
Время на прочтение
9 мин
Количество просмотров 335K
Bash-скрипты: начало
Bash-скрипты, часть 2: циклы
Bash-скрипты, часть 3: параметры и ключи командной строки
Bash-скрипты, часть 4: ввод и вывод
Bash-скрипты, часть 5: сигналы, фоновые задачи, управление сценариями
Bash-скрипты, часть 6: функции и разработка библиотек
Bash-скрипты, часть 7: sed и обработка текстов
Bash-скрипты, часть 8: язык обработки данных awk
Bash-скрипты, часть 9: регулярные выражения
Bash-скрипты, часть 10: практические примеры
Bash-скрипты, часть 11: expect и автоматизация интерактивных утилит
В прошлый раз, в третьей части этой серии материалов по bash-скриптам, мы говорили о параметрах командной строки и ключах. Наша сегодняшняя тема — ввод, вывод, и всё, что с этим связано.

Вы уже знакомы с двумя методами работы с тем, что выводят сценарии командной строки:
- Отображение выводимых данных на экране.
- Перенаправление вывода в файл.
Иногда что-то надо показать на экране, а что-то — записать в файл, поэтому нужно разобраться с тем, как в Linux обрабатывается ввод и вывод, а значит — научиться отправлять результаты работы сценариев туда, куда нужно. Начнём с разговора о стандартных дескрипторах файлов.
Стандартные дескрипторы файлов
Всё в Linux — это файлы, в том числе — ввод и вывод. Операционная система идентифицирует файлы с использованием дескрипторов.
Каждому процессу позволено иметь до девяти открытых дескрипторов файлов. Оболочка bash резервирует первые три дескриптора с идентификаторами 0, 1 и 2. Вот что они означают.
0,STDIN —стандартный поток ввода.1,STDOUT —стандартный поток вывода.2,STDERR —стандартный поток ошибок.
Эти три специальных дескриптора обрабатывают ввод и вывод данных в сценарии.
Вам нужно как следует разобраться в стандартных потоках. Их можно сравнить с фундаментом, на котором строится взаимодействие скриптов с внешним миром. Рассмотрим подробности о них.
STDIN
STDIN — это стандартный поток ввода оболочки. Для терминала стандартный ввод — это клавиатура. Когда в сценариях используют символ перенаправления ввода — <, Linux заменяет дескриптор файла стандартного ввода на тот, который указан в команде. Система читает файл и обрабатывает данные так, будто они введены с клавиатуры.
Многие команды bash принимают ввод из STDIN, если в командной строке не указан файл, из которого надо брать данные. Например, это справедливо для команды cat.
Когда вы вводите команду cat в командной строке, не задавая параметров, она принимает ввод из STDIN. После того, как вы вводите очередную строку, cat просто выводит её на экран.
STDOUT
STDOUT — стандартный поток вывода оболочки. По умолчанию это — экран. Большинство bash-команд выводят данные в STDOUT, что приводит к их появлению в консоли. Данные можно перенаправить в файл, присоединяя их к его содержимому, для этого служит команда >>.
Итак, у нас есть некий файл с данными, к которому мы можем добавить другие данные с помощью этой команды:
pwd >> myfile
То, что выведет pwd, будет добавлено к файлу myfile, при этом уже имеющиеся в нём данные никуда не денутся.
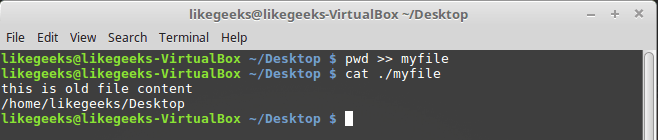
Перенаправление вывода команды в файл
Пока всё хорошо, но что если попытаться выполнить что-то вроде показанного ниже, обратившись к несуществующему файлу xfile, задумывая всё это для того, чтобы в файл myfile попало сообщение об ошибке.
ls –l xfile > myfileПосле выполнения этой команды мы увидим сообщения об ошибках на экране.

Попытка обращения к несуществующему файлу
При попытке обращения к несуществующему файлу генерируется ошибка, но оболочка не перенаправила сообщения об ошибках в файл, выведя их на экран. Но мы-то хотели, чтобы сообщения об ошибках попали в файл. Что делать? Ответ прост — воспользоваться третьим стандартным дескриптором.
STDERR
STDERR представляет собой стандартный поток ошибок оболочки. По умолчанию этот дескриптор указывает на то же самое, на что указывает STDOUT, именно поэтому при возникновении ошибки мы видим сообщение на экране.
Итак, предположим, что надо перенаправить сообщения об ошибках, скажем, в лог-файл, или куда-нибудь ещё, вместо того, чтобы выводить их на экран.
▍Перенаправление потока ошибок
Как вы уже знаете, дескриптор файла STDERR — 2. Мы можем перенаправить ошибки, разместив этот дескриптор перед командой перенаправления:
ls -l xfile 2>myfile
cat ./myfile
Сообщение об ошибке теперь попадёт в файл myfile.

Перенаправление сообщения об ошибке в файл
▍Перенаправление потоков ошибок и вывода
При написании сценариев командной строки может возникнуть ситуация, когда нужно организовать и перенаправление сообщений об ошибках, и перенаправление стандартного вывода. Для того, чтобы этого добиться, нужно использовать команды перенаправления для соответствующих дескрипторов с указанием файлов, куда должны попадать ошибки и стандартный вывод:
ls –l myfile xfile anotherfile 2> errorcontent 1> correctcontent
Перенаправление ошибок и стандартного вывода
Оболочка перенаправит то, что команда ls обычно отправляет в STDOUT, в файл correctcontent благодаря конструкции 1>. Сообщения об ошибках, которые попали бы в STDERR, оказываются в файле errorcontent из-за команды перенаправления 2>.
Если надо, и STDERR, и STDOUT можно перенаправить в один и тот же файл, воспользовавшись командой &>:
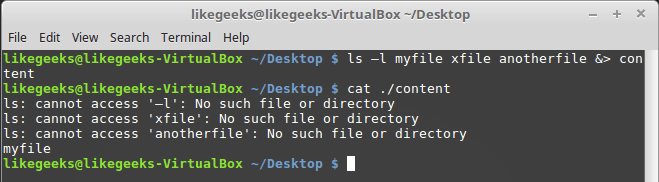
Перенаправление STDERR и STDOUT в один и тот же файл
После выполнения команды то, что предназначено для STDERR и STDOUT, оказывается в файле content.
Перенаправление вывода в скриптах
Существует два метода перенаправления вывода в сценариях командной строки:
- Временное перенаправление, или перенаправление вывода одной строки.
- Постоянное перенаправление, или перенаправление всего вывода в скрипте либо в какой-то его части.
▍Временное перенаправление вывода
В скрипте можно перенаправить вывод отдельной строки в STDERR. Для того, чтобы это сделать, достаточно использовать команду перенаправления, указав дескриптор STDERR, при этом перед номером дескриптора надо поставить символ амперсанда (&):
#!/bin/bash
echo "This is an error" >&2
echo "This is normal output"Если запустить скрипт, обе строки попадут на экран, так как, как вы уже знаете, по умолчанию ошибки выводятся туда же, куда и обычные данные.

Временное перенаправление
Запустим скрипт так, чтобы вывод STDERR попадал в файл.
./myscript 2> myfileКак видно, теперь обычный вывод делается в консоль, а сообщения об ошибках попадают в файл.
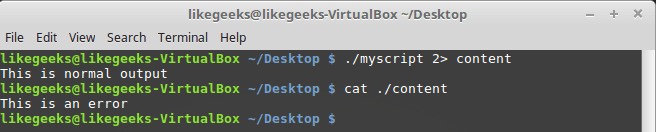
Сообщения об ошибках записываются в файл
▍Постоянное перенаправление вывода
Если в скрипте нужно перенаправлять много выводимых на экран данных, добавлять соответствующую команду к каждому вызову echo неудобно. Вместо этого можно задать перенаправление вывода в определённый дескриптор на время выполнения скрипта, воспользовавшись командой exec:
#!/bin/bash
exec 1>outfile
echo "This is a test of redirecting all output"
echo "from a shell script to another file."
echo "without having to redirect every line"Запустим скрипт.

