
Как отмечалось в п.2.1, по ограниченным
данным выборки объема n можно
построить модель лишь с некоторой
точностью. её параметры a и b
являются оценками истинных значений α
и β, которые определяются генеральной
совокупностью объема N >> n.
Последней приписываются вероятностные
свойства с применением аксиом теории
вероятности, определений случайной
величины, вероятности, плотности
вероятности, оператора усреднения и
т.д. В рамках свойств генеральной
совокупности объема N рассматривается
спецификация модели линейной
регрессии
![]()
,
в
которой α, β, xi –
детерминированные (фиксированные или
известные) величины, а значения показателя
yi и ошибки модели i
– случайные величины (СВ) с
заданным распределением (например,
плотности вероятности). Часто yi,
i считаются
нормальными СВ (НСВ), тогда модель
называют нормальной.
Ограниченные данные выборки объема n
<< N позволяют вместо точной
модели (2.1) с параметрами α и β
построить приближенную модель (2.2)
![]()
.
Здесь еі – остатки
регрессии, вероятностные свойства
которых считаются аналогичными ошибкам
i , а
a, b – некоторые оценки (приближенные
значения) параметров модели.
Мы
будем оценивать дисперсии и
среднеквадратичные ошибки (СКО) для
оценок параметров модели и величины :
![]()
;
![]()
;
![]()
,
где M[X], D[X] – математическое
ожидание и дисперсия случайной величины
Х.
Для непрерывной случайной величины Х
с плотностью вероятности р(х)
они определяются как
![]()
,
![]()
.
Следовательно, для точного определения
того или иного параметра случайной
величины достаточно знать (или задать)
её распределение плотности вероятности.
2.4.1. Основные условия (гипотезы) анализа ошибок
Поскольку в корреляционно-регрессионном
анализе мы опираемся на методы
математической статистики и теории
вероятности, любые оценки ошибок
моделирования являются корректными
лишь при выполнении исходно принятых
условий (гипотез) в отношении величин
и переменных, входящих в модель. Примем
следующие гипотезы:
1. В спецификации модели (2.1) фактор х
и параметры модели α, β – детерминированные
величины, а показатель уi
и ошибки моделирования i
– случайные величины.
2. Ошибки моделирования имеют нулевое
среднее значение и некоррелированны:
![]()
Невыполнение второго условия называют
автокорреляцией ошибок модели.
3. Дисперсия ошибок моделирования i
показателя не зависят от номера i
(гомоскедастичность):
![]()
Невыполнение этого условия называют
гетероскедастичностью.
Дополнительным условием, которое может
не выполняться в ряде случаев, является
свойство нормальной модели:
4. Ошибки i
являются нормальными СВ:
N(0,
2) c нулевым
математическим ожиданием mε
= 0 и дисперсией 2.
2.4.2. Ошибки оценок параметров модели
Покажем сначала, что оценки МНК параметров
линейной модели являются несмещенными,
т.е. математические ожидания оценок
совпадают с истинными значениями
параметров:
M[b] = β, M[a] = α.
Действительно, согласно (2.12) и (2.7) имеем:

. (2.27)
С учетом (2.1), детерминированности vi
и условия
M[i]
= 0 гипотезы 2 получим в результате
усреднения оценки b в рамках
генеральной совокупности
![]()
.
Здесь использовано одно из свойств для
коэффициентов vi

(2.28)
которые
следуют из (2.27).
Аналогично, для параметра a с учетом
(2.6) и несмещенности b получим
![]()
.
Таким
образом, обе оценки МНК параметров
линейной модели являются несмещенными,
то есть сходятся при неограниченном
увеличении объема выборки к точным
значениям параметров α и β. Поэтому при
определении их дисперсий усредняются
квадраты разностей оценок и истинных
значений параметров.
Определим дисперсию коэффициента
регрессии. Известными свойствами
дисперсии СВ Х, умножаемой или
складываемой с константой с, являются:
![]()
. (2.29)
Тогда
с использованием (2.27) – (2.29)

.(2.30)
Здесь принято во внимание, что дисперсии
D[yi] =D[i],
так как показатель и ошибка модели
как случайные величины отличаются на
детерминированное слагаемое a+ bxi.
Дисперсию
постоянной составляющей модели определим
как
![]()
. (2.31)
Так как
![]()
. (2.32)
и
![]()
, (2.33)
то с
учетом (2.32), (2.33) дисперсия (2.31) становится
равной

. (2.34)
Более
сложным является определение оценки
дисперсии ошибок модели. Опуская вывод,
приведем окончательную формулу для
несмещенной оценки дисперсии ошибок
моделирования
![]()
, (2.35)
выраженную
через остатки регрессии (2.2).
Выражения (2.30), (2.34) дают точные значения
дисперсий оценок параметров модели,
однако практически воспользоваться
ими нельзя, так как точное значение
дисперсии ошибок 2
неизвестно (оно определяется из
генеральной совокупности, а не из
выборки). На основе выборочных данных
можно лишь оценить с помощью (2.35) эту
дисперсию. Поэтому на практике в формулы
(2.31), (2.35) вместо 2
подставляют её оценку (2.35) и получают
оценки дисперсий параметров b и a:

, (2.36)

. (2.37)
Эти
оценки используют лишь выборочные
данные. СКО этих оценок равны положительным
значениям квадратного корня из дисперсий.
В
лияние
СКО оценок параметров на точность модели
отражается на рис.2.5, а, б. Сдвиг
постоянной составляющей в пределах а
а
не является существенным при моделировании,
так как он не изменяется при всех
значениях фактора х и его можно
легко скорректировать. Более существенные
последствия имеет ошибка в определении
коэффициента регрессии b. Как видно
из рис.2.5, б, ошибки в прогнозах
показателя у* становятся тем
больше, чем больше отклонение от среднего
значения фактора х. Стандартное отклонение
у* b
имеет место при
![]()
.
В общем случае граничная ошибка регрессии
(с доверительной вероятностью 68%)
пропорциональна величине
![]()
.
Иначе говоря, чем больше отличается
значение фактора х при прогнозе от
среднего, тем больше можно ошибиться в
результате прогнозирования. Ясно также,
что СКО b
уменьшается с ростом объема выборки n,
так как растет число положительных
слагаемых в знаменателе (2.36).

