
Дефекты программного обеспечения можно обнаружить на каждом этапе разработки и тестирования продукта. Чтобы гарантировать исправление наиболее серьезных дефектов программного обеспечения, тестировщикам важно иметь хорошее представление о различных типах дефектов, которые могут возникнуть.

В этой статье мы обсудим самые распространенные типы ПО дефекты и способы их выявления.
Что такое дефект?
Дефект программного обеспечения — это ошибка, изъян, сбой или неисправность в компьютерной программе, из-за которой она выдает неправильный или неожиданный результат или ведет себя непреднамеренным образом. Программная ошибка возникает, когда фактические результаты не совпадают с ожидаемыми. Разработчики и программисты иногда допускают ошибки, которые создают ошибки, называемые дефектами. Большинство ошибок возникает из-за ошибок, которые допускают разработчики или программисты.
Обязательно прочтите: Разница между дефектом, ошибкой, ошибкой и сбоем
Типы программных ошибок при тестировании программного обеспечения
Существует множество различных типов дефектов программного обеспечения, и тестировщикам важно знать наиболее распространенные из них, чтобы они могут эффективно тестировать их.
Ошибки программного обеспечения подразделяются на три типа:
- Дефекты программного обеспечения по своей природе
- Дефекты программного обеспечения по их приоритету
- Дефекты программного обеспечения по их серьезности
Обычно мы можем видеть приоритет и серьезность классификаторов в большинстве инструментов отслеживания ошибок. Если мы настроим классификатор в соответствии с характером ошибки, а также приоритетом и серьезностью, это поможет легко управлять распределением обязанностей по исправлению ошибок соответствующим командам.
#1. Дефекты программного обеспечения по своей природе
Ошибки в программном обеспечении имеют широкий спектр природы, каждая из которых имеет свой собственный набор симптомов. Несмотря на то, что таких багов много, сталкиваться с ними можно не часто. Вот наиболее распространенные ошибки программного обеспечения, классифицированные по характеру, с которыми вы, скорее всего, столкнетесь при тестировании программного обеспечения.
#1. Функциональные ошибки
Как следует из названия, функциональные ошибки — это те, которые вызывают сбои в работе программного обеспечения. Хорошим примером этого может служить кнопка, при нажатии на которую должно открываться новое окно, но вместо этого ничего не происходит.
Функциональные ошибки можно исправить, выполнив функциональное тестирование.
#2. Ошибки на уровне модуля
Ошибки на уровне модуля — это дефекты, связанные с функциональностью отдельного программного модуля. Программный модуль — это наименьшая тестируемая часть приложения. Примеры программных модулей включают классы, методы и процедуры. Ошибки на уровне подразделения могут существенно повлиять на общее качество программного обеспечения.
Ошибки на уровне модуля можно исправить, выполнив модульное тестирование.
#3. Ошибки уровня интеграции
Ошибки уровня интеграции — это дефекты, возникающие при объединении двух или более программных модулей. Эти дефекты может быть трудно найти и исправить, потому что они часто требуют координации между несколькими командами. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки интеграции можно исправить, выполнив интеграционное тестирование.
#4. Дефекты юзабилити
Ошибки юзабилити — это дефекты, влияющие на работу пользователя с программным обеспечением и затрудняющие его использование. Дефект юзабилити — это дефект пользовательского опыта программного обеспечения, который затрудняет его использование. Ошибки юзабилити — это такие ошибки, как если веб-сайт сложен для доступа или обойти, или процесс регистрации сложен для прохождения.
Во время тестирования удобства использования тестировщики программного обеспечения проверяют приложения на соответствие требованиям пользователей и Руководству по доступности веб-контента (WCAG) для выявления таких проблем. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки, связанные с удобством использования, можно исправить, выполнив тестирование удобства использования.
#5. Дефекты производительности
Ошибки производительности — это дефекты, влияющие на производительность программного обеспечения. Это может включать в себя такие вещи, как скорость программного обеспечения, объем используемой памяти или количество потребляемых ресурсов. Ошибки уровня производительности сложно отследить и исправить, поскольку они могут быть вызваны рядом различных факторов.
Ошибки юзабилити можно исправить, выполнив тестирование производительности.
#6. Дефекты безопасности
Ошибки безопасности — это тип дефекта программного обеспечения, который может иметь серьезные последствия, если его не устранить. Эти дефекты могут позволить злоумышленникам получить доступ к конфиденциальным данным или системам или даже позволить им получить контроль над уязвимым программным обеспечением. Таким образом, очень важно, чтобы ошибкам уровня безопасности уделялось первоочередное внимание и устранялись как можно скорее.
Ошибки безопасности можно исправить, выполнив тестирование безопасности.
#7. Дефекты совместимости
Дефекты совместимости — это те ошибки, которые возникают, когда приложение несовместимо с оборудованием, на котором оно работает, или с другим программным обеспечением, с которым оно должно взаимодействовать. Несовместимость программного и аппаратного обеспечения может привести к сбоям, потере данных и другому непредсказуемому поведению. Тестировщики должны знать о проблемах совместимости и проводить соответствующие тесты. Программное приложение, имеющее проблемы с совместимостью, не работает последовательно на различных видах оборудования, операционных системах, веб-браузерах и устройствах при подключении к определенным программам или работе в определенных сетевых условиях.
Ошибки совместимости можно исправить, выполнение тестирования совместимости.
#8. Синтаксические ошибки
Синтаксические ошибки являются самым основным типом дефекта. Они возникают, когда код нарушает правила языка программирования. Например, использование неправильной пунктуации или забывание закрыть скобку может привести к синтаксической ошибке. Синтаксические ошибки обычно мешают запуску кода, поэтому их относительно легко обнаружить и исправить.
#9. Логические ошибки
Логические ошибки — это дефекты, из-за которых программа выдает неправильные результаты. Эти ошибки может быть трудно найти и исправить, потому что они часто не приводят к каким-либо видимым ошибкам. Логические ошибки могут возникать в любом типе программного обеспечения, но они особенно распространены в приложениях, требующих сложных вычислений или принятия решений.
Общие симптомы логических ошибок включают:
- Неверные результаты или выходные данные
- Неожиданное поведение
- Сбой или зависание программного обеспечения
Чтобы найти и исправить логические ошибки, тестировщикам необходимо иметь четкое представление о коде программы и о том, как она должна работать. Часто лучший способ найти такие ошибки — использовать инструменты отладки или пошаговое выполнение, чтобы отслеживать выполнение программы и видеть, где что-то идет не так.
#2. Дефекты программного обеспечения по степени серьезности
Уровень серьезности присваивается дефекту по его влиянию. В результате серьезность проблемы отражает степень ее влияния на функциональность или работу программного продукта. Дефекты серьезности классифицируются как критические, серьезные, средние и незначительные в зависимости от степени серьезности.
#1. Критические дефекты
Критический дефект — это программная ошибка, имеющая серьезные или катастрофические последствия для работы приложения. Критические дефекты могут привести к сбою, зависанию или некорректной работе приложения. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение критическим дефектам, поскольку их необходимо исправить как можно скорее.
#2. Серьезные дефекты
Серьезный дефект — это программная ошибка, существенно влияющая на работу приложения. Серьезные дефекты могут привести к замедлению работы приложения или другому неожиданному поведению. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение серьезным дефектам, поскольку их необходимо исправить как можно скорее.
#3. Незначительные дефекты
Незначительный дефект — это программная ошибка, которая оказывает небольшое или незначительное влияние на работу приложения. Незначительные дефекты могут привести к тому, что приложение будет работать немного медленнее или демонстрировать другое неожиданное поведение. Разработчики и тестировщики часто не придают незначительным дефектам приоритет, потому что их можно исправить позже.
#4. Тривиальные дефекты
Тривиальный дефект – это программная ошибка, не влияющая на работу приложения. Тривиальные дефекты могут привести к тому, что приложение отобразит сообщение об ошибке или проявит другое неожиданное поведение. Разработчики и тестировщики часто присваивают тривиальным дефектам самый низкий приоритет, потому что они могут быть исправлены позже.
#3. Дефекты программного обеспечения по приоритету
#1. Дефекты с низким приоритетом
Дефекты с низким приоритетом, как правило, не оказывают серьезного влияния на работу программного обеспечения и могут быть отложены для исправления в следующей версии или выпуске. В эту категорию попадают косметические ошибки, такие как орфографические ошибки, неправильное выравнивание и т. д.
#2. Дефекты со средним приоритетом
Дефекты со средним приоритетом — это ошибки, которые могут быть исправлены после предстоящего выпуска или в следующем выпуске. Приложение, возвращающее ожидаемый результат, которое, однако, неправильно форматируется в конкретном браузере, является примером дефекта со средним приоритетом.
#3. Дефекты с высоким приоритетом
Как следует из названия, дефекты с высоким приоритетом — это те, которые сильно влияют на функционирование программного обеспечения. В большинстве случаев эти дефекты необходимо исправлять немедленно, так как они могут привести к серьезным нарушениям нормального рабочего процесса. Дефекты с высоким приоритетом обычно классифицируются как непреодолимые, так как они могут помешать пользователю продолжить выполнение поставленной задачи.
Некоторые распространенные примеры дефектов с высоким приоритетом включают:
- Дефекты, из-за которых приложение не работает. сбой
- Дефекты, препятствующие выполнению задачи пользователем
- Дефекты, приводящие к потере или повреждению данных
- Дефекты, раскрывающие конфиденциальную информацию неавторизованным пользователям
- Дефекты, делающие возможным несанкционированный доступ к системе
- Дефекты, приводящие к потере функциональности
- Дефекты, приводящие к неправильным результатам или неточным данным
- Дефекты, вызывающие проблемы с производительностью, такие как чрезмерное использование памяти или медленное время отклика
#4. Срочные дефекты
Срочные дефекты — это дефекты, которые необходимо устранить в течение 24 часов после сообщения о них. В эту категорию попадают дефекты со статусом критической серьезности. Однако дефекты с низким уровнем серьезности также могут быть классифицированы как высокоприоритетные. Например, опечатка в названии компании на домашней странице приложения не оказывает технического влияния на программное обеспечение, но оказывает существенное влияние на бизнес, поэтому считается срочной.
#4. Дополнительные дефекты
#1. Отсутствующие дефекты
Отсутствующие дефекты возникают из-за требований, которые не были включены в продукт. Они также считаются несоответствиями спецификации проекта и обычно негативно сказываются на пользовательском опыте или качестве программного обеспечения.
#2. Неправильные дефекты
Неправильные дефекты — это те дефекты, которые удовлетворяют требованиям, но не должным образом. Это означает, что хотя функциональность достигается в соответствии с требованиями, но не соответствует ожиданиям пользователя.
#3. Дефекты регрессии
Дефект регрессии возникает, когда изменение кода вызывает непреднамеренное воздействие на независимую часть программного обеспечения.
Часто задаваемые вопросы — Типы программных ошибок< /h2>
Почему так важна правильная классификация дефектов?
Правильная классификация дефектов важна, поскольку она помогает эффективно использовать ресурсы и управлять ими, правильно приоритизировать дефекты и поддерживать качество программного продукта.
Команды тестирования программного обеспечения в различных организациях используют различные инструменты отслеживания дефектов, такие как Jira, для отслеживания дефектов и управления ими. Несмотря на то, что в этих инструментах есть несколько вариантов классификации дефектов по умолчанию, они не всегда могут наилучшим образом соответствовать конкретным потребностям организации.
Следовательно, важно сначала определить и понять типы дефектов программного обеспечения, которые наиболее важны для организации, а затем соответствующим образом настроить инструмент управления дефектами.
Правильная классификация дефектов также гарантирует, что команда разработчиков сможет сосредоточиться на критических дефектах и исправить их до того, как они повлияют на конечных пользователей.
Кроме того, это также помогает определить потенциальные области улучшения в процессе разработки программного обеспечения, что может помочь предотвратить появление подобных дефектов в будущих выпусках.
Таким образом, отслеживание и устранение дефектов программного обеспечения может показаться утомительной и трудоемкой задачей. , правильное выполнение может существенно повлиять на качество конечного продукта.
Как найти лежащие в основе ошибки программного обеспечения?
Определение основной причины программной ошибки может быть сложной задачей даже для опытных разработчиков. Чтобы найти лежащие в основе программные ошибки, тестировщики должны применять систематический подход. В этот процесс входят различные этапы:
1) Репликация. Первым этапом является воспроизведение ошибки. Это включает в себя попытку воспроизвести тот же набор шагов, в котором возникла ошибка. Это поможет проверить, является ли ошибка реальной или нет.
2) Изоляция. После того, как ошибка воспроизведена, следующим шагом будет попытка ее изоляции. Это включает в себя выяснение того, что именно вызывает ошибку. Для этого тестировщики должны задать себе несколько вопросов, например:
– Какие входные данные вызывают ошибку?
– При каких различных условиях возникает ошибка?
– Каковы различные способы проявления ошибки?
3) Анализ: после Изолируя ошибку, следующим шагом будет ее анализ. Это включает в себя понимание того, почему возникает ошибка. Тестировщики должны задать себе несколько вопросов, таких как:
– Какова основная причина ошибки?
– Какими способами можно исправить ошибку?
– Какое исправление было бы наиболее эффективным? эффективно?
4) Отчет. После анализа ошибки следующим шагом является сообщение о ней. Это включает в себя создание отчета об ошибке, который включает всю соответствующую информацию об ошибке. Отчет должен быть четким и кратким, чтобы разработчики могли его легко понять.
5) Проверка. После сообщения об ошибке следующим шагом является проверка того, была ли она исправлена. Это включает в себя повторное тестирование программного обеспечения, чтобы убедиться, что ошибка все еще существует. Если ошибка исправлена, то тестер может подтвердить это и закрыть отчет об ошибке. Если ошибка все еще существует, тестировщик может повторно открыть отчет об ошибке.
Заключение
В индустрии программного обеспечения дефекты — неизбежная реальность. Однако благодаря тщательному анализу и пониманию их характера, серьезности и приоритета дефектами можно управлять, чтобы свести к минимуму их влияние на конечный продукт.
Задавая правильные вопросы и применяя правильные методы, тестировщики могут помочь обеспечить чтобы дефекты обнаруживались и исправлялись как можно раньше в процессе разработки.
TAG: qa
Error: A discrepancy between a computed, observed, or measured value or condition and the true, specified, or theoretically correct value or condition. This can be a misunderstanding of the internal state of the software, an oversight in terms of memory management, confusion about the proper way to calculate a value, etc.
Failure: The inability of a system or component to perform its required functions within specified performance requirements. See: bug, crash, exception, and fault.
Bug: A fault in a program which causes the program to perform in an unintended or unanticipated manner. See: anomaly, defect, error, exception, and fault. Bug is terminology of Tester.
Fault: An incorrect step, process, or data definition in a computer program which causes the program to perform in an unintended or unanticipated manner. See: bug, defect, error, exception.
Defect:Commonly refers to several troubles with the software products, with its external behavior or with its internal features.
Поиск
Новые материалы
 С дефектами та же ситуация, что и с тест кейсами – нужно знать что такое дефект, для чего он нужен (и когда нужен), как и из чего он формируется. Пожалуй это основные вопросы на интервью по теме дефектов и их обязательно нужно разобрать во время подготовки к собеседованию. Также в случае с дефектом важно представлять его жизненный цикл – переходы по статусам, кто и в какой момент подключается к работе над дефектом. Понимание жизненного цикла дефекта очень важно не только для прохождения собеседования, но и для ежедневной работы. Далее рассмотрим все эти пункты и вопросы по порядку.
С дефектами та же ситуация, что и с тест кейсами – нужно знать что такое дефект, для чего он нужен (и когда нужен), как и из чего он формируется. Пожалуй это основные вопросы на интервью по теме дефектов и их обязательно нужно разобрать во время подготовки к собеседованию. Также в случае с дефектом важно представлять его жизненный цикл – переходы по статусам, кто и в какой момент подключается к работе над дефектом. Понимание жизненного цикла дефекта очень важно не только для прохождения собеседования, но и для ежедневной работы. Далее рассмотрим все эти пункты и вопросы по порядку.

1. Что такое дефект и ошибка?
- Дефект (Defect, Bug Report) – это документ, в котором описано неправильное поведение тестируемой системы или ПО. Не нужно путать дефект с ошибкойбагом. В терминологии тестирования ПО ошибка или баг — это непосредственно проблема ПО (например, ошибка в коде), а дефект — это описание данной проблемы.
2. Для чего необходимо описывать дефекты?
- Описывая ошибку мы даем возможность другому человеку воспроизвести тот же результат и убедиться в наличии проблемы. Такое описание необходимо аналитикам, чтобы убедиться в том, что требования действительно не выполняются а также разработчикам, чтобы понять что и как им исправлять
- Когда мы получаем исправленное ПО для повторной проверки, детальное описание ошибки дает возможность ничего не забыть и убедиться, что все действительно исправлено
- Имея описание ошибки (даже уже исправленной ранее) мы можем повторно проверить, что она не повторяется в новой версии ПО. По такому принципу можно строить скоп регрессионного тестирования
3. Как формируется дефект и из чего он состоит?
- Для описания дефектов могут использоваться как специализированные программы (Bugzilla, HP ALM, Redmine, JIRA и д.р.), так и обычные офисные приложения типа Excel, Word и даже Notepad. Вне зависимости от средств и систем для описания дефекта самым важным будет наличие основных параметров и полей, таких как (список основных атрибутов дефекта также приведен на схеме Шаблон типового дефекта):
- Номер и краткое описание дефекта
- Версия ПО и название модулякомпонентаприложения
- Серьезность (Severity) и срочность (Priority) ошибки. На вопросе различия Severity и Priority остановимся немного подробнее, т.к. он очень часто возникает на собеседовании. В этом случае Severity – показывает насколько ошибка критична для работоспособности всей системы (например, Severity=Blocker), а Priority – говорить как быстро ошибку необходимо исправить с точки зрения планов проекта. Тут главное понимать и помнить, что высокая срочность не означает, что ошибка серьезная как и наоборот – серьезность не говорит, что дефект необходимо исправлять в первую очередь. Например, ошибка серьезная и блокирует часть функциональности новой системы, однако в ближайшем релизе мы не планируем выпускать этот функционал. В этом случае более срочным будет исправление ошибок в той части, которая войдет в релиз, пусть даже эти ошибки будут локальными и не такими значительными. Обычно используются следующие варианты серьезности и срочности:
- Severity = Blocker, Critical, Major, Minor, Trivial
- Priority = High, Medium, Low
- Ссылка на требование, нарушение которого описано в дефекте
- Автор дефекта, тот кто обнаружил и описал ошибку
- Описание конфигурации и состояния системы, при котором удалось обнаружить ошибку
- Детальное описание самой ошибки, которое состоит из:
- Шагов по воспроизведению ошибки
- Ожидаемого результата (в соответствии с требованиями)
- Фактического результата, который мы наблюдаем
- Дополнительным плюсом будут различные логи и скриншоты экрана, которые помогут увидеть, как проявилась ошибка. Любой разработчик точно скажет за это спасибо.
4. Жизненный цикл дефектов – это последовательность перехода дефекта между разными статусами и специалистами, которые с ним работают. Типичный жизненный цикл дефекта представлен на схеме Жизненный цикл дефекта.
Список требований к тестировщику ПО
- Требования к тестировщику ч.1: ожидания и вопросы на собеседовании
- Требования к тестировщику ч.2: процессы и этапы разработки ПО
- Требования к тестировщику ч.3: термины и определения
- Требования к тестировщику ч.4: этапы тестирования ПО
- Требования к тестировщику ч.5: среды тестирования
- Требования к тестировщику ч.6: инструменты тестирования ПО
-
Требования к тестировщику ч.7: разработка тестов
- Требования к тестировщику ч.8: дефекты и ошибки ПО
- Требования к тестировщику ч.9: оценка времени на тестирование
- Требования к тестировщику ч.10: мотивация кандидата
-
Подготовка и прохождение собеседования -
Требования к тестировщику ПО -
04 февраля 2017
О проекте
- Проведение тренингов и вебинаров: QA, Time management, People management, Agile
- Консалтинг в области организации рабочих процессов в ИТ
- Проведение и подготовка к собеседованиям
Информация об авторе проекта
Последние новости
Контакты
Группа вконтакте
Лекция 61
Различные подходы к тестированию ПО
Основные понятия процесса тестирования
Тестироваться могут самые разные представления знаний о разрабатываемой или сопровождаемой программе на любой фазе ее жизненного цикла. Это могут быть требования к программному продукту, cпецификации проекта или структур данных, фрагменты программного кода.
В литературе имеется несколько различных определений понятия “тестирование”. Будем использовать следующее:
Определение. Тестирование – это контролируемое выполнение программы на конечном множестве наборов данных и анализ результатов этого выполнения с целью обнаружения ошибок.
Часто тестирование программы в соответствии с этим определением называют динамическим тестированием, а статический анализ, не требующий выполнения программы (просмотр, инспекция), – статическим тестированием.
Принято выделять методы тестирования и критерии тестирования программного продукта.
Определение. Методы тестирования – это совокупность правил, регламентирующих последовательность шагов по тестированию.
Определение. Критерии тестирования – соображения, позволяющие судить о достаточности проведенного тестирования.
Под ошибкой принято понимать различие между вычисленным, обозреваемым или измеренным значением или условием и действительным, специфицированным или теоретически корректным значением или условием, т.е. в программе имеется ошибка, если ее выполнение не оправдывает ожиданий пользователя.
Любой программный продукт – от простейших приложений до сложных комплексов реального времени, – вряд ли можно считать свободным от ошибок.
Результативным (удачным) считается тест, прогон которого привел к обнаружению ошибки. Из данного свойства теста вытекает важное следствие: тестирование – процесс деструктивный (обратный созидательному, конструктивному). Именно этим объясняется, почему многие считают его трудным. Большинство людей склонны к конструктивному процессу созидания объектов и в меньшей степени – к деструктивному процессу.
При существующих в реальной работе ограничениях на время, стоимость, надежность и т.п. разработки программного продукта ключевым является следующий вопрос тестирования: Какое подмножество всех возможных тестов имеет наивысшую вероятность обнаружения большинства ошибок?
