
Повторный и бесповторный отбор.
Ошибка выборки
Краткая теория
На основании выборочных данных дается оценка статистических
показателей по всей (генеральной) совокупности. Подобное возможно, если выборка
основывается на принципах случайности отбора и репрезентативности
(представительности) выборочных данных. Каждая единица генеральной совокупности
должна иметь равную возможность (вероятность) попасть в выборку.
При формировании выборочной совокупности используются следующие
способы отбора: а) собственно-случайный отбор; б) механическая выборка; в)
типический (районированный) отбор; г) многоступенчатая (комбинированная)
выборка; д) моментно-выборочное наблюдение.
Выборка может осуществляться по схеме повторного и бесповторного
отбора.
В первом случае единицы совокупности, попавшие в выборку, снова
возвращаются в генеральную, а во втором случае – единицы совокупности, попавшие
в выборку, в генеральную совокупность уже не возвращаются.
Выборка может осуществляться отдельными единицами или сериями
(гнездами).
Собственно-случайная выборка
Отбор в этом случае производится либо по жребию, либо по таблицам
случайных чисел.
На основании приемов классической выборки решаются следующие
задачи:
а) определяются границы среднего значения показателя по генеральной
совокупности;
б) определяются границы доли признака по генеральной совокупности.
Предельная ошибка средней при собственно-случайном отборе
исчисляется по формулам:
а) при повторном отборе:
б) при бесповторном отборе:
где
– численность выборочной совокупности;
– численность генеральной совокупности;
– дисперсия признака;
– критерий кратности ошибки: при
;
при
;
при
.
Значения
определяются
по таблице функции Лапласа.
Границы (пределы) среднего значения признака по генеральной
совокупности определяются следующим неравенством:
где
– среднее значение признака по выборочной
совокупности.
Предельная ошибка доли при собственно-случайном отборе определяется
по формулам:
а) при повторном отборе:
при бесповторном отборе:
где
– доля единиц совокупности с заданным
значением признака в обзей численности выборки,
– дисперсия доли признака.
Границы (пределы) доли признака по всей (генеральной) совокупности
определяются неравенством:
где
– доля признака по генеральной совокупности.
Типическая (районированная) выборка
Особенность этого вида
выборки заключается в том, что предварительно генеральная совокупность по
признаку типизации разбивается на частные группы (типы, районы), а затем в
пределах этих групп производится выборка.
Предельная ошибка средней
при типическом бесповторном отборе определяется по формуле:
где
– средняя из внутригрупповых дисперсий
по каждой типичной группе.
При пропорциональном отборе из групп генеральной совокупности
средняя из внутригрупповых дисперсий определяется по формуле:
где
– численности единиц совокупности групп по выборке.
Границы (пределы) средней по генеральной совокупности на основании
данных типической выборки определяются по тому же неравенству, что при
собственно-случайной выборке. Только предварительно необходимо вычислить общую
выборочную среднюю
из частных выборочных средних
.
Для случая пропорционального отбора это определяется по формуле:
При непропорциональном отборе средняя из внутригрупповых дисперсий вычисляется по
формуле:
где
– численность единиц групп по генеральной
совокупности.
Общая выборочная средняя в этом случае определяется по формуле:
Предельная ошибка доли
признака при типическом бесповторном отборе определяется формулой:
Средняя дисперсия доли
признака из групповых дисперсий доли
при
типической пропорциональной выборке вычисляется по формуле:
Средняя доля признака по
выборке из показателей групповых долей рассчитывается формуле:
Средняя дисперсия доли при
непропорциональном типическом отборе определяется следующим образом:
а средняя доля признака:
Формулы ошибок выборки при типическом повторном отборе будут те же,
то и для случая бесповторного отбора. Отличие заключается только в том, что в
них будет отсутствовать по корнем сомножитель
.
Серийная выборка
Серийная ошибка выборки
может применяться в двух вариантах:
а) объем серий различный
б) все серии имеют
одинаковое число единиц (равновеликие серии).
