
Перевод публикуется с сокращениями, автор оригинальной статьи David
Amos.
Выявление ошибок называется
дебаггингом, а дебаггер – помогающий понять причину их появления инструмент. Умение находить
и исправлять ошибки в коде – важный навык в работе программиста, не
пренебрегайте им.
IDLE (Integrated Development and Learning Environment) – кроссплатформенная интегрированная среда разработки и обучения для Python, созданная Гвидо ван Россумом.
Используйте окно управления отладкой
Основным интерфейсом отладки в IDLE является специальное окно управления (Debug Control window). Открыть его
можно, выбрав в меню интерактивного окна пункт Debug→Debugger.
Примечание: если отладка отсутствует в строке меню, убедитесь, что интерактивное окно находится
в фокусе.
Всякий раз, когда окно отладки
открыто, интерактивное окно отображает [DEBUG ON].
Обзор окна управления отладкой
Чтобы увидеть работу отладчика, напишем простую
программу без ошибок. Введите в редактор следующий код:
for i in range(1, 4):
j = i * 2
print(f"i is {i} and j is {j}")
Сохраните все, откройте окно отладки и нажмите клавишу F5 –
выполнение не завершилось.
Окно отладки будет выглядеть следующим образом:
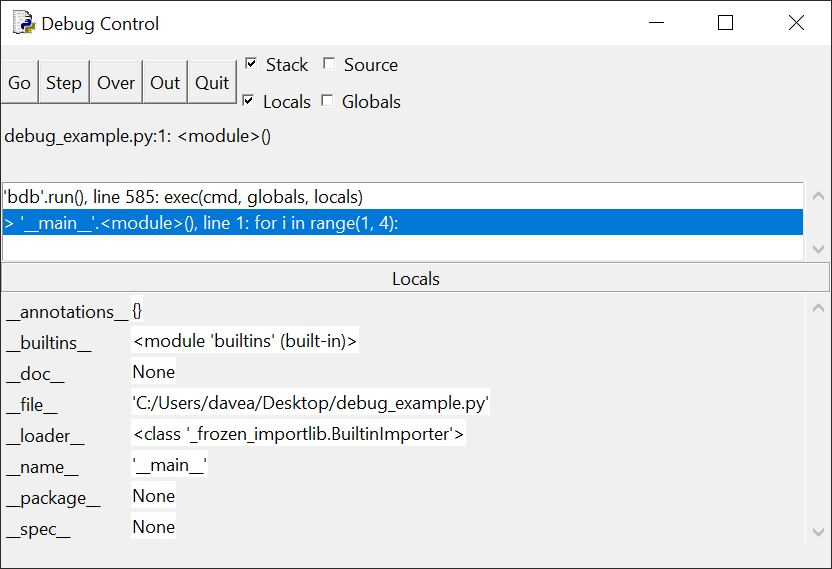
Обратите внимание, что панель в верхней части окна содержит сообщение:
> '__main__'.<module>(), line 1: for i in range(1, 4):
Расшифруем: код for i in range(1, 4): еще не запущен, а '__main__'.module() сообщает, что в данный момент мы находимся в
основном разделе программы, а не в определении функции.
Ниже панели стека находится панель Locals, в которой
перечислены непонятные вещи: __annotations__, __builtins__, __doc__ и т. д. – это
внутренние системные переменные, которые пока можно игнорировать. По мере
выполнения программы переменные, объявленные в коде и отображаемые в этом окне,
помогут в отслеживании их значений.
В левом верхнем углу окна расположены пять кнопок:
Go, Step, Over, Out и Quit – они управляют перемещением отладчика по коду.
В следующих разделах вы узнаете, что делает каждая из
этих кнопок.
Кнопка Step
Нажмите Step и окно отладки будет выглядеть
следующим образом:
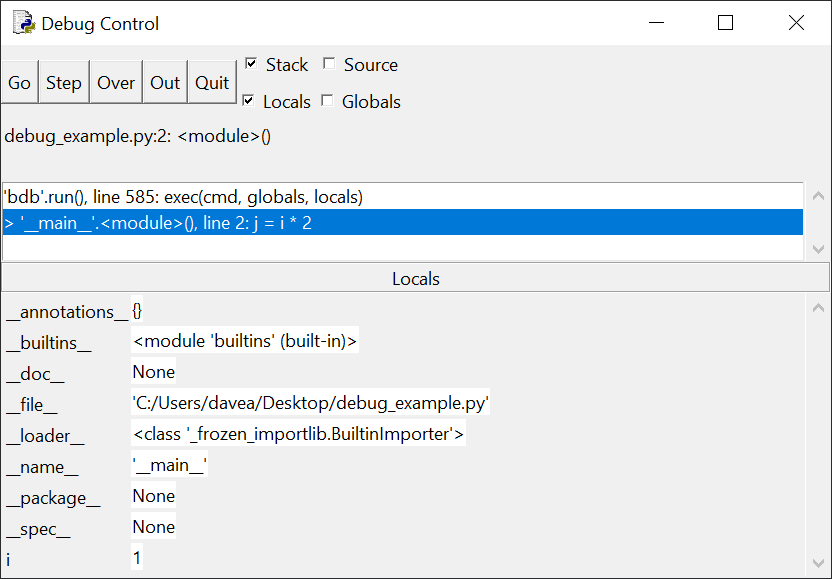
Обратите внимание на два отличия. Во-первых, сообщение на
панели стека изменилось:
> '__main__'.<module>(), line 2: j = i * 2:
На этом этапе выполняется line 1 и отладчик останавливается перед
выполнением line 2.
Во-вторых – новая переменная i со значением 1 на панели Locals. Цикл for в line 1
создал переменную и присвоил ей это значение.
Продолжайте нажимать кнопку Step, чтобы пройтись по коду
строка за строкой, и наблюдайте, что происходит в окне отладчика. Когда
доберетесь до строки print(f"i is {i} and j is {j}"), сможете увидеть
вывод, отображаемый в интерактивном окне по одному фрагменту за раз.
Здесь важно, что можно отслеживать растущие значения i и j по
мере прохождения цикла for. Это полезная фича поиска источника ошибок в коде.
Знание значения каждой переменной в каждой строке кода может помочь точно
определить проблемную зону.
Точки останова и кнопка Go
Часто вам известно, что ошибка должна всплыть в определенном куске
кода, но неизвестно, где именно. Чтобы не нажимать кнопку Step весь
день, установите точку останова, которая скажет отладчику запускать весь код,
пока он ее не достигнет.
Точки останова сообщают отладчику, когда следует
приостановить выполнение кода, чтобы вы могли взглянуть на текущее состояние
программы.
Чтобы установить точку останова, щелкните правой кнопкой мыши
(Ctrl для Mac) по строке кода, на которой хотите сделать паузу, и выберите
пункт Set Breakpoint – IDLE выделит линию желтым. Чтобы удалить ее, выберите Clear
Breakpoint.
Установите точку останова в строке с оператором print(). Окно
редактора должно выглядеть так:
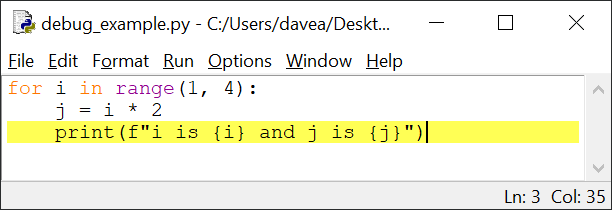
Сохраните и запустите. Как и раньше, панель стека указывает, что отладчик запущен и ожидает выполнения line 1. Нажмите
кнопку Go и посмотрите, что произойдет:
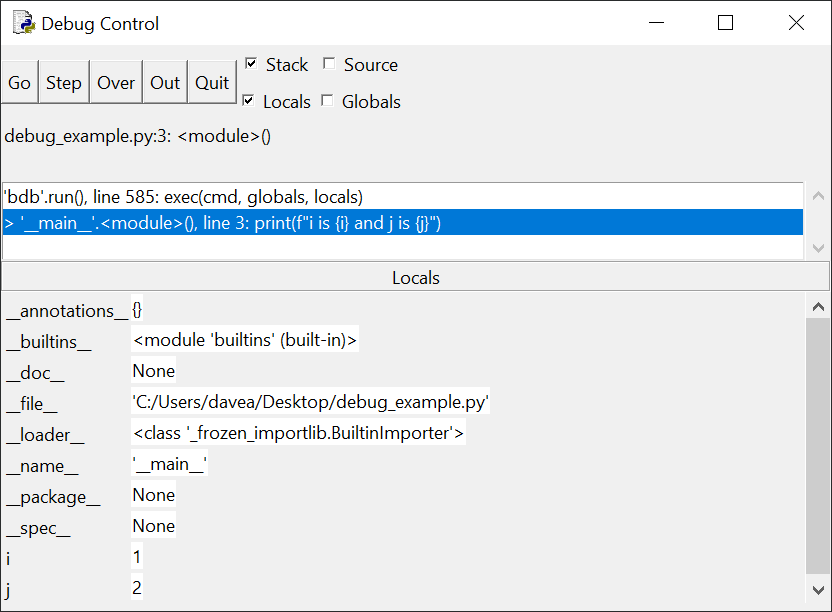
Теперь на панели стека информация о выполнении line 3:
> '__main__'.<module>(), line 3: print(f"i is {i} and j is {j}")
На панели Locals мы видим, что переменные i и j имеют значения 1
и 2 соответственно. Нажмем кнопку Go и попросим отладчик запускать код до точки
останова или до конца программы. Снова нажмите Go – окно отладки теперь выглядит так:
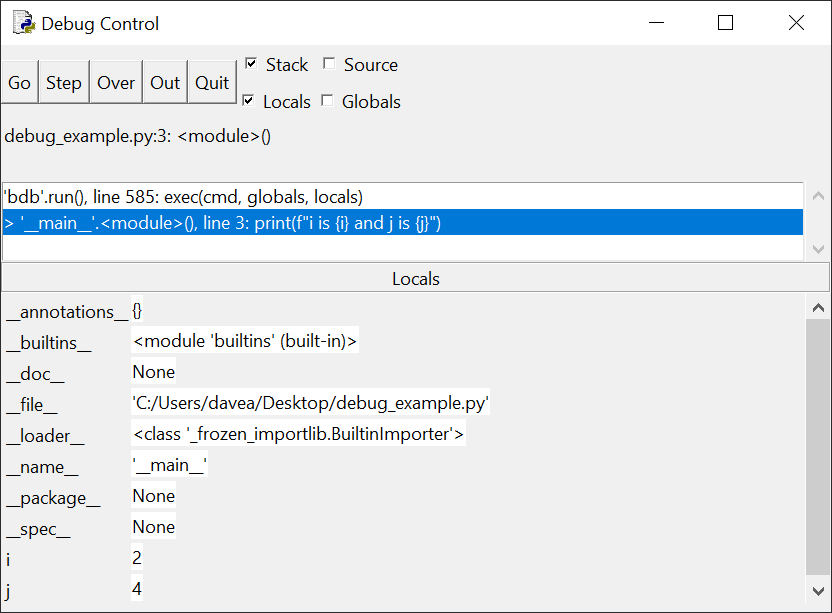
На панели стека отображается то же сообщение, что и раньше –
отладчик ожидает выполнения line 3. Однако значения переменных i и j теперь
равны 2 и 4. Интерактивное окно также отображает выходные данные после первого
запуска строки с помощью функции print() через цикл.