Перенаправление всего вывода в файл
Если просмотреть файл, указанный в команде перенаправления вывода, окажется, что всё, что выводилось командами echo, попало в этот файл.
Команду exec можно использовать не только в начале скрипта, но и в других местах:
#!/bin/bash
exec 2>myerror
echo "This is the start of the script"
echo "now redirecting all output to another location"
exec 1>myfile
echo "This should go to the myfile file"
echo "and this should go to the myerror file" >&2Вот что получится после запуска скрипта и просмотра файлов, в которые мы перенаправляли вывод.
![]()
Перенаправление вывода в разные файлы
Сначала команда exec задаёт перенаправление вывода из STDERR в файл myerror. Затем вывод нескольких команд echo отправляется в STDOUT и выводится на экран. После этого команда exec задаёт отправку того, что попадает в STDOUT, в файл myfile, и, наконец, мы пользуемся командой перенаправления в STDERR в команде echo, что приводит к записи соответствующей строки в файл myerror.
Освоив это, вы сможете перенаправлять вывод туда, куда нужно. Теперь поговорим о перенаправлении ввода.
Перенаправление ввода в скриптах
Для перенаправления ввода можно воспользоваться той же методикой, которую мы применяли для перенаправления вывода. Например, команда exec позволяет сделать источником данных для STDIN какой-нибудь файл:
exec 0< myfile
Эта команда указывает оболочке на то, что источником вводимых данных должен стать файл myfile, а не обычный STDIN. Посмотрим на перенаправление ввода в действии:
#!/bin/bash
exec 0< testfile
count=1
while read line
do
echo "Line #$count: $line"
count=$(( $count + 1 ))
doneВот что появится на экране после запуска скрипта.

Перенаправление ввода
В одном из предыдущих материалов вы узнали о том, как использовать команду read для чтения данных, вводимых пользователем с клавиатуры. Если перенаправить ввод, сделав источником данных файл, то команда read, при попытке прочитать данные из STDIN, будет читать их из файла, а не с клавиатуры.
Некоторые администраторы Linux используют этот подход для чтения и последующей обработки лог-файлов.
Создание собственного перенаправления вывода
Перенаправляя ввод и вывод в сценариях, вы не ограничены тремя стандартными дескрипторами файлов. Как уже говорилось, можно иметь до девяти открытых дескрипторов. Остальные шесть, с номерами от 3 до 8, можно использовать для перенаправления ввода или вывода. Любой из них можно назначить файлу и использовать в коде скрипта.
Назначить дескриптор для вывода данных можно, используя команду exec:
#!/bin/bash
exec 3>myfile
echo "This should display on the screen"
echo "and this should be stored in the file" >&3
echo "And this should be back on the screen"
После запуска скрипта часть вывода попадёт на экран, часть — в файл с дескриптором 3.
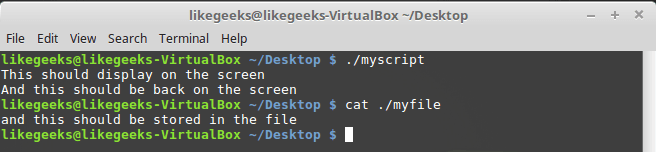
Перенаправление вывода, используя собственный дескриптор
Создание дескрипторов файлов для ввода данных
Перенаправить ввод в скрипте можно точно так же, как и вывод. Сохраните STDIN в другом дескрипторе, прежде чем перенаправлять ввод данных.
После окончания чтения файла можно восстановить STDIN и пользоваться им как обычно:
#!/bin/bash
exec 6<&0
exec 0< myfile
count=1
while read line
do
echo "Line #$count: $line"
count=$(( $count + 1 ))
done
exec 0<&6
read -p "Are you done now? " answer
case $answer in
y) echo "Goodbye";;
n) echo "Sorry, this is the end.";;
esacИспытаем сценарий.
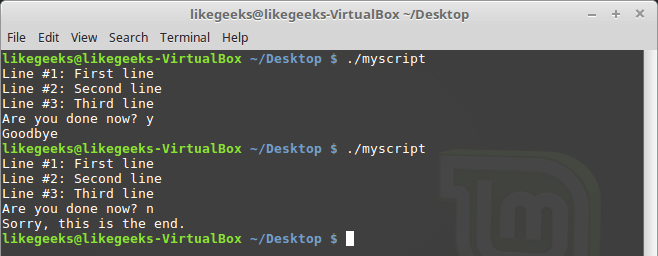
Перенаправление ввода
В этом примере дескриптор файла 6 использовался для хранения ссылки на STDIN. Затем было сделано перенаправление ввода, источником данных для STDIN стал файл. После этого входные данные для команды read поступали из перенаправленного STDIN, то есть из файла.
После чтения файла мы возвращаем STDIN в исходное состояние, перенаправляя его в дескриптор 6. Теперь, для того, чтобы проверить, что всё работает правильно, скрипт задаёт пользователю вопрос, ожидает ввода с клавиатуры и обрабатывает то, что введено.
Закрытие дескрипторов файлов
Оболочка автоматически закрывает дескрипторы файлов после завершения работы скрипта. Однако, в некоторых случаях нужно закрывать дескрипторы вручную, до того, как скрипт закончит работу. Для того, чтобы закрыть дескриптор, его нужно перенаправить в &-. Выглядит это так:
#!/bin/bash
exec 3> myfile
echo "This is a test line of data" >&3
exec 3>&-
echo "This won't work" >&3После исполнения скрипта мы получим сообщение об ошибке.

Попытка обращения к закрытому дескриптору файла
Всё дело в том, что мы попытались обратиться к несуществующему дескриптору.
Будьте внимательны, закрывая дескрипторы файлов в сценариях. Если вы отправляли данные в файл, потом закрыли дескриптор, потом — открыли снова, оболочка заменит существующий файл новым. То есть всё то, что было записано в этот файл ранее, будет утеряно.
Получение сведений об открытых дескрипторах
Для того, чтобы получить список всех открытых в Linux дескрипторов, можно воспользоваться командой lsof. Во многих дистрибутивах, вроде Fedora, утилита lsof находится в /usr/sbin. Эта команда весьма полезна, так как она выводит сведения о каждом дескрипторе, открытом в системе. Сюда входит и то, что открыли процессы, выполняемые в фоне, и то, что открыто пользователями, вошедшими в систему.
У этой команды есть множество ключей, рассмотрим самые важные.
-pПозволяет указатьIDпроцесса.-dПозволяет указать номер дескриптора, о котором надо получить сведения.
Для того, чтобы узнать PID текущего процесса, можно использовать специальную переменную окружения $$, в которую оболочка записывает текущий PID.
Ключ -a используется для выполнения операции логического И над результатами, возвращёнными благодаря использованию двух других ключей:
lsof -a -p $$ -d 0,1,2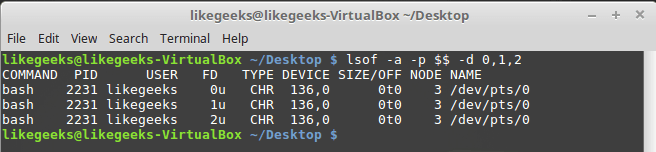
Вывод сведений об открытых дескрипторах
Тип файлов, связанных с STDIN, STDOUT и STDERR — CHR (character mode, символьный режим). Так как все они указывают на терминал, имя файла соответствует имени устройства, назначенного терминалу. Все три стандартных файла доступны и для чтения, и для записи.
Посмотрим на вызов команды lsof из скрипта, в котором открыты, в дополнение к стандартным, другие дескрипторы:
#!/bin/bash
exec 3> myfile1
exec 6> myfile2
exec 7< myfile3
lsof -a -p $$ -d 0,1,2,3,6,7Вот что получится, если этот скрипт запустить.
