
Средняя квадратичная ошибка.
При ответственных
измерениях, когда необходимо знать
надежность полученных результатов,
используется средняя квадратичная
ошибка (или
стандартное отклонение), которая
определяется формулой
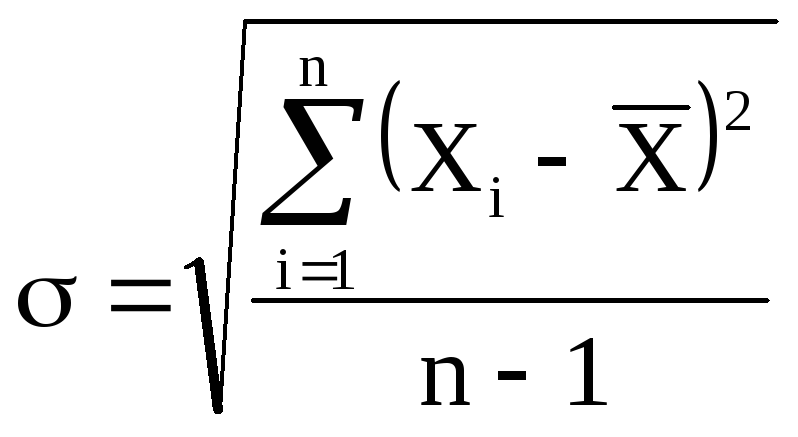
(5)
Величина
характеризует отклонение отдельного
единичного измерения от истинного
значения.
Если мы вычислили
по n
измерениям среднее значение
![]()
по формуле (2), то это значение будет
более точным, то есть будет меньше
отличаться от истинного, чем каждое
отдельное измерение. Средняя квадратичная
ошибка среднего значения
![]()
равна
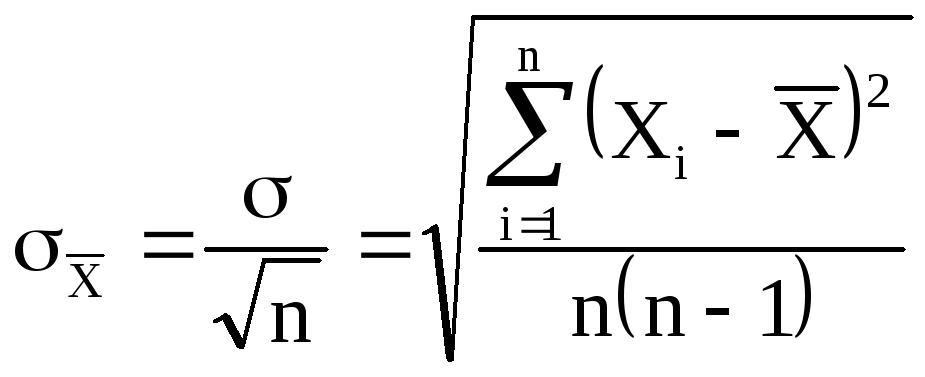
(6)
где — среднеквадратичная
ошибка каждого отдельного измерения,
n
– число измерений.
Таким образом,
увеличивая число опытов, можно уменьшить
случайную ошибку в величине среднего
значения.
В настоящее время
результаты научных и технических
измерений принято представлять в виде
![]()
(7)
Как показывает
теория, при такой записи мы знаем
надежность полученного результата, а
именно, что истинная величина Х с
вероятностью 68% отличается от
![]()
не более, чем на
![]() .
.
При использовании
же средней арифметической (абсолютной)
ошибки (формула 2) о надежности результата
ничего сказать нельзя. Некоторое
представление о точности проведенных
измерений в этом случае дает относительная
ошибка (формула 4).
При выполнении
лабораторных работ студенты могут
использовать как среднюю абсолютную
ошибку, так и среднюю квадратичную.
Какую из них применять указывается
непосредственно в каждой конкретной
работе (или указывается преподавателем).
Обычно если число
измерений не превышает 3 – 5, то
можно использовать среднюю абсолютную
ошибку. Если число измерений порядка
10 и более, то следует использовать более
корректную оценку с помощью средней
квадратичной ошибки среднего (формулы
5 и 6).
Учет систематических ошибок.
Увеличением числа
измерений можно уменьшить только
случайные ошибки опыта, но не
систематические.
Максимальное
значение систематической ошибки обычно
указывается на приборе или в его паспорте.
Для измерений с помощью обычной
металлической линейки систематическая
ошибка составляет не менее 0,5 мм; для
измерений штангенциркулем –
0,1 – 0,05 мм;
микрометром – 0,01 мм.
Часто в качестве
систематической ошибки берется половина
цены деления прибора.
На шкалах
электроизмерительных приборов указывается
класс точности. Зная класс точности К,
можно вычислить систематическую ошибку
прибора ∆Х по формуле
![]()
где К – класс
точности прибора, Хпр – предельное
значение величины, которое может быть
измерено по шкале прибора.
Так, амперметр
класса 0,5 со шкалой до 5А измеряет ток с
ошибкой не более
![]()
Погрешность
цифрового прибора равна единице
наименьшего индицируемого разряда.
Среднее значение
полной погрешности складывается из
случайной и систематической
погрешностей.
![]()
Ответ с учетом
систематических и случайных ошибок
записывается в виде
![]()
Погрешности косвенных измерений
В физических
экспериментах чаще бывает так, что
искомая физическая величина сама на
опыте измерена быть не может, а является
функцией других величин, измеряемых
непосредственно. Например, чтобы
определить объём цилиндра, надо измерить
диаметр D и высоту h, а затем вычислить
объем по формуле
![]()
Величины D и h будут измерены с
некоторой ошибкой. Следовательно,
вычисленная величина V
получится также с некоторой ошибкой.
Надо уметь выражать погрешность
вычисленной величины через погрешности
измеренных величин.
Как и при прямых
измерениях можно вычислять среднюю
абсолютную (среднюю арифметическую)
ошибку или среднюю квадратичную ошибку.
Общие правила
вычисления ошибок для обоих случаев
выводятся с помощью дифференциального
исчисления.
Пусть искомая
величина φ является функцией нескольких
переменных Х,
У, Z…
φ(Х,
У, Z…).
Путем прямых
измерений мы можем найти величины
![]() ,
,
а также оценить их средние абсолютные
ошибки
![]() …
…
или средние квадратичные ошибки Х,
У,
Z…
Тогда средняя
арифметическая погрешность
вычисляется по формуле
![]()
где
![]() — частные
— частные
производные от φ по
Х, У, Z. Они
вычисляются для средних значений
![]() …
…
Средняя квадратичная
погрешность вычисляется по формуле
![]()
Пример.
Выведем формулы погрешности для
вычисления объёма цилиндра.
а) Средняя
арифметическая погрешность.
Величины
D и h
измеряются соответственно с ошибкой
D
и h.
Погрешность
величины объёма будет равна
![]()
б) Средняя
квадратичная погрешность.
Величины
D и h
измеряются соответственно с ошибкой
D,
h.
Погрешность
величины объёма будет равна
![]()
Если формула
представляет выражение удобное для
логарифмирования (то есть произведение,
дробь, степень), то удобнее вначале
вычислять относительную погрешность.
Для этого (в случае средней арифметической
погрешности) надо проделать следующее.
1. Прологарифмировать
выражение.
2. Продифференцировать
его.
3. Объединить
все члены с одинаковым дифференциалом
и вынести его за скобки.
4. Взять выражение
перед различными дифференциалами по
модулю.
5. Заменить
значки дифференциалов d
на значки абсолютной погрешности .
В итоге получится
формула для относительной погрешности
![]()
Затем,
зная ,
можно вычислить абсолютную погрешность
=
Пример.
![]()
![]()
![]()
![]()
Аналогично можно
записать относительную среднюю
квадратичную погрешность
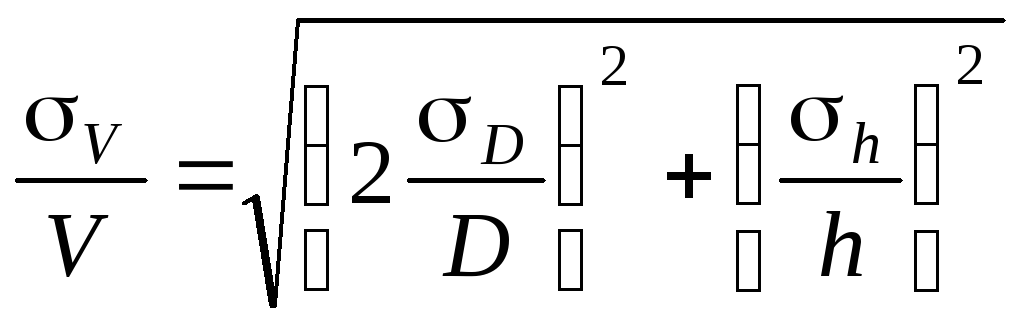
Правила
представления результатов измерения
следующие:
-
погрешность должна
округляться до одной значащей цифры:
правильно = 0,04,
неправильно —
= 0,0382;
-
последняя значащая
цифра результата должна быть того же
порядка величины, что и погрешность:
правильно
= 9,830,03,
неправильно —
= 9,8260,03;
-
если результат
имеет очень большую или очень малую
величину, необходимо использовать
показательную форму записи — одну и ту
же для результата и его погрешности,
причем запятая десятичной дроби должна
следовать за первой значащей цифрой
результата:
правильно —
= (5,270,03)10-5,
неправильно —
= 0,00005270,0000003,
= 5,2710-50,0000003,
=
= 0,0000527310-7,
= (5273)10-7,
= (0,5270,003)
10-4.
-
Если результат
имеет размерность, ее необходимо
указать:
правильно – g=(9,820,02)
м/c2,
неправильно – g=(9,820,02).
Соседние файлы в папке Методички физика
- #
02.04.2015275.46 Кб40оформление заготовки и отчета.ppt
- #
From Wikipedia, the free encyclopedia
In statistics, the mean squared error (MSE)[1] or mean squared deviation (MSD) of an estimator (of a procedure for estimating an unobserved quantity) measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss.[2] The fact that MSE is almost always strictly positive (and not zero) is because of randomness or because the estimator does not account for information that could produce a more accurate estimate.[3] In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk (the average loss on an observed data set), as an estimate of the true MSE (the true risk: the average loss on the actual population distribution).
The MSE is a measure of the quality of an estimator. As it is derived from the square of Euclidean distance, it is always a positive value that decreases as the error approaches zero.
The MSE is the second moment (about the origin) of the error, and thus incorporates both the variance of the estimator (how widely spread the estimates are from one data sample to another) and its bias (how far off the average estimated value is from the true value).[citation needed] For an unbiased estimator, the MSE is the variance of the estimator. Like the variance, MSE has the same units of measurement as the square of the quantity being estimated. In an analogy to standard deviation, taking the square root of MSE yields the root-mean-square error or root-mean-square deviation (RMSE or RMSD), which has the same units as the quantity being estimated; for an unbiased estimator, the RMSE is the square root of the variance, known as the standard error.
Definition and basic properties[edit]
The MSE either assesses the quality of a predictor (i.e., a function mapping arbitrary inputs to a sample of values of some random variable), or of an estimator (i.e., a mathematical function mapping a sample of data to an estimate of a parameter of the population from which the data is sampled). The definition of an MSE differs according to whether one is describing a predictor or an estimator.
Predictor[edit]
If a vector of  predictions is generated from a sample of data points on all variables, and
predictions is generated from a sample of data points on all variables, and  is the vector of observed values of the variable being predicted, with
is the vector of observed values of the variable being predicted, with  being the predicted values (e.g. as from a least-squares fit), then the within-sample MSE of the predictor is computed as
being the predicted values (e.g. as from a least-squares fit), then the within-sample MSE of the predictor is computed as

