
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.

Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:

Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:

Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:

Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:

Стандартное отклонение этих средних значений известно как стандартная ошибка.

Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
What Is the Standard Error?
The standard error (SE) of a statistic is the approximate standard deviation of a statistical sample population.
The standard error is a statistical term that measures the accuracy with which a sample distribution represents a population by using standard deviation. In statistics, a sample mean deviates from the actual mean of a population; this deviation is the standard error of the mean.
Key Takeaways
- The standard error (SE) is the approximate standard deviation of a statistical sample population.
- The standard error describes the variation between the calculated mean of the population and one which is considered known, or accepted as accurate.
- The more data points involved in the calculations of the mean, the smaller the standard error tends to be.
Standard Error
Understanding Standard Error
The term «standard error» is used to refer to the standard deviation of various sample statistics, such as the mean or median. For example, the «standard error of the mean» refers to the standard deviation of the distribution of sample means taken from a population. The smaller the standard error, the more representative the sample will be of the overall population.
The relationship between the standard error and the standard deviation is such that, for a given sample size, the standard error equals the standard deviation divided by the square root of the sample size. The standard error is also inversely proportional to the sample size; the larger the sample size, the smaller the standard error because the statistic will approach the actual value.
The standard error is considered part of inferential statistics. It represents the standard deviation of the mean within a dataset. This serves as a measure of variation for random variables, providing a measurement for the spread. The smaller the spread, the more accurate the dataset.
Standard error and standard deviation are measures of variability, while central tendency measures include mean, median, etc.
Formula and Calculation of Standard Error
The standard error of an estimate can be calculated as the standard deviation divided by the square root of the sample size:
SE = σ / √n
where
- σ = the population standard deviation
- √n = the square root of the sample size
If the population standard deviation is not known, you can substitute the sample standard deviation, s, in the numerator to approximate the standard error.
Requirements for Standard Error
When a population is sampled, the mean, or average, is generally calculated. The standard error can include the variation between the calculated mean of the population and one which is considered known, or accepted as accurate. This helps compensate for any incidental inaccuracies related to the gathering of the sample.
In cases where multiple samples are collected, the mean of each sample may vary slightly from the others, creating a spread among the variables. This spread is most often measured as the standard error, accounting for the differences between the means across the datasets.
The more data points involved in the calculations of the mean, the smaller the standard error tends to be. When the standard error is small, the data is said to be more representative of the true mean. In cases where the standard error is large, the data may have some notable irregularities.
The standard deviation is a representation of the spread of each of the data points. The standard deviation is used to help determine the validity of the data based on the number of data points displayed at each level of standard deviation. Standard errors function more as a way to determine the accuracy of the sample or the accuracy of multiple samples by analyzing deviation within the means.
Standard Error vs. Standard Deviation
The standard error normalizes the standard deviation relative to the sample size used in an analysis. Standard deviation measures the amount of variance or dispersion of the data spread around the mean. The standard error can be thought of as the dispersion of the sample mean estimations around the true population mean. As the sample size becomes larger, the standard error will become smaller, indicating that the estimated sample mean value better approximates the population mean.
Example of Standard Error
Say that an analyst has looked at a random sample of 50 companies in the S&P 500 to understand the association between a stock’s P/E ratio and subsequent 12-month performance in the market. Assume that the resulting estimate is -0.20, indicating that for every 1.0 point in the P/E ratio, stocks return 0.2% poorer relative performance. In the sample of 50, the standard deviation was found to be 1.0.
The standard error is thus:
SE = 1.0/√50 = 1/7.07 = 0.141
Therefore, we would report the estimate as -0.20% ± 0.14, giving us a confidence interval of (-0.34 — -0.06). The true mean value of the association of the P/E on returns of the S&P 500 would therefore fall within that range with a high degree of probability.
Say now that we increase the sample of stocks to 100 and find that the estimate changes slightly from -0.20 to -0.25, and the standard deviation falls to 0.90. The new standard error would thus be:
SE = 0.90/√100 = 0.90/10 = 0.09.
The resulting confidence interval becomes -0.25 ± 0.09 = (-0.34 — -0.16), which is a tighter range of values.
What Is Meant by Standard Error?