Нажмите кнопку в третий раз. Теперь i и j равны 3 и 6. Если
нажать Go еще раз, программа завершит работу.
Over и Out
Кнопка Over работает, как сочетание Step и Go – она
перешагивает через функцию или цикл. Другими словами, если вы собираетесь попасть
в функцию с помощью отладчика, можно и не запускать код этой функции – кнопка
Over приведет непосредственно к результату ее выполнения.
Аналогично если вы уже находитесь внутри функции или цикла –
кнопка Out выполняет оставшийся код внутри тела функции или цикла, а затем
останавливается.
В следующем разделе мы изучим некоторые ошибки и узнаем, как
их исправить с помощью IDLE.
Борьба с багами
Взглянем на «глючную» программу.
Следующий код определяет функцию add_underscores(), принимающую
в качестве аргумента строковый объект и возвращающую новую строку – копию слова с каждым символом, окруженным подчеркиванием. Например,
add_underscores("python") вернет «_p_y_t_h_o_n_».
Вот неработающий код:
def add_underscores(word):
new_word = "_"
for i in range(len(word)):
new_word = word[i] + "_"
return new_word
phrase = "hello"
print(add_underscores(phrase))
Введите этот код в редактор, сохраните и нажмите F5.
Ожидаемый результат – _h_e_l_l_o_, но вместо этого выведется o_.
Если вы нашли, в чем проблема, не исправляйте ее. Наша цель – научиться
использовать для этого IDLE.
Рассмотрим 4 этапа поиска бага:
- предположите, где может быть ошибка;
- установите точку останова и проверьте код по строке за раз;
- определите строку и внесите изменения;
- повторяйте шаги 1-3, пока код не заработает.
Шаг 1: Предположение
Сначала вы не сможете точно определить местонахождение ошибки,
но обычно проще логически представить, в какой раздел кода смотреть.
Обратите внимание, что программа разделена на два раздела:
определение функции add_underscores() и основной блок, определяющий переменную
со значением «hello» и выводящий результат.
Посмотрим на основной раздел:
phrase = "hello"
print(add_underscores(phrase))
Очевидно, что здесь все хорошо и проблема должна быть в
определении функции:
def add_underscores(word):
new_word = "_"
for i in range(len(word)):
new_word = word[i] + "_"
return new_word
Первая строка создает переменную new_word со значением «_». Промах,
проблема находится где-то в теле цикла for.
Шаг 2: точка останова
Определив, где может быть ошибка, установите точку
останова в начале цикла for, чтобы проследить за происходящим внутри кода:
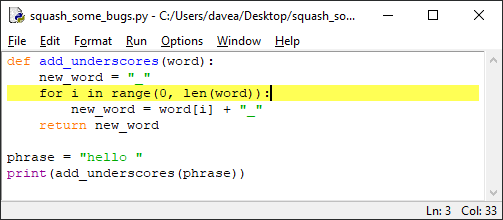
Запустим. Выполнение останавливается на строке с определением
функции.
Нажмите кнопку Go, чтобы выполнить код до точки останова:
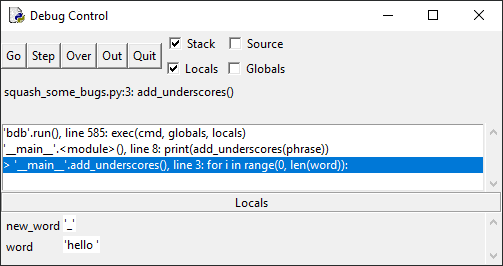
Код останавливается перед циклом for в функции
add_underscores(). Обратите внимание, что на панели Locals отображаются две
локальные переменные – word со значением «hello», и new_word со значением «_»,
Нажмите кнопку Step, чтобы войти в цикл for. Окно отладки
изменится, и новая переменная i со значением 0 отобразится на панели Locals:
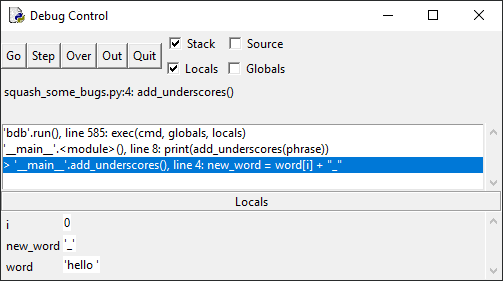
Переменная i – это счетчик для цикла for, который можно
использовать, чтобы отслеживать активную на данный момент итерацию.
Нажмите кнопку Step еще раз и посмотрите на панель Locals –
переменная new_word приняла значение «h_»:
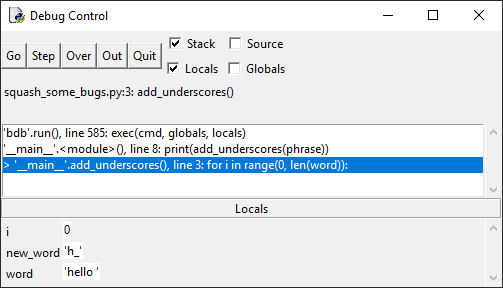
Это неправильно т. к. сначала в new_word было значение «_», на
второй итерации цикла for в ней должно быть «_h_». Если нажать Step еще
несколько раз, то увидим, что в new_word попадает значение e_, затем l_ и так
далее.
Шаг 3: Определение ошибки и исправление
Как мы уже выяснили – на каждой итерации цикла new_word
перезаписывается следующим символом в строке «hello» и подчеркиванием.
Поскольку внутри цикла есть только одна строка кода, проблема должна быть именно
там:
new_word = word[i] + "_"
Код указывает Python получить следующий символ word,
прикрепить подчеркивание и назначить новую строку переменной new_word. Это
именно то неверное поведение, которое мы наблюдали.
Чтобы все починить, нужно объединить word[i] + "_"
с существующим значением new_word. Нажмите кнопку Quit в окне отладки, но не
закрывайте его. Откройте окно редактора и измените строку внутри цикла for на
следующую:
new_word = new_word + word[i] + "_"
Примечание: Если бы вы закрыли
отладчик, не нажав кнопку Quit, при повторном открытии окна отладки могла
появиться ошибка:
You can only toggle the debugger when
idle
Всегда нажимайте кнопку Go или Quit, когда заканчиваете отладку,
иначе могут возникнуть проблемы с ее повторным запуском.
Шаг 4: повторение шагов 1-3, пока ошибка не исчезнет
Сохраните изменения в программе и запустите ее снова. В окне
отладки нажмите кнопку Go, чтобы выполнить код до точки останова. Понажимайте
Step несколько раз и смотрите, что происходит с переменной new_word на каждой
итерации – все работает, как положено. Иногда необходимо повторять этот процесс
несколько раз, прежде чем исправится ошибка.
Альтернативные способы поиска ошибок
Использование отладчика может быть сложным и трудоемким, но
это самый надежный способ найти ошибки в коде. Однако отладчики не всегда есть в наличии. В подобных ситуациях можно использовать print debugging для поиска
ошибок в коде. PD задействует функцию print() для отображения в консоли текста, указывающего место выполнения программы и состояние
переменных.
