
Оперативная память
Устранение ошибок памяти
- Подробности
- Родительская категория: Оперативная память
- Категория: Прочая информация про оперативную память
Устранить ошибки памяти довольно сложно, поскольку не всегда удается идентифициро
вать вызвавшую их проблему. Чаще всего пользователи винят во всех сбоях программное обеспечение, хотя на самом деле во всем виновата память. В этом разделе речь пойдет о выявлении ошибок памяти и способах их устранения.
Для устранения ошибок памяти необходимо иметь под рукой несколько диагностических программ. Следует отметить, что некоторые ошибки памяти могут быть выявлены одной программой и остаться невидимыми для другой. При включении компьютера системная BIOS проверяет память. В большинстве случаев к компьютеру прилагается компакт-диск, содержащий специальные программы диагностики. Также на рынке можно встретить множество других диагностических утилит, практически каждая из которых содержит свои тесты памяти.
При запуске компьютера тест POST не только проверяет память, но и вычисляет ее объем. Затем этот объем памяти сравнивается с записанным в параметрах BIOS и в случае несоответствия генерируется сообщение об ошибке. При проверке памяти тест POST записывает в каждый из блоков памяти некоторый шаблон, а затем считывает его и сверяет с оригиналом. При обнаружении ошибок выводится соответствующее сообщение или генерируется звуковой сигнал. Звуковой сигнал, как правило, используется для индикации критических ошибок в областях, важных для выполнения системных операций. Если система может получить доступ к объему памяти, достаточному для запуска видеосистемы, вместо звукового сигнала будет отображено сообщение об ошибке.
На прилагаемом к книге компакт-диске содержится подробный перечень звуковых сигналов BIOS и кодов ошибок, характерных для той или иной BIOS, в формате PDF. К примеру, в большинстве материнских плат Intel используется Phoenix BIOS, которая для индикации критических ошибок использует несколько звуковых кодов.
Если процедура POST не обнаружила ошибок памяти, следовательно, причина возникновения ошибок лежит не в аппаратной среде, или программа POST не справилась со своей задачей. Нерегулярные ошибки зачастую не обнаруживаются POST, что справедливо и для других аппаратных дефектов. Данная процедура проводится достаточно быстро и не претендует на тщательный анализ. Поэтому для доскональной проверки применяется загрузка DOS, режим консоли восстановления в Windows XP или диагностический диск. Тесты такого рода могут в случае необходимости проводиться в течение нескольких дней для определения неуловимого дефекта.
В Интернете доступно множество хороших бесплатных программ тестирования памяти.
- Microsoft Windows Memory Diagnostic (http://oca.microsoft.com/en/windiag)
- DocMemory Diagnostic (http://www.simmtester.com/page/products/doc/docinfo.asp)
- Memtest86 (http://www.memtest86.com)
Следует отметить, что все эти утилиты имеют загружаемый формат, т.е. их не нужно устанавливать в тестируемой системе, а достаточно записать на загрузочный компакт-диск. Это связано с тем, что многие операционные системы, работающие в защищенном режиме, в частности Windows, пресекают прямой доступ к памяти и другим устройствам. По этой причине загрузку системы нужно выполнять с компакт-диска. Все эти программы используют алгоритмы, записывающие определенные шаблоны в различные области системной памяти, после чего считывают их и проверяют на совпадение каждый бит. При этом они отключают системный кэш, чтобы результат операции отражал поведение модулей памяти, без каких-либо посредников. Некоторые утилиты, в частности Windows Memory Diagnostic, даже способны указать на конкретный модуль памяти, в котором произошла ошибка.
Однако эти программы могут только записать данные и проверить при считывании их соответствие, не более того. Они не определяют, насколько близка память к критической точке сбоя. Повышенный уровень диагностики памяти обеспечивают только специальные аппаратные тестеры модулей SIMM/DIMM. Эти устройства позволяют вставить в них модуль памяти и проверить ее на множестве скоростей, при разных напряжениях питания и таймингах, в результате чего выдать свой вердикт относительно пригодности модуля. Существуют версии таких тестеров, позволяющие проверять модули памяти практически всех типов, начиная от ранних версий SIMM и заканчивая самыми современными модулями DDR DIMM и RIMM. К примеру, я сталкивался с модулями, которые отлично работали в одних компьютерах и выдавали ошибки в других. Это значит, что одни и те же программы диагностики, запущенные на разных компьютерах, выдавали для одних и тех же модулей памяти противоположные результаты. В аппаратных тестерах источник ошибки можно выявить с точностью до конкретного бита, при этом узнать реальное быстродействие памяти, а не номинальное, указанное на маркировке. К числу компаний, которые занимаются реализацией тестеров модулей памяти, относятся Tanisys (www.tanisys.com), CST (www.simmtester.com) и Aristo (www.memorytester.com). Предлагаемые тестеры довольно дорого стоят, но для специалистов, занимающихся ремонтом ПК на профессиональном уровне, тестеры SIMM/DIMM просто необходимы.
Чаще всего память служит причиной следующих ошибок:
- ошибки четности, генерируемые системной платой;
- общие ошибки защиты, вызванные повреждением данных запущенной программы в памяти, что приводит к остановке приложения (часто они вызваны ошибками программ);
- критические ошибки исключений, возникающие при выполнении программой недопустимых инструкций, при доступе к некорректным данным или некорректном уровне привилегий операции;
- ошибки деления, вызванные попыткой деления на нуль, которая приводит к невозможности записи результата в регистр памяти.
Некоторые из приведенных типов ошибок могут быть следствием аппаратных (сбои в цепи питания, статические заряды и т.д.) или программных (некорректно написанные драйверы устройств, ошибки в программах и т.д.) сбоев.
Если причиной возникновения ошибок является оперативная память, следует воспользоваться помощью либо одной программы тестирования, либо нескольких диагностических приложений.
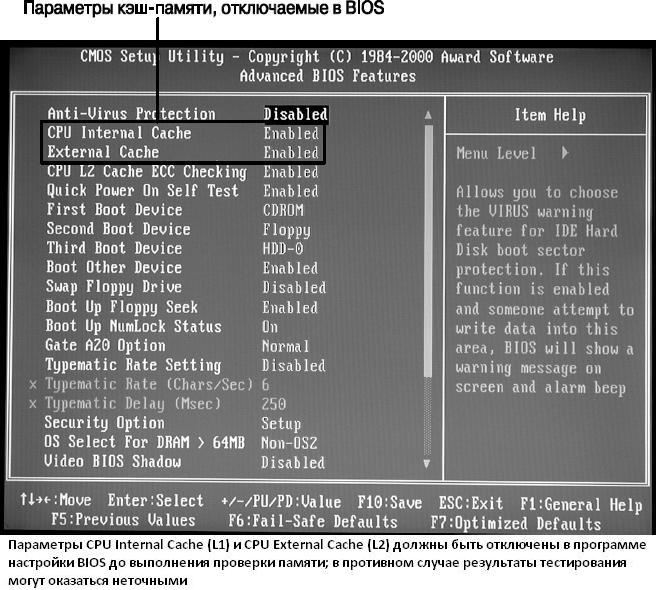
Многие допускают существенную ошибку в использовании диагностических программ,например выполняют диагностику с включенным системным кэшированием. Это затрудняет тестирование, поскольку в большинстве систем используется так называемый кэш с обратной записью. Принцип его работы состоит в том, что данные, записываемые в основную память, в первую очередь записываются в кэш. Поскольку диагностическая программа изначально записывает данные и затем сразу же их считывает, данные считываются из кэша, а не из основной памяти. При этом тестирование проводится очень быстро, но проверке подвергается лишь сам кэш. Таким образом, обязательно отключайте кэширование перед тестированием оперативной памяти. Компьютер будет работать довольно медленно, диагностика отнимет на порядок больше времени, однако проверяться будет именно оперативная память, а не кэш.
При проверке памяти придерживайтесь алгоритма, схематически показанного на рисунке ниже.
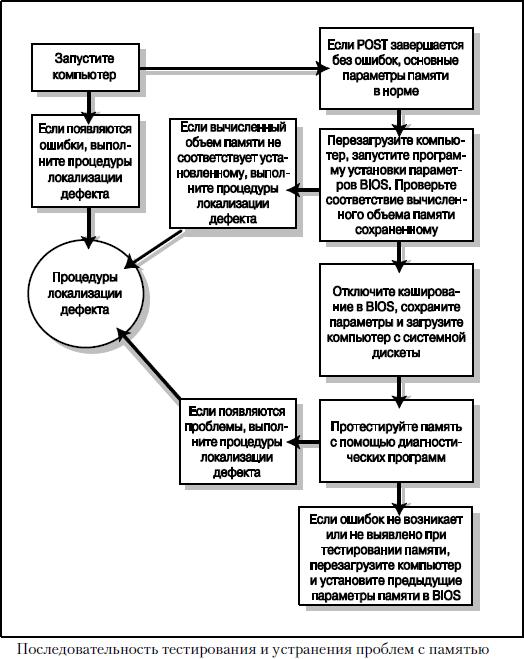
Теперь ознакомимся с процедурой проверки и устранения ошибок памяти.
- Включите систему и проследите за выполнением процедуры POST. Если этот тест завершается без ошибок, следовательно, основные параметры памяти успешно проверены. При обнаружении ошибок перейдите к выполнению процедуры локализации дефектов.
- Перезапустите систему и войдите в программу настройки BIOS. Для этого во время выполнения POST (но до начала процесса загрузки) нажмите клавишу <F2>. Проверьте в параметрах BIOS, совпадает ли объем обнаруженной и установленной памяти. В том случае, если вычисленный объем памяти не соответствует установленному, обратитесь к процедуре локализации дефектов.
- В программе настройки BIOS отключите параметры кэширования. На рисунке ниже представлено типичное меню Advanced BIOS Features, в котором выделены параметры кэш-памяти. Сохраните выполненные изменения и загрузите компьютер с отформатированной системной дискеты, содержащей выбранные диагностические программы. Если в комплект поставки компьютера входил компакт-диск с программами диагностики, можете воспользоваться им. К тому же на рынке доступно множество коммерческих программ диагностики, таких как PC-Technician от Windsor Technologies, Norton System Works от Symantec и Doc Memory от SIMMTester.
- Следуя инструкциям, появляющимся при выполнении диагностической программы, протестируйте основную и дополнительную (XMS) память. Обычно в таких программах существует специальный режим, допускающий непрерывное циклическое выполнение диагностических процедур. Это позволяет обнаружить периодические ошибки. При выявлении ошибок памяти перейдите к выполнению процедуры локализации дефектов.
- Отсутствие ошибок при выполнении POST или во время более полного тестирования памяти говорит о ее нормальном функционировании на аппаратном уровне. Перезагрузите компьютер и установите предыдущие параметры памяти в настройках BIOS, в частности включите параметр использования кэш-памяти.
- Отсутствие выявленных ошибок при наличии каких#либо проблем говорит о том, что существующие ошибки памяти не могут быть обнаружены стандартными методами или же их причина, вероятно, связана с программным обеспечением. Для более полной проверки модулей SIMM/DIMM на аппаратном тестере обратитесь в сервисный центр. Я бы обратил внимание и на программное обеспечение (в частности, на версии драйверов), блок питания, а также на системное окружение, особенно на источники статического электричества, радиопередатчики и т.п.
Выбирайте на страницах сайта услуги разных индивидуалок. Все индивидуалки Пятигорска доступны к взятию в способное для потребителей время. В качестве их услуг затруднений нет!
Панель управления Система и безопасность Администрирование Системный монитор
5000–100000 ошибок кеша в секунду
что это значит?
Привет,
Укажите код, название и описание ошибки
http://gayevoy.spaces.live.com/
Источник: https://answers.microsoft.com/ru-ru/windows/forum/all/system/5a51c58d-8757-4e9f-8b01-ca92c4b3de3d

Современные операционные системы ветки Виндовс оснащены функцией кэширования данных. Это ускоряет загрузку программ и упрощает работу ПК. Но когда кэш забит, начинаются проблемы: виснет браузер, игры и приложения долго запускаются и могут вылетать. Чтобы такого не случалось, нужно знать, как отключить кэширование оперативной памяти или очистить кэш в Windows 10.
Как убрать кэширование оперативной памяти Windows 10
Чем шире объем запоминающего устройства, там резвее работает компьютер. И, соответственно, тем больше программ в фоновом режиме могут функционировать без каких-либо проблем.
Тем не менее, при работе с некоторыми их них кэш нужно отключать или обнулять. В противном случае возможна потеря информации, сбои системы или оборудования. Забитый кэш негативно сказывается на производительности ПК, особенно когда места уже нет, а процесс сжатия продолжается. Чтобы не рисковать программным обеспечением, нужно своевременно решать данную проблему.