Наиболее распространенной
в практике статистических исследований является серийная выборка с
равновеликими сериями. Генеральная совокупность делится на одинаковые по объему
группы-серии
и
производится отбор не единиц совокупности, а серий
. Группы (серии) для обследования отбирают в
случайном порядке или путем механической выборки как повторным, так и
бесповторными способами. Внутри каждой отобранной серии осуществляется сплошное
наблюдение. Предельные ошибки выборки
при
серийном отборе исчисляются по формулам:
а) при повторном отборе
б) при бесповторном отборе
где
– число
серий в генеральной совокупности;
– число
отобранных серий;
– межсерийная дисперсия, исчисляемая для случая равновеликих
серий по формуле:
где
–
среднее значение признака в каждой из отобранных серий;
– межсерийная
средняя, исчисляемая для случая равновеликих серий по формуле:
Определение численности выборочной совокупности
При проектировании
выборочного наблюдения важно наряду с организационными вопросами решить одну из
основных постановочных задач: какова должна быть необходимая численность
выборки с тем, чтобы с заданной степенью точности (вероятности) заранее
установленная ошибка выборки не была бы превзойдена.
Примеры решения задач
Задача 1
На основании результатов проведенного на заводе 5%
выборочного наблюдения (отбор случайный, бесповторный) получен следующий ряд
распределения рабочих по заработной плате:
| Группы рабочих по размеру заработной платы, тыс.р. | до 200 | 200-240 | 240-280 | 280-320 | 320 и выше | Итого |
| Число рабочих | 33 | 35 | 47 | 45 | 40 | 200 |
На основании приведенных данных определите:
1) с вероятностью 0,954 (t=2) возможные пределы, в которых
ожидается средняя заработная плата рабочего в целом по заводу (по генеральной
совокупности);
2) с вероятностью 0,997 (t=3) предельную ошибку и границы доли
рабочих с заработной платой от 320 тыс.руб. и выше.
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Вычислим среднюю з/п: Для этого просуммируем произведения середин
интервалов и соответствующих частот, и полученную сумму разделим на сумму
частот.
2) Выборочная дисперсия:
Найдем доверительный интервал для средней. Предельная ошибка выборочной
средней считается по формуле:
где
—
аргумент функции Лапласа.
Искомые возможные пределы, в которых ожидается средняя заработная плата
рабочего в целом по заводу:
Найдем доверительный интервал для выборочной доли. Предельная ошибка
выборочной доли считается по формуле:
Доля рабочих с з/п от 320 тыс.р.:
Искомые границы доли рабочих с заработной платой от 320 тыс.руб. и выше:
Задача 2
В
городе 23560 семей. В порядке механической выборки предполагается определить
количество семей в городе с числом детей трое и более. Какова должна быть
численность выборки, чтобы с вероятностью 0,954 ошибка выборки не превышала
0,02 человека. На основе предыдущих обследований известно, что дисперсия равна
0,3.
Решение
Численность
выборки можно найти по формуле:
В нашем случае:
Вывод к задаче
Таким образом численность
выборки должна составить 2661 чел.
Задача 3
С
целью определения средней месячной заработной платы персонала фирмы было
проведено 25%-ное выборочное обследование с отбором
единиц пропорционально численности типических групп. Для отбора сотрудников
внутри каждого филиала использовался механический отбор. Результаты
обследования представлены в следующей таблице:
| Номер филиала |
Средняя месячная заработная плата, руб. |
Среднее квадратическое отклонение, руб. |
Число сотрудников, чел. |
| 1 | 870 | 40 | 30 |
| 2 | 1040 | 160 | 80 |
| 3 | 1260 | 190 | 140 |
| 4 | 1530 | 215 | 190 |
С
вероятностью 0,954 определите пределы средней месячной заработной платы всех
сотрудников гостиниц.
Решение
Предельная
ошибка выборочной средней:
Средняя
из внутригрупповых дисперсий:
Получаем:
Средняя
месячная заработная плата по всей совокупности филиалов:
Искомые
пределы средней месячной заработной платы:
Вывод к задаче
Таким
образом с вероятностью 0,954 средняя месячная заработная плата всех сотрудников
гостиниц находится в пределах от 1294,3 руб. до 1325,7 руб.
Чтобы
получить суждение о точности результатов
выборочного наблюдения, математическая
статистика дает аппарат характеристики
состава генеральной совокупности и
формулу
средней ошибки,
т.е. средней величины из всех возможных
ошибок при бесчисленном множестве
случайных выборок.