Например, вместо отладки предыдущего примера можно добавить
следующую строку в конец цикла for:
print(f"i = {i}; new_word = {new_word}")
Измененный код будет выглядеть следующим образом:
def add_underscores(word):
new_word = "_"
for i in range(len(word)):
new_word = word[i] + "_"
print(f"i = {i}; new_word = {new_word}")
return new_word
phrase = "hello"
print(add_underscores(phrase))
Вывод должен выглядеть так:
i = 0; new_word = h_
i = 1; new_word = e_
i = 2; new_word = l_
i = 3; new_word = l_
i = 4; new_word = o_
o_
PD работает, но имеет
несколько недостатков по сравнению с отладкой дебаггером. Вы должны запускать
всю программу каждый раз, когда хотите проверить значения переменных, а также помнить про удаление вызовов функций print().
Один из способов улучшить наш цикл – перебирать символы в
word:
def add_underscores(word):
new_word = "_"
for letter in word:
new_word = new_word + letter + "_"
return new_word
Заключение
Теперь вы знаете все об отладке с помощью DLE.
Вы можете использовать этот принцип с
различными дебагерами.
В статье мы разобрали следующие темы:
- использование окна управления отладкой;
- установку точки останова для глубокого понимания работы кода;
- применение кнопок Step, Go, Over и Out;
- четырехэтапный процессом выявления и удаления ошибок.
Не останавливайтесь в обучении и практикуйте дебаггинг – это
весело!
Дополнительные материалы:
- ТОП-10 книг по Python: эффективно, емко, доходчиво
- Парсинг сайтов на Python: подробный видеокурс и программный код
- Python + Visual Studio Code = успешная разработка
- 29 Python-проектов, оказавших огромное влияние на разработку
- 15 вопросов по Python: как джуниору пройти собеседование
Pricing
Select your desired amount of credits
500 Credits / 24$ Popular
Only 0.048$ per 1 credit
Get 500 credits, and use them to access any tool on CodePal
Credits are available for you forever ❤️
- Single user
- Multiple users
Access to 26+ Coding Tools
Access to- Technical Support
- Advanced language models
- API Access
- Unlimited credits
Frequently Asked Questions
-
What are CodePal Credits?
Credits are digital tokens that grant you access to any of the 26+ coding tools to use with 80+
programming languages and technologies available on CodePal.Each credit represents one usage of any tool on CodePal website, and they are available for you forever.
-
Which tools do credits give me access to?
CodePal is a comprehensive platform that offers a range of coding helpers and tools to assist developers.
Credits provide access to all the services available on CodePal, including
new and upcoming tools. -
Which programming languages and technologies are supported at CodePal?
CodePal supports the following programming languages, technologies and frameworks:
ActionScript, Ada, AppleScript, Arduino, Assembly, Assembly, AutoHotkey, Visual Basic, Brainfuck, Cobol, CoffeeScript, Elixir, MoonScript, ObjectiveC, PineScript, Prolog, VBScript, ZenScript, Python, Java, Bash, PowerShell, C++, C++, C++, C#, C#, C, JavaScript, JavaScript, PHP, Swift, Ruby, Go, Go, Kotlin, Perl, SQL, Clojure, R, Rust, Scala, Haskell, Lua, Erlang, Julia, TypeScript, TypeScript, MongoDB, GraphQL, Redis, Dart, LaTeX, LaTeX, Excel, Google Sheets, Google Sheets, XML, JSON, YAML, YAML, SQL, MongoDB, Makefile, Dockerfile, Terraform, Jenkins, CircleCI, GitlabCI, GitHub Actions, Travis CI, Azure Pipelines, AWS CodePipeline, Google Cloud Build, Bamboo Groovy, TeamCity, Bitbucket Pipelines, Drone, Spinnaker, Tekton, Kubernetes, and more.Credits grants access to use any of the supported languages on CodePal.
-
What is code refactoring?
Code refactoring is the process of restructuring existing code to improve its design,
readability, and maintainability, without changing its behavior. It involves making small modifications
to the code to eliminate duplication, improve performance, or simplify complex logic. -
Why is code refactoring important?
Code refactoring helps to reduce technical debt, which is the cost of maintaining and improving software over time. By improving the quality of the code, refactoring makes it easier to maintain, modify, and extend the software in the future. It also helps to improve the performance and reliability of the software.
-
What are some common code smells that indicate the need for refactoring?
Code smells are symptoms of poor design or implementation that can indicate the need for refactoring. Some common code smells include long methods or classes, duplication of code, complex conditionals, and too many levels of nesting.
-
What is automated code refactoring?
Automated code refactoring is the process of using tools or software to automatically analyze and modify code, based on predefined rules or patterns. This can help to save time and effort when refactoring large or complex codebases, and can help to ensure that the refactoring is consistent and effective.
-
How does AI help with code refactoring?
AI can be used to automate code refactoring by analyzing the codebase and suggesting
modifications based on patterns or rules learned from existing code. This can help to identify areas of
the code that are difficult to maintain or understand, and suggest ways to improve the code quality. -
What are some benefits of using AI for code refactoring?
Using AI for code refactoring can help to reduce the time and effort required for manual
refactoring, and can help to identify potential issues or areas of improvement that may be difficult for
humans to spot. It can also help to ensure that the refactoring is consistent and effective,
and can improve the quality and maintainability of the codebase. -
What are some challenges of using AI for code refactoring?
One challenge of using AI for code refactoring is ensuring that the automated refactoring is
safe and does not introduce new bugs or issues into the code. It can also be difficult to train AI models
on large or complex codebases, and to ensure that the models are accurate and effective. -
How can developers ensure that AI-generated refactorings are correct and effective?
Developers should review and test the suggested refactorings before applying them to the
codebase. They should also ensure that the refactored code still meets the requirements and behavior of
the original code. -
Can AI completely replace human developers for code refactoring?
No, AI is not yet advanced enough to completely replace human developers for code
refactoring. However, it can assist and augment human developers by automating some of the more tedious
and time-consuming aspects of the process. -
What are some potential drawbacks or limitations of using AI for code refactoring?
AI-generated refactorings may not always be appropriate or effective, and developers may
need to manually adjust or customize them. Additionally, AI may not be able to fully understand the
context or business requirements of the codebase, which could limit its effectiveness. -
How can developers ensure that refactored code is maintainable and easy to understand for future developers?
Developers should document the refactored code and use clear and descriptive variable and
function names. They should also follow established coding conventions and best practices,
and avoid overly complex or clever code. -
What are some common types of refactorings that can be automated using AI?
Some common types of refactorings that can be automated using AI include extracting
duplicate code into a reusable function or class, simplifying complex conditional statements,
and identifying and removing dead code.
Get discounted credits and early access to new features by joining to CodePal
newsletter.
No spam. Never. Unsubscribe anytime.
Cheers! 🍻
More AI Code Refactor Tools
Ошибки совершают все — даже опытные профессиональные разработчики!
Интерактивный интерпретатор Python, IDLE, довольно хорошо выявляет такие ошибки, как синтаксические ошибки и ошибки времени выполнения, но есть третий тип ошибок, с которыми вы, возможно, уже сталкивались. Логические ошибки возникают, когда действующая в остальном программа не выполняет то, что было задумано. Логические ошибки вызывают непредвиденное поведение, называемое ошибками. Удаление ошибок называется отладкой.
В этом уроке:
- Используйте окно управления отладкой
- Окно управления отладкой: обзор
- Кнопка Step
- Точки останова и кнопка перехода
- Снова и снова
- Устранение некоторых ошибок
- Делай 1. Угадайте, где находится ошибка
- Делай 2. Установите точку останова и проверьте код
- Делай 3. Определите ошибку и попытайтесь ее исправить
- Делай 4. Повторяйте шаги с 1 по 3, пока ошибка не исчезнет
- Альтернативные способы поиска ошибок
- Заключение: отладка Python с помощью IDLE
Отладчик — это инструмент, который помогает выявлять ошибки и понимать, почему они возникают. Умение находить и исправлять ошибки в коде — это навык, который вы будете использовать на протяжении всей своей карьеры программиста!
В этом уроке вы:
- Узнайте, как использовать окно управления отладкой IDLE;
- Попрактикуйтесь в отладке ошибочной функции;
- Изучите альтернативные методы отладки вашего кода.
Используйте окно управления отладкой
Основным интерфейсом отладчика IDLE является окно Debug Control, или для краткости окно Debug. Вы можете открыть окно «Debug», выбрав «Debug» → «Debugger» в главном меню интерактивного окна. Идите вперед и откройте окно отладки.
Примечание. Если в строке меню отсутствует меню «Debug», убедитесь, что интерактивное окно находится в фокусе, щелкнув его.
Каждый раз, когда открыто окно отладки, интерактивное окно отображает [DEBUG ON] рядом с приглашением, указывающим, что отладчик открыт. Теперь откройте новое окно редактора и расположите три окна на экране так, чтобы вы могли видеть их все одновременно.
В этом разделе вы узнаете, как организовано окно отладки, как по-шагово выполнять код с отладчиком по одной строке за раз и как устанавливать точки останова, чтобы ускорить процесс отладки.
