

Автоматически генерируемые ошибки JavaScript – почему они происходят
Первый шаг к пониманию ошибок JavaScript – разобраться, откуда они берутся. Большинство ошибок JavaScript, встречающихся в природе, автоматически генерируются самим движком JavaScript. Существует множество типов ошибок, но, как правило, все они относятся к одному из трех классов.
TypeError
Один из наиболее распространенных классов ошибок. Такая ошибка возникает, когда некоторое значение относится не к тому типу, к которому должно относиться. Часто это возникает, когда код вызывает как функцию некоторую сущность, функцией не являющуюся. Это может быть неопределенное (“undefined”) или какое-нибудь другое значение.
window.foo()
// => TypeError: window.foo это не функция
[].length
// => 0
[].length()
// => TypeError: array.length это не функцияЕще один распространенный случай, в котором возникает TypeError – при попытке обратиться к свойству неопределенного значения.
window.foo.bar
// => TypeError: Невозможно прочитать свойство 'bar' у undefinedSyntaxError
Эти ошибки возникают, когда движок JavaScript разбирает скрипт и встречает синтаксически неверный код. Если в файле JavaScript содержится синтаксическая ошибка, то никакой код из него не выполнится.
console.log('hello')
notValid(Мало того, что этот код выдаст ошибку, но и console.log перед неверным кодом даже не запустится.
ReferenceError
Такие ошибки возникают, когда код ссылается на значение, отсутствующее в актуальной области видимости. Например:
console.log(somethingMadeUp)
// => ReferenceError: somethingMadeUp не определеноВыбрасывание ошибок вручную
Не все ошибки случайны. Их можно спровоцировать и намеренно. Когда приложение работает неправильно, предпочтительно сделать так, чтобы оно рушилось громко, явно и четко. В противном случае причина проблемы может оставаться невыясненной, либо, хуже того, даже незамеченной для разработчика.
Простейший способ вручную спровоцировать ошибку – при помощи оператора throw:
throw 'Invalid input';В таком случае автоматически создается экземпляр объекта Error с сообщением “Invalid input”, но экземпляр ошибки также можно создать вручную и передавать его в коде.
let error = new Error('Invalid input')
// позже
throw error;Вручную выбрасывать ошибки JS особенно удобно авторам библиотек, поскольку так можно подсказать разработчику, пользующемуся их библиотекой, как именно совершается ошибка. Например, при вызове функции с недействительным аргументом.
function sayName(name) {
if(typeof name !== 'string') {
throw new Error('name must be a string, received:' + typeof name);
}
}Перехват ошибок в блоке try/catch
Если вы знаете, что конкретный блок кода устроен рискованно и может выбрасывать ошибку, то эту ошибку можно обернуть в блок try/catch.
try {
someCrashyFunction()
} catch(error) {
// может быть, отобразить это пользователю
// и сообщить об ошибке разработчику
Bugsnag.notify(error);
}Блоки try/catch также можно вкладывать друг в друга. Как только ошибка будет обработана, желательно передать ее выше по стеку вызовов, чтобы там она могла быть выброшена повторно.
try {
someCrashyFunction()
} catch(error) {
// Обработать ошибку здесь:
// ...
// а затем передать вверх по цепочке
throw error;
}Давайте включим глобальную обработку ошибок и выловим их все
Даже в самый аккуратно написанный код иногда могут вкрадываться ошибки. Это нормально. Ошибки случаются. Но, когда они случаются, о них важно быстро узнавать. Именно для такой цели пригодится инструмент для отчетов об ошибках, например, Bugsnag.
Как устроена глобальная обработка ошибок
Чтобы выловить и обработать все ошибки JavaScript, которые могут возникнуть в браузерном сеансе, можно прибегнуть к обработчику событий window.onerror. Так можно задать глобальный обработчик для всех необработанных ошибок, которые могли бы всплыть в коде. Именно такое событие применяется в библиотеке Bugsnag для сообщения о неотловленных ошибках в браузерных JavaScript-приложениях.
В среде Node нет объекта window, поэтому аналогичный функционал связан с использованием process.on(‘unhandledException, callback).
Глобальная обработка ошибок не может заменить детализированного контроля, который достигается при помощи операторов try/catch. Глобальная обработка ошибок применяется только для подстраховки в качестве средства от тех исключений, которые проскользнут через передовые линии защиты. Устраивая обработку ошибок ближе к источнику потенциальной проблемы, мы, пожалуй, будем лучше представлять, как справиться с ошибкой и как восстановиться после нее еще до того, как пользователь заметит проблему. А если ошибка и проползет через какую-нибудь щель, то мы можем спокойно рассчитывать на то, что глобальный обработчик ошибок все равно предъявит нам возникшие проблемы.
Неисправные промисы
С появлением ES2015 промисы в JavaScript получили поддержку на уровне сущностей первого класса, и это позволило значительно повысить ясность асинхронного кода. Один недостаток промисов заключается в том, что они часто проглатывают ошибки, возникающие у них в методе.then(). Если в этом методе будет сгенерирована ошибка, то она никогда не всплывет на уровень глобального обработчика ошибок.
fetch('https://my-api.endpoint')
.then((response) => {
response.thisMethodDoesNotExist() // эта ошибка будет поглощена
doSomethingElse() // этот код никогда не будет выполнен
})Вот почему рекомендуется всегда добавлять оператор catch во все цепочки промисов, так, чтобы могли быть обработаны любые ошибки.
fetch('https://my-api.endpoint')
.then((response) => {
response.thisMethodDoesNotExist()
doSomethingElse() // этот код никогда не будет выполнен
})
.catch((error) => {
console.error(error)
// # => response.thisMethodDoesNotExist это не функция
Bugsnag.notify(error)
// показать ошибку пользователю
});Так решается проблема с невидимыми ошибками. Но и у этого подхода есть некоторые недостатки. Во-первых, довольно обременительно писать такой код обработки ошибок для каждого используемого нами промиса. Во-вторых, если ошибка возникнет в операторе catch, она также будет поглощена, и мы вернемся к проблеме, с которой начинали. Чтобы обойти эту проблему, можно воспользоваться глобальным обработчиком, включающимся в случае отклонения необработанных промисов.
window.addEventListener("unhandledrejection", (event) => {
console.error(event.reason);
// здесь сообщаем об ошибке
});Теперь любой отказавший промис, у которого нет явного обработчика catch, спровоцирует событие unhandledrejection.
Свойства ошибки
Как только ошибка схвачена, ее можно проинспектировать, чтобы извлечь из нее полезную информацию. В данном случае наиболее важны свойства name, message и stack.
Первые фрагменты полезной информации об ошибке – это name и message. Именно эти поля отображаются в сообщениях об ошибках и выводятся в консоль браузера.
Сообщение об ошибке устанавливается при ее инициализации.
let error = new Error('This is my message')
console.log(error.message)
// => это мое сообщениеПо умолчанию ошибка имеет то же имя, что и функция конструктора. Поэтому, когда ошибка создается при помощи новой Error(‘oh no!’) или throw(‘oh no!’), она называется “Error”. Если создать ошибку при помощи новой TypeError(‘oh no!’), то она будет называться “TypeError”. Имя ошибки можно переопределить, просто установив другое имя.
let myError = new Error('some message');
myError.name = 'ValidationError';
throw myError;Здесь мы переименовали ошибку в ValidationError, и, например, в дашборде Bugsnag это будет отражено. Но некоторые браузеры (напр., Chrome), все равно будут выводить в консоль просто “Error”. Чтобы справиться с этой проблемой, можно применять пользовательские классы ошибок, о которых мы поговорим ниже в этой статье.
Стектрейсы
Свойство Error.prototype.stack содержит стектрейс ошибки. Стректрейс хранится вместе с ошибкой в виде обычной последовательности символов, где разделителем между всеми функциями в стеке служат символы перехода на новую строку.
Важно отметить, что структура стектрейса зависит от того, где была инициализирована ошибка, а не где она выброшена. Таким образом, если ошибка создается в functionA и возвращается от нее, а затем выбрасывается в functionB, то на вершине стектрейса будет functionA.
Вполне вероятно, что вы минифицируете ваш код JavaScript. В таком случае строки в стектрейсе не будут совпадать со строками в оригинальном файле с исходным кодом. Чтобы найти оригинальный исходный код, используются специальные карты исходников, по которым стектрейс можно отыскать и «перевести». Об этом рассказано в статье the Anatomy of source maps.
Создание пользовательских типов ошибок
Иногда бывает полезно создавать пользовательские типы ошибок в дополнение к тем, которые уже встроены в язык JavaScript. Применить их можно, например, для того, чтобы ошибки различных типов обрабатывались в приложении по-разному.
Например, в приложении Node нам стоило бы предусмотреть специальный класс ошибок, возникающих при валидации запросов к API. Если отловлена такая ошибка валидации, то приложению будет известно, что реагировать на нее нужно кодом состояния HTTP 400.
При пользовательских ошибках также можно отловить дополнительные данные об ошибке, специфичные именно для данного класса ошибок.
Благодаря классам ES6, работа по определению пользовательских типов ошибок крайне упростилась. Например, если бы мы хотели выбрасывать ошибку конкретного типа для недействительных полей, то могли бы определить эту ситуацию вот так.
class ValidationError extends Error {
constructor(field, reason) {
super(reason);
this.field = field;
this.reason = reason;
// следующая строка важна, так как сообщает, что конструктор ValidationError
// не входит в состав результирующего стектрейса
Error.captureStackTrace(this, ValidationError);
}
// также в этом классе можно определить пользовательские методы
prettyMessage() {
return `ValidationError: [${this.fields}] reason: ${this.reason}`;
// исключение: "ValidationError: [age] причина: должно быть числом"
}
}Затем код ошибки может воспользоваться instanceof, чтобы определить, ошибка какого типа была выброшена, и отреагировать соответствующим образом. Например, в приложении на Express.js это достижимо при помощи специализированного промежуточного ПО.
app.use(function errorHandler (error, req, res, next) {
if (error instance of ValidationError) {
// выдать в ответ код 400 и включить важные детали об ошибке
return res.status(400).json({
type: error.name,
message: error.prettyMessage(),
field: error.field,
});
} else {
// Это ошибка другого рода, пусть с ней разберется обработчик ошибок, заданный по умолчанию
next(error)
}
})Хотя в этом примере и используется промежуточное ПО из Express.js, подобный подход применим и в других разновидностях приложений JavaScript, с использованием обычного try/catch.
try {
submitForm();
} catch (error) {
if (error instanceof ValidationError) {
// показать ошибку пользователю
displayErrorMessage(error.prettyMessage());
} else {
// передать ее обработчику ошибок, заданному по умолчанию
throw error;
}
}Без пользовательских классов ошибок специализированная обработка ошибок в таком стиле была бы гораздо сложнее. Требовалось бы идти на уловки, например, сравнивать сообщение об ошибке с каким-нибудь собственноручно написанным свойством. К счастью, такое сравнение с применением классов ошибок протекает гораздо более явно.
Заключение
При отказе приложения идеально сделать так, чтобы пользователь завершил работу с ним как можно более гладко. Но для разработчика приложение должно рушиться громко, так, чтобы было явно видно, какая проблема привела к отказу, и эту проблему можно было быстро проанализировать. Грамотно пользуясь предоставляемыми в JavaScript инструментами обработки ошибок, легче обрабатывать любые туманные аномалии, возникающие в приложении.
P.S.
