
Уровень сложности
Средний
Время на прочтение
8 мин
Количество просмотров 6.8K

Люди, которые пишут код, часто воспринимают работу с исключениями как необходимое зло. Но освоение системы обработки исключений в Python способно повысить профессиональный уровень программиста, сделать его эффективнее. В этом материале я разберу следующие темы, изучение которых поможет всем желающим раскрыть потенциал Python через разумный подход к обработке исключений:
-
Что такое обработка исключений?
-
Разница между оператором
ifи обработкой исключений. -
Использование разделов
elseиfinallyблокаtry-exceptдля организации правильного обращения с ошибками. -
Определение пользовательских исключений.
-
Рекомендации по обработке исключений.
Что такое обработка исключений?
Обработка исключений — это процесс написания кода для перехвата и обработки ошибок или исключений, которые могут возникать при выполнении программы. Это позволяет разработчикам создавать надёжные программы, которые продолжают работать даже при возникновении неожиданных событий или ошибок. Без системы обработки исключений подобное обычно приводит к фатальным сбоям.
Когда возникают исключения — Python выполняет поиск подходящего обработчика исключений. После этого, если обработчик будет найден, выполняется его код, в котором предпринимаются уместные действия. Это может быть логирование данных, вывод сообщения, попытка восстановить работу программы после возникновения ошибки. В целом можно сказать, что обработка исключения помогает повысить надёжность Python-приложений, улучшает возможности по их поддержке, облегчает их отладку.
Различия между оператором if и обработкой исключений
Главные различия между оператором if и обработкой исключений в Python произрастают из их целей и сценариев использования.
Оператор if — это базовый строительный элемент структурного программирования. Этот оператор проверяет условие и выполняет различные блоки кода, основываясь на том, истинно проверяемое условие или ложно. Вот пример:
temperature = int(input("Please enter temperature in Fahrenheit: "))
if temperature > 100:
print("Hot weather alert! Temperature exceeded 100°F.")
elif temperature >= 70:
print("Warm day ahead, enjoy sunny skies.")
else:
print("Bundle up for chilly temperatures.")Обработка исключений, с другой стороны, играет важную роль в написании надёжных и отказоустойчивых программ. Эта роль раскрывается через работу с неожиданными событиями и ошибками, которые могут возникать во время выполнения программы.
Исключения используются для подачи сигналов о проблемах и для выявления участков кода, которые нуждаются в улучшении, отладке, или в оснащении их дополнительными механизмами для проверки ошибок. Исключения позволяют Python достойно справляться с ситуациями, в которых возникают ошибки. В таких ситуациях исключения дают возможность продолжать выполнение скрипта вместо того, чтобы резко его останавливать.
Рассмотрим следующий код, демонстрирующий пример того, как можно реализовать обработку исключений и улучшить ситуацию с потенциальными отказами, связанными с делением на ноль:
# Определение функции, которая пытается поделить число на ноль
def divide(x, y):
result = x / y
return result
# Вызов функции divide с передачей ей x=5 и y=0
result = divide(5, 0)
print(f"Result of dividing {x} by {y}: {result}")Вывод:
Traceback (most recent call last):
File "<stdin>", line 8, in <module>
ZeroDivisionError: division by zero attemptedПосле того, как было сгенерировано исключение, программа, не дойдя до инструкции print, сразу же прекращает выполняться.
Вышеописанное исключение можно обработать, обернув вызов функции divide в блок try-except:
# Определение функции, которая пытается поделить число на ноль
def divide(x, y):
result = x / y
return result
# Вызов функции divide с передачей ей x=5 и y=0
try:
result = divide(5, 0)
print(f"Result of dividing {x} by {y}: {result}")
except ZeroDivisionError:
print("Cannot divide by zero.")Вывод:
Cannot divide by zero.Сделав это, мы аккуратно обработали исключение ZeroDivisionError, предотвратили аварийное завершение остального кода из-за необработанного исключения.
Подробности о других встроенных Python-исключениях можно найти здесь.
Использование разделов else и finally блока try-except для организации правильного обращения с ошибками
При работе с исключениями в Python рекомендуется включать в состав блоков try-except и раздел else, и раздел finally. Раздел else позволяет программисту настроить действия, производимые в том случае, если при выполнении кода, который защищают от проблем, не было вызвано исключений. А раздел finally позволяет обеспечить обязательное выполнение неких заключительных операций, вроде освобождения ресурсов, независимо от факта возникновения исключений (вот и вот — полезные материалы об этом).
Например — рассмотрим ситуацию, когда нужно прочитать данные из файла и выполнить какие-то действия с этими данными. Если при чтении файла возникнет исключение — программист может решить, что надо залогировать ошибку и остановить выполнение дальнейших операций. Но в любом случае файл нужно правильно закрыть.
Использование разделов else и finally позволяет поступить именно так — обработать данные обычным образом в том случае, если исключений не возникло, либо обработать любые исключения, но, как бы ни развивались события, в итоге закрыть файл. Без этих разделов код страдал бы уязвимостями в виде утечки ресурсов или неполной обработки ошибок. В результате оказывается, что else и finally играют важнейшую роль в создании устойчивых к ошибкам и надёжных программ.
try:
# Открытие файла в режиме чтения
file = open("file.txt", "r")
print("Successful opened the file")
except FileNotFoundError:
# Обработка ошибки, возникающей в том случае, если файл не найден
print("File Not Found Error: No such file or directory")
exit()
except PermissionError:
# Обработка ошибок, связанных с разрешением на доступ к файлу
print("Permission Denied Error: Access is denied")
else:
# Всё хорошо - сделать что-то с данными, прочитанными из файла
content = file.read().decode('utf-8')
processed_data = process_content(content)
# Прибираемся после себя даже в том случае, если выше возникло исключение
finally:
file.close()В этом примере мы сначала пытаемся открыть файл file.txt для чтения (в подобной ситуации можно использовать выражение with, которое гарантирует правильное автоматическое закрытие объекта файла после завершения работы). Если в процессе выполнения операций файлового ввода/вывода возникают ошибки FileNotFoundError или PermissionError — выполняются соответствующие разделы except. Здесь, ради простоты, мы лишь выводим на экран сообщения об ошибках и выходим из программы в том случае, если файл не найден.
В противном случае, если в блоке try исключений не возникло, мы продолжаем работу, обрабатывая содержимое файла в ветви else. И наконец — выполняется «уборка» — файл закрывается независимо от возникновения исключения. Это обеспечивает блок finally (подробности смотрите здесь).
Применяя структурированный подход к обработке исключений, напоминающий вышеописанный, можно поддерживать свой код в хорошо организованном состоянии и обеспечивать его читабельность. При этом код будет рассчитан на борьбу с потенциальными ошибками, которые могут возникнуть при взаимодействии с внешними системами или входными данными.
Определение пользовательских исключений
В Python можно определять пользовательские исключения путём создания подклассов встроенного класса Exception или любых других классов, являющихся прямыми наследниками Exception.
Для того чтобы определить собственное исключение — нужно создать новый класс, являющийся наследником одного из подходящих классов, и оснастить этот класс атрибутами, соответствующими нуждам программиста. Затем новый класс можно использовать в собственном коде, работая с ним так же, как работают со встроенными классами исключений.
Вот пример определения пользовательского исключения, названного InvalidEmailAddress:
class InvalidEmailAddress(ValueError):
def __init__(self, message):
super().__init__(message)
self.msgfmt = messageЭто исключение является наследником ValueError. Его конструктор принимает необязательный аргумент message (по умолчанию он устанавливается в значение invalid email address).
Вызвать это исключение можно в том случае, если в программе встретился адрес электронной почты, имеющий некорректный формат:
def send_email(address):
if isinstance(address, str) == False:
raise InvalidEmailAddress("Invalid email address")
# Отправка электронного письмаТеперь, если функции send_email() будет передана строка, содержащая неправильно оформленный адрес, то, вместо сообщения стандартной ошибки TypeError, будет выдано настроенное заранее сообщение об ошибке, которое чётко указывает на возникшую проблему. Например, это может выглядеть так:
>>> send_email(None)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/path/to/project/main.py", line 8, in send_email
raise InvalidEmailAddress("Invalid email address")
InvalidEmailAddress: Invalid email addressРекомендации по обработке исключений
Вот несколько рекомендаций, относящихся к обработке ошибок в Python:
-
Проектируйте код в расчёте на возможное возникновение ошибок. Заранее планируйте устройство кода с учётом возможных сбоев и проектируйте программы так, чтобы они могли бы достойно обрабатывать эти сбои. Это означает — предугадывать возможные пограничные случаи и реализовывать подходящие обработчики ошибок.
-
Используйте содержательные сообщения об ошибках. Сделайте так, чтобы программа выводила бы, на экран, или в файл журнала, подробные сообщения об ошибках, которые помогут пользователям понять — что и почему пошло не так. Старайтесь не применять обобщённые сообщения об ошибках, наподобие
Error occurredилиSomething bad happened. Вместо этого подумайте об удобстве пользователя и покажите сообщение, в котором будет дан совет по решению проблемы или будет приведена ссылка на документацию. Постарайтесь соблюсти баланс между выводом подробных сообщений и перегрузкой пользовательского интерфейса избыточными данными. -
Минимизируйте побочные эффекты. Постарайтесь свести к минимуму последствия сбойных операций, изолируя проблемные разделы кода посредством конструкции
try-finallyилиtryс использованиемwith. Сделайте так, чтобы после выполнения кода, было ли оно удачным или нет, обязательно выполнялись бы «очистительные» операции. -
Тщательно тестируйте код. Обеспечьте корректное поведение обработчиков ошибок в различных сценариях использования программы, подвергнув код всеобъемлющему тестированию.
-
Регулярно выполняйте рефакторинг кода. Выполняйте рефакторинг фрагментов кода, подверженных ошибкам, чтобы улучшить их надёжность и производительность. Постарайтесь, чтобы ваша кодовая база была бы устроена по модульному принципу, чтобы её отдельные части слабо зависели бы друг от друга. Это позволяет независимым частям код самостоятельно эволюционировать, не оказывая негативного воздействия на другие его части.
-
Логируйте важные события. Следите за интересными событиями своего приложения, записывая сведения о них в файл журнала или выводя в консоль. Это поможет вам выявлять проблемы на ранних стадиях их возникновения, не тратя время на длительный анализ большого количества неструктурированных логов.
