
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.

Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:

Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:

Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:

Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:

Стандартное отклонение этих средних значений известно как стандартная ошибка.

Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
What Is the Standard Error?
The standard error (SE) of a statistic is the approximate standard deviation of a statistical sample population.
The standard error is a statistical term that measures the accuracy with which a sample distribution represents a population by using standard deviation. In statistics, a sample mean deviates from the actual mean of a population; this deviation is the standard error of the mean.
Key Takeaways
- The standard error (SE) is the approximate standard deviation of a statistical sample population.
- The standard error describes the variation between the calculated mean of the population and one which is considered known, or accepted as accurate.
- The more data points involved in the calculations of the mean, the smaller the standard error tends to be.
Standard Error
Understanding Standard Error
The term «standard error» is used to refer to the standard deviation of various sample statistics, such as the mean or median. For example, the «standard error of the mean» refers to the standard deviation of the distribution of sample means taken from a population. The smaller the standard error, the more representative the sample will be of the overall population.
The relationship between the standard error and the standard deviation is such that, for a given sample size, the standard error equals the standard deviation divided by the square root of the sample size. The standard error is also inversely proportional to the sample size; the larger the sample size, the smaller the standard error because the statistic will approach the actual value.
The standard error is considered part of inferential statistics. It represents the standard deviation of the mean within a dataset. This serves as a measure of variation for random variables, providing a measurement for the spread. The smaller the spread, the more accurate the dataset.
Standard error and standard deviation are measures of variability, while central tendency measures include mean, median, etc.
Formula and Calculation of Standard Error
The standard error of an estimate can be calculated as the standard deviation divided by the square root of the sample size:
SE = σ / √n
where
- σ = the population standard deviation
