
Распознавание текста OCR
Сегодня в российских вузах все чаще при проверке магистерских диссертаций, выпускных квалификационных работ, курсовых, рефератов и контрольных работ на некорректные заимствования (плагиат) стали применять метод OCR — оптическое распознавание текста. Обойти его бывает зачастую сложнее, чем классическую систему антиплагиатвуз.
Сервис распознавания текстовой информации очень актуален. Сканированные документы или книги нужно перевести в формат, пригодный для редактирования. Кроме того, тексты занимают на порядок меньше места, чем даже хорошо сжатые изображения. Экономится пространство на постоянных носителях, оперативная память и ресурсы процессора по обработке файлов.
Повысить оригинальность
Преимущества онлайн-сервиса
Выполненное онлайн распознавание OCR имеет следующие преимущества по сравнению с установкой офлайн-программы:
—
меньше нагружается локальный компьютер, тексты распознаются на сервере;
—
постоянное улучшение распознавания текста, незаметное для пользователей внедрение новых алгоритмов;
—
широкий выбор форматов для конвертации.
Процедура OCR занимает огромные процессорные ресурсы, локальное исполнение других программ заметно тормозится. Передача данных через Интернет нагружает компьютер гораздо меньше, даже при сравнительно больших размерах файлов с текстом. Идущий на распознавание текст может находиться в графическом формате (JPG, PNG, GIF, BMP) или предварительно обработанном и сжатом (PDF, DJV). Результат распознавания текста выдается в таких форматах, как TXT, RTF, DOC, или взятых из операционной системы Linux. Это позволяет не зависеть от системы и установленных программ, которые часто выпускаются только для определенного окружения, например, под MS Windows.
Качество исходников и результатов
OCR online будет эффективным, когда графические источники отличаются высоким качеством. Это касается как сканирования текста, так и предобработки графики, к примеру, контрастирования, выделения переходов между светлыми и темными участками. Желательна строгая ориентация строк по вертикали и букв по горизонтали, без перегибов страниц. Лучше всего распознаются контрастные символы, как черные на белом фоне. Узнавание, скажем, зеленых на красном фоне может быть затруднено, но такие материалы встречаются крайне редко, в основном для целей тестирования распознающей программы. Для уверенности в правильности узнавания символов рекомендуется проводить вычитку текстов после машинной обработки. Еще ни один алгоритм OCR не достиг 100% качества и сравнимых с человеком навыков узнавания.

Выбор языка
Современный онлайн сервис OCR выполняет все более интеллектуальные действия на исходном материале. В частности, исправляет грамматические ошибки, делает предположения плохо различимых символах, ориентируясь на словарь. Если одна буква в слове неразличима, возможна коррекция дефектов сканирования или бумажного носителя. Работа корректора ошибок существенно зависит от выбранного пользователем языка. В особенности это касается близких по происхождению языков, как русский, украинский и белорусский. Используются словари, включающие десятки тысяч словоформ, что дает возможность распознавать материалы, необходимые узким специалистам (технические, медицинские, исторические).
Послесловие
Таким образом, проверка в системе антиплагиатвуз с оптическим распознаванием текста во многих случаях позволяет распознать, применял ли студент для того, чтобы повысить уникальность, систему технического кодирования, различные невидимые вставки в текст. Однако, современные сервисы борьбы с плагиатом не стоят на месте и некоторые научились корректно повышать уникальность, не меняя при этом текст визуально. В частности, это сервис, позволяющий повысить оригинальность (антиплагиат) с высокой степенью эффективности – сервис АнтиплагиAD. Стоимость повышения уникальности в Антиплагиатвуз + OCR такая же, как и в «обычном» Антиплагиатвузе
Почему тысячи клиентов выбирают нас
—
Повышение уникальности текста до необходимого процента
—
Время, необходимое на обработку — не более 5 минут
—
Текст внешне остается неизменным, как и таблицы и формулы
—
Круглосуточная система работы, автоматизация процесса
—
Поддержка клиентов по телефону и другим видам связи
—
Возможность неоднократно корректировать процент оригинальности бесплатно
—
Доступ к закрытому преподавательскому отчету по системе антиплагиат.вуз
—
Анонимность согласно федеральному закону №152, данные клиента не подлежат разглашению и передаче третьим лицам
Технология оптического распознавания символов (OCR) умеет преобразовывать бумажные документы в доступный для чтения и редактирования формат. OCR упрощает рутину бухгалтеров, юристов и HR-сотрудников: может распознать документы и перенести информацию в учетные системы.