Окно управления отладкой: обзор
Чтобы увидеть, как работает отладчик, вы можете начать с написания простой программы без каких-либо ошибок. Введите в окно редактора следующее:
for i in range(1, 4):
j = i * 2
print(f"i is {i} and j is {j}")
Сохраните файл, затем оставьте окно отладки открытым и нажмите F5. Вы заметите, что до исполнения не далеко.
Окно отладки будет выглядеть так:

Обратите внимание, что панель стека в верхней части окна содержит следующее сообщение:
> '__main__'.(), line 1: for i in range(1, 4):
Это говорит о том, что строка 1 (которая содержит код for i in range(1, 4):) вот-вот будет запущена, но еще не началась. Часть сообщения '__main__'.() относится к тому факту, что вы в данный момент находитесь в основном разделе программы, а не находитесь, например, в определении функции до того, как будет достигнут основной блок кода.
Под панелью Stack находится панель Locals, в которой перечислены некоторые странно выглядящие вещи, такие как __annotations__, __builtins__, __doc__ и т.д. Это внутренние системные переменные, которые пока можно игнорировать. Во время выполнения программы вы увидите переменные, объявленные в коде, отображаемом в этом окне, чтобы вы могли отслеживать их значение.
В верхнем левом углу окна отладки расположены пять кнопок: Go, Step, Over, Out и Quit. Эти кнопки управляют тем, как отладчик перемещается по вашему коду.
В следующих разделах вы узнаете, что делает каждая из этих кнопок, начиная с Step.
Кнопка Step
Идите вперед и нажмите Step в верхнем левом углу окна отладки. Окно отладки немного изменится и будет выглядеть так:

Здесь есть два отличия, на которые следует обратить внимание. Сначала сообщение на панели стека меняется на следующее:
> '__main__'.(), line 2: j = i * 2:
На этом этапе выполняется строка 1 вашего кода, а отладчик остановился непосредственно перед выполнением строки 2.
Второе изменение, которое следует отметить, — это новая переменная i, которой на панели Locals присвоено значение 1. Это потому, что цикл for в первой строке кода создал переменную i и присвоил ей значение 1.
Продолжайте нажимать кнопку Step, чтобы пройтись по вашему коду построчно, и посмотрите, что происходит в окне отладчика. Когда вы дойдете до строкового вывода (print(f"i is {i} and j is {j}")), вы сможете увидеть вывод, отображаемый в интерактивном окне, по частям.
Таким образом, вы можете отслеживать растущие значения i и j по мере прохождения цикла for. Вы, наверное, можете себе представить, насколько полезна эта функция при попытке найти источник ошибок в ваших программах. Знание значения каждой переменной в каждой строке кода может помочь вам определить, где что-то идет не так.
Точки останова и кнопка перехода
Часто вы можете знать, что ошибка должна быть в определенном разделе вашего кода, но вы можете не знать, где именно. Вместо того, чтобы нажимать кнопку Step целый день, вы можете установить точку останова, которая сообщает отладчику о необходимости непрерывно запускать весь код, пока он не достигнет точки останова.
Точка остановаએ сообщают отладчику, когда следует приостановить выполнение кода, чтобы вы могли взглянуть на текущее состояние программы. На самом деле они ничего не ломают.
Чтобы установить точку останова, на строке кода в окне редактора, на которой вы хотите сделать паузу, щелкните правой кнопкой мыши и выберите «Set Breakpoint». IDLE выделяет линию желтым цветом, чтобы указать, что ваша точка останова установлена. Чтобы удалить точку останова, щелкните правой кнопкой мыши строку с точкой останова и выберите «Clear Breakpoint».
Продолжайте и нажмите Quit в верхней части окна Debug, чтобы выключить отладчик на данный момент. Это не закроет окно,и вы захотите оставить его открытым, потому что через мгновение вы снова будете им пользоваться.
Установите точку останова в строке кода с помощью оператора print(). Окно редактора теперь должно выглядеть так:

Сохраните и запустите файл. Как и раньше, панель стека в окне отладки указывает, что отладчик запущен и ожидает выполнения строки 1. Щелкните Go и посмотрите, что происходит в окне отладки:

На панели стека теперь отображается следующее сообщение, указывающее, что он ожидает выполнения строки 3:
> '__main__'.(), line 3: print(f"i is {i} and j is {j}")
Если вы посмотрите на панель «Locals», то увидите, что обе переменные i и j имеют значения 1 и 2 соответственно. Нажав Go, вы указали отладчику, что он должен выполнять ваш код непрерывно, пока он не достигнет точки останова или конца программы. Снова нажмите Go. Окно отладки теперь выглядит так:

Вы видите, что изменилось? То же сообщение, что и раньше, отображается на панели стека, указывая, что отладчик ожидает повторного выполнения строки 3. Однако значения переменных i и j теперь равны 2 и 4. Интерактивное окно также отображает результат выполнения строки с помощью print() в первый раз в цикле.
Каждый раз, когда вы нажимаете кнопку Go, отладчик непрерывно запускает код, пока не достигнет следующей точки останова. Поскольку вы устанавливаете точку останова в строке 3, которая находится внутри цикла for, отладчик останавливается на этой строке каждый раз, когда проходит цикл.
Нажмите Go в третий раз. Теперь i и j имеют значения 3 и 6. Как вы думаете, что произойдет, если вы нажмете Go еще раз? Поскольку цикл for повторяется только три раза, когда вы снова нажмете Go, программа завершит работу.
Снова и снова
Кнопка Over работает как комбинация Step и Go — перепрыгиваем через функцию или цикл. Другими словами, если вы не собираетесь по-операторно отслеживать и отлаживать функцию, то можете запустить код без необходимости заходить в неё. Кнопка Over переводит вас прямо к результату выполнения этой функции.
Точно так же, если вы уже находитесь внутри функции или цикла, кнопка Out выполняет оставшийся код внутри функции или тела цикла, а затем приостанавливает работу.
Далее вы увидите код с ошибками и узнаете, как исправить это с помощью IDLE.
Устранение некоторых ошибок
Теперь, когда вы освоились с использованием окна Debug Control, давайте взглянем на программу с ошибками.
Следующий код определяет функцию add_underscores(), которая принимает в качестве аргумента одно строковое объектное слово и возвращает новую строку, содержащую копию слова, в которой каждый символ окружен подчеркиванием. Например, add_underscores("python") должен вернуть _p_y_t_h_o_n_.
Вот код с ошибками:
def add_underscores(word):
new_word = "_"
for i in range(len(word)):
new_word = word[i] + "_"
return new_word
phrase = "hello"
print(add_underscores(phrase))
Введите этот код в окно редактора, затем сохраните файл и нажмите F5, чтобы запустить программу. Ожидаемый результат — _h_e_l_l_o_, но вместо этого все, что вы видите, — это o_ или буква «o», за которой следует одно подчеркивание.
Если вы уже понимаете, в чем проблема с кодом, не исправляйте ее. Наша цель — узнать, как использовать отладчик IDLE для определения проблемы.
Если вы не понимаете, в чем проблема, не волнуйтесь! К концу этого раздела вы найдете его и сможете идентифицировать похожие проблемы в другом коде, с которым вы столкнетесь.
Примечание. Отладка может быть сложной и занимать много времени, а ошибки могут быть незаметными, и их трудно выявить.
Хотя в этом разделе рассматривается относительно простая ошибка, метод, используемый для проверки кода и поиска ошибки, одинаков для более сложных проблем.
Отладка — это решение проблемы, и по мере того, как вы набираетесь опыта, вы будете разрабатывать свои собственные подходы. В этом разделе вы узнаете простой четырехшаговый метод, который поможет вам начать работу:
- Угадайте, в каком разделе кода может содержаться ошибка.
- Установите точку останова и проверьте код, переходя по одной строке за раз через секцию с ошибками, отслеживая важные переменные на этом пути.
- Найдите строку кода, если таковая имеется, с ошибкой и внесите изменения, чтобы решить проблему.
- При необходимости повторите шаги 1–3, пока код не заработает должным образом.
Делай 1. Угадайте, где находится ошибка
Первым шагом является определение участка кода, который, вероятно, содержит ошибку. Возможно, сначала вы не сможете точно определить, где находится ошибка, но обычно вы можете сделать разумное предположение о том, в каком разделе вашего кода есть ошибка.
Обратите внимание, что программа разделена на два отдельных раздела: определение функции (где определено add_underscores()) и основной блок кода, который определяет переменную фразу со значением hello, а затем выводит результат вызова add_underscores(phrase) .
Посмотрите на основной раздел кода:
phrase = "hello" print(add_underscores(phrase))
Как вы думаете, здесь может быть проблема? Не похоже, правда? Все в этих двух строчках кода выглядит хорошо. Итак, проблема должна быть в определении функции:
def add_underscores(word):
new_word = "_"
for i in range(len(word)):
new_word = word[i] + "_"
return new_word
Первая строка кода внутри функции создает переменную new_word со значением "_". У вас все в порядке, поэтому вы можете сделать вывод, что проблема где-то в теле цикла for.