Итоги
Написание кода обработки ошибок — это неотъемлемая часть индустрии разработки ПО, и, в частности — разработки на Python. Это позволяет разработчикам создавать более надёжные и стабильные программы. Следуя индустриальным стандартам и рекомендациям по обработке исключений, разработчик может сократить время, необходимое на отладку кода, способен обеспечить написание качественных программ и сделать так, чтобы пользователям было бы приятно работать с этими программами.
О, а приходите к нам работать? 🤗 💰
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
Присоединяйтесь к нашей команде.
В C++ различают ошибки времени компиляции и ошибки времени выполнения. Ошибки первого типа обнаруживает компилятор до запуска программы. К ним относятся, например, синтаксические ошибки в коде. Ошибки второго типа проявляются при запуске программы. Примеры ошибок времени выполнения: ввод некорректных данных, некорректная работа с памятью, недостаток места на диске и т. д. Часто такие ошибки могут привести к неопределённому поведению программы.
Некоторые ошибки времени выполнения можно обнаружить заранее с помощью проверок в коде. Например, такими могут быть ошибки, нарушающие инвариант класса в конструкторе. Обычно, если ошибка обнаружена, то дальнейшее выполение функции не имеет смысла, и нужно сообщить об ошибке в то место кода, откуда эта функция была вызвана. Для этого предназначен механизм исключений.
Коды возврата и исключения
Рассмотрим функцию, которая считывает со стандартного потока возраст и возвращает его вызывающей стороне. Добавим в функцию проверку корректности возраста: он должен находиться в диапазоне от 0 до 128 лет. Предположим, что повторный ввод возраста в случае ошибки не предусмотрен.
int ReadAge() {
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
// Что вернуть в этом случае?
}
return age;
}
Что вернуть в случае некорректного возраста? Можно было бы, например, договориться, что в этом случае функция возвращает ноль. Но тогда похожая проверка должна быть и в месте вызова функции:
int main() {
if (int age = ReadAge(); age == 0) {
// Произошла ошибка
} else {
// Работаем с возрастом age
}
}
Такая проверка неудобна. Более того, нет никакой гарантии, что в вызывающей функции программист вообще её напишет. Фактически мы тут выбрали некоторое значение функции (ноль), обозначающее ошибку. Это пример подхода к обработке ошибок через коды возврата. Другим примером такого подхода является хорошо знакомая нам функция main. Только она должна возвращать ноль при успешном завершении и что-либо ненулевое в случае ошибки.
Другим способом сообщить об обнаруженной ошибке являются исключения. С каждым сгенерированным исключением связан некоторый объект, который как-то описывает ошибку. Таким объектом может быть что угодно — даже целое число или строка. Но обычно для описания ошибки заводят специальный класс и генерируют объект этого класса:
#include <iostream>
struct WrongAgeException {
int age;
};
int ReadAge() {
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
throw WrongAgeException(age);
}
return age;
}
Здесь в случае ошибки оператор throw генерирует исключение, которое представлено временным объектом типа WrongAgeException. В этом объекте сохранён для контекста текущий неправильный возраст age. Функция досрочно завершает работу: у неё нет возможности обработать эту ошибку, и она должна сообщить о ней наружу. Поток управления возвращается в то место, откуда функция была вызвана. Там исключение может быть перехвачено и обработано.
Перехват исключения
Мы вызывали нашу функцию ReadAge из функции main. Обработать ошибку в месте вызова можно с помощью блока try/catch:
int main() {
try {
age = ReadAge(); // может сгенерировать исключение
// Работаем с возрастом age
} catch (const WrongAgeException& ex) { // ловим объект исключения
std::cerr << "Age is not correct: " << ex.age << "n";
return 1; // выходим из функции main с ненулевым кодом возврата
}
// ...
}
Мы знаем заранее, что функция ReadAge может сгенерировать исключение типа WrongAgeException. Поэтому мы оборачиваем вызов этой функции в блок try. Если происходит исключение, для него подбирается подходящий catch-обработчик. Таких обработчиков может быть несколько. Можно смотреть на них как на набор перегруженных функций от одного аргумента — объекта исключения. Выбирается первый подходящий по типу обработчик и выполняется его код. Если же ни один обработчик не подходит по типу, то исключение считается необработанным. В этом случае оно пробрасывается дальше по стеку — туда, откуда была вызвана текущая функция. А если обработчик не найдётся даже в функции main, то программа аварийно завершается.
Усложним немного наш пример, чтобы из функции ReadAge могли вылетать исключения разных типов. Сейчас мы проверяем только значение возраста, считая, что на вход поступило число. Но предположим, что поток ввода досрочно оборвался, или на входе была строка вместо числа. В таком случае конструкция std::cin >> age никак не изменит переменную age, а лишь возведёт специальный флаг ошибки в объекте std::cin. Наша переменная age останется непроинициализированной: в ней будет лежать неопределённый мусор. Можно было бы явно проверить этот флаг в объекте std::cin, но мы вместо этого включим режим генерации исключений при таких ошибках ввода:
int ReadAge() {
std::cin.exceptions(std::istream::failbit);
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
throw WrongAgeException(age);
}
return age;
}
Теперь ошибка чтения в операторе >> у потока ввода будет приводить к исключению типа std::istream::failure. Функция ReadAge его не обрабатывает. Поэтому такое исключение покинет пределы этой функции. Поймаем его в функции main:
int main() {
try {
age = ReadAge(); // может сгенерировать исключения разных типов
// Работаем с возрастом age
} catch (const WrongAgeException& ex) {
std::cerr << "Age is not correct: " << ex.age << "n";
return 1;
} catch (const std::istream::failure& ex) {
std::cerr << "Failed to read age: " << ex.what() << "n";
return 1;
} catch (...) {
std::cerr << "Some other exceptionn";
return 1;
}
// ...
}
При обработке мы воспользовались функцией ex.what у исключения типа std::istream::failure. Такие функции есть у всех исключений стандартной библиотеки: они возвращают текстовое описание ошибки.
Обратите внимание на третий catch с многоточием. Такой блок, если он присутствует, будет перехватывать любые исключения, не перехваченные ранее.
Исключения стандартной библиотеки
Функции и классы стандартной библиотеки в некоторых ситуациях генерируют исключения особых типов. Все такие типы выстроены в иерархию наследования от базового класса std::exception. Иерархия классов позволяет писать обработчик catch сразу на группу ошибок, которые представлены базовым классом: std::logic_error, std::runtime_error и т. д.
Вот несколько примеров:
-
Функция
atу контейнеровstd::array,std::vectorиstd::dequeгенерирует исключениеstd::out_of_rangeпри некорректном индексе. -
Аналогично, функция
atуstd::map,std::unordered_mapи у соответствующих мультиконтейнеров генерирует исключениеstd::out_of_rangeпри отсутствующем ключе. -
Обращение к значению у пустого объекта
std::optionalприводит к исключениюstd::bad_optional_access. -
Потоки ввода-вывода могут генерировать исключение
std::ios_base::failure.
Исключения в конструкторах
В главе 3.1 мы написали класс Time. Этот класс должен был соблюдать инвариант на значение часов, минут и секунд: они должны были быть корректными. Если на вход конструктору класса Time передавались некорректные значения, мы приводили их к корректным, используя деление с остатком.
Более правильным было бы сгенерировать в конструкторе исключение. Таким образом мы бы явно передали сообщение об ошибке во внешнюю функцию, которая пыталась создать объект.
class Time {
private:
int hours, minutes, seconds;
public:
// Заведём класс для исключения и поместим его внутрь класса Time как в пространство имён
class IncorrectTimeException {
};
Time::Time(int h, int m, int s) {
if (s < 0 || s > 59 || m < 0 || m > 59 || h < 0 || h > 23) {
throw IncorrectTimeException();
}
hours = h;
minutes = m;
seconds = s;
}
// ...
};
Генерировать исключения в конструкторах — совершенно нормальная практика. Однако не следует допускать, чтобы исключения покидали пределы деструкторов. Чтобы понять причины, посмотрим подробнее, что происходит при генерации исключения.
Свёртка стека
Вспомним класс Logger из предыдущей главы. Посмотрим, как он ведёт себя при возникновении исключения. Воспользуемся в этом примере стандартным базовым классом std::exception, чтобы не писать свой класс исключения.
#include <exception>
#include <iostream>
void f() {
std::cout << "Welcome to f()!n";
Logger x;
// ...
throw std::exception(); // в какой-то момент происходит исключение
}
int main() {
try {
Logger y;
f();
} catch (const std::exception&) {
std::cout << "Something happened...n";
return 1;
}
}
Мы увидим такой вывод:
Logger(): 1 Welcome to f()! Logger(): 2 ~Logger(): 2 ~Logger(): 1 Something happened...
Сначала создаётся объект y в блоке try. Затем мы входим в функцию f. В ней создаётся объект x. После этого происходит исключение. Мы должны досрочно покинуть функцию. В этот момент начинается свёртка стека (stack unwinding): вызываются деструкторы для всех созданных объектов в самой функции и в блоке try, как если бы они вышли из своей области видимости. Поэтому перед обработчиком исключения мы видим вызов деструктора объекта x, а затем — объекта y.
Аналогично, свёртка стека происходит и при генерации исключения в конструкторе. Напишем класс с полем Logger и сгенерируем нарочно исключение в его конструкторе:
#include <exception>
#include <iostream>
class C {
private:
Logger x;
public:
C() {
std::cout << "C()n";
Logger y;
// ...
throw std::exception();
}
~C() {
std::cout << "~C()n";
}
};
int main() {
try {
C c;
} catch (const std::exception&) {
std::cout << "Something happened...n";
}
}
Вывод программы:
Logger(): 1 // конструктор поля x C() Logger(): 2 // конструктор локальной переменной y ~Logger(): 2 // свёртка стека: деструктор y ~Logger(): 1 // свёртка стека: деструктор поля x Something happened...
Заметим, что деструктор самого класса C не вызывается, так как объект в конструкторе не был создан.
Механизм свёртки стека гарантирует, что деструкторы для всех созданных автоматических объектов или полей класса в любом случае будут вызваны. Однако он полагается на важное свойство: деструкторы самих классов не должны генерировать исключений. Если исключение в деструкторе произойдёт в момент свёртки стека при обработке другого исключения, то программа аварийно завершится.
