

«Код должен легко считываться» — это стало главной целью для японской компании «Denso-Wave» при создании двумерного матричного кода в 1994г.
Действительно, QR-код распознается даже в перевернутом состоянии. Три угловых квадрата привязки, ставшие отличительной особенностью кода, позволяют правильно развернуть его в памяти программы сканера.

По спецификации коды делятся на версии. Номера версий варьируются от 1 до 40. Каждая версия имеет особенности в конфигурации и количестве точек(модулей) составляющих QR-код. Версия 1 содержит 21×21 модулей, версия 40 — 177×177. От версии к версии размер кода увеличивается на 4 модуля на сторону.
При создании матричного кода следует учесть, что лучшие QR-ридеры способны прочитать версию 40, стандартные мобильные устройства — вплоть до версии 4 (33x33 модулей)
Каждой версии соответствует определенная емкость с учетом уровня коррекции ошибок. Чем больше информации необходимо закодировать и чем больший уровень избыточности используется, тем большая версия кода нам потребуется. Современные QR-генераторы автоматически подбирают версию QR-кода с учетом этих моментов.
В следующей таблице показаны характеристики различных версий QR-кодов:
| Версия | Количество модулей | Уровень коррекции ошибок |
Максимальное количество символов с учетом уровня коррекции ошибок и типа символов | |||
|---|---|---|---|---|---|---|
| Числа: 0 — 9 | Числа и символы латинского алфавита*, пробел, $ % * + — . / : |
Двоичные данные | Символы японского алфавита Kanji |
|||
| 1 | 21×21 | L | 41 | 25 | 17 | 10 |
| M | 34 | 20 | 14 | 8 | ||
| Q | 27 | 16 | 11 | 7 | ||
| H | 17 | 10 | 7 | 4 | ||
| 2 | 25×25 | L | 77 | 47 | 32 | 20 |
| M | 63 | 38 | 26 | 16 | ||
| Q | 48 | 29 | 20 | 12 | ||
| H | 34 | 20 | 14 | 8 | ||
| 3 | 29×29 | L | 127 | 77 | 53 | 32 |
| M | 101 | 61 | 42 | 26 | ||
| Q | 77 | 47 | 32 | 20 | ||
| H | 58 | 35 | 24 | 15 | ||
| 4 | 33×33 | L | 187 | 114 | 78 | 48 |
| M | 149 | 90 | 62 | 38 | ||
| Q | 111 | 67 | 46 | 28 | ||
| H | 82 | 50 | 34 | 21 | ||
| 10 | 57×57 | L | 652 | 395 | 271 | 167 |
| M | 513 | 311 | 213 | 131 | ||
| Q | 364 | 221 | 151 | 93 | ||
| H | 288 | 174 | 119 | 74 | ||
| 40 | 177×177 | L | 7,089 | 4,296 | 2,953 | 1,817 |
| M | 5,596 | 3,391 | 2,331 | 1,435 | ||
| Q | 3,993 | 2,420 | 1,663 | 1,024 | ||
| H | 3,057 | 1,852 | 1,273 | 784 |
* При использовании кириллицы один символ считается за 2 латинских символа (кодировка UTF-8)
Уровни коррекции ошибок в QR-кодах
QR-код имеет специальный механизм увеличения надежности хранения зашифрованной информации. Для кодов созданных с самым высоким уровнем надежности могут быть испорчены или затерты до 30% поверхности, но они сохранят информацию и будут корректно прочитаны. Для исправления ошибок используется алгоритм Рида-Соломона (Reed-Solomon). При создании QR-кода можно использовать один из 4 уровней коррекции ошибок. Увеличение уровня способствует увеличению надежности хранения информации, но приводит к увеличению размера матричного кода.
| Допустимый процент нарушений | |
|---|---|
| L | около 7% |
| M | около 15% |
| Q | около 25% |
| H | около 30% |
Полезные ссылки:
Стандарт ISO 18004 (Automatic identification and data capture techniques — QR Code 2005 bar code symbology specification)
уровень коррекции ошибки
- уровень коррекции ошибки
-
уровень коррекции ошибки : Степень способности к обнаружению и исправлению ошибки в символике, не зафиксированная, а определяемая некоторым выбором пользователя.
Примечание — Уровень коррекции ошибок связан с символиками, использующими код с исправлением ошибок, например код с исправлением ошибок Рида-Соломона
Словарь-справочник терминов нормативно-технической документации.
.
2015.
Смотреть что такое «уровень коррекции ошибки» в других словарях:
-
уровень коррекции ошибки — Степень способности к обнаружению и исправлению ошибки в символике, не зафиксированная, а определяемая некоторым выбором пользователя. Примечание Уровень коррекции ошибок связан с символиками, использующими код с исправлением ошибок, например код … Справочник технического переводчика
-
Код коррекции ошибок Рида-Соломона — Коды Рида Соломона недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида Соломона, работающие с байтами (октетами). Код… … Википедия
-
Метод обратного распространения ошибки — (англ. backpropagation) метод обучения многослойного перцептрона. Впервые метод был описан в 1974 г. А.И. Галушкиным[1], а также независимо и одновременно Полом Дж. Вербосом[2]. Далее существенно развит в 1986 г. Дэвидом И. Румельхартом, Дж … Википедия
-
ГОСТ 30721-2000: Автоматическая идентификация. Кодирование штриховое. Термины и определения — Терминология ГОСТ 30721 2000: Автоматическая идентификация. Кодирование штриховое. Термины и определения оригинал документа: (n, k) символика : Класс символик штрихового кода, в которых ширина каждого знака символа представлена в n модулях, а сам … Словарь-справочник терминов нормативно-технической документации
-
кодовое слово — (штриховое кодирование): Значение знака символа, соответствующее промежуточному уровню кодирования между исходными данными и графическим кодированием в символе Источник: ГОСТ 30721 2000: Автоматическая идентификация. Кодирование штриховое.… … Словарь-справочник терминов нормативно-технической документации
-
ГОСТ Р 51294.9-2002: Автоматическая идентификация. Кодирование штриховое. Спецификации символики PDF417 (ПДФ417) — Терминология ГОСТ Р 51294.9 2002: Автоматическая идентификация. Кодирование штриховое. Спецификации символики PDF417 (ПДФ417) оригинал документа: 3.1.9 идентификатор глобальной метки ( Global Label Identifier): Процедура в рамках символики PDF417 … Словарь-справочник терминов нормативно-технической документации
-
кодовое слово индикатора строки ( Row Indicator codeword) — 3.1.13 кодовое слово индикатора строки ( Row Indicator codeword): Кодовое слово PDF417, примыкающее к знаку СТАРТ или знаку СТОП в строке, которое кодирует информацию о структуре символа PDF417: идентификацию строки, общее количество строк и… … Словарь-справочник терминов нормативно-технической документации
-
коррекция — 3.6.6 коррекция (correction): Действие, предпринятое для устранения обнаруженного несоответствия (3.6.2). Примечания 1 Коррекция может осуществляться в сочетании с корректирующим действием (3.6.5). 2 Коррекция может включать в себя, например,… … Словарь-справочник терминов нормативно-технической документации
-
Список алгоритмов — Эта страница информационный список. Основная статья: Алгоритм Ниже приводится список алгоритмов, группированный по категориям. Более детальные сведения приводятся в списке структур данных и … Википедия
-
Программируемые алгоритмы — Служебный список статей, созданный для координации работ по развитию темы. Данное предупреждение не устанавл … Википедия

QR-код, используемый на большом рекламном щите в Японии, ссылающийся на сайт sagasou.mobi в Сибуя (b) , Токио (b) . QR-код[lower-alpha 1] (англ. (b) Quick Response code — код быстрого отклика[2]; сокр. (b) QR code) — тип матричных штриховых кодов (или двухмерных штриховых кодов (b) ), изначально разработанных для автомобильной промышленности (b) Японии (b) . Его создателем считается Масахиро Хара[3]. Сам термин является зарегистрированным товарным знаком японской компании «Denso (b) ». Штрихкод — считываемая машиной оптическая метка, содержащая информацию об объекте, к которому она привязана. QR-код использует четыре стандартизированных режима кодирования (числовой, буквенно-цифровой, двоичный (b) и кандзи (b) ) для эффективного хранения данных; могут также использоваться расширения[4]. Система QR-кодов стала популярной за пределами автомобильной промышленности благодаря возможности быстрого считывания и большей ёмкости по сравнению со штрихкодами стандарта UPC (b) . Расширения включают отслеживание продукции, идентификацию предметов, отслеживание времени, управление документами и общий маркетинг[5]. QR-код состоит из чёрных квадратов, расположенных в квадратной сетке на белом фоне, которые могут считываться с помощью устройств обработки изображений, таких как камера, и обрабатываться с использованием кодов Рида — Соломона (b) до тех пор, пока изображение не будет надлежащим образом распознано. Затем необходимые данные извлекаются из шаблонов, которые присутствуют в горизонтальных и вертикальных компонентах изображения[5]. В те дни, когда не было QR-кода, компонентное сканирование проводилось на заводе-изготовителе Denso (b) разными штрихкодами. Однако из-за того, что их было около 10, эффективность работы была крайне низкой, и работники жаловались, что они быстро устают, а также просили, чтобы был создан код, который может содержать больше информации, чем обычный штрихкод. Чтобы ответить на этот запрос работников, Denso-Wave (b) была поставлена цель создать код, который может включать больше информации, чтобы позволить высокоскоростное компонентное сканирование.[6] Для этого Масахиро Хара, который работал в отделе разработки, начал разработку нового кода с 1992 года.[7] Вдохновением для создания QR-кода послужила игра го (b) , в которую Масахиро Хара играл во время обеденного перерыва.[7] Он решил, что цель разработки состоит не только в увеличении объема кодовой информации, но и в «точном и быстром чтении», а также в том, чтобы сделать код читаемым и устойчивым к масляным пятнам, грязи и повреждениям, предполагая, что он будет использоваться на соответствующих производствах. QR-код был представлен японской компанией Denso-Wave (b) , в 1994 году после двухлетнего периода разработки.[8][9][10] Он был разработан с учетом производственной системы компании «Toyota» (b) «Канбан (b) » (точно в срок (b) ) для использования на заводах по производству автозапчастей и в распределительных центрах. Однако, поскольку он обладает высокой способностью обнаружения и исправления ошибок (b) и сделан с открытым исходным кодом (b) , он вышел из узкой сферы производственных цепочек поставок компании «Toyota (b) » и начал использоваться в других сферах, что привело к тому, что теперь он широко используется не только в Японии, но и во всем мире. Огромная популярность штрихкодов в Японии привела к тому, что объём информации, зашифрованной в них, вскоре перестал устраивать промышленность. Японцы начали экспериментировать с новыми современными способами кодирования небольших объёмов информации в графической картинке. QR-код стал одним из наиболее часто используемых типов двумерного кода в мире.[11] Спецификация QR-кода не описывает формат данных (b) . В отличие от старого штрих-кода, который сканируют тонким лучом, QR-код определяется датчиком или камерой как двумерное изображение. Три квадрата в углах изображения и меньшие синхронизирующие квадратики по всему коду позволяют нормализовать размер изображения и его ориентацию, а также угол, под которым датчик расположен к поверхности изображения. Точки переводятся в двоичные числа (b) с проверкой по контрольной сумме (b) . Основное достоинство QR-кода — это лёгкое распознавание сканирующим (b) оборудованием, что даёт возможность использования в торговле (b) , производстве, логистике (b) . QR-код[lower-alpha 1] (англ. (b) Quick Response code — код быстрого отклика[2]; сокр. (b) QR code) — тип матричных штриховых кодов (или двухмерных штриховых кодов (b) ), изначально разработанных для автомобильной промышленности (b) Японии (b) . Его создателем считается Масахиро Хара[3]. Сам термин является зарегистрированным товарным знаком японской компании «Denso (b) ». Штрихкод — считываемая машиной оптическая метка, содержащая информацию об объекте, к которому она привязана. QR-код использует четыре стандартизированных режима кодирования (числовой, буквенно-цифровой, двоичный (b) и кандзи (b) ) для эффективного хранения данных; могут также использоваться расширения[4]. Система QR-кодов стала популярной за пределами автомобильной промышленности благодаря возможности быстрого считывания и большей ёмкости по сравнению со штрихкодами стандарта UPC (b) . Расширения включают отслеживание продукции, идентификацию предметов, отслеживание времени, управление документами и общий маркетинг[5]. QR-код состоит из чёрных квадратов, расположенных в квадратной сетке на белом фоне, которые могут считываться с помощью устройств обработки изображений, таких как камера, и обрабатываться с использованием кодов Рида — Соломона (b) до тех пор, пока изображение не будет надлежащим образом распознано. Затем необходимые данные извлекаются из шаблонов, которые присутствуют в горизонтальных и вертикальных компонентах изображения[5]. В те дни, когда не было QR-кода, компонентное сканирование проводилось на заводе-изготовителе Denso (b) разными штрихкодами. Однако из-за того, что их было около 10, эффективность работы была крайне низкой, и работники жаловались, что они быстро устают, а также просили, чтобы был создан код, который может содержать больше информации, чем обычный штрихкод. Чтобы ответить на этот запрос работников, Denso-Wave (b) была поставлена цель создать код, который может включать больше информации, чтобы позволить высокоскоростное компонентное сканирование.[6] Для этого Масахиро Хара, который работал в отделе разработки, начал разработку нового кода с 1992 года.[7] Вдохновением для создания QR-кода послужила игра го (b) , в которую Масахиро Хара играл во время обеденного перерыва.[7] Он решил, что цель разработки состоит не только в увеличении объема кодовой информации, но и в «точном и быстром чтении», а также в том, чтобы сделать код читаемым и устойчивым к масляным пятнам, грязи и повреждениям, предполагая, что он будет использоваться на соответствующих производствах. QR-код был представлен японской компанией Denso-Wave (b) , в 1994 году после двухлетнего периода разработки.[8][9][10] Он был разработан с учетом производственной системы компании «Toyota» (b) «Канбан (b) » (точно в срок (b) ) для использования на заводах по производству автозапчастей и в распределительных центрах. Однако, поскольку он обладает высокой способностью обнаружения и исправления ошибок (b) и сделан с открытым исходным кодом (b) , он вышел из узкой сферы производственных цепочек поставок компании «Toyota (b) » и начал использоваться в других сферах, что привело к тому, что теперь он широко используется не только в Японии, но и во всем мире. Огромная популярность штрихкодов в Японии привела к тому, что объём информации, зашифрованной в них, вскоре перестал устраивать промышленность. Японцы начали экспериментировать с новыми современными способами кодирования небольших объёмов информации в графической картинке. QR-код стал одним из наиболее часто используемых типов двумерного кода в мире.[11] Спецификация QR-кода не описывает формат данных (b) . В отличие от старого штрих-кода, который сканируют тонким лучом, QR-код определяется датчиком или камерой как двумерное изображение. Три квадрата в углах изображения и меньшие синхронизирующие квадратики по всему коду позволяют нормализовать размер изображения и его ориентацию, а также угол, под которым датчик расположен к поверхности изображения. Точки переводятся в двоичные числа (b) с проверкой по контрольной сумме (b) . Основное достоинство QR-кода — это лёгкое распознавание сканирующим (b) оборудованием, что даёт возможность использования в торговле (b) , производстве, логистике (b) .



Описание

Описание
Хотя обозначение «QR code» является зарегистрированным товарным знаком (b) «DENSO Corporation», использование кодов не облагается никакими лицензионными отчислениями (b) , а сами они описаны и опубликованы в качестве стандартов ISO.

