Индийские: ория |
ISCII 57007 |
|
|
Индийские: маратхи |
ISCII 57002 (деванагари) |
|
|
Индийские: панджаби |
ISCII 57011 |
|
|
Индийские: санскрит |
ISCII 57002 (деванагари) |
|
|
Индийские: телугу |
ISCII 57005 |
-
Для использования индийских языков необходима их поддержка в операционной системе и наличие соответствующих шрифтов OpenType.
-
Для непальского, ассамского, бенгальского, гуджарати, малаялам и ория доступна только ограниченная поддержка.
К началу страницы
Содержание
- Что такое кодировка
- Выбор кодировки при открытии файла
- Выбор кодировки при сохранении файла
- Вопросы и ответы

MS Word заслужено является самым популярным текстовым редактором. Следовательно, чаще всего можно столкнуться с документами в формате именно этой программы. Все, что может в них отличаться, это лишь версия Ворда и формат файла (DOC или DOCX). Однако, не смотря на общность, с открытием некоторых документов могут возникнуть проблемы.
Урок: Почему не открывается документ Word
Одно дело, если вордовский файл не открывается вовсе или запускается в режиме ограниченной функциональности, и совсем другое, когда он открывается, но большинство, а то и все символы в документе являются нечитабельными. То есть, вместо привычной и понятной кириллицы или латиницы, отображаются какие-то непонятные знаки (квадраты, точки, вопросительные знаки).
Урок: Как убрать режим ограниченной функциональности в Ворде
Если и вы столкнулись с аналогичной проблемой, вероятнее всего, виною тому неправильная кодировка файла, точнее, его текстового содержимого. В этой статье мы расскажем о том, как изменить кодировку текста в Word, тем самым сделав его пригодным для чтения. К слову, изменение кодировки может понадобиться еще и для того, чтобы сделать документ нечитабельным или, так сказать, чтобы “конвертировать” кодировку для дальнейшего использования текстового содержимого документа Ворд в других программах.
Примечание: Общепринятые стандарты кодировки текста в разных странах могут отличаться. Вполне возможно, что документ, созданный, к примеру, пользователем, проживающим в Азии, и сохраненный в местной кодировке, не будет корректно отображаться у пользователя в России, использующего на ПК и в Word стандартную кириллицу.
Что такое кодировка
Вся информация, которая отображается на экране компьютера в текстовом виде, на самом деле хранится в файле Ворд в виде числовых значений. Эти значения преобразовываются программой в отображаемые знаки, для чего и используется кодировка.
Кодировка — схема нумерации, в которой каждому текстовому символу из набора соответствует числовое значение. Сама же кодировка может содержать буквы, цифры, а также другие знаки и символы. Отдельно стоит сказать о том, что в разных языках довольно часто используются различные наборы символов, именно поэтому многие кодировки предназначены исключительно для отображения символов конкретных языков.
Выбор кодировки при открытии файла
Если текстовое содержимое файла отображается некорректно, например, с квадратами, вопросительными знаками и другими символами, значит, MS Word не удалось определить его кодировку. Для устранения этой проблемы необходимо указать правильную (подходящую) кодировку для декодирования (отображения) текста.
1. Откройте меню “Файл” (кнопка “MS Office” ранее).
2. Откройте раздел “Параметры” и выберите в нем пункт “Дополнительно”.
3. Прокрутите содержимое окна вниз, пока не найдете раздел “Общие”. Установите галочку напротив пункта “Подтверждать преобразование формата файла при открытии”. Нажмите “ОК” для закрытия окна.

Примечание: После того, как вы установите галочку напротив этого параметра, при каждом открытии в Ворде файла в формате, отличном от DOC, DOCX, DOCM, DOT, DOTM, DOTX, будет отображаться диалоговое окно “Преобразование файла”. Если же вам часто приходится работать с документами других форматов, но при этом не требуется менять их кодировку, снимите эту галочку в параметрах программы.
4. Закройте файл, а затем снова откройте его.
5. В разделе “Преобразование файла” выберите пункт “Кодированный текст”.
6. В открывшемся диалоговом окне “Преобразование файла” установите маркер напротив параметра “Другая”. Выберите необходимую кодировку из списка.
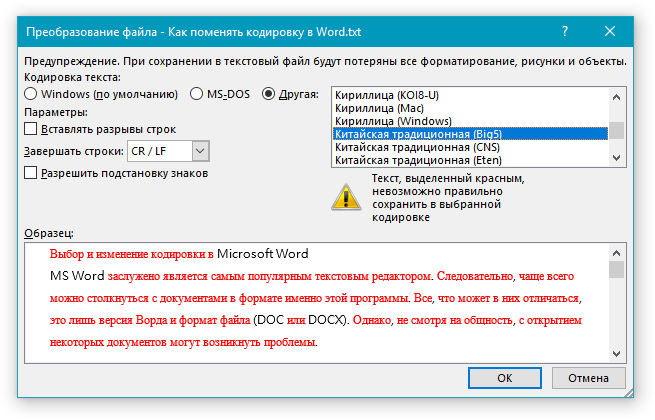
- Совет: В окне “Образец” вы можете увидеть, как будет выглядеть текст в той или иной кодировке.
7. Выбрав подходящую кодировку, примените ее. Теперь текстовое содержимое документа будет корректно отображаться.
В случае, если весь текст, кодировку для которого вы выбираете, выглядит практически одинаков (например, в виде квадратов, точек, знаков вопроса), вероятнее всего, на вашем компьютере не установлен шрифт, используемый в документе, который вы пытаетесь открыть. О том, как установить сторонний шрифт в MS Word, вы можете прочесть в нашей статье.
Урок: Как в Ворде установить шрифт
Выбор кодировки при сохранении файла
Если вы не указываете (не выбираете) кодировку файла MS Word при сохранении, он автоматически сохраняется в кодировке Юникод, чего в большинстве случаев предостаточно. Данный тип кодировки поддерживает большую часть знаков и большинство языков.
В случае, если созданный в Ворде документ вы (или кто-то другой) планируете открывать в другой программе, не поддерживающей Юникод, вы всегда можете выбрать необходимую кодировку и сохранить файл именно в ней. Так, к примеру, на компьютере с русифицированной операционной системой вполне можно создать документ на традиционном китайском с применением Юникода.
Проблема лишь в том, что в случае, если данный документ будет открываться в программе, поддерживающей китайский, но не поддерживающей Юникод, куда правильнее будет сохранить файл в другой кодировке, например, “Китайская традиционная (Big5)”. В таком случае текстовое содержимое документа при открытии его в любой программе с поддержкой китайского языка, будет отображаться корректно.
Примечание: Так как Юникод является самым популярным, да и просто обширным стандартном среди кодировок, при сохранении текста в других кодировках возможно некорректное, неполное, а то и вовсе отсутствующее отображение некоторых файлов. На этапе выбора кодировки для сохранения файла знаки и символы, которые не поддерживаются, отображаются красным цветом, дополнительно высвечивается уведомление с информацией о причине.
1. Откройте файл, кодировку которого вам необходимо изменить.
2. Откройте меню “Файл” (кнопка “MS Office” ранее) и выберите пункт “Сохранить как”. Если это необходимо, задайте имя файла.