Определение. Тест – это набор входных значений, условий выполнения и ожидаемых значений на выходе, разработанных для проверки конкретного пути выполнения программы.
Программный продукт, как объект тестирования, имеет ряд особенностей, которые отличают процесс тестирования программного обеспечения от традиционного, исторически ранее появившегося “аппаратного” тестирования:
· отсутствие полностью определенного единого эталона, которому должны соответствовать все результаты тестирования проверяемой программы;
На практике для тестирования используются в качестве эталонов косвенные данные, которые не полностью отражают функции и характеристики программ.
· высокая сложность программ и принципиальная невозможность построения тестовых наборов, достаточных для исчерпывающего тестирования;
Комплексы программ, используемые для управления и обработки информации, являются одними из самых сложных изделий, создаваемых человеком. При существующей сложности программ недостижимо исчерпывающее их тестирование, гарантирующее абсолютно полную проверку. Поэтому тестирование проводится в объемах, минимально необходимых для проверки программ в некоторых ограниченных пределах изменения параметров и условий функционирования. Ограниченность ресурсов тестирования привела к необходимости тщательного упорядочивания применяемых методов и конкретных значений параметров с целью получения при тестировании наибольшей глубины проверок программ. Это определяет необходимость применения экономичных и эффективных методов тестирования.
· наличие в программах вычислительных и логических компонент, а также компонент, характеризующихся стохастическим и динамическим поведением;
В сложных программных комплексах практически всегда имеются компоненты, осуществляющие преобразования данных. Кроме того, значительную часть программ составляют схемы принятия логических решений, обработки логических и символьных переменных. В ряде случаев процесс исполнения программ и получаемые результаты зависят от случайного изменения входных и промежуточных данных, а также от реального времени.
· относительно невысокая степень формализации критериев завершения процесса тестирования и оценки качества тестирования.
Показатели качества сложных комплексов программ трудно формализуются и еще более трудно измеряются. Вследствие этого качество процесса тестирования программ и достигаемая при этом их корректность остаются весьма неопределенными и незарегистрированными. Оценки полноты тестирования и достигаемого при этом качества программ обычно получаются в процессе испытаний и сопровождения программ.
Подытоживая перечисленные выше особенности тестирования программного продукта, необходимо подчеркнуть невозможность создания единственного универсального метода тестирования.
На практике приходится применять ряд значительно различающихся методов и критериев тестирования. Каждая категория тестов отличается целевыми задачами тестирования, проверяемыми компонентами программ и методами оценки результатов. Только совместное и систематическое применение различных методов тестирования и категорий тестов, базирующихся на различных критериях тестирования, позволяет достичь высокого качества функционирования средних и сложных программных комплексов со средней или большой длительностью эксплуатации, имеющих большой размер исходного кода (105 — 107 строк в программе).
Сформулируем основные принципы тестирования:
· Описание предполагаемых значений выходных данных или результатов должно быть неотъемлемой частью теста.
· Следует избегать тестирования программы ее автором; тестирование является более эффективным, если оно выполняется не автором программы, но отладка программы обычно более эффективно выполняется авторами.
· Организация не должна сама тестировать разработанные ею программные продукты.
· Необходиимо досконально изучать результаты применения каждого теста.
· Тесты для неправильных и непредусмотренных входных данных следует разрабатывать так же тщательно, как для правильных и предусмотренных данных.
· Необходимо проверять программу на нежелательные побочные эффекты.
· Не следует выбрасывать тесты, даже если программа уже не нужна.
· Нельзя планировать тестирование в предположении, что ошибки не будут обнаружены.
· Вероятность наличия необнаруженных ошибок в части программы пропорциональна числу ошибок, уже обнаруженных в этой части.
Категории тестов для различных объектов тестирования
На разных этапах ЖЦ программного обеспечения для каждой категории объектов тестирования ставятся свои задачи тестирования и, соответственно, применяются свои виды тестирования и категории тестов. Каждая категория имеет специфическое, частное назначение для выявления ошибок определенного класса.
Для описанных выше объектов тестирования выделяются следующие категории тестов:
1) На этапе тестирования спецификаций:
· полноты и согласованности функций программных компонент;
· согласованности интерфейса в спецификациях программных компонент.
2) На этапе тестирования программных модулей:
· структуры программного модуля;
· вычислений и преобразований данных программным модулем;
· полноты функций, выполняемых модулем.
3) На этапе тестирования функциональных групп программ:
· структуры группы программ;
· межмодульного интерфейса в группе программ;
· выполнения ограничений по использованию памяти и длительности исполнения группы программ;
· полноты решения функциональных задач группой программ.
4) На этапе тестирования комплекса программ при отладке:
· полноты решения функциональных задач комплексом программ для типовых исходных данных;
· функционирования программ в критических ситуациях по условиям и логике решения задач;
· корректности использования ресурсов памяти и производительности вычислительной системы;
· параллельного (одновременного) исполнения различных программ;
· эффективности защиты от искажения входных данных;
· определения надежности комплекса программ;
· оценки эффективности защиты от сбоев аппаратуры и не выявленных ошибок программ.
5) На этапе тестирования комплекса программ при испытаниях:
· испытаний на соответствие комплекса программ техническому заданию;
· удобства эксплуатации и взаимодействия человека с комплексом программ;
· удобства установки и подготовки рабочей версии;
· работы комплекса программ при конфигурациях оборудования;
· корректности документации;
· удобства сопровождения и модификации программ.
6) Тестирование при сопровождении комплекса программ осуществляется с использованием практически всех выше перечисленных категорий тестов, характерных для разработки и испытаний комплекса программ. С этой позиции сопровождение является повторением процесса создания программ или его отдельных этапов. Однако при. сопровождении редко применяется вся совокупность систематизированных категорий тестов.
Применение перечисленных выше категорий тестов зависит от класса разрабатываемых программ. Организация и эффективное проведение обширного систематического тестирования требуют больших затрат и высокой квалификации специалистов, которые в области тестируемых программ должны иметь квалификацию не ниже, чем их разработчики.
Одним из общих принципов тестирования ПО является проведение работ по тестированию в течение всего ЖЦ.
Если предполагать, что в программном обеспечении какие-то ошибки все же будут, то лучшая (после предупреждения ошибок) стратегия — включить средства обнаружения ошибок в само про-граммное обеспечение.
Большинство методов направлено по возможности на неза-медлительное обнаружение сбоев. Немедленное обнаружение имеет два преимущества: можно минимизировать влияние ошиб-ки и последующие затруднения для человека, которому придется извлекать информацию о ней, находить ее и исправлять.
{SITELINK-S405}Меры по обнаружению ошибок {/SITELINK}можно разбить на две под-группы: пассивные
попытки обнаружить симптомы ошибки в про-цессе «обычной» работы программного обеспечения и активные
попытки программной системы периодически обследовать свое состояние в поисках признаков ошибок.
Пассивное обнаружение
.
Меры по обнаружению ошибок могут быть приняты на нескольких структурных уровнях программной системы. Здесь мы будем рассматривать уровень подсистем, или ком-понентов, т.е. нас будут интересовать меры по обнаружению симп-томов ошибок, предпринимаемые при переходе от одного компо-нента к другому, а также внутри компонента. Все это, конечно, при-менимо также к отдельным модулям внутри компонента.
Разрабатывая эти меры, мы будем опираться на следующее.
1. Взаимное недоверие.
Каждый из компонентов должен пред-полагать, что все другие содержат ошибки. Когда он получает какие-нибудь данные от другого компонента или из источника вне системы, он должен предполагать, что данные могут быть неправильными, и пытаться найти в них ошибки.
2.
Немедленное обнаружение.
Ошибки необходимо обнаружить как можно раньше. Это не только ограничивает наносимый ими ущерб, но и значительно упрощает задачу отладки.
3. Избыточность.
Все средства обнаружения ошибок основаны на некоторой форме избыточности (явной или неявной).
Когда разрабатываются {SITELINK-S405}меры по обнаружению ошибок{/SITELINK}, важ-но принять согласованную стратегию для всей системы. Действия, предпринимаемые после обнаружения ошибки в программном обеспечении, должны быть единообразными для всех компонен-тов системы. Это ставит вопрос о том, какие именно действия следует предпринять, когда ошибка обнаружена. Наилучшее решение — немедленно завершить выполнение программы или (в случае операционной системы) перевести центральный про-цессор в состояние ожидания. С точки зрения предоставления че-ловеку, отлаживающему программу, например системному про-граммисту, самых благоприятных условий для диагностики оши-бок немедленное завершение представляется наилучшей стратегией. Конечно, во многих системах подобная стратегия бывает нецелесообразной (например, может оказаться, что при-останавливать работу системы нельзя). В таком случае использу-ется метод регистрации ошибок.
Описание симптомов ошибки и «моментальный снимок» состояния системы сохраняются во внеш-нем файле, после чего система может продолжать работу. Этот файл позднее будет изучен обслуживающим персоналом.
Всегда, когда это возможно, лучше приостановить выполне-ние программы, чем регистрировать ошибки (либо обеспечить как дополнительную возможность работу системы в любом из этих режимов). Различие между этими методами проиллюстриру-ем на способах выявления причин возникающего иногда скреже-та вашего автомобиля. Если автомеханик находится на заднем сиденье, то он может обследовать состояние машины в тот мо-мент, когда скрежет возникает. Если вы выбираете метод регист-рации ошибок, задача диагностики станет сложнее.
Активное обнаружение ошибок.
Не все ошибки можно выя-вить пассивными методами, поскольку эти методы обнаружива-ют ошибку лишь тогда, когда ее симптомы подвергаются соот-ветствующей проверке. Можно делать и дополнительные провер-ки, если спроектировать специальные программные средства для активного поиска признаков ошибок в системе. Такие средства называются средствами активного обнаружения ошибок.
Активные средства обнаружения ошибок обычно объединя-ются в диагностический монитор:
параллельный процесс, кото-рый периодически анализирует состояние системы с целью обна-ружить ошибку. Большие программные системы, управляющие ресурсами, часто содержат ошибки, приводящие к потере ресур-сов на длительное время. Например, управление памятью опера-ционной системы сдает блоки памяти «в аренду» программам пользователей и другим частям операционной системы. Ошибка в этих самых «других частях» системы может иногда вести к не-правильной работе блока управления памятью, занимающегося возвратом сданной ранее в аренду памяти, что вызывает медлен-ное вырождение системы.
Диагностический монитор можно реализовать как периоди-чески выполняемую задачу (например, она планируется на каж-дый час) либо как задачу с низким приоритетом, которая плани-руется для выполнения в то время, когда система переходит в со-стояние ожидания. Как и прежде, выполняемые монитором конкретные проверки зависят от специфики системы, но некото-рые идеи будут понятны из примеров. Монитор может обследо-вать основную память, чтобы обнаружить блоки памяти, не вы-деленные ни одной из выполняемых задач и не включенные в си-стемный список свободной памяти. Он может проверять также необычные ситуации: например, процесс не планировался для выполнения в течение некоторого разумного интервала времени. Монитор может осуществлять поиск «затерявшихся» внутри си-стемы сообщений или операций ввода-вывода, которые необыч-но долгое время остаются незавершенными, участков памяти на диске, которые не помечены как выделенные и не включены в спи-сок свободной памяти, а также различного рода странностей в файлах данных.
Иногда желательно, чтобы в чрезвычайных обстоятельствах монитор выполнял диагностические тесты системы. Он может вы-зывать определенные системные функции, сравнивая их результат с заранее определенным и проверяя, насколько разумно время вы-полнения. Монитор может также периодически предъявлять сис-теме «пустые» или «легкие» задания, чтобы убедиться, что система функционирует хотя бы самым примитивным образом.
В области информатики и управления проектами в настоящее время
нет моделей, которые могут точно прогнозировать ошибки программного
обеспечения. Существуют различные теории и модели, но ни один из
них не обеспечит вас гарантированными результатами. См. циклическая сложность как один из примеров, когда
есть несогласие с мерой корреляция с дефектами .
В вашем случае вы пытаетесь выполнить статистический анализ без
достаточных соображений, даваемых либо тестовой конструкции, либо
контролируемым переменным, либо нулевая гипотеза . Вы также вводите в заблуждение
причинность и корреляция . Даже если у вас есть
корректно сконструированный тест с адекватным контролем, и даже
если вы сможете отклонить нулевую гипотезу, вам будет крайне сложно
использовать любой из этих проектов в качестве прямого
доказательства причины и эффекта.
Просматривайте свои проекты
Лучшее использование вашего времени — это внимательно изучить
проект 2, чтобы понять, почему у вас такой высокий уровень
дефектов. Осмотрите свои процессы, сформируйте гипотезу, а затем
попытайтесь адаптировать свои процессы, чтобы уменьшить
дефекты.
Хороший руководитель проекта не будет тратить время на создание
«универсальной теории всего» на основе экстраполяции из двух
проектов. Вместо этого опытный руководитель проекта потратил на это
время fixing
Project 2, чтобы улучшить свои шансы на
успех, или сообщив о вероятности неудачи менеджера портфеля, чтобы
можно было принять стратегическое решение о том, проект должен быть
прекращен в качестве меры контроля затрат или качества.
Представьте себе, что вы определяете стоимость автомобиля,
исходя из того, как часто он был вымыт.
Разработчики, которые оставили файл
Я понятия не имею, что вы пытаетесь сделать из этого показателя.
Похоже, что пытаться предсказать популярность быстрого питания,
основанного на том, сколько кварталов они дали в качестве
изменения.
The rules
about bugs is to test from early
stages of development, and to keep a 1:1 or 2:1 ratio of
programmers to testers. Then you can safely assume the
testing-debugging stage will take as long as the time originally
estimated to write the code.
Чем позже вы начнете тестирование, тем меньше тестировщиков у
вас есть, тогда больше ошибок будет жить и начнет расти в
программном обеспечении, а этап отладки займет больше времени.
Затем вы можете удвоить или утроить время тестирования/отладки.
Поскольку код исправления, который был написан недавно
(сегодня), проще, чем исправление кода, написанного некоторое время
назад (дни, недели или месяцы). Код, который не является свежим в
голове программиста, нуждается в повторном чтении и понимании.
Более новый код часто основывается на более раннем коде,
поэтому, если раньше была ошибка, он может полностью упасть и
повредить проблемы.
Наконец: Количество ошибок
не является хорошим
показателем чего-либо, если вы не учитываете их серьезность,
важность и влияние. Важными ошибками являются и опечатка, и
прерывистая система. Один займет немного минут, чтобы исправить,
другой может занять очень много времени, так как прерывистые сбои
почти невозможно воссоздать и найти.
Введение
Данная работа посвящена описанию методов обнаружения и устранения ошибок, позволяющих существенно повысить качество программного обеспечения встраиваемых систем и сэкономить материально-временные ресурсы, затрачиваемые на отладку систем. Рассматриваемые методы без особого труда могут быть использованы при разработке самых разных проектов программного обеспечения встраиваемых систем, причем накопленный опыт полностью сохраняет свою ценность и при реализации других проектов и целевых технологий. Кроме того, они позволяют гарантировать простоту сопровождения, модификации и переноса созданных программ в устройства новых типов. Вкратце, рассматриваемые методы дают возможность не только совершенствовать существующие встроенные приложения и процессы разработки, но и гарантировать, что с распространением новых встраиваемых устройств у вас уже будет накоплен опыт, необходимый для разработки высокоэффективных приложений для этих технологий причем вовремя и в рамках выделенных средств.
Ни для кого не секрет, что отлаживать программы для встраиваемых систем чрезвычайно тяжело. Отладка сама по себе далеко не курорт, а отладка программного обеспечения встраиваемых систем предъявляет к тому же особые требования. Прежде всего, из встроенных систем очень трудно извлекать требуемую информацию. Процесс отладки, как правило, строится на основе выводимой приложением информации и соответствующей обратной связи со стороны программиста, а у программ встроенных систем нет возможности сделать распечатку изображений экрана, которой могут пользоваться разработчики другого типа программного обеспечения.
Из этой неприятной ситуации нужно как-то выходить. Одно из возможных решений подключение специального оборудования к модулю, представляющему собой набор аппаратных средств, для которых и пишется отлаживаемое программное обеспечение. Это специальное оборудование дает разработчику возможность увидеть, что происходит с его программным обеспечением. Например, так называемые мониторы памяти позволяют заносить информацию в отдельные области памяти, считывать в монитор содержимое памяти и использовать содержимое памяти монитора для анализа состояния системы в момент ее краха. Кроме того, встраиваемые системы могут отлаживаться с помощью систем моделирования, представляющих собой программные среды, в которых отлаживаемые программы исполняются так же, как они будут исполняться в целевой системе.
Системы моделирования обладают множеством достоинств. Обычно в их составе имеются отладчики и средства вывода информации на печать, однако системы моделирования это всего лишь имитаторы. Отлаживаемая программа может успешно исполняться в системе моделирования и быть полностью неработоспособной в реальных условиях. Так что системы моделирования это лишь частичное решение. Ошибки программного обеспечения вполне могут пройти мимо системы моделирования и всплыть в реальном оборудовании.
Именно в этом и скрыта главная проблема: как показано на рис. 1, исправление ошибок, которые выявляются не на этапе тестирования, а в процессе использования, обходится значительно дороже. Если ошибка найдена в программе для не-встраиваемых систем, то можно выпустить обновленную версию программы с исправлениями, стоимость таких обновлений, как правило, сравнительно невысокая. Если же ошибка найдена во встроенной системе, то для ее исправления необходим возврат и модификация самих устройств с этой системой. Стоимость такого возврата может достигать астрономических величин, и стать причиной разорения компаний.
Рис. 1. Стоимость устранения ошибок во встраиваемых системах
На мой взгляд, сроки и затраты на выявление и устранение ошибок для встраиваемых систем приблизительно удваиваются (из-за описанных выше трудностей). В свете таких немыслимых затрат любой метод, который изначально будет препятствовать появлению ошибок, имеет неоценимое значение. К счастью для разработчиков встраиваемых систем, для предотвращения ошибок можно использовать некоторые из новых технологий программной разработки. Наиболее рекомендуемые две из них: стандарты программирования и блочное тестирование.
Правда, оба этих метода сегодня не столько применяются, сколько прославляются. Практически каждый разработчик программного обеспечения согласен с их высокой ценностью, но пользуются ими единицы. Подобная непоследовательность объясняется в большинстве случаев двумя причинами. Прежде всего, многие считают следование стандартам программирования и блочное тестирование весьма утомительным делом. Учитывая, сколько времени и сил эти подходы позволяют сэкономить в будущем, разработчикам следовало бы немножко потерпеть и избежать огромных трудозатрат (и возможного отказа от проекта) впоследствии.
Разработчикам систем реального времени еще труднее они в дополнение ко всему должны решать проблемы, связанные с соблюдением различных временных зависимостей. В конце статьи мы рассмотрим трудности, возникающие при отладке систем реального времени, и познакомимся с некоторыми методами отладки, которые рассчитаны на преодоление этих трудностей и которые также могут быть использованы при разработке любого программного обеспечения.
Способы отладки программ
Отладка программ заключается в проверке правильности работы программы и аппаратуры. Программа, не содержащая синтаксических ошибок тем не менее может содержать логические ошибки, не позволяющие программе выполнять заложенные в ней функции. Логические ошибки могут быть связаны с алгоритмом программы или с неправильным пониманием работы аппаратуры, подключённой к портам микроконтроллера.
Встроенный в состав интегрированной среды программирования отладчик позволяет отладить те участки кода программы, которые не зависят от работы аппаратуры, не входящей в состав микросхемы микроконтроллера. Обычно это относится к вычислению математических выражений или преобразованию форматов представления данных.
Для отладки программ обычно применяют три способа: Пошаговая отладка программ с заходом в подпрограммы; Пошаговая отладка программ с выполнением подпрограммы как одного оператора; Выполнение программы до точки останова.
Пошаговая отладка программ заключается в том, что выполняется один оператор программы и, затем контролируются те переменные, на которые должен был воздействовать данный оператор.
Если в программе имеются уже отлаженные подпрограммы, то подпрограмму можно рассматривать, как один оператор программы и воспользоваться вторым способом отладки программ.
Если в программе существует достаточно большой участок программы, уже отлаженный ранее, то его можно выполнить, не контролируя переменные, на которые он воздействует. Использование точек останова позволяет пропускать уже отлаженную часть программы. Точка останова устанавливается в местах, где необходимо проверить содержимое переменных или просто проконтролировать, передаётся ли управление данному оператору.
Практически во всех отладчиках поддерживается это свойство (а также выполнение программы до курсора и выход из подпрограммы). Затем отладка программы продолжается в пошаговом режиме с контролем локальных и глобальных переменных, а также внутренних регистров микроконтроллера и напряжений на выводах этой микросхемы. Следуйте стандартам программирования!
Самый лучший способ повысить качество ПО это стараться не допускать ошибок в процессе ввода исходного текста.
Первый шаг на пути предотвращения ошибок это осознание того, что ошибки действительно можно предотвратить. Больше всего препятствует контролю над ошибками распространенное убеждение в том, что ошибки неизбежны. Это заблуждение! Ошибки сами по себе не появляются их вносит в текст разработчик. Человеку свойственно ошибаться, так что даже самые лучшие программисты время от времени допускают ошибки, если у них есть такая возможность. Поэтому чтобы уменьшить число ошибок, надо сократить возможности их появления. Один из лучших способов здесь следование стандартам программирования, что ликвидирует благодатную почву для возникновения ошибок на первых этапах.
Стандарты программирования это специфичные для языка «правила», которые, если их соблюдать, значительно снижают вероятность внесения ошибок в процессе разработки приложения. Следовать стандартам программирования нужно на этапе написания программ, до их переноса в целевые платформы, при этом стандартизация должна существовать для всех языков. Поскольку большая часть разработчиков встраиваемых систем пользуется языком С, больше внимания уделим именно стандартам программирования на C, хотя такие же стандарты существуют и для других языков, включая С++ и Java.
Как правило, стандарты программирования делятся на две категории:
отраслевые стандарты программирования: правила, принятые всеми программистами на данном языке (например, запрет входа в цикл не через его заголовок).