Пример с динамической памятью
Подчеркнём, что свёртка стека работает только с автоматическими объектами. В этом нет ничего удивительного: ведь за временем жизни объектов, созданных в динамической памяти, программист должен следить самостоятельно. Исключения вносят дополнительные сложности в ручное управление динамическими объектами:
void f() {
Logger* ptr = new Logger(); // конструируем объект класса Logger в динамической памяти
// ...
g(); // вызываем какую-то функцию
// ...
delete ptr; // вызываем деструктор и очищаем динамическую память
}
На первый взгляд кажется, что в этом коде нет ничего опасного: delete вызывается в конце функции. Однако функция g может сгенерировать исключение. Мы не перехватываем его в нашей функции f. Механизм свёртки уберёт со стека лишь сам указатель ptr, который является автоматической переменной примитивного типа. Однако он ничего не сможет сделать с объектом в памяти, на которую ссылается этот указатель. В логе мы увидим только вызов конструктора класса Logger, но не увидим вызова деструктора. Нам придётся обработать исключение вручную:
void f() {
Logger* ptr = new Logger();
// ...
try {
g();
} catch (...) { // ловим любое исключение
delete ptr; // вручную удаляем объект
throw; // перекидываем объект исключения дальше
}
// ...
delete ptr;
}
Здесь мы перехватываем любое исключение и частично обрабатываем его, удаляя объект в динамической памяти. Затем мы прокидываем текущий объект исключения дальше с помощью оператора throw без аргументов.
Согласитесь, этот код очень далёк от совершенства. При непосредственной работе с объектами в динамической памяти нам приходится оборачивать в try/catch любую конструкцию, из которой может вылететь исключение. Понятно, что такой код чреват ошибками. В главе 3.6 мы узнаем, как с точки зрения C++ следует работать с такими ресурсами, как память.
Гарантии безопасности исключений
Предположим, что мы пишем свой класс-контейнер, похожий на двусвязный список. Наш контейнер позволяет добавлять элементы в хранилище и отдельно хранит количество элементов в некотором поле elementsCount. Один из инвариантов этого класса такой: значение elementsCount равно реальному числу элементов в хранилище.
Не вдаваясь в детали, давайте посмотрим, как могла бы выглядеть функция добавления элемента.
template <typename T>
class List {
private:
struct Node { // узел двусвязного списка
T element;
Node* prev = nullptr; // предыдущий узел
Node* next = nullptr; // следующий узел
};
Node* first = nullptr; // первый узел списка
Node* last = nullptr; // последний узел списка
int elementsCount = 0;
public:
// ...
size_t Size() const {
return elementsCount;
}
void PushBack(const T& elem) {
++elementsCount;
// Конструируем в динамической памяти новой узел списка
Node* node = new Node(elem, last, nullptr);
// Связываем новый узел с остальными узлами
if (last != nullptr) {
last->next = node;
} else {
first = node;
}
last = node;
}
};
Не будем здесь рассматривать другие функции класса — конструкторы, деструктор, оператор присваивания… Рассмотрим функцию PushBack. В ней могут произойти такие исключения:
-
Выражение
newможет сгенерировать исключениеstd::bad_allocиз-за нехватки памяти. -
Конструктор копирования класса
Tможет сгенерировать произвольное исключение. Этот конструктор вызывается при инициализации поляelementсоздаваемого узла в конструкторе классаNode. В этом случаеnewведёт себя как транзакция: выделенная перед этим динамическая память корректно вернётся системе.
Эти исключения не перехватываются в функции PushBack. Их может перехватить код, из которого PushBack вызывался:
#include <iostream>
class C; // какой-то класс
int main() {
List<C> data;
C element;
try {
data.PushBack(element);
} catch (...) { // не получилось добавить элемент
std::cout << data.Size() << "n"; // внезапно 1, а не 0
}
// работаем дальше с data
}
Наша функция PushBack сначала увеличивает счётчик элементов, а затем выполняет опасные операции. Если происходит исключение, то в классе List нарушается инвариант: значение счётчика elementsCount перестаёт соответствовать реальности. Можно сказать, что функция PushBack не даёт гарантий безопасности.
Всего выделяют четыре уровня гарантий безопасности исключений (exception safety guarantees):
-
Гарантия отсутствия сбоев. Функции с такими гарантиями вообще не выбрасывают исключений. Примерами могут служить правильно написанные деструктор и конструктор перемещения, а также константные функции вида
Size. -
Строгая гарантия безопасности. Исключение может возникнуть, но от этого объект нашего класса не поменяет состояние: количество элементов останется прежним, итераторы и ссылки не будут инвалидированы и т. д.
-
Базовая гарантия безопасности. При исключении состояние объекта может поменяться, но оно останется внутренне согласованным, то есть, инварианты будут соблюдаться.
-
Отсутсвие гарантий. Это довольно опасная категория: при возникновении исключений могут нарушаться инварианты.
Всегда стоит разрабатывать классы, обеспечивающие хотя бы базовую гарантию безопасности. При этом не всегда возможно эффективно обеспечить строгую гарантию.
Переместим в нашей функции PushBack изменение счётчика в конец:
void PushBack(const T& elem) {
Node* node = new Node(elem, last, nullptr);
if (last != nullptr) {
last->next = node;
} else {
first = node;
}
last = node;
++elementsCount; // выполнится только если раньше не было исключений
}
Теперь такая функция соответствует строгой гарантии безопасности.
В документации функций из классов стандартной библиотеки обычно указано, какой уровень гарантии они обеспечивают. Рассмотрим, например, гарантии безопасности класса std::vector.
-
Деструктор, функции
empty,size,capacity, а такжеclearпредоставляют гарантию отсутствия сбоев. -
Функции
push_backиresizeпредоставляют строгую гарантию. -
Функция
insertпредоставляет лишь базовую гарантию. Можно было бы сделать так, чтобы она предоставляла строгую гарантию, но за это пришлось бы заплатить её эффективностью: при вставке в середину вектора пришлось бы делать реаллокацию.
Функции класса, которые гарантируют отсутсвие сбоев, следует помечать ключевым словом noexcept:
class C {
public:
void f() noexcept {
// ...
}
};
С одной стороны, эта подсказка позволяет компилятору генерировать более эффективный код. С другой — эффективно обрабатывать объекты таких классов в стандартных контейнерах. Например, std::vector<C> при реаллокации будет использовать конструктор перемещения класса C, если он помечен как noexcept. В противном случае будет использован конструктор копирования, который может быть менее эффективен, но зато позволит обеспечить строгую гарантию безопасности при реаллокации.
Исключение (exception) — это ненормальная ситуация (термин «исключение» здесь следует понимать как «исключительная ситуация»), возникающая во время выполнения программного кода. Иными словами, исключение — это ошибка, возникающая во время выполнения программы (в runtime).
Исключение — это способ системы Java (в частности, JVM — виртуальной машины Java) сообщить вашей программе, что в коде произошла ошибка. К примеру, это может быть деление на ноль, попытка обратиться к массиву по несуществующему индексу, очень распространенная ошибка нулевого указателя (NullPointerException) — когда вы обращаетесь к ссылочной переменной, у которой значение равно null и так далее.
В любом случае, с формальной точки зрения, Java не может продолжать выполнение программы.
Обработка исключений (exception handling) — название объектно-ориентированной техники, которая пытается разрешить эти ошибки.
Программа в Java может сгенерировать различные исключения, например:
-
программа может пытаться прочитать файл из диска, но файл не существует;
-
программа может попытаться записать файл на диск, но диск заполнен или не отформатирован;
-
программа может попросить пользователя ввести данные, но пользователь ввел данные неверного типа;
-
программа может попытаться осуществить деление на ноль;
-
программа может попытаться обратиться к массиву по несуществующему индексу.
Используя подсистему обработки исключений Java, можно управлять реакцией программы на появление ошибок во время выполнения. Средства обработки исключений в том или ином виде имеются практически во всех современных языках программирования. В Java подобные инструменты отличаются большей гибкостью, понятнее и удобнее в применении по сравнению с большинством других языков программирования.
Преимущество обработки исключений заключается в том, что она предусматривает автоматическую реакцию на многие ошибки, избавляя от необходимости писать вручную соответствующий код.
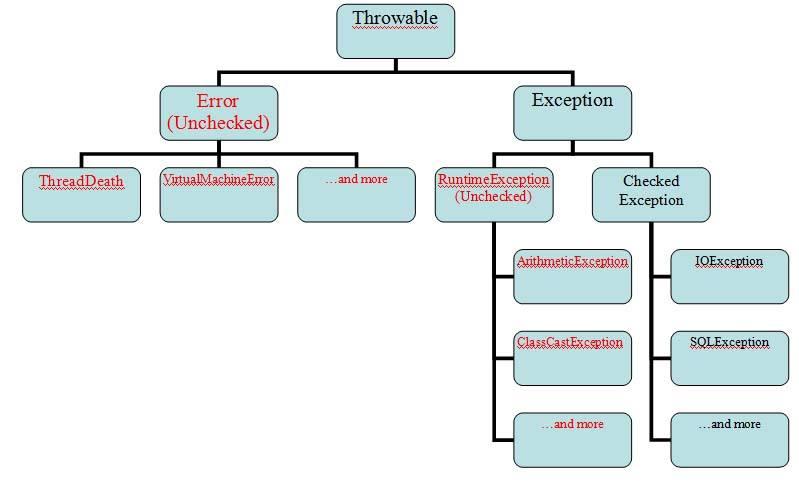
В Java все исключения представлены отдельными классами. Все классы исключений являются потомками класса Throwable. Так, если в программе возникнет исключительная ситуация, будет сгенерирован объект класса, соответствующего определенному типу исключения. У класса Throwable имеются два непосредственных подкласса: Exception и Error.
Исключения типа Error относятся к ошибкам, возникающим в виртуальной машине Java, а не в прикладной программе. Контролировать такие исключения невозможно, поэтому реакция на них в приложении, как правило, не предусматривается. В связи с этим исключения данного типа не будут рассматриваться в книге.
Ошибки, связанные с работой программы, представлены отдельными подклассами, производными от класса Exception. В частности, к этой категории относятся ошибки деления на нуль, выхода за пределы массива и обращения к файлам. Подобные ошибки следует обрабатывать в самой программе. Важным подклассом, производным от Exception, является класс RuntimeException, который служит для представления различных видов ошибок, часто возникающих во время выполнения программ.
Каждой исключительной ситуации поставлен в соответствие некоторый класс. Если подходящего класса не существует, то он может быть создан разработчиком.