Standard error is intuitively the standard deviation of the sampling distribution. In other words, it depicts how much disparity there is likely to be in a point estimate obtained from a sample relative to the true population mean.
What Is a Good Standard Error?
Standard error measures the amount of discrepancy that can be expected in a sample estimate compared to the true value in the population. Therefore, the smaller the standard error the better. In fact, a standard error of zero (or close to it) would indicate that the estimated value is exactly the true value.
How Do You Find the Standard Error?
The standard error takes the standard deviation and divides it by the square root of the sample size. Many statistical software packages automatically compute standard errors.
The Bottom Line
The standard error (SE) measures the dispersion of estimated values obtained from a sample around the true value to be found in the population. Statistical analysis and inference often involves drawing samples and running statistical tests to determine associations and correlations between variables. The standard error thus tells us with what degree of confidence we can expect the estimated value to approximate the population value.
Стандартная ошибка появляется при прогнозировании каких-либо данных или арифметических вычислениях, поэтому важно научиться находить этот параметр. В этой публикации разбираем, как найти и исправить стандартную ошибку путем использования инструментов Excel.
Расчет средней арифметической ошибки
В Microsoft Excel цельность и однородность выборки определяется при помощи стандартной ошибки. Стандартная ошибка — это квадратный корень из дисперсии. В приложении предусмотрено два варианта поиска стандартной ошибки: при помощи пакетного анализа и расширенных функций программы.
Чтобы найти значение средней арифметической, необходимо выполнить деление суммарной величины выборки на ее количество в электронной книге.
Расчет стандартной ошибки при помощи встроенных функций
Для того, чтобы правильно вычислять, необходимо изучить пошаговую инструкцию. В этом способе подбор результатов будет осуществляться с помощью комбинированных манипуляций.
- Для расчетов будем использовать таблицу с выборкой чисел. Кликаем на любой пустой ячейке на листе, где будет отображаться результат. Затем нажимаем кнопку «Вставить функцию.
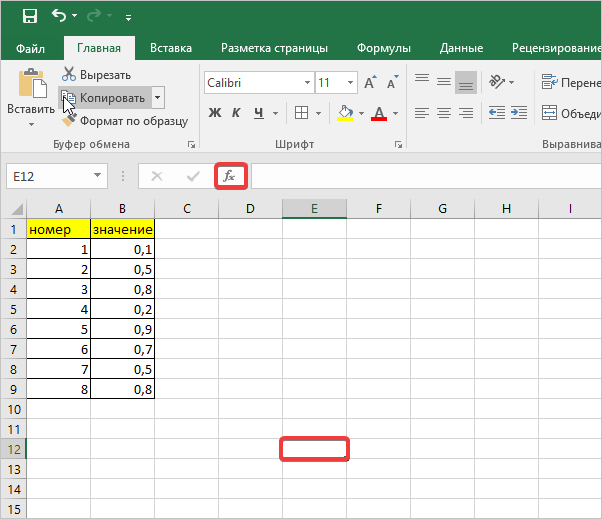
- Далее перед вами открывается диалоговое окно, в котором необходимо использовать «СТАНДОТКЛ.В», для этого в поле «Категория» необходимо выбрать «Полный алфавитный перечень». Затем нажмите кнопку «ОК».
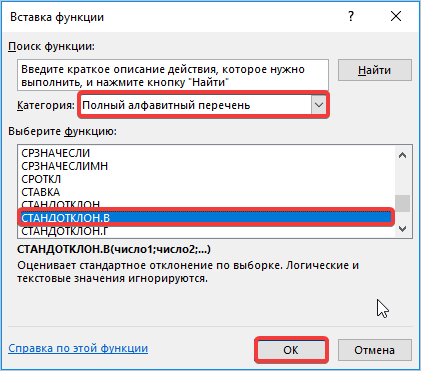
- В окне «Аргументы функции» кликаем в первом поле «Число 1», затем выполняем выделение мышью диапазона ячеек со значениями таблицы и нажимаем кнопку «ОК».