Наиболее популярные программы просмотра QR-кодов поддерживают такие форматы данных: URL (b) , закладка в браузер (b) , Email (b) (с темой письма), SMS (b) на номер (c темой), MeCard, vCard (b) , географические координаты (b) , подключение к сети Wi-Fi (b) .
Также некоторые программы могут распознавать файлы GIF (b) , JPG (b) , PNG (b) или MID (b) меньше 4 КБ и зашифрованный текст (b) , но эти форматы не получили популярности.[13]
Применение
QR-коды больше всего распространены в Японии. Уже в начале 2000 года QR-коды получили столь широкое распространение в стране, что их можно было встретить на большом количестве плакатов, упаковок и товаров, там подобные коды наносятся практически на все товары, продающиеся в магазинах, их размещают в рекламных буклетах и справочниках. С помощью QR-кода даже организовывают различные конкурсы и ролевые игры (b) . Ведущие японские операторы мобильной связи совместно выпускают под своим брендом мобильные телефоны со встроенной поддержкой распознавания QR-кода[14].
В настоящее время QR-код также широко распространён в странах Азии, постепенно развивается в Европе и Северной Америке. Наибольшее признание он получил среди пользователей мобильной связи — установив программу-распознаватель, абонент может моментально заносить в свой телефон текстовую информацию, подключаться к сети Wi-Fi (b) , отправлять письма по электронной почте (b) , добавлять контакты в адресную книгу, переходить по web-ссылкам, отправлять SMS-сообщения (b) и т. д.
Как показало исследование, проведённое компанией comScore (b) [en] в 2011 году, 20 млн жителей США (b) использовали мобильные телефоны для сканирования QR-кодов[15].
В Японии, Австрии (b) и России (b) QR-коды также используются на кладбищах (b) и содержат информацию об усопшем[16][17][18].
В китайском городе Хэфэй (b) пожилым людям были розданы значки с QR-кодами, благодаря которым прохожие могут помочь потерявшимся старикам вернуться домой[19].
QR-коды активно используются музеями[20], а также и в туризме, как вдоль туристических маршрутов, так и у различных объектов. Таблички, изготовленные из металла, более долговечны и устойчивы к вандализму.
Использование QR-кодов для подтверждения вакцинации
Одновременно с началом массовой вакцинации против COVID-19 (b) весной 2021 года почти во всех странах мира началась выдача документов о вакцинации — цифровых или бумажных сертификатов, на которые повсеместно помещали QR-коды. К 9 ноября 2021 года QR-коды для подтверждения вакцинации или перенесённого заболевания (COVID-19 (b) ) были введены в 77 субъектах Российской Федерации (в некоторых из них начало действия QR-кодов было отсрочено, чтобы дать населению возможность привиться). В Татарстане (b) введение QR-кодов привело к столпотворениям на входах в метро и многочисленным конфликтам между пассажирами и кондукторами общественного транспорта[21].
Общая техническая информация
Самый маленький QR-код (версия 1) имеет размер 21×21 пиксель (без учёта полей), самый большой (версия 40) — 177×177 пикселей. Связь номера версии с количеством модулей простая — QR-код последующей версии больше предыдущего строго на 4 модуля по горизонтали и по вертикали.
Существует четыре основные кодировки QR-кодов:
- Цифровая: 10 битов на три цифры, до 7089 цифр.
- Алфавитно-цифровая: поддерживаются 10 цифр, буквы от A до Z и несколько спецсимволов. 11 битов на два символа, до 4296 символов
- Байтовая: данные в любой подходящей кодировке (по умолчанию ISO 8859-1 (b) ), до 2953 байт.
- Кандзи (b) : 13 битов на иероглиф, до 1817 иероглифов.
Также существуют «псевдокодировки»: задание способа кодировки в данных, разбиение длинного сообщения на несколько кодов и т. д.
Для исправления ошибок применяется код Рида — Соломона (b) с 8-битным кодовым словом. Есть четыре уровня избыточности: 7, 15, 25 и 30 %. Благодаря исправлению ошибок удаётся нанести на QR-код рисунок и всё равно оставить его читаемым.
Чтобы в коде не было элементов, способных запутать сканер, область данных складывается по модулю 2 (b) со специальной маской. Корректно работающий кодер должен перепробовать все варианты масок, посчитать штрафные очки для каждой по особым правилам и выбрать самую удачную.
-

Миниатюрное издание А. С. Пушкина «Евгений Онегин (b) » в QR-коде[12] Наиболее популярные программы просмотра QR-кодов поддерживают такие форматы данных: URL (b) , закладка в браузер (b) , Email (b) (с темой письма), SMS (b) на номер (c темой), MeCard, vCard (b) , географические координаты (b) , подключение к сети Wi-Fi (b) .
Также некоторые программы могут распознавать файлы GIF (b) , JPG (b) , PNG (b) или MID (b) меньше 4 КБ и зашифрованный текст (b) , но эти форматы не получили популярности.[13]

Применение
QR-коды больше всего распространены в Японии. Уже в начале 2000 года QR-коды получили столь широкое распространение в стране, что их можно было встретить на большом количестве плакатов, упаковок и товаров, там подобные коды наносятся практически на все товары, продающиеся в магазинах, их размещают в рекламных буклетах и справочниках. С помощью QR-кода даже организовывают различные конкурсы и ролевые игры (b) . Ведущие японские операторы мобильной связи совместно выпускают под своим брендом мобильные телефоны со встроенной поддержкой распознавания QR-кода[14].
В настоящее время QR-код также широко распространён в странах Азии, постепенно развивается в Европе и Северной Америке. Наибольшее признание он получил среди пользователей мобильной связи — установив программу-распознаватель, абонент может моментально заносить в свой телефон текстовую информацию, подключаться к сети Wi-Fi (b) , отправлять письма по электронной почте (b) , добавлять контакты в адресную книгу, переходить по web-ссылкам, отправлять SMS-сообщения (b) и т. д.
Как показало исследование, проведённое компанией comScore (b) [en] в 2011 году, 20 млн жителей США (b) использовали мобильные телефоны для сканирования QR-кодов[15].
В Японии, Австрии (b) и России (b) QR-коды также используются на кладбищах (b) и содержат информацию об усопшем[16][17][18].
В китайском городе Хэфэй (b) пожилым людям были розданы значки с QR-кодами, благодаря которым прохожие могут помочь потерявшимся старикам вернуться домой[19].
QR-коды активно используются музеями[20], а также и в туризме, как вдоль туристических маршрутов, так и у различных объектов. Таблички, изготовленные из металла, более долговечны и устойчивы к вандализму.
Использование QR-кодов для подтверждения вакцинации
Одновременно с началом массовой вакцинации против COVID-19 (b) весной 2021 года почти во всех странах мира началась выдача документов о вакцинации — цифровых или бумажных сертификатов, на которые повсеместно помещали QR-коды. К 9 ноября 2021 года QR-коды для подтверждения вакцинации или перенесённого заболевания (COVID-19 (b) ) были введены в 77 субъектах Российской Федерации (в некоторых из них начало действия QR-кодов было отсрочено, чтобы дать населению возможность привиться). В Татарстане (b) введение QR-кодов привело к столпотворениям на входах в метро и многочисленным конфликтам между пассажирами и кондукторами общественного транспорта[21].
Общая техническая информация
Самый маленький QR-код (версия 1) имеет размер 21×21 пиксель (без учёта полей), самый большой (версия 40) — 177×177 пикселей. Связь номера версии с количеством модулей простая — QR-код последующей версии больше предыдущего строго на 4 модуля по горизонтали и по вертикали.
Существует четыре основные кодировки QR-кодов:
- Цифровая: 10 битов на три цифры, до 7089 цифр.
- Алфавитно-цифровая: поддерживаются 10 цифр, буквы от A до Z и несколько спецсимволов. 11 битов на два символа, до 4296 символов
- Байтовая: данные в любой подходящей кодировке (по умолчанию ISO 8859-1 (b) ), до 2953 байт.
- Кандзи (b) : 13 битов на иероглиф, до 1817 иероглифов.
Также существуют «псевдокодировки»: задание способа кодировки в данных, разбиение длинного сообщения на несколько кодов и т. д.
Для исправления ошибок применяется код Рида — Соломона (b) с 8-битным кодовым словом. Есть четыре уровня избыточности: 7, 15, 25 и 30 %. Благодаря исправлению ошибок удаётся нанести на QR-код рисунок и всё равно оставить его читаемым.
Чтобы в коде не было элементов, способных запутать сканер, область данных складывается по модулю 2 (b) со специальной маской. Корректно работающий кодер должен перепробовать все варианты масок, посчитать штрафные очки для каждой по особым правилам и выбрать самую удачную.
-

1 – Введение
-
2 – Структура
-
2 – Структура
-
3 – Кодирование
-
4 – Уровни
-
4 – Уровни
-
5 – Протоколы