Так как в Java ВСЁ ЯВЛЯЕТСЯ ОБЪЕКТОМ, то исключение тоже является объектом некоторого класса, который описывает исключительную ситуацию, возникающую в определенной части программного кода.
«Обработка исключений» работает следующим образом:
-
когда возникает исключительная ситуация, JVM генерирует (говорят, что JVM ВЫБРАСЫВАЕТ исключение, для описания этого процесса используется ключевое слово
throw) объект исключения и передает его в метод, в котором произошло исключение; -
вы можете перехватить исключение (используется ключевое слово
catch), чтобы его каким-то образом обработать. Для этого, необходимо определить специальный блок кода, который называется обработчиком исключений, этот блок будет выполнен при возникновении исключения, код должен содержать реакцию на исключительную ситуацию; -
таким образом, если возникнет ошибка, все необходимые действия по ее обработке выполнит обработчик исключений.
Если вы не предусмотрите обработчик исключений, то исключение будет перехвачено стандартным обработчиком Java. Стандартный обработчик прекратит выполнение программы и выведет сообщение об ошибке.
Рассмотрим пример исключения и реакцию стандартного обработчика Java.
public static void main(String[] args) {
System.out.println(5 / 0);
Мы видим, что стандартный обработчик вывел в консоль сообщение об ошибке. Давайте разберемся с содержимым этого сообщения:
«C:Program FilesJavajdk1.8.0_60binjava»…
Exception in thread «main» java.lang.ArithmeticException: / by zero
at ua.opu.Main.main(Main.java:6)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
Process finished with exit code 1
Exception in thread «main» java.lang.ArithmeticException: / by zero
сообщает нам тип исключения, а именно класс ArithmeticException (про классы исключений мы будем говорить позже), после чего сообщает, какая именно ошибка произошла. В нашем случае это деление на ноль.
at ua.opu.Main.main(Main.java:6)
в каком классе, методе и строке произошло исключение. Используя эту информацию, мы можем найти ту строчку кода, которая привела к исключительной ситуации, и предпринять какие-то действия. Строки
at ua.opu.Main.main(Main.java:6)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
называются «трассировкой стека» (stack tracing). О каком стеке идет речь? Речь идет о стеке вызовов (call stack). Соответственно, эти строки означают последовательность вызванных методов, начиная от метода, в котором произошло исключение, заканчивая самым первым вызванным методом.
Для вызова методов в программе используется инструкция «call». Когда вы вызываете метод в программе, важно сохранить адрес следующей инструкции, чтобы, когда вызванный метод отработал, программа продолжила работу со следующей инструкции. Этот адрес нужно где-то хранить в памяти. Также перед вызовом необходимо сохранить аргументы функции, которые тоже необходимо где-то хранить.
Вся эта информация хранится в специальной структуре – стеке вызовов. Каждая запись в стеке вызовов называется кадром или фреймом (stack frame).
Таким образом, зная, какая строка привела к возникновению исключения, вы можете изменить код либо предусмотреть обработчик событий.
Как уже было сказано выше, исключение это объект некоторого класса. В Java существует разветвленная иерархия классов исключений.
В Java, класс исключения служит для описания типа исключения. Например, класс NullPointerException описывает исключение нулевого указателя, а FileNotFoundException означает исключение, когда файл, с которым пытается работать приложение, не найден. Рассмотрим иерархию классов исключений:

На самом верхнем уровне расположен класс Throwable, который является базовым для всех исключений (как мы помним, JVM «выбрасывает» исключение», поэтому класс Throwable означает – то, что может «выбросить» JVM).
От класса Throwable наследуются классы Error и Exception. Среди подклассов Exception отдельно выделен класс RuntimeException, который играет важную роль в иерархии исключений.
В Java существует некоторая неопределенность насчет того – существует ли два или три вида исключений.
Если делить исключения на два вида, то это:
-
1.
контролируемые исключения (checked exceptions) – подклассы класса
Exception, кроме подклассаRuntimeExceptionи его производных; -
2.
неконтролируемые исключения (unchecked exceptions) – класс
Errorс подклассами, а также классRuntimeExceptionи его производные;
В некоторых источниках класс Error и его подклассы выделяют в отдельный вид исключений — ошибки (errors).
Далее мы видим класс Error. Классы этой ветки составляют вид исключений, который можно обозначить как «ошибки» (errors). Ошибки представляют собой серьезные проблемы, которые не следует пытаться обработать в собственной программе, поскольку они связаны с проблемами уровня JVM.
На самом деле, вы конечно можете предпринять некоторые действия при возникновении ошибок, например, вывести сообщение для пользователя в удобном формате, выслать трассировку стека себе на почту, чтобы понять – что вообще произошло.
Но, по факту, вы ничего не можете предпринять в вашей программе, чтобы эту ошибку исправить, и ваша программа, как правило, при возникновении такой ошибки дальше работать не может.
В качестве примеров «ошибок» можно привести: переполнение стека вызова (класс StackOverflowError); нехватка памяти в куче (класс OutOfMemoryError), вследствие чего JVM не может выделить память под новый объект и сборщик мусора не помогает; ошибка виртуальной машины, вследствие которой она не может работать дальше (класс VirtualMachineError) и так далее.
Несмотря на то, что в нашей программе мы никак не можем помочь этой проблеме, и приложение не может работать дальше (ну как может работать приложение, если стек вызовов переполнен или JVM не может дальше выполнять код?!); знание природы этих ошибок поможет вам предпринять некоторые действия, чтобы избежать этих ошибок в дальнейшем. Например, ошибки типа StackOverflowError и OutOfMemoryError могут быть следствием вашего некорректного кода.
Например, попробуем спровоцировать ошибку StackOverflowError
public static void main(String[] args) {
public static void methodA() {
private static void methodB() {
Получим такое сообщение об ошибке
Exception in thread «main» java.lang.StackOverflowError
at com.company.Main.methodB(Main.java:14)
at com.company.Main.methodA(Main.java:10)
at com.company.Main.methodB(Main.java:14)
at com.company.Main.methodA(Main.java:10)
at com.company.Main.methodB(Main.java:14)
at com.company.Main.methodA(Main.java:10)
at com.company.Main.methodB(Main.java:14)
at com.company.Main.methodA(Main.java:10)
Ошибка OutOfMemoryError может быть вызвана тем, что ваш код, вследствие ошибки при программировании, создает очень большое количество массивных объектов, которые очень быстро заполняют кучу и свободного места не остается.
Exception in thread «main» java.lang.OutOfMemoryError: Java heap space
at java.base/java.util.Arrays.copyOf(Arrays.java:3511)
at java.base/java.util.Arrays.copyOf(Arrays.java:3480)
at java.base/java.util.ArrayList.grow(ArrayList.java:237)
at java.base/java.util.ArrayList.grow(ArrayList.java:244)
at java.base/java.util.ArrayList.add(ArrayList.java:454)
at java.base/java.util.ArrayList.add(ArrayList.java:467)
at com.company.Main.main(Main.java:13)
Process finished with exit code 1
Ошибка VirtualMachineError может означать, что следует переустановить библиотеки Java.
В любом случае, следует относиться к типу Error не как к неизбежному злу и «воле богов», а просто как к сигналу к тому, что в вашем приложении что-то не так, или что-то не так с программным или аппаратным обеспечением, которое вы используете.
Класс Exception описывает исключения, связанные непосредственно с работой программы. Такого рода исключения «решаемы» и их грамотная обработка позволит программе работать дальше в нормальном режиме.
В классе Exception описаны исключения двух видов: контролируемые исключения (checked exceptions) и неконтролируемые исключения (unchecked exceptions).
Неконтролируемые исключения содержатся в подклассе RuntimeException и его наследниках. Контролируемые исключения содержатся в остальных подклассах Exception.
В чем разница между контролируемыми и неконтролируемыми исключениями, мы узнаем позже, а теперь рассмотрим вопрос – а как же именно нам обрабатывать исключения?
Обработка исключений в методе может выполняться двумя способами:
-
1.
с помощью связки
try-catch; -
2.
с помощью ключевого слова
throwsв сигнатуре метода.
Рассмотрим оба метода поподробнее:
Способ 1. Связка try-catch
Этот способ кратко можно описать следующим образом.
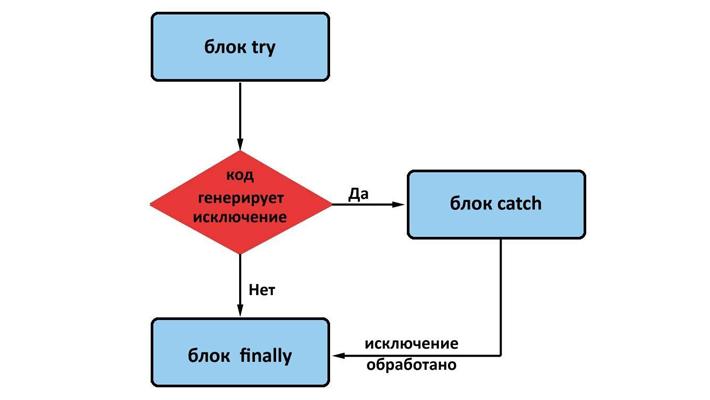
Код, который теоретически может вызвать исключение, записывается в блоке try{}. Сразу за блоком try идет блок код catch{}, в котором содержится код, который будет выполнен в случае генерации исключения. В блоке finally{} содержится код, который будет выполнен в любом случае – произошло ли исключение или нет.
Теперь разберемся с этим способом более подробно. Рассмотрим следующий пример – программу, которая складывает два числа, введенные пользователем из консоли
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println(«Введите первое число: «);
String firstNumber = scanner.nextLine();
System.out.println(«Введите второе число: «);
String secondNumber = scanner.nextLine();
a = Integer.parseInt(firstNumber);
b = Integer.parseInt(secondNumber);
System.out.println(«Результат: « + (a + b));
Первое, что нам нужно определить – и что является главным при работе с исключениями, КАКАЯ ИНСТРУКЦИЯ МОЖЕТ ПРИВЕСТИ К ВОЗНИКНОВЕНИЮ ИСКЛЮЧЕНИЯ?
То есть, мы должны понять – где потенциально у нас может возникнуть исключение? Понятно, что речь идет не об операции сложения и не об операции чтения данных из консоли. Потенциально опасными строчками кода здесь являются строчки
a = Integer.parseInt(firstNumber);
b = Integer.parseInt(secondNumber);
в которых происходит преобразование ввода пользователя в целое число (метод parseInt() преобразует цифры в строке в число).
