
Искать ошибки в программах — непростая задача. Здесь нет никаких готовых методик или рецептов успеха. Можно даже сказать, что это — искусство. Тем не менее есть общие советы, которые помогут вам при поиске. В статье описаны основные шаги, которые стоит предпринять, если ваша программа работает некорректно.
Шаг 1: Занесите ошибку в трекер
После выполнения всех описанных ниже шагов может так случиться, что вы будете рвать на себе волосы от безысходности, все еще сидя на работе, когда поймете, что:
- Вы забыли какую-то важную деталь об ошибке, например, в чем она заключалась.
- Вы могли делегировать ее кому-то более опытному.
Трекер поможет вам не потерять нить размышлений и о текущей проблеме, и о той, которую вы временно отложили. А если вы работаете в команде, это поможет делегировать исправление коллеге и держать все обсуждение в одном месте.
Вы должны записать в трекер следующую информацию:
- Что делал пользователь.
- Что он ожидал увидеть.
- Что случилось на самом деле.
Это должно подсказать, как воспроизвести ошибку. Если вы не сможете воспроизвести ее в любое время, ваши шансы исправить ошибку стремятся к нулю.
Шаг 2: Поищите сообщение об ошибке в сети
Если у вас есть сообщение об ошибке, то вам повезло. Или оно будет достаточно информативным, чтобы вы поняли, где и в чем заключается ошибка, или у вас будет готовый запрос для поиска в сети. Не повезло? Тогда переходите к следующему шагу.
Шаг 3: Найдите строку, в которой проявляется ошибка
Если ошибка вызывает падение программы, попробуйте запустить её в IDE под отладчиком и посмотрите, на какой строчке кода она остановится. Совершенно необязательно, что ошибка будет именно в этой строке (см. следующий шаг), но, по крайней мере, это может дать вам информацию о природе бага.
Шаг 4: Найдите точную строку, в которой появилась ошибка
Как только вы найдете строку, в которой проявляется ошибка, вы можете пройти назад по коду, чтобы найти, где она содержится. Иногда это может быть одна и та же строка. Но чаще всего вы обнаружите, что строка, на которой упала программа, ни при чем, а причина ошибки — в неправильных данных, которые появились ранее.
Если вы отслеживаете выполнение программы в отладчике, то вы можете пройтись назад по стектрейсу, чтобы найти ошибку. Если вы находитесь внутри функции, вызванной внутри другой функции, вызванной внутри другой функции, то стектрейс покажет список функций до самой точки входа в программу (функции main()). Если ошибка случилась где-то в подключаемой библиотеке, предположите, что ошибка все-таки в вашей программе — это случается гораздо чаще. Найдите по стектрейсу, откуда в вашем коде вызывается библиотечная функция, и продолжайте искать.
Шаг 5: Выясните природу ошибки
Ошибки могут проявлять себя по-разному, но большинство из них можно отнести к той или иной категории. Вот наиболее частые.
- Ошибка на единицу
Вы начали циклforс единицы вместо нуля или наоборот. Или, например, подумали, что метод.count()или.length()вернул индекс последнего элемента. Проверьте документацию к языку, чтобы убедиться, что нумерация массивов начинается с нуля или с единицы. Эта ошибка иногда проявляется в виде исключенияIndex out of range. - Состояние гонки
Ваш процесс или поток пытается использовать результат выполнения дочернего до того, как тот завершил свою работу. Ищите использованиеsleep()в коде. Возможно, на мощной машине дочерний поток выполняется за миллисекунду, а на менее производительной системе происходят задержки. Используйте правильные способы синхронизации многопоточного кода: мьютексы, семафоры, события и т. д. - Неправильные настройки или константы
Проверьте ваши конфигурационные файлы и константы. Я однажды потратил ужасные 16 часов, пытаясь понять, почему корзина на сайте с покупками виснет на стадии отправки заказа. Причина оказалась в неправильном значении в/etc/hosts, которое не позволяло приложению найти ip-адрес почтового сервера, что вызывало бесконечный цикл в попытке отправить счет заказчику. - Неожиданный null
Бьюсь об заклад, вы не раз получали ошибку с неинициализированной переменной. Убедитесь, что вы проверяете ссылки наnull, особенно при обращении к свойствам по цепочке. Также проверьте случаи, когда возвращаемое из базы данных значениеNULLпредставлено особым типом. - Некорректные входные данные
Вы проверяете вводимые данные? Вы точно не пытаетесь провести арифметические операции с введенными пользователем строками? - Присваивание вместо сравнения
Убедитесь, что вы не написали=вместо==, особенно в C-подобных языках. - Ошибка округления
Это случается, когда вы используете целое вместоDecimal, илиfloatдля денежных сумм, или слишком короткое целое (например, пытаетесь записать число большее, чем 2147483647, в 32-битное целое). Кроме того, может случиться так, что ошибка округления проявляется не сразу, а накапливается со временем (т. н. Эффект бабочки). - Переполнение буфера и выход за пределы массива
Проблема номер один в компьютерной безопасности. Вы выделяете память меньшего объема, чем записываемые туда данные. Или пытаетесь обратиться к элементу за пределами массива. - Программисты не умеют считать
Вы используете некорректную формулу. Проверьте, что вы не используете целочисленное деление вместо взятия остатка, или знаете, как перевести рациональную дробь в десятичную и т. д. - Конкатенация строки и числа
Вы ожидаете конкатенации двух строк, но одно из значений — число, и компилятор пытается произвести арифметические вычисления. Попробуйте явно приводить каждое значение к строке. - 33 символа в varchar(32)
Проверяйте данные, передаваемые вINSERT, на совпадение типов. Некоторые БД выбрасывают исключения (как и должны делать), некоторые просто обрезают строку (как MySQL). Недавно я столкнулся с такой ошибкой: программист забыл убрать кавычки из строки перед вставкой в базу данных, и длина строки превысила допустимую как раз на два символа. На поиск бага ушло много времени, потому что заметить две маленькие кавычки было сложно. - Некорректное состояние
Вы пытаетесь выполнить запрос при закрытом соединении или пытаетесь вставить запись в таблицу прежде, чем обновили таблицы, от которых она зависит. - Особенности вашей системы, которых нет у пользователя
Например: в тестовой БД между ID заказа и адресом отношение 1:1, и вы программировали, исходя из этого предположения. Но в работе выясняется, что заказы могут отправляться на один и тот же адрес, и, таким образом, у вас отношение 1:многим.
Если ваша ошибка не похожа на описанные выше, или вы не можете найти строку, в которой она появилась, переходите к следующему шагу.
Шаг 6: Метод исключения
Если вы не можете найти строку с ошибкой, попробуйте или отключать (комментировать) блоки кода до тех пор, пока ошибка не пропадет, или, используя фреймворк для юнит-тестов, изолируйте отдельные методы и вызывайте их с теми же параметрами, что и в реальном коде.
Попробуйте отключать компоненты системы один за другим, пока не найдете минимальную конфигурацию, которая будет работать. Затем подключайте их обратно по одному, пока ошибка не вернется. Таким образом вы вернетесь на шаг 3.
Шаг 7: Логгируйте все подряд и анализируйте журнал
Пройдитесь по каждому модулю или компоненту и добавьте больше сообщений. Начинайте постепенно, по одному модулю. Анализируйте лог до тех пор, пока не проявится неисправность. Если этого не случилось, добавьте еще сообщений.
Ваша задача состоит в том, чтобы вернуться к шагу 3, обнаружив, где проявляется ошибка. Также это именно тот случай, когда стоит использовать сторонние библиотеки для более тщательного логгирования.
Шаг 8: Исключите влияние железа или платформы
Замените оперативную память, жесткие диски, поменяйте сервер или рабочую станцию. Установите обновления, удалите обновления. Если ошибка пропадет, то причиной было железо, ОС или среда. Вы можете по желанию попробовать этот шаг раньше, так как неполадки в железе часто маскируют ошибки в ПО.
Если ваша программа работает по сети, проверьте свитч, замените кабель или запустите программу в другой сети.
Ради интереса, переключите кабель питания в другую розетку или к другому ИБП. Безумно? Почему бы не попробовать?
Если у вас возникает одна и та же ошибка вне зависимости от среды, то она в вашем коде.
Шаг 9: Обратите внимание на совпадения
- Ошибка появляется всегда в одно и то же время? Проверьте задачи, выполняющиеся по расписанию.
- Ошибка всегда проявляется вместе с чем-то еще, насколько абсурдной ни была бы эта связь? Обращайте внимание на каждую деталь. На каждую. Например, проявляется ли ошибка, когда включен кондиционер? Возможно, из-за этого падает напряжение в сети, что вызывает странные эффекты в железе.
- Есть ли что-то общее у пользователей программы, даже не связанное с ПО? Например, географическое положение (так был найден легендарный баг с письмом за 500 миль).
- Ошибка проявляется, когда другой процесс забирает достаточно большое количество памяти или ресурсов процессора? (Я однажды нашел в этом причину раздражающей проблемы «no trusted connection» с SQL-сервером).
Шаг 10: Обратитесь в техподдержку
Наконец, пора попросить помощи у того, кто знает больше, чем вы. Для этого у вас должно быть хотя бы примерное понимание того, где находится ошибка — в железе, базе данных, компиляторе. Прежде чем писать письмо разработчикам, попробуйте задать вопрос на профильном форуме.
Ошибки есть в операционных системах, компиляторах, фреймворках и библиотеках, и ваша программа может быть действительно корректна. Но шансы привлечь внимание разработчика к этим ошибкам невелики, если вы не сможете предоставить подробный алгоритм их воспроизведения. Дружелюбный разработчик может помочь вам в этом, но чаще всего, если проблему сложно воспроизвести вас просто проигнорируют. К сожалению, это значит, что нужно приложить больше усилий при составлении багрепорта.
Полезные советы (когда ничего не помогает)
- Позовите кого-нибудь еще.
Попросите коллегу поискать ошибку вместе с вами. Возможно, он заметит что-то, что вы упустили. Это можно сделать на любом этапе. - Внимательно просмотрите код.
Я часто нахожу ошибку, просто спокойно просматривая код с начала и прокручивая его в голове. - Рассмотрите случаи, когда код работает, и сравните их с неработающими.