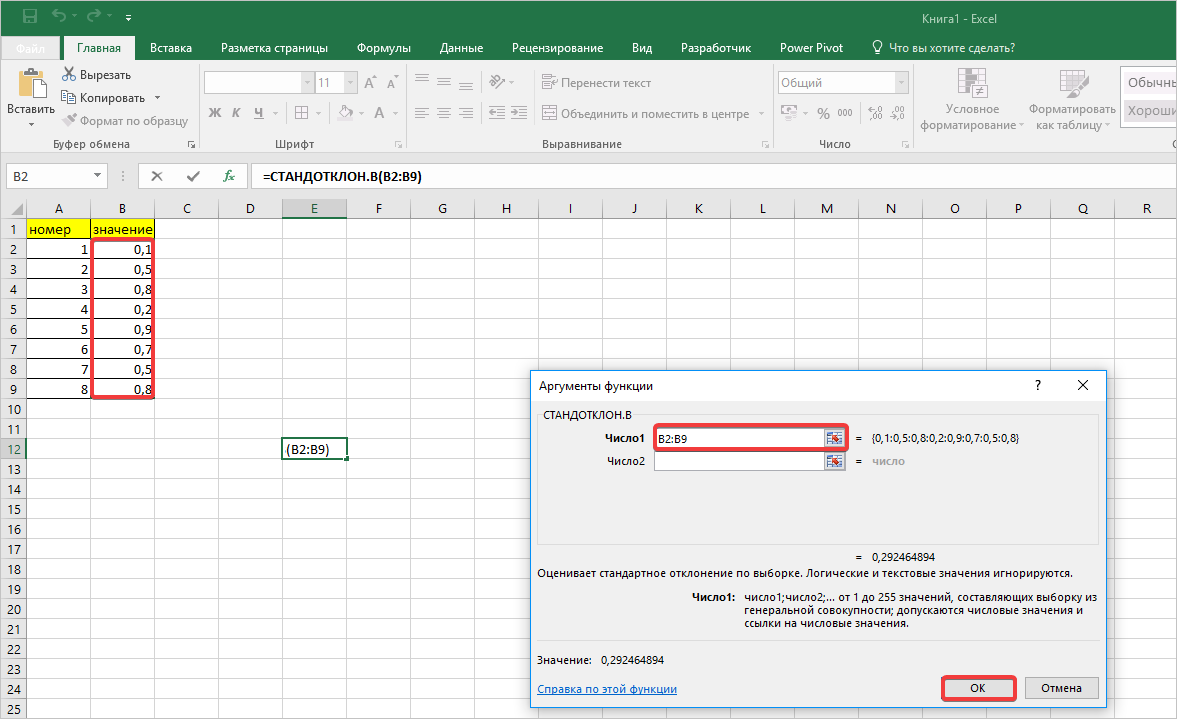
- Далее активируем ячейку с нашими значениями, переходим в строку формулы и ставим после значений наклонную линию. Переходим в поле наименования, кликаем на указывающий вниз флажок, где из списка выбираем «Другие функции».
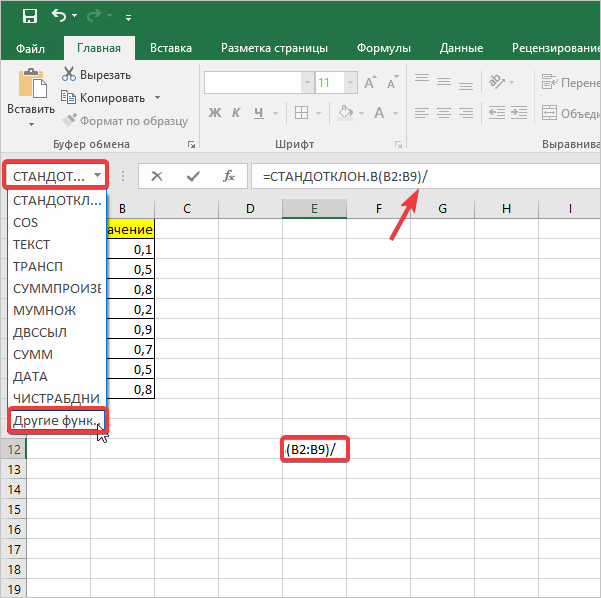
- Снова активируется окно с перечнем функций, в котором необходимо выбрать категорию «Математические», затем функцию «Корень». Далее нажмите кнопку «ОК».