Почему здесь может возникнуть исключение? Потому что пользователь может ввести не число, а просто какой-то текст и тогда непонятно – что записывать в переменную a или b. И да, действительно, если пользователь введет некорректное значение, возникнет исключение в методе Integer.parseInt().
Итак, что мы можем сделать. «Опасный код» нужно поместить в блок try{}
Обратите внимание на синтаксис блока try. В самом простом случае это просто ключевое слово try, после которого идут парные фигурные скобки. Внутри этих скобок и заключается «опасный» код, который может вызвать исключение. Сразу после блока try должен идти блок catch().
a = Integer.parseInt(firstNumber);
b = Integer.parseInt(secondNumber);
} catch (NumberFormatException e) {
// сохранить текст ошибки в лог
System.out.println(«Одно или оба значения некорректны!»);
System.out.println(«Результат: « + (a + b));
Обратите внимание на синтаксис блока catch. После ключевого слова, в скобках описывается аргумент с именем e типа NumberFormatException.
Когда произойдет исключение, то система Java прервет выполнение инструкций в блоке try и передаст управление блоку catch и запишет в этот аргумент объект исключения, который сгенерировала Java-машина.
То есть, как только в блоке try возникнет исключение, то дальше инструкции в блоке try выполняться не будут! А сразу же начнут выполняться действия в блоке catch.
Обработчик исключения находится в блоке catch, в котором мы можем отреагировать на возникновение исключения. Также, в этом блоке нам будет доступен объект исключения, от которого мы можем получить дополнительные сведения об исключении.
Блок catch сработает только в том случае, если указанный в скобках тип объекта исключения будет суперклассом или будет того же типа, что и объект исключения, который сгенерировала Java.
Например, если в нашем примере мы напишем код, который потенциально может выбросить исключение типа IOException, но не изменим блок catch
} catch (NumberFormatException e) {
// сохранить текст ошибки в лог
System.out.println(«Одно или оба значения некорректны!»);
тогда обработчик не будет вызван и исключение будет обработано стандартным обработчиком Java.
Способ 2. Использование ключевого слова throws
Второй способ позволяет передать обязанность обработки исключения тому методу, который вызывает данный метод (а тот, в свою очередь может передать эту обязанность выше и т.д.).
Изменим наш пример и выделим в отдельный метод код, который будет запрашивать у пользователя число и возвращать его как результат работы метода
public static void main(String[] args) {
int a = getNumberFromConsole(«Введите первое число»);
int b = getNumberFromConsole(«Введите второе число»);
System.out.println(«Результат: « + (a + b));
public static int getNumberFromConsole(String message) {
Scanner scanner = new Scanner(System.in);
System.out.print(message + «: «);
String s = scanner.nextLine();
return Integer.parseInt(s);
Мы понимаем, что в данном методе может произойти исключение, но мы не хотим или не можем его обработать. Причины могут быть разными, например:
-
1.
обработка исключений может происходить централизованно однотипным способом (например, показ окошка с сообщением и с определенным текстом);
-
2.
это не входит в нашу компетенцию как программиста – обработкой исключений занимается другой программист;
-
3.
мы пишем только некоторую часть программы и непонятно – как будет обрабатывать исключение другой программист, который потом будет использовать наш код (например, мы пишем просто какую-то библиотеку, которая производит вычисления, и как будет выглядеть обработка – это не наше дело).
В любом случае, мы знаем, что в этом коде может быть исключение, но мы не хотим его обрабатывать, а хотим просто предупредить другой метод, который будет вызывать наш код, что выполнение кода может привести к исключению. В этом случае, используется ключевое слово throws, которое указывается в сигнатуре метода
public static int getNumberFromConsole(String message) throws NumberFormatException {
Scanner scanner = new Scanner(System.in);
System.out.print(message + «: «);
String s = scanner.nextLine();
return Integer.parseInt(s);
Обратите внимание на расположение сигнатуру метода. Мы привыкли, что при объявлении метода сразу после скобок входных аргументов мы открываем фигурную скобку и записываем тело метода. Здесь же, после входных аргументов, мы пишем ключевое слово throws и потом указываем тип исключения, которое может быть сгенерировано в нашем методе. Если метод может выбрасывать несколько типов исключений, они записываются через запятую
public static void foo() throws NumberFormatException, ArithmeticException, IOException {
Тогда, в методе main мы должны написать примерно следующее
public static void main(String[] args) {
a = getNumberFromConsole(«Введите первое число»);
b = getNumberFromConsole(«Введите второе число»);
} catch (NumberFormatException e) {
// сохранить текст ошибки в лог
System.out.println(«Одно или оба значения некорректны!»);
System.out.println(«Результат: « + (a + b));
Основное преимущество этого подхода – мы передаем обязанность по обработке исключений другому, вышестоящему методу.
Отличия между контролируемыми и неконтролируемыми исключениями
Отличия между контролируемыми и неконтролируемыми исключениями
Если вы вызываете метод, который выбрасывает checked исключение, то вы ОБЯЗАНЫ предусмотреть обработку возможного исключения, то есть связку try-catch.
Яркий пример checked исключения – класс IOException и его подклассы.
Рассмотрим пример – попробуем прочитать файл и построчно вывести его содержимое на экран консоли:
public static void main(String[] args) {
Path p = Paths.get(«c:\temp\file.txt»);
BufferedReader reader = Files.newBufferedReader(p);
while ((line = reader.readLine()) != null) {
System.out.println(line);
Как мы видим, компилятор не хочет компилировать наш код. Чем же он недоволен? У нас в коде происходит вызов двух методов – статического метода Files.newBufferedReader() и обычного метода BufferedReader.readLine().
Если посмотреть на сигнатуры этих методов то можно увидеть, что оба этих метода выбрасывают исключения типа IOException. Этот тип исключения относится к checked-исключению и поэтому, если вы вызываете эти методы, компилятор ТРЕБУЕТ от вас предусмотреть блок catch, либо в самом вашем методе указать throws IOException и, таким образом, передать обязанность обрабатывать исключение другому методу, который будет вызывать ваш.
Таким образом, «оборачиваем» наш код в блок try и пишем блок catch.
public static void main(String[] args) {
Path p = Paths.get(«c:\temp\file.txt»);
BufferedReader reader = Files.newBufferedReader(p);
while ((line = reader.readLine()) != null) {
System.out.println(line);
} catch (IOException e) {
System.out.println(«Ошибка при чтении файла!»);
Еще один способ — указать в сигнатуре метода, что он выбрасывает исключение типа IOException и переложить обязанность обработать ошибку в вызывающем коде
public static void main(String[] args) {
Path p = Paths.get(«c:\temp\file.txt»);
} catch (IOException e) {
System.out.println(«Ошибка при чтении файла!»);
public static void printFile(Path p) throws IOException {
BufferedReader reader = Files.newBufferedReader(p);
while ((line = reader.readLine()) != null) {
System.out.println(line);
Eсли метод выбрасывает checked-исключение, то проверка на наличие catch-блока происходит на этапе компиляции. И вы обязаны предусмотреть обработку исключения для checked-исключения.
Что касается unchecked-исключения, то обязательной обработки исключения нет – вы можете оставить подобные ситуации без обработки.
Зачем необходимо наличие двух видов исключений?
Зачем необходимо наличие двух видов исключений?
В большинстве языков существует всего лишь один тип исключений – unchecked. Некоторые языки, например, C#, в свое время отказались от checked-исключений.
Во-первых, мы не можем сделать все исключения checked, т.к. очень многие операции могут генерировать исключения, и если каждый такой участок кода «оборачивать» в блок try-catch, то код получится слишком громоздким и нечитабельным.
С другой стороны, зачем нужно делать некоторые типы исключений checked? Почему просто не сделать все исключения unchecked и оставить решения об обработке исключений целиком на совести программиста?
В официальной документации написано, что unchecked-исключения – это те исключения, от которых программа «не может восстановиться», тогда как checked-исключения позволяют откатить некоторую операцию и повторить ее снова.
На самом деле, если вы посмотрите на различные типы unchecked-исключений, то вы увидите, что большинство их связаны с ошибками самого программиста. Выход за пределы массива, исключение нулевого указателя, деление на ноль – большинство из подобного рода исключений целиком лежат на совести программистов. Тогда мы можем сказать, что лучше программист пишет более хороший код, чем везде вставляет проверки на исключения.
Контролируемые исключения, как правило, представляют те ошибки, которые возникают не из-за программиста и предусмотреть которые программист не может. Например, это отсутствующие файлы, работа с сокетами, подключение к базе данных, сетевые соединения, некорректный пользовательский ввод.
Вы можете написать идеальный код, но потом вы отдадите приложение пользователю, а он введет название файла, которого нет или напишет неправильный IP для сокет-соединения. Таким образом, мы заранее должны быть готовыми к неверным действиям пользователя или к программным или аппаратным проблемам на его стороне и в обязательном порядке предусмотреть обработку возможных исключений.
Дополнительно об исключениях
Дополнительно об исключениях
Рассмотрим детально различные возможности механизма исключений, которые позволяют программисту максимально эффективно противодействовать исключениям:
Java позволяет вам для одного блока try предусмотреть несколько блоков catch, каждый из которых должен обрабатывать свой тип исключения
public static void foo() {
} catch (ArithmeticException e) {
// обработка арифметического исключения
} catch (IndexOutOfBoundsException e) {
// обработка выхода за пределы коллекции
} catch (IllegalArgumentException e) {
// обработка некорректного аргумента
Важно помнить, что Java обрабатывает исключения последовательно. Java просматривает блок catch сверху вниз и выполняет первый подходящий блок, который может обработать данное исключение.
Так как вы можете указать как точный класс, так и суперкласс, то если первым блоком будет блок для суперкласса – выполнится он. Например, исключение FileNotFoundException является подклассом IOException. И поэтому если вы первым поставите блок с IOException – он будет вызываться для всех подтипов исключений, в том числе и для FileNotFoundException и блок c FileNotFoundException никогда не выполнится.
public static void main(String[] args) {
Path p = Paths.get(«c:\temp\file.txt»);
} catch (IOException e) {
System.out.println(«Ошибка при чтении файла!»);
} catch (FileNotFoundException e) {
// данный блок никогда не будет вызван
public static void printFile(Path p) throws IOException {
BufferedReader reader = Files.newBufferedReader(p);
while ((line = reader.readLine()) != null) {
System.out.println(line);
Один блок для обработки нескольких типов исключений
Один блок для обработки нескольких типов исключений
Начиная с версии Java 7, вы можете использовать один блок catch для обработки исключений нескольких, не связанных друг с другом типов. Приведем пример
public static void foo() {
} catch (ArithmeticException | IllegalArgumentException | IndexOutOfBoundsException e) {
// три типа исключений обрабатываются одинаково
Как мы видим, один блок catch используется для обработки и типа IOException и NullPointerException и NumberFormaException.
