
Расхождения
между величиной какого-либо показателя,
найденного посредством статистического
наблюдения, и действительными его
размерами называются ошибками
наблюдения.В зависимости от
причин возникновения различают ошибки
регистрации и ошибки репрезентативности.
Ошибки
регистрациивозникают в результате
неправильного установления фактов или
ошибочной записи в процессе наблюдения
или опроса. Они бывают случайными или
систематическими. Случайные ошибки
регистрации могут быть допущены как
опрашиваемыми в их ответах, так и
регистраторами. Систематические ошибки
могут быть и преднамеренными, и
непреднамеренными. Преднамеренные –
сознательные, тенденциозные искажения
действительного положения дела.
Непреднамеренные вызываются различными
случайными причинами (небрежность,
невнимательность).
Ошибки
репрезентативности(представительности)
возникают в результате неполного
обследования и в случае, если обследуемая
совокупность недостаточно полно
воспроизводит генеральную совокупность.
Они могут быть случайными и систематическими.
Случайные ошибки репрезентативности
– это отклонения, возникающие при
несплошном наблюдении из-за того, что
совокупность отобранных единиц наблюдения
(выборка) неполно воспроизводит всю
совокупность в целом. Систематические
ошибки репрезентативности – это
отклонения, возникающие вследствие
нарушения принципов случайного отбора
единиц. Ошибки репрезентативности
органически присущи выборочному
наблюдению и возникают в силу того, что
выборочная совокупность не полностью
воспроизводит генеральную. Избежать
ошибок репрезентативности нельзя,
однако, пользуясь методами теории
вероятностей, основанными на использовании
предельных теорем закона больших чисел,
эти ошибки можно свести к минимальным
значениям, границы которых устанавливаются
с достаточно большой точностью.
Ошибки
выборки –разность между
характеристиками выборочной и генеральной
совокупности. Для среднего значения
ошибка будет определяться по формуле
![]()
(7.1)
где
![]()
Величина
![]() называетсяпредельной ошибкойвыборки.
называетсяпредельной ошибкойвыборки.
Предельная
ошибка выборки – величина случайная.
Исследованию закономерностей случайных
ошибок выборки посвящены предельные
теоремы закона больших чисел. Наиболее
полно эти закономерности раскрыты в
теоремах П. Л. Чебышева и А. М. Ляпунова.
Теорему П.
Л. Чебышева применительно к
рассматриваемому методу можно
сформулировать следующим образом: при
достаточно большом числе независимых
наблюдений можно с вероятностью, близкой
к единице (т. е. почти с достоверностью),
утверждать, что отклонение выборочной
средней от генеральной будет сколько
угодно малым. В теореме П. Л. Чебышева
доказано, что величина ошибки не должна
превышать![]() .
.
В свою очередь величина![]() ,
,
выражающая среднее квадратическое
отклонение выборочной средней от
генеральной средней, зависит от
колеблемости признака в генеральной
совокупности![]() и числа отобранных единицn. Эта
и числа отобранных единицn. Эта
зависимость выражается формулой
![]() ,
,
(7.2)
где
![]() зависит также от способа производства
зависит также от способа производства
выборки.
Величину
![]() =
=![]() называютсредней ошибкой выборки. В
называютсредней ошибкой выборки. В
этом выражении![]() – генеральная дисперсия,n– объем
– генеральная дисперсия,n– объем
выборочной совокупности.
Рассмотрим, как
влияет на величину средней ошибки число
отбираемых единиц n. Логически
нетрудно убедиться, что при отборе
большого числа единиц расхождения между
средними будут меньше, т. е. существует
обратная связь между средней ошибкой
выборки и числом отобранных единиц. При
этом здесь образуется не просто обратная
математическая зависимость, а такая
зависимость, которая показывает, что
квадрат расхождения между средними
обратно пропорционален числу отобранных
единиц.
Увеличение
колеблемости признака влечет за собой
увеличение среднего квадратического
отклонения, а следовательно, и ошибки.
Если предположить, что все единицы будут
иметь одинаковую величину признака, то
среднее квадратическое отклонение
станет равно нулю и ошибка выборки
также исчезнет. Тогда нет необходимости
применять выборку. Однако следует иметь
в виду, что величина колеблемости
признака в генеральной совокупности
неизвестна, поскольку неизвестны размеры
единиц в ней. Можно рассчитать лишь
колеблемость признака в выборочной
совокупности. Соотношение между
дисперсиями генеральной и выборочной
совокупности выражается формулой
![]()
Поскольку
величина
![]() при достаточно большихnблизка к
при достаточно большихnблизка к
единице, можно приближенно считать, что
выборочная дисперсия равна генеральной
дисперсии, т. е.![]()
Следовательно,
средняя ошибка выборки показывает,
какие возможны отклонения характеристик
выборочной совокупности от соответствующих
характеристик генеральной совокупности.
Однако о величине этой ошибки можно
судить с определенной вероятностью. На
величину вероятности указывает множитель
![]()
Теорема А.
М. Ляпунова. А. М. Ляпунов доказал,
что распределение выборочных средних
(следовательно, и их отклонений от
генеральной средней) при достаточно
большом числе независимых наблюдений
приближенно нормально при условии, что
генеральная совокупность обладает
конечной средней и ограниченной
дисперсией.
Математически
теорему Ляпуноваможно записать
так:
 (7.3)
(7.3)
где
![]() ,
,
(7.4)
где ![]() – математическая постоянная;
– математическая постоянная;
![]() –предельная ошибка выборки,которая дает возможность выяснить, в
–предельная ошибка выборки,которая дает возможность выяснить, в
каких пределах находится величина
генеральной средней.
Значения этого
интеграла для различных значений
коэффициента доверия tвычислены и
приводятся в специальных математических
таблицах. В частности, при:

Поскольку tуказывает на вероятность расхождения![]() ,
,
т. е. на вероятность того, на какую
величину генеральная средняя будет
отличаться от выборочной средней, то
это может быть прочитано так: с вероятностью
0,683 можно утверждать, что разность между
выборочной и генеральной средними не
превышает одной величины средней ошибки
выборки. Другими словами, в 68,3 % случаев
ошибка репрезентативности не выйдет
за пределы![]() С вероятностью 0,954 можно утверждать,
С вероятностью 0,954 можно утверждать,
что ошибка репрезентативности не
превышает![]() (т. е. в 95 % случаев). С вероятностью
(т. е. в 95 % случаев). С вероятностью
0,997, т. е. довольно близкой к единице,
можно ожидать, что разность между
выборочной и генеральной средней не
превзойдет трехкратной средней ошибки
выборки и т. д.
Логически связь
здесь выглядит довольно ясно: чем больше
пределы, в которых допускается
возможная ошибка, тем с большей
вероятностью судят о ее величине.
Зная выборочную
среднюю величину признака
![]() и предельную ошибку выборки
и предельную ошибку выборки![]() ,
,
можно определить границы (пределы),
в которых заключена генеральная
средняя
![]() (7.5)
(7.5)
1.
Собственно-случайная выборка–
этот способ ориентирован на выборку
единиц из генеральной совокупности без
всякого расчленения на части или группы.
При этом для соблюдения основного
принципа выборки – равной возможности
всем единицам генеральной совокупности
быть отобранным – используются схема
случайного извлечения единиц путем
жеребьевки (лотереи) или таблицы случайных
чисел. Возможен повторный и бесповторный
отбор единиц
Средняя ошибка
собственно-случайной выборки
представляет собой среднеквадратическое
отклонение возможных значений выборочной
средней от генеральной средней. Средние
ошибки выборки при собственно-случайном
методе отбора представлены в табл. 7.2.
Таблица 7.2
|
Средняя ошибка |
При отборе |
|
|
повторном |
бесповторном |
|
|
Для средней |
|
|
|
Для доли |
|
|