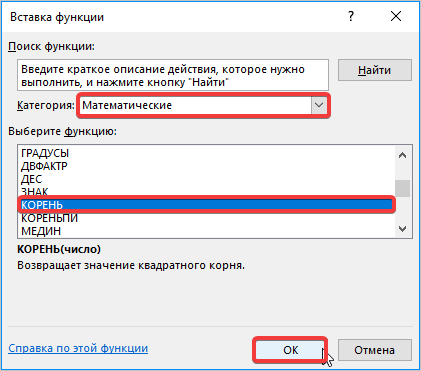
- Далее открывается окно, в котором необходимо заполнить поле с числом. Для этого переходим в поле «Имя», где спускаемся к пункту «Счет». Если его нет, ищите в дополнительных функциях.
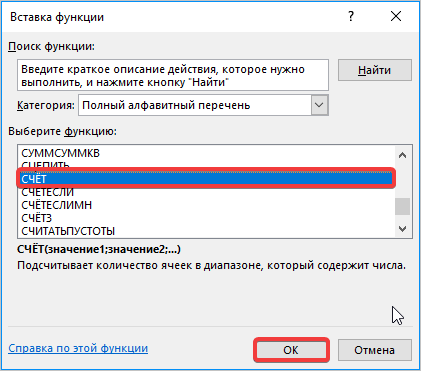
После выполнения этих шагов, стандартная ошибка высчитывается автоматически, пользователю остается только сверить их и проверить значение на некорректное отображение.
Для малых и стандартных выборок необходимо использовать разные формулы. В первом случае (если находится до 30 значений), ее необходимо видоизменить.
Решение задачи с помощью опции «Описательная статистика»
Благодаря опции «Описательная статистика» удается выполнить вычисление по различным критериям. По этим правилам удается найти среднюю арифметическую ошибку. Для использования данного метода предварительно нужно запустить «Пакет анализа».
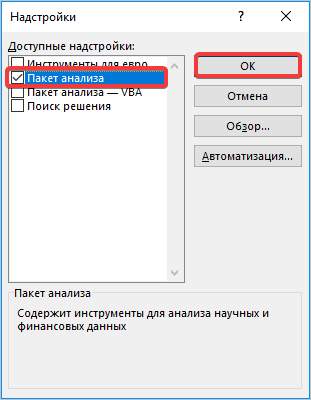
- Переходим во вкладку «Файл», где перемещаемся в пункт «Параметры». Далее нажимаем на запись «Надстройки».
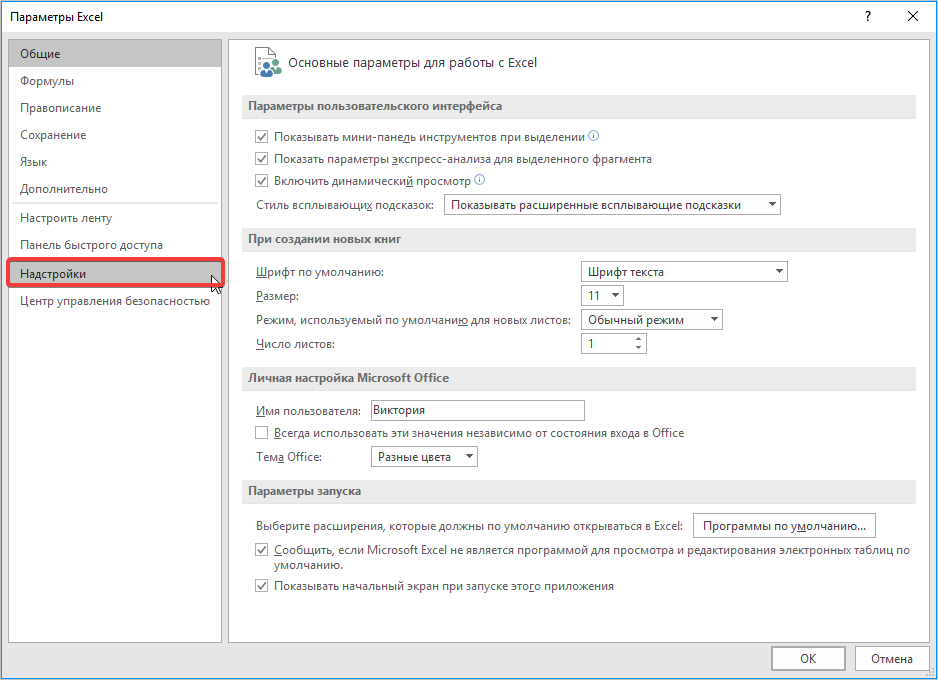
- Открывается окошко, в нем в графе «Управление» должно быть прописано «Надстройки Excel», затем рядом нажимаем кнопку «Параметры».