3. В разделе “Тип файла” выберите параметр “Обычный текст”.
4. Нажмите кнопку “Сохранить”. Перед вами появится окно “Преобразование файла».
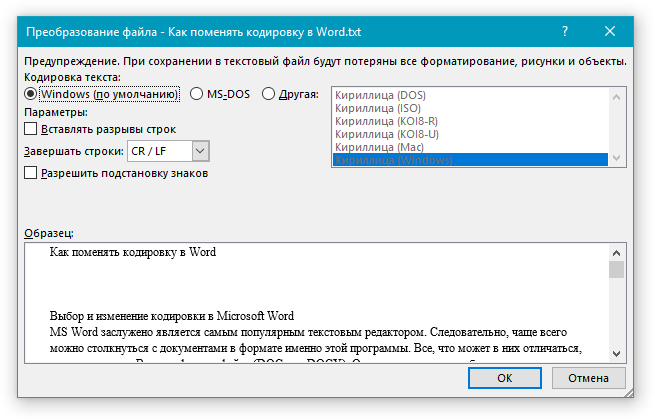
5. Выполните одно из следующих действий:
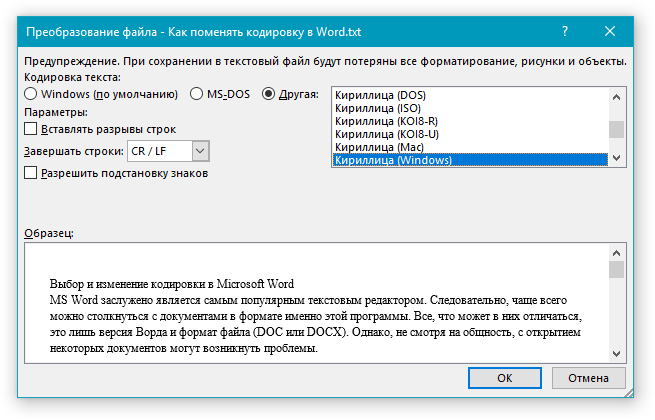
Примечание: Если при выборе той или иной (“Другой”) кодировки вы видите сообщение “Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке”, выберите другую кодировку (иначе содержимое файла будет отображаться некорректно) или же установите галочку напротив параметра “разрешить подстановку знаков”.
Если подстановка знаков разрешена, все те знаки, которые отобразить в выбранной кодировке невозможно, будут автоматически заменены на эквивалентные им символы. Например, многоточие может быть заменено на три точки, а угловые кавычки — на прямые.
6. Файл будет сохранен в выбранной вами кодировке в виде обычного текста (формат “TXT”).
На этом, собственно, и все, теперь вы знаете, как в Word сменить кодировку, а также знаете о том, как ее подобрать, если содержимое документа отображается некорректно.
Вместо текста, иероглифов, квадратов и крякозабры (в браузере, Word, тексте, окне Windows)… Это происходит потому, что текст на странице написан в той же кодировке (подробнее об этом из Википедии) и браузер пытается открыть его в другом.
Как убрать кодировку текста в ворде?
вы можете указать кодировку, которая будет использоваться для просмотра (декодирования) текста.
- Щелкните вкладку Файл.
- Щелкните кнопку Параметры.
- Щелкните кнопку Advanced.
- Перейдите в раздел Общие и установите флажок Подтверждать преобразование формата файла при открытии. …
- Закройте и снова откройте файл.
Как изменить иероглифы в ворде?
Чтобы изменить кодировку документа Word, когда никакой метод не помогает, вам необходимо сделать следующее: откройте этот документ, затем Файл — Сохранить как — Тип файла (в этом поле выберите формат Обычный текст * .Txt и нажмите Сохранить, тогда откроется окно с кодировкой.
Почему при копировании текста из PDF иероглифы?
Это все равно, что пытаться скопировать текст с обычного фото, сделанного на вашем смартфоне… В этом случае текст должен распознаваться специальной программой, например ABBYY FineReader.
Почему документ Word открывается иероглифами?
Чаще всего Word автоматически определяет нужную кодировку, но текст не всегда читается… Word — файл в порядке (кодировка правильная)! Изменение кодировки в браузере Когда браузер неправильно определяет кодировку веб-страницы, вы увидите точно такие же иероглифы (см.
Какую выбрать кириллицу в ворде?
После открытия файла в Word (или в Word) выберите меню «Файл»; Нажмите «Сохранить как…» и укажите, где разместить документ с правильной кодировкой; Введите имя и нажмите кнопку «Сохранить»; В открывшемся окне атрибутов установите необходимую кодировку (наиболее универсальная — «Юникод»).
Как изменить формат текста в ворде?
Форматирование текста в Microsoft Word
- Выделите текст, который хотите выделить.
- На вкладке Главная щелкните стрелку Цвет выделения текста. Появится раскрывающееся меню с возможными вариантами цвета.
- Укажите желаемый цвет выделения. Выбранный текст в документе будет выделен.
Как поменять кириллицу на латиницу в ворде?
В текстовом поле введите русский текст, выберите нужные параметры и нажмите кнопку «Перевести на латынь». Чтобы отменить последнее действие, используйте кнопку «Отменить передачу».
Как изменить код текста в ворде?
Затем для шифрования пользователь должен открыть нужный файл Word, перейти на вкладку «Файл», в разделе «Информация» выбрать пункт «Безопасность документа» и подпункт «Зашифровать с помощью пароля». Далее в появившемся окне нужно ввести пароль, затем подтвердить его.
Как открыть файл формата PDF в Word?
- Выберите Файл> Открыть.
- Найдите файл PDF и откройте его (для этого вам может потребоваться нажать кнопку «Обзор» и найти файл в папке).
- Появится предупреждение о том, что копия файла PDF будет создана и преобразована в поддерживаемый формат. Это не меняет исходный файл PDF. Щелкните ОК.
Как изменить Юникод в Windows 10?
Просмотр региональных настроек для Windows
- Щелкните Пуск, затем щелкните Панель управления
- Нажмите Часы, язык и регион
- Windows 10, Windows 8: щелкните Регион …
- Щелкните вкладку Администрирование …
- В разделе «Язык для программ, не поддерживающих Юникод» щелкните «Изменить язык системы» и выберите нужный язык.
- Нажмите ОК
Как исправить иероглифы в программе?
Итак, чтобы исправить иероглифы, вам следует перейти в панель управления / группу «Часы, язык и регион» / Изменить формат даты, время и число, затем выбрать вкладку «Дополнительно» и выбрать русский или украинский для программ, которые не поддерживают Юникод. После этого остается только перезагрузить систему.
Как включить кириллицу в Windows 10?
Нажмите клавиши Win + R на клавиатуре, введите regedit и нажмите Enter, откроется редактор реестра и с правой стороны прокрутите до конца этого раздела. Дважды щелкните параметр ACP, установите значение 1251 (кодовая страница кириллицы), нажмите кнопку ОК и закройте редактор реестра.
Как поменять кодировку в Word
Когда человек работает с программой MS Word, ему редко приходится вникать в нюансы кодирования. Но как только вам нужно поделиться документом с коллегами, есть вероятность, что отправленный пользователем файл может просто не быть прочитан получателем. Происходит это из-за несовпадения настроек и особенно кодировок в разных версиях программы.
Что представляет собой кодировка и от чего она зависит?
Для каждого региона кодировка может значительно отличаться. Чтобы понять кодировку, вам необходимо знать, что информация в текстовом документе хранится в виде некоторых числовых значений. Персональный компьютер автономно преобразует числа в текст, используя алгоритм единственного кодирования. Для стран СНГ используется кодировка файлов с названием «Кириллица», а для других регионов, например, Западной Европы, используется «Западная Европа (Windows)». Если текстовый документ был сохранен в кириллической кодировке и открыт в западноевропейском формате, символы будут отображаться совершенно некорректно, представляя бессмысленный набор символов.

Чтобы избежать недоразумений и облегчить работу, разработчики ввели специальную уникальную кодировку для всех алфавитов — «Unicode». Этот общепринятый стандарт кодирования содержит почти все символы большинства письменных языков нашей планеты. Более того, он преобладает в Интернете, где такое объединение так необходимо для охвата большего числа пользователей и удовлетворения их потребностей.

«Word 2013» работает только на основе Unicode, что позволяет обмениваться текстовыми файлами без использования сторонних программ и правильных кодировок в настройках. Но часто пользователи сталкиваются с ситуацией, когда при открытии, казалось бы, простого файла вместо текста отображаются только символы. В этом случае Word неправильно определил существующую исходную кодировку текста.
Ссылка! Некоторые кодировки применимы к определенным языкам. Кодировка «Shift JIS» была разработана специально для японского, «EUC-KR» для корейского и «ISO-2022» и «EUC» для китайского».
Изменение кодировки текста в «Word 2013»
Первый способ изменения кодировки в «Word»
Чтобы исправить текстовый документ с неверно определенной исходной кодировкой, вам необходимо:
Шаг 1. Запустите текстовый документ и откройте вкладку «Файл».
Шаг 2. Перейдите в меню настроек «Параметры».
Шаг 3. Выберите пункт «Дополнительно» и перейдите в раздел «Общие».

Шаг 4. Активируйте настройку в столбце «Подтверждать преобразование формата файла при открытии», щелкнув соответствующую область».
Шаг 5. Сохраните изменения и закройте текстовый документ.
Шаг 6. Снова запустите нужный файл. Перед пользователем появится окно «Преобразование файла», в котором необходимо выбрать пункт «Закодированный текст» и сохранить изменения, нажав «ОК».
Шаг 7. Появится еще одна область, в которой нужно выбрать пункт кодировки «Другая» и выбрать подходящую из списка. Поле «Пример» поможет пользователю выбрать необходимую кодировку, изменения отображены в тексте. Выбрав подходящий, сохраняем изменения кнопкой «ОК».
Второй способ изменения кодировки в «Word»
- Запускаем файл, кодировку текста которого необходимо сделать.
- Перейдите на вкладку «Файл».

На чтение 13 мин Просмотров 7.9к.
Содержание
- Случаи некорректного отображения текста
- Определение
- Как поменять кодировку в Word. Способ первый
- Способ второй: во время сохранения документа
- Исправляем иероглифы на текст
Ввиду того, что текстовый редактор «Майкрософт Ворд» является самым популярным на рынке, именно форматы документов, которые присущи ему, можно чаще всего встретить в сети. Они могут отличаться лишь версиями (DOCX или DOC). Но даже с этими форматами программа может быть несовместима или же совместима не полностью.

Случаи некорректного отображения текста
Конечно, когда в программе наотрез отказываются открываться, казалось бы, родные форматы, это поправить очень сложно, а то и практически невозможно. Но, бывают случаи, когда они открываются, а их содержимое невозможно прочесть. Речь сейчас идет о тех случаях, когда вместо текста, кстати, с сохраненной структурой, вставлены какие-то закорючки, «перевести» которые невозможно.
Эти случаи чаще всего связаны лишь с одним – с неверной кодировкой текста. Точнее, конечно, будет сказать, что кодировка не неверная, а просто другая. Не воспринимающаяся программой. Интересно еще то, что общего стандарта для кодировки нет. То есть, она может разниться в зависимости от региона. Так, создав файл, например, в Азии, скорее всего, открыв его в России, вы не сможете его прочитать.
В этой статье речь пойдет непосредственно о том, как поменять кодировку в Word. Кстати, это пригодится не только лишь для исправления вышеописанных «неисправностей», но и, наоборот, для намеренного неправильного кодирования документа.
Определение
Перед рассказом о том, как поменять кодировку в Word, стоит дать определение этому понятию. Сейчас мы попробуем это сделать простым языком, чтобы даже далекий от этой тематики человек все понял.
Зайдем издалека. В «вордовском» файле содержится не текст, как многими принято считать, а лишь набор чисел. Именно они преобразовываются во всем понятные символы программой. Именно для этих целей применяется кодировка.
Кодировка – схема нумерации, числовое значение в которой соответствует конкретному символу. К слову, кодировка может в себя вмещать не только лишь цифровой набор, но и буквы, и специальные знаки. А ввиду того, что в каждом языке используются разные символы, то и кодировка в разных странах отличается.
Как поменять кодировку в Word. Способ первый
После того, как этому явлению было дано определение, можно переходить непосредственно к тому, как поменять кодировку в Word. Первый способ можно осуществить при открытии файла в программе.
В том случае, когда в открывшемся файле вы наблюдаете набор непонятных символов, это означает, что программа неверно определила кодировку текста и, соответственно, не способна его декодировать. Все, что нужно сделать для корректного отображения каждого символа, – это указать подходящую кодировку для отображения текста.
Говоря о том, как поменять кодировку в Word при открытии файла, вам необходимо сделать следующее:
- Нажать на вкладку «Файл» (в ранних версиях это кнопка «MS Office»).
- Перейти в категорию «Параметры».
- Нажать по пункту «Дополнительно».
- В открывшемся меню пролистать окно до пункта «Общие».
- Поставить отметку рядом с «Подтверждать преобразование формата файла при открытии».
- Нажать»ОК».
Итак, полдела сделано. Скоро вы узнаете, как поменять кодировку текста в Word. Теперь, когда вы будете открывать файлы в программе «Ворд», будет появляться окно. В нем вы сможете поменять кодировку открывающегося текста.
Выполните следующие действия:
- Откройте двойным кликом файл, который необходимо перекодировать.
- Кликните по пункту «Кодированный текст», что находится в разделе «Преобразование файла».
- В появившемся окне установите переключатель на пункт «Другая».
- В выпадающем списке, что расположен рядом, определите нужную кодировку.
- Нажмите «ОК».
Если вы выбрали верную кодировку, то после всего проделанного откроется документ с понятным для восприятия языком. В момент, когда вы выбираете кодировку, вы можете посмотреть, как будет выглядеть будущий файл, в окне «Образец». Кстати, если вы думаете, как поменять кодировку в Word на MAC, для этого нужно выбрать из выпадающего списка соответствующий пункт.
Способ второй: во время сохранения документа
Суть второго способа довольно проста: открыть файл с некорректной кодировкой и сохранить его в подходящей. Делается это следующим образом:
- Нажмите «Файл».
- Выберите «Сохранить как».
- В выпадающем списке, что находится в разделе «Тип файла», выберите «Обычный текст».
- Кликните по «Сохранить».
- В окне преобразования файла выберите предпочитаемую кодировку и нажмите «ОК».
Теперь вы знаете два способа, как можно поменять кодировку текста в Word. Надеемся, что эта статья помогла вам в решении вопроса.

