

Чтобы устранить ошибки передачи, вносимые атмосферой Земли (слева), ученые Годдарда применили исправление ошибок Рида – Соломона (справа), которое обычно используется на компакт-дисках и DVD. Типичные ошибки включают отсутствие пикселей (белые) и ложные сигналы (черные). Белая полоса указывает на короткий период, когда передача была приостановлена.
В теория информации и теория кодирования с приложениями в Информатика и телекоммуникации, обнаружение и исправление ошибок или же контроль ошибок методы, которые обеспечивают надежную доставку цифровые данные чрезмерно ненадежный каналы связи. Многие каналы связи подлежат канальный шум, и, таким образом, ошибки могут быть внесены во время передачи от источника к приемнику. Методы обнаружения ошибок позволяют обнаруживать такие ошибки, а исправление ошибок во многих случаях позволяет восстановить исходные данные.
Определения
Обнаружение ошибок это обнаружение ошибок, вызванных шумом или другими помехами во время передачи от передатчика к приемнику. Исправление ошибки это обнаружение ошибок и восстановление исходных безошибочных данных.
История
Современное развитие коды исправления ошибок зачисляется на Ричард Хэмминг в 1947 г.[1] Описание Код Хэмминга появился в Клод Шеннон с Математическая теория коммуникации[2] и был быстро обобщен Марсель Дж. Э. Голей.[3]
Вступление
Все схемы обнаружения и исправления ошибок добавляют избыточность (т.е. некоторые дополнительные данные) к сообщению, которые получатели могут использовать для проверки согласованности доставленного сообщения и для восстановления данных, которые были определены как поврежденные. Схемы обнаружения и исправления ошибок могут быть либо систематический или несистематический. В систематической схеме передатчик отправляет исходные данные и прикрепляет фиксированное количество проверить биты (или же данные о четности), которые получены из битов данных некоторыми детерминированный алгоритм. Если требуется только обнаружение ошибок, приемник может просто применить тот же алгоритм к полученным битам данных и сравнить свой вывод с полученными контрольными битами; если значения не совпадают, в какой-то момент во время передачи произошла ошибка. В системе, которая использует несистематический код, исходное сообщение преобразуется в закодированное сообщение, несущее ту же информацию и имеющее по крайней мере такое же количество битов, как и исходное сообщение.
Хорошая эффективность контроля ошибок требует, чтобы схема была выбрана на основе характеристик канала связи. Общий модели каналов включают без памяти модели, в которых ошибки возникают случайно и с определенной вероятностью, и динамические модели, в которых ошибки возникают в основном в всплески. Следовательно, коды обнаружения и исправления ошибок можно в целом различать между обнаружение / исправление случайных ошибок и обнаружение / исправление пакетных ошибок. Некоторые коды также могут подходить для сочетания случайных ошибок и пакетных ошибок.
Если характеристики канала не могут быть определены или сильно варьируются, схему обнаружения ошибок можно комбинировать с системой для повторных передач ошибочных данных. Это известно как автоматический повторный запрос (ARQ), и наиболее часто используется в Интернете. Альтернативный подход к контролю ошибок: гибридный автоматический запрос на повторение (HARQ), который представляет собой комбинацию ARQ и кодирования с исправлением ошибок.
Виды исправления ошибок
Есть три основных типа исправления ошибок.[4]
Автоматический повторный запрос (ARQ)
Автоматический повторный запрос (ARQ) — это метод контроля ошибок для передачи данных, который использует коды обнаружения ошибок, сообщения подтверждения и / или отрицательного подтверждения, и таймауты для достижения надежной передачи данных. An подтверждение это сообщение, отправленное получателем, чтобы указать, что он правильно получил кадр данных.
Обычно, когда передатчик не получает подтверждения до истечения тайм-аута (т. Е. В течение разумного промежутка времени после отправки кадра данных), он повторно передает кадр до тех пор, пока он не будет либо правильно принят, либо ошибка сохранится сверх заранее определенного количества повторных передач. .
Есть три типа протоколов ARQ. Остановка и ожидание ARQ, Go-Back-N ARQ, и Селективный повторный ARQ.
ARQ подходит, если канал связи имеет изменяющийся или неизвестный емкость, например, в Интернете. Однако ARQ требует наличия задний канал, приводит к возможному увеличению задержка из-за повторных передач и требует обслуживания буферов и таймеров для повторных передач, что в случае перегрузка сети может вызвать нагрузку на сервер и общую пропускную способность сети.[5]
Например, ARQ используется на коротковолновых радиоканалах в виде ARQ-E, или в сочетании с мультиплексированием как ARQ-M.
Прямое исправление ошибок
Прямое исправление ошибок (FEC) — это процесс добавления избыточный данные, такие как код исправления ошибок (ECC) в сообщение, чтобы оно могло быть восстановлено получателем, даже если было внесено несколько ошибок (в зависимости от возможностей используемого кода) либо в процессе передачи, либо при хранении. Поскольку получатель не должен запрашивать у отправителя повторную передачу данных, обратный канал не требуется при упреждающем исправлении ошибок и поэтому подходит для симплексная связь Такие как вещание. Коды с исправлением ошибок часто используются в нижний слой коммуникации, а также для надежного хранения на таких носителях, как Компакт-диски, DVD, жесткие диски, и баран.
Коды с исправлением ошибок обычно различают между сверточные коды и блочные коды:
- Сверточные коды обрабатываются побитно. Они особенно подходят для аппаратной реализации, а Декодер Витерби позволяет оптимальное декодирование.
- Коды блокировки обрабатываются на блок за блоком основание. Ранние примеры блочных кодов: коды повторения, Коды Хэмминга и многомерные коды проверки на четность. За ними последовал ряд эффективных кодов, Коды Рида – Соломона являются наиболее заметными из-за их широкого распространения в настоящее время. Турбо коды и коды с низкой плотностью проверки четности (LDPC) — относительно новые конструкции, которые могут обеспечить почти оптимальная эффективность.
Теорема Шеннона является важной теоремой для прямого исправления ошибок и описывает максимальную скорость передачи информации при котором возможна надежная связь по каналу с определенной вероятностью ошибки или соотношение сигнал шум (SNR). Этот строгий верхний предел выражается в терминах пропускная способность канала. В частности, теорема утверждает, что существуют такие коды, что с увеличением длины кодирования вероятность ошибки на дискретный канал без памяти можно сделать сколь угодно малым при условии, что кодовая скорость меньше пропускной способности канала. Кодовая скорость определяется как доля к / п из k исходные символы и п закодированные символы.
Фактическая максимальная допустимая кодовая скорость зависит от используемого кода исправления ошибок и может быть ниже. Это связано с тем, что доказательство Шеннона носило исключительно экзистенциальный характер и не показало, как построить коды, которые одновременно являются оптимальными и имеют эффективный алгоритмы кодирования и декодирования.
Гибридные схемы
Гибридный ARQ представляет собой комбинацию ARQ и прямого исправления ошибок. Есть два основных подхода:[5]
- Сообщения всегда передаются с данными четности FEC (и избыточностью обнаружения ошибок). Приемник декодирует сообщение, используя информацию о четности, и запрашивает повторную передачу с использованием ARQ только в том случае, если данных четности было недостаточно для успешного декодирования (идентифицированного посредством неудачной проверки целостности).
- Сообщения передаются без данных четности (только с информацией об обнаружении ошибок). Если приемник обнаруживает ошибку, он запрашивает информацию FEC от передатчика с помощью ARQ и использует ее для восстановления исходного сообщения.
Последний подход особенно привлекателен на канал стирания при использовании код бесскоростного стирания.
Схемы обнаружения ошибок
Обнаружение ошибок чаще всего осуществляется с помощью подходящего хеш-функция (или, в частности, контрольная сумма, циклическая проверка избыточности или другой алгоритм). Хеш-функция добавляет фиксированную длину тег в сообщение, что позволяет получателям проверять доставленное сообщение путем пересчета тега и сравнения его с предоставленным.
Существует огромное количество различных конструкций хеш-функций. Однако некоторые из них особенно широко используются из-за их простоты или их пригодности для обнаружения определенных видов ошибок (например, производительность циклического контроля избыточности при обнаружении пакетные ошибки ).
Кодирование минимального расстояния
Код с исправлением случайных ошибок, основанный на кодирование минимального расстояния может предоставить строгую гарантию количества обнаруживаемых ошибок, но не может защитить от атака на прообраз.
Коды повторения
А код повторения представляет собой схему кодирования, которая повторяет биты по каналу для достижения безошибочной связи. Учитывая поток данных, которые необходимо передать, данные разделяются на блоки битов. Каждый блок передается определенное количество раз. Например, чтобы отправить битовую комбинацию «1011», четырехбитовый блок можно повторить три раза, таким образом получая «1011 1011 1011». Если этот двенадцатибитовый шаблон был получен как «1010 1011 1011» — где первый блок не похож на два других, — произошла ошибка.
Код повторения очень неэффективен и может быть подвержен проблемам, если ошибка возникает в одном и том же месте для каждой группы (например, «1010 1010 1010» в предыдущем примере будет обнаружено как правильное). Преимущество кодов повторения состоит в том, что они чрезвычайно просты и фактически используются в некоторых передачах номера станций.[6][7]
Бит четности
А бит четности — это бит, который добавляется к группе исходных битов, чтобы гарантировать, что количество установленных битов (то есть битов со значением 1) в результате будет четным или нечетным. Это очень простая схема, которую можно использовать для обнаружения одного или любого другого нечетного числа (т. Е. Трех, пяти и т. Д.) Ошибок в выводе. Четное число перевернутых битов сделает бит четности правильным, даже если данные ошибочны.
Расширения и варианты механизма битов четности продольный контроль избыточности, поперечный контроль избыточности и аналогичные методы группировки битов.
Контрольная сумма
А контрольная сумма сообщения — это модульная арифметика сумма кодовых слов сообщения фиксированной длины слова (например, байтовых значений). Сумма может быть отменена с помощью дополнение операция перед передачей для обнаружения непреднамеренных сообщений с нулевым значением.
Схемы контрольной суммы включают биты четности, проверить цифры, и продольный контроль избыточности. Некоторые схемы контрольных сумм, такие как Алгоритм дамма, то Алгоритм Луна, а Алгоритм Верхоффа, специально разработаны для обнаружения ошибок, обычно вносимых людьми при записи или запоминании идентификационных номеров.
Циклическая проверка избыточности
А циклическая проверка избыточности (CRC) небезопасный хеш-функция предназначен для обнаружения случайных изменений цифровых данных в компьютерных сетях. Он не подходит для обнаружения злонамеренно внесенных ошибок. Характеризуется спецификацией порождающий полином, который используется как делитель в полиномиальное деление в столбик через конечное поле, принимая входные данные как дивиденд. В остаток становится результатом.
CRC имеет свойства, которые делают его хорошо подходящим для обнаружения пакетные ошибки. CRC особенно легко реализовать на оборудовании и поэтому обычно используются в компьютерная сеть и устройства хранения, такие как жесткие диски.
Бит четности можно рассматривать как 1-битную CRC особого случая.
Криптографическая хеш-функция
Выход криптографическая хеш-функция, также известный как Дайджест сообщения, может дать твердую уверенность в целостность данных независимо от того, являются ли изменения данных случайными (например, из-за ошибок передачи) или намеренно внесены. Любая модификация данных, скорее всего, будет обнаружена по несоответствию хеш-значения. Кроме того, с учетом некоторого хэш-значения, как правило, невозможно найти некоторые входные данные (кроме заданных), которые дадут такое же хеш-значение. Если злоумышленник может изменить не только сообщение, но и значение хеш-функции, то ключевой хеш или же код аутентификации сообщения (MAC) можно использовать для дополнительной безопасности. Не зная ключа, злоумышленник не может легко или удобно вычислить правильное ключевое значение хеш-функции для измененного сообщения.
Код исправления ошибок
Для обнаружения ошибок можно использовать любой код исправления ошибок. Код с минимум Расстояние Хэмминга, d, может обнаруживать до d — 1 ошибка в кодовом слове. Использование кодов с коррекцией ошибок на основе минимального расстояния для обнаружения ошибок может быть подходящим, если требуется строгое ограничение на минимальное количество обнаруживаемых ошибок.
Коды с минимальным расстоянием Хэмминга d = 2 являются вырожденными случаями кодов с исправлением ошибок и могут использоваться для обнаружения одиночных ошибок. Бит четности является примером кода обнаружения одиночной ошибки.
Приложения
Приложения, требующие малой задержки (например, телефонные разговоры), не могут использовать автоматический повторный запрос (ARQ); они должны использовать упреждающее исправление ошибок (FEC). К тому времени, когда система ARQ обнаружит ошибку и повторно передаст ее, повторно отправленные данные прибудут слишком поздно, чтобы их можно было использовать.
Приложения, в которых передатчик сразу же забывает информацию, как только она отправляется (например, большинство телекамер), не могут использовать ARQ; они должны использовать FEC, потому что при возникновении ошибки исходные данные больше не доступны.
Приложения, использующие ARQ, должны иметь обратный канал; приложения, не имеющие обратного канала, не могут использовать ARQ.
Приложения, требующие крайне низкого уровня ошибок (например, цифровые денежные переводы), должны использовать ARQ из-за возможности неисправимых ошибок с помощью FEC.
Техника обеспечения надежности и контроля также использует теорию кодов с исправлением ошибок.[8]
Интернет
В типичном TCP / IP стек, контроль ошибок выполняется на нескольких уровнях:
- Каждый Кадр Ethernet использует CRC-32 обнаружение ошибок. Кадры с обнаруженными ошибками отбрасываются аппаратурой приемника.
- В IPv4 заголовок содержит контрольная сумма защита содержимого заголовка. Пакеты с неверными контрольными суммами сбрасываются в сети или на приемнике.
- Контрольная сумма не указана в IPv6 заголовок, чтобы минимизировать затраты на обработку в сетевая маршрутизация и потому что текущий уровень связи предполагается, что технология обеспечивает достаточное обнаружение ошибок (см. также RFC 3819 ).
- UDP имеет необязательную контрольную сумму, покрывающую полезную нагрузку и адресную информацию в заголовках UDP и IP. Пакеты с неверными контрольными суммами отбрасываются Сетевой стек. Контрольная сумма не является обязательной для IPv4 и требуется для IPv6. Если этот параметр опущен, предполагается, что уровень канала передачи данных обеспечивает желаемый уровень защиты от ошибок.
- TCP предоставляет контрольную сумму для защиты полезной нагрузки и адресной информации в заголовках TCP и IP. Пакеты с неверными контрольными суммами отбрасываются сетевым стеком и в конечном итоге повторно передаются с использованием ARQ либо явно (например, через тройной удар ) или неявно из-за тайм-аут.
Телекоммуникации в дальнем космосе
Разработка кодов исправления ошибок была тесно связана с историей полетов в дальний космос из-за чрезмерного ослабления мощности сигнала на межпланетных расстояниях и ограниченной доступной мощности на борту космических зондов. В то время как ранние миссии отправляли свои данные в незашифрованном виде, начиная с 1968 года, цифровое исправление ошибок было реализовано в форме (субоптимально декодированные) сверточные коды и Коды Рида – Маллера.[9] Код Рида-Мюллера хорошо подходил к шуму, которому подвергался космический корабль (приблизительно соответствуя кривая колокола ), и был реализован для космического корабля Mariner и использовался в миссиях с 1969 по 1977 год.
В Вояджер 1 и Вояджер 2 миссии, начатые в 1977 году, были предназначены для доставки цветных изображений и научной информации из Юпитер и Сатурн.[10] Это привело к повышенным требованиям к кодированию, и, таким образом, космический аппарат поддерживался (оптимально Витерби-декодированный ) сверточные коды, которые могут быть соединенный с внешним Код Голая (24,12,8). Корабль «Вояджер-2» дополнительно поддерживал реализацию Код Рида – Соломона. Конкатенированный код Рида – Соломона – Витерби (RSV) позволил произвести очень мощную коррекцию ошибок и позволил космическому аппарату совершить длительный путь к Уран и Нептун. После модернизации системы ECC в 1989 году оба корабля использовали кодирование V2 RSV.
