
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.

Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:

Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:

Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:

Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:

Стандартное отклонение этих средних значений известно как стандартная ошибка.

Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
Среднее
квадратическое отклонение
характеризует среднее отклонение
всех вариант вариационного ряда от
средней арифметической
величины. Поскольку отклонения вариант
от средней,
имеют значения с «+» и «-», то при
суммировании
они взаимоуничтожаются. Чтобы избежать
этого, отклонения возводятся
во вторую степень, а затем, после
определенных вычислений,
производится обратное действие —
извлечение корня квадратного. Поэтому
среднее отклонение именуется
квадратическим.
Среднее
квадратическое отклонение определяют
по формуле:

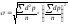
(отклонение
d
— это разность между каждой вариантой
и средней величиной, т. е. d
= V-M;
р –частота; количество вариант n
(при числе наблюдений менее 30 сумма
делится
на n-1);
При
вычислении среднеквад. отклонения по
способу
моментов используется следующая формула.
Т.о.
, формула вычисления сред. отклонения
по способу моментов будет читаться как
корень квадратный
из
разности момента второй степени и
квадрата момента первой степени.
Результаты
вычисления сред. отклонения обычным
способом и способом моментов идентичны.
Однако, как указывалось
выше, второй способ значительно убыстряет
и упрощает
расчеты. Итак,
нахождение сред. отклонения позволяет
судить о характере однородности
исследуемой группы наблюдений. Если
величина среднеквад. отклонения
небольшая, то
это свидетельствует о достаточно высокой
однородности изучаемого
явления. Среднюю арифметическую в таком
случае следует признать
вполне характерной для данного
вариационного ряда. Однако
слишком малая величина сигмы заставляет
думать об искусственном
подборе наблюдений. При очень большой
сигме средняя арифметическая в меньшей
степени характеризует вариационный
ряд,
что говорит о значительной вариабельности
изучаемого признака
или явления или о неоднородности
исследуемой группы. Значение:
Определение
среднеквад. отклонения представляет
немалую ценность для медицинской науки
и практики. При диагностике
отдельных заболеваний очень важно
оценить на основании конкретных
исследований, какие признаки проявляются
у соответствующей
группы больных относительно одинаково,
с небольшими колебаниями,
а для каких признаков характерны большие
индивидуальные
колебания. Очень широко используется
это свойство при оценке
физического развития отдельных групп
населения, при выработке
стандартов школьной меб.
Ошибка
репрезентативности (сред.
ошибка сред. арифметич.)
Чтобы
определить степень точности выборочного
наблюдения, необходимо оценить величину
ошибки, которая может
случайно произойти в процессе выборки.
Такие ошибки носят название
случайных ошибок репрезентативности
т.
Они
фактически являются разностью
между средними числами, полученными
при выборочном статистическом
наблюдении, и аналогичными величинами,
которые были бы
получены при сплошном исследовании
того же объекта (т. е. при исследовании
генеральной совокупности).
Ошибки
репрезентативности вытекают из самой
сущности выборочного
исследования. С помощью ошибок
репрезентативности числовые характеристики
выборочной совокупности распространяются
на всю генеральную совокупность, то
есть она характеризуется с учетом
определенной погрешности. Величины
ошибок репрезентативности определяются
как объемом
выборки, так и разнообразием признака.
Чем больше число наблюдений,
тем меньше ошибка, чем больше изменчив
признак, тем больше
величина статистической ошибки.
На
практике для определения средней ошибки
выборки в статистических
исследованиях пользуются следующей
формулой:
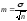
(где
m
— ошибка репрезентативности;
σ
— среднее квадратическое отклонение;
n
— число наблюдений в выборке (при числе
наблюдений менее 30
в подкоренное выражение вносится
значение п-1)).
Размер
средней ошибки прямо пропорционален
среднему квадратичному отклонению, т.
е. вариабельности изучаемого
признака, и обратно пропорционален
корню квадратному из
числа наблюдений
Билет 25
What Is the Standard Error?
The standard error (SE) of a statistic is the approximate standard deviation of a statistical sample population.