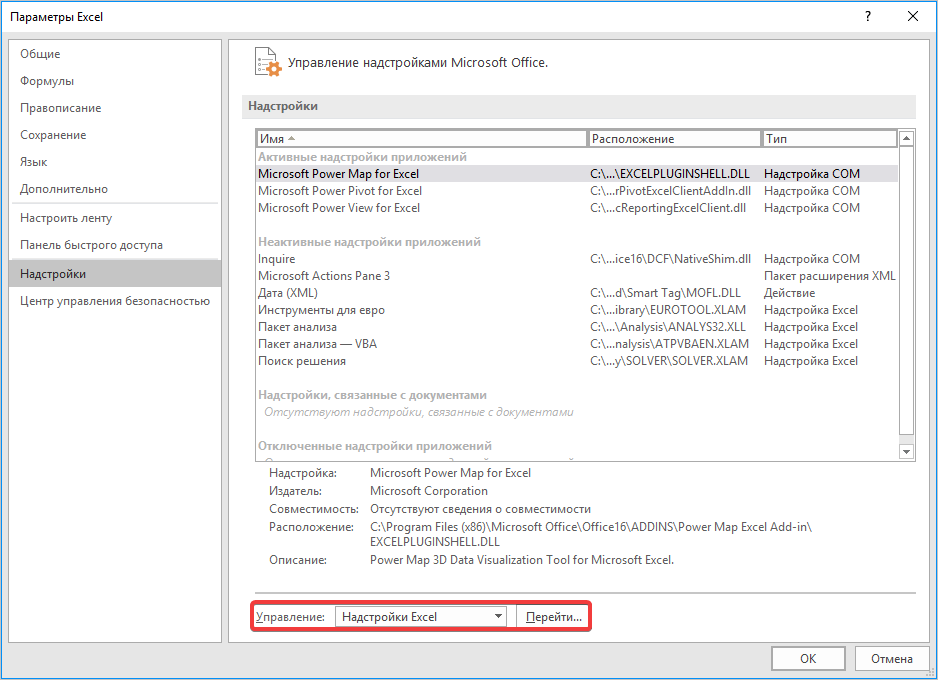
- В появившемся окне находим «Пакет анализа» и нажимаем кнопку «ОК».
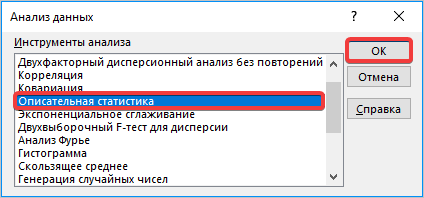
- Далее выбираем любую свободную ячейку, переходим во вкладку «Данные» и нажимаем «Анализ данных» в блоке «Анализ».

- Происходит запуск вспомогательного окошка, в котором необходимо выбрать из всех инструментов «Описательную статистику» и нажать кнопку «ОК».
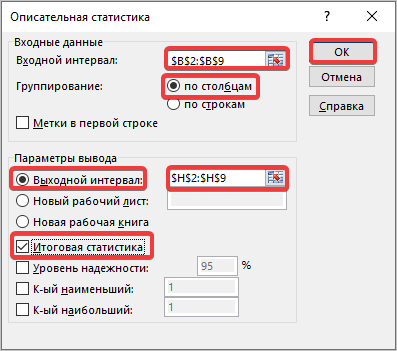
- Открывается новый мастер значений. Здесь нужно вводить данные предельно внимательно. В поле «Входной интервал» вносим адрес диапазона ячеек с выборкой. Затем указываем параметр «Группирование» «По столбцам». Затем выбираем место для «выходного интервала», его должно быть столько же, сколько и «входного». Ставим галочку напротив «Итоговая статистика» и нажимаем кнопку «ОК».