Средняя
ошибка выборки для средней величины
признака
определяется по формуле:
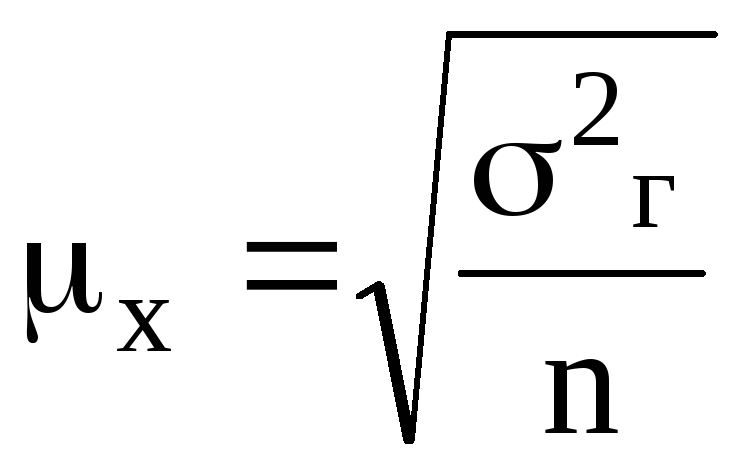 ,
,
где
2г
– дисперсия количественного признака
в генеральной совокупности.
Если
при выборочном наблюдении изучению
подлежит альтернативный признак (доля
признака), то средняя
ошибка выборки для доли единиц,
обладающих данным признаком, определяется
по теореме Я. Бернулли:
![]() ,
,
где
p – доля единиц, обладающих данным
качеством, в генеральной совокупности;
p(1-p) – дисперсия альтернативного признака
в генеральной совокупности.
Средняя
ошибка выборки
по значениям выборочной дисперсии 2
для средней и w(1–w) для доли признака
при повторном
способе
выборки определяется по формуле:
![]() ,
,
![]() ,
,
где w – доля признака в выборочной
совокупности.
На
практике повторная выборка, при которой
численность генеральной совокупности
остается неизменной и для каждой единицы
вероятность попасть в выборку одинакова,
встречается редко (например, при изучении
населения в качестве пользователей,
пациентов, избирателей).
При
бесповторной
выборке
численность генеральной совокупности
в процессе отбора сокращается на 1–n/N,
где n/N – доля отобранных единиц. В связи
с этим формулы средней
ошибки выборки
приобретают следующий вид:
![]() ;
;
![]() .
.
Так
как доля единиц генеральной совокупности,
не попавших в выборку (1–n/N), всегда
меньше единицы, то ошибка
выборки при бесповторном отборе при
прочих равных условиях меньше, чем при
повторном отборе.
Как
и сама выборочная характеристика, ошибка
выборки является случайной величиной,
она может быть в каждом конкретном
случае меньше, равна или больше .
Академик А.М. Ляпунов доказал, что
вероятность
появления случайной ошибки выборки
при достаточно большом ее объеме
подчиняется закону нормального
распределения:
![]() ,
,
где
∆ — предельная
ошибка
выборки, t – коэффициент доверия,
зависящий от вероятности (Р), с которой
предельная ошибка определяется,
— средняя ошибка выборки.
Значения функции
Ф(t) табулированы при разных значениях,
например:
при
t=1 P()
= Ф(1) = 0,683;
при
t=2 P(2)
= Ф(2) = 0,9545;
при
t=3 P(3)
= Ф(3) = 0,9973 и т.д.
В
общем виде
= t*
характеризует предельную
ошибку
выборки, показывающую максимально
возможное расхождение выборочной и
генеральной характеристик при заданной
вероятности этого утверждения. Так, при
t=2 возможная ошибка
не превысит 2,
что гарантируется с вероятностью 0,9545.
Это значит, что в 9545 выборках из 10000
подобных максимальная ошибка не выйдет
за пределы 2.
При
проведении выборочного учета массовых
социально-экономических явлений
считается
достаточным максимальный размах 3.
Возможная
ошибка выборки указывается с определенной
вероятностью Р, с которой гарантируются
границы рассчитанной случайной ошибки
репрезентативности. На практике наиболее
часто пользуются значениями вероятности
Р=0,95 (t=1,96), Р=0,99 (t=2,58) и Р=0,999 (t=3,28),
гарантирующими репрезентативность
выборки соответственно с ошибкой 5; 1;
0,1%.