Подскажите пожалуйста, почему у меня некоторые странички в браузере отображают вместо текста иероглифы, квадратики и не пойми что (ничего нельзя прочесть). Раньше такого не было.
Доброго времени суток!
Действительно, иногда при открытии какой-нибудь интернет-странички вместо текста показываются различные «крякозабры» (как я их называю), и прочитать это нереально.
Происходит это из-за того, что текст на страничке написан в одной кодировке (более подробно об этом можете узнать из Википедии), а браузер пытается его открыть в другой. Из-за такого рассогласования, вместо текста – непонятный набор символов.
Попробуем исправить это.
Исправляем иероглифы на текст
Браузер
Вообще, раньше Internet Explorer часто выдавал подобные крякозабры, современные же браузеры (Chrome, Яндекс-браузер, Opera, Firefox) – довольно неплохо определяет кодировку, и ошибаются очень редко. Скажу даже больше, в некоторых версиях браузера уже убрали выбор кодировки, и для «ручной» настройки этого параметра нужно скачивать дополнения, или лезть в дебри настроек за 10-ток галочек.
И так, предположим браузер неправильно определили кодировку и вы увидели следующее (как на скрине ниже).

Неправильно выбранная кодировка
Чаще всего путаница бывает между кодировками UTF (Юникод) и Windows-1251 (большинство русскоязычных сайтов выполнены в этих кодировках).
Поэтому, я рекомендую в ручном режиме попробовать их обе. Например, чтобы это сделать в браузере Firefox, нужно:
- нажать левый ALT – чтобы сверху показалось меню. Нажать меню «Вид»;
- выбрать пункт «Кодировка текста» , далее выбрать Юникод . Вуаля – иероглифы на странички сразу же стали обычным текстом (скрин ниже)!
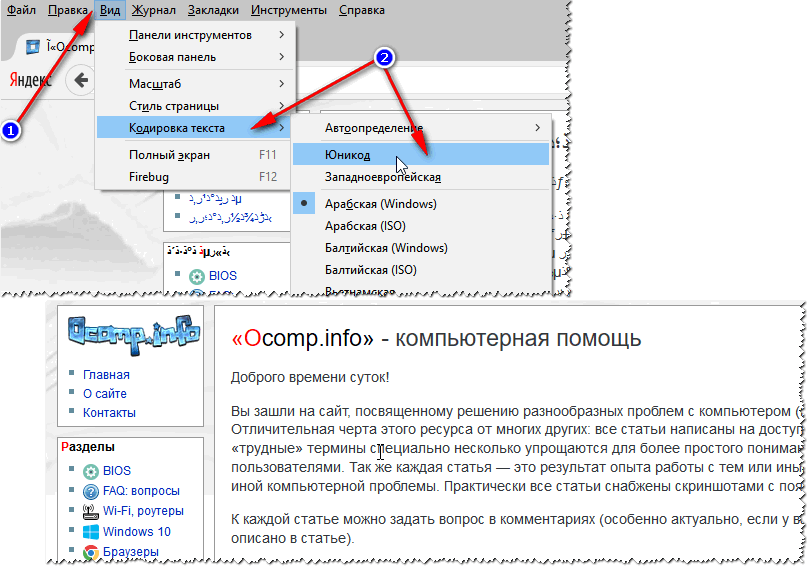
Смена кодировки в Firefox
Еще один совет : если в браузере не можете найти, как сменить кодировку (а дать инструкцию для каждого браузера – вообще нереально!), я рекомендую попробовать открыть страничку в другом браузере. Очень часто другая программа открывает страницу так, как нужно.
Текстовые документы
Очень много вопросов по крякозабрам задаются при открытии каких-нибудь текстовых документов. Особенно старых, например при чтении Readme в какой-нибудь программе прошлого века (например, к играм).
Разумеется, что многие современные блокноты просто не могут прочитать DOS’овскую кодировку, которая использовалась ранее. Чтобы решить сию проблему, рекомендую использовать редактор Bread 3.
Простой и удобный текстовый блокнот. Незаменимая вещь, когда нужно работать со старыми текстовыми файлами. Bred 3 за один клик мышкой позволяет менять кодировку и делать не читаемый текст читаемым! Поддерживает кроме текстовых файлов довольно большое разнообразие документов. В общем, рекомендую!
Попробуйте открыть в Bred 3 свой текстовый документ (с которым наблюдаются проблемы). Пример показан у меня на скрине ниже.
Иероглифы при открытии текстового документа
Далее в Bred 3 есть кнопка для смены кодировки: просто попробуйте поменять ANSI на OEM – и старый текстовый файл станет читаемым за 1 сек.!
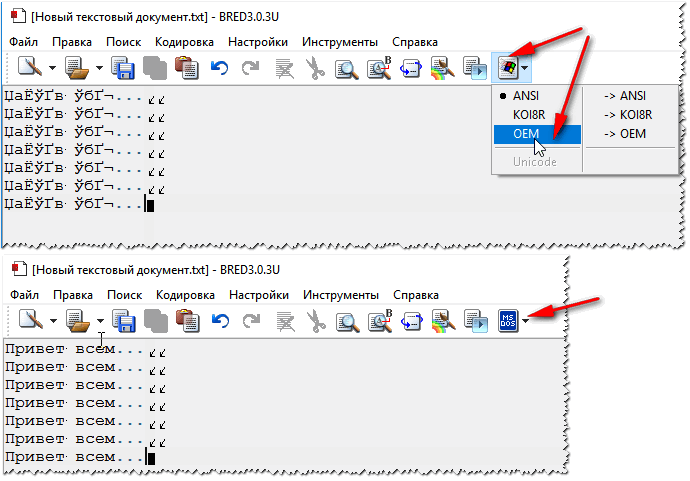
Исправление иероглифов на текст
Для работы с текстовыми файлами различных кодировок так же подойдет еще один блокнот – Notepad++. Вообще, конечно, он больше подходит для программирования, т.к. поддерживает различные подсветки, для более удобного чтения кода.
Надежный, удобный, поддерживающий громадное число форматов файлов блокнот. Позволяет легко и быстро переключать различные кодировки.
Пример смены кодировки показан ниже: чтобы прочитать текст, достаточно в примере ниже, достаточно было сменить кодировку ANSI на UTF-8.
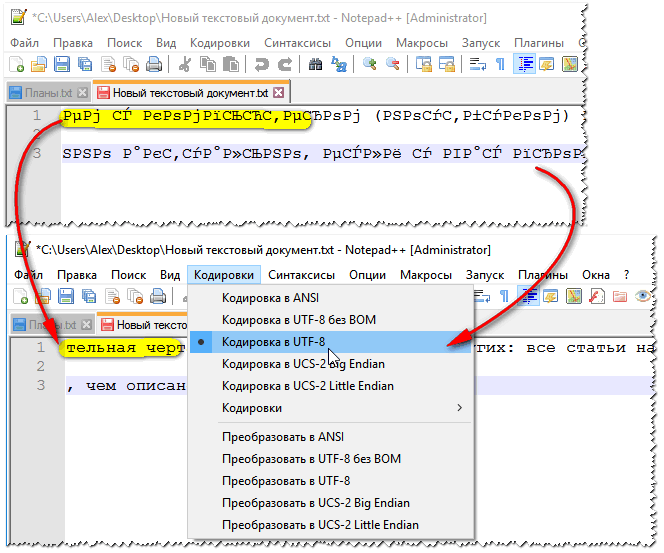
Смена кодировки в блокноте Notepad++
WORD’овские документы
Очень часто проблема с крякозабрами в Word связана с тем, что путают два формата Doc и Docx . Дело в том, что с 2007 Word (если не ошибаюсь) появился формат Docx (позволяет более сильнее сжимать документ, чем Doc, да и надежнее защищает его).
Так вот, если у вас старый Word, который не поддерживает этот формат – то вы, при открытии документа в Docx, увидите иероглифы и ничего более.
- скачать на сайте Microsoft спец. дополнение, которое позволяет открывать в старом Word новые документы. Только из личного опыта могу сказать, что открываются далеко не все документы, к тому же сильно страдает разметка документа (что в некоторых случаях очень критично);
- использовать аналоги Word (правда, тоже разметка в документе будет страдать);
- обновить Word до современной версии.
Так же при открытии любого документа в Word (в кодировке которого он «сомневается»), он на выбор предлагает вам самостоятельно указать оную. Пример показан на рисунке ниже, попробуйте выбрать:
-
W >
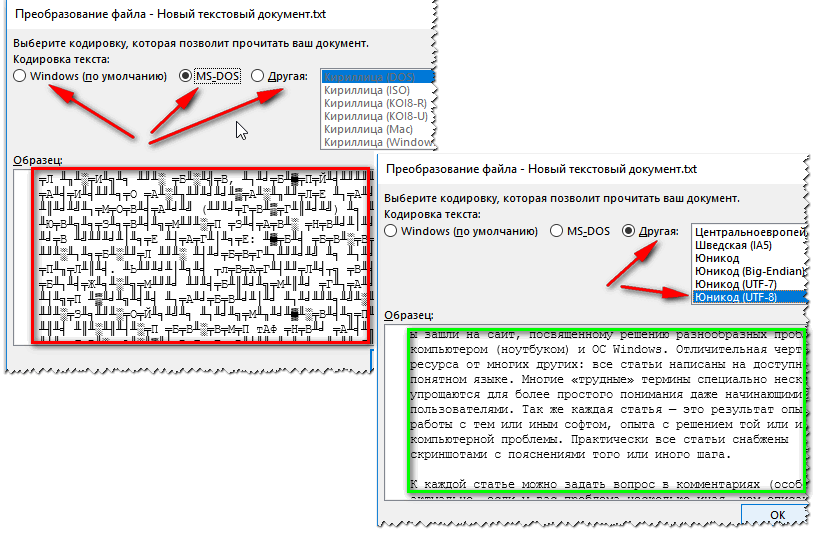
Переключение кодировки в Word при открытии документа
Окна в различных приложениях Windows
Бывает такое, что какое-нибудь окно или меню в программе показывается с иероглифами (разумеется, прочитать что-то или разобрать – нереально).
Могу дать несколько рекомендаций:
- Руссификатор. Довольно часто официальной поддержки русского языка в программе нет, но многие умельца делают руссификаторы. Скорее всего, на вашей системе – данный руссификатор работать отказался. Поэтому, совет простой: попробовать поставить другой;
- Переключение языка. Многие программы можно использовать и без русского, переключив в настройках язык на английский. Ну в самом деле: зачем вам в какой-то утилите, вместо кнопки «Start» перевод «начать»?
- Если у вас раньше текст отображался нормально, а щас нет – попробуйте восстановить Windows, если, конечно, у вас есть точки восстановления (подробно об этом здесь – https://ocomp.info/vosstanovlenie-windows-10.html);
- Проверить настройки языков и региональных стандартов в Windows, часто причина кроется именно в них.
Языки и региональные стандарты в Windows
Чтобы открыть меню настроек:
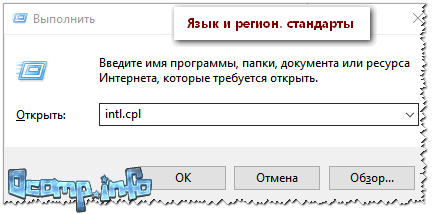
intl.cpl – язык и регион. стандарты
Проверьте чтобы во вкладке «Форматы» стояло «Русский (Россия) // Использовать язык интерфейса Windows (рекомендуется)» (пример на скрине ниже).
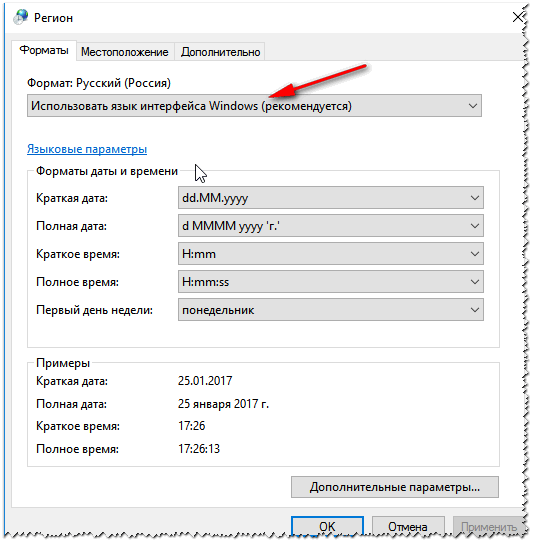
Формат – русский // Россия
Во вкладке местоположение поставьте расположение Россия.
И во вкладке дополнительно установите язык системы на «Русский (Россия)». После этого сохраните настройки и перезагрузите ПК. Затем вновь проверьте, нормально ли отображается интерфейс нужной программы.
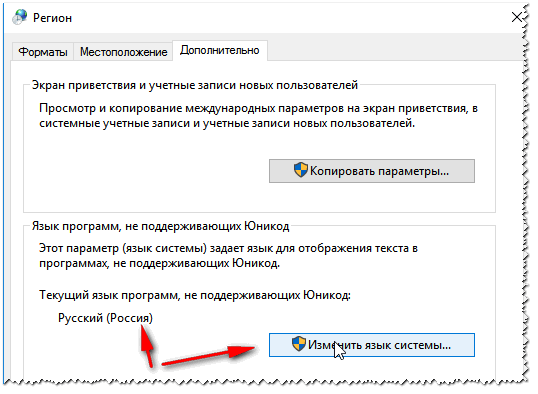
Текущий язык программ
PS
И напоследок, наверное, для многих это очевидно, и все же некоторые открывают определенные файлы в программах, которые не предназначены для этого: к примеру в обычном блокноте пытаются прочитать файл DOCX или PDF. Естественно, в этом случае вы вместо текста будут наблюдать за крякозабрами, используйте те программы, которые предназначены для данного типа файла (WORD 2007+ и Adobe Reader для примера выше).
 Доброго дня.
Доброго дня.
Наверное, каждый пользователь ПК сталкивался с подобной проблемой: открываешь интернет-страничку или документ Microsoft Word — а вместо текста видишь иероглифы (различные «крякозабры», незнакомые буквы, цифры и т.д. (как на картинке слева…)).
Хорошо, если вам этот документ (с иероглифами) не особо важен, а если нужно обязательно его прочитать?! Довольно часто подобные вопросы и просьбы помочь с открытием подобных текстов задают и мне. В этой небольшой статье я хочу рассмотреть самые популярные причины появления иероглифов (разумеется, и устранить их).
Иероглифы в текстовых файлах (.txt)
Самая популярная проблема. Дело в том, что текстовый файл (обычно в формате txt, но так же ими являются форматы: php, css, info и т.д.) может быть сохранен в различных кодировках .
Кодировка — это набор символов, необходимый для того, чтобы полностью обеспечить написание текста на определенном алфавите (в том числе цифры и специальные знаки). Более подробно об этом здесь: https://ru.wikipedia.org/wiki/Набор_символов
Чаще всего происходит одна вещь: документ открывается просто не в той кодировке из-за чего происходит путаница, и вместо кода одних символов, будут вызваны другие. На экране появляются различные непонятные символы (см. рис. 1)…
Рис. 1. Блокнот — проблема с кодировкой
Как с этим бороться?
На мой взгляд лучший вариант — это установить продвинутый блокнот, например Notepad++ или Bred 3. Рассмотрим более подробно каждую из них.
Notepad++
Один из лучших блокнотов как для начинающих пользователей, так и для профессионалов. Плюсы: бесплатная программа, поддерживает русский язык, работает очень быстро, подсветка кода, открытие всех распространенных форматов файлов, огромное количество опций позволяют подстроить ее под себя.
В плане кодировок здесь вообще полный порядок: есть отдельный раздел «Кодировки» (см. рис. 2). Просто попробуйте сменить ANSI на UTF-8 (например).
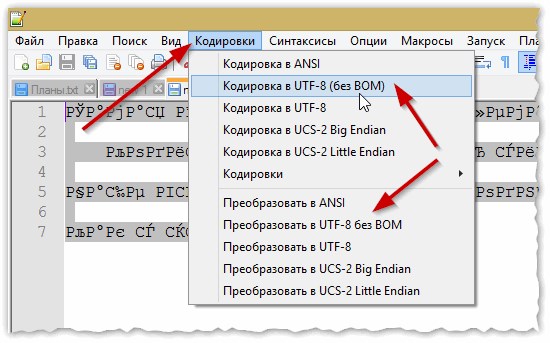
Рис. 2. Смена кодировки в Notepad++
После смены кодировки мой текстовый документ стал нормальным и читаемым — иероглифы пропали (см. рис. 3)!