Недавно я обнаружил ошибку, заключавшуюся в том, что когда вводимые данные в XML-формате содержали строкуxsi:type='xs:string', все ломалось, но если этой строки не было, все работало корректно. Оказалось, что дополнительный атрибут ломал механизм десериализации. - Идите спать.
Не бойтесь идти домой до того, как исправите ошибку. Ваши способности обратно пропорциональны вашей усталости. Вы просто потратите время и измотаете себя. - Сделайте творческий перерыв.
Творческий перерыв — это когда вы отвлекаетесь от задачи и переключаете внимание на другие вещи. Вы, возможно, замечали, что лучшие идеи приходят в голову в душе или по пути домой. Смена контекста иногда помогает. Сходите пообедать, посмотрите фильм, полистайте интернет или займитесь другой проблемой. - Закройте глаза на некоторые симптомы и сообщения и попробуйте сначала.
Некоторые баги могут влиять друг на друга. Драйвер для dial-up соединения в Windows 95 мог сообщать, что канал занят, при том что вы могли отчетливо слышать звук соединяющегося модема. Если вам приходится держать в голове слишком много симптомов, попробуйте сконцентрироваться только на одном. Исправьте или найдите его причину и переходите к следующему. - Поиграйте в доктора Хауса (только без Викодина).
Соберите всех коллег, ходите по кабинету с тростью, пишите симптомы на доске и бросайте язвительные комментарии. Раз это работает в сериалах, почему бы не попробовать?
Что вам точно не поможет
- Паника
Не надо сразу палить из пушки по воробьям. Некоторые менеджеры начинают паниковать и сразу откатываться, перезагружать сервера и т. п. в надежде, что что-нибудь из этого исправит проблему. Это никогда не работает. Кроме того, это создает еще больше хаоса и увеличивает время, необходимое для поиска ошибки. Делайте только один шаг за раз. Изучите результат. Обдумайте его, а затем переходите к следующей гипотезе. - «Хелп, плиииз!»
Когда вы обращаетесь на форум за советом, вы как минимум должны уже выполнить шаг 3. Никто не захочет или не сможет вам помочь, если вы не предоставите подробное описание проблемы, включая информацию об ОС, железе и участок проблемного кода. Создавайте тему только тогда, когда можете все подробно описать, и придумайте информативное название для нее. - Переход на личности
Если вы думаете, что в ошибке виноват кто-то другой, постарайтесь по крайней мере говорить с ним вежливо. Оскорбления, крики и паника не помогут человеку решить проблему. Даже если у вас в команде не в почете демократия, крики и применение грубой силы не заставят исправления магическим образом появиться.
Ошибка, которую я недавно исправил
Это была загадочная проблема с дублирующимися именами генерируемых файлов. Дальнейшая проверка показала, что у файлов различное содержание. Это было странно, поскольку имена файлов включали дату и время создания в формате yyMMddhhmmss. Шаг 9, совпадения: первый файл был создан в полпятого утра, дубликат генерировался в полпятого вечера того же дня. Совпадение? Нет, поскольку hh в строке формата — это 12-часовой формат времени. Вот оно что! Поменял формат на yyMMddHHmmss, и ошибка исчезла.
Перевод статьи «How to fix bugs, step by step»
From Wikipedia, the free encyclopedia
Automatic bug-fixing is the automatic repair of software bugs without the intervention of a human programmer.[1][2] It is also commonly referred to as automatic patch generation, automatic bug repair, or automatic program repair.[3] The typical goal of such techniques is to automatically generate correct patches to eliminate bugs in software programs without causing software regression.[4]
Specification[edit]
Automatic bug fixing is made according to a specification of the expected behavior which can be for instance a formal specification or a test suite.[5]
A test-suite – the input/output pairs specify the functionality of the program, possibly captured in assertions can be used as a test oracle to drive the search. This oracle can in fact be divided between the bug oracle that exposes the faulty behavior, and the regression oracle, which encapsulates the functionality any program repair method must preserve. Note that a test suite is typically incomplete and does not cover all possible cases. Therefore, it is often possible for a validated patch to produce expected outputs for all inputs in the test suite but incorrect outputs for other inputs.[6] The existence of such validated but incorrect patches is a major challenge for generate-and-validate techniques.[6] Recent successful automatic bug-fixing techniques often rely on additional information other than the test suite, such as information learned from previous human patches, to further identify correct patches among validated patches.[7]
Another way to specify the expected behavior is to use formal specifications[8][9] Verification against full specifications that specify the whole program behavior including functionalities is less common because such specifications are typically not available in practice and the computation cost of such verification is prohibitive. For specific classes of errors, however, implicit partial specifications are often available. For example, there are targeted bug-fixing techniques validating that the patched program can no longer trigger overflow errors in the same execution path.[10]
Techniques[edit]
Generate-and-validate[edit]
Generate-and-validate approaches compile and test each candidate patch to collect all validated patches that produce expected outputs for all inputs in the test suite.[5][6] Such a technique typically starts with a test suite of the program, i.e., a set of test cases, at least one of which exposes the bug.[5][7][11][12] An early generate-and-validate bug-fixing systems is GenProg.[5] The effectiveness of generate-and-validate techniques remains controversial, because they typically do not provide patch correctness guarantees.[6] Nevertheless, the reported results of recent state-of-the-art techniques are generally promising. For example, on systematically collected 69 real world bugs in eight large C software programs, the state-of-the-art bug-fixing system Prophet generates correct patches for 18 out of the 69 bugs.[7]
One way to generate candidate patches is to apply mutation operators on the original program. Mutation operators manipulate the original program, potentially via its abstract syntax tree representation, or a more coarse-grained representation such as operating at the statement-level or block-level. Earlier genetic improvement approaches operate at the statement level and carry out simple delete/replace operations such as deleting an existing statement or replacing an existing statement with another statement in the same source file.[5][13] Recent approaches use more fine-grained operators at the abstract syntax tree level to generate more diverse set of candidate patches.[12] Notably, the statement deletion mutation operator, and more generally removing code, is a reasonable repair strategy, or at least a good fault localization strategy.[14]
Another way to generate candidate patches consists of using fix templates. Fix templates are typically predefined changes for fixing specific classes of bugs.[15] Examples of fix templates include inserting a conditional statement to check whether the value of a variable is null to fix null pointer exception, or changing an integer constant by one to fix off-by-one errors.[15]
Synthesis-based[edit]
Repair techniques exist that are based on symbolic execution. For example, Semfix[16] uses symbolic execution to extract a repair constraint. Angelix[17] introduced the concept of angelic forest in order to deal with multiline patches.
Under certain assumptions, it is possible to state the repair problem as a synthesis problem.
SemFix[16] uses component-based synthesis.[18]
Dynamoth uses dynamic synthesis.[19]
S3[20] is based on syntax-guided synthesis.[21]
SearchRepair[22] converts potential patches into an SMT formula and queries candidate patches that allow the patched program to pass all supplied test cases.
Data-driven[edit]
Machine learning techniques can improve the effectiveness of automatic bug-fixing systems.[7] One example of such techniques learns from past successful patches from human developers collected from open source repositories in GitHub and SourceForge.[7] It then use the learned information to recognize and prioritize potentially correct patches among all generated candidate patches.[7] Alternatively, patches can be directly mined from existing sources. Example approaches include mining patches from donor applications[10] or from QA web sites.[23]
Getafix[24] is a language-agnostic approach developed and used in production at Facebook. Given a sample of code commits where engineers fixed a certain kind of bug, it learns human-like fix patterns that apply to future bugs of the same kind. Besides using Facebook’s own code repositories as training data, Getafix learnt some fixes from open source Java repositories. When new bugs get detected, Getafix applies its previously learnt patterns to produce candidate fixes and ranks them within seconds. It presents only the top-ranked fix for final validation by tools or an engineer, in order to save resources and ideally be so fast that no human time was spent on fixing the same bug, yet.
Template-based repair[edit]
For specific classes of errors, targeted automatic bug-fixing techniques use specialized templates:
- null pointer exception repair[25][26][15] with insertion of a conditional statement to check whether the value of a variable is null.
- integer overflow repair[10]
- buffer overflow repair[10]
- memory leak repair,[27] with automated insertion of missing memory deallocation statements.
Comparing to generate-and-validate techniques, template-based techniques tend to have better bug-fixing accuracy but a much narrowed scope.[6][27]
Use[edit]
There are multiple uses of automatic bug fixing:
- In a development environment: When encountering a bug the developer activates a feature to search for a patch (for instance by clicking on a button). This search can also happen in the background, when the IDE proactively searches for solutions to potential problems, without waiting for explicit action from the developer.[28]
- At runtime: When a failure happens at runtime, a binary patch can be searched for and applied online. An example of such a repair system is ClearView,[29] which does repair on x86 code, with x86 binary patches.
Search space[edit]
In essence, automatic bug fixing is a search activity, whether deductive-based or heuristic-based. The search space of automatic bug fixing is composed of all edits that can be possibly made to a program. There have been studies to understand the structure of this search space. Qi et al.[30] showed that the original fitness function of Genprog is not better than random search to drive the search. Long et al.’s[31] study indicated that correct patches can be considered as sparse in the search space and that incorrect overfitting patches are vastly more abundant (see also discussion about overfitting below).
Overfitting[edit]
Sometimes, in test-suite based program repair, tools generate patches that pass the test suite, yet are actually incorrect, this is known as the «overfitting» problem.[32] «Overfitting» in this context refers to the fact that the patch overfits to the test inputs. There are different kinds of overfitting: incomplete fixing means that only some buggy inputs are fixed, regression introduction means some previously working features are broken after the patch (because they were poorly tested). Early prototypes for automatic repair suffered a lot from overfitting: on the Manybugs C benchmark, Qi et al.[6] reported that 104/110 of plausible GenProg patches were overfitting. In the context of synthesis-based repair, Le et al.[33] obtained more than 80% of overfitting patches.
One way to avoid overfitting is to filter out the generated patches. This can be done based on dynamic analysis.[34]
Alternatively, Tian et al. propose heuristic approaches to assess patch correctness. [35][36]
Limitations of automatic bug-fixing[edit]
Automatic bug-fixing techniques that rely on a test suite do not provide patch correctness guarantees, because the test suite is incomplete and does not cover all cases.[6] A weak test suite may cause generate-and-validate techniques to produce validated but incorrect patches that have negative effects such as eliminating desirable functionalities, causing memory leaks, and introducing security vulnerabilities.[6] One possible approach is to amplify the failing test suite by automatically generating further test cases that are then labelled as passing or failing. To minimize the human labelling effort, an automatic test oracle can be trained that gradually learns to automatically classify test cases as passing or failing and only engages the bug-reporting user for uncertain cases.[37]
A limitation of generate-and-validate repair systems is the search space explosion.[31] For a program, there are a large number of statements to change and for each statement there are a large number of possible modifications. State-of-the-art systems address this problem by assuming that a small modification is enough for fixing a bug, resulting in a search space reduction.