В Консультативный комитет по системам космических данных в настоящее время рекомендует использовать коды исправления ошибок с производительностью, как минимум, аналогичной коду Voyager 2 RSV. Составные коды все больше теряют популярность в космических миссиях и заменяются более мощными кодами, такими как Турбо коды или же Коды LDPC.
Различные виды дальних космических и орбитальных миссий предполагают, что попытка найти универсальную систему исправления ошибок будет постоянной проблемой. Для миссий, близких к Земле, характер шум в канал связи отличается от того, что испытывает космический корабль в межпланетной миссии. Кроме того, по мере того как космический корабль удаляется от Земли, проблема коррекции шума становится все более сложной.
Спутниковое вещание
Спрос на спутник транспондер пропускная способность продолжает расти, чему способствует желание предоставлять телевидение (включая новые каналы и телевидение высокой четкости ) и данные IP. Доступность транспондеров и ограничения полосы пропускания ограничили этот рост. Емкость транспондера определяется выбранным модуляция схема и доля мощности, потребляемой ТЭК.
Хранилище данных
Коды обнаружения и исправления ошибок часто используются для повышения надежности носителей данных.[11] «Трек паритета» присутствовал на первом хранение данных на магнитной ленте в 1951 г. «Оптимальный прямоугольный код», использованный в групповая кодированная запись ленты не только обнаруживают, но и исправляют однобитовые ошибки. Немного форматы файлов, особенно форматы архивов, включить контрольную сумму (чаще всего CRC32 ) для обнаружения повреждения и усечения и может использовать избыточность и / или файлы четности для восстановления частей поврежденных данных. Коды Рида-Соломона используются в компакт-диски для исправления ошибок, вызванных царапинами.
Современные жесткие диски используют коды CRC для обнаружения и коды Рида – Соломона для исправления незначительных ошибок при чтении секторов, а также для восстановления данных из «испорченных» секторов и сохранения этих данных в резервных секторах.[12] RAID системы используют различные методы исправления ошибок для исправления ошибок, когда жесткий диск полностью выходит из строя. Файловые системы, такие как ZFS или же Btrfs, а также некоторые RAID внедрения, поддержка очистка данных и повторное обновление, которое позволяет обнаруживать и (надеюсь) восстанавливать плохие блоки перед их использованием.[13] Восстановленные данные могут быть перезаписаны точно в том же физическом месте, чтобы освободить блоки в другом месте на том же оборудовании, или данные могут быть перезаписаны на заменяющее оборудование.
Память с исправлением ошибок
DRAM память может обеспечить более надежную защиту от мягкие ошибки полагаясь на коды исправления ошибок.[14] Такой исправляющая память, известный как ECC или же EDAC-защищенный память, особенно желательна для критически важных приложений, таких как научные вычисления, финансы, медицина и т. д., а также для приложений дальнего космоса из-за увеличения радиация в космосе.
Контроллеры памяти с исправлением ошибок традиционно используют Коды Хэмминга, хотя некоторые используют тройное модульное резервирование.
Чередование позволяет распределить эффект одного космического луча, потенциально нарушающего несколько физически соседних битов по множеству слов, путем связывания соседних битов с разными словами. Пока одно событие расстроено (SEU) не превышает порог ошибки (например, одиночная ошибка) в любом конкретном слове между обращениями, это может быть исправлено (например, с помощью однобитового кода исправления ошибок), и иллюзия безошибочной системы памяти может быть сохранен.[15]
Помимо оборудования, обеспечивающего функции, необходимые для работы памяти ECC, операционные системы обычно содержат соответствующие средства отчетности, которые используются для предоставления уведомлений о прозрачном восстановлении мягких ошибок. Увеличение количества мягких ошибок может указывать на то, что DIMM модуль нуждается в замене, и такая обратная связь не была бы легко доступна без соответствующих возможностей отчетности. Одним из примеров является Ядро Linux с EDAC подсистема (ранее известная как Bluesmoke), который собирает данные от компонентов компьютерной системы с включенной функцией проверки ошибок; Помимо сбора и отправки отчетов о событиях, связанных с памятью ECC, он также поддерживает другие ошибки контрольной суммы, в том числе обнаруженные на Шина PCI.[16][17][18]
Некоторые системы также поддерживают очистка памяти.
Смотрите также
- Код Бергера
- Пакетный код исправления ошибок
- Плевать будильник
- Память ECC, тип компьютерного хранилища данных
- Запрещенный ввод
- Адаптация ссылки
- Список алгоритмов обнаружения и исправления ошибок
- Список кодов исправления ошибок
- Список хеш-функций
- Надежность (компьютерные сети)
Рекомендации
- ^ Томпсон, Томас М. (1983), От кодов с исправлением ошибок до сферических упаковок и простых групп, Математические монографии Каруса (№ 21), Математическая ассоциация Америки, стр. vii, ISBN 0-88385-023-0
- ^ Шеннон, C.E. (1948), «Математическая теория коммуникации», Технический журнал Bell System, п. 418, г. 27 (3): 379–423, Дои:10.1002 / j.1538-7305.1948.tb01338.x, HDL:10338.dmlcz / 101429, PMID 9230594CS1 maint: location (связь)
- ^ Голей, Марсель Дж. Э. (1949), «Заметки о цифровом кодировании», Proc.I.R.E. (I.E.E.E.), п. 657, г. 37CS1 maint: location (связь)
- ^ Гупта, Викас; Верма, Чандеркант (ноябрь 2012 г.). «Обнаружение и исправление ошибок: Введение». Международный журнал перспективных исследований в области компьютерных наук и программной инженерии. 2 (11). S2CID 17499858.
- ^ а б А. Дж. Маколи, Надежная широкополосная связь с использованием кода коррекции стирания пакетов, ACM SIGCOMM, 1990.
- ^ Франк ван Гервен. «Номера (и другие загадочные) станции». Получено 12 марта 2012.
- ^ Гэри Катлак (25 августа 2010 г.). «Таинственная русская» цифровая станция «изменила вещание через 20 лет». Gizmodo. Получено 12 марта 2012.
- ^ Бен-Гал I .; Herer Y .; Раз Т. (2003). «Самокорректирующаяся процедура проверки при ошибках проверки» (PDF). IIE Сделки по качеству и надежности, 34 (6), стр. 529-540. Архивировано из оригинал (PDF) на 2013-10-13. Получено 2014-01-10.
- ^ К. Эндрюс и др., Разработка кодов Turbo и LDPC для приложений дальнего космоса, Труды IEEE, Vol. 95, № 11, ноябрь 2007 г.
- ^ Хаффман, Уильям Кэри; Плесс, Вера С. (2003). Основы кодов с исправлением ошибок. Издательство Кембриджского университета. ISBN 978-0-521-78280-7.
- ^ Куртас, Эрозан М .; Васич, Бэйн (2018-10-03). Расширенные методы контроля ошибок для систем хранения данных. CRC Press. ISBN 978-1-4200-3649-7.[постоянная мертвая ссылка ]
- ^ Мой жесткий диск умер. Скотт А. Моултон
- ^ Цяо, Чжи; Фу, песня; Чен, Синь-Бунг; Сеттлмайер, Брэдли (2019). «Создание надежных высокопроизводительных систем хранения: эмпирическое и аналитическое исследование». Международная конференция IEEE 2019 по кластерным вычислениям (CLUSTER): 1–10. Дои:10.1109 / CLUSTER.2019.8891006. ISBN 978-1-7281-4734-5. S2CID 207951690.
- ^ «Обзор методов повышения устойчивости DRAM к ошибкам «, Журнал системной архитектуры, 2018
- ^ «Использование StrongArm SA-1110 в бортовом компьютере наноспутника». Космический центр Цинхуа, Университет Цинхуа, Пекин. Архивировано из оригинал на 2011-10-02. Получено 2009-02-16.
- ^ Джефф Лейтон. «Обнаружение и исправление ошибок». Журнал Linux. Получено 2014-08-12.
- ^ «Проект EDAC». bluesmoke.sourceforge.net. Получено 2014-08-12.
- ^ «Документация / edac.txt». Документация ядра Linux. kernel.org. 2014-06-16. Архивировано из оригинал на 2009-09-05. Получено 2014-08-12.
дальнейшее чтение
- Шу Линь; Дэниел Дж. Костелло-младший (1983). Кодирование с контролем ошибок: основы и приложения. Prentice Hall. ISBN 0-13-283796-X.
внешняя ссылка
- Он-лайн учебник: теория информации, выводы и алгоритмы обучения, к Дэвид Дж. К. Маккей, содержит главы, посвященные элементарным кодам, исправляющим ошибки; о теоретических пределах исправления ошибок; и на последних современных кодах исправления ошибок, в том числе коды с низкой плотностью проверки четности, турбокоды, и коды фонтанов.
- Вычислить параметры линейных кодов — интерактивный интерфейс для генерации и вычисления параметров (например, минимальное расстояние, радиус покрытия ) из линейные коды исправления ошибок.
- Страница ECC
- SoftECC: система проверки целостности программной памяти
- Настраиваемая программная библиотека обнаружения и исправления ошибок DRAM для HPC
- Обнаружение и исправление скрытых искажений данных для крупномасштабных высокопроизводительных вычислений
CASE обеспечивает автоматическую верификацию и контроль проекта на полноту и состоятельность на ранних этапах ЖЦ, что влияет на успех разработки в целом.
В CASE диаграммеры и верификаторы способны осуществлять следующие типы контроля.
1) Контроль синтаксиса диаграмм и типов их элементов. Обычно такой контроль осуществляется при вводе и редактировании элементов диаграмм. Примеры контролируемых ситуаций:
— по синтаксису: любой функциональный элемент диаграммы должен иметь, по крайней мере, один входной и один выходной поток; два элемента данных не могут быть непосредственно связаны (например, два хранилища на DFD);
— по типам: функциональный элемент должен всегда использоваться для представления процедурной компоненты; поток данных всегда должен быть представлен компонентой данных.
2) Контроль полноты и состоятельности диаграмм: все элементы диаграмм должны быть идентифицированы и отражены в репозитарии. Например, для DFD контролируются неименованные или несвязанные потоки данных, процессы и хранилища данных; источники и стоки данных (внешние сущности) вне контекстной диаграммы; хранилища данных на контекстной диаграмме и т.п. При анализе словаря данных необходимо выявлять циклические определения, эквивалентные определения, неопределенные объекты.
3) Контроль декомпозиции функций включает оценку качества на основе различных метрик ПО и частичный семантический контроль. (Семантика — это правила, определяющие смысл предложений).
4) Сквозной контроль диаграмм одного или различных типов на предмет их состоятельности по уровням — вертикальное и горизонтальное балансирование диаграмм.
При вертикальном балансировании диаграмм одного типа выявляются несбалансированные потоки данных между детализируемой и детализирующей диаграммами.
Горизонтальное балансирование определяет некорректности между DFD, ERD, STD, словарями данных и миниспецификациями процессов.
Так, при балансировании DFD — ERD контролируется соответствие каждого накопителя данных на DFD сущности или отношению на ERD.
Контроль DFD — STD осуществляется по следующим правилам:
— каждый управляющий процесс на DFD детализируется спецификацией управления STD, и наоборот, каждой STD должен соответствовать управляющий процесс;
— каждое условие/действие в STD должно соответствовать входному/выходному управляющему потоку на DFD, и наоборот, каждому управляющему потоку в зависимости от его направленности должно соответствовать условие/действие на STD.
При балансировании DFD — словарь данных — миниспецификация должны проверяться следующие правила:
— каждый поток и накопитель данных должны быть определены в словаре данных (контроль неопределенных значений), и наоборот, каждое определение в словаре должно быть отражено на диаграмме, в миниспецификации или другом определении (контроль неиспользуемых значений);
— каждый процесс на DFD должен детализироваться с помощью DFD или миниспецификации (но не тем и другим одновременно), и наоборот, каждая миниспецификация должна соответствовать единственному процессу;
— ссылки к данным в миниспецификациях должны соответствовать объектам на диаграммах и в словаре данных;
— по возможности должна контролироваться семантика миниспецификации.
To clean up transmission errors introduced by Earth’s atmosphere (left), Goddard scientists applied Reed–Solomon error correction (right), which is commonly used in CDs and DVDs. Typical errors include missing pixels (white) and false signals (black). The white stripe indicates a brief period when transmission was interrupted.
In information theory and coding theory with applications in computer science and telecommunication, error detection and correction (EDAC) or error control are techniques that enable reliable delivery of digital data over unreliable communication channels. Many communication channels are subject to channel noise, and thus errors may be introduced during transmission from the source to a receiver. Error detection techniques allow detecting such errors, while error correction enables reconstruction of the original data in many cases.
Definitions[edit]
Error detection is the detection of errors caused by noise or other impairments during transmission from the transmitter to the receiver.
Error correction is the detection of errors and reconstruction of the original, error-free data.
History[edit]
In classical antiquity, copyists of the Hebrew Bible were paid for their work according to the number of stichs (lines of verse). As the prose books of the Bible were hardly ever written in stichs, the copyists, in order to estimate the amount of work, had to count the letters.[1] This also helped ensure accuracy in the transmission of the text with the production of subsequent copies.[2][3] Between the 7th and 10th centuries CE a group of Jewish scribes formalized and expanded this to create the Numerical Masorah to ensure accurate reproduction of the sacred text. It included counts of the number of words in a line, section, book and groups of books, noting the middle stich of a book, word use statistics, and commentary.[1] Standards became such that a deviation in even a single letter in a Torah scroll was considered unacceptable.[4] The effectiveness of their error correction method was verified by the accuracy of copying through the centuries demonstrated by discovery of the Dead Sea Scrolls in 1947–1956, dating from c.150 BCE-75 CE.[5]
The modern development of error correction codes is credited to Richard Hamming in 1947.[6] A description of Hamming’s code appeared in Claude Shannon’s A Mathematical Theory of Communication[7] and was quickly generalized by Marcel J. E. Golay.[8]
Introduction[edit]
All error-detection and correction schemes add some redundancy (i.e., some extra data) to a message, which receivers can use to check consistency of the delivered message, and to recover data that has been determined to be corrupted. Error-detection and correction schemes can be either systematic or non-systematic. In a systematic scheme, the transmitter sends the original data, and attaches a fixed number of check bits (or parity data), which are derived from the data bits by some deterministic algorithm. If only error detection is required, a receiver can simply apply the same algorithm to the received data bits and compare its output with the received check bits; if the values do not match, an error has occurred at some point during the transmission. In a system that uses a non-systematic code, the original message is transformed into an encoded message carrying the same information and that has at least as many bits as the original message.
Good error control performance requires the scheme to be selected based on the characteristics of the communication channel. Common channel models include memoryless models where errors occur randomly and with a certain probability, and dynamic models where errors occur primarily in bursts. Consequently, error-detecting and correcting codes can be generally distinguished between random-error-detecting/correcting and burst-error-detecting/correcting. Some codes can also be suitable for a mixture of random errors and burst errors.
If the channel characteristics cannot be determined, or are highly variable, an error-detection scheme may be combined with a system for retransmissions of erroneous data. This is known as automatic repeat request (ARQ), and is most notably used in the Internet. An alternate approach for error control is hybrid automatic repeat request (HARQ), which is a combination of ARQ and error-correction coding.
Types of error correction[edit]
There are three major types of error correction.[9]
Automatic repeat request[edit]
