
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code, (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complicated function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]

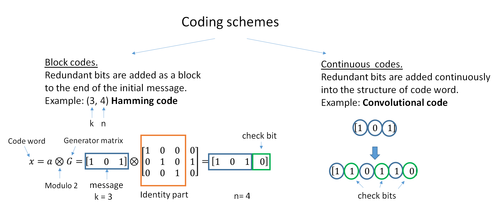
A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.

A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- Algebraic geometry code
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most
 bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters


See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
- Linear code
- Quantum error correction
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
Искать ошибки в программах — непростая задача. Здесь нет никаких готовых методик или рецептов успеха. Можно даже сказать, что это — искусство. Тем не менее есть общие советы, которые помогут вам при поиске. В статье описаны основные шаги, которые стоит предпринять, если ваша программа работает некорректно.
Шаг 1: Занесите ошибку в трекер
После выполнения всех описанных ниже шагов может так случиться, что вы будете рвать на себе волосы от безысходности, все еще сидя на работе, когда поймете, что:
- Вы забыли какую-то важную деталь об ошибке, например, в чем она заключалась.
- Вы могли делегировать ее кому-то более опытному.
Трекер поможет вам не потерять нить размышлений и о текущей проблеме, и о той, которую вы временно отложили. А если вы работаете в команде, это поможет делегировать исправление коллеге и держать все обсуждение в одном месте.
Вы должны записать в трекер следующую информацию:
- Что делал пользователь.
- Что он ожидал увидеть.
- Что случилось на самом деле.
Это должно подсказать, как воспроизвести ошибку. Если вы не сможете воспроизвести ее в любое время, ваши шансы исправить ошибку стремятся к нулю.
Шаг 2: Поищите сообщение об ошибке в сети
Если у вас есть сообщение об ошибке, то вам повезло. Или оно будет достаточно информативным, чтобы вы поняли, где и в чем заключается ошибка, или у вас будет готовый запрос для поиска в сети. Не повезло? Тогда переходите к следующему шагу.
Шаг 3: Найдите строку, в которой проявляется ошибка
Если ошибка вызывает падение программы, попробуйте запустить её в IDE под отладчиком и посмотрите, на какой строчке кода она остановится. Совершенно необязательно, что ошибка будет именно в этой строке (см. следующий шаг), но, по крайней мере, это может дать вам информацию о природе бага.
Шаг 4: Найдите точную строку, в которой появилась ошибка
Как только вы найдете строку, в которой проявляется ошибка, вы можете пройти назад по коду, чтобы найти, где она содержится. Иногда это может быть одна и та же строка. Но чаще всего вы обнаружите, что строка, на которой упала программа, ни при чем, а причина ошибки — в неправильных данных, которые появились ранее.
Если вы отслеживаете выполнение программы в отладчике, то вы можете пройтись назад по стектрейсу, чтобы найти ошибку. Если вы находитесь внутри функции, вызванной внутри другой функции, вызванной внутри другой функции, то стектрейс покажет список функций до самой точки входа в программу (функции main()). Если ошибка случилась где-то в подключаемой библиотеке, предположите, что ошибка все-таки в вашей программе — это случается гораздо чаще. Найдите по стектрейсу, откуда в вашем коде вызывается библиотечная функция, и продолжайте искать.
Шаг 5: Выясните природу ошибки
Ошибки могут проявлять себя по-разному, но большинство из них можно отнести к той или иной категории. Вот наиболее частые.
- Ошибка на единицу
Вы начали циклforс единицы вместо нуля или наоборот. Или, например, подумали, что метод.count()или.length()вернул индекс последнего элемента. Проверьте документацию к языку, чтобы убедиться, что нумерация массивов начинается с нуля или с единицы. Эта ошибка иногда проявляется в виде исключенияIndex out of range. - Состояние гонки
Ваш процесс или поток пытается использовать результат выполнения дочернего до того, как тот завершил свою работу. Ищите использованиеsleep()в коде. Возможно, на мощной машине дочерний поток выполняется за миллисекунду, а на менее производительной системе происходят задержки. Используйте правильные способы синхронизации многопоточного кода: мьютексы, семафоры, события и т. д. - Неправильные настройки или константы
Проверьте ваши конфигурационные файлы и константы. Я однажды потратил ужасные 16 часов, пытаясь понять, почему корзина на сайте с покупками виснет на стадии отправки заказа. Причина оказалась в неправильном значении в/etc/hosts, которое не позволяло приложению найти ip-адрес почтового сервера, что вызывало бесконечный цикл в попытке отправить счет заказчику. - Неожиданный null
Бьюсь об заклад, вы не раз получали ошибку с неинициализированной переменной. Убедитесь, что вы проверяете ссылки наnull, особенно при обращении к свойствам по цепочке. Также проверьте случаи, когда возвращаемое из базы данных значениеNULLпредставлено особым типом. - Некорректные входные данные
Вы проверяете вводимые данные? Вы точно не пытаетесь провести арифметические операции с введенными пользователем строками? - Присваивание вместо сравнения
Убедитесь, что вы не написали=вместо==, особенно в C-подобных языках. - Ошибка округления
Это случается, когда вы используете целое вместоDecimal, илиfloatдля денежных сумм, или слишком короткое целое (например, пытаетесь записать число большее, чем 2147483647, в 32-битное целое). Кроме того, может случиться так, что ошибка округления проявляется не сразу, а накапливается со временем (т. н. Эффект бабочки). - Переполнение буфера и выход за пределы массива
Проблема номер один в компьютерной безопасности. Вы выделяете память меньшего объема, чем записываемые туда данные. Или пытаетесь обратиться к элементу за пределами массива. - Программисты не умеют считать
Вы используете некорректную формулу. Проверьте, что вы не используете целочисленное деление вместо взятия остатка, или знаете, как перевести рациональную дробь в десятичную и т. д. - Конкатенация строки и числа
Вы ожидаете конкатенации двух строк, но одно из значений — число, и компилятор пытается произвести арифметические вычисления. Попробуйте явно приводить каждое значение к строке. - 33 символа в varchar(32)
Проверяйте данные, передаваемые вINSERT, на совпадение типов. Некоторые БД выбрасывают исключения (как и должны делать), некоторые просто обрезают строку (как MySQL). Недавно я столкнулся с такой ошибкой: программист забыл убрать кавычки из строки перед вставкой в базу данных, и длина строки превысила допустимую как раз на два символа. На поиск бага ушло много времени, потому что заметить две маленькие кавычки было сложно. - Некорректное состояние
Вы пытаетесь выполнить запрос при закрытом соединении или пытаетесь вставить запись в таблицу прежде, чем обновили таблицы, от которых она зависит. - Особенности вашей системы, которых нет у пользователя
Например: в тестовой БД между ID заказа и адресом отношение 1:1, и вы программировали, исходя из этого предположения. Но в работе выясняется, что заказы могут отправляться на один и тот же адрес, и, таким образом, у вас отношение 1:многим.
