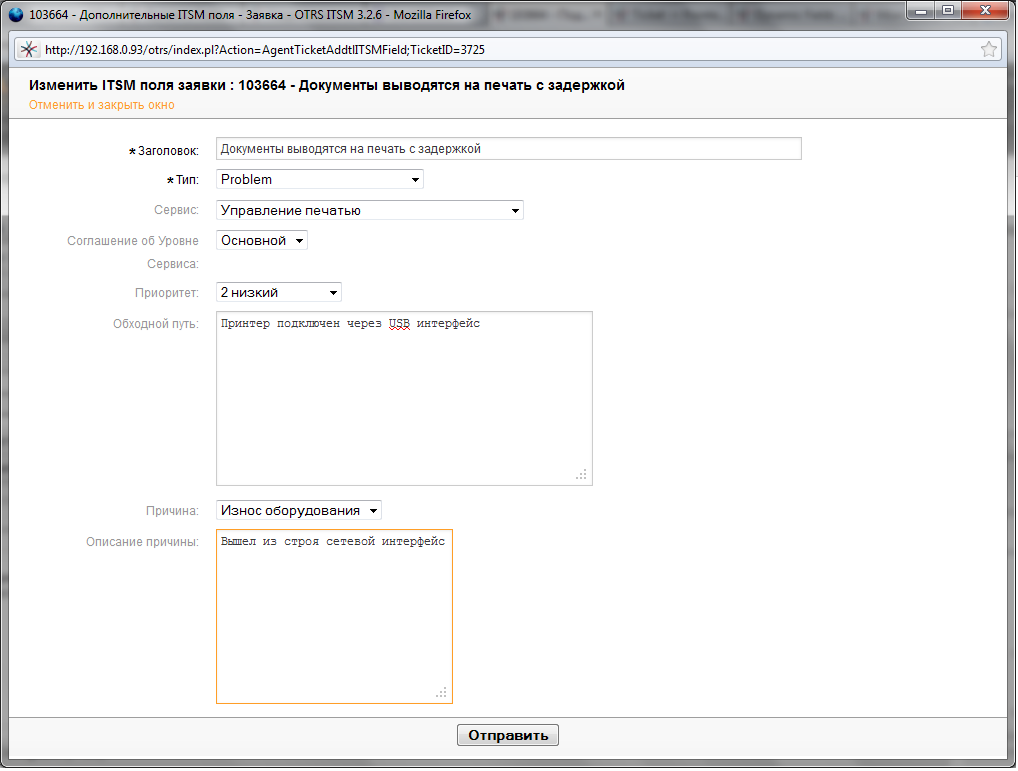
Совсем недавно у Игоря Фадеева вышла статья с разбором разницы между инцидентами и известными ошибками. Действительно запутаться в понятиях очень легко, на курсе ITIL® 4 Foundation мы регулярно с этим «распутываемся».
Для того, чтобы не путаться в понятиях и разговаривать на одном языке, всем участникам проекта рекомендуем Вам пройти наш курс ITIL® 4 Foundation.
Например, инциденты часто называют проблемами, хотя в ITIL это совсем разные понятия. Скорее всего это происходит из-за того, что в бытовом языке всё непонятное и неприятное мы называем проблемой.
Значение этого слова в ITIL отличается от бытового, его не стоит использовать для всего подряд, в том числе — для инцидентов. Что же такое инцидент? А остальное? Разберёмся вместе в этой статье.
Инцидент
Пользователь звонит в службу поддержки и сообщает, что не получается распечатать документ. Специалист службы поддержки отправляется на помощь.
Если прерывание этой услуги не входило в наши планы, то это — инцидент. Произошло незапланированное прерывание или снижение, если более официально — деградация качества услуги.
Инцидент здесь — услуга «Печать документов» недоступна. Пользователь не может распечатать нужные ему документы.
Исключением может быть ситуация в которой происходят плановые работы, из-за которых услуга недоступна. В таком случаем произошедшее не будет являться инцидентом. Хотя, конечно, мы можем задать себе вопрос: а почему пользователь не знает об этих плановых работах?
Проблема
Что стоит за этим инцидентом? Почему услуга недоступна?
Наш сотрудник отправляется к принтеру и изучает, что случилось. По ходу диагностики сотрудник обнаруживает, что диспетчер печати Windows время от времени «теряет» определённые сетевые принтеры из-за конфликта с драйвером данной модели сетевого принтера. Это — проблема, которая привела к инциденту.
В ITIL проблема — это причина или потенциальная причина инцидента или инцидентов.
Известная ошибка
Наш сотрудник изучил проблему, но ещё не успел решить. Ему нужно срочно бежать и тушить более важный пожар.
Убегая, он вспомнил, что почти всегда помогает перезагрузка компьютера и предложил такой вариант пользователю. Действительно, всё заработало. Инцидент решён, и мы нашли обходное решение: перезагрузка клиентского ПК или перезапуск диспетчера печати помогут нам на какое-то время.
Теперь, когда мы уже проанализировали проблему — знаем, чем она вызвана, как она проявляется, но еще не решили, а только нашли обходное решение, мы можем назвать её известной ошибкой.
Известная ошибка в ITIL — это проблема, которая уже была проанализирована, но ещё не была решена.
Системное решение мы можем применить не всегда. Иногда нам нужно время на подготовку. А иногда мы не видим возможности или экономической целесообразности. И нам приходится использовать обходные решения.
В нашем примере системное решение — обновление версии драйвера принтера с помощью обновления от производителя. Это обновление мы пока ждём, производитель в курсе и обещал предоставить.
Управление проблемами и управление инцидентами
При управлении ИТ-услугами мы неизбежно сталкиваемся с перебоями в работе, снижением производительности, нарушениями структур данных и прочим.
То, как мы работаем с этими ситуациями, определяет то, как потребители и другие заинтересованные стороны воспринимают нашу организацию.
Именно здесь вступают в игру две важнейшие практики ITIL: управление инцидентами и управление проблемами.
Управление инцидентами — это способность максимально быстро восстановить нормальную работу услуги после инцидента, а управление проблемами нужно, чтобы снизить вероятность возникновения и негативное влияние от инцидентов.
Управление инцидентами может быть более заметно пользователям: у меня сломалось, мне быстро починили. А управление проблемами, кажется, не заметно вообще, ведь это внутренняя кухня ИТ.
На самом деле это не так: косвенно управление проблемами заметно и для пользователей.
У меня редко ломается, у меня никогда не ломается снова то, что уже чинили. Мне не нужно обращаться в поддержку каждый день из-за поломок.
А зачем так много терминов?

Пользователи и бизнес ожидают «чтобы работало», а не наша терминология.
Разделение «чего-то плохого, что случилось с нашими услугами» на инциденты, проблемы и известные ошибки нужно именно нам, чтобы уделять одинаковое внимание двум одинаково-важным активностям.
Поскорее поднять то, что упало и при этом не допустить падения снова. Ведь когда что-то упало нужно скорее поднимать. И здесь обходные решения — отличная практика.
Но если вся система будет состоять из обходных решений, то она будет очень хрупкой. Обходные решения не отменяют необходимость затем найти и устранить корневую причину, проблему. Сделать так, чтобы больше не падало. Вот почему две практики, а не одна. Вот почему они обе важны.
На нашем YouTube канале Вы можете посмотреть видео-версию этой заметки и еще много полезных роликов от экспертов Cleverics.
Что такое управление проблемами?
Управление проблемами — это процесс выявления причин инцидентов в ИТ-услугах и управления этими причинами. Это — основа фреймворков ITSM.
Чем ближе вы к настоящим экспертам по инцидентам, тем реже слышите вопрос: «Что вызвало инцидент?» Конечно, его часто задают руководители, клиенты и пресса. Но только не эксперты.
Потому что ответ на вопрос: «Что вызвало инцидент?» часто бывает сухим и бесполезным: «Перезаписанный файл конфигурации» или «Поврежденная запись в базе данных».
Но какие причины способствовали возникновению инцидента? Какие факторы привели к инциденту? Как получилось, что файл конфигурации был перезаписан? При каких условиях была создана поврежденная запись в базе данных? Такие вопросы задают эксперты. И эти вопросы лежат в основе управления проблемами.
Управление проблемами — это не только поиск и устранение инцидентов, но также выявление и изучение причин, способствовавших их возникновению, и поиск наилучшего способа устранения первопричины. Более того, точное определение причины не имеет ценности для организации, если это неструктурированный процесс, выполненный изолированной командой. То есть управление проблемами должно быть постоянным и широко применяться множеством команд, включая команды ИТ, обеспечения безопасности и разработки ПО. Инцидент может закончиться после восстановления работы сервиса, но пока не будут устранены первопричины и способствующие факторы, проблема остается.
Какие преимущества дает управление проблемами?
Управление проблемами при правильном использовании дает много преимуществ бизнесу.
Более быстрое устранение инцидентов
Команды, которые выявляют проблемы, лежащие в основе текущих инцидентов, будут лучше подготовлены к реагированию на инциденты в будущем. Систематизируя рекомендации по анализу проблем, команды смогут более оперативно реагировать и принимать меры при следующих перебоях в обслуживании.
Возможность избежать дорогостоящих инцидентов
Возможность избежать инцидентов экономит время, средства и нервы. По данным компании Gartner, во многих организациях время простоя обходится более чем в 300 000 $ в час. Если же речь идет о веб-сервисах, эта цифра может оказаться гораздо больше.
Повышайте продуктивность
Перестав так часто реагировать на инциденты, вы освободите ресурсы и время в командах, которые теперь смогут уделять больше внимания созданию ценности для клиентов.
Предоставление команде возможности находить и изучать первопричины инцидентов
В организациях, где эффективно управляют проблемами, команды постоянно расследуют инциденты, извлекают из них уроки и поставляют ценные обновления. К сожалению, на многих предприятиях создаются изолированные команды управления проблемами, которые слишком далеки от повседневной работы, чтобы устранить наиболее серьезные проблемы.
Поддержка постоянного улучшения обслуживания
Управление проблемами предотвращает инциденты и одновременно повышает эффективность. Например, устранение инцидента, вызывающего снижение производительности, приводит к улучшению качества обслуживания.
Повышение удовлетворенности клиентов
Более эффективное управление проблемами сокращает число инцидентов и повышает удовлетворенность клиентов. И наоборот, если один и тот же инцидент возникает снова и снова, терпение клиентов иссякает. Уменьшение числа повторных инцидентов укрепляет доверие клиентов.
Процесс управления проблемами
Компания Atlassian выступает за сближение процессов управления проблемами и инцидентами.
Если процесс управления проблемами громоздкий, изолированный и оторванный от остальных, для компании это может закончиться появлением целого вороха нерешенных проблем. Бэклог — это место, в где проблемы у некоторых команд уходят в небытие. Проблемы лучше всего ставить перед командами, которые могут их решить и способны провести ценные исследования.
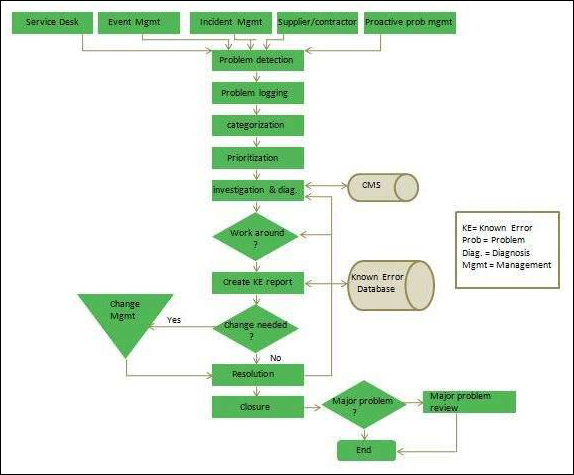
При этом важно знать основные этапы процесса управления проблемами. Они перечислены ниже.
- Обнаружение проблемы. Занимайтесь поиском проблем заблаговременно, чтобы их можно было решить, или предусматривайте способы обхода инцидентов до того, как они возникнут.
- Присвоение категории и назначение приоритета. Отслеживайте и оценивайте известные проблемы, чтобы команды могли организованно работать над решением наиболее насущных и важных проблем.
- Изучение и диагностика. Определите первопричины, которые привели к возникновению проблемы, и выберите наилучший способ их устранения.
- Создание записи об известной ошибке. В ITIL известная ошибка — это «проблема, имеющая документированную основную причину и способ обхода». Регистрация этих сведений позволит сократить простои, если проблема вызовет инцидент. Обычно эта информация хранится в документе, который называется базой данных известных ошибок.
- Создание способа обхода (при необходимости). Способ обхода — это временное решение, которое снижает негативное воздействие проблемы и не позволяет ей перерасти в инцидент. Способы обхода не идеальны, но могут ограничить влияние на бизнес и не позволят клиентам столкнуться с инцидентом, если проблему не удастся быстро обнаружить и устранить.
- Решение и закрытие проблемы. Закрытая проблема — это проблема, которая устранена и больше не может вызвать инцидент.
В ITIL Проблема определяется как неизвестная причина одного или нескольких инцидентов.
Управление проблемами обеспечивает выявление проблем и выполняет анализ первопричин. Это также обеспечивает минимизацию повторяющихся инцидентов и предотвращение проблем.
Диспетчер проблем является владельцем этого процесса.
Ключевые моменты
-
Управление проблемами состоит из действий, необходимых для диагностики первопричины инцидента и определения решения этих проблем.
-
Когда проблема решается после анализа первопричины, становится известной ошибкой.
-
Управление проблемами также записывает информацию о проблемах в системе, называемой базой данных известных ошибок (KED) .
Управление проблемами состоит из действий, необходимых для диагностики первопричины инцидента и определения решения этих проблем.
Когда проблема решается после анализа первопричины, становится известной ошибкой.
Управление проблемами также записывает информацию о проблемах в системе, называемой базой данных известных ошибок (KED) .
Управление проблемами состоит из следующих двух процессов –
-
Реактивное управление проблемами выполняется как часть сервисной операции.
-
Упреждающее управление проблемами, инициированное в процессе эксплуатации сервиса, но, как правило, в рамках непрерывного улучшения сервиса
Реактивное управление проблемами выполняется как часть сервисной операции.
Упреждающее управление проблемами, инициированное в процессе эксплуатации сервиса, но, как правило, в рамках непрерывного улучшения сервиса
Процесс управления проблемами
Следующая диаграмма описывает действия, связанные с управлением проблемами –
Обнаружение проблемы
Проблема может быть обнаружена следующими способами –
-
Анализ инцидента группой технической поддержки.
-
Автоматическое обнаружение сбоя инфраструктуры или приложения, автоматически использующее средства оповещения для оповещения об инциденте, который может выявить необходимость решения проблем.
-
Уведомление от поставщика о наличии проблемы, которая должна быть решена.
Анализ инцидента группой технической поддержки.
Автоматическое обнаружение сбоя инфраструктуры или приложения, автоматически использующее средства оповещения для оповещения об инциденте, который может выявить необходимость решения проблем.
Уведомление от поставщика о наличии проблемы, которая должна быть решена.
Проблема регистрации
Проблема должна быть полностью зарегистрирована и содержит следующую информацию:
-
Данные пользователя
-
Детали сервиса
-
Детали оборудования
-
Приоритет и детализация по категориям
-
Дата / время изначально зарегистрированы
Данные пользователя
Детали сервиса
Детали оборудования
Приоритет и детализация по категориям
Дата / время изначально зарегистрированы
Проблема классификации
Чтобы отследить истинную природу Проблемы, необходимо классифицировать Проблемы так же, как Инциденты.
Определение приоритетов
Проблемы должны быть классифицированы так же, как и инциденты, чтобы определить, насколько серьезна проблема с точки зрения инфраструктуры.
обходные
Это временный способ преодоления трудностей. Подробности обходного пути всегда должны быть задокументированы в записи проблемы.
Создание записи об известных ошибках
Известная ошибка должна быть вызвана и помещена в базу данных известных ошибок для дальнейшего использования.
Разрешение проблемы
Как только решение найдено, оно должно быть применено и задокументировано с подробностями проблемы.
Проблема закрытия
Во время закрытия следует выполнить проверку, чтобы убедиться, что запись содержит полные исторические описания всех событий.
Обзор основных проблем
Необходимо сделать обзор следующих вещей:
Те вещи, которые были сделаны правильно
Те вещи, которые были сделаны неправильно
Что можно сделать лучше в будущем
Как предотвратить рецидив
Введение
Управление ИТ-услугами (ITSM) включает работу с инцидентами и проблемами. По мере возрастания роли ИТ в компании растет и потребность в обеспечении хорошего уровня сервиса, обеспечении максимальной доступности ИТ-услуг. Бизнес-пользователь должен иметь возможность получить решение своих проблем, если они возникают, как можно быстрее, и работать в любое время. Реализация процессов управления инцидентами и проблемами нацелена именно на это. В данной статье мы описываем, как может быть устроена работа ИТ-службы в рамках управления инцидентами и проблемами. Это описание основано на предложениях ITIL и опыте наших клиентов.