Automatic repeat request (ARQ) is an error control method for data transmission that makes use of error-detection codes, acknowledgment and/or negative acknowledgment messages, and timeouts to achieve reliable data transmission. An acknowledgment is a message sent by the receiver to indicate that it has correctly received a data frame.
Usually, when the transmitter does not receive the acknowledgment before the timeout occurs (i.e., within a reasonable amount of time after sending the data frame), it retransmits the frame until it is either correctly received or the error persists beyond a predetermined number of retransmissions.
Three types of ARQ protocols are Stop-and-wait ARQ, Go-Back-N ARQ, and Selective Repeat ARQ.
ARQ is appropriate if the communication channel has varying or unknown capacity, such as is the case on the Internet. However, ARQ requires the availability of a back channel, results in possibly increased latency due to retransmissions, and requires the maintenance of buffers and timers for retransmissions, which in the case of network congestion can put a strain on the server and overall network capacity.[10]
For example, ARQ is used on shortwave radio data links in the form of ARQ-E, or combined with multiplexing as ARQ-M.
Forward error correction[edit]
Forward error correction (FEC) is a process of adding redundant data such as an error-correcting code (ECC) to a message so that it can be recovered by a receiver even when a number of errors (up to the capability of the code being used) are introduced, either during the process of transmission or on storage. Since the receiver does not have to ask the sender for retransmission of the data, a backchannel is not required in forward error correction. Error-correcting codes are used in lower-layer communication such as cellular network, high-speed fiber-optic communication and Wi-Fi,[11][12] as well as for reliable storage in media such as flash memory, hard disk and RAM.[13]
Error-correcting codes are usually distinguished between convolutional codes and block codes:
- Convolutional codes are processed on a bit-by-bit basis. They are particularly suitable for implementation in hardware, and the Viterbi decoder allows optimal decoding.
- Block codes are processed on a block-by-block basis. Early examples of block codes are repetition codes, Hamming codes and multidimensional parity-check codes. They were followed by a number of efficient codes, Reed–Solomon codes being the most notable due to their current widespread use. Turbo codes and low-density parity-check codes (LDPC) are relatively new constructions that can provide almost optimal efficiency.
Shannon’s theorem is an important theorem in forward error correction, and describes the maximum information rate at which reliable communication is possible over a channel that has a certain error probability or signal-to-noise ratio (SNR). This strict upper limit is expressed in terms of the channel capacity. More specifically, the theorem says that there exist codes such that with increasing encoding length the probability of error on a discrete memoryless channel can be made arbitrarily small, provided that the code rate is smaller than the channel capacity. The code rate is defined as the fraction k/n of k source symbols and n encoded symbols.
The actual maximum code rate allowed depends on the error-correcting code used, and may be lower. This is because Shannon’s proof was only of existential nature, and did not show how to construct codes which are both optimal and have efficient encoding and decoding algorithms.
Hybrid schemes[edit]
Hybrid ARQ is a combination of ARQ and forward error correction. There are two basic approaches:[10]
- Messages are always transmitted with FEC parity data (and error-detection redundancy). A receiver decodes a message using the parity information, and requests retransmission using ARQ only if the parity data was not sufficient for successful decoding (identified through a failed integrity check).
- Messages are transmitted without parity data (only with error-detection information). If a receiver detects an error, it requests FEC information from the transmitter using ARQ, and uses it to reconstruct the original message.
The latter approach is particularly attractive on an erasure channel when using a rateless erasure code.
Error detection schemes[edit]
Error detection is most commonly realized using a suitable hash function (or specifically, a checksum, cyclic redundancy check or other algorithm). A hash function adds a fixed-length tag to a message, which enables receivers to verify the delivered message by recomputing the tag and comparing it with the one provided.
There exists a vast variety of different hash function designs. However, some are of particularly widespread use because of either their simplicity or their suitability for detecting certain kinds of errors (e.g., the cyclic redundancy check’s performance in detecting burst errors).
Minimum distance coding[edit]
A random-error-correcting code based on minimum distance coding can provide a strict guarantee on the number of detectable errors, but it may not protect against a preimage attack.
Repetition codes[edit]
A repetition code is a coding scheme that repeats the bits across a channel to achieve error-free communication. Given a stream of data to be transmitted, the data are divided into blocks of bits. Each block is transmitted some predetermined number of times. For example, to send the bit pattern «1011», the four-bit block can be repeated three times, thus producing «1011 1011 1011». If this twelve-bit pattern was received as «1010 1011 1011» – where the first block is unlike the other two – an error has occurred.
A repetition code is very inefficient, and can be susceptible to problems if the error occurs in exactly the same place for each group (e.g., «1010 1010 1010» in the previous example would be detected as correct). The advantage of repetition codes is that they are extremely simple, and are in fact used in some transmissions of numbers stations.[14][15]
Parity bit[edit]
A parity bit is a bit that is added to a group of source bits to ensure that the number of set bits (i.e., bits with value 1) in the outcome is even or odd. It is a very simple scheme that can be used to detect single or any other odd number (i.e., three, five, etc.) of errors in the output. An even number of flipped bits will make the parity bit appear correct even though the data is erroneous.
Parity bits added to each «word» sent are called transverse redundancy checks, while those added at the end of a stream of «words» are called longitudinal redundancy checks. For example, if each of a series of m-bit «words» has a parity bit added, showing whether there were an odd or even number of ones in that word, any word with a single error in it will be detected. It will not be known where in the word the error is, however. If, in addition, after each stream of n words a parity sum is sent, each bit of which shows whether there were an odd or even number of ones at that bit-position sent in the most recent group, the exact position of the error can be determined and the error corrected. This method is only guaranteed to be effective, however, if there are no more than 1 error in every group of n words. With more error correction bits, more errors can be detected and in some cases corrected.
There are also other bit-grouping techniques.
Checksum[edit]
A checksum of a message is a modular arithmetic sum of message code words of a fixed word length (e.g., byte values). The sum may be negated by means of a ones’-complement operation prior to transmission to detect unintentional all-zero messages.
Checksum schemes include parity bits, check digits, and longitudinal redundancy checks. Some checksum schemes, such as the Damm algorithm, the Luhn algorithm, and the Verhoeff algorithm, are specifically designed to detect errors commonly introduced by humans in writing down or remembering identification numbers.
Cyclic redundancy check[edit]
A cyclic redundancy check (CRC) is a non-secure hash function designed to detect accidental changes to digital data in computer networks. It is not suitable for detecting maliciously introduced errors. It is characterized by specification of a generator polynomial, which is used as the divisor in a polynomial long division over a finite field, taking the input data as the dividend. The remainder becomes the result.
A CRC has properties that make it well suited for detecting burst errors. CRCs are particularly easy to implement in hardware and are therefore commonly used in computer networks and storage devices such as hard disk drives.
The parity bit can be seen as a special-case 1-bit CRC.
Cryptographic hash function[edit]
The output of a cryptographic hash function, also known as a message digest, can provide strong assurances about data integrity, whether changes of the data are accidental (e.g., due to transmission errors) or maliciously introduced. Any modification to the data will likely be detected through a mismatching hash value. Furthermore, given some hash value, it is typically infeasible to find some input data (other than the one given) that will yield the same hash value. If an attacker can change not only the message but also the hash value, then a keyed hash or message authentication code (MAC) can be used for additional security. Without knowing the key, it is not possible for the attacker to easily or conveniently calculate the correct keyed hash value for a modified message.
Error correction code[edit]
Any error-correcting code can be used for error detection. A code with minimum Hamming distance, d, can detect up to d − 1 errors in a code word. Using minimum-distance-based error-correcting codes for error detection can be suitable if a strict limit on the minimum number of errors to be detected is desired.
Codes with minimum Hamming distance d = 2 are degenerate cases of error-correcting codes, and can be used to detect single errors. The parity bit is an example of a single-error-detecting code.
Applications[edit]
Applications that require low latency (such as telephone conversations) cannot use automatic repeat request (ARQ); they must use forward error correction (FEC). By the time an ARQ system discovers an error and re-transmits it, the re-sent data will arrive too late to be usable.
Applications where the transmitter immediately forgets the information as soon as it is sent (such as most television cameras) cannot use ARQ; they must use FEC because when an error occurs, the original data is no longer available.
Applications that use ARQ must have a return channel; applications having no return channel cannot use ARQ.
Applications that require extremely low error rates (such as digital money transfers) must use ARQ due to the possibility of uncorrectable errors with FEC.
Reliability and inspection engineering also make use of the theory of error-correcting codes.[16]
Internet[edit]
In a typical TCP/IP stack, error control is performed at multiple levels:
- Each Ethernet frame uses CRC-32 error detection. Frames with detected errors are discarded by the receiver hardware.
- The IPv4 header contains a checksum protecting the contents of the header. Packets with incorrect checksums are dropped within the network or at the receiver.
- The checksum was omitted from the IPv6 header in order to minimize processing costs in network routing and because current link layer technology is assumed to provide sufficient error detection (see also RFC 3819).
- UDP has an optional checksum covering the payload and addressing information in the UDP and IP headers. Packets with incorrect checksums are discarded by the network stack. The checksum is optional under IPv4, and required under IPv6. When omitted, it is assumed the data-link layer provides the desired level of error protection.
- TCP provides a checksum for protecting the payload and addressing information in the TCP and IP headers. Packets with incorrect checksums are discarded by the network stack, and eventually get retransmitted using ARQ, either explicitly (such as through three-way handshake) or implicitly due to a timeout.
Deep-space telecommunications[edit]
The development of error-correction codes was tightly coupled with the history of deep-space missions due to the extreme dilution of signal power over interplanetary distances, and the limited power availability aboard space probes. Whereas early missions sent their data uncoded, starting in 1968, digital error correction was implemented in the form of (sub-optimally decoded) convolutional codes and Reed–Muller codes.[17] The Reed–Muller code was well suited to the noise the spacecraft was subject to (approximately matching a bell curve), and was implemented for the Mariner spacecraft and used on missions between 1969 and 1977.
The Voyager 1 and Voyager 2 missions, which started in 1977, were designed to deliver color imaging and scientific information from Jupiter and Saturn.[18] This resulted in increased coding requirements, and thus, the spacecraft were supported by (optimally Viterbi-decoded) convolutional codes that could be concatenated with an outer Golay (24,12,8) code. The Voyager 2 craft additionally supported an implementation of a Reed–Solomon code. The concatenated Reed–Solomon–Viterbi (RSV) code allowed for very powerful error correction, and enabled the spacecraft’s extended journey to Uranus and Neptune. After ECC system upgrades in 1989, both crafts used V2 RSV coding.
The Consultative Committee for Space Data Systems currently recommends usage of error correction codes with performance similar to the Voyager 2 RSV code as a minimum. Concatenated codes are increasingly falling out of favor with space missions, and are replaced by more powerful codes such as Turbo codes or LDPC codes.
The different kinds of deep space and orbital missions that are conducted suggest that trying to find a one-size-fits-all error correction system will be an ongoing problem. For missions close to Earth, the nature of the noise in the communication channel is different from that which a spacecraft on an interplanetary mission experiences. Additionally, as a spacecraft increases its distance from Earth, the problem of correcting for noise becomes more difficult.
Satellite broadcasting[edit]
The demand for satellite transponder bandwidth continues to grow, fueled by the desire to deliver television (including new channels and high-definition television) and IP data. Transponder availability and bandwidth constraints have limited this growth. Transponder capacity is determined by the selected modulation scheme and the proportion of capacity consumed by FEC.
Data storage[edit]
Error detection and correction codes are often used to improve the reliability of data storage media.[19] A parity track capable of detecting single-bit errors was present on the first magnetic tape data storage in 1951. The optimal rectangular code used in group coded recording tapes not only detects but also corrects single-bit errors. Some file formats, particularly archive formats, include a checksum (most often CRC32) to detect corruption and truncation and can employ redundancy or parity files to recover portions of corrupted data. Reed-Solomon codes are used in compact discs to correct errors caused by scratches.
Modern hard drives use Reed–Solomon codes to detect and correct minor errors in sector reads, and to recover corrupted data from failing sectors and store that data in the spare sectors.[20] RAID systems use a variety of error correction techniques to recover data when a hard drive completely fails. Filesystems such as ZFS or Btrfs, as well as some RAID implementations, support data scrubbing and resilvering, which allows bad blocks to be detected and (hopefully) recovered before they are used.[21] The recovered data may be re-written to exactly the same physical location, to spare blocks elsewhere on the same piece of hardware, or the data may be rewritten onto replacement hardware.
Error-correcting memory[edit]
Dynamic random-access memory (DRAM) may provide stronger protection against soft errors by relying on error-correcting codes. Such error-correcting memory, known as ECC or EDAC-protected memory, is particularly desirable for mission-critical applications, such as scientific computing, financial, medical, etc. as well as extraterrestrial applications due to the increased radiation in space.