На сайте издательства продолжается осенняя распродажа.
Murphy’s law states that whatever can go wrong will eventually go wrong. This applies a tad too well in the world of programming. If you create an application, chances are you’ll create bugs and other issues. Errors in JavaScript are one such common issue!
A software product’s success depends on how well its creators can resolve these issues before hurting their users. And JavaScript, out of all programming languages, is notorious for its average error handling design.
If you’re building a JavaScript application, there’s a high chance you’ll mess up with data types at one point or another. If not that, then you might end up replacing an undefined with a null or a triple equals operator (===) with a double equals operator (==).
It’s only human to make mistakes. This is why we will show you everything you need to know about handling errors in JavaScript.
This article will guide you through the basic errors in JavaScript and explain the various errors you might encounter. You’ll then learn how to identify and fix these errors. There are also a couple of tips to handle errors effectively in production environments.
Without further ado, let’s begin!
Check Out Our Video Guide to Handling JavaScript Errors
What Are JavaScript Errors?
Errors in programming refer to situations that don’t let a program function normally. It can happen when a program doesn’t know how to handle the job at hand, such as when trying to open a non-existent file or reaching out to a web-based API endpoint while there’s no network connectivity.
These situations push the program to throw errors to the user, stating that it doesn’t know how to proceed. The program collects as much information as possible about the error and then reports that it can not move ahead.
Murphy’s law states that whatever can go wrong will eventually go wrong 😬 This applies a bit too well in the world of JavaScript 😅 Get prepped with this guide 👇Click to Tweet
Intelligent programmers try to predict and cover these scenarios so that the user doesn’t have to figure out a technical error message like “404” independently. Instead, they show a much more understandable message: “The page could not be found.”
Errors in JavaScript are objects shown whenever a programming error occurs. These objects contain ample information about the type of the error, the statement that caused the error, and the stack trace when the error occurred. JavaScript also allows programmers to create custom errors to provide extra information when debugging issues.
Properties of an Error
Now that the definition of a JavaScript error is clear, it’s time to dive into the details.
Errors in JavaScript carry certain standard and custom properties that help understand the cause and effects of the error. By default, errors in JavaScript contain three properties:
- message: A string value that carries the error message
- name: The type of error that occurred (We’ll dive deep into this in the next section)
- stack: The stack trace of the code executed when the error occurred.
Additionally, errors can also carry properties like columnNumber, lineNumber, fileName, etc., to describe the error better. However, these properties are not standard and may or may not be present in every error object generated from your JavaScript application.
Understanding Stack Trace
A stack trace is the list of method calls a program was in when an event such as an exception or a warning occurs. This is what a sample stack trace accompanied by an exception looks like:
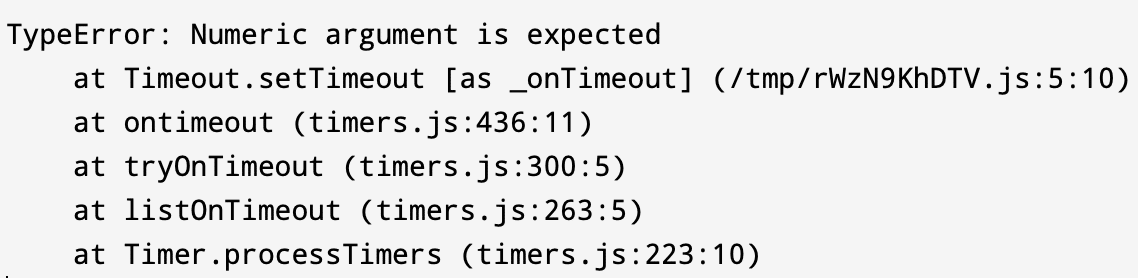
As you can see, it starts by printing the error name and message, followed by a list of methods that were being called. Each method call states the location of its source code and the line at which it was invoked. You can use this data to navigate through your codebase and identify which piece of code is causing the error.
This list of methods is arranged in a stacked fashion. It shows where your exception was first thrown and how it propagated through the stacked method calls. Implementing a catch for the exception will not let it propagate up through the stack and crash your program. However, you might want to leave fatal errors uncaught to crash the program in some scenarios intentionally.
Errors vs Exceptions
Most people usually consider errors and exceptions as the same thing. However, it’s essential to note a slight yet fundamental difference between them.
To understand this better, let’s take a quick example. Here is how you can define an error in JavaScript:
const wrongTypeError = TypeError("Wrong type found, expected character")And this is how the wrongTypeError object becomes an exception:
throw wrongTypeErrorHowever, most people tend to use the shorthand form which defines error objects while throwing them:
throw TypeError("Wrong type found, expected character")This is standard practice. However, it’s one of the reasons why developers tend to mix up exceptions and errors. Therefore, knowing the fundamentals is vital even though you use shorthands to get your work done quickly.
Types of Errors in JavaScript
There’s a range of predefined error types in JavaScript. They are automatically chosen and defined by the JavaScript runtime whenever the programmer doesn’t explicitly handle errors in the application.
This section will walk you through some of the most common types of errors in JavaScript and understand when and why they occur.
RangeError
A RangeError is thrown when a variable is set with a value outside its legal values range. It usually occurs when passing a value as an argument to a function, and the given value doesn’t lie in the range of the function’s parameters. It can sometimes get tricky to fix when using poorly documented third-party libraries since you need to know the range of possible values for the arguments to pass in the correct value.
Some of the common scenarios in which RangeError occurs are:
- Trying to create an array of illegal lengths via the Array constructor.
- Passing bad values to numeric methods like
toExponential(),toPrecision(),toFixed(), etc. - Passing illegal values to string functions like
normalize().
ReferenceError
A ReferenceError occurs when something is wrong with a variable’s reference in your code. You might have forgotten to define a value for the variable before using it, or you might be trying to use an inaccessible variable in your code. In any case, going through the stack trace provides ample information to find and fix the variable reference that is at fault.
Some of the common reasons why ReferenceErrors occur are:
- Making a typo in a variable name.
- Trying to access block-scoped variables outside of their scopes.
- Referencing a global variable from an external library (like $ from jQuery) before it’s loaded.
SyntaxError
These errors are one of the simplest to fix since they indicate an error in the syntax of the code. Since JavaScript is a scripting language that is interpreted rather than compiled, these are thrown when the app executes the script that contains the error. In the case of compiled languages, such errors are identified during compilation. Thus, the app binaries are not created until these are fixed.
Some of the common reasons why SyntaxErrors might occur are:
- Missing inverted commas
- Missing closing parentheses
- Improper alignment of curly braces or other characters
It’s a good practice to use a linting tool in your IDE to identify such errors for you before they hit the browser.
TypeError
TypeError is one of the most common errors in JavaScript apps. This error is created when some value doesn’t turn out to be of a particular expected type. Some of the common cases when it occurs are:
- Invoking objects that are not methods.
- Attempting to access properties of null or undefined objects
- Treating a string as a number or vice versa
There are a lot more possibilities where a TypeError can occur. We’ll look at some famous instances later and learn how to fix them.
InternalError
The InternalError type is used when an exception occurs in the JavaScript runtime engine. It may or may not indicate an issue with your code.
More often than not, InternalError occurs in two scenarios only:
- When a patch or an update to the JavaScript runtime carries a bug that throws exceptions (this happens very rarely)
- When your code contains entities that are too large for the JavaScript engine (e.g. too many switch cases, too large array initializers, too much recursion)
The most appropriate approach to solve this error is to identify the cause via the error message and restructure your app logic, if possible, to eliminate the sudden spike of workload on the JavaScript engine.
URIError
URIError occurs when a global URI handling function such as decodeURIComponent is used illegally. It usually indicates that the parameter passed to the method call did not conform to URI standards and thus was not parsed by the method properly.
Diagnosing these errors is usually easy since you only need to examine the arguments for malformation.
EvalError
An EvalError occurs when an error occurs with an eval() function call. The eval() function is used to execute JavaScript code stored in strings. However, since using the eval() function is highly discouraged due to security issues and the current ECMAScript specifications don’t throw the EvalError class anymore, this error type exists simply to maintain backward compatibility with legacy JavaScript code.
If you’re working on an older version of JavaScript, you might encounter this error. In any case, it’s best to investigate the code executed in the eval() function call for any exceptions.
Creating Custom Error Types
While JavaScript offers an adequate list of error type classes to cover for most scenarios, you can always create a new error type if the list doesn’t satisfy your requirements. The foundation of this flexibility lies in the fact that JavaScript allows you to throw anything literally with the throw command.
So, technically, these statements are entirely legal:
throw 8
throw "An error occurred"However, throwing a primitive data type doesn’t provide details about the error, such as its type, name, or the accompanying stack trace. To fix this and standardize the error handling process, the Error class has been provided. It’s also discouraged to use primitive data types while throwing exceptions.
You can extend the Error class to create your custom error class. Here is a basic example of how you can do this:
class ValidationError extends Error {
constructor(message) {
super(message);
this.name = "ValidationError";
}
}And you can use it in the following way:
throw ValidationError("Property not found: name")And you can then identify it using the instanceof keyword:
try {
validateForm() // code that throws a ValidationError
} catch (e) {
if (e instanceof ValidationError)
// do something
else
// do something else
}Top 10 Most Common Errors in JavaScript
Now that you understand the common error types and how to create your custom ones, it’s time to look at some of the most common errors you’ll face when writing JavaScript code.
Check Out Our Video Guide to The Most Common JavaScript Errors
1. Uncaught RangeError
This error occurs in Google Chrome under a few various scenarios. First, it can happen if you call a recursive function and it doesn’t terminate. You can check this out yourself in the Chrome Developer Console:
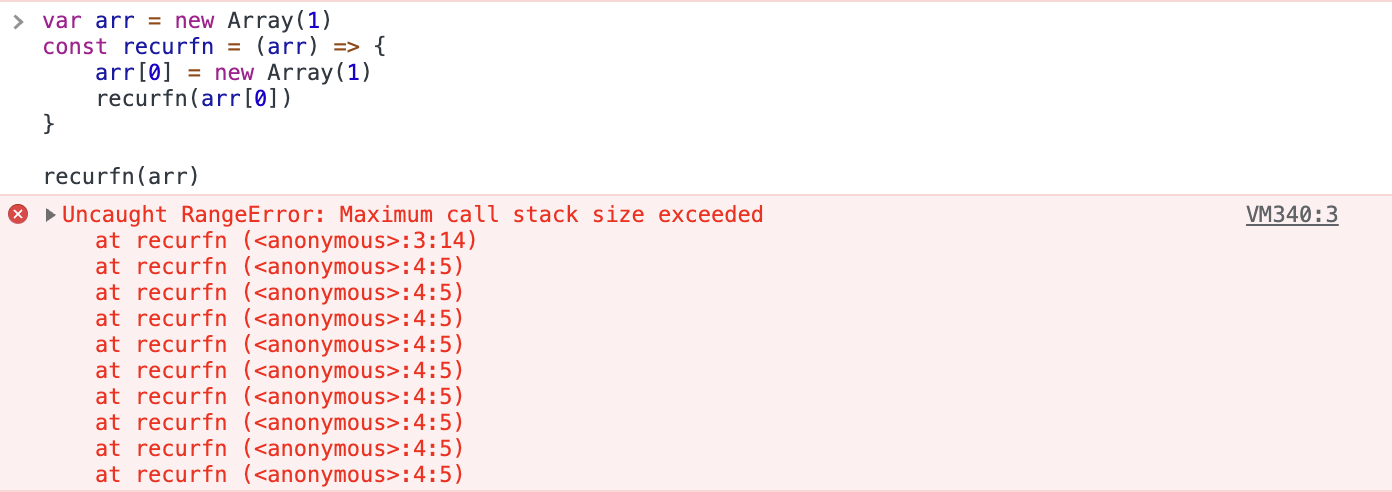
So to solve such an error, make sure to define the border cases of your recursive function correctly. Another reason why this error happens is if you have passed a value that is out of a function’s parameter’s range. Here’s an example:

The error message will usually indicate what is wrong with your code. Once you make the changes, it will be resolved.

2. Uncaught TypeError: Cannot set property
This error occurs when you set a property on an undefined reference. You can reproduce the issue with this code:
var list
list.count = 0Here’s the output that you’ll receive:

To fix this error, initialize the reference with a value before accessing its properties. Here’s how it looks when fixed:

3. Uncaught TypeError: Cannot read property
This is one of the most frequently occurring errors in JavaScript. This error occurs when you attempt to read a property or call a function on an undefined object. You can reproduce it very easily by running the following code in a Chrome Developer console:
var func
func.call()Here’s the output:

An undefined object is one of the many possible causes of this error. Another prominent cause of this issue can be an improper initialization of the state while rendering the UI. Here’s a real-world example from a React application:
import React, { useState, useEffect } from "react";
const CardsList = () => {
const [state, setState] = useState();
useEffect(() => {
setTimeout(() => setState({ items: ["Card 1", "Card 2"] }), 2000);
}, []);
return (
<>
{state.items.map((item) => (
<li key={item}>{item}</li>
))}
</>
);
};
export default CardsList;The app starts with an empty state container and is provided with some items after a delay of 2 seconds. The delay is put in place to imitate a network call. Even if your network is super fast, you’ll still face a minor delay due to which the component will render at least once. If you try to run this app, you’ll receive the following error:
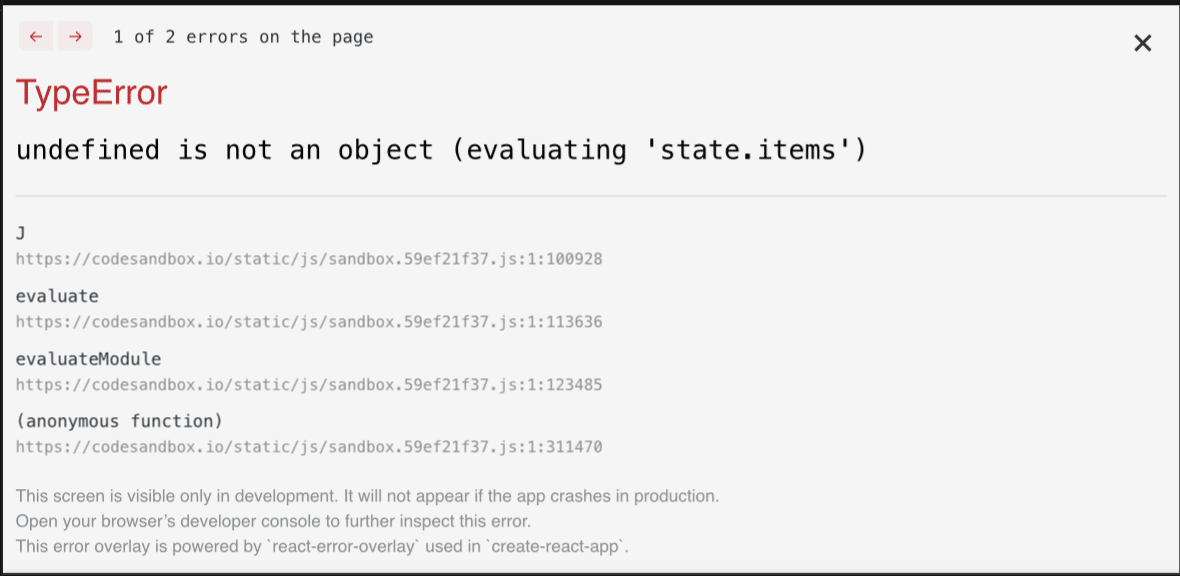
This is because, at the time of rendering, the state container is undefined; thus, there exists no property items on it. Fixing this error is easy. You just need to provide an initial default value to the state container.
// ...
const [state, setState] = useState({items: []});
// ...Now, after the set delay, your app will show a similar output:

The exact fix in your code might be different, but the essence here is to always initialize your variables properly before using them.
4. TypeError: ‘undefined’ is not an object
This error occurs in Safari when you try to access the properties of or call a method on an undefined object. You can run the same code from above to reproduce the error yourself.

The solution to this error is also the same — make sure that you have initialized your variables correctly and they are not undefined when a property or method is accessed.
5. TypeError: null is not an object
This is, again, similar to the previous error. It occurs on Safari, and the only difference between the two errors is that this one is thrown when the object whose property or method is being accessed is null instead of undefined. You can reproduce this by running the following piece of code:
var func = null
func.call()Here’s the output that you’ll receive:

Since null is a value explicitly set to a variable and not assigned automatically by JavaScript. This error can occur only if you’re trying to access a variable you set null by yourself. So, you need to revisit your code and check if the logic that you wrote is correct or not.
6. TypeError: Cannot read property ‘length’
This error occurs in Chrome when you try to read the length of a null or undefined object. The cause of this issue is similar to the previous issues, but it occurs quite frequently while handling lists; hence it deserves a special mention. Here’s how you can reproduce the problem:
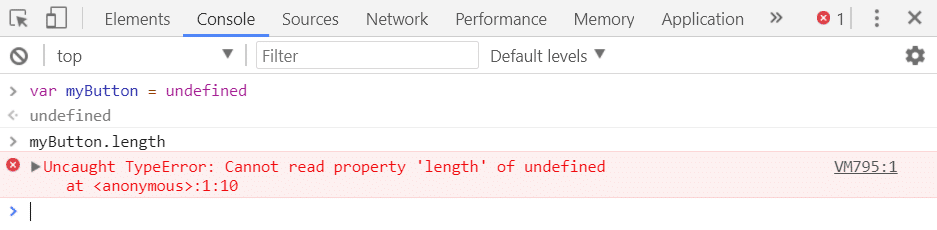
However, in the newer versions of Chrome, this error is reported as Uncaught TypeError: Cannot read properties of undefined. This is how it looks now:

The fix, again, is to ensure that the object whose length you’re trying to access exists and is not set to null.
7. TypeError: ‘undefined’ is not a function
This error occurs when you try to invoke a method that doesn’t exist in your script, or it does but can not be referenced in the calling context. This error usually occurs in Google Chrome, and you can solve it by checking the line of code throwing the error. If you find a typo, fix it and check if it solves your issue.
If you have used the self-referencing keyword this in your code, this error might arise if this is not appropriately bound to your context. Consider the following code:
function showAlert() {
alert("message here")
}
document.addEventListener("click", () => {
this.showAlert();
})If you execute the above code, it will throw the error we discussed. It happens because the anonymous function passed as the event listener is being executed in the context of the document.
In contrast, the function showAlert is defined in the context of the window.
To solve this, you must pass the proper reference to the function by binding it with the bind() method:
document.addEventListener("click", this.showAlert.bind(this))8. ReferenceError: event is not defined
This error occurs when you try to access a reference not defined in the calling scope. This usually happens when handling events since they often provide you with a reference called event in the callback function. This error can occur if you forget to define the event argument in your function’s parameters or misspell it.
This error might not occur in Internet Explorer or Google Chrome (as IE offers a global event variable and Chrome attaches the event variable automatically to the handler), but it can occur in Firefox. So it’s advisable to keep an eye out for such small mistakes.
9. TypeError: Assignment to constant variable
This is an error that arises out of carelessness. If you try to assign a new value to a constant variable, you’ll be met with such a result:

While it seems easy to fix right now, imagine hundreds of such variable declarations and one of them mistakenly defined as const instead of let! Unlike other scripting languages like PHP, there’s minimal difference between the style of declaring constants and variables in JavaScript. Therefore it’s advisable to check your declarations first of all when you face this error. You could also run into this error if you forget that the said reference is a constant and use it as a variable. This indicates either carelessness or a flaw in your app’s logic. Make sure to check this when trying to fix this issue.
10. (unknown): Script error
A script error occurs when a third-party script sends an error to your browser. This error is followed by (unknown) because the third-party script belongs to a different domain than your app. The browser hides other details to prevent leaking sensitive information from the third-party script.
You can not resolve this error without knowing the complete details. Here’s what you can do to get more information about the error:
- Add the
crossoriginattribute in the script tag. - Set the correct
Access-Control-Allow-Originheader on the server hosting the script. - [Optional] If you don’t have access to the server hosting the script, you can consider using a proxy to relay your request to the server and back to the client with the correct headers.
Once you can access the details of the error, you can then set down to fix the issue, which will probably be with either the third-party library or the network.
How to Identify and Prevent Errors in JavaScript
While the errors discussed above are the most common and frequent in JavaScript, you’ll come across, relying on a few examples can never be enough. It’s vital to understand how to detect and prevent any type of error in a JavaScript application while developing it. Here is how you can handle errors in JavaScript.
Manually Throw and Catch Errors
The most fundamental way of handling errors that have been thrown either manually or by the runtime is to catch them. Like most other languages, JavaScript offers a set of keywords to handle errors. It’s essential to know each of them in-depth before you set down to handle errors in your JavaScript app.
throw
The first and most basic keyword of the set is throw. As evident, the throw keyword is used to throw errors to create exceptions in the JavaScript runtime manually. We have already discussed this earlier in the piece, and here’s the gist of this keyword’s significance:
- You can
throwanything, including numbers, strings, andErrorobjects. - However, it’s not advisable to throw primitive data types such as strings and numbers since they don’t carry debug information about the errors.
- Example:
throw TypeError("Please provide a string")
try
The try keyword is used to indicate that a block of code might throw an exception. Its syntax is:
try {
// error-prone code here
}It’s important to note that a catch block must always follow the try block to handle errors effectively.
catch
The catch keyword is used to create a catch block. This block of code is responsible for handling the errors that the trailing try block catches. Here is its syntax:
catch (exception) {
// code to handle the exception here
}And this is how you implement the try and the catch blocks together:
try {
// business logic code
} catch (exception) {
// error handling code
}Unlike C++ or Java, you can not append multiple catch blocks to a try block in JavaScript. This means that you can not do this:
try {
// business logic code
} catch (exception) {
if (exception instanceof TypeError) {
// do something
}
} catch (exception) {
if (exception instanceof RangeError) {
// do something
}
}Instead, you can use an if...else statement or a switch case statement inside the single catch block to handle all possible error cases. It would look like this:
try {
// business logic code
} catch (exception) {
if (exception instanceof TypeError) {
// do something
} else if (exception instanceof RangeError) {
// do something else
}
}finally
The finally keyword is used to define a code block that is run after an error has been handled. This block is executed after the try and the catch blocks.
Also, the finally block will be executed regardless of the result of the other two blocks. This means that even if the catch block cannot handle the error entirely or an error is thrown in the catch block, the interpreter will execute the code in the finally block before the program crashes.
To be considered valid, the try block in JavaScript needs to be followed by either a catch or a finally block. Without any of those, the interpreter will raise a SyntaxError. Therefore, make sure to follow your try blocks with at least either of them when handling errors.
Handle Errors Globally With the onerror() Method
The onerror() method is available to all HTML elements for handling any errors that may occur with them. For instance, if an img tag cannot find the image whose URL is specified, it fires its onerror method to allow the user to handle the error.
Typically, you would provide another image URL in the onerror call for the img tag to fall back to. This is how you can do that via JavaScript:
const image = document.querySelector("img")
image.onerror = (event) => {
console.log("Error occurred: " + event)
}However, you can use this feature to create a global error handling mechanism for your app. Here’s how you can do it:
window.onerror = (event) => {
console.log("Error occurred: " + event)
}With this event handler, you can get rid of the multiple try...catch blocks lying around in your code and centralize your app’s error handling similar to event handling. You can attach multiple error handlers to the window to maintain the Single Responsibility Principle from the SOLID design principles. The interpreter will cycle through all handlers until it reaches the appropriate one.
Pass Errors via Callbacks
While simple and linear functions allow error handling to remain simple, callbacks can complicate the affair.
Consider the following piece of code:
const calculateCube = (number, callback) => {
setTimeout(() => {
const cube = number * number * number
callback(cube)
}, 1000)
}
const callback = result => console.log(result)
calculateCube(4, callback)The above function demonstrates an asynchronous condition in which a function takes some time to process operations and returns the result later with the help of a callback.
If you try to enter a string instead of 4 in the function call, you’ll get NaN as a result.
This needs to be handled properly. Here’s how:
const calculateCube = (number, callback) => {
setTimeout(() => {
if (typeof number !== "number")
throw new Error("Numeric argument is expected")
const cube = number * number * number
callback(cube)
}, 1000)
}
const callback = result => console.log(result)
try {
calculateCube(4, callback)
} catch (e) { console.log(e) }This should solve the problem ideally. However, if you try passing a string to the function call, you’ll receive this:

Even though you have implemented a try-catch block while calling the function, it still says the error is uncaught. The error is thrown after the catch block has been executed due to the timeout delay.
This can occur quickly in network calls, where unexpected delays creep in. You need to cover such cases while developing your app.
Here’s how you can handle errors properly in callbacks:
const calculateCube = (number, callback) => {
setTimeout(() => {
if (typeof number !== "number") {
callback(new TypeError("Numeric argument is expected"))
return
}
const cube = number * number * number
callback(null, cube)
}, 2000)
}
const callback = (error, result) => {
if (error !== null) {
console.log(error)
return
}
console.log(result)
}
try {
calculateCube('hey', callback)
} catch (e) {
console.log(e)
}Now, the output at the console will be:

This indicates that the error has been appropriately handled.
Handle Errors in Promises
Most people tend to prefer promises for handling asynchronous activities. Promises have another advantage — a rejected promise doesn’t terminate your script. However, you still need to implement a catch block to handle errors in promises. To understand this better, let’s rewrite the calculateCube() function using Promises:
const delay = ms => new Promise(res => setTimeout(res, ms));
const calculateCube = async (number) => {
if (typeof number !== "number")
throw Error("Numeric argument is expected")
await delay(5000)
const cube = number * number * number
return cube
}
try {
calculateCube(4).then(r => console.log(r))
} catch (e) { console.log(e) }The timeout from the previous code has been isolated into the delay function for understanding. If you try to enter a string instead of 4, the output that you get will be similar to this:

Again, this is due to the Promise throwing the error after everything else has completed execution. The solution to this issue is simple. Simply add a catch() call to the promise chain like this:
calculateCube("hey")
.then(r => console.log(r))
.catch(e => console.log(e))Now the output will be:

You can observe how easy it is to handle errors with promises. Additionally, you can chain a finally() block and the promise call to add code that will run after error handling has been completed.
Alternatively, you can also handle errors in promises using the traditional try-catch-finally technique. Here’s how your promise call would look like in that case:
try {
let result = await calculateCube("hey")
console.log(result)
} catch (e) {
console.log(e)
} finally {
console.log('Finally executed")
}However, this works inside an asynchronous function only. Therefore the most preferred way to handle errors in promises is to chain catch and finally to the promise call.
throw/catch vs onerror() vs Callbacks vs Promises: Which is the Best?
With four methods at your disposal, you must know how to choose the most appropriate in any given use case. Here’s how you can decide for yourselves:
throw/catch
You will be using this method most of the time. Make sure to implement conditions for all possible errors inside your catch block, and remember to include a finally block if you need to run some memory clean-up routines after the try block.
However, too many try/catch blocks can make your code difficult to maintain. If you find yourself in such a situation, you might want to handle errors via the global handler or the promise method.
When deciding between asynchronous try/catch blocks and promise’s catch(), it’s advisable to go with the async try/catch blocks since they will make your code linear and easy to debug.
onerror()
It’s best to use the onerror() method when you know that your app has to handle many errors, and they can be well-scattered throughout the codebase. The onerror method enables you to handle errors as if they were just another event handled by your application. You can define multiple error handlers and attach them to your app’s window on the initial rendering.
However, you must also remember that the onerror() method can be unnecessarily challenging to set up in smaller projects with a lesser scope of error. If you’re sure that your app will not throw too many errors, the traditional throw/catch method will work best for you.
Callbacks and Promises
Error handling in callbacks and promises differs due to their code design and structure. However, if you choose between these two before you have written your code, it would be best to go with promises.
This is because promises have an inbuilt construct for chaining a catch() and a finally() block to handle errors easily. This method is easier and cleaner than defining additional arguments/reusing existing arguments to handle errors.
Keep Track of Changes With Git Repositories
Many errors often arise due to manual mistakes in the codebase. While developing or debugging your code, you might end up making unnecessary changes that may cause new errors to appear in your codebase. Automated testing is a great way to keep your code in check after every change. However, it can only tell you if something’s wrong. If you don’t take frequent backups of your code, you’ll end up wasting time trying to fix a function or a script that was working just fine before.
This is where git plays its role. With a proper commit strategy, you can use your git history as a backup system to view your code as it evolved through the development. You can easily browse through your older commits and find out the version of the function working fine before but throwing errors after an unrelated change.
You can then restore the old code or compare the two versions to determine what went wrong. Modern web development tools like GitHub Desktop or GitKraken help you to visualize these changes side by side and figure out the mistakes quickly.
A habit that can help you make fewer errors is running code reviews whenever you make a significant change to your code. If you’re working in a team, you can create a pull request and have a team member review it thoroughly. This will help you use a second pair of eyes to spot out any errors that might have slipped by you.
Best Practices for Handling Errors in JavaScript
The above-mentioned methods are adequate to help you design a robust error handling approach for your next JavaScript application. However, it would be best to keep a few things in mind while implementing them to get the best out of your error-proofing. Here are some tips to help you.
1. Use Custom Errors When Handling Operational Exceptions
We introduced custom errors early in this guide to give you an idea of how to customize the error handling to your application’s unique case. It’s advisable to use custom errors wherever possible instead of the generic Error class as it provides more contextual information to the calling environment about the error.
On top of that, custom errors allow you to moderate how an error is displayed to the calling environment. This means that you can choose to hide specific details or display additional information about the error as and when you wish.
You can go so far as to format the error contents according to your needs. This gives you better control over how the error is interpreted and handled.
2. Do Not Swallow Any Exceptions
Even the most senior developers often make a rookie mistake — consuming exceptions levels deep down in their code.
You might come across situations where you have a piece of code that is optional to run. If it works, great; if it doesn’t, you don’t need to do anything about it.
In these cases, it’s often tempting to put this code in a try block and attach an empty catch block to it. However, by doing this, you’ll leave that piece of code open to causing any kind of error and getting away with it. This can become dangerous if you have a large codebase and many instances of such poor error management constructs.
The best way to handle exceptions is to determine a level on which all of them will be dealt and raise them until there. This level can be a controller (in an MVC architecture app) or a middleware (in a traditional server-oriented app).
This way, you’ll get to know where you can find all the errors occurring in your app and choose how to resolve them, even if it means not doing anything about them.
3. Use a Centralized Strategy for Logs and Error Alerts
Logging an error is often an integral part of handling it. Those who fail to develop a centralized strategy for logging errors may miss out on valuable information about their app’s usage.
An app’s event logs can help you figure out crucial data about errors and help to debug them quickly. If you have proper alerting mechanisms set up in your app, you can know when an error occurs in your app before it reaches a large section of your user base.
It’s advisable to use a pre-built logger or create one to suit your needs. You can configure this logger to handle errors based on their levels (warning, debug, info, etc.), and some loggers even go so far as to send logs to remote logging servers immediately. This way, you can watch how your application’s logic performs with active users.
4. Notify Users About Errors Appropriately
Another good point to keep in mind while defining your error handling strategy is to keep the user in mind.
All errors that interfere with the normal functioning of your app must present a visible alert to the user to notify them that something went wrong so the user can try to work out a solution. If you know a quick fix for the error, such as retrying an operation or logging out and logging back in, make sure to mention it in the alert to help fix the user experience in real-time.
In the case of errors that don’t cause any interference with the everyday user experience, you can consider suppressing the alert and logging the error to a remote server for resolving later.
5. Implement a Middleware (Node.js)
The Node.js environment supports middlewares to add functionalities to server applications. You can use this feature to create an error-handling middleware for your server.
The most significant benefit of using middleware is that all of your errors are handled centrally in one place. You can choose to enable/disable this setup for testing purposes easily.
Here’s how you can create a basic middleware:
const logError = err => {
console.log("ERROR: " + String(err))
}
const errorLoggerMiddleware = (err, req, res, next) => {
logError(err)
next(err)
}
const returnErrorMiddleware = (err, req, res, next) => {
res.status(err.statusCode || 500)
.send(err.message)
}
module.exports = {
logError,
errorLoggerMiddleware,
returnErrorMiddleware
}You can then use this middleware in your app like this:
const { errorLoggerMiddleware, returnErrorMiddleware } = require('./errorMiddleware')
app.use(errorLoggerMiddleware)
app.use(returnErrorMiddleware)You can now define custom logic inside the middleware to handle errors appropriately. You don’t need to worry about implementing individual error handling constructs throughout your codebase anymore.
6. Restart Your App To Handle Programmer Errors (Node.js)
When Node.js apps encounter programmer errors, they might not necessarily throw an exception and try to close the app. Such errors can include issues arising from programmer mistakes, like high CPU consumption, memory bloating, or memory leaks. The best way to handle these is to gracefully restart the app by crashing it via the Node.js cluster mode or a unique tool like PM2. This can ensure that the app doesn’t crash upon user action, presenting a terrible user experience.
7. Catch All Uncaught Exceptions (Node.js)
You can never be sure that you have covered every possible error that can occur in your app. Therefore, it’s essential to implement a fallback strategy to catch all uncaught exceptions from your app.
Here’s how you can do that:
process.on('uncaughtException', error => {
console.log("ERROR: " + String(error))
// other handling mechanisms
})You can also identify if the error that occurred is a standard exception or a custom operational error. Based on the result, you can exit the process and restart it to avoid unexpected behavior.
8. Catch All Unhandled Promise Rejections (Node.js)
Similar to how you can never cover for all possible exceptions, there’s a high chance that you might miss out on handling all possible promise rejections. However, unlike exceptions, promise rejections don’t throw errors.
So, an important promise that was rejected might slip by as a warning and leave your app open to the possibility of running into unexpected behavior. Therefore, it’s crucial to implement a fallback mechanism for handling promise rejection.
Here’s how you can do that:
const promiseRejectionCallback = error => {
console.log("PROMISE REJECTED: " + String(error))
}
process.on('unhandledRejection', callback)If you create an application, there are chances that you’ll create bugs and other issues in it as well. 😅 Learn how to handle them with help from this guide ⬇️Click to Tweet
Summary
Like any other programming language, errors are quite frequent and natural in JavaScript. In some cases, you might even need to throw errors intentionally to indicate the correct response to your users. Hence, understanding their anatomy and types is very crucial.
Moreover, you need to be equipped with the right tools and techniques to identify and prevent errors from taking down your application.
In most cases, a solid strategy to handle errors with careful execution is enough for all types of JavaScript applications.
Are there any other JavaScript errors that you still haven’t been able to resolve? Any techniques for handling JS errors constructively? Let us know in the comments below!
JavaScript Errors Handbook
This README contains information that I’ve learned over the years about dealing with JavaScript errors, reporting them to the server, and navigating through a lot of bugs that can make this all really hard. Browsers have improved in this area, but there is still room left to improve to make sure that all applications can sanely and soundly handle any error that happens.
Test cases for content found in this guide can be found at https://mknichel.github.io/javascript-errors/.
Table of Contents
- Introduction
- Anatomy of a JavaScript Error
- Producing a JavaScript Error
- Error Messages
- Stack Trace Format
- Catching JavaScript Errors
- window.onerror
- try/catch
- Protected Entry Points
- Promises
- Web Workers
- Chrome Extensions
Introduction
Catching, reporting, and fixing errors is an important part of any application to ensure the health and stability of the application. Since JavaScript code is also executed on the client and in many different browser environments, staying on top of JS Errors from your application can also be hard. There are no formal web specs for how to report JS errors which cause differences in each browser’s implementation. Additionally, there have been many bugs in browsers’ implementation of JavaScript errors as well that have made this even harder. This page navigates through these aspects of JS Errors so that future developers can handle errors better and browsers will hopefully converge on standardized solutions.
Anatomy of a JavaScript Error
A JavaScript error is composed of two primary pieces: the error message and the stack trace. The error message is a string that describes what went wrong, and the stack trace describes where in the code the error happened. JS Errors can be produced either by the browser itself or thrown by application code.
Producing a JavaScript Error
A JS Error can be thrown by the browser when a piece of code doesn’t execute properly, or it can be thrown directly by code.
For example:
In this example, a variable that is actually a number can’t be invoked as a function. The browser will throw an error like TypeError: a is not a function with a stack trace that points to that line of code.
A developer might also want to throw an error in a piece of code if a certain precondition is not met. For example
if (!checkPrecondition()) { throw new Error("Doesn't meet precondition!"); }
In this case, the error will be Error: Doesn't meet precondition!. This error will also contain a stack trace that points to the appropriate line. Errors thrown by the browser and application code can be handled the same.
There are multiple ways that developers can throw an error in JavaScript:
throw new Error('Problem description.')throw Error('Problem description.')<— equivalent to the first onethrow 'Problem description.'<— badthrow null<— even worse