Делай 2. Установите точку останова и проверьте код
Теперь, когда вы определили, где должна быть ошибка, установите точку останова в начале цикла for, чтобы вы могли точно отслеживать, что происходит внутри кода, с помощью окна отладки:

Откройте окно отладки и запустите файл. Выполнение по-прежнему приостанавливается на самой первой строке, которую он видит, то есть в определении функции.
Нажмите Go, чтобы просмотреть код, пока не встретится точка останова. Окно отладки теперь будет выглядеть так:

На этом этапе выполнение кода приостанавливается непосредственно перед входом в цикл for в функции add_underscores(). Обратите внимание, что на панели Locals отображаются две локальные переменные, word и new_word. В настоящее время word имеет значение "hello", а new_word — значение "_", как и ожидалось.
Щелкните Step один раз, чтобы войти в цикл for. Окно отладки изменится и новая переменная i со значением 0 отображается на панели Locals:

i — это счетчик, используемый в цикле for, и вы можете использовать его, чтобы отслеживать, какую итерацию цикла for вы просматриваете в данный момент.
Еще раз нажмите Step. Если вы посмотрите на панель Locals, то увидите, что переменная new_word приняла значение h_:

Это неправильно. Первоначально new_word имело значение "_", а на второй итерации цикла for теперь оно должно иметь значение "_h_". Если вы нажмете Step еще несколько раз, вы увидите, что для new_word устанавливается значение "e_", затем "l_" и т.д.
Делай 3. Определите ошибку и попытайтесь ее исправить
Вывод, который вы можете сделать на этом этапе, заключается в том, что на каждой итерации цикла for new_word перезаписывается следующим символом в строке "hello" и завершающим символом подчеркивания. Поскольку внутри цикла for всего одна строка кода, вы знаете, что проблема должна быть в следующем коде:
new_word = word[i] + "_"
Посмотрите внимательно на строку. Она сообщает Python, что нужно получить следующий символ слова, прикрепить к нему подчеркивание и присвоить эту новую строку переменной new_word. Это именно то поведение, свидетелем которого вы стали, пройдя цикл for!
Для решения проблемы вам нужно указать Python объединить строковое слово [i] + "_" с существующим значением new_word. Нажмите Quit в окне Debug, но пока не закрывайте окно. Откройте окно редактора и измените строку внутри цикла for на следующую:
new_word = new_word + word[i] + "_"
Делай 4. Повторяйте шаги с 1 по 3, пока ошибка не исчезнет
Сохраните новые изменения в программе и снова запустите. В окне отладки нажмите Go, чтобы выполнить код до точки останова.
Примечание. Если вы закрыли отладчик на предыдущем шаге, не нажав кнопку Quit, при повторном открытии окна отладки вы можете увидеть следующую ошибку:
You can only toggle the debugger when idle
(Вы можете переключать отладчик только в режиме ожидания)
По завершении сеанса отладки всегда нажимайте кнопку Go или Quit, а не просто закрывайте отладчик, иначе у вас могут возникнуть проблемы с его повторным открытием.Чтобы избавиться от этой ошибки, вам придется закрыть и снова открыть IDLE.
Программа приостанавливается непосредственно перед входом в цикл for в add_underscores(). Несколько раз нажмите Step и посмотрите, что происходит с переменной new_word на каждой итерации. Успех! Все работает как положено!
Ваша первая попытка исправить ошибку сработала, поэтому вам больше не нужно повторять шаги 1–3. Так будет не всегда. Иногда, прежде чем исправлять ошибку, вам придется повторить этот процесс несколько раз.
Альтернативные способы поиска ошибок
Использование отладчика может быть сложным и трудоемким, но это самый надежный способ найти ошибки в вашем коде. Однако отладчики не всегда доступны. Системы с ограниченными ресурсами, такие как небольшие устройства Интернет вещейએ, часто не имеют встроенных отладчиков.
В подобных ситуациях вы можете использовать отладку печатью, чтобы найти ошибки в вашем коде. Отладка печатью использует print() для отображения текста в консоли, который указывает, где выполняется программа и каково состояние переменных программы в определенных точках кода.
Например, вместо отладки предыдущей программы с помощью окна отладки вы можете добавить следующую строку в конец цикла for в add_underscores():
print(f"i = {i}; new_word = {new_word}")
В этом случае измененный код будет выглядеть так:
def add_underscores(word):
new_word = "_"
for i in range(len(word)):
new_word = word[i] + "_"
print(f"i = {i}; new_word = {new_word}")
return new_word
phrase = "hello"
print(add_underscores(phrase))
Когда вы запускаете файл, интерактивное окно отображает следующий вывод:
i = 0; new_word = h_ i = 1; new_word = e_ i = 2; new_word = l_ i = 3; new_word = l_ i = 4; new_word = o_ o_
Здесь показано, какие значение имеет new_word на каждой итерации цикла for. Последняя строка, содержащая только один знак подчеркивания, является результатом выполнения print(add_underscore(phrase)) в конце программы.
Посмотрев на вышеприведенный вывод, вы можете прийти к тому же выводу, что и при отладке с помощью окна отладки. Проблема в том, что new_word перезаписывается на каждой итерации.
Отладка печатью работает, но имеет несколько недостатков по сравнению с отладкой с помощью отладчика. Во-первых, вы должны запускать всю свою программу каждый раз, когда хотите проверить значения ваших переменных. Это может быть огромной тратой времени по сравнению с использованием точек останова. Вы также должны не забыть удалить эти вызовы функции print() из вашего кода, когда закончите отладку!
Пример цикла в этом разделе может быть хорошим примером для иллюстрации процесса отладки, но это не лучший пример кода Pythonic. Использование индекса i свидетельствует о том, что может быть лучший способ написать цикл. Один из способов улучшить этот цикл — напрямую перебирать символы в слове. Вот один из способов сделать это:
def add_underscores(word):
new_word = "_"
for letter in word:
new_word = new_word + letter + "_"
return new_word
Процесс переписывания существующего кода, чтобы он был более чистым, более легким для чтения и понимания или в большей степени соответствовал стандартам, установленным командой, называется рефакторингએ. Мы не будем обсуждать рефакторингએ в этом уроке, но это важная часть написания кода профессионального качества.
Вот так то! Теперь вы знаете все об отладке с помощью окна Debug IDLE. Вы можете использовать базовые принципы, которые вы использовали здесь, с рядом различных инструментов отладки. Теперь у вас есть все необходимое, чтобы начать отладку кода Python.
В этом уроке вы узнали:
- Как использовать окно управления отладкой IDLE для проверки значений переменных.
- Как вставить точки останова, чтобы лучше понять, как работает ваш код.
- Как использовать кнопки Step, Go, Over и Out для построчного отслеживания ошибок.
Вы также получили некоторую практику отладки неисправной функции, используя процесс из четырёх шагов выявления и удаления ошибок:
- Угадай, где находится ошибка.
- Установите точку останова и проверьте код. Определите ошибку и попытайтесь ее исправить.
- Повторяйте шаги с 1 по 3, пока ошибка не будет исправлена.
- Отладка — это не только наука, но и искусство.
Единственный способ овладеть отладкой — это много практиковаться с ней! Один из способов попрактиковаться — открыть окно Debug Control и использовать его для пошагового выполнения кода, работая над упражнениями и задачами, которые вы найдете в наших Практикумах.
Find & Fix Code Bugs in Python: Debug With IDLE

Уровень сложности
Средний
Время на прочтение
8 мин
Количество просмотров 6.8K

Люди, которые пишут код, часто воспринимают работу с исключениями как необходимое зло. Но освоение системы обработки исключений в Python способно повысить профессиональный уровень программиста, сделать его эффективнее. В этом материале я разберу следующие темы, изучение которых поможет всем желающим раскрыть потенциал Python через разумный подход к обработке исключений:
-
Что такое обработка исключений?
-
Разница между оператором
ifи обработкой исключений. -
Использование разделов
elseиfinallyблокаtry-exceptдля организации правильного обращения с ошибками. -
Определение пользовательских исключений.
-
Рекомендации по обработке исключений.
Что такое обработка исключений?
Обработка исключений — это процесс написания кода для перехвата и обработки ошибок или исключений, которые могут возникать при выполнении программы. Это позволяет разработчикам создавать надёжные программы, которые продолжают работать даже при возникновении неожиданных событий или ошибок. Без системы обработки исключений подобное обычно приводит к фатальным сбоям.
Когда возникают исключения — Python выполняет поиск подходящего обработчика исключений. После этого, если обработчик будет найден, выполняется его код, в котором предпринимаются уместные действия. Это может быть логирование данных, вывод сообщения, попытка восстановить работу программы после возникновения ошибки. В целом можно сказать, что обработка исключения помогает повысить надёжность Python-приложений, улучшает возможности по их поддержке, облегчает их отладку.
Различия между оператором if и обработкой исключений
Главные различия между оператором if и обработкой исключений в Python произрастают из их целей и сценариев использования.
Оператор if — это базовый строительный элемент структурного программирования. Этот оператор проверяет условие и выполняет различные блоки кода, основываясь на том, истинно проверяемое условие или ложно. Вот пример:
temperature = int(input("Please enter temperature in Fahrenheit: "))
if temperature > 100:
print("Hot weather alert! Temperature exceeded 100°F.")
elif temperature >= 70:
print("Warm day ahead, enjoy sunny skies.")
else:
print("Bundle up for chilly temperatures.")Обработка исключений, с другой стороны, играет важную роль в написании надёжных и отказоустойчивых программ. Эта роль раскрывается через работу с неожиданными событиями и ошибками, которые могут возникать во время выполнения программы.