Язык инцидентов и проблем
ITIL Service Support — признанная в мире модель. Она основана на передовом опыте и используется как руководство ИТ-организациями при разработке подходов к управлению обслуживанием. Эта модель перспективна. Также она определяет дополнительные элементы, необходимые для успешного функционирования ИТ-организации как сервисного бизнеса. Она предоставляет технический словарь для обсуждения службы поддержки, определяет понятия и раскрывает отличия между различными видами деятельности. Например, деятельность, необходимая для реагирования на прерывания сервиса, его восстановления, отлична от деятельности по поиску и устранению причин, из-за которых прерывается обслуживание.
Инциденты
Инцидент — есть любое событие, которое не является частью стандартных операций сервиса и вызывает, или может вызвать, прерывание обслуживания или снижение качества сервиса.
Примерами инцидентов являются:
- Пользователь не может получить e-mail
- Средство мониторинга сети указывает, что канал связи вскоре переполнится
- Пользователь ощущает замедление работы приложения
Проблемы
Проблема — есть неизвестная причина одного или более инцидентов.Одна проблема может породить несколько инцидентов.
Ошибки
Известная ошибка — есть инцидент или проблема, для которой выявлена причина и разработано решение по ее обходу или устранению. Ошибки могут выявляться в результате анализа жалоб пользователей или анализа систем.
Примеры ошибок включают:
- Неправильная сетевая конфигурация компьютера
- Средство мониторинга неверно определяет статус канала в момент занятости маршрутизатора
Соотношение понятий управления инцидентами и проблемами показано на рисунке 1. Инциденты, проблемы и известные ошибки связаны в своего рода жизненный цикл: инциденты часто являются индикаторами проблем ⇒ выявление причины проблемы определяет ошибку ⇒ ошибки затем систематически исправляются.
Система ИнфраМенеджер – мощная российская система управления инцидентами и проблемами
Возможности Web-портала ИнфраМенеджер Организация Service Desk с помощью ИнфраМенеджер
Управление инцидентами
Управление инцидентами — есть деятельность по восстановлению нормального обслуживания с минимальными задержками и влиянием на бизнес-операции, являющаяся реактивным, сфокусированным на краткосрочную перспективу сервисом восстановления.
Она включает в себя:
- Выявление и регистрация инцидентов
- Классификация и начальная поддержка
- Исследование и диагностика
- Решение и восстановление
- Закрытие
- Владение, мониторинг, отслеживание и связь
Управление проблемами
Управление проблемами — есть деятельность по минимизации воздействия на бизнес проблем, которые вызываются ошибками в ИТ-инфраструктуре, по предотвращению повторения инцидентов, связанных с такими ошибками. Управление проблемами выявляет причины проблем, идентифицирует решения по их обходу или устранению.
Управление проблемами включает:
- Контроль проблем
- Контроль ошибок
- Предотвращение проблем
- Анализ основных проблем
Контроль проблем
Цель контроля проблем — найти причину проблемы, выполнив следующие шаги:
- Идентификация и регистрация проблем
- Классификация проблем и определение приоритетов их решений
- Исследование и диагностика причин
Контроль ошибок
Контроль ошибок обеспечивает исправление проблем за счет следующих действий:
- Идентификация и регистрация известных ошибок
- Оценка способов устранения и расстановка приоритетов
- Регистрация по временному обходу ошибки в средствах службы поддержки
- Закрытие известных ошибок путем осуществления исправлений
- Мониторинг известных ошибок для определения необходимости в изменении приоритетов
Анализ проблем
Цель анализа проблем состоит в улучшении процессов управления инцидентами и управления проблемами. Что достигается изучением качества результатов деятельности по устранению основных проблем и инцидентов.
Организационные роли и распределение ответственности
Наиболее часто встречаемой структурой системы поддержки является многоуровневая модель, в которой все возрастающий уровень технических возможностей применяется для решения инцидента или проблемы. Фактические роли и распределение ответственности, используемые в многоуровневой реализации системы поддержки, могут быть различными в зависимости от персонала, истории и политики конкретной организации. Тем не менее, следующее описание многоуровневой системы поддержки типично для многих организаций.
Первый уровень поддержки
Организация (подразделение), представляющая первый уровень поддержки обычно относится к оперативным службам. Как правило, она называется диспетчерской службой, Call Center, Help Desk, Service Desk.
Роли. Владелец процесса
Первый уровень поддержки гарантирует, что установлен и поддерживается хорошо определенный, единообразно исполняемый, измеряемый соответствующим образом, эффективный процесс управления инцидентами. Получение и управление всеми вопросами обслуживания потребителей. Первый уровень поддержки является единственной точкой контакта для передачи вопросов с обслуживанием, и он действует как адвокат конечного пользователя, который гарантирует, что вопросы с обслуживанием решаются своевременно.
Первая линия поддержки
Организация первого уровня поддержки предпринимает первую попытку разрешить вопрос с обслуживанием, о котором сообщил конечный пользователь.
Обязанности
-
Точная регистрация инцидентов. Первый уровень поддержки гарантирует, что информация об инциденте вносится в журнал системы. Для этого должно быть:
- Гарантировано, что карточка инцидента содержит точное и достаточно детальное описание проблемы
- Гарантирован правильный выбор важности/приоритета инцидента
- Определена природа проблемы, контакты пользователя, влияние на бизнес и ожидаемое время решения
-
Владение каждым инцидентом. Как адвокат конечного пользователя первый уровень поддержки обеспечивает успешное разрешение каждого инцидента. При этом гарантируется своевременное решение вопросов за счет:
- Разработки и управления планом действий по решению вопроса
- Инициации конкретных назначений заданий для персонала и бизнес-партнеров
- Эскалации инцидента, если требуется, когда цель не достигается во время
- Обеспечения внутреннего взаимодействия в соответствии с целями обслуживания
- Защиты интересов вовлеченных бизнес-партнеров
-
Первый уровень поддержки использует базу данных управления проблемами для сопоставления инцидентов известным ошибкам и применения ранее найденных способов разрешения инцидентов. Цель заключается в разрешении 80 процентов инцидентов. Остальные инциденты передаются (эскалируются) на второй уровень.
-
Непрерывное улучшение процесса управления инцидентами. Как владелец данного процесса первый уровень поддержки гарантирует улучшение при необходимости процесса посредством:
- Оценки эффективности данного процесса и таких механизмов поддержки, как отчеты, виды связи и форматы сообщений, процедуры эскалации
- Разработки специфических для подразделений отчетов и процедур
- Поддержки и совершенствования взаимодействия и списков эскалации
- Участие в процессе анализа проблем
Способности и навыки
-
Навыки межличностного общения первостепенны. Персонал первого уровня поддержки вовлечен главным образом в расстановку приоритетов и управление проблемами. На этом уровне поддержки проводятся лишь незначительные технические изыскания. Способность применять «консервированные» решения. Персонал первого уровня должен уметь распознавать симптомы, применять поисковые инструменты для обнаружения ранее разработанных решений и помогать конечным пользователям в применении таких решений.
Второй уровень поддержки
Этот уровень также обычно относится к оперативным службам.
Роли
- Исследование инцидентов. Второй уровень поддержки изучает, диагностирует и решает большинство инцидентов, которые не были решены на первом уровне. Эти инциденты имеют тенденцию указывать на новые проблемы.
- Владелец процесса управления проблемами. Второй уровень поддержки обеспечивает, что имеет место хорошо определенный и эффективный процесс управления проблемами.
- Упреждающее управление инфраструктурой. Второй уровень поддержки использует инструменты и процессы, чтобы гарантировать, что проблемы выявляются и решаются до возникновения инцидентов.
Обязанности
- Решение инцидентов, переданных с первого уровня. Если для первого уровня поддержки ожидается, что он решает 80% инцидентов, то от второго уровня поддержки ожидается, что он решает 75% инцидентов, переданных ему первым уровнем, то есть 15% от числа зарегистрированных инцидентов. Остальные инциденты передаются на третий уровень.
- Определение причин проблем. Второй уровень поддержки определяет причины проблем и предлагает меры по их обходу или устранению. Они привлекают и управляют другими ресурсами по мере необходимости для определения причин. Решение проблем передается на третий уровень, когда причина заключается в архитектурном или техническом вопросе, который превышает их уровень квалификации.
- Обеспечение реализации исправлений и устранений проблем. Второй уровень поддержки обеспечивает инициирование проектов в организациях разработчиках для реализации планов устранения известных ошибок. Они обеспечивают документирование найденных решений, сообщают о них персоналу первого уровня и реализуют их в инструментах.
- Постоянный мониторинг инфраструктуры. Второй уровень поддержки пытается идентифицировать проблемы до возникновения инцидентов посредством наблюдения за компонентами инфраструктуры и принятия корректирующих действий при обнаружении дефектов или ошибочных тенденций.
- Заблаговременный анализ тенденций инцидентов. Уже случившиеся инциденты исследуются для того, чтобы определить не свидетельствуют ли они о наличии проблем, которые следует исправить, чтобы они не вызвали новые инциденты. Исследуются те инциденты, которые закрыты и не сопоставлены известным проблемам, на предмет наличия потенциальных проблем.
- Постоянное совершенствование процесса управления проблемами. Как владелец процесса управления проблемами второй уровень поддержки гарантирует, что процесс и имеющиеся возможности адекватны и улучшает их при необходимости. Они проводят сессии анализа проблем, чтобы выявить полученные уроки и гарантировать, что средства контроля над процессом, такие как совещания и отчеты, адекватны.
Способности и навыки
- Технически компетентны с разумными навыками общения. Персонал второго уровня поддержки должен иметь спектр технических навыков по всем поддерживаемым технологиям, включая сети, сервера и приложения. Общим дефицитом в организациях второго уровня являются знания в области операционных систем и приложений. Не должно быть значительного разрыва между организациями второго и третьего уровней. Некоторые сотрудники второго уровня должны быть так же квалифицированы, как и сотрудники третьего уровня.
- Знание сетей, серверов и приложений. Организации второго уровня должны быть способны решить инциденты и проблемы по всему спектру технологий, используемых в компании.
Третий уровень поддержки
Этот уровень поддержки обычно относится к группе разработки приложений и сетевой инфраструктуры.
Роли
- Планирование и проектирование ИТ-инфраструктуры. Обычно группа поддержки третьего уровня играет небольшую роль в управлении инцидентами и управлении проблемами, так как такие организации главным образом заняты планированием и конструированием ИТ-инфраструктуры. В этом качестве их цель состоит в реализации бездефектной инфраструктуры, которая не является источником проблем и инцидентов.
- Последний рубеж в эскалации. Если инцидент или проблема оказывается выше возможностей группы поддержки второго уровня, то группа поддержки третьего уровня принимает ответственность за поиск решения.
Обязанности
- Решение инцидентов, переданных со второго уровня. Так как большинство инцидентов вызывается известными ошибками, то очень немного инцидентов (5%) проходит через второй уровень на третий. Третий уровень отвечает за решение всех инцидентов, которые к ним поступают.
- Участие в деятельности по управлению проблемами.Третий уровень поддержки задействован в поиске причин, способов обхода и устранения ошибок.
- Реализация мер по устранению ошибок из инфраструктуры. У третьего уровня значительная роль в планировании, конструировании и реализации проектов по устранению недостатков инфраструктуры. Выполнение этих проектов должно быть согласовано с обычной работой по развитию инфраструктуры для достижения нужного баланса.
Способности и навыки
- Эксперты в соответствующих областях. Команды третьего уровня должны быть экспертами, которые планируют и проектируют ИТ-инфраструктуру.
Процессы
Можно выделить три основных процесса, связанных с управлением инцидентами и управлением проблемами:
- процесс управления инцидентами
- процесс контроля проблем
- процесс контроля ошибок
Эти основные процессы присутствуют практически во всех передовых организациях, хотя могут иметь и другие названия.
Процесс управления инцидентами
Данный процесс сфокусирован на скорейшем восстановлении прерванного сервиса. В таблице 1 приведены основные параметры этого процесса, а на рисунке 1 показана диаграмма его работы.
Таблица 1. Параметры процесса
|
Параметр процесса |
Описание |
|---|---|
|
Назначение |
|
|
Владелец |
|
|
Вход |
|
|
Выход |
|
|
Типичные числовые параметры |
|

Рисунок 1. Модель процесса
Процесс контроля проблем
Процесс контроля проблем сфокусирован на расстановке приоритетов, выделении и мониторинге усилий на определении причин проблем, способов их временного или постоянного устранения. Этот процесс может быть уподоблен управлению портфелем проектов, где каждая проблема суть проект, который должен управляться в рамках портфеля таких же проектов. Основные параметры проекта контроля проблем приведены в таблице 2.
|
Параметр процесса |
Описание |
|---|---|
|
Назначение |
|
|
Владелец |
|
|
Вход |
|
|
Выход |
|
|
Типичные числовые параметры |
|
Таблица 2. Параметры процесса управления проблемами
Вход в процесс может поступать из нескольких источников. Обычно инциденты высокого уровня серьезности автоматически передаются процессу контроля проблем. В организациях с крепким вторым уровнем поддержки инциденты, передаваемые на третий уровень поддержки, также в плановом порядке направляются процессу контроля проблем. И, наконец, ежедневное совещание может перенаправить те или иные инциденты процессы контроля проблем. Процесс, реализующий контроль проблем, показан на рисунке 2.

Рисунок 2. Модель процесса контроля проблем
Фокус процесса контроля проблем направлен на определение причин. Состав участников анализа причин и длительность времени, необходимого для выполнения такого анализа зависит от самой проблемы. Можно считать правильными следующие утверждения:
- Если у вас достаточное количество проблем, то назначьте постоянную команду. Иначе создавайте команду при появлении проблемы, во многом также как формируется команда под какой-либо проект;
- Команда почти всегда должна быть с междисциплинарным опытом и знаниями. И это конечно зависит от природы возникшей проблемы;
- Следует давать оценку времени на определение причины (разрабатывать план проекта) в момент появления проблемы. В соответствии с этой оценкой следует измерять прогресс в деятельности команды.
После того как ресурсы выделены и расставлены приоритеты, фактическая механика определения причины может принимать различные формы. Хорошо зарекомендовали себя такие методы поиска причин как Анализ Кепнера и Трего, диаграммы Ишикавы, диаграммы Парето и прочее.
Процесс контроля ошибок
Контроль ошибок обеспечивает документирование способов преодоления неисправностей и оповещения о них (способах) персонала поддержки. К нему же относится поддержание связи с другими техническими и разрабатывающими организациями, также способствующее выявлению ошибок. Более того, контроль ошибок влияет на разработчиков с целью реализации исправлений известных ошибок. В таблице 3 приведены основные параметры процесса контроля ошибок. На рисунке 3 изображена модель процесса контроля ошибок.
|
Параметр процесса |
Описание |
|---|---|
|
Назначение |
|
|
Владелец |
|
|
Вход |
|
|
Выход |
|
|
Типичные числовые параметры |
|
Таблица 3. Параметры процесса управления ошибками

Рисунок 3. Модель процесса контроля ошибок
Взаимодействия
Как правило, взаимодействия в данном процессе принимают одну из двух форм. Это либо сообщения о статусе инцидента или проблемы, которые предоставляются различным группам и/или отдельным лицам на основе утвержденных правил и шаблонов, либо сообщения о запросах, которые требуют от получателя определенных действий, обычно содержащих кроме фактического запроса/требования еще ссылку на инцидент, номер телефона пользователя или иную ссылку на него.
Многие компании полагаются на возможности автоматической рассылки сообщений, предоставляемые программным обеспечением. Такие сообщения рассылаются в соответствии с жесткими регламентами для поддержания эскалации. Сообщения о статусе из программных систем, как правило, порождаются из данных, введенных в поля карточки инцидента. Поэтому такие сообщения часто неполны и похожи на шифровку из-за того, что используемые для построения автоматических сообщений поля могут обновляться нерегулярно своевременной информацией или автоматически заполняются программными средствами мониторинга с использованием жаргона сообщений об ошибках.
Для исправления этих недостатков автоматические возможности коммуникации дополняются, особенно в случае инцидентов высокого уровня важности, сообщениями составленными вручную.
Эскалация
Механизм эскалации помогает своевременно решить инцидент путем увеличения возможностей персонала, уровня усилий и приоритета, нацеленных на решение этого инцидента. Лучшие организации имеют хорошо определенные пути эскалации с временными рамками и ответственности ясно определенными на каждом шаге. Они используют средства управления инцидентами для автоматической передачи ответственности на все возрастающий уровень поддержки в соответствии с временными рамками и сложностью.