Throwing a string or null is really not recommended since the browser will not attach a stack trace to that error, losing the context of where that error ocurred in the code. It is best to throw an actual Error object, which will contain the error message as well as a stack trace that points to the right lines of code where the error happened.
Error Messages
Each browser has its own set of messages that it uses for the built in exceptions, such as the example above for trying to call a non-function. Browsers will try to use the same messages, but since there is no spec, this is not guaranteed. For example, both Chrome and Firefox use {0} is not a function for the above example while IE11 will report Function expected (notably also without reporting what variable was attempted to be called).
However, browsers tend to diverge often as well. When there are multiple default statements in a switch statement, Chrome will throw "More than one default clause in switch statement" while Firefox will report "more than one switch default". As new features are added to the web, these error messages have to be updated. These differences can come into play later when you are trying to handle reported errors from obfuscated code.
You can find the templates that browsers use for error messages at:
- Firefox — http://mxr.mozilla.org/mozilla1.9.1/source/js/src/js.msg
- Chrome — https://code.google.com/p/v8/source/browse/branches/bleeding_edge/src/messages.js
- Internet Explorer — https://github.com/Microsoft/ChakraCore/blob/4e4d4f00f11b2ded23d1885e85fc26fcc96555da/lib/Parser/rterrors.h
 Browsers will produce different error messages for some exceptions.
Browsers will produce different error messages for some exceptions.
Stack Trace Format
The stack trace is a description of where the error happened in the code. It is composed of a series of frames, where each frames describe a particular line in the code. The topmost frame is the location where the error was thrown, while the subsequent frames are the function call stack — or how the code was executed to get to that point where the error was thrown. Since JavaScript is usually concatenated and minified, it is also important to have column numbers so that the exact statement can be located when a given line has a multitude of statements.
A basic stack trace in Chrome looks like:
at throwError (http://mknichel.github.io/javascript-errors/throw-error-basic.html:8:9)
at http://mknichel.github.io/javascript-errors/throw-error-basic.html:12:3
Each stack frame consists of a function name (if applicable and the code was not executed in the global scope), the script that it came from, and the line and column number of the code.
Unfortunately, there is no standard for the stack trace format so this differs by browser.
Microsoft Edge and IE 11’s stack trace looks similar to Chrome’s except it explicitly lists Global code:
at throwError (http://mknichel.github.io/javascript-errors/throw-error-basic.html:8:3)
at Global code (http://mknichel.github.io/javascript-errors/throw-error-basic.html:12:3)
Firefox’s stack trace looks like:
throwError@http://mknichel.github.io/javascript-errors/throw-error-basic.html:8:9
@http://mknichel.github.io/javascript-errors/throw-error-basic.html:12:3
Safari’s format is similar to Firefox’s format but is also slightly different:
throwError@http://mknichel.github.io/javascript-errors/throw-error-basic.html:8:18
global code@http://mknichel.github.io/javascript-errors/throw-error-basic.html:12:13
The same basic information is there, but the format is different.
Also note that in the Safari example, aside from the format being different than Chrome, the column numbers are different than both Chrome and Firefox. The column numbers also can deviate more in different error situations — for example in the code (function namedFunction() { throwError(); })();, Chrome will report the column for the throwError() function call while IE11 reports the column number as the start of the string. These differences will come back into play later when the server needs to parse the stack trace for reported errors and deobfuscate obfuscated stack traces.
See https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Error/Stack for more information on the stack property of errors. When accessing the Error.stack property, Chrome does include the error message as part of the stack but Safari 10+ does not.
The format of stack traces is different by browser in form and column numbers used.
Diving in more, there are a lot of nuances to stack trace formats that are discussed in the below sections.
Naming anonymous functions
By default, anonymous functions have no name and either appear as empty string or «Anonymous function» in the function names in the stack trace (depending on the browser). To improve debugging, you should add a name to all functions to ensure it appears in the stack frame. The easiest way to do this is to ensure that anonymous functions are specified with a name, even if that name is not used anywhere else. For example:
setTimeout(function nameOfTheAnonymousFunction() { ... }, 0);
This will cause the stack trace to go from:
at http://mknichel.github.io/javascript-errors/javascript-errors.js:125:17
to
at nameOfTheAnonymousFunction (http://mknichel.github.io/javascript-errors/javascript-errors.js:121:31)
In Safari, this would go from:
https://mknichel.github.io/javascript-errors/javascript-errors.js:175:27
to
nameOfTheAnonymousFunction@https://mknichel.github.io/javascript-errors/javascript-errors.js:171:41
This method ensures that nameOfTheAnonymousFunction appears in the frame for any code from inside that function, making debugging much easier. See http://www.html5rocks.com/en/tutorials/developertools/async-call-stack/#toc-debugging-tips for more information.
Assigning functions to a variable
Browsers will also use the name of the variable or property that a function is assigned to if the function itself does not have a name. For example, in
var fnVariableName = function() { ... };
browsers will use fnVariableName as the name of the function in stack traces.
at throwError (http://mknichel.github.io/javascript-errors/javascript-errors.js:27:9)
at fnVariableName (http://mknichel.github.io/javascript-errors/javascript-errors.js:169:37)
Even more nuanced than that, if this variable is defined within another function, all browsers will use just the name of the variable as the name of the function in the stack trace except for Firefox, which will use a different form that concatenates the name of the outer function with the name of the inner variable. Example:
function throwErrorFromInnerFunctionAssignedToVariable() { var fnVariableName = function() { throw new Error("foo"); }; fnVariableName(); }
will produce in Firefox:
throwErrorFromInnerFunctionAssignedToVariable/fnVariableName@http://mknichel.github.io/javascript-errors/javascript-errors.js:169:37
In other browsers, this would look like:
at fnVariableName (http://mknichel.github.io/javascript-errors/javascript-errors.js:169:37)
Firefox uses different stack frame text for functions defined within another function.
displayName Property
The display name of a function can also be set by the displayName property in all major browsers except for IE11. In these browsers, the displayName will appear in the devtools debugger, but in all browsers but Safari, it will not be used in Error stack traces (Safari differs from the rest by also using the displayName in the stack trace associated with an error).
var someFunction = function() {}; someFunction.displayName = " # A longer description of the function.";
There is no official spec for the displayName property, but it is supported by all the major browsers. See https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/displayName and http://www.alertdebugging.com/2009/04/29/building-a-better-javascript-profiler-with-webkit/ for more information on displayName.
IE11 doesn’t support the displayName property.
Safari uses the displayName property as the symbol name in Error stack traces.
Programatically capturing stack traces
If an error is reported without a stack trace (see more details when this would happen below), then it’s possible to programatically capture a stack trace.
In Chrome, this is really easy to do by using the Error.captureStackTrace API. See https://github.com/v8/v8/wiki/Stack%20Trace%20API for more information on the use of this API.
For example:
function ignoreThisFunctionInStackTrace() { var err = new Error(); Error.captureStackTrace(err, ignoreThisFunctionInStackTrace); return err.stack; }
In other browsers, a stack trace can also be collected by creating a new error and accessing the stack property of that object:
var err = new Error(''); return err.stack;
However, IE10 only populates the stack trace when the error is actually thrown:
try { throw new Error(''); } catch (e) { return e.stack; }
If none of these approaches work, then it’s possible to create a rough stack trace without line numbers or columns by iterating over the arguments.callee.caller object — this won’t work in ES5 Strict Mode though and it’s not a recommended approach.
Async stack traces
It is very common for asynchronous points to be inserted into JavaScript code, such as when code uses setTimeout or through the use of Promises. These async entry points can cause problems for stack traces, since they cause a new execution context to form and the stack trace starts from scratch again.
Chrome DevTools has support for async stack traces, or in other words making sure the stack trace of an error also shows the frames that happened before the async point was introduced. With the use of setTimeout, this will capture who called the setTimeout function that eventually produced an error. See http://www.html5rocks.com/en/tutorials/developertools/async-call-stack/ for more information.
An async stack trace will look like:
throwError @ throw-error.js:2
setTimeout (async)
throwErrorAsync @ throw-error.js:10
(anonymous function) @ throw-error-basic.html:14
Async stack traces are only supported in Chrome DevTools right now, only for exceptions that are thrown when DevTools are open. Stack traces accessed from Error objects in code will not have the async stack trace as part of it.
It is possible to polyfill async stack traces in some cases, but this could cause a significant performance hit for your application since capturing a stack trace is not cheap.
Only Chrome DevTools natively supports async stack traces.
Naming inline scripts and eval
Stack traces for code that was eval’ed or inlined into a HTML page will use the page’s URL and line/column numbers for the executed code.
For example:
at throwError (http://mknichel.github.io/javascript-errors/throw-error-basic.html:8:9)
at http://mknichel.github.io/javascript-errors/throw-error-basic.html:12:3
If these scripts actually come from a script that was inlined for optimization reasons, then the URL, line, and column numbers will be wrong. To work around this problem, Chrome and Firefox support the //# sourceURL= annotation (Safari, Edge, and IE do not). The URL specified in this annotation will be used as the URL for all stack traces, and the line and column number will be computed relative to the start of the <script> tag instead of the HTML document. For the same error as above, using the sourceURL annotation with a value of «inline.js» will produce a stack trace that looks like:
at throwError (http://mknichel.github.io/javascript-errors/inline.js:8:9)
at http://mknichel.github.io/javascript-errors/inline.js:12:3
This is a really handy technique to make sure that stack traces are still correct even when using inline scripts and eval.
http://www.html5rocks.com/en/tutorials/developertools/sourcemaps/#toc-sourceurl describes the sourceURL annotation in more detail.
Safari, Edge, and IE do not support the sourceURL annotation for naming inline scripts and evals. If you use inline scripts in IE or Safari and you obfuscate your code, you will not be able to deobfuscate errors that come from those scripts.
Up until Chrome 42, Chrome did not compute line numbers correctly for inline scripts that use the sourceURL annotation. See https://bugs.chromium.org/p/v8/issues/detail?id=3920 for more information.
Line numbers for stack frames from inline scripts are incorrect when the sourceURL annotation is used since they are relative to the start of the HTML document instead of the start of the inline script tag (making correct deobfuscation not possible). https://code.google.com/p/chromium/issues/detail?id=578269
Eval stack traces
For code that uses eval, there are other differences in the stack trace besides whether or not it uses the sourceURL annotation. In Chrome, a stack trace from a statement used in eval could look like:
Error: Error from eval
at evaledFunction (eval at evalError (http://mknichel.github.io/javascript-errors/javascript-errors.js:137:3), <anonymous>:1:36)
at eval (eval at evalError (http://mknichel.github.io/javascript-errors/javascript-errors.js:137:3), <anonymous>:1:68)
at evalError (http://mknichel.github.io/javascript-errors/javascript-errors.js:137:3)
In MS Edge and IE11, this would look like:
Error from eval
at evaledFunction (eval code:1:30)
at eval code (eval code:1:2)
at evalError (http://mknichel.github.io/javascript-errors/javascript-errors.js:137:3)
In Safari:
Error from eval
evaledFunction
eval code
eval@[native code]
evalError@http://mknichel.github.io/javascript-errors/javascript-errors.js:137:7
and in Firefox:
Error from eval
evaledFunction@http://mknichel.github.io/javascript-errors/javascript-errors.js line 137 > eval:1:36
@http://mknichel.github.io/javascript-errors/javascript-errors.js line 137 > eval:1:11
evalError@http://mknichel.github.io/javascript-errors/javascript-errors.js:137:3
These differences can make it hard to parse eval code the same across all browsers.
Each browser uses a different stack trace format for errors that happened inside eval.
Stack traces with native frames
Your JavaScript code can also be called directly from native code. Array.prototype.forEach is a good example — you pass a function to forEach and the JS engine will call that function for you.
function throwErrorWithNativeFrame() { var arr = [0, 1, 2, 3]; arr.forEach(function namedFn(value) { throwError(); }); }
This produces different stack traces in different browsers. Chrome and Safari append the name of the native function in the stack trace itself as a separate frame, such as:
(Chrome)
at namedFn (http://mknichel.github.io/javascript-errors/javascript-errors.js:153:5)
at Array.forEach (native)