Рис. 3. Текст стал читаемый… Notepad++
Bred 3
Еще одна замечательная программа, призванная полностью заменить стандартный блокнот в Windows. Она так же «легко» работает со множеством кодировок, легко их меняет, поддерживает огромное число форматов файлов, поддерживает новые ОС Windows (8, 10).
Кстати, Bred 3 очень помогает при работе со «старыми» файлами, сохраненных в MS DOS форматах. Когда другие программы показывают только иероглифы — Bred 3 легко их открывает и позволяет спокойно работать с ними (см. рис. 4).
Если вместо текста иероглифы в Microsoft Word
Самое первое, на что нужно обратить внимание — это на формат файла. Дело в том, что начиная с Word 2007 появился новый формат — « docx » (раньше был просто « doc «). Обычно, в «старом» Word нельзя открыть новые форматы файлов, но случается иногда так, что эти «новые» файлы открываются в старой программе.
Просто откройте свойства файла, а затем посмотрите вкладку « Подробно » (как на рис. 5). Так вы узнаете формат файла (на рис. 5 — формат файла «txt»).
Если формат файла docx — а у вас старый Word (ниже 2007 версии) — то просто обновите Word до 2007 или выше (2010, 2013, 2016).
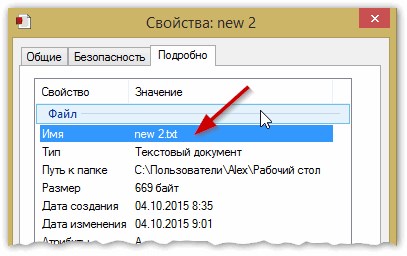
Рис. 5. Свойства файла
Далее при открытии файла обратите внимание (по умолчанию данная опция всегда включена, если у вас, конечно, не «не пойми какая сборка») — Word вас переспросит: в какой кодировке открыть файл (это сообщение появляется при любом «намеке» на проблемы при открытии файла, см. рис. 5).
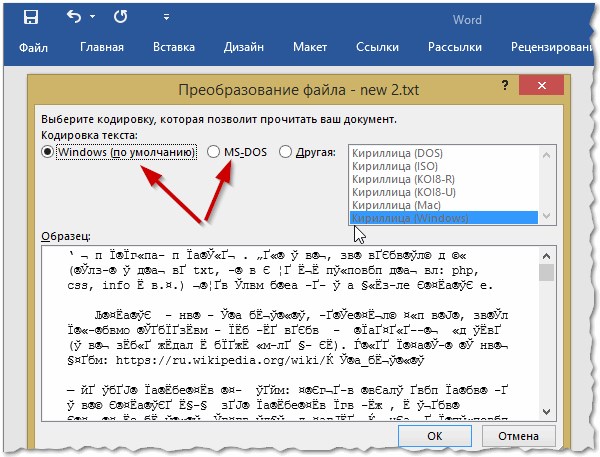
Рис. 6. Word — преобразование файла
Чаще всего Word определяет сам автоматически нужную кодировку, но не всегда текст получается читаемым. Вам нужно установить ползунок на нужную кодировку, когда текст станет читаемым. Иногда, приходится буквально угадывать, в как был сохранен файл, чтобы его прочитать.
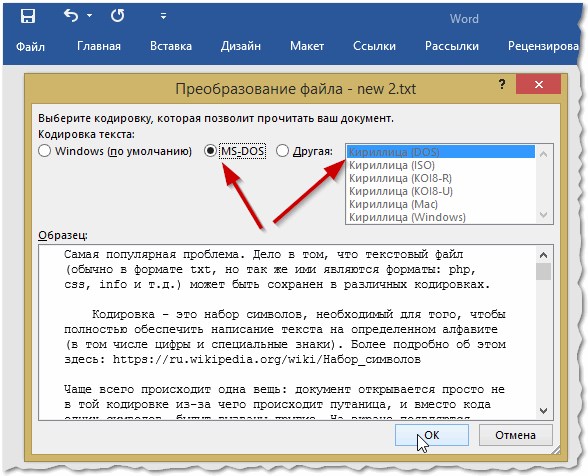
Рис. 7. Word — файл в норме (кодировка выбрана верно)!
Смена кодировки в браузере
Когда браузер ошибочно определяет кодировку интернет-странички — вы увидите точно такие же иероглифы (см. рис 8).