The limitation of approaches based on symbolic analysis[16][17] is that real world programs are often converted to intractably large formulas especially for modifying statements with side effects.
Benchmarks[edit]
Benchmarks of bugs typically focus on one specific programming language.
In C, the Manybugs benchmark collected by GenProg authors contains 69 real world defects and it is widely used to evaluate many other bug-fixing tools for C.[13][7][12][17]
In Java, the main benchmark is Defects4J now extensively used in most research papers on program repair for Java.[38][39] Alternative benchmarks exist, such as the Quixbugs benchmark,[40] which contains original bugs for program repair. Other benchmarks of Java bugs include Bugs.jar,[41] based on past commits.
Example tools[edit]
Automatic bug-fixing is an active research topic in computer science. There are many implementations of various bug-fixing techniques especially for C and Java programs. Note that most of these implementations are research prototypes for demonstrating their techniques, i.e., it is unclear whether their current implementations are ready for industrial usage or not.
C[edit]
- ClearView:[29] A generate-and-validate tool of generating binary patches for deployed systems. It is evaluated on 10 security vulnerability cases. A later study shows that it generates correct patches for at least 4 of the 10 cases.[6]
- GenProg:[5][13] A seminal generate-and-validate bug-fixing tool. It has been extensively studied in the context of the ManyBugs benchmark.
- SemFix:[16] The first solver-based bug-fixing tool for C.
- CodePhage:[10] The first bug-fixing tool that directly transfer code across programs to generate patch for C program. Note that although it generates C patches, it can extract code from binary programs without source code.[10]
- LeakFix:[27] A tool that automatically fixes memory leaks in C programs.
- Prophet:[7] The first generate-and-validate tool that uses machine learning techniques to learn useful knowledge from past human patches to recognize correct patches. It is evaluated on the same benchmark as GenProg and generate correct patches (i.e., equivalent to human patches) for 18 out of 69 cases.[7]
- SearchRepair:[22] A tool for replacing buggy code using snippets of code from elsewhere. It is evaluated on the IntroClass benchmark[42] and generates much higher quality patches on that benchmark than GenProg, RSRepair, and AE.
- Angelix:[17] An improved solver-based bug-fixing tool. It is evaluated on the GenProg benchmark. For 10 out of the 69 cases, it generate patches that is equivalent to human patches.
- Learn2Fix:[37] The first human-in-the-loop semi-automatic repair tool. Extends GenProg to learn the condition under which a semantic bug is observed by systematic queries to the user who is reporting the bug. Only works for programs that take and produce integers.
Java[edit]
- PAR:[15] A generate-and-validate tool that uses a set of manually defined fix templates.
- QACrashFix:[23] A tool that fixes Java crash bugs by mining fixes from Q&A web site.
- ARJA:[43] A repair tool for Java based on multi-objective genetic programming.
- NpeFix:[44] An automatic repair tool for NullPointerException in Java, available on Github.
Other languages[edit]
- AutoFixE:[8] A bug-fixing tool for Eiffel language. It relies the contracts (i.e., a form of formal specification) in Eiffel programs to validate generated patches.
- Getafix:[24] Operates purely on AST transformations and thus requires only a parser and formatter. At Facebook it has been applied to Hack, Java and Objective-C.
Proprietary[edit]
- DeepCode integrates public and private GitHub, GitLab and Bitbucket repositories to identify code-fixes and improve software.[45]
- Kodezi utilizes opensource data from GitHub repositories, Stack Overflow, and private trained models to analyze code, provide solutions, and descriptions about the coding bugs instantly.[46]
References[edit]
- ^ Rinard, Martin C. (2008). «Technical perspective Patching program errors». Communications of the ACM. 51 (12): 86. doi:10.1145/1409360.1409381. S2CID 28629846.
- ^ Harman, Mark (2010). «Automated patching techniques». Communications of the ACM. 53 (5): 108. doi:10.1145/1735223.1735248. S2CID 9729944.
- ^ Gazzola, Luca; Micucci, Daniela; Mariani, Leonardo (2019). «Automatic Software Repair: A Survey» (PDF). IEEE Transactions on Software Engineering. 45 (1): 34–67. doi:10.1109/TSE.2017.2755013. hdl:10281/184798. S2CID 57764123.
- ^ Tan, Shin Hwei; Roychoudhury, Abhik (2015). «relifix: Automated repair of software regressions». 2015 IEEE/ACM 37th IEEE International Conference on Software Engineering. IEEE. pp. 471–482. doi:10.1109/ICSE.2015.65. ISBN 978-1-4799-1934-5. S2CID 17125466.
- ^ a b c d e f Weimer, Westley; Nguyen, ThanhVu; Le Goues, Claire; Forrest, Stephanie (2009). «Automatically finding patches using genetic programming». Proceedings of the 31st International Conference on Software Engineering. IEEE. pp. 364–374. CiteSeerX 10.1.1.147.8995. doi:10.1109/ICSE.2009.5070536. ISBN 978-1-4244-3453-4. S2CID 1706697.
- ^ a b c d e f g h i Qi, Zichao; Long, Fan; Achour, Sara; Rinard, Martin (2015). «An Anlysis of Patch Plausibility and Correctness for Generate-and-Validate Patch Generation Systems». Proceedings of the 2015 International Symposium on Software Testing and Analysis. ACM. CiteSeerX 10.1.1.696.5616. doi:10.1145/2771783.2771791. ISBN 978-1-4503-3620-8. S2CID 6845282.
- ^ a b c d e f g h i Long, Fan; Rinard, Martin (2016). «Automatic patch generation by learning correct code». Proceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages. ACM. pp. 298–312. doi:10.1145/2837614.2837617. ISBN 978-1-4503-3549-2. S2CID 6091588.
- ^ a b Pei, Yu; Furia, Carlo A.; Nordio, Martin; Wei, Yi; Meyer, Bertrand; Zeller, Andreas (May 2014). «Automated Fixing of Programs with Contracts». IEEE Transactions on Software Engineering. 40 (5): 427–449. arXiv:1403.1117. Bibcode:2014arXiv1403.1117P. doi:10.1109/TSE.2014.2312918. S2CID 53302638.
- ^ «Contract-based Data Structure Repair Using Alloy». CiteSeerX 10.1.1.182.4390.
- ^ a b c d e f Sidiroglou, Stelios; Lahtinen, Eric; Long, Fan; Rinard, Martin (2015). «Automatic Error Elimination by Multi-Application Code Transfer». Proceedings of the 36th ACM SIGPLAN Conference on Programming Language Design and Implementation.
- ^ Qi, Yuhua; Mao, Xiaoguang; Lei, Yan; Dai, Ziying; Wang, Chengsong (2014). «The Strength of Random Search on Automated Program Repair». Proceedings of the 36th International Conference on Software Engineering. ICSE 2014. Austin, Texas: ACM. pp. 254–265. doi:10.1145/2568225.2568254. ISBN 978-1-4503-2756-5. S2CID 14976851.
- ^ a b c Long, Fan; Rinard, Martin (2015). «Staged Program Repair with Condition Synthesis». Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. ESEC/FSE 2015. Bergamo, Italy: ACM. pp. 166–178. CiteSeerX 10.1.1.696.9059. doi:10.1145/2786805.2786811. ISBN 978-1-4503-3675-8. S2CID 5987616.
- ^ a b c Le Goues, Claire; Dewey-Vogt, Michael; Forrest, Stephanie; Weimer, Westley (2012). «A Systematic Study of Automated Program Repair: Fixing 55 out of 105 Bugs for $8 Each». 2012 34th International Conference on Software Engineering (ICSE). IEEE. pp. 3–13. CiteSeerX 10.1.1.661.9690. doi:10.1109/ICSE.2012.6227211. ISBN 978-1-4673-1067-3. S2CID 10987936.
- ^ Qi, Zichao; Long, Fan; Achour, Sara; Rinard, Martin (2015-07-13). «An analysis of patch plausibility and correctness for generate-and-validate patch generation systems». Proceedings of the 2015 International Symposium on Software Testing and Analysis. New York, NY, USA: ACM: 24–36. doi:10.1145/2771783.2771791. hdl:1721.1/101586. ISBN 9781450336208. S2CID 6845282.
- ^ a b c d Kim, Dongsun; Nam, Jaechang; Song, Jaewoo; Kim, Sunghun (2013). «Automatic Patch Generation Learned from Human-written Patches». Proceedings of the 2013 International Conference on Software Engineering. ICSE ’13’. IEEE Press. pp. 802–811. ISBN 978-1-4673-3076-3.
- ^ a b c d Nguyen, Hoang Duong Thien; Qi, Dawei; Roychoudhury, Abhik; Chandra, Satish (2013). «SemFix: Program Repair via Semantic Analysis». Proceedings of the 2013 International Conference on Software Engineering. ICSE ’13’. San Francisco, California: IEEE Press. pp. 772–781. ISBN 978-1-4673-3076-3.
- ^ a b c d Mechtaev, Sergey; Yi, Jooyong; Roychoudhury, Abhik (2016). «Angelix: scalable multiline program patch synthesis via symbolic analysis». Proceedings of the 38th International Conference on Software Engineering, ICSE 2016, Austin, Texas, May 14-22, 2016. pp. 691–701.
- ^ Jha, Susmit; Gulwani, Sumit; Seshia, Sanjit A.; Tiwari, Ashish (2010-05-01). Oracle-guided component-based program synthesis. ACM. pp. 215–224. doi:10.1145/1806799.1806833. ISBN 9781605587196. S2CID 6344783.
- ^ Galenson, Joel; Reames, Philip; Bodik, Rastislav; Hartmann, Björn; Sen, Koushik (2014-05-31). CodeHint: dynamic and interactive synthesis of code snippets. ACM. pp. 653–663. doi:10.1145/2568225.2568250. ISBN 9781450327565. S2CID 10656182.