at throwErrorWithNativeFrame (http://mknichel.github.io/javascript-errors/javascript-errors.js:152:7)
(Safari)
namedFn@http://mknichel.github.io/javascript-errors/javascript-errors.js:153:15
forEach@[native code]
throwErrorWithNativeFrame@http://mknichel.github.io/javascript-errors/javascript-errors.js:152:14
(Edge)
at namedFn (http://mknichel.github.io/javascript-errors/javascript-errors.js:153:5)
at Array.prototype.forEach (native code)
at throwErrorWithNativeFrame (http://mknichel.github.io/javascript-errors/javascript-errors.js:152:7)
However, Firefox and IE11 do not show that forEach was called as part of the stack:
namedFn@http://mknichel.github.io/javascript-errors/javascript-errors.js:153:5
throwErrorWithNativeFrame@http://mknichel.github.io/javascript-errors/javascript-errors.js:152:3
Some browsers include native code frames in stack traces, while others do not.
Catching JavaScript Errors
To detect that your application had an error, some code must be able to catch that error and report about it. There are multiple techniques for catching errors, each with their pros and cons.
window.onerror
window.onerror is one of the easiest and best ways to get started catching errors. By assigning window.onerror to a function, any error that is uncaught by another part of the application will be reported to this function, along with some information about the error. For example:
window.onerror = function(msg, url, line, col, err) { console.log('Application encountered an error: ' + msg); console.log('Stack trace: ' + err.stack); }
https://developer.mozilla.org/en-US/docs/Web/API/GlobalEventHandlers/onerror describes this in more detail.
Historically, there have been a few problems with this approach:
No Error object provided
The 5th argument to the window.onerror function is supposed to be an Error object. This was added to the WHATWG spec in 2013: https://html.spec.whatwg.org/multipage/webappapis.html#errorevent. Chrome, Firefox, and IE11 now properly provide an Error object (along with the critical stack property), but Safari, MS Edge, and IE10 do not. This works in Firefox since Firefox 14 (https://bugzilla.mozilla.org/show_bug.cgi?id=355430) and in Chrome since late 2013 (https://mikewest.org/2013/08/debugging-runtime-errors-with-window-onerror, https://code.google.com/p/chromium/issues/detail?id=147127). Safari 10 launched support for the Error object in window.onerror.
Safari (versions below 10), MS Edge, and IE10 do not support an Error object with a stack trace in window.onerror.
Cross domain sanitization
In Chrome, errors that come from another domain in the window.onerror handler will be sanitized to «Script error.», «», 0. This is generally okay if you really don’t want to process the error if it comes from a script that you don’t care about, so the application can filter out errors that look like this. However, this does not happen in Firefox or Safari or IE11, nor does Chrome do this for try/catch blocks that wrap the offending code.
If you would like to receive errors in window.onerror in Chrome with full fidelity from cross domain scripts, those resources must provide the appropriate cross origin headers. See https://mikewest.org/2013/08/debugging-runtime-errors-with-window-onerror for more information.
Chrome is the only browser that will sanitize errors that come from another origin. Take care to filter these out, or set the appropriate headers.
Chrome Extensions
In old versions of Chrome, Chrome extensions that are installed on a user’s machine could also throw errors that get reported to window.onerror. This has been fixed in newer versions of Chrome. See the dedicated Chrome Extensions section below.
window.addEventListener(«error»)
The window.addEventListener("error") API works the same as the window.onerror API. See http://www.w3.org/html/wg/drafts/html/master/webappapis.html#runtime-script-errors for more information on this approach.
Showing errors in DevTools console for development
Catching errors via window.onerror does not prevent that error from also appearing in the DevTools console. This is most likely the right behavior for development since the developer can easily see the error. If you don’t want these errors to show up in production to end users, e.preventDefault() can be called if using the window.addEventListener approach.
Recommendation
window.onerror is the best tool to catch and report JS errors. It’s recommended that only JS errors with valid Error objects and stack traces are reported back to the server, otherwise the errors may be hard to investigate or you may get a lot of spam from Chrome extensions or cross domain scripts.
try/catch
Given the above section, unfortunately it’s not possible to rely on window.onerror in all browsers to capture all error information. For catching exceptions locally, a try/catch block is the obvious choice. It’s also possible to wrap entire JavaScript files in a try/catch block to capture error information that can’t be caught with window.onerror. This improves the situations for browsers that don’t support window.onerror, but also has some downsides.
Doesn’t catch all errors
A try/catch block won’t capture all errors in a program, such as errors that are thrown from an async block of code through window.setTimeout. Try/catch can be used with Protected Entry Points to help fill in the gaps.
try/catch blocks wrapping the entire application aren’t sufficient to catch all errors.
Deoptimizations
Old versions of V8 (and potentially other JS engines), functions that contain a try/catch block won’t be optimized by the compiler (http://www.html5rocks.com/en/tutorials/speed/v8/). Chrome fixed this in TurboFan (https://codereview.chromium.org/1996373002).
Protected Entry Points
An «entry point» into JavaScript is any browser API that can start execution of your code. Examples include setTimeout, setInterval, event listeners, XHR, web sockets, or promises. Errors that are thrown from these entry points will be caught by window.onerror, but in the browsers that don’t support the full Error object in window.onerror, an alternative mechanism is needed to catch these errors since the try/catch method mentioned above won’t catch them either.
Thankfully, JavaScript allows these entry points to be wrapped so that a try/catch block can be inserted before the function is invoked to catch any errors thrown by the code.
Each entry point will need slightly different code to protect the entry point, but the gist of the methodology is:
function protectEntryPoint(fn) { return function protectedFn() { try { return fn(); } catch (e) { // Handle error. } } } _oldSetTimeout = window.setTimeout; window.setTimeout = function protectedSetTimeout(fn, time) { return _oldSetTimeout.call(window, protectEntryPoint(fn), time); };
Promises
Sadly, it’s easy for errors that happen in Promises to go unobserved and unreported. Errors that happen in a Promise but are not handled by attaching a rejection handler are not reported anywhere else — they do not get reported to window.onerror. Even if a Promise attaches a rejection handler, that code itself must manually report those errors for them to be logged. See http://www.html5rocks.com/en/tutorials/es6/promises/#toc-error-handling for more information. For example:
window.onerror = function(...) { // This will never be invoked by Promise code. }; var p = new Promise(...); p.then(function() { throw new Error("This error will be not handled anywhere."); }); var p2 = new Promise(...); p2.then(function() { throw new Error("This error will be handled in the chain."); }).catch(function(error) { // Show error message to user // This code should manually report the error for it to be logged on the server, if applicable. });
One approach to capture more information is to use Protected Entry Points to wrap invocations of Promise methods with a try/catch to report errors. This might look like:
var _oldPromiseThen = Promise.prototype.then; Promise.prototype.then = function protectedThen(callback, errorHandler) { return _oldPromiseThen.call(this, protectEntryPoint(callback), protectEntryPoint(errorHandler)); };
Sadly, errors from Promises will go unhandled by default.
Error handling in Promise polyfills
Promise implementations, such as Q, Bluebird, and Closure handle errors in different ways which are better than the error handling in the browser implementation of Promises.
- In Q, you can «end» the Promise chain by calling
.done()which will make sure that if an error wasn’t handled in the chain, it will get rethrown and reported. See https://github.com/kriskowal/q#handling-errors - In Bluebird, unhandled rejections are logged and reported immediately. See http://bluebirdjs.com/docs/features.html#surfacing-unhandled-errors
- In Closure’s goog.Promise implementation, unhandled rejections are logged and reported if no chain in the Promise handles the rejection within a configurable time interval (in order to allow code later in the program to add a rejection handler).
Long stack traces
The async stack trace section above discusses that browsers don’t capture stack information when there is an async hook, such as calling Promise.prototype.then. Promise polyfills feature a way to capture the async stack trace points which can make diagnosing errors much easier. This approach is expensive, but it can be really useful for capturing more debug information.
- In Q, call
Q.longStackSupport = true;. See https://github.com/kriskowal/q#long-stack-traces - In Bluebird, call
Promise.longStackTraces()somewhere in the application. See http://bluebirdjs.com/docs/features.html#long-stack-traces. - In Closure, set
goog.Promise.LONG_STACK_TRACESto true.
Promise Rejection Events
Chrome 49 added support for events that are dispatched when a Promise is rejected. This allows applications to hook into Promise errors to ensure that they get centrally reported along with the rest of the errors.
window.addEventListener('unhandledrejection', event => { // event.reason contains the rejection reason. When an Error is thrown, this is the Error object. });
See https://googlechrome.github.io/samples/promise-rejection-events/ and https://www.chromestatus.com/feature/4805872211460096 for more information.
This is not supported in any other browser.
Web Workers
Web workers, including dedicated workers, shared workers, and service workers, are becoming more popular in applications today. Since all of these workers are separate scripts from the main page, they each need their own error handling code. It is recommended that each worker script install its own error handling and reporting code for maximum effectiveness handling errors from workers.
Dedicated workers
Dedicated web workers execute in a different execution context than the main page, so errors from workers aren’t caught by the above mechanisms. Additional steps need to be taken to capture errors from workers on the page.
When a worker is created, the onerror property can be set on the new worker:
var worker = new Worker('worker.js'); worker.onerror = function(errorEvent) { ... };
This is defined in https://html.spec.whatwg.org/multipage/workers.html#handler-abstractworker-onerror. The onerror function on the worker has a different signature than the window.onerror discussed above. Instead of accepting 5 arguments, worker.onerror takes a single argument: an ErrorEvent object. The API for this object can be found at https://developer.mozilla.org/en-US/docs/Web/API/ErrorEvent. It contains the message, filename, line, and column, but no stable browser today contains the «Error» object that contains the stack trace (errorEvent.error is null). Since this API is executed in the parent page’s scope, it would be useful for using the same reporting mechanism as the parent page; unfortunately due to the lack of a stack trace, this API is of limited use.
Inside of the JS run by the worker, you can also define an onerror API that follows the usual window.onerror API: https://html.spec.whatwg.org/multipage/webappapis.html#onerroreventhandler. In the worker code:
self.onerror = function(message, filename, line, col, error) { ... };
The discussion of this API mostly follows the discussion above for window.onerror. However, there are 2 notable things to point out:
Firefox and Safari do not report the «error» object as the 5th argument to the function, so these browsers do not get a stack trace from the worker (Chrome, MS Edge, and IE11 do get a stack trace). Protected Entry Points for the onmessage function within the worker can be used to capture stack trace information for these browsers.
Since this code executes within the worker, the code must choose how to report the error back to the server: It must either use postMessage to communicate the error back to the parent page, or install an XHR error reporting mechanism (discussed more below) in the worker itself.
In Firefox, Safari, and IE11 (but not in Chrome), the parent page’s window.onerror function will also be called after the worker’s own onerror and the onerror event listener set by the page has been called. However, this window.onerror will also not contain an error object and therefore won’t have a stack trace also. These browsers must also take care to not report errors from workers multiple times.
Shared workers
Chrome and Firefox support the SharedWorker API for sharing a worker among multiple pages. Since the worker is shared, it is not attached to one parent page exclusively; this leads to some differences in how errors are handled, although SharedWorker mostly follows the same information as the dedicated web worker.
In Chrome, when there is an error in a SharedWorker, only the worker’s own error handling within the worker code itself will be called (like if they set self.onerror). The parent page’s window.onerror will not be called, and Chrome does not support the inherited AbstractWorker.onerror that can be called in the parent page as defined in the spec.
In Firefox, this behavior is different. An error in the shared worker will cause the parent page’s window.onerror to be called, but the error object will be null. Additionally, Firefox does support the AbstractWorker.onerror property, so the parent page can attach an error handler of its own to the worker. However, when this error handler is called, the error object will be null so there will be no stack trace, so it’s of limited use.
Error handling for shared workers differs by browser.
Service Workers
Service Workers are a brand new spec that is currently only available in recent Chrome and Firefox versions. These workers follow the same discussion as dedicated web workers.