- √n = the square root of the sample size
If the population standard deviation is not known, you can substitute the sample standard deviation, s, in the numerator to approximate the standard error.
Requirements for Standard Error
When a population is sampled, the mean, or average, is generally calculated. The standard error can include the variation between the calculated mean of the population and one which is considered known, or accepted as accurate. This helps compensate for any incidental inaccuracies related to the gathering of the sample.
In cases where multiple samples are collected, the mean of each sample may vary slightly from the others, creating a spread among the variables. This spread is most often measured as the standard error, accounting for the differences between the means across the datasets.
The more data points involved in the calculations of the mean, the smaller the standard error tends to be. When the standard error is small, the data is said to be more representative of the true mean. In cases where the standard error is large, the data may have some notable irregularities.
The standard deviation is a representation of the spread of each of the data points. The standard deviation is used to help determine the validity of the data based on the number of data points displayed at each level of standard deviation. Standard errors function more as a way to determine the accuracy of the sample or the accuracy of multiple samples by analyzing deviation within the means.
Standard Error vs. Standard Deviation
The standard error normalizes the standard deviation relative to the sample size used in an analysis. Standard deviation measures the amount of variance or dispersion of the data spread around the mean. The standard error can be thought of as the dispersion of the sample mean estimations around the true population mean. As the sample size becomes larger, the standard error will become smaller, indicating that the estimated sample mean value better approximates the population mean.
Example of Standard Error
Say that an analyst has looked at a random sample of 50 companies in the S&P 500 to understand the association between a stock’s P/E ratio and subsequent 12-month performance in the market. Assume that the resulting estimate is -0.20, indicating that for every 1.0 point in the P/E ratio, stocks return 0.2% poorer relative performance. In the sample of 50, the standard deviation was found to be 1.0.
The standard error is thus:
SE = 1.0/√50 = 1/7.07 = 0.141