- ^ Le, Xuan-Bach D.; Chu, Duc-Hiep; Lo, David; Le Goues, Claire; Visser, Willem (2017-08-21). Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering — ESEC/FSE 2017. ACM. pp. 593–604. doi:10.1145/3106237.3106309. ISBN 9781450351058. S2CID 1503790.
- ^ Alur, Rajeev; Bodik, Rastislav; Juniwal, Garvit; Martin, Milo M. K.; Raghothaman, Mukund; Seshia, Sanjit A.; Singh, Rishabh; Solar-Lezama, Armando; Torlak, Emina; Udupa, Abhishek (2013). «Syntax-guided synthesis». 2013 Formal Methods in Computer-Aided Design. pp. 1–8. CiteSeerX 10.1.1.377.2829. doi:10.1109/fmcad.2013.6679385. ISBN 9780983567837.
- ^ a b Ke, Yalin; Stolee, Kathryn; Le Goues, Claire; Brun, Yuriy (2015). «Repairing Programs with Semantic Code Search». Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering. ASE 2015. Lincoln, Nebraska: ACM. pp. 295–306. doi:10.1109/ASE.2015.60. ISBN 978-1-5090-0025-8. S2CID 16361458.
- ^ a b Gao, Qing; Zhang, Hansheng; Wang, Jie; Xiong, Yingfei; Zhang, Lu; Mei, Hong (2015). «Fixing Recurring Crash Bugs via Analyzing Q&A Sites». 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE. pp. 307–318. doi:10.1109/ASE.2015.81. ISBN 978-1-5090-0025-8. S2CID 2513924.
- ^ a b Bader, Johannes; Scott, Andrew; Pradel, Michael; Chandra, Satish (2019-10-10). «Getafix: learning to fix bugs automatically». Proceedings of the ACM on Programming Languages. 3 (OOPSLA): 159:1–159:27. doi:10.1145/3360585.
- ^ Long, Fan; Sidiroglou-Douskos, Stelios; Rinard, Martin (2014). «Automatic Runtime Error Repair and Containment via Recovery Shepherding». Proceedings of the 35th ACM SIGPLAN Conference on Programming Language Design and Implementation. PLDI ’14’. New York, New York: ACM. pp. 227–238. doi:10.1145/2594291.2594337. ISBN 978-1-4503-2784-8. S2CID 6252501.
- ^ Dobolyi, Kinga; Weimer, Westley (2008). «Changing Java’s Semantics for Handling Null Pointer Exceptions». 2008 19th International Symposium on Software Reliability Engineering (ISSRE). pp. 47–56. CiteSeerX 10.1.1.147.6158. doi:10.1109/ISSRE.2008.59. S2CID 1454939.
- ^ a b c Gao, Qing; Xiong, Yingfei; Mi, Yaqing; Zhang, Lu; Yang, Weikun; Zhou, Zhaoping; Xie, Bing; Mei, Hong (2015). «Safe Memory-leak Fixing for C Programs». Proceedings of the 37th International Conference on Software Engineering – Volume 1. ICSE ’15’. Piscataway, New Jersey: IEEE Press. pp. 459–470. ISBN 978-1-4799-1934-5.
- ^ Muşlu, Kıvanç; Brun, Yuriy; Holmes, Reid; Ernst, Michael D.; Notkin, David; Muşlu, Kıvanç; Brun, Yuriy; Holmes, Reid; Ernst, Michael D.; Notkin, David (19 October 2012). «Speculative analysis of integrated development environment recommendations, Speculative analysis of integrated development environment recommendations». ACM SIGPLAN Notices. 47 (10): 669, 669–682, 682. CiteSeerX 10.1.1.259.6341. doi:10.1145/2384616.2384665. ISSN 0362-1340. S2CID 5795141.
- ^ a b Perkins, Jeff H.; et al. (2009). «Automatically patching errors in deployed software». Proceedings of the ACM SIGOPS 22nd symposium on Operating systems principles. ACM. pp. 87–102. CiteSeerX 10.1.1.157.5877. doi:10.1145/1629575.1629585. ISBN 978-1-60558-752-3. S2CID 7597529.
- ^ Qi, Yuhua; Mao, Xiaoguang; Lei, Yan; Dai, Ziying; Wang, Chengsong (2014-05-31). The strength of random search on automated program repair. ACM. pp. 254–265. doi:10.1145/2568225.2568254. ISBN 9781450327565. S2CID 14976851.
- ^ a b Long, Fan; Rinard, Martin (2016). «An Analysis of the Search Spaces for Generate and Validate Patch Generation Systems». Proceedings of the 38th International Conference on Software Engineering. ICSE ’16. New York, New York: ACM. pp. 702–713. arXiv:1602.05643. doi:10.1145/2884781.2884872. hdl:1721.1/113656. ISBN 978-1-4503-3900-1. S2CID 7426809.
- ^ Smith, Edward K.; Barr, Earl T.; Le Goues, Claire; Brun, Yuriy (2015). «Is the Cure Worse Than the Disease? Overfitting in Automated Program Repair». Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. ESEC/FSE 2015. New York, New York: ACM. pp. 532–543. doi:10.1145/2786805.2786825. ISBN 978-1-4503-3675-8. S2CID 6300790.
- ^ Le, Xuan Bach D.; Thung, Ferdian; Lo, David; Goues, Claire Le (2018-03-02). «Overfitting in semantics-based automated program repair». Empirical Software Engineering. 23 (5): 3007–3033. doi:10.1007/s10664-017-9577-2. ISSN 1382-3256. S2CID 3635768.
- ^ Xin, Qi; Reiss, Steven P. (2017-07-10). «Identifying test-suite-overfitted patches through test case generation». Proceedings of the 26th ACM SIGSOFT International Symposium on Software Testing and Analysis. New York, NY, USA: ACM: 226–236. doi:10.1145/3092703.3092718. ISBN 978-1-4503-5076-1. S2CID 20562134.
- ^ Tian, Haoye; Liu, Kui; Kaboré, Abdoul Kader; Koyuncu, Anil; Li, Li; Klein, Jacques; Bissyandé, Tegawendé F. (27 January 2021). «Evaluating representation learning of code changes for predicting patch correctness in program repair». Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering. Association for Computing Machinery. pp. 981–992. doi:10.1145/3324884.3416532.
- ^ Tian, Haoye; Tang, Xunzhu; Habib, Andrew; Wang, Shangwen; Liu, Kui; Xia, Xin; Klein, Jacques; BissyandÉ, TegawendÉ F. (5 January 2023). «Is this Change the Answer to that Problem? Correlating Descriptions of Bug and Code Changes for Evaluating Patch Correctness». Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. Association for Computing Machinery: 1–13. doi:10.1145/3551349.3556914.
- ^ a b Böhme, Marcel; Geethal, Charaka; Pham, Van-Thuan (2020). «Human-In-The-Loop Automatic Program Repair». Proceedings of the 13th International Conference on Software Testing, Validation and Verification. ICST 2020. Porto, Portugal: IEEE. pp. 274–285. arXiv:1912.07758. doi:10.1109/ICST46399.2020.00036. ISBN 978-1-7281-5778-8. S2CID 209386817.
- ^ Wen, Ming; Chen, Junjie; Wu, Rongxin; Hao, Dan; Cheung, Shing-Chi (2018). «Context-aware patch generation for better automated program repair». Proceedings of the 40th International Conference on Software Engineering — ICSE ’18. New York, New York, USA: ACM Press: 1–11. doi:10.1145/3180155.3180233. ISBN 9781450356381. S2CID 3374770.
- ^ Hua, Jinru; Zhang, Mengshi; Wang, Kaiyuan; Khurshid, Sarfraz (2018). «Towards practical program repair with on-demand candidate generation». Proceedings of the 40th International Conference on Software Engineering — ICSE ’18. New York, New York, USA: ACM Press: 12–23. doi:10.1145/3180155.3180245. ISBN 9781450356381. S2CID 49666327.
- ^ Lin, Derrick; Koppel, James; Chen, Angela; Solar-Lezama, Armando (2017). «QuixBugs: a multi-lingual program repair benchmark set based on the quixey challenge». Proceedings Companion of the 2017 ACM SIGPLAN International Conference on Systems, Programming, Languages, and Applications: Software for Humanity — SPLASH Companion 2017. New York, New York, USA: ACM Press: 55–56. doi:10.1145/3135932.3135941. ISBN 9781450355148.
- ^ Saha, Ripon K.; Lyu, Yingjun; Lam, Wing; Yoshida, Hiroaki; Prasad, Mukul R. (2018). «Bugs.jar: a large-scale, diverse dataset of real-world Java bugs». Proceedings of the 15th International Conference on Mining Software Repositories. MSR ’18: 10–13. doi:10.1145/3196398.3196473. ISBN 9781450357166. S2CID 50770093.
- ^ Le Goues, Claire; Holtschulte, Neal; Smith, Edward; Brun, Yuriy; Devanbu, Premkumar; Forrest, Stephanie; Weimer, Westley (2015). «The Many Bugs and Intro Class Benchmarks for Automated Repair of C Programs». IEEE Transactions on Software Engineering. 41 (12): 1236–1256. doi:10.1109/TSE.2015.2454513.
- ^ Yuan, Yuan; Banzhaf, Wolfgang (2020). «ARJA: Automated Repair of Java Programs via Multi-Objective Genetic Programming». IEEE Transactions on Software Engineering. 46 (10): 1040–1067. arXiv:1712.07804. doi:10.1109/TSE.2018.2874648. S2CID 25222219.
- ^ Durieux, Thomas (2017). «Dynamic Patch Generation for Null Pointer Exceptions Using Metaprogramming». 2017 IEEE 24th International Conference on Software Analysis, Evolution and Reengineering (SANER). pp. 349–358. arXiv:1812.00409. doi:10.1109/SANER.2017.7884635. ISBN 978-1-5090-5501-2. S2CID 2736203.
- ^ «AI is coming for your coding job». Sifted. 13 March 2019. Retrieved 2019-04-15.
- ^ «Ishraq Khan, Revolutionizing the Programming Scene in 2021». TechTimes. 13 September 2019. Retrieved 2022-10-15.
External links[edit]
- program-repair.org datasets, tools, etc., related to automated program repair research.