Средствами ОС
Самый простой способ — это использовать специальные системные утилиты, которые очистят кэш ОЗУ.
- При помощи комбинации клавиш «Win+R» вызвать окно «Выполнить».
- Ввести в поле окна адрес C:windowssystem32rundll32.exe.
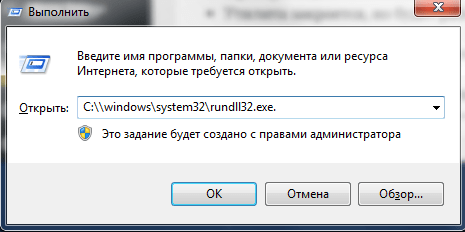
- Если Виндовс имеет битность х64, то адрес меняется: C:windowsSysWOW64rundll32.exe.
- Проверить данные и кликнуть «ОК».
- Утилита закроется, но будет работать на фоне, то есть без каких-либо окон и полей. Спустя 10-15 минут кэш будет обнулен.
Чтобы полностью отключить функцию сжатия данных на диск, нужно будет произвести другую операцию:
- Кликнуть на значок моего компьютера правой кнопкой мышки, далее выбрать пункт «Свойства».
- Открыть вкладку с оборудованием, отыскать Диспетчер устройств.
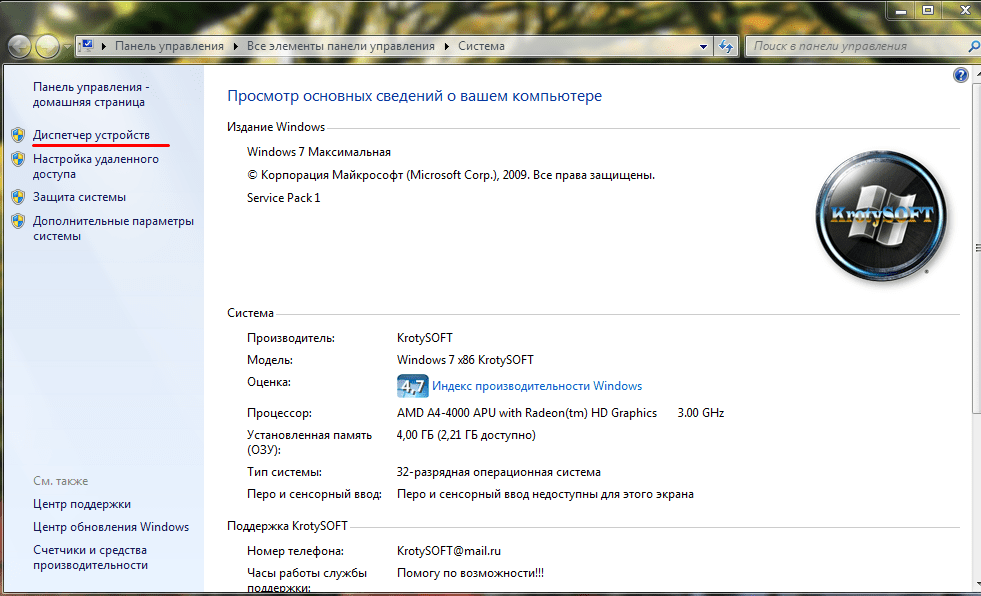
- Открыть папку «Дисковые накопители».
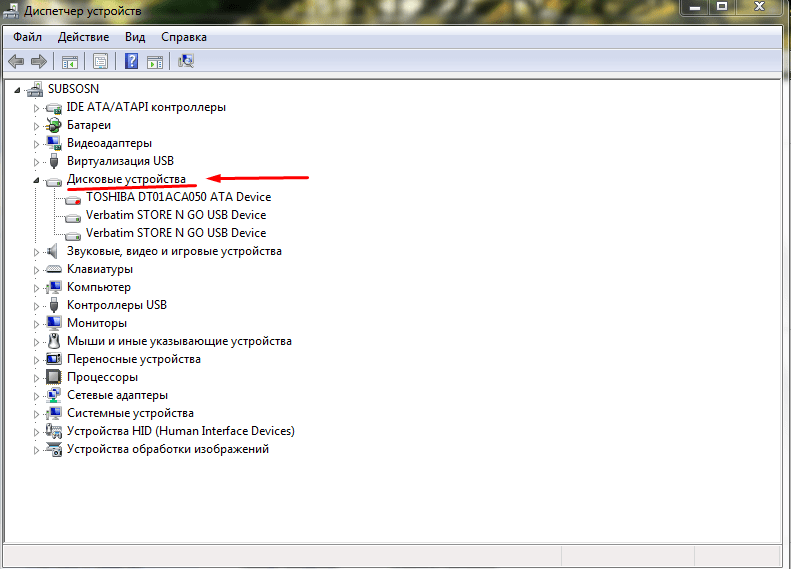
- Выбрать необходимый накопитель, щелкнуть правой кнопкой на него опять, выбрать также «Свойства».
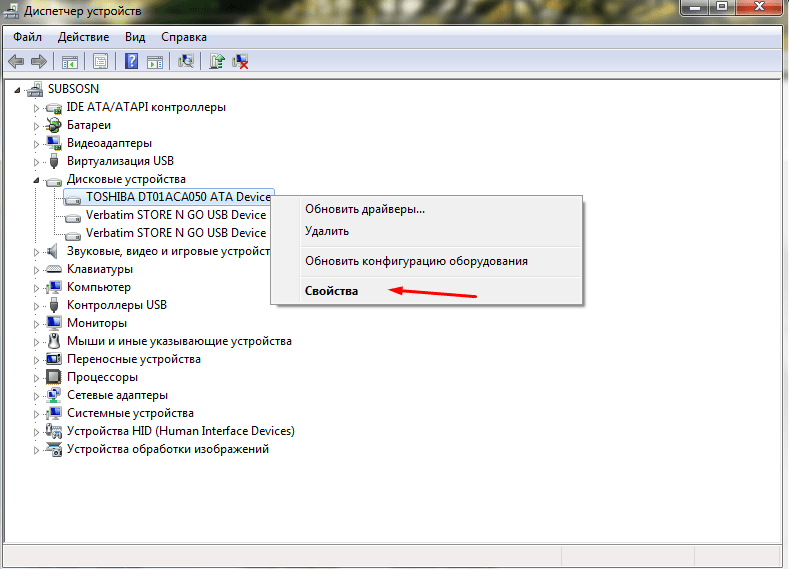
- Переключиться в раздел политики.
- Убрать галочку в поле «Включить кэширование записи», нажать «ОК».

Перезагрузка ПК
Этот вариант для тех, кто не хочет копаться во внутренних алгоритмах и заморачиваться с поиском необходимых функций. Элементарная перезагрузка компьютера спасет положение. Во время нее на некоторое время обесточивается модуль RAM, что стирает сжатые данные из ОЗУ. Тем не менее, злоупотреблять им не стоит, поскольку частая перезагрузка в полном функционале негативно сказывается не только на скорости работы системы, но и на «железной начинке».
ATM
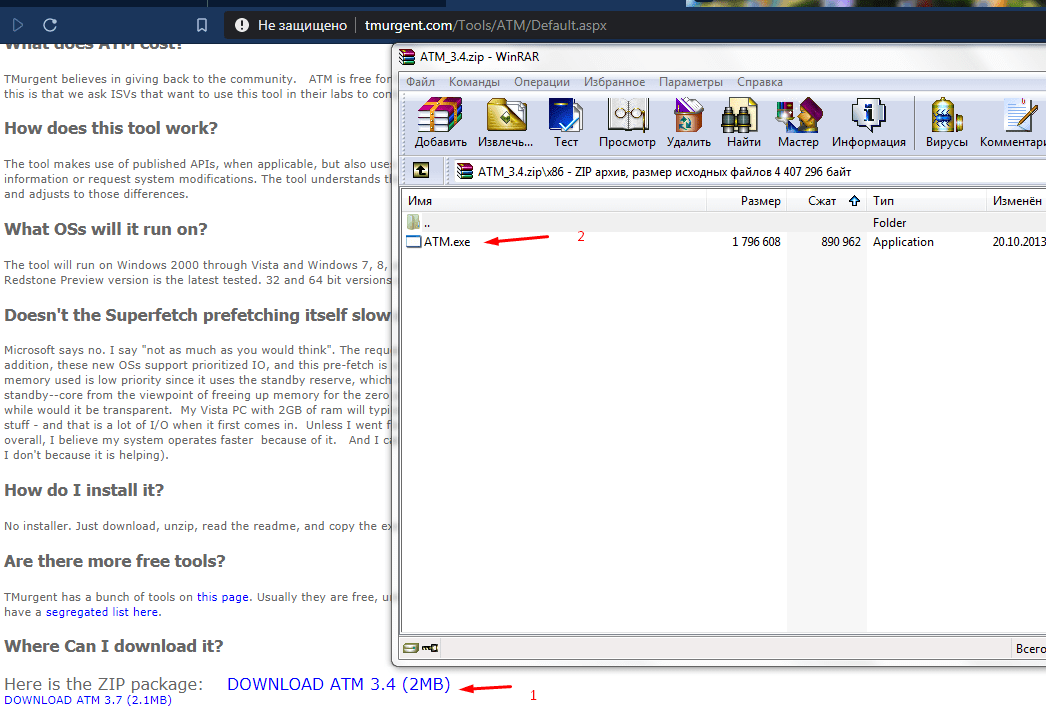
Когда стандартные методы не помогают, остается прибегнуть к стороннему решению, например, к программе ATM:
- Скачать приложение по ссылке http://www.tmurgent.com/Tools/ATM/Default.aspx.
- Распаковать архив и открыть папку со значением х86(х32).
- 2 раза щелкнуть на файл exe.
- Откроется окно с программным кодом. В самом низу окна найти 2 кнопки – «Flush Cache WS» и «Flush All Standby» – и нажать их именно в такой последовательности.
RAMMap
Другая программа выступает детищем самого «Майкрософта», который борется с проблемой утечки данных ОЗУ в кэш.
- Скачать приложение https://docs.microsoft.com/en-us/sysinternals/downloads/rammap.
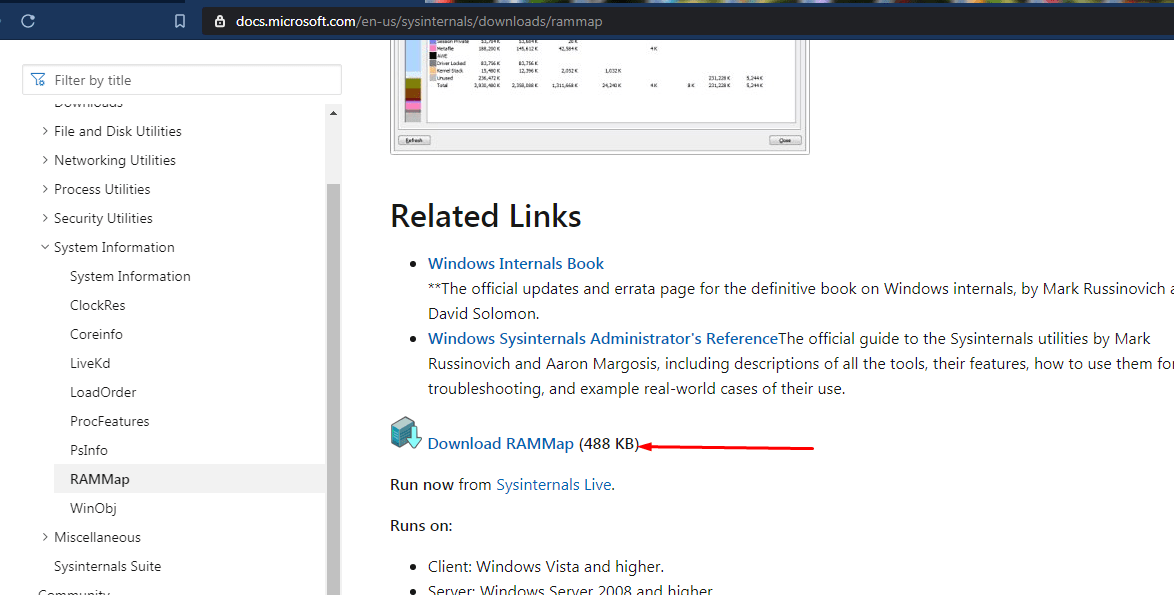
- Установка не требуется, нужно открыть один из корневых файлов.
- В открывшемся окне вверху открыть вкладку «Empty» и выбрать «Empty Standby List».