Therefore, we would report the estimate as -0.20% ± 0.14, giving us a confidence interval of (-0.34 — -0.06). The true mean value of the association of the P/E on returns of the S&P 500 would therefore fall within that range with a high degree of probability.
Say now that we increase the sample of stocks to 100 and find that the estimate changes slightly from -0.20 to -0.25, and the standard deviation falls to 0.90. The new standard error would thus be:
SE = 0.90/√100 = 0.90/10 = 0.09.
The resulting confidence interval becomes -0.25 ± 0.09 = (-0.34 — -0.16), which is a tighter range of values.
What Is Meant by Standard Error?
Standard error is intuitively the standard deviation of the sampling distribution. In other words, it depicts how much disparity there is likely to be in a point estimate obtained from a sample relative to the true population mean.
What Is a Good Standard Error?
Standard error measures the amount of discrepancy that can be expected in a sample estimate compared to the true value in the population. Therefore, the smaller the standard error the better. In fact, a standard error of zero (or close to it) would indicate that the estimated value is exactly the true value.
How Do You Find the Standard Error?
The standard error takes the standard deviation and divides it by the square root of the sample size. Many statistical software packages automatically compute standard errors.
The Bottom Line
The standard error (SE) measures the dispersion of estimated values obtained from a sample around the true value to be found in the population. Statistical analysis and inference often involves drawing samples and running statistical tests to determine associations and correlations between variables. The standard error thus tells us with what degree of confidence we can expect the estimated value to approximate the population value.
Стандартная ошибка появляется при прогнозировании каких-либо данных или арифметических вычислениях, поэтому важно научиться находить этот параметр. В этой публикации разбираем, как найти и исправить стандартную ошибку путем использования инструментов Excel.
Расчет средней арифметической ошибки
В Microsoft Excel цельность и однородность выборки определяется при помощи стандартной ошибки. Стандартная ошибка — это квадратный корень из дисперсии. В приложении предусмотрено два варианта поиска стандартной ошибки: при помощи пакетного анализа и расширенных функций программы.
Чтобы найти значение средней арифметической, необходимо выполнить деление суммарной величины выборки на ее количество в электронной книге.
Расчет стандартной ошибки при помощи встроенных функций