Как компьютер распознает текст
OCR (англ. optical character recognition) — технология автоматического анализа текста и превращения его в данные, которые может обработать компьютер. Человек распознает символы с помощью глаз и мозга. Компьютер использует камеру сканера, которая создает графическое изображение текстовой страницы. Для компьютера нет разницы между сканом текстового документа и фотографией: и то, и другое — набор пикселей.
Человек легко поймет, что на картинке изображен текст. Для компьютера есть два способа: распознавать символы целостно, то есть распознавать паттерн, или выделять отдельные черты, из которых состоит символ — выявлять признаки.
Метод распознавания паттерна
В 1968 году компания American Type Founders, которая с конца XIX века занималась созданием печатных шрифтов, придумала шрифт OCR-A с буквами одинаковой ширины. В основном шрифт использовали в банковских чеках, а для его чтения компьютером было создано специальное программное обеспечение.
Поскольку шрифт был стандартизирован, его распознавание стало относительно простой задачей. Программы «знали» OCR-A и могли переводить информацию с чеков в машиночитаемую форму. Однако в случае ошибки человек мог вмешаться в процесс и также прочитать банковский чек. Следующим шагом стало обучение программ OCR распознавать символы еще в нескольких самых распространенных шрифтах.
Выявление признаков
Этот способ еще называют интеллектуальным распознаванием символов — ICR. Программа, работающая с выявлением паттернов, не сможет определить символы, если шрифты ей неизвестны. Вместо распознавания паттерна ICR выделяет характерные индивидуальные черты, из которых состоит символ.
Большинство современных OCR-программ работают по этому принципу. Чаще всего в них используются классификаторы на основе машинного обучения, но в последнее время некоторые OCR-системы перешли на нейронные сети.
Что делать с рукописным вводом
Задачу распознавания рукописного текста для компьютера иногда упрощают. Например, просят людей писать почтовый индекс в специальном месте на конверте особым шрифтом или заполнять специальные поля форм печатными буквами для дальнейшей обработки компьютером.
Планшеты и смартфоны, которые поддерживают рукописный ввод, часто используют принцип выявления признаков. При написании определенной буквы экран устройства распознает, что сначала человек написал одну линию, потом вторую. Компьютеру помогает то, что все признаки появляются последовательно, в отличие от варианта, когда весь текст уже написан от руки на бумаге.
Шаги распознавания текста
Чем лучше качество исходного текста на бумаге, тем лучше качество распознавания. Первый этап — создание черно-белой или серой копии. Если все прошло без ошибок, то все черное — это символы, а все белое — фон. Хорошие OCR-программы автоматически отмечают трудные элементы: колонки, таблицы или картинки. Все OCR-программы распознают текст последовательно, символ за символом, словом за словом и строчка за строчкой.
Сначала OCR-программа объединяет пиксели в буквы, а буквы — в вероятные комбинации, затем система сопоставляет их со словарем. Если комбинация букв находится, то она отмечается как распознанное слово. Если нет — программа подставляет наиболее вероятный вариант.
| Качественный результат в короткие сроки |
| Поддержка по всем вопросам в режиме 24/7 |
| Ручное повышение уникальности от 70% |
| Доступ ко всем системам антиплагиата |
Почему стоит заказать работу у нас

Выбор языка
Современный онлайн сервис OCR выполняет все более интеллектуальные действия на исходном материале. В частности, исправляет грамматические ошибки, делает предположения плохо различимых символах, ориентируясь на словарь. Если одна буква в слове неразличима, возможна коррекция дефектов сканирования или бумажного носителя. Работа корректора ошибок существенно зависит от выбранного пользователем языка. В особенности это касается близких по происхождению языков, как русский, украинский и белорусский. Используются словари, включающие десятки тысяч словоформ, что дает возможность распознавать материалы, необходимые узким специалистам (технические, медицинские, исторические).