The standard error is a statistical term that measures the accuracy with which a sample distribution represents a population by using standard deviation. In statistics, a sample mean deviates from the actual mean of a population; this deviation is the standard error of the mean.
Key Takeaways
- The standard error (SE) is the approximate standard deviation of a statistical sample population.
- The standard error describes the variation between the calculated mean of the population and one which is considered known, or accepted as accurate.
- The more data points involved in the calculations of the mean, the smaller the standard error tends to be.
Standard Error
Understanding Standard Error
The term «standard error» is used to refer to the standard deviation of various sample statistics, such as the mean or median. For example, the «standard error of the mean» refers to the standard deviation of the distribution of sample means taken from a population. The smaller the standard error, the more representative the sample will be of the overall population.
The relationship between the standard error and the standard deviation is such that, for a given sample size, the standard error equals the standard deviation divided by the square root of the sample size. The standard error is also inversely proportional to the sample size; the larger the sample size, the smaller the standard error because the statistic will approach the actual value.
The standard error is considered part of inferential statistics. It represents the standard deviation of the mean within a dataset. This serves as a measure of variation for random variables, providing a measurement for the spread. The smaller the spread, the more accurate the dataset.
Standard error and standard deviation are measures of variability, while central tendency measures include mean, median, etc.
Formula and Calculation of Standard Error
The standard error of an estimate can be calculated as the standard deviation divided by the square root of the sample size:
SE = σ / √n
where
- σ = the population standard deviation
- √n = the square root of the sample size
If the population standard deviation is not known, you can substitute the sample standard deviation, s, in the numerator to approximate the standard error.
Requirements for Standard Error
When a population is sampled, the mean, or average, is generally calculated. The standard error can include the variation between the calculated mean of the population and one which is considered known, or accepted as accurate. This helps compensate for any incidental inaccuracies related to the gathering of the sample.
In cases where multiple samples are collected, the mean of each sample may vary slightly from the others, creating a spread among the variables. This spread is most often measured as the standard error, accounting for the differences between the means across the datasets.
The more data points involved in the calculations of the mean, the smaller the standard error tends to be. When the standard error is small, the data is said to be more representative of the true mean. In cases where the standard error is large, the data may have some notable irregularities.
The standard deviation is a representation of the spread of each of the data points. The standard deviation is used to help determine the validity of the data based on the number of data points displayed at each level of standard deviation. Standard errors function more as a way to determine the accuracy of the sample or the accuracy of multiple samples by analyzing deviation within the means.
Standard Error vs. Standard Deviation
The standard error normalizes the standard deviation relative to the sample size used in an analysis. Standard deviation measures the amount of variance or dispersion of the data spread around the mean. The standard error can be thought of as the dispersion of the sample mean estimations around the true population mean. As the sample size becomes larger, the standard error will become smaller, indicating that the estimated sample mean value better approximates the population mean.
Example of Standard Error
Say that an analyst has looked at a random sample of 50 companies in the S&P 500 to understand the association between a stock’s P/E ratio and subsequent 12-month performance in the market. Assume that the resulting estimate is -0.20, indicating that for every 1.0 point in the P/E ratio, stocks return 0.2% poorer relative performance. In the sample of 50, the standard deviation was found to be 1.0.
The standard error is thus:
SE = 1.0/√50 = 1/7.07 = 0.141
Therefore, we would report the estimate as -0.20% ± 0.14, giving us a confidence interval of (-0.34 — -0.06). The true mean value of the association of the P/E on returns of the S&P 500 would therefore fall within that range with a high degree of probability.
Say now that we increase the sample of stocks to 100 and find that the estimate changes slightly from -0.20 to -0.25, and the standard deviation falls to 0.90. The new standard error would thus be:
SE = 0.90/√100 = 0.90/10 = 0.09.
The resulting confidence interval becomes -0.25 ± 0.09 = (-0.34 — -0.16), which is a tighter range of values.
What Is Meant by Standard Error?
Standard error is intuitively the standard deviation of the sampling distribution. In other words, it depicts how much disparity there is likely to be in a point estimate obtained from a sample relative to the true population mean.
What Is a Good Standard Error?