Micro QR

Пример Micro QR-кода

Пример Micro QR-кода
Отдельно существует микро QR-код ёмкостью до 35 цифр.
Эффективность хранения данных по сравнению с традиционным QR кодом значительно улучшена благодаря использованию всего одной метки позиционирования, по сравнению с тремя метками в обычном QR коде. Из-за этого освобождается определённое пространство, которое может быть использовано под данные. Кроме того, QR код требует свободного поля вокруг кода шириной минимум в 4 модуля (минимальной единицы построения QR-кода), в то время как Micro QR код требует поля в два модуля шириной. Из-за большей эффективности хранения данных, размер Micro QR кода увеличивается не столь значительно с увеличением объёма закодированных данных по сравнению с традиционным QR кодом.
По аналогии с уровнями коррекции ошибок в QR кодах, Micro QR код бывает четырёх версий, М1-М4[22][23].
| Версия кода | Количество модулей | Уровень коррекции ошибок | Цифры | Цифры и буквы | Двоичные данные | Кандзи |
|---|---|---|---|---|---|---|
| M1 | 11 | — | 5 | — | — | — |
| M2 | 13 | L (7 %) | 10 | 6 | — | — |
| M (15 %) | 8 | 5 | — | — | ||
| M3 | 15 | L (7 %) | 23 | 14 | 9 | 6 |
| M (15 %) | 18 | 11 | 7 | 4 | ||
| M4 | 17 | L (7 %) | 35 | 21 | 15 | 9 |
| M (15 %) | 30 | 18 | 13 | 8 | ||
| Q (25 %) | 21 | 13 | 9 | 5 |
Кодирование данных
Закодировать информацию в QR-код можно несколькими способами, а выбор конкретного способа зависит от того, какие символы используются. Если используются только цифры от 0 до 9, то можно применить цифровое кодирование, если кроме цифр необходимо зашифровать буквы латинского алфавита, пробел и символы $%*+-./:, используется алфавитно-цифровое кодирование. Ещё существует кодирование кандзи, которое применяется для шифрования китайских и японских иероглифов, и побайтовое кодирование. Перед каждым способом кодирования создаётся пустая последовательность бит, которая затем заполняется.
Цифровое кодирование
Этот тип кодирования требует 10 бит на 3 символа. Вся последовательность символов разбивается на группы по 3 цифры, и каждая группа (трёхзначное число) переводится в 10-битное двоичное число и добавляется к последовательности бит. Если общее количество символов не кратно 3, то если в конце остаётся 2 символа, полученное двузначное число кодируется 7 битами, а если 1 символ, то 4 битами.
Например, есть строка «12345678», которую надо закодировать. Последовательность разбивается на числа: 123, 456 и 78, затем каждое число переводится в двоичный вид: 0001111011, 0111001000 и 1001110, и объединяется это в один битовый поток: 000111101101110010001001110.
Буквенно-цифровое кодирование
В отличие от цифрового кодирования, для кодирования 2 символов требуется 11 бит информации. Последовательность символов разбивается на группы по 2, в группе каждый символ кодируется согласно таблице «Значения символов в буквенно-цифровом кодировании». Значение первого символа умножается на 45, затем к этому произведению прибавляется значение второго символа. Полученное число переводится в 11-битное двоичное число и добавляется к последовательности бит. Если в последней группе остаётся один символ, то его значение кодируется 6-битным числом. Рассмотрим на примере: «PROOF». Разбиваем последовательность символов на группы: PR, OO, F. Находим соответствующие значения символам к каждой группе (смотрим в таблицу): PR — (25,27), OO — (24,24), F — (15). Находим значения для каждой группы: 25 × 45 + 27 = 1152, 24 × 45 + 24 = 1104, 15 = 15. Переводим каждое значение в двоичный вид: 1152 = 10010000000, 1104 = 10001010000, 15 = 001111. Объединяем в одну последовательность: 1001000000010001010000001111.
Байтовое кодирование
Таким способом кодирования можно закодировать любые символы. Входной поток символов кодируется в любой кодировке (рекомендовано в UTF-8 (b) ), затем переводится в двоичный вид, после чего объединяется в один битовый поток.
Например, слово «Мир» кодируем в Unicode (HEX) в UTF-8 (b) : М — D09C; и — D0B8; р — D180. Переводим каждое значение в двоичную систему счисления: D0 = 11010000, 9C = 10011100, D0 = 11010000, B8 = 10111000, D1 = 11010001 и 80 = 10000000; объединяем в один поток битов: 11010000 10011100 11010000 10111000 11010001 10000000.
Кандзи
В основе кодирования иероглифов (как и прочих символов) лежит визуально воспринимаемая таблица или список изображений иероглифов с их кодами. Такая таблица называется «character set». Для японского языка основное значение имеют две таблицы символов: JIS 0208:1997 и JIS 0212:1990. Вторая из них служит в качестве дополнения по отношению к первой. JIS 0208:1997 разбита на 94 страницы по 94 символа. К примеру, страница 4 — хирагана, 5 — катакана, 7 — кириллица, 16—43 — кандзи уровня 1, 48—83 — кандзи уровня 2. Кандзи уровня 1 («JIS дайити суйдзюн кандзи») упорядочены по онам. Кандзи уровня 2 («JIS дайни суйдзюн кандзи») упорядочены по ключам, и внутри них — по количеству черт.
Добавление служебной информации
После определения версии кода и кодировки необходимо определиться с уровнем коррекции ошибок. В таблице представлены максимальные значения уровней коррекции для различных версий QR-кода. Для исправления ошибок применяется код Рида — Соломона (b) с 8-битным кодовым словом.
Таблица. Максимальное количество информации.
Строка — уровень коррекции, столбец — номер версии.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |
| L | 152 | 272 | 440 | 640 | 864 | 1088 | 1248 | 1552 | 1856 | 2192 | 2592 | 2960 | 3424 | 3688 | 4184 | 4712 | 5176 | 5768 | 6360 | 6888 |
| M | 128 | 224 | 352 | 512 | 688 | 864 | 992 | 1232 | 1456 | 1728 | 2032 | 2320 | 2672 | 2920 | 3320 | 3624 | 4056 | 4504 | 5016 | 5352 |
| Q | 104 | 176 | 272 | 384 | 496 | 608 | 704 | 880 | 1056 | 1232 | 1440 | 1648 | 1952 | 2088 | 2360 | 2600 | 2936 | 3176 | 3560 | 3880 |
| H | 72 | 128 | 208 | 288 | 368 | 480 | 528 | 688 | 800 | 976 | 1120 | 1264 | 1440 | 1576 | 1784 | 2024 | 2264 | 2504 | 2728 | 3080 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | |
| L | 7456 | 8048 | 8752 | 9392 | 10208 | 10960 | 11744 | 12248 | 13048 | 13880 | 14744 | 15640 | 16568 | 17528 | 18448 | 19472 | 20528 | 21616 | 22496 | 23648 |
| M | 5712 | 6256 | 6880 | 7312 | 8000 | 8496 | 9024 | 9544 | 10136 | 10984 | 11640 | 12328 | 13048 | 13800 | 14496 | 15312 | 15936 | 16816 | 17728 | 18672 |
| Q | 4096 | 4544 | 4912 | 5312 | 5744 | 6032 | 6464 | 6968 | 7288 | 7880 | 8264 | 8920 | 9368 | 9848 | 10288 | 10832 | 11408 | 12016 | 12656 | 13328 |
| H | 3248 | 3536 | 3712 | 4112 | 4304 | 4768 | 5024 | 5288 | 5608 | 5960 | 6344 | 6760 | 7208 | 7688 | 7888 | 8432 | 8768 | 9136 | 9776 | 10208 |
После определения уровня коррекции ошибок необходимо добавить служебные поля, они записываются перед последовательностью бит, полученной после этапа кодирования. В них указывается способ кодирования и количество данных. Значение поля способа кодирования состоит из 4 бит, оно не изменяется, а служит знаком, который показывает, какой способ кодирования используется. Оно имеет следующие значения:
- 0001 для цифрового кодирования,
- 0010 для буквенно-цифрового и
- 0100 для побайтового
Пример:
Ранее в примере байтового кодирования кодировалось слово «Мир», при этом получилась следующая последовательность двоичного кода:
11010000 10011100 11010000 10111000 11010001 10000000, содержащая 48 бит информации.
Пусть необходим уровень коррекции ошибок Н, позволяющий восстанавливать 30 % утраченной информации. По таблице максимальное количество информации выбирается оптимальная версия QR-кода (в данном случае 1 версия, которая позволяет закодировать 72 бита полезной информации при уровне коррекции ошибок Н).
Информация о способе кодирования: побайтовому кодированию соответствует поле 0100.
Указание количества данных (для цифрового и буквенно-цифрового кодирования — количество символов, для побайтового — количество байт): данная последовательность содержит 6 байт данных (в двоичной системе счисления: 110).
По таблице определяется необходимая длина двоичного числа — 8 бит. Дописываются недостающие нули: 00000110.
| Версия 1-9 | Версия 10-26 | Версия 27-40 | |
|---|---|---|---|
| Цифровое | 10 бит | 12 бит | 14 бит |
| Буквенно-цифровое | 9 бит | 11 бит | 13 бит |
| Побайтовое | 8 бит | 16 бит | 16 бит |
Вся информация записывается в порядке <способ кодирования> <количество данных> <данные>, получается последовательность бит:
0100 00000110 11010000 10011100 11010000 10111000 11010001 10000000.
Разделение на блоки
Последовательность байт разделяется на определённое для версии и уровня коррекции количество блоков, которое приведено в таблице «Количество блоков». Если количество блоков равно одному, то этот этап можно пропустить. А при повышении версии — добавляются специальные блоки.
Сначала определяется количество байт (данных) в каждом из блоков. Для этого надо разделить всё количество байт на количество блоков данных. Если это число не целое, то надо определить остаток от деления. Этот остаток определяет, сколько блоков из всех дополнены (такие блоки, количество байт в которых больше на один, чем в остальных). Вопреки ожиданию, дополненными блоками должны быть не первые блоки, а последние. Затем идёт последовательное заполнение блоков.
Пример: для версии 9 и уровня коррекции M количество данных — 182 байта, количество блоков — 5. Поделив количество байт данных на количество блоков, получаем 36 байт и 2 байта в остатке. Это значит, что блоки данных будут иметь следующие размеры: 36, 36, 36, 37, 37 (байт). Если бы остатка не было, то все 5 блоков имели бы размер по 36 байт.
Блок заполняется байтами из данных полностью. Когда текущий блок полностью заполняется, очередь переходит к следующему. Байтов данных должно хватить ровно на все блоки, не больше и не меньше.
Создание байтов коррекции
Процесс основан на алгоритме Рида — Соломона (b) . Он должен быть применён к каждому блоку информации QR-кода. Сначала определяется количество байт коррекции, которые необходимо создать, а затем, с ориентиром на эти данные, создаётся многочлен генерации. Количество байтов коррекции на один блок определятся по выбранной версии кода и уровню коррекции ошибок (приведено в таблице).
Таблица. Количество байтов коррекции на один блок
Строка — уровень коррекции, столбец — номер версии.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | |
| L | 7 | 10 | 15 | 20 | 26 | 18 | 20 | 24 | 30 | 18 | 20 | 24 | 26 | 30 | 22 | 24 | 28 | 30 | 28 | 28 | 28 | 28 | 30 | 30 | 26 | 28 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
| M | 10 | 16 | 26 | 18 | 24 | 16 | 18 | 22 | 22 | 26 | 30 | 22 | 22 | 24 | 24 | 28 | 28 | 26 | 26 | 26 | 26 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 | 28 |
| Q | 13 | 22 | 18 | 26 | 18 | 24 | 18 | 22 | 20 | 24 | 28 | 26 | 24 | 20 | 30 | 24 | 28 | 28 | 26 | 30 | 28 | 30 | 30 | 30 | 30 | 28 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
| H | 17 | 28 | 22 | 16 | 22 | 28 | 26 | 26 | 24 | 28 | 24 | 28 | 22 | 24 | 24 | 30 | 28 | 28 | 26 | 28 | 30 | 24 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
По количеству байтов коррекции определяется генерирующий многочлен (приведено в таблице).
Таблица. Генерирующие многочлены.
| Количество байт коррекции | Генерирующий многочлен |
|---|---|
| 7 | 87, 229, 146, 149, 238, 102, 21 |
| 10 | 251, 67, 46, 61, 118, 70, 64, 94, 32, 45 |
| 13 | 74, 152, 176, 100, 86, 100, 106, 104, 130, 218, 206, 140, 78 |
| 15 | 8, 183, 61, 91, 202, 37, 51, 58, 58, 237, 140, 124, 5, 99, 105 |
| 16 | 120, 104, 107, 109, 102, 161, 76, 3, 91, 191, 147, 169, 182, 194, 225, 120 |
| 17 | 43, 139, 206, 78, 43, 239, 123, 206, 214, 147, 24, 99, 150, 39, 243, 163, 136 |
| 18 | 215, 234, 158, 94, 184, 97, 118, 170, 79, 187, 152, 148, 252, 179, 5, 98, 96, 153 |
| 20 | 17, 60, 79, 50, 61, 163, 26, 187, 202, 180, 221, 225, 83, 239, 156, 164, 212, 212, 188, 190 |
| 22 | 210, 171, 247, 242, 93, 230, 14, 109, 221, 53, 200, 74, 8, 172, 98, 80, 219, 134, 160, 105, 165, 231 |
| 24 | 229, 121, 135, 48, 211, 117, 251, 126, 159, 180, 169, 152, 192, 226, 228, 218, 111, 0, 117, 232, 87, 96, 227, 21 |
| 26 | 173, 125, 158, 2, 103, 182, 118, 17, 145, 201, 111, 28, 165, 53, 161, 21, 245, 142, 13, 102, 48, 227, 153, 145, 218, 70 |
| 28 | 168, 223, 200, 104, 224, 234, 108, 180, 110, 190, 195, 147, 205, 27, 232, 201, 21, 43, 245, 87, 42, 195, 212, 119, 242, 37, 9, 123 |
| 30 | 41, 173, 145, 152, 216, 31, 179, 182, 50, 48, 110, 86, 239, 96, 222, 125, 42, 173, 226, 193, 224, 130, 156, 37, 251, 216, 238, 40, 192, 180 |
Расчёт производится исходя из значений исходного массива данных и значений генерирующего многочлена, причём для каждого шага цикла отдельно.
Объединение информационных блоков
На данном этапе имеется два готовых блока: исходных данных и блоков коррекции (из прошлого шага), их необходимо объединить в один поток байт. По очереди необходимо брать один байт информации из каждого блока данных, начиная от первого и заканчивая последним. Когда же очередь доходит до последнего блока, из него берётся байт и очередь переходит к первому блоку. Так продолжается до тех пор, пока в каждом блоке не закончатся байты. Есть исключения, когда текущий блок пропускается, если в нём нет байт (ситуация, когда обычные блоки уже пусты, а в дополненных ещё есть по одному байту). Так же поступается и с блоками байтов коррекции. Они берутся в том же порядке, что и соответствующие блоки данных.
В итоге получается следующая последовательность данных: <1-й байт 1-го блока данных><1-й байт 2-го блока данных>…<1-й байт n-го блока данных><2-й байт 1-го блока данных>…<(m — 1)-й байт 1-го блока данных>…<(m — 1)-й байт n-го блока данных>…<1-й байт 1-го блока байтов коррекции><1-й байт 2-го блока байтов коррекции>…<1-й байт n-го блока байтов коррекции><2-й байт 1-го блока байтов коррекции>…….
Здесь n — количество блоков данных, m — количество байтов на блок данных у обычных блоков, l — количество байтов коррекции, k — количество блоков данных минус количество дополненных блоков данных (тех, у которых на 1 байт больше).
Этап размещения информации на поле кода
На QR-коде есть обязательные поля, они не несут закодированной информации, а содержат информацию для декодирования. Это:
- Поисковые узоры
- Выравнивающие узоры
- Полосы синхронизации
- Код маски и уровня коррекции
- Код версии (с 7-й версии)
а также обязательный отступ вокруг кода. Отступ — это рамка из белых модулей, её ширина — 4 модуля.
Поисковые узоры — это 3 квадрата по углам кроме правого нижнего. Используются для определения расположения кода. Они состоят из квадрата 3×3 из чёрных модулей, вокруг рамка из белых модулей шириной 1, потом ещё одна рамка из чёрных модулей, так же шириной 1, и ограждение от остальной части кода — половина рамки из белых модулей шириной 1. Итого эти объекты имеют размер 8×8 модулей.
Выравнивающие узоры — появляются, начиная со второй версии, используются для дополнительной стабилизации кода, более точном его размещении при декодировании. Состоят они из 1 чёрного модуля, вокруг которого стоит рамка из белых модулей шириной 1, а потом ещё одна рамка из чёрных модулей, также шириной 1. Итоговый размер выравнивающего узора — 5×5. Стоят такие узоры на разных позициях в зависимости от номера версии. Выравнивающие узоры не могут накладываться на поисковые узоры. Ниже представлена таблица расположения центрального чёрного модуля, там указаны цифры — это возможные координаты, причём как по горизонтали, так и по вертикали. Эти модули стоят на пересечении таких координат. Отсчёт ведётся от верхнего левого узла, его координаты (0,0).
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| — | 18 | 22 | 26 | 30 | 34 | 6, 22, 38 | 6, 24, 42 | 6, 26, 46 | 6, 28, 50 | 6, 30, 54 | 6, 32, 58 | 6, 34, 62 | 6, 26, 46, 66 | 6, 26, 48, 70 | 6, 26, 50, 74 | 6, 30, 54, 78 | 6, 30, 56, 82 | 6, 30, 58, 86 | 6, 34, 62, 90 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 |
| 6, 28, 50, 72, 94 | 6, 26, 50, 74, 98 | 6, 30, 54, 78, 102 | 6, 28, 54, 80, 106 | 6, 32, 58, 84, 110 | 6, 30, 58, 86, 114 | 6, 34, 62, 90, 118 | 6, 26, 50, 74, 98, 122 | 6, 30, 54, 78, 102, 126 | 6, 26, 52, 78, 104, 130 | 6, 30, 56, 82, 108, 134 | 6, 34, 60, 86, 112, 138 | 6, 30, 58, 86, 114, 142 | 6, 34, 62, 90, 118, 146 | 6, 30, 54, 78, 102, 126, 150 | 6, 24, 50, 76, 102, 128, 154 | 6, 28, 54, 80, 106, 132, 158 | 6, 32, 58, 84, 110, 136, 162 | 6, 26, 54, 82, 110, 138, 166 | 6, 30, 58, 86, 114, 142, 170 |
Полосы синхронизации — используются для определения размера модулей. Располагаются они уголком, начинается одна от левого нижнего поискового узора (от края чёрной рамки, но переступив через белую), идёт до левого верхнего, а оттуда начинается вторая, по тому же правилу, заканчивается она у правого верхнего. При наслоении на выравнивающий модуль он должен остаться без изменений. Выглядят полосы синхронизации как линии чередующихся между собой чёрных и белых модулей.
Код маски и уровня коррекции — расположен рядом с поисковыми узорами: под правым верхним (8 модулей) и справа от левого нижнего (7 модулей), и дублируются по бокам левого верхнего, с пробелом на 7 ячейке — там, где проходят полосы синхронизации, причём горизонтальный код в вертикальную часть, а вертикальный — в горизонтальную.
Код версии — нужен для определения версии кода. Находятся слева от верхнего правого и сверху от нижнего левого, причём дублируются. Дублируются они так — зеркальную копию верхнего кода поворачивают против часовой стрелки на 90 градусов. Ниже представлена таблица кодов, 1 — чёрный модуль, 0 — белый.
| Версия | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| Код версии | 000010 011110 100110 | 010001 011100 111000 | 110111 011000 000100 | 101001 111110 000000 | 001111 111010 111100 | 001101 100100 011010 | 101011 100000 100110 | 110101 000110 100010 | 010011 000010 011110 | 011100 010001 011100 | 111010 010101 100000 | 100100 110011 100100 | 000010 110111 011000 | 000000 101001 111110 | 100110 101101 000010 | 111000 001011 000110 | 011110 001111 111010 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | |
| 001101 001101 100100 | 101011 001001 011000 | 110101 101111 011100 | 010011 101011 100000 | 010001 110101 000110 | 110111 110001 111010 | 101001 010111 111110 | 001111 010011 000010 | 101000 011000 101101 | 001110 011100 010001 | 010000 111010 010101 | 110110 111110 101001 | 110100 100000 001111 | 010010 100100 110011 | 001100 000010 110111 | 101010 000110 001011 | 111001 000100 010101 |
Занесение данных
Оставшееся место делят на столбики шириной в 2 модуля и заносят туда информацию, причём делают это «змейкой». Сначала в правый нижний квадратик заносят первый бит информации, потом в его левого соседа, потом в тот, который был над первым и так далее. Заполнение столбцов ведётся снизу вверх, а потом сверху вниз и т. д., причём по краям заполнение битов ведётся от крайнего бита одного столбца до крайнего бита соседнего столбца, что задаёт «змейку» на столбцы с направлением вниз. Если информации окажется недостаточно, то поля просто оставляют пустыми (белые модули). При этом на каждый модуль накладывается маска.
-

Описание полей QR-кода.
-

Описание полей QR-кода.
-
Код маски и уровня коррекции, возможные XOR-маски
-

-
-
-

8-цветный код JAB, содержащий текст «Добро пожаловать в Википедию, бесплатную энциклопедию, которую может редактировать каждый».
-

8-цветный код JAB, содержащий текст «Добро пожаловать в Википедию, бесплатную энциклопедию, которую может редактировать каждый».
-
Примеры цветного двухмерного кода большой емкости (HCC2D): (a) 4-цветный код HCC2D и (b) 8-цветный код HCC2D.
-
Версия 1
-
Версия 1
-
Функциональные области QR-кода версии 1
-
Версия 40
-