Если ваша ошибка не похожа на описанные выше, или вы не можете найти строку, в которой она появилась, переходите к следующему шагу.
Шаг 6: Метод исключения
Если вы не можете найти строку с ошибкой, попробуйте или отключать (комментировать) блоки кода до тех пор, пока ошибка не пропадет, или, используя фреймворк для юнит-тестов, изолируйте отдельные методы и вызывайте их с теми же параметрами, что и в реальном коде.
Попробуйте отключать компоненты системы один за другим, пока не найдете минимальную конфигурацию, которая будет работать. Затем подключайте их обратно по одному, пока ошибка не вернется. Таким образом вы вернетесь на шаг 3.
Шаг 7: Логгируйте все подряд и анализируйте журнал
Пройдитесь по каждому модулю или компоненту и добавьте больше сообщений. Начинайте постепенно, по одному модулю. Анализируйте лог до тех пор, пока не проявится неисправность. Если этого не случилось, добавьте еще сообщений.
Ваша задача состоит в том, чтобы вернуться к шагу 3, обнаружив, где проявляется ошибка. Также это именно тот случай, когда стоит использовать сторонние библиотеки для более тщательного логгирования.
Шаг 8: Исключите влияние железа или платформы
Замените оперативную память, жесткие диски, поменяйте сервер или рабочую станцию. Установите обновления, удалите обновления. Если ошибка пропадет, то причиной было железо, ОС или среда. Вы можете по желанию попробовать этот шаг раньше, так как неполадки в железе часто маскируют ошибки в ПО.
Если ваша программа работает по сети, проверьте свитч, замените кабель или запустите программу в другой сети.
Ради интереса, переключите кабель питания в другую розетку или к другому ИБП. Безумно? Почему бы не попробовать?
Если у вас возникает одна и та же ошибка вне зависимости от среды, то она в вашем коде.
Шаг 9: Обратите внимание на совпадения
- Ошибка появляется всегда в одно и то же время? Проверьте задачи, выполняющиеся по расписанию.
- Ошибка всегда проявляется вместе с чем-то еще, насколько абсурдной ни была бы эта связь? Обращайте внимание на каждую деталь. На каждую. Например, проявляется ли ошибка, когда включен кондиционер? Возможно, из-за этого падает напряжение в сети, что вызывает странные эффекты в железе.
- Есть ли что-то общее у пользователей программы, даже не связанное с ПО? Например, географическое положение (так был найден легендарный баг с письмом за 500 миль).
- Ошибка проявляется, когда другой процесс забирает достаточно большое количество памяти или ресурсов процессора? (Я однажды нашел в этом причину раздражающей проблемы «no trusted connection» с SQL-сервером).
Шаг 10: Обратитесь в техподдержку
Наконец, пора попросить помощи у того, кто знает больше, чем вы. Для этого у вас должно быть хотя бы примерное понимание того, где находится ошибка — в железе, базе данных, компиляторе. Прежде чем писать письмо разработчикам, попробуйте задать вопрос на профильном форуме.
Ошибки есть в операционных системах, компиляторах, фреймворках и библиотеках, и ваша программа может быть действительно корректна. Но шансы привлечь внимание разработчика к этим ошибкам невелики, если вы не сможете предоставить подробный алгоритм их воспроизведения. Дружелюбный разработчик может помочь вам в этом, но чаще всего, если проблему сложно воспроизвести вас просто проигнорируют. К сожалению, это значит, что нужно приложить больше усилий при составлении багрепорта.
Полезные советы (когда ничего не помогает)
- Позовите кого-нибудь еще.
Попросите коллегу поискать ошибку вместе с вами. Возможно, он заметит что-то, что вы упустили. Это можно сделать на любом этапе. - Внимательно просмотрите код.
Я часто нахожу ошибку, просто спокойно просматривая код с начала и прокручивая его в голове. - Рассмотрите случаи, когда код работает, и сравните их с неработающими.
Недавно я обнаружил ошибку, заключавшуюся в том, что когда вводимые данные в XML-формате содержали строкуxsi:type='xs:string', все ломалось, но если этой строки не было, все работало корректно. Оказалось, что дополнительный атрибут ломал механизм десериализации. - Идите спать.
Не бойтесь идти домой до того, как исправите ошибку. Ваши способности обратно пропорциональны вашей усталости. Вы просто потратите время и измотаете себя. - Сделайте творческий перерыв.
Творческий перерыв — это когда вы отвлекаетесь от задачи и переключаете внимание на другие вещи. Вы, возможно, замечали, что лучшие идеи приходят в голову в душе или по пути домой. Смена контекста иногда помогает. Сходите пообедать, посмотрите фильм, полистайте интернет или займитесь другой проблемой. - Закройте глаза на некоторые симптомы и сообщения и попробуйте сначала.
Некоторые баги могут влиять друг на друга. Драйвер для dial-up соединения в Windows 95 мог сообщать, что канал занят, при том что вы могли отчетливо слышать звук соединяющегося модема. Если вам приходится держать в голове слишком много симптомов, попробуйте сконцентрироваться только на одном. Исправьте или найдите его причину и переходите к следующему. - Поиграйте в доктора Хауса (только без Викодина).
Соберите всех коллег, ходите по кабинету с тростью, пишите симптомы на доске и бросайте язвительные комментарии. Раз это работает в сериалах, почему бы не попробовать?
Что вам точно не поможет
- Паника
Не надо сразу палить из пушки по воробьям. Некоторые менеджеры начинают паниковать и сразу откатываться, перезагружать сервера и т. п. в надежде, что что-нибудь из этого исправит проблему. Это никогда не работает. Кроме того, это создает еще больше хаоса и увеличивает время, необходимое для поиска ошибки. Делайте только один шаг за раз. Изучите результат. Обдумайте его, а затем переходите к следующей гипотезе. - «Хелп, плиииз!»