В таблице
использованы следующие обозначения:
![]() – дисперсия выборочной совокупности;
– дисперсия выборочной совокупности;
![]() – численность выборки;
– численность выборки;
![]() – численность генеральной совокупности;
– численность генеральной совокупности;
![]() – выборочная доля единиц, обладающих
– выборочная доля единиц, обладающих
изучаемым признаком;
![]() – число единиц, обладающих изучаемым
– число единиц, обладающих изучаемым
признаком;
![]() – численность выборки.
– численность выборки.
Для увеличения
точности вместо множителя
![]() следует
следует
брать множитель
![]() ,
,
но при большой численностиNразличие
между этими выражениями практического
значения не имеет.
Предельная
ошибка собственно-случайной выборки
![]() рассчитывается по формуле
рассчитывается по формуле
![]() ,
,
(7.6)
где t
– коэффициент доверия зависит от
значения вероятности.
Пример.При
обследовании ста образцов изделий,
отобранных из партии в случайном порядке,
20 оказалось нестандартными. С вероятностью
0,954 определите пределы, в которых
находится доля нестандартной продукции
в партии.
Решение.
Вычислим генеральную долю (Р):
![]() .
.
Доля нестандартной
продукции:
 .
.
Предельная
ошибка выборочной доли с вероятностью
0,954 рассчитывается по формуле (7.6) с
применением формулы табл. 7.2 для доли:

![]()
С вероятностью
0,954 можно утверждать, что доля нестандартной
продукции в партии товара находится в
пределах 12 % ≤ P≤ 28 %.
В практике
проектирования выборочного наблюдения
возникает потребность определения
численности выборки, которая необходима
для обеспечения определенной точности
расчета генеральных средних. Предельная
ошибка выборки и ее вероятность при
этом являются заданными. Из формулы
![]() и формул средних ошибок выборки
и формул средних ошибок выборки
устанавливается необходимая численность
выборки. Формулы для определения
численности выборки (n) зависят от
способа отбора. Расчет численности
выборки для собственно-случайной выборки
приведен в табл. 7.3.
Таблица 7.3
|
Предполагаемый |
Формулы |
|
|
для средней |
для доли |
|
|
Повторный |
|
|
|
Бесповторный |
|
|



2.
Механическая выборка– при этом
методе исходят из учета некоторых
особенностей расположения объектов в
генеральной совокупности, их упорядоченности
(по списку, номеру, алфавиту). Механическая
выборка осуществляется путем отбора
отдельных объектов генеральной
совокупности через определенный интервал
(каждый 10-й или 20-й). Интервал рассчитывается
по отношению![]() ,
,
гдеn– численность выборки,N–
численность генеральной совокупности.
Так, если из совокупности в 500 000 единиц
предполагается получить 2 %-ную выборку,
т. е. отобрать 10 000
единиц, то пропорция отбора составит![]() Отбор
Отбор
единиц осуществляется в соответствии
с установленной пропорцией через равные
интервалы. Если расположение объектов
в генеральной совокупности носит
случайный характер, то механическая
выборка по содержанию аналогична
случайному отбору. При механическом
отборе применяется только бесповторная
выборка [1, 5–10].
Средняя ошибка
и численность выборки при механическом
отборе подсчитывается по формулам
собственно-случайной выборки (см.
табл. 7.2 и 7.3).
3.
Типическая выборка, при котрой
генеральная совокупность делится по
некоторым существенным признакам на
типические группы; отбор единиц
производится из типических групп. При
этом способе отбора генеральная
совокупность расчленяется на однородные
в некотором отношении группы, которые
имеют свои характеристики, и вопрос
сводится к определению объема выборок
из каждой группы. Может бытьравномерная
выборка– при этом способе из каждой
типической группы отбирается одинаковое
число единиц![]() Такой подход оправдан лишь при равенстве
Такой подход оправдан лишь при равенстве
численностей исходных типических групп.
При типическом отборе, непропорциональном
объему групп, общее число отбираемых
единиц делится на число типических
групп, полученная величина дает
численность отбора из каждой типической
группы.
Более совершенной
формой отбора является пропорциональная
выборка. Пропорциональной называется
такая схема формирования выборочной
совокупности, когда численность выборок,
взятых из каждой типической группы в
генеральной совокупности, пропорциональна
численностям, дисперсиям (или комбинированно
и численностям, и дисперсиям). Условно
определяем численность выборки в 100
единиц и отбираем единицы из групп:
– пропорционально
численности их генеральной совокупности
(табл. 7.4). В таблице
обозначено:
Ni– численность типической группы;
dj
– доля (Ni/N);
N– численность
генеральной совокупности;
ni– численность выборки из типической
группы вычисляется:
![]() , (7.7)
, (7.7)
n – численность выборки из генеральной
совокупности.
Таблица
7.4
-
Группы
Ni
dj
ni
1
300
0,3
30
2
500
0,5
50
3
200
0,2
20
1000
1,0
100
–
пропорционально среднему квадратическому
отклонению(табл. 7.5).
здесь
i– среднее
квадратическое отклонение типических
групп;
ni
– численность выборки из типической
группы вычисляется по формуле

(7.8)
Таблица
7.5
-
Ni
i

ni
300
5
0,25
25
500
7
0,35
35
200
8
0,40
40
1000
20
1,0
100
–
комбинированно (табл. 7.6).
Численность
выборки вычисляется по формуле
![]() . (7.9)
. (7.9)
Таблица 7.6
-

i
iNi


300
5
1500
0,23
23
500
7
2100
0,53
53
200
8
1600
0.24
24
1000
20
6600
1,0
100
При проведении
типической выборки непосредственный
отбор из каждой группы проводится
методом случайного отбора.
Средние ошибки
выборки рассчитываются по формулам
табл. 7.7 в зависимости от способа отбора
из типических групп.
Таблица 7.7
|
Способ |
Повторный |
Бесповторный |
||
|
для |
для |
для |
для |
|
|
Непропорциональный |
|
|
|
|
|
Пропорциональный объему групп |
|
|
|
|
|
Пропорциональный |
|
|
|
|





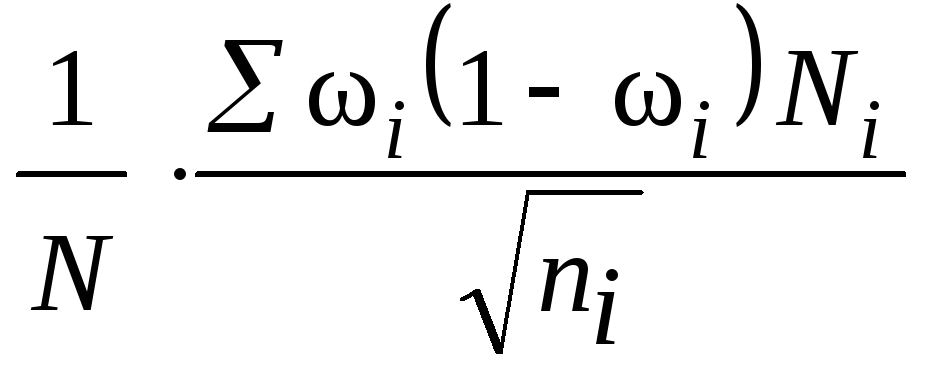


здесь
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
типических групп;
![]() – доля единиц, обладающих изучаемым
– доля единиц, обладающих изучаемым
признаком;
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
для доли;
![]() – среднее квадратическое отклонение
– среднее квадратическое отклонение
в выборке изi-й типической группы;
![]() – объем выборки из типической группы;
– объем выборки из типической группы;
![]() – общий объем выборки;
– общий объем выборки;
![]() –
–
объем типической группы;
![]() – объем генеральной совокупности.
– объем генеральной совокупности.
Численность
выборки из каждой типической группы
должна быть пропорциональна среднему
квадратическому отклонению в этой
группе
![]() .Расчет численности
.Расчет численности
![]() производится по формулам, приведенным
производится по формулам, приведенным
в табл. 7.8.
Таблица 7.8
|
Повторный |
Бесповторный |
|
|
Для определения |
|
|
|
Для определения |
|
|
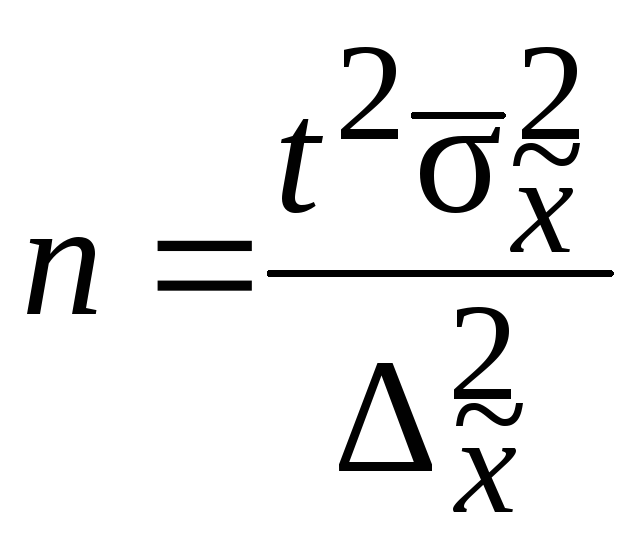