Исключения используются для подачи сигналов о проблемах и для выявления участков кода, которые нуждаются в улучшении, отладке, или в оснащении их дополнительными механизмами для проверки ошибок. Исключения позволяют Python достойно справляться с ситуациями, в которых возникают ошибки. В таких ситуациях исключения дают возможность продолжать выполнение скрипта вместо того, чтобы резко его останавливать.
Рассмотрим следующий код, демонстрирующий пример того, как можно реализовать обработку исключений и улучшить ситуацию с потенциальными отказами, связанными с делением на ноль:
# Определение функции, которая пытается поделить число на ноль
def divide(x, y):
result = x / y
return result
# Вызов функции divide с передачей ей x=5 и y=0
result = divide(5, 0)
print(f"Result of dividing {x} by {y}: {result}")Вывод:
Traceback (most recent call last):
File "<stdin>", line 8, in <module>
ZeroDivisionError: division by zero attemptedПосле того, как было сгенерировано исключение, программа, не дойдя до инструкции print, сразу же прекращает выполняться.
Вышеописанное исключение можно обработать, обернув вызов функции divide в блок try-except:
# Определение функции, которая пытается поделить число на ноль
def divide(x, y):
result = x / y
return result
# Вызов функции divide с передачей ей x=5 и y=0
try:
result = divide(5, 0)
print(f"Result of dividing {x} by {y}: {result}")
except ZeroDivisionError:
print("Cannot divide by zero.")Вывод:
Cannot divide by zero.Сделав это, мы аккуратно обработали исключение ZeroDivisionError, предотвратили аварийное завершение остального кода из-за необработанного исключения.
Подробности о других встроенных Python-исключениях можно найти здесь.
Использование разделов else и finally блока try-except для организации правильного обращения с ошибками
При работе с исключениями в Python рекомендуется включать в состав блоков try-except и раздел else, и раздел finally. Раздел else позволяет программисту настроить действия, производимые в том случае, если при выполнении кода, который защищают от проблем, не было вызвано исключений. А раздел finally позволяет обеспечить обязательное выполнение неких заключительных операций, вроде освобождения ресурсов, независимо от факта возникновения исключений (вот и вот — полезные материалы об этом).
Например — рассмотрим ситуацию, когда нужно прочитать данные из файла и выполнить какие-то действия с этими данными. Если при чтении файла возникнет исключение — программист может решить, что надо залогировать ошибку и остановить выполнение дальнейших операций. Но в любом случае файл нужно правильно закрыть.
Использование разделов else и finally позволяет поступить именно так — обработать данные обычным образом в том случае, если исключений не возникло, либо обработать любые исключения, но, как бы ни развивались события, в итоге закрыть файл. Без этих разделов код страдал бы уязвимостями в виде утечки ресурсов или неполной обработки ошибок. В результате оказывается, что else и finally играют важнейшую роль в создании устойчивых к ошибкам и надёжных программ.
try:
# Открытие файла в режиме чтения
file = open("file.txt", "r")
print("Successful opened the file")
except FileNotFoundError:
# Обработка ошибки, возникающей в том случае, если файл не найден
print("File Not Found Error: No such file or directory")
exit()
except PermissionError:
# Обработка ошибок, связанных с разрешением на доступ к файлу
print("Permission Denied Error: Access is denied")
else:
# Всё хорошо - сделать что-то с данными, прочитанными из файла
content = file.read().decode('utf-8')
processed_data = process_content(content)
# Прибираемся после себя даже в том случае, если выше возникло исключение
finally:
file.close()В этом примере мы сначала пытаемся открыть файл file.txt для чтения (в подобной ситуации можно использовать выражение with, которое гарантирует правильное автоматическое закрытие объекта файла после завершения работы). Если в процессе выполнения операций файлового ввода/вывода возникают ошибки FileNotFoundError или PermissionError — выполняются соответствующие разделы except. Здесь, ради простоты, мы лишь выводим на экран сообщения об ошибках и выходим из программы в том случае, если файл не найден.
В противном случае, если в блоке try исключений не возникло, мы продолжаем работу, обрабатывая содержимое файла в ветви else. И наконец — выполняется «уборка» — файл закрывается независимо от возникновения исключения. Это обеспечивает блок finally (подробности смотрите здесь).
Применяя структурированный подход к обработке исключений, напоминающий вышеописанный, можно поддерживать свой код в хорошо организованном состоянии и обеспечивать его читабельность. При этом код будет рассчитан на борьбу с потенциальными ошибками, которые могут возникнуть при взаимодействии с внешними системами или входными данными.
Определение пользовательских исключений
В Python можно определять пользовательские исключения путём создания подклассов встроенного класса Exception или любых других классов, являющихся прямыми наследниками Exception.
Для того чтобы определить собственное исключение — нужно создать новый класс, являющийся наследником одного из подходящих классов, и оснастить этот класс атрибутами, соответствующими нуждам программиста. Затем новый класс можно использовать в собственном коде, работая с ним так же, как работают со встроенными классами исключений.
Вот пример определения пользовательского исключения, названного InvalidEmailAddress:
class InvalidEmailAddress(ValueError):
def __init__(self, message):
super().__init__(message)
self.msgfmt = messageЭто исключение является наследником ValueError. Его конструктор принимает необязательный аргумент message (по умолчанию он устанавливается в значение invalid email address).
Вызвать это исключение можно в том случае, если в программе встретился адрес электронной почты, имеющий некорректный формат:
def send_email(address):
if isinstance(address, str) == False:
raise InvalidEmailAddress("Invalid email address")
# Отправка электронного письмаТеперь, если функции send_email() будет передана строка, содержащая неправильно оформленный адрес, то, вместо сообщения стандартной ошибки TypeError, будет выдано настроенное заранее сообщение об ошибке, которое чётко указывает на возникшую проблему. Например, это может выглядеть так:
>>> send_email(None)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/path/to/project/main.py", line 8, in send_email
raise InvalidEmailAddress("Invalid email address")
InvalidEmailAddress: Invalid email addressРекомендации по обработке исключений
Вот несколько рекомендаций, относящихся к обработке ошибок в Python:
-
Проектируйте код в расчёте на возможное возникновение ошибок. Заранее планируйте устройство кода с учётом возможных сбоев и проектируйте программы так, чтобы они могли бы достойно обрабатывать эти сбои. Это означает — предугадывать возможные пограничные случаи и реализовывать подходящие обработчики ошибок.
-
Используйте содержательные сообщения об ошибках. Сделайте так, чтобы программа выводила бы, на экран, или в файл журнала, подробные сообщения об ошибках, которые помогут пользователям понять — что и почему пошло не так. Старайтесь не применять обобщённые сообщения об ошибках, наподобие
Error occurredилиSomething bad happened. Вместо этого подумайте об удобстве пользователя и покажите сообщение, в котором будет дан совет по решению проблемы или будет приведена ссылка на документацию. Постарайтесь соблюсти баланс между выводом подробных сообщений и перегрузкой пользовательского интерфейса избыточными данными. -
Минимизируйте побочные эффекты. Постарайтесь свести к минимуму последствия сбойных операций, изолируя проблемные разделы кода посредством конструкции
try-finallyилиtryс использованиемwith. Сделайте так, чтобы после выполнения кода, было ли оно удачным или нет, обязательно выполнялись бы «очистительные» операции. -
Тщательно тестируйте код. Обеспечьте корректное поведение обработчиков ошибок в различных сценариях использования программы, подвергнув код всеобъемлющему тестированию.
-
Регулярно выполняйте рефакторинг кода. Выполняйте рефакторинг фрагментов кода, подверженных ошибкам, чтобы улучшить их надёжность и производительность. Постарайтесь, чтобы ваша кодовая база была бы устроена по модульному принципу, чтобы её отдельные части слабо зависели бы друг от друга. Это позволяет независимым частям код самостоятельно эволюционировать, не оказывая негативного воздействия на другие его части.
-
Логируйте важные события. Следите за интересными событиями своего приложения, записывая сведения о них в файл журнала или выводя в консоль. Это поможет вам выявлять проблемы на ранних стадиях их возникновения, не тратя время на длительный анализ большого количества неструктурированных логов.
Итоги
Написание кода обработки ошибок — это неотъемлемая часть индустрии разработки ПО, и, в частности — разработки на Python. Это позволяет разработчикам создавать более надёжные и стабильные программы. Следуя индустриальным стандартам и рекомендациям по обработке исключений, разработчик может сократить время, необходимое на отладку кода, способен обеспечить написание качественных программ и сделать так, чтобы пользователям было бы приятно работать с этими программами.
О, а приходите к нам работать? 🤗 💰
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
Присоединяйтесь к нашей команде.
() translation by (you can also view the original English article)
В этом уроке вы узнаете, как обрабатывать ошибки в Python со всех возможных точек зрения. Обработка ошибок является важнейшим аспектом проектирования, и она проходит от самых низких уровней (иногда это аппаратное обеспечение) через весь путь к конечным пользователям. Если у вас нет продуманной стратегии в этой области, ваша система будет ненадежной, а пользовательский опыт будет плохим, и вы будете иметь много проблем с отладкой и устранением неполадок.