В результате вычислений вы получаете небольшую таблицу, в которой указаны все данные с определенной стандартной ошибкой.
Чтобы
судить о том, насколько точно проведенные
измерения отражают состав генеральной
совокупности, необходимо вычислить
стандартную ошибку средней арифметической
выборочной совокупности.
Стандартная
ошибка средней арифметической
характеризует степень отклонения
выборочной средней арифметической от
средней арифметической генеральной
совокупности.
Стандартная
ошибка средней арифметической вычисляется
по формуле:
![]() ,
,
где
– стандартное отклонение результатов
измерений, n
– объем выборки.
Зачастую
мы имеем дело с одной случайной выборкой
и с одной полученной при ее обработке
выборочной средней. Задача заключается
в суждении о величине неизвестной
генеральной средней по полученной
неточной величине случайной выборочной
средней.
Вычислим
среднюю ошибку найденного выборочного
среднего значения роста:
![]() 195
195
см; σ = 8,8 см;
![]() см.
см.
2,8 см
составляют не максимальную, а среднюю
возможную ошибку среднего. Отдельные
выборочные средние могут отклоняться
от генеральной как больше, так и меньше,
чем на 2,8 см.
Каковы
же пределы возможных ошибок случайной
выборки, какова ее максимальная ошибка?
Величина максимальной ошибки зависит
от величины средней ошибки и вычисляется
по формуле
![]() .
.
При
объеме выборки n
= 10:
![]() .
.
Все
случайные выборочные средние, которые
могут быть получены в подобных опытах
(в том числе и фактически полученная
выборочная средняя
![]() = 195 см), при своем варьировании около
= 195 см), при своем варьировании около
неизвестного генерального среднего в
подавляющем количестве группируются
около него так, что лишь ничтожный
процент их отклоняется от генеральной
средней более, чем на величину максимальной
ошибки.
Другими
словами, генеральная средняя определяется
как
![]() .
.
Эти пределы
колебаний значительно сужаются, если
средняя ошибка уменьшается благодаря
увеличению численности выборки.
Искомая
генеральная средняя лежит между
![]() и
и![]() .
.
Таким образом, при высокой точности
выполнения эксперимента и достаточно
большом числе измерений можно определить
среднюю арифметическую бесконечно
большого числа экспериментов.
До сих
пор мы определяли максимальную ошибку
выборочной средней, исходя из того, что
все остальные показатели известны. Если
же мы хотим достичь определенной
точности, определенного приближения к
генеральной средней, в этом случае
встает вопрос о численности выборки (о
том, сколько измерений, опытов необходимо
провести).
Допустим, что
максимальная ошибка должна быть равна
5 см. Сколько человек надо обследовать
(измерить) в нашем случае?
![]() .
.
Следовательно,
мы должны провести измерения роста у
36 баскетболистов высокого класса.
10. Достоверность различий
Следующим
важным вопросом практически для каждого
экспериментатора является умение
доказать достоверность различий между
двумя рядами признаков.
Проверку
достоверности различия двух рядов
измерений производят путем вычисления
критерия достоверности различия – t:
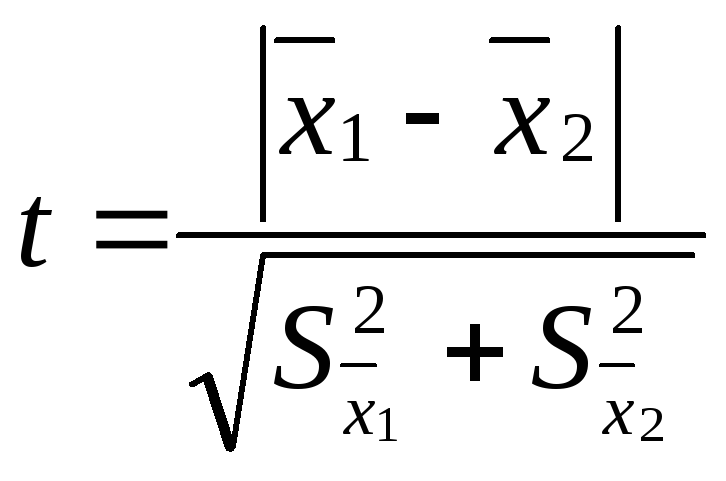 ,
,
где
![]() – средняя одной выборки;
– средняя одной выборки;![]() – средняя другой выборки;
– средняя другой выборки;![]() – средняя ошибка первой выборки;
– средняя ошибка первой выборки;![]() – второй выборки. Если t < 2, то различие
– второй выборки. Если t < 2, то различие
между двумя выборками считается
недостоверным, если t
2, то различие между двумя выборками
достоверно на 95%.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Представление результатов исследования
В научных публикациях важно представление результатов исследования. Очень часто окончательный результат приводится в следующем виде: M±m, где M – среднее арифметическое, m –ошибка среднего арифметического. Например, 163,7±0,9 см.