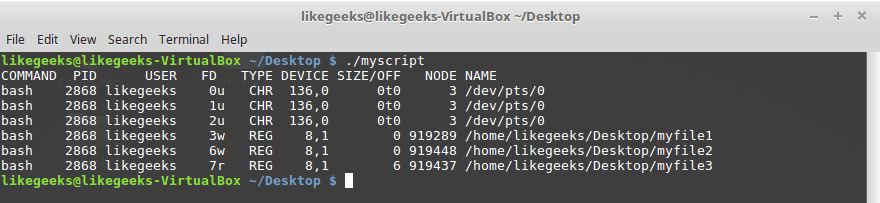
Просмотр дескрипторов файлов, открытых скриптом
Скрипт открыл два дескриптора для вывода (3 и 6) и один — для ввода (7). Тут же показаны и пути к файлам, использованных для настройки дескрипторов.
Подавление вывода
Иногда надо сделать так, чтобы команды в скрипте, который, например, может исполняться как фоновый процесс, ничего не выводили на экран. Для этого можно перенаправить вывод в /dev/null. Это — что-то вроде «чёрной дыры».
Вот, например, как подавить вывод сообщений об ошибках:
ls -al badfile anotherfile 2> /dev/nullТот же подход используется, если, например, надо очистить файл, не удаляя его:
cat /dev/null > myfileИтоги
Сегодня вы узнали о том, как в сценариях командной строки работают ввод и вывод. Теперь вы умеете обращаться с дескрипторами файлов, создавать, просматривать и закрывать их, знаете о перенаправлении потоков ввода, вывода и ошибок. Всё это очень важно в деле разработки bash-скриптов.
В следующий раз поговорим о сигналах Linux, о том, как обрабатывать их в сценариях, о запуске заданий по расписанию и о фоновых задачах.
Уважаемые читатели! В этом материале даны основы работы с потоками ввода, вывода и ошибок. Уверены, среди вас есть профессионалы, которые могут рассказать обо всём этом то, что приходит лишь с опытом. Если так — передаём слово вам.
From Wikipedia, the free encyclopedia
This article is about standard I/O file descriptors. For System V streams, see STREAMS.
In computer programming, standard streams are interconnected input and output communication channels[1] between a computer program and its environment when it begins execution. The three input/output (I/O) connections are called standard input (stdin), standard output (stdout) and standard error (stderr). Originally I/O happened via a physically connected system console (input via keyboard, output via monitor), but standard streams abstract this. When a command is executed via an interactive shell, the streams are typically connected to the text terminal on which the shell is running, but can be changed with redirection or a pipeline. More generally, a child process inherits the standard streams of its parent process.
Application[edit]
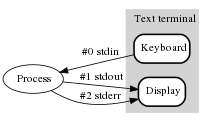
The standard streams for input, output, and error
Users generally know standard streams as input and output channels that handle data coming from an input device, or that write data from the application. The data may be text with any encoding, or binary data.
In many modern systems, the standard error stream of a program is redirected into a log file, typically for error analysis purposes.
Streams may be used to chain applications, meaning that the output stream of one program can be redirected to be the input stream to another application. In many operating systems this is expressed by listing the application names, separated by the vertical bar character, for this reason often called the pipeline character. A well-known example is the use of a pagination application, such as more, providing the user control over the display of the output stream on the display.
Background[edit]
In most operating systems predating Unix, programs had to explicitly connect to the appropriate input and output devices. OS-specific intricacies caused this to be a tedious programming task. On many systems it was necessary to obtain control of environment settings, access a local file table, determine the intended data set, and handle hardware correctly in the case of a punch card reader, magnetic tape drive, disk drive, line printer, card punch, or interactive terminal.
One of Unix’s several groundbreaking advances was abstract devices, which removed the need for a program to know or care what kind of devices it was communicating with[citation needed]. Older operating systems forced upon the programmer a record structure and frequently non-orthogonal data semantics and device control. Unix eliminated this complexity with the concept of a data stream: an ordered sequence of data bytes which can be read until the end of file. A program may also write bytes as desired and need not, and cannot easily declare their count or grouping.
Another Unix breakthrough was to automatically associate input and output to terminal keyboard and terminal display, respectively, by default[citation needed] — the program (and programmer) did absolutely nothing to establish input and output for a typical input-process-output program (unless it chose a different paradigm). In contrast, previous operating systems usually required some—often complex—job control language to establish connections, or the equivalent burden had to be orchestrated by the program.[citation needed]
Since Unix provided standard streams, the Unix C runtime environment was obliged to support it as well. As a result, most C runtime environments (and C’s descendants), regardless of the operating system, provide equivalent functionality.
Standard input (stdin)[edit]
Standard input is a stream from which a program reads its input data. The program requests data transfers by use of the read operation. Not all programs require stream input. For example, the dir and ls programs (which display file names contained in a directory) may take command-line arguments, but perform their operations without any stream data input.
Unless redirected, standard input is inherited from the parent process. In the case of an interactive shell, that is usually associated with the keyboard.
The file descriptor for standard input is 0 (zero); the POSIX <unistd.h> definition is STDIN_FILENO; the corresponding C <stdio.h> variable is FILE* stdin; similarly, the C++ <iostream> variable is std::cin.
Standard output (stdout)[edit]
Standard output is a stream to which a program writes its output data. The program requests data transfer with the write operation. Not all programs generate output. For example, the file rename command (variously called mv, move, or ren) is silent on success.
Unless redirected, standard output is inherited from the parent process. In the case of an interactive shell, that is usually the text terminal which initiated the program.
The file descriptor for standard output is 1 (one); the POSIX <unistd.h> definition is STDOUT_FILENO; the corresponding C <stdio.h> variable is FILE* stdout; similarly, the C++ <iostream> variable is std::cout.
Standard error (stderr)[edit]
Standard error is another output stream typically used by programs to output error messages or diagnostics. It is a stream independent of standard output and can be redirected separately.
This solves the semi-predicate problem, allowing output and errors to be distinguished, and is analogous to a function returning a pair of values – see Semi-predicate problem: Multi valued return. The usual destination is the text terminal which started the program to provide the best chance of being seen even if standard output is redirected (so not readily observed). For example, output of a program in a pipeline is redirected to input of the next program or a text file, but errors from each program still go directly to the text terminal so they can be reviewed by the user in real time.[2]
It is acceptable and normal to direct standard output and standard error to the same destination, such as the text terminal. Messages appear in the same order as the program writes them, unless buffering is involved. For example, in common situations the standard error stream is unbuffered but the standard output stream is line-buffered; in this case, text written to standard error later may appear on the terminal earlier, if the standard output stream buffer is not yet full.
The file descriptor for standard error is defined by POSIX as 2 (two); the <unistd.h> header file provides the symbol STDERR_FILENO;[3] the corresponding C <stdio.h> variable is FILE* stderr. The C++ <iostream> standard header provides two variables associated with this stream: std::cerr and std::clog, the former being unbuffered and the latter using the same buffering mechanism as all other C++ streams.
Bourne-style shells allow standard error to be redirected to the same destination that standard output is directed to using
2>&1
csh-style shells allow standard error to be redirected to the same destination that standard output is directed to using
>&
Standard error was added to Unix in the 1970s after several wasted phototypesetting runs ended with error messages being typeset instead of displayed on the user’s terminal.[4]
Timeline[edit]
1950s: Fortran[edit]
Fortran has the equivalent of Unix file descriptors: By convention, many Fortran implementations use unit numbers UNIT=5 for stdin, UNIT=6 for stdout and UNIT=0 for stderr. In Fortran-2003, the intrinsic ISO_FORTRAN_ENV module was standardized to include the named constants INPUT_UNIT, OUTPUT_UNIT, and ERROR_UNIT to portably specify the unit numbers.
! FORTRAN 77 example PROGRAM MAIN INTEGER NUMBER READ(UNIT=5,*) NUMBER WRITE(UNIT=6,'(A,I3)') ' NUMBER IS: ',NUMBER END
! Fortran 2003 example program main use iso_fortran_env implicit none integer :: number read (unit=INPUT_UNIT,*) number write (unit=OUTPUT_UNIT,'(a,i3)') 'Number is: ', number end program
1960: ALGOL 60[edit]
ALGOL 60 was criticized for having no standard file access.[citation needed]
1968: ALGOL 68[edit]
ALGOL 68’s input and output facilities were collectively referred to as the transput.[5] Koster coordinated the definition of the transput standard. The model included three standard channels: stand in, stand out, and stand back.