In other words, the MSE is the mean  of the squares of the errors
of the squares of the errors  . This is an easily computable quantity for a particular sample (and hence is sample-dependent).
. This is an easily computable quantity for a particular sample (and hence is sample-dependent).
In matrix notation,

where  is
is  and
and  is the
is the  column vector.
column vector.
The MSE can also be computed on q data points that were not used in estimating the model, either because they were held back for this purpose, or because these data have been newly obtained. Within this process, known as statistical learning, the MSE is often called the test MSE,[4] and is computed as

Estimator[edit]
The MSE of an estimator  with respect to an unknown parameter
with respect to an unknown parameter  is defined as[1]
is defined as[1]
![{displaystyle operatorname {MSE} ({hat {theta }})=operatorname {E} _{theta }left[({hat {theta }}-theta )^{2}right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a0e1b3bac58f9ba2d2f4ff8b85b2e35a8f4bf78)
This definition depends on the unknown parameter, but the MSE is a priori a property of an estimator. The MSE could be a function of unknown parameters, in which case any estimator of the MSE based on estimates of these parameters would be a function of the data (and thus a random variable). If the estimator is derived as a sample statistic and is used to estimate some population parameter, then the expectation is with respect to the sampling distribution of the sample statistic.
The MSE can be written as the sum of the variance of the estimator and the squared bias of the estimator, providing a useful way to calculate the MSE and implying that in the case of unbiased estimators, the MSE and variance are equivalent.[5]