Временные рамки и ответственность в рамках эскалации сильно отличаются в зависимости от организации, промышленности и уровня сложности проблем. В передовых организациях проводятся переговоры с конечными пользователями для определения подходящих временных рамок и эскалации ответственности. Результат таких переговоров реализуются в виде соглашений об уровне сервиса, автоматизированных средств, списков, шаблонов.
Функциональная эскалация
Функциональная эскалация есть передача инцидента на более высокий уровень поддержки, когда знаний или опыта недостаточно или истек согласованный интервал времени. В передовых организациях определяется матрица уровней важности, основанная на степени влияния на бизнес, временных рамках разрешения инцидента и интервалах времени, в которые инцидент должен быть передан в более продвинутую группу. Таблица 4. представляет собой такую матрицу.
В большинстве организаций группы поддержки первого и второго уровней, ориентированы на эксплуатацию существующей инфраструктуры, тогда как третий уровень поддержки предоставляется обычно группами, которые отвечают за планирование развития инфраструктуры, ее проектирование. Поэтому тщательное планирование того, каким образом ответственность будет функционально передана на третий уровень, критически важно.
Таблица 4. Матрица эскалаций
|
Уровень инцидента |
Описание |
Срок решения |
Начальный уровень |
Первая эскалация |
Вторая эскалация |
Третья эскалация |
|---|---|---|---|---|---|---|
|
1 |
Свыше 50 пользователей не могут выполнять бизнес-транзакции |
2 часа |
1-ый уровень поддержки |
0 минут 2-ый уровень поддержки |
30 минут 3-ий уровень поддержки |
30 минут 1-ый менеджер Экстренное совещание |
|
2 |
От 10 до 49 пользователей не могут выполнять бизнес-транзакции |
4 часа |
1-ый уровень поддержки |
0 минут 2-ый уровень поддержки |
60 минут 3-ий уровень поддержки |
60 минут 1-ый менеджер Экстренное совещание |
|
3 |
От 1 до 9 пользователей не могут выполнять бизнес-транзакции |
8 часов |
1-ый уровень поддержки |
30 минут 2-ый уровень поддержки |
120 минут 3-ий уровень поддержки |
120 минут 1-ый менеджер |
В передовых организациях обычно определяется дежурный пейджер. Менеджер каждой технологической группы отвечает за подготовку расписания обработки вызовов, поступающих на такой пейджер, и гарантирует, что вызовы обслуживаются в любое время. Кроме того, для каждой технологической группы должна быть определена процедура иерархической (управленческой) эскалации. Обычно линейный руководитель группы третьего уровня является первым руководителем в эскалации.
Иерархическая эскалация
Для того, чтобы обеспечить предоставление инциденту соответствующего приоритета и выделение необходимых ресурсов до того, как будут перекрыты временные рамки его разрешения, иерархическая эскалация вовлекает в процесс руководство. Иерархическая эскалация может выполняться на любом уровне поддержки. В таблице 4 иерархическая эскалация происходит на третьем шаге эскалации для проблем всех уровней важности.
В передовых организациях эскалация к руководству происходит автоматически в соответствии с предопределенной процедурой на основе серьезности проблемы. После того, как эскалация произошла, ожидается, что соответствующий менеджер активно управляет решением проблем и становится единым контактом для сообщений о статусе.
Отчеты и совершенствование процессов
Статистические отчеты в передовых организациях используются для контроля, непрерывного проведения улучшения процесса и анализа соответствия показателей производительности уровню сервиса, согласованному с потребителями.
Для контроля процессов управления инцидентами и управления проблемами могут, например, использоваться отчеты, содержащие значения следующих параметров:
- Количество карточек инцидентов, открытых в данный момент в разрезах по уровню важности, затраченному времени, группам ответственности
- Количество карточек проблем, открытых в данный момент (причина которых еще не выявлена)
Такие отчеты позволяют руководителям принимать решения о распределении ресурсов, направлении усилий персонала. Регулярное использование параметров типа:
- Среднее время обработки карточек на каждом из уровней
- Количество карточек, переданных и решенных на каждый из уровней, могут помочь выявить слабости ИТ-инфраструктуры
Наконец жизненно необходимый набор отчетов, типа:
- Процент инцидентов, решенных в заданные сроки
- Среднее время на восстановление сервиса, позволяет взаимодействовать ИТ-организации со своими потребителями и соотносить достигнутый уровень производительности с целевым уровнем сервиса
Заключение
Разработка процессов и процедур управления инцидентами проводится многими организациями, но далеко не все эти организации делают то же самое для управления проблемами. Часто это происходит из-за недостаточно ясного понимания характеристик этих двух видов деятельности. Управление инцидентами — простейший вид деятельности для понимания, поскольку он просто создает механизм для реагирования на прерывания сервиса. Поскольку «визгливое колесо всегда будет смазано», то управление инцидентами развивается достаточно быстро. Однако для развития управления проблемами часто имеется меньше поводов.
Управление проблемами в большей степени похоже на управление портфелем проектов, целью каждого из которых является определение причин проблемы. Инциденты часто являются первым индикатором проблемы и, однажды столкнувшись с инцидентом, организация должна иметь процесс и процедуры выяснения причины.
Продолжая аналогию с портфелем проектов, организация, занимающаяся управлением проблемами, должна разработать критерий определения проблем, которые следует исследовать для определения причин, во многом таким же образом как она это делает в части критерия принятия решения о выборе нового проекта. Проблемы, которые не исследуются, продолжают отслеживаться для исследования их в будущем. Когда причина найдена и решение разработано, организация отслеживает прогресс в реализации решения.
известная ошибка
- известная ошибка
-
известная ошибка
(ITIL Service Operation)
Проблема, имеющая задокументированные корневую причину и обходное решение. Известные ошибки создаются и управляются на протяжении их жизненного цикла в рамках процесса управления проблемами. Известные ошибки также могут быть выявлены разработчиками или подрядчиками.
[Словарь терминов ITIL версия 1.0, 29 июля 2011 г.]EN
known error
(ITIL Service Operation)
A problem that has a documented root cause and a workaround. Known errors are created and managed throughout their lifecycle by problem management. Known errors may also be identified by development or suppliers.
[Словарь терминов ITIL версия 1.0, 29 июля 2011 г.]Тематики
- информационные технологии в целом
Справочник технического переводчика. – Интент.
2009-2013.
Смотреть что такое «известная ошибка» в других словарях:
-
ошибка логическая — нарушения к. л. законов, правил и схем логики. Если ошибка допущена неумышленно, она называется паралогизмом; если правила логики нарушают умышленно, то это софизм. Логические ошибки следует отличать от фактических ошибок. Последние обусловлены… … Словарь терминов логики
-
Игрок — (Player) Определение биржевого игрока, условия игры на бирже Информация об определении биржевого игрока, игра на бирже, покупка и продажа акций Содержание Содержание Определения описываемого предмета Истоки игры на Зачем играть на бирже Как… … Энциклопедия инвестора
-
Антипаттерн — Возможно, эта статья содержит оригинальное исследование. Добавьте ссылки на источники, в противном случае она может быть выставлена на удаление. Дополнительные сведения могут быть на странице обсуждения. (25 мая 2011) … Википедия
-
ИТ Сервис Менеджмент — ITSM (IT Service Management, управление IT услугами) подмножество библиотеки ITIL получила наибольшую известность в силу того, что предоставление и поддержка IT услуг является первичной задачей IT подразделений и специализированных IT компаний,… … Википедия
-
Omega (Вавилон-5) — «Вавилон 5» Эсминец «Омега» Вооруженных Сил Земного Альянса Общая информация Мир: Земля, Марс, колонии Земного Альянса Статус: на вооружении Приписка: Земной Альянс Технические параметры … Википедия
-
Алгоритм Бойера — Мура — Алгоритм Бойера Мура поиска строки считается наиболее быстрым среди алгоритмов общего назначения, предназначенных для поиска подстроки в строке. Был разработан Робертом Бойером (англ. Robert S. Boyer) и Джеем Муром (англ. J Strother Moore)… … Википедия
-
Бойера-Мура алгоритм — Алгоритм Бойера Мура поиска строки считается наиболее быстрым среди алгоритмов общего назначения, предназначенных для поиска подстроки в строке. Был разработан Робертом Бойером (англ. Robert S. Boyer) и Джеем Муром (англ. J Strother Moore) в… … Википедия
-
Официальный день рождения королевы — Не путать с Днём королевы в Нидерландах. «Королева» в этой статье означает монарха Соединённого королевства и Содружества наций и заменяется на слово «король» со сменой пола монарха. Королева и герцог Эдинбургский на параде в день рожд … Википедия
-
Алгоритм Бойера — Алгоритм поиска строки Бойера Мура считается наиболее быстрым среди алгоритмов общего назначения, предназначенных для поиска подстроки в строке. Был разработан Робертом Бойером (англ. Robert S. Boyer) и Джеем Муром (англ. J… … Википедия
-
запись об известной ошибке — (ITIL Service Operation) Запись, содержащая детальное описание Известной ошибки. В каждой Записи об известной ошибке документируется Жизненный цикл Известной ошибки, включая Статус, Корневую причину и Обходное решение. В некоторых реализациях… … Справочник технического переводчика
IT departments deal with an enormous number of complaints and problems daily. Jammed printers, internet outages, email errors, and requests for new laptops are just a few of the issues that can impact staff productivity. In order to keep technology working and operations running, business can implement frameworks such as the IT Infrastructure Library (ITIL) to support and streamline IT processes.
In this article, we will discuss the ITIL framework and its associated processes. We’ll also dive into the workflow, benefits, key performance indicators, and best practices associated with problem management.
The Origins of ITIL
ITIL emerged in the late 1980s when the British government became dissatisfied by the quality and focus of IT services. The government tasked the former Central Computer and Telecommunications Agency (CCTA) with the development of a framework that would ensure high-quality and cost-effective IT services that focused on client needs. ITIL’s original name was Government Information Technology Infrastructure Management (GITIM).
European government agencies and large nongovernment organizations began adopting the framework in the 1990s. In 2000, the CCTA and the Office of Government Commerce (OGC) merged. As one, they reworked and released ITIL version 2 in 2001, ITIL v3 in 2007, and an update, ITIL 2011, in 2011. ITIL became the most widely adopted IT service management (ITSM) framework around the world. Axelos, set up by the U.K. government in 2014, is now charged with managing methodologies, including ITIL, that were formerly owned by the OGC. The next version, ITIL v4, will be released in Q1 2019.
Five core publications detail the entire ITIL service lifecycle:
-
ITIL Service Strategy
-
ITIL Service Design
-
ITIL Service Transition
-
ITIL Service Operation
-
ITIL Continual Service Improvement
In this article, we will focus on the ITIL service operation publication, specifically the problem management process.
Service operation focuses on ensuring IT services are delivered successfully and efficiently. The processes within service operation include the following :
-
Access management
-
Application management
-
Event management
-
Facilities management
-
Incident management
-
IT operations control
-
Problem management
-
Request fulfilment
-
Technical management
What Is Problem Management?
Each ITIL publication and its associated processes focus on supporting the ultimate goal of ITIL: to improve the way IT delivers and supports essential IT services. The problem management process identifies problems quickly, provides end-to-end management, and diagnoses the underlying root cause. The plan is to prevent problems from occurring, thus eliminating recurring incidents. If an incident does occur, problem management helps minimize the impact on the business.
That said, it’s virtually impossible to avoid all IT problems. Some of the most common IT complaints include recurring network outages, hardware failures, nonfunctional database queries due to integration issues, software bugs, and data backup errors.
Below are important terms associated with ITIL problem management:
- Problem: The cause of one or more incidents, such as a recurring internet outage.
- Error: The failure of an IT service due to a design flaw or system failure.
- Known Error: A problem that is documented with a workaround.
- Root Cause Analysis: The analysis or systemic investigation performed to identify the fundamental cause of a problem. Organizations use various techniques to perform root cause analyses. Depending on the problem, they may be used alone or in conjunction with one another. Some of these techniques include the following:
- Brainstorming
- Flowcharting
- Affinity Diagram
- Chronology of events
- Fault detection and isolation
- Rapid Problem Resolution (RPR)
The following techniques also include a free, downloadable template to help you get started.
Pareto Analysis Template
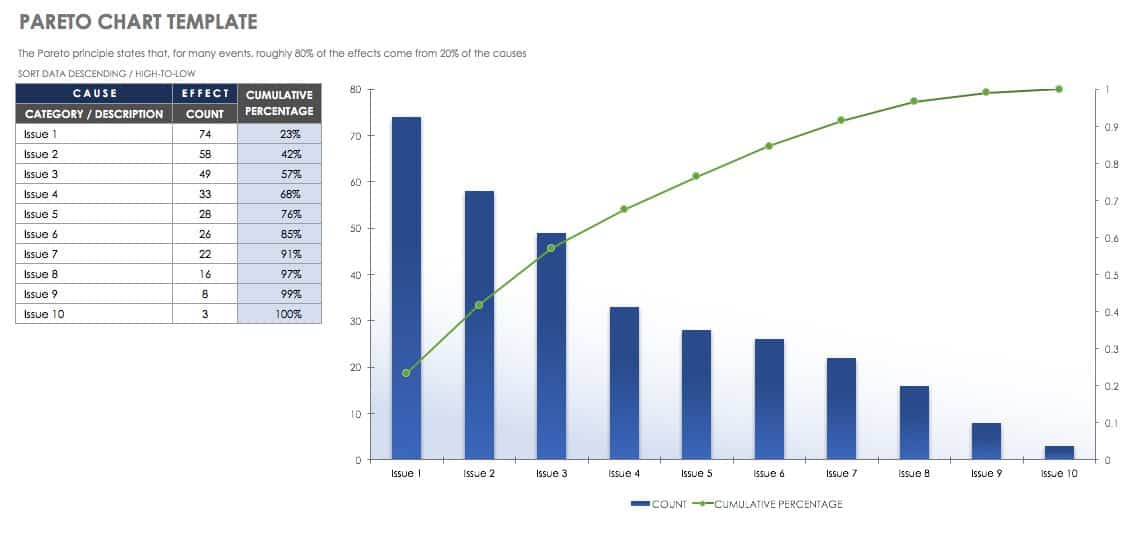
The Pareto analysis can be used to determine the frequency of problems occuring in a process. This template includes a Pareto diagram, bar chart, and line graph for analysis.
Download Pareto Analysis Template
The 5 Whys
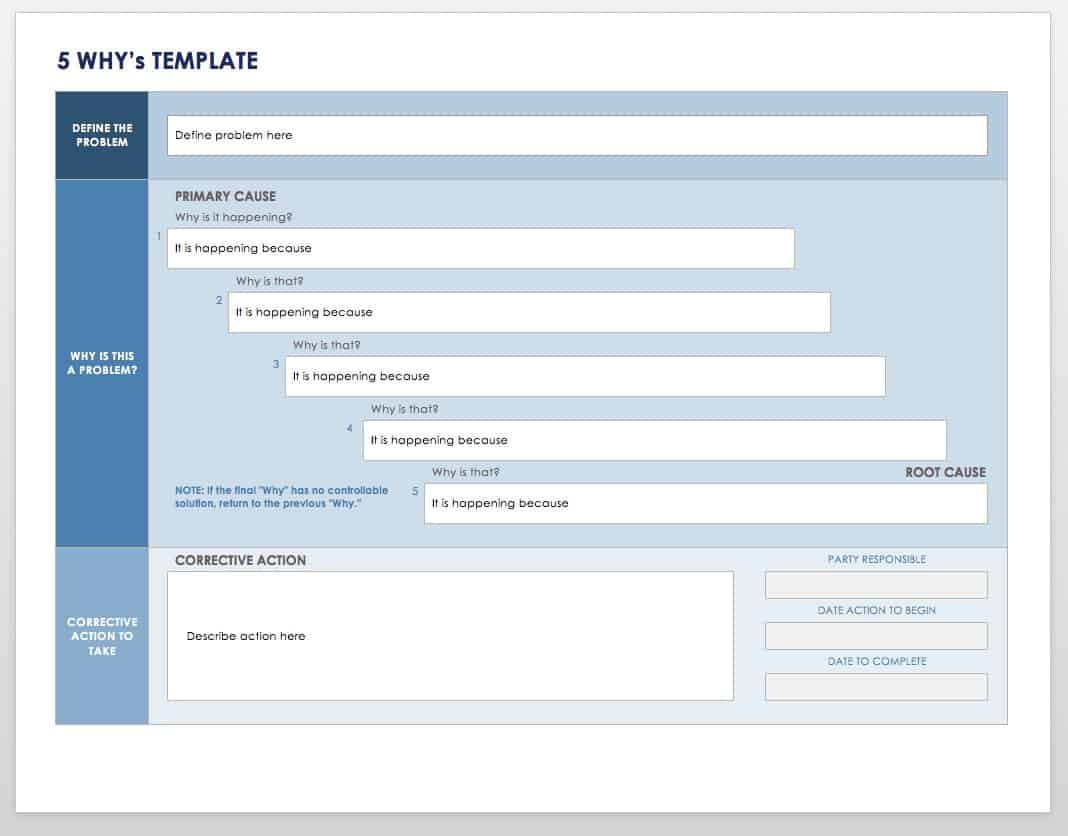
The 5 Whys root cause analysis template is used to ask a series of questions until the root cause can be uncovered. Use this template as a framework for asking “why” questions and noting corrective actions to prevent recurrence.