# ALGOL 68 example # main:( REAL number; getf(stand in,($g$,number)); printf(($"Number is: "g(6,4)"OR "$,number)); # OR # putf(stand out,($" Number is: "g(6,4)"!"$,number)); newline(stand out) ) |
|
| Input: | Output: |
|---|---|
3.14159 |
Number is: +3.142 OR Number is: +3.142! |
1970s: C and Unix[edit]
In the C programming language, the standard input, output, and error streams are attached to the existing Unix file descriptors 0, 1 and 2 respectively.[6] In a POSIX environment the <unistd.h> definitions STDIN_FILENO, STDOUT_FILENO or STDERR_FILENO should be used instead rather than magic numbers. File pointers stdin, stdout, and stderr are also provided.
Ken Thompson (designer and implementer of the original Unix operating system) modified sort in Version 5 Unix to accept «-» as representing standard input, which spread to other utilities and became a part of the operating system as a special file in Version 8. Diagnostics were part of standard output through Version 6, after which Dennis M. Ritchie created the concept of standard error.[7]
1995: Java[edit]
In Java, the standard streams are referred to by System.in (for stdin), System.out (for stdout), and System.err (for stderr).[8]
public static void main(String args[]) { try { BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); String s = br.readLine(); double number = Double.parseDouble(s); System.out.println("Number is:" + number); } catch (Exception e) { System.err.println("Error:" + e.getMessage()); } }
2000s: .NET[edit]
In C# and other .NET languages, the standard streams are referred to by System.Console.In (for stdin), System.Console.Out (for stdout) and System.Console.Error (for stderr).[9] Basic read and write capabilities for the stdin and stdout streams are also accessible directly through the class System.Console (e.g. System.Console.WriteLine() can be used instead of System.Console.Out.WriteLine()).
System.Console.In, System.Console.Out and System.Console.Error are System.IO.TextReader (stdin) and System.IO.TextWriter (stdout, stderr) objects, which only allow access to the underlying standard streams on a text basis. Full binary access to the standard streams must be performed through the System.IO.Stream objects returned by System.Console.OpenStandardInput(), System.Console.OpenStandardOutput() and System.Console.OpenStandardError() respectively.
// C# example public static int Main(string[] args) { try { string s = System.Console.In.ReadLine(); double number = double.Parse(s); System.Console.Out.WriteLine("Number is: {0:F3}", number); return 0; // If Parse() threw an exception } catch (ArgumentNullException) { System.Console.Error.WriteLine("No number was entered!"); } catch (FormatException) { System.Console.Error.WriteLine("The specified value is not a valid number!"); } catch (OverflowException) { System.Console.Error.WriteLine("The specified number is too big!"); } return -1; }
' Visual Basic .NET example Public Function Main() As Integer Try Dim s As String = System.Console.[In].ReadLine() Dim number As Double = Double.Parse(s) System.Console.Out.WriteLine("Number is: {0:F3}", number) Return 0 ' If Parse() threw an exception Catch ex As System.ArgumentNullException System.Console.[Error].WriteLine("No number was entered!") Catch ex2 As System.FormatException System.Console.[Error].WriteLine("The specified value is not a valid number!") Catch ex3 As System.OverflowException System.Console.[Error].WriteLine("The specified number is too big!") End Try Return -1 End Function
When applying the System.Diagnostics.Process class one can use the instance properties StandardInput, StandardOutput, and StandardError of that class to access the standard streams of the process.
2000 — : Python (2 or 3)[edit]
The following example shows how to redirect the standard input both to the standard output
and to a text file.
#!/usr/bin/env python import sys # Save the current stdout so that we can revert sys.stdout # after we complete our redirection stdin_fileno = sys.stdin stdout_fileno = sys.stdout # Redirect sys.stdout to the file sys.stdout = open('myfile.txt', 'w') ctr = 0 for inps in stdin_fileno: ctrs = str(ctr) # Prints to the redirected stdout () sys.stdout.write(ctrs + ") this is to the redirected --->" + inps + 'n') # Prints to the actual saved stdout handler stdout_fileno.write(ctrs + ") this is to the actual --->" + inps + 'n') ctr = ctr + 1 # Close the file sys.stdout.close() # Restore sys.stdout to our old saved file handler sys.stdout = stdout_fileno
GUIs[edit]
Graphical user interfaces (GUIs) don’t always make use of the standard streams; they do when GUIs are wrappers of underlying scripts and/or console programs, for instance the Synaptic package manager GUI, which wraps apt commands in Debian and/or Ubuntu. GUIs created with scripting tools like Zenity and KDialog by KDE project[10] make use of stdin, stdout, and stderr, and are based on simple scripts rather than a complete GUI programmed and compiled in C/C++ using Qt, GTK, or other equivalent proprietary widget framework.
The Services menu, as implemented on NeXTSTEP and Mac OS X, is also analogous to standard streams. On these operating systems, graphical applications can provide functionality through a system-wide menu that operates on the current selection in the GUI, no matter in what application.
Some GUI programs, primarily on Unix, still write debug information to standard error. Others (such as many Unix media players) may read files from standard input. Popular Windows programs that open a separate console window in addition to their GUI windows are the emulators pSX and DOSBox.
GTK-server can use stdin as a communication interface with an interpreted program to realize a GUI.
The Common Lisp Interface Manager paradigm «presents» GUI elements sent to an extended output stream.
See also[edit]
- Redirection (computing)
- Stream (computing)
- Input/output
- C file input/output
- SYSIN and SYSOUT
- Standard streams in OpenVMS
References[edit]
- ^ D. M. Ritchie, «A Stream Input-Output System», AT&T Bell Laboratories Technical Journal, 68(8), October 1984.
- ^ «What are stdin, stdout and stderr in Linux? | CodePre.com». 2 December 2021. Retrieved 8 April 2022.
- ^ «<unistd.h>». The Open Group Base Specifications Issue 6—IEEE Std 1003.1, 2004 Edition. The Open Group. 2004.
- ^ Johnson, Steve (2013-12-11). «[TUHS] Graphic Systems C/A/T phototypesetter» (Mailing list). Archived from the original on 2020-09-25. Retrieved 2020-11-07.
- ^ Revised
Report on the Algorithmic Language Algol 68, Edited by
A. van Wijngaarden,
B.J. Mailloux,
J.E.L. Peck,
C.H.A. Koster,
M. Sintzoff,
C.H. Lindsey,
L.G.L.T. Meertens
and R.G. Fisker, http://www.softwarepreservation.org/projects/ALGOL/report/Algol68_revised_report-AB.pdf, Section 10.3 - ^ «Stdin(3): Standard I/O streams — Linux man page».
- ^ McIlroy, M. D. (1987). A Research Unix reader: annotated excerpts from the Programmer’s Manual, 1971–1986 (PDF) (Technical report). CSTR. Bell Labs. 139.
- ^ «System (Java Platform SE 7)». Retrieved 20 July 2012.
- ^ «C# Reference Source, .NET Framework 4.7.1, mscorlib, Console class». referencesource.microsoft.com. Retrieved 2017-12-10.
- ^ Kißling, Kristian (2009). «Adding graphic elements to your scripts with Zenity and KDialog». Linux Magazine. Retrieved 2021-04-11.
Sources[edit]
- «Standard Streams», The GNU C Library
- KRONOS 2.1 Reference Manual, Control Data Corporation, Part Number 60407000, 1974
- NOS Version 1 Applications Programmer’s Instant, Control Data Corporation, Part Number 60436000, 1978
- Level 68 Introduction to Programming on MULTICS, Honeywell Corporation, 1981
- Evolution of the MVS Operating System, IBM Corporation, 1981
- Lions’ Commentary on UNIX Sixth Edition, John Lions, ISBN 1-57398-013-7, 1977
- Console Class, .NET Framework Class Library, Microsoft Corporation, 2008
External links[edit]
- Standard Input Definition — by The Linux Information Project
- Standard Output Definition — by The Linux Information Project
- Standard Error Definition — by The Linux Information Project
Операционная система linux написана на языке программирования C, в котором по умолчанию открыты три файловых дескриптора, имеющих следующие значения:
- 1 (stdin) стандартный поток ввода. Из этого потока программа может читать данные.