Вы можете использовать вложенные блоки try, которые могут помещаться в других блоках try. После вложенного блока try обязательно идет блок catch
public static void foo() {
} catch (IllegalArgumentException e) {
// обработка вложенного блока try
} catch (ArithmeticException e) {
Выбрасывание исключения с помощью ключевого слова throw
С помощью ключевого слова throw вы можете преднамеренно «выбросить» определенный тип исключения.
public static void foo(int a) {
throw new IllegalArgumentException(«Аргумент не может быть отрицательным!»);
Кроме блока try и catch существует специальный блок finally. Его отличительная особенность – он гарантированно отработает, вне зависимости от того, будет выброшено исключение в блоке try или нет. Как правило, блок finally используется для того, чтобы выполнить некоторые «завершающие» операции, которые могли быть инициированы в блоке try.
public static void foo(int a) {
FileOutputStream fout = null;
File file = new File(«file.txt»);
fout = new FileOutputStream(file);
} catch (IOException e) {
// обработка исключения при записи в файл
} catch (IOException e) {
При любом развитии события в блоке try, код в блоке finally отработает в любом случае.
Блок finally отработает, даже если в try-catch присутствует оператор return.
Как правило, блок finally используется, когда мы в блоке try работаем с ресурсами (файлы, базы данных, сокеты и т.д.), когда по окончании блока try-catch мы освобождаем ресурсы. Например, допустим, в процессе работы программы возникло исключение, требующее ее преждевременного закрытия. Но в программе открыт файл или установлено сетевое соединение, а, следовательно, файл нужно закрыть, а соединение – разорвать. Для этого удобно использовать блок finally.
Блок try-with-resources является модификацией блока try. Данный блок позволяет автоматически закрывать ресурс после окончания работы блока try и является удобной альтернативой блоку finally.
public static void foo() {
Path p = Paths.get(«c:\temp\file.txt»);
try (BufferedReader reader = Files.newBufferedReader(p)) {
while ((line = reader.readLine()) != null)
System.out.println(line);
} catch (IOException e) {
Внутри скобок блока try объявляется один или несколько ресурсов, которые после отработки блока try-catch будут автоматически освобождены. Для этого объект ресурса должен реализовывать интерфейс java.lang.AutoCloseable.
Создание собственных подклассов исключений
Создание собственных подклассов исключений
Встроенные в Java исключения позволяют обрабатывать большинство распространенных ошибок. Тем не менее, вы можете создавать и обрабатывать собственные типы исключений. Для того, чтобы создать класс собственного исключения, достаточно определить как его произвольный от Exception или от RuntimeException (в зависимости от того, хотите ли вы использовать checked или unchecked – исключения).
Насчет создания рекомендуется придерживаться двух правил:
-
1.
определитесь, исключения какого типа вы хотите использовать для собственных исключений (checked или unchecked) и старайтесь создавать исключения только этого типа;
-
2.
старайтесь максимально использовать стандартные типы исключений и создавать свои типы только в том случае, если существующие типы исключений не отражают суть того исключения, которое вы хотите добавить.
Плохие практики при обработке исключений
Плохие практики при обработке исключений
Ниже представлены действия по обработке ошибок, которые характерны для плохого программиста. Ни в коем случае не рекомендуется их повторять!
-
1.
Указание в блоке catch объекта исключения типа Exception. Существует очень большой соблазн при создании блока
catchуказать тип исключенияExceptionи, таким образом, перехватывать все исключения, которые относятся к этому классу (а это все исключения, кроме системных ошибок). Делать так крайне не рекомендуется, т.к. вместо того чтобы решать проблему с исключениями, мы фактически игнорируем ее и просто реализуем некоторую «заглушку», чтобы приложение продолжило работу дальше. Кроме того, каждый тип исключения должен быть обработан своим определенным образом. -
2.
Помещение в блок
tryвсего тела метода. Следующий плохой прием используется, когда программист не хочет разбираться с кодом, который вызывает исключение и просто, опять же, реализует «заглушку». Этот прием очень «хорошо» сочетается с первым приемом. В блокtryдолжен помещаться только тот код, который потенциально может вызвать исключение, а не всё подряд, т.к. лень обрабатывать исключения нормально. -
3.
Игнорирование исключения. Следующий плохой прием состоит в том, что мы просто игнорируем исключение и оставляем блок
catchпустым. Программа должна реагировать на исключения и должна информировать пользователя и разработчика о том, что что-то пошло не так. Безусловно, исключение это не повод тут же закрывать приложение, а попытаться повторить то действие, которое привело к исключению (например, повторно указать название файла, попытаться открыть базу данных через время и т.д.). В любом случае, когда приложение в ответ на ошибку никак не реагирует – не выдает сообщение, но и не делает того, чего от нее ожидали – это самый плохой вариант.


В нашей жизни нередко возникают ситуации, которые мы не планировали. К примеру, пошли вы утром умываться и с досадой обнаружили, что отключили воду. Вышли на улицу, сели в машину, а она не заводится. Позвонили другу, а он недоступен. И так далее и тому подобное… В большинстве случаев человек без труда справится с подобными проблемами. А вот как с непредвиденными ситуациями справляется Java, мы сейчас и поговорим.
Что называют исключением. Исключения в мире программирования
В программировании исключением называют возникновение ошибки (ошибок) и различных непредвиденных ситуаций в процессе выполнения программы. Исключения могут появляться как в итоге неправильных действий юзера, так и из-за потери сетевого соединения с сервером, отсутствии нужного ресурса на диске и т. п. Также среди причин исключений — ошибки программирования либо неверное использование API.
При этом в отличие от «человеческого мира», программное приложение должно чётко понимать, как поступать в подобной ситуации. И вот как раз для этого в Java и существует механизм исключений (exception).
Используемые ключевые слова
При обработке исключений в Java применяются следующие ключевые слова:
— try – служит для определения блока кода, в котором может произойти исключение;
— catch – необходим для определения блока кода, где происходит обработка исключения;
— finally – применяется для определения блока кода, являющегося необязательным, однако при его наличии он выполняется в любом случае вне зависимости от результата выполнения блока try.
Вышеперечисленные ключевые слова необходимы для создания в коде ряда специальных обрабатывающих конструкций: try{}finally{}, try{}catch, try{}catch{}finally.
Кроме того:
1. Для возбуждения исключения используем throw.
2. Для предупреждения в сигнатуре методов о том, что метод может выбросить исключение, применяем throws.
Давайте на примере посмотрим, как используются ключевые слова в Java-программе:
//метод считывает строку с клавиатуры public String input() throws MyException {//предупреждаем с помощью throws, // что метод может выбросить исключение MyException BufferedReader reader = new BufferedReader(new InputStreamReader(System.in)); String s = null; //в блок try заключаем код, в котором может произойти исключение, в данном // случае компилятор нам подсказывает, что метод readLine() класса // BufferedReader может выбросить исключение ввода/вывода try { s = reader.readLine(); // в блок catch заключаем код по обработке исключения IOException } catch (IOException e) { System.out.println(e.getMessage()); // в блоке finally закрываем поток чтения } finally { // при закрытии потока тоже возможно исключение, например, если он не был открыт, поэтому “оборачиваем” код в блок try try { reader.close(); // пишем обработку исключения при закрытии потока чтения } catch (IOException e) { System.out.println(e.getMessage()); } } if (s.equals("")) { // мы решили, что пустая строка может нарушить в дальнейшем работу нашей программы, например, на результате этого метода нам надо вызывать метод substring(1,2), поэтому мы вынуждены прервать выполнение программы с генерацией своего типа исключения MyException с помощью throw throw new MyException("String can not be empty!"); } return s; }Зачем нам механизм исключений?
Для понимания опять приведём пример из обычного мира. Представьте, что на какой-нибудь автодороге имеется участок с аварийным мостом, на котором ограничена грузоподъёмность. И если по такому мосту проедет грузовик со слишком большой массой, мост разрушится, а в момент этого ЧП ситуация для шофёра станет, мягко говоря, исключительной. И вот, дабы такого не произошло, дорожные службы заранее устанавливают на дороге соответствующие предупреждающие знаки. И тогда водитель, посмотрев на знак, сравнит массу своего авто со значением разрешённой грузоподъёмности и примет соответствующее решение, например, поедет по другой дороге.
То есть мы видим, что из-за правильных действий дорожной службы шоферы крупногабаритных транспортных средств:
1) получили возможность заранее изменить свой путь;
2) были предупреждены об опасности;
3) были предупреждены о невозможности проезжать по мосту при определённых условиях.Вот как наш жизненный пример соотносится с применением исключения на Java:
Исходя из вышесказанного, мы можем назвать одну из причин применения исключений в Java. Заключается она в возможности предупреждения исключительной ситуации для её последующего разрешения и продолжения работы программы. То есть механизм исключений позволит защитить написанный код от неверного применения пользователем путём валидации входящих данных.
Что же, давайте ещё раз побудем дорожной службой. Чтобы установить знак, мы ведь должны знать места, где водителей ТС могут ждать различные неприятности. Это первое. Далее, нам ведь надо заготовить и установить знаки. Это второе. И, наконец, надо предусмотреть маршруты объезда, позволяющие избежать опасности.
В общем, механизм исключений в Java работает схожим образом. На стадии разработки программы мы выполняем «ограждение» опасных участков кода в отношении наших исключений, используя блок try{}. Чтобы предусмотреть запасные пути, применяем блок catch{}. Код, выполняемый в программе при любом исходе, пишем в блоке finally{}.
Иногда бывает, что мы не можем предусмотреть «запасной аэродром» либо специально желаем предоставить право его выбора юзеру. Но всё равно мы должны как минимум предупредить пользователя об опасности. Иначе он превратится в разъярённого шофёра, который ехал долго, не встретил ни одного предупреждающего знака и в итоге добрался до аварийного моста, проехать по которому не представляется возможным.