Standard error measures the amount of discrepancy that can be expected in a sample estimate compared to the true value in the population. Therefore, the smaller the standard error the better. In fact, a standard error of zero (or close to it) would indicate that the estimated value is exactly the true value.
How Do You Find the Standard Error?
The standard error takes the standard deviation and divides it by the square root of the sample size. Many statistical software packages automatically compute standard errors.
The Bottom Line
The standard error (SE) measures the dispersion of estimated values obtained from a sample around the true value to be found in the population. Statistical analysis and inference often involves drawing samples and running statistical tests to determine associations and correlations between variables. The standard error thus tells us with what degree of confidence we can expect the estimated value to approximate the population value.
Основные выводы:
-
Стандартная ошибка среднего указывает, насколько среднее значение генеральной совокупности может отличаться от среднего выборочного.
-
Вы можете уменьшить стандартную ошибку, увеличив размер выборки.
-
Стандартная ошибка среднего и стандартное отклонение являются мерами изменчивости, используемыми для обобщения наборов данных.
Если вы собираете данные для научных или статистических целей, стандартная ошибка среднего может помочь вам определить, насколько точно набор данных представляет фактическую совокупность. Проверка точности вашего образца подтверждает ваше клиническое исследование и помогает вам сделать правильные выводы.
В этой статье мы определяем стандартную ошибку среднего, объясняем, как она отличается от стандартного отклонения, и предлагаем формулу для ее расчета.
Какова стандартная ошибка среднего?
Стандартная ошибка среднего (SEM) используется для определения различий между более чем одной выборкой данных. Это помогает вам оценить, насколько хорошо ваши выборочные данные представляют всю совокупность, измеряя точность, с которой выборочные данные представляют совокупность, используя стандартное отклонение.
В статистике, среднеквадратичное отклонение является мерой того, насколько разбросаны числа. Иметь в виду относится к среднему числу. Стандартные функции ошибок используются для проверки точности выборки из нескольких выборок путем анализа отклонений в пределах средних значений.
Высокая стандартная ошибка показывает, что средние значения выборки широко разбросаны по среднему значению генеральной совокупности, поэтому ваша выборка может не точно представлять вашу генеральную совокупность. Низкая стандартная ошибка показывает, что средние значения выборки близко распределены вокруг среднего значения совокупности, что означает, что ваша выборка репрезентативна для вашей совокупности. Вы можете уменьшить стандартную ошибку, увеличив размер выборки.
Например, если вы измерите вес большой выборки мужчин, их вес может варьироваться от 125 до более чем 300 фунтов. Однако, если вы посмотрите на среднее значение выборочных данных, образцы будут различаться всего на несколько фунтов. Затем вы можете использовать стандартную ошибку среднего, чтобы определить, насколько вес отличается от среднего.
Связанный: Как рассчитать стандартную ошибку в Excel (с советами)
Стандартная ошибка среднего по сравнению со стандартным отклонением
Стандартная ошибка среднего и стандартное отклонение являются мерами изменчивости, используемыми для суммирования наборов данных.
Стандартная ошибка среднего значенияСтандартное отклонениеОценивает изменчивость в нескольких выборках генеральной совокупностиОписывает изменчивость в пределах одной выборкиВыводная статистика, которую можно оценитьОписательная статистика, которую можно рассчитатьИзмеряет, насколько вероятно, что среднее значение выборки будет отличаться от фактического среднего значения в популяции. выборка отличается от фактического среднего значенияСтандартная ошибка — это стандартное отклонение, деленное на квадратный корень размера выборкиСтандартное отклонение — это квадратный корень из дисперсии
Стандартная ошибка средней формулы
Формула для стандартной ошибки среднего выражается как:
SE = σ/√n
-
SE = стандартная ошибка выборки
-
σ = стандартное отклонение выборки
-
n = размер выборки
Обратите внимание, что σ — это греческая буква сигма, а √ — символ квадратного корня.
Формула стандартного отклонения выборки выражается следующим образом:
-
x̄ = среднее значение выборки, сначала найдите это значение
-
xᵢ = отдельные значения x
-
x = значение в наборе данных
-
n = количество точек данных
-
Σ — это сигма-обозначение для суммирования
Вот шаги, которые вы можете использовать для расчета стандартной ошибки среднего, используя выборку из пяти результатов теста SAT. Сначала рассчитайте стандартное отклонение, а затем подставьте это значение в формулу SEM.