специальные стандарты программирования: правила, соблюдаемые конкретной группой разработчиков, в рамках конкретного проекта, или даже единственным программистом. Существует три типа специальных стандартов, которыми может воспользоваться разработчик встраиваемой программной системы: внутренние стандарты, персональные стандарты и стандарты, определяемые целевой платформой.
Внутренние стандарты программирования это правила, которые специфичны для вашей организации или группы разработчиков. Так, уникальные для организации правила присвоения имен это пример внутренних стандартов программирования.
Персональные стандарты это правила, которые помогут вам избежать ваших наиболее частых ошибок. Каждый раз при появлении какой-либо ошибки программист должен проанализировать причину ее появления и выработать собственное правило, препятствующее повторному ее возникновению. Например, если в операторе условия вы часто пишете знак присваивания вместо знака проверки на равенство (т.е. «if (a=b)» вместо «if (a= =b)»), то вам необходимо создать для себя следующий стандарт: «Остерегаться применения знака присваивания в операторе проверки условия».
Стандарты, определяемые целевой платформой, это правила, нарушение которых в данной платформе может привести к появлению определенных проблем. Например, такими стандартами могут быть ограничения на использование памяти или размер переменных, налагаемые целевой платформой.
Чтобы лучше разобраться в том, что такое стандарты программирования и как они работают, познакомимся с ними на конкретных примерах. Рассмотрим следующую запись на языке С:
{
.
.
.
}
Здесь размер одномерного массива декларируется в списке аргументов функции. Это опасная конструкция, поскольку в языке С аргумент-массив передается как указатель на его первый элемент, и в разных обращениях к функции в числе ее фактических аргументов могут указываться массивы с разной размерностью. Создав такую конструкцию, вы предполагаете пользоваться буфером фиксированного размера на 80 элементов, считая, что именно такой буфер и будет передаваться функции, а это может привести к разрушению памяти. Если бы автор этого оператора следовал стандарту программирования «не объявлять размер одномерного массива в числе аргументов функции» (взятому из набора стандартов программирования на языке С одной из ведущих телекоммуникационных компаний), то этот текст выглядел бы следующим образом и проблем с разрушением памяти удалось бы избежать:
char *substring (char string, int start_pos, int length)
{
.
.
.
}
Стандарты программирования позволяют также избегать проблем, которые до момента портирования кода на другую платформу могут не проявляться. Например, следующий кусок кода будет исправно работать на одних платформах и порождать ошибки после переноса его на другие платформы:
#include
void test(char c) {
if(a }
if(islower(c)) {// Правильно
}
while (A }
while (isupper(c)) { // Правильно
}
}
Проблемы портации могут быть связаны с символьными тестами, в которых не используется функции ctype.h (isalnum, isalpha, iscntrl, isdigit, isgraph, islower, isprint, ispunct, isspace, isupper, isxdigit, tolower, toupper). Функции ctype.h для символьной проверки и преобразования прописных букв в строчные и наоборот работают с самыми разными наборами символов, обычно очень эффективны и гарантируют международную применимость программного продукта.
Лучший способ внедрить эти и другие стандарты программирования это обеспечить их автоматическое применение в составе какой-либо технологии программирования, вместе с набором целенаправленных отраслевых стандартов и механизмами создания и поддержки стандартов программирования, ориентированных на конкретную систему. При выборе подобной технологии необходимо сначала найти ответы на вопросы, среди которых следующие:
Применима ли она к данной программе и/или компилятору?
Содержит ли она набор отраслевых стандартов программирования?
Позволяет ли она создавать и поддерживать специальные стандарты программирования (включая стандарты, определяемые целевой платформой)?
Легко ли структурировать отчеты в соответствии с вашими групповыми и проектными приоритетами?
Насколько легко она интегрируется в существующий процесс разработки?
Блочное тестирование
Зачастую, слыша о блочном тестировании, разработчики воспринимают его как синоним модульного тестирования. Другими словами, проверяя отдельный модуль или подпрограмму более крупной программной единицы, разработчики считают, что выполняют блочное тестирование. Конечно, модульное тестирование имеет очень большое значение и, безусловно, должно проводиться, но это не тот метод, на котором я бы хотел остановиться. Говоря о «блочном тестировании», я имею в виду тестирование на еще более низком уровне: тестирование самых минимально возможных программных единиц, из которых состоит прикладная программа, всё ещё находясь в инструментальной среде (хост-системе) в случае языка С, это будут функции, которые проверяются сразу же после их компиляции.
Блочное тестирование значительно повышает качество программного обеспечения и эффективность процесса разработки. При тестировании на уровне объектов вы гораздо ближе к этой методике и обладаете гораздо большими возможностями построения входных наборов, выявляющих ошибки со стопроцентным покрытием (рис. 2). Кроме того, тестируя блок кода сразу после того, как он был написан, вы тем самым избегаете необходимости «продираться» через наслоения ошибок, чтобы найти и исправить единственную исходную в данном случае вы сразу ее устраняете, и вся проблема решена. Это существенно ускоряет и облегчает процесс разработки, поскольку на поиск и устранение ошибок тратится значительно меньше материальных и временных ресурсов.
Рис. 2. Простота нахождения ошибок при блочном тестировании
Блочное тестирование можно разделить минимум на два отдельных процесса. Первый это тестирование «черного ящика», или процесс определения функциональных проблем. На уровне отдельных блоков тестирование «черного ящика» заключается в проверке функциональных характеристик посредством определения степени соответствия параметров открытого интерфейса функции ее спецификации; подобная проверка выполняется без учета способов реализации. Результатом тестирования «черного ящика» на блочном уровне является уверенность в том, что данная функция ведет себя в полном соответствии с определением и что незначительная функциональная ошибка не приведет к лавине трудноразрешимых проблем.
Рис. 3. Тестирование «черного ящика»
Второй процесс называется тестированием «белого ящика» и предназначен для выявления конструктивных недостатков. На уровне отдельных блоков проверяется, не произойдёт ли крах всей программы при передаче в функцию неожидаемых ею параметров. Этот вид тестирования должен проводиться специалистом, имеющим полное представление о способе реализации проверяемой функции. После такой проверки можно быть уверенным в том, что приводящих к краху системы ошибок нет и что функция будет устойчиво работать в любых условиях (т.е. выдавать предсказуемые результаты даже при вводе непредвиденных входных параметров).
Рис. 4. Тестирование «белого ящика»
Оба вышеописанных процесса могут служить основой третьего, регрессивного тестирования. Сохранив тестовые наборы для «черного» и «белого» ящиков, можно использовать их для регрессивного тестирования на уровне блоков и контролировать целостность кода по мере того, как вы его модифицируете. Концепция регрессивного тестирования на этом уровне является новым оригинальным подходом. При выполнении регрессивного тестирования на уровне блоков можно сразу же после изменения вами текста определять, не появились ли новые проблемы, и устранять их немедленно после возникновения, тем самым препятствуя распространению ошибки по вышележащим уровням.
Главная проблема, связанная с блочным тестированием, заключается в том, что если не пользоваться технологиями автоматического блочного тестирования, проводить его трудно, утомительно и слишком долго. Рассмотрим вкратце причины, по которым включать неавтоматизированное блочное тестирование в сегодняшние процессы разработки трудно (если вообще возможно).
Первый этап блочного тестирования ПО встраиваемых систем заключается в создании такой среды, которая позволит запускать и тестировать интересующую функцию в хост-системе. Это требует выполнения следующих двух действий:
разработка программного текста, который будет запускать функцию,
написание фиктивных модулей, которые будут возвращать результаты вместо внешних ресурсов, к которым обращается функция и которые в текущий момент отсутствуют или недоступны.
Второй этап разработка тестовых наборов. Для полноты охвата конструктивных и функциональных особенностей функции необходимо создавать тестовые наборы двух типов: для «черного ящика» и для «белого ящика».
Основой разработки тестовых наборов для «черного ящика» должна стать спецификация функции. В частности, для каждой записи в спецификации должен быть создан хотя бы один тестовый набор, при этом желательно, чтобы эти наборы учитывали указанные в спецификации граничные условия. Проверять того, что некоторые входные параметры приводят к ожидаемым результатам, недостаточно; необходимо определить диапазон взаимосвязей входов и выходов, который позволит сделать вывод о корректной реализации указанных функциональных характеристик, и затем создавать тестовые наборы, полностью покрывающие данный диапазон. Можно также тестировать не указанные в спецификации и ошибочные условия.
Цель тестовых наборов для «белого ящика» обнаружить все скрытые дефекты путем всестороннего тестирования функции разнообразными входными параметрами. Эти наборы должны обладать следующими возможностями:
обеспечивать максимально возможное (100%) покрытие функции: как уже говорилось, такая степень покрытия на уровне блоков возможна, поскольку создавать наборы для тестирования каждой характеристики функции вне приложения гораздо проще (стопроцентное покрытие во всех случаях невозможно, но это цель, к которой надо стремиться);
выявлять условия краха функции.
Следует заметить, что самостоятельно создание подобных наборов, не владея технологиями их построения, невероятно тяжелое занятие. Чтобы создать эффективные тестовые наборы для «белого ящика», необходимо сначала получить полное представление о внутренней структуре функции, написать наборы, обеспечивающие максимальное покрытие функции, и найти совокупность входов, приводящих к отказу функции. Получить спектр покрытия, необходимый для высокоэффективного тестирования «белого ящика», возможно лишь при исследовании значительного числа путей прохода по функции. Например, в обычной программе, состоящей из 10000 операторов, имеется приблизительно сто миллионов возможных путей прохода; вручную создать тестовые наборы для проверки всех этих путей невозможно.
После создания тестовых наборов необходимо провести тестирование функции в полном объеме и проанализировать результаты с целью выявления причин ошибок, крахов и слабых мест. Необходимо иметь способ прогона всех тестовых наборов и быстрого определения, какие из них приводят к возникновению проблем. Необходимо также иметь инструмент измерения степени покрытия для оценки полноты тестирования функции и определения необходимости в дополнительных тестовых наборах.
При любых изменениях функции следует проводить регрессивное тестирование, чтобы убедиться в отсутствии новых и/или устранении предыдущих ошибок. Включение блочного регрессивного тестирования в процесс разработки позволит защититься от многих ошибок они будут обнаружены сразу же после возникновения и не смогут стать причинами распространения ошибок в приложении.
Регрессивное тестирование можно проводить двумя способами. Первый заключается в том, что разработчик или испытатель анализирует каждый тестовый набор и определяет, на работе которого из них может сказаться измененный код. Этот подход характеризуется экономией машинного времени за счет работы, проводимой человеком. Второй, более эффективный, заключается в автоматическом прогоне на компьютере всех тестовых наборов после каждого изменения текста. Данный подход гарантирует большую эффективность труда разработчика, поскольку он не должен тратить время на анализ всей совокупности тестовых наборов, для того чтобы определить, какие наборы следует прогонять, а какие нет.
Если вы сможете автоматизировать процесс блочного тестирования, то не только повысите качество тестирования, но и высвободите для себя значительно больше временных и материальных ресурсов, чем уйдёт на этот процесс. Если вы пишете программы на языке С, то для автоматизации блочного тестирования можете воспользоваться существующими технологиями. Чем больше процессов вы сможете автоматизировать, тем больше пользы вы получите.
При выборе технологии блочного тестирования сначала следует ответить на следующие вопросы:
Подходит ли эта технология для вашего текста и/или компилятора?
Может ли она автоматически создавать тестовые схемы?
Может ли она автоматически генерировать тестовые наборы?
Позволяет ли она вводить создаваемые пользователем тестовые наборы и фиктивные модули?
Автоматизировано ли регрессивное тестирование?
Имеется ли в ее составе технология или связь с технологией автоматического распознавания ошибки в процессе прогона?
Средства отладки, не меняющие режим работы программ
Из-за того, что операционные системы реального времени должны выполнять определенные задачи в условиях заранее определенных временных ограничений, временные соотношения превращаются в важнейший параметр, который разработчики должны учитывать при установке тестового ПО. Обычно в процессе исполнения программ возникает множество различных прерываний, и чрезвычайно необходимо, чтобы в момент возникновения прерывания приложение реагировало корректно. Ситуация еще более усложняется, когда несколько прерываний возникает сразу или когда в системе исполняется несколько приложений с несколькими взаимодействующими друг с другом тредами. По сути, это приложения с несколькими одновременными путями исполнения различные кодовые последовательности как бы исполняются в одно и то же время, даже если в системе всего один центральный процессор. Интересно заметить, что если бы эти приложения исполнялись в нескольких процессорах, то различные треды на практике были бы загружены в разные процессоры.
Если возникающие в приложениях реального времени ошибки проявляются во взаимодействиях между программой и прерываниями, то они будут в значительной мере чувствительны ко времени. В этом случае критически важно регистрировать порядок возникновения ошибок, поскольку это позволит разобраться в причинах и следствиях каждой ошибки. В этом как раз и кроется главная проблема отладки систем реального времени: существует достаточное количество трудновыявляемых ошибок, которые проявляются только при определенных временных соотношениях.
Эта проблема осложняется тем, что подобные ошибки не так-то просто воспроизводятся. Очень трудно воссоздать ситуацию с такими же временными соотношениями, что и приведшие к возникновению ошибки в реальной программе. Механизм отладки таких приложений должен быть максимально возможно щадящим. Любое вмешательство в ход исполнения программ может привести к изменению ее временных характеристик и отсутствию условий возникновения ошибок. Конечно, создание условий, при которых ошибки не возникают, это хорошо, но в данном случае это является препятствием отладке программы.
Теоретической основой проблемы отладки систем реального времени может послужить известный всем из курса физики принцип неопределенности немецкого физика Вернера Гейзенберга, согласно которому одновременно определить скорость и местоположение движущейся частицы невозможно. Гейзенберг считал, что, определяя координаты частицы, экспериментатор тем самым изменяет её местоположение, что не позволяет определить её координаты точно. Операция измерения влияет на измеряемый объект и искажает результаты измерения. Принцип неопределенности это одна из аксиом квантовой механики.
Применительно же к нашей теме, этот принцип означает, что отладка системы требует сбора информации о ее состоянии. Однако сбор информации о состоянии системы меняет ее временные характеристики и существенно затрудняет надежное воспроизведение условий возникновения ошибки.
Таким образом, суть этой проблемы в том, что нужно найти способ обнаружения ошибок реального времени и анализа поведения программы без влияния на существующие временные соотношения. Наверное, вашим первым порывом было бы обращение к отладчику, но отладчики, как правило, прерывают исполнение программы и, соответственно, изменяют ее временные характеристики. Малопригодны и системы моделирования, поскольку они не могут воссоздать временные характеристики реальных технических средств. Еще никто не создал такую систему моделирования, которая могла бы смоделировать режим реального времени; временные параметры можно определить, только загрузив программу в само железо.
Последнее требует наличия специального механизма для упрощенной регистрации состояния системы. Один из возможных и подходящих механизмов запись информации в оперативную память, поскольку такая операция выполняется чрезвычайно быстро. Один из способов применения этого механизма организация где-нибудь в памяти специального буфера и использование в вашей программе указателя на этот буфер. Указатель всегда ссылается на начало буфера. В программу вставляются операции записи в ячейку, определяемую указателем. После каждой операции записи значение указателя меняется соответствующим образом. Иногда полезно пользоваться кольцевым буфером (т.е. когда после записи в последнюю ячейку буфера указатель начинает показывать на начало буфера), что позволяет отслеживать ситуации, приводящие к возникновению проблемы. Необходимо при этом предусмотреть способ сохранения содержимого буфера после нормального или аварийного завершения программы, чтобы впоследствии иметь к нему доступ и проводить так называемую «посмертную отладку». Способ реализации зависит от аппаратных средств, обычно это можно сделать, если не выполнять повторную инициализацию (reset) оборудования.
Теперь вам нужен механизм чтения этой памяти. Здесь можно использовать и отладчик, и другие средства извлечения информации из оперативной памяти. В частности, можно написать простенькую программу, которая будет пересылать эти данные в файл или на принтер. Каким бы средством вы не пользовались, конечным этапом, вероятнее всего, будет ручной анализ содержимого буфера. Если ваш буфер кольцевой, то вам необходимо иметь точные сведения о значении указателя; события, которые стали началом последовательности, будут непосредственно перед указателем, события, которые возникли непосредственно перед крахом, будут сразу же после указателя.
Рис. 5. Последовательность событий в кольцевом буфере
Теперь ваша главная задача попытаться разобраться в последовательности данных, записанных в буфере. Эта задача аналогична исследованию причин катастрофы самолета по показаниям приборов, зарегистрированных «черным ящиком» самолета. Анализ характеристик программы в этом случае проводится после свершившегося события, что, естественно, гораздо меньше влияет на ее исполнение, чем контроль в течение работы.
Иногда бывает очень трудно восстановить приведшие к краху события, и четкого понятия о моменте возникновения ошибки нет. Только на выяснение причины ошибки могут уходить многие месяцы. В таких случаях для поиска ошибочного оператора можно воспользоваться логарифмическим методом отладки. В разных местах отлаживаемого кода расставляются маркеры (например, операторы типа exit), а перед ними операторы записи в память. Затем запускаете программу и ожидаете момента краха. В случае краха вы знаете, между какими маркерами он произошел. Этот метод позволяет выявлять и проблемы согласования по времени, поскольку он позволяет находить сегменты кода, в которых возникают нарушения временных соотношений.
Ещё одно решение это применение в качестве технологии отладки так называемых брандмауэров. Брандмауэр это точка в логическом потоке программы, в которой доказывается справедливость предположений, на которые опирается последующий код. Проверка этих предположений отличается от обычного контроля ошибок. Срабатывание брандмауэра представляет собой сигнал разработчику о том, что внутреннее состояние системы неустойчиво. Это может произойти, например, если ожидающая строго положительного аргумента функция получает нулевую или отрицательную величину. Неискушённым разработчикам большинство брандмауэров кажутся тривиальными и ненужными. Однако опыт разработки крупных проектов показывает, что по мере развития и совершенствования программных систем неявные предположения в отношении среды исполнения нарушаются все чаще и чаще. Во многих случаях даже сам автор затрудняется сформулировать, что представляют собой надлежащие условия исполнения того или иного участка кода.
Реализуемые внутри встраиваемых систем брандмауэры нуждаются в специальных средствах связи для передачи сообщений во внешний мир; обсуждение способа установления таких каналов передачи выходит за рамки настоящей статьи.
Заключение
Рассмотренные выше методы предотвращения и обнаружения ошибок, а также технологии отладки могут значительно повысить качество программного обеспечения встраиваемых систем и уменьшить затрачиваемые на проведение отладки материальные и временные ресурсы. Вышеупомянутые методы без особого труда могут быть использованы в разработке самых разных проектов программного обеспечения встраиваемых систем, причем накопленный опыт полностью сохраняет свою ценность и при реализации иных проектов и целевых технологий. Кроме того, они позволяют гарантировать простоту сопровождения, модификации и портации созданных программ в устройства новых типов. И говоря коротко, рассматриваемые методы дают возможность не только совершенствовать существующие встроенные приложения и процессы разработки, но и гарантировать, что с распространением новых встраиваемых устройств у вас уже будет накоплен опыт, необходимый для разработки высокоэффективных приложений для этих технологий причем вовремя и в соответствии с выделенным бюджетом.
Литература
1. M. Aivazis and W. Hicken. «C++ Defensive Programming: Firewalls and Debugging Information.» C++ Report (July-August 1999): 34 40.
1
Источниками ошибок в программном обеспечении являются специалисты — конкретные люди с их индивидуальными особенностями, квалификацией, талантом и опытом.
В большинстве случаев поток программных ошибок может быть описан негомогенным процессом Пуассона. Это означает, что программные ошибки проявляются в статистически независимые моменты времени, наработки подчиняются экспоненциальному распределению, а интенсивность проявления ошибок изменяется во времени. Обычно используют убывающую интенсивность проявления ошибок. Т. е. ошибки, как только они выявлены, эффективно устраняются без введения новых ошибок.
Применительно к надежности программного обеспечения ошибка это погрешность или искажение кода программы, неумышленно внесенные в нее в процессе разработки, которые в ходе функционирования этой программы могут вызвать отказ или снижение эффективности функционирования. Под отказом в общем случае понимают событие, заключающееся в нарушении работоспособности объекта. При этом критерии отказов, как признак или совокупность признаков нарушения работоспособного состояния программного обеспечения, должны определяться исходя из его предназначения в нормативно — технической документации.
В общем случае отказ программного обеспечения можно определить как:
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) на время превышающее заданный порог;
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) на время не превышающее заданный порог, но с потерей всех или части обрабатываемых данных;
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) потребовавшее перезагрузки ЭВМ, на которой функционирует программное обеспечение.
Из данного определения программной ошибки следует, что ошибки могут по разному влиять на надежность программного обеспечения и можно определить тяжесть ошибки, как количественную или качественную оценку последствий этой ошибки. При этом категорией тяжести последствий ошибки будет являться классификационная группа ошибок по тяжести их последствий. Ниже представлены возможные категории тяжести ошибок в программном обеспечении общего применения в соответствии с ГОСТ 51901.12 — 2007 «Менеджмент риска. Метод анализа видов и последствий отказов».
|
Описание последствий проявления ошибки |
||
|
Критическая |
проявление ошибки с высокой вероятностью влечет за собой прекращение функционирования программного обеспечения (его отказ) |
|
|
Существенная |
проявление ошибки влечет за собой снижение эффективности функционирования программного обеспечения и может вызвать прекращение функционирования программного обеспечения (его отказ) |
|
|
Несущественная |
проявление ошибки может повлечь за собой снижение эффективности функционирования программного обеспечения и практически не приводит к возникновению отказа в нем (вероятность возникновения отказа очень низкая) |
В качестве показателя степени тяжести ошибки, позволяющего дать количественную оценку тяжести проявления последствий ошибки можно использовать условную вероятность отказа программного обеспечения при проявлении ошибки. Оценку степени тяжести ошибки как условной вероятности возникновения отказа, можно производить согласно ГОСТ 28195 — 89 «Оценка качества программных средств. Общие положения», используя метрики и оценочные элементы, характеризующие устойчивость программного обеспечения. При этом оценку необходимо производить для каждой ошибки в отдельности, а не для всего программного обеспечения.