- 2 (stdout) стандартный поток вывода. В этот поток программа может выводить данные.
- 3 (stderr) стандартный поток ошибок. В этот поток программа может выводит сообщения об ошибках.
В shell-оболочке bash стандартный поток ввода stdin соответственно имеет номер 1, а потоки вывода номера 1 для stdout и 2 для stderr.
При запуске shell, например при логине или при запуске командой sh, открывается новая shell-сессия, внутри которой создаются псевдофайлы символьных ссылок на устройства ввода-вывода /dev/stdin, /dev/stdout и /dev/stderr, в которые потоки ввода-вывода можно перенаправлять так же, как в обычные текстовые файлы.
Введение
Стандартные потоки ввода и вывода в Linux являются одним из наиболее распространенных средств для обмена информацией процессов, а перенаправление >, >> и | является одной из самых популярных конструкций командного интерпретатора.
В данной статье мы ознакомимся с возможностями перенаправления потоков ввода/вывода, используемых при работе файлами и командами.
Требования
- Linux-система, например, Ubuntu 20.04
Потоки
Стандартный ввод при работе пользователя в терминале передается через клавиатуру.
Стандартный вывод и стандартная ошибка отображаются на дисплее терминала пользователя в виде текста.
Ввод и вывод распределяется между тремя стандартными потоками:
- stdin — стандартный ввод (клавиатура),
- stdout — стандартный вывод (экран),
- stderr — стандартная ошибка (вывод ошибок на экран).
Потоки также пронумерованы:
- stdin — 0,
- stdout — 1,
- stderr — 2.
Из стандартного ввода команда может только считывать данные, а два других потока могут использоваться только для записи. Данные выводятся на экран и считываются с клавиатуры, так как стандартные потоки по умолчанию ассоциированы с терминалом пользователя. Потоки можно подключать к чему угодно: к файлам, программам и даже устройствам. В командном интерпретаторе bash такая операция называется перенаправлением:
- < file — использовать файл как источник данных для стандартного потока ввода.
- > file — направить стандартный поток вывода в файл. Если файл не существует, он будет создан, если существует — перезаписан сверху.
- 2> file — направить стандартный поток ошибок в файл. Если файл не существует, он будет создан, если существует — перезаписан сверху.
- >>file — направить стандартный поток вывода в файл. Если файл не существует, он будет создан, если существует — данные будут дописаны к нему в конец.
- 2>>file — направить стандартный поток ошибок в файл. Если файл не существует, он будет создан, если существует — данные будут дописаны к нему в конец.
- &>file или >&file — направить стандартный поток вывода и стандартный поток ошибок в файл. Другая форма записи: >file 2>&1.
Стандартный ввод
Стандартный входной поток обычно переносит данные от пользователя к программе. Программы, которые предполагают стандартный ввод, обычно получают входные данные от устройства типа клавиатура. Стандартный ввод прекращается по достижении EOF (конец файла), который указывает на то, что данных для чтения больше нет.
EOF вводится нажатием сочетания клавиш Ctrl+D.
Рассмотрим работу со стандартным выводом на примере команды cat (от CONCATENATE, в переводе «связать» или «объединить что-то»).
Cat обычно используется для объединения содержимого двух файлов.
Cat отправляет полученные входные данные на дисплей терминала в качестве стандартного вывода и останавливается после того как получает EOF.
Пример
catВ открывшейся строке введите, например, 1 и нажмите клавишу Enter. На дисплей выводится 1. Введите a и нажмите клавишу Enter. На дисплей выводится a.
Дисплей терминала выглядит следующим образом:
test@111:~/stream$ cat
1
1
a
aДля завершения ввода данных следует нажать сочетание клавиш Ctrl + D.
Стандартный вывод
Стандартный вывод записывает данные, сгенерированные программой. Когда стандартный выходной поток не перенаправляется в какой-либо файл, он выводит текст на дисплей терминала.
При использовании без каких-либо дополнительных опций, команда echo выводит на экран любой аргумент, который передается ему в командной строке:
echo ПримерАргументом является то, что получено программой, в результате на дисплей терминала будет выведено:
ПримерПри выполнении echo без каких-либо аргументов, возвращается пустая строка.
Пример
Команда объединяет три файла: file1, file2 и file3 в один файл bigfile:
cat file1 file1 file1 > bigfileКоманда cat по очереди выводит содержимое файлов, перечисленных в качестве параметров на стандартный поток вывода. Стандартный поток вывода перенаправлен в файл bigfile.
Стандартная ошибка
Стандартная ошибка записывает ошибки, возникающие в ходе исполнения программы. Как и в случае стандартного вывода, по умолчанию этот поток выводится на терминал дисплея.
Пример
Рассмотрим пример стандартной ошибки с помощью команды ls, которая выводит список содержимого каталогов.
При запуске без аргументов ls выводит содержимое в пределах текущего каталога.
Введем команду ls с каталогом % в качестве аргумента:
ls %В результате должно выводиться содержимое соответствующей папки. Но так как каталога % не существует, на дисплей терминала будет выведен следующий текст стандартной ошибки:
ls: cannot access %: No such file or directoryПеренаправление потока
Linux включает в себя команды перенаправления для каждого потока.
Команды со знаками > или < означают перезапись существующего содержимого файла:
- > — стандартный вывод,
- < — стандартный ввод,
- 2> — стандартная ошибка.
Команды со знаками >> или << не перезаписывают существующее содержимое файла, а присоединяют данные к нему:
- >> — стандартный вывод,
- << — стандартный ввод,
- 2>> — стандартная ошибка.
Пример
В приведенном примере команда cat используется для записи в файл file1, который создается в результате цикла:
cat > file1
a
b
cДля завершения цикла нажмите сочетание клавиш Ctrl + D.
Если файла file1 не существует, то в текущем каталоге создается новый файл с таким именем.
Для просмотра содержимого файла file1 введите команду:
cat file1В результате на дисплей терминала должно быть выведено следующее:
a
b
cДля перезаписи содержимого файла введите следующее:
cat > file1
1
2
3Для завершения цикла нажмите сочетание клавиш Ctrl + D.
В результате на дисплей терминала должно быть выведено следующее:
1
2
3Предыдущего текста в текущем файле больше не существует, так как содержимое файла было переписано командой >.
Для добавления нового текста к уже существующему в файле с помощью двойных скобок >> выполните команду:
cat >> file1
a
b
cДля завершения цикла нажмите сочетание клавиш Ctrl + D.
Откройте file1 снова и в результате на дисплее монитора должно быть отражено следующее:
1
2
3
a
b
cКаналы
Каналы используются для перенаправления потока из одной программы в другую. Стандартный вывод данных после выполнения одной команды перенаправляется в другую через канал. Данные первой программы, которые получает вторая программа, не будут отображаться. На дисплей терминала будут выведены только отфильтрованные данные, возвращаемые второй командой.
Пример
Введите команду:
ls | lessВ результате каждый файл текущего каталога будет размещен на новой строке:
file1
file2
t1
t2Перенаправлять данные с помощью каналов можно как из одной команды в другую, так и из одного файла к другому, а перенаправление с помощью > и >> возможно только для перенаправления данных в файлах.
Пример
Для сохранения имен файлов, содержащих строку «LOG», используется следующая команда:
dir /catalog | find "LOG" > loglistВывод команды dir отсылается в команду-фильтр find. Имена файлов, содержащие строку «LOG», хранятся в файле loglist в виде списка (например, Config.log, Logdat.svd и Mylog.bat).
При использовании нескольких фильтров в одной команде рекомендуется разделять их с помощью знака канала |.