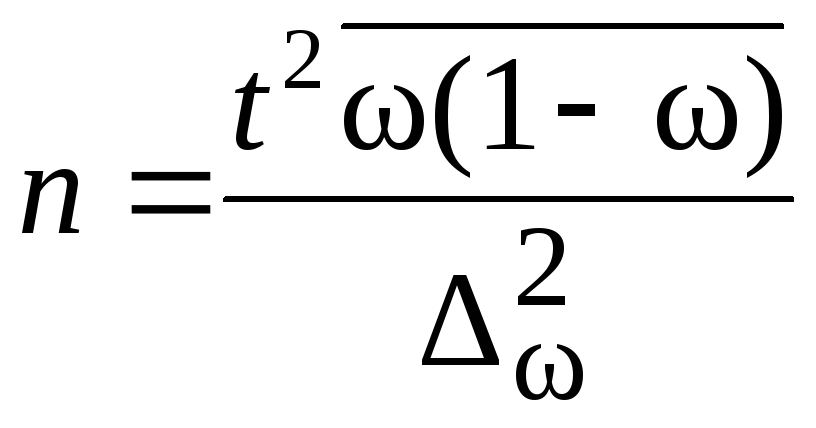

4. Серийная
выборка– удобена в тех случаях,
когда единицы совокупности объединены
в небольшие группы или серии. При серийной
выборке генеральную совокупность делят
на одинаковые по объему группы – серии.
В выборочную совокупность отбираются
серии. Сущность серийной выборки
заключается в случайном или механическом
отборе серий, внутри которых производится
сплошное обследование единиц. Средняя
ошибка серийной выборки с равновеликими
сериями зависит от величины только
межгрупповой дисперсии. Средние ошибки
сведены в табл. 7.9.
Таблица 7.9
|
Способ |
Формулы |
|
|
для |
для |
|
|
Повторный |
|
|
|
Бесповторный |
|
|


Здесь
R– число серий в генеральной
совокупности;
r – число
отобранных серий;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
средних;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
доли.
При серийном
отборе необходимую численность отбираемых
серий определяют так же, как и при
собственно-случайном методе отбора.
Расчет численности
серийной выборки производится по
формулам, приведенным в табл. 7.10.
Таблица 7.10
|
Повторный |
Бесповторный |
|
|
Для |
|
|
|
Для |
|
|
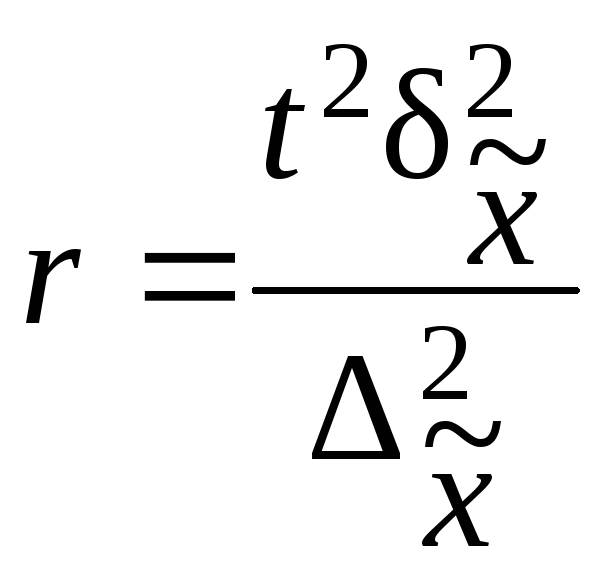

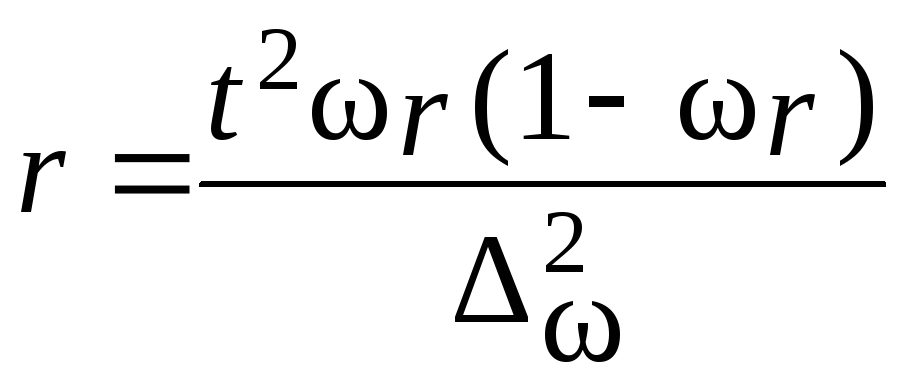

Пример.В
механическом цехе завода в десяти
бригадах работает 100 рабочих. В целях
изучения квалификации рабочих была
произведена 20 %-ная серийная бесповторная
выборка, в которую вошли две бригады.
Получено следующее распределение
обследованных рабочих по разрядам:
|
Рабочие |
Разряды рабочих |
Разряды рабочих |
Рабочие |
Разряды |
Разряды |
|
1 2 3 4 5 |
2 4 5 2 5 |
3 6 1 5 3 |
6 7 8 9 10 |
6 5 8 4 5 |
4 2 1 3 2 |
Необходимо
определить с вероятностью 0,997 пределы,
в которых находится средний разряд
рабочих механического цеха.
Решение.
Определим выборочные средние по
бригадам и общую среднюю как среднюю
взвешенную из групповых средних:

Определим
межсерийную дисперсию по формулам
(5.25):
![]()
Рассчитаем
среднюю ошибку выборки по формуле табл.
7.9:
![]()
Вычислим
предельную ошибку выборки с вероятностью
0,997:
![]()
С вероятностью
0,997 можно утверждать, что средний разряд
рабочих механического цеха находится
в пределах
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Ошибка
репрезентативности
— расхождение между выборочной
характеристикой и характеристикой
генеральной совокупности.
Ошибки
репрезентативности
-
Систематические
— возникают в результате нарушения
научных принципов отбора единиц
совокупности (преднамеренные и
непреднамеренные). -
Случайные
возникают в результате несплошного
характера наблюдения (средняя и
предельная ошибки выбора).
Случайные
ошибки могут быть доведены до незначительных
размеров, а главное, их размеры и пределы
можно определить с достаточной точностью
на основании закона больших чисел.
Средняя
ошибка выборки
— такое расхождение между средними
выборочной и генеральной совокупностями,
которое не превышает ±.
В
математической статистике доказывается,
что значения средней ошибки выборки
определяются по формулам:
Формула
для определения величины средней ошибки
выборки для количественного признака:
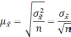
Формула
для определения величины средней ошибки
выборки для альтернативного признака:

Полученное
значение средней ошибки необходимо для
установления возможного значения 
 .
.
Которое определяется по формуле:
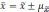
Но
такое суждение можно гарантировать не
с абсолютной
достоверностью, а лишь с определенной
степенью
вероятности.
В
математической статистике доказывается,
что пределы значений характеристик
генеральной совокупности отличаются
от характеристик выборочной совокупности
лишь с вероятностью, которая определена
числом 0,683.
Это
означает, что в 683 случаях из 1000 генеральная
средняя будет находиться в установленных
пределах, т.е. отклонение ГС от ВС не
превысит однократной средней ошибки
выборки. В остальных 317 случаях они могут
выйти за эти пределы. Вероятность можно
повысить, если расширить пределы
отклонений. Так, при удвоенном значении

 ,
,
вероятность достигает 0,954 (
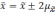 ).
).
Если утроить значение то вероятность
увеличится до 0,997 (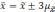
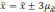 ).
).
|
Возможное |
Вероятность |
|
|
0,683 |
|
|
0,954 |
|
|
0,997 |
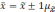
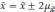
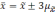
Если
обозначить значение увеличения 

за
t,
то можно записать в общем виде:
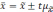
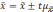
Множитель
t
называется коэффициентом
доверия.
Известный русский математик А.М.Ляпунов
дал выражение конкретных значений
множителя t
для различных степеней вероятности в
виде функции:
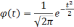
На
практике пользуются готовыми таблицами
этой функции.
|
t |
0 |
0,1 |
0,5 |
1 |
1,5 |
2 |
2,5 |
2,6 |
3 |
4 |
|
(t) |
0,1 |
0,0797 |
0,3829 |
0,6827 |
0,8664 |
0,9545 |
0,9876 |
0,9907 |
0,9973 |
0,99994 |
Из
вышесказанного следует, что лишь с
определенной степенью вероятности
можно утверждать, что показатели
генеральной совокупности и их отклонения
не превысят величину 
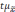 .
.
Полученную величину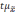
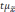 называетсяпредельной
называетсяпредельной
ошибкой выборки.
Предельная
ошибка выборки
—
максимально
возможное расхождение выборочной и
генеральной средних,
т.е.
максимум ошибки при заданной вероятности
ее появления.
Предельная
ошибка выборки для количественного
признака:
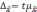
Предельная
ошибка выборки для альтернативного
признака:
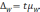
В
связи с тем, что существуют различные
методы, виды и способы отбора единиц из
генеральной совокупности формулы для
расчета средней ошибки выборки также
будут различаться:
|
Способ |
Оцениваемый |
Повторный |
Бесповторный |
|
Собственно случайный механический |
Средняя |
|
|
|
Доля |
|
|
|
|
Типический |
Средняя |
|
|
|
Доля |
|
|
|
|
Серийный |
Средняя |
|
|
|
Доля |
|
|
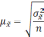
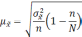
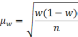
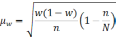
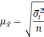
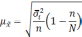
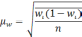
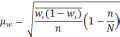
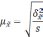
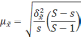

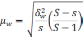
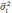
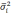
— средняя из групповых дисперсий;
wi
— доля
единиц совокупности, обладающих изучаемым
признаком в i-й
типической
группе;
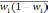
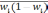
— средняя из групповых дисперсий для
доли. В табл. 6.6 представлены формулы
для исчисления средней ошибки выборки
при типическом отборе;
S
– общее число серий;
s
– число отобранных серий;

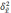 —
—
межгрупповая дисперсия средних,
определяемая по формуле:
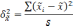
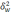
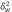 —
—
межгрупповая дисперсия доли, определяемая
по формуле:
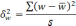
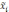
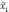
— средняя
i-й
серии;


—
средняя по всей выборочной совокупности;
w
— доля признака i-й
серии;


— общая доля признака во всей выборочной
совокупности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
-
Помощь студентам
-
Онлайн тесты
-
Экономика
-
Тесты с ответами по статистике
Тест по теме «Тесты с ответами по статистике»
-

Обновлено: 15.04.2021
-

479 832
97 вопросов
Выполним любые типы работ
- Дипломные работы
- Курсовые работы
- Рефераты
- Контрольные работы
- Отчет по практике
- Эссе
Популярные тесты по экономике