а б
Рис.2.5
Пример 2.2. Оценим
СКО и доверительные интервалы оценок
параметров модели примера 2.1 для малой
выборки объема n
= 5, приняв доверительную вероятность Р
= 0,954.
Оценка дисперсии
ошибок модели согласно (2.36) и расчетов,
приведенных в таблице 2.1, равна
![]()
.
Тогда СКО оценок
b
= 0,588 a
= – 0,529 параметров модели в соответствии
с (2.37), (2.38) равны
![]()
.
Ошибки оказались
сравнительно большими в связи с малым
объемом выборки (n
= 5). Найденные значения СКО являются
точечными ошибками оценок параметров.
Определим далее доверительные интервалы
этих оценок. Для нормальной модели
граничная ошибка равна
Δ = tσ,
где
параметр доверия t
= 1 при доверительной вероятности Р
= 0,68,
t = 2
при Р
= 0,954,
t =
3 при Р
= 0,997.
В нашем примере
t = 2
(Р
= 0,954), Δb
= 0,256, Δa
= 1,678,
тогда
доверительные интервалы для истинных
значений параметров
и α с границами b
Δb,
a
Δa
определяются как
[0,332; 0,844],
α
[ – 2,207; 1,149].
Это значит, что
при доверительной вероятности 95,4%
коэффициент регрессии
b (и,
соответственно, наклон прямой линии
модели) может измениться более чем в
2,5 раза, а девиация (отклонение) постоянной
составляющей а
близка к
1,7 у.е. Очевидно, подобные ошибки малой
выборки неприемлемы для практических
целей, поэтому реальные объемы выборки
должны составлять десятки, сотни и более
элементов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Когда мы подгоняем регрессионную модель к набору данных, нас часто интересует, насколько хорошо регрессионная модель «подходит» к набору данных. Две метрики, обычно используемые для измерения согласия, включают R -квадрат (R2) и стандартную ошибку регрессии , часто обозначаемую как S.
В этом руководстве объясняется, как интерпретировать стандартную ошибку регрессии (S), а также почему она может предоставить более полезную информацию, чем R 2 .
Стандартная ошибка по сравнению с R-квадратом в регрессии
Предположим, у нас есть простой набор данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их баллы за экзамен:

Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:

R-квадрат — это доля дисперсии переменной отклика, которая может быть объяснена предикторной переменной. При этом 65,76% дисперсии экзаменационных баллов можно объяснить количеством часов, потраченных на учебу.
Стандартная ошибка регрессии — это среднее расстояние, на которое наблюдаемые значения отклоняются от линии регрессии. В этом случае наблюдаемые значения отклоняются от линии регрессии в среднем на 4,89 единицы.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:

Обратите внимание, что некоторые наблюдения попадают очень близко к линии регрессии, в то время как другие не так близки. Но в среднем наблюдаемые значения отклоняются от линии регрессии на 4,19 единицы .
Стандартная ошибка регрессии особенно полезна, поскольку ее можно использовать для оценки точности прогнозов. Примерно 95% наблюдений должны находиться в пределах +/- двух стандартных ошибок регрессии, что является быстрым приближением к 95% интервалу прогнозирования.
Если мы заинтересованы в прогнозировании с использованием модели регрессии, стандартная ошибка регрессии может быть более полезной метрикой, чем R-квадрат, потому что она дает нам представление о том, насколько точными будут наши прогнозы в единицах измерения.
Чтобы проиллюстрировать, почему стандартная ошибка регрессии может быть более полезной метрикой для оценки «соответствия» модели, рассмотрим другой пример набора данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их экзаменационная оценка:

Обратите внимание, что это точно такой же набор данных, как и раньше, за исключением того, что все значения s сокращены вдвое.Таким образом, студенты из этого набора данных учились ровно в два раза дольше, чем студенты из предыдущего набора данных, и получили ровно половину экзаменационного балла.
Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:

Обратите внимание, что R-квадрат 65,76% точно такой же, как и в предыдущем примере.
Однако стандартная ошибка регрессии составляет 2,095 , что ровно вдвое меньше стандартной ошибки регрессии в предыдущем примере.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:

Обратите внимание на то, что наблюдения располагаются гораздо плотнее вокруг линии регрессии. В среднем наблюдаемые значения отклоняются от линии регрессии на 2,095 единицы .
Таким образом, несмотря на то, что обе модели регрессии имеют R-квадрат 65,76% , мы знаем, что вторая модель будет давать более точные прогнозы, поскольку она имеет более низкую стандартную ошибку регрессии.
Преимущества использования стандартной ошибки
Стандартную ошибку регрессии (S) часто бывает полезнее знать, чем R-квадрат модели, потому что она дает нам фактические единицы измерения. Если мы заинтересованы в использовании регрессионной модели для получения прогнозов, S может очень легко сказать нам, достаточно ли точна модель для прогнозирования.
Например, предположим, что мы хотим создать 95-процентный интервал прогнозирования, в котором мы можем прогнозировать результаты экзаменов с точностью до 6 баллов от фактической оценки.
Наша первая модель имеет R-квадрат 65,76%, но это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. К счастью, мы также знаем, что у первой модели показатель S равен 4,19. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*4,19 = +/- 8,38 единиц, что слишком велико для нашего интервала прогнозирования.
Наша вторая модель также имеет R-квадрат 65,76%, но опять же это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. Однако мы знаем, что вторая модель имеет S 2,095. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*2,095= +/- 4,19 единиц, что меньше 6 и, следовательно, будет достаточно точным для использования для создания интервалов прогнозирования.
Дальнейшее чтение
Введение в простую линейную регрессию
Что такое хорошее значение R-квадрата?
Ошибки, встроенные в систему: их роль в статистике
Время на прочтение
6 мин
Количество просмотров 13K
В прошлой статье я указал, как распространена проблема неправильного использования t-критерия в научных публикациях (и это возможно сделать только благодаря их открытости, а какой трэш творится при его использовании во всяких курсовых, отчетах, обучающих задачах и т.д. — неизвестно). Чтобы обсудить это, я рассказал об основах дисперсионного анализа и задаваемом самим исследователем уровне значимости α. Но для полного понимания всей картины статистического анализа необходимо подчеркнуть ряд важных вещей. И самая основная из них — понятие ошибки.
Ошибка и некорректное применение: в чем разница?
В любой физической системе содержится какая-либо ошибка, неточность. В самой разнообразной форме: так называемый допуск — отличие в размерах разных однотипных изделий; нелинейная характеристика — когда прибор или метод измеряют что-то по строго известному закону в определенных пределах, а дальше становятся неприменимыми; дискретность — когда мы чисто технически не можем обеспечить плавность выходной характеристики.
И в то же время существует чисто человеческая ошибка — некорректное использование устройств, приборов, математических законов. Между ошибкой, присущей системе, и ошибкой применения этой системы есть принципиальная разница. Важно различать и не путать между собой эти два понятия, называемые одним и тем же словом «ошибка». Я в данной статье предпочитаю использовать слово «ошибка» для обозначения свойства системы, а «некорректное применение» — для ошибочного ее использования.
То есть, ошибка линейки равна допуску оборудования, наносящего штрихи на ее полотно. А ошибкой в смысле некорректного применения было бы использовать ее при измерении деталей наручных часов. Ошибка безмена написана на нем и составляет что-то около 50 граммов, а неправильным использованием безмена было бы взвешивание на нем мешка в 25 кг, который растягивает пружину из области закона Гука в область пластических деформаций. Ошибка атомно-силового микроскопа происходит из его дискретности — нельзя «пощупать» его зондом предметы мельче, чем диаметром в один атом. Но способов неправильно использовать его или неправильно интерпретировать данные существует множество. И так далее.
Так, а что же за ошибка имеет место в статистических методах? А этой ошибкой как раз и является пресловутый уровень значимости α.
Ошибки первого и второго рода
Ошибкой в математическом аппарате статистики является сама ее Байесовская вероятностная сущность. В прошлой статье я уже упоминал, на чем стоят статистические методы: определение уровня значимости α как наибольшей допустимой вероятности неправомерно отвергнуть нулевую гипотезу, и самостоятельное задание исследователем этой величины перед исследователем.
Вы уже видите эту условность? На самом деле, в критериальных методах нету привычной математической строгости. Математика здесь оперирует вероятностными характеристиками.
И тут наступает еще один момент, где возможна неправильная трактовка одного слова в разном контексте. Необходимо различать само понятие вероятности и фактическую реализацию события, выражающуюся в распределении вероятности. Например, перед началом любого нашего эксперимента мы не знаем, какую именно величину мы получим в результате. Есть два возможных исхода: загадав некоторое значение результата, мы либо действительно его получим, либо не получим. Логично, что вероятность и того, и другого события равна 1/2. Но показанная в предыдущей статье Гауссова кривая показывает распределение вероятности того, что мы правильно угадаем совпадение.
Наглядно можно проиллюстрировать это примером. Пусть мы 600 раз бросаем два игральных кубика — обычный и шулерский. Получим следующие результаты:

До эксперимента для обоих кубиков выпадение любой грани будет равновероятно — 1/6. Однако после эксперимента проявляется сущность шулерского кубика, и мы можем сказать, что плотность вероятности выпадения на нем шестерки — 90%.
Другой пример, который знают химики, физики и все, кто интересуется квантовыми эффектами — атомные орбитали. Теоретически электрон может быть «размазан» в пространстве и находиться практически где угодно. Но на практике есть области, где он будет находиться в 90 и более процентах случаев. Эти области пространства, образованные поверхностью с плотностью вероятности нахождения там электрона 90%, и есть классические атомные орбитали, в виде сфер, гантелей и т.д.
Так вот, самостоятельно задавая уровень значимости, мы заведомо соглашаемся на описанную в его названии ошибку. Из-за этого ни один результат нельзя считать «стопроцентно достоверным» — всегда наши статистические выводы будут содержать некоторую вероятность сбоя.
Ошибка, формулируемая определением уровня значимости α, называется ошибкой первого рода. Ее можно определить, как «ложная тревога», или, более корректно, ложноположительный результат. В самом деле, что означают слова «ошибочно отвергнуть нулевую гипотезу»? Это значит, по ошибке принять наблюдаемые данные за значимые различия двух групп. Поставить ложный диагноз о наличии болезни, поспешить явить миру новое открытие, которого на самом деле нет — вот примеры ошибок первого рода.
Но ведь тогда должны быть и ложноотрицательные результаты? Совершенно верно, и они называются ошибками второго рода. Примеры — не поставленный вовремя диагноз или же разочарование в результате исследования, хотя на самом деле в нем есть важные данные. Ошибки второго рода обозначаются буквой, как ни странно, β. Но само это понятие не так важно для статистики, как число 1-β. Число 1-β называется мощностью критерия, и как нетрудно догадаться, оно характеризует способность критерия не упустить значимое событие.
Однако содержание в статистических методах ошибок первого и второго рода не является только лишь их ограничением. Само понятие этих ошибок может использоваться непосредственным образом в статистическом анализе. Как?
ROC-анализ
ROC-анализ (от receiver operating characteristic, рабочая характеристика приёмника) — это метод количественного определения применимости некоторого признака к бинарной классификации объектов. Говоря проще, мы можем придумать некоторый способ, как отличить больных людей от здоровых, кошек от собак, черное от белого, а затем проверить правомерность такого способа. Давайте снова обратимся к примеру.
Пусть вы — подающий надежды криминалист, и разрабатываете новый способ скрытно и однозначно определять, является ли человек преступником. Вы придумали количественный признак: оценивать преступные наклонности людей по частоте прослушивания ими Михаила Круга. Но будет ли давать адекватные результаты ваш признак? Давайте разбираться.
Вам понадобится две группы людей для валидации вашего критерия: обычные граждане и преступники. Положим, действительно, среднегодовое время прослушивания ими Михаила Круга различается (см. рисунок):