Service workers are installed by calling the navigator.serviceWorker.register function. This function returns a Promise which will be rejected if there was an error installing the service worker, such as it throwing an error during initialization. This error will only contain a string message and nothing else. Additionally, since Promises don’t report errors to window.onerror handlers, the application itself would have to add a catch block to the Promise to catch the error.
navigator.serviceWorker.register('service-worker-installation-error.js').catch(function(error) { // error typeof string });
Just like the other workers, service workers can set a self.onerror function within the service workers to catch errors. Installation errors in the service worker will be reported to the onerror function, but unfortunately they won’t contain an error object or stack trace.
The service worker API contains an onerror property inherited from the AbstractWorker interface, but Chrome does not do anything with this property.
Worker Try/Catch
To capture stack traces in Firefox + Safari within a worker, the onmessage function can be wrapped in a try/catch block to catch any errors that propagate to the top.
self.onmessage = function(event) { try { // logic here } catch (e) { // Report exception. } };
The normal try/catch mechanism will capture stack traces for these errors, producing an exception that looks like:
Error from worker
throwError@http://mknichel.github.io/javascript-errors/worker.js:4:9
throwErrorWrapper@http://mknichel.github.io/javascript-errors/worker.js:8:3
self.onmessage@http://mknichel.github.io/javascript-errors/worker.js:14:7
Chrome Extensions
Chrome Extensions deserve their own section since errors in these scripts can operate slightly differently, and historically (but not anymore) errors from Chrome Extensions have also been a problem for large popular sites.
Content Scripts
Content scripts are scripts that run in the context of web pages that a user visits. These scripts run in an isolated execution environment so they can access the DOM but they can not access JavaScript on the parent page (and vice versa).
Since content scripts have their own execution environment, they can assign to the window.onerror handler in their own script and it won’t affect the parent page. However, errors caught by window.onerror in the content script are sanitized by Chrome resulting in a «Script error.» with null filename and 0 for line and column. This bug is tracked by https://code.google.com/p/chromium/issues/detail?id=457785. Until that bug is fixed, a try/catch block or protected entry points are the only ways to catch JS errors in a content script with stack traces.
In years past, errors from content scripts would be reported to the window.onerror handler of the parent page which could result in a large amount of spammy error reports for popular sites. This was fixed in late 2013 though (https://code.google.com/p/chromium/issues/detail?id=225513).
Errors in Chrome Extensions are sanitized before being handled by window.onerror.
Browser Actions
Chrome extensions can also generate browser action popups, which are small HTML pages that spawn when a user clicks a Chrome extension icon to the right of the URL bar. These pages can also run JavaScript, in an entirely different execution environment from everything else. window.onerror works properly for this JavaScript.
Reporting Errors to the Server
Once the client is configured to properly catch exceptions with correct stack traces, these exceptions should be reported back to the server so they can be tracked, analyzed, and then fixed. Typically this is done with a XHR endpoint that records the error message and the stack trace information, along with any relevant client context information, such as the version of the code that’s running, the user agent, the user’s locale, and the top level URL of the page.
If the application uses multiple mechanisms to catch errors, it’s important to not report the same error twice. Errors that contain a stack trace should be preferred; errors reported without a stack trace can be hard to track down in a large application.
Error Объекты ошибок выбрасываются при возникновении ошибок времени выполнения. Объект Error также можно использовать в качестве базового объекта для пользовательских исключений. См. Ниже стандартные встроенные типы ошибок.
Description
Error types
Помимо общей Error конструктора, есть и другие конструкторы основной ошибки в JavaScript. Информацию об исключениях на стороне клиента см. В разделе Операторы обработки исключений .
EvalError-
Создает экземпляр, представляющий ошибку, возникающую в отношении глобальной функции
eval(). RangeError-
Создает экземпляр,представляющий ошибку,которая возникает,когда числовая переменная или параметр выходит за пределы допустимого диапазона.
ReferenceError-
Создает экземпляр,представляющий собой ошибку,которая возникает при удалении недействительной ссылки.
SyntaxError-
Создает экземпляр,представляющий синтаксическую ошибку.
TypeError-
Создает экземпляр,представляющий собой ошибку,которая возникает,когда переменная или параметр не имеет допустимого типа.
URIError-
Создает экземпляр, представляющий ошибку, которая возникает, когда
encodeURI()илиdecodeURI()передаются недопустимые параметры. AggregateError-
Создает экземпляр, представляющий несколько ошибок, заключенных в одну ошибку, когда операция должна сообщить о нескольких ошибках, например с помощью
Promise.any(). -
InternalErrorNon-standard -
Создает экземпляр,представляющий собой ошибку,которая возникает при выбросе внутренней ошибки в движке JavaScript.Например,»слишком большая рекурсия».
Constructor
Error()-
Создает новый объект
Error.
Static methods
-
Error.captureStackTrace()Non-standard -
Нестандартная функция V8, которая создает свойство
stackв экземпляре Error. -
Error.stackTraceLimitNon-standard -
Нестандартное числовое свойство V8,которое ограничивает количество кадров стека для включения в трассировку стека ошибок.
-
Error.prepareStackTrace()Non-standard Optional -
Нестандартная функция V8,которая,если она предусмотрена usercode,вызывается движком V8 JavaScript для брошенных исключений,позволяя пользователю обеспечить пользовательское форматирование стековых трасс.
Instance properties
Error.prototype.message-
Сообщение об ошибке. Для созданных пользователем объектов
Errorэто строка, предоставляемая в качестве первого аргумента конструктора. Error.prototype.name-
Имя ошибки.Оно определяется функцией конструктора.
Error.prototype.cause-
Причина ошибки, указывающая причину, по которой возникает текущая ошибка — обычно это другая пойманная ошибка. Для созданных пользователем объектов
Errorэто значение, указанное в качестве свойстваcauseвторого аргумента конструктора. -
Error.prototype.fileNameNon-standard -
Нестандартное свойство Mozilla для пути к файлу,вызвавшему эту ошибку.
-
Error.prototype.lineNumberNon-standard -
Нестандартное свойство Mozilla для номера строки в файле,вызвавшем эту ошибку.
-
Error.prototype.columnNumberNon-standard -
Нестандартное свойство Mozilla для номера столбца в строке,вызвавшей эту ошибку.
-
Error.prototype.stackNon-standard -
Нестандартное свойство для трассировки стека.
Instance methods
Examples
Бросая общую ошибку
Обычно вы создаете объект Error с намерением поднять его с помощью ключевого слова throw . Вы можете обработать ошибку, используя конструкцию try...catch :
try { throw new Error('Whoops!'); } catch (e) { console.error(`${e.name}: ${e.message}`); }
Обработка ошибок определенного типа
Вы можете выбрать обработку только определенных типов ошибок, проверив тип ошибки с помощью свойства constructor ошибки или, если вы пишете для современных движков JavaScript, ключевое слово instanceof :
try { foo.bar(); } catch (e) { if (e instanceof EvalError) { console.error(`${e.name}: ${e.message}`); } else if (e instanceof RangeError) { console.error(`${e.name}: ${e.message}`); } else { throw e; } }
Различайте похожие ошибки
Иногда блок кода может не сработать по причинам,требующим разной обработки,но вызывающим очень похожие ошибки (т.е.с одинаковым типом и сообщением).
Если у вас нет контроля над исходными выдаваемыми ошибками, один из вариантов — их перехватить и выбросить новые объекты Error с более конкретными сообщениями. Исходная ошибка должна быть передана в новую Error в option параметра конструктора ( свойство cause ), так как это гарантирует, что исходная ошибка и трассировка стека будут доступны для блоков try / catch более высокого уровня.
В приведенном ниже примере показано это для двух методов, которые в противном случае потерпели бы неудачу с аналогичными ошибками ( doFailSomeWay() и doFailAnotherWay() ):
function doWork() { try { doFailSomeWay(); } catch (err) { throw new Error('Failed in some way', { cause: err }); } try { doFailAnotherWay(); } catch (err) { throw new Error('Failed in another way', { cause: err }); } } try { doWork(); } catch (err) { switch(err.message) { case 'Failed in some way': handleFailSomeWay(err.cause); break; case 'Failed in another way': handleFailAnotherWay(err.cause); break; } }
Примечание. Если вы создаете библиотеку, вам лучше использовать причину ошибки, чтобы различать разные выдаваемые ошибки, а не просить ваших потребителей анализировать сообщение об ошибке. См . пример на странице причины ошибки .
Пользовательские типы ошибок также могут использовать свойство cause при условии, что конструктор подклассов передает параметр options при вызове super() :
class MyError extends Error { constructor() { super(message, options); } }
Пользовательские типы ошибок
Возможно, вы захотите определить свои собственные типы ошибок, производные от Error , чтобы иметь возможность throw new MyError() и использовать instanceof MyError для проверки типа ошибки в обработчике исключений. Это приводит к более чистому и последовательному коду обработки ошибок.
См. «Какой хороший способ расширить Error в JavaScript?» на StackOverflow для подробного обсуждения.
Класс ES6 CustomError
Предупреждение. Версии Babel до 7 могут обрабатывать методы класса CustomError , но только если они объявлены с помощью Object.defineProperty () . В противном случае старые версии Babel и других транспилеров не будут правильно обрабатывать следующий код без дополнительной настройки .
Примечание. Некоторые браузеры включают конструктор CustomError в трассировку стека при использовании классов ES2015.
class CustomError extends Error { constructor(foo = 'bar', ...params) { super(...params); if (Error.captureStackTrace) { Error.captureStackTrace(this, CustomError); } this.name = 'CustomError'; this.foo = foo; this.date = new Date(); } } try { throw new CustomError('baz', 'bazMessage'); } catch (e) { console.error(e.name); console.error(e.foo); console.error(e.message); console.error(e.stack); }
Объект ES5 CustomError
Предупреждение: все браузеры включают конструктор CustomError в трассировку стека при использовании объявления прототипа.
function CustomError(foo, message, fileName, lineNumber) { var instance = new Error(message, fileName, lineNumber); instance.foo = foo; Object.setPrototypeOf(instance, CustomError.prototype); if (Error.captureStackTrace) { Error.captureStackTrace(instance, CustomError); } return instance; } Object.setPrototypeOf(CustomError.prototype, Error.prototype); Object.setPrototypeOf(CustomError, Error); CustomError.prototype.name = 'CustomError'; try { throw new CustomError('baz', 'bazMessage'); } catch (e) { console.error(e.name); console.error(e.foo); console.error(e.message); }
Specifications
Browser compatibility
| Desktop | Mobile | Server | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Chrome | Edge | Firefox | Internet Explorer | Opera | Safari | WebView Android | Chrome Android | Firefox для Android | Opera Android | Safari на IOS | Samsung Internet | Deno | Node.js | |
Error |
1 |
12 |
1 |
6 |
4 |
1 |
4.4 |
18 |
4 |
10.1 |
1 |
1.0 |
1.0 |
0.10.0 |
Error |
1 |
12 |
1 |
6 |
4 |
1 |
4.4 |
18 |
4 |
10.1 |
1 |
1.0 |
1.0 |
0.10.0 |
cause |
93 |
93 |
91 |
No |
No |
15 |
93 |
93 |
91 |
No |
15 |
17.0 |
1.13 |
16.9.0 |
columnNumber |
No |
No |
1 |
No |
No |
No |
No |
No |
4 |
No |
No |
No |
No |
No |
fileName |
No |
No |
1 |
No |
No |
No |
No |
No |
4 |
No |
No |
No |
No |
No |
lineNumber |
No |
No |
1 |
No |
No |
No |
No |
No |
4 |
No |
No |
No |
No |
No |
message |
1 |
12 |
1 |
6 |
5 |
1 |
4.4 |
18 |
4 |
10.1 |
1 |
1.0 |
1.0 |
0.10.0 |
name |
1 |
12 |
1 |
6 |
4 |
1 |
4.4 |
18 |
4 |
10.1 |
1 |
1.0 |
1.0 |
0.10.0 |
serializable_object |
77 |
79 |
103 [«Версия 103 сериализует свойства: |
No |
64 |
No |
77 |
77 |
103 [«Версия 103 сериализует свойства: |
55 |
No |
12.0 |
No |
No |
stack |
3 |
12 |
1 |
10 |
10.5 |
6 |
≤37 |
18 |
4 |
11 |
6 |
1.0 |
1.0 |
0.10.0 |
toString |
1 |
12 |
1 |
6 |
4 |
1 |
4.4 |
18 |
4 |
10.1 |
1 |
1.0 |
1.0 |
0.10.0 |
See also
-
Полифил
Errorс современным поведением, таким какcauseподдержки , доступен вcore-js. throwtry...catch- Документация V8 для
Error.captureStackTrace(),Error.stackTraceLimitиError.prepareStackTrace().
JavaScript
-
encodeURI()
Функция encodeURI()кодирует a,заменяя каждый экземпляр определенных символов двумя,тремя или четырьмя управляющими последовательностями,представляющими кодировку UTF-8 (будет
-
encodeURIComponent()
Функция encodeURIComponent()кодирует a,заменяя каждый экземпляр определенных символов двумя,тремя или четырьмя управляющими последовательностями,представляющими кодировку UTF-8
-
Error.prototype.cause
Свойство cause указывает на конкретную причину ошибки.
-
Error.prototype.columnNumber
Нестандартный:Эта функция не соответствует стандартам.
Опубликовано: среда, 29 марта 2023 г. в 09:06
- JavaScript
В этом руководстве мы погрузимся в обработку ошибок JavaScript, чтобы вы могли выбрасывать исключения, обнаруживать и обрабатывать собственные ошибки.
Опытные разработчики ожидают неожиданного. Если что-то может пойти не так, так оно и будет — обычно в тот момент, когда первый пользователь получает доступ к вашему новому приложению.
Некоторых ошибок веб-приложений можно избежать, например:
- Хороший редактор или линтер может отлавливать синтаксические ошибки.
- Хорошая валидация может выявить ошибки пользовательского ввода.
- Надёжные процессы тестирования могут обнаруживать логические ошибки.
И всё же ошибки остаются. Браузеры могут сбоить или не поддерживать API, который мы используем. Серверы могут дать сбой или слишком долго отвечать. Сетевое соединение может выйти из строя или стать ненадёжным. Проблемы могут быть временными, но мы не может программировать такие проблемы. Однако мы можем предвидеть проблемы, принимать меры по их устранению и повышать отказоустойчивость нашего приложения.