Proof of variance and bias relationship[edit]
![{displaystyle {begin{aligned}operatorname {MSE} ({hat {theta }})&=operatorname {E} _{theta }left[({hat {theta }}-theta )^{2}right]\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]+operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}+2left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)left(operatorname {E} _{theta }[{hat {theta }}]-theta right)+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+operatorname {E} _{theta }left[2left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)left(operatorname {E} _{theta }[{hat {theta }}]-theta right)right]+operatorname {E} _{theta }left[left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+2left(operatorname {E} _{theta }[{hat {theta }}]-theta right)operatorname {E} _{theta }left[{hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right]+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}&&operatorname {E} _{theta }[{hat {theta }}]-theta ={text{const.}}\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+2left(operatorname {E} _{theta }[{hat {theta }}]-theta right)left(operatorname {E} _{theta }[{hat {theta }}]-operatorname {E} _{theta }[{hat {theta }}]right)+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}&&operatorname {E} _{theta }[{hat {theta }}]={text{const.}}\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}\&=operatorname {Var} _{theta }({hat {theta }})+operatorname {Bias} _{theta }({hat {theta }},theta )^{2}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ac524a751828f971013e1297a33ca1cc4c38cd6)
An even shorter proof can be achieved using the well-known formula that for a random variable  ,
,  . By substituting with,
. By substituting with,  , we have
, we have
![{displaystyle {begin{aligned}operatorname {MSE} ({hat {theta }})&=mathbb {E} [({hat {theta }}-theta )^{2}]\&=operatorname {Var} ({hat {theta }}-theta )+(mathbb {E} [{hat {theta }}-theta ])^{2}\&=operatorname {Var} ({hat {theta }})+operatorname {Bias} ^{2}({hat {theta }})end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/864646cf4426e2b62a3caf9460382eec1a77fe4e)
But in real modeling case, MSE could be described as the addition of model variance, model bias, and irreducible uncertainty (see Bias–variance tradeoff). According to the relationship, the MSE of the estimators could be simply used for the efficiency comparison, which includes the information of estimator variance and bias. This is called MSE criterion.
In regression[edit]
In regression analysis, plotting is a more natural way to view the overall trend of the whole data. The mean of the distance from each point to the predicted regression model can be calculated, and shown as the mean squared error. The squaring is critical to reduce the complexity with negative signs. To minimize MSE, the model could be more accurate, which would mean the model is closer to actual data. One example of a linear regression using this method is the least squares method—which evaluates appropriateness of linear regression model to model bivariate dataset,[6] but whose limitation is related to known distribution of the data.
The term mean squared error is sometimes used to refer to the unbiased estimate of error variance: the residual sum of squares divided by the number of degrees of freedom. This definition for a known, computed quantity differs from the above definition for the computed MSE of a predictor, in that a different denominator is used. The denominator is the sample size reduced by the number of model parameters estimated from the same data, (n−p) for p regressors or (n−p−1) if an intercept is used (see errors and residuals in statistics for more details).[7] Although the MSE (as defined in this article) is not an unbiased estimator of the error variance, it is consistent, given the consistency of the predictor.
In regression analysis, «mean squared error», often referred to as mean squared prediction error or «out-of-sample mean squared error», can also refer to the mean value of the squared deviations of the predictions from the true values, over an out-of-sample test space, generated by a model estimated over a particular sample space. This also is a known, computed quantity, and it varies by sample and by out-of-sample test space.
Examples[edit]
Mean[edit]
Suppose we have a random sample of size from a population,  . Suppose the sample units were chosen with replacement. That is, the units are selected one at a time, and previously selected units are still eligible for selection for all draws. The usual estimator for the
. Suppose the sample units were chosen with replacement. That is, the units are selected one at a time, and previously selected units are still eligible for selection for all draws. The usual estimator for the  is the sample average
is the sample average

which has an expected value equal to the true mean (so it is unbiased) and a mean squared error of
![{displaystyle operatorname {MSE} left({overline {X}}right)=operatorname {E} left[left({overline {X}}-mu right)^{2}right]=left({frac {sigma }{sqrt {n}}}right)^{2}={frac {sigma ^{2}}{n}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4647a2cc4c8f9a4c90b628faad2dcf80c4aae84)
where  is the population variance.
is the population variance.
For a Gaussian distribution, this is the best unbiased estimator (i.e., one with the lowest MSE among all unbiased estimators), but not, say, for a uniform distribution.
Variance[edit]
The usual estimator for the variance is the corrected sample variance:

This is unbiased (its expected value is ), hence also called the unbiased sample variance, and its MSE is[8]

where  is the fourth central moment of the distribution or population, and
is the fourth central moment of the distribution or population, and  is the excess kurtosis.
is the excess kurtosis.
However, one can use other estimators for which are proportional to  , and an appropriate choice can always give a lower mean squared error. If we define
, and an appropriate choice can always give a lower mean squared error. If we define

then we calculate:
![{displaystyle {begin{aligned}operatorname {MSE} (S_{a}^{2})&=operatorname {E} left[left({frac {n-1}{a}}S_{n-1}^{2}-sigma ^{2}right)^{2}right]\&=operatorname {E} left[{frac {(n-1)^{2}}{a^{2}}}S_{n-1}^{4}-2left({frac {n-1}{a}}S_{n-1}^{2}right)sigma ^{2}+sigma ^{4}right]\&={frac {(n-1)^{2}}{a^{2}}}operatorname {E} left[S_{n-1}^{4}right]-2left({frac {n-1}{a}}right)operatorname {E} left[S_{n-1}^{2}right]sigma ^{2}+sigma ^{4}\&={frac {(n-1)^{2}}{a^{2}}}operatorname {E} left[S_{n-1}^{4}right]-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}&&operatorname {E} left[S_{n-1}^{2}right]=sigma ^{2}\&={frac {(n-1)^{2}}{a^{2}}}left({frac {gamma _{2}}{n}}+{frac {n+1}{n-1}}right)sigma ^{4}-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}&&operatorname {E} left[S_{n-1}^{4}right]=operatorname {MSE} (S_{n-1}^{2})+sigma ^{4}\&={frac {n-1}{na^{2}}}left((n-1)gamma _{2}+n^{2}+nright)sigma ^{4}-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf22322412b8454c706d78671e5d94208675a6e0)
This is minimized when

For a Gaussian distribution, where  , this means that the MSE is minimized when dividing the sum by
, this means that the MSE is minimized when dividing the sum by  . The minimum excess kurtosis is
. The minimum excess kurtosis is  ,[a] which is achieved by a Bernoulli distribution with p = 1/2 (a coin flip), and the MSE is minimized for
,[a] which is achieved by a Bernoulli distribution with p = 1/2 (a coin flip), and the MSE is minimized for  Hence regardless of the kurtosis, we get a «better» estimate (in the sense of having a lower MSE) by scaling down the unbiased estimator a little bit; this is a simple example of a shrinkage estimator: one «shrinks» the estimator towards zero (scales down the unbiased estimator).
Hence regardless of the kurtosis, we get a «better» estimate (in the sense of having a lower MSE) by scaling down the unbiased estimator a little bit; this is a simple example of a shrinkage estimator: one «shrinks» the estimator towards zero (scales down the unbiased estimator).
Further, while the corrected sample variance is the best unbiased estimator (minimum mean squared error among unbiased estimators) of variance for Gaussian distributions, if the distribution is not Gaussian, then even among unbiased estimators, the best unbiased estimator of the variance may not be 
Gaussian distribution[edit]
The following table gives several estimators of the true parameters of the population, μ and σ2, for the Gaussian case.[9]
| True value | Estimator | Mean squared error |
|---|---|---|
 |
= the unbiased estimator of the population mean,  |