Возможная
ошибка выборки позволяет определять
предельные значения характеристик
генеральной совокупности при заданной
вероятности, т.е. их доверительные
интервалы. Поэтому вероятность
Р называется доверительной,
она представляет собой вероятность
того, что ошибка выборки не превысит
некоторую заданную величину .
Доверительные интервалы для:
генеральной
средней —
![]() (от
(от![]() до
до![]() ),
),
генеральной
доли –
![]() (от w–
(от w–
до w+).
Наряду
с абсолютной величиной предельной
ошибки выборки рассчитывается и
относительная
ошибка
выборки, которая определяется отношением
предельной ошибки средней или доли к
соответствующей характеристике
выборочной совокупности:
![]() %;
%;
![]() %.
%.
При
проведении выборочного наблюдения в
экономических исследованиях преимущественно
стремятся к тому, чтобы относительная
ошибка репрезентативности выборки не
превышала 5 … 10%.
5.3
Определение необходимого объёма выборки
для обеспечения репрезентативности
выборочных наблюдений при повторном и
бесповторном способе отбора. Виды
отбора (случайный, механический,
типический, стратифицированный,
комбинированный).
Необходимый
объем выборки (![]() )определяется
)определяется
из формул предельных ошибок выборки ,
соответствующих различным способам
отбора.
Так,
для случайного
повторного отбора
имеем:
x
=
![]() , откуда
, откуда![]() .
.
Уменьшение
(увеличение) предельной ошибки в несколько
раз ведет к увеличению (уменьшению)
выборочной совокупности в квадрат раз.
Для уменьшения предельной ошибки,
например, в 2 раза численность выборки
должна быть увеличена в 4 раза. Из трех
параметров два (t и )
задаются исследователем.
При
бесповторном
отборе
необходимая численность выборки
рассчитывается по формуле:
![]() .
.
При прочих равных
условиях при бесповторном отборе
требуется меньший объем выборочной
совокупности, чем при повторном.
При
изучении альтернативного признака
(доли р) необходимый объем выборки
определяется по формулам при отборе:
повторном:
![]() ,
,
бесповторном:![]() .
.
Репрезентативность
выборки зависит не только от количества
отобранных единиц совокупности и степени
их колеблемости по изучаемым признакам,
но и от способа отбора.
В
зависимости от способа выборки единиц
из генеральной совокупности различают
следующие виды
отбора (выборки):
собственно
случайный; механический;
типический
(районированный, стратифицированный);
серийный
(гнездовой); комбинированный, многофазный
и др.
При
собственно
случайном
отборе
единицы отбираются из генеральной
совокупности в строгом соответствии с
научными принципами и правилами
случайного отбора.
Формировать
выборку в строгом соответствии с
правилами случайного отбора практически
очень сложно. Используются таблицы
случайных чисел, нумеруются все единицы
генеральной совокупности, при жеребьевке
на каждую единицу заготавливаются
соответствующие карточки или фишки.
При большой генеральной совокупности
проводить такую предварительную работу
практически невозможно и нецелесообразно.
Для
удобства проведения выборочного
наблюдения на практике применяют другие
формы отбора, организуемые таким образом,
чтобы была обеспечена случайность
выборки.
При
механическом
отборе
генеральная совокупность делится на n
равных частей
в соответствии с естественным расположением
ее границ (географическим, пространственным,
алфавитным и др.) и из каждой части
обследуется одна единица. Например,
если нужно отобрать 10% рабочих, то
обследуют каждого десятого рабочего
по списку, упорядоченного по алфавиту.
Ошибки репрезентативности при механическом
отборе возникают не в результате
случайности отбора, а в результате
случайности размещения единиц изучаемой
совокупности.
Если
единицы в генеральной совокупности
размещены случайно в отношении изучаемого
признака (в алфавитном порядке, в порядке
времени поступления писем, телеграмм,
телефонных соединений), то ошибка
механической выборки становится
случайной и ее можно определять по
формуле ошибки случайной выборки.
Механический отбор удобно проводить,
когда уже имеются списки единиц
совокупности и когда имеют дело с
генеральной совокупностью, численность
которой известна лишь приблизительно
и единицы которой появляются постепенно,
например, при контроле качества услуг
и средств связи.
Типический
(районированный, стратифицированный)
отбор
осуществляется на основе предварительного
разделения единиц генеральной совокупности
на типические группы (районы, страты)
по изучаемым признакам. В качестве
групп, страт в зависимости от характера
изучаемого признака могут использоваться
округа, регионы, отрасли, предприятия.