Для того, чтобы правильно вычислять, необходимо изучить пошаговую инструкцию. В этом способе подбор результатов будет осуществляться с помощью комбинированных манипуляций.
- Для расчетов будем использовать таблицу с выборкой чисел. Кликаем на любой пустой ячейке на листе, где будет отображаться результат. Затем нажимаем кнопку «Вставить функцию.
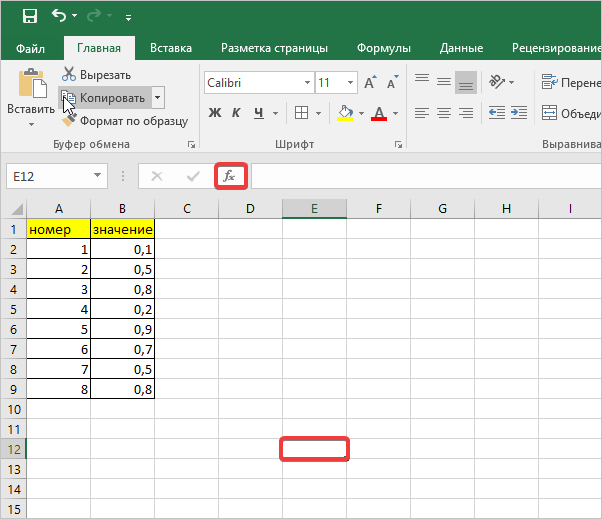
- Далее перед вами открывается диалоговое окно, в котором необходимо использовать «СТАНДОТКЛ.В», для этого в поле «Категория» необходимо выбрать «Полный алфавитный перечень». Затем нажмите кнопку «ОК».
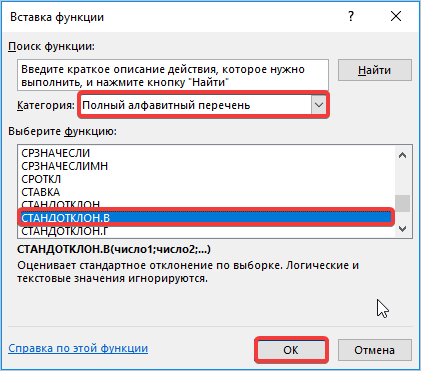
- В окне «Аргументы функции» кликаем в первом поле «Число 1», затем выполняем выделение мышью диапазона ячеек со значениями таблицы и нажимаем кнопку «ОК».
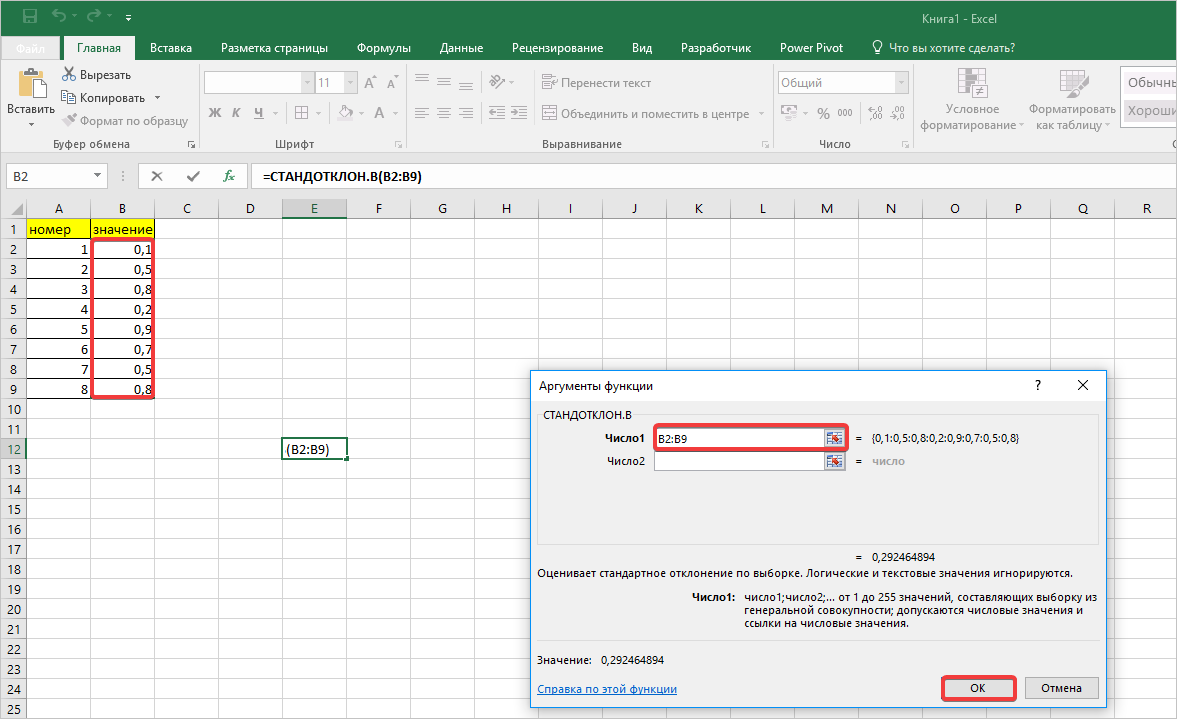
- Далее активируем ячейку с нашими значениями, переходим в строку формулы и ставим после значений наклонную линию. Переходим в поле наименования, кликаем на указывающий вниз флажок, где из списка выбираем «Другие функции».
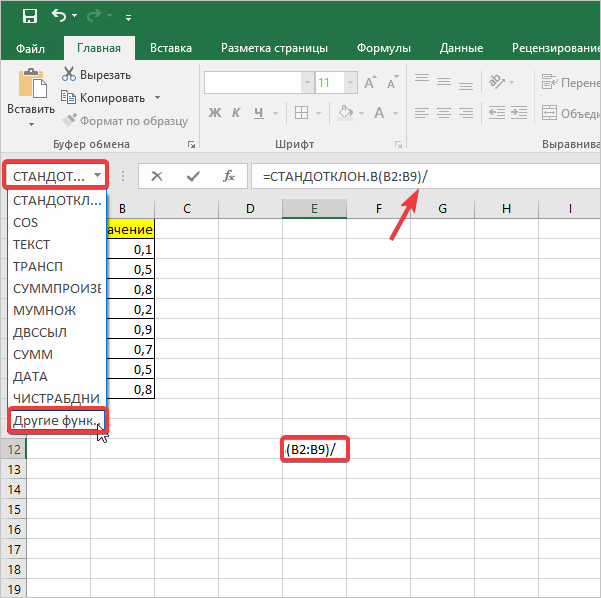
- Снова активируется окно с перечнем функций, в котором необходимо выбрать категорию «Математические», затем функцию «Корень». Далее нажмите кнопку «ОК».
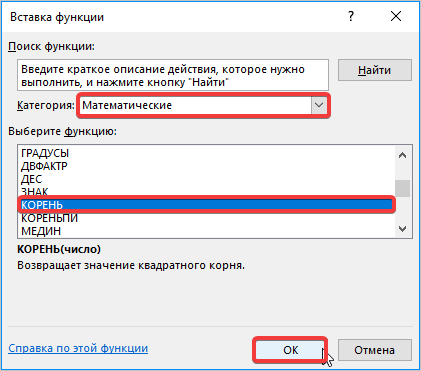
- Далее открывается окно, в котором необходимо заполнить поле с числом. Для этого переходим в поле «Имя», где спускаемся к пункту «Счет». Если его нет, ищите в дополнительных функциях.
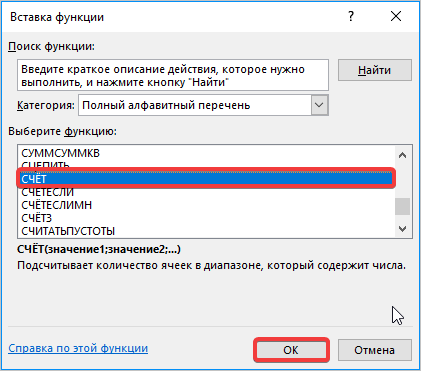
После выполнения этих шагов, стандартная ошибка высчитывается автоматически, пользователю остается только сверить их и проверить значение на некорректное отображение.
Для малых и стандартных выборок необходимо использовать разные формулы. В первом случае (если находится до 30 значений), ее необходимо видоизменить.
Решение задачи с помощью опции «Описательная статистика»
Благодаря опции «Описательная статистика» удается выполнить вычисление по различным критериям. По этим правилам удается найти среднюю арифметическую ошибку. Для использования данного метода предварительно нужно запустить «Пакет анализа».
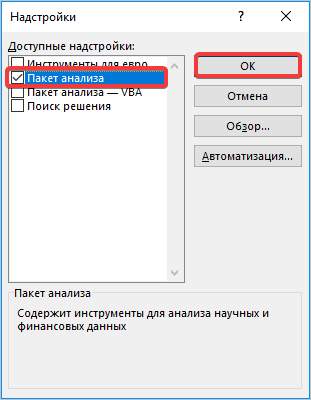
- Переходим во вкладку «Файл», где перемещаемся в пункт «Параметры». Далее нажимаем на запись «Надстройки».
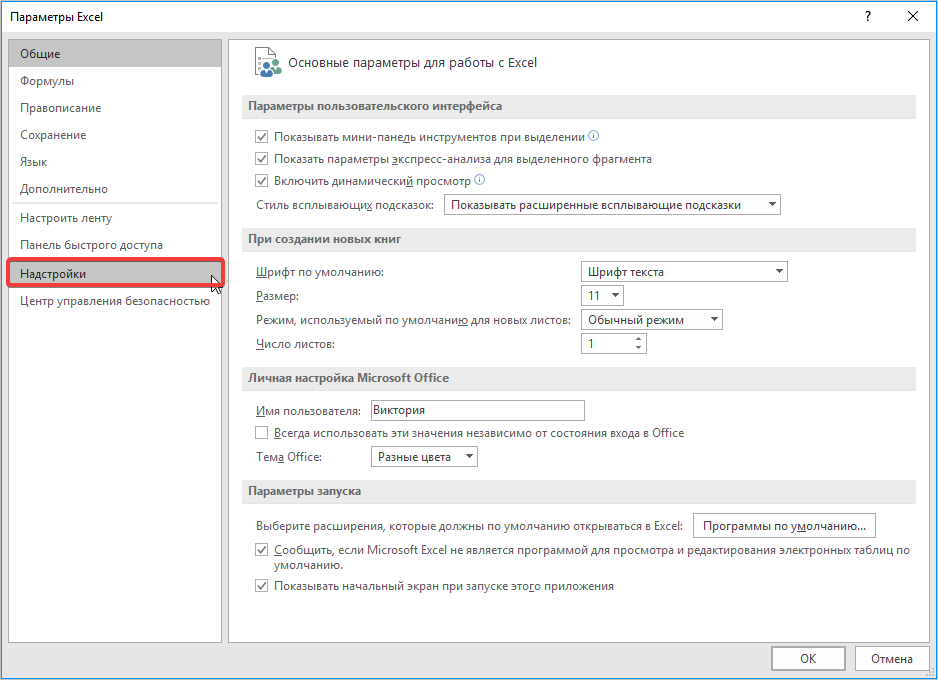
- Открывается окошко, в нем в графе «Управление» должно быть прописано «Надстройки Excel», затем рядом нажимаем кнопку «Параметры».
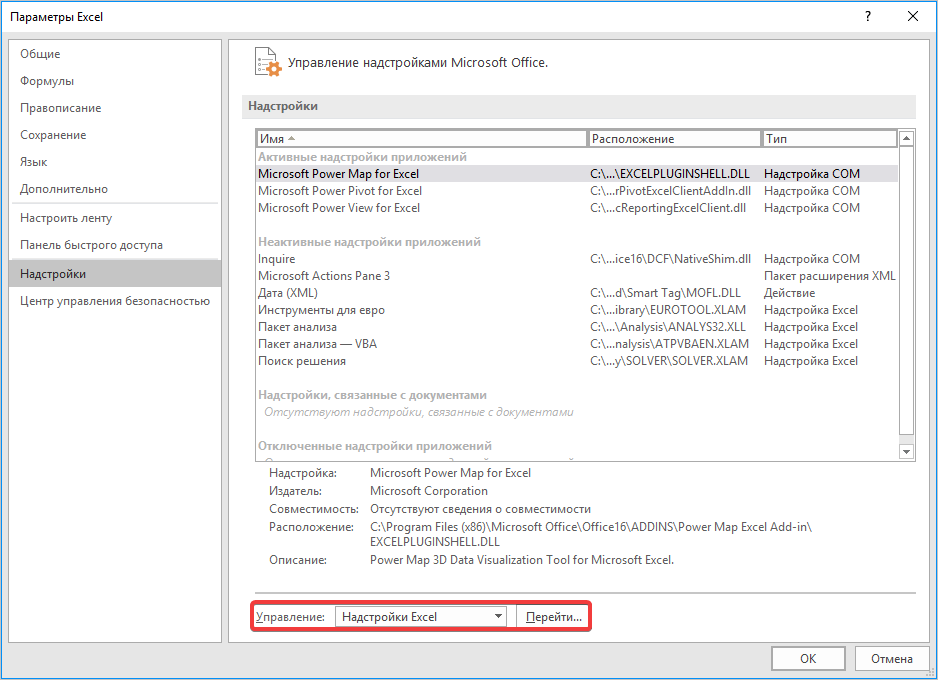
- В появившемся окне находим «Пакет анализа» и нажимаем кнопку «ОК».
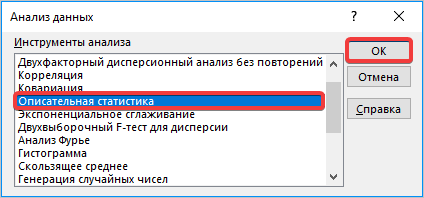
- Далее выбираем любую свободную ячейку, переходим во вкладку «Данные» и нажимаем «Анализ данных» в блоке «Анализ».