Error-correcting memory controllers traditionally use Hamming codes, although some use triple modular redundancy. Interleaving allows distributing the effect of a single cosmic ray potentially upsetting multiple physically neighboring bits across multiple words by associating neighboring bits to different words. As long as a single-event upset (SEU) does not exceed the error threshold (e.g., a single error) in any particular word between accesses, it can be corrected (e.g., by a single-bit error-correcting code), and the illusion of an error-free memory system may be maintained.[22]
In addition to hardware providing features required for ECC memory to operate, operating systems usually contain related reporting facilities that are used to provide notifications when soft errors are transparently recovered. One example is the Linux kernel’s EDAC subsystem (previously known as Bluesmoke), which collects the data from error-checking-enabled components inside a computer system; besides collecting and reporting back the events related to ECC memory, it also supports other checksumming errors, including those detected on the PCI bus.[23][24][25] A few systems[specify] also support memory scrubbing to catch and correct errors early before they become unrecoverable.
See also[edit]
- Berger code
- Burst error-correcting code
- ECC memory, a type of computer data storage
- Link adaptation
- List of algorithms § Error detection and correction
- List of hash functions
References[edit]
- ^ a b «Masorah». Jewish Encyclopedia.
- ^ Pratico, Gary D.; Pelt, Miles V. Van (2009). Basics of Biblical Hebrew Grammar: Second Edition. Zondervan. ISBN 978-0-310-55882-8.
- ^ Mounce, William D. (2007). Greek for the Rest of Us: Using Greek Tools Without Mastering Biblical Languages. Zondervan. p. 289. ISBN 978-0-310-28289-1.
- ^ Mishneh Torah, Tefillin, Mezuzah, and Sefer Torah, 1:2. Example English translation: Eliyahu Touger. The Rambam’s Mishneh Torah. Moznaim Publishing Corporation.
- ^ Brian M. Fagan (5 December 1996). «Dead Sea Scrolls». The Oxford Companion to Archaeology. Oxford University Press. ISBN 0195076184.
- ^ Thompson, Thomas M. (1983), From Error-Correcting Codes through Sphere Packings to Simple Groups, The Carus Mathematical Monographs (#21), The Mathematical Association of America, p. vii, ISBN 0-88385-023-0
- ^ Shannon, C.E. (1948), «A Mathematical Theory of Communication», Bell System Technical Journal, 27 (3): 379–423, doi:10.1002/j.1538-7305.1948.tb01338.x, hdl:10338.dmlcz/101429, PMID 9230594
- ^ Golay, Marcel J. E. (1949), «Notes on Digital Coding», Proc.I.R.E. (I.E.E.E.), 37: 657
- ^ Gupta, Vikas; Verma, Chanderkant (November 2012). «Error Detection and Correction: An Introduction». International Journal of Advanced Research in Computer Science and Software Engineering. 2 (11). S2CID 17499858.
- ^ a b A. J. McAuley, Reliable Broadband Communication Using a Burst Erasure Correcting Code, ACM SIGCOMM, 1990.
- ^ Shah, Pradeep M.; Vyavahare, Prakash D.; Jain, Anjana (September 2015). «Modern error correcting codes for 4G and beyond: Turbo codes and LDPC codes». 2015 Radio and Antenna Days of the Indian Ocean (RADIO): 1–2. doi:10.1109/RADIO.2015.7323369. ISBN 978-9-9903-7339-4. S2CID 28885076. Retrieved 22 May 2022.
- ^ «IEEE SA — IEEE 802.11ac-2013». IEEE Standards Association.
- ^ «Transition to Advanced Format 4K Sector Hard Drives | Seagate US». Seagate.com. Retrieved 22 May 2022.
- ^ Frank van Gerwen. «Numbers (and other mysterious) stations». Archived from the original on 12 July 2017. Retrieved 12 March 2012.
- ^ Gary Cutlack (25 August 2010). «Mysterious Russian ‘Numbers Station’ Changes Broadcast After 20 Years». Gizmodo. Retrieved 12 March 2012.
- ^ Ben-Gal I.; Herer Y.; Raz T. (2003). «Self-correcting inspection procedure under inspection errors» (PDF). IIE Transactions. IIE Transactions on Quality and Reliability, 34(6), pp. 529-540. Archived from the original (PDF) on 2013-10-13. Retrieved 2014-01-10.
- ^ K. Andrews et al., The Development of Turbo and LDPC Codes for Deep-Space Applications, Proceedings of the IEEE, Vol. 95, No. 11, Nov. 2007.
- ^ Huffman, William Cary; Pless, Vera S. (2003). Fundamentals of Error-Correcting Codes. Cambridge University Press. ISBN 978-0-521-78280-7.
- ^ Kurtas, Erozan M.; Vasic, Bane (2018-10-03). Advanced Error Control Techniques for Data Storage Systems. CRC Press. ISBN 978-1-4200-3649-7.[permanent dead link]
- ^ Scott A. Moulton. «My Hard Drive Died». Archived from the original on 2008-02-02.
- ^ Qiao, Zhi; Fu, Song; Chen, Hsing-Bung; Settlemyer, Bradley (2019). «Building Reliable High-Performance Storage Systems: An Empirical and Analytical Study». 2019 IEEE International Conference on Cluster Computing (CLUSTER): 1–10. doi:10.1109/CLUSTER.2019.8891006. ISBN 978-1-7281-4734-5. S2CID 207951690.
- ^ «Using StrongArm SA-1110 in the On-Board Computer of Nanosatellite». Tsinghua Space Center, Tsinghua University, Beijing. Archived from the original on 2011-10-02. Retrieved 2009-02-16.
- ^ Jeff Layton. «Error Detection and Correction». Linux Magazine. Retrieved 2014-08-12.
- ^ «EDAC Project». bluesmoke.sourceforge.net. Retrieved 2014-08-12.
- ^ «Documentation/edac.txt». Linux kernel documentation. kernel.org. 2014-06-16. Archived from the original on 2009-09-05. Retrieved 2014-08-12.
Further reading[edit]
- Shu Lin; Daniel J. Costello, Jr. (1983). Error Control Coding: Fundamentals and Applications. Prentice Hall. ISBN 0-13-283796-X.
- SoftECC: A System for Software Memory Integrity Checking
- A Tunable, Software-based DRAM Error Detection and Correction Library for HPC
- Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing
External links[edit]
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay, contains chapters on elementary error-correcting codes; on the theoretical limits of error-correction; and on the latest state-of-the-art error-correcting codes, including low-density parity-check codes, turbo codes, and fountain codes.
- ECC Page — implementations of popular ECC encoding and decoding routines
To clean up transmission errors introduced by Earth’s atmosphere (left), Goddard scientists applied Reed–Solomon error correction (right), which is commonly used in CDs and DVDs. Typical errors include missing pixels (white) and false signals (black). The white stripe indicates a brief period when transmission was interrupted.
In information theory and coding theory with applications in computer science and telecommunication, error detection and correction (EDAC) or error control are techniques that enable reliable delivery of digital data over unreliable communication channels. Many communication channels are subject to channel noise, and thus errors may be introduced during transmission from the source to a receiver. Error detection techniques allow detecting such errors, while error correction enables reconstruction of the original data in many cases.
Definitions[edit]
Error detection is the detection of errors caused by noise or other impairments during transmission from the transmitter to the receiver.
Error correction is the detection of errors and reconstruction of the original, error-free data.
History[edit]
In classical antiquity, copyists of the Hebrew Bible were paid for their work according to the number of stichs (lines of verse). As the prose books of the Bible were hardly ever written in stichs, the copyists, in order to estimate the amount of work, had to count the letters.[1] This also helped ensure accuracy in the transmission of the text with the production of subsequent copies.[2][3] Between the 7th and 10th centuries CE a group of Jewish scribes formalized and expanded this to create the Numerical Masorah to ensure accurate reproduction of the sacred text. It included counts of the number of words in a line, section, book and groups of books, noting the middle stich of a book, word use statistics, and commentary.[1] Standards became such that a deviation in even a single letter in a Torah scroll was considered unacceptable.[4] The effectiveness of their error correction method was verified by the accuracy of copying through the centuries demonstrated by discovery of the Dead Sea Scrolls in 1947–1956, dating from c.150 BCE-75 CE.[5]
The modern development of error correction codes is credited to Richard Hamming in 1947.[6] A description of Hamming’s code appeared in Claude Shannon’s A Mathematical Theory of Communication[7] and was quickly generalized by Marcel J. E. Golay.[8]
Introduction[edit]
All error-detection and correction schemes add some redundancy (i.e., some extra data) to a message, which receivers can use to check consistency of the delivered message, and to recover data that has been determined to be corrupted. Error-detection and correction schemes can be either systematic or non-systematic. In a systematic scheme, the transmitter sends the original data, and attaches a fixed number of check bits (or parity data), which are derived from the data bits by some deterministic algorithm. If only error detection is required, a receiver can simply apply the same algorithm to the received data bits and compare its output with the received check bits; if the values do not match, an error has occurred at some point during the transmission. In a system that uses a non-systematic code, the original message is transformed into an encoded message carrying the same information and that has at least as many bits as the original message.
Good error control performance requires the scheme to be selected based on the characteristics of the communication channel. Common channel models include memoryless models where errors occur randomly and with a certain probability, and dynamic models where errors occur primarily in bursts. Consequently, error-detecting and correcting codes can be generally distinguished between random-error-detecting/correcting and burst-error-detecting/correcting. Some codes can also be suitable for a mixture of random errors and burst errors.
If the channel characteristics cannot be determined, or are highly variable, an error-detection scheme may be combined with a system for retransmissions of erroneous data. This is known as automatic repeat request (ARQ), and is most notably used in the Internet. An alternate approach for error control is hybrid automatic repeat request (HARQ), which is a combination of ARQ and error-correction coding.
Types of error correction[edit]
There are three major types of error correction.[9]
Automatic repeat request[edit]
Automatic repeat request (ARQ) is an error control method for data transmission that makes use of error-detection codes, acknowledgment and/or negative acknowledgment messages, and timeouts to achieve reliable data transmission. An acknowledgment is a message sent by the receiver to indicate that it has correctly received a data frame.
Usually, when the transmitter does not receive the acknowledgment before the timeout occurs (i.e., within a reasonable amount of time after sending the data frame), it retransmits the frame until it is either correctly received or the error persists beyond a predetermined number of retransmissions.
Three types of ARQ protocols are Stop-and-wait ARQ, Go-Back-N ARQ, and Selective Repeat ARQ.
ARQ is appropriate if the communication channel has varying or unknown capacity, such as is the case on the Internet. However, ARQ requires the availability of a back channel, results in possibly increased latency due to retransmissions, and requires the maintenance of buffers and timers for retransmissions, which in the case of network congestion can put a strain on the server and overall network capacity.[10]
For example, ARQ is used on shortwave radio data links in the form of ARQ-E, or combined with multiplexing as ARQ-M.
Forward error correction[edit]
Forward error correction (FEC) is a process of adding redundant data such as an error-correcting code (ECC) to a message so that it can be recovered by a receiver even when a number of errors (up to the capability of the code being used) are introduced, either during the process of transmission or on storage. Since the receiver does not have to ask the sender for retransmission of the data, a backchannel is not required in forward error correction. Error-correcting codes are used in lower-layer communication such as cellular network, high-speed fiber-optic communication and Wi-Fi,[11][12] as well as for reliable storage in media such as flash memory, hard disk and RAM.[13]
Error-correcting codes are usually distinguished between convolutional codes and block codes:
- Convolutional codes are processed on a bit-by-bit basis. They are particularly suitable for implementation in hardware, and the Viterbi decoder allows optimal decoding.
- Block codes are processed on a block-by-block basis. Early examples of block codes are repetition codes, Hamming codes and multidimensional parity-check codes. They were followed by a number of efficient codes, Reed–Solomon codes being the most notable due to their current widespread use. Turbo codes and low-density parity-check codes (LDPC) are relatively new constructions that can provide almost optimal efficiency.
Shannon’s theorem is an important theorem in forward error correction, and describes the maximum information rate at which reliable communication is possible over a channel that has a certain error probability or signal-to-noise ratio (SNR). This strict upper limit is expressed in terms of the channel capacity. More specifically, the theorem says that there exist codes such that with increasing encoding length the probability of error on a discrete memoryless channel can be made arbitrarily small, provided that the code rate is smaller than the channel capacity. The code rate is defined as the fraction k/n of k source symbols and n encoded symbols.
The actual maximum code rate allowed depends on the error-correcting code used, and may be lower. This is because Shannon’s proof was only of existential nature, and did not show how to construct codes which are both optimal and have efficient encoding and decoding algorithms.
Hybrid schemes[edit]
Hybrid ARQ is a combination of ARQ and forward error correction. There are two basic approaches:[10]
- Messages are always transmitted with FEC parity data (and error-detection redundancy). A receiver decodes a message using the parity information, and requests retransmission using ARQ only if the parity data was not sufficient for successful decoding (identified through a failed integrity check).
- Messages are transmitted without parity data (only with error-detection information). If a receiver detects an error, it requests FEC information from the transmitter using ARQ, and uses it to reconstruct the original message.
The latter approach is particularly attractive on an erasure channel when using a rateless erasure code.
Error detection schemes[edit]
Error detection is most commonly realized using a suitable hash function (or specifically, a checksum, cyclic redundancy check or other algorithm). A hash function adds a fixed-length tag to a message, which enables receivers to verify the delivered message by recomputing the tag and comparing it with the one provided.
There exists a vast variety of different hash function designs. However, some are of particularly widespread use because of either their simplicity or their suitability for detecting certain kinds of errors (e.g., the cyclic redundancy check’s performance in detecting burst errors).
Minimum distance coding[edit]
A random-error-correcting code based on minimum distance coding can provide a strict guarantee on the number of detectable errors, but it may not protect against a preimage attack.
Repetition codes[edit]
A repetition code is a coding scheme that repeats the bits across a channel to achieve error-free communication. Given a stream of data to be transmitted, the data are divided into blocks of bits. Each block is transmitted some predetermined number of times. For example, to send the bit pattern «1011», the four-bit block can be repeated three times, thus producing «1011 1011 1011». If this twelve-bit pattern was received as «1010 1011 1011» – where the first block is unlike the other two – an error has occurred.
A repetition code is very inefficient, and can be susceptible to problems if the error occurs in exactly the same place for each group (e.g., «1010 1010 1010» in the previous example would be detected as correct). The advantage of repetition codes is that they are extremely simple, and are in fact used in some transmissions of numbers stations.[14][15]
Parity bit[edit]
A parity bit is a bit that is added to a group of source bits to ensure that the number of set bits (i.e., bits with value 1) in the outcome is even or odd. It is a very simple scheme that can be used to detect single or any other odd number (i.e., three, five, etc.) of errors in the output. An even number of flipped bits will make the parity bit appear correct even though the data is erroneous.