Версия 40
-
IQR-код










См. также
- Q-код (b)
- Сравнение характеристик штрихкодов (b)
- Data Matrix (b)
- Semacode (b)
- PDF417 (b)
- Aztec Code (b)
- Microsoft Tag (b)
- QRpedia (b)
- Перфокарта (b)
Примечания
- ↑ Специалист по словообразованию М. А. Осадчий (b) предлагает использовать в качестве русскоязычного эквивалента словосочетание «графический код»[2].
- ↑ QR codes on China’s train tickets may leak personal information. Архивировано 12 декабря 2013 года. Дата обращения: 16 марта 2013.
- 1 2 В Институте имени Пушкина предложили переименовать QR-кодАрхивная копия от 10 февраля 2022 на Wayback Machine (b) // Радио Sputnik (b) , 10.02.2022
- ↑ История QR-кода Эту технологию придумал японский инженер во время игры в го на работе. Дата обращения: 8 ноября 2021. Архивировано 8 ноября 2021 года.
- ↑ QR Code features (англ.). Denso-Wave. Дата обращения: 27 августа 2017. Архивировано 29 января 2013 года.
- 1 2 QR Code Essentials (англ.). Denso ADC (2011). Дата обращения: 28 августа 2017. Архивировано из оригинала 12 мая 2013 года.
- ↑ Borko Furht. Handbook of Augmented Reality. — Springer, 2011. — С. 341. — ISBN 9781461400646.
- 1 2 ヒントは休憩中の“囲碁”だった…『QRコード』開発秘話 生みの親が明かす「特許オープンにした」ワケ, 東海テレビ放送 (b) (29 ноября 2019). Архивировано 30 сентября 2020 года. Дата обращения: 29 ноября 2019.
- ↑ NHKビジネス特集 「QRコード」生みの親に聞いてみたАрхивная копия от 20 мая 2019 на Wayback Machine (b) 、2019年5月20日
- ↑ 2D Barcodes. NHK World-Japan (b) (26 марта 2020). Дата обращения: 24 апреля 2020. Архивировано 7 апреля 2020 года.
- ↑ Сайт компании Denso-Wave. Дата обращения: 18 сентября 2012. Архивировано 16 октября 2012 года.
- ↑ QR Code—About 2D Code. Denso-Wave. Дата обращения: 27 мая 2016. Архивировано из оригинала 5 июня 2016 года.
- ↑ «Евгений Онегин» — теперь и в QR-коде. Дата обращения: 23 ноября 2020. Архивировано из оригинала 27 ноября 2020 года.
- ↑ Популярность QR-кодов. Дата обращения: 8 января 2022. Архивировано 8 января 2022 года.
- ↑ QR-код: использование. Дата обращения: 14 марта 2010. Архивировано 6 июня 2014 года.
- ↑ Леонид Бугаев. 2012, стр. 167
- ↑ QR коды на кладбищах. Дата обращения: 24 апреля 2020. Архивировано 15 мая 2021 года.
- ↑ QR коды на кладбищах. Дата обращения: 24 октября 2012. Архивировано из оригинала 6 июня 2014 года.
- ↑ Внук Юрия Никулина рассказывает про интерактивный мемориал. Цифровое наследие (21 августа 2017). Дата обращения: 27 августа 2017. Архивировано из оригинала 23 августа 2017 года.
- ↑ Бейджи с QR-кодами для поиска дороги домой. Дата обращения: 15 октября 2014. Архивировано 19 ноября 2014 года.
- ↑ Реклама «Дня музеев — 2012». Дата обращения: 2 марта 2012. Архивировано 24 апреля 2014 года.
- ↑ Что известно о законопроекте о введении QR-кодов в общественных местахАрхивная копия от 20 декабря 2021 на Wayback Machine (b) // ТАСС (b) , 16.12.2021.
- ↑ Описание Micro QR кода | QR коды нового поколения. qrcc.ru. Дата обращения: 9 июня 2018. Архивировано 12 июня 2018 года.
- ↑ Micro QR Code | QRcode.com | DENSO WAVE (англ.). www.qrcode.com. Дата обращения: 31 мая 2019. Архивировано 31 мая 2019 года.
Литература
- Бугаев Л. Мобильный маркетинг. Как зарядить свой бизнес в мобильном мире. — М.: Альпина Паблишер (b) , 2012. — 214 с. — ISBN 978-5-9614-2222-1.
- ГОСТ Р ИСО/МЭК 18004-2015 Информационные технологии. Технологии автоматической идентификации и сбора данных. Спецификация символики штрихового кода QR Code
Ссылки
- Сайт компании Denso Wave, посвящённый QR-кодам (англ.)
Стандарты ISO (b) |
|
|---|---|
|
|
| 1 по 9999 |
|
| 10000 по 19999 |
|
| 20000+ |
|
|
См. также:Список статей, названия которых начинаются с «ISO» |
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code, (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
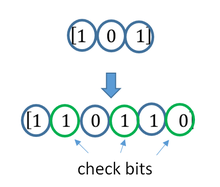
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]

Стандарты ISO (b)
- Перечни: Перечень стандартов ИСО (b)
- Перечень романизаций ISO (b)
- Перечень стандартов IEC (b)
- Категории: Категория:Стандарты ISO
- Категория:Протоколы OSI
по
9999
- 1 (b)
- 2 (b)
- 3 (b)
- 4 (b)
- 5 (b)
- 6 (b)
- 7 (b)
- 9 (b)
- 16 (b)
- 31 (b)
- -0 (b)
- -1 (b)
- -2 (b)
- -3 (b)
- -4 (b)
- -5 (b)
- -6 (b)
- -7 (b)
- -8 (b)
- -9 (b)
- -10 (b)
- -11 (b)
- -12 (b)
- -13 (b)
- 128 (b)
- 216 (b)
- 217 (b)
- 226 (b)
- 228 (b)
- 233 (b)
- 259 (b)
- 269 (b)
- 296 (b)
- 302 (b)
- 306 (b)
- 428 (b)
- 639 (b)
- -1 (b)
- 646 (b)
- 668 (b)
- 690 (b)
- 732 (b)
- 764 (b)
- 796
- 843 (b)
- 898 (b)
- 1000 (b)
- 1004 (b)
- 1007 (b)
- 1073-1 (b)
- 1413 (b)
- 1538 (b)
- 1745
- 2014 (b)
- 2015 (b)
- 2022 (b)
- 2108 (b)
- 2145 (b)
- 2146 (b)
- 2281 (b)
- 2709 (b)
- 2711 (b)
- 2788 (b)
- 3029 (b)
- 3103 (b)
- 3166 (b)
- -1 (b)
- -2 (b)
- -3 (b)
- 3297 (b)
- 3307 (b)
- 3602 (b)
- 3864 (b)
- 3901 (b)
- 3977 (b)
- 4031 (b)
- 4157 (b)
- 4217 (b)
- 5218 (b)
- 5775 (b)
- 5776 (b)
- 5964 (b)
- 6166 (b)
- 6344 (b)
- 6346 (b)
- 6425 (b)
- 6429 (b)
- 6438 (b)
- 6523 (b)
- 6709 (b)
- 7001 (b)
- 7002 (b)
- 7098 (b)
- 7185 (b)
- 7388 (b)
- 7498 (b)
- 7736 (b)
- 7810 (b)
- 7811 (b)
- 7812 (b)
- 7813 (b)
- 7816 (b)
- 8000 (b)
- 8217 (b)
- 8571 (b)
- 8583 (b)
- 8601 (b)
- 8632 (b)
- 8652 (b)
- 8691 (b)
- 8807 (b)
- 8820-5 (b)
- 8859 (b)
- -1 (b)
- -2 (b)
- -3 (b)
- -4 (b)
- -5 (b)
- -6 (b)
- -7 (b)
- -8 (b)
- -9 (b)
- -10 (b)
- -11 (b)
- -12 (b)
- -13 (b)
- -14 (b)
- -15 (b)
- -16 (b) )
- 8879 (b)
- 9000 (b)
- 9075 (b)
- 9126 (b)
- 9241 (b)
- 9362 (b)
- 9407 (b)
- 9506 (b)
- 9529 (b)
- 9564 (b)
- 9594 (b)
- 9660 (b)
- 9897 (b)
- 9945 (b)
- 9984 (b)
- 9985 (b)
- 9995 (b)
по
19999
- 10006 (b)
- 10118-3 (b)
- 10160 (b)
- 10161 (b)
- 10165 (b)
- 10179 (b)
- 10206 (b)
- 10303 (b)
- 10303-11 (b)
- 10303-21 (b)
- 10303-22 (b)
- 10303-238 (b)
- 10303-28 (b)
- 10383 (b)
- 10487 (b)
- 10585 (b)
- 10589 (b)
- 10646 (b)
- 10664 (b)
- 10746 (b)
- 10861
- 10957 (b)
- 10962 (b)
- 10967 (b)
- 11073 (b)
- 11170 (b)
- 11179 (b)
- 11404 (b)
- 11544 (b)
- 11783 (b)
- 11784 (b)
- 11785 (b)
- 11801 (b)
- 11898 (b)
- 11940 (b)
- 11941 (b)
- 11941 (TR) (b)
- 11992 (b)
- 12006 (b)
- 12164 (b)
- 12182:1998
- 12207:1995
- 12207:2008
- 12234-2 (b)
- 13211 (b)
- -1 (b)
- -2 (b)
- 13216 (b)
- 13250 (b)
- 13399 (b)
- 13406-2 (b)
- 13407 (b)
- 13450 (b)
- 13485 (b)
- 13490 (b)
- 13567 (b)
- 13568 (b)
- 13584 (b)
- 13616 (b)
- 14000 (b)
- 14031 (b)
- 14396 (b)
- 14443 (b)
- 14496-10 (b)
- 14496-14 (b)
- ISO 14575 (b)
- 14644 (b)
- -1 (b)
- -2 (b)
- -3 (b)
- -4 (b)
- -5 (b)
- -6 (b)
- -7 (b)
- -8 (b)
- -9 (b)
- 14649 (b)
- 14651 (b)
- 14698 (b)
- 14698-2 (b)
- 14750 (b)
- 14882 (b)
- 14971 (b)
- 15022 (b)
- 15189 (b)
- 15288 (b)
- 15291 (b)
- 15292 (b)
- 15408 (b)
- 15444 (b)
- 15445 (b)
- 15438 (b)
- 15504 (b)
- 15511 (b)
- 15686 (b)
- 15693 (b)
- 15706 (b)
- 15706-2 (b)
- 15707 (b)
- 15897 (b)
- 15919 (b)
- 15924 (b)
- 15926 (b)
- 15926 WIP (b)
- 15930 (b)
- 16023 (b)
- 16262 (b)
- 16750 (b)
- 17024 (b)
- 17025 (b)
- 17369 (b)
- 17799 (b)
- 17987 (b)
- 18000 (b)
- 18004 (b)
- 18014 (b)
- 18245 (b)
- 18629 (b)
- 18916 (b)
- 19005 (b)
- 19011 (b)
- 19092-1 (b)
- 19092-2 (b)
- 19114 (b)
- 19115 (b)
- 19439 (b)
- 19501:2005 (b)
- 19752 (b)
- 19757 (b)
- 19770 (b)
- 19775-1 (b)
- 19794-5 (b)
- 20000 (b)
- 20022 (b)
- 20121 (b)
- 21000 (b)
- 21047 (b)
- 21500 (b)
- 21827:2002
- 22000 (b)
- 23008-2 (b)
- 23270 (b)
- 23360 (b)
- 24613 (b)
- 24707 (b)
- 25964-1 (b)
- 25178 (b)
- 26000 (b)
- 26300 (b)
- 26324 (b)
- 27000 series (b)
- 27000 (b)
- 27001 (b)
- 27002 (b)
- 27003 (b)
- 27004 (b)
- 27005 (b)
- 27006 (b)
- 27007 (b)
- 27729 (b)
- 27799 (b)
- 29199-2 (b)
- 29500 (b)
- 31000 (b)
- 32000 (b)
- 38500 (b)
- 42010 (b)
- 50001 (b)
- 80000 (b)
См. также:Список статей, названия которых начинаются с «ISO»
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code, (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]
A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.

A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters


See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code, (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]
A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
5 ноября 2012
Двухмерные штрихкоды — что это такое и с чем их едят
Что такое двухмерный штрихкод (2d barcode)? Многие считают, что этот синоним «QR-код». Однако, на самом деле, это не совсем так — видов двухмерных штрихкодов намного больше. Именно о них мы и поговорим в этой статье.
Хочу сразу предупредить, что в этот раз текста будет довольно много, а цветных картинок мало. Да и тема довольно специфическая, и будет интересна далеко не всем. Тем более, что недавно на сайте уже была статья Виталия Буздалова про QR коды, где были четко и лаконично описаны все основные моменты — http://android.mobile-review.com/market/10514/

К сожалению, WorldPress не позволяет вставлять видео с youtube в текст статьи (либо я не разобрался как это сделать). Из-за этого пришлось вставлять картинку, при клике на которую откроется само видео.
Основное достоинство любого штрих кода — простота использования. Двухмерные коды не являются исключением, все работает по принципу «навел — снял — прочитал» и не требует каких-то специальных пояснений. Сами же программы-сканеры обычно имеют стандартный набор функций, и в детальном обзоре тоже не нуждаются. Поэтому получился в большей степени обзор самих разновидностей двухмерных штрихкодов, а не программ для их распознавания. Какой-то эксклюзивной информации в статье нет, все данные взяты из открытых источников.
Статья делится на две части — теоретическая (разновидности 2D кодов, их особенности и способы применения) и практическая (программы для сканирования и генерации кодов, сайты-генераторы и пр. )
ТЕОРИЯ
Все штрихкоды можно разделить на два типа: линейные и двухмерные.
Линейный штрихкод — это код, который читается в одном направлении. Такие штрихкоды очень просты и дешевы в использовании.
Авторами первого линейного штрихкода можно считать Бернарда Сильвера и Джозефа Вудланда. В 1948 они стали случайными свидетелями разговора между президентом крупной сети продуктовых компаний и деканом Института Технологии Университета Дрекселя, которые обсуждали создание системы, автоматически считывающей информацию о продукте.
Идея штрихкода родилась не сразу. Вначале было перепробовано несколько других вариантов, таких как метки, нанесенные ультрафиолетовыми чернилами и др. Но по разным причинам, все эти идеи оказались нежизнеспособны. На идею же самого штрихкода Джозефа Вудланда натолкнула Азбука Морзе. По его словам, он просто расширил точки и тире вниз и сделал из них узкие и широкие линии.
В 1951 году они показали свое изобретение компании IBM, но в ней почитали, что ее реализация потребует слишком сложного оборудования. Отчасти это было правдой — лазерных сканеров тогда еще не существовало и считывать штрихкоды было довольно сложно. Фактически, идея Джозефа и Сильвера опередила свое время более чем на десять лет.
Впервые широкой публике штрихкоды были продемонстрированы лишь в 1971 году на конференции по розничной торговле. Они были нанесены на лотерейные жетоны и состояли не из линий, а из окружностей. В дальнейшим от круглого варианта штрихкодов отказались — при их печати краска часто смазывалась и они становились нечитаемы.
Первый коммерческий формат штрихкода был разработан в 1972 году и получил название UPC — Universal Product Code. С тех пор форматы штрихкод многократно совершенствовались и менялись. На сегодняшний день существует более 300 стандартов штрих-кодирования.
Главный недостаток линейных штрихкодов — малое кол-во кодируемой информации. Именно для преодоления этого недостатка и были разработаны двухмерные штрихкоды.
PDF417
Сайт-генератор — http://barcode.tec-it.com
Программа-сканер — Accusoft Barcode Scanner
PDF417 был разработан компанией Symbol Technologies в 1991 году. Название PDF происходит от «Portable Data File». Число «417» отражает структуру кода — штрихкод имеет длинну в 17 модулей, состоящих из 4-х «штрихов» и «пробелов». По сути, такие блоки являются одномерным штрихкодом.

Теоретически, это должно упростить его считывание и декодирование. И скорее всего, для специальных сканеров именно так оно и есть. А вот с программами-сканерами для мобильных устройств часто бывают проблемы. Во всяком случае, у меня такие коды считываются в лучшем случае через раз. Впрочем, винить тут стоит не сам код, а исключительно программы-сканеры.
Код можно встретить на товарах, документах, билетах. Если не ошибаюсь, именно он используется на билетах АэроЭкспресса. Правда, прочитать его программой-сканером я не смог. Часто его можно увидеть и в мaгазинах, в частности на бутылках с алкогольной продукцией.

DataMatrix
Сайт-генератор — http://www.qrcc.ru/generator.php
Программа-сканер — Barcode Scanner
Код DataMatrix был изобретен компанией International Data Matrix, которая позже была объединена в Acuity CiMatrix и в 2005 году куплена компанией Siemens. Существенное влияние на разработку кода DataMatrix оказал предшествующий ему многострочный штрих-код PDF-417. В настоящее время Data Matrix описывается соответствующими стандартами ISO. Код может быть использован свободно, без каких либо лицензионных отчислений.
Код представляет собой двухмерную матрицу из черно-белых точек или модулей. В коде должно содержаться четное число таких модулей как по вертикали, так и по горизонтали. DataMatrix код может состоять как из одного, так и из нескольких блоков. В каждом блоке обязательно содержится две сплошные пересекающиеся линии в виде буквы L — так называемый «шаблон поиска», который помогает понять ориентацию кода для считывающего устройства. Две другие стороны блока состоят из чередующихся черных и белых точек, которые указывают считывающему устройству размер кода. Код использует стандарт коррекции ошибок, основанный на алгоритме Рида-Соломона. В случае повреждения кода, это позволит восстановить до 30% полезной информации.