Рис. 8. браузер определил неверно кодировку
Чтобы исправить отображение сайта: измените кодировку. Делается это в настройках браузера:
- Google chrome: параметры (значок в правом верхнем углу)/дополнительные параметры/кодировка/Windows-1251 (или UTF-8);
- Firefox: левая кнопка ALT (если у вас выключена верхняя панелька), затем вид/кодировка страницы/выбрать нужную (чаще всего Windows-1251 или UTF-8) ;
- Opera: Opera (красный значок в верхнем левом углу)/страница/кодировка/выбрать нужное.
PS
Таким образом в этой статье были разобраны самые частые случаи появления иероглифов, связанных с неправильно определенной кодировкой. При помощи выше приведенных способов — можно решить все основные проблемы с неверной кодировкой.
Буду благодарен за дополнения по теме. Good Luck 🙂
Что делать, если документ Ворд открывается иероглифами, как исправить?
Статья расскажет, как исправить проблему, если при открытии документа «Word» вместо текста отображаются иероглифы.
Многие пользователи знакомы с проблемой, когда в каком-либо документе при его открытии вместо привычного и понятного текста отображаются какие-то иероглифы. Такая проблема может произойти в разных ситуациях, а сегодня мы рассмотрим это на примере программы «Word».
Что делать, если в документе «Word» открываются иероглифы?
Первым долгом нам нужно проверить расширение файла, который мы открываем. Если это документ «Word», то он может быть представлен в двух форматах – «doc» и «docx». Расширение «doc» привязано к программе «Word» ниже версии 2007 года, а «docx» — соответственно, используется в «Word 2007/2010/2013/2016».
Если вы в более старой версии «Word» откроете файл с расширением «docx», то увидите эти самые непонятные иероглифы. То есть новые файлы не поддерживаются более ранней версией текстового редактора. И что в этом случае нужно сделать? Просто установить новую версию от 2007 года.
Если вам нужно проверить, какое расширение имеет тот или иной документ «Word», то кликните по нему правой кнопкой мышки, зайдите в контекстном меню в «Свойства» и в открывшемся окне на вкладке «Подробно» обратите внимание на имя файла:

Также при открытии непонятного документа программа «Word» (официальной непиратской версии) должна спросить, в какой кодировке следует представить текст:

Программа «Word» должна спросить, в какой кодировке следует представить текст
Обычно кодировка определяется автоматически, но возможны и случаи исключения. Если программа предлагает вам выбрать кодировку, то тут могут возникнуть некоторые проблемы. Дело в том, что иногда сделать правильный выбор придется при помощи «метода тыка», хотя по умолчанию следует выбирать «Windows (по умолчанию)», если вы не открываете какой-то редкий документ:
Вместо текста иероглифы, квадратики и крякозабры (в браузере, Word, тексте, окне Windows)
Вопрос пользователя
Здравствуйте.
Подскажите пожалуйста, почему у меня некоторые странички в браузере отображают вместо текста иероглифы, квадратики и не пойми что (ничего нельзя прочесть). Раньше такого не было.
Заранее спасибо.
Доброго времени суток!
Действительно, иногда при открытии какой-нибудь интернет-странички вместо текста показываются различные «крякозабры» (как я их называю), и прочитать это нереально.
Происходит это из-за того, что текст на страничке написан в одной кодировке (более подробно об этом можете узнать из Википедии ), а браузер пытается открыть его в другой. Из-за такого рассогласования, вместо текста — непонятный набор символов.
Попробуем исправить это.
Исправляем иероглифы на текст
Браузер
Вообще, раньше Internet Explorer часто выдавал подобные крякозабры, 👉 современные же браузеры (Chrome, Яндекс-браузер, Opera, Firefox) — довольно неплохо определяют кодировку, и ошибаются очень редко. 👌
Скажу даже больше, в некоторых версиях браузера уже убрали выбор кодировки, и для «ручной» настройки этого параметра нужно скачивать дополнения, или лезть в дебри настроек за 10-ток галочек.
И так, предположим браузер неправильно определили кодировку и вы увидели следующее (как на скрине ниже 👇).
Неправильно выбранная кодировка
👉 Кстати!
Чаще всего путаница бывает между кодировками UTF (Юникод) и Windows-1251 (большинство русскоязычных сайтов выполнены в этих кодировках).
Поэтому, я рекомендую в ручном режиме попробовать их обе. Например, чтобы это сделать в браузере Firefox, нужно:
- нажать левый ALT — чтобы сверху показалось меню. Нажать меню «Вид» ;
- выбрать пункт «Кодировка текста» , далее выбрать Юникод . И, ву-а-ля — иероглифы на странички сразу же стали обычным текстом (скрин ниже 👇) !
👉 В помощь! Если у вас иероглифы в браузере Chrome — ознакомьтесь с этим
Смена кодировки в Firefox
Еще один совет : если в браузере не можете найти, как сменить кодировку (а дать инструкцию для каждого браузера — вообще нереально!) , я рекомендую попробовать открыть страничку в другом браузере. Очень часто другая программа открывает страницу так, как нужно.
Текстовые документы
Очень много вопросов по крякозабрам задаются при открытии каких-нибудь текстовых документов. Особенно старых, например, при чтении Readme в какой-нибудь программе прошлого века (скажем, к играм) .
Разумеется, что многие современные блокноты просто не могут прочитать DOS‘овскую кодировку, которая использовалась ранее. Чтобы решить сию проблему, рекомендую использовать редактор Bread 3.
Bred 3
Сайт: http://www.astonshell.ru/freeware/bred3/
Простой и удобный текстовый блокнот. Незаменимая вещь, когда нужно работать со старыми текстовыми файлами.
Bred 3 за один клик мышкой позволяет менять кодировку и делать не читаемый текст читаемым! Поддерживает кроме текстовых файлов довольно большое разнообразие документов. В общем, рекомендую! ✌
Попробуйте открыть в Bred 3 свой тексто вый документ (с которым наблюдаются проблемы) . Пример показан у меня на скрине ниже.
Иероглифы при открытии текстового документа
Далее в Bred 3 есть кнопка для смены кодировки: просто попробуйте поменять ANSI на OEM — и старый текстовый файл станет читаемым за 1 сек.!
Исправление иероглифов на текст
Для работы с текстовыми файлами различных кодировок также подойдет еще один блокнот — Notepad++. Вообще, конечно, он больше подходит для программирования, т.к. поддерживает различные подсветки, для более удобного чтения кода.
Notepad++
Сайт: https://notepad-plus-plus.org/
Надежный, удобный, поддерживающий громадное число форматов файлов блокнот. Позволяет легко и быстро переключать различные кодировки.
Пример смены кодировки показан ниже: чтобы прочитать текст, достаточно в примере ниже, достаточно было сменить кодировку ANSI на UTF-8.
Смена кодировки в блокноте Notepad++
Штирлиц
Сайт разработчика: http://www.shtirlitz.ru/
Эта программа специализируется на «расшифровке» текстов, написанных в разных кодировках: Win-1251, KOI-8r, DOS, ISO-8859-5, MAC и др.
Причем, программа нормально работает даже с текстами со смешанной кодировкой (что не могут др. аналоги). Пример см. на скрине ниже. 👇

Пример работы ПО «Штирлиц»
WORD’овские документы
Очень часто проблема с крякозабрами в Word связана с тем, что путают два формата Doc и Docx . Дело в том, что с 2007 года в Word (если не ошибаюсь) появился формат Docx (позволяет более сильнее сжимать документ, чем Doc, да и надежнее защищает его).
Так вот, если у вас старый Word, который не поддерживает этот формат — то вы, при открытии документа в Docx, увидите иероглифы и ничего более.
Решения есть два:
- скачать на сайте Microsoft спец. дополнение, которое позволяет открывать в старом Word новые документы (с 2020г. дополнение с офиц. сайта удалено) . Только из личного опыта могу сказать, что открываются далеко не все документы, к тому же сильно страдает разметка документа (что в некоторых случаях очень критично) ;
- использовать 👉 аналоги Word (правда, тоже разметка в документе будет страдать);
- обновить Word до современной версии.
Так же при открытии любого документа в Word (в кодировке которого он «сомневается»), он на выбор предлагает вам самостоятельно указать оную. Пример показан на рисунке ниже, попробуйте выбрать:
- Widows (по умолчанию);
- MS DOS;
- Другая.
Переключение кодировки в Word при открытии документа
Окна в различных приложениях Windows
Бывает такое, что какое-нибудь окно или меню в программе показывается с иероглифами (разумеется, прочитать что-то или разобрать — нереально) .
Могу дать несколько рекомендаций:
- Русификатор. Довольно часто официальной поддержки русского языка в программе нет, но многие умельцы делают русификаторы. Скорее всего, на вашей системе — данный русификатор работать отказался. Поэтому, совет простой: попробовать поставить другой;
- Переключение языка. Многие программы можно использовать и без русского, переключив в настройках язык на английский. Ну в самом деле: зачем вам в какой-то утилите, вместо кнопки «Start» перевод «начать» ?
- Если у вас раньше текст отображался нормально, а сейчас нет — попробуйте 👉 восстановить Windows, если, конечно, у вас есть точки восстановления;
- Проверить настройки языков и региональных стандартов в Windows, часто причина кроется именно в них (👇).
Языки и региональные стандарты в Windows
Чтобы открыть меню настроек:
- нажмите Win+R ;
- введите intl.cpl , нажмите Enter.
intl.cpl — язык и регион. стандарты
Проверьте чтобы во вкладке «Форматы» стояло «Русский (Россия) / Использовать язык интерфейса Windows (рекомендуется)» (пример на скрине ниже 👇).
Формат — русский / Россия
Во вкладке «Местоположение» — укажите «Россия» .
И во вкладке «Дополнительно» установите язык системы «Русский (Россия)» .
После этого сохраните настройки и перезагрузите ПК. Затем вновь проверьте, нормально ли отображается интерфейс нужной программы.
Текущий язык программ
PS
И напоследок, наверное, для многих это очевидно, и все же некоторые открывают определенные файлы в программах, которые не предназначены для этого: к примеру в обычном блокноте пытаются прочитать файл DOCX или PDF.
Естественно, в этом случае вы вместо текста будут наблюдать за крякозабрами, используйте те программы, которые предназначены для данного типа файла (WORD 2016+ и Adobe Reader для примера выше).
Иероглифы вместо русских букв, вместо текста квадратики, что делать?
 Автор Вероника и Влад Дата Ноя 2, 2016
Автор Вероника и Влад Дата Ноя 2, 2016