Parity bits added to each «word» sent are called transverse redundancy checks, while those added at the end of a stream of «words» are called longitudinal redundancy checks. For example, if each of a series of m-bit «words» has a parity bit added, showing whether there were an odd or even number of ones in that word, any word with a single error in it will be detected. It will not be known where in the word the error is, however. If, in addition, after each stream of n words a parity sum is sent, each bit of which shows whether there were an odd or even number of ones at that bit-position sent in the most recent group, the exact position of the error can be determined and the error corrected. This method is only guaranteed to be effective, however, if there are no more than 1 error in every group of n words. With more error correction bits, more errors can be detected and in some cases corrected.
There are also other bit-grouping techniques.
Checksum[edit]
A checksum of a message is a modular arithmetic sum of message code words of a fixed word length (e.g., byte values). The sum may be negated by means of a ones’-complement operation prior to transmission to detect unintentional all-zero messages.
Checksum schemes include parity bits, check digits, and longitudinal redundancy checks. Some checksum schemes, such as the Damm algorithm, the Luhn algorithm, and the Verhoeff algorithm, are specifically designed to detect errors commonly introduced by humans in writing down or remembering identification numbers.
Cyclic redundancy check[edit]
A cyclic redundancy check (CRC) is a non-secure hash function designed to detect accidental changes to digital data in computer networks. It is not suitable for detecting maliciously introduced errors. It is characterized by specification of a generator polynomial, which is used as the divisor in a polynomial long division over a finite field, taking the input data as the dividend. The remainder becomes the result.
A CRC has properties that make it well suited for detecting burst errors. CRCs are particularly easy to implement in hardware and are therefore commonly used in computer networks and storage devices such as hard disk drives.
The parity bit can be seen as a special-case 1-bit CRC.
Cryptographic hash function[edit]
The output of a cryptographic hash function, also known as a message digest, can provide strong assurances about data integrity, whether changes of the data are accidental (e.g., due to transmission errors) or maliciously introduced. Any modification to the data will likely be detected through a mismatching hash value. Furthermore, given some hash value, it is typically infeasible to find some input data (other than the one given) that will yield the same hash value. If an attacker can change not only the message but also the hash value, then a keyed hash or message authentication code (MAC) can be used for additional security. Without knowing the key, it is not possible for the attacker to easily or conveniently calculate the correct keyed hash value for a modified message.
Error correction code[edit]
Any error-correcting code can be used for error detection. A code with minimum Hamming distance, d, can detect up to d − 1 errors in a code word. Using minimum-distance-based error-correcting codes for error detection can be suitable if a strict limit on the minimum number of errors to be detected is desired.
Codes with minimum Hamming distance d = 2 are degenerate cases of error-correcting codes, and can be used to detect single errors. The parity bit is an example of a single-error-detecting code.
Applications[edit]
Applications that require low latency (such as telephone conversations) cannot use automatic repeat request (ARQ); they must use forward error correction (FEC). By the time an ARQ system discovers an error and re-transmits it, the re-sent data will arrive too late to be usable.
Applications where the transmitter immediately forgets the information as soon as it is sent (such as most television cameras) cannot use ARQ; they must use FEC because when an error occurs, the original data is no longer available.
Applications that use ARQ must have a return channel; applications having no return channel cannot use ARQ.
Applications that require extremely low error rates (such as digital money transfers) must use ARQ due to the possibility of uncorrectable errors with FEC.
Reliability and inspection engineering also make use of the theory of error-correcting codes.[16]
Internet[edit]
In a typical TCP/IP stack, error control is performed at multiple levels:
- Each Ethernet frame uses CRC-32 error detection. Frames with detected errors are discarded by the receiver hardware.
- The IPv4 header contains a checksum protecting the contents of the header. Packets with incorrect checksums are dropped within the network or at the receiver.
- The checksum was omitted from the IPv6 header in order to minimize processing costs in network routing and because current link layer technology is assumed to provide sufficient error detection (see also RFC 3819).
- UDP has an optional checksum covering the payload and addressing information in the UDP and IP headers. Packets with incorrect checksums are discarded by the network stack. The checksum is optional under IPv4, and required under IPv6. When omitted, it is assumed the data-link layer provides the desired level of error protection.
- TCP provides a checksum for protecting the payload and addressing information in the TCP and IP headers. Packets with incorrect checksums are discarded by the network stack, and eventually get retransmitted using ARQ, either explicitly (such as through three-way handshake) or implicitly due to a timeout.
Deep-space telecommunications[edit]
The development of error-correction codes was tightly coupled with the history of deep-space missions due to the extreme dilution of signal power over interplanetary distances, and the limited power availability aboard space probes. Whereas early missions sent their data uncoded, starting in 1968, digital error correction was implemented in the form of (sub-optimally decoded) convolutional codes and Reed–Muller codes.[17] The Reed–Muller code was well suited to the noise the spacecraft was subject to (approximately matching a bell curve), and was implemented for the Mariner spacecraft and used on missions between 1969 and 1977.
The Voyager 1 and Voyager 2 missions, which started in 1977, were designed to deliver color imaging and scientific information from Jupiter and Saturn.[18] This resulted in increased coding requirements, and thus, the spacecraft were supported by (optimally Viterbi-decoded) convolutional codes that could be concatenated with an outer Golay (24,12,8) code. The Voyager 2 craft additionally supported an implementation of a Reed–Solomon code. The concatenated Reed–Solomon–Viterbi (RSV) code allowed for very powerful error correction, and enabled the spacecraft’s extended journey to Uranus and Neptune. After ECC system upgrades in 1989, both crafts used V2 RSV coding.
The Consultative Committee for Space Data Systems currently recommends usage of error correction codes with performance similar to the Voyager 2 RSV code as a minimum. Concatenated codes are increasingly falling out of favor with space missions, and are replaced by more powerful codes such as Turbo codes or LDPC codes.
The different kinds of deep space and orbital missions that are conducted suggest that trying to find a one-size-fits-all error correction system will be an ongoing problem. For missions close to Earth, the nature of the noise in the communication channel is different from that which a spacecraft on an interplanetary mission experiences. Additionally, as a spacecraft increases its distance from Earth, the problem of correcting for noise becomes more difficult.
Satellite broadcasting[edit]
The demand for satellite transponder bandwidth continues to grow, fueled by the desire to deliver television (including new channels and high-definition television) and IP data. Transponder availability and bandwidth constraints have limited this growth. Transponder capacity is determined by the selected modulation scheme and the proportion of capacity consumed by FEC.
Data storage[edit]
Error detection and correction codes are often used to improve the reliability of data storage media.[19] A parity track capable of detecting single-bit errors was present on the first magnetic tape data storage in 1951. The optimal rectangular code used in group coded recording tapes not only detects but also corrects single-bit errors. Some file formats, particularly archive formats, include a checksum (most often CRC32) to detect corruption and truncation and can employ redundancy or parity files to recover portions of corrupted data. Reed-Solomon codes are used in compact discs to correct errors caused by scratches.
Modern hard drives use Reed–Solomon codes to detect and correct minor errors in sector reads, and to recover corrupted data from failing sectors and store that data in the spare sectors.[20] RAID systems use a variety of error correction techniques to recover data when a hard drive completely fails. Filesystems such as ZFS or Btrfs, as well as some RAID implementations, support data scrubbing and resilvering, which allows bad blocks to be detected and (hopefully) recovered before they are used.[21] The recovered data may be re-written to exactly the same physical location, to spare blocks elsewhere on the same piece of hardware, or the data may be rewritten onto replacement hardware.
Error-correcting memory[edit]
Dynamic random-access memory (DRAM) may provide stronger protection against soft errors by relying on error-correcting codes. Such error-correcting memory, known as ECC or EDAC-protected memory, is particularly desirable for mission-critical applications, such as scientific computing, financial, medical, etc. as well as extraterrestrial applications due to the increased radiation in space.
Error-correcting memory controllers traditionally use Hamming codes, although some use triple modular redundancy. Interleaving allows distributing the effect of a single cosmic ray potentially upsetting multiple physically neighboring bits across multiple words by associating neighboring bits to different words. As long as a single-event upset (SEU) does not exceed the error threshold (e.g., a single error) in any particular word between accesses, it can be corrected (e.g., by a single-bit error-correcting code), and the illusion of an error-free memory system may be maintained.[22]
In addition to hardware providing features required for ECC memory to operate, operating systems usually contain related reporting facilities that are used to provide notifications when soft errors are transparently recovered. One example is the Linux kernel’s EDAC subsystem (previously known as Bluesmoke), which collects the data from error-checking-enabled components inside a computer system; besides collecting and reporting back the events related to ECC memory, it also supports other checksumming errors, including those detected on the PCI bus.[23][24][25] A few systems[specify] also support memory scrubbing to catch and correct errors early before they become unrecoverable.
See also[edit]
- Berger code
- Burst error-correcting code
- ECC memory, a type of computer data storage
- Link adaptation
- List of algorithms § Error detection and correction
- List of hash functions
References[edit]
- ^ a b «Masorah». Jewish Encyclopedia.
- ^ Pratico, Gary D.; Pelt, Miles V. Van (2009). Basics of Biblical Hebrew Grammar: Second Edition. Zondervan. ISBN 978-0-310-55882-8.
- ^ Mounce, William D. (2007). Greek for the Rest of Us: Using Greek Tools Without Mastering Biblical Languages. Zondervan. p. 289. ISBN 978-0-310-28289-1.
- ^ Mishneh Torah, Tefillin, Mezuzah, and Sefer Torah, 1:2. Example English translation: Eliyahu Touger. The Rambam’s Mishneh Torah. Moznaim Publishing Corporation.
- ^ Brian M. Fagan (5 December 1996). «Dead Sea Scrolls». The Oxford Companion to Archaeology. Oxford University Press. ISBN 0195076184.
- ^ Thompson, Thomas M. (1983), From Error-Correcting Codes through Sphere Packings to Simple Groups, The Carus Mathematical Monographs (#21), The Mathematical Association of America, p. vii, ISBN 0-88385-023-0
- ^ Shannon, C.E. (1948), «A Mathematical Theory of Communication», Bell System Technical Journal, 27 (3): 379–423, doi:10.1002/j.1538-7305.1948.tb01338.x, hdl:10338.dmlcz/101429, PMID 9230594
- ^ Golay, Marcel J. E. (1949), «Notes on Digital Coding», Proc.I.R.E. (I.E.E.E.), 37: 657
- ^ Gupta, Vikas; Verma, Chanderkant (November 2012). «Error Detection and Correction: An Introduction». International Journal of Advanced Research in Computer Science and Software Engineering. 2 (11). S2CID 17499858.
- ^ a b A. J. McAuley, Reliable Broadband Communication Using a Burst Erasure Correcting Code, ACM SIGCOMM, 1990.
- ^ Shah, Pradeep M.; Vyavahare, Prakash D.; Jain, Anjana (September 2015). «Modern error correcting codes for 4G and beyond: Turbo codes and LDPC codes». 2015 Radio and Antenna Days of the Indian Ocean (RADIO): 1–2. doi:10.1109/RADIO.2015.7323369. ISBN 978-9-9903-7339-4. S2CID 28885076. Retrieved 22 May 2022.
- ^ «IEEE SA — IEEE 802.11ac-2013». IEEE Standards Association.
- ^ «Transition to Advanced Format 4K Sector Hard Drives | Seagate US». Seagate.com. Retrieved 22 May 2022.
- ^ Frank van Gerwen. «Numbers (and other mysterious) stations». Archived from the original on 12 July 2017. Retrieved 12 March 2012.
- ^ Gary Cutlack (25 August 2010). «Mysterious Russian ‘Numbers Station’ Changes Broadcast After 20 Years». Gizmodo. Retrieved 12 March 2012.
- ^ Ben-Gal I.; Herer Y.; Raz T. (2003). «Self-correcting inspection procedure under inspection errors» (PDF). IIE Transactions. IIE Transactions on Quality and Reliability, 34(6), pp. 529-540. Archived from the original (PDF) on 2013-10-13. Retrieved 2014-01-10.
- ^ K. Andrews et al., The Development of Turbo and LDPC Codes for Deep-Space Applications, Proceedings of the IEEE, Vol. 95, No. 11, Nov. 2007.
- ^ Huffman, William Cary; Pless, Vera S. (2003). Fundamentals of Error-Correcting Codes. Cambridge University Press. ISBN 978-0-521-78280-7.
- ^ Kurtas, Erozan M.; Vasic, Bane (2018-10-03). Advanced Error Control Techniques for Data Storage Systems. CRC Press. ISBN 978-1-4200-3649-7.[permanent dead link]
- ^ Scott A. Moulton. «My Hard Drive Died». Archived from the original on 2008-02-02.
- ^ Qiao, Zhi; Fu, Song; Chen, Hsing-Bung; Settlemyer, Bradley (2019). «Building Reliable High-Performance Storage Systems: An Empirical and Analytical Study». 2019 IEEE International Conference on Cluster Computing (CLUSTER): 1–10. doi:10.1109/CLUSTER.2019.8891006. ISBN 978-1-7281-4734-5. S2CID 207951690.
- ^ «Using StrongArm SA-1110 in the On-Board Computer of Nanosatellite». Tsinghua Space Center, Tsinghua University, Beijing. Archived from the original on 2011-10-02. Retrieved 2009-02-16.
- ^ Jeff Layton. «Error Detection and Correction». Linux Magazine. Retrieved 2014-08-12.
- ^ «EDAC Project». bluesmoke.sourceforge.net. Retrieved 2014-08-12.
- ^ «Documentation/edac.txt». Linux kernel documentation. kernel.org. 2014-06-16. Archived from the original on 2009-09-05. Retrieved 2014-08-12.
Further reading[edit]
- Shu Lin; Daniel J. Costello, Jr. (1983). Error Control Coding: Fundamentals and Applications. Prentice Hall. ISBN 0-13-283796-X.
- SoftECC: A System for Software Memory Integrity Checking
- A Tunable, Software-based DRAM Error Detection and Correction Library for HPC
- Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing
External links[edit]
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay, contains chapters on elementary error-correcting codes; on the theoretical limits of error-correction; and on the latest state-of-the-art error-correcting codes, including low-density parity-check codes, turbo codes, and fountain codes.
- ECC Page — implementations of popular ECC encoding and decoding routines
Программы для исправления ошибок бывают необходимы во многих случаях: когда нужно проверить документ большого объема или быстро устранить опечатки в тексте. Часто пользователи жалуются на то, что вычитывают текст по нескольку раз, но все равно пропускают ряд ошибок, списывая это на собственную невнимательность. В чем бы ни заключалась проблема, без программ для исправления ошибок работать действительно сложно — даже тем, у кого с внимательностью нет никаких проблем. В этой статье мы расскажем, какими программами для исправления ошибок пользуются юзеры сети и почему.