Фильтры
Фильтры представляют собой стандартные команды Linux, которые могут быть использованы без каналов:
- find — возвращает файлы с именами, которые соответствуют передаваемому аргументу.
- grep — возвращает только строки, содержащие (или не содержащие) заданное регулярное выражение.
- tee — перенаправляет стандартный ввод как стандартный вывод и один или несколько файлов.
- tr — находит и заменяет одну строку другой.
- wc — подсчитывает символы, линии и слова.
Как правило, все нижеприведенные команды работают как фильтры, если у них нет аргументов (опции могут быть):
- cat — считывает данные со стандартного потока ввода и передает их на стандартный поток вывода. Без опций работает как простой повторитель. С опциями может фильтровать пустые строки, нумеровать строки и делать другую подобную работу.
- head — показывает первые 10 строк (или другое заданное количество), считанных со стандартного потока ввода.
- tail — показывает последние 10 строк (или другое заданное количество), считанные со стандартного потока ввода. Важный частный случай tail -f, который в режиме слежения показывает концовку файла. Это используется, в частности, для просмотра файлов журнальных сообщений.
- cut — вырезает столбец (по символам или полям) из потока ввода и передает на поток вывода. В качестве разделителей полей могут использоваться любые символы.
- sort — сортирует данные в соответствии с какими-либо критериями, например, арифметически по второму столбцу.
- uniq — удаляет повторяющиеся строки. Или (с ключом -с) не просто удалить, а написать сколько таких строк было. Учитываются только подряд идущие одинаковые строки, поэтому часто данные сортируются перед тем как отправить их на вход программе.
- bc — вычисляет каждую отдельную строку потока и записывает вместо нее результат вычисления.
- hexdump — показывает шестнадцатеричное представление данных, поступающих на стандартный поток ввода.
- strings — выделяет и показывает в стандартном потоке (или файле) то, что напоминает строки. Всё что не похоже на строковые последовательности, игнорируется. Команда полезна в сочетании с grep для поиска интересующих строковых последовательностей в бинарных файлах.
- sed — обрабатывает текст в соответствии с заданным скриптом. Наиболее часто используется для замены текста в потоке: sed s/было/стало/g.
- awk — обрабатывает текст в соответствии с заданным скриптом. Как правило, используется для обработки текстовых таблиц, например, вывод ps aux и т.д.
- sh -s — текст, который передается на стандартный поток ввода sh -s. может интерпретироваться как последовательность команд shell. На выход передается результат их исполнения.
- ssh — средство удаленного доступа ssh, может работать как фильтр, который подхватывает данные, переданные ему на стандартный поток ввода, затем передает их на удаленный хост и подает на вход процессу программы, имя которой было передано ему в качестве аргумента. Результат выполнения программы (то есть то, что она выдала на стандартный поток вывода) передается со стандартного вывода ssh.
Если в качестве аргумента передается файл, команда-фильтр считывает данные из этого файла, а не со стандартного потока ввода (есть исключения, например, команда tr, обрабатывающая данные, поступающие исключительно через стандартный поток ввода).
Пример
Команда tee, как правило, используется для просмотра выводимого содержимого при одновременном сохранении его в файл.
wc ~/stream | tee file2Пример
Допускается перенаправление нескольких потоков в один файл:
ls -z >> file3 2>&1В результате сообщение о неверной опции «z» в команде ls будет записано в файл t2, поскольку stderr перенаправлен в файл.
Для просмотра содержимого файла file3 введите команду cat:
cat file3В результате на дисплее терминала отобразиться следующее:
ls: invalid option -- 'z'
Try 'ls --help' for more information.Заключение
Мы рассмотрели возможности работы с перенаправлениями потоков >, >> и |, использование которых позволяет лучше работать с bash-скриптами.
Материал из Xgu.ru
Перейти к: навигация, поиск
- Короткий URL: stdin
Стандартные потоки ввода и вывода в UNIX/Linux наряду с файлами
являются одним из наиболее распространённых средств
для обмена информацией процессов с внешним миром,
а перенаправления >, >> и |,
одной из самых популярных конструкций командного интерпретатора.
На этой странице рассматриваются как базовые вопросы использования потоков ввода/вывода,
так и тонкости и хитрости, например, почему не работает echo text | read ver
и многие другие.
Содержание
- 1 Потоки и файлы
- 2 Каналы
- 3 Программы фильтры
- 4 Переменные командного интерпретатора и потоки
- 5 Именованные каналы
- 6 Потоки ввода/вывода и терминал
- 7 Подстановка процесса
- 8 Перенаправление вывода скрипта
- 9 Поменять местами стандартный поток вывода и стандартный поток ошибок
- 10 Просмотр прогресса и скорости обработки данных в потоке
- 11 Дополнительная информация
[править] Потоки и файлы
Процесс взаимодействия с пользователем выполняется в терминах записи и чтения в файл. То есть вывод на экран представляется как запись в файл, а ввод — как чтение файла. Файл, из которого осуществляется чтение, называется стандартным потоком ввода, а в который осуществляется запись — стандартным потоком вывода.

Стандартные потоки — воображаемые файлы, позволяющие осуществлять взаимодействие с пользователем как чтение и запись в файл.
Кроме потоков ввода и вывода, существует еще и стандартный поток ошибок, на который выводятся все сообщения об ошибках и те информативные сообщения о ходе работы программы, которые не могут быть выведены в стандартный поток вывода.
Стандартные потоки привязаны к файловым дескрипторам с номерами 0, 1 и 2.
- Стандартный поток ввода (stdin) — 0;
- Стандартный поток вывода (stdout) — 1;
- Стандартный поток ошибок (stderr) — 2.
Вывод данных на экран и чтение их с клавиатуры происходит потому, что по умолчанию стандартные потоки ассоциированы с терминалом пользователя. Это не является обязательным — потоки можно подключать к чему угодно — к файлам, программам и даже устройствам. В командном интерпретаторе bash такая операция называется перенаправлением.
- < файл
- Использовать файл как источник данных для стандартного потока ввода.
- > файл
- Направить стандартный поток вывода в файл. Если файл не существует, он будет создан; если существует — перезаписан сверху.
- 2> файл
- Направить стандартный поток ошибок в файл. Если файл не существует, он будет создан; если существует — перезаписан сверху.
- >>файл
- Направить стандартный поток вывода в файл. Если файл не существует, он будет создан; если существует — данные будут дописаны к нему в конец.
- 2>>файл
- Направить стандартный поток ошибок в файл. Если файл не существует, он будет создан; если существует — данные будут дописаны к нему в конец.
- &>файл или >&файл
- Направить стандартный поток вывода и стандартный поток ошибок в файл. Другая форма записи: >файл 2>&1.
- >&-
- Закрыть поток вывода перед вызовом команды (спасибо [1]);
- 2>&-
- Закрыть поток ошибок перед вызовом команды (спасибо [2]);
- cat <<EOF
Весь текст между блоками EOF (в общем случае вместо EOF можно использовать любое слово) будет выведен на экран. Важно: перед последним EOF не должно быть пробелов! (heredoc синтаксис).
- EOF
- <<<string
- Аналогично, но только для одной строки (для bash версии 3 и выше)
Пример.
Эта команда объединяет три файла: header, body и footer в один файл letter:
%$ cat header body footer > letter
Команда cat по очереди выводит содержимое файлов, перечисленных в качестве параметров на стандартный поток вывода. Стандартный поток вывода перенаправлен в файл letter.
Здесь используется сразу перенаправление стандартного потока ввода и стандартного потока вывода:
%$ sort < unsortedlines > sortedlines
Программа sort сортирует данные, поступившие в стандартный поток ввода, и выводит их на стандартный поток вывода. Стандартный поток ввода подключен к файлу unsortedlines, а выход записывается в sortedlines.
Здесь перенаправлены потоки вывода и ошибок:
%$ find /home -name '*.rpm' >rpmlist 2> /dev/null
Программа find ищет в каталоге /home файлы с суффиксом .rpm. Список найденных файлов записывается в файл rpmlist. Все сообщения об ошибках удаляются. Удаление достигается при помощи перенаправления потока ошибок на устройство /dev/null — специальный файл, означающий ничто. Данные, отправленные туда, безвозвратно исчезают. Если же прочитать содержимое этого файла, он окажется пуст.