Автоматическое исправление ошибок — это автоматическое исправление ошибок программного обеспечения без вмешательства человека-программиста. Это также обычно называют автоматическим генерированием исправлений, автоматическим исправлением ошибок или автоматическим исправлением программ. Типичная цель таких методов — автоматически генерировать правильные исправления для устранения ошибок в программах, не вызывая регрессию программного обеспечения.
Содержание
- 1 Спецификация
- 2 Методы
- 2.1 Создание и проверка
- 2.2 На основе синтеза
- 2.3 На основе данных
- 2.4 Другое
- 3 Использование
- 4 Пространство поиска
- 5 Ограничения автоматического исправления ошибок
- 6 Тесты
- 7 Примеры инструментов
- 7.1 C
- 7.2 Java
- 7.3 Другие языки
- 7.4 Собственные
- 8 Ссылки
- 9 Внешние ссылки
Спецификация
Автоматическое исправление ошибок выполняется в соответствии со спецификацией ожидаемого поведения, которая может быть, например, формальной спецификацией или набором тестов.
Набор тестов — пары ввода / вывода определяют функциональность программы, возможно, зафиксированную в , утверждения могут использоваться как тестовый оракул для управления поиском. Фактически, этот оракул можно разделить между оракулом ошибок, который выявляет ошибочное поведение, и оракулом регрессии, который инкапсулирует функциональность, которую должен сохранить любой метод восстановления программы. Обратите внимание, что набор тестов обычно неполный и не охватывает все возможные случаи. Следовательно, проверенный патч часто может выдавать ожидаемые выходные данные для всех входных данных в наборе тестов, но неправильные выходные данные для других входных данных. Существование таких проверенных, но некорректных исправлений является серьезной проблемой для методов генерации и проверки. Недавние успешные методы автоматического исправления ошибок часто полагаются на дополнительную информацию, отличную от набора тестов, такую как информация, полученная из предыдущих исправлений, выполненных человеком, для дальнейшего выявления правильных исправлений среди проверенных исправлений.
Другой способ указать ожидаемое поведение — это использовать формальные спецификации Проверка на соответствие полным спецификациям, которые определяют поведение всей программы, включая функциональные возможности, менее распространена, потому что такие спецификации обычно недоступны на практике, а стоимость вычислений такой проверки является непомерно высокой. Однако для определенных классов ошибок часто доступны неявные частичные спецификации. Например, существуют целевые методы исправления ошибок, подтверждающие, что исправленная программа больше не может вызывать ошибки переполнения в том же пути выполнения.
Методы
Генерировать и проверять
Подходы генерации и проверки компилируют и тестируют каждый патч-кандидат для сбора всех проверенных патчей, которые дают ожидаемые результаты для всех входных данных в наборе тестов. Такой метод обычно начинается с набора тестов программы, т. Е. Набора из тестовых случаев, по крайней мере один из которых выявляет ошибку. GenProg — одна из первых систем генерации и проверки ошибок. Эффективность методов генерации и-Validate остается спорным, так как они обычно не обеспечивают патч корректности гарантии. Тем не менее, опубликованные результаты новейших современных методов в целом обнадеживают. Например, для систематически собранных 69 реальных ошибок в восьми крупных программах на языке C современная система исправления ошибок Prophet генерирует правильные исправления для 18 из 69 ошибок.
Один способ исправить генерировать патчи-кандидаты — применить операторы мутации к исходной программе. Операторы мутации манипулируют исходной программой, возможно, через ее представление абстрактного синтаксического дерева или более грубое представление, такое как работа на уровне инструкции или блоке -уровень. Более ранние подходы к генетическому усовершенствованию работают на уровне операторов и выполняют простые операции удаления / замены, такие как удаление существующего оператора или замена существующего оператора другим оператором в том же исходном файле. В последних подходах используются более мелкие операторы на уровне абстрактного синтаксического дерева для создания более разнообразного набора исправлений-кандидатов.
Другой способ создания исправлений-кандидатов состоит в использовании шаблонов исправлений. Шаблоны исправлений обычно представляют собой предварительно определенные изменения для исправления определенных классов ошибок. Примеры шаблонов исправлений включают вставку условного оператора , чтобы проверить, является ли значение переменной нулевым, чтобы исправить исключение нулевого указателя, или изменение целочисленной константы на единицу, чтобы исправить отдельные ошибки. Также возможно автоматическое извлечение шаблонов исправлений для подходов генерации и проверки.
Многие методы генерации и проверки полагаются на понимание избыточности: код исправления можно найти в другом месте приложения. Эта идея была представлена в системе Genprog, где два оператора, добавление и замена узлов AST, были основаны на коде, взятом из другого места (то есть добавлении существующего узла AST). Эта идея была подтверждена эмпирически двумя независимыми исследованиями, которые показали, что значительная часть коммитов (3–17%) состоит из существующего кода. Помимо того факта, что код для повторного использования существует где-то еще, также было показано, что контекст потенциальных ингредиентов для восстановления полезен: часто контекст донора аналогичен контексту получателя.
На основе синтеза
Существуют техники ремонта, основанные на символическом исполнении. Например, Semfix использует символьное выполнение для извлечения исправления ограничения. Анжеликс ввел концепцию ангельского леса, чтобы иметь дело с многострочными патчами.
При определенных предположениях проблему ремонта можно сформулировать как проблему синтеза. SemFix и Nopol используют компонентный синтез. Dynamoth использует динамический синтез. S3 основан на синтаксическом синтезе. SearchRepair преобразует потенциальные исправления в формулу SMT и запрашивает исправления-кандидаты, которые позволяют пропатченной программе пройти все предоставленные тестовые примеры.
Управляемые данными
методы машинного обучения могут повысить эффективность систем автоматического исправления ошибок. Один из примеров таких методов основан на прошлых успешных исправлениях от разработчиков-людей, собранных из репозиториев с открытым исходным кодом в GitHub и SourceForge. Затем он использует полученную информацию для распознавания и определения приоритета потенциально правильных исправлений среди всех сгенерированных исправлений-кандидатов. Как вариант, патчи можно добывать напрямую из существующих источников. Примеры подходов включают добычу патчей из донорских приложений или с веб-сайтов QA.
SequenceR использует последовательное обучение в исходном коде для создания однострочных патчей. Он определяет архитектуру нейронной сети, которая хорошо работает с исходным кодом, с механизмом копирования, который позволяет создавать патчи с токенами, которых нет в изученном словаре. Эти токены взяты из кода ремонтируемого класса Java.
Другое
Целевые методы автоматического исправления ошибок генерируют исправления для определенных классов ошибок, таких как исключение нулевого указателя целочисленное переполнение, буфер переполнение, утечка памяти и т. д. Такие методы часто используют шаблоны эмпирических исправлений для исправления ошибок в целевой области. Например, вставьте условный оператор , чтобы проверить, является ли значение переменной нулевым, или вставьте отсутствующие операторы освобождения памяти. По сравнению с методами генерации и проверки, целевые методы, как правило, имеют лучшую точность исправления ошибок, но значительно сужены.
Использование
Существует несколько вариантов использования автоматического исправления ошибок:
- в среде разработки: когда разработчик обнаруживает ошибку, она активирует функцию для поиска патча (например, нажав кнопку). Этот поиск может даже происходить в фоновом режиме, когда IDE упреждающе ищет решения потенциальных проблем, не дожидаясь явных действий разработчика.
- на сервере непрерывной интеграции: при сбое сборки во время непрерывного поиска исправлений можно попытаться выполнить, как только сборка не удалась. Если поиск успешен, патч передается разработчику до того, как она начнет работу над ним или до того, как она найдет решение. Когда синтезированный патч предлагается разработчикам в качестве запроса на вытягивание, помимо изменений кода должно быть предоставлено объяснение (например, заголовок и описание запроса на извлечение). Эксперимент показал, что сгенерированные исправления могут быть приняты разработчиками с открытым исходным кодом и объединены в репозиторий кода.
- во время выполнения: когда сбой происходит во время выполнения, можно выполнить поиск двоичного исправления и применить онлайн. Примером такой системы восстановления является ClearView, которая выполняет восстановление кода x86 с помощью двоичных исправлений x86. Система Itzal отличается от Clearview: в то время как поиск исправлений происходит во время выполнения, в производственной среде производимые исправления находятся на уровне исходного кода. Система BikiniProxy выполняет оперативное исправление ошибок Javascript, возникающих в браузере.
Область поиска
По сути, автоматическое исправление ошибок — это поисковая деятельность, основанная на дедуктивных или эвристических методах. Область поиска автоматического исправления ошибок состоит из всех изменений, которые могут быть внесены в программу. Были проведены исследования, чтобы понять структуру этого поискового пространства. Qi et al. показал, что исходная фитнес-функция Genprog не лучше случайного поиска для управления поиском. Martinez et al. исследовал дисбаланс между возможными ремонтными действиями, показав его значительное влияние на поиск. Исследование Лонга и др. Показало, что правильные участки могут считаться редкими в пространстве поиска и что неправильных участков с переобучением гораздо больше (см. Также обсуждение переобучения ниже).
Если явно перечислить все возможные варианты в алгоритме восстановления, это определяет пространство разработки для восстановления программы. Каждый вариант выбирает алгоритм, задействованный в какой-то момент в процессе исправления (например, алгоритм локализации неисправности), или выбирает конкретную эвристику, которая дает разные исправления. Например, в области проектирования восстановления программы с помощью генерации и проверки существует одна точка вариации в отношении степени детализации изменяемых элементов программы: выражение, оператор, блок и т. Д.