Навигация по статье
- ТОП-10 программ по исправлению ошибок в тексте
- Сравнение возможностей сервисов

ТОП-10 программ по исправлению ошибок в тексте
Мы сделали для вас подборку из десяти самых популярных программ и сервисов, которые проверяют текст на наличие ошибок и подсвечивают их, чтобы пользователь мог легко их обнаружить и устранить.

Orfogrammka.ru
Это платная платформа, которая дает возможность проверить до 1 млн символов текста в течение одного месяца. Данный сервис, помимо синтаксических и орфографических ошибок, дает возможность проверить:
- наличие тавтологии;
- водность текста;
- иностранные слова;
- замену символов.
Сервис работает по подписке, которая предоставляет доступ к полноценной работе на один месяц. Стоимость ее обойдется пользователю в 300 рублей. Здесь также есть возможность проверить 6 тысяч символов текста с пробелами в тестовом режиме. Это же касается и исправления ошибок.
Яндекс.Спеллер
Сервис от известной группы разработчиков Яндекс — “Спеллер”, был создан для тех, кто хочет быстро осуществить проверку текста и исправить ошибки в режиме онлайн. Как и в большинстве других программ и сервисов подобного типа, здесь в окно проверки текста помещается сам текст, после чего сервис осуществляет проверку последнего в порядке очередности на сервере. В нижнем окне представлены варианты исправления.