Экономика
Тесты с ответами по статистике
Экономика
Тесты с ответами по Макроэкономике
Экономика
Тесты с ответами по предмету экономика предприятия
Экономика
Тест с ответами по Мировой экономике
Экономика
Тесты с ответами по АФХД
Экономика
Тест с ответами по инвестициям
Экономика
Тест с ответами по Инновационному менеджменту
Экономика
Тесты по логистике с ответами
Экономика
Экономическая теория. Тема 6. Эластичность спроса и предложения
Мы поможем сдать на отлично и без пересдач
-
Контрольная работа
-
Курсовая работа
-
Дипломная работа
-
Реферат
-
Онлайн-помощь
Нужна помощь с тестами?
Оставляй заявку — и мы пройдем все тесты за тебя!
Ошибки репрезентативности
- Ошибки репрезентативности
- возможные пределы отклонений выборочной доли и выборочной средней от доли и средней в генеральной совокупности. По своей природе такие ошибки могут быть систематическими и случайными. В социологической и статистической литературе систематические ошибки часто называются также ошибками смещения. Ошибки такого рода имеют в основном одну и ту же постоянную величину или измеряются по определенному закону, имеющему функциональный характер. Систематическими ошибками называются ошибки, являющиеся следствием действия (в одних и тех же условиях) определенной причины или небольшого числа причин, которые искажают полученную информацию в определенном направлении, причем эти причины поддаются изучению. Систематические О. р. наиболее опасны, так как их источником являются неправильные принципы проведения процедуры исследования, способы формирования выборочной совокупности, методы сбора и расчета полученной информации.
К основным причинам появления систематических ошибок репрезентативности относят: 1) преднамеренное или непреднамеренное отступление от принципов случайного отбора при формировании выборочной совокупности; 2) замена единиц наблюдения другими единицами, которые не попали в выборочную совокупность; 3) неполный охват опросом единиц выборочной совокупности; 4) практическая невозможность абсолютно точно реализовать первоначальный план выборки вследствие отказов респондентов от участия в опросе, естественной смертности и подвижности населения, ошибочно написанных адресов, изменений адресов респондентов и пр. Случайными являются такие О. р., которые при повторных измерениях принимают различные взаимонезависимые положительные или отрицательные значения. О случайных ошибках речь может идти только тогда, когда помимо основных у нас имеются еще и дополнительно проведенные измерения. Случайные О. р. предстают в форме случайных величин или функций, то есть пределов, в которых находится результат. Их с некоторой вероятностью можно предвидеть. Т. е. величину случайной ошибки можно априори измерить.
Социологический справочник. — К.: Политиздат Украины.
.
1990.
Полезное
Смотреть что такое «Ошибки репрезентативности» в других словарях:
-
Ошибки — вид неадекватности знания объекту познания. О. являются неотъемлемой частью любого исследования так как их невозможно исключить полностью. Их просто необходимо учитывать как неоспоримый факт того, что получение определенного количества искомой… … Социологический справочник
-
ВЫБОРКИ ОШИБКИ СЛУЧАЙНЫЕ — англ. sample error, random; нем. Stichprobenfehler, zufalliger. Статист, погрешности, представляющие собой отклонения характеристик выборочного распределения от генеральной совокупности (ошибка репрезентативности). Antinazi. Энциклопедия… … Энциклопедия социологии
-
ВЫБОРКИ ОШИБКИ СЛУЧАЙНЫЕ — англ. sample error, random; нем. Stichprobenfehler, zufalliger. Статист, погрешности, представляющие собой отклонения характеристик выборочного распределения от генеральной совокупности (ошибка репрезентативности) … Толковый словарь по социологии
-
Контролирование репрезентативности — сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение … Социология: словарь
-
Многоступенчатая выборка — характеризуется тем, что на всех ступенях осуществляется отбор объектов репрезентации, а наблюдение единиц производится на последней ступени. Необходимость многоступенчатого отбора вызвана, как правило, огсутствием информации по всей генеральной… … Социологический справочник
-
ОБЪЕМ ВЫБОРКИ — число элементов, включенных в выборочную совокупность; зависит от вероятности заключения о достоверности выводов, от величины предельной ошибки репрезентативности, от вероятности появлений события и определяется: 1) задачами исследования; 2)… … Современный образовательный процесс: основные понятия и термины
-
Статистическое наблюдение — Начальной стадией статистического исследования является статистическое наблюдение научно организованный сбор ссведений об изучаемых социально экономических процессах или явлений. Полученные данные являются исходным материалом для последующих… … Википедия
-
Отбор случайный единиц совокупности — это такой отбор социологической информации, при котором каждая единица генеральной совокупности имеет равную вероятность попадания в выборочную совокупность. Существует несколько видов О. с.: а) вероятностный отбор при котором, во первых, каждая… … Социологический справочник
-
Коэффициент корреляции — (Correlation coefficient) Коэффициент корреляции это статистический показатель зависимости двух случайных величин Определение коэффициента корреляции, виды коэффициентов корреляции, свойства коэффициента корреляции, вычисление и применение… … Энциклопедия инвестора
-
ИЗМЕРЕНИЕ НАДЕЖНОСТИ СОЦИОЛОГИЧЕСКОЙ ИНФОРМАЦИИ — один из этапов, необходимых для обеспечения требуемого качества социологич. исследования. Надежность является наиболее общей характеристикой качества эмпирич. данных, полученных в социологич. исследовании. Под надежной понимают информацию, в к… … Российская социологическая энциклопедия
1. Статистика как наука изучает:
а) единичные явления;
б) массовые явления;
в) периодические события.
2. Термин «статистика» происходит от слова:
а) статика;
б) статный;
в) статус.
3. Статистика зародилась и оформилась как самостоятельная учебная дисциплина:
а) до новой эры, в Китае и Древнем Риме;
б) в 17-18 веках, в Европе;
в) в 20 веке, в России.
4. Статистика изучает явления и процессы посредством изучения:
а) определенной информации;
б) статистических показателей;
в) признаков различных явлений.
5. Статистическая совокупность – это:
а) множество изучаемых разнородных объектов;
б) множество единиц изучаемого явления;
в) группа зафиксированных случайных событий.
6. Основными задачами статистики на современном этапе являются:
а) исследование преобразований экономических и социальных процессов в обществе; б) анализ и прогнозирование тенденций развития экономики; в) регламентация и планирование хозяйственных процессов;
а) а, в
б) а, б
в) б, в
7. Статистический показатель дает оценку свойства изучаемого явления:
а) количественную;
б) качественную;
в) количественную и качественную.
8. Основные стадии экономико-статистического исследования включают: а) сбор первичных данных, б) статистическая сводка и группировка данных, в) контроль и управление объектами статистического изучения, г) анализ статистических данных
а) а, б, в
б) а, в, г
в) а ,б, г
г) б, в, г
9. Закон больших чисел утверждает, что:
а) чем больше единиц охвачено статистическим наблюдением,тем лучше проявляется общая закономерность;
б) чем больше единиц охвачено статистическим наблюдением, тем хуже проявляется общая закономерность;
в) чем меньше единиц охвачено статистическим наблюдением, тем лучше проявляется общая закономерность.
10. Современная организация статистики включает: а) в России — Росстат РФ и его территориальные органы, б) в СНГ — Статистический комитет СНГ, в) в ООН — Статистическая комиссия и статистическое бюро, г) научные исследования в области теории и методологии статистики
а) а, б, г
б) а, б, в
в) а, в, г
1. Статистическое наблюдение – это:
а) научная организация регистрации информации;
б) оценка и регистрация признаков изучаемой совокупности;
в) работа по сбору массовых первичных данных;
г) обширная программа статистических исследований.
2. Назовите основные организационные формы статистического наблюдения:
а) перепись и отчетность;
в) разовое наблюдение;
г) опрос.
3. Перечень показателей (вопросов) статистического наблюдения, цель, метод, вид, единица наблюдения, объект, период статистического наблюдения излагаются:
а) в инструкции по проведению статистического наблюдения;
б) в формуляре статистического наблюдения;
в) в программе статистического наблюдения.
4. Назовите виды статистического наблюдения по степени охвата единиц совокупности:
а) анкета;
б) непосредственное;
в) сплошное;
г) текущее.
5. Назовите виды статистического наблюдения по времени регистрации:
а) текущее, б) единовременное; в) выборочное; г) периодическое; д) сплошное
а) а, в, д
б) а, б, г
в) б, г, д
6. Назовите основные виды ошибок регистрации: а) случайные; б) систематические; в) ошибки репрезентативности; г) расчетные
а) а
б) а, б
в) а, б, в,
г) а, б, в, г
7. Несплошное статистическое наблюдение имеет виды: а) выборочное;
б) монографическое; в) метод основного массива; г) ведомственная отчетность
а) а, б, в
б) а, б, г
в) б, в, г
8. Организационный план статистического наблюдения регламентирует: а) время и сроки наблюдения; б) подготовительные мероприятия;
в) прием, сдачу и оформление результатов наблюдения; г) методы обработки данных
а) а, б, г
б) а, б, в
9. Является ли статистическим наблюдением наблюдения покупателя за качеством товаров или изменением цен на городских рынках?
а) да
б) нет
10. Ошибка репрезентативности относится к:
а) сплошному наблюдению;
б) не сплошному выборочному наблюдению.
1. Статистическая сводка — это:
а) систематизация и подсчет итогов зарегистрированных фактов и данных;
б) форма представления и развития изучаемых явлений;
в) анализ и прогноз зарегистрированных данных.
2. Статистическая группировка — это:
а) объединение данных в группы по времени регистрации;
б) расчленение изучаемой совокупности на группы по существенным признакам;
в) образование групп зарегистрированной информации по мере ее поступления.
3. Статистические группировки могут быть: а) типологическими; б) структурными; в) аналитическими; г) комбинированными
а) а
б) а, б
в) а, б, в
г) а, б, в, г
4. Группировочные признаки, которыми одни единицы совокупности обладают, а другие — нет, классифицируются как:
а) факторные;
б) атрибутивные;
в) альтернативные.
5. К каким группировочным признакам относятся: образование сотрудников, профессия бухгалтера, семейное положение:
а) к атрибутивным;
б) к количественны.
6. Ряд распределения — это:
а) упорядоченное расположение единиц изучаемой совокупности по группам;
б) ряд значений показателя, расположенных по каким-то правилам.
7. К каким группировочным признакам относятся: сумма издержек обращения, объем продаж, стоимость основных фондов
а) к дискретным;
б) к непрерывным.
8. Какие виды статистических таблиц встречаются:
а) простые и комбинационные;
б) линейные и нелинейные.
1. Статистический показатель — это
а) размер изучаемого явления в натуральных единицах измерения
б) количественная характеристика свойств в единстве с их качественной определенностью
в) результат измерения свойств изучаемого объекта
2. Статистические показатели могут характеризовать:
а) объемы изучаемых процессов
б) уровни развития изучаемых явлений