Здесь мы видим, что по количественному признаку времени прослушивания наши выборки пересекаются. Кто-то слушает Круга спонтанно по радио, не совершая преступлений, а кто-то нарушает закон, слушая другую музыку или даже будучи глухим. Какие у нас есть граничные условия? ROC-анализ вводит понятия селективности (чувствительности) и специфичности. Чувствительность определяется как способность выявлять все-все интересующие нас точки (в данном примере — преступников), а специфичность — не захватывать ничего ложноположительного (не ставить под подозрение простых обывателей). Мы можем задать некоторую критическую количественную черту, отделяющую одних от других (оранжевая), в пределах от максимальной чувствительности (зеленая) до максимальной специфичности (красная).
Посмотрим на следующую схему:
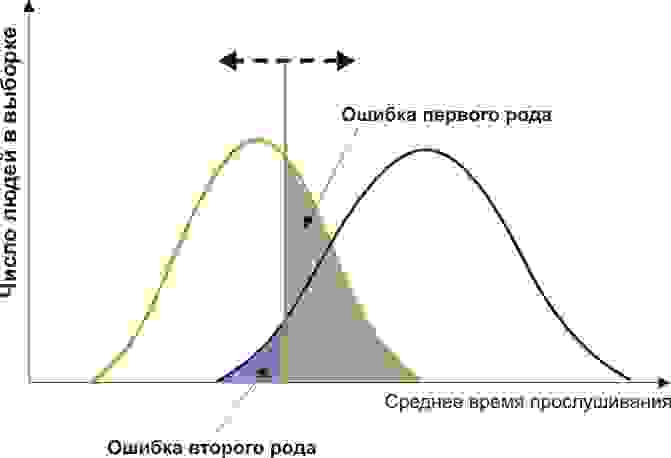
Смещая значение нашего признака, мы меняем соотношения ложноположительного и ложноотрицательного результатов (площади под кривыми). Точно так же мы можем дать определения Чувствительность = Полож. рез-т/(Полож. рез-т + ложноотриц. рез-т) и Специфичность = Отриц. рез-т/(Отриц. рез-т + ложноположит. рез-т).
Но главное, мы можем оценить соотношение положительных результатов к ложноположительным на всем отрезке значений нашего количественного признака, что и есть наша искомая ROC-кривая (см. рисунок):
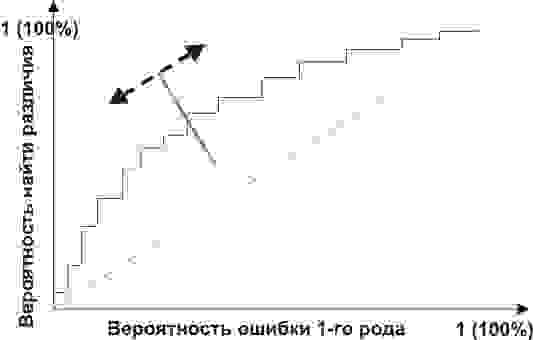
А как нам понять из этого графика, насколько хорош наш признак? Очень просто, посчитать площадь под кривой (AUC, area under curve). Пунктирная линия (0,0; 1,1) означает полное совпадение двух выборок и совершенно бессмысленный критерий (площадь под кривой равна 0,5 от всего квадрата). А вот выпуклость ROC кривой как раз и говорит о совершенстве критерия. Если же нам удастся найти такой критерий, что выборки вообще не будут пересекаться, то площадь под кривой займет весь график. В целом же признак считается хорошим, позволяющим надежно отделить одну выборку от другой, если AUC > 0,75-0,8.
С помощью такого анализа вы можете решать самые разные задачи. Решив, что слишком много домохозяек оказались под подозрением из-за Михаила Круга, а кроме того упущены опасные рецидивисты, слушающие Ноггано, вы можете отвергнуть этот критерий и разработать другой.
Возникнув, как способ обработки радиосигналов и идентификации «свой-чужой» после атаки на Перл-Харбор (отсюда и пошло такое странное название про характеристику приемника), ROC-анализ нашел широкое применение в биомедицинской статистике для анализа, валидации, создания и характеристики панелей биомаркеров и т.д. Он гибок в использовании, если оно основано на грамотной логике. Например, вы можете разработать показания для медицинской диспансеризации пенсионеров-сердечников, применив высокоспецифичный критерий, повысив эффективность выявления болезней сердца и не перегружая врачей лишними пациентами. А во время опасной эпидемии ранее неизвестного вируса вы наоборот, можете придумать высокоселективный критерий, чтобы от вакцинации в прямом смысле не ускользнул ни один чих.
С ошибками обоих родов и их наглядностью в описании валидируемых критериев мы познакомились. Теперь же, двигаясь от этих логических основ, можно разрушить ряд ложных стереотипных описаний результатов. Некоторые неправильные формулировки захватывают наши умы, часто путаясь своими схожими словами и понятиями, а также из-за очень малого внимания, уделяемого неверной интерпретации. Об этом, пожалуй, нужно будет написать отдельно.
From Wikipedia, the free encyclopedia
In statistics and optimization, errors and residuals are two closely related and easily confused measures of the deviation of an observed value of an element of a statistical sample from its «true value» (not necessarily observable). The error of an observation is the deviation of the observed value from the true value of a quantity of interest (for example, a population mean). The residual is the difference between the observed value and the estimated value of the quantity of interest (for example, a sample mean). The distinction is most important in regression analysis, where the concepts are sometimes called the regression errors and regression residuals and where they lead to the concept of studentized residuals.
In econometrics, «errors» are also called disturbances.[1][2][3]
Introduction[edit]
Suppose there is a series of observations from a univariate distribution and we want to estimate the mean of that distribution (the so-called location model). In this case, the errors are the deviations of the observations from the population mean, while the residuals are the deviations of the observations from the sample mean.
A statistical error (or disturbance) is the amount by which an observation differs from its expected value, the latter being based on the whole population from which the statistical unit was chosen randomly. For example, if the mean height in a population of 21-year-old men is 1.75 meters, and one randomly chosen man is 1.80 meters tall, then the «error» is 0.05 meters; if the randomly chosen man is 1.70 meters tall, then the «error» is −0.05 meters. The expected value, being the mean of the entire population, is typically unobservable, and hence the statistical error cannot be observed either.
A residual (or fitting deviation), on the other hand, is an observable estimate of the unobservable statistical error. Consider the previous example with men’s heights and suppose we have a random sample of n people. The sample mean could serve as a good estimator of the population mean. Then we have:
- The difference between the height of each man in the sample and the unobservable population mean is a statistical error, whereas
- The difference between the height of each man in the sample and the observable sample mean is a residual.
Note that, because of the definition of the sample mean, the sum of the residuals within a random sample is necessarily zero, and thus the residuals are necessarily not independent. The statistical errors, on the other hand, are independent, and their sum within the random sample is almost surely not zero.
One can standardize statistical errors (especially of a normal distribution) in a z-score (or «standard score»), and standardize residuals in a t-statistic, or more generally studentized residuals.
In univariate distributions[edit]
If we assume a normally distributed population with mean μ and standard deviation σ, and choose individuals independently, then we have