Когда вы обращаетесь на форум за советом, вы как минимум должны уже выполнить шаг 3. Никто не захочет или не сможет вам помочь, если вы не предоставите подробное описание проблемы, включая информацию об ОС, железе и участок проблемного кода. Создавайте тему только тогда, когда можете все подробно описать, и придумайте информативное название для нее. - Переход на личности
Если вы думаете, что в ошибке виноват кто-то другой, постарайтесь по крайней мере говорить с ним вежливо. Оскорбления, крики и паника не помогут человеку решить проблему. Даже если у вас в команде не в почете демократия, крики и применение грубой силы не заставят исправления магическим образом появиться.
Ошибка, которую я недавно исправил
Это была загадочная проблема с дублирующимися именами генерируемых файлов. Дальнейшая проверка показала, что у файлов различное содержание. Это было странно, поскольку имена файлов включали дату и время создания в формате yyMMddhhmmss. Шаг 9, совпадения: первый файл был создан в полпятого утра, дубликат генерировался в полпятого вечера того же дня. Совпадение? Нет, поскольку hh в строке формата — это 12-часовой формат времени. Вот оно что! Поменял формат на yyMMddHHmmss, и ошибка исчезла.
Перевод статьи «How to fix bugs, step by step»
Коды, исправляющие ошибки. Варианты программной реализации
Время на прочтение
2 мин
Количество просмотров 7.7K
Сразу прошу не «прогонять пинками», я старался, и это может быть полезно для таких же школьников как я.
Коды, исправляющие ошибки.
Существует множество кодов, исправляющих ошибки в двоичном коде. Это очень полезно, потому что множество информации портиться при хранении или передачи информации. Одним из примеров данных кодов можно привести «код Хемминга»(Подробно о нём уже написал другой автор http://habrahabr.ru/post/140611/). Они добавляют к бинарному тексту дополнительные, кодовые биты, при помощи которых мы сможем исправить полученные ошибки.
Каждый такой код имеет две характеристики – k и n. Такой код называется (n,k)-кодом. Здесь “n” обозначает общее количество символов в блоке закодированного текста, а “k” – число значимых символов.
Например, простейшим кодом является код с повторениями. В этом коде к каждому символу двоичного кода добавляется по n-1 кодовых битов, которые дублируют, значимый символ и в последствие мы сможем исправить ошибку. Например (3,1)-код дописывает к каждому символу в двоичной системе два таких же и при зашумлении, если меняется один символ из блока, то остаётся 2 одинаковых и по ним мы возвращаем исходный символ.
Описание проекта
В моей программе мы использовали 2 вида таких кодов, это (3,1)-код с повторением и (7,4)-код, который является одним из так называемых «кодов Хэмминга». Однако моя программа написана так, что в неё без особых усилий и затрат времени можно добавить любой другой код типа (n,k).
Для того чтобы осуществить свою цель, мне потребовалось переводить обычный текст в бинарный вид, затем добавлять кодовые биты, помогающие мне восстановить текст. И для того, чтобы с эмитировать ошибки в бинарном коде, я написал процедуру, зашумляющую текст (совершающую ошибки в бинарном коде).
Затем я переводил в обычный текст зашумлённый код, чтобы продемонстрировать пользователю действенность зашумления. Следующим действием я исправлял оставшийся у мой зашумленный код и переводили его в обычный текст.
Для создания своей программы я использовал справку программы Pascal, мои собственные знания и «великий» Google.com.
Выводы и перспективы.
Я создал программу, реализующую два кода исправляющих ошибки в тексте, полученные при переносе или длительном хранении файла с информацией. А так же улучшил свои навыки в языке программирования Pascal.
Исходные коды
Прошу прощения за «еврейский код» и за турбо паскаль тоже(нормальный компьютер сломался, писал на пеньтиуме втором). Код может помочь школьникам на уроках информатике и олимпиадникам.
«Перемежитель» перенаправляется сюда. Для оптоволоконного устройства см. Оптический перемежитель .
В вычислительной , телекоммуникационной , теории информации и теории кодирования , в код коррекции ошибок , иногда кода коррекции ошибок ( ECC ) используется для контроля ошибок в данных по ненадежным или зашумленных каналов связи . Основная идея заключается в том, что отправитель кодирует сообщение с избыточной информацией в форме ECC. Избыточность позволяет получателю обнаруживать ограниченное количество ошибок, которые могут возникнуть в любом месте сообщения, и часто исправлять эти ошибки без повторной передачи. Американский математик Ричард Хэмминг был пионером в этой области в 1940-х годах и изобрел первый исправляющий ошибки код в 1950 году: код Хэмминга (7,4) .
ECC отличается от обнаружения ошибок тем, что обнаруженные ошибки можно исправлять, а не просто обнаруживать. Преимущество состоит в том, что системе, использующей ECC, не требуется обратный канал для запроса повторной передачи данных при возникновении ошибки. Обратной стороной является то, что к сообщению добавляются фиксированные накладные расходы, что требует большей полосы пропускания прямого канала. Таким образом, ECC применяется в ситуациях, когда повторные передачи являются дорогостоящими или невозможными, например, при односторонних каналах связи и при многоадресной передаче на несколько приемников . Соединения с большой задержкой также выигрывают; в случае спутника, вращающегося вокруг Урана , повторная передача из-за ошибок может вызвать задержку в пять часов. Информация ECC обычно добавляется к запоминающим устройствам для восстановления поврежденных данных, широко используется в модемах и используется в системах, где первичной памятью является память ECC .
Обработка ECC в приемнике может применяться к цифровому потоку битов или при демодуляции несущей с цифровой модуляцией. Для последнего ECC является неотъемлемой частью начального аналого-цифрового преобразования в приемнике. Декодер Витерби реализует алгоритм мягкого решения для демодуляции цифровых данных из аналогового сигнала на фоне шума. Многие кодеры / декодеры ECC могут также генерировать сигнал частоты ошибок по битам (BER), который можно использовать в качестве обратной связи для точной настройки аналоговой принимающей электроники.