Ключ к успеху, зная обо всех связанных сторонах вопроса, рассматривать их целостно и сформировать решение, которое учитывает каждый аспект.
Коды статуса против Исключений
Существует две основных модели обработок ошибок: Коды статуса и Исключения. Коды статуса могут использоваться в любом языке программирования. Исключения требуют поддержки языка/среды исполнения.
Python поддерживает исключения. Python и его стандартная библиотека использует исключения свободно для того, чтобы сообщить о различных состояниях, таких как IO ошибки, ошибки деления на ноль, ошибки пределов индексации, а также некоторые некритичные ситуаций, такие как конец итерации (хотя обычно эти ошибки скрыты). Большинство библиотек придерживаются этого принципа и вызывают исключения.
Это означает, что ваш код будет обрабатывать исключения, возникающие в Python или в библиотеке, во всяком случае, так что вы можете также вызывать исключения напрямую из вашего кода, когда это необходимо и не полагаться на коды статуса.
Небольшой пример
Прежде чем погрузиться в святая святых лучших практик обработки исключений и ошибок Python, давайте рассмотрим некоторые исключения в действии:
1 |
def f(): |
2 |
|
3 |
return 4 / 0 |
4 |
|
5 |
|
6 |
|
7 |
def g(): |
8 |
|
9 |
raise Exception("Don't call us. We'll call you") |
10 |
|
11 |
|
12 |
|
13 |
def h(): |
14 |
|
15 |
try: |
16 |
|
17 |
f() |
18 |
|
19 |
except Exception as e: |
20 |
|
21 |
print(e) |
22 |
|
23 |
try: |
24 |
|
25 |
g() |
26 |
|
27 |
except Exception as e: |
28 |
|
29 |
print(e) |
При вызове h(), мы получаем на выходе:
1 |
h()
|
2 |
|
3 |
division by zero |
4 |
|
5 |
Don't call us. We'll call you
|
Исключения Python
Python исключениями являются объекты организованные в классовой иерархии.
Вот иерархия целиком:
1 |
BaseException |
2 |
|
3 |
+-- SystemExit |
4 |
|
5 |
+-- KeyboardInterrupt |
6 |
|
7 |
+-- GeneratorExit |
8 |
|
9 |
+-- Exception |
10 |
|
11 |
+-- StopIteration |
12 |
|
13 |
+-- StandardError |
14 |
|
15 |
| +-- BufferError |
16 |
|
17 |
| +-- ArithmeticError |
18 |
|
19 |
| | +-- FloatingPointError |
20 |
|
21 |
| | +-- OverflowError |
22 |
|
23 |
| | +-- ZeroDivisionError |
24 |
|
25 |
| +-- AssertionError |
26 |
|
27 |
| +-- AttributeError |
28 |
|
29 |
| +-- EnvironmentError |
30 |
|
31 |
| | +-- IOError |
32 |
|
33 |
| | +-- OSError |
34 |
|
35 |
| | +-- WindowsError (Windows) |
36 |
|
37 |
| | +-- VMSError (VMS) |
38 |
|
39 |
| +-- EOFError |
40 |
|
41 |
| +-- ImportError |
42 |
|
43 |
| +-- LookupError |
44 |
|
45 |
| | +-- IndexError |
46 |
|
47 |
| | +-- KeyError |
48 |
|
49 |
| +-- MemoryError |
50 |
|
51 |
| +-- NameError |
52 |
|
53 |
| | +-- UnboundLocalError |
54 |
|
55 |
| +-- ReferenceError |
56 |
|
57 |
| +-- RuntimeError |
58 |
|
59 |
| | +-- NotImplementedError |
60 |
|
61 |
| +-- SyntaxError |
62 |
|
63 |
| | +-- IndentationError |
64 |
|
65 |
| | +-- TabError |
66 |
|
67 |
| +-- SystemError |
68 |
|
69 |
| +-- TypeError |
70 |
|
71 |
| +-- ValueError |
72 |
|
73 |
| +-- UnicodeError |
74 |
|
75 |
| +-- UnicodeDecodeError |
76 |
|
77 |
| +-- UnicodeEncodeError |
78 |
|
79 |
| +-- UnicodeTranslateError |
80 |
|
81 |
+-- Warning |
82 |
|
83 |
+-- DeprecationWarning |
84 |
|
85 |
+-- PendingDeprecationWarning |
86 |
|
87 |
+-- RuntimeWarning |
88 |
|
89 |
+-- SyntaxWarning |
90 |
|
91 |
+-- UserWarning |
92 |
|
93 |
+-- FutureWarning |
94 |
|
95 |
+-- ImportWarning |
96 |
|
97 |
+-- UnicodeWarning |
98 |
|
99 |
+-- BytesWarning |
100 |
|
Существует несколько специальных исключений, которые являются производными от BaseException, такие как SystemExit, KeyboardInterrupt и GeneratorExit. Еще есть класс Exception, который является базовым классом для StopIteration, StandardError и Warning. Все стандартные ошибки являются производными от StandardError.
Когда вы получаете исключение или функция, которую вы выполнили вызывает исключение, обычный порядок кода завершается и исключение начинает распространятся вверх по стеку вызовов до тех пор, пока не встречает обработчик соответствующих исключений. Если обработчик не доступен, процесс (или, точнее, текущий поток) будет прекращен с сообщением о необработанном исключении.
Вызов исключений
Вызов исключений очень прост. Вы просто используете ключевое слово raise чтобы вызвать объект, который является подклассом Exception. Это может быть экземпляр Exception, одно из стандартных исключений (напр., RuntimeError), или подкласс Exception, который вы получили. Вот небольшой фрагмент кода, который демонстрирует эти случаи:
1 |
# Raise an instance of the Exception class itself
|
2 |
|
3 |
raise Exception('Ummm... something is wrong') |
4 |
|
5 |
|
6 |
|
7 |
# Raise an instance of the RuntimeError class
|
8 |
|
9 |
raise RuntimeError('Ummm... something is wrong') |
10 |
|
11 |
|
12 |
|
13 |
# Raise a custom subclass of Exception that keeps the timestamp the exception was created
|
14 |
|
15 |
from datetime import datetime |
16 |
|
17 |
|
18 |
|
19 |
class SuperError(Exception): |
20 |
|
21 |
def __init__(self, message): |
22 |
|
23 |
Exception.__init__(message) |
24 |
|
25 |
self.when = datetime.now() |
26 |
|
27 |
|
28 |
|
29 |
|
30 |
|
31 |
raise SuperError('Ummm... something is wrong') |
Перехват исключений
Вы получили исключение, с условием except, как вы видели в примере. Когда вы получили исключение, у вас есть три варианта:
- Пропустить (обработать его и продолжить работу).
- Сделать что-то вроде записи в журнал, но получить повторно то же самое исключение, чтобы продолжить его обработку на более высоком уровне.
- Вызвать другое исключение вместо текущего.
Пропустить исключение
Если вы знаете, как его обработать и как его полностью восстановить, можно пропустить исключение.
Например, если вы получаете входящий файл, который может быть в различных форматах (JSON, YAML), вы можете попробовать проанализировать его с помощью различных средств. Если анализатор JSON создаёт исключение, которое показывает, что файл имеет некорректный формат JSON, вы пропускаете его и пробуете проанализировать через парсер YAML. Если парсер YAML также не справляется с задачей, тогда вы даёте исключению перейти на следующий уровень.
1 |
import json |
2 |
|
3 |
import yaml |
4 |
|
5 |
|
6 |
|
7 |
def parse_file(filename): |
8 |
|
9 |
try: |
10 |
|
11 |
return json.load(open(filename)) |
12 |
|
13 |
except json.JSONDecodeError |
14 |
|
15 |
return yaml.load(open(filename)) |
Обратите внимание, что другие исключения (например, file not found или no read permissions) будут переходить на следующий уровень и не будут обработаны конкретным исключением. Это хорошая тактика в том случае, если вы хотите использовать YAML парсер, когда анализ с помощью JSON парсера не удался.
Если вы хотите обрабатывать все исключения, тогда используйте except Exception. Например:
1 |
def print_exception_type(func, *args, **kwargs): |
2 |
|
3 |
try: |
4 |
|
5 |
return func(*args, **kwargs) |
6 |
|
7 |
except Exception as e: |
8 |
|
9 |
print type(e) |
Обратите внимание, что, добавляя as e, вы привязываете объект к имении e в вашем исключении.
Перезапуск исключения
Чтобы перезапустить исключение, просто напишите raise без аргументов внутри обработчика. Это позволит выполнить некоторую локальную обработку, но также пропустит исключение для обработки на верхние уровни. Здесь, функция invoke_function() выводит тип исключения в консоль и затем повторно вызывает его.
1 |
def invoke_function(func, *args, **kwargs): |
2 |
|
3 |
try: |
4 |
|
5 |
return func(*args, **kwargs) |
6 |
|
7 |
except Exception as e: |
8 |
|
9 |
print type(e) |
10 |
|
11 |
raise
|
Вызов Различных Исключений
Есть несколько случаев, когда вы хотели бы вызвать другое исключение. Иногда вы хотите сгруппировать несколько различных низкоуровневых исключений в одну категорию, которая равномерно обрабатывается на более высоком уровне кода. В других случаях вам нужно преобразовать исключение на уровне пользователя и предоставить контекст конкретного приложения.