Прежде чем разбираться в правилах представления результатов исследования, давайте точно усвоим, что же такое ошибка среднего арифметического.
Ошибка среднего арифметического
Среднее арифметическое, вычисленное на основе выборочных данных (выборочное среднее), как правило, не совпадает с генеральным средним (средним арифметическим генеральной совокупности). Экспериментально проверить это утверждение невозможно, потому что нам неизвестно генеральное среднее. Но если из одной и той же генеральной совокупности брать повторные выборки и вычислять среднее арифметическое, то окажется, что для разных выборок среднее арифметическое будет разным.
Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности.
Ошибка среднего арифметического обозначается как m или ![]()
Ошибка среднего арифметического рассчитывается по формуле:

где: S — стандартное отклонение, n – объем выборки; Например, если стандартное отклонение равно S=5 см, объем выборки n=36 человек, то ошибка среднего арифметического равна: m=5/6 = 0,833.
Ошибка среднего арифметического показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего выборочное среднее.
Так как при небольшом объеме выборки истинное значение генерального среднего не может быть определено сколь угодно точно, поэтому при вычислении выборочного среднего арифметического нет смысла оставлять большое число значащих цифр.
Правила записи результатов исследования
- В записи ошибки среднего арифметического оставляем две значащие цифры, если первые цифры в ошибке «1» или «2».
- В остальных случаях в записи ошибки среднего арифметического оставляем одну значащую цифру.
- В записи среднего арифметического положение последней значащей цифры должно соответствовать положению первой значащей цифры в записи ошибки среднего арифметического.
Представление результатов научных исследований
В своей статье «Осторожно, статистика!», опубликованной в 1989 году В.М. Зациорский указал, какие числовые характеристики должны быть представлены в публикации, чтобы она имела научную ценность. Он писал, что исследователь «…должен назвать: 1) среднюю величину (или другой так называемый показатель положения); 2) среднее квадратическое отклонение (или другой показатель рассеяния) и 3) число испытуемых. Без них его публикация научной ценности иметь не будет “с. 52
В научных публикациях в области физической культуры и спорта очень часто окончательный результат приводится в виде: (М±m) (табл.1).
Таблица 1 — Изменение механических свойств латеральной широкой мышцы бедра под воздействием физической нагрузки (n=34)
| Эффективный модуль
упругости (Е), кПа |
Эффективный модуль
вязкости (V), Па с |
|||
| Этап
эксперимента |
Рассл. | Напряж. | Рассл. | Напряж. |
| До ФН | 7,0±0,3 | 17,1±1,4 | 29,7±1,7 | 46±4 |
| После ФН | 7,7±0,3 | 18,7±1,4 | 30,9±2,0 | 53±6 |
Литература
- Высшая математика и математическая статистика: учебное пособие для вузов / Под общ. ред. Г. И. Попова. – М. Физическая культура, 2007.– 368 с.
- Гласс Дж., Стэнли Дж. Статистические методы в педагогике и психологии. М.: Прогресс. 1976.- 495 с.
- Зациорский В.М. Осторожно — статистика! // Теория и практика физической культуры, 1989.- №2.
- Катранов А.Г. Компьютерная обработка данных экспериментальных исследований: Учебное пособие/ А. Г. Катранов, А. В. Самсонова; СПб ГУФК им. П.Ф. Лесгафта. – СПб.: изд-во СПб ГУФК им. П.Ф. Лесгафта, 2005. – 131 с.
- Основы математической статистики: Учебное пособие для ин-тов физ. культ / Под ред. В.С. Иванова.– М.: Физкультура и спорт, 1990. 176 с.