Библиографическая ссылка
Дроботун Е.Б. КРИТИЧНОСТЬ ОШИБОК В ПРОГРАММНОМ ОБЕСПЕЧЕНИИ И АНАЛИЗ ИХ ПОСЛЕДСТВИЙ // Фундаментальные исследования. – 2009. – № 4. – С. 73-74;
URL: http://fundamental-research.ru/ru/article/view?id=4467 (дата обращения: 06.04.2019).
Предлагаем вашему вниманию журналы, издающиеся в издательстве «Академия Естествознания»
Одной
из основных причин изменений комплексов
программ являются
организационные
дефекты при модификации и расширении
функ
ций
ПС,
которые
отличаются от остальных типов и условно
могут быть выделены
как самостоятельные (см. рис. 10.2). Ошибки
и дефекты данного
типа появляются из-за недостаточного
понимания коллективом специалистов
технологии процесса ЖЦ ПС, а также
вследствие отсутствия четкой
его организации и поэтапного контроля
качества продуктов и изменений.
Это порождается пренебрежением
руководителей к организации всего
технологического
процесса ЖЦ сложных ПС и приводит к
серьезной недооценке его дефектов, а
также трудоемкости и сложности
модификаций. При
отсутствии планомерной и методичной
разработки и тестирования изменений
ПС остается невыявленным значительное
количество ошибок, и,
прежде всего, дефекты взаимодействия
отдельных функциональных компонентов
между собой и с внешней средой. Для
сокращения этого типа массовых
ошибок активную роль должны играть
лидеры — менеджеры и системотехники,
способные вести контроль и конфигурационное
управление
требованиями, изменениями и развитием
версий и компонентов ПС.
Изменения
характеристик системы и внешней среды,
принятые
в процессе
разработки ПС за исходные, могут быть
результатом аналитических
расчетов, моделирования или исследования
аналогичных систем. В ряде случаев может
отсутствовать полная адекватность
предполагаемых и реальных
характеристик, что является причиной
сложных и трудно об
наруживаемых
системных ошибок и дефектов развития
проекта.
Ситуация
с такими ошибками дополнительно
усложняется тем, что эксперименты
по проверке взаимодействия ПС с реальной
внешней средой во всей области изменения
параметров зачастую сложны и дороги, а
в отдельных случаях, при создании опасных
ситуаций, недопустимы. В этих случаях
приходится использовать моделирование
и имитацию внешней среды
с заведомым упрощением ее отдельных
элементов и характеристик, хотя степень
упрощения не всегда удается оценить с
необходимой точностью.
Однако полной адекватности моделей
внешней среды и реальной системы добиться
трудно, а во многих случаях и невозможно,
что может являться причиной значительного
числа крупных дефектов.
Первичные
ошибки в программах проектов можно
анализировать с разной степенью
детализации и в зависимости от различных
факторов. Практический
опыт показал, что наиболее
существенными факторами,
влияющими
на характеристики обнаруживаемых
ошибок, являются».
методология,
технология и уровень автоматизации
системного и структурного
проектирования ПС, а также непосредственного
программирования
компонентов;
длительность
с начала процесса тестирования и текущий
этап разработки
или сопровождения и модификации
комплекса программ;
класс
ПС, масштаб (размер) и типы компонентов,
в которых обнаруживаются
ошибки;
методы,
виды и уровень автоматизации верификации
и тестирования, их адекватность
характеристикам компонентов и
потенциально возможным
в программах ошибкам;
виды
и достоверность эталонов-тестов, которые
используются для обнаружения
ошибок.
Первичные
ошибки в ПС в порядке уменьшения их
влияния на
сложность
обнаружения и масштабы корректировок
можно разделить на следующие
группы (см. рис. 10.2):
ошибки,
обусловленные сложностью компонентов
и ПС в целом и наиболее
сильно влияющие на размеры модификаций;
ошибки
вследствие большого масштаба — размера
комплекса программ,
а также высоких требований к его
качеству;
ошибки
планирования и корректности требований
модификаций часто
могут быть наиболее критичным для
общего успеха ЖЦ ПС и системы;
ошибки
проектирования, разработки структуры
и функций ПС в более полные и точные
технические описания сценариев того,
как комплекс программ и система будут
функционировать;
системные
ошибки, обусловленные отклонением
функционирования
ПС в реальной системе, и характеристик
внешних объектов от предполагавшихся
при проектировании;
алгоритмические
ошибки, связанные с неполным формированием
необходимых условий решения и некорректной
постановкой целей функциональных
задач;
ошибки
реализации спецификаций изменений —
программные дефекты,
возможно, ошибки нарушения требований
или структуры компонентов ПС;
программные
ошибки, вследствие неправильной записи
текстов программ
на языке программирования и ошибок
трансляции текстов изменений
программ в объектный код;
ошибки
в документации, которые наиболее легко
обнаруживаются и в наименьшей степени
влияют на функционирование и применение
версий
ПС;
технологические
ошибки подготовки физических носителей
и документации, а также ввода программ
в память ЭВМ и вывода результатов на
средства отображения.
Сложность
проявления, обнаружения и устранения
ошибок
значительно
конкретизируется и становится измеримой,
когда устанавливается связь этого
понятия с конкретными ресурсами,
необходимыми для решения
соответствующей задачи, и возможными
проявлениями дефектов. При разработке
и сопровождении программ основным
лимитирующим ресурсом
обычно являются допустимые трудозатраты
специалистов, а также ограничения
на сроки разработки, параметры ЭВМ,
технологию проектирования корректировок
ПС. Показатели сложности при анализе
можно разделить
на две
большие группы:
сложность
ошибок при создании корректировок
компонентов
и комплекса
программ — статическая сложность,
когда реализуются его требуемые функции,
вносятся основные дефекты и ошибки;
сложность
проявления ошибок функционирования
программ
и получения
результатов — динамическая сложность,
когда проявляются дефекты и ошибки,
отражающиеся на функциональном
назначении, рисках и качестве применения
версии ПС.
К
группе факторов, влияющих на сложность
ошибок
комплексов
программ, относятся:
величина
— размер модифицируемой программы,
выраженная числом
строк текста, функциональных точек или
количеством программных модулей в
комплексе;
количество
обрабатываемых переменных или размер
и структура памяти, используемой для
размещения базы данных корректировок;
трудоемкость
разработки изменений комплекса программ;
длительность
разработки и реализации корректировок;
число
специалистов, участвующих в ЖЦ комплекса
программ.
Некоторые
из перечисленных параметров коррелированы
между собой,
причем определяющими часто являются
размер изменений программы
и объем базы данных. Остальные
характеристики можно рассматривать
как
вторичные, однако они могут представлять
самостоятельный интерес при анализе
сложности и прогнозировании вероятного
числа дефектов в измененной
программе. Сложность
ошибок
комплексов
программ целесообразно
анализировать на базе трех наиболее
специфических компонентов:
—сложность
ошибок изменяемых программных компонентов
и
модулей
определяется
конструктивной сложностью модификации
оформ-
ленного
компонента программы и может быть
оценена с позиции сложности
внутренней структуры и преобразования
данных в каждом модуле, а также
интегрально по некоторым внешним
статистическим характеристикам
размеров модулей;
сложность
ошибок корректировок структуры комплекса
или
компонентов и связей между модулями
по передачам управления и по обмену
информацией определяется глубиной
взаимодействия модулей и регулярностью
структуры межмодульных связей;
сложность
ошибок изменения структуры данных
определяется
количеством
и структурой глобальных и обменных
переменных в базе данных,
регулярностью их размещения в массивах,
а также сложностью доступа
к этим данным.
Масштаб
—
размер
комплексов программ и их изменяемой
части
наиболее
сильно влияет на количество ошибок, а
также на требования к качеству
ПС
(см. лекцию 5). Качество откорректированного
ПС характеризуется
многими показателями, состав которых
зависит от класса и конкретного
назначения комплекса программ. Ниже
предполагается, что всегда модификации
ПС соответствуют заданному функциональному
назначению и основным требованиям
заказчика к их качеству. По мере увеличения
размера и повышения требований к качеству
ПС и его корректировкам
затраты на обнаружение и устранение
ошибок ПС увеличиваются
все более высокими темпами. Одновременно
расширяется диапазон неопределенности
достигаемого качества. В зоне высокого
качества программ возрастают трудности
измерения этих характеристик, что может
приводить
к необходимости изменения затрат в
несколько раз в зависимости
от применяемых методов и результатов
оценки качества ПС. Вследствие этого в
ЖЦ сложных и сверхсложных ПС всегда
велики проявления неустраненных ошибок
и недостаточна достоверность оценок
достигнутого
качества.
Ошибки
корректности формирования и планирования
выполне
ния
требований к ПС
часто
считаются наиболее критичными для
общего успеха
версий программного продукта и системы.
Ошибки требований являются наиболее
трудными для обнаружения и наиболее
сложными для исправления.
Вот почему исправление ошибок требований
может быть в 15-70
раз дороже, чем ошибок их программирования.
Требование к изме-
нению
может быть пропущено в спецификации к
системе и ПС. Это ведет к
неудовлетворенности пользователя, и
программа считается заказчиком и
пользователем ошибочной. Пропуск
некоторых требований — это наиболее
обычная проблема среди ошибок требований.
Ошибка требований может представлять
собой конфликтующие требования в
спецификации модификаций.
Например, два требования, которым
необходимо следовать, имеют противоположный
смысл. Может проявляться неопределенность
требований
— такой способ формулирования требования,
что даже если и не
конфликтует с другим требованием, оно
выражено недостаточно ясно, чтобы
привести к единственному, конструктивному
решению при разработке изменения.
Конечный пользователь часто называет
это ошибкой, хотя
на самом деле это выбор конструктивного
решения на основе неполного или
неопределенного требования. Многочисленные
исследования показали,
что ошибки требований дороже всего
исправить и труднее всего обнаружить.
Ошибки
проектирования и разработки структуры
ПС
определяются
процессами перевода неопределенных и
общих положений, сделанных на стадии
спецификаций требований, в более точные
технические описания
сценариев того, как измененные ПС и
система должны работать. Ошибки
структуры легче обнаружить, чем ошибки
требований, но они в конечном итоге
могут оказаться при корректировках
такими же дорогостоящими. Главная
причина того, что ошибки структуры
дорого исправлять,
состоит в том, что они могут влиять на
систему в целом. Исправление изменений
всей системы сложнее, и при этом возникает
большая опасность занести новые ошибки,
чем при исправлении нескольких нарушенных
строк кода или при замене одного модуля.
Ошибки
структуры можно разделить на три
категории: пропуски, конфликты
и ошибки перевода. Пропуски означают
неспособность включить изменения одного
или более требований в окончательную
структуру ПС. Когда пропуск новой функции
или компонента попадает в окончательную
структуру, он станет ошибкой в конечном
программном продукте.
Конфликты возникают, когда модификация
двух различных, конструктивных
свойств имеют конфликтующую структуру.
Это может происходить
в случае явного конфликта, когда в
структуре установлено, что файл может
быть открыт двумя разными людьми в одно
и то же время, тогда
как в
базовом классе определяется только
однопользовательский доступ. Ошибки,
которые основаны на конфликтах на этом
уровне, часто невозможно
исправить без полного переписывания
модулей версии ПС.
Ошибки
перевода — наиболее коварные среди
всех ошибок структурного
уровня. Они проявляются, когда требования
заказчика интерпретируются
неправильно, по крайней мере, с точки
зрения конечного пользователя.
Если разработчик структуры либо неверно
прочитает требования, либо
не увидит содержание требования, так
же как конечный пользователь,
появится ошибка разработки структуры
данного компонента или ПС.
Системные
ошибки в ПС
определяются,
прежде всего, неполной информацией
о реальных процессах, происходящих в
источниках и потребителях
информации. Кроме того, эти процессы
зачастую зависят от самих
алгоритмов и поэтому не могут быть
достаточно определены и описаны
заранее без исследования изменений
функционирования ПС во взаимодействии
с внешней средой. На начальных этапах
не всегда удается точно и полно
сформулировать целевую задачу всей
системы, а также целевые задачи основных
групп программ, и эти задачи уточняются
в процессе
проектирования. В соответствии с этим
уточняются и конкретизируются
спецификации на отдельные компоненты
и выявляются отклонения
от уточненного задания, которые могут
квалифицироваться как системные
ошибки.
Характеристики
внешних объектов, принятые в качестве
исходных данных в процессе разработки
алгоритмов, могут являться результатом
аналитических расчетов, моделирования
или исследования аналогичных систем.
Во всех случаях может отсутствовать
полная адекватность условий получения
предполагаемых и реальных характеристик
внешней среды, что является причиной
сложных и трудно обнаруживаемых ошибок.
Это
усугубляется тем, что очень часто
невозможно заранее предусмотреть все
разнообразие возможных внешних условий
и реальных сценариев функционирования
и применения версий программного
продукта.
При
автономной и в начале комплексной
отладки версий ПС относительная доля
системных ошибок может быть невелика
(около 10%), но она существенно
возрастает (до 35-40%) на завершающих
этапах комплексной отладки новых базовых
версий ПС. В процессе сопровождения
системные ошибки являются преобладающими
(около 60-80% от всех оши-
бок).
Следует также отметить большое количество
команд, корректируемых при исправлении
каждой такой ошибки (около 20-50 команд
на одну ошибку).
Алгоритмические
ошибки
программ
трудно поддаются обнаружению
методами статического автоматического
контроля. Трудность их обнаружения
и локализация определяется, прежде
всего, отсутствием для многих логических
программ строго формализованной
постановки задачи,
полной и точной спецификации, которую
можно использовать в качестве
эталона для сравнения результатов
функционирования программ. К алгоритмическим
ошибкам следует отнести, прежде всего,
ошибки, обусловленные
некорректной постановкой требований
к функциональным задачам,
когда в спецификациях не полностью
оговорены все условия, необходимые
для получения правильного результата.
Эти условия формируются и уточняются
в значительной части в процессе
тестирования и выявления ошибок в
результатах функционирования программ.
Ошибки, обусловленные
неполным учетом всех условий решения
задач, являются наиболее
частыми в этой группе и составляют до
50-70% всех алгоритмических ошибок.
К
алгоритмическим ошибкам следует отнести
также ошибки интерфейса
модулей и функциональных групп программ,
когда информация, необходимая
для функционирования некоторой части
программы, оказывается не полностью
подготовленной программами, предшествующими
по
времени включения, или неправильно
передаются информация и управление
между взаимодействующими модулями.
Этот вид ошибок составляет около 10% от
общего количества, и их можно квалифицировать
как ошибки некорректной постановки
задач. Алгоритмические ошибки проявляются
в неполном учете диапазонов изменения
переменных, в неправильной оценке
точности используемых и получаемых
величин, в неправильном
учете корреляции между различными
переменными, в неадекватном
представлении формализованных условий
решения задачи в виде частных спецификаций
или блок-схем, подлежащих программированию.
Эти
обстоятельства являются причиной того,
что для исправления каждой алгоритмической
ошибки приходится изменять в среднем
около 20 команд (строк
текста), т.е. существенно больше, чем при
программных ошибках.
Особую,
весьма существенную, часть алгоритмических
ошибок в системах
реального времени, при сопровождении
составляют просчеты в
использовании
доступных ресурсов вычислительной
системы. Получающиеся
при модификации программ попытки
превышения использования выделенных
ресурсов следует квалифицировать как
ошибку, так как затем всегда
следует корректировка с целью
удовлетворения имеющимся ограничениям.
Одновременная разработка множества
модулей различными специалистами
затрудняет оптимальное и сбалансированное
распределение ограниченных
ресурсов ЭВМ по всем задачам, так как
отсутствуют достоверные данные потребных
ресурсов для решения каждой из них. В
результате
возникает либо недостаточное использование,
либо, в подавляющем большинстве случаев,
нехватка каких-то ресурсов ЭВМ для
решения задач в первоначальном варианте.
Наиболее крупные просчеты обычно
допускаются
при оценке времени реализации различных
групп программ реального времени и при
распределении производительности ЭВМ.
Алгоритмические
ошибки этого типа обусловлены технической
сложностью расчета времени реализации
программ и сравнительно невысокой
достоверностью
определения вероятности различных
маршрутов обработки информации.
Ошибки
реализации спецификаций компонентов
—
это программные
дефекты, возможно, ошибки требований,
структуры или программные ошибки
компонентов. Ошибки реализации наиболее
обычны и, в общем, наиболее легки для
исправления в системе, что не делает
проблему легче для
программистов (см. таблицу 10.1). В отличие
от ошибок требований и структурных
ошибок, которые обычно специфичны для
приложения, программисты часто совершают
при кодировании одни и те же виды ошибок.
Первую
категорию составляют дефекты, которые
приводят к отображению
для пользователя сообщений об ошибках
при точном следовании порядку
выполнения требуемых функций. Хотя эти
сообщения могут быть вполне
законны, пользователи могут посчитать
это ошибкой, поскольку они
делали все правильно и, тем не менее,
получили сообщение об ошибке.
Часто ошибки этого типа вызваны либо
проблемами с ресурсами, либо специфическими
зависимостями от данных.
Вторая
категория модификаций может содержать
ошибки, связанные с дефектами в графическом
интерфейсе пользователя. Такие ошибки
могут
являться либо нестандартными модификациями
пользовательского интерфейса, которые
приводят к тому, что пользователь
совершает неверные
действия,
либо они могут быть стандартными
компонентами пользовательского
интерфейса, используемыми иначе, чем
ожидает конечный пользователь.
Третья
категория может содержать пропущенные
на стадии реализации
функции, что всегда считается ошибкой,
возможно, с большим риском.
Многие тестировщики и пользователи
бета-версий сообщают об ошибках,
которые на самом деле являются желательными
улучшениями. В данном
случае можно не замечать обнаруженные
таким образом отсутствия функций,
которых не было в спецификациях.
Программные
ошибки модифицированных компонентов
по
количеству и типам в первую очередь
определяются степенью автоматизации
программирования и глубиной статического
контроля текстов программ. Количество
программных ошибок зависит от квалификаций
программистов,
от общего размера комплекса программ,
от глубины информационного
взаимодействия модулей и от ряда других
факторов. При разработке ПС программные
ошибки можно классифицировать по видам
используемых операций на следующие
крупные группы: ошибки типов операций;
ошибки переменных; ошибки управления
и циклов. В логических компонентах
ПС эти виды ошибок близки по удельному
весу, однако для автоматизации
их обнаружения применяются различные
методы. На начальных
этапах разработки и автономной отладки
модулей программные ошибки
составляют около одной трети всех
ошибок. Каждая программная ошибка
влечет за собой необходимость изменения
около 10 команд, что существенно
меньше, чем при алгоритмических и
системных ошибках.
Ошибки
в документации модификаций
состоят
в том, что система делает
что-то одним образом, а документация
отражает сценарий, что она должна
работать иначе. Во многих случаях права
должна быть документация,
поскольку она написана на основе
оригинальной спецификации требований
системы. Иногда документация пишется
и включает допущения и комментарии о
том, как, по мнению авторов документации,
система должна работать. В других случаях
ошибку можно проследить не до кода, а
до документации
конечных пользователей, внутренних
технологических документов, характеризующих
систему, и даже до экранных подсказок
и файлов помощи. Ошибки документации
можно разделить на три категории —
неясность,
неполнота и неточность.
Неясность
— это когда
пользователю
не дается достаточно информации, чтобы
определить, как сделать процедуру
должным образом. Неполная документация
оставляет пользователя
без информации о том, как правильно
реализовать и завершить задачу.
Пользователь считает, что задача
выполнена, хотя на самом деле это не
так. Такие ошибки ведут к тому, что
пользователь не удовлетворен
версией ПС, даже если программа в
действительности может сделать все,
что хочет пользователь. Неточная
документация — это худший вид ошибок
документации. Такие ошибки часто
возникают, когда при сопровождении в
систему позже вносятся изменения и об
этих изменениях не сообщают лицу,
пишущему документацию.
Технологические
ошибки
документации
и фиксирования программ в памяти ЭВМ
составляют иногда до 10% от общего числа
ошибок, обнаруживаемых
при тестировании. Большинство
технологических ошибок выявляется
автоматически статическими методами.
При ручной подготовке текстов машинных
носителей при однократном фиксировании
исходные данные
имеют вероятность искажения около 10
» 3 —
10~ 4
на символ. Дублированной
подготовкой и логическим контролем
вероятность технологической
ошибки может быть снижена до уровня 10
5
—
10″ 7
на символ. Непосредственное
участие человека в подготовке данных
для ввода в ЭВМ и
при анализе результатов функционирования
программ по данным на дисплеях определяет
в значительной степени их уровень
достоверности и не позволяет полностью
пренебрегать этим типом ошибок в
программах.
В
примере
анализа ошибок конкретного крупного
проекта
было
принято, что завершилась инспекция
начального запрограммированного кода
крупного ПС на предмет его соответствия
рабочей проектной спецификации,
в ходе которой было обнаружено 3,48 ошибки
на тысячу строк кода. Наибольшее
совпадение аппроксимации рэлеевской
кривой распределения
ошибок с фактическими данными установлено
для момента получения этих данных, ему
соответствует значение, равное также
3,48. Значения
числа ошибок на тысячу строк получены
при пересчетах на более ранние
этапы соответственно эскизного — (3,3)
и рабочего — (7,8) проектирования
программ. При прогнозировании в
соответствии с рэлеевской кривой
распределения вероятности проявления
дефектов программ на следующем
этапе квалификационного тестирования
компонентов следовало ожидать
обнаружения около 2,12 ошибки на тысячу
строк исходного кода.
В
случае сохранения той же закономерности
в момент поставки клиенту на
испытания программный продукт мог
содержать менее 0,07 ошибки на тысячу
строк кода. Отмечается также, что частость
проявления 0,1-0,05 ошибки
на тысячу строк кода можно считать
допустимой для ответственных
систем реального времени.
В
исследованиях 20 крупных поставляемых
программных продуктов, созданных в 13
различных организациях, коллективы
специалистов добились среднего уровня
0,06 дефекта на тысячу строк нового и
измененного программного
кода. При использовании структурного
метода в пяти проектах достигнуто
0,04-0,075 ошибки на тысячу строк. Таким
образом, уровень
ошибок около 0,05 на тысячу строк кода
в
разных публикациях считается близким
к предельному для высококачественных
программных продуктов.