Download The 5 Whys Template
Excel | Word | PDF | Smartsheet
Kepner Tregoe Rational Model
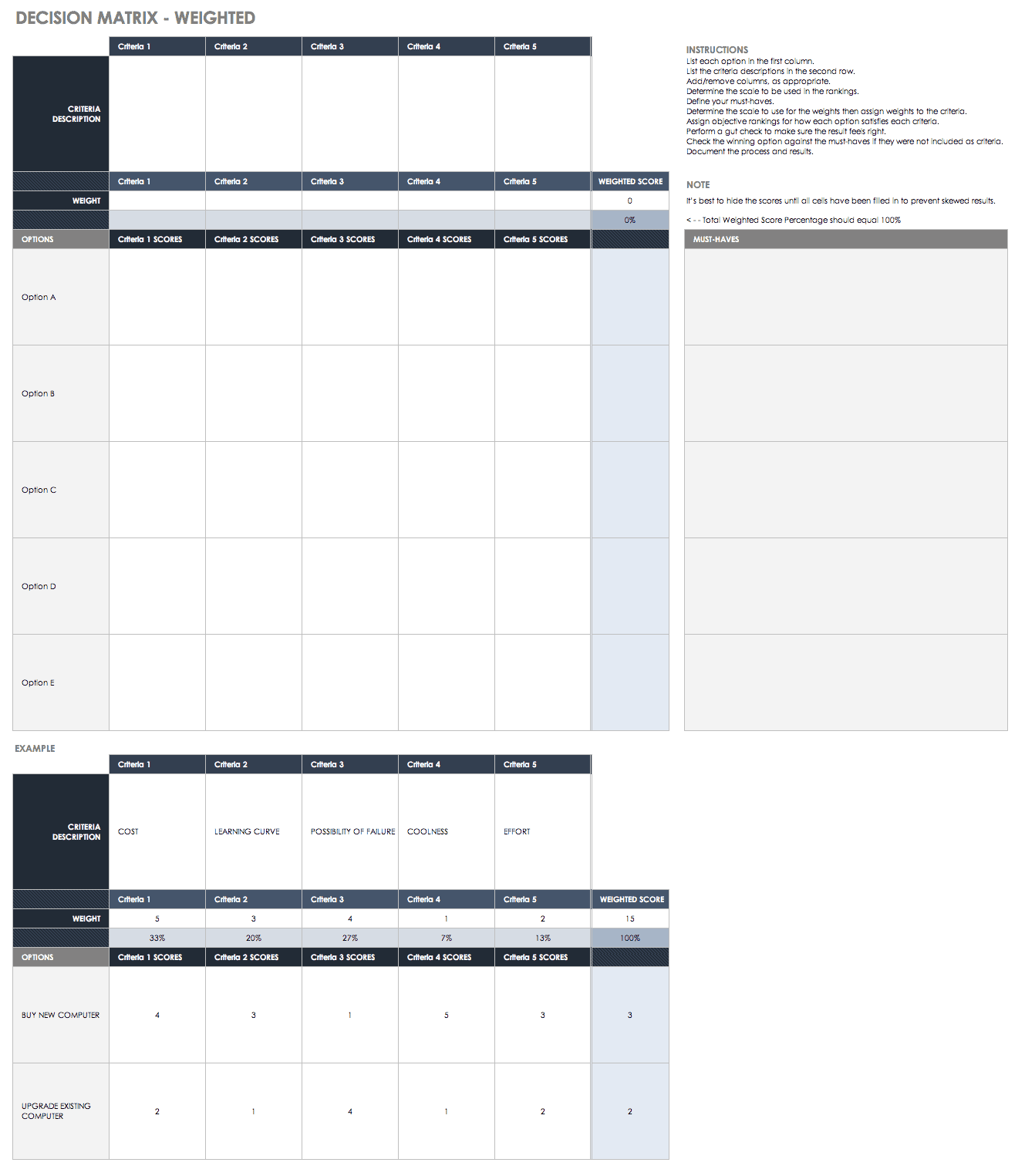
Created by Charles Kepner and Benjamin Tregoe, this model provides a method for gathering, evaluating, and prioritizing information to identify the root cause of a problem and prevent it in the future. There are four major steps — appraise the situation, analyze the problem, analyze decisions, and analyze potential problems. When analyzing decisions, it is important to identify alternatives and perform a risk analysis for each by using a weighted decision matrix.
Download Kepner Tregoe Decision Matrix Template
Ishikawa Fishbone Diagram
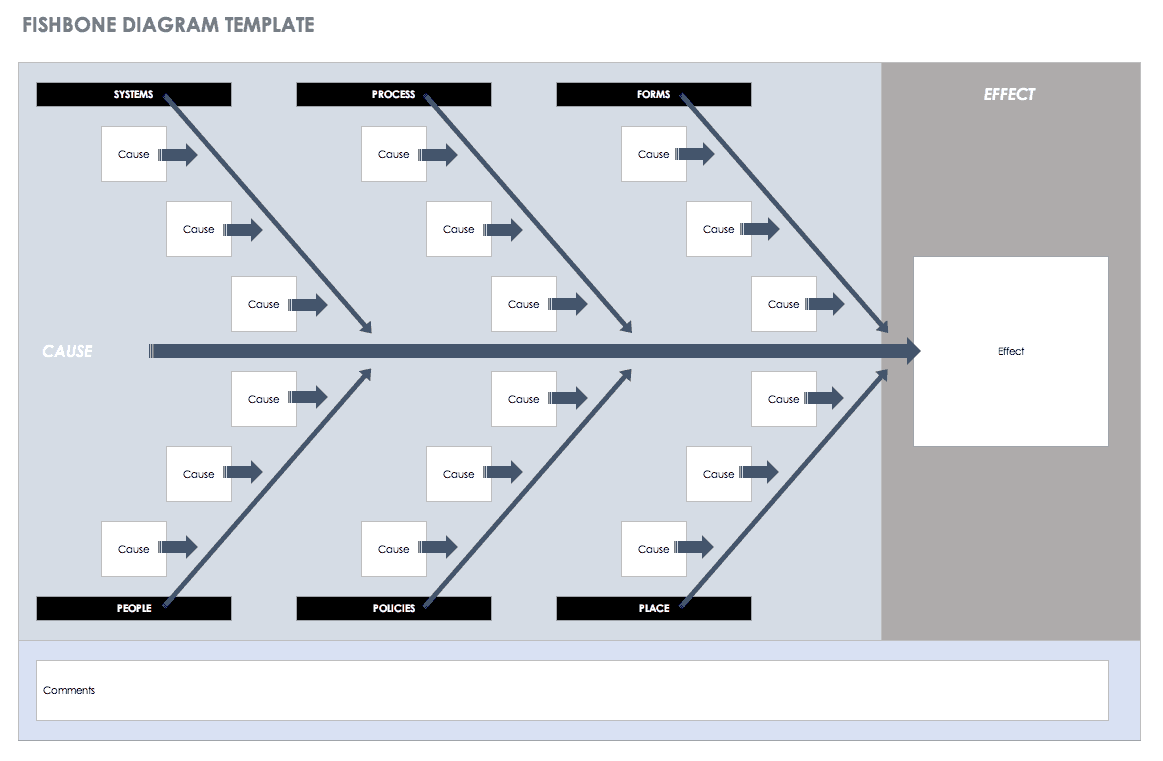
Also known as a cause and effect diagram, the fishbone diagram is a visual compilation of information that helps teams brainstorm to find the cause of an issue.
Download Ishikawa Fishbone Diagram Template
Six Sigma DMAIC
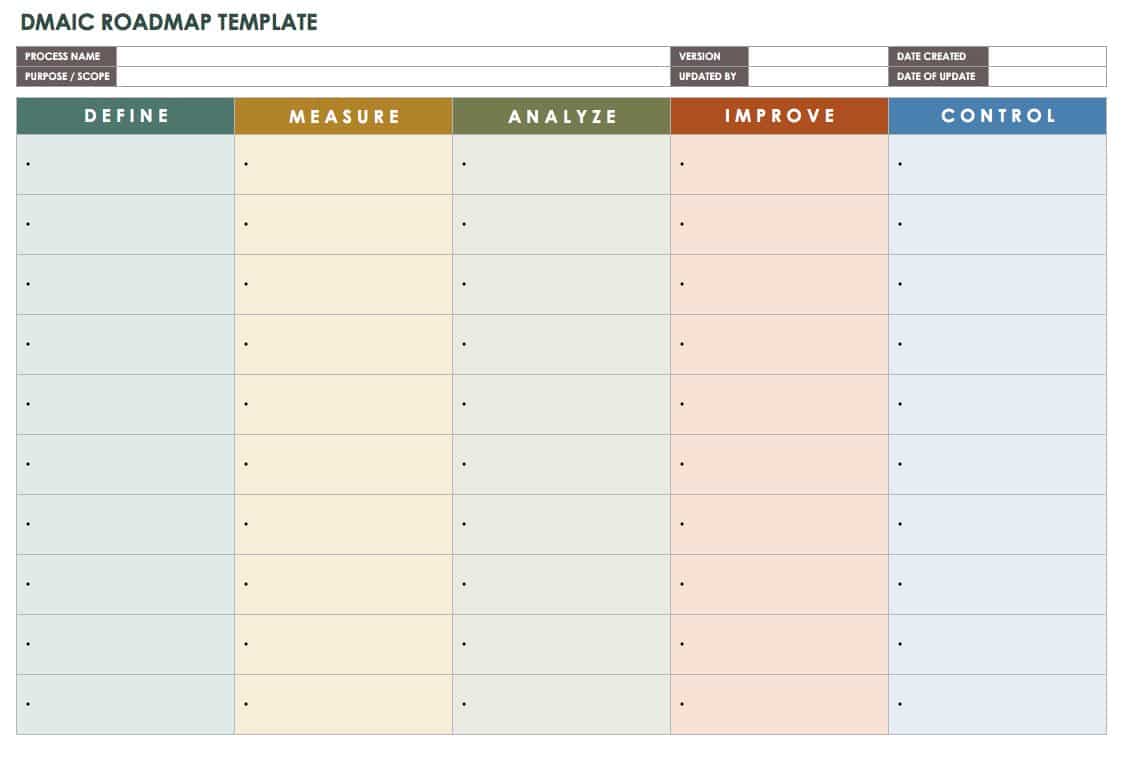
DMAIC focuses on incrementally improving existing processes. It stands for the five phases of a Six Sigma improvement cycle: Define, Measure, Analyze, Improve, This template can be used as a DMAIC roadmap.
Download Six Sigma DMAIC Template
Excel | Word
Problem Management Process Workflow
Many times, an organization detects a problem when users report the same or similar incidents to the service desk in a short time frame. For example, if one user reports that their email is not working, it’s likely an isolated incident or user error that can be quickly resolved. However, if the service desk receives five reports of email errors within a 30 minutes, it’s likely a more impactful problem that requires analysis to resolve.
The problem management process includes the following workflow stages:
- Problem Detection: The organization identifies problems from a user’s incident report, analysis of existing incidents, or an automated event monitoring solution.
- Problem Logging: The organization logs problems with all relevant details, including the reporting user’s information, date and time, category, priority, severity, description, configuration item impacted, linked incidents, and resolution.
- Problem Investigation: The service desk team examines the root cause of the problem. The service desk typically investigates problems based on their priority (high-priority issues have the greatest impact on IT services).
- Problem Diagnosis: The business identifies the cause of the problem based on the results of the investigation.
- Workaround: The team takes temporary measures to restore services until the problem is resolved.
- Known Error Creation: They log the problem as a known error (in the known error database, or KEDB) so future related incidents can be linked to and addressed quickly.
- Problem Resolution: When a business addresses the underlying cause of the problem and restores normal service operation, it prevents recurring incidents and the problem is considered resolved.
- Problem Closure: Once the problem is confirmed effectively resolved, the business can close the problem and associated incidents. The problem management process includes the following workflow stages:
- Problem Detection: The organization identifies problems from a user’s incident report, analysis of existing incidents, or an automated event monitoring solution.
- Problem Logging: The organization logs problems with all relevant details, including the reporting user’s information, date and time, category, priority, severity, description, configuration item impacted, linked incidents, and resolution.
- Problem Investigation: The service desk team examines the root cause of the problem. The service desk typically investigates problems based on their priority (high-priority issues have the greatest impact on IT services).
- Problem Diagnosis: The business identifies the cause of the problem based on the results of the investigation.
- Workaround: The team takes temporary measures to restore services until the problem is resolved.
- Known Error Creation: They log the problem as a known error (in the known error database, or KEDB) so future related incidents can be linked to and addressed quickly.
- Problem Resolution: When a business addresses the underlying cause of the problem and restores normal service operation, it prevents recurring incidents and the problem is considered resolved.
- Problem Closure: Once the problem is confirmed effectively resolved, the business can close the problem and associated incidents.
Reactive vs. Proactive Problem Management
Problem management takes on different forms depending on the organization culture, technology resources, and skill set of the IT team. Most ITIL-focused teams take both a reactive and proactive approach to problem management.
Reactive problem management takes place after the incident has been reported. It is a reaction to a problem that already exists and follows the workflow stages described in the previous section.
Proactive problem management is a preventative approach that aims to thwart incidents from occurring in the first place by identifying IT infrastructure weaknesses. Proactive problem management can be difficult for many organizations because it requires both the resources and skill set to perform extensive trend analysis to identify an incident before it even occurs. Preventative activities include ongoing maintenance (especially for hardware and software reaching the end of their lifecycle), regulatory audits, automated performance monitoring, capacity planning, disaster recovery and service continuity planning, release management planning and testing, change management process, and a documented security management policy.
One activity that may aid in proactive problem management is major problem review. Organizations classify major problems based on their impact to the business. By reviewing major problems, organizations can help identify what they did correctly and incorrectly, as well as areas of improvement that, when fixed, can improve overall problem management and prevent the recurrence of problems.
Problem Management Team Members
Who is involved in the problem management process? The answer varies, but most large organizations that follow the ITIL framework employ the following team members:
-
Problem manager/process owner
-
Analysts
-
Network operations staff
-
Engineers
-
Change management team
-
Configuration management team
-
Service desk technicians (first-, second-, and third-level support)
-
Call center staff
The problem manager owns the problem management process, but also relies on other IT staff. For example, an engineer may analyze a problem in order to identify the root cause, and a change management team member will work to implement the fix.
Benefits of Problem Management
When an organization succeeds at problem management, the entire business benefits from fewer technology issues. Unfortunately, the constantly changing technology landscape means 100 percent protection from downtime is impossible, but problem management minimizes the disruptions that occur. Additional benefits of problem management include the following:
-
Reduced downtime and disruption
-
Improved service availability
-
Decreased workload and stress on service desk staff
-
Improved customer satisfaction (CSAT)
-
Decreased costs associated with downtime
-
Decreased incident impact
-
Improved service quality
-
Faster resolution time and increased first call resolution rate (FCR)
-
Fewer high-priority incidents
-
Decreased business disruption
-
Increased staff productivity
-
Improved training and learning documentation for new and existing staff
-
Prevents incident recurrence
-
Supports ISO/IEC 20000 certification requirements
The Challenges of Problem Management
As with any new or existing process, day-to-day problem management can cause a headache for the process manager, staff, and even ancillary business associates. Below are some of the challenges that may arise:
-
Lack of Knowledge and Training: ITIL can be extremely helpful to an organization, but that comes with the challenge of understanding the framework and its terminology. This is where ITIL training and certification can help, especially for team members who will be directly involved in the problem management process.
-
Leadership Buy-In/Commitment and Resistance to Change: Change is difficult, and without the buy-in of upper management, team members may be reluctant to take on a new process workflow.
-
Competing Priorities: Different IT managers may not have the same priorities when dealing with a service disruption.
-
Missing Information: Problem management depends on thorough documentation. If the organization doesn’t collect essential information during the initial incident report, problem managers may have difficulty resolving the problem quickly. Thus, the service desk is responsible for receiving and documenting all incident reports in order to ensure technicians have full access to critical information – for example, assigning the proper priority and severity help to determine the true impact to the organization.
-
Reliance on Other Teams for Accountability, and Review: The problem management process must rely on team members across IT during the analysis and resolution phase. It is difficult for problem managers to hold staff that do not report to him/her accountable. In addition, KPIs must be applied and managed across all teams involved in the process.