в) соотношение между элементами явлений
г) а, б, в
3. По способу выражения абсолютные статистические показатели подразделяются на: а) суммарные; б) индивидуальные; в) относительные; г) средние; д) структурные
а) а, д
б) б, в
в) в, г
г) а, б
4. В каких единицах выражаются абсолютные статистические показатели?
а) в коэффициентах
б) в натуральных
в) в трудовых
5. В каких единицах будет выражаться относительный показатель, если база сравнения принимается за единицу?
а) в процентах
б) в натуральных
в) в коэффициентах
6. Относительные показатели динамики с переменной базой сравнения подразделяются на:
а) цепные
б) базисные
7. Сумма всех удельных весов показателя структуры
а) строго равна 1
б) больше или равна 1
в) меньше или равна 1
8. Относительные показатели по своему познавательному значению подразделяются на показатели: а) выполнения и сравнения, б) структуры и динамики, в) интенсивности и координации, г) прогнозирования и экстраполяции
а) а, б, г
б) б, в, г
в) а, б, в
9. Статистические показатели по сущности изучаемых явлений могут быть:
а) качественными
б) объёмными
в) а, б
10. Статистические показатели в зависимости от характера изучаемых явлений могут быть:
а) интервальными
б) моментными
в) а, б
1. Исчисление средних величин — это
а) способ изучения структуры однородных элементов совокупности
б) прием обобщения индивидуальных значений показателя
в) метод анализа факторов
2. Требуется вычислить средний стаж деятельности работников фирмы: 6,5,4,6,3,1,4,5,4,5. Какую формулу Вы примените?
а) средняя арифметическая
б) средняя арифметическая взвешенная
в) средняя гармоническая
3. Средняя геометрическая — это:
а) корень из произведения индивидуальных показателей
б) произведение корней из индивидуальных показателей
4. По какой формуле производится вычисление средней величины в интервальном ряду?
а) средняя арифметическая взвешенная
б) средняя гармоническая взвешенная
5. Могут ли взвешенные и невзвешенные средние, рассчитанные по одним и тем же данным, совпадать?
а) да
б) нет
6. Как изменяется средняя арифметическая, если все веса уменьшить в А раз?
а) уменьшатся
б) увеличится
в) не изменится
7. Как изменится средняя арифметическая, если все значения определенного признака увеличить на число А?
а) уменьшится
б) увеличится
в) не изменится
8. Значения признака, повторяющиеся с наибольшей частотой, называется
а) модой
б) медианой
9. Средняя хронологическая исчисляется
а) в моментных рядах динамики с равными интервалами
б) в интервальных рядах динамики с равными интервалами
в) в интервальных рядах динамики с неравными интервалами
10. Медиана в ряду распределения с четным числом членов ряда равна
а) полусумме двух крайних членов
б) полусумме двух срединных членов
1. Что понимается в статистике под термином «вариация показателя»?
а) изменение величины показателя
б) изменение названия показателя
в) изменение размерности показателя
2. Укажите показатели вариации
а) мода и медиана
б) сигма и дисперсия
в) темп роста и прироста
3. Показатель дисперсии — это:
а) квадрат среднего отклонения
б) средний квадрат отклонений
в) отклонение среднего квадрата
4. Коэффициент вариации измеряет колеблемость признака
а) в относительном выражении
б) в абсолютном выражении
5. Среднеквадратическое отклонение характеризует
а) взаимосвязь данных
б) разброс данных
в) динамику данных
6. Размах вариации исчисляется как
а) разность между максимальным и минимальным значением показателя
б) разность между первым и последним членом ряда распределения
7. Показатели вариации могут быть
а) простыми и взвешенными
б) абсолютными и относительными
в) а) и б)
8. Закон сложения дисперсий характеризует
а) разброс сгруппированных данных
б) разброс неупорядоченных данных
9. Средне квадратическое отклонение исчисляется как
а) корень квадратный из медианы
б) корень квадратный из коэффициента вариации
в) корень квадратный из дисперсии
10. Кривая закона распределения характеризует
а) разброс данных в зависимости от уровня показателя
б) разброс данных в зависимости от времени
1. Выборочный метод в статистических исследованиях используется для:
а) экономии времени и снижения затрат на проведение статистического исследования;
б) повышения точности прогноза;
в) анализа факторов взаимосвязи.
2. Выборочный метод в торговле используется:
а) при анализе ритмичности оптовых поставок;
б) при прогнозировании товарооборота;
в) при разрушающих методах контроля качества товаров.
3. Ошибка репрезентативности обусловлена:
а) самим методом выборочного исследования;
б) большой погрешностью зарегистрированных данных.
4. Коэффициент доверия в выборочном методе может принимать значения:
а) 1, 2, 3;
б) 4, 5, 6;
в) 7, 8, 9.
5. Выборка может быть: а) случайная, б) механическая, в) типическая, серийная, д) техническая
а) а, б, в, г,
б) а, б, в, д
в) б, в, г, д
6. Необходимая численность выборочной совокупности определяется:
а) колеблемостью признака;
б) условиями формирования выборочной совокупности;
7. Выборочная совокупность отличается от генеральной:
а) разными единицами измерения наблюдаемых объектов;
б) разным объемом единиц непосредственного наблюдения;
в) разным числом зарегистрированных наблюдений.
8. Средняя ошибка выборки:
а) прямо пропорциональна рассеяности данных;
б) обратно пропорциональна разбросу варьирующего признака;
в) никак не зависит от колеблемости данных;
9. Повторный отбор отличается от бесповторного тем, что:
а) отбор повторяется, если в процессе выборки произошел сбой;
б) отобранная однажды единица наблюдения возвращается в генеральную совокупность;
в) повторяется несколько раз расчет средней ошибки выборки.
10. Малая выборка — это выборка объемом:
а) 4-5 единиц изучаемой совокупности;
б) до 50 единиц изучаемой совокупности;
в) до 30 единиц изучаемой совокупности.
1. Ряд динамики характеризует: а) структуру совокупности по какому-то признаку; б) изменение характеристик совокупности во времени; в) определенное значение признака в совокупности; г) величину показателя на определенную дату или за определенный период
а) а, б
б) б, г
в) б, в
2. Ряд динамики может состоять: а) из абсолютных суммарных величин; б) из относительных и средних величин;
а) а
б) б
в) а, б
3. Ряд динамики, характеризующий уровень развития социально-экономического явления на определенные даты времени, называется:
а) интервальным;
б) моментным.
4. Средний уровень интервального ряда динамики определяется как:
а) средняя арифметическая;
б) средняя хронологическая.
5. Средний уровень моментного ряда динамики исчисляется как: а) средняя арифметическая взвешенная при равных интервалах между датами; б) при неравных интервалах между датами как средняя хронологическая, в) при равных интервалах между датами как средняя хронологическая;
а) а
б) б
в) б, в
6. Абсолютный прирост исчисляется как: а) отношение уровней ряда; б) разность уровней ряда. Темп роста исчисляется как: в) отношение уровней ряда; г) разность уровней ряда;
а) а, в
б) б, в
в) а, г
7. Для выявления основной тенденции развития используется: а) метод укрупнения интервалов; б) метод скользящей средней; в) метод аналитического выравнивания; г) метод наименьших квадратов;
а) а, г
б) б, г
в) а, б, г
г) а, б, в
8. Трендом ряда динамики называется:
а) основная тенденция;
б) устойчивый темп роста.
9. Прогнозирование в статистике ‑ это:
а) предсказание предполагаемого события в будущем;
б) оценка возможной меры изучаемого явления в будущем.
10. К наиболее простым методам прогнозирования относят:
а) индексный метод;
б) метод скользящей средней;
в) метод на основе среднего абсолютного прироста.
1. Статистический индекс — это:
а) критерий сравнения относительных величин;
б) сравнительная характеристика двух абсолютных величин;
в) относительная величина сравнения двух показателей.
2. Индексы позволяют соизмерить социально-экономические явления:
а) в пространстве;
б) во времени;
в) в пространстве и во времени.
3. В индексном методе анализа несуммарность цен на разнородные товары преодолевается:
а) переходом от абсолютных единиц измерения цен к относительной форме;
б) переходом к стоимостной форме измерения товарной массы.
4. Можно ли утверждать, что индивидуальные индексы по методологии исчисления адекватны темпам роста:
а) можно;
б) нельзя.
5. Сводные индексы позволяют получить обобщающую оценку изменения:
а) по товарной группе;
б) одного товара за несколько периодов.
6. Может ли в отдельных случаях средний гармонический индекс рассчитываться по средней гармонической невзвешенной:
а) может;
б) не может.
7. Индексы переменного состава рассчитываются:
а) по товарной группе;
б) по одному товару.
8. Может ли индекс переменного состава превышать индекс фиксированного состава:
а) может;
б) не может.
9. Первая индексная мультипликативная модель товарооборота – это:
а) произведение индекса цен на индекс физического объема товарооборота;
б) произведение индекса товарооборота в сопоставимых ценах на индекс средней цены постоянного состава;
в) а, б.
10. Вторая факторная индексная мультипликативная модель анализа – это:
а) произведение индекса постоянного состава на индекс структурных сдвигов;
б) частное от деления индекса переменного состава на индекс структурных сдвигов;
в) а, б.
1. Статистическая связь — это:
а) когда зависимость между факторным и результирующим
показателями неизвестна;
б) когда каждому факторному соответствует свой результирующий показатель;
в) когда каждому факторному соответствует несколько разных значений результирующего показателя.
2. Термин корреляция в статистике понимают как:
а) связь, зависимость;
б) отношение, соотношение;
в) функцию, уравнение.
3. По направлению связь классифицируется как:
а) линейная;
б) прямая;
в) обратная.
4. Анализ взаимосвязи в статистике исследует:
а) тесноту связи;
б) форму связи;
в) а, б
5. При каком значении коэффициента корреляции связь можно считать умеренной?
а) r = 0,43;
б) r = 0,71.
6. Термин регрессия в статистике понимают как: а) функцию связи, зависимости; б) направление развития явления вспять; в) функцию анализа случайных событий во времени; г) уравнение линии связи
а) а, б
б) в, г
в) а, г
7. Для определения тесноты связи двух альтернативных показателей применяют:
а) коэффициенты ассоциации и контингенции;
б) коэффициент Спирмена.
8. Дайте классификацию связей по аналитическому выражению:
а) обратная;
б) сильная;
в) прямая;
г) линейная.
9. Какой коэффициент корреляции характеризует связь между YиX:
а) линейный;
б) частный;
в) множественный.
10. При каком значении линейного коэффициента корреляции связь между YиXможно признать более существенной:
а) ryx = 0,25;
б) ryx = 0,14;
в) ryx = — 0,57.
Понятие репрезентативности часто встречается в статистических отчетностях и при подготовке выступлений и докладов. Пожалуй, без нее трудно представить себе какой-либо из видов подачи информации на обозрение.
Репрезентативность — что это?
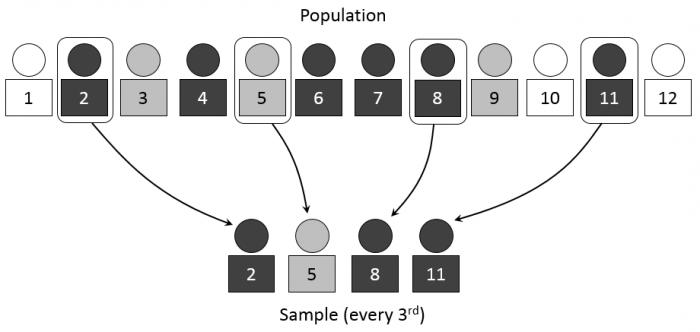
Репрезентативность отражает, насколько выбранные объекты или части соответствуют содержанию и смыслу совокупности данных, из которой они были выбраны.
Другие определения
Понятие репрезентативности можно раскрывать в разных контекстах. Но по своему смыслу репрезентативность – это соответствие черт и свойств выбранных единиц из общей совокупности, которые точно отражают характеристики всей генеральной базы данных в целом.