1. Рассчитайте среднее
Сложите все образцы вместе и разделите общую сумму на количество образцов.
Пример: пять общих баллов SAT: 1000 + 1200 + 820 + 1300 + 680 = 5000.
Среднее (мк) = 5000 / 5 = 1000
2. Рассчитать отклонение от среднего
Рассчитайте отклонение каждого измерения от среднего, вычитая отдельные измерения из среднего.
Пример. Вычтите средний балл SAT, равный 1000, из каждого балла SAT.
хᵢ — мю
1000 — 1000 = 0
1200 — 1000 = 200
820 — 1000 = -180
1300 — 1000 = 300
680 — 1000 = -320
3. Возведите в квадрат каждое отклонение от среднего
Вычислите квадрат отклонения каждого измерения от среднего. Измерения, которые были отрицательными, после возведения в квадрат станут положительными.
Пример: Найдите квадратный корень отклонения каждой оценки от среднего.
(xᵢ — μ)²
0² = 0
200² = 40000
-180² = 32400
300² = 90000
-320² = 102400
4. Рассчитайте сумму квадратов отклонений
Определить сумму квадратов отклонений, сложив все числа из третьего шага.
Пример: 0 + 10 + 40000 + 32400 + 90000 + 102400 = 264810 = Σ
5. Разделите эту сумму на количество точек данных.
Возьмите сумму, которую вы подсчитали на четвертом шаге, и разделите ее на единицу меньше размера выборки. Используя приведенную выше формулу, это будет выглядеть как n-1.
Пример: 264810 / (5-1) = 66202,5
6. Вычислить квадратный корень, чтобы найти стандартное отклонение
Возьмите квадратный корень из числа, которое вы вычислили на пятом шаге. Это даст вам стандартное отклонение.
Пример: σ = √ 66202,5 = 257,298
7. Разделите стандартное отклонение на квадратный корень из размера выборки.
Используя стандартное отклонение, которое вы определили на шестом шаге, разделите это число на квадратный корень из размера выборки. Это позволит вам определить стандартную ошибку.
Пример: SE = σ/√n
SE = 257,298/√5
SE = 115,067
8. Рассчитайте стандартную ошибку среднего
Вычтите из среднего значения стандартную ошибку и запишите это число. Это стандартная ошибка ниже среднего. Затем добавьте стандартную ошибку к среднему значению и запишите число. Это стандартная ошибка выше среднего.
Пример:
SE ниже среднего: 1000 — 115,067 = 884,933
SE выше среднего: 1000 + 115,067 = 1115,067
Стандартная ошибка среднего может быть представлена следующим образом:
Средний балл SAT случайной выборки испытуемых составляет 1000 ± 115,067.
Пример СЭМ
Чтобы понять силу информации, которую вы можете получить из случайной выборки, используя стандартную ошибку среднего, рассмотрим следующий пример.
Вам дан вес при рождении 17 000 детей, рожденных в больницах Нью-Йорка. Средний вес при рождении составлял семь фунтов и три унции, а стандартное отклонение — один фунт три унции. Допустим, вы хотели узнать средний вес при рождении в этом районе, но получили веса только 30 случайных рождений по сравнению с общей численностью населения. Если бы эта выборка была взята только из всего населения, то вам лучше всего было бы предположить, что средний вес при рождении в выборке также будет равен семи фунтам и трем унциям.
Это предположение вряд ли будет точным, поскольку среднее значение выборки из 30 не будет таким точным, как среднее значение выборки из 17 000. Если бы вы продолжали брать случайные выборки из 30, вполне вероятно, что среднее значение каждой из них несколько изменилось бы.
Поскольку стандартное отклонение генеральной совокупности обычно неизвестно, вам необходимо оценить его, используя стандартное отклонение выборки. Чтобы сделать это с некоторой точностью, ваша выборка должна иметь нормальное распределение и состоять как минимум из 20 измерений. Хотя оценка может быть не совсем точной даже при большой выборке, ошибки в выборочной оценке стандартного отклонения генеральной совокупности будут уменьшены, если вы разделите его на квадратный корень из размера выборки.