Максимальная доля ошибок или пропущенных битов, которые могут быть исправлены, определяется конструкцией кода ECC, поэтому разные коды исправления ошибок подходят для разных условий. Как правило, более сильный код вызывает большую избыточность, которую необходимо передавать с использованием доступной полосы пропускания, что снижает эффективную скорость передачи данных при одновременном улучшении принимаемого эффективного отношения сигнал / шум. Кодирования шумным канала теорема о Клода Шеннона может быть использована для вычисления максимальной достижимой пропускной способности канала связи для заданной максимальной допустимой вероятности ошибки. Это устанавливает границы теоретической максимальной скорости передачи информации канала с некоторым заданным базовым уровнем шума. Однако это доказательство неконструктивно и, следовательно, не дает представления о том, как создать код, обеспечивающий производительность. После многих лет исследований некоторые передовые системы ECC по состоянию на 2016 год очень близко подошли к теоретическому максимуму.
Прямое исправление ошибок
В связи , теории информации и теории кодирования , с прямым исправлением ошибок ( FEC ) или канального кодирования является метод , используемый для контроля ошибок в передаче данных по ненадежным или зашумленных каналов связи . Основная идея состоит в том, что отправитель кодирует сообщение избыточным способом, чаще всего с помощью ECC.
Избыточность позволяет получателю обнаруживать ограниченное количество ошибок, которые могут возникнуть в любом месте сообщения, и часто исправлять эти ошибки без повторной передачи. FEC дает приемнику возможность исправлять ошибки без необходимости использования обратного канала для запроса повторной передачи данных, но за счет фиксированной более высокой полосы пропускания прямого канала. Поэтому FEC применяется в ситуациях, когда повторная передача является дорогостоящей или невозможной, например, при односторонних каналах связи и при передаче на несколько приемников в многоадресной передаче . Информация FEC обычно добавляется в устройства массовой памяти (магнитные, оптические и твердотельные / флеш-накопители), чтобы обеспечить восстановление поврежденных данных, широко используется в модемах , используется в системах, где первичной памятью является память ECC, и в ситуациях вещания, где приемник не имеет возможности запрашивать повторную передачу, иначе это может вызвать значительную задержку. Например, в случае спутника, вращающегося вокруг Урана , повторная передача из-за ошибок декодирования может вызвать задержку не менее 5 часов.
Обработка FEC в приемнике может применяться к цифровому битовому потоку или при демодуляции несущей с цифровой модуляцией. Для последнего FEC является неотъемлемой частью начального аналого-цифрового преобразования в приемнике. Декодер Витерби реализует алгоритм мягкого решения для демодуляции цифровых данных из аналогового сигнала на фоне шума. Многие кодеры FEC могут также генерировать сигнал частоты ошибок по битам (BER), который можно использовать в качестве обратной связи для точной настройки аналоговой приемной электроники.
Максимальная доля ошибок или недостающих битов, которые могут быть исправлены, определяется конструкцией ECC, поэтому разные коды прямого исправления ошибок подходят для разных условий. Как правило, более сильный код вызывает большую избыточность, которую необходимо передавать с использованием доступной полосы пропускания, что снижает эффективную скорость передачи данных при одновременном улучшении принимаемого эффективного отношения сигнал / шум. Шумная-канальное кодирование теоремы Клод Шеннон отвечает на вопрос о том, сколько трафика остался для передачи данных при использовании наиболее эффективного кода , который превращает вероятность ошибки декодирования к нулю. Это устанавливает границы теоретической максимальной скорости передачи информации канала с некоторым заданным базовым уровнем шума. Его доказательство неконструктивно и, следовательно, не дает представления о том, как создать код, обеспечивающий производительность. Однако после многих лет исследований некоторые продвинутые системы FEC, такие как полярный код, достигают пропускной способности канала Шеннона в рамках гипотезы кадра бесконечной длины.
Как это работает
ECC достигается путем добавления избыточности к передаваемой информации с использованием алгоритма. Избыточный бит может быть сложной функцией многих исходных информационных битов. Исходная информация может появляться или не появляться буквально в закодированном выводе; коды, которые включают немодифицированный ввод в вывод, являются систематическими , тогда как те, которые не включают, являются несистематичными .
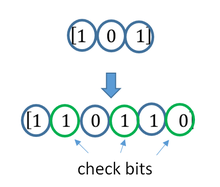
Упрощенный пример ECC — это передача каждого бита данных 3 раза, что известно как код повторения (3,1) . Через шумный канал приемник может видеть 8 версий вывода, см. Таблицу ниже.
| Триплет получил | Интерпретируется как |
|---|---|
| 000 | 0 (без ошибок) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (без ошибок) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
Это позволяет исправить ошибку в любой из трех выборок «большинством голосов» или «демократическим голосованием». Корректирующая способность этого ECC:
- Ошибка до 1 бита триплета, или
- пропущено до 2 битов триплета (случаи не указаны в таблице).
Хотя эта тройная модульная избыточность проста в реализации и широко используется, она является относительно неэффективной ECC. Более совершенные коды ECC обычно проверяют последние несколько десятков или даже несколько последних сотен ранее принятых битов, чтобы определить, как декодировать текущую небольшую группу битов (обычно в группах от 2 до 8 бит).
Усреднение шума для уменьшения ошибок
Можно сказать, что ECC работает путем «усреднения шума»; поскольку каждый бит данных влияет на многие передаваемые символы, искажение одних символов шумом обычно позволяет извлекать исходные пользовательские данные из других, неповрежденных принятых символов, которые также зависят от тех же пользовательских данных.
- Из-за этого эффекта «объединения рисков» цифровые системы связи, использующие ECC, как правило, работают значительно выше определенного минимального отношения сигнал / шум, а вовсе не ниже него.
- Эта тенденция «все или ничего» — эффект обрыва — становится более выраженным по мере использования более сильных кодов, которые ближе подходят к теоретическому пределу Шеннона .
- Перемежение данных, закодированных с помощью ЕСС, может уменьшить свойства «все или ничего» передаваемых кодов ЕСС, когда ошибки канала имеют тенденцию возникать в пакетах. Однако у этого метода есть ограничения; его лучше всего использовать для узкополосных данных.