Послесловие
Таким образом, проверка в системе антиплагиатвуз с оптическим распознаванием текста во многих случаях позволяет распознать, применял ли студент для того, чтобы повысить уникальность, систему технического кодирования, различные невидимые вставки в текст. Однако, современные сервисы борьбы с плагиатом не стоят на месте и некоторые научились корректно повышать уникальность, не меняя при этом текст визуально. В частности, это сервис, позволяющий повысить оригинальность (антиплагиат) с высокой степенью эффективности – сервис АнтиплагиAD. Стоимость повышения уникальности в Антиплагиатвуз + OCR такая же, как и в «обычном» Антиплагиатвузе
Почему тысячи клиентов выбирают нас
—
Повышение уникальности текста до необходимого процента
—
Время, необходимое на обработку — не более 5 минут
—
Текст внешне остается неизменным, как и таблицы и формулы
—
Круглосуточная система работы, автоматизация процесса
—
Поддержка клиентов по телефону и другим видам связи
—
Возможность неоднократно корректировать процент оригинальности бесплатно
—
Доступ к закрытому преподавательскому отчету по системе антиплагиат.вуз
—
Анонимность согласно федеральному закону №152, данные клиента не подлежат разглашению и передаче третьим лицам
Технология оптического распознавания символов (OCR) умеет преобразовывать бумажные документы в доступный для чтения и редактирования формат. OCR упрощает рутину бухгалтеров, юристов и HR-сотрудников: может распознать документы и перенести информацию в учетные системы.
Как компьютер распознает текст
OCR (англ. optical character recognition) — технология автоматического анализа текста и превращения его в данные, которые может обработать компьютер. Человек распознает символы с помощью глаз и мозга. Компьютер использует камеру сканера, которая создает графическое изображение текстовой страницы. Для компьютера нет разницы между сканом текстового документа и фотографией: и то, и другое — набор пикселей.
Человек легко поймет, что на картинке изображен текст. Для компьютера есть два способа: распознавать символы целостно, то есть распознавать паттерн, или выделять отдельные черты, из которых состоит символ — выявлять признаки.
Метод распознавания паттерна
В 1968 году компания American Type Founders, которая с конца XIX века занималась созданием печатных шрифтов, придумала шрифт OCR-A с буквами одинаковой ширины. В основном шрифт использовали в банковских чеках, а для его чтения компьютером было создано специальное программное обеспечение.
Поскольку шрифт был стандартизирован, его распознавание стало относительно простой задачей. Программы «знали» OCR-A и могли переводить информацию с чеков в машиночитаемую форму. Однако в случае ошибки человек мог вмешаться в процесс и также прочитать банковский чек. Следующим шагом стало обучение программ OCR распознавать символы еще в нескольких самых распространенных шрифтах.
Выявление признаков
Этот способ еще называют интеллектуальным распознаванием символов — ICR. Программа, работающая с выявлением паттернов, не сможет определить символы, если шрифты ей неизвестны. Вместо распознавания паттерна ICR выделяет характерные индивидуальные черты, из которых состоит символ.
Большинство современных OCR-программ работают по этому принципу. Чаще всего в них используются классификаторы на основе машинного обучения, но в последнее время некоторые OCR-системы перешли на нейронные сети.
Что делать с рукописным вводом
Задачу распознавания рукописного текста для компьютера иногда упрощают. Например, просят людей писать почтовый индекс в специальном месте на конверте особым шрифтом или заполнять специальные поля форм печатными буквами для дальнейшей обработки компьютером.
Планшеты и смартфоны, которые поддерживают рукописный ввод, часто используют принцип выявления признаков. При написании определенной буквы экран устройства распознает, что сначала человек написал одну линию, потом вторую. Компьютеру помогает то, что все признаки появляются последовательно, в отличие от варианта, когда весь текст уже написан от руки на бумаге.
Шаги распознавания текста
Чем лучше качество исходного текста на бумаге, тем лучше качество распознавания. Первый этап — создание черно-белой или серой копии. Если все прошло без ошибок, то все черное — это символы, а все белое — фон. Хорошие OCR-программы автоматически отмечают трудные элементы: колонки, таблицы или картинки. Все OCR-программы распознают текст последовательно, символ за символом, словом за словом и строчка за строчкой.