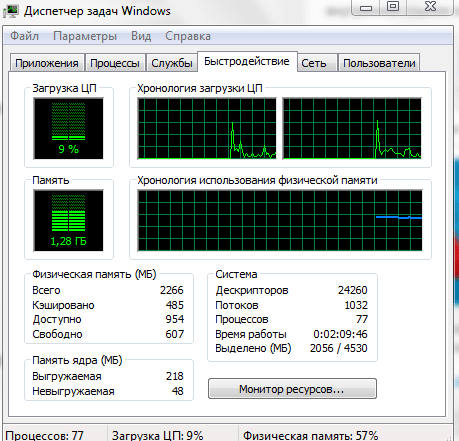
- Результат можно проверить через вкладку «Производительность», открыв Диспетчер задач.
Возможные проблемы
Во время отключения или очистки кэша можно столкнуться с:
- Ошибками, когда программа не может найди диск, на котором следует отключить эту функцию. Решение: переустановить ее из другого источника.
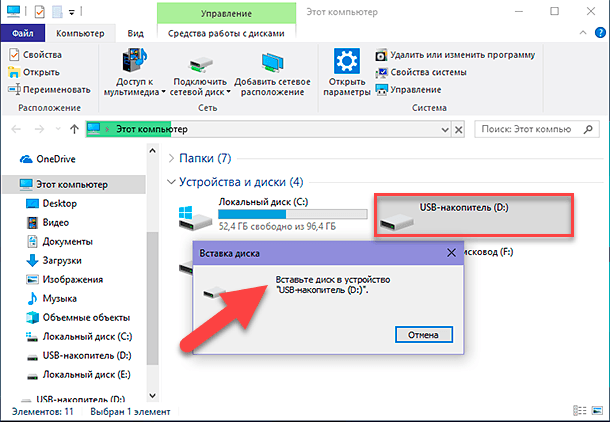
Кэш не очищается по причине открытых программ. Решение: закрыть все лишнее и попробовать снова.

Вам помогло? Поделитесь с друзьями — помогите и нам!
С развитием компьютерных систем объем памяти и объем информации внутри ПК также постепенно увеличивались. Обработка этой информации памяти является нормальной частью серьезных сбоев. Жесткие ошибки не связаны с качеством или маркой памяти, а являются исключением, обычно возникающим при нормальной или нерегулярной обработке. В этом руководстве мы узнаем гораздо больше о серьезных ошибках памяти в секунду, о том, почему возникает чрезмерное количество серьезных ошибок, а также о некоторых методах, которые помогут решить проблему с жесткими ошибками памяти. Если вы ищете решения для серьезных сбоев, связанных с проблемой свободной памяти, присоединяйтесь и ознакомьтесь с некоторыми из эффективных исправлений, которые устранят серьезные сбои монитора ресурсов Windows.
Что такое Жесткие ошибки в секунду? Как это исправить
Как обсуждалось ранее, серьезные сбои, ранее известные как сбои страниц, являются нормальной частью обработки информации о памяти в компьютере. Это не проблема, но возникают серьезные ошибки, когда операционная система извлекает страницы памяти из файла подкачки (виртуальная память), а не из физической памяти (ОЗУ). Однако, как излишество во всем плохо, так и в случае с жесткими недостатками. Если вы испытываете большее количество серьезных сбоев, чем обычно, это может означать, что вашему компьютеру требуется больше физической памяти (ОЗУ). Количество серьезных сбоев полностью зависит от характеристик и задач вашего ПК.
Что вызывает серьезные сбои со свободной памятью?
Несмотря на то, что вы уже знакомы с основной причиной серьезных сбоев, которая заключается в нехватке оперативной памяти в ПК, при проверке системы. Многие пользователи сообщают о наличии свободной памяти, сталкиваясь с десятками серьезных сбоев. В этом случае не вводите в заблуждение доступную или свободную память, отображаемую в диспетчере задач вашего ПК. Большая часть этой памяти не свободна и уже используется, что приводит к большому противоречию.
Помимо проблем с памятью, число выше обычного (20 или меньше, учитывая объем вашей оперативной памяти) является проблемой для вас. Это может быть вызвано различными причинами, перечисленными ниже:
- Жесткие ошибки в секунду возникают, когда адресная память конкретной программы была переключена на основной файл подкачки, а не на слот основной памяти. Это приводит к замедлению работы ПК и повышению активности жесткого диска из-за попыток найти недостающую память.
- Кроме того, проблема высоких аппаратных сбоев может возникнуть во время перегрузки жесткого диска. В этом случае жесткий диск продолжает работать на полной скорости, пока на вашем компьютере происходит перегрузка диска или когда программа перестает отвечать на запросы.
- Кроме того, серьезные сбои могут возникнуть при одновременном запуске слишком большого количества программ на ПК.
Что такое серьезные сбои монитора ресурсов Windows?
Монитор ресурсов является важным инструментом для ПК, который передает информацию о потоках данных в режиме реального времени о важных системах, работающих на вашем компьютере. Утилита чрезвычайно полезна для мониторинга состояния вашей системы и устранения проблем, связанных с ее производительностью. Вы можете проверить наличие и распределение нескольких ресурсов в вашей системе с помощью монитора ресурсов. Вы также можете проверить информацию об использовании оборудования, включая память, ЦП, диск и сеть, а также программное обеспечение, включая дескрипторы файлов и модули. В разделе «Память» вы, скорее всего, проверите количество серьезных сбоев в секунду, представляющее процент используемой физической памяти. В общем, Resource Monitor — удивительно важная утилита во всех версиях Windows.
Как исправить серьезные ошибки памяти в секунду
Если вы столкнулись с большим количеством серьезных сбоев (сотни в секунду) в вашей системе, вам необходимо решить проблему, помня о возможных причинах, упомянутых выше, которые могут вызвать эту ситуацию. Итак, давайте начнем с методов устранения неполадок, чтобы исправить эту ситуацию для вас.
Способ 1: добавить больше оперативной памяти
Как мы уже обсуждали, основной причиной большего количества серьезных сбоев в секунду является нехватка оперативной памяти. Следовательно, чтобы решить проблему серьезных сбоев, вам нужно больше оперативной памяти. Чем больше у вас их, тем меньше серьезных ошибок в секунду вы будете сталкиваться. Для этого вы можете начать с проверки конфигурации вашей системы, чтобы узнать, достаточно ли у вас оперативной памяти в текущей версии Windows. Если вы не соответствуете требованиям (для 64-битной версии требуется в два раза больше памяти, чем для 32-битной версии), вам необходимо купить дополнительную оперативную память или добавить больше на свой компьютер. Вы можете ознакомиться с нашим руководством о том, как увеличить объем оперативной памяти в Windows 7 и 10.
Кроме того, чтобы увеличить видеопамять (VRAM), вы можете ознакомиться с нашим руководством по 3 способам увеличения выделенной видеопамяти в Windows 10.
Способ 2: повторно включить Pagefile.sys
В случае, если у вас возникли серьезные проблемы со свободной памятью, этот метод поможет вам решить проблему довольно эффективно. Это включает в себя отключение и повторное включение Pagefile.sys. Ваш ПК с Windows предназначен для использования файла подкачки.
- Файл подкачки помогает более эффективно использовать физическую память, удаляя из ОЗУ редко используемые измененные страницы.
- Файл подкачки необходим, чтобы максимально эффективно использовать оперативную память. Вы можете вносить в него изменения, регулируя его размер, настраивая его конфигурации, а также отключая его, чтобы уменьшить количество серьезных сбоев.
Вот как вы можете сначала отключить, а затем снова включить Pagefile.sys:
Примечание. Если файл подкачки отключен, некоторые программы не будут работать должным образом, поскольку они предназначены исключительно для его использования.
1. Откройте проводник, одновременно нажав клавиши Windows + E.
2. Теперь щелкните правой кнопкой мыши «Этот компьютер» и выберите «Свойства» в меню.
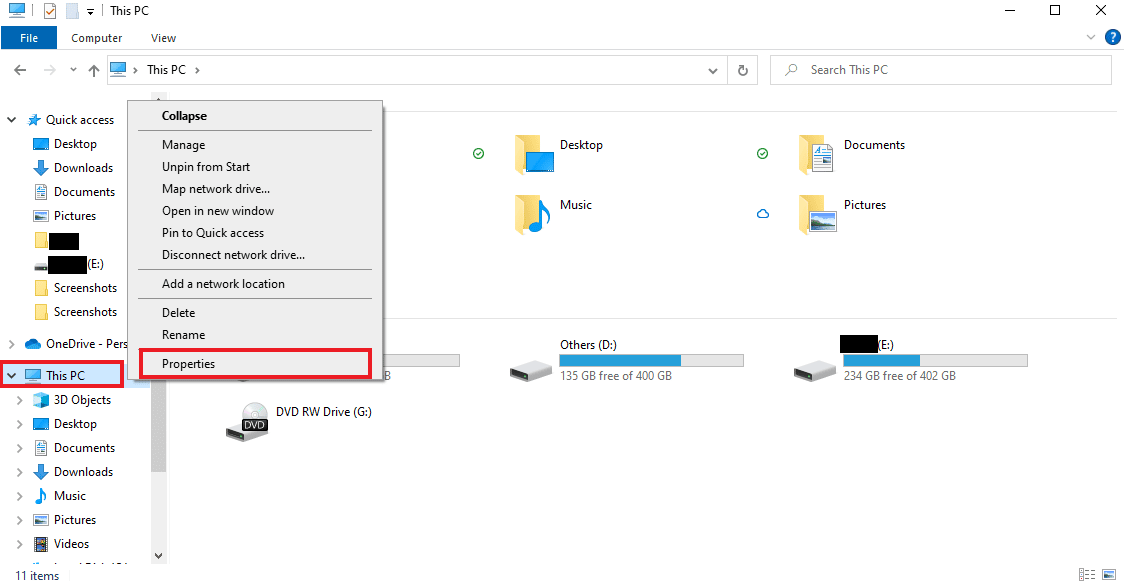
3. Нажмите Дополнительные параметры системы на боковой панели.
4. На вкладке «Дополнительно» нажмите «Настройки…» в разделе «Производительность».
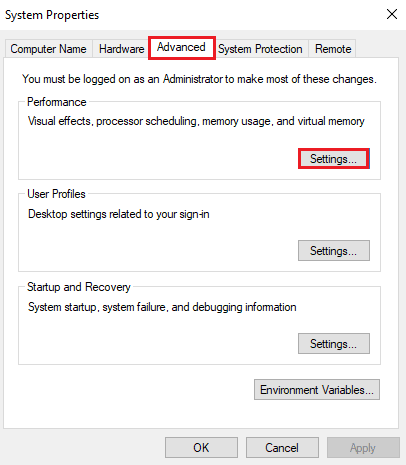
5. Теперь на вкладке «Дополнительно» нажмите кнопку «Изменить…».
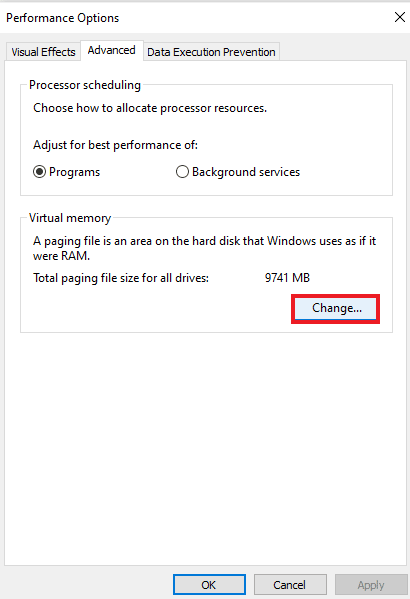
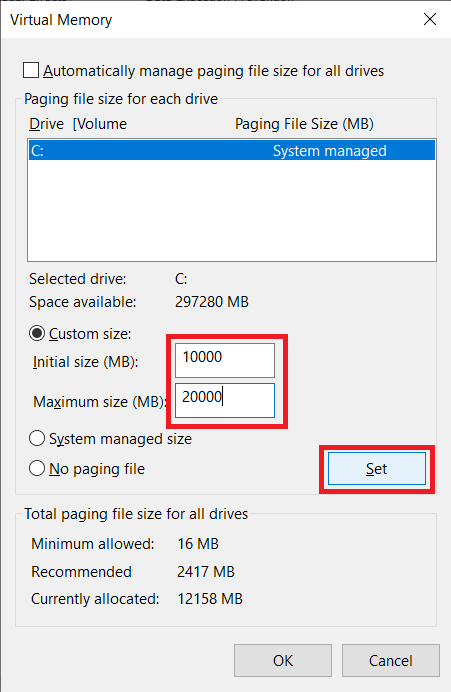
6. Затем снимите флажок Автоматически управлять размером файла подкачки для всех дисков.