Репрезентативность отражает, насколько выбранные объекты или части соответствуют содержанию и смыслу совокупности данных, из которой они были выбраны.
Другие определения
Понятие репрезентативности можно раскрывать в разных контекстах. Но по своему смыслу репрезентативность – это соответствие черт и свойств выбранных единиц из общей совокупности, которые точно отражают характеристики всей генеральной базы данных в целом.
Также репрезентативность информации определяют как способность выборочных данных представить параметры и свойства совокупности, важные с точки зрения проводимого исследования.
Репрезентативная выборка
Принцип формирования выборки заключается в избрании наиболее важных и точно отображающих свойства общей совокупности данных. Для этого используются различные методы, которые позволяют получать точные результаты и общее представление о генеральной совокупности, используя только выборочные материалы, описывающие качества всех данных.
Таким образом, нет необходимости изучать весь материал, а достаточно рассмотреть выборочную репрезентативность. Что это? Это выборка отдельных данных для того, чтобы иметь понятие об общей массе информации.

Их в зависимости от способа различают как вероятностные и невероятностные. Вероятностная – это выборка, которая производится путем вычисления наиболее важных и интересных данных, являющихся в дальнейшем представителями генеральной совокупности. Это обдуманный выбор или случайная выборка, тем не менее, обоснованная своим содержанием.
Невероятностная – это одна из разновидностей случайной выборки, составляющаяся по принципу обычной лотереи. В таком случае не учитывается мнение того, кто составляет такую выборку. Используется лишь слепой жребий.
Вероятностная выборка
Вероятностные выборки также могут подразделяться на несколько видов:
- Одна из самых простых и понятных принципов – это нерепрезентативная выборка. К примеру, такой способ часто используется при проведении социальных опросов. При этом участники опроса не выбираются из толпы по каким-либо определенным признакам, и получение информации производится у первых 50 людей, принявших участие в нём.
- Преднамеренные выборки отличаются тем, что имеют ряд требований и условий при отборе, однако все же полагаются на случайное совпадение, не преследуя своей целью достижение хорошей статистики.
- Выборка на основании квот – это еще одна из вариаций невероятностной выборки, которая часто используется для исследования больших совокупностей данных. Для нее используется множество условий и норм. Подбираются объекты, которые должны им соответствовать. То есть на примере социального опроса можно предположить, что опрошены будут 100 человек, но только мнение некоторого числа людей, которые будут соответствовать установленным требованиям, будут учтены при составлении статистического отчета.

Их в зависимости от способа различают как вероятностные и невероятностные. Вероятностная – это выборка, которая производится путем вычисления наиболее важных и интересных данных, являющихся в дальнейшем представителями генеральной совокупности. Это обдуманный выбор или случайная выборка, тем не менее, обоснованная своим содержанием.
Невероятностная – это одна из разновидностей случайной выборки, составляющаяся по принципу обычной лотереи. В таком случае не учитывается мнение того, кто составляет такую выборку. Используется лишь слепой жребий.
Вероятностная выборка
Вероятностные выборки также могут подразделяться на несколько видов:
- Одна из самых простых и понятных принципов – это нерепрезентативная выборка. К примеру, такой способ часто используется при проведении социальных опросов. При этом участники опроса не выбираются из толпы по каким-либо определенным признакам, и получение информации производится у первых 50 людей, принявших участие в нём.
- Преднамеренные выборки отличаются тем, что имеют ряд требований и условий при отборе, однако все же полагаются на случайное совпадение, не преследуя своей целью достижение хорошей статистики.
- Выборка на основании квот – это еще одна из вариаций невероятностной выборки, которая часто используется для исследования больших совокупностей данных. Для нее используется множество условий и норм. Подбираются объекты, которые должны им соответствовать. То есть на примере социального опроса можно предположить, что опрошены будут 100 человек, но только мнение некоторого числа людей, которые будут соответствовать установленным требованиям, будут учтены при составлении статистического отчета.
Вероятностные выборки
Для вероятностных выборок исчисляется ряд параметров, которым объекты в выборке будут соответствовать, и среди них разными способами могут избираться именно те факты и данные, которые будут представлены как репрезентативность данных выборки. Такими способами вычисления нужных данных могут быть:
- Простая случайная выборка. Заключается в том, что среди выбранного сегмента совершенно случайным методом лотереи выбирается необходимое количество данных, которые будут являться репрезентативной выборкой.
- Систематическая и случайная выборка дает возможность составить систему вычисления необходимых данных на основе случайно выбранного сегмента. Таким образом, если первое случайное число, которое указывает на порядковый номер данных, выбранных из общей совокупности, будет 5, то последующими данными, которые будут выбраны, могут стать, например, 15, 25, 35 и так далее. Этот пример наглядно объясняет, что даже случайный выбор может основываться на систематических вычислениях необходимых исходных данных.
Выборка потребителей
Осмысленная выборка – это способ, который заключается в рассмотрении каждого отдельного сегмента, и на основании его оценки составляется совокупность, отражающая характеристики и свойства общей базы данных. Таким образом набирается большее количество данных, соответствующих требованиям репрезентативной выборки. Можно легко отобрать некоторое количество вариантов, которые не войдут в общее число, не потеряв при этом качество отобранных данных, представляющих общую совокупность. Таким способом определяется репрезентативность результатов исследования.
Размер выборки
Не последний вопрос, который необходимо решить, – это размер выборки для репрезентативного представления генеральной совокупности. Размер выборки не всегда зависит от количества исходников в генеральной совокупности. Однако репрезентативность выборочной совокупности напрямую зависит от того, на сколько сегментов должен быть в итоге разделён результат. Чем больше таких сегментов, тем больше данных попадает в результативную выборку. Если результаты требуют общего обозначения и не требуют конкретики, тогда, соответственно, выборка становится меньше, поскольку, не вдаваясь в детали, информация излагается более поверхностно, а значит, ее прочтение будет общим.