- Происходит запуск вспомогательного окошка, в котором необходимо выбрать из всех инструментов «Описательную статистику» и нажать кнопку «ОК».
- Открывается новый мастер значений. Здесь нужно вводить данные предельно внимательно. В поле «Входной интервал» вносим адрес диапазона ячеек с выборкой. Затем указываем параметр «Группирование» «По столбцам». Затем выбираем место для «выходного интервала», его должно быть столько же, сколько и «входного». Ставим галочку напротив «Итоговая статистика» и нажимаем кнопку «ОК».
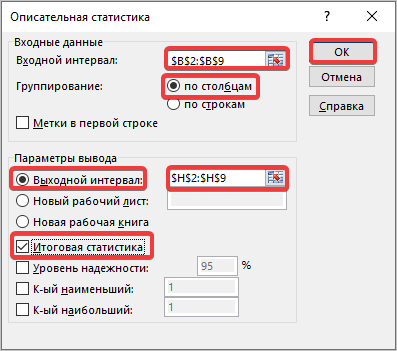
В результате вычислений вы получаете небольшую таблицу, в которой указаны все данные с определенной стандартной ошибкой.
Что такое Стандартная формула ошибки?
Стандартная ошибка — это ошибка, которая возникает в распределении выборки при выполнении статистического анализа. Это вариант стандартного отклонения, так как оба понятия соответствуют мерам спреда. Высокая стандартная ошибка соответствует более высокому разбросу данных для взятой выборки. Вычисление формулы стандартной ошибки выполняется для выборки. В то же время стандартное отклонение определяет генеральную совокупность.
Оглавление
- Что такое Стандартная формула ошибки?
- Объяснение
- Пример формулы стандартной ошибки
- Калькулятор стандартной ошибки
- Актуальность и использование
- Стандартная формула ошибки в Excel
- Рекомендуемые статьи
Следовательно, стандартная ошибка среднего значения будет выражаться и определяться в соответствии с соотношением, описанным следующим образом:
σ͞x = σ/√n