Большинство систем электросвязи используют код фиксированного канала, рассчитанный на то, чтобы выдерживать ожидаемую частоту ошибок по битам в наихудшем случае , а затем вообще не работают, если частота ошибок по битам становится еще хуже. Однако некоторые системы адаптируются к заданным условиям ошибки канала: некоторые экземпляры гибридного автоматического запроса на повторение используют фиксированный метод ECC, пока ECC может обрабатывать частоту ошибок, а затем переключаются на ARQ, когда частота ошибок становится слишком высокой;
адаптивная модуляция и кодирование используют различные скорости ECC, добавляя больше битов исправления ошибок на пакет, когда в канале более высокие частоты ошибок, или удаляя их, когда они не нужны.
Типы ECC
Краткая классификация кодов исправления ошибок
Двумя основными категориями кодов ECC являются блочные коды и сверточные коды .
- Блочные коды работают с блоками (пакетами) фиксированного размера, состоящими из битов или символов заранее определенного размера. Практические блочные коды обычно могут быть жестко декодированы за полиномиальное время до их длины блока.
- Сверточные коды работают с битовыми или символьными потоками произвольной длины. Чаще всего они декодируются с помощью алгоритма Витерби , хотя иногда используются и другие алгоритмы. Декодирование Витерби обеспечивает асимптотически оптимальную эффективность декодирования с увеличением длины ограничения сверточного кода, но за счет экспоненциально возрастающей сложности. Завершенный сверточный код также является «блочным кодом» в том смысле, что он кодирует блок входных данных, но размер блока сверточного кода, как правило, произвольный, в то время как блочные коды имеют фиксированный размер, определяемый их алгебраическими характеристиками. Типы завершения для сверточных кодов включают «концевую передачу» и «сброс битов».
Есть много типов блочных кодов; Кодирование Рида-Соломона примечательно тем, что оно широко используется на компакт-дисках , DVD и жестких дисках . К другим примерам классических блочных кодов относятся коды Голея , BCH , многомерная четность и коды Хэмминга .
ECC Хэмминга обычно используется для исправления ошибок флэш- памяти NAND . Это обеспечивает исправление однобитовых ошибок и обнаружение двухбитовых ошибок. Коды Хэмминга подходят только для более надежной одноуровневой ячейки (SLC) NAND. Более плотная многоуровневая ячейка (MLC) NAND может использовать многобитовый корректирующий ECC, такой как BCH или Reed-Solomon. NOR Flash обычно не использует никаких исправлений ошибок.
Классические блочные коды обычно декодируются с использованием алгоритмов жесткого решения , что означает, что для каждого входного и выходного сигнала принимается жесткое решение, соответствует ли он единице или нулю. Напротив, сверточные коды обычно декодируются с использованием алгоритмов мягкого решения , таких как алгоритмы Витерби, MAP или BCJR , которые обрабатывают (дискретизированные) аналоговые сигналы и которые обеспечивают гораздо более высокую производительность исправления ошибок, чем декодирование с жестким решением.
Почти все классические блочные коды применяют алгебраические свойства конечных полей . Поэтому классические блочные коды часто называют алгебраическими кодами.
В отличие от классических блочных кодов, которые часто определяют способность обнаружения или исправления ошибок, многие современные блочные коды, такие как коды LDPC, не имеют таких гарантий. Вместо этого современные коды оцениваются с точки зрения их частоты ошибок по битам.
Большинство кодов прямого исправления ошибок исправляют только перевороты битов, но не вставки или удаления битов. В этом случае расстояние Хэмминга является подходящим способом измерения частоты ошибок по битам . Несколько кодов прямого исправления ошибок предназначены для исправления вставки и удаления битов, например, коды маркеров и коды водяных знаков. Расстояние Левенштейна — более подходящий способ измерения частоты ошибок по битам при использовании таких кодов.
Кодовая скорость и компромисс между надежностью и скоростью передачи данных
Основным принципом ECC является добавление избыточных битов, чтобы помочь декодеру узнать истинное сообщение, закодированное передатчиком. Кодовая скорость данной системы ЕСС определяется как отношение между количеством информационных битов и общим количеством битов (т. Е. Информация плюс биты избыточности) в данном коммуникационном пакете. Кодовая скорость, следовательно, является действительным числом. Низкая кодовая скорость, близкая к нулю, подразумевает сильный код, который использует много избыточных битов для достижения хорошей производительности, в то время как большая кодовая скорость, близкая к 1, подразумевает слабый код.
Избыточные биты, защищающие информацию, должны передаваться с использованием тех же коммуникационных ресурсов, которые они пытаются защитить. Это вызывает принципиальный компромисс между надежностью и скоростью передачи данных. В одном крайнем случае сильный код (с низкой кодовой скоростью) может вызвать значительное увеличение SNR приемника (отношение сигнал / шум), уменьшая частоту ошибок по битам, за счет снижения эффективной скорости передачи данных. С другой стороны, без использования какого-либо ECC (т. Е. Кодовая скорость, равная 1), используется полный канал для целей передачи информации за счет того, что биты остаются без какой-либо дополнительной защиты.
Один интересный вопрос заключается в следующем: насколько эффективным с точки зрения передачи информации может быть ECC, имеющий незначительную частоту ошибок декодирования? На этот вопрос ответил Клод Шеннон с его второй теоремой, в которой говорится, что пропускная способность канала — это максимальная скорость передачи данных, достижимая для любого ECC, частота ошибок которого стремится к нулю: его доказательство опирается на гауссовское случайное кодирование, которое не подходит для реального мира. Приложения. Верхняя граница, заданная работой Шеннона, вдохновила на долгий путь к разработке ECC, которые могут приблизиться к конечной границе производительности. Различные коды сегодня могут достигать почти предела Шеннона. Однако ECC, обеспечивающие пропускную способность, обычно чрезвычайно сложно реализовать.
Самые популярные ECC имеют компромисс между производительностью и вычислительной сложностью. Обычно их параметры дают диапазон возможных кодовых скоростей, которые можно оптимизировать в зависимости от сценария. Обычно эта оптимизация выполняется для достижения низкой вероятности ошибки декодирования при минимальном влиянии на скорость передачи данных. Другим критерием оптимизации кодовой скорости является уравновешивание низкой частоты ошибок и количества повторных передач с учетом затрат энергии на связь.