|
 |
= the unbiased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
Interpretation[edit]
An MSE of zero, meaning that the estimator predicts observations of the parameter with perfect accuracy, is ideal (but typically not possible).
Values of MSE may be used for comparative purposes. Two or more statistical models may be compared using their MSEs—as a measure of how well they explain a given set of observations: An unbiased estimator (estimated from a statistical model) with the smallest variance among all unbiased estimators is the best unbiased estimator or MVUE (Minimum-Variance Unbiased Estimator).
Both analysis of variance and linear regression techniques estimate the MSE as part of the analysis and use the estimated MSE to determine the statistical significance of the factors or predictors under study. The goal of experimental design is to construct experiments in such a way that when the observations are analyzed, the MSE is close to zero relative to the magnitude of at least one of the estimated treatment effects.
In one-way analysis of variance, MSE can be calculated by the division of the sum of squared errors and the degree of freedom. Also, the f-value is the ratio of the mean squared treatment and the MSE.
MSE is also used in several stepwise regression techniques as part of the determination as to how many predictors from a candidate set to include in a model for a given set of observations.
Applications[edit]
- Minimizing MSE is a key criterion in selecting estimators: see minimum mean-square error. Among unbiased estimators, minimizing the MSE is equivalent to minimizing the variance, and the estimator that does this is the minimum variance unbiased estimator. However, a biased estimator may have lower MSE; see estimator bias.
- In statistical modelling the MSE can represent the difference between the actual observations and the observation values predicted by the model. In this context, it is used to determine the extent to which the model fits the data as well as whether removing some explanatory variables is possible without significantly harming the model’s predictive ability.
- In forecasting and prediction, the Brier score is a measure of forecast skill based on MSE.
Loss function[edit]
Squared error loss is one of the most widely used loss functions in statistics[citation needed], though its widespread use stems more from mathematical convenience than considerations of actual loss in applications. Carl Friedrich Gauss, who introduced the use of mean squared error, was aware of its arbitrariness and was in agreement with objections to it on these grounds.[3] The mathematical benefits of mean squared error are particularly evident in its use at analyzing the performance of linear regression, as it allows one to partition the variation in a dataset into variation explained by the model and variation explained by randomness.
Criticism[edit]
The use of mean squared error without question has been criticized by the decision theorist James Berger. Mean squared error is the negative of the expected value of one specific utility function, the quadratic utility function, which may not be the appropriate utility function to use under a given set of circumstances. There are, however, some scenarios where mean squared error can serve as a good approximation to a loss function occurring naturally in an application.[10]
Like variance, mean squared error has the disadvantage of heavily weighting outliers.[11] This is a result of the squaring of each term, which effectively weights large errors more heavily than small ones. This property, undesirable in many applications, has led researchers to use alternatives such as the mean absolute error, or those based on the median.
See also[edit]
- Bias–variance tradeoff
- Hodges’ estimator
- James–Stein estimator
- Mean percentage error
- Mean square quantization error
- Mean square weighted deviation
- Mean squared displacement
- Mean squared prediction error
- Minimum mean square error
- Minimum mean squared error estimator
- Overfitting
- Peak signal-to-noise ratio
Notes[edit]
- ^ This can be proved by Jensen’s inequality as follows. The fourth central moment is an upper bound for the square of variance, so that the least value for their ratio is one, therefore, the least value for the excess kurtosis is −2, achieved, for instance, by a Bernoulli with p=1/2.
References[edit]
- ^ a b «Mean Squared Error (MSE)». www.probabilitycourse.com. Retrieved 2020-09-12.
- ^ Bickel, Peter J.; Doksum, Kjell A. (2015). Mathematical Statistics: Basic Ideas and Selected Topics. Vol. I (Second ed.). p. 20.
If we use quadratic loss, our risk function is called the mean squared error (MSE) …
- ^ a b Lehmann, E. L.; Casella, George (1998). Theory of Point Estimation (2nd ed.). New York: Springer. ISBN 978-0-387-98502-2. MR 1639875.
- ^ Gareth, James; Witten, Daniela; Hastie, Trevor; Tibshirani, Rob (2021). An Introduction to Statistical Learning: with Applications in R. Springer. ISBN 978-1071614174.
- ^ Wackerly, Dennis; Mendenhall, William; Scheaffer, Richard L. (2008). Mathematical Statistics with Applications (7 ed.). Belmont, CA, USA: Thomson Higher Education. ISBN 978-0-495-38508-0.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Steel, R.G.D, and Torrie, J. H., Principles and Procedures of Statistics with Special Reference to the Biological Sciences., McGraw Hill, 1960, page 288.
- ^ Mood, A.; Graybill, F.; Boes, D. (1974). Introduction to the Theory of Statistics (3rd ed.). McGraw-Hill. p. 229.
- ^ DeGroot, Morris H. (1980). Probability and Statistics (2nd ed.). Addison-Wesley.
- ^ Berger, James O. (1985). «2.4.2 Certain Standard Loss Functions». Statistical Decision Theory and Bayesian Analysis (2nd ed.). New York: Springer-Verlag. p. 60. ISBN 978-0-387-96098-2. MR 0804611.
- ^ Bermejo, Sergio; Cabestany, Joan (2001). «Oriented principal component analysis for large margin classifiers». Neural Networks. 14 (10): 1447–1461. doi:10.1016/S0893-6080(01)00106-X. PMID 11771723.
И снова о погрешностях
Окончание. См. № 15/07
Д.А.ИВАШКИНА,
лицей г. Троицка, Московская обл.
aivashkin@mail.ru
И снова о погрешностях
4. Учёт случайных погрешностей при
прямых измерениях
Если, проведя одно и то же измерение
несколько раз, вы видите, что результат остаётся
одним и тем же, то случайные погрешности
эксперимента малы, их не следует учитывать. Но
если при повторении измерения получаются разные
значения, то следует взять среднее значение из
серии измерений:
![]()
где n – число измерений. Как
узнать, какова погрешность результата? Логично, и
ученики сами обычно предлагают это, определить
среднее отклонение результата от среднего
значения. Полученная величина носит название средней
арифметической ошибки: ![]() Она показывает, на сколько в
Она показывает, на сколько в
среднем каждое измеренное значение отклоняется
от среднего значения. Но эта величина слабо
зависит от количества проведённых измерений. В
чём же тогда смысл многократных измерений?
Для среднеквадратичной погрешности,
которая определяется немного сложнее:
![]()
есть простое правило: средняя
квадратичная погрешность среднего
арифметического равна средней квадратичной
погрешности отдельного результата, делённой на
корень квадратный из числа измерений: ![]() Из формулы ясно,
Из формулы ясно,
что с увеличением числа измерений случайная
погрешность среднего значения уменьшается.
Поэтому необходимо проводить столько измерений,
чтобы случайная погрешность стала меньше
значения систематической погрешности данного
измерения.
К сожалению, в лабораторных работах и
при любых других экспериментах в школе провести
достаточное количество измерений невозможно в
силу нехватки времени. Как поступать, может
решить сам учитель. На мой взгляд, для нахождения
средней арифметической погрешности среднего
значения можно использовать формулу,
аналогичную формуле для средней квадратичной
ошибки: ![]()
Хотя эта формула и неверна, она
помогает понять смысл проведения большого числа
измерений. Использоваться же она будет всего в
нескольких работах, и, следовательно, нет нужды
специально обучать нахождению погрешности
среднего значения. Зато, получив в этих работах
случайную погрешность меньше погрешности
систематической, ученик запомнит, что каждое
измерение следует производить несколько раз при
малейшем подозрении, что в данном эксперименте
имеется случайная погрешность. Как правило, уже
при пяти измерениях достигается необходимая
малость случайной погрешности по сравнению с
систематической.
5. Определение погрешности
результата косвенных измерений
К определению погрешности результата
косвенных измерений учащиеся готовы, на мой
взгляд, уже к 8-му классу. В зависимости от уровня
класса впервые метод границ [1, 12] можно
применить или в работе по сравнению количеств
теплоты при смешивании воды, или при нахождении
сопротивления проводника. Поясню на примерах.
-
Допустим, при нагревании холодной
воды в процессе смешивания мы имеем следующие
результаты измерений:
– температура холодной воды t1
= (16,0 ± 1,5) °С;
– температура смеси t = (43,0 ± 1,5) °С;
– объём холодной воды V1 = (80
± 2) мл = (80 ± 2) • 10–6 м3.
Получаем количество теплоты,
полученное холодной водой:
Q = 4190 Дж/(кг • °С) • 1000 кг/м3
• 80 • 10–6 м3 ![]() (43 – 16) °С = 9050,4 Дж.
(43 – 16) °С = 9050,4 Дж.
(1)
Возникает вопрос: а какова погрешность
полученного значения? Другими словами, на
сколько мы можем ошибиться, если точные значения
не равны измеренным, а лежат где-то в интервале,
даваемом погрешностью? Например, начальная
температура воды может быть равна 16,5 °С, 17,0 °С и
т.д. Тогда вычисленное количество теплоты будет
меньше. Логично посмотреть, на сколько мы можем
ошибиться по максимуму. Максимальное количество
теплоты получится, если взять для всех
сомножителей максимальные значения, т.е. верхние
границы интервалов значений с погрешностью, для
уменьшаемого взять верхнюю границу значения, а
для вычитаемого – нижнюю:
Qв = 4190 Дж/(кг • °С) • 1000
кг/м3 • 82 • 10–6 м3 ![]() (44,5 – 14,5)°С = 10 307,4 Дж.
(44,5 – 14,5)°С = 10 307,4 Дж.
Аналогично вычисляем нижнюю границу
значения количества теплоты:
Qн = 4190 Дж/(кг • °С) • 1000
кг/м3 • 78 • 10–6 м3 ![]() (41,5 – 17,5) °С = 7843,68
(41,5 – 17,5) °С = 7843,68
Дж.
В данных пределах и лежит искомое
значение. Чтобы сравнивать методом интервалов
это значение с количеством теплоты, отданным
горячей водой, надо округлить значения верхней и