Отбор из каждой группы может осуществляться
в случайном (повторном или бесповторном)
или механическом порядке.
Объем
выборки в каждой типической группе
обычно устанавливается пропорционально
ее удельному весу в генеральной
совокупности или дифференцированному
признаку. Это повышает точность
выборочного наблюдения, поскольку более
точно, чем при собственно случайной
выборке, отражается структура генеральной
совокупности.
При
типической выборке устраняется влияние
межгрупповой вариации изучаемого
признака на точность ее результатов,
так как имеется представительство в
выборочной совокупности каждой из
типических групп. Средняя ошибка выборки
здесь зависит не от общей дисперсии 2,
а от средней из групповых дисперсий
![]() .
.
Так как средняя из групповых дисперсий
всегда меньше общей дисперсии, при
прочих равных условияхошибка
типической выборки меньше ошибки
собственно случайного отбора.
При
определении ошибки типической выборки
в случае пропорционального
отбора для
расчета предельной
ошибки
выборки применяется формула случайной
выборки, в которой применяется средняя
из групповых дисперсий
![]() .
.
∆ = t*µ или для
выборки:
повторной
—
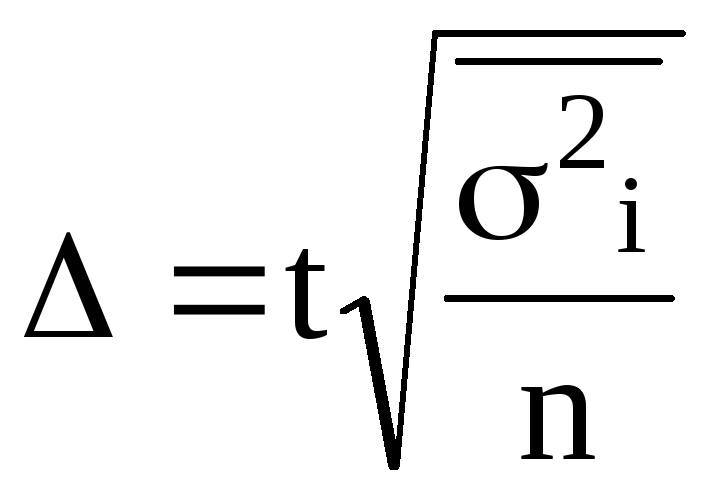
; бесповторной —
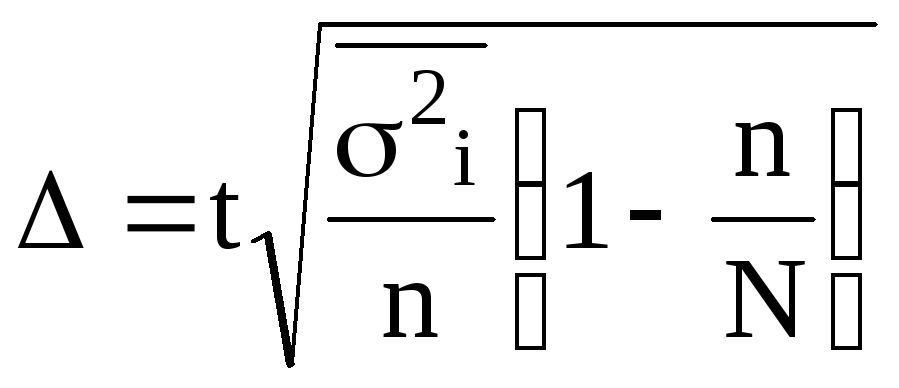 .
.
Отбор
единиц в типическую выборку производится
пропорционально объему типических
групп:
![]() ,
,
где
![]() =2ini/ni;
=2ini/ni;
ni
– численность единиц выборочной
совокупности i-й группы; 2i
– выборочная дисперсия i-й группы; N
– объем всей совокупности;
![]() —
—
объем типических групп.
При
определении ошибки типической выборки
в случае отбора
по
дифференциальному признаку
для расчета предельной
ошибки
выборки применяется формула случайной
выборки, в которой применяется
внутригрупповые дисперсии 2i.