Другим
примером оценок уровня ошибок критического
ПС особенно высокого
качества может служить программный
продукт бортовых систем «Шаттла»,
созданный NASA.
По оценке авторов, в нем содержится
менее
одной ошибки на 10 000 строк кода. Однако
стоимость программного
продукта достигает 1000 $ за строку кода,
что в среднем в сто раз больше,
чем для административных систем, и в
десять раз больше, чем для ряда
ординарных критических управляющих
систем реального времени.
Приведенные
характеристики типов дефектов и
количественные данные
могут служить ориентирами
при прогнозировании возможного наличия
невыявленных ошибок
в
ЖЦ различных сложных ПС высокого
качества. Следующим логическим шагом
процесса их оценивания может быть
усреднение для большого числа проектов
фактических данных о количестве
ошибок на конкретном предприятии,
приходящихся на тысячу строк
кода, которые обнаружены в различных
ПС. Тогда в следующем проекте будет
иметься возможность использования этих
данных, в качестве
меры количества ошибок, обнаружение
которых следует ожидать при выполнении
проекта с таким же уровнем качества ПС,
или с целью повышения
производительности при разработке для
оценки момента прекращения дальнейшего
тестирования. Подобные оценки гарантируют
от
из
быточного
оптимизма
при
определении сроков и при разработке
графиков
разработки, сопровождения и реализации
модификаций программ с заданным
качеством. Непредсказуемость конкретных
ошибок в програм-
мах
приводит к целесообразности
последовательного, методичного
фиксирования и анализа возможности
проявления любого типа дефектов и
необходимости их исключения на наиболее
ранних этапах ЖЦ ПС при минимальных
затратах.
Причинами
возникновения и проявления рисков могут
быть: злоумышленные,
активные воздействия заинтересованных
лиц
или
слу
чайные
негативные проявления дефектов
внешней
среды, системы или пользователей.
В первом случае риски могут быть
обусловлены искажениями
программ и информационных ресурсов и
их уязвимостью от предумышленных,
внешних воздействий (атак) с целью
незаконного использования
или искажения информации и программ,
которые по своему содержанию
предназначены для применения ограниченным
кругом лиц. Для решения этой проблемы
созданы и активно развиваются методы,
средства и стандарты обеспечения защиты
программ и данных от предумышленных
негативных внешних воздействий.
Специфические
факторы обеспечения информационной
безопасности и риски, характерные для
сложных информационных систем, —
целостность, доступность и конфиденциальность
информационных ресурсов, а также ряд
типовых процедур систем
защиты — криптографическая поддержка,
идентификация и аутентификация,
защита и сохранность данных пользователей
при
предумышленных атаках из внешней среды
далее не рассматриваются.
Риски
при случайных, дестабилизирующих
воздействиях
дефектов
программных
средств и отсутствии предумышленного
негативного влияния
на системы, ПС или информацию баз данных
существенно отличаются
от предшествующих задач. Эти риски
объектов и систем зависят от отказовых
ситуаций, отрицательно отражающихся
на работоспособности и
реализации их основных функций, причинами
которых могут быть дефекты
и аномалии в аппаратуре, программах,
данных или вычислительных процессах.
При этом катастрофически, критически
или существенно искажается процесс
функционирования систем, что может
наносить значительный ущерб при их
применении. Основными источниками
отказо-
вых
ситуаций могут быть некорректные
исходные требования, сбои и отказы в
аппаратуре, дефекты или ошибки в
программах и данных функциональных
задач, проявляющиеся при их исполнении
в соответствии с назначением. При таких
воздействиях внешняя, функциональная
работоспособность систем может
разрушаться не полностью, однако
невозможно полноценное выполнение
заданных функций и требований к качеству
информации
для потребителей. Вредные и катастрофические
последствия таких отказов в ряде областей
применения систем могут превышать по
результатам последствия злоумышленных
воздействий, имеют свою природу,
особенности и характеристики.
Рассматриваемые
риски могут быть обусловлены нарушениями
технологий или ограничениями при
использовании ресурсов — бюджета,
планов, коллектива специалистов,
инструментальных средств, выделенных
на разработку ПС. Результирующий ущерб
в
совокупности зависит от величины
и вероятности проявления каждого
негативного воздействия. Этот
ущерб — риск характеризуется разнообразными
метриками, зависящими от объектов
анализа, и в некоторых случаях может
измеряться прямыми
материальными, информационными,
функциональными потерями применяемых
ПС или систем. Одним из косвенных методов
определения величины риска может быть
оценка
совокупных затрат,
необходимых
для
ликвидации негативных последствий в
ПС, системе или внешней среде,
проявившихся в результате конкретного
рискового события.
Процессы
анализа и сокращения рисков должны
сопутствовать основным этапам разработки
и обеспечения ЖЦ сложных программных
средств
в соответствии с международными
стандартами, а также методам систем
обеспечения качества ПС. Эти процессы
могут быть отражены пятью
этапами работ и процедур,
которые
рекомендуется выполнять при поддержке
базовых работ жизненного цикла проектов
сложных программных
средств, и могут служить основой для
разработки соответствующих
планов работ при управлении и сокращении
рисков — рис. 10.3:
анализ
рисков следует начинать с подготовки
детальных исходных требований
и характеристик проекта ПС, системы и
внешней среды, для которых должны
отсутствовать риски функционирования
и применения;
для
управления рисками и их сокращения в
рассматриваемых проектах
сложных комплексов программ рекомендуется
выделять три класса
рисков:
функциональной пригодности ПС,
конструктивных характеристик качества
и нарушения ограничений ресурсов при
реализации процессов ЖЦ ПС;
1. Основные понятия в тестировании
Ручное тестирование
Урок 1
Основные понятия в
тестировании
Что представляет собой тестирование. Как
определить качество ПО. Категории
программных ошибок. Терминология.
2. Регламент курса
● 8 уроков по 2 часа
● Домашние задания
● Видеозапись будет
● Задавайте вопросы
3. Вопросы?
Почему я пришел на курс по ручному тестированию?
Для чего в принципе нужно ручное тестирование?
Как я буду использовать знания о тестировании?
4. Цель курса
Нравится ли мне тестировать?
Как тестировать?
Что делать с результатами тестирования?
Куда двигаться дальше?
Практика тестирования.
5. План урока
1. Общие знания о тестировании и тестировщиках
2. Как определить качество ПО
3. Категории программных ошибок
4. Терминология
К концу урока мы будем уметь выявлять ошибки, опираться на
рекомендуемые стандарты и понимать терминологию
6. Что такое тестирование?
Тестирование ПО – это проверка соответствия между
реальным и ожидаемым поведением программы,
осуществляемая на конечном наборе тестов, выбранном
определенным образом (IEEE).
7. Что представляет собой тестирование?
8. Что представляет собой тестирование?
9. Что делает тестировщик?
Поиск ошибок и сбоев
Моделирование ситуаций использования ПО
Создание тестовых данных
Регистрация ошибок в баг-трекере
Ведение отчетности по тестированию
10. — Цель тестирования — Цель тестировщика
11. Что такое качество ПО?
Четкое следование
спецификации
надежность
функциональность
12. Что такое качество ПО?
Качество программного обеспечения — это степень, в которой ПО обладает
требуемой комбинацией свойств. [1061-1998 IEEE Standard for Software
Quality Metrics Methodology]
Качество программного обеспечения — это совокупность характеристик ПО,
относящихся к его способности удовлетворять установленные и
предполагаемые потребности. [ISO 8402:1994 Quality management and quality
assurance]
13. Как определить качество ПО?
1. Функциональность
2. Надежность
3. Удобство использования
4. Эффективность
5. Удобство сопровождения
6. Портативность
14. Как контролировать качество ПО?
• Верификация — проверка того, что ПО разработано в
соответствии со всеми требованиями к нему или что
очередной этап разработки выполнен в соответствии с
ограничениями, сформулированными на предшествующих
этапах.
• Валидация — это проверка того, что сам продукт правилен,
т.е. подтверждение того, что он действительно
удовлетворяет требованиям и ожиданиям пользователей,
заказчиков и других заинтересованных сторон.
15. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
16. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
1. Составили ли вы тест, который представляет неравносторонний
треугольник?
(Заметим, что ответ «да» на тесты, со значениями 1, 2, 3 и 2, 5, 10 не
обоснован, так как не существует треугольников, имеющих такие
стороны.)
17. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
2. Составили ли вы тест, который представляет равносторонний
треугольник?
18. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
3. Составили ли вы тест, который представляет равнобедренный
треугольник? (Тесты со значениями 2, 2, 4 принимать в расчет не следует,
т.к сумма двух сторон должна быть больше третьей.)
19. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
4. Составили ли вы, по крайней мере, три теста, которые представляют
равнобедренные треугольники, полученные перестановкой двух равных
сторон треугольника ( например, 3, 3, 4; 3, 4, 3 и 4, 3, 3)?
20. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
5. Составили ли вы тест, в котором длина одной из сторон треугольника
принимает нулевое значение?
21. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
6. Составили ли вы тест, в котором длина одной из сторон треугольника
принимает отрицательное значение?
22. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
7. Составили ли вы тест, включающий три положительных целых числа, сумма
двух из которых равна третьему?
Другими словами, если программа выдала сообщение о том, что числа 1, 2, 3
представляют собой стороны неравностороннего треугольника, то такая
программа содержит ошибку.
23. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
8. Составили ли вы, по крайней мере, три теста с заданными значениями
всех трех перестановок, в которых длина одной стороны равна сумме
длин двух других сторон (например, 1, 2, 3; 1, 3, 2 и 3, 1, 2)?
24. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
9. Составили ли вы тест из трех целых положительных чисел, таких, что
сумма двух из них меньше третьего числа (т. е. 1, 2, 4 или 12, 15, 30)?
25. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
10. Составили ли вы, по крайней мере, три теста из категории 9, в которых
вами испытаны все три перестановки (например, 1, 2, 4; 1, 4, 2 и 4, 1, 2)?
26. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
11. Составили ли вы тест, в котором все стороны треугольника имеют
длину, равную нулю (т. е. 0, 0, 0)?
27. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
12. Составили ли вы, по крайней мере, один тест, содержащий нецелые
значения?
28. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
13. Составили ли вы хотя бы один тест, содержащий неправильное число
значений (например, два, а не три целых числа)?
29. Тест для оценки себя тестировщиком
Введите длины сторон треугольника
Проверить
+1 балл, если:
14. Описали ли вы заранее в каждом тесте не только входные значения,
но и выходные данные программы?
30. Категории программных ошибок
Ошибка в работе программы – BUG:
—
Пользовательский интерфейс
—
Вычисления
—
Начальное и последующее состояние
—
Управление потоком
—
…
31. Категории ошибок
Функциональность:
В программе отсутствует описанная в спецификации или очевидно необходимая
функция.
Функция программы должна выполнять одно, а делает нечто другое.
Взаимодействие программы с пользователем:
Отсутствует название программы.
Отсутствует индикатор оставшегося времени обработки.
Одна и та же функция не должна иметь в программе несколько значений: либо ОК,
либо Сохранить — нужно выбрать что-то одно.
В сообщениях об ошибках не должно быть восклицательных знаков, слов “авария”,
“сбой”, “нарушение”, “потеря данных”, шрифта красного цвета.
Не выделены активные элементы экрана.
32. Категории ошибок
Организация программы:
Неудачная организация меню.
Диалоговые окна должны выводиться в одном и том же месте экрана
Цвета, используемые в программе должны гармонично сочетаться.
При возникновении ошибки в программе, ее поведение должно быть
предсказуемым и последовательным.
В меню не должно быть команд, которые невозможно выполнить.
Слишком много путей к одному и тому же месту.
Пропущенные команды:
У пользователя должна быть возможность отменить последнее выполненное
действие.
У пользователя должна быть возможность прервать выполнение программой
текущего задания и вернуться к исходному состоянию.
33. Категории ошибок
Производительность:
Низкая скорость работы программы.
Замедленное отображение вводимых пользователем данных.
Замедленное перемещение курсора мыши, голосового ввода.
Выходные данные:
Неверные данные в сформированном отчете.
Неверные данные в сохраненных файлах.
34. Категории ошибок
Обработка ошибок:
Пользователь может ввести в программу неверные данные.
Переполнение.
Невозможные значения.
Ошибки, связанные с обработкой граничных условий:
Числовые ограничения.
Количественные ограничения.
Пространственные ограничения.
Ограничения времени.
Ограничения объема памяти.
35. Категории ошибок
Ошибки вычислений:
Выполнение сложения вместо вычитания.
Выражения с обилием скобок.
Неправильный порядок операторов.
Переполнение и потеря значащих разрядов.
Ошибки отсечения и округления.
Неверная формула.
Начальные и последующие состояния
Ошибки управления потоком
36. Категории ошибок
Ошибки передачи или интерпретации данных:
Неправильная интерпретация данных.
Неадекватная информация об ошибке.
Затирание кода другого процесса.
Не сохранены введенные данные.
Ситуация гонок:
Гонки при обновлении данных.
Предположение, что одно задание завершится до начала другого.
Сообщения приходят одновременно или не в том порядке, в котором они были
отправлены.
37. Категории ошибок
Перегрузки:
Требуемый ресурс недоступен
Потеря информации о нажатых клавишах из-за недостаточного размера буфера
ввода или очереди.
Аппаратное обеспечение:
Неверный адрес устройства.
Устройство недоступно.
Данной программе или устройству доступ к устройству запрещен.
38. Категории ошибок
Контроль версий:
В программе появляются старые ошибки, ранее исправлявшиеся.
Ошибка, исправленная в одном месте программы, может быть обнаружена в
другом.
Неверный номер версии программы в заголовке экрана.
Неверная информация об авторских правах.
Документация
Документация считается частью программного продукта. И если она плохо
написана, пользователь может подумать, что и сама программа ненамного лучше.
Ошибки тестирования
39. А теперь поработаем головой и руками!
40. Тестировать можно все!
41. Организационные вопросы
Пишите комментарии к уроку. Я буду отвечать на них каждый день;
Личные сообщения;
Видео буду выкладывать в день урока (самое позднее — на следующий
день)
42. Домашнее задание
Попробуем протестировать страницу авторизации в электронной почте.
Для этого, предварительно нужно создать тестовый аккаунт (можно использовать
свой). Далее, опираясь на описание категорий ошибок в методичке, выписать в
таблицу действия, которые можно совершить пытаясь войти в почту.
№
1
2
…
Действие
Результат
43. Вопросы участников …
-
Классификация ошибок
Задача любого
тестировщика заключается в нахождении
наибольшего количества ошибок, поэтому
он должен хорошо знать наиболее часто
допускаемые ошибки и уметь находить их
за минимально короткий период времени.
Остальные ошибки, которые не являются
типовыми, обнаруживаются только тщательно
созданными наборами тестов. Однако из
этого не следует, что для типовых ошибок
не нужно составлять тесты.
Для классификации
ошибок мы должны определить термин
«ошибка».
Ошибка – это
расхождение между вычисленным, наблюдаемым
и истинным, заданным или теоретически
правильным значением.
Итак, по времени
появления ошибки можно разделить на
три вида:
– структурные ошибки
набора;
– ошибки компиляции;
– ошибки периода
выполнения.
Структурные
ошибки
возникают непосредственно при наборе
программы. К данному типу ошибок относятся
такие как: несоответствие числа
открывающих скобок числу закрывающих,
отсутствие парного оператора (например,
try
без catch).
Ошибки
компиляции
возникают из-за ошибок в тексте кода.
Они включают ошибки в синтаксисе,
неверное использование конструкции
языка (оператор else
в операторе for
и т. п.), использование несуществующих
объектов или свойств, методов у объектов,
употребление синтаксических знаков и
т. п.
Ошибки
периода выполнения
возникают, когда программа выполняется
и компилятор (или операционная система,
виртуальная машина) обнаруживает, что
оператор делает попытку выполнить
недопустимое или невозможное действие.
Например, деление на ноль.
Если проанализировать
все типы ошибок согласно первой
классификации, то можно прийти к
заключению, что при тестировании
приходится иметь дело с ошибками периода
выполнения, так как первые два типа
ошибок определяются на этапе кодирования.
В теоретической
информатике программные ошибки
классифицируют по степени нарушения
логики на:
– синтаксические;
–семантические;
– прагматические.
Синтаксические
ошибки
заключаются в нарушении правописания
или пунктуации в записи выражений,
операторов и т. п., т. е. в нарушении
грамматических правил языка. В качестве
примеров синтаксических ошибок можно
назвать:
– пропуск необходимого
знака пунктуации;
– несогласованность
скобок;
– пропуск нужных
скобок;
– неверное написание
зарезервированных слов;
– отсутствие описания
массива.
Все ошибки данного
типа обнаруживаются компилятором.
Семантические
ошибки
заключаются в нарушении порядка
операторов, параметров функций и
употреблении выражений. Например,
параметры у функции add
(на языке Java)
в следующем выражении указаны в
неправильном порядке:
GregorianCalendar.add(1,
Calendar.MONTH).
Параметр, указывающий
изменяемое поле (в примере – месяц),
должен идти первым. Семантические ошибки
также обнаруживаются компилятором.
Надо отметить, что некоторые исследователи
относят семантические ошибки к следующей
группе ошибок.
Прагматические
ошибки (или
логические) заключаются в неправильной
логике алгоритма, нарушении смысла
вычислений и т. п. Они являются самыми
сложными и крайне трудно обнаруживаются.
Компилятор может выявить только следствие
прагматической ошибки.
Таким образом, после
рассмотрения двух классификаций ошибок
можно прийти к выводу, что на этапе
тестирования ищутся прагматические
ошибки периода выполнения, так как
остальные выявляются в процессе
программирования.
На этом можно было
бы закончить рассмотрение классификаций,
но с течением времени накапливался опыт
обнаружения ошибок и сами ошибки,
некоторые из которых образуют характерные
группы, которые могут тоже служить
характерной классификацией.
Ошибка
адресации
– ошибка, состоящая в неправильной
адресации данных (например, выход за
пределы участка памяти).
Ошибка
ввода-вывода
– ошибка, возникающая в процессе обмена
данными между устройствами памяти,
внешними устройствами.
Ошибка
вычисления
– ошибка, возникающая при выполнении
арифметических операций (например,
разнотипные данные, деление на нуль и
др.).
Ошибка
интерфейса
– программная ошибка, вызванная
несовпадением характеристик фактических
и формальных параметров (как правило,
семантическая ошибка периода компиляции,
но может быть и логической ошибкой
периода выполнения).
Ошибка
обращения к данным
– ошибка, возникающая при обращении
программы к данным (например, выход
индекса за пределы массива, не
инициализированные значения переменных
и др.).
Ошибка
описания данных
– ошибка, допущенная в ходе описания
данных.[2]
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Дефекты программного обеспечения можно обнаружить на каждом этапе разработки и тестирования продукта. Чтобы гарантировать исправление наиболее серьезных дефектов программного обеспечения, тестировщикам важно иметь хорошее представление о различных типах дефектов, которые могут возникнуть.
В этой статье мы обсудим самые распространенные типы ПО дефекты и способы их выявления.
Что такое дефект?
Дефект программного обеспечения — это ошибка, изъян, сбой или неисправность в компьютерной программе, из-за которой она выдает неправильный или неожиданный результат или ведет себя непреднамеренным образом. Программная ошибка возникает, когда фактические результаты не совпадают с ожидаемыми. Разработчики и программисты иногда допускают ошибки, которые создают ошибки, называемые дефектами. Большинство ошибок возникает из-за ошибок, которые допускают разработчики или программисты.
Обязательно прочтите: Разница между дефектом, ошибкой, ошибкой и сбоем
Типы программных ошибок при тестировании программного обеспечения
Существует множество различных типов дефектов программного обеспечения, и тестировщикам важно знать наиболее распространенные из них, чтобы они могут эффективно тестировать их.
Ошибки программного обеспечения подразделяются на три типа:
- Дефекты программного обеспечения по своей природе
- Дефекты программного обеспечения по их приоритету
- Дефекты программного обеспечения по их серьезности
Обычно мы можем видеть приоритет и серьезность классификаторов в большинстве инструментов отслеживания ошибок. Если мы настроим классификатор в соответствии с характером ошибки, а также приоритетом и серьезностью, это поможет легко управлять распределением обязанностей по исправлению ошибок соответствующим командам.
#1. Дефекты программного обеспечения по своей природе
Ошибки в программном обеспечении имеют широкий спектр природы, каждая из которых имеет свой собственный набор симптомов. Несмотря на то, что таких багов много, сталкиваться с ними можно не часто. Вот наиболее распространенные ошибки программного обеспечения, классифицированные по характеру, с которыми вы, скорее всего, столкнетесь при тестировании программного обеспечения.
#1. Функциональные ошибки
Как следует из названия, функциональные ошибки — это те, которые вызывают сбои в работе программного обеспечения. Хорошим примером этого может служить кнопка, при нажатии на которую должно открываться новое окно, но вместо этого ничего не происходит.
Функциональные ошибки можно исправить, выполнив функциональное тестирование.
#2. Ошибки на уровне модуля
Ошибки на уровне модуля — это дефекты, связанные с функциональностью отдельного программного модуля. Программный модуль — это наименьшая тестируемая часть приложения. Примеры программных модулей включают классы, методы и процедуры. Ошибки на уровне подразделения могут существенно повлиять на общее качество программного обеспечения.
Ошибки на уровне модуля можно исправить, выполнив модульное тестирование.
#3. Ошибки уровня интеграции
Ошибки уровня интеграции — это дефекты, возникающие при объединении двух или более программных модулей. Эти дефекты может быть трудно найти и исправить, потому что они часто требуют координации между несколькими командами. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки интеграции можно исправить, выполнив интеграционное тестирование.
#4. Дефекты юзабилити
Ошибки юзабилити — это дефекты, влияющие на работу пользователя с программным обеспечением и затрудняющие его использование. Дефект юзабилити — это дефект пользовательского опыта программного обеспечения, который затрудняет его использование. Ошибки юзабилити — это такие ошибки, как если веб-сайт сложен для доступа или обойти, или процесс регистрации сложен для прохождения.