Для того чтобы лучше понять, что потоки работают как файлы,
рассмотрим такой пример:
%$ cat > /tmp/fff & [1] 28378 [1]+ Stopped cat > /tmp/fff %$ ls -l /proc/28378/fd/ total 0 lrwx------ 1 igor igor 64 2009-06-24 18:58 0 -> /dev/pts/1 l-wx------ 1 igor igor 64 2009-06-24 18:58 1 -> /tmp/fff lrwx------ 1 igor igor 64 2009-06-24 18:58 2 -> /dev/pts/1 l-wx------ 1 igor igor 64 2009-06-24 18:58 5 -> pipe:[13325] lr-x------ 1 igor igor 64 2009-06-24 18:58 7 -> pipe:[13329]
Программа cat запускается для записи данных в файл /tmp/fff.
Он запускается в фоне (&), и получает номер работы 1 ([1]).
Процесс этой программы имеет номер 28378.
Информация о процессе 28738 находится в каталоге /proc/28738
специальной псевдофайловой системы /proc.
В частности, в подкаталоге /proc/28738/fd/
находится список файловых дескрипторов для открытых процессом файлов.
Здесь видно, что стандартный поток ввода (0), и стандартный поток ошибок (2) процесса
подключены на терминал, а вот стандартный поток вывода (1) перенаправлен в файл.
Завершить работу программы cat можно командой kill %1.
Командный интерпретатор — это тоже процесс.
И у него есть стандартные потоки ввода и вывода.
Если интерпретатор работает в интерактивном режиме,
то они подключены на консоль (вывода на экран; чтение с клавиатуры).
Можно обратиться напрямую к этим потокам изнутри интерпретатора:
- /dev/stdin — стандартный поток ввода;
- /dev/stdout — стандартный поток вывода;
- /dev/stderr — стандартный поток ошибок.
Например, здесь видно, что потоки ссылаются в конечном итоге на файл-устройство
терминала, с которым работает интерпретатор:
%$ ls -l /dev/std* lrwxrwxrwx 1 root root 15 2009-06-17 23:54 /dev/stderr -> /proc/self/fd/2 lrwxrwxrwx 1 root root 15 2009-06-17 23:54 /dev/stdin -> /proc/self/fd/0 lrwxrwxrwx 1 root root 15 2009-06-17 23:54 /dev/stdout -> /proc/self/fd/1 %$ ls -l /proc/self/fd/[012] lrwx------ 1 igor igor 64 2009-06-24 18:16 /proc/self/fd/0 -> /dev/pts/1 lrwx------ 1 igor igor 64 2009-06-24 18:16 /proc/self/fd/1 -> /dev/pts/1 lrwx------ 1 igor igor 64 2009-06-24 18:16 /proc/self/fd/2 -> /dev/pts/1 %$ tty /dev/pts/1
[править] Каналы
Стандартные потоки можно перенаправлять не только в файлы, но и на вход других программ. Если поток вывода одной программы соединить с потоком ввода другой программы, получится конструкция, называемая каналом, конвейером или пайпом (от англ. pipe, труба).

В bash канал выглядит как последовательность команд, отделенных друг от друга символом |:
- команда1 | команда2 | команда3 …
Стандартный поток вывода команды1 подключается к стандартному потоку ввода команды2,
стандартный поток вывода команды2 в свою очередь подключается к потоку ввода команды3 и т.д.
В UNIX/Linux существует целый класс команд, предназначенных для преобразования потоков данных в каналах. Такие программы известны как фильтры. Программа-фильтр читает данные, поступающие со стандартного потока ввода (на вход), преобразовывает их требуемым образом и выводит на стандартный поток вывода (на выход). Существует множество хорошо известных фильтров, призванных решать определенные задачи, и являющихся незаменимым инструментом в руках пользователя ОС.
|
|
Каналы в ОС Linux являются одной из наиболее часто применяемых конструкций, а фильтры — наиболее часто применяемых программ. Большинство повседневных задач в Linux легко решаются при помощи конструкций построенных на основе нескольких фильтров. |
Программы, образующие канал, выполняются параллельно как независимые процессы.
Можно создавать ответвление в каналах. Команда tee позволяет сохранять данные, передающиеся в канале:
- tee [опции] файл
Программа tee копирует данные, поступающие на стандартный поток ввода, в указанные в качестве аргументов команды файлы, и передает данные на стандартный поток вывода.
Рассмотренный ниже пример: сортируется файл unsortedlines и результат записывается в sortedlines.
%$ cat unsortedlines | sort > sortedlines
Команда выполняет те же действия, но запись является более наглядной.
Вот пример посложнее. Вывести название и размер пользовательского каталога, занимающее наибольшее место на диске.
$ du -s /home/* | sort -nr | head -1
Программа du, при вызове ее с ключом -s, сообщает суммарный объем каждого каталога или файла, перечисленного в ее параметрах.
Ключ -n команды sort означает, что сортировка должна быть арифметической, т.е. строки должны рассматриваться как числа, а не как последовательности символов (Например, 12>5 в то время как строка ’12′<‘5’ т.к. сравнение строк производится посимвольно и ‘1’<‘5’). Ключ -r означает изменения порядка сортировки — с возрастающего на убывающий.
Команда head выводит несколько первых строк поступающего на ее вход потока, отбрасывая все остальные. Ключ -1 означает, что надо вывести только одну строку.
Таким образом, список пользовательских каталогов с их суммарным объемом арифметически сортируется по убыванию, и из полученного списка берется первая строка, т.е. строка с наибольшим числом, соответствующая самому объемному каталогу.
Использование команды tee:
$ sort text | tee sorted_text | head -n 1
Содержимое файла text сортируется, и результат сортировки записывается в файл sorted_text. Первая строка отсортированного текста выдается на экран.
[править] Программы фильтры
В UNIX/Linux существует целый класс команд, которые
принимают данные со стандартного потока ввода,
каким-то образом обрабатывают их,
и выдают результат на стандартный поток вывода.
Такие программы называются программами-фильтрами.
Как правило, все эти программы работают как фильтры,
если у них нет аргументов (опции могут быть),
но как только им в качестве аргумента передаётся файл,
они считывают данные из этого файла, а не со стандартного потока ввода
(существуют и исключения, например, программа tr, которая обрабатывает данные
поступающие исключительно через стандартный поток ввода).

- cat
- Считывает данные со стандартного потока ввода и передаёт их на стандартный поток вывода. Без опций работает как простой повторитель. С опциями может фильтровать пустые строки, нумеровать строки и делать другую подобную работу.
- head
- Показывает первые 10 строк (или другое заданное количество), считанных со стандартного потока ввода.
- tail
- Показывает последние 10 строк (или другое заданное количество), считанные со стандартного потока ввода. Важный частный случай tail -f, который в режиме слежения показывает концовку файла. Это используется, в частности, для просмотра файлов журнальных сообщений.
- cut
- Вырезает столбец (по символам или полям) из потока ввода и передаёт на поток вывода. В качестве разделителей полей могут использоваться любые символы.
- sort
- Отсортировать данные в соответствии с какими-либо критериями, например, арифметически по второму столбцу.
- uniq
- Удалить повторяющиеся строки. Или (с ключом -с) не просто удалить, а написать сколько таких строк было. Учитываются только подряд идущие одинаковые строки, поэтому часто данные сортируются перед тем как отправить их на вход программе.
- tee
- Ответвить данные в файл. Используется для сохранения промежуточных данных, передающихся в потоке, в файл.
- bc
- Вычислить каждую отдельную строку потока и записать вместо неё результат вычисления.
- hexdump
- Показать шестнадцатеричное представление данных, поступающих на стандартный поток ввода.
- strings
- вычленить и показать в стандартном потоке (или файле) то, что напоминает строки. Всё что не похоже на строковые последовательности, игнорировать. Полезна в сочетании с grep для поиска интересующих строковых последовательностей в бинарных файлах.