Сначала OCR-программа объединяет пиксели в буквы, а буквы — в вероятные комбинации, затем система сопоставляет их со словарем. Если комбинация букв находится, то она отмечается как распознанное слово. Если нет — программа подставляет наиболее вероятный вариант.
| Качественный результат в короткие сроки |
| Поддержка по всем вопросам в режиме 24/7 |
| Ручное повышение уникальности от 70% |
| Доступ ко всем системам антиплагиата |
Почему стоит заказать работу у нас
Ручное повышение
уникальности

Бесплатные доработки
в течении года

Вы сами назначаете
цену
Проверку по системе антиплагиат студенты ждут с ужасом. Ведь один прогон текста по программе отправляет в топку многострадальные ночи и дни учащихся. Отсюда и возникает высокий интерес о том, как же пройти антиплагиат без потерь, какие модули есть программе и как их обмануть.
Как обойти
Антиплагиат с включенным модулем OCR распознает текст и не считывает другие символы и коды, а значит технические средства для поднятия уникальности здесь не подойдут. Чтобы обойти этот модуль, необходимо воспользоваться ручными средствами повышения оригинальности.
Рерайт, замена синонимами, перефраз и пересказ. Эти проверенные способы помогают не только получить высокий процент уникальности при проверке работы, но и провести глубокий анализ заимствованного текста, что положительно сказывается на работе в целом.
Нет времени или возможности провести все операции самостоятельно? Обратитесь за помощью к экспертам Студворк, которые в курсе всех тонкостей и деталей.
Что такое модуль OCR
Не так давно Антиплагиат ввел в свою систему модуль OCR, который вызвал много вопросов. Разберемся, что это такое. Если дословно переводить то получается «оптическое распознавание символов». Что же это такое, переводя на доступный язык? Все мы хоть раз пользовались сканером. Машина переносит напечатанный текст в электронный вид и с ним можно начинать работать.
Модуль OCR работает по похожему принципу. Он распознает текст в документе, переносит его в программу и потом анализирует через источники открытого доступа. На это уходит много времени. Как минимум нужно около двух часов для обработки одного документа. А если система загружена, например, во время сессии или тотальной проверки курсовых и дипломных, то на такую проверку может понадобится гораздо больше пары часов.
При переносе печатного текста все скрытые символы и коды остаются в документе и не распознаются. А значит технические способы поднятия уникальности автоматически становятся неэффективными при проверке и процент уникальности будет низкий.
Процесс заказа работы

1. Размещаете
задачу
Заполните форму заказа и опубликуйте его в ленте.

2. Выбираете исполнителя
Выберите автора, учитывая отзывы и рейтинг.

3. Получаете результат
Оплатите и скачайте работу, когда автор ее выполнит.
Статьи по теме
Отзывы о сайте
2 850 492
отзыва
4.96
средняя оценка

Отличный сервис для тех кому нужна помощь в обучении и тех кто хочет заработать.
Благодарен руководителям studwork!!!!

Спасибо Вам, очень помогает Ваш ресурс для тех, кто и так все знает, но не находит времени на учебу при большой нагрузке на работе. У кого первое образование рекомендую всем учиться самостоятельно
На сайте я недавно, но он оставил приятные впечатления. Очень быстро познакомилась с правилами работы на сайте, получила первые заказы. Очень приятно!
Нормально у Вас. Клиенты те же, зато с выводом проблем нет.
На других платформах вечно какие задержки, какие-то договора заключать надо.
Отличная платформа, для работающих людей, которым, в силу занятости, некогда сидеть за книгами, помогают профессионалы своего дела!
Мне понравилось очень, если бы не вы я бы завалила сессию ( и очень хороший парень, который взял мою заявку!!!