Главное прeимущество этой разновидности двухмерных кодов — его сверхмалый размер. С помощью DataMatrix можно поместить информацию в 50 символов на площадь размером в два квадратных миллиметра. При этом, код может быть нанесен на поверхность огромным кол-вом способов : это и струйная печать, и гравировка, и лазер и многое другое. Кроме того, у кода есть две возможные формы: квадрат и прямоугольник. Это позволяет еще более эффективно использовать доступную для размещения кода площадь.
Все это делает DataMatix отличным кодом для маркировки малых объектов, например, микросхем. И именно поэтому Data Matrix очень активно применяется в промышленности. В частности, его активно используют такие крупные компании как Intel, AMD, BMW, Mercedes Benz, Siemens, Philips, NASA, Vodaphoone. Во многих странах он также используется для сортировки почты, но как с этим обстоит дело в России я не знаю. Впрочем, потихоньку он начинает появляться и у нас. Например, текущий формат больничного листа предусматривает специальное поле для размещения Data Matrix кода:
«для упрощения процедуры машинной обработки данных из больничного, в левый верхний угол бланка было добавлено поле для впечатывания в него двухмерного штрих-кода в формате Data Matrix, содержащего те же сведения, что и сам листок, причем этот штрих-код нужно иметь возможность впечатывать в заполненный ранее бланк отдельно даже в том случае, если бланк уже был сложен в несколько раз»
информация взята с сайта ФСС. Разумеется, пока наличие такого кода не является обязательным, но в будущем ситуация может и поменяться.

Хотя в промышленности DataMatrix является безусловным фаворитом, в повседневной жизни намного более распространен другой тип двумерного штрихкода — QR-код.
QR-код
Сайт-генератор – http://qrcc.ru/generator.php
Программа-сканер – Barcode Scanner
QR код это еще одна разновидность матричного кода. Его название происходит от английского «Quick Response» — «Быстрый Отклик». Он был создан компанией Denso-Wave в 1994 году в Японии. И именно в Японии он получил наиболее широкое распространение. Согласно данным опросов, в этой стране его использует более половины всех пользователей мобильной связи. В первую очередь это связано с тем, что в отличие от многих конкурентов, он понимает символы каны.
Само название «QR Code» является официально зарегистрированной торговой маркой компании Denso Wave Incorporated. Тем не менее, его использование бесплатно как для физический, так и юридических лиц и не попадает под действия каких либо лицензий.
Размеры кода могут варьироваться в довольно широких пределах : от 11 модулей в версии Micro QR (M1) до 177×177 модулей в Version 40 QR code. Официальных стандартов QR кодов, насколько мне известно, не существует. Ниже приведены примеры QR кодов разных версий, взятых из Википедии.




Как вы видите, любой QR код содержит несколько обязательных элементов. В первую очередь, это три больших «квадратика», окруженных пустым пространством. Именно по ним программа-сканер определяет позицию кода и корректирует искажение перспективы. Кроме того, код содержит еще один «квадратик» меньшего размера. Он служит для определения ориентации служебных областей. Стоит отметить, что в версии Micro QR используется всего одна метка позиционирования. Как и многие другие штрихкоды, QR код требует свободное пространство вокруг самого кода. Для полной версии кода оно состовляет 4 модуля, для микро версии — два модуля.
| Как и в DataMatrix, в QR коде используется метод коррекции ошибок, основанный на алгоритме Рида-Соломона. Это позволяет легко прочитать даже поврежденный или загрязненный QR код. Существует четыре уровня коррекции ошибок. Они отличаются кол-вом информации, доступной для восстановления – L (7%), M (15%), Q (25%), H (30%). Благодаря такому «запасу прочности» можно разместить на QR коде произвольное изображение или текст. И если не будут задеты служебные области, то код все равно останется читаемым. Правда, стоит понимать, что в этом случае дальнейшая возможность коррекции ошибок сильно падает. |  |
Подробнее про разметку QR кодов можно прочитать на сайте анг. Википедии. Кроме того, на habrahabr.ru есть статья о том, как можно вручную прочитать QR код
У QR кодов довольно много применений. В первую очередь, они очень активно используются в рекламе и маркетинге. Начиная от банальной ссылки на рекламный ролик, размещенной на рекламном щите и заканчивая целыми интерактивными стендами. Например, на видео ниже вы видите стенд компании Tesco, размешенный в метро Южной Кореи.

С помощью мобильного телефона, люди могут на ходу заказать нужный товар, который будет доставлен им курьером как раз к моменту их приезда домой. Такие интерактивные стенды позволили компании увеличить прибыль от доставки товаров на 130%
А на фотографии ниже представлена реклама купальников Victoria’s Secret в Америке. Самое интересное заключается в том, что самих купальников на билбордах как раз нет. Есть только сама модель и QR код, сосканировав который можно увидеть альтернативный вариант плаката. С остальными фотографиями вы сможете ознакомиться на сайте первоисточника — http://ibigdan.livejournal.com/9908100.html

Интересно, насколько возросли продажи? =)
Не менее широко распространены QR коды и в туризме. Например, QR коды все чаще стали размещать на туристических объектах. В самом простом случае, такой код будет содержать короткую справку об объекте на разных языках или ссылку на Wikipedia. Но есть и более интересные варианты — например, прочитав QR код, вы сможете увидеть, как выглядел этот объект 100 лет назад. В качестве примера можно привести город Львов, где QR кодами отмечено более сотни туристических объектов. Информация есть, например, на этом сайте Аналогичные решения очень часто применяются и в музеях. Один клик — и вы находитесь на веб странице, содержащей всю информацию о заинтересовавшем вас экспонате.
Отдельно хочу отметить одно очень оригинальное решение, при котором сканируя один и тот же QR код, каждый пользователь автоматически попадет на статью именно на своем родном языке. Это стало возможно благодаря проекту QRpedia. Подробнее о нем можно прочесть тут: http://ru.wikipedia.org/wiki/QRpedia
С QR кодами можно все чаще встретиться и при оформлении билетов. В этом году и в России и в Украине собирались ввести QR коды на железнодорожных билетах. Это даст возможность заказать билет через интернет и просто распечатать QR код (или просто открыть его на экране мобильного телефона) для прохода через турникет или для предъявления проводнику. К сожалению, не знаю, работает ли уже такая система в РЖД, но точно могу сказать, что именно так обстоят дела в АэроЭкспрессе. На заказ билета через интернет я потратил несколько минут, после чего не пришлось даже его печатать – турникет успешно считал код с экрана телефона. Правда, код там используется не QR, а скорее PDF417.
Применений QR кодов сотни, они все чаще начинают проникать в нашу повседневную жизнь. Например, буквально на днях впервые «вживую» увидел визитку с QR кодом. И это оказалась действительно очень удобная штука, которая избавляет от необходимости вбивать все данные контакта вручную. Достаточно сосканировать QR код, и все данные контакта в вашем телефоне: имя, фамилия, компания, должность, e-mail, рабочие и мобильные телефоны. Не знаю, насколько такие визитки приживутся, но, на мой взгляд, идея отличная. Разумеется, на этом идеи использования QR кодов не заканчиваются. Есть масса других вариантов — татуировки с QR кодом, содержащим ссылку на страничку в соц. сети, брелоки с QR кодом, в котором зашифрованы имя и телефон владельца, QR код со ссылкой на аудио поздравление на подарке… Хорошо проиллюстрировано применение QR кодов в статье Виталия Буздалова.




Двумерный код данного формата начинает применяться и в Сбербанке (Источник — http://www.arendamest.ru/qr-kod-v-terminalach-sberbanka)
Почему он стал столь популярен на фоне уже довольно распространенного Data Matrix? Точного ответа на этот вопрос я не знаю, но мне кажется, что дело главным образом в его узнаваемости. В отличие от несколько безликого Data Matrix, он имеет свое лицо, интереснее выглядит, на него проще обратить внимание потенциальных пользователей. Учитывая, что чаще всего он применяется в маркетинге, это оказалось весьма важно. А сильные стороны Data Matrix (меньший размер, стандарт ISO ) здесь наоборот, практически не имеют значения.
Напоследок приведу данные опроса, проведенного в 2012 году компаниями J’son&Partners Consulting, SMARTEST и WapStart в России. Согласно ему, треть респондентов (33%) информированы о QR-кодах — они знают и понимают, как можно использовать эту технологию. 59% не знают о QR-кодах, а 8% неправильно информированы (ошибаются в знании технологии). 23% пользователей уже сканировали своим телефоном QR-коды, причем почти половина из них (48%) делают это постоянно или проводили такие манипуляции много раз. Большая часть пользователей QR-кодов (84%) переходила после их считывания на веб-сайт; третья часть (33%) смогла считать контактные данные человека и сохранить их на телефон; 28% получали рекламу; 21% — другой контент (музыку, картинки, презентации и пр.) и 8% — видео. Только 6% указали, что QR-технология помогла им зарегистрироваться на рейс или мероприятие.
Как мы видим, хотя в России QR коды пока распространены не так сильно, как во многих других странах, но, тем не менее, они постепенно становятся популярны и у нас.
Aztec Code
Сайт-генератор — http://barcode.tec-it.com/
Программа-сканер — Accusoft Barcode Scanner
| Еще один тип 2D штрихкода, внешне чем-то похожий на QR-код. Он был разработан в 1995 году доктором Andrew Longacre из компании Welch Allyn. Основная идея состояла в том, чтобы взять все лучшее, что есть в других существующих на тот момент кодах (Data Matrix, PDF417, MaxiCode и др.) и дополнить своими наработками. Код был запатентован и опубликован компанией AIM International через два года после окончания разработки. Хотя данный код и был запатентован, позже он был передан в общественное достояние. |  |
 |
Структура кода состоит из следующих элементов: «мишень» , элементы ориентации, решетка привязки, слои данных. Программа сканер опознает код по наличию «мишени», определяет ее центр и углы. Далее программа вычисляет расстояние между углами мишени и их углы наклона. По этим данным вычисляется угол наклона и поворот кода относительно камеры телефона. Стоит отметить, что код может быть распознан не только при больших искажениях от угла наклона и ориентации камеры, но даже при зеркальном отражении. |
Подробнее с алгоритмом декодирования Aztec Code можно ознакомиться на сайте odamis.ru по следующей ссылке. Как и в случае QR кода, у Aztec существует своя компактная версия.
Как и DataMatrix, Aztec код возможно применять там, где площадь для нанесения кода сильно ограничена. В первую очередь это обусловлено тем, что он не требует свободного места вокруг кода. Но, в отличие от DataMatrix, Aztec код может быть только квадратным. Сторона квадрата содержит от 15 до 151 модуля. Код может объединяться в блоки. Разумеется, как и остальные типы кодов, Aztec код поддерживает коррекцию данных по принципу Рида-Соломона. При этом он позволяет настроить избыточность данных от 5% до 95%.
Во многих странах данный код используется железнодорожными компаниями в электронных билетах. Кроме того, он был выбран международной ассоциацией воздушного транспорта для электронных билетов. В частности, по информации Википедии, он используется на электронных билетах Российской авиакомпании S7 Airlines. Ниже приведу цитату с офф. сайта s7.ru :
«В аэропорту вашего вылета должно быть специальное устройство, распознающее 2D-штрихкод мобильного посадочного талона. Оно находится перед входом в зону контроля безопасности и работает следующим образом: считывает информацию 2D-штрихкода мобильного посадочного талона с экрана вашего телефона, а затем распечатывает посадочный талон на бумаге.»
К сожалению, тип 2D штрихкода в этом сообщении не указан, но думаю, что Википедия не ошиблась.
Microsoft tag (High Capacity Color Barcode — HCCB)
Сайт-генератор — http://tag.microsoft.com
Программа-сканер — Microsoft Tag
Данный штрихкод был специально разработан компанией Microsoft для мобильных фотокамер. Это дает ряд преимуществ при сканировании и декодировании кода. Например, код удастся расшифровать, даже если он оказывается не в фокусе, что весьма актуально для простеньких телефонных камер без автофокуса.

Microsoft Tag довольно сильно отличается от большинства своих собратьев. Первое, что сразу бросается в глаза: в отличие от QR, Data Matrix и других монохромных кодов, он может быть цветным. Помимо белого используется еще три цвета: Yellow, Magenta, Cyan. Такой выбор цветов позволяет избежать ошибок декодирования из-за плохой цветопередачи CMYK принтера. Дополнительные цвета позволяют «впихнуть» в код больше информации не меняя его размер. Тем не менее, у штрихкода существует и черно-белый вариант.

Второе, не менее важное отличие: в штрихкоде содержатся не сами данные, а только ссылка на них (13 байт + 1 контрольный). Сами же данные хранятся на сервере Microsoft. Очевидный минус такого решения состоит в том, что без доступа в интернет воспользоваться таким кодом невозможно. С другой стороны, это дает и дополнительные возможности: можно в любой момент отредактировать «привязанную» к коду информацию, можно узнать кол-во считываний кода, можно установить срок действия кода.
Кроме того, у Microsoft Tag есть огромные возможности кастомизации. В штрихкоде этого формата вся информация закодирована в цветных точках в центрах треугольников. Все остальное поле может быть каким угодно. Это позволяет сделать штрих код действительно уникальным. Главное не перестараться, иначе кроме вас никто вообще не поймет, что это штрихкод.
 . . . . . .
. . . . . . 
Microsoft Tag распространен намного меньше, чем его аналоги. Тем не менее, кое-где он постепенно начинает входить в обиход. Например, в Татарстане, если верить новостям, правительство обязало владельцев туристических и спортивных объектов Универсиады размещать такие штрихкоды для доступа к соответствующим сайтам интернета. Новость проскальзывала, в частности, на этом сайте. Кроме того, с помощью таких же кодов можно оплачивать и гос. услуги.
У меня эта технология оставила смешанное чувство. Когда упоминание о Microsoft Tag впервые попалось мне на глаза, я отмахнулся от него, не вникая в детали. Штрихкод, для декодирования которого нужен доступ к интернету? Это не для Российских реалий. Да и напечатать цветной код сложнее, чем черно-белый. Изначально мне казалось, что при таких недостатках все плюсы этого кода уже не имеют значения. Но давайте на минуту задумаемся, какая именно информация чаще всего закодирована в 2D штрихкоде? В большинстве случаев, это ссылка на ресурс в интернете. Это может быть что угодно : сайт компании, рекламный ролик, статья об историческом объекте, но в любом случае, без доступа в интернет эта ссылка не имеет никакой практической ценности. И вот тут уже Microsoft Tag смотрится очень выигрышным вариантом. Информацию можно в любой момент поменять или обновить не меняя сам код, собрать статистику просмотров и пр. Потенциал у Microsoft Tag, безусловно, есть, но сможет ли Microsoft его реализовать — вопрос открытый.
Взгляд вперед
Вначале появились линейные штрихкоды. Затем двухмерные. Что может ждать нас в будущем?
Весьма интересной выглядит идея компании MIT Media Lab — bokode. Название произошло от слов bokeh и barcode. Прототип был показан еще в 2009 году. Диаметр метки данного кода составлял всего несколько квадратных миллиметров. Сама метка состоит из светодиода, на который накладывается специальная маска и особой линзы. Информация поступает на считывающее устройства в виде потоков света, проходящих через маску на светодиоде.
Такой код способен передавать в тысячи раз больше информации, чем линейные штрихкоды. Кроме того, его можно считать с расстояния в несколько метров (теоретический предел — 20 метров).
Более подробную информацию можно найти на сайте BBC или посмотрев видео от самой MIT Media Lab :

ПРАКТИКА
Сайт-генератор http://qrcc.ru
Один из популярных генераторов 2D штрихкодов. Позволяет создавать коды QR, Micro QR и DataMatrix. Интерфейс сайта интуитивно понятен, и я думаю, что нет смысла останавливаться на нем подробно. Вверху можно выбрать тип кода. В левой колонке — указать тип содержания. Внизу можно выбрать дополнительные параметры: иконку, которая будет отображаться на коде, текст над и под кодом, цвета текста и самого кода.

В отличие от многих подобных сайтов, qrcc.ru поддерживает большое кол-во разных типов данных. Разумеется, данные любого типа можно просто закодировать как обычный текст. Но в этом случае смартфон не сможет автоматически распознать их тип и понять, что с ними делать. В качестве примера приведу два кода с одинаковым текстом.