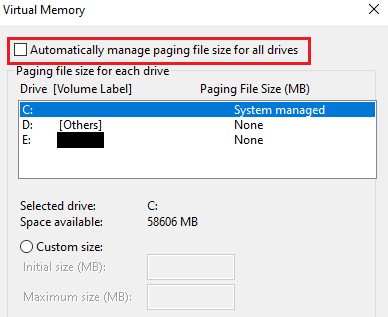
7. Теперь выберите диск, для которого вы хотите отключить Pagefile.sys, и выберите «Нет файла подкачки».
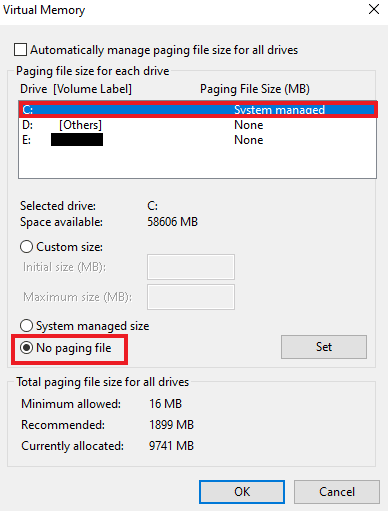
8. Затем нажмите Set > OK, чтобы сохранить изменения.
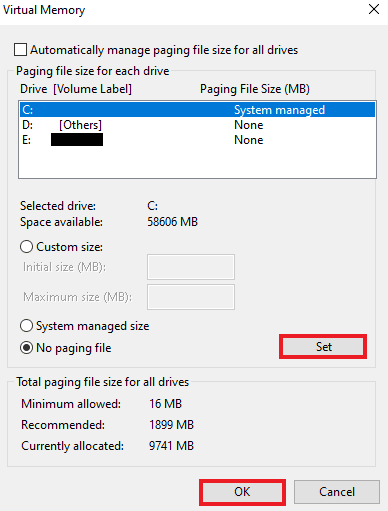
9. После этого перезагрузите компьютер, чтобы изменения вступили в силу.
10. Наконец, вы можете снова включить Pagefile.sys с помощью шагов, описанных выше.
Способ 3: определить сборщик ресурсов и завершить дерево процессов
Если вы все еще боретесь с серьезными сбоями монитора ресурсов Windows, вы должны попытаться определить программу, которая увеличивает число серьезных сбоев в секунду. Этот процесс несет ответственность за слишком много памяти на вашем ПК и, следовательно, является виновником. С помощью Resource Monitor вы можете легко найти основной процесс, ответственный за эту ситуацию. Итак, следуйте инструкциям ниже, чтобы найти пожиратель ресурсов в вашей системе:
1. Нажмите одновременно клавиши Ctrl + Shift + Esc, чтобы запустить диспетчер задач.
2. Перейдите на вкладку «Производительность» и нажмите «Открыть монитор ресурсов».
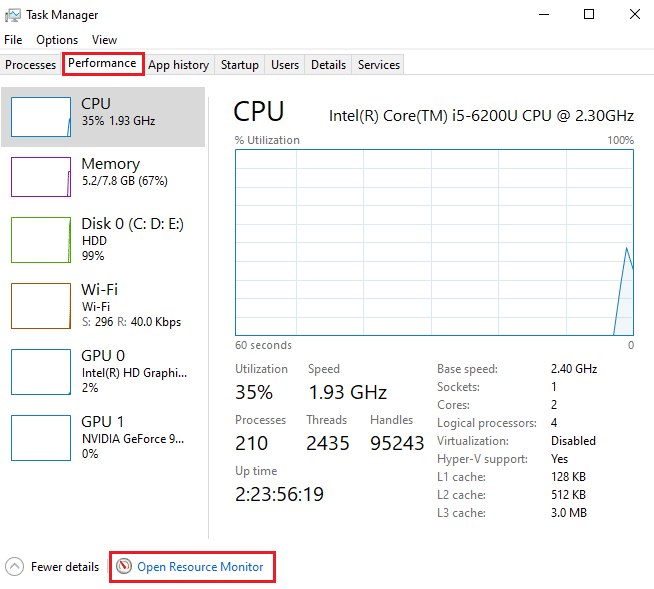
3. На вкладке «Память» окна «Монитор ресурсов» щелкните столбец «Серьезные сбои».
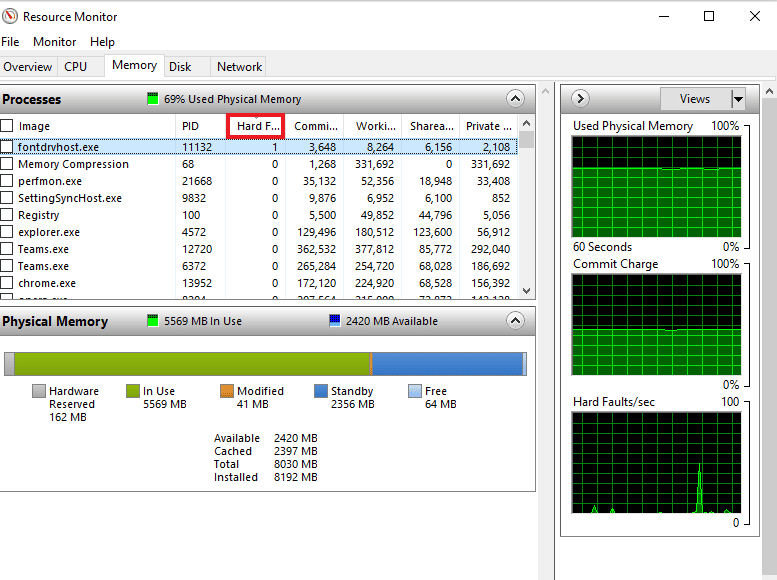
4. Теперь проверьте процесс, замедляющий работу вашего ПК, и щелкните его правой кнопкой мыши.
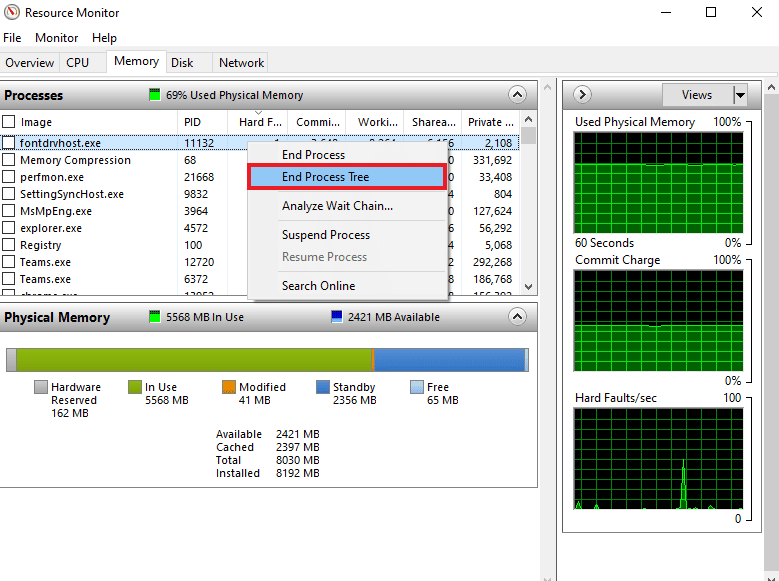
5. Выберите в меню Завершить дерево процессов, чтобы завершить задачу.
Примечание. Если программа не важна, ее можно удалить.
Часто задаваемые вопросы (FAQ)
Q1. Сколько серьезных ошибок в секунду является нормальным?
Ответ В среднем 20 или менее серьезных ошибок в секунду являются нормальными, в зависимости от оперативной памяти вашей системы.
Q2. Часто ли возникают серьезные сбои памяти?
Ответ Да. Жесткие ошибки памяти распространены и являются частью обработки памяти. Их не следует воспринимать как ошибки. Они означают, что блочная память должна была быть извлечена из виртуальной памяти, а не из ОЗУ.
Q3. Как я могу отслеживать отказы жестких страниц?
Ответ Сбои жесткой страницы можно отслеживать с помощью консоли Performance Monitor (Perfmon). Он представляет собой кумулятивное количество ошибок страниц в системе.
Q4. Что приводит к зависанию диска?
Ответ Пробуксовка диска вызвана использованием виртуальной памяти. Он включает в себя быстрый обмен данными с жесткого диска, когда программа перестает отвечать на запросы.
Q5. В чем причина высокого использования памяти?
Ответ Высокое использование памяти в системе является результатом перегрузки многих внутренних процессов.
***
Мы надеемся, что наш документ поможет вам, и вы сможете много узнать о серьезных ошибках в секунду и способах устранения избыточных серьезных ошибок в вашей системе. Если да, то сообщите нам, какой из методов помог вам решить проблему с памятью. Вы можете оставить свои вопросы или предложения в разделе комментариев ниже.
Проблемы при работе с кэшем и способы их решения
Время на прочтение
12 мин
Количество просмотров 35K
Привет, Хабр!
Меня зовут Виктор Пряжников, я работаю в SRV-команде Badoo. Наша команда занимается разработкой и поддержкой внутреннего API для наших клиентов со стороны сервера, и кэширование данных — это то, с чем мы сталкиваемся каждый день.
Существует мнение, что в программировании есть только две по-настоящему сложные задачи: придумывание названий и инвалидация кэша. Я не буду спорить с тем, что инвалидация — это сложно, но мне кажется, что кэширование — довольно хитрая вещь даже без учёта инвалидации. Есть много вещей, о которых следует подумать, прежде чем начинать использовать кэш. В этой статье я попробую сформулировать некоторые проблемы, с которыми можно столкнуться при работе с кэшем в большой системе.

Я расскажу о проблемах разделения кэшируемых данных между серверами, параллельных обновлениях данных, «холодном старте» и работе системы со сбоями. Также я опишу возможные способы решения этих проблем и приведу ссылки на материалы, где эти темы освещены более подробно. Я не буду рассказывать, что такое кэш в принципе и касаться деталей реализации конкретных систем.
При работе я исхожу из того, что рассматриваемая система состоит из приложения, базы данных и кэша для данных. Вместо базы данных может использоваться любой другой источник (например, какой-то микросервис или внешний API).
Деление данных между кэширующими серверами
Если вы хотите использовать кэширование в достаточно большой системе, нужно позаботиться о том, чтобы можно было поделить кэшируемые данные между доступными серверами. Это необходимо по нескольким причинам:
- данных может быть очень много, и они физически не поместятся в память одного сервера;
- данные могут запрашиваться очень часто, и один сервер не в состоянии обработать все эти запросы;
- вы хотите сделать кэширование более надёжным. Если у вас только один кэширующий сервер, то при его падении вся система останется без кэша, что может резко увеличить нагрузку на базу данных.
Самый очевидный способ разбивки данных — вычисление номера сервера псевдослучайным образом в зависимости от ключа кэширования.
Есть разные алгоритмы для реализации этого. Самый простой — вычисление номера сервера как остатка от целочисленного деления численного представления ключа (например, CRC32) на количество кэширующих серверов:
$cache_server_index = crc32($cache_key) % count($cache_servers_list);Такой алгоритм называется хешированием по модулю (англ. modulo hashing). CRC32 здесь использован в качестве примера. Вместо него можно взять любую другую хеширующую функцию, из результатов которой можно получить число, большее или равное количеству серверов, с более-менее равномерно распределённым результатом.
Этот способ легко понять и реализовать, он достаточно равномерно распределяет данные между серверами, но у него есть серьёзный недостаток: при изменении количества серверов (из-за технических проблем или при добавлении новых) значительная часть кэша теряется, поскольку для ключей меняется остаток от деления.
Я написал небольшой скрипт, который продемонстрирует эту проблему.
В нём генерируется 1 млн уникальных ключей, распределённых по пяти серверам с помощью хеширования по модулю и CRC32. Я эмулирую выход из строя одного из серверов и перераспределение данных по четырём оставшимся.
В результате этого «сбоя» примерно 80% ключей изменят своё местоположение, то есть окажутся недоступными для последующего чтения:
Total keys count: 1000000
Shards count range: 4, 5
Самое неприятное тут то, что 80% — это далеко не предел. С увеличением количества серверов процент потери кэша будет расти и дальше. Единственное исключение — это кратные изменения (с двух до четырёх, с девяти до трёх и т. п.), при которых потери будут меньше обычного, но в любом случае не менее половины от имеющегося кэша:

Я выложил на GitHub скрипт, с помощью которого я собрал данные, а также ipynb-файл, рисующий данную таблицу, и файлы с данными.