- Текстовые документы
- Notepad +++
- Bred 3
- Word
- Иероглифы в браузере
Текстовые документы
Именно в документах Ворда, Блокнота и т.п. такая кодировка встречается чаще всего. Кодировка – набор знаков, благодаря которым происходит печать текста на определенном алфавите. Теоретически, любой документ сохраняется в различных шифрованиях, но пользователи почти никогда не прибегают к таким действиям. Потому, если Вы видите вместо букв вопросительные знаки и т.п., то маловероятно, что это сделано намеренно. Скорее всего, ввиду системного сбоя у пользователя, создавшего документ, он сохранился не в той кодировки. Кроме того, дело может быть и в сбои на Вашем ПК, в результате чего файл не открывается правильно.
Наиболее часто проблема возникает при использовании Блокнота. Также встречается в файлах php, css, info и подобных текстовых. Гораздо реже в Ворде. Кроме того, путаница с шифрованием встречается в браузере, там Вы также можете увидеть кракозябры вместо русских букв. В последнем случае избавиться от нее особенно трудно.

Notepad +++
Самый простой способ открыть документ Блокнот, где вместо букв квадратики – применить сторонний софт. Популярен Notepad+++. Это тот же Блокнот, но обладающий дополнительными функциями. Имеет следующие преимущества:
- Распространяется бесплатно;
- Как и Ворд, имеет кнопку отмены последнего действия;
- Поддерживает одновременную работу с несколькими файлами;
- Позволяет изменить или выбрать шифрование.
- Автоматически дописывает тексты;

Чтобы иероглифы вместо русских букв преобразовались, откройте документ Блокнота в данной программе. В ленте меню сверху найдите вкладку Кодировки. Нажмите на нее. Откроется меню с перечислением всех их типов. Не всегда очевидно, какой именно тип шифрования применялся, потому, чтобы выбрать правильный для перекодировки, нужно попробовать несколько. Текст пред этим выделите.
По мере применения кодировок, символы в документе могут меняться (по одному нажатию в меню) или оставаться неизменными. В результате, после применения определенной, текст станет читаемым.

Bred 3
Программа аналогична предыдущей. Представляет собой Блокнот с расширенными возможностями. Успешно применяется вместо стандартного Блокнота Виндовс. Кодировки представлены в отдельной вкладке в верхнем меню. Откройте документ, в котором видны лишь текстовые значки или иероглифы, выделите текст, и пробуйте менять шифрования по очереди. В результате текст станет читаемым.

Поддерживает множество, даже редких, форматов. Работает со старой DOS- кодировкой, которую не открывают современные программы. Работает на Windows 8, 8.1, 10.
Иногда кодировка появляется и в документах Ворд. Иногда причиной того, что в ворде появились непонятные символы, является то, что у Вас на ПК установлен старый Ворд (до 2007 года), а документ создан в более поздних версиях софта. Чаще всего, такие «новые» файлы просто не открываются в старой версии, но иногда открываются в странной кодировке. Чтобы понять, так ли это, посмотрите в Свойствах файла, какой он имеет формат. «Новые» документы имеют формат docx. Преобразование файла в word до старого формата невозможно. Лучше установить обновление на MS Word. Изменить формат текстового документа на читаемый не сложно.
- Еще до открытия файла, софт «понимает», что в нем проблема. При двойном клике на него Ворд откроет окно, где спросит – в какой кодировке открыть файл. Чтобы изменить кодировку текста в word, выполните алгоритм;
- Попробуйте кодировку, предложенную программой;
- Если не сработало, кликайте по очереди на предлагаемые типы;
Набор символов, которые мы видим на экране при открытии документа, называется кодировкой. Когда она выставлена неправильно, вместо понятных и привычных букв и цифр вы увидите бессвязные символы. Эта проблема часто возникала на заре развития технологий, но сейчас текстовые процессоры умеют сами автоматически выбирать подходящие комплекты. Свою роль сыграло появление и развитие utf-8, так называемого Юникода, в состав которого входит множество самых разных символов, в том числе русских. Документы в такой кодировке не нуждаются в смене и настройке, так как показывают текст правильно по умолчанию.

Современные текстовые редакторы определяют кодировку при открытии документа
С другой стороны, такая ситуация всё же иногда случается. И получить нечитаемый документ очень досадно, особенно если он важный и нужный. Как раз для таких случаев в Microsoft Word есть возможность указать для текста кодировку. Это вернёт его в читаемый вид.
Принудительная смена
Если вы получили из какого-то источника текстовый файл, но не можете прочитать его содержимое, то нужна операция ручной смены кодировки. Для этого зайдите в раздел «Сведения» во вкладке «Файл». Тут собраны глобальные настройки распознавания и отображения, и если вы будете изменять их в открытом документе, то для него они станут индивидуальными, а для остальных — не изменятся. Воспользуемся этим. В разделе «Дополнительно» появившегося окна находим заголовок «Общие» и ставим галочку «Подтверждать преобразование файлов при открытии». Подтвердите изменения и закройте Word. Теперь откройте документ снова, как бы применяя настройки, и перед вами появится окно преобразования файла. В нём будет список возможных форматов, среди которых находим «Кодированный текст», и получим следующий диалог.

В этом новом окне будет три переключателя. Первый, по умолчанию, — это CP-1251, кодировка Windows. Второй — MS-DOS. Нам нужен третий пункт — ручной выбор, справа от него перечислены разнообразные наборы символов. Но, как правило, пользователь не знает, какими символами был набран текст предыдущим автором, поэтому в нижней части этого окна есть поле под названием «Образец», в котором фрагмент из текста будет в реальном времени отображаться при выборе того или иного комплекта символов. Это очень удобно, потому что не нужно каждый раз закрывать и отрывать документ снова, чтобы подобрать нужную.

Перебирая варианты по одному и глядя на текст в поле образцов, выберите ту кодировку, при которой символы будут русскими. Но обратите внимание, что это ещё ничего не значит, — внимательно смотрите, чтобы они складывались в осмысленные слова. Дело в том, что для русского языка есть не одна кодировка, и текст в одной из них не будет отображаться корректно в другой. Так что будьте внимательны.
Нужно сказать, что с файлами, сделанными на современных текстовых процессорах, крайне редко возникают подобные проблемы. Однако есть ещё и такой бич современного информационного общества, как несовместимость форматов. Дело в том, что существует целый ряд текстовых редакторов, и каждым кто-то пользуется. Возможно, для кого-то не нужна функциональность Ворда, кто-то не считает нужным за него платить и т. п. Причин может быть множество.
Если при сохранении документа автор выбрал формат, совместимый в MS Word, то проблем возникнуть не должно. Но так бывает нечасто. Например, если текст сохранён с расширением .rtf, то диалог выбора кодировки отобразится перед вами сразу же при открытии текста. А вот форматы другого популярного текстового процессора OpenOffice Ворд даже не откроет, поэтому, если им пользуетесь, не забывайте выбирать пункт «Сохранить как», когда отправляете файл пользователю Office.
Сохранение с указанием кодировки
У пользователя может возникнуть ситуация, когда он специально указывает определённую кодировку. Например, такое требование ему предъявляет получатель документа. В этом случае нужно будет сохранить документ как обычный текст через меню «Файл». Смысл в том, что для заданных форматов в Ворде есть привязанные глобальными системными настройками кодировки, а для «Обычного текста» такой связи не установлено. Поэтому Ворд предложит самостоятельно выбрать для него кодировку, показав уже знакомое нам окно преобразования документа. Выбирайте для него нужную вам кодировку, сохраняйте, и можно отправлять или передавать этот документ. Как вы понимаете, конечному получателю нужно будет сменить в своём текстовом редакторе кодировку на такую же, чтобы прочитать ваш текст.

Заключение
Вопрос смены кодировки в Вордовских документах перед рядовыми пользователями встаёт не так уж часто. Как правило, текстовый процессор может сам автоматически определить требуемый для корректного отображения набор символов и показать текст в читаемом виде. Но из любого правила есть исключения, так что нужно и полезно уметь сделать это самому, благо, реализован процесс в Word достаточно просто.
То, что мы рассмотрели, действительно и для других программ из пакета Office. В них также могут возникнуть проблемы из-за, скажем, несовместимости форматов сохранённых файлов. Здесь пользователю придётся выполнить всё те же действия, так что эта статья может помочь не только работающим в Ворде. Унификация правил настройки для всех программ офисного пакета Microsoft помогает не запутаться в них при работе с любым видом документов, будь то тексты, таблицы или презентации.
Напоследок нужно сказать, что не всегда стоит обвинять кодировку. Возможно, всё гораздо проще. Дело в том, что многие пользователи в погоне за «красивостями» забывают о стандартизации. Если такой автор выберет установленный у него шрифт, наберёт с его помощью документ и сохранит, у него текст будет отображаться корректно. Но когда этот документ попадёт к человеку, у которого такой шрифт не установлен, то на экране окажется нечитаемый набор символов. Это очень похоже на «слетевшую» кодировку, так что легко ошибиться. Поэтому перед тем как пытаться раскодировать текст в Word, сначала попробуйте просто сменить шрифт.
Вопрос пользователя
Здравствуйте.
Подскажите пожалуйста, почему у меня некоторые странички в браузере отображают вместо текста иероглифы, квадратики и не пойми что (ничего нельзя прочесть). Раньше такого не было.
Заранее спасибо…
Доброго времени суток!
Действительно, иногда при открытии какой-нибудь интернет-странички вместо текста показываются различные «крякозабры» (как я их называю), и прочитать это нереально.
Происходит это из-за того, что текст на страничке написан в одной кодировке (более подробно об этом можете узнать из Википедии), а браузер пытается открыть его в другой. Из-за такого рассогласования, вместо текста — непонятный набор символов.
Попробуем исправить это…
*
Содержание статьи
- 1 Исправляем иероглифы на текст
- 1.1 Браузер
- 1.2 Текстовые документы
- 1.3 BAT-файлы (скрипты)
- 1.4 Документы MS WORD
- 1.5 Окна в различных приложениях Windows