and the sample mean

is a random variable distributed such that:

The statistical errors are then

with expected values of zero,[4] whereas the residuals are

The sum of squares of the statistical errors, divided by σ2, has a chi-squared distribution with n degrees of freedom:

However, this quantity is not observable as the population mean is unknown. The sum of squares of the residuals, on the other hand, is observable. The quotient of that sum by σ2 has a chi-squared distribution with only n − 1 degrees of freedom:

This difference between n and n − 1 degrees of freedom results in Bessel’s correction for the estimation of sample variance of a population with unknown mean and unknown variance. No correction is necessary if the population mean is known.
[edit]
It is remarkable that the sum of squares of the residuals and the sample mean can be shown to be independent of each other, using, e.g. Basu’s theorem. That fact, and the normal and chi-squared distributions given above form the basis of calculations involving the t-statistic:

where  represents the errors,
represents the errors,  represents the sample standard deviation for a sample of size n, and unknown σ, and the denominator term
represents the sample standard deviation for a sample of size n, and unknown σ, and the denominator term  accounts for the standard deviation of the errors according to:[5]
accounts for the standard deviation of the errors according to:[5]

The probability distributions of the numerator and the denominator separately depend on the value of the unobservable population standard deviation σ, but σ appears in both the numerator and the denominator and cancels. That is fortunate because it means that even though we do not know σ, we know the probability distribution of this quotient: it has a Student’s t-distribution with n − 1 degrees of freedom. We can therefore use this quotient to find a confidence interval for μ. This t-statistic can be interpreted as «the number of standard errors away from the regression line.»[6]
Regressions[edit]
In regression analysis, the distinction between errors and residuals is subtle and important, and leads to the concept of studentized residuals. Given an unobservable function that relates the independent variable to the dependent variable – say, a line – the deviations of the dependent variable observations from this function are the unobservable errors. If one runs a regression on some data, then the deviations of the dependent variable observations from the fitted function are the residuals. If the linear model is applicable, a scatterplot of residuals plotted against the independent variable should be random about zero with no trend to the residuals.[5] If the data exhibit a trend, the regression model is likely incorrect; for example, the true function may be a quadratic or higher order polynomial. If they are random, or have no trend, but «fan out» — they exhibit a phenomenon called heteroscedasticity. If all of the residuals are equal, or do not fan out, they exhibit homoscedasticity.
However, a terminological difference arises in the expression mean squared error (MSE). The mean squared error of a regression is a number computed from the sum of squares of the computed residuals, and not of the unobservable errors. If that sum of squares is divided by n, the number of observations, the result is the mean of the squared residuals. Since this is a biased estimate of the variance of the unobserved errors, the bias is removed by dividing the sum of the squared residuals by df = n − p − 1, instead of n, where df is the number of degrees of freedom (n minus the number of parameters (excluding the intercept) p being estimated — 1). This forms an unbiased estimate of the variance of the unobserved errors, and is called the mean squared error.[7]
Another method to calculate the mean square of error when analyzing the variance of linear regression using a technique like that used in ANOVA (they are the same because ANOVA is a type of regression), the sum of squares of the residuals (aka sum of squares of the error) is divided by the degrees of freedom (where the degrees of freedom equal n − p − 1, where p is the number of parameters estimated in the model (one for each variable in the regression equation, not including the intercept)). One can then also calculate the mean square of the model by dividing the sum of squares of the model minus the degrees of freedom, which is just the number of parameters. Then the F value can be calculated by dividing the mean square of the model by the mean square of the error, and we can then determine significance (which is why you want the mean squares to begin with.).[8]
However, because of the behavior of the process of regression, the distributions of residuals at different data points (of the input variable) may vary even if the errors themselves are identically distributed. Concretely, in a linear regression where the errors are identically distributed, the variability of residuals of inputs in the middle of the domain will be higher than the variability of residuals at the ends of the domain:[9] linear regressions fit endpoints better than the middle. This is also reflected in the influence functions of various data points on the regression coefficients: endpoints have more influence.
Thus to compare residuals at different inputs, one needs to adjust the residuals by the expected variability of residuals, which is called studentizing. This is particularly important in the case of detecting outliers, where the case in question is somehow different from the others in a dataset. For example, a large residual may be expected in the middle of the domain, but considered an outlier at the end of the domain.