нижней границ. Лучше это сделать, оценив
абсолютную погрешность найденного значения
количества теплоты.
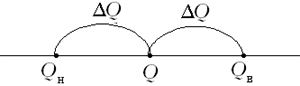
Рис. 2
Из рис. 2 видно, что
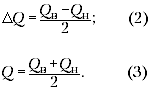
Найденное выше значение (1) близко к (3),
поэтому его не стоит находить ещё раз. А вот для
погрешности найдём с помощью (2):
![]() (две
(две
значащие цифры, т.к. первая «1»). Поэтому
количество теплоты, полученное холодной водой,
можно округлить: Qполуч = 9000 Дж ±
1200 Дж (т.е. между 7800 Дж и 10 200 Дж). Если количество
теплоты, отданное горячей водой, лежит между 8500
Дж и 11 500 Дж (Qотдан = 10 000 Дж ± 1500 Дж), то
можно видеть, что эти количества теплоты
совпадают в пределах погрешности эксперимента
(рис. 3).
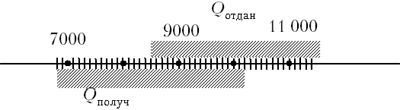
Рис.3
-
Определение сопротивления резистора.
Пусть измеренные значения напряжения и силы тока
следующие:
– U = 2,60 В ± 0,15 В (инструментальная
погрешность 0,15 В; погрешность отсчёта может быть
взята равной 0,05 В, т.е. в 3 раза меньше
инструментальной, поэтому ею можно пренебречь);
– I = 1,2 А ± 0,1 А (инструментальная
погрешность 0,05 А, погрешность отсчёта 0,05 А).
Тогда для сопротивления получаем:
![]()
Но на самом резисторе написано: «2 ± 0,1 ![]() ». Получается, что
». Получается, что
мы неверно определили сопротивление? Рассчитаем
погрешность нашего определения значения
сопротивления:
Uв = 2,75 В; Uн = 2,45 В; Iв
= 1,3 А, Iн = 1,1 А;
![]()
Полученное экспериментально значение
сопротивления R = (2,2 ± 0,3) Ом совпадает в
пределах погрешности со значением R = (2,0 ± 0,1)
Ом, указанным на резисторе.
С помощью метода границ можно вывести
и формулы для погрешности при обобщении темы
«Определение погрешности косвенных измерений»,
но уже в 9-м классе.
Определение погрешности разности. Пусть
А = В – С. Рассчитаем погрешность А в
общем виде:
Ав = Вв – Сн
= (В + ![]() В)
В)
– (С – ![]() С)
С)
= (В – С) + (![]() В
В
+ ![]() С);
С);
Ан = Вн – Св
= (В – ![]() В)
В)
– (С + ![]() С)
С)
= (В – С) – (![]() В
В
+ ![]() С);
С);
![]()
Полученное очень важно: в некоторых
работах в формулах для вычисления результата
встречается разность двух близких по значению
величин, что приводит к большой относительной
погрешности результата.
-
В cтарой работе «Определение модуля
Юнга резины» [11] удлинение резинового жгута
находилось как разность его результирующей и
начальной длин. Если условия опыта таковы, что
эта разность мала, например, составляет 1,5 см, то
относительная погрешность определения разности (погрешность
(погрешность
отсчёта взята гораздо меньше инструментальной
погрешности). Ясно, что такое измерение
использовать для определения модуля Юнга
нежелательно, – может получиться погрешность
больше 100%. Лучше увеличить нагрузку на жгут.
Аналогичная проблема возникает в работе
«Измерение ЭДС и внутреннего сопротивления
источника» [2] (одно сопротивление должно быть в
несколько раз больше другого) и др.
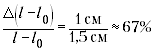
Определение погрешности частного
двух величин. Пусть ![]() Рассчитаем погрешность в общем виде:
Рассчитаем погрешность в общем виде:
![]()
Такую формулу трудно запоминать.
Поэтому найдём относительную погрешность
величины А:
![]()
Итак, относительная погрешность
частного равна сумме относительных погрешностей
величин, входящих в него. Такая же формула
получается и для относительной погрешности
произведения.
Важным я считаю не сам процесс расчёта
погрешности. Эти формулы дают мощный инструмент
для оценки обоснованности проведения
эксперимента. При их использовании легко
объяснить, при измерении какой из величин
следует увеличить точность, чтобы получить
лучший результат.
Рассмотрим формулу для нахождения
модуля Юнга: 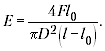
Если воспользоваться для расчёта погрешности
результата методом границ, то неясным останется,
какая из величин в формуле вносит наибольшую
погрешность.
Для нахождения относительной
погрешности результата лучше воспользоваться
формулой:
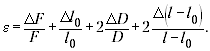
При подстановке значений оказывается,
что слагаемое 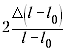
даёт максимальный вклад в сумму, а остальные
слагаемые в несколько раз меньше, так что ими
можно пренебречь. Если l – l0 будет
невелико, то значение относительной погрешности
окажется очень большим, порой выше 100%. Какой
вывод сделают в таком случае ученики?
Такая ситуация – пример того, как
применение упрощённого способа вычисления
погрешностей может привести к большим ошибкам.
Конечно же, этот эксперимент совершенно
обоснован, с помощью него можно найти модуль
Юнга. Только следует выбрать те измерения, где l
– l0 достаточно велико, и не забыть
пренебречь малыми слагаемыми при расчёте
погрешности.
6. Определение коэффициента
прямой пропорциональности
В лабораторных работах нередко
встречается ситуация, когда необходимо по
графику определить коэффициент
пропорциональности в зависимости одной величины
от другой. И здесь в учебниках встречаются две
ситуации.
В работе «Определение модуля Юнга» [13]
после нахождения модуля Юнга для измерений с
тремя различными нагрузками учащимся
предлагается найти среднее арифметическое трёх
полученных значений. Такой подход ошибочен, т.к.
каждое значение получено с различными
систематическими погрешностями, т.е. с разной
степенью точности. Нельзя суммировать эти
значения «с одинаковым весом». При подобных
вычислениях в теории ошибок находится сумма этих
значений с разными коэффициентами.
Далее, в работе «Измерение жёсткости
пружины» [7] в аналогичной ситуации совершенно
справедливо отмечено, что, поскольку жёсткость
пружины в каждом из опытов получена при разных
условиях, среднее арифметическое этих значений
находить нельзя. И предлагается найти среднее
значение коэффициента жёсткости по графику как
коэффициент пропорциональности. Однако,
поскольку учащиеся не могут найти погрешность
найденного таким образом коэффициента
пропорциональности, предлагается взять в
качестве этой погрешности погрешность
наихудшего результата. Я считаю, что такой подход
не оправдан. Зачем брать погрешность самого
ненадёжного результата, если сам способ
нахождения коэффициента жёсткости из графика
применяется для того, чтобы определить этот
коэффициент наиболее точно? Думаю, авторы просто
не хотели заострять внимание на этом вопросе.
На мой взгляд, для определения
коэффициента пропорциональности по графику
можно предложить несколько вариантов.
Вариант 1. Самый простой, а потому
пригодный для младших классов. Отмечаем на
графике экспериментальные значения с указанием
погрешности. Обращаем внимание учащихся на то,
что если бы мы не нанесли погрешности на графики,
то провести прямую было бы затруднительно. В 7-м
классе достаточно просто отметить тот факт, что
зависимость между двумя величинами прямо
пропорциональна. Но если всё-таки необходимо
найти значение коэффициента пропорциональности,
можно обойтись без расчёта погрешности, отметив
только, что этот способ (многократные измерения
при различных условиях и построение графика)
используется именно для того, чтобы уменьшить
погрешность результата.
Вариант 2. Чертим прямую, находим
экспериментальную точку, которая лежит ближе
всего к прямой, и именно эту точку и считаем самой
точной. Остаётся вычислить результат для неё по
обычным формулам, рассчитав также и погрешность.
Вариант 3. Самый логичный. Пробуем
провести через точки вместе с их погрешностями
две прямые: с наибольшим и с наименьшим наклоном.
Значения коэффициентов для них и будут верхней и
нижней границами для результата. Зная границы,
рассчитываем среднее значение коэффициента и
погрешность. Данная погрешность неявно будет
содержать в себе как систематическую
погрешность экспериментально измеренных
величин, так и случайную погрешность определения
среднего, но уже с учётом точности каждого
результата. Этот вариант годится для
использования в экспериментах, когда
коэффициент должен быть оценён достаточно точно.
Но он достаточно сложен, поэтому не стоит его
использовать во всех случаях.
Вариант 4. Использование
встроенных программ в калькуляторах или готовых
компьютерных программ для вычисления
коэффициентов по методу наименьших квадратов.
Этот способ пригоден для практикума в старших
классах и/или в классах физматпрофиля. К
сожалению, в такие программы, как правило,
встроен метод наименьших квадратов, не
учитывающий погрешностей экспериментальных
точек. Применение имеет смысл в случаях, когда
погрешности всех точек практически одинаковы
или когда доминирующей является случайная
погрешность. Она и будет учтена.
Какой из этих вариантов выбрать, может
решать сам учитель. К счастью, таких работ
довольно мало. Продемонстрируем все эти варианты
на примере.
-
Возьмём данные эксперимента по
зависимости пути от времени равномерного
движения (машинка из конструктора с
электрическим приводом):
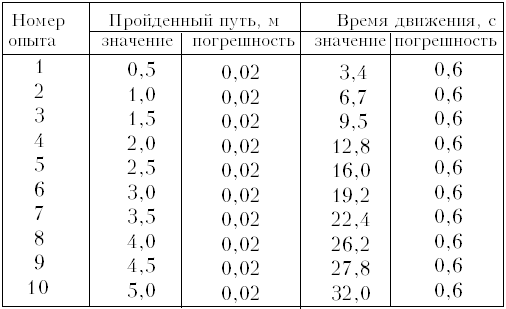
Действуя так, как описано в варианте 1,
строим график (рис. 4).
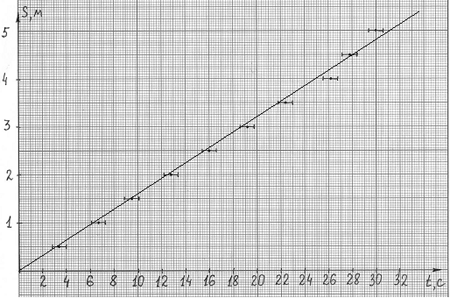
Рис. 4
Так как точек на графике много, можно с
уверенностью утверждать, что 8-я и 10-я точки
являются «выбросами», т.е. измерены небрежно.
Учитывая погрешность эксперимента, можно
провести прямую практически единственным
способом: соответствующая скорость 0,16 м/с. Если
воспользоваться методом наименьших квадратов
(например, встроенной функцией ЛИНЕЙН в
программе MicrosoftExcel), то для коэффициента мы
получим значение 0,158 ± 0,002 м/с (вариант 4).
Для варианта 2 подходит 3-я точка.
Скорость, вычисленная по данным для этой точки,
0,158 м/с. Рассчитаем погрешность: ![]() Так как относительная
Так как относительная
погрешность пути мала по сравнению с
относительной погрешностью времени,
пренебрегаем ею. Абсолютная погрешность
результата: ![]() 0,063
0,063
• 0,158 = 0,010 м/с. То есть скорость, вычисленная в
варианте 2: (0,158 ± 0,010) м/с.
Из приведённого примера видно, что
значения коэффициента пропорциональности
получаются очень близкими. В этом примере
погрешности отдельных измерений были достаточно
малы, а точек, наоборот, было много. Рассмотрим
пример, когда погрешности, напротив, велики, а
количество опытов в силу объективных причин
мало.
-
Найдём плотности пластмассы путём
измерения массы и объёмов тел.
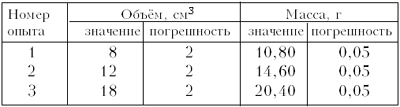
В случае варианта 1 прямую проводим
так, чтобы количество точек над и под прямой было
одинаково (рис. 5), т.е. в данном случае – одна
сверху, одна снизу (прямая 1). Плотность в
этом случае равна 1,23 г/см3.