Для решения этой проблемы есть другой алгоритм разбивки — согласованное хеширование (англ. consistent hashing). Основная идея этого механизма очень простая: здесь добавляется дополнительное отображение ключей на слоты, количество которых заметно превышает количество серверов (их могут быть тысячи и даже больше). Сами слоты, в свою очередь, каким-то образом распределяются по серверам.
При изменении количества серверов количество слотов не меняется, но меняется распределение слотов между этими серверами:
- если один из серверов выходит из строя, то все слоты, которые к нему относились, распределяются между оставшимися;
- если добавляется новый сервер, то ему передаётся часть слотов от уже имеющихся серверов.
Обычно идею согласованного хеширования визуализируют с помощью колец, точки на окружностях которых показывают слоты или границы диапазонов слотов (в случае если этих слотов очень много). Вот простой пример перераспределения для ситуации с небольшим количеством слотов (60), которые изначально распределены по четырём серверам:
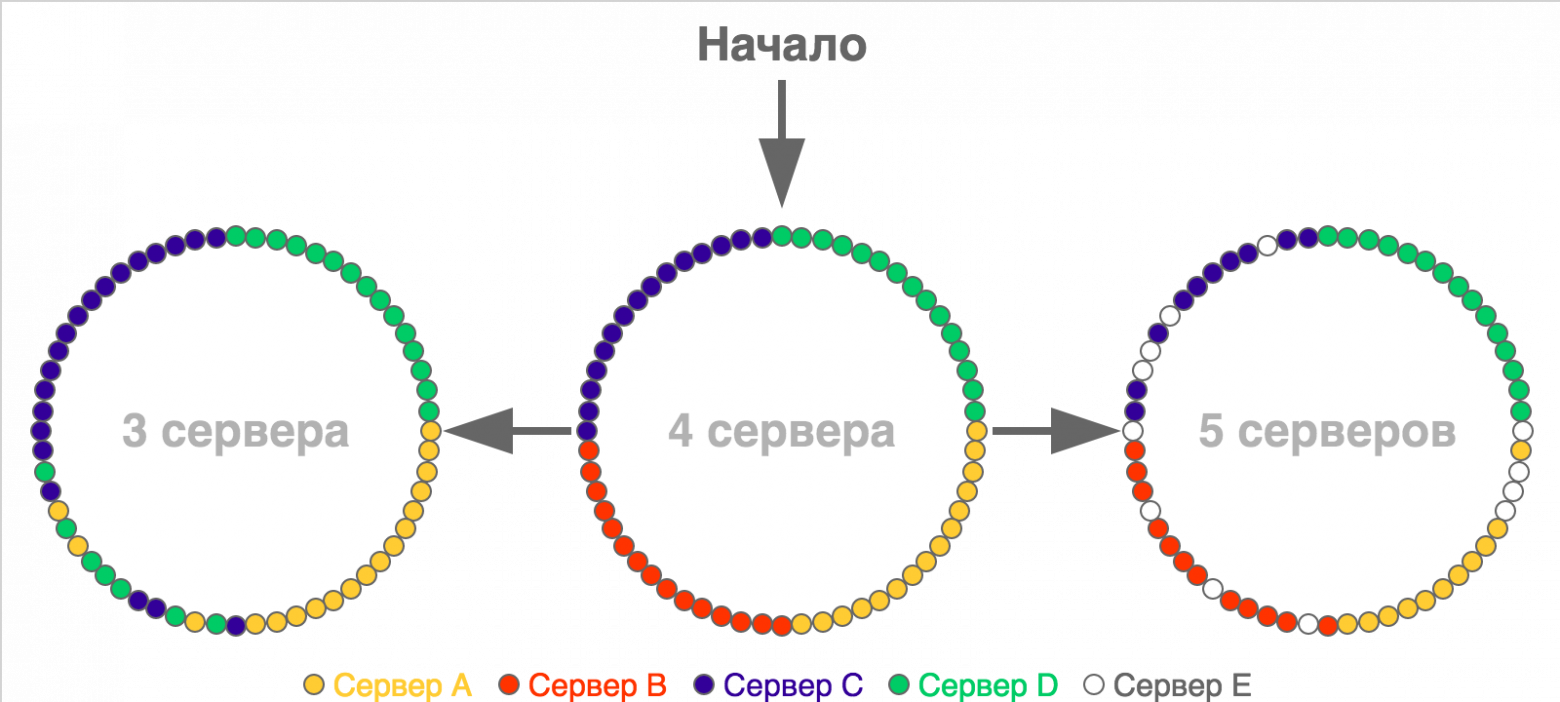
На картинке начального разбиения все слоты одного сервера расположены подряд, но в реальности это не обязательное условие — они могут быть расположены как угодно.
Основное преимущество этого способа перед предыдущим заключается в том, что здесь каждому серверу соответствует не одно значение, а целый диапазон, и при изменении количества серверов между ними перераспределяется гораздо меньшая часть ключей (k / N, где k — общее количество ключей, а N — количество серверов).
Если вернуться к сценарию, который я использовал для демонстрации недостатка хеширования по модулю, то при той же ситуации с падением одного из пяти серверов (с одинаковым весом) и перераспределением ключей с него между оставшимися мы потерям не 80% кэша, а только 20%. Если считать, что изначально все данные находятся в кэше и все они будут запрошены, то эта разница означает, что при согласованном хешировании мы получим в четыре раза меньше запросов к базе данных.
Код, реализующий этот алгоритм, будет сложнее, чем код предыдущего, поэтому я не буду его приводить в статье. При желании его легко можно найти — на GitHub есть масса реализаций на самых разных языках.
Наряду с согласованным хешированием есть и другие способы решения этой проблемы (например, rendezvous hashing), но они гораздо менее распространены.
Вне зависимости от выбранного алгоритма выбор сервера на основе хеша ключа может работать плохо. Обычно в кэше находится не набор однотипных данных, а большое количество разнородных: кэшированные значения занимают разное место в памяти, запрашиваются с разной частотой, имеют разное время генерации, разную частоту обновлений и разное время жизни. При использовании хеширования вы не можете управлять тем, куда именно попадёт ключ, и в результате может получиться «перекос» как в объёме хранимых данных, так и в количестве запросов к ним, из-за чего поведение разных кэширующих серверов будет сильно различаться.
Чтобы решить эту проблему, необходимо «размазать» ключи так, чтобы разнородные данные были распределены между серверами более-менее однородно. Для этого для выбора сервера нужно использовать не ключ, а какой-то другой параметр, к которому нужно будет применить один из описанных подходов. Нельзя сказать, что это будет за параметр, поскольку это зависит от вашей модели данных.
В нашем случае почти все кэшируемые данные относятся к одному пользователю, поэтому мы используем User ID в качестве параметра шардирования данных в кэше. Благодаря этому у нас получается распределить данные более-менее равномерно. Кроме того, мы получаем бонус — возможность использования multi_get для загрузки сразу нескольких разных ключей с информацией о юзере (что мы используем в предзагрузке часто используемых данных для текущего пользователя). Если бы положение каждого ключа определялось динамически, то невозможно было бы использовать multi_get при таком сценарии, так как не было бы гарантии, что все запрашиваемые ключи относятся к одному серверу.
См. также:
- Статья «Distributed hash table» в Wikipedia
- Статья «Consistent hashing» в Wikipedia
- A Guide to Consistent Hashing
- Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web
- Building a Consistent Hashing Ring
Параллельные запросы на обновление данных
Посмотрите на такой простой кусочек кода:
public function getContactsCountCached(int $user_id) : ?int
{
$contacts_count = ContactsCache::getContactsCount($user_id);
if ($contacts_count !== false) {
return $contacts_count;
}
$contacts_count = $this->getContactsCount($user_id);
if (is_null($contacts_count)) {
return null;
}
ContactsCache::setContactsCount($user_id, $contacts_count);
return $contacts_count;
}
Что произойдёт при отсутствии запрашиваемых данных в кэше? Судя по коду, должен запуститься механизм, который достанет эти данные. Если код выполняется только в один поток, то всё будет хорошо: данные будут загружены, помещены в кэш и при следующем запросе взяты уже оттуда. А вот при работе в несколько параллельных потоков всё будет иначе: загрузка данных будет происходить не один раз, а несколько.
Выглядеть это будет примерно так:
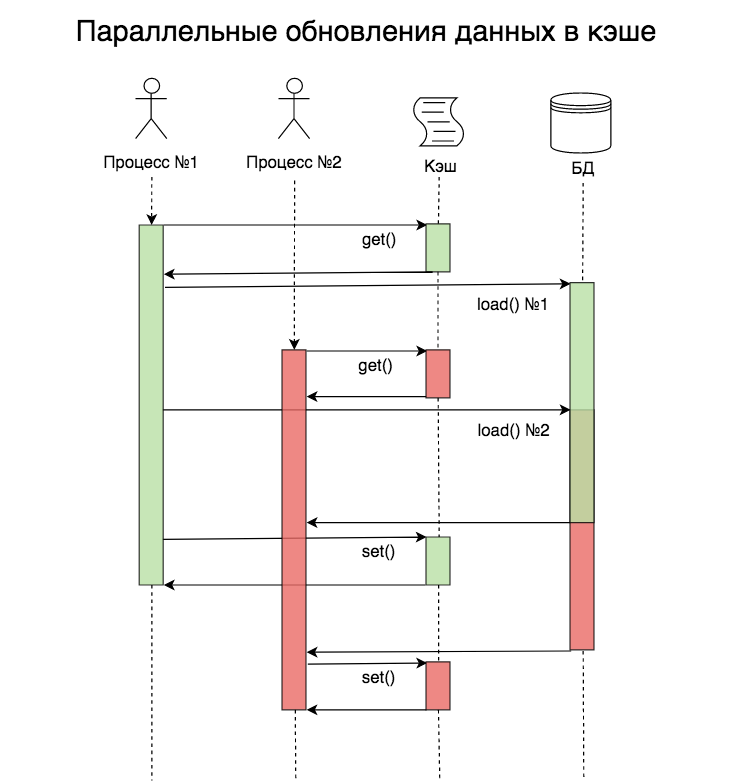
На момент начала обработки запроса в процессе №2 данных в кэше ещё нет, но они уже читаются из базы данных в процессе №1. В этом примере проблема не такая существенная, ведь запроса всего два, но их может быть гораздо больше.
Количество параллельных загрузок зависит от количества параллельных пользователей и времени, которое требуется на загрузку необходимых данных.
Предположим, у вас есть какой-то функционал, использующий кэш с нагрузкой 200 запросов в секунду. Если на на загрузку данных нужно 50 мс, то за это время вы получите 50 / (1000 / 200) = 10 запросов.
То есть при отсутствии кэша один процесс начнёт загружать данные, и за время загрузки придут ещё девять запросов, которые не увидят данные в кэше и тоже станут их загружать.
Эта проблема называется cache stampede (русского аналога этого термина я не нашёл, дословно это можно перевести как «паническое бегство кэша», и картинка в начале статьи показывает пример этого действия в дикой природе), hit miss storm («шторм непопаданий в кэш») или dog-pile effect («эффект собачьей стаи»). Есть несколько способов её решения:
Блокировка перед началом выполнения операции пересчёта/ загрузки данных
Суть этого метода состоит в том, что при отсутствии данных в кэше процесс, который хочет их загрузить, должен захватить лок, который не даст сделать то же самое другим параллельно выполняющимся процессам. В случае memcached простейший способ блокировки — добавление ключа в тот же кэширующий сервер, в котором должны храниться сами закэшированные данные.
При этом варианте данные обновляются только в одном процессе, но нужно решить, что делать с процессами, которые попали в ситуацию с отсутствующим кэшем, но не смогли получить блокировку. Они могут отдавать ошибку или какое-то значение по умолчанию, ждать какое-то время, после чего пытаться получить данные ещё раз.
Кроме того, нужно тщательно выбирать время самой блокировки — его гарантированно должно хватить на то, чтобы загрузить данные из источника и положить в кэш. Если не хватит, то повторную загрузку данных может начать другой параллельный процесс. С другой стороны, если этот временной промежуток будет слишком большим и процесс, получивший блокировку, умрёт, не записав данные в кэш и не освободив блокировку, то другие процессы также не смогут получить эти данные до окончания времени блокировки.
Вынос обновлений в фон
Основная идея этого способа — разделение по разным процессам чтения данных из кэша и записи в него. В онлайн-процессах происходит только чтение данных из кэша, но не их загрузка, которая идёт только в отдельном фоновом процессе. Данный вариант делает невозможными параллельные обновления данных.
Этот способ требует дополнительных «расходов» на создание и мониторинг отдельного скрипта, пишущего данные в кэш, и синхронизации времени жизни записанного кэша и времени следующего запуска обновляющего его скрипта.