Ограничения автоматического исправления ошибок
Методы автоматического исправления ошибок, основанные на наборе тестов, не обеспечивают гарантии правильности исправлений, поскольку набор тестов является неполным и не охватывает все случаи. Слабый набор тестов может привести к тому, что методы генерации и проверки будут создавать проверенные, но неправильные исправления, которые имеют негативные последствия, такие как устранение желаемых функций, вызывая утечки памяти и вводя уязвимости безопасности. Один из возможных подходов состоит в том, чтобы расширить набор тестов, которые не прошли проверку, путем автоматической генерации дополнительных тестовых примеров, которые затем помечаются как пройденные или не выполненные. Чтобы свести к минимуму усилия человека по присвоению ярлыков, можно обучить автоматический тестовый оракул, который постепенно учится автоматически классифицировать тестовые случаи как пройденные или неуспешные и вовлекающий пользователя, сообщающего об ошибках, только в неопределенных случаях. Иногда при ремонте программ на основе набора тестов инструменты генерируют исправления, которые проходят набор тестов, но на самом деле являются некорректными, это называется проблемой «переобучения». «Переобучение» в этом контексте относится к тому факту, что патч переоснащается тестовым входам. Существуют различные виды переобучения: неполное исправление означает, что исправлены только некоторые ошибочные входные данные, введение регрессии означает, что некоторые ранее работавшие функции нарушены после исправления (потому что они были плохо протестированы). Ранние прототипы для автоматического ремонта сильно страдали от переоснащения: в тесте Manybugs C Qi et al. сообщил, что 104/110 вероятных патчей GenProg переоснащены; по тесту Java Defects4J Мартинес и др. сообщили, что 73/84 правдоподобных исправлений переобучены. В контексте репарации на основе синтеза Le et al. получено более 80% исправлений переобучения.
Еще одно ограничение систем генерации и проверки — это взрывное пространство поиска. Для программы необходимо изменить большое количество операторов, и для каждого оператора существует большое количество возможных модификаций. Современные системы решают эту проблему, предполагая, что для исправления ошибки достаточно небольшой модификации, что приводит к сокращению пространства поиска.
Ограничение подходов, основанных на символьном анализе, состоит в том, что программы реального мира часто преобразуются в трудноразрешимые большие формулы, особенно для модификации операторов с побочными эффектами.
Тесты
Тесты ошибок обычно сосредоточиться на одном конкретном языке программирования. В языке C тест Manybugs, собранный авторами GenProg, содержит 69 реальных дефектов и широко используется для оценки многих других инструментов исправления ошибок для C.
В Java основным тестом является Defects4J, первоначально исследованный Мартинесом. et al., и в настоящее время широко используется в большинстве исследовательских работ по восстановлению программ для Java. Существуют альтернативные тесты, такие как тест Quixbugs, который содержит оригинальные ошибки для исправления программ. Другие тесты ошибок Java включают Bugs.jar, основанные на прошлых коммитах, и BEARS, который является эталоном сбоев при непрерывной интеграции.
Примеры инструментов
Автоматическое исправление ошибок — активная тема исследований в области компьютерных наук. Существует множество реализаций различных методов исправления ошибок, особенно для программ C и Java. Обратите внимание, что большинство из этих реализаций являются исследовательскими прототипами для демонстрации своих методов, то есть неясно, готовы ли их текущие реализации для промышленного использования или нет.
C
- ClearView: инструмент для создания и проверки бинарных исправлений для развернутых систем. Он оценивается по 10 случаям уязвимости безопасности. Более позднее исследование показывает, что он генерирует правильные исправления как минимум для 4 из 10 случаев.
- GenProg: оригинальный инструмент для создания и проверки ошибок. Он был тщательно изучен в контексте теста ManyBugs.
- SemFix: первый инструмент для исправления ошибок на основе решателя для C.
- CodePhage: первый инструмент для исправления ошибок, который напрямую передает код в программах для создания патча для программы C. Обратите внимание, что хотя он генерирует исправления C, он может извлекать код из двоичных программ без исходного кода.
- LeakFix: инструмент, который автоматически устраняет утечки памяти в программах на C.
- Prophet: Первый инструмент генерации и проверки, использующий методы машинного обучения для извлечения полезных знаний из прошлых человеческих патчей и распознавания правильных патчей. Он оценивается на том же тесте, что и GenProg, и генерирует правильные исправления (т. Е. Эквивалентные человеческим исправлениям) в 18 из 69 случаев.
- SearchRepair: инструмент для замены ошибочного кода с помощью фрагментов кода из других источников. Он оценивается в тесте IntroClass и генерирует исправления гораздо более высокого качества в этом тесте, чем GenProg, RSRepair и AE.
- Angelix: улучшенный инструмент для исправления ошибок на основе решателя. Он оценивается на тесте GenProg. В 10 из 69 случаев он генерирует заплатки, которые эквивалентны человеческим.
- Learn2Fix: первый полуавтоматический инструмент для исправления ошибок. Расширяет GenProg для изучения условий, при которых наблюдается семантическая ошибка, путем систематических запросов к пользователю, сообщающему об ошибке. Работает только для программ, которые принимают и производят целые числа.
Java
- PAR: инструмент создания и проверки, использующий набор вручную определенных шаблонов исправлений. В более позднем исследовании высказывались опасения по поводу возможности обобщения шаблонов исправлений в PAR.
- NOPOL: инструмент на основе решателя, ориентированный на изменение операторов условий.
- QACrashFix: инструмент, который исправляет ошибки сбоя Java путем исправления майнинга с веб-сайта вопросов и ответов.
- Astor: библиотека автоматического восстановления для Java, содержащая jGenProg, Java-реализацию GenProg.
- NpeFix: инструмент автоматического восстановления для NullPointerException в Java, доступен на Github.
Другие языки
- AutoFixE: инструмент для исправления ошибок для языка Eiffel. Он полагается на контракты (т.е. форму формальной спецификации) в программах Eiffel для проверки сгенерированных исправлений.
Собственный
- DeepCode объединяет общедоступные и частные GitHub, GitLab и Bitbucket репозитории для выявления исправлений кода и улучшения программного обеспечения.
Ссылки
Внешние ссылки
- program-repair.org наборы данных, инструменты и т. д., относящиеся к исследованиям автоматического восстановления программ.
Время на прочтение
8 мин
Количество просмотров 12K
Всем привет! Вдохновленные успехом предыдущей статьи, которая была написана в преддверии запуска курса «Fullstack разработчик JavaScript«, мы решили продолжить серию статей для новичков и всех тех, кто только начинает заниматься программированием на языке JavaScript. Cегодня мы поговорим об ошибках, которые случаются в JS, а также о том, как именно с ними бороться.

Отдебажь за человека одну ошибку, и он будет благодарен тебе один пулл реквест. Научи его дебажить самостоятельно, и он будет благодарен тебе весь проект.
Неизвестный тимлид
Типичные ошибки начинающих
Итак, начнем с самых примитивных ошибок. Допустим, вы только недавно закончили изучать основы HTML и CSS и теперь активно принялись за программирование на JavaScript. Для примера: вы хотите, чтобы при клике на кнопку у вас открывалось, к примеру, скрытое до этого момента модальное окно. Так же вы хотите, чтобы у вас по нажатию на крестик это окно закрывалось. Интерактивный пример доступен здесь (я выбрал bitbucket из-за того, что его интерфейс мне кажется самым простым, да и не все же на гитхабе сидеть).
let modal_alert = document.querySelector(".modal_alert")
let hero__btn = document.querySelector(".hero__btn")
let modal_close = document.querySelector(".modal-close ")
//мы выбрали из DOM модели наши элементы. К слову, я использую bulma для упрощения процесса верстки
//теперь мы хотим провести над нашими элементами какие-то операции:
hero__btn.addEventListener("click", function(){
modal_alert.classList.add("helper_visible");
})
modal_close.addEventListener("click", function(){
modal_alert.classList.remove("helper_visible");
})
//если мы хотим увидеть форму, то просто вешаем доп. класс, в котором прописано css-свойство display:flex. И наоборот, если хотим скрыть.
В нашем index.html, кроме верстки, мы внутри тэга head вставляем наш script:
<script src="code.js"></script>
В index.html кроме верстки внутри тэга head мы вставляем наш script:
<script src="code.js"></script>
Однако, несмотря на то, что мы все подключили, ничего не заработает и вылетит ошибка:
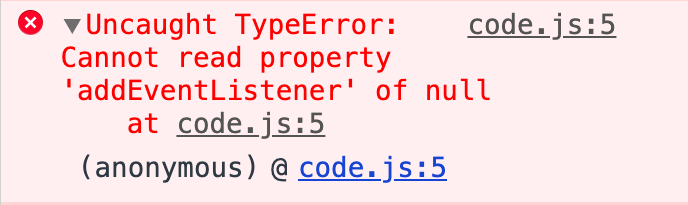
Что весьма печально, новички часто теряются и не понимают, что делать с красными строчками, словно это приговор какой-то, а не подсказка о том, что не так в вашей программе. Если перевести, то браузер говорит нам, что он не может прочитать свойство addEventListener нулевого значения. Значит, почему-то из DOM модели мы не получили наш элемент. Какой алгоритм действий нужно предпринять?
Во-первых, посмотрите в какой момент у вас вызывается javascript. Браузер читает ваш html-код сверху вниз, как вы читаете, например, книгу. Когда он увидит тэг script, то сразу исполнит его содержимое и продолжит чтение следующих элементов, не особо заботясь о том, что в своем скрипте вы пытаетесь получить элементы DOM, а он их еще не прочитал и, следовательно, не построил модель.
Что делать в таком случае? Просто добавьте атрибут defer внутрь вашего тэга скрипт (или async, но я не буду сейчас вдаваться в подробности их работы, это можно прочитать здесь ). Или можете просто переместить вниз ваш тэг script перед закрывающим body, это тоже сработает.
Во-вторых, проверьте опечатки. Изучите методологию БЭМ — она полезна ещё и тем, что вы хорошо знаете, как пишется ваш элемент — ведь пишите классы по единой логике, и стараетесь пользоваться только правильным английским языком. Или копируете сразу название элемента в JS файл.
Отлично. Теперь, когда вы поправили ошибки, можете насладиться рабочей версией кода по следующему адресу.
Загадочная ошибка
Больше всего новичков вводит в ступор странная ошибка последней строчки кода. Приведем пример:

В консоли выводится что-то непонятное. Если переводить, то буквально это «Неожиданный конец ввода» — и что с этим делать? Кроме того, новичок по привычке смотрит на номер строки. На ней вроде все нормально. И почему тогда консоль на нее указывает?
Все просто. Что бы понимать, как интерпретировать вашу программу, интерпретатору JS нужно знать, где заканчивается тело функции, и где заканчивается тело цикла. В данном варианте кода я абсолютно намеренно забыл последнюю фигурную скобку:
// тут у нас просто два массива с заголовками и статьями
let root = document.getElementById("root"); // реактно подобно использую root
let article__btn = document.querySelector("article__btn");
// при клике на кнопку прочитаем статью
article__btn.onclick = () => {
for (let i = 0; i < headers.length; i++) {
root.insertAdjacentHTML("beforeend", `
<div class="content is-medium">
<h1>${headers[i]} </h1>
<p>${paragraps[i]}</p>
</div>`)
//изъятие фигурной скобки выполнено профессионалами. Не повторять на продакшене
}
Теперь JavaScript не понимает, где у него конец тела функции, а где конец цикла и не может интерпретировать код.