Other uses of the word «error» in statistics[edit]
The use of the term «error» as discussed in the sections above is in the sense of a deviation of a value from a hypothetical unobserved value. At least two other uses also occur in statistics, both referring to observable prediction errors:
The mean squared error (MSE) refers to the amount by which the values predicted by an estimator differ from the quantities being estimated (typically outside the sample from which the model was estimated).
The root mean square error (RMSE) is the square-root of MSE.
The sum of squares of errors (SSE) is the MSE multiplied by the sample size.
Sum of squares of residuals (SSR) is the sum of the squares of the deviations of the actual values from the predicted values, within the sample used for estimation. This is the basis for the least squares estimate, where the regression coefficients are chosen such that the SSR is minimal (i.e. its derivative is zero).
Likewise, the sum of absolute errors (SAE) is the sum of the absolute values of the residuals, which is minimized in the least absolute deviations approach to regression.
The mean error (ME) is the bias.
The mean residual (MR) is always zero for least-squares estimators.
See also[edit]
- Absolute deviation
- Consensus forecasts
- Error detection and correction
- Explained sum of squares
- Innovation (signal processing)
- Lack-of-fit sum of squares
- Margin of error
- Mean absolute error
- Observational error
- Propagation of error
- Probable error
- Random and systematic errors
- Reduced chi-squared statistic
- Regression dilution
- Root mean square deviation
- Sampling error
- Standard error
- Studentized residual
- Type I and type II errors
References[edit]
- ^ Kennedy, P. (2008). A Guide to Econometrics. Wiley. p. 576. ISBN 978-1-4051-8257-7. Retrieved 2022-05-13.
- ^ Wooldridge, J.M. (2019). Introductory Econometrics: A Modern Approach. Cengage Learning. p. 57. ISBN 978-1-337-67133-0. Retrieved 2022-05-13.
- ^ Das, P. (2019). Econometrics in Theory and Practice: Analysis of Cross Section, Time Series and Panel Data with Stata 15.1. Springer Singapore. p. 7. ISBN 978-981-329-019-8. Retrieved 2022-05-13.
- ^ Wetherill, G. Barrie. (1981). Intermediate statistical methods. London: Chapman and Hall. ISBN 0-412-16440-X. OCLC 7779780.
- ^ a b Frederik Michel Dekking; Cornelis Kraaikamp; Hendrik Paul Lopuhaä; Ludolf Erwin Meester (2005-06-15). A modern introduction to probability and statistics : understanding why and how. London: Springer London. ISBN 978-1-85233-896-1. OCLC 262680588.
- ^ Peter Bruce; Andrew Bruce (2017-05-10). Practical statistics for data scientists : 50 essential concepts (First ed.). Sebastopol, CA: O’Reilly Media Inc. ISBN 978-1-4919-5296-2. OCLC 987251007.
- ^ Steel, Robert G. D.; Torrie, James H. (1960). Principles and Procedures of Statistics, with Special Reference to Biological Sciences. McGraw-Hill. p. 288.
- ^ Zelterman, Daniel (2010). Applied linear models with SAS ([Online-Ausg.]. ed.). Cambridge: Cambridge University Press. ISBN 9780521761598.
- ^ «7.3: Types of Outliers in Linear Regression». Statistics LibreTexts. 2013-11-21. Retrieved 2019-11-22.
- Cook, R. Dennis; Weisberg, Sanford (1982). Residuals and Influence in Regression (Repr. ed.). New York: Chapman and Hall. ISBN 041224280X. Retrieved 23 February 2013.
- Cox, David R.; Snell, E. Joyce (1968). «A general definition of residuals». Journal of the Royal Statistical Society, Series B. 30 (2): 248–275. JSTOR 2984505.
- Weisberg, Sanford (1985). Applied Linear Regression (2nd ed.). New York: Wiley. ISBN 9780471879572. Retrieved 23 February 2013.
- «Errors, theory of», Encyclopedia of Mathematics, EMS Press, 2001 [1994]
External links[edit]
 Media related to Errors and residuals at Wikimedia Commons
Media related to Errors and residuals at Wikimedia Commons
Когда мы подгоняем регрессионную модель к набору данных, нас часто интересует, насколько хорошо регрессионная модель «подходит» к набору данных. Две метрики, обычно используемые для измерения согласия, включают R -квадрат (R2) и стандартную ошибку регрессии , часто обозначаемую как S.
В этом руководстве объясняется, как интерпретировать стандартную ошибку регрессии (S), а также почему она может предоставить более полезную информацию, чем R 2 .
Стандартная ошибка по сравнению с R-квадратом в регрессии
Предположим, у нас есть простой набор данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их баллы за экзамен:
Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:
R-квадрат — это доля дисперсии переменной отклика, которая может быть объяснена предикторной переменной. При этом 65,76% дисперсии экзаменационных баллов можно объяснить количеством часов, потраченных на учебу.
Стандартная ошибка регрессии — это среднее расстояние, на которое наблюдаемые значения отклоняются от линии регрессии. В этом случае наблюдаемые значения отклоняются от линии регрессии в среднем на 4,89 единицы.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:
Обратите внимание, что некоторые наблюдения попадают очень близко к линии регрессии, в то время как другие не так близки. Но в среднем наблюдаемые значения отклоняются от линии регрессии на 4,19 единицы .
Стандартная ошибка регрессии особенно полезна, поскольку ее можно использовать для оценки точности прогнозов. Примерно 95% наблюдений должны находиться в пределах +/- двух стандартных ошибок регрессии, что является быстрым приближением к 95% интервалу прогнозирования.