Как вы видите, в первом случае программа — сканер предлагает позвонить по этому номеру или сохранить его в телефонной книге. Во втором случае, программа не воспринимает этот набор цифр как номер и предлагает стандартный набор действий: поиск этих данных в интернете либо «поделиться» данными через электронную почту или смс. Впрочем, возможно это зависит еще и от самой программы.
Сайт позволяет сгенерировать данные следующих типов:
Визитка (VCARD) — после сканирования кода у пользователя будет возможность в один клик создать контакт со всеми данными в телефонной книге.
Адрес сайта (URL) — у пользователя будет три варианта: перейти на сайт либо поделиться ссылкой через смс и электронную почту. По сути , тут нет никаких отличий от стандартного типа данных (произвольный текст). Единственным преимуществом является возможность создать «короткую ссылку» при генерации кода.
Произвольный текст — просто набор данных, программа-сканер будет реагировать на него стандартным образом
Телефонный звонок — после сканирования кода, программа предложит сохранить введенный вами номер в адресной книге либо позвонить на него.
СМС-сообщение — программа-сканер предложит пользователю отправить заданный им текст, указанный им номер в виде смс или ммс сообщения
Координаты Google Maps — позволяет вам выбрать на карте определенную точку и закодировать ее местоположение в 2D штрихкод. Сами данные по сути являются обычной ссылкой на Google Maps. Пользователю предложат перейти по ссылке, либо поделиться ей. При переходе по ссылке, сам смартфон предлагает открыть ее в браузере либо Google Maps (зависит от настроек смартфона).
E-mail адрес — пользователь сможет либо отправить по этому адресу письмо, либо добавить его в телефонную книгу. Тоже самое будет, если закодировать e-mail адрес и обычным способом, как «произвольный текст».
E-mail сообщение — содержит поля «E-mail получателя», «Тема» и «Текст». Предлагает пользователю отправить введенное им сообщение на соответствующий адрес.
Запланированное событие(VCALENDAR) — позволяет ввести название, начало и конец события. При сканировании такого кода будет возможность импортировать данное событие в календарь.
WI-FI — позволяет ввести SSID сети, пароль и тип шифрования. После сканирования такого кода, смартфон предложит вам подключиться к этой сети.
Сайт-генератор http://barcode.tec-it.com
Еще один хороший сайт-генератор. Позволяет создавать коды десятков различных типов, как линейные, так и двухмерные. Имеет более запутанный интерфейс, но предлагает больше возможностей.

Вверху сайта необходимо выбрать тип кода. Предлагает следующие варианты:
1D коды. Сюда входят 12 типов линейных штрихкодов, такие как Code-128, Code-11 и другие. У каждого кода указывается допустимый тип данных (только цифры, полный набор ASCII и пр.). Открыв раздел «дополнительные опции штрихкода» можно настроить такие параметры, как цвет кода, ориентация, зона молчания (место вокруг штрих кода).
2D коды. Сюда входят такие коды как QR, DataMatrix, Aztec, Codablock-F, PDF417, MaxiCode, MicroPDF417, Micro QR. Настройки кода аналогичны прошлой категории, но в «дополнительных параметрах» добавилась опция «корректировка ошибок» (пока поддерживается только QR кодом). Она позволяет вручную указать уровень коррекции — L, M, Q, H
Мобильный Тэг — как и http://qrcc.ru , позволяет создавать коды для мобильных телефонов, с разными типами данных. Позволяет создавать коды трех типов — QR, DataMatrix, Aztec. Поддерживает несколько новых типов кодов, такие как отправка твита, «лайк» в Facebook, поиск приложения в AndroidMarket и другие.
Далее идет еще множество различных категорий линейных кодов: UAN UPC (ипользуются на товарах в магазинах), ISBN (книги и другая печатная продукция), почтовые коды, др. В конце списка представлены «Визитки» (поддерживается QR и DataMatrix), «События» (тоже QR и DataMatrix), WI-FI коды (QR и DataMatrix) — в этих пунктах все аналогично qrcc.ru
Сайт-генератор http://tag.microsoft.com
tag.microsoft.com заметно отличается от прошлых рассмотренных нами ресурсов. И в первую очередь, это связанно с особенностями формата Microsoft Tag. На самом сайте содержится масса справочного материала как по особенностям этого формата кода, так и по работе с самим генератором. К сожалению, информация доступна только на английском.
Для работы с сайтом требуется Microsoft account. Если у вас его нет — придется регистрироваться. Далее заходим в «My Tag» — «Tag manager». Для создания новой метки, выбираем «Create a tag» в левом верхнем углу менеджера.
Tag Title — имя метки, которое будет отображаться под самим штрихкодом в «истории» программы сканера
Tag Tipe — тип метки. Поддерживаются метки следующих типов: URL (ссылка), App Download (загрузка приложения, позволяет задать для каждой платформы отдельные ссылки на скачивание), Free Text (произвольный текст, до 1000 знаков), vCard (можно как загрузить готовую vCard, так и внести данные контакта вручную), Dialer (ввод телефонного номера)
Tag Notes — описание метки, длинной до 200 символов. Описание отображается только на сайте в самом в самом менеджере. Пользователь его не увидит.
Upload Thumbnail — загрузка эскиза метки, рекомендованный размер — 200 x 200, форматы JPEG, GIF, PNG
Start Date — дата, с которой метка начнет работать
End Date — дата окончания работы метки. Можно выбрать вариант «No End Date»
Поле для ввода данных — зависит от выбранного вами типа метки.
После ввода всех данных сохраняем метку, нажав на кнопку «Save». Созданная метка теперь отображается в менеджере. При необходимости, ее в любой момент можно отредактировать либо удалить. Кроме того, всегда можно посмотреть график кол-ва просмотров. Теперь загружаем созданную метку, нажав на синюю стрелочку «Download» справа.
Перед загрузкой метки необходимо выбрать формат ее кодирования. Доступные варианты: Tag Barcode (стандартный Microsoft Tag с рисунком в виде треугольников), Custom Tag Barcode (Microsoft Tag, на который нанесены только сами точки, в которых кодируется информация), QR Code, NFC URL. Здесь же можно выбрать формат файла и сам размер кода. В случае использования Microsoft Tag можно выбрать его монохромный вариант.
При сканировании QR кода обычной программой-сканером отобразится просто ссылка вида tagr.com/xxx. Для получения доступа к самой информации, необходимо открыть ее в браузере. При сканировании кода «родной» программой Microsoft Tag данные загрузятся с сервера MS автоматически. При этом будет отображена и дополнительная информация, такая как название метки, картинка метки в «истории» и пр. В общем и целом, использования QR кода в данном случае совершенно нецелесообразно.
Подробнее о сканировании кодов Microsoft Tag можно будет прочесть в описании самого сканера. Скажу только пару слов про формат Custom Tag Barcode. Как я уже писал, формат Microsoft Tag имеет огромный потенциал кастомизации. Фактически, код можно перекрашивать как угодно, главное не менять цвет точек, несущих информацию и не залезать на служебные области. При этом сами точки могут являться частью рисунка, их не требуется как-то выделять из окружающего их фона.

Проще всего открыть скаченный файл в Photoshop или любом другом редакторе, умеющем работать со слоями. Сам слой с точками не трогаем, под ним просто создаем еще один и делаем с ним все, что хотим. Более подробно ознакомиться с кастомизацией Microsoft Tag можно по следующей ссылке (англ.)
Программы сканеры
Barcode Scanner
Поддерживаемые форматы 2D кодов: QR, DataMatrix
Программа бесплатна. Имеет платную версию с поддержкой дополнительных форматов.
Начать хотел бы с классики жанра — программы Barcode Scanner (Zxing от Google).
Кто-то считает этот сканер слишком простым, но лично мне он очень нравится. В программе есть все, что нужно для выполнения ее основной функции и никаких лишних «наворотов». Этакий Linux way. Кому-то такой подход нравится, кому-то нет.
Обзор программы на Android.MR уже есть — http://android.mobile-review.com/market/87/ Отмечу только то, что программа умеет не только сканировать коды, но и генерировать их. Все происходит предельно просто и быстро. Например, содержимое буфера можно перевести в QR код буквально в один клик. Зачем это нужно? Например, быстро поделиться контактом, длинной ссылкой, координатами в Google Maps и пр. Один человек выводи QR код на экран своего телефона, другой считывает его. Получается некий аналог Android Beam, который не требует поддержки NFC. Которая пока встречается далеко не в каждом аппарате.
Accusoft Barcode Scanner
Поддерживаемые форматы 2D кодов: QR, DataMatrix, Aztec и PDF417
Как показала практика, многие сканеры в Play.Market сделаны на основе Barcode Scanner, а вернее Zxing от Google — http://code.google.com/p/zxing/wiki/GetTheReader . Поэтому, они в большинстве своем имеют очень похожий интерфейс и функционал. В качестве примера можно привести программу Accusoft Barcode Scanner, которая по сути является клоном Barcode Scanner. Главное отличие — дополнительная поддержка кодов Aztec и PDF417
QR Droid
Именно эта программа упоминалась в недавней статье Виталия Буздалова. Она также использует библиотеки Zxing, но обладает большим функционалом. К примеру, есть возможность предпросмотра ссылки, редактирования смс из самой программы, назначать действия по умолчанию для разных типов кодов и пр.
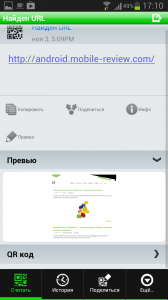
Нужно это или нет, каждый решает для себя сам. Кроме того, в программе есть довольно функциональный генератор кодов.
Кроме стандартных действий по генерации и чтению кодов, программа предлагает и ряд других полезных функций. Например, через нее можно быстро создать короткую ссылку. Это может быть весьма полезно для того, чтобы избежать излишнего «раздувания» QR кода. Кроме того, у вас всегда будет возможность посмотреть статистику переходов по такой ссылке. Еще один пример: можно загрузить изображение в интернет и сразу же сгенерировать на него ссылку в виде QR кода.
Microsoft Tag
Сканер, в первую очередь рассчитанный на работу с Microsoft Tag и QR кодами с сайта tag.microsoft.com . С обычными QR кодами программа работает значительно хуже. В качестве примера можно посмотреть на следующий скриншот, где показан результат декодирования QR кода типа «смс».
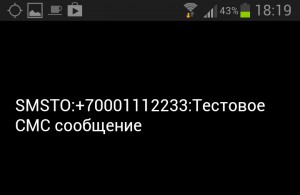
В то время, как обычный сканер предлагает отправить смску, сканер Microsoft Tag выводит просто весь набор закодированных данных.
В верхней части окна программы находится кнопка «Scan», в центре — список меток истории сканирования. Метки представлены в виде иконок, которые были назначены автором кода. Тут же отображается и название метки. Обычные QR коды, которые не имеют названия и иконки, в списке не отображаются. Разумеется, метки из списка истории можно открывать повторно.
На скриншоте ниже приведет результат сканирования кодов с закодированным текстом и с закодированной ссылкой на Android.MR


Обратите внимание, что ссылка сразу открывается в самой программе-сканере, а не предлагает пользователю открыть ее в браузере. Кроме того, в верхней части окна отображается название метки.
Выводы
Разумеется, рассказать о всех видах штрихкодов, программ для их чтения и ресурсах в рамках одной статьи невозможно. Поэтому, я упомянул только про некоторые из них, которые на мой взгляд, являются самыми актуальными.
В комментариях к прошлой статье про QR коды некоторые читатели высказывали мнение, что из-за появления NFC, двухмерные штрихкоды скоро исчезнут. Мне кажется, что этого не случится. Это две разные технологии, применение которых пересекается лишь частично. NFC удобнее для передачи информации. Иногда он используется для этого напрямую, иногда применяется только для установки соединения по более быстрому протоколу. Но вот напечатать NFC метку в домашних условиях еще очень долгое время будет проблематично. Из-за этого NFC врядли будет применяться, скажем, на электронных билетах. Да и размещать на объявлениях бесперспективно — чтобы считать ее, каждый будет вынужден подходить к такому объявлению вплотную, что не всегда возможно. Разумеется, при желании можно придумать и реализовать любой сценарий. Вопрос только в том, стоит ли ?
QR-код также известен как QR-код, QR-код обозначает Quick Response. Это очень популярный метод кодирования на мобильных устройствах в последние годы. Он может хранить больше информации и отображать больше данных, чем традиционный штрих-код штрих-кода. Тип: например: символы, цифры, японский, китайский и т. Д. В последние два дня я изучил детали генерации изображения QR-кода и думаю, что это криптографический алгоритм. Я напишу здесь статью, чтобы разоблачить его. Для образованных учиться вместе.
Для спецификации QR-кода, пожалуйста, обратитесь к этому PDF:http://raidenii.net/files/datasheets/misc/qr_code.pdf
Базовые знания
Прежде всего, давайте поговорим о 40 размерах QR-кодов. Официальная версия называется Версия. Версия 1 — это матрица 21 x 21, Версия 2 — это матрица 25 x 25, а Версия 3 — размер 29. Каждая дополнительная версия увеличивает размер 4. Формула: (V-1) * 4 + 21 ( V — номер версии) Наивысшая версия 40, (40-1) * 4 + 21 = 177, поэтому наивысшая — это квадрат 177 x 177.
Давайте посмотрим на образец QR-кода:

Шаблон позиционирования
- Шаблон определения местоположения — это шаблон определения местоположения, используемый для обозначения прямоугольного размера двумерного кода. Эти три шаблона позиционирования имеют белые границы, называемые разделителями для шаблонов определения положения. Причина трех вместо четырех означает, что три могут идентифицировать прямоугольник.
- Шаблоны синхронизации также используются для позиционирования. Причина в том, что QR-код имеет 40 размеров, и если размер слишком велик, требуется стандартная строка, в противном случае она может быть перекошена при сканировании.
- Эти шаблоны требуются только для QR-кодов выше Версии 2 (включая Версию 2), которая также используется для позиционирования.
Функциональные данные
- Информация о формате существует во всех размерах и используется для хранения некоторых форматированных данных.
- Информация о версии выше> = Версия 7, две области 3 x 6 должны быть зарезервированы для хранения некоторой информации о версии.
Код данных и код исправления ошибок
- За исключением упомянутых выше мест, в остальных местах хранятся код данных и код исправления ошибок.
Кодировка данных
Давайте сначала поговорим о кодировании данных. QR-код поддерживает следующую кодировку:
Numeric modeЦифровое кодирование, от 0 до 9. Если количество кодируемых цифр не кратно 3, то оставшиеся 1 или 2 цифры будут преобразованы в 4 или 7 битов, а все остальные 3 цифры будут скомпилированы в 10, 12, 14 битов. Длина зависит от размера QR-кода (ниже приведена таблица 3 для иллюстрации)
Alphanumeric modeКодировка символов. Включите от 0 до 9, прописные буквы от A до Z (без строчных букв) и символ $% * + -. /: Включая пробелы. Эти символы будут отображены в таблицу индексов символов. Как показано ниже: (где SP — это пробел, Char — это символ, а Value — его значение индекса) Процесс кодирования состоит в том, чтобы сгруппировать символы два по два, а затем преобразовать их в 45 шестнадцатеричное в приведенной ниже таблице, а затем преобразовать в двоичный 11-битный код, если Если есть заказ, он будет преобразован в двоичный 6-битный. Режим кодирования и количество символов должны быть скомпилированы в 9, 11 или 13 двоичных файлов в соответствии с различными размерами версии (таблица 3 в следующей таблице)

Byte modeБайтовая кодировка, может быть ISO-8859-1, символы 0-255. Некоторые сканеры двумерного кода могут автоматически определять, является ли это кодировкой UTF-8.
Kanji modeЭто японская кодировка и двухбайтовая кодировка. Точно так же это может также использоваться для китайского кодирования. Кодировка японских и китайских символов вычтет значение. Например: символы от 0X8140 до 0X9FFC вычтут 8140, символы от 0XE040 до 0XEBBF должны вычесть 0XC140, затем взять первые две цифры и умножить на 0XC0, затем добавить последние две цифры и, наконец, преобразовать в 13 бит кодирование. Пример, как показано ниже:

Extended Channel Interpretation (ECI) modeОн в основном используется для специальных наборов символов. Не все сканеры поддерживают эту кодировку.
Structured Append modeИспользуется для смешанного кодирования, то есть этот QR-код содержит несколько форматов кодирования.
FNC1 modeЭтот метод кодирования в основном используется для некоторых специальных отраслей или отраслей. Например, GS1 штрих-код и тому подобное.
Для простоты последние три не будут обсуждаться в этой статье.
В следующих двух таблицах
- Таблица 2 — это «число» каждого формата кодирования, которое должно быть записано в информации о формате. Примечание: китайский — 1101
- В таблице 3 показаны двумерные коды разных версий (размеров) для цифр, символов, байтов и режима кандзи для двоичного двоичного кода. (Существуют различные таблицы спецификаций кодирования в спецификациях QR-кодов, которые будут упомянуты позже)