→ Задать вопрос | дополнить
Исправляем иероглифы на текст
Браузер
Вообще, раньше Internet Explorer часто выдавал подобные крякозабры, 👉 современные же браузеры (Chrome, Яндекс-браузер, Opera, Firefox) — довольно неплохо определяют кодировку, и ошибаются очень редко. 👌
Скажу даже больше, в некоторых версиях браузера уже убрали выбор кодировки, и для «ручной» настройки этого параметра нужно скачивать дополнения, или лезть в дебри настроек за 10-ток галочек…
Итак, предположим браузер неправильно определили кодировку и вы увидели следующее (как на скрине ниже 👇).
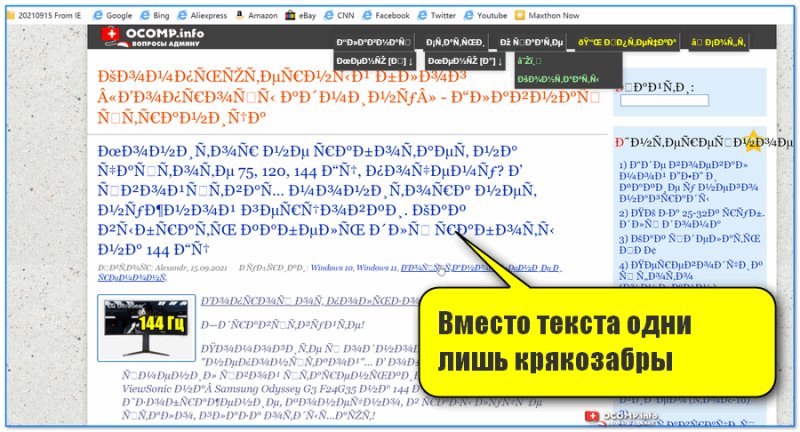
Вместо текста одни лишь крякозабры // Браузер выставил кодировку неверно!
*
📌 Кстати!
Чаще всего путаница бывает между кодировками UTF (Юникод) и Windows-1251 (большинство русскоязычных сайтов выполнены в этих кодировках).
*
Поэтому, я рекомендую в ручном режиме попробовать их обе. Для этого нам понадобиться браузер MX5 (ссылка на офиц. сайт). Он один из немногих позволяет в ручном режиме выбирать кодировку (при необходимости):
- необходимо открыть нужный сайт;
- далее зайти в меню «Инструменты / кодировка»;
- выбрать вручную UTF 8 или «Авто-определение»;
- перезагрузить страницу. И, ву-а-ля, — иероглифы на страничке сразу же стали обычным текстом (скрин ниже 👇)!
📌 В помощь!
Если у вас иероглифы в браузере Chrome — ознакомьтесь с этим
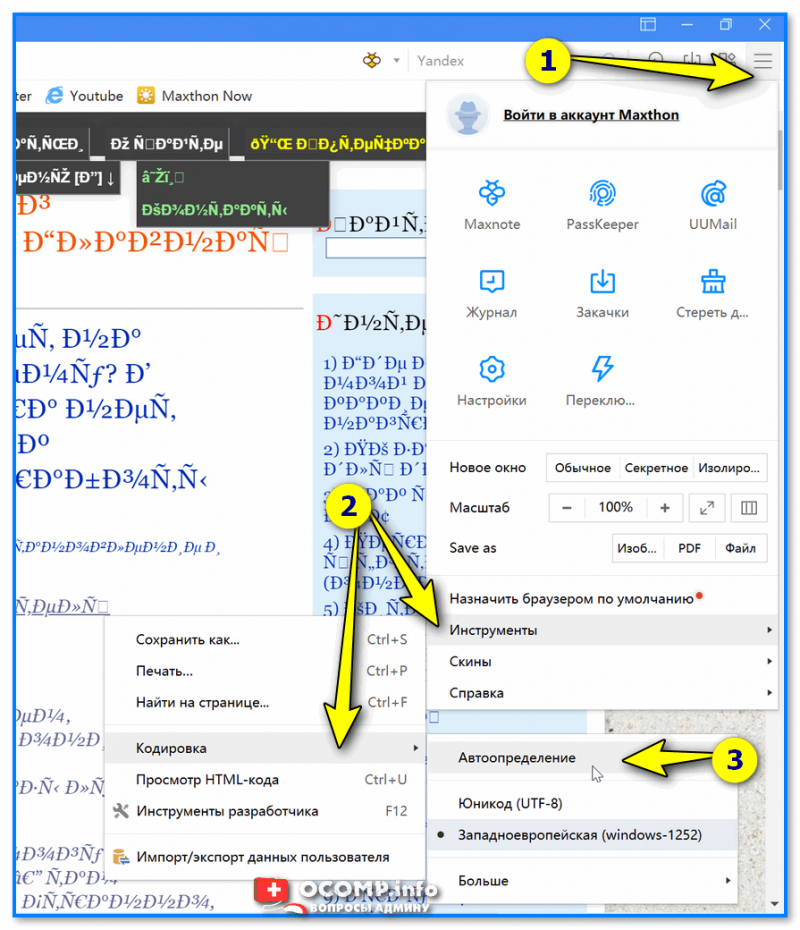
Браузер MX5 — выбор кодировки UTF8 или авто-определение
Теперь отображается русский текст норм.
*
📌 Еще один совет: если вы в своем браузере не можете найти, как сменить кодировку (а дать инструкцию для каждого браузера — вообще нереально!), я рекомендую попробовать открыть страничку в другом браузере (например, в MX5). Очень часто другая программа открывает страницу так, как нужно!
*
Текстовые документы
Очень много вопросов по крякозабрам задаются при открытии каких-нибудь текстовых документов. Особенно старых, например, при чтении Readme в какой-нибудь программе прошлого века (скажем, к играм).
Разумеется, что многие современные блокноты просто не могут прочитать DOS‘овскую кодировку, которая использовалась ранее. Чтобы решить сию проблему, рекомендую использовать редактор Bread 3.
*
Bred 3
Сайт: http://www.astonshell.ru/freeware/bred3/
Простой и удобный текстовый блокнот. Незаменимая вещь, когда нужно работать со старыми текстовыми файлами.
Bred 3 за один клик мышкой позволяет менять кодировку и делать не читаемый текст читаемым! Поддерживает кроме текстовых файлов довольно большое разнообразие документов. В общем, рекомендую! ✌
*
Попробуйте открыть в Bred 3 свой текстовый документ (с которым наблюдаются проблемы). Пример показан у меня на скрине ниже. 👇
Иероглифы при открытии текстового документа
Далее в Bred 3 есть кнопка для смены кодировки: просто попробуйте поменять ANSI на OEM — и старый текстовый файл станет читаемым за 1 сек.!
Исправление иероглифов на текст
👉 Для работы с текстовыми файлами различных кодировок также подойдет еще один блокнот — Notepad++. Вообще, конечно, он больше подходит для программирования, т.к. поддерживает различные подсветки, для более удобного чтения кода.
*
Notepad++
Сайт: https://notepad-plus-plus.org/
Надежный, удобный, поддерживающий громадное число форматов файлов блокнот. Позволяет легко и быстро переключать различные кодировки.
*
Пример смены кодировки показан ниже: чтобы прочитать текст, достаточно в примере ниже, достаточно было сменить кодировку ANSI на UTF-8.
Смена кодировки в блокноте Notepad++
*
Штирлиц
Сайт разработчика: http://www.shtirlitz.ru/
Эта программа специализируется на «расшифровке» текстов, написанных в разных кодировках: Win-1251, KOI-8r, DOS, ISO-8859-5, MAC и др.
Причем, программа нормально работает даже с текстами со смешанной кодировкой (что не могут др. аналоги). Пример см. на скрине ниже. 👇
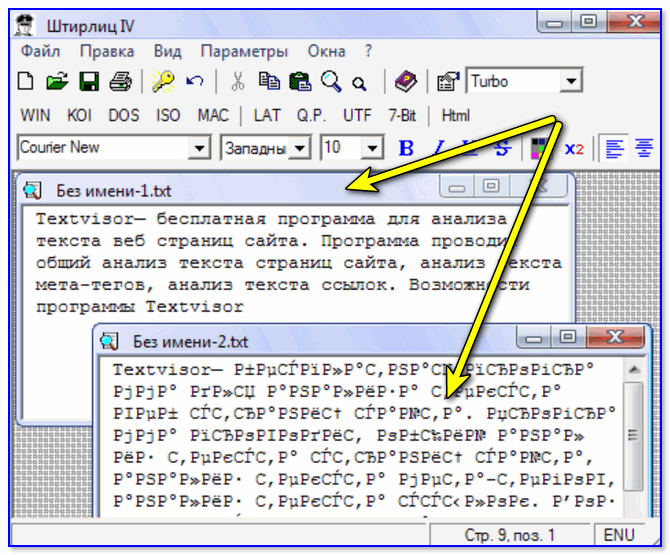
Пример работы ПО «Штирлиц»
*
BAT-файлы (скрипты)
Для начала простой пример о чем идет речь. 👇
На скрине видно, что вместо русского текста отображаются различные квадратики, буквы «г» перевернутые, и пр. иероглифы.
Как выглядит русский текст при выполнении BAT-файла
*
📌 Чтобы это исправить — можно прибегнуть к следующему:
- в начало BAT-файла добавить код @chcp 1251;
- установить программу Notepad++ и в меню выбрать OEM-866: «Кодировки/Кодировки/Кириллица/OEM-866»;
- установить программу Akelpad, в разделе «Кодировки» выбрать «Сохранить в DOS-866».
*
Документы MS WORD
Очень часто проблема с крякозабрами в Word связана с тем, что путают два формата Doc и Docx. Дело в том, что с 2007 года в Word (если не ошибаюсь) появился формат Docx (позволяет более сильнее сжимать документ, чем Doc, да и надежнее защищает его).
Так вот, если у вас старый Word, который не поддерживает этот формат — то вы, при открытии документа в Docx, увидите иероглифы и ничего более.
*
📌 Есть неск. путей решения:
- скачать на сайте Microsoft спец. дополнение, которое позволяет открывать в старом Word новые документы (с 2020г. дополнение с офиц. сайта удалено). Только из личного опыта могу сказать, что открываются далеко не все документы, к тому же сильно страдает разметка документа (что в некоторых случаях очень критично);
- использовать 👉 аналоги Word (правда, тоже разметка в документе будет страдать);
- обновить Word до современной версии (2019+);
- если речь идет о документы TXT — открыть его в Notepad++.
*
Так же при открытии любого документа в Word (в кодировке которого он «сомневается»), он на выбор предлагает вам самостоятельно указать оную. Пример показан на рисунке ниже, попробуйте выбрать:
- Widows (по умолчанию);
- MS DOS;
- Другая…
Переключение кодировки в Word при открытии документа
*
Окна в различных приложениях Windows
Бывает такое, что какое-нибудь окно или меню в программе показывается с иероглифами (разумеется, прочитать что-то или разобрать — нереально).
*
📌 Могу дать несколько рекомендаций:
- Русификатор. Довольно часто официальной поддержки русского языка в программе нет, но многие умельцы делают русификаторы. Скорее всего, на вашей системе — данный русификатор работать отказался. Поэтому, совет простой: попробовать поставить другой;
- Переключение языка. Многие программы можно использовать и без русского, переключив в настройках язык на английский. Ну в самом деле: зачем вам в какой-то утилите, вместо кнопки «Start» перевод «начать»?
- Если у вас раньше текст отображался нормально, а сейчас нет — попробуйте 👉 восстановить Windows, если, конечно, у вас есть точки восстановления;
- Проверить настройки языков и региональных стандартов в Windows, часто причина кроется именно в них (👇).
*
Языки и региональные стандарты в Windows
Чтобы открыть меню настроек:
- нажмите Win+R;
- введите intl.cpl, нажмите Enter.
intl.cpl — язык и регион. стандарты
Проверьте чтобы во вкладке «Форматы» стояло «Русский (Россия) / Использовать язык интерфейса Windows (рекомендуется)» (пример на скрине ниже 👇).
Формат — русский / Россия
Во вкладке «Местоположение» — укажите «Россия».
Местоположение — Россия
И во вкладке «Дополнительно» установите язык системы «Русский (Россия)».
После этого сохраните настройки и перезагрузите ПК. Затем вновь проверьте, нормально ли отображается интерфейс нужной программы.
Текущий язык программ
*
PS
И напоследок, наверное, для многих это очевидно, и все же некоторые открывают определенные файлы в программах, которые не предназначены для этого: к примеру в обычном блокноте пытаются прочитать файл DOCX или PDF.
📌 В помощь! Незаменимые программы для чтения PDF-файлов
Естественно, в этом случае вы вместо текста будут наблюдать за крякозабрами, используйте те программы, которые предназначены для данного типа файла (WORD 2016+ и Adobe Reader для примера выше).
*
На сим пока всё, удачи!
👋
Первая публикация: 26.01.2017
Корректировка: 14.06.2022