Понятие ошибки репрезентативности
Ошибка репрезентативности – это конкретные расхождения между характеристиками генеральной совокупности и выборочных данных. При проведении любого выборочного исследования невозможно получить абсолютно точные данные, как при полном исследовании генеральных совокупностей и выборки, представленной лишь частью сведений и параметров, тогда как более детальное изучение возможно только при исследовании всей совокупности. Таким образом, неизбежны некоторые погрешности и ошибки.
Виды ошибок
Различают некоторые ошибки, которые возникают при составлении репрезентативной выборки:
- Систематические.
- Случайные.
- Преднамеренные.
- Непреднамеренные.
- Стандартные.
- Предельные.
Основанием для появления случайных ошибок может быть несплошной характер исследования общей совокупности. Обычно случайная ошибка репрезентативности имеет незначительный размер и характер.
Систематические ошибки между тем возникают при нарушении правил отбора данных из общей совокупности.

Понятие ошибки репрезентативности
Ошибка репрезентативности – это конкретные расхождения между характеристиками генеральной совокупности и выборочных данных. При проведении любого выборочного исследования невозможно получить абсолютно точные данные, как при полном исследовании генеральных совокупностей и выборки, представленной лишь частью сведений и параметров, тогда как более детальное изучение возможно только при исследовании всей совокупности. Таким образом, неизбежны некоторые погрешности и ошибки.
Виды ошибок
Различают некоторые ошибки, которые возникают при составлении репрезентативной выборки:
- Систематические.
- Случайные.
- Преднамеренные.
- Непреднамеренные.
- Стандартные.
- Предельные.
Основанием для появления случайных ошибок может быть несплошной характер исследования общей совокупности. Обычно случайная ошибка репрезентативности имеет незначительный размер и характер.
Систематические ошибки между тем возникают при нарушении правил отбора данных из общей совокупности.
Средняя ошибка – это разница между усредненными значениями выборки и основной совокупностью. Она не зависит от количества единиц в выборке. Она обратно пропорциональна объему выборки. Тогда чем больше объем, тем меньше значение средней ошибки.
Предельная ошибка – это наибольшая возможная разница между усредненными значениями сделанной выборки и общей совокупностью. Такая ошибка охарактеризовывается как максимум вероятных ошибок при заданных условиях их появления.
Преднамеренные и непреднамеренные ошибки репрезентативности
Ошибки смещения данных бывают преднамеренными и непреднамеренными.
Тогда причинами появления преднамеренных ошибок является подход к подбору данных по методу определения тенденций. Непреднамеренные ошибки возникают еще на стадии подготовки выборочного наблюдения, формирования репрезентативной выборки. Для недопущения подобных ошибок необходимо создать хорошую основу для выборки, составляющей списки единиц отбора. Она должна полностью соответствовать целям проведения выборки, быть достоверной, охватывающей все аспекты исследования.
Валидность, надежность, репрезентативность. Расчет ошибок
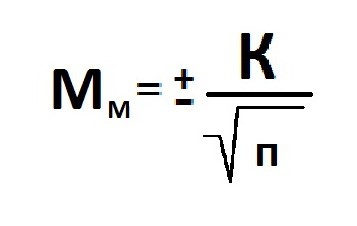
Расчет ошибки репрезентативности (Мм) средней арифметической величины (М).
Среднее квадратическое отклонение: численность выборки (>30).
Ошибка репрезентативности (Мр) и относительная величина (Р): численность выборки (n>30).
В том случае, когда приходится изучать совокупность, где количество выборки мало и составляет меньше 30 единиц, тогда число наблюдений станет меньше на одну единицу.
Величина ошибки прямо порциональна объему выборки. Репрезентативность информации и вычисление степени возможности составления точного прогноза отражает определенная величина предельной ошибки.
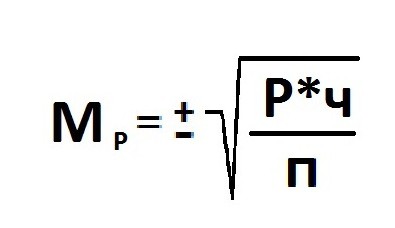
Расчет ошибки репрезентативности (Мм) средней арифметической величины (М).
Среднее квадратическое отклонение: численность выборки (>30).
Ошибка репрезентативности (Мр) и относительная величина (Р): численность выборки (n>30).
В том случае, когда приходится изучать совокупность, где количество выборки мало и составляет меньше 30 единиц, тогда число наблюдений станет меньше на одну единицу.
Величина ошибки прямо порциональна объему выборки. Репрезентативность информации и вычисление степени возможности составления точного прогноза отражает определенная величина предельной ошибки.
Репрезентативные системы
Не только в процессе оценки подачи информации используется репрезентативная выборка, но и сам человек, получающий информацию, использует репрезентативные системы. Таким образом, мозг обрабатывает некоторое количество информации, создавая репрезентативную выборку из всего потока информации, чтобы качественно и быстро оценить подаваемые данные и понять суть вопроса. Ответить на вопрос: «Репрезентативность — что это?» — в масштабах человеческого сознания довольно просто. Для этого мозг использует все подвластные органы чувств, в зависимости от того, какую именно информацию необходимо вычленить из общего потока. Таким образом, различают:
- Визуальную репрезентативную систему, где задействуются органы зрительного восприятия глаза. Люди, часто использующие подобную систему, называются визуалами. С помощью этой системы человек обрабатывает информацию, поступающую в виде изображений.
- Аудиальная репрезентативная система. Главный орган, который используется – это слух. Информация, подаваемая в виде звуковых файлов или речи, обрабатываются именно этой системой. Люди, лучше воспринимающие информацию на слух, называются аудиалами.
- Кинестетическая репрезентативная система представляет собой обработку потока информации, путем восприятия его с помощью обонятельных и осязательных каналов.
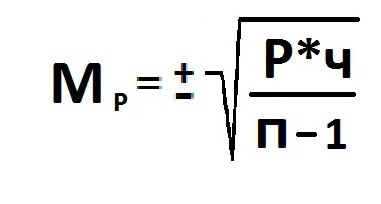
- Визуальную репрезентативную систему, где задействуются органы зрительного восприятия глаза. Люди, часто использующие подобную систему, называются визуалами. С помощью этой системы человек обрабатывает информацию, поступающую в виде изображений.
- Аудиальная репрезентативная система. Главный орган, который используется – это слух. Информация, подаваемая в виде звуковых файлов или речи, обрабатываются именно этой системой. Люди, лучше воспринимающие информацию на слух, называются аудиалами.
- Кинестетическая репрезентативная система представляет собой обработку потока информации, путем восприятия его с помощью обонятельных и осязательных каналов.
- Дигитальная репрезентативная система используется вместе с другими как средство получения информации извне. Это субъективно-логическое восприятие и осмысление полученных данных.

Итак, репрезентативность — что это? Простая выборка из множества или неотъемлемая процедура при обработке информации? Однозначно можно сказать, что репрезентативность во многом определяет наше восприятие потоков данных, помогая вычленить из него наиболее веские и значимые.