- grep
- Отфильтровать поток, и показать только строки, содержащие (или не содержащие) заданное регулярное выражение.
- tr
- Посимвольная замена текста в потоке. Например, tr A-Z a-z меняет регистр символов с большого на маленький.
- sed
- Обработать текст в соответствии с заданным скриптом. Наиболее часто используется для замены текста в потоке: sed s/было/стало/g
- awk
- Обработать текст в соответствии с заданным скриптом. Как правило, используется для обработки текстовых таблиц, например таких как вывод ps aux и тому подобных, но не только.
- perl
- Обработать текст в соответствии с заданным скриптом. Возможности языка Perl выходят далеко за рамки однострочников для командной строки, но с однострочниками он справляется особенно виртуозно. В Perl существует оператор <> (diamond operator) и конструкция while(<>) { … }, которая предполагает обработку данных со стандартного потока ввода (или из файлов, если они переданы в качестве аргументов). При написании однострочников можно использовать ключи -n (равносильный оборачиванию кода в while(<>) { … }) или -p (равносильный while(<>) { … }).

- sh -s
- Текст, который передаётся на стандартный поток ввода sh -s может интерпретироваться как последовательность команд shell. На выход передаётся результат их исполнения.
- ssh
- Средство удалённого доступа ssh, может работать как фильтр. ssh подхватывает данные, переданные ему на стандартный поток ввода, передаёт их на удалённых хост и подаёт на вход процессу программы, имя которой было передано ему в качестве аргумента. Результат выполнения программы (то есть то, что она выдала на стандартный поток вывода) передаётся со стандартного вывода ssh.
[править] Переменные командного интерпретатора и потоки
Для того чтобы вывести содержимое переменной командного интерпретатора
на стандартный поток вывода, используется команда echo:
%$ echo $VAR
На стандартный поток ошибок данные можно передать с помощью перенаправления:
%$ echo $VAR > /dev/stderr
Содержимое переменной (или любой другой текст) поступят не на стандартный поток вывода,
а на стандартный поток ошибок.
Считать данные со стандартного потока ввода внутрь одной или нескольких переменных
можно при помощи команды read:
%$ read VAR
Строка из стандартного потока ввода считается внутрь переменной VAR.
Если указать несколько переменных,
то в первую попадёт первое слово; во вторую — второе слово; в последнюю — всё остальное.
%$ df -h | head -1
Filesystem Size Used Avail Use% Mounted on
%$ df -h | head -1 | { read VAR1 VAR2 VAR3; echo $VAR1; echo $VAR2; echo $VAR3 ; }
Filesystem
Size
Used Avail Use% Mounted on
|
|
Обратите внимание на конструкцию { read VAR; echo $VAR }. |
Если прочитать данные со стандартного потока ввода не удалось,
то команда read возвращает код завершения отличный от нуля.
Это позволяет использовать read, например, в такой конструкции:
%$ cat users | while read user
do
useradd $user
done
В этом примере read считывает строки из файла users,
и для каждой прочитанной строки вызывается команда useradd, которая добавляет пользователя в системе.
В результате: создаются учётные записи пользователей, имена которых перечислены в файле users.
|
|
Переменная user после выхода из цикла остаётся в том же виде, в каком она была до входа в цикл |
[править] Именованные каналы
Безымянный канал можно построить только между процессами,
которые порождены от одного процесса (и на практике они должны быть порождены одновременно, а не последовательно,
хотя теоретически это не обязательно).
Если же процессы имеют разных родителей,
то между ними обычный, безымянный канал построить не получится.

Например, в данном случае d и e, и f и g
легко могут быть соединены при помощи канала,
но e и f соединить с помощью канала не получится.
Для решения этой задачи используются именованные каналы fifo (first in, first out).
Они во всём повторяют обычные каналы (pipe), только имеют привязку к файловой системе.
Создать именованный канал можно командой mkfifo:
%$ mkfifo /tmp/fifo
Созданный канал можно использовать для соединения процессов
между собой.
Например, эти перенаправления будут работать одинаково:
%$ f | g
и
%$ f > /tmp/fifo & g < /tmp/fifo
(здесь f и g — процессы из вышеуказанной иерархии процессов).
Процессы f и g имеют общего предка. А вот для процессов e и g,
не связанных между собой, обычный канал использовать не получится,
только именованный:
%$ e > /tmp/fifo& %$ g < /tmp/fifo # в другом интерпретаторе
[править] Потоки ввода/вывода и терминал
Большинство программ, которые работают с потоками ввода и вывода,
работают с ними как с простыми файлами, и не рассчитывают на то,
что поток подключен к терминалу.
Но не все.
Если потоки ввода/вывода отключаются от терминала
и перенаправляются в файл, часть возможностей программы может пропасть.
Например, если командный интерпретатор отвязать от терминала,
то у него потеряется множество интерактивных возможностей:
%$ cat | sh -i | cat
Например, возможности прокручивать историю команд
у него теперь нет. Возможности по редактированию
теперь тоже сильно урезаны.
Фактически, редактирование команды теперь выполняется
уже с помощью программы cat, которая держит терминал,
а интерпретатору поступают уже полностью введённые команды.
Проверить, подключен ли наш стандартный поток
к терминалу, или он перенаправлен в файл,
можно при помощи test, ключ -t:
%$ test -t 0 && echo terminal terminal %$ cat | test -t 0 && echo terminal %$ cat | test -t 0 || echo file file
[править] Подстановка процесса
Есть хитрый трюк, который в чистом виде перенаправлением потока ввода/вывода не является,
но имеет к нему отношение — подстановка процесса.
Результат выполнения процесса можно представить в виде воображаемого файла
и передать его другому процессу.
Форма вызова:
команда1 <(команда2)
При таком вызове процессу команда1 передаётся файл (созданный налету канал или файл /dev/fd/…),
в котором находятся данные, которые выводит команда2.
Например, у вас есть два файла с различными словами по одному в строке.
Вы хотите определить, какие из них встречаются в одном файле,
но не встречаются во втором. И наоборот.
%$ cat f1 a b c b b %$ cat f2 a c c c %$ diff <(sort -u f1) <(sort -u f2) 2d1 < b
Получается, что в первом файле присутствует слово, которое отсутствует во втором (слово b).
Подробнее: [3]
[править] Перенаправление вывода скрипта
Потоки ввода/вывода скрипта, исполняющегося сейчас,
изнутри самого скрипта можно следующим образом:
exec > file exec 2>&1
Подробнее:
- How do I redirect the output of an entire shell script within the script itself?

[править] Поменять местами стандартный поток вывода и стандартный поток ошибок
$ cmd 3>&2 2>&1 1>&3
Подробнее:
- IO Redirection — Swapping stdout and stderr (Advanced)
[править] Просмотр прогресса и скорости обработки данных в потоке
Если пропустить данные, передающиеся в канале, через программу pv,
то будет видна скорость обработки,
время в течение которого работает канал
и, если известно сколько данных должно быть обработано,
приблизительное время окончания выполнения.
$ pv /tmp/shre.tar.gz | tar xz 62MB 0:00:18 [12,6MB/s] [==> ] 10% ETA 0:02:27
Подробнее: [4], [5].
[править] Дополнительная информация
- Monadic i/o and UNIX shell programming (англ.) — взгляд на каналы (pipelines) как на монады
- http://wiki.bash-hackers.org/howto/redirection_tutorial (англ.) — очень подробно на живых примерах разобраны различные виды перенаправлений
- How do I write stderr to a file while using “tee” with a pipe? — прекрасный пример использования подстановки процесса (process substitution); в этом примере таким образом перенаправляется поток ошибок
- http://mywiki.wooledge.org/BashGuide/InputAndOutput (англ.) — всевозможные манипуляции со стандартными потоками ввода и вывода
| |
|
|---|---|
| Основы | Потоки ввода/вывода • Командная строка |
| Пользовательское окружение | Оболочка интерпретатора • Приглашение командного интерпретатора • bash_completion • shopt |
| Скриптинг | Скриптинг • Интерпретатор • Shebang • Shell-скриптинг • shell-framework • expect • awk • sed |