Составные коды ECC для повышения производительности
Классические (алгебраические) блочные коды и сверточные коды часто комбинируются в схемах конкатенированного кодирования, в которых сверточный код, декодированный по Витерби с короткой ограниченной длиной, выполняет большую часть работы, а блочный код (обычно Рида-Соломона) с большим размером символа и длиной блока «стирает» любые ошибки, сделанные сверточным декодером. Однопроходное декодирование с помощью этого семейства кодов с исправлением ошибок может дать очень низкий уровень ошибок, но для условий передачи на большие расстояния (например, в глубоком космосе) рекомендуется итеративное декодирование.
Составные коды стали стандартной практикой в спутниковой связи и связи в дальнем космосе с тех пор, как « Вояджер-2» впервые применил эту технику во время своей встречи с Ураном в 1986 году . Аппарат Galileo использовал итеративные сцепленные коды для компенсации условий очень высокой частоты ошибок, вызванных неисправной антенной.
Проверка четности с низкой плотностью (LDPC)
Коды с низкой плотностью проверки на четность (LDPC) представляют собой класс высокоэффективных линейных блочных кодов, состоящих из множества кодов одиночной проверки на четность (SPC). Они могут обеспечить производительность, очень близкую к пропускной способности канала (теоретический максимум), используя подход итеративного декодирования с мягким решением, при линейной временной сложности с точки зрения длины их блока. Практические реализации в значительной степени полагаются на параллельное декодирование составляющих кодов SPC.
Коды LDPC были впервые представлены Робертом Г. Галлагером в его докторской диссертации в 1960 году, но из-за вычислительных усилий при реализации кодировщика и декодера и введения кодов Рида-Соломона они в основном игнорировались до 1990-х годов.
Коды LDPC теперь используются во многих последних стандартах высокоскоростной связи, таких как DVB-S2 (цифровое видеовещание — спутниковое — второе поколение), WiMAX ( стандарт IEEE 802.16e для микроволновой связи), высокоскоростная беспроводная локальная сеть ( IEEE 802.11n). ), 10GBase-T Ethernet (802.3an) и G.hn/G.9960 (стандарт ITU-T для сетей по линиям электропередач, телефонным линиям и коаксиальному кабелю). Другие коды LDPC стандартизированы для стандартов беспроводной связи в рамках 3GPP MBMS (см. Исходные коды ).
Турбо коды
Турбокодирование — это итеративная схема мягкого декодирования, которая объединяет два или более относительно простых сверточных кода и перемежитель для создания блочного кода, который может работать с точностью до доли децибела от предела Шеннона . Предваряя коды LDPC с точки зрения практического применения, теперь они обеспечивают аналогичную производительность.
Одним из первых коммерческих приложений турбо-кодирования была технология цифровой сотовой связи CDMA2000 1x (TIA IS-2000), разработанная Qualcomm и продаваемая Verizon Wireless , Sprint и другими операторами связи. Он также используется для развития CDMA2000 1x специально для доступа в Интернет, 1xEV-DO (TIA IS-856). Как и 1x, EV-DO был разработан Qualcomm и продается Verizon Wireless , Sprint и другими операторами (маркетинговое название Verizon для 1xEV-DO — широкополосный доступ , потребительские и бизнес-маркетинговые названия Sprint для 1xEV-DO — Power Vision и Mobile. Широкополосный соответственно).
Локальное декодирование и тестирование кодов
Иногда необходимо декодировать только отдельные биты сообщения или проверить, является ли данный сигнал кодовым словом, и сделать это, не глядя на весь сигнал. Это может иметь смысл в настройке потоковой передачи, где кодовые слова слишком велики, чтобы их можно было классически декодировать достаточно быстро, и где на данный момент интересны только несколько битов сообщения. Также такие коды стали важным инструментом в теории сложности вычислений , например, для разработки вероятностно проверяемых доказательств .
Локально декодируемые коды — это коды с исправлением ошибок, для которых отдельные биты сообщения могут быть вероятностно восстановлены, если смотреть только на небольшое (скажем, постоянное) количество позиций кодового слова, даже после того, как кодовое слово было искажено в некоторой постоянной доле позиций. Локально тестируемые коды — это коды с исправлением ошибок, для которых можно вероятностно проверить, близок ли сигнал к кодовому слову, только посмотрев на небольшое количество позиций сигнала.
Чередование
«Перемежитель» перенаправляется сюда. Для оптоволоконного устройства см. Оптический перемежитель .
Краткая иллюстрация идеи чередования
Перемежение часто используется в системах цифровой связи и хранения для повышения производительности кодов прямого исправления ошибок. Многие каналы связи не лишены памяти: ошибки обычно возникают пакетами, а не независимо друг от друга. Если количество ошибок в кодовом слове превышает возможности кода исправления ошибок, ему не удается восстановить исходное кодовое слово. Чередование облегчает эту проблему, перетасовывая исходные символы по нескольким кодовым словам, тем самым создавая более равномерное распределение ошибок. Поэтому перемежение широко используется для исправления пакетных ошибок .
Анализ современных итеративных кодов, как турбо — коды и LDPC — коды , как правило , предполагает независимое распределение ошибок. Поэтому системы, использующие коды LDPC, обычно используют дополнительное перемежение символов в кодовом слове.
Для турбокодов перемежитель является неотъемлемым компонентом, и его правильная конструкция имеет решающее значение для хорошей производительности. Алгоритм итеративного декодирования работает лучше всего, когда в графе факторов , представляющем декодер , нет коротких циклов ; перемежитель выбран, чтобы избежать коротких циклов.
Конструкции перемежителя включают:
- прямоугольные (или однородные) перемежители (аналогично методу с использованием коэффициентов пропуска, описанному выше)
- сверточные перемежители
- случайные перемежители (где перемежитель — известная случайная перестановка)
- S-случайный перемежитель (где перемежитель — это известная случайная перестановка с ограничением, что никакие входные символы на расстоянии S не появляются на расстоянии S на выходе).
- бесконкурентный квадратичный многочлен с перестановками (QPP). Пример использования — стандарт мобильной связи 3GPP Long Term Evolution .
В системах связи с множеством несущих перемежение по несущим может использоваться для обеспечения частотного разнесения , например, для уменьшения частотно-избирательного замирания или узкополосных помех.
Пример
Передача без чередования :
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Здесь каждая группа одинаковых букв представляет собой 4-битное однобитовое кодовое слово с исправлением ошибок. Кодовое слово cccc изменяется в один бит и может быть исправлено, но кодовое слово dddd изменяется в трех битах, поэтому либо оно не может быть декодировано вообще, либо может быть декодировано неправильно .