Полезный софт:
-

- Видео-Монтаж

Отличное ПО для создания своих первых видеороликов (все действия идут по шагам!).
Видео сделает даже новичок!
-
- Ускоритель компьютера

Программа для очистки Windows от «мусора» (удаляет временные файлы, ускоряет систему, оптимизирует реестр).
Время на прочтение
3 мин
Количество просмотров 22K
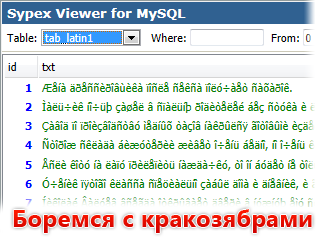 В связи с тем, что довольно много людей обращается с просьбой помочь исправить проблему с кодировками MySQL, решил написать статью с описанием, как «лечить» наиболее часто встречающиеся случаи.
В связи с тем, что довольно много людей обращается с просьбой помочь исправить проблему с кодировками MySQL, решил написать статью с описанием, как «лечить» наиболее часто встречающиеся случаи.
В статье описывается не то, как первоначально правильно настроить кодировки MySQL (об этом уже довольно много написано), а о случаях, когда есть довольно большие таблицы с неправильными кодировками и нужно всё исправить.
Самое плохое в неправильно настроенных кодировках — то, что зачастую проблему сложно обнаружить, и с первого взгляда может казаться, что сайт работает правильно, и никаких проблем нет.
Небольшое отступление. Sypex Viewer
В какой-то момент надоело отправлять людей в громоздкий phpMyAdmin, и была написана крошечная утилитка Sypex Viewer. Она представляет собой один PHP-файл, использует современные Web 2.0 технологии AJAX, JSON и другие. Основные задачи, которые ставилась при создании — минимальный вес, и максимальное удобство и скорость работы. В дальнейшем в примерах будут скриншоты из неё, но все те же действия можно сделать и в phpMyAdmin.
Данные в cp1251 таблицы в latin1
Наверное, самая популярная проблема. Когда данные в кодировке cp1251 (Windows-1251), а у таблиц указана кодировка по умолчанию latin1. Такие ситуации возникают в следующих случаях:
- при неграмотном обновлении с версии MySQL меньше 4.1 на более новые;
- очень часто возникает в «буржуйских» скриптах, которых вполне устраивает кодировка по умолчанию, и они «забывают», что неплохо бы указывать кодировку, как таблиц, так и соединения;
- также бывают случаи, когда переезжают с одного сервера (у которого установлена дефолтная кодировка cp1251, в частности, так сделано в Денвере) на другой (у которого стоит стандартная кодировка latin1).
В результате на сайте вроде как всё нормально, но если посмотреть в Sypex Viewer, то русские символы будут выглядеть как «кракозябры» (как их обычно называют пользователи).
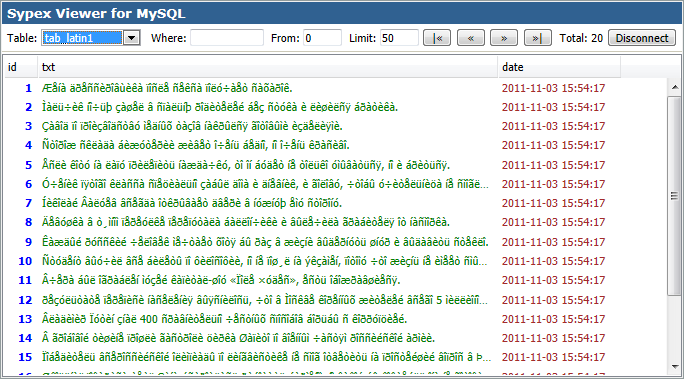
В статье я рассмотрю один из вариантов преобразование кодировок с помощью бесплатного php-скрипта Sypex Dumper, в качестве готового решения.
- На вкладке «Экспорт» выбираем нужные таблицы.
- Кодировка должна быть auto (остальные параметры неважны, можно комментарий добавить, например, «Дамп перед исправлением кодировки»).
- Нажимаем «Выполнить». Теперь у нас есть бэкап (его в любом случае желательно делать при любых преобразованиях базы данных).
- Переходим на вкладку «Импорт»
- Выбираем только что сделанный файл бэкапа.
- Выбираем кодировку cp1251 и помечаем опцию «Коррекция кодировки».
- Нажимаем «Выполнить».
- Вот и всё заходим в Sypex Viewer, чтобы убедиться, что русские символы выводятся корректно.

Данные и таблицы в utf8, но кодировка соединения latin1
Теперь рассмотрим более запущенный случай. Набирающая популярность в последнее время проблема, в связи с повальным увлечением UTF-8. Создатели софта стали переводить свои детища на UTF-8, но и тут не всё так гладко, как хотелось бы.
Возникает проблема в основном в случае, когда у таблиц указана кодировка UTF-8, данные в UTF-8, но кодировка соединения установлена по умолчанию latin1 (типичный пример, vBulletin 4, хоть там и есть в конфигах настройка кодировки соединения, но она закомментирована по умолчанию).
В результате в MySQL присылаются данные в UTF-8, но поскольку указана кодировка соединения latin1, то MySQL пытается преобразовать данные из latin1 в UTF-8. В итоге русские символы выглядят так:
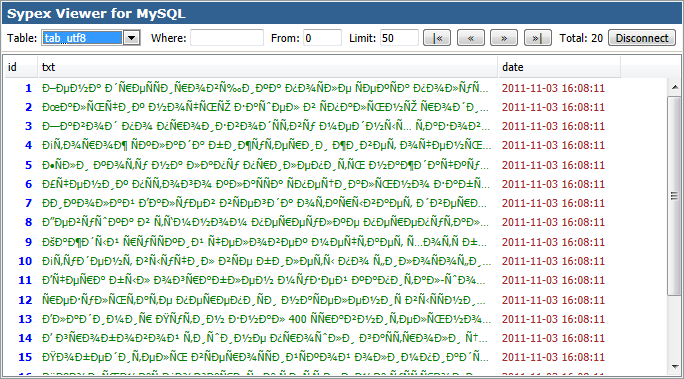
Ситуация более запущенная, но исправляется проблема почти также, как в первом случае, только в пункте 2 нужно выбрать кодировку latin1, а в пункте 6 нужно выбрать utf8 кодировку.
Изменение кодировки
Также часто встречающаяся проблема преобразования кодировки из cp1251 в UTF-8. До выполнения этого шага обязательно убедитесь, что русские символы у вас правильно показываются в Sypex Viewer или phpMyAdmin, если это не так, то предварительно исправьте кодировку.
Итак, опять заходим в Sypex Dumper.
- Во вкладке «Экспорт» выбираем нужные таблицы.
- Устанавливаем кодировку, в которую хотите преобразовать таблицы, в данном случае utf8.
- Нажимаем «Выполнить».
- После чего заходим в «Импорт» и выбираем нужный файл.
- Выставляем кодировку utf8 и опцию «Коррекция кодировки».
- Нажимаем «Выполнить».
- Вот и всё таблицы в UTF-8. Не забываем, что нужно еще установить кодировку соединения, сконвертировать ваши скрипты и шаблоны в UTF-8, выставить правильную кодировку в заголовках.
Кодировка соединения
Не забываем, что после исправлений кодировки, нужно убедиться, что ваши скрипты используют правильную кодировку соединения (в принципе, это будет сразу видно, они будут неправильно показывать русские символы без нужной кодировки соединения). У некоторых она выставляется в настройках, в некоторых придется добавить самостоятельно.
Для чего достаточно пройтись поиском по файлам, и найти где вызывается функция mysql_connect (или mysqli_connect). После этой строки нужно добавить строку которая укажет кодировку соединения.
mysql_query("SET NAMES 'cp1251'");Где вместо cp1251, указать нужную кодировку соединения.
Не забывайте перед преобразованиями кодировок делать бэкап, тут как с презервативами, лучше пусть он будет и не понадобится, чем когда понадобится — его не будет.
P.S. Спасибо Шортикам за веселый контент для примеров.