Доброго времени! Первый раз на сайте заказала работу. С сайтом разобралась, но не быстро, сейчас всё понятно, помогала поддержка, ребята отвечали быстро и всё подробное объясняли. Для меня, бонусом оказалось то, что стоимость, которая приходила на почту с откликами исполнителей, включает в себя и комиссию. Это поняла не сразу, поэтому долго думала и считала, что к этой сумме надо прибавить ещё 25%, а получалось очень дорого. Если бы не этот момент, то заказала бы ещё вчера. Заказ ещё не получила. Как получу, сразу напишу отзыв в Яндексе. Пока всем довольна. Спасибо.
хорошо, что есть такой сервис, не всегда получается справиться со всеми заданиями в срок, но с вами это возможно, спасибо!
Сайт отличный. Информация и инструкции по работе с сайтом доступны и просты для понимания. Все замечательно. Спасибо.
Я автор, выполняю дипломные работы по журналистике. Площадка просто супер как для формата основной работы, так и для подработки. Большое количество различных бонусов для исполнителей. Внушительный инструментарий по заказу, что встречается довольно редко. Очень рекомендую)
Все отзывы
Доверьтесь экспертам
Экспертов онлайн
Наша система отправит ваш заказ на оценку
72 972
авторам.
Первые отклики появятся уже в течение 10 минут.
Разместить заказ
Optical Character Recognition, commonly referred to as OCR, is the process of converting scanned images of letters and words into a electronic versions. For example, you can use the Recognize Text feature in Acrobat DC to convert an image of a page into a searchable version in which you can select text, comment on it and even edit it.
OCR is an imperfect process. While some very good originals will process at or near 100% accuracy, if you feed Acrobat a poor quality document, results will suffer. So, yes, a fax of a fax of fax is not going to OCR well. Scanned documents may also contain handwriting which seldom is recognized as text.
OCR affects search quality and that should be a concern to legal professionals. Consider a contract that may be part of your case. Perhaps the only place your client’s name can be found in the document is in handwritten Name and Signature fields.
If you use Acrobat (or other tools) to search for your client name, no result will be returned. Since your client’s name is an important term for most cases, you might want to consider correcting key documents to enhance search results.
Fortunately, Acrobat DC includes tools to help you audit OCR quality and correct OCR errors.
Auditing OCR Quality
Acrobat offers a feature in Preflight called “Make OCR Text Visible” which can help you audit OCR quality. Here’s how to use it:
- OCR the document or open a previously OCR’d document.
Tip: Choose the Enhance Scans option in the Right Hand Pane, then choose Recognize Text - In the Right Hand Pane
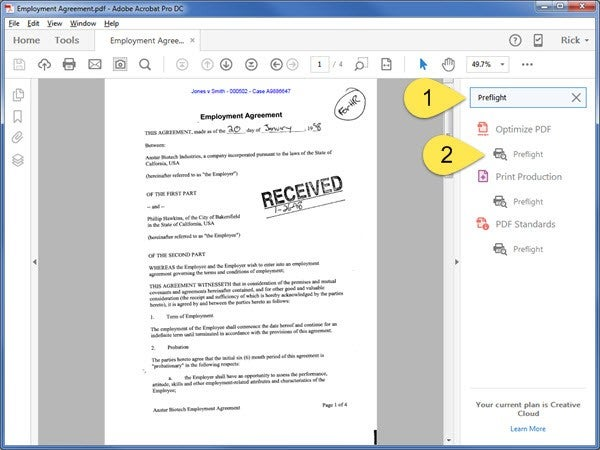
- Enter Preflight in the search field
- Click the Preflight tool
-

- The Preflight window opens.
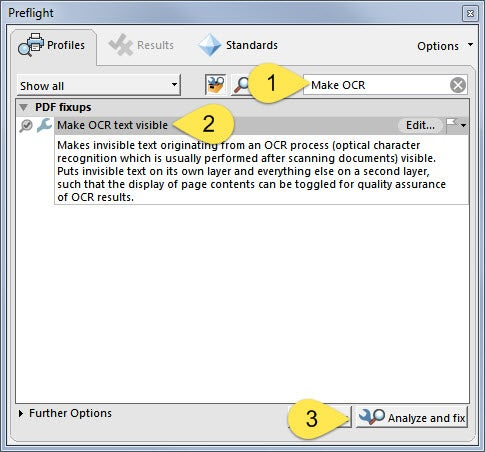
- In the search field, enter Make OCR
- Select the Make OCR text visible fixup function
- Click Analyze and Fix
-

- Acrobat will ask you to renamed the file. I suggest adding “_QA” to the file name.