Во время тестирования удобства использования тестировщики программного обеспечения проверяют приложения на соответствие требованиям пользователей и Руководству по доступности веб-контента (WCAG) для выявления таких проблем. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки, связанные с удобством использования, можно исправить, выполнив тестирование удобства использования.
#5. Дефекты производительности
Ошибки производительности — это дефекты, влияющие на производительность программного обеспечения. Это может включать в себя такие вещи, как скорость программного обеспечения, объем используемой памяти или количество потребляемых ресурсов. Ошибки уровня производительности сложно отследить и исправить, поскольку они могут быть вызваны рядом различных факторов.
Ошибки юзабилити можно исправить, выполнив тестирование производительности.
#6. Дефекты безопасности
Ошибки безопасности — это тип дефекта программного обеспечения, который может иметь серьезные последствия, если его не устранить. Эти дефекты могут позволить злоумышленникам получить доступ к конфиденциальным данным или системам или даже позволить им получить контроль над уязвимым программным обеспечением. Таким образом, очень важно, чтобы ошибкам уровня безопасности уделялось первоочередное внимание и устранялись как можно скорее.
Ошибки безопасности можно исправить, выполнив тестирование безопасности.
#7. Дефекты совместимости
Дефекты совместимости — это те ошибки, которые возникают, когда приложение несовместимо с оборудованием, на котором оно работает, или с другим программным обеспечением, с которым оно должно взаимодействовать. Несовместимость программного и аппаратного обеспечения может привести к сбоям, потере данных и другому непредсказуемому поведению. Тестировщики должны знать о проблемах совместимости и проводить соответствующие тесты. Программное приложение, имеющее проблемы с совместимостью, не работает последовательно на различных видах оборудования, операционных системах, веб-браузерах и устройствах при подключении к определенным программам или работе в определенных сетевых условиях.
Ошибки совместимости можно исправить, выполнение тестирования совместимости.
#8. Синтаксические ошибки
Синтаксические ошибки являются самым основным типом дефекта. Они возникают, когда код нарушает правила языка программирования. Например, использование неправильной пунктуации или забывание закрыть скобку может привести к синтаксической ошибке. Синтаксические ошибки обычно мешают запуску кода, поэтому их относительно легко обнаружить и исправить.
#9. Логические ошибки
Логические ошибки — это дефекты, из-за которых программа выдает неправильные результаты. Эти ошибки может быть трудно найти и исправить, потому что они часто не приводят к каким-либо видимым ошибкам. Логические ошибки могут возникать в любом типе программного обеспечения, но они особенно распространены в приложениях, требующих сложных вычислений или принятия решений.
Общие симптомы логических ошибок включают:
- Неверные результаты или выходные данные
- Неожиданное поведение
- Сбой или зависание программного обеспечения
Чтобы найти и исправить логические ошибки, тестировщикам необходимо иметь четкое представление о коде программы и о том, как она должна работать. Часто лучший способ найти такие ошибки — использовать инструменты отладки или пошаговое выполнение, чтобы отслеживать выполнение программы и видеть, где что-то идет не так.
#2. Дефекты программного обеспечения по степени серьезности
Уровень серьезности присваивается дефекту по его влиянию. В результате серьезность проблемы отражает степень ее влияния на функциональность или работу программного продукта. Дефекты серьезности классифицируются как критические, серьезные, средние и незначительные в зависимости от степени серьезности.
#1. Критические дефекты
Критический дефект — это программная ошибка, имеющая серьезные или катастрофические последствия для работы приложения. Критические дефекты могут привести к сбою, зависанию или некорректной работе приложения. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение критическим дефектам, поскольку их необходимо исправить как можно скорее.
#2. Серьезные дефекты
Серьезный дефект — это программная ошибка, существенно влияющая на работу приложения. Серьезные дефекты могут привести к замедлению работы приложения или другому неожиданному поведению. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение серьезным дефектам, поскольку их необходимо исправить как можно скорее.
#3. Незначительные дефекты
Незначительный дефект — это программная ошибка, которая оказывает небольшое или незначительное влияние на работу приложения. Незначительные дефекты могут привести к тому, что приложение будет работать немного медленнее или демонстрировать другое неожиданное поведение. Разработчики и тестировщики часто не придают незначительным дефектам приоритет, потому что их можно исправить позже.
#4. Тривиальные дефекты
Тривиальный дефект – это программная ошибка, не влияющая на работу приложения. Тривиальные дефекты могут привести к тому, что приложение отобразит сообщение об ошибке или проявит другое неожиданное поведение. Разработчики и тестировщики часто присваивают тривиальным дефектам самый низкий приоритет, потому что они могут быть исправлены позже.
#3. Дефекты программного обеспечения по приоритету
#1. Дефекты с низким приоритетом
Дефекты с низким приоритетом, как правило, не оказывают серьезного влияния на работу программного обеспечения и могут быть отложены для исправления в следующей версии или выпуске. В эту категорию попадают косметические ошибки, такие как орфографические ошибки, неправильное выравнивание и т. д.
#2. Дефекты со средним приоритетом
Дефекты со средним приоритетом — это ошибки, которые могут быть исправлены после предстоящего выпуска или в следующем выпуске. Приложение, возвращающее ожидаемый результат, которое, однако, неправильно форматируется в конкретном браузере, является примером дефекта со средним приоритетом.
#3. Дефекты с высоким приоритетом
Как следует из названия, дефекты с высоким приоритетом — это те, которые сильно влияют на функционирование программного обеспечения. В большинстве случаев эти дефекты необходимо исправлять немедленно, так как они могут привести к серьезным нарушениям нормального рабочего процесса. Дефекты с высоким приоритетом обычно классифицируются как непреодолимые, так как они могут помешать пользователю продолжить выполнение поставленной задачи.
Некоторые распространенные примеры дефектов с высоким приоритетом включают:
- Дефекты, из-за которых приложение не работает. сбой
- Дефекты, препятствующие выполнению задачи пользователем
- Дефекты, приводящие к потере или повреждению данных
- Дефекты, раскрывающие конфиденциальную информацию неавторизованным пользователям
- Дефекты, делающие возможным несанкционированный доступ к системе
- Дефекты, приводящие к потере функциональности
- Дефекты, приводящие к неправильным результатам или неточным данным
- Дефекты, вызывающие проблемы с производительностью, такие как чрезмерное использование памяти или медленное время отклика
#4. Срочные дефекты
Срочные дефекты — это дефекты, которые необходимо устранить в течение 24 часов после сообщения о них. В эту категорию попадают дефекты со статусом критической серьезности. Однако дефекты с низким уровнем серьезности также могут быть классифицированы как высокоприоритетные. Например, опечатка в названии компании на домашней странице приложения не оказывает технического влияния на программное обеспечение, но оказывает существенное влияние на бизнес, поэтому считается срочной.
#4. Дополнительные дефекты
#1. Отсутствующие дефекты
Отсутствующие дефекты возникают из-за требований, которые не были включены в продукт. Они также считаются несоответствиями спецификации проекта и обычно негативно сказываются на пользовательском опыте или качестве программного обеспечения.
#2. Неправильные дефекты
Неправильные дефекты — это те дефекты, которые удовлетворяют требованиям, но не должным образом. Это означает, что хотя функциональность достигается в соответствии с требованиями, но не соответствует ожиданиям пользователя.
#3. Дефекты регрессии
Дефект регрессии возникает, когда изменение кода вызывает непреднамеренное воздействие на независимую часть программного обеспечения.
Часто задаваемые вопросы — Типы программных ошибок< /h2>
Почему так важна правильная классификация дефектов?
Правильная классификация дефектов важна, поскольку она помогает эффективно использовать ресурсы и управлять ими, правильно приоритизировать дефекты и поддерживать качество программного продукта.
Команды тестирования программного обеспечения в различных организациях используют различные инструменты отслеживания дефектов, такие как Jira, для отслеживания дефектов и управления ими. Несмотря на то, что в этих инструментах есть несколько вариантов классификации дефектов по умолчанию, они не всегда могут наилучшим образом соответствовать конкретным потребностям организации.
Следовательно, важно сначала определить и понять типы дефектов программного обеспечения, которые наиболее важны для организации, а затем соответствующим образом настроить инструмент управления дефектами.
Правильная классификация дефектов также гарантирует, что команда разработчиков сможет сосредоточиться на критических дефектах и исправить их до того, как они повлияют на конечных пользователей.
Кроме того, это также помогает определить потенциальные области улучшения в процессе разработки программного обеспечения, что может помочь предотвратить появление подобных дефектов в будущих выпусках.
Таким образом, отслеживание и устранение дефектов программного обеспечения может показаться утомительной и трудоемкой задачей. , правильное выполнение может существенно повлиять на качество конечного продукта.
Как найти лежащие в основе ошибки программного обеспечения?
Определение основной причины программной ошибки может быть сложной задачей даже для опытных разработчиков. Чтобы найти лежащие в основе программные ошибки, тестировщики должны применять систематический подход. В этот процесс входят различные этапы:
1) Репликация. Первым этапом является воспроизведение ошибки. Это включает в себя попытку воспроизвести тот же набор шагов, в котором возникла ошибка. Это поможет проверить, является ли ошибка реальной или нет.
2) Изоляция. После того, как ошибка воспроизведена, следующим шагом будет попытка ее изоляции. Это включает в себя выяснение того, что именно вызывает ошибку. Для этого тестировщики должны задать себе несколько вопросов, например:
– Какие входные данные вызывают ошибку?
– При каких различных условиях возникает ошибка?
– Каковы различные способы проявления ошибки?
3) Анализ: после Изолируя ошибку, следующим шагом будет ее анализ. Это включает в себя понимание того, почему возникает ошибка. Тестировщики должны задать себе несколько вопросов, таких как:
– Какова основная причина ошибки?
– Какими способами можно исправить ошибку?
– Какое исправление было бы наиболее эффективным? эффективно?
4) Отчет. После анализа ошибки следующим шагом является сообщение о ней. Это включает в себя создание отчета об ошибке, который включает всю соответствующую информацию об ошибке. Отчет должен быть четким и кратким, чтобы разработчики могли его легко понять.
5) Проверка. После сообщения об ошибке следующим шагом является проверка того, была ли она исправлена. Это включает в себя повторное тестирование программного обеспечения, чтобы убедиться, что ошибка все еще существует. Если ошибка исправлена, то тестер может подтвердить это и закрыть отчет об ошибке. Если ошибка все еще существует, тестировщик может повторно открыть отчет об ошибке.
Заключение
В индустрии программного обеспечения дефекты — неизбежная реальность. Однако благодаря тщательному анализу и пониманию их характера, серьезности и приоритета дефектами можно управлять, чтобы свести к минимуму их влияние на конечный продукт.
Задавая правильные вопросы и применяя правильные методы, тестировщики могут помочь обеспечить чтобы дефекты обнаруживались и исправлялись как можно раньше в процессе разработки.
TAG: qa
7.3.2. Классификация ошибок и тестов
Каждая организация, разрабатывающая ПО общесистемного назначения, сталкивается с проблемами нахождения ошибок. Поэтому приходится классифицировать типы обнаруживаемых ошибок и определять свое отношение к устранению этих ошибок.
На основе многолетней деятельности в области создания ПО разные фирмы создали свою классификацию ошибок, основанную на выявлении причин их появления в процессе разработки, в функциях и в области функциональной деятельности ПО.
Известно много различных подходов к классификации ошибок, рассмотрим некоторые из них.
Фирма IВМ разработала подход к классификации ошибок, называемый ортогональной классификацией дефектов [7.4]. Подход предусматривает разбиение ошибок по категориям с соответствующей ответственностью разработчиков за них.
Схема классификации не зависит от продукта, организации разработки и может применяться ко всем стадиям разработки ПО разного назначения. табл. 7.1 дает список ошибок согласно данной классификации. Используя эту таблицу, разработчик имеет возможность идентифицировать не только типы ошибок, но и места, где пропущены или совершены ошибки. Предусмотрены ситуации, когда найдена неинициализированная переменная или инициализированной переменной присвоено неправильное значение.
Ортогональность схемы классификации заключается в том, что любой ее термин принадлежит только одной категории.
Таблица
7.1.
Ортогональная классификация дефектов IBM
| Контекст ошибки | Классификация дефектов |
|---|---|
| Функция | Ошибки интерфейсов конечных пользователей ПО, вызванные аппаратурой или связаны с глобальными структурами данных |
| Интерфейс | Ошибки во взаимодействии с другими компонентами, в вызовах, макросах, управляющих блоках или в списке параметров |
| Логика | Ошибки в программной логике, неохваченной валидацией, а также в использовании значений переменных |
| Присваивание | Ошибки в структуре данных или в инициализации переменных отдельных частей программы |
| Зацикливание | Ошибки, вызванные ресурсом времени, реальным временем или разделением времени |
| Среда | Ошибки в репозитории, в управлении изменениями или в контролируемых версиях проекта |
| Алгоритм | Ошибки, связанные с обеспечением эффективности, корректности алгоритмов или структур данных системы |
| Документация | Ошибки в записях документов сопровождения или в публикациях |
Другими словами, прослеживаемая ошибка в системе должна находиться в одном из классов, что дает возможность разным разработчикам классифицировать ошибки одинаковым способом.
Фирма Hewlett-Packard использовала классификацию Буча, установив процентное соотношение ошибок, обнаруживаемых в ПО на разных стадиях разработки (рис. 7.2) [7.12].
Это соотношение — типичное для многих фирм, производящих ПО, имеет некоторые отклонения.
Исследования фирм IBM показали, чем позже обнаруживается ошибка в программе, тем дороже обходится ее исправление, эта зависимость близка к экспоненциальной. Так военновоздушные силы США оценили стоимость разработки одной инструкции в 75 долларов, а ее стоимость сопровождения составляет около 4000 долларов.

Рис.
7.2.
Процентное соотношение ошибок при разработке ПО
Согласно данным [7.6, 7.11] стоимость анализа и формирования требований, внесения в них изменений составляет примерно 10%, аналогично оценивается стоимость спецификации продукта. Стоимость кодирования оценивается более чем 20%, а стоимость тестирования продукта составляет более 45% от его общей стоимости. Значительную часть стоимости составляет сопровождение готового продукта и исправление обнаруженных в нем ошибок.
Определение теста.Для проверки правильности программ специально разрабатываются тесты и тестовые данные. Под тестом понимается некоторая программа, предназначенная для проверки работоспособности другой программы и обнаружения в ней ошибочных ситуаций. Тестовую проверку можно провести также путем введения в проверяемую программу отладочных операторов, которые будут сигнализировать о ходе ее выполнения и получения результатов.
Тестовые данные служат для проверки работы системы и составляются разными способами: генератором тестовых данных, проектной группой на основе внемашинных документов или имеющихся файлов, пользователем по спецификациям требований и др. Очень часто разрабатываются специальные формы входных документов, в которых отображается процесс выполнения программы с помощью тестовых данных [7.11].
Создаются тесты, проверяющие:
- полноту функций;
- согласованность интерфейсов;
- корректность выполнения функций и правильность функционирования системы в заданных условиях;- надежность выполнения системы;
- защиту от сбоев аппаратуры и не выявленных ошибок и др.
Тестовые данные готовятся как для проверки отдельных программных элементов, так и для групп программ или комплексов на разных стадиях процесса разработки. На рис. 7.3. приведена классификация тестов проверки по объектам тестирования на основных этапах разработки.
Многие типы тестов готовятся заказчиком для проверки работы программной системы. Структура и содержание тестов зависят от вида тестируемого элемента, которым может быть модуль, компонент, группа компонентов, подсистема или система. Некоторые тесты зависят от цели и необходимости знать: работает ли система в соответствии с ее проектом, удовлетворены ли требования и участвует ли заказчик в проверке работы тестов и т.п.
В зависимости от задач, которые ставятся перед тестированием программ, составляются тесты проверки промежуточных результатов проектирования элементов на этапах ЖЦ, а также создаются тесты испытаний окончательного кода системы.
Тесты интегрированной системы.Тесты для проверки отдельных элементов системы и тесты интегрированной системы имеют общие и отличительные черты. Так, на рис. 7.4 в качестве примера приведена схема интеграции готовых оттестированных элементов. В ней заданы связи между разными уровнями тестирования интегрируемой ПС.
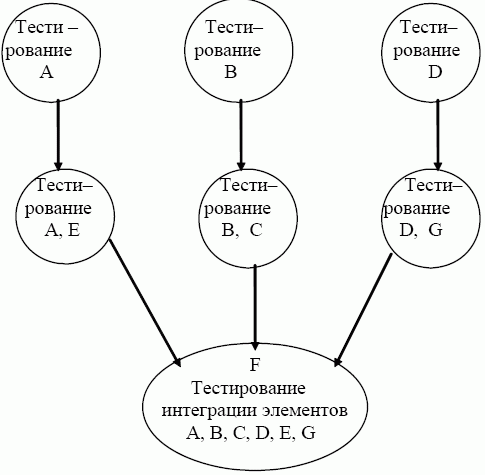
Рис.
7.4.
Интегрированное тестирование компонент
Рассмотрим этот процесс более подробно. Каждый компонент этой схемы тестируется отдельно от других компонентов с помощью тестов, включающих наборы данных и сценарии, составленные в соответствии с их типами и функциями, специфицированные в проекте системы. Тестирование проводится в контрольной операционной среде на предопределенном множестве тестовых данных и операциях, производимых над ними.
Тесты обеспечивают проверку внутренней структуры, логики и граничных условий выполнения для каждого компонента.
Согласно приведенной схеме сначала тестируются компоненты А, В, D независимо друг от друга и каждый с отдельным тестом. После их проверки выполняется проверка интерфейсов для последующей их интеграции, суть которой заключается в анализе выполнения операторов вызова А -> E, B -> C, D -> G, на нижних уровнях графа: компоненты Е, С, G. При этом предполагается, что указанные вызываемые компоненты, так же должны быть отлажены отдельно. Аналогично проверяются все обращения к компоненту F, являющемуся связывающим звеном с вышележащими элементами.
При этом могут возникать ошибки, в случае неправильного задания параметров в операторах вызова или при вычислениях процедур или функций. Возникающие ошибки в связях устраняются, а затем повторно проверяется связь с компонентом F в виде троек: компонентинтерфейскомпонент.Следующим шагом тестирования комплексной системы является проверка функционирования системы с помощью тестов проверки функций и требований к ним. После проверки системы на функциональных тестах происходит проверка на исполнительных и испытательных тестах, подготовленных согласно требованиям к ПО, аппаратуре и выполняемым функциям. Испытательному тесту предшествует верификация и валидация ПО.
Тест испытаний системы в соответствии с требованиями заказчика проверяется в реальной среде, в которой система будет в дальнейшем функционировать.
Обработка исключительных ситуаций. Методы и способы идентификации сбоев и ошибок.
Конструкция try..catch..finally
Иногда при выполнении программы возникают ошибки, которые трудно предусмотреть или предвидеть, а иногда и вовсе невозможно. Например, при передачи файла по сети может неожиданно оборваться сетевое подключение. такие ситуации называются исключениями. Язык C# предоставляет разработчикам возможности для обработки таких ситуаций. Для этого в C# предназначена конструкция try…catch…finally.
try { } catch { } finally { }
При использовании блока try…catch..finally вначале пытаются выполниться инструкции в блоке try. Если в этом блоке не возникло исключений, то после его выполнения начинает выполняться блок finally. И затем конструкция try..catch..finally завершает свою работу.
Если же в блоке try вдруг возникает исключение, то обычный порядок выполнения останавливается, и среда CLR (Common Language Runtime) начинает искать блок catch, который может обработать данное исключение. Если нужный блок catch найден, то он выполняется, и после его завершения выполняется блок finally.
Если нужный блок catch не найден, то при возникновении исключения программа аварийно завершает свое выполнение.
Рассмотрим следующий пример:
class Program { static void Main(string[] args) { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); Console.WriteLine("Конец программы"); Console.Read(); } }
В данном случае происходит деление числа на 0, что приведет к генерации исключения. И при запуске приложения в режиме отладки мы увидим в Visual Studio окошко, которое информирует об исключении:

В этом окошке мы видим, что возникло исключение, которое представляет тип System.DivideByZeroException, то есть попытка деления на ноль. С помощью пункта View Details можно посмотреть более детальную информацию об исключении.
И в этом случае единственное, что нам остается, это завершить выполнение программы.
Чтобы избежать подобного аварийного завершения программы, следует использовать для обработки исключений конструкцию try…catch…finally. Так, перепишем пример следующим образом:
class Program { static void Main(string[] args) { try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch { Console.WriteLine("Возникло исключение!"); } finally { Console.WriteLine("Блок finally"); } Console.WriteLine("Конец программы"); Console.Read(); } }
В данном случае у нас опять же возникнет исключение в блоке try, так как мы пытаемся разделить на ноль. И дойдя до строки
выполнение программы остановится. CLR найдет блок catch и передаст управление этому блоку.
После блока catch будет выполняться блок finally.
Возникло исключение!
Блок finally
Конец программы
Таким образом, программа по-прежнему не будет выполнять деление на ноль и соответственно не будет выводить результат этого деления, но теперь она не будет аварийно завершаться, а исключение будет обрабатываться в блоке catch.
Следует отметить, что в этой конструкции обязателен блок try. При наличии блока catch мы можем опустить блок finally:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch { Console.WriteLine("Возникло исключение!"); }
И, наоборот, при наличии блока finally мы можем опустить блок catch и не обрабатывать исключение:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } finally { Console.WriteLine("Блок finally"); }
Однако, хотя с точки зрения синтаксиса C# такая конструкция вполне корректна, тем не менее, поскольку CLR не сможет найти нужный блок catch, то исключение не будет обработано, и программа аварийно завершится.