Что касается программирования на Java, то мы, когда пишем свои классы и методы, далеко не всегда можем предвидеть контекст их применения другими программистами в своих программах, а значит, не можем со стопроцентной вероятностью предвидеть правильный путь для разрешения исключительных ситуаций. Но предупредить коллег о возможной исключительной ситуации мы всё-таки должны, и это не что иное, как правило хорошего тона.
Выполнить это правило в Java нам как раз и помогает механизм исключений с помощью throws. Выбрасывая исключение, мы, по сути, объявляем общее поведение нашего метода и предоставляем пользователю метода право написания кода по обработке исключения.
Предупреждаем о неприятностях
Если мы не планируем обрабатывать исключение в собственном методе, но желаем предупредить пользователей метода о возможной исключительной ситуации, мы используем, как это уже было упомянуто, ключевое слово throws. В сигнатуре метода оно означает, что при некоторых обстоятельствах метод может выбросить исключение. Это предупреждение становится частью интерфейса метода и даёт право пользователю на создание своего варианта реализации обработчика исключения.
После упоминания ключевого слова throws мы указываем тип исключения. Как правило, речь идёт о наследниках класса Exception Java. Но так как Java — это объектно-ориентированный язык программирования, все исключения представляют собой объекты.
Иерархия исключений в Java
Когда возникают ошибки при выполнении программы, исполняющая среда Java Virtual Machine обеспечивает создание объекта нужного типа, используя иерархию исключений Java — речь идёт о множестве возможных исключительных ситуаций, которые унаследованы от класса Throwable — общего предка. При этом исключительные ситуации, которые возникают в программе, делят на 2 группы:
1. Ситуации, при которых восстановление нормальной дальнейшей работы невозможно.
2. Ситуации с возможностью восстановления.К первой группе можно отнести случаи, при которых возникают исключения, которые унаследованы из класса Error. Это ошибки, возникающие во время выполнения программы при сбое работы Java Virtual Machine, переполнении памяти либо сбое системы. Как правило, такие ошибки говорят о серьёзных проблемах, устранение которых программными средствами невозможно. Данный вид исключений в Java относят к неконтролируемым исключениям на стадии компиляции (unchecked). К этой же группе относятся и исключения-наследники класса Exception, генерируемые Java Virtual Machine в процессе выполнения программы — RuntimeException. Данные исключения тоже считаются unchecked на стадии компиляции, а значит, написание кода по их обработке необязательно.
Что касается второй группы, то к ней относят ситуации, которые можно предвидеть ещё на стадии написания приложения, поэтому для них код обработки должен быть написан. Это контролируемые исключения (checked). И в большинстве случаев Java-разработчики работают именно с этими исключениями, выполняя их обработку.
Создание исключения
В процессе исполнения программы исключение генерируется Java Virtual Machine либо вручную посредством оператора throw. В таком случае в памяти происходит создание объекта исключения, выполнение основного кода прерывается, а встроенный в JVM обработчик исключений пробует найти способ обработать это самое исключение.
Обработка исключения
Обработка исключений в Java подразумевает создание блоков кода и производится в программе посредством конструкций try{}finally{}, try{}catch, try{}catch{}finally.
В процессе возбуждения исключения в try обработчик исключения ищется в блоке catch, который следует за try. При этом если в catch присутствует обработчик данного вида исключения, происходит передача управления ему. Если же нет, JVM осуществляет поиск обработчика данного типа исключения, используя для этого цепочку вызова методов. И так происходит до тех пор, пока не находится подходящий catch. После того, как блок catch выполнится, управление переходит в необязательный блок finally. Если подходящий блок catch найден не будет, Java Virtual Machine остановит выполнение программы, выведя стек вызовов методов под названием stack trace. Причём перед этим выполнится код блока finally при наличии такового.
Рассмотрим практический пример обработки исключений:
public class Print { void print(String s) { if (s == null) { throw new NullPointerException("Exception: s is null!"); } System.out.println("Inside method print: " + s); } public static void main(String[] args) { Print print = new Print(); List list= Arrays.asList("first step", null, "second step"); for (String s:list) { try { print.print(s); } catch (NullPointerException e) { System.out.println(e.getMessage()); System.out.println("Exception was processed. Program continues"); } finally { System.out.println("Inside bloсk finally"); } System.out.println("Go program...."); System.out.println("-----------------"); } } }А теперь глянем на результаты работы метода main:
Inside method print: first step Inside bloсk finally Go program.... ----------------- Exception: s is null! Exception was processed. Program continues Inside bloсk finally Go program.... ----------------- Inside method print: second step Inside bloсk finally Go program.... -----------------Блок finally чаще всего используют, чтобы закрыть открытые в try потоки либо освободить ресурсы. Но при написании программы уследить за закрытием всех ресурсов возможно не всегда. Чтобы облегчить жизнь разработчикам Java, была предложена конструкция try-with-resources, автоматически закрывающая ресурсы, открытые в try. Используя try-with-resources, мы можем переписать наш первый пример следующим образом:
public String input() throws MyException { String s = null; try(BufferedReader reader = new BufferedReader(new InputStreamReader(System.in))){ s = reader.readLine(); } catch (IOException e) { System.out.println(e.getMessage()); } if (s.equals("")){ throw new MyException ("String can not be empty!"); } return s; }А благодаря появившимся возможностям Java начиная с седьмой версии, мы можем ещё и объединять в одном блоке перехват разнотипных исключений, делая код компактнее и читабельнее:
public String input() { String s = null; try (BufferedReader reader = new BufferedReader(new InputStreamReader(System.in))) { s = reader.readLine(); if (s.equals("")) { throw new MyException("String can not be empty!"); } } catch (IOException | MyException e) { System.out.println(e.getMessage()); } return s; }Итоги
Итак, применение исключений в Java повышает отказоустойчивость программы благодаря использованию запасных путей. Кроме того, появляется возможность отделить код обработки исключительных ситуаций от логики основного кода за счёт блоков catch и переложить обработку исключений на пользователя кода посредством throws.
Основные вопросы об исключениях в Java
1.Что такое проверяемые и непроверяемые исключения?
Если говорить коротко, то первые должны быть явно пойманы в теле метода либо объявлены в секции throws метода. Вторые вызываются проблемами, которые не могут быть решены. Например, это нулевой указатель или деление на ноль. Проверяемые исключения очень важны, ведь от других программистов, использующих ваш API, вы ожидаете, что они знают, как обращаться с исключениями. К примеру, наиболее часто встречаемое проверяемое исключение — IOException, непроверяемое — RuntimeException.
2.Почему переменные, определённые в try, нельзя использовать в catch либо finally?
Давайте посмотрим на нижеследующий код. Обратите внимание, что строку s, которая объявлена в блоке try, нельзя применять в блоке catch. То есть данный код не скомпилируется.try { File file = new File("path"); FileInputStream fis = new FileInputStream(file); String s = "inside"; } catch (FileNotFoundException e) { e.printStackTrace(); System.out.println(s); }А всё потому, что неизвестно, где конкретно в try могло быть вызвано исключение. Вполне вероятно, что оно было вызвано до объявления объекта.
3.Почему Integer.parseInt(null) и Double.parseDouble(null) вызывают разные исключения?
Это проблема JDK. Так как они были разработаны разными людьми, то заморачиваться вам над этим не стоит:Integer.parseInt(null); // вызывает java.lang.NumberFormatException: null Double.parseDouble(null); // вызывает java.lang.NullPointerException4.Каковы основные runtime exceptions в Java?
Вот лишь некоторые из них:IllegalArgumentException ArrayIndexOutOfBoundsExceptionИх можно задействовать в операторе if, если условие не выполняется:
if (obj == null) { throw new IllegalArgumentException("obj не может быть равно null");5.Возможно ли поймать в одном блоке catch несколько исключений?
Вполне. Пока классы данных исключений можно отследить вверх по иерархии наследования классов до одного и того же суперкласса, возможно применение только этого суперкласса.
6.Способен ли конструктор вызывать исключения?
Способен, ведь конструктор — это лишь особый вид метода.class FileReader{ public FileInputStream fis = null; public FileReader() throws IOException{ File dir = new File(".");//get current directory File fin = new File(dir.getCanonicalPath() + File.separator + "not-existing-file.txt"); fis = new FileInputStream(fin); } }7.Возможен ли вызов исключений в final?
В принципе, можете сделать таким образом:public static void main(String[] args) { File file1 = new File("path1"); File file2 = new File("path2"); try { FileInputStream fis = new FileInputStream(file1); } catch (FileNotFoundException e) { e.printStackTrace(); } finally { try { FileInputStream fis = new FileInputStream(file2); } catch (FileNotFoundException e) { e.printStackTrace(); } } }Но если желаете сохранить читабельность, объявите вложенный блок try-catch в качестве нового метода и вставьте вызов данного метода в блок finally.
finally. public static void main(String[] args) { File file1 = new File("path1"); File file2 = new File("path2"); try { FileInputStream fis = new FileInputStream(file1); } catch (FileNotFoundException e) { e.printStackTrace(); } finally { methodThrowException(); } }
Данная статья является переводом. Ссылка на оригинал.
В статье рассмотрим:
- Объект Error
- Try…catch
- Throw
- Call stack
- Наименование функций
- Парадигму асинхронного программирования Promise
Представьте, как разрабатываете RESTful web API на Node.js.
- Пользователи отправляют запросы к серверу для получения данных.
- Вопрос времени, когда в программу придут значения, которые не ожидались.
- В таком случае, когда программа получит эти значения, пользователи будут рады видеть подробное и конкретное описание ошибки.
- В случае когда нет соответствующего обработчика ошибки, отобразится стандартное сообщение об ошибке. Таким образом, пользователь увидит сообщение об ошибке «Невозможно выполнить запрос», что не несет полезной информации о том, что произошло.
- Поэтому стоит уделять внимание обработке ошибок, чтобы наша программа стала безопасной, отказоустойчивой, высокопроизводительной и без ошибок.
Анатомия Объекта Error
Первое, с чего стоит начать изучение – это объект Error.
Разберем на примере:
throw new Error('database failed to connect');
Здесь происходят две вещи: создается объект Error и выбрасывается исключение.
Начнем с рассмотрения объекта Error, и того, как он работает. К ключевому слову throw вернемся чуть позже.
Объект Error представляет из себя реализацию функции конструктора, которая использует набор инструкций (аргументы и само тело конструктора) для создания объекта.
Тем не менее, что же такое объекты ошибок? Почему они должны быть однородными? Это важные вопросы, поэтому давайте перейдем к ним.
Первым аргументом для объекта Error является его описание.