С чередованием :
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
В каждом из кодовых слов «aaaa», «eeee», «ffff» и «gggg» изменяется только один бит, поэтому однобитовый код с исправлением ошибок все декодирует правильно.
Передача без чередования :
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
Термин «пример» в большинстве случаев оказывается непонятным и трудным для исправления.
С чередованием :
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
Ни одно слово не потеряно полностью, а недостающие буквы можно восстановить с минимальными догадками.
Недостатки чередования
Использование методов чередования увеличивает общую задержку. Это связано с тем, что перед декодированием пакетов должен быть принят весь чередующийся блок. Также перемежители скрывают структуру ошибок; без перемежителя более совершенные алгоритмы декодирования могут использовать структуру ошибок и обеспечивать более надежную связь, чем более простой декодер, объединенный с перемежителем. Пример такого алгоритма основан на структурах нейронной сети .
Программное обеспечение для кодов исправления ошибок
Моделирование поведения кодов исправления ошибок (ECC) в программном обеспечении — обычная практика для разработки, проверки и улучшения ECC. Предстоящий стандарт беспроводной связи 5G поднимает новый диапазон приложений для программных ECC: облачные сети радиодоступа (C-RAN) в контексте программно-определяемого радио (SDR) . Идея состоит в том, чтобы напрямую использовать программные ECC в коммуникациях. Например, в 5G программные ECC могут быть расположены в облаке, а антенны подключены к этим вычислительным ресурсам: таким образом повышается гибкость сети связи и, в конечном итоге, повышается энергоэффективность системы.
В этом контексте существует различное доступное программное обеспечение с открытым исходным кодом, перечисленное ниже (не является исчерпывающим).
- AFF3CT (A Fast Forward Error Correction Toolbox): полная коммуникационная цепочка на C ++ (многие поддерживаемые коды, такие как Turbo, LDPC, полярные коды и т. Д.), Очень быстрая и специализированная на канальном кодировании (может использоваться как программа для моделирования или как библиотека для SDR).
- IT ++ : библиотека классов и функций C ++ для линейной алгебры, численной оптимизации, обработки сигналов, связи и статистики.
- OpenAir : реализация (на языке C) спецификаций 3GPP, касающихся Evolved Packet Core Networks.
Список кодов исправления ошибок
| Расстояние | Код |
|---|---|
| 2 (обнаружение одиночной ошибки) | Паритет |
| 3 (исправление одиночных ошибок) | Тройное модульное резервирование |
| 3 (исправление одиночных ошибок) | идеальный Хэмминга, такой как Хэмминга (7,4) |
| 4 ( ВТОРОЕ ) | Расширенный Хэмминга |
| 5 (исправление двойной ошибки) | |
| 6 (исправление двойной ошибки / обнаружение тройной ошибки) | |
| 7 (исправление трех ошибок) | совершенный двоичный код Голея |
| 8 (ТЕКФЕД) | расширенный двоичный код Голея |
- Коды AN
- Код BCH , который может быть разработан для исправления произвольного количества ошибок в каждом блоке кода.
- Код Бергера
- Код постоянного веса
- Сверточный код
- Коды расширителей
- Групповые коды
- Коды Голея , из которых двоичный код Голея представляет практический интерес.
- Код Гоппа , используемый в криптосистеме Мак-Элиса
- Код Адамара
- Код Хагельбаргера
- Код Хэмминга
- Код на основе латинского квадрата для небелого шума (преобладающий, например, в широкополосной связи по линиям электропередач)
- Лексикографический код
- Линейное сетевое кодирование , тип кода с исправлением стирания в сетях вместо двухточечных ссылок
- Длинный код
- Код проверки на четность с низкой плотностью , также известный как код Галлагера , как архетип для кодов разреженных графов
- Код LT , который является почти оптимальным кодом бесскоростной коррекции стирания (код Фонтана)
- m из n кодов
- Онлайн-код , почти оптимальный код бесскоростной коррекции стирания
- Полярный код (теория кодирования)
- Код Raptor , почти оптимальный код бесскоростной коррекции стирания
- Исправление ошибок Рида – Соломона
- Код Рида – Мюллера
- Повторно-накопительный код
- Коды повторения , такие как тройное модульное резервирование
- Спинальный код, бесскоростной нелинейный код, основанный на псевдослучайных хэш-функциях
- Код Торнадо , почти оптимальный код коррекции стирания и предшественник кодов Фонтана
- Турбо код
- Код Уолша-Адамара
-
Циклические проверки избыточности (CRC) могут исправлять 1-битные ошибки для сообщений длиной не более бит для оптимальных порождающих полиномов степени , см. Математика циклических проверок избыточности # Битовые фильтры
Смотрите также
- Скорость кода
- Коды стирания
- Декодер мягкого решения
- Пакетный код исправления ошибок
- Обнаружение и исправление ошибок
- Коды исправления ошибок с обратной связью
использованная литература
дальнейшее чтение
- МакВильямс, Флоренс Джессим ; Слоан, Нил Джеймс Александр (2007) [1977]. Написано в AT&T Shannon Labs, Флорхэм-Парк, Нью-Джерси, США. Теория кодов, исправляющих ошибки . Математическая библиотека Северной Голландии. 16 (цифровой отпечаток 12-го оттиска, 1-е изд.). Амстердам / Лондон / Нью-Йорк / Токио: Северная Голландия / Elsevier BV . ISBN 978-0-444-85193-2. LCCN 76-41296 . (xxii + 762 + 6 страниц)
- Кларк младший, Джордж К.; Каин, Дж. Бибб (1981). Кодирование с коррекцией ошибок для цифровой связи . Нью-Йорк, США: Plenum Press . ISBN 0-306-40615-2.
- Арази, Бенджамин (1987). Swetman, Herb (ред.). Здравый подход к теории кодов, исправляющих ошибки . Серия MIT Press в компьютерных системах. 10 (1-е изд.). Кембридж, Массачусетс, США / Лондон, Великобритания: Массачусетский технологический институт . ISBN 0-262-01098-4. LCCN 87-21889 . (x + 2 + 208 + 4 страницы)
- Плетеный, Стивен Б. (1995). Системы контроля ошибок для цифровой связи и хранения . Энглвуд Клиффс, Нью-Джерси, США: Прентис-Холл . ISBN 0-13-200809-2.