Обработка исключений и условные конструкции
Ряд исключительных ситуаций может быть предвиден разработчиком. Например, пусть программа предусматривает ввод числа и вывод его квадрата:
static void Main(string[] args) { Console.WriteLine("Введите число"); int x = Int32.Parse(Console.ReadLine()); x *= x; Console.WriteLine("Квадрат числа: " + x); Console.Read(); }
Если пользователь введет не число, а строку, какие-то другие символы, то программа выпадет в ошибку. С одной стороны, здесь как раз та ситуация, когда можно применить блок try..catch, чтобы обработать возможную ошибку. Однако гораздо оптимальнее было бы проверить допустимость преобразования:
static void Main(string[] args) { Console.WriteLine("Введите число"); int x; string input = Console.ReadLine(); if (Int32.TryParse(input, out x)) { x *= x; Console.WriteLine("Квадрат числа: " + x); } else { Console.WriteLine("Некорректный ввод"); } Console.Read(); }
Метод Int32.TryParse() возвращает true, если преобразование можно осуществить, и false — если нельзя. При допустимости преобразования переменная x будет содержать введенное число. Так, не используя try…catch можно обработать возможную исключительную ситуацию.
С точки зрения производительности использование блоков try..catch более накладно, чем применение условных конструкций. Поэтому по возможности вместо try..catch лучше использовать условные конструкции на проверку исключительных ситуаций.
Блок catch и фильтры исключений
Определение блока catch
За обработку исключения отвечает блок catch, который может иметь следующие формы:
-
Обрабатывает любое исключение, которое возникло в блоке try. Выше уже был продемонстрирован пример подобного блока.
catch { // выполняемые инструкции }
-
Обрабатывает только те исключения, которые соответствуют типу, указаному в скобках после оператора catch.
catch (тип_исключения) { // выполняемые инструкции }
Например, обработаем только исключения типа DivideByZeroException:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch(DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); }
Однако если в блоке try возникнут исключения каких-то других типов, отличных от DivideByZeroException, то они не будут обработаны.
-
Обрабатывает только те исключения, которые соответствуют типу, указаному в скобках после оператора catch. А вся информация об исключении помещается в переменную данного типа.
catch (тип_исключения имя_переменной) { // выполняемые инструкции }
Например:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch(DivideByZeroException ex) { Console.WriteLine($"Возникло исключение {ex.Message}"); }
Фактически этот случай аналогичен предыдущему за тем исключением, что здесь используется переменная. В данном случае в переменную ex, которая представляет тип DivideByZeroException, помещается информация о возникшем исключени. И с помощью свойства Message мы можем получить сообщение об ошибке.
Если нам не нужна информация об исключении, то переменную можно не использовать как в предыдущем случае.
Фильтры исключений
Фильтры исключений позволяют обрабатывать исключения в зависимости от определенных условий. Для их применения после выражения catch идет выражение when, после которого в скобках указывается условие:
В этом случае обработка исключения в блоке catch производится только в том случае, если условие в выражении when истинно. Например:
int x = 1; int y = 0; try { int result = x / y; } catch(DivideByZeroException) when (y==0 && x == 0) { Console.WriteLine("y не должен быть равен 0"); } catch(DivideByZeroException ex) { Console.WriteLine(ex.Message); }
В данном случае будет выброшено исключение, так как y=0. Здесь два блока catch, и оба они обрабатывают исключения типа DivideByZeroException, то есть по сути все исключения, генерируемые при делении на ноль. Но поскольку для первого блока указано условие y == 0 && x == 0, то оно не будет обрабатывать исключение — условие, указанное после оператора when возвращает false. Поэтому CLR будет дальше искать соответствующие блоки catch далее и для обработки исключения выберет второй блок catch. В итоге если мы уберем второй блок catch, то исключение вобще не будет обрабатываться.
Типы исключений. Класс Exception
Базовым для всех типов исключений является тип Exception. Этот тип определяет ряд свойств, с помощью которых можно получить информацию об исключении.
-
InnerException: хранит информацию об исключении, которое послужило причиной текущего исключения
-
Message: хранит сообщение об исключении, текст ошибки
-
Source: хранит имя объекта или сборки, которое вызвало исключение
-
StackTrace: возвращает строковое представление стека вызывов, которые привели к возникновению исключения
-
TargetSite: возвращает метод, в котором и было вызвано исключение
Например, обработаем исключения типа Exception:
static void Main(string[] args) { try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch (Exception ex) { Console.WriteLine($"Исключение: {ex.Message}"); Console.WriteLine($"Метод: {ex.TargetSite}"); Console.WriteLine($"Трассировка стека: {ex.StackTrace}"); } Console.Read(); }

Однако так как тип Exception является базовым типом для всех исключений, то выражение catch (Exception ex) будет обрабатывать все исключения, которые могут возникнуть.
Но также есть более специализированные типы исключений, которые предназначены для обработки каких-то определенных видов исключений. Их довольно много, я приведу лишь некоторые:
-
DivideByZeroException: представляет исключение, которое генерируется при делении на ноль
-
ArgumentOutOfRangeException: генерируется, если значение аргумента находится вне диапазона допустимых значений
-
ArgumentException: генерируется, если в метод для параметра передается некорректное значение
-
IndexOutOfRangeException: генерируется, если индекс элемента массива или коллекции находится вне диапазона допустимых значений
-
InvalidCastException: генерируется при попытке произвести недопустимые преобразования типов
-
NullReferenceException: генерируется при попытке обращения к объекту, который равен null (то есть по сути неопределен)
И при необходимости мы можем разграничить обработку различных типов исключений, включив дополнительные блоки catch:
static void Main(string[] args) { try { int[] numbers = new int[4]; numbers[7] = 9; // IndexOutOfRangeException int x = 5; int y = x / 0; // DivideByZeroException Console.WriteLine($"Результат: {y}"); } catch (DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); } catch (IndexOutOfRangeException ex) { Console.WriteLine(ex.Message); } Console.Read(); }
В данном случае блоки catch обрабатывают исключения типов IndexOutOfRangeException, DivideByZeroException и Exception. Когда в блоке try возникнет исключение, то CLR будет искать нужный блок catch для обработки исключения. Так, в данном случае на строке
происходит обращение к 7-му элементу массива. Однако поскольку в массиве только 4 элемента, то мы получим исключение типа IndexOutOfRangeException. CLR найдет блок catch, который обрабатывает данное исключение, и передаст ему управление.
Следует отметить, что в данном случае в блоке try есть ситуация для генерации второго исключения — деление на ноль. Однако поскольку после генерации IndexOutOfRangeException управление переходит в соответствующий блок catch, то деление на ноль int y = x / 0 в принципе не будет выполняться, поэтому исключение типа DivideByZeroException никогда не будет сгенерировано.
Однако рассмотрим другую ситуацию:
static void Main(string[] args) { try { object obj = "you"; int num = (int)obj; // InvalidCastException Console.WriteLine($"Результат: {num}"); } catch (DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); } catch (IndexOutOfRangeException) { Console.WriteLine("Возникло исключение IndexOutOfRangeException"); } Console.Read(); }
В данном случае в блоке try генерируется исключение типа InvalidCastException, однако соответствующего блока catch для обработки данного исключения нет. Поэтому программа аварийно завершит свое выполнение.
Мы также можем определить для InvalidCastException свой блок catch, однако суть в том, что теоретически в коде могут быть сгенерированы сами различные типы исключений. А определять для всех типов исключений блоки catch, если обработка исключений однотипна, не имеет смысла. И в этом случае мы можем определить блок catch для базового типа Exception:
static void Main(string[] args) { try { object obj = "you"; int num = (int)obj; // InvalidCastException Console.WriteLine($"Результат: {num}"); } catch (DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); } catch (IndexOutOfRangeException) { Console.WriteLine("Возникло исключение IndexOutOfRangeException"); } catch (Exception ex) { Console.WriteLine($"Исключение: {ex.Message}"); } Console.Read(); }
И в данном случае блок catch (Exception ex){} будет обрабатывать все исключения кроме DivideByZeroException и IndexOutOfRangeException. При этом блоки catch для более общих, более базовых исключений следует помещать в конце — после блоков catch для более конкретный, специализированных типов. Так как CLR выбирает для обработки исключения первый блок catch, который соответствует типу сгенерированного исключения. Поэтому в данном случае сначала обрабатывается исключение DivideByZeroException и IndexOutOfRangeException, и только потом Exception (так как DivideByZeroException и IndexOutOfRangeException наследуется от класса Exception).
Создание классов исключений
Если нас не устраивают встроенные типы исключений, то мы можем создать свои типы. Базовым классом для всех исключений является класс Exception, соответственно для создания своих типов мы можем унаследовать данный класс.
Допустим, у нас в программе будет ограничение по возрасту:
class Program { static void Main(string[] args) { try { Person p = new Person { Name = "Tom", Age = 17 }; } catch (Exception ex) { Console.WriteLine($"Ошибка: {ex.Message}"); } Console.Read(); } } class Person { private int age; public string Name { get; set; } public int Age { get { return age; } set { if (value < 18) { throw new Exception("Лицам до 18 регистрация запрещена"); } else { age = value; } } } }
В классе Person при установке возраста происходит проверка, и если возраст меньше 18, то выбрасывается исключение. Класс Exception принимает в конструкторе в качестве параметра строку, которое затем передается в его свойство Message.
Но иногда удобнее использовать свои классы исключений. Например, в какой-то ситуации мы хотим обработать определенным образом только те исключения, которые относятся к классу Person. Для этих целей мы можем сделать специальный класс PersonException:
class PersonException : Exception { public PersonException(string message) : base(message) { } }
По сути класс кроме пустого конструктора ничего не имеет, и то в конструкторе мы просто обращаемся к конструктору базового класса Exception, передавая в него строку message. Но теперь мы можем изменить класс Person, чтобы он выбрасывал исключение именно этого типа и соответственно в основной программе обрабатывать это исключение:
class Program { static void Main(string[] args) { try { Person p = new Person { Name = "Tom", Age = 17 }; } catch (PersonException ex) { Console.WriteLine("Ошибка: " + ex.Message); } Console.Read(); } } class Person { private int age; public int Age { get { return age; } set { if (value < 18) throw new PersonException("Лицам до 18 регистрация запрещена"); else age = value; } } }
Однако необязательно наследовать свой класс исключений именно от типа Exception, можно взять какой-нибудь другой производный тип. Например, в данном случае мы можем взять тип ArgumentException, который представляет исключение, генерируемое в результате передачи аргументу метода некорректного значения:
class PersonException : ArgumentException { public PersonException(string message) : base(message) { } }
Каждый тип исключений может определять какие-то свои свойства. Например, в данном случае мы можем определить в классе свойство для хранения устанавливаемого значения:
class PersonException : ArgumentException { public int Value { get;} public PersonException(string message, int val) : base(message) { Value = val; } }
В конструкторе класса мы устанавливаем это свойство и при обработке исключения мы его можем получить:
class Person { public string Name { get; set; } private int age; public int Age { get { return age; } set { if (value < 18) throw new PersonException("Лицам до 18 регистрация запрещена", value); else age = value; } } } class Program { static void Main(string[] args) { try { Person p = new Person { Name = "Tom", Age = 13 }; } catch (PersonException ex) { Console.WriteLine($"Ошибка: {ex.Message}"); Console.WriteLine($"Некорректное значение: {ex.Value}"); } Console.Read(); } }
Поиск блока catch при обработке исключений
Если код, который вызывает исключение, не размещен в блоке try или помещен в конструкцию try..catch, которая не содержит соответствующего блока catch для обработки возникшего исключения, то система производит поиск соответствующего обработчика исключения в стеке вызовов.
Например, рассмотрим следующую программу:
using System; namespace HelloApp { class Program { static void Main(string[] args) { try { TestClass.Method1(); } catch (DivideByZeroException ex) { Console.WriteLine($"Catch в Main : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Main"); } Console.WriteLine("Конец метода Main"); Console.Read(); } } class TestClass { public static void Method1() { try { Method2(); } catch (IndexOutOfRangeException ex) { Console.WriteLine($"Catch в Method1 : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Method1"); } Console.WriteLine("Конец метода Method1"); } static void Method2() { try { int x = 8; int y = x / 0; } finally { Console.WriteLine("Блок finally в Method2"); } Console.WriteLine("Конец метода Method2"); } } }
В данном случае стек вызовов выглядит следующим образом: метод Main вызывает метод Method1, который, в свою очередь, вызывает метод Method2. И в методе Method2 генерируется исключение DivideByZeroException. Визуально стек вызовов можно представить следующим образом:

Внизу стека метод Main, с которого началось выполнение, и на самом верху метод Method2.
Что будет происходить в данном случае при генерации исключения?
-
Метод Main вызывает метод Method1, а тот вызывает метод Method2, в котором генерируется исключение DivideByZeroException.
-
Система видит, что код, который вызывал исключение, помещен в конструкцию try..catch
try { int x = 8; int y = x / 0; } finally { Console.WriteLine("Блок finally в Method2"); }
Система ищет в этой конструкции блок catch, который обрабатывает исключение DivideByZeroException. Однако такого блока catch нет.
-
Система опускается в стеке вызовов в метод Method1, который вызывал Method2. Здесь вызов Method2 помещен в конструкцию try..catch
try { Method2(); } catch (IndexOutOfRangeException ex) { Console.WriteLine($"Catch в Method1 : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Method1"); }
Система также ищет в этой конструкции блок catch, который обрабатывает исключение DivideByZeroException. Однако здесь также подобный блок catch отсутствует.
-
Система далее опускается в стеке вызовов в метод Main, который вызывал Method1. Здесь вызов Method1 помещен в конструкцию try..catch
try { TestClass.Method1(); } catch (DivideByZeroException ex) { Console.WriteLine($"Catch в Main : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Main"); }
Система снова ищет в этой конструкции блок catch, который обрабатывает исключение DivideByZeroException. И в данном случае ткой блок найден.
-
Система наконец нашла нужный блок catch в методе Main, для обработки исключения, которое возникло в методе Method2 — то есть к начальному методу, где непосредственно возникло исключение. Но пока данный блок catch НЕ выполняется. Система поднимается обратно по стеку вызовов в самый верх в метод Method2 и выполняет в нем блок finally:
finally { Console.WriteLine("Блок finally в Method2"); }
-
Далее система возвращается по стеку вызовов вниз в метод Method1 и выполняет в нем блок finally:
finally { Console.WriteLine("Блок finally в Method1"); }
-
Затем система переходит по стеку вызовов вниз в метод Main и выполняет в нем найденный блок catch и последующий блок finally:
catch (DivideByZeroException ex) { Console.WriteLine($"Catch в Main : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Main"); }
-
Далее выполняется код, который идет в методе Main после конструкции try..catch:
Console.WriteLine("Конец метода Main");
Стоит отметить, что код, который идет после конструкции try…catch в методах Method1 и Method2, не выполняется, потому что обработчик исключения найден именно в методе Main.
Консольный вывод программы:
Блок finally в Method2
Блок finally в Method1
Catch в Main: Попытка деления на нуль.
Блок finally в Main
Конец метода Main
Генерация исключения и оператор throw
Обычно система сама генерирует исключения при определенных ситуациях, например, при делении числа на ноль. Но язык C# также позволяет генерировать исключения вручную с помощью оператора throw. То есть с помощью этого оператора мы сами можем создать исключение и вызвать его в процессе выполнения.
Например, в нашей программе происходит ввод строки, и мы хотим, чтобы, если длина строки будет больше 6 символов, возникало исключение:
static void Main(string[] args) { try { Console.Write("Введите строку: "); string message = Console.ReadLine(); if (message.Length > 6) { throw new Exception("Длина строки больше 6 символов"); } } catch (Exception e) { Console.WriteLine($"Ошибка: {e.Message}"); } Console.Read(); }
После оператора throw указывается объект исключения, через конструктор которого мы можем передать сообщение об ошибке. Естественно вместо типа Exception мы можем использовать объект любого другого типа исключений.
Затем в блоке catch сгенерированное нами исключение будет обработано.
Подобным образом мы можем генерировать исключения в любом месте программы. Но существует также и другая форма использования оператора throw, когда после данного оператора не указывается объект исключения. В подобном виде оператор throw может использоваться только в блоке catch:
try { try { Console.Write("Введите строку: "); string message = Console.ReadLine(); if (message.Length > 6) { throw new Exception("Длина строки больше 6 символов"); } } catch { Console.WriteLine("Возникло исключение"); throw; } } catch (Exception ex) { Console.WriteLine(ex.Message); }
В данном случае при вводе строки с длиной больше 6 символов возникнет исключение, которое будет обработано внутренним блоком catch. Однако поскольку в этом блоке используется оператор throw, то исключение будет передано дальше внешнему блоку catch.
Методы поиска ошибок в программах
Международный стандарт ANSI/IEEE-729-83 разделяет все ошибки в разработке программ на следующие типы.
Ошибка (error) — состояние программы, при котором выдаются неправильные результаты, причиной которых являются изъяны (flaw) в операторах программы или в технологическом процессе ее разработки, что приводит к неправильной интерпретации исходной информации, следовательно, и к неверному решению.
Дефект (fault) в программе — следствие ошибок разработчика на любом из этапов разработки, которая может содержаться в исходных или проектных спецификациях, текстах кодов программ, эксплуатационной документация и т.п. В процессе выполнения программы может быть обнаружен дефект или сбой.
Отказ (failure) — это отклонение программы от функционирования или невозможность программы выполнять функции, определенные требованиями и ограничениями, что рассматривается как событие, способствующее переходу программы в неработоспособное состояние из-за ошибок, скрытых в ней дефектов или сбоев в среде функционирования [7.6, 7.11]. Отказ может быть результатом следующих причин:
- ошибочная спецификация или пропущенное требование, означающее, что спецификация точно не отражает того, что предполагал пользователь;
- спецификация может содержать требование, которое невозможно выполнить на данной аппаратуре и программном обеспечении;
- проект программы может содержать ошибки (например, база данных спроектирована без средств защиты от несанкционированного доступа пользователя, а требуется защита);
- программа может быть неправильной, т.е. она выполняет несвойственный алгоритм или он реализован не полностью.
Таким образом, отказы, как правило, являются результатами одной или более ошибок в программе, а также наличия разного рода дефектов.
Ошибки на этапах процесса тестирования. Приведенные типы ошибок распределяются по этапам ЖЦ и им соответствуют такие источники их возникновения:
- непреднамеренное отклонение разработчиков от рабочих стандартов или планов реализации;
- спецификации функциональных и интерфейсных требований выполнены без соблюдения стандартов разработки, что приводит к нарушению функционирования программ;
- организации процесса разработки — несовершенная или недостаточное управление руководителем проекта ресурсами (человеческими, техническими, программными и т.д.) и вопросами тестирования и интеграции элементов проекта.
Рассмотрим процесс тестирования, исходя из рекомендаций стандарта ISO/IEC 12207, и приведем типы ошибок, которые обнаруживаются на каждом процессе ЖЦ.
Процесс разработки требований. При определении исходной концепции системы и исходных требований к системе возникают ошибки аналитиков при спецификации верхнего уровня системы и построении концептуальной модели предметной области.
Характерными ошибками этого процесса являются:
- неадекватность спецификации требований конечным пользователям;
- некорректность спецификации взаимодействия ПО со средой функционирования или с пользователями;
- несоответствие требований заказчика к отдельным и общим свойствам ПО;
- некорректность описания функциональных характеристик;
- необеспеченность инструментальными средствами всех аспектов реализации требований заказчика и др.
Процесс проектирования. Ошибки при проектировании компонентов могут возникать при описании алгоритмов, логики управления, структур данных, интерфейсов, логики моделирования потоков данных, форматов ввода-вывода и др. В основе этих ошибок лежат дефекты спецификаций аналитиков и недоработки проектировщиков. К ним относятся ошибки, связанные:
- с определением интерфейса пользователя со средой;
- с описанием функций (неадекватность целей и задач компонентов, которые обнаруживаются при проверке комплекса компонентов);
- с определением процесса обработки информации и взаимодействия между процессами (результат некорректного определения взаимосвязей компонентов и процессов);
- с некорректным заданием данных и их структур при описании отдельных компонентов и ПС в целом;
- с некорректным описанием алгоритмов модулей;
- с определением условий возникновения возможных ошибок в программе;
- с нарушением принятых для проекта стандартов и технологий.
Этап кодирования. На данном этапе возникают ошибки, которые являются результатом дефектов проектирования, ошибок программистов и менеджеров в процессе разработки и отладки системы. Причиной ошибок являются:
- бесконтрольность значений входных параметров, индексов массивов, параметров циклов, выходных результатов, деления на 0 и др.;
- неправильная обработка нерегулярных ситуаций при анализе кодов возврата от вызываемых подпрограмм, функций и др.;
- нарушение стандартов кодирования (плохие комментарии, нерациональное выделение модулей и компонент и др.);
- использование одного имени для обозначения разных объектов или разных имен одного объекта, плохая мнемоника имен;
- несогласованное внесение изменений в программу разными разработчиками и др.
Процесс тестирования. На этом процессе ошибки допускаются программистами и тестировщиками при выполнении технологии сборки и тестирования, выбора тестовых наборов и сценариев тестирования и др. Отказы в программном обеспечении, вызванные такого рода ошибками, должны выявляться, устраняться и не отражаться на статистике ошибок компонент и программного обеспечения в целом.
Процесс сопровождения. На процессе сопровождения обнаруживаются ошибки, причиной которых являются недоработки и дефекты эксплуатационной документации, недостаточные показатели модифицируемости и удобочитаемости, а также некомпетентность лиц, ответственных за сопровождение и/или усовершенствование ПО. В зависимости от сущности вносимых изменений на этом этапе могут возникать практически любые ошибки, аналогичные ранее перечисленным ошибкам на предыдущих этапах.
Все ошибки, которые возникают в программах, принято подразделять на следующие классы:
- логические и функциональные ошибки;
- ошибки вычислений и времени выполнения;
- ошибки вводавывода и манипулирования данными;
- ошибки интерфейсов;
- ошибки объема данных и др.
Логические ошибки являются причиной нарушения логики алгоритма, внутренней несогласованности переменных и операторов, а также правил программирования. Функциональные ошибки — следствие неправильно определенных функций, нарушения порядка их применения или отсутствия полноты их реализации и т.д.
Ошибки вычислений возникают по причине неточности исходных данных и реализованных формул, погрешностей методов, неправильного применения операций вычислений или операндов. Ошибки времени выполнения связаны с необеспечением требуемой скорости обработки запросов или времени восстановления программы.