Этот вариант мы в Badoo используем, например, для счётчика общего количества пользователей, про который ещё пойдёт речь дальше.
Вероятностные методы обновления
Суть этих методов заключается в том, что данные в кэше обновляются не только при отсутствии, но и с какой-то вероятностью при их наличии. Это позволит обновлять их до того, как закэшированные данные «протухнут» и потребуются сразу всем процессам.
Для корректной работы такого механизма нужно, чтобы в начале срока жизни закэшированных данных вероятность пересчёта была небольшой, но постепенно увеличивалась. Добиться этого можно с помощью алгоритма XFetch, который использует экспоненциальное распределение. Его реализация выглядит примерно так:
function xFetch($key, $ttl, $beta = 1)
{
[$value, $delta, $expiry] = cacheRead($key);
if (!$value || (time() − $delta * $beta * log(rand())) > $expiry) {
$start = time();
$value = recomputeValue($key);
$delta = time() – $start;
$expiry = time() + $ttl;
cacheWrite(key, [$value, $delta, $expiry], $ttl);
}
return $value;
}
В данном примере $ttl — это время жизни значения в кэше, $delta — время, которое потребовалось для генерации кэшируемого значения, $expiry — время, до которого значение в кэше будет валидным, $beta — параметр настройки алгоритма, изменяя который, можно влиять на вероятность пересчёта (чем он больше, тем более вероятен пересчёт при каждом запросе). Подробное описание этого алгоритма можно прочитать в white paper «Optimal Probabilistic Cache Stampede Prevention», ссылку на который вы найдёте в конце этого раздела.
Нужно понимать, что при использовании подобных вероятностных механизмов вы не исключаете параллельные обновления, а только снижаете их вероятность. Чтобы исключить их, можно «скрестить» несколько способов сразу (например, добавив блокировку перед обновлением).
См. также:
- Статья «Cache stampede» в Wikipedia
- Optimal Probabilistic Cache Stampede Prevention
- Репозиторий на GitHub с описанием и тестами разных способов
- Статья «Кэши для “чайников”»
«Холодный» старт и «прогревание» кэша
Нужно отметить, что проблема массового обновления данных из-за их отсутствия в кэше может быть вызвана не только большим количеством обновлений одного и того же ключа, но и большим количеством одновременных обновлений разных ключей. Например, такое может произойти, когда вы выкатываете новый «популярный» функционал с применением кэширования и фиксированным сроком жизни кэша.
В этом случае сразу после выкатки данные начнут загружаться (первое проявление проблемы), после чего попадут в кэш — и какое-то время всё будет хорошо, а после истечения срока жизни кэша все данные снова начнут загружаться и создавать повышенную нагрузку на базу данных.
От такой проблемы нельзя полностью избавиться, но можно «размазать» загрузки данных по времени, исключив тем самым резкое количество параллельных запросов к базе. Добиться этого можно несколькими способами:
- плавным включением нового функционала. Для этого необходим механизм, который позволит это сделать. Простейший вариант реализации — выкатывать новый функционал включённым на небольшую часть пользователей и постепенно её увеличивать. При таком сценарии не должно быть сразу большого вала обновлений, так как сначала функционал будет доступен только части пользователей, а по мере её увеличения кэш уже будет «прогрет».
- разным временем жизни разных элементов набора данных. Данный механизм можно использовать, только если система в состоянии выдержать пик, который наступит при выкатке всего функционала. Его особенность заключается в том, что при записи данных в кэш у каждого элемента будет своё время жизни, и благодаря этому вал обновлений сгладится гораздо быстрее за счёт распределения последующих обновления во времени. Простейший способ реализовать такой механизм — умножить время жизни кэша на какой-то случайный множитель:
public function getNewSnapshotTTL()
{
$random_factor = rand(950, 1050) / 1000;
return intval($this->getSnapshotTTL() * $random_factor);
}
Если по какой-то причине не хочется использовать случайное число, можно заменить его псевдослучайным значением, полученным с помощью хеш-функции на базе каких-нибудь данных (например, User ID).
Пример
Я написал небольшой скрипт, который эмулирует ситуацию «непрогретого» кэша.
В нём я воспроизвожу ситуацию, при которой пользователь при запросе загружает данные о себе (если их нет в кэше). Конечно, пример синтетический, но даже на нём можно увидеть разницу в поведении системы.
Вот как выглядит график количества hit miss-ов в ситуации с фиксированным (fixed_cache_misses_count) и различным (random_cache_misses_count) сроками жизни кэша:
Видно, что в начале работы в обоих случаях пики нагрузки очень заметны, но при использовании псевдослучайного времени жизни они сглаживаются гораздо быстрее.
«Горячие» ключи
Данные в кэше разнородные, некоторые из них могут запрашиваться очень часто. В этом случае проблемы могут создавать даже не параллельные обновления, а само количество чтений. Примером подобного ключа у нас является счётчик общего количества пользователей:

Этот счётчик — один из самых популярных ключей, и при использовании обычного подхода все запросы к нему будут идти на один сервер (поскольку это всего один ключ, а не множество однотипных), поведение которого может измениться и замедлить работу с другими ключами, хранящимися там же.
Чтобы решить эту проблему, нужно писать данные не в один кэширующий сервер, а сразу в несколько. В этом случае мы кратно снизим количество чтений этого ключа, но усложним его обновления и код выбора сервера — ведь нам нужно будет использовать отдельный механизм.
Мы в Badoo решаем эту проблему тем, что пишем данные во все кэширующие серверы сразу. Благодаря этому при чтении мы можем использовать общий механизм выбора сервера — в коде можно использовать обычный механизм шардирования по User ID, и при чтении не нужно ничего знать про специфику этого «горячего» ключа. В нашем случае это работает, поскольку у нас сравнительно немного серверов (примерно десять на площадку).
Если бы кэширующих серверов было намного больше, то этот способ мог бы быть не самым удобным — просто нет смысла дублировать сотни раз одни и те же данные. В таком случае можно было бы дублировать ключ не на все серверы, а только на их часть, но такой вариант требует чуть больше усилий.
Если вы используете определение сервера по ключу кэша, то можно добавить к нему ограниченное количество псевдослучайных значений (сделав из total_users_count что-то вроде total_users_count_1, total_users_count_2 и т. д.). Подобный подход используется, например, в Etsy.
Если вы используете явные указания параметра шардирования, то просто передавайте туда разные псевдослучайные значения.
Главная проблема с обоими способами — убедиться, что разные значения действительно попадают на разные кэширующие серверы.
См. также:
- How Etsy caches: hashing, Ketama, and cache smearing
Сбои в работе
Система не может быть надёжной на 100%, поэтому нужно предусмотреть, как она будет вести себя при сбоях. Сбои могут быть как в работе самого кэша, так и в работе базы данных.
Про сбои в работе кэша я уже рассказывал в предыдущих разделах. Единственное, что можно добавить, — хорошо было бы предусмотреть возможность отключения части функционала на работающей системе. Это полезно, когда система не в состоянии справиться с пиком нагрузки.
При сбоях в работе базы данных и отсутствии кэша мы можем попасть в ситуацию cache stampede, про которую я тоже уже рассказывал раньше. Выйти из неё можно уже описанными способами, а можно записать в кэш заведомо некорректное значение с небольшим сроком жизни. В этом случае система сможет определить, что источник недоступен, и на какое-то время перестанет пытаться запрашивать данные.
Заключение
В статье я затронул основные проблемы при работе с кэшем, но уверен, что, кроме них, есть множество других, и продолжать этот разговор можно очень долго. Надеюсь, что после прочтения моей статьи ваш кэш станет более эффективным.
#статьи
- 5 апр 2023
-

0
Разбираемся, что такое кэш, для чего он нужен, зачем и как его чистят
Статью писали как ликбез для маркетологов и новичков в IT. Но поняли, что это нужно знать каждому.
Иллюстрация: Polina Vari для Skillbox Media

Редактор и иллюстратор. Перепробовал пару десятков профессий — от тестировщика до модели, но нашёл себя в удалёнке. Учится в Skillbox и делится в своих текстах новыми знаниями.
Кэш есть на любом цифровом устройстве. Если вы понимаете, как он работает, то сможете ускорить работу программ и предотвратить ошибки в браузере.
В этом материале Skillbox Media разберёмся:
- что такое кэш;
- какие есть типы кэш-памяти;
- для чего нужно чистить кэш;
- как очистить кэш компьютера и браузера.
Кэш — это память программы или устройства, которая сохраняет временные или часто используемые файлы для быстрого доступа к ним. Это увеличивает скорость работы приложений и операционной системы. Процесс сохранения таких файлов в специальном месте называется кэшированием.
Для примера рассмотрим кэш браузера. Это папка с файлами, которые браузер загрузил в память устройства. В файлах могут быть видео, музыка, изображения или скрипты с какого-то сайта. Когда вы в следующий раз вернётесь на сайт, то браузер не будет запрашивать эти файлы, а возьмёт их из кэша. Нужная вам страница загрузится быстрее.
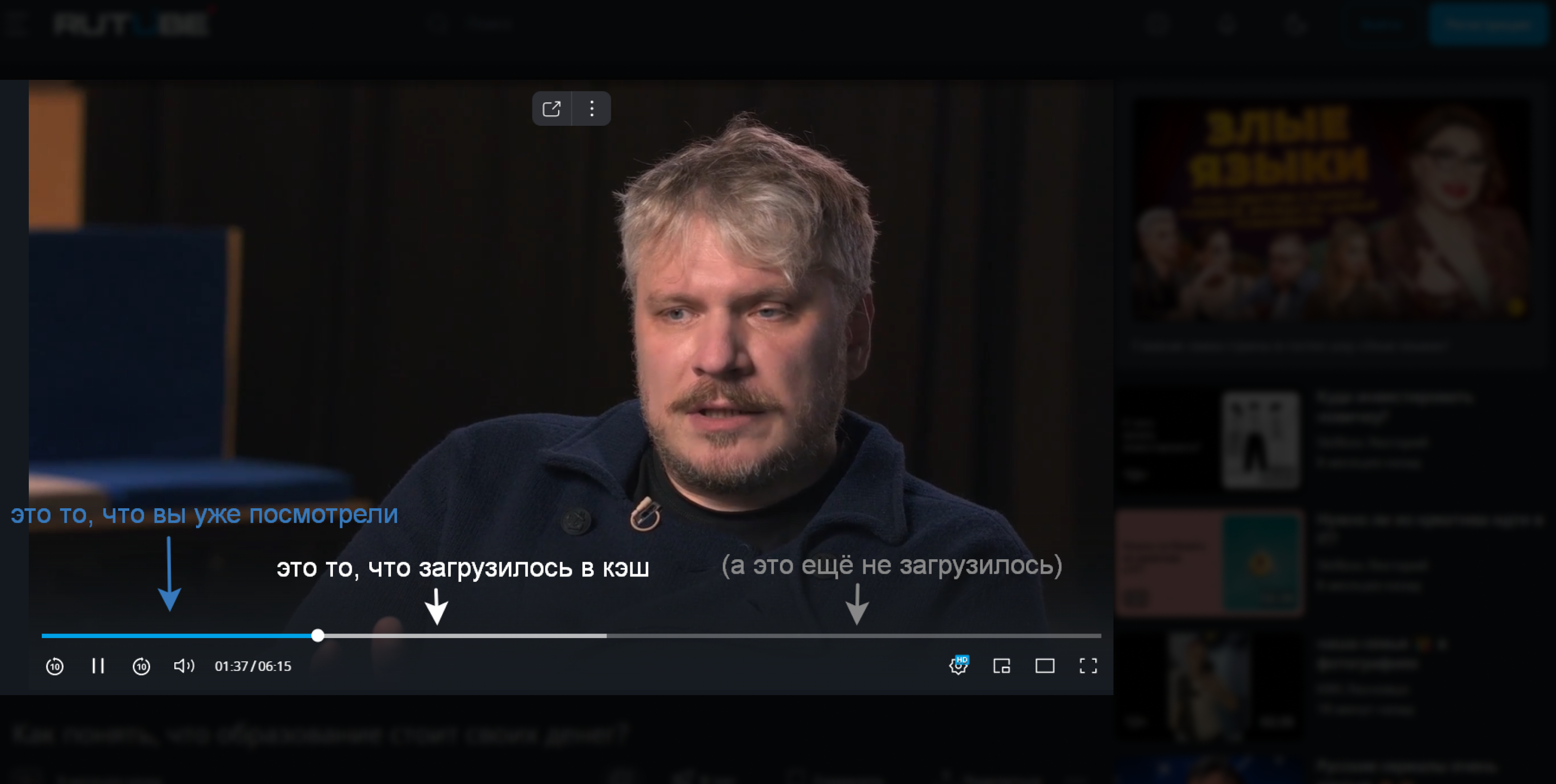
Увидеть, как кэшируются файлы, можно при просмотре онлайн-видео. Пока вы смотрите видеоролик, он загружается в кэш вашего устройства. Если видео загрузится полностью, его можно будет досмотреть даже с отключённым интернетом.