- Уилсон, Стивен Г. (1996). Цифровая модуляция и кодирование . Энглвуд Клиффс, Нью-Джерси, США: Прентис-Холл . ISBN 0-13-210071-1.
- «Код коррекции ошибок в флеш-памяти NAND с одноуровневой ячейкой» 2007-02-16
- «Код исправления ошибок во флеш-памяти NAND» 2004-11-29
- Наблюдения за ошибками, исправлениями и доверием зависимых систем , Джеймс Гамильтон, 26 февраля 2012 г.
- Сферические упаковки, решетки и группы, Дж. Х. Конвей, Нил Джеймс Александр Слоан, Springer Science & Business Media , 2013-03-09 — Математика — 682 страницы.
внешние ссылки
- Морелос-Сарагоса, Роберт (2004). «Страница корректирующих кодов (ECC)» . Проверено 5 марта 2006 года .
- lpdec: библиотека для декодирования LP и связанных вещей (Python)
Отладка программы призвана выискивать «вредителей» кода и устранять их. За это отвечают отладчик и журналирование для вывода сведений о программе.
В предыдущей части мы рассмотрели исходный код и его составляющие.
После того, как вы начнете проверять фрагменты кода или попытаетесь решить связанные с ним проблемы, вы очень скоро поймете, что существуют моменты, когда программа крашится, прерывается и прекращает работу.

Это часто вызвано ошибками, известными как дефекты или исключительные ситуации во время выполнения. Акт обнаружения и удаления ошибок из нашего кода – это отладка программы. Вы лучше разберетесь в отладке на практике, используя ее как можно чаще. Мы не только отлаживаем собственный код, но и порой дебажим написанное другими программистами.
Для начала необходимо рассортировать общие ошибки, которые могут возникнуть в исходном коде.

Синтаксические ошибки
Эти эрроры не позволяют скомпилировать исходный код на компилируемых языках программирования. Они обнаруживаются во время компиляции или интерпретации исходного кода. Они также могут быть легко обнаружены статическими анализаторами (линтами). Подробнее о линтах мы узнаем немного позже.
Синтаксические ошибки в основном вызваны нарушением ожидаемой формы или структуры языка, на котором пишется программа. Как пример, это может быть отсутствующая закрывающая скобка в уравнении.
Семантические ошибки
Отладка программы может потребоваться и по причине семантических ошибок, также известных как логические. Они являются наиболее сложными из всех, потому что не могут быть легко обнаружены. Признак того, что существует семантическая ошибка, – это когда программа запускается, отрабатывает, но не дает желаемого результата.
Рассмотрим данный пример:
3 + 5 * 6
По порядку приоритета, называемому старшинством операции, с учетом математических правил мы ожидаем, что сначала будет оценена часть умножения, и окончательный результат будет равен 33. Если программист хотел, чтобы сначала происходило добавление двух чисел, следовало поступить иначе. Для этого используются круглые скобки, которые отвечают за смещение приоритетов в математической формуле. Исправленный пример должен выглядеть так:
(3 + 5) * 6
3 + 5, заключенные в скобки, дадут желаемый результат, а именно 48.
Ошибки в процессе выполнения
Как и семантические, ошибки во время выполнения никогда не обнаруживаются при компиляции. В отличие от семантических ошибок, эти прерывают программу и препятствуют ее дальнейшему выполнению. Они обычно вызваны неожиданным результатом некоторых вычислений в исходном коде.
Вот хороший пример:
input = 25 x = 0.8/(Math.sqrt(input) - 5)
Фрагмент кода выше будет скомпилирован успешно, но input 25 приведет к ZeroDivisionError. Это ошибка во время выполнения. Другим популярным примером является StackOverflowError или IndexOutofBoundError. Важно то, что вы идентифицируете эти ошибки и узнаете, как с ними бороться.
Существуют ошибки, связанные с тем, как ваш исходный код использует память и пространство на платформе или в среде, в которой он запущен. Они также являются ошибками во время выполнения. Такие ошибки, как OutOfMemoryErrorand и HeapError обычно вызваны тем, что ваш исходный код использует слишком много ресурсов. Хорошее знание алгоритмов поможет написать код, который лучше использует ресурсы. В этом и заключается отладка программы.
Процесс перезаписи кода для повышения производительности называется оптимизацией. Менее популярное наименование процесса – рефакторинг. Поскольку вы тратите больше времени на кодинг, то должны иметь это в виду.
Отладка программы
Вот несколько советов о том, как правильно выполнять отладку:
- Использовать Linters. Linters – это инструменты, которые помогают считывать исходный код, чтобы проверить, соответствует ли он ожидаемому стандарту на выбранном языке программирования. Существуют линты для многих языков.
- Превалирование IDE над простыми редакторами. Вы можете выбрать IDE, разработанную для языка, который изучаете. IDE – это интегрированные среды разработки. Они созданы для написания, отладки, компиляции и запуска кода. Jetbrains создают отличные IDE, такие как Webstorm и IntelliJ. Также есть NetBeans, Komodo, Qt, Android Studio, XCode (поставляется с Mac), etc.
- Чтение кода вслух. Это полезно, когда вы ищете семантическую ошибку. Читая свой код вслух, есть большая вероятность, что вы зачитаете и ошибку.
- Чтение логов. Когда компилятор отмечает Error, обязательно посмотрите, где он находится.
Двигаемся дальше
Поздравляем! Слово «ошибка» уже привычно для вас, равно как и «отладка программы». В качестве новичка вы можете изучать кодинг по книгам, онлайн-урокам или видео. И даже чужой код вам теперь не страшен 
В процессе кодинга измените что-нибудь, чтобы понять, как он работает. Но будьте уверены в том, что сами написали.
Викторина
- Какая ошибка допущена в фрагменте кода Python ниже?
items = [0,1,2,3,4,5] print items[8] //комментарий: элементы здесь представляют собой массив с шестью элементами. Например, чтобы получить 4-й элемент, вы будете использовать [3]. Мы начинаем отсчет с 0.
- Какая ошибка допущена в фрагменте кода Python ниже?
input = Hippo' if input == 'Hippo': print 'Hello, Hippo'
Ответы на вопросы
- Ошибка выполнения: ошибка индекса вне диапазона.
2. Синтаксическая ошибка: Отсутствует стартовая кавычка в первой строке.