Ошибки ввода-вывода и манипулирования данными являются следствием некачественной подготовки данных для выполнения программы, сбоев при занесении их в базы данных или при выборке из нее.
Ошибки интерфейса относятся к ошибкам взаимосвязи отдельных элементов друг с другом, что проявляется при передаче данных между ними, а также при взаимодействии со средой функционирования.
Ошибки объема относятся к данным и являются следствием того, что реализованные методы доступа и размеры баз данных не удовлетворяют реальным объемам информации системы или интенсивности их обработки.
Приведенные основные классы ошибок свойственны разным типам компонентов ПО и проявляются они в программах по разному. Так, при работе с БД возникают ошибки представления и манипулирования данными, логические ошибки в задании прикладных процедур обработки данных и др. В программах вычислительного характера преобладают ошибки вычислений, а в программах управления и обработки — логические и функциональные ошибки. В ПО, которое состоит из множества разноплановых программ, реализующих разные функции, могут содержаться ошибки разных типов. Ошибки интерфейсов и нарушение объема характерны для любого типа систем.
Анализ типов ошибок в программах является необходимым условием создания планов тестирования и методов тестирования для обеспечения правильности ПО.
На современном этапе развития средств поддержки разработки ПО (CASE-технологии, объектно-ориентированные методы и средства проектирования моделей и программ) проводится такое проектирование, при котором ПО защищается от наиболее типичных ошибок и тем самым предотвращается появление программных дефектов.
Связь ошибки с отказом. Наличие ошибки в программе, как правило, приводит к отказу ПО при его функционировании. Для анализа причинно-следственных связей «ошибкаотказ» выполняются следующие действия:
- идентификация изъянов в технологиях проектирования и программирования;
- взаимосвязь изъянов процесса проектирования и допускаемых человеком ошибок;
- классификация отказов, изъянов и возможных ошибок, а также дефектов на каждом этапе разработки;
- сопоставление ошибок человека, допускаемых на определенном процессе разработки, и дефектов в объекте, как следствий ошибок спецификации проекта, моделей программ;
- проверка и защита от ошибок на всех этапах ЖЦ, а также обнаружение дефектов на каждом этапе разработки;
- сопоставление дефектов и отказов в ПО для разработки системы взаимосвязей и методики локализации, сбора и анализа информации об отказах и дефектах;
- разработка подходов к процессам документирования и испытания ПО.
Конечная цель причинно-следственных связей «ошибка-отказ» заключается в определении методов и средств тестирования и обнаружения ошибок определенных классов, а также критериев завершения тестирования на множестве наборов данных; в определении путей совершенствования организации процесса разработки, тестирования и сопровождения ПО.
Приведем следующую классификацию типов отказов:
- аппаратный, при котором общесистемное ПО не работоспособно;
- информационный, вызванный ошибками во входных данных и передаче данных по каналам связи, а также при сбое устройств ввода (следствие аппаратных отказов);
- эргономический, вызванный ошибками оператора при его взаимодействии с машиной (этот отказ — вторичный отказ, может привести к информационному или функциональному отказам);
- программный, при наличии ошибок в компонентах и др.
Некоторые ошибки могут быть следствием недоработок при определении требований, проекта, генерации выходного кода или документации. С другой стороны, они порождаются в процессе разработки программы или при разработке интерфейсов отдельных элементов программы (нарушение порядка параметров, меньше или больше параметров и т.п.).
Источники ошибок. Ошибки могут быть порождены в процессе разработки проекта, компонентов, кода и документации. Как правило, они обнаруживаются при выполнении или сопровождении программного обеспечения в самых неожиданных и разных ее точках.
Некоторые ошибки в программе могут быть следствием недоработок при определении требований, проекта, генерации кода или документации. С другой стороны, ошибки порождаются в процессе разработки программы или интерфейсов ее элементов (например, при нарушении порядка задания параметров связи — меньше или больше, чем требуется и т.п.).
Причиной появления ошибок — непонимание требований заказчика; неточная спецификация требований в документах проекта и др. Это приводит к тому, что реализуются некоторые функции системы, которые будут работать не так, как предлагает заказчик. В связи с этим проводится совместное обсуждение заказчиком и разработчиком некоторых деталей требований для их уточнения.
Команда разработчиков системы может также изменить синтаксис и семантику описания системы. Однако некоторые ошибки могут быть не обнаружены (например, неправильно заданы индексы или значения переменных этих операторов).
Software testing is the process of testing and verifying that a software product or application is doing what it is supposed to do. The benefits of testing include preventing distractions, reducing development costs, and improving performance. There are many different types of software testing, each with specific goals and strategies. Some of them are below:
- Acceptance Testing: Ensuring that the whole system works as intended.
- Integration Testing: Ensuring that software components or functions work together.
- Unit Testing: To ensure that each software unit is operating as expected. The unit is a testable component of the application.
- Functional Testing: Evaluating activities by imitating business conditions, based on operational requirements. Checking the black box is a common way to confirm tasks.
- Performance Testing: A test of how the software works under various operating loads. Load testing, for example, is used to assess performance under real-life load conditions.
- Re-Testing: To test whether new features are broken or degraded. Hygiene checks can be used to verify menus, functions, and commands at the highest level when there is no time for a full reversal test.
What is a Bug?
A malfunction in the software/system is an error that may cause components or the system to fail to perform its required functions. In other words, if an error is encountered during the test it can cause malfunction. For example, incorrect data description, statements, input data, design, etc.
Reasons Why Bugs Occur?
1. Lack of Communication: This is a key factor contributing to the development of software bug fixes. Thus, a lack of clarity in communication can lead to misunderstandings of what the software should or should not do. In many cases, the customer may not fully understand how the product should ultimately work. This is especially true if the software is designed for a completely new product. Such situations often lead to many misinterpretations from both sides.
2. Repeated Definitions Required: Constantly changing software requirements creates confusion and pressure in both software development and testing teams. Usually, adding a new feature or deleting an existing feature can be linked to other modules or software components. Observing such problems causes software interruptions.
3. Policy Framework Does Not Exist: Also, debugging a software component/software component may appear in a different or similar component. Lack of foresight can cause serious problems and increase the number of distractions. This is one of the biggest problems because of what interruptions occur as engineers are often under pressure related to timelines; constantly changing needs, increasing the number of distractions, etc. Addition, Design and redesign, UI integration, module integration, database management all add to the complexity of the software and the system as a whole.
4. Performance Errors: Significant problems with software design and architecture can cause problems for systems. Improved software tends to make mistakes as programmers can also make mistakes. As a test tester, data/announcement reference errors, control flow errors, parameter errors, input/output errors, etc.
5. Lots of Recycling: Resetting resources, redoing or discarding a finished work, changes in hardware/software requirements may also affect the software. Assigning a new developer to a project in the middle of nowhere can cause software interruptions. This can happen if proper coding standards are not followed, incorrect coding, inaccurate data transfer, etc. Discarding part of existing code may leave traces on other parts of the software; Ignoring or deleting that code may cause software interruptions. In addition, critical bugs can occur especially with large projects, as it becomes difficult to pinpoint the location of the problem.
Life Cycle of a Bug in Software Testing
Below are the steps in the lifecycle of the bug in software testing:
- Open: The editor begins the process of analyzing bugs here, where possible, and works to fix them. If the editor thinks the error is not enough, the error for some reason can be transferred to the next four regions, Reject or No, i.e. Repeat.
- New: This is the first stage of the distortion of distractions in the life cycle of the disorder. In the later stages of the bug’s life cycle, confirmation and testing are performed on these bugs when a new feature is discovered.
- Shared: The engineering team has been provided with a new bug fixer recently built at this level. This will be sent to the designer by the project leader or team manager.
- Pending Review: When fixing an error, the designer will give the inspector an error check and the feature status will remain pending ‘review’ until the tester is working on the error check.
- Fixed: If the Developer completes the debugging task by making the necessary changes, the feature status can be called “Fixed.”
- Confirmed: If the tester had no problem with the feature after the designer was given the feature on the test device and thought that if it was properly adjusted, the feature status was given “verified”.
- Open again / Reopen: If there is still an error, the editor will then be instructed to check and the feature status will be re-opened.
- Closed: If the error is not present, the tester changes the status of the feature to ‘Off’.
- Check Again: The inspector then begins the process of reviewing the error to check that the error has been corrected by the engineer as required.
- Repeat: If the engineer is considering a factor similar to another factor. If the developer considers a feature similar to another feature, or if the definition of malfunction coincides with any other malfunction, the status of the feature is changed by the developer to ‘duplicate’.
Few more stages to add here are:
- Rejected: If a feature can be considered a real factor the developer will mean “Rejected” developer.
- Duplicate: If the engineer finds a feature similar to any other feature or if the concept of the malfunction is similar to any other feature the status of the feature is changed to ‘Duplicate’ by the developer.
- Postponed: If the developer feels that the feature is not very important and can be corrected in the next release, however, in that case, he can change the status of the feature such as ‘Postponed’.
- Not a Bug: If the feature does not affect the performance of the application, the corrupt state is changed to “Not a Bug”.

Fig 1.1 Diagram of Bug Life Cycle
Bug Report
- Defect/ Bug Name: A short headline describing the defect. It should be specific and accurate.
- Defect/Bug ID: Unique identification number for the defect.
- Defect Description: Detailed description of the bug including the information of the module in which it was detected. It contains a detailed summary including the severity, priority, expected results vs actual output, etc.
- Severity: This describes the impact of the defect on the application under test.
- Priority: This is related to how urgent it is to fix the defect. Priority can be High/ Medium/ Low based on the impact urgency at which the defect should be fixed.
- Reported By: Name/ ID of the tester who reported the bug.
- Reported On: Date when the defect is raised.
- Steps: These include detailed steps along with the screenshots with which the developer can reproduce the same defect.
- Status: New/ Open/ Active
- Fixed By: Name/ ID of the developer who fixed the defect.
- Data Closed: Date when the defect is closed.
Factors to be Considered while Reporting a Bug:
- The whole team should clearly understand the different conditions of the trauma before starting research on the life cycle of the disability.
- To prevent future confusion, a flawed life cycle should be well documented.
- Make sure everyone who has any work related to the Default Life Cycle understands his or her best results work very clearly.
- Everyone who changes the status quo should be aware of the situation which should provide sufficient information about the nature of the feature and the reason for it so that everyone working on that feature can easily see the reason for that feature.
- A feature tracking tool should be carefully handled in the course of a defective life cycle work to ensure consistency between errors.
Bug Tracking Tools
Below are some of the bug tracking tools–
1. KATALON TESTOPS: Katalon TestOps is a free, powerful orchestration platform that helps with your process of tracking bugs. TestOps provides testing teams and DevOps teams with a clear, linked picture of their testing, resources, and locations to launch the right test, in the right place, at the right time.
Features:
- Applies to Cloud, Desktop: Window and Linux program.
- Compatible with almost all test frames available: Jasmine, JUnit, Pytest, Mocha, etc .; CI / CD tools: Jenkins, CircleCI, and management platforms: Jira, Slack.
- Track real-time data for error correction, and for accuracy.
- Live and complete performance test reports to determine the cause of any problems.
- Plan well with Smart Scheduling to prepare for the test cycle while maintaining high quality.
- Rate release readiness to improve release confidence.
- Improve collaboration and enhance transparency with comments, dashboards, KPI tracking, possible details – all in one place.
2. KUALITEE: Collection of specific results and analysis with solid failure analysis in any framework. The Kualitee is for development and QA teams look beyond the allocation and tracking of bugs. It allows you to build high-quality software using tiny bugs, fast QA cycles, and better control of your build. The comprehensive suite combines all the functions of a good error management tool and has a test case and flow of test work built into it seamlessly. You would not need to combine and match different tools; instead, you can manage all your tests in one place.
Features:
- Create, assign, and track errors.
- Tracing between disability, needs, and testing.
- Easy-to-use errors, test cases, and test cycles.
- Custom permissions, fields, and reporting.
- Interactive and informative dashboard.
- Integration of external companies and REST API.
- An intuitive and easy-to-use interface.
3. QA Coverage: QACoverage is the place to go for successfully managing all your testing processes so that you can produce high-quality and trouble-free products. It has a disability control module that will allow you to manage errors from the first diagnostic phase until closed. The error tracking process can be customized and tailored to the needs of each client. In addition to negative tracking, QACoverage has the ability to track risks, issues, enhancements, suggestions, and recommendations. It also has full capabilities for complex test management solutions that include needs management, test case design, test case issuance, and reporting.
Features:
- Control the overall workflow of a variety of Tickets including risk, issues, tasks, and development management.
- Produce complete metrics to identify the causes and levels of difficulty.
- Support a variety of information that supports the feature with email attachments.
- Create and set up a workflow for enhanced test visibility with automatic notifications.
- Photo reports based on difficulty, importance, type of malfunction, disability category, expected correction date, and much more.
4. BUG HERD: BugHerd is an easy way to track bugs, collect and manage webpage responses. Your team and customers search for feedback on web pages, so they can find the exact problem. BugHerd also scans the information you need to replicate and resolve bugs quickly, such as browser, CSS selector data, operating system, and screenshot. Distractions and feedback, as well as technical information, are submitted to the Kanban Style Task Board, where distractions can be assigned and managed until they are eliminated. BugHerd can also integrate with your existing project management tools, helping to keep your team on the same page with bug fixes.
Software testing is the process of testing and verifying that a software product or application is doing what it is supposed to do. The benefits of testing include preventing distractions, reducing development costs, and improving performance. There are many different types of software testing, each with specific goals and strategies. Some of them are below:
- Acceptance Testing: Ensuring that the whole system works as intended.
- Integration Testing: Ensuring that software components or functions work together.
- Unit Testing: To ensure that each software unit is operating as expected. The unit is a testable component of the application.
- Functional Testing: Evaluating activities by imitating business conditions, based on operational requirements. Checking the black box is a common way to confirm tasks.
- Performance Testing: A test of how the software works under various operating loads. Load testing, for example, is used to assess performance under real-life load conditions.
- Re-Testing: To test whether new features are broken or degraded. Hygiene checks can be used to verify menus, functions, and commands at the highest level when there is no time for a full reversal test.
What is a Bug?
A malfunction in the software/system is an error that may cause components or the system to fail to perform its required functions. In other words, if an error is encountered during the test it can cause malfunction. For example, incorrect data description, statements, input data, design, etc.
Reasons Why Bugs Occur?
1. Lack of Communication: This is a key factor contributing to the development of software bug fixes. Thus, a lack of clarity in communication can lead to misunderstandings of what the software should or should not do. In many cases, the customer may not fully understand how the product should ultimately work. This is especially true if the software is designed for a completely new product. Such situations often lead to many misinterpretations from both sides.
2. Repeated Definitions Required: Constantly changing software requirements creates confusion and pressure in both software development and testing teams. Usually, adding a new feature or deleting an existing feature can be linked to other modules or software components. Observing such problems causes software interruptions.
3. Policy Framework Does Not Exist: Also, debugging a software component/software component may appear in a different or similar component. Lack of foresight can cause serious problems and increase the number of distractions. This is one of the biggest problems because of what interruptions occur as engineers are often under pressure related to timelines; constantly changing needs, increasing the number of distractions, etc. Addition, Design and redesign, UI integration, module integration, database management all add to the complexity of the software and the system as a whole.
4. Performance Errors: Significant problems with software design and architecture can cause problems for systems. Improved software tends to make mistakes as programmers can also make mistakes. As a test tester, data/announcement reference errors, control flow errors, parameter errors, input/output errors, etc.
5. Lots of Recycling: Resetting resources, redoing or discarding a finished work, changes in hardware/software requirements may also affect the software. Assigning a new developer to a project in the middle of nowhere can cause software interruptions. This can happen if proper coding standards are not followed, incorrect coding, inaccurate data transfer, etc. Discarding part of existing code may leave traces on other parts of the software; Ignoring or deleting that code may cause software interruptions. In addition, critical bugs can occur especially with large projects, as it becomes difficult to pinpoint the location of the problem.
Life Cycle of a Bug in Software Testing
Below are the steps in the lifecycle of the bug in software testing:
- Open: The editor begins the process of analyzing bugs here, where possible, and works to fix them. If the editor thinks the error is not enough, the error for some reason can be transferred to the next four regions, Reject or No, i.e. Repeat.
- New: This is the first stage of the distortion of distractions in the life cycle of the disorder. In the later stages of the bug’s life cycle, confirmation and testing are performed on these bugs when a new feature is discovered.
- Shared: The engineering team has been provided with a new bug fixer recently built at this level. This will be sent to the designer by the project leader or team manager.
- Pending Review: When fixing an error, the designer will give the inspector an error check and the feature status will remain pending ‘review’ until the tester is working on the error check.
- Fixed: If the Developer completes the debugging task by making the necessary changes, the feature status can be called “Fixed.”
- Confirmed: If the tester had no problem with the feature after the designer was given the feature on the test device and thought that if it was properly adjusted, the feature status was given “verified”.
- Open again / Reopen: If there is still an error, the editor will then be instructed to check and the feature status will be re-opened.
- Closed: If the error is not present, the tester changes the status of the feature to ‘Off’.
- Check Again: The inspector then begins the process of reviewing the error to check that the error has been corrected by the engineer as required.
- Repeat: If the engineer is considering a factor similar to another factor. If the developer considers a feature similar to another feature, or if the definition of malfunction coincides with any other malfunction, the status of the feature is changed by the developer to ‘duplicate’.
Few more stages to add here are:
- Rejected: If a feature can be considered a real factor the developer will mean “Rejected” developer.
- Duplicate: If the engineer finds a feature similar to any other feature or if the concept of the malfunction is similar to any other feature the status of the feature is changed to ‘Duplicate’ by the developer.
- Postponed: If the developer feels that the feature is not very important and can be corrected in the next release, however, in that case, he can change the status of the feature such as ‘Postponed’.
- Not a Bug: If the feature does not affect the performance of the application, the corrupt state is changed to “Not a Bug”.
Fig 1.1 Diagram of Bug Life Cycle
Bug Report
- Defect/ Bug Name: A short headline describing the defect. It should be specific and accurate.
- Defect/Bug ID: Unique identification number for the defect.
- Defect Description: Detailed description of the bug including the information of the module in which it was detected. It contains a detailed summary including the severity, priority, expected results vs actual output, etc.
- Severity: This describes the impact of the defect on the application under test.
- Priority: This is related to how urgent it is to fix the defect. Priority can be High/ Medium/ Low based on the impact urgency at which the defect should be fixed.
- Reported By: Name/ ID of the tester who reported the bug.
- Reported On: Date when the defect is raised.
- Steps: These include detailed steps along with the screenshots with which the developer can reproduce the same defect.
- Status: New/ Open/ Active
- Fixed By: Name/ ID of the developer who fixed the defect.
- Data Closed: Date when the defect is closed.
Factors to be Considered while Reporting a Bug:
- The whole team should clearly understand the different conditions of the trauma before starting research on the life cycle of the disability.
- To prevent future confusion, a flawed life cycle should be well documented.
- Make sure everyone who has any work related to the Default Life Cycle understands his or her best results work very clearly.
- Everyone who changes the status quo should be aware of the situation which should provide sufficient information about the nature of the feature and the reason for it so that everyone working on that feature can easily see the reason for that feature.
- A feature tracking tool should be carefully handled in the course of a defective life cycle work to ensure consistency between errors.
Bug Tracking Tools
Below are some of the bug tracking tools–
1. KATALON TESTOPS: Katalon TestOps is a free, powerful orchestration platform that helps with your process of tracking bugs. TestOps provides testing teams and DevOps teams with a clear, linked picture of their testing, resources, and locations to launch the right test, in the right place, at the right time.
Features:
- Applies to Cloud, Desktop: Window and Linux program.
- Compatible with almost all test frames available: Jasmine, JUnit, Pytest, Mocha, etc .; CI / CD tools: Jenkins, CircleCI, and management platforms: Jira, Slack.
- Track real-time data for error correction, and for accuracy.
- Live and complete performance test reports to determine the cause of any problems.
- Plan well with Smart Scheduling to prepare for the test cycle while maintaining high quality.
- Rate release readiness to improve release confidence.
- Improve collaboration and enhance transparency with comments, dashboards, KPI tracking, possible details – all in one place.
2. KUALITEE: Collection of specific results and analysis with solid failure analysis in any framework. The Kualitee is for development and QA teams look beyond the allocation and tracking of bugs. It allows you to build high-quality software using tiny bugs, fast QA cycles, and better control of your build. The comprehensive suite combines all the functions of a good error management tool and has a test case and flow of test work built into it seamlessly. You would not need to combine and match different tools; instead, you can manage all your tests in one place.
Features:
- Create, assign, and track errors.
- Tracing between disability, needs, and testing.
- Easy-to-use errors, test cases, and test cycles.
- Custom permissions, fields, and reporting.
- Interactive and informative dashboard.
- Integration of external companies and REST API.
- An intuitive and easy-to-use interface.
3. QA Coverage: QACoverage is the place to go for successfully managing all your testing processes so that you can produce high-quality and trouble-free products. It has a disability control module that will allow you to manage errors from the first diagnostic phase until closed. The error tracking process can be customized and tailored to the needs of each client. In addition to negative tracking, QACoverage has the ability to track risks, issues, enhancements, suggestions, and recommendations. It also has full capabilities for complex test management solutions that include needs management, test case design, test case issuance, and reporting.
Features:
- Control the overall workflow of a variety of Tickets including risk, issues, tasks, and development management.
- Produce complete metrics to identify the causes and levels of difficulty.
- Support a variety of information that supports the feature with email attachments.
- Create and set up a workflow for enhanced test visibility with automatic notifications.
- Photo reports based on difficulty, importance, type of malfunction, disability category, expected correction date, and much more.
4. BUG HERD: BugHerd is an easy way to track bugs, collect and manage webpage responses. Your team and customers search for feedback on web pages, so they can find the exact problem. BugHerd also scans the information you need to replicate and resolve bugs quickly, such as browser, CSS selector data, operating system, and screenshot. Distractions and feedback, as well as technical information, are submitted to the Kanban Style Task Board, where distractions can be assigned and managed until they are eliminated. BugHerd can also integrate with your existing project management tools, helping to keep your team on the same page with bug fixes.