На момент начала обработки запроса в процессе №2 данных в кэше ещё нет, но они уже читаются из базы данных в процессе №1. В этом примере проблема не такая существенная, ведь запроса всего два, но их может быть гораздо больше.
Количество параллельных загрузок зависит от количества параллельных пользователей и времени, которое требуется на загрузку необходимых данных.
Предположим, у вас есть какой-то функционал, использующий кэш с нагрузкой 200 запросов в секунду. Если на на загрузку данных нужно 50 мс, то за это время вы получите 50 / (1000 / 200) = 10 запросов.
То есть при отсутствии кэша один процесс начнёт загружать данные, и за время загрузки придут ещё девять запросов, которые не увидят данные в кэше и тоже станут их загружать.
Эта проблема называется cache stampede (русского аналога этого термина я не нашёл, дословно это можно перевести как «паническое бегство кэша», и картинка в начале статьи показывает пример этого действия в дикой природе), hit miss storm («шторм непопаданий в кэш») или dog-pile effect («эффект собачьей стаи»). Есть несколько способов её решения:
Блокировка перед началом выполнения операции пересчёта/ загрузки данных
Суть этого метода состоит в том, что при отсутствии данных в кэше процесс, который хочет их загрузить, должен захватить лок, который не даст сделать то же самое другим параллельно выполняющимся процессам. В случае memcached простейший способ блокировки — добавление ключа в тот же кэширующий сервер, в котором должны храниться сами закэшированные данные.
При этом варианте данные обновляются только в одном процессе, но нужно решить, что делать с процессами, которые попали в ситуацию с отсутствующим кэшем, но не смогли получить блокировку. Они могут отдавать ошибку или какое-то значение по умолчанию, ждать какое-то время, после чего пытаться получить данные ещё раз.
Кроме того, нужно тщательно выбирать время самой блокировки — его гарантированно должно хватить на то, чтобы загрузить данные из источника и положить в кэш. Если не хватит, то повторную загрузку данных может начать другой параллельный процесс. С другой стороны, если этот временной промежуток будет слишком большим и процесс, получивший блокировку, умрёт, не записав данные в кэш и не освободив блокировку, то другие процессы также не смогут получить эти данные до окончания времени блокировки.
Вынос обновлений в фон
Основная идея этого способа — разделение по разным процессам чтения данных из кэша и записи в него. В онлайн-процессах происходит только чтение данных из кэша, но не их загрузка, которая идёт только в отдельном фоновом процессе. Данный вариант делает невозможными параллельные обновления данных.
Этот способ требует дополнительных «расходов» на создание и мониторинг отдельного скрипта, пишущего данные в кэш, и синхронизации времени жизни записанного кэша и времени следующего запуска обновляющего его скрипта.
Этот вариант мы в Badoo используем, например, для счётчика общего количества пользователей, про который ещё пойдёт речь дальше.
Вероятностные методы обновления
Суть этих методов заключается в том, что данные в кэше обновляются не только при отсутствии, но и с какой-то вероятностью при их наличии. Это позволит обновлять их до того, как закэшированные данные «протухнут» и потребуются сразу всем процессам.
Для корректной работы такого механизма нужно, чтобы в начале срока жизни закэшированных данных вероятность пересчёта была небольшой, но постепенно увеличивалась. Добиться этого можно с помощью алгоритма XFetch, который использует экспоненциальное распределение. Его реализация выглядит примерно так:
function xFetch($key, $ttl, $beta = 1)
{
[$value, $delta, $expiry] = cacheRead($key);
if (!$value || (time() − $delta * $beta * log(rand())) > $expiry) {
$start = time();
$value = recomputeValue($key);
$delta = time() – $start;
$expiry = time() + $ttl;
cacheWrite(key, [$value, $delta, $expiry], $ttl);
}
return $value;
}
В данном примере $ttl — это время жизни значения в кэше, $delta — время, которое потребовалось для генерации кэшируемого значения, $expiry — время, до которого значение в кэше будет валидным, $beta — параметр настройки алгоритма, изменяя который, можно влиять на вероятность пересчёта (чем он больше, тем более вероятен пересчёт при каждом запросе). Подробное описание этого алгоритма можно прочитать в white paper «Optimal Probabilistic Cache Stampede Prevention», ссылку на который вы найдёте в конце этого раздела.
Нужно понимать, что при использовании подобных вероятностных механизмов вы не исключаете параллельные обновления, а только снижаете их вероятность. Чтобы исключить их, можно «скрестить» несколько способов сразу (например, добавив блокировку перед обновлением).
См. также:
- Статья «Cache stampede» в Wikipedia
- Optimal Probabilistic Cache Stampede Prevention
- Репозиторий на GitHub с описанием и тестами разных способов
- Статья «Кэши для “чайников”»
«Холодный» старт и «прогревание» кэша
Нужно отметить, что проблема массового обновления данных из-за их отсутствия в кэше может быть вызвана не только большим количеством обновлений одного и того же ключа, но и большим количеством одновременных обновлений разных ключей. Например, такое может произойти, когда вы выкатываете новый «популярный» функционал с применением кэширования и фиксированным сроком жизни кэша.
В этом случае сразу после выкатки данные начнут загружаться (первое проявление проблемы), после чего попадут в кэш — и какое-то время всё будет хорошо, а после истечения срока жизни кэша все данные снова начнут загружаться и создавать повышенную нагрузку на базу данных.
От такой проблемы нельзя полностью избавиться, но можно «размазать» загрузки данных по времени, исключив тем самым резкое количество параллельных запросов к базе. Добиться этого можно несколькими способами:
- плавным включением нового функционала. Для этого необходим механизм, который позволит это сделать. Простейший вариант реализации — выкатывать новый функционал включённым на небольшую часть пользователей и постепенно её увеличивать. При таком сценарии не должно быть сразу большого вала обновлений, так как сначала функционал будет доступен только части пользователей, а по мере её увеличения кэш уже будет «прогрет».
- разным временем жизни разных элементов набора данных. Данный механизм можно использовать, только если система в состоянии выдержать пик, который наступит при выкатке всего функционала. Его особенность заключается в том, что при записи данных в кэш у каждого элемента будет своё время жизни, и благодаря этому вал обновлений сгладится гораздо быстрее за счёт распределения последующих обновления во времени. Простейший способ реализовать такой механизм — умножить время жизни кэша на какой-то случайный множитель:
public function getNewSnapshotTTL()
{
$random_factor = rand(950, 1050) / 1000;
return intval($this->getSnapshotTTL() * $random_factor);
}
Если по какой-то причине не хочется использовать случайное число, можно заменить его псевдослучайным значением, полученным с помощью хеш-функции на базе каких-нибудь данных (например, User ID).
Пример
Я написал небольшой скрипт, который эмулирует ситуацию «непрогретого» кэша.
В нём я воспроизвожу ситуацию, при которой пользователь при запросе загружает данные о себе (если их нет в кэше). Конечно, пример синтетический, но даже на нём можно увидеть разницу в поведении системы.
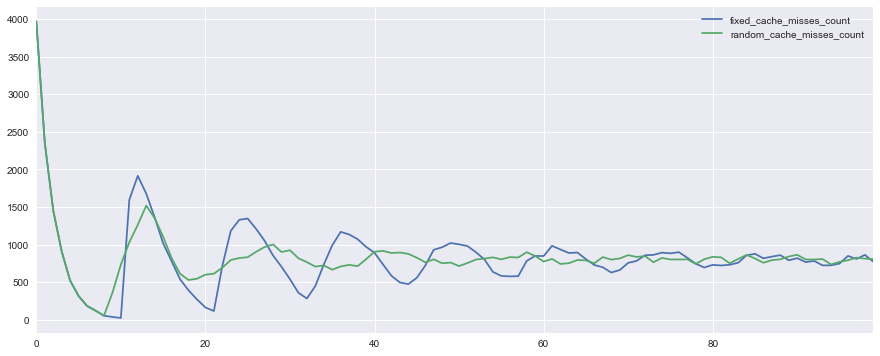
Вот как выглядит график количества hit miss-ов в ситуации с фиксированным (fixed_cache_misses_count) и различным (random_cache_misses_count) сроками жизни кэша:
Видно, что в начале работы в обоих случаях пики нагрузки очень заметны, но при использовании псевдослучайного времени жизни они сглаживаются гораздо быстрее.
«Горячие» ключи
Данные в кэше разнородные, некоторые из них могут запрашиваться очень часто. В этом случае проблемы могут создавать даже не параллельные обновления, а само количество чтений. Примером подобного ключа у нас является счётчик общего количества пользователей:
Этот счётчик — один из самых популярных ключей, и при использовании обычного подхода все запросы к нему будут идти на один сервер (поскольку это всего один ключ, а не множество однотипных), поведение которого может измениться и замедлить работу с другими ключами, хранящимися там же.
Чтобы решить эту проблему, нужно писать данные не в один кэширующий сервер, а сразу в несколько. В этом случае мы кратно снизим количество чтений этого ключа, но усложним его обновления и код выбора сервера — ведь нам нужно будет использовать отдельный механизм.
Мы в Badoo решаем эту проблему тем, что пишем данные во все кэширующие серверы сразу. Благодаря этому при чтении мы можем использовать общий механизм выбора сервера — в коде можно использовать обычный механизм шардирования по User ID, и при чтении не нужно ничего знать про специфику этого «горячего» ключа. В нашем случае это работает, поскольку у нас сравнительно немного серверов (примерно десять на площадку).
Если бы кэширующих серверов было намного больше, то этот способ мог бы быть не самым удобным — просто нет смысла дублировать сотни раз одни и те же данные. В таком случае можно было бы дублировать ключ не на все серверы, а только на их часть, но такой вариант требует чуть больше усилий.
Если вы используете определение сервера по ключу кэша, то можно добавить к нему ограниченное количество псевдослучайных значений (сделав из total_users_count что-то вроде total_users_count_1, total_users_count_2 и т. д.). Подобный подход используется, например, в Etsy.
Если вы используете явные указания параметра шардирования, то просто передавайте туда разные псевдослучайные значения.
Главная проблема с обоими способами — убедиться, что разные значения действительно попадают на разные кэширующие серверы.
См. также:
- How Etsy caches: hashing, Ketama, and cache smearing
Сбои в работе
Система не может быть надёжной на 100%, поэтому нужно предусмотреть, как она будет вести себя при сбоях. Сбои могут быть как в работе самого кэша, так и в работе базы данных.
Про сбои в работе кэша я уже рассказывал в предыдущих разделах. Единственное, что можно добавить, — хорошо было бы предусмотреть возможность отключения части функционала на работающей системе. Это полезно, когда система не в состоянии справиться с пиком нагрузки.
При сбоях в работе базы данных и отсутствии кэша мы можем попасть в ситуацию cache stampede, про которую я тоже уже рассказывал раньше. Выйти из неё можно уже описанными способами, а можно записать в кэш заведомо некорректное значение с небольшим сроком жизни. В этом случае система сможет определить, что источник недоступен, и на какое-то время перестанет пытаться запрашивать данные.
Заключение
В статье я затронул основные проблемы при работе с кэшем, но уверен, что, кроме них, есть множество других, и продолжать этот разговор можно очень долго. Надеюсь, что после прочтения моей статьи ваш кэш станет более эффективным.
#статьи
- 5 апр 2023
-
0
Разбираемся, что такое кэш, для чего он нужен, зачем и как его чистят
Статью писали как ликбез для маркетологов и новичков в IT. Но поняли, что это нужно знать каждому.
Иллюстрация: Polina Vari для Skillbox Media
Редактор и иллюстратор. Перепробовал пару десятков профессий — от тестировщика до модели, но нашёл себя в удалёнке. Учится в Skillbox и делится в своих текстах новыми знаниями.
Кэш есть на любом цифровом устройстве. Если вы понимаете, как он работает, то сможете ускорить работу программ и предотвратить ошибки в браузере.
В этом материале Skillbox Media разберёмся:
- что такое кэш;
- какие есть типы кэш-памяти;
- для чего нужно чистить кэш;
- как очистить кэш компьютера и браузера.
Кэш — это память программы или устройства, которая сохраняет временные или часто используемые файлы для быстрого доступа к ним. Это увеличивает скорость работы приложений и операционной системы. Процесс сохранения таких файлов в специальном месте называется кэшированием.