Looking at the Results
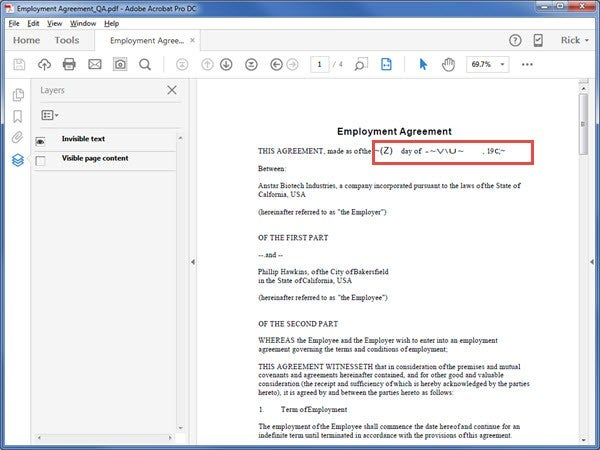
To QA the document, first open the Layers Panel in the file:
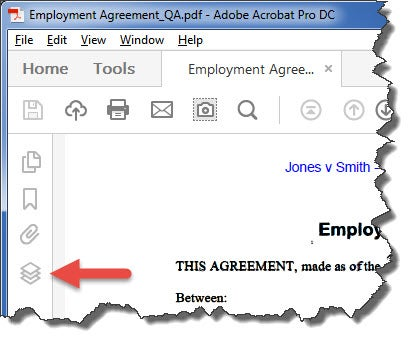
The Layers panel show two layers:
- Invisible text
- Visible Page Content
In the image below, both layers are turned on which means that the original scanned image is showing.
I added a red oiutline to some handwritten text in the document. Do you think Acrobat will recognize the handwriting? Let’s see . . .
Click the Visible Page Content eyeball to turn the layer off:
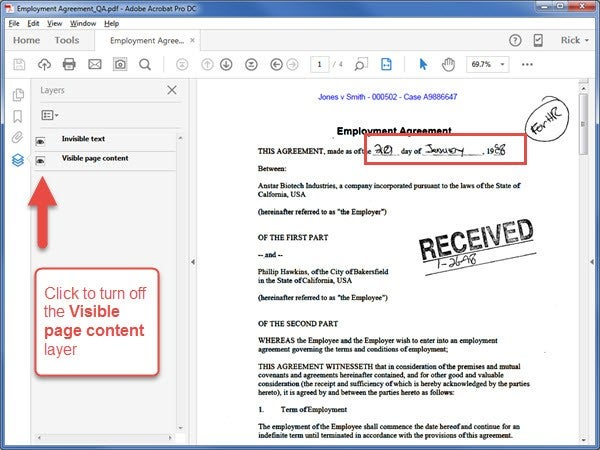
Now, only the OCR text is visible in the document. I’ve added a red outline to show you that Acrobat did not recognize the handwritten text.
Correcting OCR Text in Acrobat
Acrobat makes it possible to correct OCR errors to enhance search quality. This can be a time-consuming process, but may be worthwhile when archiving high-value documents or in situations where you can identify certain documents in a case for which you want to ensure good search results.