Допустим, у вас есть шесть случайных выборок из 30 масс при рождении со стандартными отклонениями 1,3 фунта, 1,16 фунта, 1,14 фунта, 1,2 фунта, 1,25 фунта и 1,19 фунта, что на 0,098 фунта отличается от истинного значения стандартного отклонения населения. Эти шесть образцов приводят к оценкам стандартной ошибки, которые находятся в пределах 0,017 фунта от истинного значения. Ошибки стандартной ошибки средних оценок меньше, чем ошибки оценок стандартного отклонения, а значит, они более точные. Если бы размер выборки был больше 30, стандартная ошибка среднего была бы еще больше уменьшена.
Стандартное отклонение (SD), измеряет количество изменчивости или дисперсии, из отдельных значений данных, к среднему значению, в то время как стандартная ошибка среднего (SEM) мер, как далеко образец среднее (среднее) данных, вероятно, будет от истинного среднего значения населения. SEM всегда меньше SD.
Ключевые выводы
- Стандартное отклонение (SD) измеряет разброс набора данных относительно его среднего значения.
- Стандартная ошибка среднего (SEM) измеряет, насколько вероятно расхождение между средним значением выборки по сравнению со средним значением генеральной совокупности.
- SEM берет SD и делит его на квадратный корень из размера выборки.
SEM против SD
Стандартное отклонение и стандартная ошибка используются во всех типах статистических исследований, включая исследования в области финансов, медицины, биологии, инженерии, психологии и т. Д. В этих исследованиях стандартное отклонение (SD) и расчетная стандартная ошибка среднего (SEM) ) используются для представления характеристик данных выборки и объяснения результатов статистического анализа. Однако некоторые исследователи иногда путают SD и SEM. Таким исследователям следует помнить, что расчеты SD и SEM включают разные статистические выводы, каждый из которых имеет свое значение. SD — это разброс отдельных значений данных.
Другими словами, SD указывает, насколько точно среднее значение представляет данные выборки. Однако значение SEM включает статистический вывод, основанный на распределении выборки. SEM — это стандартное отклонение теоретического распределения выборочных средних (выборочное распределение).
Расчет стандартного отклонения

Формула SD требует нескольких шагов:
- Во-первых, возьмите квадрат разницы между каждой точкой данных и средним значением выборки, найдя сумму этих значений.
- Затем разделите эту сумму на размер выборки минус один, который представляет собой дисперсию.
- Наконец, извлеките квадратный корень из дисперсии, чтобы получить стандартное отклонение.
Стандартная ошибка среднего
SEM рассчитывается путем деления стандартного отклонения на квадратный корень из размера выборки.
Стандартная ошибка дает точность выборочного среднего путем измерения изменчивости выборочного среднего от образца к образцу. SEM описывает, насколько точное среднее значение выборки является оценкой истинного среднего значения совокупности. По мере увеличения размера выборки данных SEM уменьшается по сравнению с SD; следовательно, по мере увеличения размера выборки среднее значение выборки оценивает истинное среднее значение генеральной совокупности с большей точностью. Напротив, увеличение размера выборки не обязательно делает SD больше или меньше, это просто становится более точной оценкой SD населения.
Стандартная ошибка и стандартное отклонение в финансах
В финансах стандартная ошибка средней дневной доходности актива измеряет точность выборочного среднего как оценки долгосрочной (постоянной) средней дневной доходности актива.
С другой стороны, стандартное отклонение доходности измеряет отклонения индивидуальных доходов от среднего значения. Таким образом, SD является мерой волатильности и может использоваться в качестве меры риска для инвестиций. Активы с более высокими ежедневными движениями цен имеют более высокое SD, чем активы с меньшими ежедневными движениями. Предполагая нормальное распределение, около 68% дневных изменений цен находятся в пределах одного стандартного отклонения от среднего, при этом около 95% дневных изменений цен находятся в пределах двух стандартных значений среднего.