Ниже мы рассмотрим несколько примеров,
Пример 1: Цифровое кодирование
В размере версии 1, когда уровень исправления ошибок равен H, код: 01234567
- Разделите вышеуказанные цифры на три группы: 012 345 67
- Преобразуйте их в двоичные: от 012 до 0000001100; от 345 до 0101011001; от 67 до 1000011.
- Строка этих трех двоичных файлов: 0000001100 0101011001 1000011
- Преобразовать количество цифр в двоичный код (версия 1-H — 10 бит): двоичный код из 8 цифр — 0000001000.
- Добавьте в цифровую форму логотип 0001 и код шага 4 на лицевой стороне: 0001 0000001000 0000001100 0101011001 1000011
Пример 2: Кодировка символов
В размере версии 1, когда уровень исправления ошибок равен H, кодирование: AC-42
1. Найдите индекс пяти записей AC-42 из таблицы индексов символов (10,12,41,4,2)
2. Сгруппировать по два: (10,12) (41,4) (2)
3. Преобразуйте каждую группу в 11-битный двоичный файл:
(10,12) 10 * 45 + 12 равно 462 до 00111001110
(41,4) 41 * 45 + 4 равняется 1849 — 11100111001
(2) равно от 2 до 000010
4. Подключите эти двоичные файлы: 00111001110 11100111001 000010
5. Преобразуйте количество символов в двоичное (версия 1-H — 9 бит): 5 символов, от 5 до 000000101.
6. Добавьте идентификатор кода 0010 и цифровой код шага 5 к заголовку: 0010 000000101 00111001110 11100111001 000010
Терминатор и дополнение
Если у нас есть строка HELLO WORLD для кодирования, согласно второму примеру выше, мы можем получить следующую кодировку:
| кодирование | Количество символов | Кодировка HELLO WORLD |
|---|---|---|
| 0010 | 000001011 | 01100001011 01111000110 10001011100 10110111000 10011010100 001101 |
Нам также нужно добавить терминатор:
| кодирование | Количество символов | Кодировка HELLO WORLD | конец |
|---|---|---|---|
| 0010 | 000001011 | 01100001011 01111000110 10001011100 10110111000 10011010100 001101 | 0000 |
Переставить на 8 бит
Если все кодировки не кратны 8, мы должны добавить достаточно 0 в конце, например, всего 78 битов, поэтому мы должны добавить 2 0, а затем разделить группы на 8 бит:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000
Заполнение байтов
Наконец, если мы не достигли предела максимального количества битов, мы должны добавить несколько кодов заполнения (байтов заполнения), байты заполнения должны повторить следующие два байта: 11101100 00010001 (двоичный двоичный код, преобразованный в десятичное число, равен 236). И 17, я не знаю, почему, я знаю только то, что оно написано в спецификации). Максимальный битовый предел для каждого уровня исправления ошибок в каждой версии см. В Таблице 7 на стр. 28–32 спецификации QR-кода. Стол.
Предполагая, что нам нужно закодировать уровень коррекции ошибок Q в Версии 1, тогда ему нужно максимум 104 бита, а у нас всего 80 бит выше, поэтому нам нужно 24 бита, то есть нам нужно 3 байта заполнения, мы добавляем Три, так что получите следующий код:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000 11101100 00010001 11101100
Код исправления ошибок
Выше мы говорили о некоторых уровнях исправления ошибок, уровне кода исправления ошибок, в QR-коде есть четыре уровня исправления ошибок, поэтому QR-код можно сканировать по дефекту, поэтому кто-то находится в центре QR-кода. Присоединиться к иконке.
| Возможность исправления ошибок | |
|---|---|
| Уровень L | 7% кода может быть изменено |
| Уровень М | 15% кода может быть изменено |
| Уровень Q | 25% кода может быть изменено |
| Уровень H | 30% кода может быть изменено |
Итак, как QR добавляет код исправления ошибок в код данных? Во-первых, нам нужно сгруппировать коды данных, то есть по разным блокам, а затем выполнить кодирование с исправлением ошибок для каждого блока. Таблица определения 22. Обратите внимание на последние два столбца:
- Number of Error Code Correction Blocks: Сколько блоков нужно разделить
- Error Correction Code Per Blocks: Количество кодов в каждом блоке, так называемое количество кодов, то есть сколько 8-битных байтов.

Например: вышеуказанный уровень исправления ошибок версии 5 + Q: требуется 4 блока (2 блока в группе, всего две группы), 15 бит данных в каждом из первых двух блоков + 9 бит каждого Код с исправлением ошибок (Примечание. Кодовые слова в таблице представляют собой 8-битный байт). (Renote: формула (c, k, r) в последнем примере: c = k + 2 * r, поскольку сноска объясняет: исправление. Емкость кода ошибки составляет менее половины кода исправления ошибок)
На следующем рисунке приведен пример 5-Q (поскольку запись в двоичном виде сделает таблицу слишком большой, поэтому я использовал десятичную)
| группа | блок | данные | Код исправления ошибок для каждого блока |
|---|---|---|---|
| 1 | 1 | 67 85 70 134 87 38 85 194 119 50 6 18 6 103 38 | 213 199 11 45 115 247 241 223 229 248 154 117 154 111 86 161 111 39 |
| 2 | 246 246 66 7 118 134 242 7 38 86 22 198 199 146 6 | 87 204 96 60 202 182 124 157 200 134 27 129 209 17 163 163 120 133 | |
| 2 | 1 | 182 230 247 119 50 7 118 134 87 38 82 6 134 151 50 7 | 148 116 177 212 76 133 75 242 238 76 195 230 189 10 108 240 192 141 |
| 2 | 70 247 118 86 194 6 151 50 16 236 17 236 17 236 17 236 | 235 159 5 173 24 147 59 33 106 40 255 172 82 2 131 32 178 236 |
Примечание. Код коррекции ошибок двумерного кода в основном реализуется с помощью коррекции ошибок Рида-Соломона (алгоритм коррекции ошибок Рида-Соломона). Для этого алгоритма он довольно сложен для меня, есть много математических вычислений, таких как: полиномиальное деление, число 1-255 отображается в степени n от 2 (0 <= n <= 255) Подобные Богу вещи, такие как Поле Галуа и математические формулы для исправления ошибок, основанные на этих основах, потому что мое основание данных плохое, оно слишком сложное для меня, поэтому я некоторое время не понимал его. В обучении, поэтому, я не буду говорить об этих вещах здесь. Пожалуйста, прости меня. (Конечно, если есть друг, который хорошо понимает, я бы тоже посоветовался со мной)
Окончательное кодирование
Вперемежку размещение
Если вы думаете, что мы можем начать рисовать, вы не правы. Хаотическая технология двумерного кода еще не закончена, она также попеременно объединяет кодовые слова кода данных и кода исправления ошибок. Как чередовать, правила таковы:
Для кодов данных: вынуть первые кодовые слова каждого блока и расположить их по порядку, затем взять второй из первого блока и так далее. Например: Кодовые слова данных в приведенном выше примере:
| Блок 1 | 67 | 85 | 70 | 134 | 87 | 38 | 85 | 194 | 119 | 50 | 6 | 18 | 6 | 103 | 38 | |
| Блок 2 | 246 | 246 | 66 | 7 | 118 | 134 | 242 | 7 | 38 | 86 | 22 | 198 | 199 | 146 | 6 | |
| Блок 3 | 182 | 230 | 247 | 119 | 50 | 7 | 118 | 134 | 87 | 38 | 82 | 6 | 134 | 151 | 50 | 7 |
| Блок 4 | 70 | 247 | 118 | 86 | 194 | 6 | 151 | 50 | 16 | 236 | 17 | 236 | 17 | 236 | 17 | 236 |
Сначала мы берем первый столбец: 67, 246, 182, 70
Затем возьмите второй столбец: 67, 246, 182, 70, 85, 246, 230, 247
И так далее: 67, 246, 182, 70, 85, 246, 230, 247 ………, 38, 6, 50, 17, 7, 236
То же самое верно для кодов исправления ошибок:
| Блок 1 | 213 | 199 | 11 | 45 | 115 | 247 | 241 | 223 | 229 | 248 | 154 | 117 | 154 | 111 | 86 | 161 | 111 | 39 |
| Блок 2 | 87 | 204 | 96 | 60 | 202 | 182 | 124 | 157 | 200 | 134 | 27 | 129 | 209 | 17 | 163 | 163 | 120 | 133 |
| Блок 3 | 148 | 116 | 177 | 212 | 76 | 133 | 75 | 242 | 238 | 76 | 195 | 230 | 189 | 10 | 108 | 240 | 192 | 141 |
| Блок 4 | 235 | 159 | 5 | 173 | 24 | 147 | 59 | 33 | 106 | 40 | 255 | 172 | 82 | 2 | 131 | 32 | 178 | 236 |
Аналогично коду данных, получите: 213, 87, 148, 235, 199, 204, 116, 159, … 39 133 141 236
Затем соедините эти две группы (код исправления ошибок ставится после кода данных), чтобы получить:
67, 246, 182, 70, 85, 246, 230, 247, 70, 66, 247, 118, 134, 7, 119, 86, 87, 118, 50, 194, 38, 134, 7, 6, 85, 242, 118, 151, 194, 7, 134, 50, 119, 38, 87, 16, 50, 86, 38, 236, 6, 22, 82, 17, 18, 198, 6, 236, 6, 199, 134, 17, 103, 146, 151, 236, 38, 6, 50, 17, 7, 236, 213, 87, 148, 235, 199, 204, 116, 159, 11, 96, 177, 5, 45, 60, 212, 173, 115, 202, 76, 24, 247, 182, 133, 147, 241, 124, 75, 59, 223, 157, 242, 33, 229, 200, 238, 106, 248, 134, 76, 40, 154, 27, 195, 255, 117, 129, 230, 172, 154, 209, 189, 82, 111, 17, 10, 2, 86, 163, 108, 131, 161, 163, 240, 32, 111, 120, 192, 178, 39, 133, 141, 236
Remainder Bits
Наконец, добавьте биты напоминания. Для некоторых версий QR вышеупомянутое недостаточно, но также добавьте биты остатка, например: вышеприведенная версия QR-кода 5Q плюс 7 битов, биты остатка плюс ноль Просто отлично Информацию о версии и количестве битов остатка см. В таблице определения в таблице 1 на стр. 15 спецификации QR-кода.
Нарисуйте QR-код
Position Detection Pattern
Сначала нарисуйте шаблон определения местоположения по трем углам.

Alignment Pattern
Затем нарисуйте шаблон выравнивания снова

Для определения местоположения Выравнивания вы можете проверить таблицу определений Таблицы E.1 на стр. 81 спецификации QR Code (следующая таблица является неполной таблицей)

На следующем рисунке приведен пример, основанный на версии 8 в приведенной выше таблице (6, 24, 42).

Timing Pattern
Далее идет линия Timing Pattern (это само собой разумеется)

Format Information
Далее идет информация о формации, синяя часть на рисунке ниже.

Информация о формате — это 15-битная информация, положение каждого бита показано на следующем рисунке: (обратите внимание на темный модуль на рисунке, он всегда появляется)

Эти 15 бит включают в себя:
- 5 битов данных: среди них 2 бита используются для указания того, какой уровень исправления ошибок используется, а 3 бита используются для указания того, какой тип маски используется
- 10 бит исправления ошибок. В основном рассчитывается по коду БЧХ
Затем 15 битов XORed с 101010000010010. Таким образом, мы гарантируем, что мы не сделаем уровень коррекции ошибок 00 и Маску 000 полностью белым, что увеличит сложность распознавания изображений нашим сканером.
Вот пример:

Уровень исправления ошибок показан в следующей таблице:

Шаблон маски показан в таблице 23 ниже.
Version Information
Далее идет информация о версии (этот код требуется после версии 7), синяя часть на рисунке ниже.
Информация о версии — всего 18 бит, включая номер версии 6 бит и код исправления ошибок 12 бит. Ниже приведен пример:

И его позиция заполнения выглядит следующим образом:

Данные и коды исправления ошибок данных
Затем мы заполняем наш окончательный код, который заполняется следующим образом: из левого нижнего угла заполняем наши биты вдоль красной линии, 1 — черный, 0 — белый. Если обнаружена вышеуказанная область без данных, пропустите или пропустите.

Шаблон маски
Таким образом, наша картинка заполняется, но, возможно, эти точки не сбалансированы, поэтому нам все еще нужно выполнить операцию маскировки (полагайте, это не слишком сложно). QR Spec говорит, что QR имеет 8 масок, которые вы можете Используйте следующим образом: среди них формула каждой маски ниже каждой фигуры. Говоря прямо, так называемая маска — это операция XOR с изображением выше. Маска будет только XOR с областью данных и не повлияет на функциональную область.

Идентификационный код маски выглядит следующим образом: (где i, j соответствуют x, y на рисунке выше)

Ниже приведены некоторые из появлений после Mask, мы можем видеть, что данные XOR, определенные некоторыми Mask, стали более разбросанными.

QR-код после маски становится окончательной картиной.
«Код должен легко считываться» — это стало главной целью для японской компании «Denso-Wave» при создании двумерного матричного кода в 1994г.
Действительно, QR-код распознается даже в перевернутом состоянии. Три угловых квадрата привязки, ставшие отличительной особенностью кода, позволяют правильно развернуть его в памяти программы сканера.
По спецификации коды делятся на версии. Номера версий варьируются от 1 до 40. Каждая версия имеет особенности в конфигурации и количестве точек(модулей) составляющих QR-код. Версия 1 содержит 21×21 модулей, версия 40 — 177×177. От версии к версии размер кода увеличивается на 4 модуля на сторону.
При создании матричного кода следует учесть, что лучшие QR-ридеры способны прочитать версию 40, стандартные мобильные устройства — вплоть до версии 4 (33x33 модулей)
Каждой версии соответствует определенная емкость с учетом уровня коррекции ошибок. Чем больше информации необходимо закодировать и чем больший уровень избыточности используется, тем большая версия кода нам потребуется. Современные QR-генераторы автоматически подбирают версию QR-кода с учетом этих моментов.
В следующей таблице показаны характеристики различных версий QR-кодов:
| Версия | Количество модулей | Уровень коррекции ошибок |
Максимальное количество символов с учетом уровня коррекции ошибок и типа символов | |||
|---|---|---|---|---|---|---|
| Числа: 0 — 9 | Числа и символы латинского алфавита*, пробел, $ % * + — . / : |
Двоичные данные | Символы японского алфавита Kanji |
|||
| 1 | 21×21 | L | 41 | 25 | 17 | 10 |
| M | 34 | 20 | 14 | 8 | ||
| Q | 27 | 16 | 11 | 7 | ||
| H | 17 | 10 | 7 | 4 | ||
| 2 | 25×25 | L | 77 | 47 | 32 | 20 |
| M | 63 | 38 | 26 | 16 | ||
| Q | 48 | 29 | 20 | 12 | ||
| H | 34 | 20 | 14 | 8 | ||
| 3 | 29×29 | L | 127 | 77 | 53 | 32 |
| M | 101 | 61 | 42 | 26 | ||
| Q | 77 | 47 | 32 | 20 | ||
| H | 58 | 35 | 24 | 15 | ||
| 4 | 33×33 | L | 187 | 114 | 78 | 48 |
| M | 149 | 90 | 62 | 38 | ||
| Q | 111 | 67 | 46 | 28 | ||
| H | 82 | 50 | 34 | 21 | ||
| 10 | 57×57 | L | 652 | 395 | 271 | 167 |
| M | 513 | 311 | 213 | 131 | ||
| Q | 364 | 221 | 151 | 93 | ||
| H | 288 | 174 | 119 | 74 | ||
| 40 | 177×177 | L | 7,089 | 4,296 | 2,953 | 1,817 |
| M | 5,596 | 3,391 | 2,331 | 1,435 | ||
| Q | 3,993 | 2,420 | 1,663 | 1,024 | ||
| H | 3,057 | 1,852 | 1,273 | 784 |
* При использовании кириллицы один символ считается за 2 латинских символа (кодировка UTF-8)
Уровни коррекции ошибок в QR-кодах
QR-код имеет специальный механизм увеличения надежности хранения зашифрованной информации. Для кодов созданных с самым высоким уровнем надежности могут быть испорчены или затерты до 30% поверхности, но они сохранят информацию и будут корректно прочитаны. Для исправления ошибок используется алгоритм Рида-Соломона (Reed-Solomon). При создании QR-кода можно использовать один из 4 уровней коррекции ошибок. Увеличение уровня способствует увеличению надежности хранения информации, но приводит к увеличению размера матричного кода.
| Допустимый процент нарушений | |
|---|---|
| L | около 7% |
| M | около 15% |
| Q | около 25% |
| H | около 30% |
Полезные ссылки:
Стандарт ISO 18004 (Automatic identification and data capture techniques — QR Code 2005 bar code symbology specification)
В отличие от традиционных штрих-кодов, 2D-коды поддерживают комплексную функцию исправления ошибок QR-кода по сравнению с аналогом.
В цифровую эпоху совершение ошибки в бизнес-индустрии может привести к тому, что компании потеряют миллионы прибыли.
Из-за этого маркетологи ищут решение для цифрового маркетинга, которое уменьшает количество ошибок, которые оно совершает, например.особенно при выборе инструмента хранения данных, такого как штрих-коды.
Поскольку сложно определить, какие штрих-коды имеют встроенную систему исправления ошибок, специалисты по QR-коду представляют технологию QR-кода.
Благодаря алгоритму исправления ошибок Ирвинга Рида и Гюстава Соломона Рида-Соломона QR-коды можно сканировать, даже если они загрязнились или изношены.
Из-за этого информация, которую человек хранит в QR-коде, является надежной и полезной в течение длительного времени.
Пока срок действия контента, например URL-адреса, не истекает и не перенаправляется на другой домен, проблем не будет.
Как и в случае любого технологического прогресса, понимание того, как оно работает, становится частью технологического обучения человека.
Если вы хотите узнать больше о том, как работает функция исправления ошибок QR-кода и какой генератор QR-кода лучше всего использовать, вот следующие концепции.