How to Choose a Problem Management Software Solution
ITIL-verified software is a great way to guide and manage your problem management process. Consider the following features as you evaluate software solutions:
-
Customer self-service portal
-
Service-level agreements
-
Reporting and key performance indicators (KPIs)
-
Workflow automation
-
ITIL-verified
-
Internal and/or third-party knowledge management with the ability to search
-
Customer satisfaction surveys
-
Assignments and escalations to individuals and/or teams
-
Historical audit log
-
Templates for recurring issues
-
Unique identifier assigned to each record
-
Time tracking
The ideal problem management software solution should also have the following abilities:
-
Adhere to the appropriate problem management process (create, categorize, edit, resolve, and close)
-
Classify priority and severity to determine impact
-
Be configurable to meet organization’s unique requirements (processes, forms, categories, fields, user permissions, etc.)
-
Integrate with other ITIL processes (incident, change, knowledge, and configuration management)
-
Link incidents to problems and resolve all incidents when the problem is resolved
-
Differentiate, but allow links between incidents, problems, known errors, knowledge articles, and changes
-
Document root cause
-
Integrate with configuration management for easy visibility into impacted configuration items (CI)
Key Performance Indicators and Critical Success Factors in Problem Management
In addition to the above-mentioned features, the ability to measure performance is critical to problem management success. KPIs and critical success factors (CSF) are specific to each organization, but when applied, they help identify areas for improvement. Some common KPIs and CSFs include the following:
-
Number of problems per time frame/category/department/user
-
Number of incidents per problem
-
Reduced time to problem resolution
-
Met and breached SLAs
-
Average time from incident report to problem root cause
-
Reduction/growth of problem backlog
-
Reduced costs associated with problem management
-
Root cause analysis trends
-
Service quality improvements
-
Increase in proactive change submission
-
Decrease in number of incidents over time
-
Reduced problem impact
-
Reduction in problem backlog
-
Increase first call resolution rate
Tips for Implementing Effective ITIL Problem Management
Implementing ITIL processes is not simple, but it can make a huge difference in IT success. To implement any ITIL process, start by gaining a thorough understanding of the ITIL methodology. This will help team members understand the ITIL processes and the business value. The goal of ITIL is not to offer a prescriptive, step-by-step implementation process, but a flexible framework to guide IT departments in improving their processes. There is no requirement to implement all processes. Rather, you want to choose the processes that best fit the needs of the organization.
Although ITIL requires a time and resource commitment, it does not have to bring business to a halt. Third-party organizations offer training and certification classes around the world. Send a dedicated representative to a training course to begin the implementation process. As you progress, you have the option to train the entire team.
Teams implementing ITIL problem management can also follow these tips:
-
Gain IT and senior leadership support.
-
Create a clear vision and purpose with clearly defined processes and goals.
-
Define the relationship between various processes, specifically incident, problem, and change management.
-
Take a process-by-process approach to minimize disruption and gain quick wins.
-
Dedicate resources to both reactive and proactive problem management.
-
Take a preventative approach to problem management.
-
Communicate successes with the entire organization.
-
Implement incident management prior to implementing problem management.
-
Implement a software solution that supports your specific problem management requirements.
-
Dedicate time to problem management efforts.
-
Train and educate service desk staff.
IT success is not simply a result of keeping computers and printers running within your organization, but also of aligning IT with the goals of the business as a whole. IT is the heart and soul of business and a key contributor to revenue and competitive differentiation, and ITIL provides the framework to reach those goals.
ITIL is constantly evolving as technology becomes more complex and business needs change. More than 150 industry experts have been involved in ITIL version 4, which will be released in Q1 2019 and is expected to integrate with DevOps, Agile, and Lean.
Improve ITIL Problem Management with Smartsheet for IT & Ops
Empower your people to go above and beyond with a flexible platform designed to match the needs of your team — and adapt as those needs change.
The Smartsheet platform makes it easy to plan, capture, manage, and report on work from anywhere, helping your team be more effective and get more done. Report on key metrics and get real-time visibility into work as it happens with roll-up reports, dashboards, and automated workflows built to keep your team connected and informed.
When teams have clarity into the work getting done, there’s no telling how much more they can accomplish in the same amount of time. Try Smartsheet for free, today.
IT departments deal with an enormous number of complaints and problems daily. Jammed printers, internet outages, email errors, and requests for new laptops are just a few of the issues that can impact staff productivity. In order to keep technology working and operations running, business can implement frameworks such as the IT Infrastructure Library (ITIL) to support and streamline IT processes.
In this article, we will discuss the ITIL framework and its associated processes. We’ll also dive into the workflow, benefits, key performance indicators, and best practices associated with problem management.
The Origins of ITIL
ITIL emerged in the late 1980s when the British government became dissatisfied by the quality and focus of IT services. The government tasked the former Central Computer and Telecommunications Agency (CCTA) with the development of a framework that would ensure high-quality and cost-effective IT services that focused on client needs. ITIL’s original name was Government Information Technology Infrastructure Management (GITIM).
European government agencies and large nongovernment organizations began adopting the framework in the 1990s. In 2000, the CCTA and the Office of Government Commerce (OGC) merged. As one, they reworked and released ITIL version 2 in 2001, ITIL v3 in 2007, and an update, ITIL 2011, in 2011. ITIL became the most widely adopted IT service management (ITSM) framework around the world. Axelos, set up by the U.K. government in 2014, is now charged with managing methodologies, including ITIL, that were formerly owned by the OGC. The next version, ITIL v4, will be released in Q1 2019.
Five core publications detail the entire ITIL service lifecycle:
-
ITIL Service Strategy
-
ITIL Service Design
-
ITIL Service Transition
-
ITIL Service Operation
-
ITIL Continual Service Improvement
In this article, we will focus on the ITIL service operation publication, specifically the problem management process.
Service operation focuses on ensuring IT services are delivered successfully and efficiently. The processes within service operation include the following :
-
Access management
-
Application management
-
Event management
-
Facilities management
-
Incident management
-
IT operations control
-
Problem management
-
Request fulfilment
-
Technical management
What Is Problem Management?
Each ITIL publication and its associated processes focus on supporting the ultimate goal of ITIL: to improve the way IT delivers and supports essential IT services. The problem management process identifies problems quickly, provides end-to-end management, and diagnoses the underlying root cause. The plan is to prevent problems from occurring, thus eliminating recurring incidents. If an incident does occur, problem management helps minimize the impact on the business.
That said, it’s virtually impossible to avoid all IT problems. Some of the most common IT complaints include recurring network outages, hardware failures, nonfunctional database queries due to integration issues, software bugs, and data backup errors.
Below are important terms associated with ITIL problem management:
- Problem: The cause of one or more incidents, such as a recurring internet outage.
- Error: The failure of an IT service due to a design flaw or system failure.
- Known Error: A problem that is documented with a workaround.
- Root Cause Analysis: The analysis or systemic investigation performed to identify the fundamental cause of a problem. Organizations use various techniques to perform root cause analyses. Depending on the problem, they may be used alone or in conjunction with one another. Some of these techniques include the following:
- Brainstorming
- Flowcharting
- Affinity Diagram
- Chronology of events
- Fault detection and isolation
- Rapid Problem Resolution (RPR)
The following techniques also include a free, downloadable template to help you get started.
Pareto Analysis Template
The Pareto analysis can be used to determine the frequency of problems occuring in a process. This template includes a Pareto diagram, bar chart, and line graph for analysis.
Download Pareto Analysis Template
The 5 Whys
The 5 Whys root cause analysis template is used to ask a series of questions until the root cause can be uncovered. Use this template as a framework for asking “why” questions and noting corrective actions to prevent recurrence.
Download The 5 Whys Template
Excel | Word | PDF | Smartsheet
Kepner Tregoe Rational Model
Created by Charles Kepner and Benjamin Tregoe, this model provides a method for gathering, evaluating, and prioritizing information to identify the root cause of a problem and prevent it in the future. There are four major steps — appraise the situation, analyze the problem, analyze decisions, and analyze potential problems. When analyzing decisions, it is important to identify alternatives and perform a risk analysis for each by using a weighted decision matrix.
Download Kepner Tregoe Decision Matrix Template
Ishikawa Fishbone Diagram
Also known as a cause and effect diagram, the fishbone diagram is a visual compilation of information that helps teams brainstorm to find the cause of an issue.
Download Ishikawa Fishbone Diagram Template
Six Sigma DMAIC
DMAIC focuses on incrementally improving existing processes. It stands for the five phases of a Six Sigma improvement cycle: Define, Measure, Analyze, Improve, This template can be used as a DMAIC roadmap.
Download Six Sigma DMAIC Template
Excel | Word
Problem Management Process Workflow
Many times, an organization detects a problem when users report the same or similar incidents to the service desk in a short time frame. For example, if one user reports that their email is not working, it’s likely an isolated incident or user error that can be quickly resolved. However, if the service desk receives five reports of email errors within a 30 minutes, it’s likely a more impactful problem that requires analysis to resolve.
The problem management process includes the following workflow stages:
- Problem Detection: The organization identifies problems from a user’s incident report, analysis of existing incidents, or an automated event monitoring solution.
- Problem Logging: The organization logs problems with all relevant details, including the reporting user’s information, date and time, category, priority, severity, description, configuration item impacted, linked incidents, and resolution.
- Problem Investigation: The service desk team examines the root cause of the problem. The service desk typically investigates problems based on their priority (high-priority issues have the greatest impact on IT services).
- Problem Diagnosis: The business identifies the cause of the problem based on the results of the investigation.
- Workaround: The team takes temporary measures to restore services until the problem is resolved.
- Known Error Creation: They log the problem as a known error (in the known error database, or KEDB) so future related incidents can be linked to and addressed quickly.
- Problem Resolution: When a business addresses the underlying cause of the problem and restores normal service operation, it prevents recurring incidents and the problem is considered resolved.
- Problem Closure: Once the problem is confirmed effectively resolved, the business can close the problem and associated incidents. The problem management process includes the following workflow stages:
- Problem Detection: The organization identifies problems from a user’s incident report, analysis of existing incidents, or an automated event monitoring solution.
- Problem Logging: The organization logs problems with all relevant details, including the reporting user’s information, date and time, category, priority, severity, description, configuration item impacted, linked incidents, and resolution.
- Problem Investigation: The service desk team examines the root cause of the problem. The service desk typically investigates problems based on their priority (high-priority issues have the greatest impact on IT services).
- Problem Diagnosis: The business identifies the cause of the problem based on the results of the investigation.
- Workaround: The team takes temporary measures to restore services until the problem is resolved.
- Known Error Creation: They log the problem as a known error (in the known error database, or KEDB) so future related incidents can be linked to and addressed quickly.
- Problem Resolution: When a business addresses the underlying cause of the problem and restores normal service operation, it prevents recurring incidents and the problem is considered resolved.
- Problem Closure: Once the problem is confirmed effectively resolved, the business can close the problem and associated incidents.
Reactive vs. Proactive Problem Management
Problem management takes on different forms depending on the organization culture, technology resources, and skill set of the IT team. Most ITIL-focused teams take both a reactive and proactive approach to problem management.
Reactive problem management takes place after the incident has been reported. It is a reaction to a problem that already exists and follows the workflow stages described in the previous section.
Proactive problem management is a preventative approach that aims to thwart incidents from occurring in the first place by identifying IT infrastructure weaknesses. Proactive problem management can be difficult for many organizations because it requires both the resources and skill set to perform extensive trend analysis to identify an incident before it even occurs. Preventative activities include ongoing maintenance (especially for hardware and software reaching the end of their lifecycle), regulatory audits, automated performance monitoring, capacity planning, disaster recovery and service continuity planning, release management planning and testing, change management process, and a documented security management policy.
One activity that may aid in proactive problem management is major problem review. Organizations classify major problems based on their impact to the business. By reviewing major problems, organizations can help identify what they did correctly and incorrectly, as well as areas of improvement that, when fixed, can improve overall problem management and prevent the recurrence of problems.
Problem Management Team Members
Who is involved in the problem management process? The answer varies, but most large organizations that follow the ITIL framework employ the following team members:
-
Problem manager/process owner
-
Analysts
-
Network operations staff
-
Engineers
-
Change management team
-
Configuration management team
-
Service desk technicians (first-, second-, and third-level support)
-
Call center staff
The problem manager owns the problem management process, but also relies on other IT staff. For example, an engineer may analyze a problem in order to identify the root cause, and a change management team member will work to implement the fix.
Benefits of Problem Management
When an organization succeeds at problem management, the entire business benefits from fewer technology issues. Unfortunately, the constantly changing technology landscape means 100 percent protection from downtime is impossible, but problem management minimizes the disruptions that occur. Additional benefits of problem management include the following:
-
Reduced downtime and disruption
-
Improved service availability
-
Decreased workload and stress on service desk staff
-
Improved customer satisfaction (CSAT)
-
Decreased costs associated with downtime
-
Decreased incident impact
-
Improved service quality
-
Faster resolution time and increased first call resolution rate (FCR)
-
Fewer high-priority incidents
-
Decreased business disruption
-
Increased staff productivity
-
Improved training and learning documentation for new and existing staff
-
Prevents incident recurrence
-
Supports ISO/IEC 20000 certification requirements
The Challenges of Problem Management
As with any new or existing process, day-to-day problem management can cause a headache for the process manager, staff, and even ancillary business associates. Below are some of the challenges that may arise:
-
Lack of Knowledge and Training: ITIL can be extremely helpful to an organization, but that comes with the challenge of understanding the framework and its terminology. This is where ITIL training and certification can help, especially for team members who will be directly involved in the problem management process.
-
Leadership Buy-In/Commitment and Resistance to Change: Change is difficult, and without the buy-in of upper management, team members may be reluctant to take on a new process workflow.
-
Competing Priorities: Different IT managers may not have the same priorities when dealing with a service disruption.
-
Missing Information: Problem management depends on thorough documentation. If the organization doesn’t collect essential information during the initial incident report, problem managers may have difficulty resolving the problem quickly. Thus, the service desk is responsible for receiving and documenting all incident reports in order to ensure technicians have full access to critical information – for example, assigning the proper priority and severity help to determine the true impact to the organization.
-
Reliance on Other Teams for Accountability, and Review: The problem management process must rely on team members across IT during the analysis and resolution phase. It is difficult for problem managers to hold staff that do not report to him/her accountable. In addition, KPIs must be applied and managed across all teams involved in the process.
How to Choose a Problem Management Software Solution
ITIL-verified software is a great way to guide and manage your problem management process. Consider the following features as you evaluate software solutions:
-
Customer self-service portal
-
Service-level agreements
-
Reporting and key performance indicators (KPIs)
-
Workflow automation
-
ITIL-verified
-
Internal and/or third-party knowledge management with the ability to search
-
Customer satisfaction surveys
-
Assignments and escalations to individuals and/or teams
-
Historical audit log
-
Templates for recurring issues
-
Unique identifier assigned to each record
-
Time tracking
The ideal problem management software solution should also have the following abilities:
-
Adhere to the appropriate problem management process (create, categorize, edit, resolve, and close)
-
Classify priority and severity to determine impact
-
Be configurable to meet organization’s unique requirements (processes, forms, categories, fields, user permissions, etc.)
-
Integrate with other ITIL processes (incident, change, knowledge, and configuration management)
-
Link incidents to problems and resolve all incidents when the problem is resolved
-
Differentiate, but allow links between incidents, problems, known errors, knowledge articles, and changes
-
Document root cause
-
Integrate with configuration management for easy visibility into impacted configuration items (CI)
Key Performance Indicators and Critical Success Factors in Problem Management
In addition to the above-mentioned features, the ability to measure performance is critical to problem management success. KPIs and critical success factors (CSF) are specific to each organization, but when applied, they help identify areas for improvement. Some common KPIs and CSFs include the following:
-
Number of problems per time frame/category/department/user
-
Number of incidents per problem
-
Reduced time to problem resolution
-
Met and breached SLAs
-
Average time from incident report to problem root cause
-
Reduction/growth of problem backlog
-
Reduced costs associated with problem management
-
Root cause analysis trends
-
Service quality improvements
-
Increase in proactive change submission
-
Decrease in number of incidents over time
-
Reduced problem impact
-
Reduction in problem backlog
-
Increase first call resolution rate
Tips for Implementing Effective ITIL Problem Management
Implementing ITIL processes is not simple, but it can make a huge difference in IT success. To implement any ITIL process, start by gaining a thorough understanding of the ITIL methodology. This will help team members understand the ITIL processes and the business value. The goal of ITIL is not to offer a prescriptive, step-by-step implementation process, but a flexible framework to guide IT departments in improving their processes. There is no requirement to implement all processes. Rather, you want to choose the processes that best fit the needs of the organization.
Although ITIL requires a time and resource commitment, it does not have to bring business to a halt. Third-party organizations offer training and certification classes around the world. Send a dedicated representative to a training course to begin the implementation process. As you progress, you have the option to train the entire team.