Рис. 5
В случае варианта 2 пригодна 2-я точка.
Для неё значение плотности (1,2 ± 0,2) г/см3.
Вариант 3: проведём прямые 2 и 3.
Для прямой 2 коэффициент пропорциональности
1,09 г/см3 является нижней границей
искомого значения плотности, а для прямой 3
(1,27 г/см3) – верхней. Полусумма этих
значений есть значение плотности (1,18 г/см3),
а полуразность – значение погрешности (0,09 г/см3).
Вариант 4 в данном случае менее
пригоден, т.к. не учитывает больших значений
погрешностей при измерении объёма с помощью
мерного цилиндра, но и в этом варианте плотность
(1,18 ± 0,05) г/см3.
Следует заметить, что в двух последних
примерах на графиках были обозначены только
погрешности вдоль горизонтальной оси, т.к.
погрешности значений второй переменной были
очень малы.
Послесловие
Научиться обрабатывать результаты
экспериментов учащиеся могут, лишь обрабатывая
результаты экспериментов. Это означает, что
помимо стандартного набора лабораторных работ
необходимо проводить много фронтальных и
демонстрационных экспериментов с обработкой
результатов. Это большая работа, и я хочу
пожелать успехов всем учителям, кто вступит на
этот путь или уже стоит на нём.
Литература
1. Анофрикова С.В., Стефанова Г.П.
Практическая методика преподавания физики.
Часть первая. – Астрахань: Издательство
Астраханского ГПИ, 1995.
2. Физика: Под ред. А.А.Пинского: Учебник
для 10 кл. школ и классов с угл. изучением физики. –
М.: Просвещение, 2002.
3. Попова О.Н. Обучение учащихся
выявлению устойчивых связей и отношений между
физическими величинами: Методическое пособие
для учителей физики. – Элиста: Элистинский лицей,
1998.
4. Анофрикова С.В. Азбука
учительской деятельности, иллюстрированная
примерами деятельности учителя физики. Ч. 1.
Разработка уроков. – М.: МПГУ, 2001.
5. Пёрышкин А.В. Физика-8. – М.:
Дрофа, 2004.
6. Громов С.В., Родина Н.А. Физика-8.
– М.: Просвещение, 2000.
7. Кикоин И.К., Кикоин А.К. Физика-10.
Механика. – М.: Просвещение, 2001.
8. Фронтальные лабораторные занятия по
физике в 7–11 классах общеобразовательных
учреждений. Книга для учителя: Под ред. В.А.Бурова,
Г.Г.Никифорова. – М.: Просвещение, Учебная
литература, 1996.
9. Зайдель А.Н. Элементарные оценки
ошибок измерений. – Л.: Наука, 1967.
10. Хорозов С.А. Работа над
ошибками: В кн. «Энциклопедия для детей», т. 16
«Физика», ч. 1 «Биография физики. Путешествие в
глубь материи. Механистическая картина мира». –
М.: Аванта+, 2000.
11. Мякишев Г.Я., Буховцев Б.Б., Сотский
Н.Н. Физика-10. – М.: Просвещение, 2004.
12. Кирик Л.А. Физика-9: Методические
материалы. – М.: Илекса, 2003.
13. Шахмаев Н.М., Шахмаев С.Н., Шодиев
Д.Ш. Физика-10. – М.: Просвещение, 1994.
Случайные погрешности в лабораторных работах по физике можно оценивать только с использованием калькулятора
О теории случайных погрешностей
Теория случайных погрешностей была создана К.Ф.Гауссом в первой половине XIX в. в связи с его занятиями астрономией и геодезией.
Напомним, что случайные погрешности δi = xi — a проявляются при проведении серии измерений одной и той же физической величины в неизменных условиях одним и тем же методом.
Одним из фундаментальных положений теории Гаусса является «принцип арифметической середины». В соответствии с этим принципом за истинное значение величины а принимается среднее значение
![]()
при n → ∞, если метод не сопровождается систематическими погрешностями.
Для случайных погрешностей характерны следующие свойства:
- Положительные и отрицательные случайные погрешности встречаются с одинаковой вероятностью, т. е. одинаково часто.
- Среднее арифметическое из алгебраической суммы случайных погрешностей при неограниченном возрастании числа наблюдений стремится к нулю, т. е.