Для примера рассмотрим кэш браузера. Это папка с файлами, которые браузер загрузил в память устройства. В файлах могут быть видео, музыка, изображения или скрипты с какого-то сайта. Когда вы в следующий раз вернётесь на сайт, то браузер не будет запрашивать эти файлы, а возьмёт их из кэша. Нужная вам страница загрузится быстрее.
Увидеть, как кэшируются файлы, можно при просмотре онлайн-видео. Пока вы смотрите видеоролик, он загружается в кэш вашего устройства. Если видео загрузится полностью, его можно будет досмотреть даже с отключённым интернетом.
Скриншот: Rutube / Skillbox Media
Кэш-память нужна, чтобы приложения и система работали быстрее. Также она:
- снижает нагрузку на основное хранилище;
- даёт системе возможность выполнять больше действий одновременно;
- экономит трафик.
Термин «кэш» произошёл от французского слова cache — тайник. Его придумал в 1967 году редактор журнала IBM Systems Journal Лайл Джонсон. При подготовке статьи про усовершенствование памяти в новых компьютерах он попросил заменить сложное определение «высокочастотный буфер», а затем сам предложил слово cache. После выхода статьи слово стали использовать в компьютерной литературе как общепринятый термин.
Есть два типа кэш-памяти: аппаратная и программная.
Аппаратная кэш-память — память системы. Свой кэш есть у жёсткого диска, графического ускорителя и процессора.
Чаще всего, когда говорят про аппаратную кэш-память, имеют в виду память процессора. Иногда её ещё называют сверхоперативной памятью. Она загружает данные из оперативной памяти для самого быстрого доступа к ним. Она энергозависима — работает, пока устройство включено. Если вы выключите компьютер, кэш процессора автоматически очистится.
Программная кэш-память — это папки на диске устройства, в которых программы и сервисы сохраняют свои файлы для быстрого доступа. У каждой программы своя папка.
Например, кэш «Яндекс Браузера» на компьютере можно найти по такому пути: C: → Пользователи → Имя вашей учётной записи → AppData → Local → Yandex → YandexBrowser → User Data → Default → Cache. AppData — скрытая папка. Вам придётся включить отображение скрытых папок, чтобы её увидеть.
Размер программного кэша ограничивают, чтобы не ухудшалось быстродействие всей системы. Когда место заканчивается, то удаляется часть старой информации и записывается новая.
Есть четыре причины очищать кэш.
Первая — медленная работа программ. Если кэш-память будет переполнена, то производительность программ снизится.
Вторая — старые файлы из кэша могут привести к ошибкам в программах. Например, браузер может хранить в кэше старые скрипты сайта. Если на сайте выйдет обновление, браузер продолжит брать данные из своего кэша и не сможет корректно отобразить сайт.
Третья — с помощью кэшированных файлов посторонний человек может проследить за вами, если воспользуется вашим устройством. Также это может произойти, если вы пользуетесь общедоступным устройством — например, компьютером в интернет-кафе.
Четвёртая — кэш занимает место на диске. Память вашего устройства может переполниться. Очистка кэша позволит освободить немного места.
Чтобы не возникало проблем, кэш стоит очищать раз в 2–4 недели. Во время этой процедуры будут удалены только временные файлы, ваши личные данные останутся.
Кэш на компьютере можно очистить с помощью специальных программ. Например, использовать CCleaner для Windows и CleanMyMacX для компьютеров Apple. Также можно сделать это в настройках самому.
Чтобы удалить программный кэш на Windows самостоятельно, откройте меню «Пуск». Наберите на клавиатуре «параметры хранилища». Нажмите «Параметры хранилища» → «Временные файлы» → «Удалить файлы».
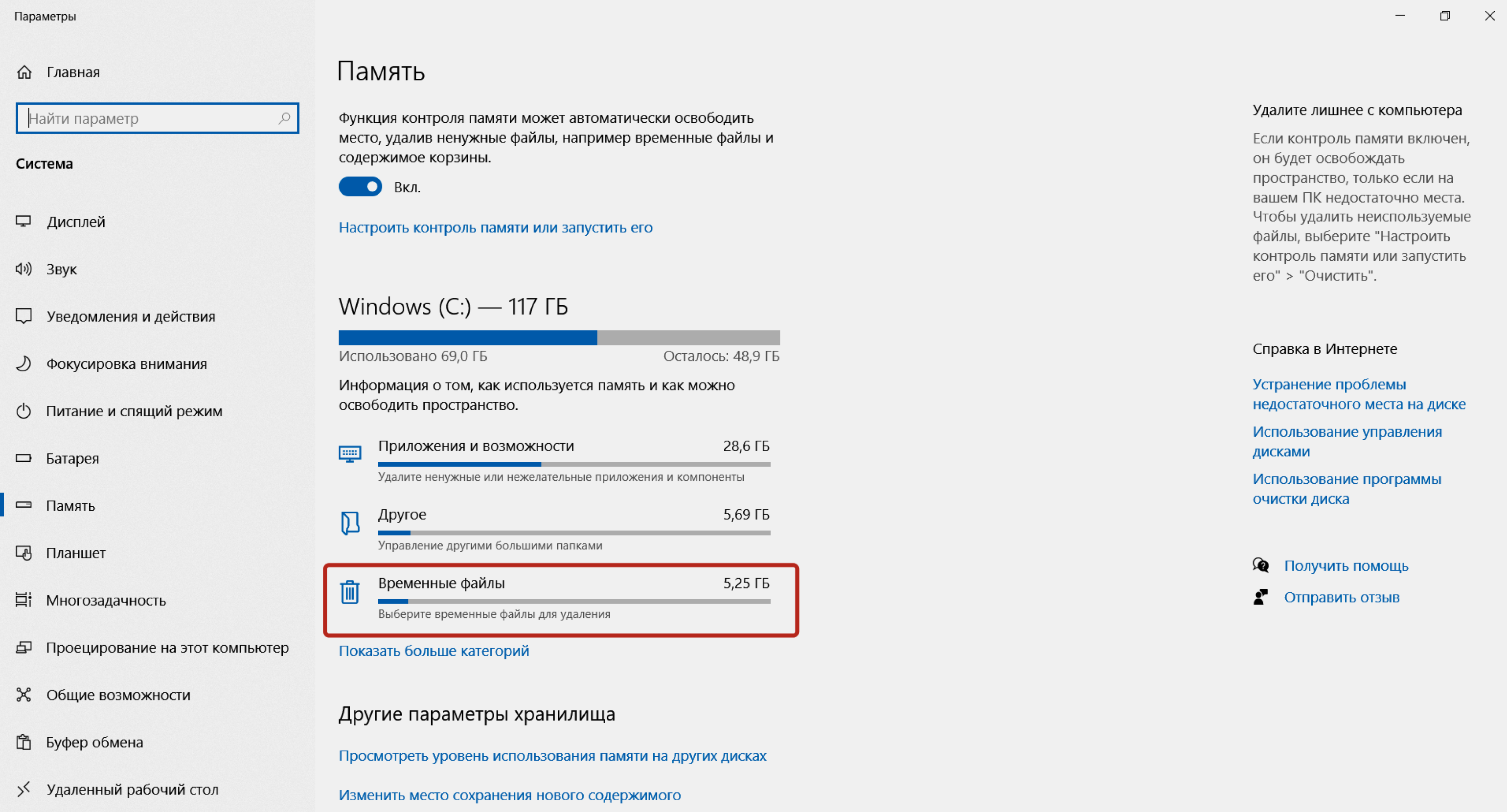
Скриншот: Skillbox Media
Также можно чистить кэш отдельно в программах, которыми вы пользуетесь.
Чаще всего есть необходимость очистить кэш браузера. Во время работы на странице сайта можно нажать комбинацию клавиш Ctrl + F5. Её кэш сбросится, и страница обновится. Чтобы удалить весь сохранённый кэш всех сайтов, вам нужно будет зайти в настройки браузера.
Рассмотрим эту процедуру на примере «Яндекс Браузера». Вам нужно будет зайти в настройки «Яндекс Браузера» (три горизонтальные полоски) → «Дополнительно» → «Очистить историю». После этого установите флажок рядом с «Файлы, сохранённые в кеше» и нажмите «Очистить».
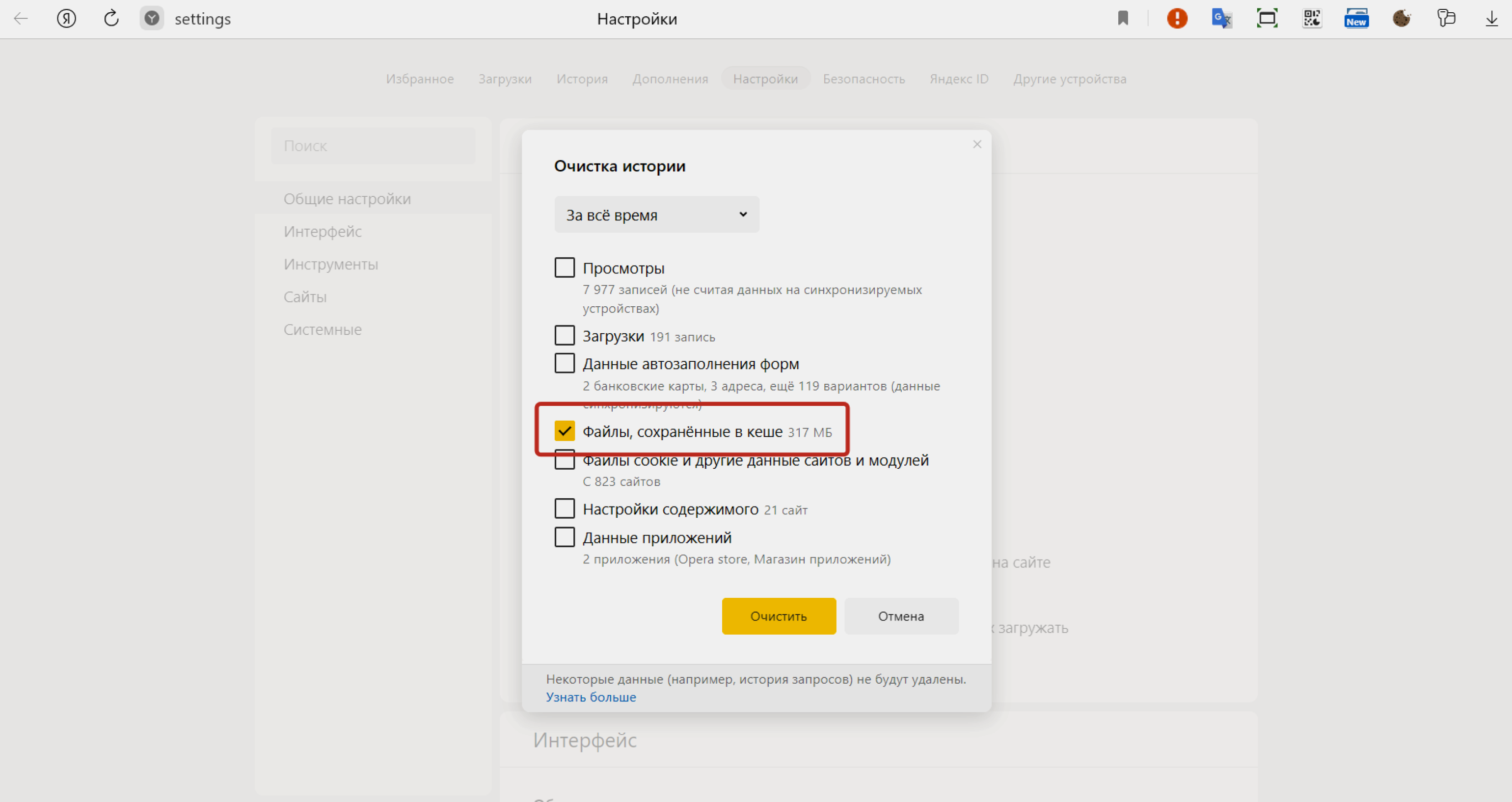
Скриншот: Skillbox Media
- Кэш — это память программы или устройства, в которой сохраняются временные или часто используемые файлы для быстрого доступа к ним. Это увеличивает скорость работы приложений и операционной системы.
- Кэш-память бывает двух типов: программная и аппаратная. Назначение у них одинаковое.
- Кэш нужно чистить, чтобы увеличить скорость работы программ и предотвратить ошибки в них. Желательно делать это раз в 2–4 недели.
- Кэш на компьютере можно очистить в настройках системы или с помощью специальных программ. Например, использовать CCleaner для Windows и CleanMyMacX для компьютеров Apple.

Научитесь: Профессия Интернет-маркетолог
Узнать больше