Функция исправления ошибок работает за счет использованияАлгоритм исправления ошибок Рида-Соломона к исходным данным.
Этот алгоритм исправления ошибок работает путем дублирования исходных данных для оптимальной возможности сканирования.
Таким образом, он все еще будет сканироваться, даже еслиQR код испытать разрыв или повреждение из-за экстремальных погодных условий.
До того, как алгоритм исправления ошибок Рида-Соломона использовался для таких технологий, как компакт-диски и DVD-диски.
Этот тип кода измеряет шум связи, создаваемый искусственными спутниками и планетарными зондами. Производители CD и DVD используют этот код для исправления данных на уровне байтов и других пакетных ошибок.
При различных видах разрывов или повреждений возможны следующие уровни исправления ошибок QR-кода. Начиная с уровня L до уровня H.
Уровень L
Это самый низкий уровень скорости исправления ошибок, который может иметь QR-код. Программное обеспечение QR-кода использует этот уровень, если пользователь намеревается создать менее плотное изображение QR-кода.
Уровень L имеет самую высокую скорость исправления ошибок QR-кода примерно семь процентов (7%).
Уровень М
Уровень M — это средний уровень исправления ошибок, который эксперты QR-кода рекомендуют для использования в маркетинге. Из-за этого маркетологи могут корректировать свои QR-коды на среднем уровне. Уровень M имеет самую высокую скорость исправления ошибок примерно пятнадцать процентов (15%).
Уровень Q
Этот уровень является вторым после самого высокого уровня исправления ошибок. Этот уровень исправления ошибок имеет самую высокую скорость исправления ошибок приблизительно двадцать пять процентов (25%).
Уровень Н
Уровень H — это самый высокий уровень исправления ошибок, который может выдержать экстремальный уровень повреждения их QR-кода.
Уровни исправления ошибок уровня Q и H наиболее рекомендуются для промышленных и производственных компаний.
Эти коды могут испытывать экологические и техногенные условия, что приводит к неизбежному повреждению.
Этот уровень имеет самую высокую скорость исправления ошибок примерно тридцать процентов (30%).
Зная эти следующие уровни, вы можете определитьуровень исправления ошибок QR-кода без необходимости запуска программного обеспечения для декодирования.
Эти уровни можно найти, ища следующие знаки на кодах.
Как определить эти уровни исправления ошибок?
Существует четыре различных символа уровня исправления ошибок, которые вы можете увидеть на этих черных и клетчатых полях.
Эти символы позволяют определить, какой тип QR-кода генерирует пользователь.
Эти символы уровня следующие. Вот следующие способы, как их обнаружить.
1. Просмотрите копию своего QR-кода и найдите область исправления ошибок.
Первый шаг, который нужно сделать при просмотре области исправления ошибок, — найти QR-код, который вы можете найти в своей комнате.
Эти коды можно найти в вашей электронике или гаджетах. Как только вы его найдете, посмотрите на нижнюю левую часть кода рядом с нижним глазом.
Эта нижняя левая часть кода рядом с нижним глазом — это область, где вы можете увидеть скорость исправления ошибок.
2. Знайте, какой у него уровень исправления ошибок.
После того, как вы нашли область исправления ошибок, вы можете определить уровень исправления ошибок, взглянув на характер кода.
Если код полностью заштрихован, его уровень равен L.
Когда код заштрихован наполовину внизу, он имеет уровень M. Если он заштрихован наполовину в верхней части, то он имеет скорость исправления ошибок уровня Q.
Наконец, когда код в нижней левой части рядом с нижним глазом не виден, он имеет самый высокий уровень исправления ошибок, уровень H.
3. Протестируйте создание QR-кода и решите, какой генератор QR-кода имеет высокий уровень исправления ошибок.
Лучший способ создать QR-код, который предлагает безопасные и надежные QR-коды, — это найти лучшийГенератор QR-кодакоторый генерирует QR-коды с высоким уровнем исправления ошибок.
Благодаря этому вы гарантируете, что генератор QR-кода, который вы используете, обеспечивает безопасные и надежные QR-коды для вашего личного, промышленного и производственного использования.
Одним из известных генераторов QR-кода, который создает QR-коды с уровнем исправления ошибок уровня H, является QR TIGER.
QR TIGER — это безопасный и надежный генератор QR-кода, в котором вы также можете генерировать креативный дизайн QR-кодаи сделать их более привлекательными по сравнению с традиционными черно-белыми QR-кодами.
Благодаря простому в использовании интерфейсу без рекламы пользователи могут безопасно и легко выполнять генерацию QR-кода.
Преимущества просмотра области исправления ошибок QR-кода
Чтобы узнать цель использования QR-кода
Одним из его преимуществ является знание цели его использования.
Таким образом, люди будут знать, с какой скоростью исправления ошибок предназначен для защиты QR-код.
Благодаря этому они могут определить, предназначен ли этот QR-код для личного, маркетингового или промышленного использования.
Измерьте его устойчивость к повреждениям
Глядя на область исправления ошибок кода, люди могут определить и измерить его устойчивость к любым повреждениям или загрязнениям.
Из-за этого компании и маркетологи могут сэкономить средства, выбрав правильную функцию исправления ошибок, которую они хотят внедрить в свои QR-коды.
Позвольте пользователям экономить деньги
Поскольку компании и маркетологи знают, какую функцию исправления ошибок кода они хотят добавить в свой QR-код, они экономят деньги, которые они тратят на долгосрочную маркетинговую кампанию. Благодаря этому они могут сэкономить деньги и ресурсы на будущее.
Сохраняет окружающую среду
Функция исправления ошибок помогает маркетологам и компаниям экономить деньги и ресурсы. Из-за этого им больше не нужно будет печатать больше QR-кодов, поскольку они могут противостоять любым повреждениям.
Благодаря его использованию они могут сократить использование бумаги и помочь сохранить окружающую среду.
Расскажите людям, как работает исправление ошибок QR-кода.
Если вы любите технологии и хотите поделиться своими знаниями о тривиальных технологиях, таких как QR-коды, использование обнаружения его чуда при исправлении ошибок может помочь просветить людей.
Из-за этого они могут расширить знания других людей об этом и стать экспертом по QR-коду в процессе.
Люди могут понять, какой генератор исправления ошибок QR-кода они хотят использовать при создании этих кодов.
Коррекция ошибок QR-кода — максимально сохраняет и защищает информацию
Сегодня технические специалисты используют для улучшения и улучшения структуры QR-кода, чтобы обеспечить возможность его сканирования. Из-за этого одной из улучшенных функций является возможность исправления ошибок.
Пользователи могутгенерировать бесплатные QR-коды не беспокоясь о каких-либо ошибках сканирования.
Создайте свой QR-код прямо сейчас с помощью QR TIGER — самого передового программного обеспечения для создания QR-кодов с высоким уровнем функции исправления ошибок.
QR TIGER используется такими брендами, как Cartier, Vaynermedia, Hilton и многими другими из-за высокого уровня исправления ошибок.
Это онлайн-генератор QR-кода, который Сертификат ISO 27001 так вы можете быть уверены, что данные ваших QR-кодов надежно защищены.
png_800_75.jpeg)
уровень коррекции ошибки
- уровень коррекции ошибки
-
уровень коррекции ошибки : Степень способности к обнаружению и исправлению ошибки в символике, не зафиксированная, а определяемая некоторым выбором пользователя.
Примечание — Уровень коррекции ошибок связан с символиками, использующими код с исправлением ошибок, например код с исправлением ошибок Рида-Соломона
Словарь-справочник терминов нормативно-технической документации.
.
2015.
Смотреть что такое «уровень коррекции ошибки» в других словарях:
-
уровень коррекции ошибки — Степень способности к обнаружению и исправлению ошибки в символике, не зафиксированная, а определяемая некоторым выбором пользователя. Примечание Уровень коррекции ошибок связан с символиками, использующими код с исправлением ошибок, например код … Справочник технического переводчика
-
Код коррекции ошибок Рида-Соломона — Коды Рида Соломона недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида Соломона, работающие с байтами (октетами). Код… … Википедия
-
Метод обратного распространения ошибки — (англ. backpropagation) метод обучения многослойного перцептрона. Впервые метод был описан в 1974 г. А.И. Галушкиным[1], а также независимо и одновременно Полом Дж. Вербосом[2]. Далее существенно развит в 1986 г. Дэвидом И. Румельхартом, Дж … Википедия
-
ГОСТ 30721-2000: Автоматическая идентификация. Кодирование штриховое. Термины и определения — Терминология ГОСТ 30721 2000: Автоматическая идентификация. Кодирование штриховое. Термины и определения оригинал документа: (n, k) символика : Класс символик штрихового кода, в которых ширина каждого знака символа представлена в n модулях, а сам … Словарь-справочник терминов нормативно-технической документации
-
кодовое слово — (штриховое кодирование): Значение знака символа, соответствующее промежуточному уровню кодирования между исходными данными и графическим кодированием в символе Источник: ГОСТ 30721 2000: Автоматическая идентификация. Кодирование штриховое.… … Словарь-справочник терминов нормативно-технической документации
-
ГОСТ Р 51294.9-2002: Автоматическая идентификация. Кодирование штриховое. Спецификации символики PDF417 (ПДФ417) — Терминология ГОСТ Р 51294.9 2002: Автоматическая идентификация. Кодирование штриховое. Спецификации символики PDF417 (ПДФ417) оригинал документа: 3.1.9 идентификатор глобальной метки ( Global Label Identifier): Процедура в рамках символики PDF417 … Словарь-справочник терминов нормативно-технической документации
-
кодовое слово индикатора строки ( Row Indicator codeword) — 3.1.13 кодовое слово индикатора строки ( Row Indicator codeword): Кодовое слово PDF417, примыкающее к знаку СТАРТ или знаку СТОП в строке, которое кодирует информацию о структуре символа PDF417: идентификацию строки, общее количество строк и… … Словарь-справочник терминов нормативно-технической документации
-
коррекция — 3.6.6 коррекция (correction): Действие, предпринятое для устранения обнаруженного несоответствия (3.6.2). Примечания 1 Коррекция может осуществляться в сочетании с корректирующим действием (3.6.5). 2 Коррекция может включать в себя, например,… … Словарь-справочник терминов нормативно-технической документации
-
Список алгоритмов — Эта страница информационный список. Основная статья: Алгоритм Ниже приводится список алгоритмов, группированный по категориям. Более детальные сведения приводятся в списке структур данных и … Википедия
-
Программируемые алгоритмы — Служебный список статей, созданный для координации работ по развитию темы. Данное предупреждение не устанавл … Википедия
Что такое QR-код и где его использовать
QR-код – это двухмерный штрих-код, который состоит из контрастных по цвету (чаще всего черных и белых) блоков и позволяет кодировать до нескольких сотен символов. Сохраненную в коде информацию можно быстро распознать и посмотреть при помощи смартфона или планшета.

Здесь закодирована ссылка на главную страницу mobizon.ua.
При помощи QR-кода вы можете закодировать любую информацию, например: ссылку на сайт, визитку, номер телефона, email, адрес или текст.
Как создать QR-код
- Вызовите Конструктор QR-кодов в Панели управления.
- Откроется окно конструктора.
Выберите тип данных, которые требуется зашифровать: ссылка, визитка, номер телефона, email, географические координаты, текст, параметры Wi-Fi, SMS-сообщение. Введите эти данные в соответствующие поля. - QR-код будет показан в окне предварительного просмотра. Нажмите кнопку Скачать QR-код.
- Настройте параметры скачиваемого изображения в открывшемся окне.
Параметры:
Ширина рамки — расстояние от края изображения до кода.
Уровень коррекции ошибок — количество информации, после утраты которого код прекращает распознаваться (подробнее см. подраздел Уровни коррекции ошибок ниже).
Размер, px — ширина и высота изображения (в пикселях). Не более 1500 px.
Цвет кода и цвет фона — цвет соответствующих элементов QR-кода. Выберите на палитре или задайте в виде шестнадцатеричного кода цвета. Рекомендуем выбирать наиболее контрастирующие друг с другом цвета. Следует учесть, что многие программы и устройства не поддерживают распознавание цветных QR-кодов, поэтому, прежде чем размещать такие коды на печатной продукции, тщательно тестируйте их.
Скачать в формате — выбор формата файла изображения. - Нажмите на кнопку с требуемым форматом изображения — PNG, JPG, GIF или SVG. Начнется скачивание файла.

Печать QR-кодов
Рекомендуется использовать форматы печати с высоким разрешением: растровые JPG и PNG, векторные форматы EPS и SVG. Они подходят, прежде всего, для крупноформатной печати, так как изображения в этих форматах возможно увеличить без потери качества. Перед публикацией кодов следует проверить их считываемость при помощи различных смартфонов и приложений.
Стоит учитывать и другие параметры печати помимо формата файла. Размер оттиска кода выбирайте в зависимости от количества зашифрованных символов. Чем больше информации шифруется, тем больше требуется места.
Делайте размер оттиска не менее, чем 2х2 см.
Размещайте QR-код только на ровных поверхностях.
Как сканировать QR-коды
Для сканирования требуется мобильный телефон и установленное приложение для сканирования QR-кодов (QR ридер). Такие приложения доступны для бесплатной загрузки в магазинах приложений.
Чтобы отсканировать код:
- Откройте QR-ридер на своем устройстве.
- Поднесите камеру к QR-коду. Сканирование выполняется мгновенно.
Уровни коррекции ошибок
У QR-кода есть специальный механизм, который позволяет увеличить надежность хранения зашифрованной информации — коррекция ошибок. С помощью него становится возможным распознавать даже коды, часть которых была испорчена или затерта.
У кодов с самым высоким уровнем надежности (H) могут быть искажены до 30% поверхности, тем не менее информация сохранится и её будет возможно корректно прочитать.
Всего существует 4 уровня коррекции ошибок: L — низкий, M — средний, Q — выше среднего и H — высокий. Чем выше уровень, тем надежнее код, но вместе с уровнем возрастает и размер файла изображения.