- Малые по абсолютной величине случайные погрешности встречаются с большей вероятностью, чем большие.
Основная идея теории Гаусса может быть выражена следующим образом
Возможные конкретные значения случайной погрешности, как и сам результат измерения, предсказать невозможно. Однако после того как экспериментатор определил измеряемый параметр и метод его измерения, сразу «возник» объективный закон, неизвестный исследователю. Этот закон определяет совокупность случайных погрешностей, которые возникают в процессе измерений.
Всегда можно эмпирически (на конкретных опытах) выявить закон распределения случайных погрешностей, который обычно выражается в виде так называемой функции распределения f(δ). Этот закон позволяет определить вероятность, с которой погрешность может оказаться в интервале от δ1 до δ2. Вероятность эта равна площади заштрихованной криволинейной трапеции, представленной на графике функции распределения.

Гауссу удалось определить универсальный закон распределения, которому подчиняется огромный класс случайных погрешностей измерений самых разных величин различными методами.
Этот закон носит название нормального закона распределения. Конечно, существуют измерения, погрешность которых не распределена по нормальному закону. Однако всегда можно определить степень их отклонения от нормального закона.
Функция распределения φ(δ), открытая Гауссом, имеет следующие свойства:

1) Функция δ(φ) четная, т. е. δ-(φ-)δ(φ), и в силу этого симметрична относительно оси координат.
2) Функция δ(φ) имеет максимум при значениях случайной погрешности, равных нулю.
3) Функция δ(φ) имеет две точки перегиба, расположенные симметрично относительно оси координат. Координаты точек перегиба равны ±σ.
4) Касательные к кривой δ(φ) в точках перегиба отсекают на оси абcцисс отрезки, равные ±2σ.
5) Максимальное значение функции δ(φ) равно
![]()
6) Площадь под всей кривой δ(φ) стремится к 1. Площадь криволинейной трапеции, ограниченной прямыми, проходящими через точки δ1,2 = ±σ, составляет 0,68 от всей площади; если прямые проходят через точки δ3,4 = ±2σ, то площадь составляет 0,95; площадь криволинейной трапеции, ограниченной прямыми δ5,6 = ±3σ, равна 0,99.
Параметр σ, определяющий все фундаментальные свойства нормального закона, называется средним квадратическим отклонением. Этот параметр может быть определен после получения достаточно большой серии результатов измерений x1, х2, х3, …, хn. Тогда

Важность параметра σ состоит в том, что он позволяет определить границы случайных погрешностей. Действительно, вероятность получения случайных погрешностей, превосходящих по абсолютной величине 3σ, равна 1%.
При обычной организации измерений не представляется возможности провести не только бесконечно большое число измерений, но и провести просто большое их число.
Специальные исследования показали, что такая граница может быть определена при небольшом числе опытов в серии.
В такой серии из k измерений находят так называемую среднюю квадратичную погрешность

Затем Δхкв увеличивают в S раз.
Число S называется коэффициентом Стьюдента (коэффициент был предложен в 1908 г. английским математиком В. С. Госсетом, публиковавшим свои работы под псевдонимом Стьюдент — студент). Коэффициент Стьюдента позволяет определить границу случайной погрешности серии: Δхслуч = S Δхкв.
Таблица коэффициентов S для различного числа опытов в серии

Погрешность среднего арифметического
После проведения серии равноточных измерений и нахождения хср и σ легко определяется интервал, к которому с вероятностью 99% принадлежит результат любого следующего измерения. Этот интервал равен [хср ± 3σ], если в серии достаточно много измерений, и имеет вид [хср ± S Δхкв] при небольшом числе опытов. Это означает, что 3σ (или S Δхкв) характеризует погрешность каждого опыта серии. Итак, среднее квадратичное отклонение серии опытов есть погрешность каждого опыта серии. Именно поэтому вводится обозначение σх или ΔSкв.х. Однако среднее арифметическое есть разумная комбинация всех измерений, и поэтому следует ожидать, что истинное значение находится в более узком интервале около хср, чем [xcp ± 3σх].
Понять, почему должно быть именно так, помогут следующие рассуждения
Выполняется N серий по n опытов в каждой. В каждой серии из n опытов определяется среднее значение хср. Таких средних значений получается N: хср1, хср2, …, xcpN. Для этой совокупности средних определяется среднее квадратичное отклонение
![]()
Погрешность среднего арифметического
После проведения серии равноточных измерений и нахождения хср и σ легко определяется интервал, к которому с вероятностью 99% принадлежит результат любого следующего измерения. Этот интервал равен [хср ± 3σ], если в серии достаточно много измерений, и имеет вид [хср ± S Δхкв] при небольшом числе опытов. Это означает, что 3σ (или S Δхкв) характеризует погрешность каждого опыта серии. Итак, среднее квадратичное отклонение серии опытов есть погрешность каждого опыта серии. Именно поэтому вводится обозначение σх или ΔSкв.х. Однако среднее арифметическое есть разумная комбинация всех измерений, и поэтому следует ожидать, что истинное значение находится в более узком интервале около хср, чем [xcp ± 3σх].
Понять, почему должно быть именно так, помогут следующие рассуждения
Выполняется N серий по n опытов в каждой. В каждой серии из n опытов определяется среднее значение хср. Таких средних значений получается N: хср1, хср2, …, xcpN. Для этой совокупности средних определяется среднее квадратичное отклонение