Отображение сообщения об ошибке — крайняя мера
В идеале пользователи никогда не должны видеть сообщения об ошибке.
Мы можем игнорировать незначительные проблемы, такие как невозможность загрузки декоративного изображения. Мы могли бы решить более серьёзные проблемы, такие как сбои сохранения данных Ajax локально и загружая их позже. Ошибка становиться необходимой только тогда, когда пользователь рискует потерять данные, предполагая, что он может что-то с этим сделать.
Поэтому необходимо выявлять ошибки по мере их возникновения и определять наилучшие действия. Вызов и перехват ошибок в приложении JavaScript поначалу может быть пугающим, но, возможно, это проще, чем вы ожидаете.
Как JavaScript обрабатывает ошибки
Когда оператор JavaScript приводит к ошибке, говорят, что он генерирует (выбрасывает) исключение. JavaScript создаёт и выбрасывает объект Error, описывающий ошибку. Мы можем увидеть это в действии на CodePen. Если установить в десятичные разряды (decimal places) отрицательное число, мы увидим сообщение об ошибке в консоли внизу. (Обратите внимание, что мы не встраиваем CodePen в это руководство, потому что нужно иметь возможно видеть вывод консоли, чтобы этот пример имел смысл)
Результат не обновиться, и мы увидим сообщение RangeError в консоли. Следующая функция выдаёт ошибку, когда dp имеет отрицательно значение:
// division calculation
function divide(v1, v2, dp) {
return (v1 / v2).toFixed(dp);
}После выдачи ошибки интерпретатор JavaScript проверяет наличие кода обработки исключений. В функции Division() ничего нет, поэтому она проверяет вызывающую функцию:
// show result of division
function showResult() {
result.value = divide(
parseFloat(num1.value),
parseFloat(num2.value),
parseFloat(dp.value)
);
}Интерпретатор повторяет процесс для каждой функции в стеке вызовов, пока не произойдёт одно из следующих событий:
- Он находит обработчик исключений.
- Он достигает верхнего уровня кода (что приводит к завершению программы и отображению ошибки в консоли, как показано в примере на CodePen выше).
Перехват исключений
Мы можем добавить обработчик исключений в функцию divide() с помощью блока try...catch:
// division calculation
function divide(v1, v2, dp) {
try {
return (v1 / v2).toFixed(dp);
}
catch(e) {
console.log(`
error name : ${ e.name }
error message: ${ e.message }
`);
return 'ERROR';
}
}Функция выполняет код в блоке try {}, но при возникновении исключения выполняется блок catch {} и получает выброшенный объект ошибки. Как и прежде, попробуйте в decimal places установить отрицательное число в этой демонстрации CodePen.
Теперь result показывает ERROR. Консоль показывает имя ошибки и сообщение, но это выводится оператором console.log и не завершает работу программы.
Примечание: эта демонстрация блока
try...catchизлишняя для базовой функции, такой какdivide(). Как мы увидим ниже, проще убедиться, чтоdpравен нулю или больше.
Можно определить не обязательный блок finally {}, если требуется, чтобы код запускался при выполнении кода try или catch:
function divide(v1, v2, dp) {
try {
return (v1 / v2).toFixed(dp);
}
catch(e) {
return 'ERROR';
}
finally {
console.log('done');
}
}В консоль выведется done
, независимо от того, успешно ли выполнено вычисление или возникла ошибка. Блок finally обычно выполняет действия, которые в противном случае нам пришлось бы повторять как в блоке try, так и в блоке catch. Например, отмену вызова API или закрытие соединения с базой данных.
Для блока try требуется либо блок catch, либо блок finally, либо и то и другое. Обратите внимание, что когда блок finally содержит оператор return, это значение становится возвращаемым значением для всей функции; другие операторы в блоках try или catch игнорируются.
Вложенные обработчики исключений
Что произойдёт, если мы добавим обработчик исключений к вызывающей функции showResult()?
// show result of division
function showResult() {
try {
result.value = divide(
parseFloat(num1.value),
parseFloat(num2.value),
parseFloat(dp.value)
);
}
catch(e) {
result.value = 'FAIL!';
}
}Ответ… ничего! Блок catch никогда не выполняется, потому что в функции divide() блок catch обрабатывает ошибку.
Тем не менее мы могли бы программно генерировать новый объект Error в divide() и при желании передать исходную ошибку в свойстве cause второго аргумента:
function divide(v1, v2, dp) {
try {
return (v1 / v2).toFixed(dp);
}
catch(e) {
throw new Error('ERROR', { cause: e });
}
}Это вызовет блок catch в вызывающей функции:
// show result of division
function showResult() {
try {
//...
}
catch(e) {
console.log( e.message ); // ERROR
console.log( e.cause.name ); // RangeError
result.value = 'FAIL!';
}
}Стандартные типы ошибок JavaScript
Когда возникает исключение, JavaScript создаёт и выдаёт объект, описывающий ошибку, используя один из следующих типов.
SyntaxError
Ошибка, возникающая из-за синтаксически недопустимого кода, такого как отсутствующая скобка:
if condition) { // SyntaxError
console.log('condition is true');
}Примечание: такие языки, как C++ и Java, сообщают об ошибках синтаксиса во время компиляции. JavaScript — интерпретируемый язык, поэтому синтаксические ошибки не выявляются до тех пор, пока код не запустится. Любой хороший редактор кода или линтер могут обнаружить синтаксические ошибки до того, как мы попытаемся запустить код.
ReferenceError
Ошибка при доступе к несуществующей переменной:
function inc() {
value++; // ReferenceError
}Опять, хороший редактор кода или линтер могут обнаружить эту проблему.
TypeError
Ошибка возникает, когда значение не соответствует ожидаемому типу, например, при вызове несуществующего метода объекта:
const obj = {};
obj.missingMethod(); // TypeErrorRangeError
Ошибка возникает, когда значение не входит в набор или диапазон допустимых значений. Используемый выше метод toFixed() генерирует эту ошибку, потому что он ожидает значение от 0 до 100:
const n = 123.456;
console.log( n.toFixed(-1) ); // RangeErrorURIError
Ошибка выдаваемая функциями обработки URI, такими как encodeURI() и decodeURI(), при обнаружении неправильных URI:
const u = decodeURIComponent('%'); // URIErrorEvalError
Ошибка возникающая при передаче строки, содержащей не валидный JavaScript код, в функцию eval():
eval('console.logg x;'); // EvalErrorПримечание: пожалуйста, не используйте
eval()! Выполнение произвольного кода, содержащегося в строке, возможно, созданной на основе пользовательского ввода, слишком опасно!
AggregateError
Ошибка возникает, когда несколько ошибок объединены в одну ошибку. Обычно возникает при вызове такой операции, как Promise.all(), которая возвращает результаты нескольких промисов.
InternalError
Нестандартная ошибка (только в Firefox) возникает при возникновении внутренней ошибки движка JavaScript. Обычно это результат того, что что-то занимает слишком много памяти, например, большой массив или слишком много рекурсии
.
Error
Наконец, есть общий объект Error, чаще всего используемый при реализации собственных исключений… о котором мы поговорим дальше.
Генерация/выбрасывание собственных исключений
Мы можем использовать throw для генерации/выбрасывания собственных исключений, когда возникает ошибка — или должна произойти. Например:
- нашей функции не передаются валидные параметры
- ajax-запрос не возвращает ожидаемые данные
- обновление DOM завершается ошибкой, поскольку узел не существует
Оператор throw фактически принимает любое значение или объект. Например:
throw 'A simple error string';
throw 42;
throw true;
throw { message: 'An error', name: 'MyError' };Исключения генерируются для каждой функции в стеке вызовов до тех пор, пока они не будут перехвачены обработчиком исключений (catch). Однако на практике мы хотим создать и сгенерировать объект Error, чтобы он действовал идентично стандартным ошибкам, выдаваемым JavaScript.
Можно создать общий объект Error, передав необязательное сообщение конструктору:
throw new Error('An error has occurred');Так же Error можно использовать как функцию, без new. Она возвращает объект Error, идентичный приведённому выше:
throw Error('An error has occurred');При желании можно передать имя файла и номер строки в качестве второго и третьего параметров:
throw new Error('An error has occurred', 'script.js', 99);В этом редко возникает необходимость, так как по умолчанию они относятся к файлу и строке, где мы вызвали объект Error. (Также их сложно поддерживать, поскольку наши файлы меняются!)
Мы можем определить общие объекты Error, но по возможности следует использовать стандартный тип Error. Например:
throw new RangeError('Decimal places must be 0 or greater');Все объекты Error имеют следующие свойства, которые можно проверить в блоке catch:
.name: имя типа ошибки, напримерErrorилиRangeError..message: сообщение об ошибке.
В Firefox поддерживаются следующие нестандартные свойства:
.fileName: файл, в котором произошла ошибка..lineNumber: номер строки, в которой произошла ошибка..columnNumber: номер столбца, в котором произошла ошибка..stack: трассировка стека со списком вызовов функций, сделанных до возникновения ошибки.
Мы можем изменить функцию divide() так, чтобы она вызывала ошибку RangeError, когда количество знаков после запятой не является числом, меньше нуля и больше восьми:
// division calculation
function divide(v1, v2, dp) {
if (isNaN(dp) || dp < 0 || dp > 8) {
throw new RangeError('Decimal places must be between 0 and 8');
}
return (v1 / v2).toFixed(dp);
}Точно так же мы могли бы выдать Error или TypeError, когда значения делимого не является числом, чтобы предотвратить результат NaN:
if (isNaN(v1)) {
throw new TypeError('Dividend must be a number');
}Также можно обрабатывать делитель, который не является числом или равен нулю. JavaScript возвращает Infinity при делении на ноль, но это может запутать пользователя. Вместо того чтобы вызывать общую ошибку, мы могли бы создать собственный тип ошибки DivByZeroError:
// new DivByZeroError Error type
class DivByZeroError extends Error {
constructor(message) {
super(message);
this.name = 'DivByZeroError';
}
}Затем вызывать/выбрасывать его подобным образом:
if (isNaN(v2) || !v2) {
throw new DivByZeroError('Divisor must be a non-zero number');
}Теперь добавьте блок try...catch к вызывающей функции showResult(). Он сможет получить тип любой ошибки и отреагировать соответствующим образом — в данном случае, выводя сообщение об ошибке:
// show result of division
function showResult() {
try {
result.value = divide(
parseFloat(num1.value),
parseFloat(num2.value),
parseFloat(dp.value)
);
errmsg.textContent = '';
}
catch (e) {
result.value = 'ERROR';
errmsg.textContent = e.message;
console.log( e.name );
}
}Попробуйте ввести недопустимые нечисловые, нулевые и отрицательные значения в демонстрации на CodePen.
Окончательная версия функции divide() проверяет все входящие значения и при необходимости выдаёт соответствующую ошибку:
// division calculation
function divide(v1, v2, dp) {
if (isNaN(v1)) {
throw new TypeError('Dividend must be a number');
}
if (isNaN(v2) || !v2) {
throw new DivByZeroError('Divisor must be a non-zero number');
}
if (isNaN(dp) || dp < 0 || dp > 8) {
throw new RangeError('Decimal places must be between 0 and 8');
}
return (v1 / v2).toFixed(dp);
}Больше нет необходимости размещать блок try...catch вокруг финального return, так как он никогда не должен генерировать ошибку. Если бы это произошло, JavaScript сгенерировал бы свою собственную ошибку и обработал бы её блоком catch в showResult()/
Ошибки асинхронной функции
Мы не можем перехватывать исключения, генерируемые асинхронными функциями на основе обратного вызова, потому что после завершения выполнения блока try...catch выдаётся ошибка. Этот код выглядит правильно, но блок catch никогда не выполнится, и через секунду консоль отобразит сообщение Uncaught Error:
function asyncError(delay = 1000) {
setTimeout(() => {
throw new Error('I am never caught!');
}, delay);
}
try {
asyncError();
}
catch(e) {
console.error('This will never run');
}Соглашение, принятое в большинстве фреймворков и серверных сред выполнения, таких как Node.js, заключается в том, чтобы возвращать ошибку в качестве первого параметра функции обратного вызова. Это не приведёт к возникновению исключения, хотя при необходимости мы можем вручную сгенерировать ошибку:
function asyncError(delay = 1000, callback) {
setTimeout(() => {
callback('This is an error message');
}, delay);
}
asyncError(1000, e => {
if (e) {
throw new Error(`error: ${ e }`);
}
});Ошибки на основе промисов
Обратные вызовы могут стать громоздкими, поэтому при написании асинхронного кода предпочтительнее использовать промисы. При возникновении ошибки метод reject() промиса может вернуть новый объект Error или любое другое значение:
function wait(delay = 1000) {
return new Promise((resolve, reject) => {
if (isNaN(delay) || delay < 0) {
reject( new TypeError('Invalid delay') );
}
else {
setTimeout(() => {
resolve(`waited ${ delay } ms`);
}, delay);
}
})
}Примечание: функции должны быть либо 100% синхронными, либо 100% асинхронными. Вот почему необходимо проверять значение
delayвнутри возвращаемого промиса. Если бы мы проверили значениеdelayи выдали ошибку перед возвратом промиса, функция стала бы синхронной при возникновении ошибки.
Метод Promise.catch() выполняется при передаче недопустимого параметра delay и получает возвращённый объект Error:
// invalid delay value passed
wait('INVALID')
.then( res => console.log( res ))
.catch( e => console.error( e.message ) )
.finally( () => console.log('complete') );Я считаю цепочки промисов немного сложными для чтения. К счастью, мы можем использовать await для вызова любой функции, возвращающей промис. Это должно происходить внутри асинхронной функции, но мы можем перехватывать ошибки с помощью стандартного блока try...catch.
Следующая (вызываемая немедленно) асинхронная функция функционально идентична цепочке промисов выше:
(async () => {
try {
console.log( await wait('INVALID') );
}
catch (e) {
console.error( e.message );
}
finally {
console.log('complete');
}
})();Исключительная обработка исключения
Выбрасывать объекты Error и обрабатывать исключения в JavaScript легко:
try {
throw new Error('I am an error!');
}
catch (e) {
console.log(`error ${ e.message }`)
}Создание отказоустойчивого приложения, адекватно реагирующего на ошибки и облегчающее жизнь пользователя, является сложным испытанием. Всегда ожидайте неожиданного.
Дополнительная информация:
- MDN Порядок выполнения и обработка ошибок
- MDN try…catch
- MDN Error