Финальное утверждение
Иногда вы хотите убедиться, что код очистки выполняется, даже если где-то по пути возникло исключение. Например, у вас может быть подключение к базе данных, которое требуется закрыть, как только вы закончите. Это неправильный способ сделать это:
1 |
def fetch_some_data(): |
2 |
|
3 |
db = open_db_connection() |
4 |
|
5 |
query(db) |
6 |
|
7 |
close_db_Connection(db) |
Если функция query() вызывает исключение, то вызов close_db_connection() никогда не будет выполнен и подключение останется открытым. Утверждение finally всегда выполняется после всех попыток обработчика. Вот как сделать это правильно:
1 |
def fetch_some_data(): |
2 |
|
3 |
db = None |
4 |
|
5 |
try: |
6 |
|
7 |
db = open_db_connection() |
8 |
|
9 |
query(db) |
10 |
|
11 |
finally: |
12 |
|
13 |
if db is not None: |
14 |
|
15 |
close_db_connection(db) |
Вызов open_db_connection() может не вернуть подключение или вызвать исключение. В этом случае нет необходимости закрывать соединение.
При использовании finally, вы должны быть осторожны, чтобы не вызвать другие исключения, потому, что они скроют исходное.
Диспетчеров Контекста
Контекстные менеджеры обеспечивают еще один механизм обработки ресурсов, таких как файлы или подключения к БД, которые выполняются автоматически, даже если исключения были вызваны. Вместо блоков try-finally, можно использовать определение with. Вот пример с файлом:
1 |
def process_file(filename): |
2 |
|
3 |
with open(filename) as f: |
4 |
|
5 |
process(f.read()) |
Теперь, даже если process() вызывает исключение, этот файл будет закрыт правильно сразу же когда область видимости блока with завершена, независимо от того, было исключение обработано или нет.
Ведение журнала
Ведение журнала обычно требуется в нетривиальных, масштабных системах. Это особенно полезно в веб-приложениях, где вы можете исправить все исключения универсальным способом: Просто записать в журнал исключение и вернуть сообщение об ошибке.
При записи полезно учитывать тип исключения, сообщение и маршрут ошибки. Вся эта информация доступна через объект sys.exc_info, но если вы используете logger.exception() метод в обработчике исключений, Python извлечёт всю необходимую для вас информацию.
Это лучший пример, которую я рекомендую:
1 |
import logging |
2 |
|
3 |
logger = logging.getLogger() |
4 |
|
5 |
|
6 |
|
7 |
def f(): |
8 |
|
9 |
try: |
10 |
|
11 |
flaky_func() |
12 |
|
13 |
except Exception: |
14 |
|
15 |
logger.exception() |
16 |
|
17 |
raise
|
Если вы будете придерживаться этому шаблону,тогда (предполагаю, что вы настроили запись в журнал правильно), независимо от того, что происходит, вы будете иметь очень понятные записи в ваших журналах о что пошло не так, и будете иметь возможность исправить проблему.
Если вы повторно вызываете исключение, убедитесь что вы не записывайте в журнал повторно одну и туже ошибку на разных уровнях. Эту будет бесполезный мусор. который может запутать вас и заставить думать что произошло несколько ошибок, хотя на самом деле одна ошибка была зарегистрирована несколько раз.
Самый простой способ сделать это заключается в том, чтобы позволить всем исключениям переходить дальше (если они могут быть обработаны и пропущены ранее), и затем выполнить запись в журнал на самом верхнем уровне системы/приложения.
Sentry
Ведение журнала это возможность. Наиболее распространенные реализации которой, является использование журнала. Но, для крупномасштабных распределенных систем с сотнями, тысячами или более серверов, это не всегда лучшее решение.
Для отслеживания исключений во всей инфраструктуре, такой сервис как sentry очень полезен. Он централизует все сообщения об исключениях, и в дополнении к маршруту ошибки он добавляет состояние каждого состояния стека (значение переменных в то время, когда было вызвано исключение). Он также предоставляет приятный интерфейс с панелью мониторинга, отчетами и способами получать сообщения по нескольким проектам сразу. Он предоставляется с открытым исходным кодом, так что вы можете запустить свой собственный сервер или оформить подписку на предустановленную версию.
Работа с временной ошибкой
Некоторые ошибки являются временными, в частности при работе с распределенными системами. Система, которая начинает ругаться при первом признаке ошибки не очень полезна.
Если ваш код получает доступ к удаленной системе, которая не отвечает, традиционное решение, это таймауты, но иногда случается не каждая система разработана с таймаутами. Таймауты, не всегда удобны для калибровки при изменении условий.
Другой подход заключается в том, чтобы быстро получить ошибку и затем повторить попытку. Преимущество в том, что если цель реагирует быстро, то вам не придется тратить много времени находясь в режиме ожидания и можно реагировать незамедлительно. Но если это сделать не удалось, вы можете повторять запрос несколько раз до тех пор, пока вы не решите, что ресурс действительно недоступен и вызовете исключение. В следующем разделе я расскажу об оформителе, который может сделать это для вас.
Полезные оформители
Два оформителя которые могут помочь в обработке ошибок, это @log_error, который записывает исключение и затем вновь вызывает его и @retry оформитель, который будет повторять вызов функции несколько раз.
Журнал ошибок
Вот пример простой реализации. Оформитель исключает объект logger. Когда он оформляет функцию и функция вызвана, он обработает вызов в блоке try-except, и если там было исключение сделает запись в журнал и наконец повторно вызовет исключение.
1 |
def log_error(logger) |
2 |
|
3 |
def decorated(f): |
4 |
|
5 |
@functools.wraps(f) |
6 |
|
7 |
def wrapped(*args, **kwargs): |
8 |
|
9 |
try: |
10 |
|
11 |
return f(*args, **kwargs) |
12 |
|
13 |
except Exception as e: |
14 |
|
15 |
if logger: |
16 |
|
17 |
logger.exception(e) |
18 |
|
19 |
raise
|
20 |
|
21 |
return wrapped |
22 |
|
23 |
return decorated |
Вот пример, как его использовать:
1 |
import logging |
2 |
|
3 |
logger = logging.getLogger() |
4 |
|
5 |
|
6 |
|
7 |
@log_error(logger) |
8 |
|
9 |
def f(): |
10 |
|
11 |
raise Exception('I am exceptional') |
Retrier
Здесь, очень хорошая реализация @retry оформителя.
1 |
import time |
2 |
|
3 |
import math |
4 |
|
5 |
|
6 |
|
7 |
# Retry decorator with exponential backoff
|
8 |
|
9 |
def retry(tries, delay=3, backoff=2): |
10 |
|
11 |
'''Retries a function or method until it returns True.
|
12 |
|
13 |
|
14 |
|
15 |
delay sets the initial delay in seconds, and backoff sets the factor by which
|
16 |
|
17 |
the delay should lengthen after each failure. backoff must be greater than 1,
|
18 |
|
19 |
or else it isn't really a backoff. tries must be at least 0, and delay
|
20 |
|
21 |
greater than 0.'''
|
22 |
|
23 |
|
24 |
|
25 |
if backoff <= 1: |
26 |
|
27 |
raise ValueError("backoff must be greater than 1") |
28 |
|
29 |
|
30 |
|
31 |
tries = math.floor(tries) |
32 |
|
33 |
if tries < 0: |
34 |
|
35 |
raise ValueError("tries must be 0 or greater") |
36 |
|
37 |
|
38 |
|
39 |
if delay <= 0: |
40 |
|
41 |
raise ValueError("delay must be greater than 0") |
42 |
|
43 |
|
44 |
|
45 |
def deco_retry(f): |
46 |
|
47 |
def f_retry(*args, **kwargs): |
48 |
|
49 |
mtries, mdelay = tries, delay # make mutable |
50 |
|
51 |
|
52 |
|
53 |
rv = f(*args, **kwargs) # first attempt |
54 |
|
55 |
while mtries > 0: |
56 |
|
57 |
if rv is True: # Done on success |
58 |
|
59 |
return True |
60 |
|
61 |
|
62 |
|
63 |
mtries -= 1 # consume an attempt |
64 |
|
65 |
time.sleep(mdelay) # wait... |
66 |
|
67 |
mdelay *= backoff # make future wait longer |
68 |
|
69 |
|
70 |
|
71 |
rv = f(*args, **kwargs) # Try again |
72 |
|
73 |
|
74 |
|
75 |
return False # Ran out of tries :-( |
76 |
|
77 |
|
78 |
|
79 |
return f_retry # true decorator -> decorated function |
80 |
|
81 |
return deco_retry # @retry(arg[, ...]) -> true decorator |
Заключение
Обработка ошибок имеет решающее значение для пользователей и разработчиков. Python предоставляет отличную поддержку на уровне языка и стандартной библиотеки для обработки ошибок на основе исключений. Следуя рекомендациям старательно, вы можете преодолеть этот аспект, которым так часто пренебрегают.