Величина σх ср характеризует предельное распределение средних значений, это и есть величина, которая позволяет найти интервал, в котором находится истинное значение измеряемой в опыте величины [хср ± 3σх ср]. На практике такая процедура никогда не реализуется не только потому, что это очень трудоемко, но и потому, что теория погрешностей позволяет по результатам одной серии определить погрешность среднего. Это делается на основе фундаментального результата теории погрешностей:
стандартное отклонение среднего σх ср в ![]() раз меньше стандартного отклонения каждого опыта серии σх, т.е.
раз меньше стандартного отклонения каждого опыта серии σх, т.е.
![]() раз меньше стандартного отклонения каждого опыта серии σх, т.е.
раз меньше стандартного отклонения каждого опыта серии σх, т.е.

Итак, если в серии с достаточно большим числом опытов определено хср, то граница случайной погрешности среднего равна
![]()
Если в серии небольшое число опытов, то граница случайной погрешности среднего находится по формуле:

Все расчеты случайных погрешностей возможны только с использованием режима статистических расчетов (см. раздел «Статистические расчеты»), следуя методическим рекомендациям, приведенным ниже.
Использование калькулятора CASIO fx-82EX СLASSWIZ для оценки случайных погрешностей
- Включаем калькулятор, клавиша [ON]
- Нажимаем клавишу [SHIFT](SETUP)
- Входим в режим статистики. Нажимаем клавишу [2]
- Выбираем режим 1-Variable. Нажимаем клавишу [1]
- Заполняем таблицу
- Нажимаем клавишу [OPTN]
- Выбираем режим 1-Variable. Нажимаем клавишу [3]
- На дисплее получаем ряд характеристик
8.1. Первая сверху — значение среднего значения
Все расчеты случайных погрешностей возможны только с использованием режима статистических расчетов (см. раздел «Статистические расчеты»), следуя методическим рекомендациям, приведенным ниже.
Использование калькулятора CASIO fx-82EX СLASSWIZ для оценки случайных погрешностей
- Включаем калькулятор, клавиша [ON]
- Нажимаем клавишу [SHIFT](SETUP)
- Входим в режим статистики. Нажимаем клавишу [2]
- Выбираем режим 1-Variable. Нажимаем клавишу [1]
- Заполняем таблицу
- Нажимаем клавишу [OPTN]
- Выбираем режим 1-Variable. Нажимаем клавишу [3]
- На дисплее получаем ряд характеристик
8.1. Первая сверху — значение среднего значения
8.2. Вторая снизу — случайная погрешность каждого опыта серии σх - Вычисляем погрешность среднего

- Находим границу случайной погрешности среднего

Пример
Измерялась скорость тела, брошенного горизонтально. В десяти опытах были получены следующие значения дальности полета L (в мм): 250, 245, 250, 262, 245, 248, 262, 260, 260, 248. Дальность полета тела измерялась линейкой с основной погрешностью Δ1 = 1мм. Высота, с которой брошено тело, в опыте равнялась Н = 1 м и измерялась мерной лентой с основной погрешностью Δ2 = 1 см и ценой деления С2 =1 см.

Решение
Сначала определим среднее значение дальности полета тела и вычислим его начальную скорость. Для этого сведем все данные в таблицу и проведем их первичную обработку.

Так как

Легко определить среднее значение скорости по результатам серии опытов:

Так как
Легко определить среднее значение скорости по результатам серии опытов:
Граница относительной погрешности измерения скорости:

В этой формуле ΔL — граница абсолютной погрешности измерения дальности полета, Δg — погрешность округления g, ΔН — погрешность прямого однократного измерения высоты.
ΔН = 1 см + 0,5 см = 1,5 см
ΔL складывается из погрешности линейки Δ1 и случайной погрешности ΔLслуч.:
ΔL = Δ1 + ΔLслуч.
Так как ΔLкв = 7мм, то при оценке ΔLслуч. нет смысла учитывать погрешность линейки Δ1 = 1мм.
Определим погрешность измерения скорости в любом однократном опыте, который можно провести на данной установке. В этом случае в формулу для εv следует вместо ∆L подставить его границу ∆L = S ∆Lкв. Здесь S = 3,2 (см. таблицу коэффициентов S для различного числа опытов в серии).
Имеем:

В этой формуле ΔL — граница абсолютной погрешности измерения дальности полета, Δg — погрешность округления g, ΔН — погрешность прямого однократного измерения высоты.
ΔН = 1 см + 0,5 см = 1,5 см
ΔL складывается из погрешности линейки Δ1 и случайной погрешности ΔLслуч.:
ΔL = Δ1 + ΔLслуч.
Так как ΔLкв = 7мм, то при оценке ΔLслуч. нет смысла учитывать погрешность линейки Δ1 = 1мм.
Определим погрешность измерения скорости в любом однократном опыте, который можно провести на данной установке. В этом случае в формулу для εv следует вместо ∆L подставить его границу ∆L = S ∆Lкв. Здесь S = 3,2 (см. таблицу коэффициентов S для различного числа опытов в серии).
Имеем:
Первое слагаемое в этой сумме равно 0,09; слагаемое в скобках (0,01 + 0,0075) = 0,0175. Следовательно, εv = 0,09. Граница абсолютной погрешности каждого опыта серии не превосходит
εv = ε0 = 0,565 ∙ 0,09 = 0,05 м/с
Это значит, если на данной установке провести еще один опыт, то гарантировать можно, что значение скорости, рассчитанное по его результатам, будет принадлежать интервалу [(0,56 — 0,05)м/с; (0,56 + 0,05)м/с].
Найдем границу случайной погрешности среднего значения скорости тела, брошенного горизонтально. Для этого в формулу для εv следует вместо ∆L подставить границу случайной погрешности среднего:
Таким образом,

Относительная погрешность среднего равна
0,027 + 0,01 + 0,0075
Последним слагаемым в этой сумме можно пренебречь. Итак, ср = 0,04 = 4%. Мы видим, что погрешность среднего в два раза меньше погрешности каждого опыта. Граница абсолютной погрешности среднего равна:

Таким образом, из серии 10 опытов по измерению скорости можно сделать вывод о том, что в любой другой такой серии из 10 опытов на данной установке среднее значение скорости будет находиться в интервале [(0,56 — 0,02)м/с; (0,56 + 0,02)м/с]. Этому же интервалу принадлежит неизвестное значение скорости, которое получится, если проделать серию с очень большим числом опытов, т. е. такое значение, которое можно назвать истинным значением.