Описание – это понятная человеку строка объекта ошибки. Также эта строка появляется в консоли, когда что-то пошло не так.
Объекты ошибок также имеют свойство name, которое рассказывает о типе ошибки. Когда создается нативный объект ошибки, то свойство name по умолчанию содержит Error. Вы также можете создать собственный тип ошибки, расширив нативный объект ошибки следующим образом:
class FancyError extends Error {
constructor(args){
super(args);
this.name = "FancyError"
}
}
console.log(new Error('A standard error'))
// { [Error: A standard error] }
console.log(new FancyError('An augmented error'))
// { [Your fancy error: An augmented error] name: 'FancyError' }
Обработка ошибок становится проще, когда у нас есть согласованность в объектах.
Ранее мы упоминали, что хотим, чтобы объекты ошибок были однородными. Это поможет обеспечить согласованность в объекте ошибки.
Теперь давайте поговорим о следующей части головоломки – throw.
Ключевое слово Throw
Создание объектов ошибок – это не конец истории, а только подготовка ошибки к отправке. Отправка ошибки заключается в том, чтобы выбросить исключение. Но что значит выбросить? И что это значит для нашей программы?
Throw делает две вещи: останавливает выполнение программы и находит зацепку, которая мешает выполнению программы.
Давайте рассмотрим эти идеи одну за другой:
- Когда JavaScript находит ключевое слово
throw, первое, что он делает – предотвращает запуск любых других функций. Остановка снижает риск возникновения любых дальнейших ошибок и облегчает отладку программ. - Когда программа остановлена, JavaScript начнет отслеживать последовательную цепочку функций, которые были вызваны для достижения оператора
catch. Такая цепочка называется стек вызовов (англ. call stack). Ближайшийcatch, который находит JavaScript, является местом, где возникает выброшенное исключение. Если операторыtry/catchне найдены, тогда возникает исключение, и процесс Node.js завершиться, что приведет к перезапуску сервера.
Бросаем исключения на примере
Мы рассмотрели теорию, а теперь давайте изучим пример:
function doAthing() {
byDoingSomethingElse();
}
function byDoingSomethingElse() {
throw new Error('Uh oh!');
}
function init() {
try {
doAthing();
} catch(e) {
console.log(e);
// [Error: Uh oh!]
}
}
init();
Здесь в функции инициализации init() предусмотрена обработка ошибок, поскольку она содержит try/catch блок.
init() вызывает функцию doAthing(), которая вызывает функцию byDoingSomethingElse(), где выбрасывается исключение. Именно в этот момент ошибки, программа останавливается и начинает отслеживать функцию, вызвавшую ошибку. Далее в функции init() и выполняет оператор catch. С помощью оператора catch мы решаем что делать: подавить ошибку или даже выдать другую ошибку (для распространения вверх).
Стек вызовов
То, что показано в приведенном выше примере – это проработанный пример стека вызовов. Как и большинство языков, JavaScript использует концепцию, известную как стек вызовов.
Но как работает стек вызовов?
Всякий раз, когда вызывается функция, она помещается в стек, а при завершении удаляется из стека. Именно от этого стека мы получили название «трассировки стека».
Трассировка стека – это список функций, которые были вызваны до момента, когда в программе произошло исключение.
Она часто выглядит так:
Error: Uh oh!
at byDoingSomethingElse (/filesystem/aProgram.js:7:11)
at doAthing (/filesystem/aProgram.js:3:5)
at init (/filesystem/aProgram.js:12:9)
at Object.<anonymous> (/filesystem/aProgram.js:19:1)
at Module._compile (internal/modules/cjs/loader.js:689:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:700:10)
at Module.load (internal/modules/cjs/loader.js:599:32)
at tryModuleLoad (internal/modules/cjs/loader.js:538:12)
at Function.Module._load (internal/modules/cjs/loader.js:530:3)
at Function.Module.runMain (internal/modules/cjs/loader.js:742:12)
На этом этапе вам может быть интересно, как стек вызовов помогает нам с обработкой ошибок Node.js. Давайте поговорим о важности стеков вызовов.
Стек вызовов предоставляет «хлебные крошки», помогая проследить путь, который привел к исключению(ошибке).
Почему у нас должны быть функции без имен? Иногда в наших программах мы хотим определить маленькие одноразовые функции, которые выполняют небольшую задачу. Мы не хотим утруждать себя задачей давать им имена, но именно эти анонимные функции могут вызвать у нас всевозможные головные боли. Анонимная функция удаляет имя функции из нашего стека вызовов, что делает наш стек вызовов значительно более сложным в использовании.
Обратите внимание, что присвоить имена функциям в JavaScript не так просто. Итак, давайте кратко рассмотрим различные способы определения функций, и рассмотрим некоторые ловушки в именовании функций.
Как называть функции
Чтобы понять, как называть функции, давайте рассмотрим несколько примеров:
// анонимная функция
const one = () => {};
// анонимная функция
const two = function () {};
// функция с явным названием
const three = function explicitFunction() {};
Вот три примера функций.
Первая – это лямбда (или стрелочная функция). Лямбда функции по своей природе анонимны. Не запутайтесь. Имя переменной one не является именем функции. Имя функции следующее за ключевым словом function необязательно. Но в этом примере мы вообще ничего не передаем, поэтому наша функция анонимна.
Примечание
Не помогает и то, что некоторые среды выполнения JavaScript, такие как V8, могут иногда угадывать имя вашей функции. Это происходит, даже если вы его не даете.
Во втором примере мы получили функциональное выражение. Это очень похоже на первый пример. Это анонимная функция, но просто объявленная с помощью ключевого слова function вместо синтаксиса жирной стрелки.
В последнем примере объявление переменной с подходящим именем explicitFunction. Это показывает, что это единственная функция, у которой соответствующее имя.
Как правило, рекомендуется указывать это имя везде, где это возможно, чтобы иметь более удобочитаемую трассировку стека.
Обработка асинхронных исключений
Мы познакомились с объектом ошибок, ключевым словом throw, стеком вызовов и наименованием функций. Итак, давайте обратим наше внимание на любопытный случай обработки асинхронных ошибок. Почему? Потому что асинхронный код ведет себя не так, как ожидаем. Асинхронное программирование необходимо каждому программисту на Node.js.
Javascript – это однопоточный язык программирования, а это значит, что Javascript запускается с использованием одного процессора. Из этого следует, что у нас есть блокирующий и неблокирующий код. Блокирующий код относится к тому, будет ли ваша программа ожидать завершения асинхронной задачи, прежде чем делать что-либо еще. В то время как неблокирующий код относится к тому, где вы регистрируете обратный вызов (callback) для выполнения после завершения задачи.
Стоит упомянуть, что есть два основных способа обработки асинхронности в JavaScript: promises (обещания или промисы) и callback (функция обратного вызова). Мы намеренно игнорируем async/wait, чтобы избежать путаницы, потому что это просто сахар поверх промисов.
В статье мы сфокусируемся на промисах. Существует консенсус в отношении того, что для приложений промисы превосходят обратные вызовы с точки зрения стиля программирования и эффективности. Поэтому в этой статье проигнорируем подход с callback-ами, и предположим, что вместо него вы выберете promises.
Примечание
Существует множество способов конвертировать код на основе callback-ов в promises. Например, вы можете использовать такую утилиту, как promisify, или обернуть свои обратные вызовы в промисы, например, так:
var request = require('request'); //http wrapped module
function requestWrapper(url, callback) {
request.get(url, function (err, response) {
if (err) {
callback(err);
} else {
callback(null, response);
}
})
}
Мы разберемся с этой ошибкой, обещаю!
Давайте взглянем на анатомию обещаний.
Промисы в JavaScript – это объект, представляющий будущее значение. Promise API позволяют нам моделировать асинхронный код так же, как и синхронный. Также стоит отметить, что обещание обычно идет в цепочке, где выполняется одно действие, затем другое и так далее.
Но что все это значит для обработки ошибок Node.js?
Промисы элегантно обрабатывают ошибки и перехватывают любые ошибки, которые им предшествовали в цепочке. С помощью одного обработчика обрабатывается множество ошибок во многих функциях.
Изучим код ниже:
function getData() {
return Promise.resolve('Do some stuff');
}
function changeDataFormat() {
// ...
}
function storeData(){
// ...
}
getData()
.then(changeDataFormat)
.then(storeData)
.catch((e) => {
// Handle the error!
})
Здесь видно, как объединить обработку ошибок для трех различных функций в один обработчик, т. е. код ведет себя так же, как если бы три функции заключались в синхронный блок try/catch.
Отлавливать или не отлавливать?
На данном этапе стоит спросить себя, повсеместно ли добавляется .catch к промисам, поскольку это опционально. Из-за проблем с сетью, аппаратного сбоя или истекшего времени ожидания в асинхронных вызовах возникает исключение. По этим причинам указывайте программе, что делать в случаях невыполнения промиса.
Запомните «Золотое правило» – каждый раз обрабатывать исключения в обещаниях.
Риски асинхронного try/catch
Мы приближаемся к концу в нашем путешествии по обработке ошибок в Node.js. Пришло время поговорить о ловушках асинхронного кода и оператора try/catch.
Вам может быть интересно, почему промис предоставляет метод catch, и почему мы не можем просто обернуть нашу реализацию промиса в try/catch. Если бы вы сделали это, то результаты были бы не такими, как вы ожидаете.
Рассмотрим на примере:
try {
throw new Error();
} catch(e) {
console.log(e); // [Error]
}
try {
setTimeout(() => {
throw new Error();
}, 0);
} catch(e) {
console.log(e); // Nothing, nada, zero, zilch, not even a sound
}
try/catch по умолчанию синхронны, что означает, что если асинхронная функция выдает ошибку в синхронном блоке try/catch, ошибка не будет брошена.
Однозначно это не то, что ожидаем.
***
Подведем итог! Необходимо использовать обработчик промисов, когда мы имеем дело с асинхронным кодом, а в случае с синхронным кодом подойдет try/catch.
Заключение
Из этой статьи мы узнали:
- как устроен объект Error;
- научились создавать свои собственные ошибки;
- как работает стек вызовов;
- практики наименования функций, для удобочитаемой трассировки стека;
- как обрабатывать асинхронные исключения.
***
Материалы по теме
- 🗄️ 4 базовых функции для работы с файлами в Node.js
- Цикл событий: как выполняется асинхронный JavaScript-код в Node.js
- Обработка миллионов строк данных потоками на Node.js