Teams implementing ITIL problem management can also follow these tips:
-
Gain IT and senior leadership support.
-
Create a clear vision and purpose with clearly defined processes and goals.
-
Define the relationship between various processes, specifically incident, problem, and change management.
-
Take a process-by-process approach to minimize disruption and gain quick wins.
-
Dedicate resources to both reactive and proactive problem management.
-
Take a preventative approach to problem management.
-
Communicate successes with the entire organization.
-
Implement incident management prior to implementing problem management.
-
Implement a software solution that supports your specific problem management requirements.
-
Dedicate time to problem management efforts.
-
Train and educate service desk staff.
IT success is not simply a result of keeping computers and printers running within your organization, but also of aligning IT with the goals of the business as a whole. IT is the heart and soul of business and a key contributor to revenue and competitive differentiation, and ITIL provides the framework to reach those goals.
ITIL is constantly evolving as technology becomes more complex and business needs change. More than 150 industry experts have been involved in ITIL version 4, which will be released in Q1 2019 and is expected to integrate with DevOps, Agile, and Lean.
Improve ITIL Problem Management with Smartsheet for IT & Ops
Empower your people to go above and beyond with a flexible platform designed to match the needs of your team — and adapt as those needs change.
The Smartsheet platform makes it easy to plan, capture, manage, and report on work from anywhere, helping your team be more effective and get more done. Report on key metrics and get real-time visibility into work as it happens with roll-up reports, dashboards, and automated workflows built to keep your team connected and informed.
When teams have clarity into the work getting done, there’s no telling how much more they can accomplish in the same amount of time. Try Smartsheet for free, today.
В статье рассматриваются два ключевых процесса ITIL, ориентированных на выявление неисправностей в ИТ-инфраструктуре и инициирование мер по их устранению.
The Pareto analysis can be used to determine the frequency of problems occuring in a process. This template includes a Pareto diagram, bar chart, and line graph for analysis.
Download Pareto Analysis Template
The 5 Whys
The 5 Whys root cause analysis template is used to ask a series of questions until the root cause can be uncovered. Use this template as a framework for asking “why” questions and noting corrective actions to prevent recurrence.
Download The 5 Whys Template
Excel | Word | PDF | Smartsheet
Kepner Tregoe Rational Model
Created by Charles Kepner and Benjamin Tregoe, this model provides a method for gathering, evaluating, and prioritizing information to identify the root cause of a problem and prevent it in the future. There are four major steps — appraise the situation, analyze the problem, analyze decisions, and analyze potential problems. When analyzing decisions, it is important to identify alternatives and perform a risk analysis for each by using a weighted decision matrix.
Download Kepner Tregoe Decision Matrix Template
Ishikawa Fishbone Diagram
Also known as a cause and effect diagram, the fishbone diagram is a visual compilation of information that helps teams brainstorm to find the cause of an issue.
Download Ishikawa Fishbone Diagram Template
Six Sigma DMAIC
DMAIC focuses on incrementally improving existing processes. It stands for the five phases of a Six Sigma improvement cycle: Define, Measure, Analyze, Improve, This template can be used as a DMAIC roadmap.
Download Six Sigma DMAIC Template
Excel | Word
Problem Management Process Workflow
Many times, an organization detects a problem when users report the same or similar incidents to the service desk in a short time frame. For example, if one user reports that their email is not working, it’s likely an isolated incident or user error that can be quickly resolved. However, if the service desk receives five reports of email errors within a 30 minutes, it’s likely a more impactful problem that requires analysis to resolve.
The problem management process includes the following workflow stages:
- Problem Detection: The organization identifies problems from a user’s incident report, analysis of existing incidents, or an automated event monitoring solution.
- Problem Logging: The organization logs problems with all relevant details, including the reporting user’s information, date and time, category, priority, severity, description, configuration item impacted, linked incidents, and resolution.
- Problem Investigation: The service desk team examines the root cause of the problem. The service desk typically investigates problems based on their priority (high-priority issues have the greatest impact on IT services).
- Problem Diagnosis: The business identifies the cause of the problem based on the results of the investigation.
- Workaround: The team takes temporary measures to restore services until the problem is resolved.
- Known Error Creation: They log the problem as a known error (in the known error database, or KEDB) so future related incidents can be linked to and addressed quickly.
- Problem Resolution: When a business addresses the underlying cause of the problem and restores normal service operation, it prevents recurring incidents and the problem is considered resolved.
- Problem Closure: Once the problem is confirmed effectively resolved, the business can close the problem and associated incidents. The problem management process includes the following workflow stages:
- Problem Detection: The organization identifies problems from a user’s incident report, analysis of existing incidents, or an automated event monitoring solution.
- Problem Logging: The organization logs problems with all relevant details, including the reporting user’s information, date and time, category, priority, severity, description, configuration item impacted, linked incidents, and resolution.
- Problem Investigation: The service desk team examines the root cause of the problem. The service desk typically investigates problems based on their priority (high-priority issues have the greatest impact on IT services).
- Problem Diagnosis: The business identifies the cause of the problem based on the results of the investigation.
- Workaround: The team takes temporary measures to restore services until the problem is resolved.
- Known Error Creation: They log the problem as a known error (in the known error database, or KEDB) so future related incidents can be linked to and addressed quickly.
- Problem Resolution: When a business addresses the underlying cause of the problem and restores normal service operation, it prevents recurring incidents and the problem is considered resolved.
- Problem Closure: Once the problem is confirmed effectively resolved, the business can close the problem and associated incidents.
Reactive vs. Proactive Problem Management
Problem management takes on different forms depending on the organization culture, technology resources, and skill set of the IT team. Most ITIL-focused teams take both a reactive and proactive approach to problem management.
Reactive problem management takes place after the incident has been reported. It is a reaction to a problem that already exists and follows the workflow stages described in the previous section.
Proactive problem management is a preventative approach that aims to thwart incidents from occurring in the first place by identifying IT infrastructure weaknesses. Proactive problem management can be difficult for many organizations because it requires both the resources and skill set to perform extensive trend analysis to identify an incident before it even occurs. Preventative activities include ongoing maintenance (especially for hardware and software reaching the end of their lifecycle), regulatory audits, automated performance monitoring, capacity planning, disaster recovery and service continuity planning, release management planning and testing, change management process, and a documented security management policy.
One activity that may aid in proactive problem management is major problem review. Organizations classify major problems based on their impact to the business. By reviewing major problems, organizations can help identify what they did correctly and incorrectly, as well as areas of improvement that, when fixed, can improve overall problem management and prevent the recurrence of problems.
Problem Management Team Members
Who is involved in the problem management process? The answer varies, but most large organizations that follow the ITIL framework employ the following team members:
-
Problem manager/process owner
-
Analysts
-
Network operations staff
-
Engineers
-
Change management team
-
Configuration management team
-
Service desk technicians (first-, second-, and third-level support)
-
Call center staff
The problem manager owns the problem management process, but also relies on other IT staff. For example, an engineer may analyze a problem in order to identify the root cause, and a change management team member will work to implement the fix.
Benefits of Problem Management
When an organization succeeds at problem management, the entire business benefits from fewer technology issues. Unfortunately, the constantly changing technology landscape means 100 percent protection from downtime is impossible, but problem management minimizes the disruptions that occur. Additional benefits of problem management include the following:
-
Reduced downtime and disruption
-
Improved service availability
-
Decreased workload and stress on service desk staff
-
Improved customer satisfaction (CSAT)
-
Decreased costs associated with downtime
-
Decreased incident impact
-
Improved service quality
-
Faster resolution time and increased first call resolution rate (FCR)
-
Fewer high-priority incidents
-
Decreased business disruption
-
Increased staff productivity
-
Improved training and learning documentation for new and existing staff
-
Prevents incident recurrence
-
Supports ISO/IEC 20000 certification requirements
The Challenges of Problem Management
As with any new or existing process, day-to-day problem management can cause a headache for the process manager, staff, and even ancillary business associates. Below are some of the challenges that may arise:
-
Lack of Knowledge and Training: ITIL can be extremely helpful to an organization, but that comes with the challenge of understanding the framework and its terminology. This is where ITIL training and certification can help, especially for team members who will be directly involved in the problem management process.
-
Leadership Buy-In/Commitment and Resistance to Change: Change is difficult, and without the buy-in of upper management, team members may be reluctant to take on a new process workflow.
-
Competing Priorities: Different IT managers may not have the same priorities when dealing with a service disruption.
-
Missing Information: Problem management depends on thorough documentation. If the organization doesn’t collect essential information during the initial incident report, problem managers may have difficulty resolving the problem quickly. Thus, the service desk is responsible for receiving and documenting all incident reports in order to ensure technicians have full access to critical information – for example, assigning the proper priority and severity help to determine the true impact to the organization.
-
Reliance on Other Teams for Accountability, and Review: The problem management process must rely on team members across IT during the analysis and resolution phase. It is difficult for problem managers to hold staff that do not report to him/her accountable. In addition, KPIs must be applied and managed across all teams involved in the process.
How to Choose a Problem Management Software Solution
ITIL-verified software is a great way to guide and manage your problem management process. Consider the following features as you evaluate software solutions:
-
Customer self-service portal
-
Service-level agreements
-
Reporting and key performance indicators (KPIs)
-
Workflow automation
-
ITIL-verified
-
Internal and/or third-party knowledge management with the ability to search
-
Customer satisfaction surveys
-
Assignments and escalations to individuals and/or teams
-
Historical audit log
-
Templates for recurring issues
-
Unique identifier assigned to each record
-
Time tracking
The ideal problem management software solution should also have the following abilities:
-
Adhere to the appropriate problem management process (create, categorize, edit, resolve, and close)
-
Classify priority and severity to determine impact
-
Be configurable to meet organization’s unique requirements (processes, forms, categories, fields, user permissions, etc.)
-
Integrate with other ITIL processes (incident, change, knowledge, and configuration management)
-
Link incidents to problems and resolve all incidents when the problem is resolved
-
Differentiate, but allow links between incidents, problems, known errors, knowledge articles, and changes
-
Document root cause
-
Integrate with configuration management for easy visibility into impacted configuration items (CI)
Key Performance Indicators and Critical Success Factors in Problem Management
In addition to the above-mentioned features, the ability to measure performance is critical to problem management success. KPIs and critical success factors (CSF) are specific to each organization, but when applied, they help identify areas for improvement. Some common KPIs and CSFs include the following:
-
Number of problems per time frame/category/department/user
-
Number of incidents per problem
-
Reduced time to problem resolution
-
Met and breached SLAs
-
Average time from incident report to problem root cause
-
Reduction/growth of problem backlog
-
Reduced costs associated with problem management
-
Root cause analysis trends
-
Service quality improvements
-
Increase in proactive change submission
-
Decrease in number of incidents over time
-
Reduced problem impact
-
Reduction in problem backlog
-
Increase first call resolution rate
Tips for Implementing Effective ITIL Problem Management
Implementing ITIL processes is not simple, but it can make a huge difference in IT success. To implement any ITIL process, start by gaining a thorough understanding of the ITIL methodology. This will help team members understand the ITIL processes and the business value. The goal of ITIL is not to offer a prescriptive, step-by-step implementation process, but a flexible framework to guide IT departments in improving their processes. There is no requirement to implement all processes. Rather, you want to choose the processes that best fit the needs of the organization.
Although ITIL requires a time and resource commitment, it does not have to bring business to a halt. Third-party organizations offer training and certification classes around the world. Send a dedicated representative to a training course to begin the implementation process. As you progress, you have the option to train the entire team.
Teams implementing ITIL problem management can also follow these tips:
-
Gain IT and senior leadership support.
-
Create a clear vision and purpose with clearly defined processes and goals.
-
Define the relationship between various processes, specifically incident, problem, and change management.
-
Take a process-by-process approach to minimize disruption and gain quick wins.
-
Dedicate resources to both reactive and proactive problem management.
-
Take a preventative approach to problem management.
-
Communicate successes with the entire organization.
-
Implement incident management prior to implementing problem management.
-
Implement a software solution that supports your specific problem management requirements.
-
Dedicate time to problem management efforts.
-
Train and educate service desk staff.
IT success is not simply a result of keeping computers and printers running within your organization, but also of aligning IT with the goals of the business as a whole. IT is the heart and soul of business and a key contributor to revenue and competitive differentiation, and ITIL provides the framework to reach those goals.
ITIL is constantly evolving as technology becomes more complex and business needs change. More than 150 industry experts have been involved in ITIL version 4, which will be released in Q1 2019 and is expected to integrate with DevOps, Agile, and Lean.
Improve ITIL Problem Management with Smartsheet for IT & Ops
Empower your people to go above and beyond with a flexible platform designed to match the needs of your team — and adapt as those needs change.
The Smartsheet platform makes it easy to plan, capture, manage, and report on work from anywhere, helping your team be more effective and get more done. Report on key metrics and get real-time visibility into work as it happens with roll-up reports, dashboards, and automated workflows built to keep your team connected and informed.
When teams have clarity into the work getting done, there’s no telling how much more they can accomplish in the same amount of time. Try Smartsheet for free, today.
IT departments deal with an enormous number of complaints and problems daily. Jammed printers, internet outages, email errors, and requests for new laptops are just a few of the issues that can impact staff productivity. In order to keep technology working and operations running, business can implement frameworks such as the IT Infrastructure Library (ITIL) to support and streamline IT processes.
In this article, we will discuss the ITIL framework and its associated processes. We’ll also dive into the workflow, benefits, key performance indicators, and best practices associated with problem management.
The Origins of ITIL
ITIL emerged in the late 1980s when the British government became dissatisfied by the quality and focus of IT services. The government tasked the former Central Computer and Telecommunications Agency (CCTA) with the development of a framework that would ensure high-quality and cost-effective IT services that focused on client needs. ITIL’s original name was Government Information Technology Infrastructure Management (GITIM).
European government agencies and large nongovernment organizations began adopting the framework in the 1990s. In 2000, the CCTA and the Office of Government Commerce (OGC) merged. As one, they reworked and released ITIL version 2 in 2001, ITIL v3 in 2007, and an update, ITIL 2011, in 2011. ITIL became the most widely adopted IT service management (ITSM) framework around the world. Axelos, set up by the U.K. government in 2014, is now charged with managing methodologies, including ITIL, that were formerly owned by the OGC. The next version, ITIL v4, will be released in Q1 2019.
Five core publications detail the entire ITIL service lifecycle:
-
ITIL Service Strategy
-
ITIL Service Design
-
ITIL Service Transition
-
ITIL Service Operation
-
ITIL Continual Service Improvement
In this article, we will focus on the ITIL service operation publication, specifically the problem management process.
Service operation focuses on ensuring IT services are delivered successfully and efficiently. The processes within service operation include the following :
-
Access management
-
Application management
-
Event management
-
Facilities management
-
Incident management
-
IT operations control
-
Problem management
-
Request fulfilment
-
Technical management
What Is Problem Management?
Each ITIL publication and its associated processes focus on supporting the ultimate goal of ITIL: to improve the way IT delivers and supports essential IT services. The problem management process identifies problems quickly, provides end-to-end management, and diagnoses the underlying root cause. The plan is to prevent problems from occurring, thus eliminating recurring incidents. If an incident does occur, problem management helps minimize the impact on the business.
That said, it’s virtually impossible to avoid all IT problems. Some of the most common IT complaints include recurring network outages, hardware failures, nonfunctional database queries due to integration issues, software bugs, and data backup errors.
Below are important terms associated with ITIL problem management:
- Problem: The cause of one or more incidents, such as a recurring internet outage.
- Error: The failure of an IT service due to a design flaw or system failure.
- Known Error: A problem that is documented with a workaround.
- Root Cause Analysis: The analysis or systemic investigation performed to identify the fundamental cause of a problem. Organizations use various techniques to perform root cause analyses. Depending on the problem, they may be used alone or in conjunction with one another. Some of these techniques include the following:
- Brainstorming
- Flowcharting
- Affinity Diagram
- Chronology of events
- Fault detection and isolation
- Rapid Problem Resolution (RPR)
The following techniques also include a free, downloadable template to help you get started.
Pareto Analysis Template
The Pareto analysis can be used to determine the frequency of problems occuring in a process. This template includes a Pareto diagram, bar chart, and line graph for analysis.
Download Pareto Analysis Template
The 5 Whys
The 5 Whys root cause analysis template is used to ask a series of questions until the root cause can be uncovered. Use this template as a framework for asking “why” questions and noting corrective actions to prevent recurrence.
Download The 5 Whys Template
Excel | Word | PDF | Smartsheet
Kepner Tregoe Rational Model
Created by Charles Kepner and Benjamin Tregoe, this model provides a method for gathering, evaluating, and prioritizing information to identify the root cause of a problem and prevent it in the future. There are four major steps — appraise the situation, analyze the problem, analyze decisions, and analyze potential problems. When analyzing decisions, it is important to identify alternatives and perform a risk analysis for each by using a weighted decision matrix.