∆ = t*µ или для
выборки:
повторной
—
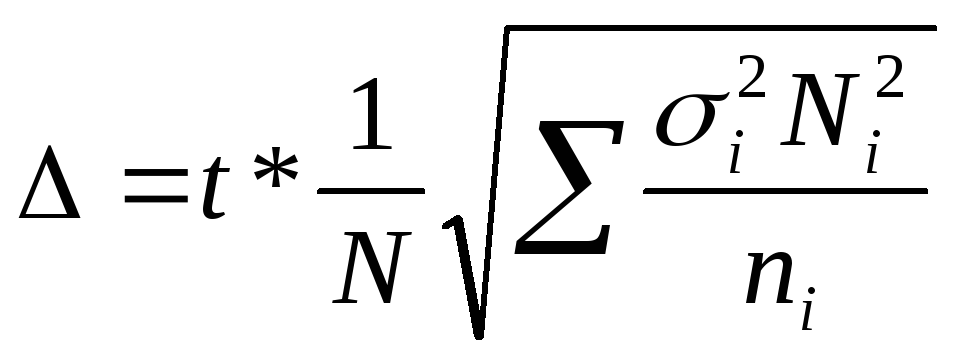
; бесповторной —
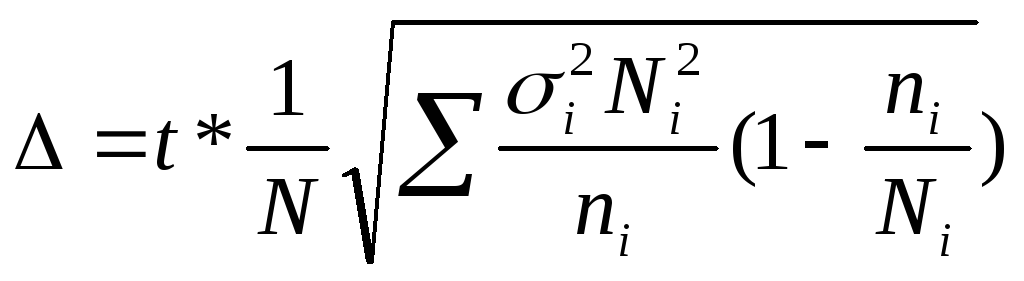 .
.
Отбор
единиц в типическую выборку производится
пропорционально дифференциальному
признаку — среднему квадратическому
отклонению
![]() :
:
![]() .
.
Выделение
типических групп в генеральной
совокупности значительно повышает
репрезентативность выборки.
Примером
типической выборки является уровень
потребления услуг связи с разделением
потребителей на население и организации
с разбивкой последних на две группы –
бюджетные и хозрасчетные.
При
серийном
(гнездовом) отборе
в случайном порядке отбираются не
единицы, а группы единиц (серии, гнезда).
Серии, или группы, единиц отбираются по
принципу случайного отбора или
механическим способом, внутри отобранных
серий (гнезд) обследованию подвергаются
все единицы. Если общее число серий в
генеральной совокупности обозначить
через R, а число отобранных серий – r, то
средняя ошибка выборки может быть
определена по формулам:
x
=
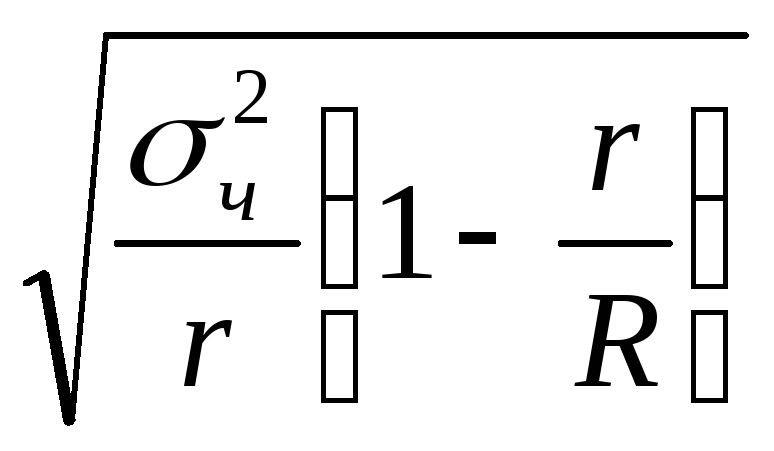
для бесповторной выборки, x
=
![]() ,
,
повторной выборки,
где
![]() –
–
межсерийная (межгрупповая) дисперсия.