Здесь,
- Стандартная ошибка, выраженная как σ͞x.
- Стандартное отклонение совокупности выражается как σ.
- Количество переменных в выборке, выраженное как n.
В статистическом анализе среднее значение, медиана и мода являются центральной тенденцией. Центральная тенденция Центральная тенденция — это статистическая мера, которая отображает центральную точку всего распределения данных, и вы можете найти ее с помощью 3 различных мер, т. е. среднего, медианы и моды.Подробнее меры. Стандартное отклонение, дисперсия и стандартная ошибка среднего классифицируются как меры изменчивости. Стандартная ошибка среднего для выборочных данных напрямую связана со стандартным отклонением большей совокупности и обратно пропорциональна или связана с квадратным корнем. число. Чтобы использовать эту функцию, введите термин =SQRT и нажмите клавишу табуляции, которая вызовет функцию SQRT. Более того, эта функция принимает один аргумент из нескольких переменных, используемых для создания выборки. Следовательно, если размер выборки Размер выборкиФормула размера выборки отображает соответствующий диапазон генеральной совокупности, в которой проводится эксперимент или опрос. Он измеряется с использованием размера генеральной совокупности, критического значения нормального распределения при требуемом доверительном уровне, доли выборки и предела погрешности. Если больше, то может быть равная вероятность того, что стандартная ошибка также будет большой.
Объяснение
Можно объяснить формулу для стандартной ошибки среднего, используя следующие шаги:
- Определите и организуйте выборку и определите количество переменных.
- Затем среднее значение выборки соответствует количеству переменных, присутствующих в выборке.
- Затем определите стандартное отклонение выборки.
- Затем определите квадратный корень из числа переменных, включенных в выборку.
- Теперь разделите стандартное отклонение, вычисленное на шаге 3, на полученное значение на шаге 4, чтобы получить стандартную ошибку.
Пример формулы стандартной ошибки
Ниже приведены примеры формул для расчета стандартной ошибки.
.free_excel_div{фон:#d9d9d9;размер шрифта:16px;радиус границы:7px;позиция:относительная;margin:30px;padding:25px 25px 25px 45px}.free_excel_div:before{content:»»;фон:url(центр центр без повтора #207245;ширина:70px;высота:70px;позиция:абсолютная;верх:50%;margin-top:-35px;слева:-35px;граница:5px сплошная #fff;граница-радиус:50%} Вы можете скачать этот шаблон стандартной формулы ошибки Excel здесь — Стандартная формула ошибки Шаблон Excel
Пример №1
Возьмем в качестве примера акции ABC. В течение 30 лет акции приносили средний долларовый доход в размере 45 долларов. Кроме того, было замечено, что акции приносят прибыль со стандартным отклонением в 2 доллара. Помогите инвестору рассчитать общую стандартную ошибку средней доходности, предлагаемой акцией ABC.
Решение:
- Стандартное отклонение (σ) = $2
- Количество лет (n) = 30
- Средняя доходность в долларах = 45 долларов.
Расчет стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 2 доллара США/√30
- = 2 доллара США / 5,4773
Стандартная ошибка,