Download Kepner Tregoe Decision Matrix Template
Ishikawa Fishbone Diagram
Also known as a cause and effect diagram, the fishbone diagram is a visual compilation of information that helps teams brainstorm to find the cause of an issue.
Download Ishikawa Fishbone Diagram Template
Six Sigma DMAIC
DMAIC focuses on incrementally improving existing processes. It stands for the five phases of a Six Sigma improvement cycle: Define, Measure, Analyze, Improve, This template can be used as a DMAIC roadmap.
Download Six Sigma DMAIC Template
Excel | Word
Problem Management Process Workflow
Many times, an organization detects a problem when users report the same or similar incidents to the service desk in a short time frame. For example, if one user reports that their email is not working, it’s likely an isolated incident or user error that can be quickly resolved. However, if the service desk receives five reports of email errors within a 30 minutes, it’s likely a more impactful problem that requires analysis to resolve.
The problem management process includes the following workflow stages:
- Problem Detection: The organization identifies problems from a user’s incident report, analysis of existing incidents, or an automated event monitoring solution.
- Problem Logging: The organization logs problems with all relevant details, including the reporting user’s information, date and time, category, priority, severity, description, configuration item impacted, linked incidents, and resolution.
- Problem Investigation: The service desk team examines the root cause of the problem. The service desk typically investigates problems based on their priority (high-priority issues have the greatest impact on IT services).
- Problem Diagnosis: The business identifies the cause of the problem based on the results of the investigation.
- Workaround: The team takes temporary measures to restore services until the problem is resolved.
- Known Error Creation: They log the problem as a known error (in the known error database, or KEDB) so future related incidents can be linked to and addressed quickly.
- Problem Resolution: When a business addresses the underlying cause of the problem and restores normal service operation, it prevents recurring incidents and the problem is considered resolved.
- Problem Closure: Once the problem is confirmed effectively resolved, the business can close the problem and associated incidents. The problem management process includes the following workflow stages:
- Problem Detection: The organization identifies problems from a user’s incident report, analysis of existing incidents, or an automated event monitoring solution.
- Problem Logging: The organization logs problems with all relevant details, including the reporting user’s information, date and time, category, priority, severity, description, configuration item impacted, linked incidents, and resolution.
- Problem Investigation: The service desk team examines the root cause of the problem. The service desk typically investigates problems based on their priority (high-priority issues have the greatest impact on IT services).
- Problem Diagnosis: The business identifies the cause of the problem based on the results of the investigation.
- Workaround: The team takes temporary measures to restore services until the problem is resolved.
- Known Error Creation: They log the problem as a known error (in the known error database, or KEDB) so future related incidents can be linked to and addressed quickly.
- Problem Resolution: When a business addresses the underlying cause of the problem and restores normal service operation, it prevents recurring incidents and the problem is considered resolved.
- Problem Closure: Once the problem is confirmed effectively resolved, the business can close the problem and associated incidents.
Reactive vs. Proactive Problem Management
Problem management takes on different forms depending on the organization culture, technology resources, and skill set of the IT team. Most ITIL-focused teams take both a reactive and proactive approach to problem management.
Reactive problem management takes place after the incident has been reported. It is a reaction to a problem that already exists and follows the workflow stages described in the previous section.
Proactive problem management is a preventative approach that aims to thwart incidents from occurring in the first place by identifying IT infrastructure weaknesses. Proactive problem management can be difficult for many organizations because it requires both the resources and skill set to perform extensive trend analysis to identify an incident before it even occurs. Preventative activities include ongoing maintenance (especially for hardware and software reaching the end of their lifecycle), regulatory audits, automated performance monitoring, capacity planning, disaster recovery and service continuity planning, release management planning and testing, change management process, and a documented security management policy.
One activity that may aid in proactive problem management is major problem review. Organizations classify major problems based on their impact to the business. By reviewing major problems, organizations can help identify what they did correctly and incorrectly, as well as areas of improvement that, when fixed, can improve overall problem management and prevent the recurrence of problems.
Problem Management Team Members
Who is involved in the problem management process? The answer varies, but most large organizations that follow the ITIL framework employ the following team members:
-
Problem manager/process owner
-
Analysts
-
Network operations staff
-
Engineers
-
Change management team
-
Configuration management team
-
Service desk technicians (first-, second-, and third-level support)
-
Call center staff
The problem manager owns the problem management process, but also relies on other IT staff. For example, an engineer may analyze a problem in order to identify the root cause, and a change management team member will work to implement the fix.
Benefits of Problem Management
When an organization succeeds at problem management, the entire business benefits from fewer technology issues. Unfortunately, the constantly changing technology landscape means 100 percent protection from downtime is impossible, but problem management minimizes the disruptions that occur. Additional benefits of problem management include the following:
-
Reduced downtime and disruption
-
Improved service availability
-
Decreased workload and stress on service desk staff
-
Improved customer satisfaction (CSAT)
-
Decreased costs associated with downtime
-
Decreased incident impact
-
Improved service quality
-
Faster resolution time and increased first call resolution rate (FCR)
-
Fewer high-priority incidents
-
Decreased business disruption
-
Increased staff productivity
-
Improved training and learning documentation for new and existing staff
-
Prevents incident recurrence
-
Supports ISO/IEC 20000 certification requirements
The Challenges of Problem Management
As with any new or existing process, day-to-day problem management can cause a headache for the process manager, staff, and even ancillary business associates. Below are some of the challenges that may arise:
-
Lack of Knowledge and Training: ITIL can be extremely helpful to an organization, but that comes with the challenge of understanding the framework and its terminology. This is where ITIL training and certification can help, especially for team members who will be directly involved in the problem management process.
-
Leadership Buy-In/Commitment and Resistance to Change: Change is difficult, and without the buy-in of upper management, team members may be reluctant to take on a new process workflow.
-
Competing Priorities: Different IT managers may not have the same priorities when dealing with a service disruption.
-
Missing Information: Problem management depends on thorough documentation. If the organization doesn’t collect essential information during the initial incident report, problem managers may have difficulty resolving the problem quickly. Thus, the service desk is responsible for receiving and documenting all incident reports in order to ensure technicians have full access to critical information – for example, assigning the proper priority and severity help to determine the true impact to the organization.
-
Reliance on Other Teams for Accountability, and Review: The problem management process must rely on team members across IT during the analysis and resolution phase. It is difficult for problem managers to hold staff that do not report to him/her accountable. In addition, KPIs must be applied and managed across all teams involved in the process.
How to Choose a Problem Management Software Solution
ITIL-verified software is a great way to guide and manage your problem management process. Consider the following features as you evaluate software solutions:
-
Customer self-service portal
-
Service-level agreements
-
Reporting and key performance indicators (KPIs)
-
Workflow automation
-
ITIL-verified
-
Internal and/or third-party knowledge management with the ability to search
-
Customer satisfaction surveys
-
Assignments and escalations to individuals and/or teams
-
Historical audit log
-
Templates for recurring issues
-
Unique identifier assigned to each record
-
Time tracking
The ideal problem management software solution should also have the following abilities:
-
Adhere to the appropriate problem management process (create, categorize, edit, resolve, and close)
-
Classify priority and severity to determine impact
-
Be configurable to meet organization’s unique requirements (processes, forms, categories, fields, user permissions, etc.)
-
Integrate with other ITIL processes (incident, change, knowledge, and configuration management)
-
Link incidents to problems and resolve all incidents when the problem is resolved
-
Differentiate, but allow links between incidents, problems, known errors, knowledge articles, and changes
-
Document root cause
-
Integrate with configuration management for easy visibility into impacted configuration items (CI)
Key Performance Indicators and Critical Success Factors in Problem Management
In addition to the above-mentioned features, the ability to measure performance is critical to problem management success. KPIs and critical success factors (CSF) are specific to each organization, but when applied, they help identify areas for improvement. Some common KPIs and CSFs include the following:
-
Number of problems per time frame/category/department/user
-
Number of incidents per problem
-
Reduced time to problem resolution
-
Met and breached SLAs
-
Average time from incident report to problem root cause
-
Reduction/growth of problem backlog
-
Reduced costs associated with problem management
-
Root cause analysis trends
-
Service quality improvements
-
Increase in proactive change submission
-
Decrease in number of incidents over time
-
Reduced problem impact
-
Reduction in problem backlog
-
Increase first call resolution rate
Tips for Implementing Effective ITIL Problem Management
Implementing ITIL processes is not simple, but it can make a huge difference in IT success. To implement any ITIL process, start by gaining a thorough understanding of the ITIL methodology. This will help team members understand the ITIL processes and the business value. The goal of ITIL is not to offer a prescriptive, step-by-step implementation process, but a flexible framework to guide IT departments in improving their processes. There is no requirement to implement all processes. Rather, you want to choose the processes that best fit the needs of the organization.
Although ITIL requires a time and resource commitment, it does not have to bring business to a halt. Third-party organizations offer training and certification classes around the world. Send a dedicated representative to a training course to begin the implementation process. As you progress, you have the option to train the entire team.
Teams implementing ITIL problem management can also follow these tips:
-
Gain IT and senior leadership support.
-
Create a clear vision and purpose with clearly defined processes and goals.
-
Define the relationship between various processes, specifically incident, problem, and change management.
-
Take a process-by-process approach to minimize disruption and gain quick wins.
-
Dedicate resources to both reactive and proactive problem management.
-
Take a preventative approach to problem management.
-
Communicate successes with the entire organization.
-
Implement incident management prior to implementing problem management.
-
Implement a software solution that supports your specific problem management requirements.
-
Dedicate time to problem management efforts.
-
Train and educate service desk staff.
IT success is not simply a result of keeping computers and printers running within your organization, but also of aligning IT with the goals of the business as a whole. IT is the heart and soul of business and a key contributor to revenue and competitive differentiation, and ITIL provides the framework to reach those goals.
ITIL is constantly evolving as technology becomes more complex and business needs change. More than 150 industry experts have been involved in ITIL version 4, which will be released in Q1 2019 and is expected to integrate with DevOps, Agile, and Lean.
Improve ITIL Problem Management with Smartsheet for IT & Ops
Empower your people to go above and beyond with a flexible platform designed to match the needs of your team — and adapt as those needs change.
The Smartsheet platform makes it easy to plan, capture, manage, and report on work from anywhere, helping your team be more effective and get more done. Report on key metrics and get real-time visibility into work as it happens with roll-up reports, dashboards, and automated workflows built to keep your team connected and informed.
When teams have clarity into the work getting done, there’s no telling how much more they can accomplish in the same amount of time. Try Smartsheet for free, today.
В статье рассматриваются два ключевых процесса ITIL, ориентированных на выявление неисправностей в ИТ-инфраструктуре и инициирование мер по их устранению.
Процессы управления инцидентами и управления проблемами во многом похожи, но имеют и существенные различия. Опишем каждый из процессов по отдельности, а затем сравним их с различных точек зрения, обсудив способы реализации.
Управление инцидентами
Основная цель процесса управления инцидентами (incident management) — восстановление нормальной работоспособности системы в максимально короткие сроки и минимизация отрицательного влияния на бизнес, пользующийся службами, работоспособность которых оказалась нарушенной [1-3]. Под «нормальным функционированием служб» понимается функционирование, соответствующее зафиксированному в соглашении об уровне обслуживания (service level agreement,SLA).
К инцидентам не могут быть отнесены события, не касающиеся качества предоставляемых ИТ-услуг, а также те, которые, снижая это качество, не выходят за оговоренные в SLA рамки. Особое место занимают случаи, когда клиент не ощутил на себе наличия инцидента (скажем, если все необходимые меры были приняты в автоматическом режиме или обслуживающим персоналом еще до того, как качество реально снизилось). Примеры: автоматическое архивирование данных и освобождение рабочего диска при приближении к моменту его переполнения; переход на резервный сервер при сбоях основного и т.д. Тем не менее, такие случаи не могут быть исключены из списка инцидентов. Правильная организация требует отработки и таких инцидентов в соответствии с полной процедурой (т.е. с последующим отображением в отчетах и принятием необходимых мер по их предотвращению в будущем).
Всякому процессу управления инцидентами можно дать формальное краткое описание путем перечисления набора характеристик.
Входными данными для описания инцидентов служат:
- детальное описание инцидента, полученное от Service Desk, служб обеспечения оперативного функционирования сетей или серверов и т.д.;
- описание конфигураций и элементов, возможно связанных с инцидентом. Описания берутся из CMDB, базы данных единиц конфигурации, к которым относятся все элементы ИТ-инфраструктуры (оборудование, программное обеспечение, документация, предоставляемые службы и т.д.);
- информация (при ее наличии) из базы проблем и базы известных ошибок;
- описание способа разрешения.
Результат процесса управления инцидентами может быть следующим:
- запрос на временное внесение изменений для устранения инцидента, обновленная регистрационная запись инцидента, включающая способ разрешения и/или обхода;
- разрешенный (устраненный) и закрытый инцидент;
- сообщение для клиента;
- управленческая информация (отчет).
Возможные мероприятия по управлению инцидентами:
- определение и регистрация инцидента;
- классификация инцидента и начальная помощь;
- исследование и диагностика;
- разрешение инцидента и восстановление системы;
- закрытие инцидента;
- собственность, мониторинг, отслеживание и взаимодействие.
Роли и функции управления инцидентами:
- группы поддержки первой, второй и третьей линий, а также группы специалистов и внешние партнеры (роли); менеджер управления инцидентами (роль); менеджер Service Desk (функция).
Возможные метрики:
- общее число инцидентов;
- среднее время устранения или обхода инцидента по различным типам инцидентов;
- процент инцидентов, устраненных за время, не превышающее оговоренного в SLA;
- средняя стоимость устранения инцидента;
- процент инцидентов, закрытых без привлечения иных специалистов;
- число и процент инцидентов, устраненных удаленно (без визита к пользователю).
В целях обеспечения соблюдения временных рамок, выделенных для выполнения тех или иных действий, применяется функциональная и иерархическая эскалация. Под «эскалацией» понимается организационный механизм, помогающий контролировать время устранения инцидента; он должен использоваться при реализации всех мероприятий в процессе разрешения инцидента. Его суть состоит в необходимости либо обязательной передачи информации об инциденте более квалифицированным специалистам, либо информировании руководства о невозможности устранить инцидент в оговоренные сроки.
Передача инцидента от Service Desk на вторую линию поддержки (функциональная эскалация) требуется при невозможности устранить инцидент на первой линии. Автоматизированная функциональная эскалация возможна, но должна быть тщательно спланирована в соответствии с SLA.
Иерархическая эскалация оказывается необходимой при невозможности устранения инцидента либо за выделенное время, либо с необходимым качеством. Как правило, она осуществляется персоналом службы Service Desk в соответствии с их опытом и вручную. Автоматизированная иерархическая эскалация тоже используется и может строиться на основе учета временных интервалов. Целесообразно чтобы она осуществлялась до времени, установленного в SLA; при этом соответствующий руководитель получит возможность предпринять дополнительные действия.
Эффект от внедрения процесса управления инцидентами
Перечислим наиболее важные полезные качества, которые приобретаются в результате внедрения процесса управления инцидентами. Для бизнеса в целом это:
- снижение отрицательного воздействия на бизнес со стороны инцидентов, достигаемое повышением эффективности и сокращении времени при их устранении;
- проактивное (упреждающее) определение необходимости расширения и коррекции важных для бизнеса систем;
- доступность необходимой для бизнеса управленческой информации, соотнесенной с условиями SLA.
Ряд полезных качеств приобретает и работа ИТ-подразделения:
- усовершенствованный мониторинг, позволяющий измерить производительность в соответствии с SLA;
- улучшенная информация для управления качеством обслуживания;
- более оптимальная загрузка персонала и более эффективная его работа;
- исключение потерь и некорректного учета инцидентов и запросов;
- более точное ведение базы данных единиц конфигурации CMDB;
- лучшее удовлетворение потребностей клиентов.
Работа же без системы управления инцидентами может обернуться рядом неприятностей. Отсутствие лиц, ответственных за устранение и эскалацию инцидентов, приводит к путанице при устранении сбоев и снижает качество обслуживания. Специалисты службы поддержки отвлекаются от исполнения своих обязанностей, что снижает эффективность их труда. Пользователи для устранения инцидентов и проблем вынуждены общаться друг с другом, отвлекаясь от основных обязанностей. Всякий раз приходится заново анализировать инциденты — даже те, которые происходят регулярно и должны быть известны.
Управление проблемами
Основная цель процесса управления проблемами — минимизация неблагоприятного влияния на основную деятельность организации инцидентов и проблем, возникающих в результате ошибок в ИТ-инфраструктуре, а также предотвращение повторного возникновения инцидентов, связанных с этими ошибками. Для этого осуществляется поиск и выяснение причин инцидентов, и осуществляются действия, направленные на улучшение ситуации или устранение выявленных причин.