Объём
серийной выборки определяется по
формуле:
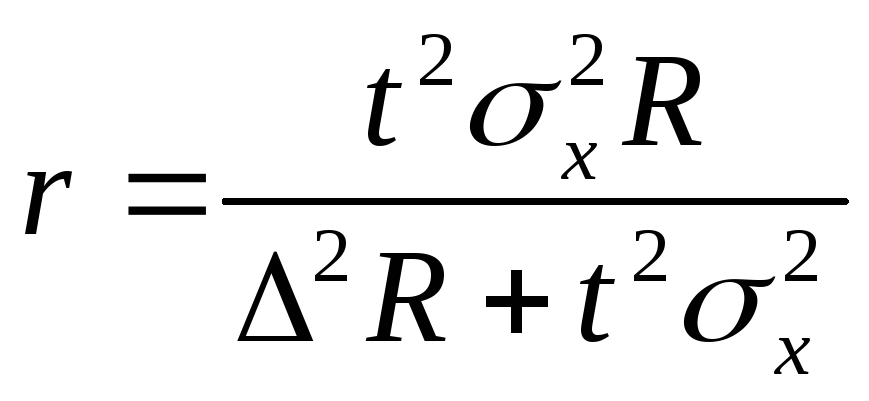
Чем
меньше серийные средние отличаются
одна от другой, т.е. чем ближе друг к
другу серии по уровню изучаемого
признака, тем точнее серийная выборка.
При
значительной вариации серийных средних
увеличивается ошибка репрезентативности
выборки.
Серийная
выборка применяется в организациях
связи для определения скорости пересылки
письменной корреспонденции и телеграмм,
доли неисправных таксофонов, массы
писем, объема передаваемой информации
электронных сообщений и т.д. В качестве
серии здесь выступает совокупность
писем, телеграмм, разговоров за сутки,
количество суток (дней) обследования
равно количеству серий, попавших в
выборочную совокупность.
На
практике в зависимости от цели и задач
выборочного обследования часто выборки
производят на основе сочетания двух и
более способов, образующих ступени
отбора:
механический и серийный, типический и
механический, серийный и собственно
случайный. Такие выборки
получили название комбинированных
(ступенчатых).
При комбинированном отборе общая ошибка
выборки состоит из ошибок на каждой ее
ступени. Например, единовременно скорость
прохождения письменной корреспонденции
учитывается с помощью трех способов,
образующих три ступени отбора: на основе
случайного отбора определяются регионы
страны, механического отбора – города
и сельские населенные пункты регионов,
серийного отбора – группы писем,
представляющие определенные направления
пересылки и подлежащие сплошному учету.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Предельная ошибка выборки
Предельная ошибка — максимально возможное расхождение средних или максимум ошибок при заданной вероятности ее появления.
1. Предельную ошибку выборки для средней при повторном отборе в контрольных по статистике в ВУЗах рассчитывают по формуле:

где t — нормированное отклонение — «коэффициент доверия», который зависит от вероятности, гарантирующей предельную ошибку выборки;
мю х — средняя ошибка выборки.
2. Предельная ошибка выборки для доли при повторном отборе определяется по формуле:

3. Предельная ошибка выборки для средней при бесповторном отборе:

4. Предельная ошибка выборки для доли при бесповторном отборе:

Предельная относительная ошибка выборки
Предельную относительную ошибку выборки определяют как процентное соотношение предельной ошибки выборки к соответствующей характеристике выборочной совокупности. Она определяется таким образом:

Малая выборка
Теория малых выборок была разработана английским статистиком Стьюдентом в начале 20 века. В 1908 г. он выявил специальное распределение, которое позволяет и при малых выборках соотносить t и доверительную вероятность F(t). При n больше 100 дают такие же результаты, что и таблицы интеграла вероятностей Лапласа, при 30 < n < 100 различия получаются незначительные. Поэтому на практике к малым выборкам относятся выборки объемом менее 30 единиц.

Средняя и предельная ошибки для малой выборки
В малой выборке средняя ошибка рассчитывается по формуле:

Предельная ошибка малой выборки рассчитывается по формуле:

где t — отношение Стьюдента
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
Материалы сайта
Обращаем Ваше внимание на то, что все материалы опубликованы для образовательных целей.