- σx = 0,3651 доллара США
Таким образом, инвестиция предлагает инвестору стандартную долларовую ошибку в среднем 0,36515 доллара при удерживании позиции ABC в течение 30 лет. Однако, если бы акции сохранялись для более высокого инвестиционного горизонта, то стандартная ошибка среднего значения в долларах значительно уменьшилась бы.
Пример #2
Возьмем в качестве примера инвестора, который получил следующую доходность акций XYZ:
Год инвестиций Предлагаемая доходность120%225%35%410%
Помогите инвестору рассчитать общую стандартную ошибку средней доходности акций XYZ.
Решение:
Сначала определите среднее значение доходности, как показано ниже: –

- ͞X = (x1+x2+x3+x4)/количество лет
- = (20+25+5+10)/4
- =15%
Теперь определите стандартное отклонение доходности, как показано ниже: –

- σ = √ ((x1-͞X)2 + (x2-͞X)2 + (x3-͞X)2 + (x4-͞X)2) / √ (количество лет -1)
- = √ ((20-15) 2 + (25-15) 2 + (5-15) 2 + (10-15) 2) / √ (4-1)
- = (√ (5) 2 + (10) 2 + (-10) 2 + (-5) 2 ) / √ (3)
- = (√25+100+100+25)/ √ (3)
- =√250/√3
- =√83,3333
- «=» 9,1287%
Теперь вычисление стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 9,128709/√4
- = 9,128709/2
Стандартная ошибка,

- σx = 4,56%
Таким образом, инвестиции предлагают инвестору стандартную ошибку в долларах в среднем 4,56% при удержании позиции XYZ в течение 4 лет.
Калькулятор стандартной ошибки
Вы можете использовать следующий калькулятор.
.cal-tbl td{ верхняя граница: 0 !важно; }.cal-tbl tr{ высота строки: 0.5em; } Только экран @media и (минимальная ширина устройства: 320 пикселей) и (максимальная ширина устройства: 480 пикселей) { .cal-tbl tr{ line-height: 1em !important; } } σnСтандартная формула ошибки
Формула стандартной ошибки =σ =√n 0 = 0√0
Актуальность и использование
Стандартная ошибка имеет тенденцию быть высокой, если размер выборки для анализа мал. Следовательно, выборка всегда берется из большей совокупности, которая включает больший размер переменных. Это всегда помогает статистику определить достоверность среднего значения выборки относительно среднего значения генеральной совокупности.
Большая стандартная ошибка говорит статистику, что выборка неоднородна в отношении среднего значения генеральной совокупности. Относительно населения наблюдается большой разброс в выборке. Точно так же небольшая стандартная ошибка говорит статистику, что выборка однородна относительно среднего значения генеральной совокупности. Отсутствуют или незначительные различия в выборке относительно населения.
Не следует смешивать его со стандартным отклонением. Вместо этого следует рассчитать стандартное отклонение для всей совокупности. Стандартная ошибкаСтандартная ошибкаСтандартная ошибка (SE) — это метрика, которая измеряет точность выборочного распределения, обозначающего совокупность, с использованием стандартного отклонения. Другими словами, это мера дисперсии среднего значения выборки, связанная со средним значением генеральной совокупности, а не стандартное отклонение. С другой стороны, оно определяется для среднего значения выборки.
Стандартная формула ошибки в Excel
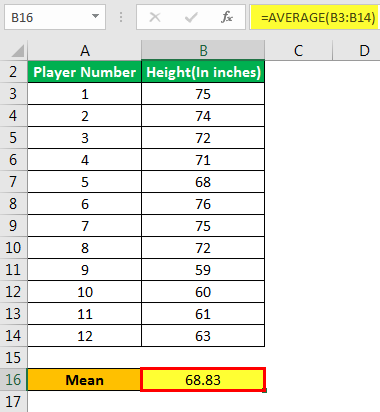
Теперь давайте возьмем пример Excel, чтобы проиллюстрировать концепцию стандартной формулы ошибки в шаблоне Excel ниже. Предположим, администрация школы хочет определить стандартную ошибку среднего значения роста футболистов.
Выборка состоит из следующих значений: –