Что делать в данном случае? В любом современном редакторе кода, если вы поставите курсор перед открывающей скобкой, подсветится его закрывающий вариант (если редактор еще не начал подчеркивать эту ошибку красным цветом). Просмотрите код еще раз внимательно, держа в голове, что в JS не бывает одиноких фигурных скобок. Проблемный вариант можно посмотреть здесь, а исправленный — вот тут.
Дробим код
Чаще всего стоит заниматься написанием кода, тестируя его работу небольшими кусочками.
Или как нормальный человек изучить TDD
К примеру, вам нужно простую программу, которая принимает данные на вход от пользователя, складывает их в массив и после этого выводит их средние значения:
let input_number = prompt("Введите количество переменных");
// определяем, какое количество переменных к нам придет
let numbers = [];
function toArray(input_number){
for (let i = 0; i < input_number; i++) {
let x = prompt(`Введите значение ${i}`);
numbers.push(x); // и складываем значения в массив
}
}
toArray(input_number);
function toAverage(numbers){
let sum = 0;
for (let i = 0; i < numbers.length; i++) {
sum += numbers[i];
}
return sum/numbers.length;
}
alert(toAverage(numbers));
На первый неискушенный взгляд, в данном коде вполне все нормально. В нем есть основная логика, раздробленная на две функции, каждую из которой можно применять потом отдельно. Однако опытный программист сразу скажет, что это не заработает, ведь из prompt данные к нам приходят в виде строки. Причем JS (таков его толерантно-пофигистичный характер) нам все запустит, но на выходе выдаст настолько невероятную чепуху, что даже будет непросто понять, как мы дошли до жизни такой. Итак, давайте попробуем что-нибудь посчитать в нашем интерактивном примере. Введем допустим число 3 в количество переменных, и 1 2 3 в поле ввода данных:
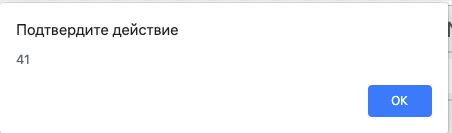
Что? Чего? Ладно, это JavaScript. Поговорим лучше, как мы могли бы избежать такого странного вывода.
Надо было писать на Python, он бы по-человечески предупредил нас об ошибке
. Нам надо было после каждого подозрительного момента сделать вывод типа переменных и смотреть, в каком состоянии находится наш массив.
Вариант кода, в котором вероятность неожиданного вывода снижена:
let input_number = prompt("Введите количество переменных");
console.log(typeof(input_number));
let numbers = [];
function toArray(input_number){
for (let i = 0; i < input_number; i++) {
let x = prompt(`Введите значение ${i}`);
numbers.push(x);
}
}
toArray(input_number);
console.log(numbers);
function toAverage(numbers){
let sum = 0;
for (let i = 0; i < numbers.length; i++) {
sum += numbers[i];
}
return sum/numbers.length;
}
console.log(typeof(toAverage(numbers)));
alert(toAverage(numbers));
Иными словами, все подозрительные места, в которых что-то могло пойти не так, я вывел в консоль, чтобы убедиться, что все идет так, как я ожидаю. Конечно, данные console.log — детские игрушки и в норме, естественно, нужно изучить любую приличную библиотеку для тестирования. Например эту. Результат этой отладочной программы можно увидеть в инструментах разработчика здесь. Как починить, я думаю, вопросов не будет, но если если интересно, то вот (и да, это можно сделать просто двумя плюсами).

Шаг вперед: осваиваем Chrome Dev Tools
Дебаг с использованием console.log в 2019 — это уже несколько архаичная штука (но мы все равно ее никогда ее не забудем, она уже нам как родная). Каждый разработчик, который мечтает носить гордое звание профессионала, должен освоить богатый инструментарий современных средств разработки.
Попробуем починить проблемные места в нашем коде с помощью Dev Tools. Если нужна документация с примерами, всё можно прочитать вот здесь. А мы попробуем разобрать предыдущий пример с помощью Dev Tools.
Итак, открываем пример. У нас явно запрятался какой-то баг в коде, но как понять, в какой момент JavaScript начал что-то неправильно считать?
Правильно, оборачиваем эту радость тестами на тип переменной, это же очень просто
Идем во вкладку Sources в инструментах разработчика. Откройте файл code.js. У вас будут 3 части: первая слева, в которой отображается список файлов и вторая — в которой у нас отображается код. Но больше всего информации мы сможете почерпнуть из третьей части снизу, в которой отображается ход выполнения нашего кода. Давайте поставим breakpoint на 15 строчке (для этого надо щелкнуть по номеру строки в окне, где у нас отображается код, после чего у вас появится голубая метка). Перезапустите страницу, и введите любые значения в нашу программу.
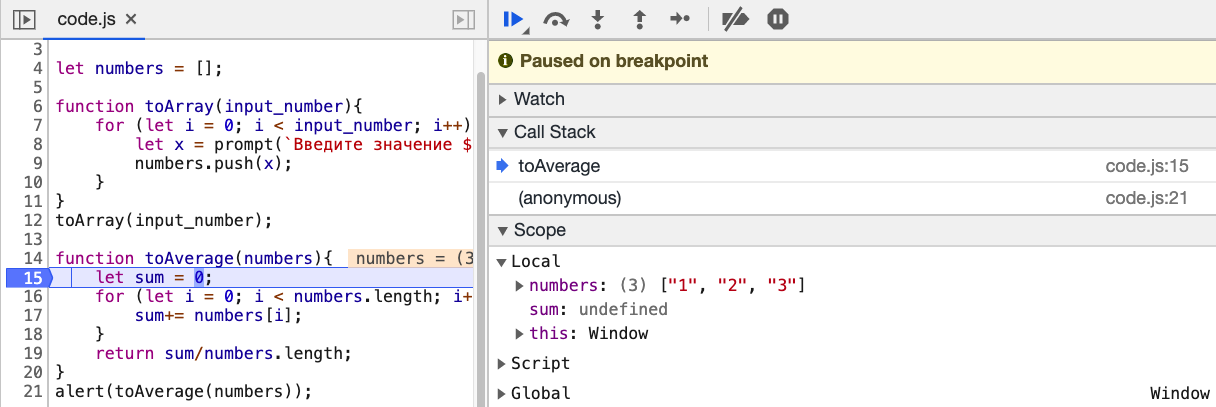
Теперь вы можете вытащить из нижней панели debug массу полезной информации. Вы обнаружите, что JS не особенно задумываясь над типом переменных
ведь статистические языки тупо лучше и нужно писать только на них, чтобы получать предсказуемо работающие и быстрые программы
складывает переменные в виде строки в наш массив. Теперь, осознав картину происходящего, мы можем принять контрмеры.
Учимся перехватывать ошибки

Конструкция try… catch встречается во всех современных языках программирования. Зачем эта синтаксическая конструкция нужна практически? Дело в том, что при возникновении ошибки в коде, он останавливает свое выполнение на месте ошибки — и все, дальнейшие инструкции интерпретатор не исполнит. В реально работающем приложении, из нескольких сотен строчек кода, нас это не устроит. И предположим, что мы хотим перехватить код ошибки, передать разработчику ее код, и продолжить выполнение дальше.
Наша статья была бы неполной без краткого описания основных типов ошибки в JavaScript:
- Error — общий конструктор объекта ошибки.
- EvalError — тип ошибки, появляющийся во время ошибок исполнения
eval(), но не синтаксических, а при неправильном использовании этой глобальной функции. - RangeError — происходит, когда вы выходите за пределы допустимого диапазона в исполнении вашего кода.
- ReferenceError — происходит, когда вы пытаетесь вызвать переменную, функцию или объект, которых нет в программе.
- SyntaxError — ошибка в синтаксисе.
- TypeError — происходит при попытке создания объекта с неизвестным типом переменной или при попытке вызова несуществующего метода
- URIError — редко встречающий код, который возникает при неправильном использовании методов encodeURL и DecodeURL.
Здорово, давайте теперь немного попрактикуемся и посмотрим на практике, где мы можем использовать конструкцию try… catch. Сам принцип работы данной конструкции совсем простой — интерпретатор пытается исполнить код внутри try, если получается — то все продолжается, словно этой конструкции никогда не было. А вот если произошла ошибка — мы ее перехватываем и можем обработать, к примеру, сказав пользователю, где именно он допустил промах.
Давайте создадим самый простой калькулятор (даже калькулятором его называть громко, я бы сказал:«исполнитель введенных выражений»). Его интерактивный пример можно найти здесь. Хорошо, давайте теперь посмотрим на наш код:
let input = document.querySelector("#enter");
let button = document.querySelector("#enter_button");
let result_el = document.querySelector("#result ");
button.onclick = () => {
try {
let result = eval(input.value); //пробуем, если все будет корректно, тогда catch не сработает
result_el.innerHTML = result;
} catch (error) {
console.error(error.name);
result_el.innerHTML = "Вы что-то не то ввели, молодой человек<br> Подумайте еще раз";
//можно пользователю объяснять, что он не прав, если он допустил ошибку
//хотя естественно пользователю лучше не давать эту возможность))
}
}
Если вы попробуете ввести корректное математическое выражение, то все сработает нормально. Однако попробуйте ввести некорректное выражение, к примеру, просто строку, тогда программа выведет пользователю соответствующее предупреждение.
Надеюсь, вы прочитаете еще статьи, в которых объясняются другие части перехвата ошибок, такие например, как эта , чтобы расширить свое понимание в отладке программ, и изучите другие синтаксические конструкции, такие как finally, а также генерацию своих собственных ошибок.
На этом все. Надеюсь, эта статья оказалась полезна и теперь, при отладке приложений, вы будете чувствовать себя более уверенно. Мы разобрали типичные ошибки от самых элементарных, которые делают новички программирующие на JS всего несколько дней, до техники перехвата ошибок, которые применяют более продвинутые разработчики.
И по традиции, полезные ссылочки:
- Пишем собственный фреймворк для тестирования. Полезно для общего понимания стратегии тестирования.