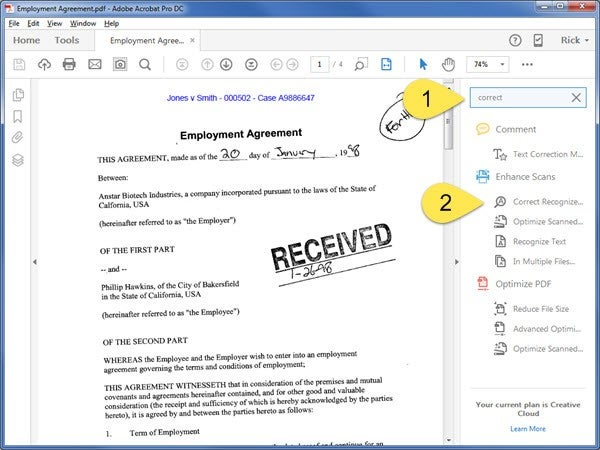
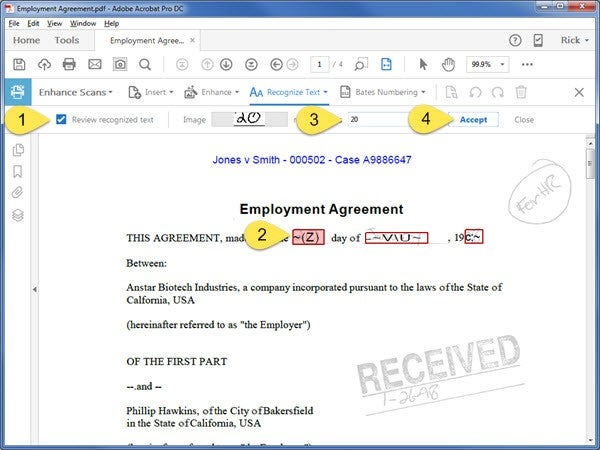
To correct OCR in document:
- OCR the document or open a previously OCR’d document
- In the Right Hand Panel:
- Click in the Search field and type “Correct”
- Click Correct Recognized Text
- The Correct Text function appears
- Enable Review Recognized text
- Select a suspect on the page. It will be highlighted in red.
- Enter the correct text for the error
- Click the Accept button
Your Corrections are Found
Tap CMD/CTRL-F to open the Find widget.
Once corrections are made, Acrobat will find the corrected text, even the text you have assigned to handwritten portions of the document:

Tips for Correcting Text
- You can toggle “Review Recognized Text” on or off to see the original scanned text
- You can make all corrections “mouse free”. Simply hit TAB to move the cursor to the correction text field and Enter to Accept.
- Your document may contain artifacts such as smudges or marks which Acrobat could see as text. Simply clear the correction text field and Acrobat will show “This is not text” in the correction field:
-

- You can assign Preflight steps such as “Make OCR Visible” and other steps mentioned in this article to Actions which let you automate multi-step processes.
OCR РАСПОЗНАВАНИЕ ТЕКСТА ИЗ PDF И ИЗОБРАЖЕНИЙ
Выбрать языки источника
Перетащите документ в эту область
(Поддерживаемые форматы: PDF, BMP, GIF, JPG, JPEG, TIFF, PNG)
Как работает наш OCR сервис
Вы когда-нибудь хотели иметь возможность найти в печатном цифровом материале или отсканированном документе конкретный текст? Или возникла ли у вас необходимость отредактировать содержимое журнала или отсканированного PDF-документа, не перепечатывая весь документ?
Классическим решением во всех этих случаях было бы перенабрать весь контент и его отредактировать. Это все еще нормальная практика, когда дело доходит до редактирования печатных контрактов, брошюр или страниц журнала. Но мы все знаем, насколько трудоемким и беспокойным может стать это решение, если источник представляет собой обыкновенное изображение. Бесплатный OCR сервис — это то, что может решить вашу проблему, сэкономить деньги, сэкономить ваше драгоценное время и обеспечить быстрые и эффективные результаты всего за несколько шагов.
С помощью нашего сервиса вы можете преобразовать документы в формате Microsoft Word в формат PDF. Также, в любое время вы можете выполнить преобразование PDF в Word. Если необъодимо сконвертировать книгу в формате DJVU, воспользуйтесь этой ссылкой Djvu в PDF. Наш сервис также позволяет конвертировать изображения в pdf. Чтобы получить PDF из электронной книги ePub или документа Fb2, воспользуйтесь ссылкой ePub в PDF. Дополнительно разделение или объединение PDF можно выполнить на соответствующих страницах: Разделить PDF и Склеить PDF.