Помогите администрации оценить стандартную ошибку среднего значения.
Шаг 1: Определите среднее значение, как показано ниже: –
Шаг 2: Определите стандартное отклонение, как показано ниже: –

Шаг 3: Определите стандартную ошибку среднего значения, как показано ниже: –

Следовательно, стандартная ошибка среднего значения для футболистов составляет 1,846 дюйма. Руководство должно заметить, что оно значительно велико. Таким образом, выборочные данные, взятые для анализа, неоднородны и имеют большую дисперсию.
Руководству следует либо исключить более мелких игроков, либо добавить игроков значительно выше, чтобы сбалансировать средний рост футбольной команды, заменив их людьми с меньшим ростом по сравнению с их сверстниками.
Рекомендуемые статьи
Эта статья была руководством по формуле стандартной ошибки. Здесь мы обсуждаем формулу для расчета среднего значения, стандартную ошибку, примеры и загружаемый лист Excel. Вы можете узнать больше из следующих статей: –
- Формула рентабельности EBITDA
- Формула валовой прибыли
- Формула относительного стандартного отклонения
- Формула погрешности
Что такое Стандартная ошибка?
Стандартная ошибка (SE) статистики — это приблизительное стандартное отклонение статистической выборки. Стандартная ошибка — это статистический термин, который измеряет точность, с которой выборочное распределение представляет генеральную совокупность с помощью стандартного отклонения. В статистике выборочное среднее отклоняется от фактического среднего для генеральной совокупности; это отклонение представляет собой стандартную ошибку среднего.
Ключевые моменты
- Стандартная ошибка — это приблизительное стандартное отклонение статистической выборки.
- Стандартная ошибка может включать вариацию между вычисленным средним для генеральной совокупности и тем, которое считается известным или принимаемым как точное.
- Чем больше точек данных участвует в расчетах среднего, тем меньше стандартная ошибка.
Понимание стандартной ошибки
Термин «стандартная ошибка» используется для обозначения стандартного отклонения различных статистических данных выборки, таких как среднее или медианное значение. Например, «стандартная ошибка среднего» относится к стандартному отклонению распределения выборочных средних, взятых из генеральной совокупности. Чем меньше стандартная ошибка, тем более репрезентативной будет выборка для генеральной совокупности.
Связь между стандартной ошибкой и стандартным отклонением такова, что для данного размера выборки стандартная ошибка равна стандартному отклонению, деленному на квадратный корень из размера выборки. Стандартная ошибка также обратно пропорциональна размеру выборки; Чем больше размер выборки, тем меньше стандартная ошибка, поскольку статистика приближается к фактическому значению.
Стандартная ошибка считается частью выводимой статистики. Он представляет собой стандартное отклонение среднего значения в наборе данных. Это служит мерой вариации случайных величин, обеспечивая измерение спреда. Чем меньше разброс, тем точнее набор данных.
Краткая справка
Стандартная ошибка и стандартное отклонение — это меры изменчивости, в то время как меры центральной тенденции включают среднее значение, медианное значение и т. Д.
Требования к стандартной ошибке
Когда производится выборка из генеральной совокупности , обычно рассчитывается среднее или среднее значение. Стандартная ошибка может включать разброс между вычисленным средним для генеральной совокупности и тем, которое считается известным или принимаемым как точное. Это помогает компенсировать любые случайные неточности, связанные со сбором пробы.
В случаях, когда собирается несколько образцов, среднее значение каждой выборки может незначительно отличаться от других, создавая разброс между переменными. Этот разброс чаще всего измеряется как стандартная ошибка, учитывающая различия между средними значениями в наборах данных.
Чем больше точек данных участвует в расчетах среднего, тем меньше стандартная ошибка. Когда стандартная ошибка мала, данные считаются более репрезентативными для истинного среднего значения. В случаях, когда стандартная ошибка велика, данные могут иметь некоторые заметные отклонения.
Стандартное отклонение — это представление разброса каждой точки данных. Стандартное отклонение используется для определения достоверности данных на основе количества точек данных, отображаемых на каждом уровне стандартного отклонения. Стандартные ошибки больше служат способом определения точности образца или точности нескольких образцов путем анализа отклонения в пределах средних.