- Полная документация по ошибкам, в том числе и экспериментальные фичи
- Невероятно полезная статья на MDN, которая описывает большинство проблем, которые возникают в начале разработки на JS: отладку, полифиллы, дебагер и многое другое
На этом все. Ждем ваши комментарии и приглашаем на бесплатный вебинар, где поговорим о возможностях фреймворка SvelteJS.
Зачем разработчики на регулярной основе переписывают свой и чужой код, не добавляя туда ни одной новой функции и не исправляя ни одной ошибки?
Сейчас все расскажу. Поговорим о чудесной процедуре рефакторинга, спасающей тысячи программистов от бессонных ночей и психологических травм.
Что такое рефакторинг
Под рефакторингом подразумевается переработка уже существующего кода с целью упростить его. Упростить не с функциональной точки зрения, чтобы увеличить производительность ПО и сократить количество потенциальных ошибок, а с точки зрения визуального восприятия. Проще говоря, рефакторинг – превращение нагромождения кода в что-то удобоваримое и более читаемое, чтобы другие программисты не мучались в попытках понять, какая функция к чему относится, как с ней работать, какой результат она выдает и т.п.

Рефакторинг позволяет приблизиться к четкому соблюдению одного из важнейших правил написания кода – он должен быть «красивым» и лаконичным.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Определение Мартина Фаулера
Вопрос «Что такое рефакторинг?» часто возникает у программистов-новичков, а иногда и у более опытных разработчиков. Поэтому он регулярно всплывает на форумах в духе StackOverflow.
Там в качестве ответа на вопрос приводят цитату из книги «Refactoring: Improving the Design of Existing Code» за авторством Мартина Фаулера:
Рефакторинг – это контролируемая техника совершенствования структуры существующего кода. Суть рефакторинга заключается во внесении серии мелких изменения (с сохранением функциональности приложения), каждое из которых «слишком мелкое, чтобы тратить на него время». Тем не менее эффект от внесения всех этих изменений достаточно ощутимый.
Также в этой книге рекомендуется выполнять рефакторинг пошагово, чтобы исключить появление ошибок. А пользователи StackOverflow советуют каждое изменение сопровождать применением юнит-тестов. И хотя многие отрицают столь тесную связь этих двух операций, большинство опытных кодеров все же не упускают возможности задействовать тесты на любом из этапов разработки или модификации ПО.
Что не является рефакторингом?
Те, кто не углубляется в изучение терминологии, часто принимает за рефакторинг целую серию других действий, отчасти похожих на рефакторинг. В их числе:
-
простое переписывание кода,
-
дебаггинг,
-
улучшения функциональной составляющей ПО,
-
оптимизация.
Первое имеет смысл при создании нового ПО или самотренировок.
Второе подразумевает поиск ошибок и их устранение, сам код при этом необязательно должен становиться проще или понятнее для других разработчиков. Цель дебаггинга – заставить программу работать корректно, не наплодив при этом новых ошибок.
Третье может быть связано с модификацией «читаемости» кода, но это необязательная составляющая. Важно сделать ПО лучше с пользовательской точки зрения, а не с точки зрения разработчика.
Четвертый термин чаще всего путают с рефакторингом, потому что они как раз иногда выполняются параллельно, но оптимизация – фокус на производительности программы. Код может стать даже сложнее, но ПО должно работать шустрее.
Но ни что из перечисленного выше не является рефакторингом, и зачастую каждая из процедур выполняется отдельно (за редким исключением, когда некорректное поведение ПО вызвано неправильно написанным кодом).
Зачем нужен рефакторинг?
Есть гласное правило для всех программистов – код должен быть лаконичным, хорошо структурированным и понятным для разработчиков, работающих с ним. Проблема в том, что написать такой код с первого раза – очень сложная задача. Каким бы опытным ни был программист, начальство заставит его спешить, заказчики будут менять требования по ходу разработки, а иногда код будет становиться непонятным из-за банального недосыпа. Более того, сами языки программирования регулярно совершенствуются и обретают новые возможности, позволяя заметно сократить количество кода. Поэтому и нужен рефакторинг.
Ожидаемые преимущества рефакторинга:
-
Улучшение объективной читаемости кода за счет его сокращения или реструктуризации.
-
Провоцирование разработчиков на более вдумчивое написание ПО с соблюдением заданной стилистики и критериев.
-
Подготовка плацдарма для создания переиспользуемых кусков кода.
-
Упрощение поиска ошибок в большом объеме кода.
Грамотно выполненный рефакторинг кода позволяет «продлить» жизнь проекту и сделать легче трудовую деятельность программистов из будущего.
В каких случаях нужен рефакторинг?
Есть ряд ситуаций, которые «кричат» о необходимости рефакторинга:
-
Попытка внести любое улучшение или добавление новой функции в приложение превращается в проблему для разработчиков, а сроки выполнения, на первый взгляд, несложных операций затягиваются на неадекватный срок из-за того, что база кода напоминает дебри.
-
Сроки добавления новых функций в приложение на постоянной основе становятся размытыми, потому что разработчикам приходится закладывать время на анализ кода.
-
Приходится выполнять идентичные процедуры в разных участках кода (объектах, классах) вместо того, чтобы внести изменение в одном классе, и оно возымело бы эффект в других участках ПО.
-
Код не соответствует общепризнанным в компании практикам оформления, из-за чего не может использоваться для дальнейшей разработки с учетом ранее установленных требований.
Впрочем, есть и другие, более индивидуальные факторы, подвигающие команду программистов на рефакторинг кода. Это зависит и от особенностей работы в конкретной компании, где серьезным поводом для рефакторинга может считаться даже неправильное количество пробелов в начале строки.
На какие аспекты кода направлен рефакторинг?
Четкой структуры рефакторинга не существует. Можно вносить любые изменения, улучшающие читаемость кода. Но обычно в поле зрения сразу же попадают следующие представители «плохого» кода…
Неиспользуемый код
В коде часто остается мусор в духе незадействованных переменных или методов. В базе кода висит текст, никак не влияющий на работу приложения, и его нужно удалить, чтобы не создавать путаницу. В этом, кстати, помогают современные тестовые редакторы, например VS Code.
Дубликаты
При длительной разработке сложного ПО можно замешкать и наплодить одинаковых функций или переменных. А еще в объектах могут существовать идентичные методы, но описанные в каждом отдельно. Такой код лучше вынести в родительский класс.
Переменные и функции названы неадекватно
К программистам предъявляются требования по оформлению кода, одно из ключевых – необходимость давать понятные имена переменным и функциям, чтобы без дополнительных комментариев можно было понять, что делает тот или иной метод. Никаких букв и случайных наборов символов.

Код, из которого невозможно что-либо понять
Избыточное количества текста в одном методе
Лучше поделить функцию на несколько составных частей, чем создавать одну слишком большую и трудночитаемую. Если ваша функция состоит из 70 строк кода – это не норма. Это же касается классов и других объектов.
Вот так может выглядеть функция преобразования текста в массиве

Та же функция, но описанная одной строкой
Избыточное количество комментариев
Если приходится пояснять каждую строчку кода, то с кодом что-то не так. Программист, который видит ваш код первый раз, должен разобраться в нем быстро, без необходимости начитывать целые тома комментариев и документации.
Некорректно оформленные куски кода
У кода есть правила визуального оформления. Нужно соблюсти корректное число пробелов от начала строки, правильно «вкладывать» одни компоненты в другие, соблюдать правила написания функций и циклов.
Для решения этих задач можно использовать специальные плагины. Расширение ESLint поможет писать красивый код, соответствующий общепринятым стандартам, а плагин Prettier самостоятельно расставит все запятые, пробелы и т.п., чтобы код отлично смотрелся в любом текстовом редакторе.
Методики рефакторинга
Разработчики и специалисты в области рефакторинга часто называют десятки различных тактик переработки кода, но почти все они четко привязаны к изменяемому компоненту (объекту, функции и т.п.), поэтому нет смысла их все перечислять. Обобщая, есть три основных способа выполнить рефакторинг:
-
Red-Green-Refactor. Это некий аналог «На старт, внимание, марш!». Находим кусок кода для переработки, пишем юнит-тест, переходим к переписыванию.
-
Абстракция. Эта стратегия используется, когда нужно почистить дубликаты. Разработчиками придумываются абстрактные классы или другие классы высокого уровня, чтобы вынести туда повторяющиеся методы.
-
Фрагментация. Стратегия изменения кода с целью увеличить количество компонентов, но сделать сами компоненты меньше. Что-то в духе методик планирования задач, часто применяемых для повышения личной эффективности.
Сложности рефакторинга
Менять рабочий код всегда опасно. Даже мелкие изменения, кажущиеся суперлогичными и неопасными, иногда ломают приложение. Из-за этого рефакторинг и сопровождают тестами, потому что некоторые горе-программисты без особого внимания к деталям переписывают целые классы, а потом не могут включить ПО, потому что оно больше не работает.
Опытные разработчики рекомендуют следующие практики:
-
Делать рефакторинг как рутину. Не раз в полгода, а регулярно, но по чуть-чуть. Тогда он будет отнимать меньше времени и не будет отвлекать от более важных задач.
-
Не делать рефакторинг священной коровой, из-за которой откладываются более важные задачи в духе внедрения новых функций или дебаггинга.
-
Не пренебрегать рефакторингом, даже если трудитесь над всей базой кода самостоятельно. Если вы что-нибудь со временем забудете, то устанете разбираться в собственном коде. Не зря про это сочинили сотни однотипных шуток еще во времена bash.org.
Вместо заключения
Как видите, рефакторинг – это хоть и простое явление с точки зрения идеи, но необходимое для избежания задержек в разработке и сохранения нервных клеток коллег. Главное – сопровождайте каждый значимый этап рефакторинга тестами, чтобы сохранить «перерабатываемый» код в рабочем состоянии. Также стоит использовать системы контроля версий, каждое новшество отправляя отдельным коммитом в хранилище наподобие GitHub или GitLab. Это поможет в случае чего «откатить» неаккуратный рефакторинг и попытаться снова. Ведь самый понятный и читаемый в мире код все еще должен выполнять свои задачи, а не просто радовать взгляд искушенных кодеров.
Обучиться рефакторингу можно на курсах по программированию общего назначения у EPAM и Hexlet, а также на узкоспециализированных ресурсах в духе Refactoring Guru.