Что такое OCR
Оптическое распознавание символов или OCR — это технология, позволяющая преобразовывать печатные или рукописные документы в редактируемые текстовый материал. Просто отсканировав напечатанные документы с помощью программного обеспечения для распознавания текста OCR, вы можете легко конвертировать файлы в печатные копии, которые можно редактировать, копировать или распространять согласно вашим требованиям. Сканеры текста OCR очень универсальны и могут сканировать текст из изображений, печатных документов и файлов PDF. Программное обеспечение OCR можно загрузить или использовать в качестве онлайн-сервисов.
Как работает OCR
Хотя понятие «машинного распознавания текста» не ново и появилось еще в 1960-х годах, в то время компьютер мог считать единственный вариант шрифта, называемый OCR-A. С развитием технологии сканеры текста OCR стали более продвинутыми и позволили пользователям использовать эту технологию для более широкого спектра приложений. В настоящее время текстовые сканеры OCR в основном используют два различных метода для преобразования печатного текста в редактируемый.
-
Метод сопоставления матриц
Первый метод — это метод сопоставления матриц. Этот метод работает по принципу сопоставления печатного текста с базой данных шаблонов символов и шрифтов. Сканер текста OCR сканирует напечатанный текст, сравнивает его с существующей библиотекой шаблонов и, когда совпадение найдено, преобразует данные в соответствующий код ASCII. Затем вы можете манипулировать этими данными в соответствии с вашими требованиями. Этот метод быстро возвращает результаты, но из-за ограниченной базы данных символов метод сопоставления матриц имеет свои ограничения. Алгоритм завершается ошибкой, когда он пытается распознать текст, которого нет в его базе данных, и выводит неверный текст. Следовательно, пользователи должны сохранять бдительность при использовании этого метода, поскольку он может генерировать ошибки, которые необходимо будет впоследствии исправить вручную.
-
Метод извлечения особенностей
Другой метод, используемый программным обеспечением OCR, — это метод извлечения признаков текста. Этот метод основан на искусственном интеллекте, где онлайн программное обеспечение OCR предназначено для определения общих точек в форме букв, таких как искривления, наклоны и пробелы в алфавите. Сканеры текста OCR ищут эти общие точки в тексте и возвращают результаты в коде символов ASCII после того, как найден определенный процент «совпадения».
Следовательно, этот метод ищет повторяющиеся шаблоны или правила, которые представляют букву, и программное обеспечение может предсказать букву, просто просматривая общие точки, найденные в шаблоне. Метод является более гибким и может работать с большим количеством печатных или рукописных документов.Кроме того, искусственный интеллект постоянно обновляет свои знания о различных почерках и шрифтах, что делает его более универсальным в использовании и оставляет возможности дальнейших улучшений и модернизаций алгоритма.
-
OCR онлайн сервисы
Самый простой способ сконвертировать распечатанные файлы в редактируемую версию — использование онлайн-сервисов OCR, в том числе нашим сервисом. Использовать онлайн-сервисы OCR чрезвычайно просто, поскольку вам нужно только отсканировать документ, загрузить его, и файл будет преобразован в редактируемую версию. Бесплатный сервис OCR — это отличная возможность для бизнеса сэкономить своё драгоценное время и деньги.
Есть несколько преимуществ использования бесплатных услуг OCR онлайн сервисов. Эти преимущества включают в себя:
- Время, затрачиваемое на весь процесс, значительно сокращается, и большие документы можно подготовить всего за несколько минут. Редактировать контракты, страницы журналов и брошюры теперь стало очень просто.
- Упрощение процесса извлечения данных из сложных документов.
- Снижение вероятности человеческой ошибки, связанной с методом чтения и перепечатывания.
- Устранение трудозатрат в часах, необходимых для затратного процесса ввода данных.
- Сканеры текста OCR являются сложными и могут также распознавать сложные почерки, которые могут занять время, чтобы человеческий глаз мог их прочитать и обработать.
Благодаря более быстрому циклу обработки и современным сканерам распознавания текста, эта технология может сэкономить достаточно значительное количество времени и средств для пользователей, которые смогут распорядиться своим временем более эффективно.
Преимущества нашего OCR сервиса
Широкий набор исходных форматов
Отсканированные PDF документы и различные форматы изображений
Нет ограничений
Как большие многостраничные книги, так и небольшие изображения
Ресурсы клиента
Всё распознавание выполняется на наших серверах