Если мы заинтересованы в прогнозировании с использованием модели регрессии, стандартная ошибка регрессии может быть более полезной метрикой, чем R-квадрат, потому что она дает нам представление о том, насколько точными будут наши прогнозы в единицах измерения.
Чтобы проиллюстрировать, почему стандартная ошибка регрессии может быть более полезной метрикой для оценки «соответствия» модели, рассмотрим другой пример набора данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их экзаменационная оценка:
Обратите внимание, что это точно такой же набор данных, как и раньше, за исключением того, что все значения s сокращены вдвое.Таким образом, студенты из этого набора данных учились ровно в два раза дольше, чем студенты из предыдущего набора данных, и получили ровно половину экзаменационного балла.
Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:
Обратите внимание, что R-квадрат 65,76% точно такой же, как и в предыдущем примере.
Однако стандартная ошибка регрессии составляет 2,095 , что ровно вдвое меньше стандартной ошибки регрессии в предыдущем примере.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:
Обратите внимание на то, что наблюдения располагаются гораздо плотнее вокруг линии регрессии. В среднем наблюдаемые значения отклоняются от линии регрессии на 2,095 единицы .
Таким образом, несмотря на то, что обе модели регрессии имеют R-квадрат 65,76% , мы знаем, что вторая модель будет давать более точные прогнозы, поскольку она имеет более низкую стандартную ошибку регрессии.
Преимущества использования стандартной ошибки
Стандартную ошибку регрессии (S) часто бывает полезнее знать, чем R-квадрат модели, потому что она дает нам фактические единицы измерения. Если мы заинтересованы в использовании регрессионной модели для получения прогнозов, S может очень легко сказать нам, достаточно ли точна модель для прогнозирования.
Например, предположим, что мы хотим создать 95-процентный интервал прогнозирования, в котором мы можем прогнозировать результаты экзаменов с точностью до 6 баллов от фактической оценки.
Наша первая модель имеет R-квадрат 65,76%, но это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. К счастью, мы также знаем, что у первой модели показатель S равен 4,19. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*4,19 = +/- 8,38 единиц, что слишком велико для нашего интервала прогнозирования.
Наша вторая модель также имеет R-квадрат 65,76%, но опять же это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. Однако мы знаем, что вторая модель имеет S 2,095. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*2,095= +/- 4,19 единиц, что меньше 6 и, следовательно, будет достаточно точным для использования для создания интервалов прогнозирования.
Дальнейшее чтение
Введение в простую линейную регрессию
Что такое хорошее значение R-квадрата?
1.2.1. Стандартная ошибка оценки по регрессии
Обозначается как
Sy,xи вычисляется по формуле
Sy,x=![]() .
.
Стандартная ошибка
оценки по регрессии показывает, на
сколько в среднем мы ошибаемся, оценивая
значение зависимой переменной по
найденному уравнению регрессии при
фиксированном значении независимой
переменной.
Квадрат стандартной
ошибки по регрессии является несмещенной
оценкой дисперсии ![]() 2,
2,
т.е.
![]() =
=
![]() =
=![]() .
.
Дисперсия ошибок
характеризует воздействие в модели
(1.1) неучтенных факторов и ошибок.
1.2.2. Оценка
значимости уравнения регрессии
(дисперсионный анализ регрессии)
Для оценки
значимости уравнения регрессии
устанавливают, соответствует ли выбранная
модель анализируемым данным. Для этого
используется дисперсионный анализ
регрессии. Основная его посылка – это
разложение общей суммы квадратов
отклонений
![]() на
на
составляющие. Известно, что такое
разложение имеет вид
![]() =
=![]() +
+![]() .
.
Второе слагаемое
в правой части разложения – это часть
общей суммы квадратов отклонений,
объясняемая действием случайных и
неучтенных факторов. Первое слагаемое
этого разложения – это часть общей
суммы квадратов отклонений, объясняемая
регрессионной зависимостью. Следовательно,
если регрессионная зависимость между
уихотсутствует, то
общая сумма квадратов отклонений
объясняется действием только случайных
факторов или ошибок, т.е.![]() =
=![]() .
.
В случае функциональной зависимости
между уихдействие
случайных факторов и ошибок отсутствует
и тогда![]() =
=![]() .
.
Будучи отнесенными к соответствующему
числу степеней свободы, эти суммы
называются средними квадратами отклонений
и служат оценками дисперсии![]() в
в
разных предположениях.
MSE= (![]() )/(n–2)
)/(n–2)
– остаточная дисперсия, которая является
оценкой![]() в
в
предположении отсутствия регрессионной
зависимости, аMSR= (![]() )/1
)/1
– аналогичная оценка без этого
предположения. Следовательно, если
регрессионная зависимость отсутствует,
то эти оценки должны быть близкими.
Сравниваются они на основе критерия
Фишера:F=MSR/MSE.
Расчетное значение
этого критерия сравнивается с критическим
значением F(с числом степеней свободы числителя,
равным 1, числом степеней свободы
знаменателя, равнымn–2,
и фиксированным уровнем значимости![]() ).
).
ЕслиF![]() <F, то гипотеза о не значимости
<F, то гипотеза о не значимости
уравнения регрессии не отклоняется, т.
е. признается, что уравнение регрессии
незначимо. В этом случае надо либо
изменить вид зависимости, либо пересмотреть
набор исходных данных.
При компьютерных
расчетах оценка значимости уравнения
регрессии осуществляется на основе
дисперсионного анализа регрессии в
таблицах вида:
Таблица
1.1
Дисперсионный
анализ регрессии
|
Источник вариации |
Суммы квадратов |
Степени свободы |
Средние квадраты |
F-отношение |
p-value |
|
Модель |
SSR |
1 |
MSR |
MSR/MSE |
Уровень |
|
Ошибки |
SSE |
n–2 |
MSE |
значимости |
|
|
общая |
SST |
n–1 |
Здесь p-value– это вероятность выполнения неравенстваF<F![]() ,
,