Процесс управления проблемами носит как реактивный, так и проактивный характер. Первый вариант касается разрешения проблем, связанных с возникшими инцидентами, второй направлен на выявление и устранение проблем, способных привести, но пока не приведших к возникновению инцидентов.
Контроль проблем и ошибок вместе с проактивным управлением проблемами составляют сферу ответственности процесса управления проблемами. На языке формальных определений, «проблема» — это неизвестная основная причина возникновения одного или нескольких инцидентов, а «известная ошибка» — успешно диагностированная проблема, для которой найден обходной путь или способ устранения.
Как и для процесса управления инцидентами, приведем группы основных характеристик процесса управления проблемами. Хотя некоторые из них и совпадают, указать их все имеет смысл, поскольку речь идет о разных процессах.
Входными данными для описания служат:
- детали инцидента, заимствованные из управления инцидентами;
- детальное описание конфигураций из CMDB;
- все известные обходные пути (из управления инцидентами).
Возможные мероприятия:
- контроль проблем и ошибок;
- проактивное предотвращение проблем;
- идентификация трендов;
- анализ накапливаемой информации и подготовка отчетов;
- подготовка управленческой информации.
Результаты могут быть следующими:
- описание новых известных ошибок;
- запросы на внесение изменений;
- обновленная регистрационная запись проблемы, включающая вариант решения проблемы и/или любой доступный обходной путь;
- для разрешенных проблем закрытая регистрационная запись проблемы;
- поиск аналогов инцидента среди известных ошибок и рассматриваемых проблем;
- управленческая информация.
Роли и функции: сотрудники, ответственные за обработку проблем (роли); менеджер управления проблемами (роль).
Возможные метрики:
- число инициированных запросов на внесение изменений, а также влияние этих запросов на надежность и доступность охваченных ими служб;
- время, затраченное на работы по исследованию и диагностике на каждое подразделение, с учетом деления на типы проблем;
- число и влияние возникших инцидентов до выявления причины проблемы или до регистрации известной ошибки;
- отношение объема усилий по немедленной помощи и поддержке к плановому;
- число проблем и ошибок, сгруппированных по различным признакам (статус, службы, влияние, категории, пользовательские группы);
- среднее и максимальное время, расходуемое на закрытие проблемы или согласование известной ошибки, рассчитываемое с момента регистрации проблемы, сгруппированное по кодам влияния и группам поддержки;
- ожидаемое время устранения открытых проблем;
- общее затраченное время на все закрытые проблемы.
Эффект от внедрения процесса управления проблемами
Перечислим наиболее важные полезные качества, которые приобретаются в результате внедрения процесса управления проблемами.
- Качество служб. Управление проблемами помогает поддерживать непрерывный цикл постоянного повышения качества ИТ-служб.
- Сокращение числа инцидентов. Процесс управления проблемами является инструментом для сокращения числа возникающих инцидентов, отрицательно влияющих на бизнес организации.
- Непрерывное решение. В результате работы процесса сокращается число и влияние на бизнес уже решенных проблем и известных ошибок.
- Усовершенствованное обучение. Процесс основывается на концепции использования накопленных знаний из прошлого и предоставляет возможности для анализа трендов и предотвращения сбоев, либо снижения их значимости и влияния на основной бизнес.
- Увеличение числа инцидентов, разрешаемых при первом обращении. Это достигается путем предоставления в распоряжение Service Desk рекомендаций по путям предотвращения и обхода возникающих инцидентов.
В свою очередь, отказ от реализации процесса сулит ряд неприятностей. Действующая исключительно «по факту» служба поддержки начинает действовать только тогда, когда услуга уже не доступна. Складывается инфраструктура, предполагающая применение пользователями ИТ-средств самостоятельно. Неэффективная, дорогая и слабо мотивированная служба поддержки многократно решает одни и те же проблемы, никак не учитывая предыдущий опыт.
Реализация и внедрение
Мы уже обращали внимание на основное отличие рассматриваемых процессов, учтенное в формировании ключевых метрик качества. Задачей управления инцидентами является устранение инцидентов в максимально короткие сроки. Управление же проблемами должно исключить возможность повторного возникновения инцидента по той же самой (а иногда — и по аналогичным) причинам.
В организационном плане это означает, что никто не может исполнять обязанности по обоим этим процессам одновременно, поскольку он был бы не в состоянии правильно расставить приоритеты. В качестве выхода из положения при традиционной ограниченности штата рекомендуется четко определить в инструкциях временные или иные рамки, позволяющие специалисту однозначно исполнять роль только в одном из процессов. Например, сотрудник службы эксплуатации сетей банка в критичное для работоспособности время прохождения основных платежей обязан при возникновении сбоев предпринять все меры по максимально быстрому устранению этих сбоев и восстановлению работоспособности систем, исполняя роль специалиста по управлению инцидентами. В относительно менее критичное время этому специалисту запрещается реагировать на возникающие инциденты и предписывается заниматься анализом накопленной информации о сбоях и поиском их причин и, тем самым исполнять мероприятия по управлению проблемами.
Допустимо (и рекомендуется) совмещение функций Service Desk и функций управления инцидентами. Однако важно помнить, что это разные процессы: первичное общение с пользователями не входит в функции процесса управления инцидентами. К тому же, пользователь может обратиться в службу поддержки не только в связи с возникшим инцидентом, но и по иной причине (потребность в информации, необходимость пополнения расходуемых материалов и т.д.). С другой стороны, при некоторых способах реализации (например, в случае построения службы поддержки на основе Web-технологий, когда пользователь самостоятельно вносит все необходимые данные в формы) необходимость выделенной службы Service Desk оказывается под вопросом. В то же время ни в коем случае нельзя отказываться от управления инцидентами — откуда бы ни поступило сообщение об их возникновении, кто-то обязательно должен отвечать за их устранение.
Понятно, что реализация управления проблемами при отсутствии управления инцидентами практически невозможна: основой и источником данных для рассмотрения проблемы является информация, накапливаемая в ходе анализа и обработки инцидентов. Порой оказывается допустимым внедрение только управления инцидентами. Обычно управление проблемами отсутствует у фирм-посредников — имея свою собственную диспетчерскую службу, такие компании организуют прием и регистрацию обращений клиентов, помогают им при наличии возможности устранить инцидент при помощи консультации, передают более сложные заявки субподрядчикам и контролируют их действия, реализуя тем самым управление инцидентами. В то же время, они не занимаются анализом проблем, поскольку не являются собственно эксплуатирующей организацией. Часто исключают управление проблемами и в случае, если нет возможности или желания этим заниматься. В отдельных случаях даже рекомендуется для анализа проблем привлекать внешних специалистов, поскольку для этого требуется очень высокая квалификация, а также дорогостоящее оборудование. Примером могут служить традиционные обращения в компании, специализирующиеся на построении и обслуживании телекоммуникаций, для определения реальной загрузки сетей передачи данных: соответствующее оборудование стоит дорого, а необходимость его использования возникает чрезвычайно редко.
В отношении средств автоматизации ITIL рекомендует, как минимум, наличие возможностей глубокой интеграции между инструментарием для управления проблемами и инцидентами. Действительно, при анализе проблем важно иметь возможность рассмотрения всех зарегистрированных инцидентов с различных точек зрения. В свою очередь, для более эффективного общения с пользователями при возникновении новых инцидентов, соответствующим специалистам необходим доступ к находящимся в рассмотрении или уже закрытым проблемам и известным ошибкам.
Это легко понять на примере следующей ситуации. Пользователь обращается в службу поддержки с сообщением о резком увеличении времени отклика от сервера. Оператор, просматривая список анализируемых проблем, находит запись о выполнении работ по анализу снижения производительности сервера, после чего сообщает пользователю, что его сообщение зарегистрировано и связано с рассматриваемой проблемой, а устранение ожидается через такое-то время, о чем пользователю будет сообщено дополнительно. При отсутствии возможности просмотра списка проблем, оператор не мог бы связать инцидент с конкретно анализируемой проблемой, в дальнейшем быстро отследить факт его устранения и сообщить об этом пользователю.
Производители инструментария стараются учитывать упомянутые рекомендации. Например, HP OpenView Service Desk 3.0 имеет модульную структуру. В виде отдельного модуля реализованы возможности регистрации и управления обращений пользователей, инцидентов и проблем, что вполне соответствует упомянутым рекомендациям: интеграция в данном случая является максимально полной. Пользователи системы, построенной на основе этого продукта, имеют возможность строить связи между регистрационными записями всех перечисленных типов, осуществлять поиск по контексту и с учетом этих связей, определять известные способы решения проявляющихся неисправностей. Разделение этих функций может снизить эффективность работы инструментального средства, а как следствие — и качество реализации процессов. В то же время, в основе всякого решения по управлению ИТ-инфраструктурой лежит учет имеющегося оборудования, приложений, документации и т.д. — всего того, что и составляет эту инфраструктуру. Такие возможности также доступны в рамках HP Service Desk 3.0. Кроме того, в виде отдельных модулей реализованы возможности, предназначенные для автоматизации управления изменениями и управления соглашениями SLA. Интеграция всех перечисленных модулей реализуется в максимально полном объеме, предоставляя возможность использовать рассматриваемый продукт в качестве основы для построения комплексной системы управления ИТ.
Продукт компании Remedy строится несколько сложнее, основой его является Remedy Action Request System, устанавливаемая на сервере. К системе в качестве прикладной части могут дополнительно приобретаться функциональные модули: Help Desk, Asset Management, Change Management и Service Level Agreement. Каждый из модулей может использоваться как самостоятельно (без других прикладных модулей), так и в составе комплексного решения. Вопросы автоматизации процессов управления проблемами и инцидентами, как и в случае решения от HP, реализуются в модуле Remedy Help Desk. При этом имеются некоторые отличия и реализуются отдельные собственные подходы к пониманию данных процессов, но основные пожелания и требования ITIL полностью учтены.

Рекомендации и возможные трудности
Для успешного внедрения процессов управления инцидентами и проблемами
необходимо выполнение, как минимум, следующих условий.
- Наличие актуальной и своевременно обновляемой базы CMDB. Если эта база недоступна, информация об имеющих отношение к инциденту единицах конфигурации будет добываться вручную, что существенно увеличит время обработки инцидента и повысит ее сложность.
- Доступность обновляемой базы знаний по ошибкам/проблемам и способам их разрешения, а также обхода. Наличие такой базы позволяет быстро разрешать многие проблемы. Желательно иметь возможность подключения к ней аналогичных баз, разработанных другими организациями и компаниями. Возникающие при этом вопросы совместимости могут привести к большим сложностям, поэтому рекомендуется использовать решения с открытой архитектурой, содержащие средства для импорта и экспорта данных. В последнее время все чаще в качестве стандартного способа доступа к информации используется Web-интерфейс, являющийся удобным и понятным, а также широко распространенным.
- С точки зрения потенциально конфликтной ситуации между управлением проблемами и управлением инцидентами (из-за их разных целей), необходимо организовать совместную работу и сотрудничество исполнителей обоих процессов. При этом нельзя забывать о том, что из тех же соображений один и тот же человек не может исполнять и те и другие обязанности одновременно: ему будет очень трудно найти баланс интересов.
- Организация эффективной автоматизированной системы регистрации инцидентов с возможностями детальной и качественной классификации, являющейся чрезвычайно важным элементом для организации функционирования как службы Service Desk, так и рассматриваемых процессов в чистом виде. Использование для этих целей бумажных технологий не рекомендуется.
Весьма удобно, если инструментальные средства, используемые для реализации рассматриваемых процессов, обладают следующими дополнительными возможностями:
- автоматической регистрацией инцидентов, происходящих в наиболее важных устройствах (серверы, сетевое оборудование и т.д.), для чего может потребоваться создание дополнительных интерфейсов;
- автоматической эскалацией инцидентов при нарушении временных графиков;
- гибкой маршрутизацией инцидентов, поскольку персонал служб поддержки может быть размещен в различных помещениях и зданиях;
- автоматическим поиском необходимых данных в базе CMDB;
- специальными решеними для облегчения классификации инцидентов;
- интеграцией с телефонными системами;
- наличием разнообразных диагностических модулей.
Проиллюстрируем перечисленные возможности на примере уже упоминавшегося Service Desk 3.0. Будучи представителем семейства продуктов HP OpenView, Service Desk содержит возможности получения сообщений от других продуктов данного семейства, в том числе от Network Node Manager, средства мониторинга и управления сетевыми устройствами, и VantagePoint Operations, средства мониторинга и управления серверами и приложениями. Данные продукты могут в автоматическом режиме, на основании собираемой информации о контролируемых объектах, генерировать запросы для Service Desk, которые автоматически передаются и анализируются операторами службы поддержки или обрабатываются в автоматическом режиме. При соответствующей настройке источниками аналогичных сообщений могут стать и иные диагностические средства. Продукт предусматривает возможности автоматического информирования путем отправки сообщений руководителей соответствующих уровней при нарушении сроков устранения инцидента. В нем реализованы расширенные возможности по поиску необходимой информации среди уже учтенных проблем, инцидентов и иных данных. В продукте представлены возможности интеграции с почтовыми, телефонными и пейджинговыми системами.
В виду актуальности и полезности перечисленных дополнительных возможностей, производители программных решений стараются включать их в свои продукты. Многое из сказанного о HP Service Desk относится и к продуктам других производителей, в том числе, Remedy, Tivoli, CA, Peregrin, FrontRange.
Тем, кто берется за работу по внедрению рассматриваемых процессов, надо быть готовым к разнообразным трудностям. Среди них:
- отсутствие поддержки со стороны руководства и персонала, что может вести к недостатку ресурсов для реализации;
- непонимание потребностей бизнеса, отсутствие согласованных уровней обслуживания, слабо определенные цели, возможности и ответственности различных служб;
- сопротивление изменениям и невозможность внесения изменений в сложившуюся практику работы;
- недостаток знаний для разрешения инцидентов, неправильная подготовка персонала, слабо формализованные правила взаимодействия пользователей со службами поддержки и различных служб между собой;
- слабая интеграция с другими процессами, некачественные средства автоматизации, невозможность связать регистрационные записи инцидентов и соответствующих им проблем существенно снижает возможности процесса, в том числе, возможности прогнозирования проблем.
***
Мы остановились на двух наиболее часто упоминаемых в связи с устранением возникающих неисправностей процессах управления элементами ИТ. Являясь довольно понятными на интуитивном уровне, данные процессы при этом сложны для реализации с точки зрения необходимости четкого соблюдения организационных мероприятий и процедур. Будучи во многом схожими, процессы управления инцидентами и управления проблемами обладают и существенными различиями, проистекающими из их основных целей. Максимальную важность при внедрении процессов приобретают используемые для этих целей средства автоматизации. К сожалению, первоисточники по ITIL доступны очень ограниченному кругу заинтересованных: стоят они весьма недешево, заказать их непросто, а получить — еще сложнее. Изложенные в статье требования и пожелания к инструментарию основываются на реальном опыте эксплуатации разнообразных средств и анализе путей решений возникавших при этом вопросов.
Литература
1. З. Алехин. ITIL — основа концепции управления ИТ-службами. «Открытые системы». 2001, № 3
2. З. Алехин. Service Desk — цели, возможности, реализации. «Открытые системы». 2001, № 5-6
3. CCTA. Best Practice for Service Support. London: The Stationery Office, 2000
Заурбек Алехин (alekhin@i-teco.ru) — руководитель проекта компании i-Teco (Москва).
Что такое инцидент
Согласно принятому в ITIL определению под «инцидентом» понимается «любое событие, не являющееся элементом нормального функционирования службы и при этом оказывающее или способное оказать влияние на предоставление службы путем ее прерывания или снижения качества».
Основные категории инцидентов
Приложения:
- служба недоступна;
- ошибка в приложении, не дающая клиенту нормально работать;
- исчерпано дисковое пространство.
Оборудование:
- сбой системы;
- внутренний сигнал тревоги;
- отказ принтера.
Заявки на обслуживание:
- поступление заявки на получение дополнительной информации, совета, документации;
- забытый пароль.
Большинство групп ИТ-специалистов имеет отношение к устранению тех или иных инцидентов. Служба Service Desk отвечает за мониторинг процесса устранения всех зарегистрированных инцидентов, поскольку является собственником всех таких инцидентов. Этот процесс в большей степени реактивный; для эффективного реагирования на инциденты должен быть определен формальный метод работы сотрудников, включающий использование необходимого программного обеспечения.
Те инциденты, которые не могут быть разрешены непосредственно службой Service Desk, должны быть переадресованы соответствующим специалистам. Способ разрешения инцидента или вариант его обхода должны быть установлены и доведены до пользователей как можно быстрее. Это вытекает из главной цели — минимизации отрицательного влияния на основную деятельность пользователей. После устранения причины инцидента и восстановления службы до оговоренного в SLA уровня инцидент закрывается.