т. е. того, что расчетное значениеF-статистики попало в
область принятия гипотезы. Если эта
вероятность мала (меньше![]() ),
),
то нулевая гипотеза отклоняется.
Для множественной регрессии формула несмещенной оценки дисперсии случайной ошибки имеет вид
begin{equation*} widehat {sigma ^2}=S^2=frac 1{n-k}{ast}sum _{i=1}^ne_i^2 end{equation*}
Она почти такая же, как для парной регрессии за тем исключением, что в знаменателе вместо выражения (left(n-2right)) стоит (left(n-kright)). Если извлечь корень из этой величины, то можно получить стандартную ошибку регрессии
begin{equation*} mathit{SEE}=sqrt{S^2}=sqrt{frac 1{n-k}{ast}sum _{i=1}^ne_i^2} end{equation*}
Расчет стандартной ошибки регрессии — это один из способов оценить точность вашей модели в целом. То есть оценить, насколько хорошо она соответствует данным. Чем меньше стандартная ошибка регрессии, тем лучше ваша модель соответствует доступным вам наблюдениям.
Следующая характеристика качества подгонки — это коэффициент детерминации (R^2).
Для множественной регрессии с константой так же, как и для парной, верно, что общая сумма квадратов может быть представлена как сумма квадратов остатков и объясненная сумма квадратов:
begin{equation*} sum _{i=1}^nleft(y_i-overline yright)^2=sum _{i=1}^ne_i^2+sum _{i=1}^nleft(widehat y_i-overline yright)^2 end{equation*}
Поэтому и (R^2) может быть рассчитан в точности таким же образом, как и для модели парной регрессии:
begin{equation*} R^2=1-frac{sum _{i=1}^ne_i^2}{sum _{i=1}^nleft(y_i-overline yright)^2}=frac{sum _{i=1}^nleft(widehat y_i-overline yright)^2}{sum _{i=1}^nleft(y_i-overline yright)^2}=frac{widehat {mathit{Var}}left(widehat yright)}{widehat {mathit{Var}}left(yright)} end{equation*}
И точно так же, как и в случае парной регрессии, он будет лежать между нулем и единицей. Если ваша модель хорошо соответствует данным, то (R^2) будет близок к единице, если нет, то к нулю. Ещё раз подчеркнем, что условие (sum _{i=1}^nleft(y_i-overline yright)^2=sum _{i=1}^ne_i^2+sum _{i=1}^nleft(widehat y_i-overline yright)^2) выполняется только тогда, когда в модели есть константа. Если же ее нет, то указанное равенство, вообще говоря, неверно, и (R^2) не обязан лежать между нулем и единицей, и интерпретировать стандартным образом его нельзя.
Некоторые эконометристы старой школы придают важное значение величине коэффициента (R^2). Действительно, если он близок к единице, то это, как правило, приятная новость. Однако не стоит переоценивать эту характеристику качества модели потому, что у коэффициента (R^2) есть существенные ограничения:
- Высокий (R^2) характеризует наличие множественной корреляции между регрессорами и зависимой переменной, но ничего не говорит о наличии или отсутствии причинно-следственной связи между анализируемыми переменными. Вспомните примеры из первой главы, где мы обсуждали, что высокая корреляция не гарантирует причинно-следственной связи.
- (R^2) не может быть использован для принятия решения о том, стоит ли добавлять в модель новые переменные или нет. Дело в том, что, когда вы добавляете новые переменные в ваше уравнение, качество подгонки данных не может стать хуже, следовательно, и сумма квадратов остатков не может увеличиться. В теории она может остаться неизменной, но на практике она всегда будет уменьшаться. А в этом случае, как видно из расчетной формулы, (R^2) будет увеличиваться. Получается, что какие бы дурацкие новые переменные вы ни добавляли в модель, коэффициент (R^2) будет увеличиваться (или, в крайнем случае, оставаться неизменным).
Последний из указанных недостатков легко можно преодолеть. Для этого есть усовершенствованная версия (R^2), которую называют скорректированным (или нормированным) коэффициентом (R^2) ( (R^2) adjusted):
begin{equation*} R_{mathit{adj}}^2=R^2-frac{k-1}{n-k}{ast}left(1-R^2right) end{equation*}
(R_{mathit{adj}}^2) меньше, чем обычный (R^2), на величину (frac{k-1}{n-k}{ast}left(1-R^2right)), которая представляет собой штраф за добавление избыточных переменных. Обратите внимание, что при прочих равных этот штраф растет по мере увеличения параметра (k), характеризующего число коэффициентов в вашей модели. Если вы будете добавлять в модель много регрессоров, которые не вносят существенного вклада в объяснение зависимой переменной, то (R^2_{mathit{adj}}) будет снижаться.
Поэтому, если вы хотите сравнить межу собой модели с разным числом объясняющих переменных, то лучше использовать (R^2_{mathit{adj}}), чем обычный (R^2). А ещё лучше обращать внимание не только на этот коэффициент, но и на прочие характеристики адекватности вашей модели, которые мы обсудим в этой книге.
Чтобы понять, откуда берется формула для скорректированного R-квадрата, запишем обычный R-квадрат следующим образом:
begin{equation*} R^2=1-frac{sum _{i=1}^ne_i^2}{sum _{i=1}^nleft(y_i-overline yright)^2}=1-frac{frac{sum _{i=1}^ne_i^2} n}{frac{sum _{i=1}^nleft(y_i-overline yright)^2} n}. end{equation*}
В числителе дроби стоит выборочная дисперсия остатков, а в знаменателе — выборочная дисперсия зависимой переменной. Если и ту, и другую дисперсии заменить их несмещенными аналогами, то получим следующее выражение:
begin{equation*} 1-frac{S^2}{frac{sum _{i=1}^nleft(y_i-overline yright)^2}{n-1}}=1-frac{frac{sum _{i=1}^ne_i^2}{n-k}}{frac{sum _{i=1}^nleft(y_i-overline yright)^2}{n-1}}. end{equation*}
Легко проверить, что это и есть скорректированный R-квадрат:
begin{equation*} 1-frac{frac{sum _{i=1}^ne_i^2}{n-k}}{frac{sum _{i=1}^nleft(y_i-overline yright)^2}{n-1}}=1-frac{n-1}{n-k}frac{sum _{i=1}^ne_i^2}{sum _{i=1}^nleft(y_i-overline yright)^2}=1-frac{n-1}{n-k}left(1-R^2right)= end{equation*}
begin{equation*} R^2-frac{k-1}{n-k}{ast}left(1-R^2right)=R_{mathit{adj}}^2. end{equation*}