Text.ru
Эта программа проверки орфографии на наличие ошибок в русском языке пользуется большой популярностью. Сервис в своем роде уникален, т.к. выполняет одновременно проверку уникальности, ошибок и SEO-данных текста.
Advego
Адвего — пожалуй, самая распространенная программа проверки текста. Это высококачественный и удобный сервис, который удерживает высокие позиции уже довольно долгое время. Он получил широкую известность как у разработчиков и SEO-специалистов, так и у копирайтеров с редакторами. Помимо функции проверки текста на наличие ошибок, здесь представлена масса других полезных возможностей:
- расчет количества символов;
- выявление орфографических ошибок;
- количество вхождений слов;
- водность текста;
- тошнота текста (академ. и классическая);
- уникальность текста.

Орфограф
Студия Артемия Лебедева представила еще один свой сервис, на этот раз, касающийся проверки текста. Как и все остальные проекты этой группы, Орфограф имеет минимальный набор функций — а именно, проверяет текст на наличие ошибок. В сервисе представлен собственный уникальный словарь, и если какая-то часть текста не имеет совпадений с базой данных Орфографа, то неизвестные слова выделяются дополнительным цветом.

Onlinecorrector
У этой программы проверки текстов есть одна специфическая функция — она способна проверять Google-документы. Это расширение требует установки в браузере, после чего с сервисом можно работать в режиме онлайн.

Орфо
Для осуществления проверок программой на ошибки в текстах многие пользователи сети предпочитают Орфо. Программу можно скачать на сайте, а также воспользоваться сервисом в режиме онлайн. Помарки в тексте подсвечиваются зеленым и красным цветом, в зависимости от того, какой тип ошибки будет обнаружен. Офлайн-версия предлагает пользователям расширенный функционал — здесь можно создавать переносы или автоматически корректировать буквы.

LanguageTool
Сервис был разработан и создан с целью предоставить функцию автоматического исправления орфографии на русском языке. Разработчики побеспокоились о том, чтобы создать две версии — онлайн и стационарную, для работы с расширением в браузере. При анализе текста, все слова с ошибками подсвечиваются другим цветом. Данная функция работает по аналогии с другими сервисами, которые предоставляют те же функции. Однако, здесь присутствует одно ключевое отличие — при нажатии на подсвеченное слово с ошибкой выпадает дополнительное меню, в котором можно выбрать один из вариантов исправления. Премиум версия программы (платная) предоставляет расширенный функционал, который может оказаться полезным для профессиональных корректоров, а также частных редакций.

Мета.ua
Этот сервис подойдет пользователям, которые ищут бесплатный инструмент, способный не только подсветить слова с ошибками, но и предоставить варианты для замены. Помимо всего прочего, данный сервис представляет еще и функции автоматического перевода. Ошибки в словах выделяются пунктирной линией. При нажатии на подсвеченное слово, пользователь может увидеть список слов для замены и выбрать из них подходящее.
Главред
Сайт Главред предлагает интересную функцию — проверку не только орфографического, но и смыслового качества текста. Это позволяет оценить текст сразу по нескольким критериям. Все предлагаемые исправления в тексте подчеркиваются пунктиром.
Присоединяйтесь к
Rush-Analytics уже сегодня
7-ми дневный бесплатный доступ к полному функционалу. Без привязки карты.
Попробовать бесплатно

Сравнение возможностей сервисов
| Название сервиса / программы | Проприетарность | Версия | Автокоррекция |
| Orfogrammka.ru | Платная | Онлайн | Нет |
| Яндекс.Спеллер | Бесплатная | Онлайн | Нет |
| Text.ru | Платная и бесплатная | Онлайн | Нет |
| Advego | Платная и бесплатная | Онлайн и офлайн | Нет |
| Орфограф | Платная | Онлайн | Нет |
| Onlinecorrector | Платная и бесплатная | Онлайн и офлайн | Нет |
| Орфо | Платная и бесплатная | Онлайн и офлайн | Да |
| LanguageTool | Платная и бесплатная | Онлайн и офлайн | Да |
| Мета.ua | Бесплатная | Онлайн | Да |
| Главред | Бесплатная | Онлайн | Нет |
Рекомендуем протестировать каждый из этих инструментов, чтобы выбрать наиболее удобный и эффективный для ваших целей.

 Доброго времени суток. На днях у меня возникла задача по реализации алгоритма пост-обработки результатов оптического распознавания текста. Для решения этой проблемы не плохо подошла одна из моделей для проверки орфографии в тексте, хотя конечно слегка модифицированная под контекст задачи. Этот пост будет посвящен модели Noisy Channel, которая позволяет осуществлять автоматическую проверку орфографии, мы изучим математическую модель, напишем на c# немного кода, обучим модель на базе Питера Норвига, и под конец протестируем то что у нас получится.
Доброго времени суток. На днях у меня возникла задача по реализации алгоритма пост-обработки результатов оптического распознавания текста. Для решения этой проблемы не плохо подошла одна из моделей для проверки орфографии в тексте, хотя конечно слегка модифицированная под контекст задачи. Этот пост будет посвящен модели Noisy Channel, которая позволяет осуществлять автоматическую проверку орфографии, мы изучим математическую модель, напишем на c# немного кода, обучим модель на базе Питера Норвига, и под конец протестируем то что у нас получится.
Математическая модель — 1
Для начала постановка задачи. Итак вы хотите написать некоторое слово w состоящее из m букв, но каким то неведомым вам способом на бумаге выходит слово x состоящее из n букв. Кстати вы как раз и есть тот самый noisy channel, канал передачи информации с шумами, который исказил правильное слово w (из вселенной правильных слов) до не правильного x (множества всех написанных слов).

Мы хотим найти такое слово, которое вы наиболее вероятно подразумевали при написании слова x. Запишем эту мысль математически, модель по своей идее похожа на модель наивного байесовского классификатора, хотя даже проще:

- V — список всех слов естественного языка.
Далее используя теорему Байеса развернем причину и следствие, полную вероятность x мы можем убрать из знаменателя, т.к. он при argmax не зависит от w:

- P(w) — априорная вероятность слова w в языке; этот член представляет из себя статистическую модель естественного языка (language model), мы будем использовать модель unigram, хотя конечно вы в праве использовать и более сложные модели; так же заметим, что значение этого члена легко вычисляется из базы слов языка;
- P(x | w) — вероятность того, что правильное слово w было ошибочно написано как x, этот член называется channel model; в принципе обладая достаточно большой базой, которая содержит все способы ошибиться при написании каждого слова языка, то вычисление этого члена не вызвало бы трудностей, но к сожалению такой большой базы нет, но есть похожие базы меньшего размера, так что придется как то выкручиваться (например здесь находится база из 333333 слов английского языка, и только для 7481 есть слова с ошибками).
Вычисление значения вероятности P(x | w)
Тут к нам на помощь приходит расстояние Дамерау-Левенштейна — это мера между двумя последовательностями символов, определяемая как минимальное количество операций вставки, удаления, замены и перестановки соседних символов для приведения строки source к строке target. Мы же далее будем использовать расстояние Левенштейна, которое отличается тем, что не поддерживает операцию перестановки соседних символов, так будет проще. Оба эти алгоритма с примерами хорошо описаны в тут, так что я повторяться не буду, а сразу приведу код:
Расстояние Левенштейна
public static int LevenshteinDistance(string s, string t)
{
int[,] d = new int[s.Length + 1, t.Length + 1];
for (int i = 0; i < s.Length + 1; i++)
{
d[i, 0] = i;
}
for (int j = 1; j < t.Length + 1; j++)
{
d[0, j] = j;
}
for (int i = 1; i <= s.Length; i++)
{
for (int j = 1; j <= t.Length; j++)
{
d[i, j] = (new int[]
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
}).Min();
}
}
return d[s.Length, t.Length];
}
Эта функция сообщает нам сколько операций удаления, вставки и замены нужно произвести для приведения одного слова к другому, но нам этого не достаточно, а хотелось бы получить так же список этих самых операций, назовем это backtrace алгоритма. Нам необходим модифицировать приведенный код таким образом, что бы при вычислении матрицы расстояний d, так же записывалась матрица операций b. Рассмотрим пример для слов ca и abc:
Как вы помните, значение ячейки (i,j) в матрице расстояний d вычисляется следующим образом:
d[i, j] = (new int[]
{
d[i - 1, j] + 1, // del - 0
d[i, j - 1] + 1, // ins - 1
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub - 2
}).Min();
Нам остается в ячейку (i,j) матрицы операций b записывать индекс операции (0 для удаления, 1 для вставки и 2 для замены), соответственно этот кусок кода преобразуется следующим образом:
IList<int> vals = new List<int>()
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
};
d[i, j] = vals.Min();
int idx = vals.IndexOf(d[i, j]);
b[i, j] = idx;
Как только обе матрицы заполнены, не составит труда вычислить backtrace (стрелочки на картинках выше). Это путь из правой нижней ячейки матрицы операций, по пути наименьшей стоимости матрицы расстояний. Опишем алгоритм:
- обозначим правую нижнюю ячейку как текущую
- делаем одно из следующих действий
- если удаление, то записываем удаленный символ, и сдвигаем текущую ячейку вверх (красная стрелка)
- если вставка, то записываем вставленный символ и сдвигаем текущую ячейку влево (красная стрелка)
- если замена, а так же заменяемые символы не равны, то записываем заменяемые символы и сдвигаем текущую ячейку налево и вверх (красная стрелка)
- если замена, но заменяемые символы равны, то только сдвигаем текущую ячейку налево и вверх (синяя стрелка)
- если количество записанных операций не равно расстоянию Левенштейна, то на пункт назад, иначе стоп
В итоге получим следующую функцию, вычисляющую расстояние Левенштейна, а так же backtrace:
Расстояние Левенштейна с backtrace’ом
//del - 0, ins - 1, sub - 2
public static Tuple<int, IList<Tuple<int, string>>> LevenshteinDistanceWithBacktrace(string s, string t)
{
int[,] d = new int[s.Length + 1, t.Length + 1];
int[,] b = new int[s.Length + 1, t.Length + 1];
for (int i = 0; i < s.Length + 1; i++)
{
d[i, 0] = i;
}
for (int j = 1; j < t.Length + 1; j++)
{
d[0, j] = j;
b[0, j] = 1;
}
for (int i = 1; i <= s.Length; i++)
{
for (int j = 1; j <= t.Length; j++)
{
IList<int> vals = new List<int>()
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
};
d[i, j] = vals.Min();
int idx = vals.IndexOf(d[i, j]);
b[i, j] = idx;
}
}
List<Tuple<int, string>> bt = new List<Tuple<int, string>>();
int x = s.Length;
int y = t.Length;
while (bt.Count != d[s.Length, t.Length])
{
switch (b[x, y])
{
case 0:
x--;
bt.Add(new Tuple<int, string>(0, s[x].ToString()));
break;
case 1:
y--;
bt.Add(new Tuple<int, string>(1, t[y].ToString()));
break;
case 2:
x--;
y--;
if (s[x] != t[y])
{
bt.Add(new Tuple<int, string>(2, s[x] + "" + t[y]));
}
break;
}
}
bt.Reverse();
return new Tuple<int, IList<Tuple<int, string>>>(d[s.Length, t.Length], bt);
}
Эта функция возвращает кортеж, в первом элементе которого записано расстояние Левенштейна, а во втором список пар <id операции, строка>, строка состоит из одного символа для операций удаления и вставки, и из двух символов для операции замены (подразумевается замена первого символа на второй).
PS: внимательный читатель заметит, что из правой нижней ячейки часто существует несколько способов движения по пути наименьшей стоимости, это один из способов увеличить выборку, но мы его для простоты так же опустим.
Математическая модель — 2
Теперь опишем полученный выше результат на языке формул. Для двух слов x и w мы можем вычислить список операций необходимых для приведений первого слова ко второму, обозначим список операции буквой f, тогда вероятность написать слово x как w будет равна вероятности произвести весь список ошибок f при условии, что мы писали именно x, а подразумевали w:

Вот тут начинаются упрощения, похожие на те что были в наивном байесовском классификаторе:
- порядок следования операций ошибки не имеет значения
- ошибка не будет зависеть от того какое слово мы написали и от того что подразумевали

Теперь для того что бы вычислить вероятности ошибок (независимо от того в каких словах они были сделаны) достаточно иметь на руках любую базу слов с их ошибочным написанием. Запишем финальную формулу, во избежание работы с числами близкими к нулю, будем работать в log space:

Итак, что же мы имеем? Если у нас на руках есть достаточный набор текстов мы можем вычислить априорные вероятности слов в языке; так же имея на руках базу слов с их ошибочным написанием, мы можем вычислить вероятности ошибок, этих двух баз достаточно что бы реализовать модель.
Размытие вероятностей ошибок
При пробеге по все базе слов при argmax, мы ни разу не наткнемся на слова с нулевой вероятностью. Но вот при вычислении операций редактирования для приведения слова x к слову w могут возникнуть такие операции, которые не встречались в нашей базе ошибок. В этом случае нам поможет additive smoothing или размытие по Лапласу (оно так же использовалось в наивном байесовском классификаторе). Напомню формулу, в контексте текущей задачи. Если некоторая операция коррекции f встречается в базе n раз, при том что всего ошибок в базе m, а типов коррекции t (например для замены, не то сколько раз встречается замена «a на b«, а сколько всего уникальных пар «* на *»), то размытая вероятность выглядит следующим образом, где k — коэффициент размытия:
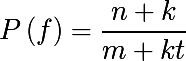
Тогда вероятность операции которая ни разу не встречалась в обучающей базе (n = 0) будет равна:
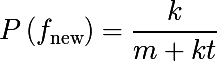
Скорость
Возникает естественный вопрос, а как быть со скоростью работы алгоритма, ведь нам придется пробегать по всей базе слов, а это сотни тысяч вызовов функции вычисления расстояния Левенштейна с backtrace’ом, а так же вычислять для всех слов вероятности ошибки (сумма чисел, если хранить в базе предвычисленные логарифмы). Тут приходит на помощь следующий статистический факт:
- 80% всех печатных ошибок находятся в пределах 1 операции редактирования, т.е. расстояния Левенштейна равным единице
- почти все печатные ошибки находятся в пределах 2 операций редактирования
Ну а далее вы можете придумывать различные алгоритмические трюки. Я использовал очевидный и очень простой способ ускорить работу алгоритма. Очевидно, что если мне требуются только слова не более чем в t операций редактирования от текущего слова, то их длина отличается от текущего не более чем на t. При инициализации класса, я создаю хэш-таблицу, в которой ключами является длины слов, а значениями — множества слов этой длины, это позволяет значительно сокращать пространство поиска.
Код
Приведу код класса NoisyChannel который у меня получился:
NoisyChannel
public class NoisyChannel
{
#region vars
private string[] _words = null;
private double[] _wLogPriors = null;
private IDictionary<int, IList<int>> _wordLengthDictionary = null; //length of word - word indices
private IDictionary<int, IDictionary<string, double>> _mistakeLogProbs = null;
private double _lf = 1d;
private IDictionary<int, int> _mNorms = null;
#endregion
#region ctor
public NoisyChannel(string[] words, long[] wordFrequency,
IDictionary<int, IDictionary<string, int>> mistakeFrequency,
int mistakeProbSmoothing = 1)
{
_words = words;
_wLogPriors = new double[_words.Length];
_wordLengthDictionary = new SortedDictionary<int, IList<int>>();
double wNorm = wordFrequency.Sum();
for (int i = 0; i < _words.Length; i++)
{
_wLogPriors[i] = Math.Log((wordFrequency[i] + 0d)/wNorm);
int wl = _words[i].Length;
if (!_wordLengthDictionary.ContainsKey(wl))
{
_wordLengthDictionary.Add(wl, new List<int>());
}
_wordLengthDictionary[wl].Add(i);
}
_lf = mistakeProbSmoothing;
_mistakeLogProbs = new Dictionary<int, IDictionary<string, double>>();
_mNorms = new Dictionary<int, int>();
foreach (int mType in mistakeFrequency.Keys)
{
int mNorm = mistakeFrequency[mType].Sum(m => m.Value);
_mNorms.Add(mType, mNorm);
int mUnique = mistakeFrequency[mType].Count;
_mistakeLogProbs.Add(mType, new Dictionary<string, double>());
foreach (string m in mistakeFrequency[mType].Keys)
{
_mistakeLogProbs[mType].Add(m,
Math.Log((mistakeFrequency[mType][m] + _lf)/
(mNorm + _lf*mUnique))
);
}
}
}
#endregion
#region correction
public IDictionary<string, double> GetCandidates(string s, int maxEditDistance = 2)
{
IDictionary<string, double> candidates = new Dictionary<string, double>();
IList<int> dists = new List<int>();
for (int i = s.Length - maxEditDistance; i <= s.Length + maxEditDistance; i++)
{
if (i >= 0)
{
dists.Add(i);
}
}
foreach (int dist in dists)
{
foreach (int tIdx in _wordLengthDictionary[dist])
{
string t = _words[tIdx];
Tuple<int, IList<Tuple<int, string>>> d = LevenshteinDistanceWithBacktrace(s, t);
if (d.Item1 > maxEditDistance)
{
continue;
}
double p = _wLogPriors[tIdx];
foreach (Tuple<int, string> m in d.Item2)
{
if (!_mistakeLogProbs[m.Item1].ContainsKey(m.Item2))
{
p += _lf/(_mNorms[m.Item1] + _lf*_mistakeLogProbs[m.Item1].Count);
}
else
{
p += _mistakeLogProbs[m.Item1][m.Item2];
}
}
candidates.Add(_words[tIdx], p);
}
}
candidates = candidates.OrderByDescending(c => c.Value).ToDictionary(c => c.Key, c => c.Value);
return candidates;
}
#endregion
#region static helper
//del - 0, ins - 1, sub - 2
public static Tuple<int, IList<Tuple<int, string>>> LevenshteinDistanceWithBacktrace(string s, string t)
{
int[,] d = new int[s.Length + 1, t.Length + 1];
int[,] b = new int[s.Length + 1, t.Length + 1];
for (int i = 0; i < s.Length + 1; i++)
{
d[i, 0] = i;
}
for (int j = 1; j < t.Length + 1; j++)
{
d[0, j] = j;
b[0, j] = 1;
}
for (int i = 1; i <= s.Length; i++)
{
for (int j = 1; j <= t.Length; j++)
{
IList<int> vals = new List<int>()
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
};
d[i, j] = vals.Min();
int idx = vals.IndexOf(d[i, j]);
b[i, j] = idx;
}
}
List<Tuple<int, string>> bt = new List<Tuple<int, string>>();
int x = s.Length;
int y = t.Length;
while (bt.Count != d[s.Length, t.Length])
{
switch (b[x, y])
{
case 0:
x--;
bt.Add(new Tuple<int, string>(0, s[x].ToString()));
break;
case 1:
y--;
bt.Add(new Tuple<int, string>(1, t[y].ToString()));
break;
case 2:
x--;
y--;
if (s[x] != t[y])
{
bt.Add(new Tuple<int, string>(2, s[x] + "" + t[y]));
}
break;
}
}
bt.Reverse();
return new Tuple<int, IList<Tuple<int, string>>>(d[s.Length, t.Length], bt);
}
public static int LevenshteinDistance(string s, string t)
{
int[,] d = new int[s.Length + 1, t.Length + 1];
for (int i = 0; i < s.Length + 1; i++)
{
d[i, 0] = i;
}
for (int j = 1; j < t.Length + 1; j++)
{
d[0, j] = j;
}
for (int i = 1; i <= s.Length; i++)
{
for (int j = 1; j <= t.Length; j++)
{
d[i, j] = (new int[]
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
}).Min();
}
}
return d[s.Length, t.Length];
}
#endregion
}
Инициализируется класс следующими параметрами:
- string[] words — список слов языка;
- long[] wordFrequency — частота слов;
- IDictionary<int, IDictionary<string, int>> mistakeFrequency
- int mistakeProbSmoothing = 1 — коэффициент размытия частоты ошибок
Тестирование
Для тестирования используем базу Питера Норвига, в которой содержится 333333 слов с частотами, а также 7481 слово с ошибочными написаниями. Следующий код используется для вычисления значений необходимых для ининциализации класса NoisyChannel:
чтение базы
string[] words = null;
long[] wordFrequency = null;
#region read priors
if (!File.Exists("../../../Data/words.bin") || !File.Exists("../../../Data/wordFrequency.bin"))
{
IDictionary<string, long> wf = new Dictionary<string, long>();
Console.Write("Reading data:");
using (StreamReader sr = new StreamReader("../../../Data/count_1w.txt"))
{
string line = sr.ReadLine();
while (line != null)
{
string[] parts = line.Split('t');
wf.Add(parts[0].Trim(), Convert.ToInt64(parts[1]));
line = sr.ReadLine();
Console.Write(".");
}
sr.Close();
}
Console.WriteLine("Done!");
words = wf.Keys.ToArray();
wordFrequency = wf.Values.ToArray();
using (FileStream fs = File.Create("../../../Data/words.bin"))
{
BinaryFormatter bf = new BinaryFormatter();
bf.Serialize(fs, words);
fs.Flush();
fs.Close();
}
using (FileStream fs = File.Create("../../../Data/wordFrequency.bin"))
{
BinaryFormatter bf = new BinaryFormatter();
bf.Serialize(fs, wordFrequency);
fs.Flush();
fs.Close();
}
}
else
{
using (FileStream fs = File.OpenRead("../../../Data/words.bin"))
{
BinaryFormatter bf = new BinaryFormatter();
words = bf.Deserialize(fs) as string[];
fs.Close();
}
using (FileStream fs = File.OpenRead("../../../Data/wordFrequency.bin"))
{
BinaryFormatter bf = new BinaryFormatter();
wordFrequency = bf.Deserialize(fs) as long[];
fs.Close();
}
}
#endregion
//del - 0, ins - 1, sub - 2
IDictionary<int, IDictionary<string, int>> mistakeFrequency = new Dictionary<int, IDictionary<string, int>>();
#region read mistakes
IDictionary<string, IList<string>> misspelledWords = new SortedDictionary<string, IList<string>>();
using (StreamReader sr = new StreamReader("../../../Data/spell-errors.txt"))
{
string line = sr.ReadLine();
while (line != null)
{
string[] parts = line.Split(':');
string wt = parts[0].Trim();
misspelledWords.Add(wt, parts[1].Split(',').Select(w => w.Trim()).ToList());
line = sr.ReadLine();
}
sr.Close();
}
mistakeFrequency.Add(0, new Dictionary<string, int>());
mistakeFrequency.Add(1, new Dictionary<string, int>());
mistakeFrequency.Add(2, new Dictionary<string, int>());
foreach (string s in misspelledWords.Keys)
{
foreach (string t in misspelledWords[s])
{
var d = NoisyChannel.LevenshteinDistanceWithBacktrace(s, t);
foreach (Tuple<int, string> ml in d.Item2)
{
if (!mistakeFrequency[ml.Item1].ContainsKey(ml.Item2))
{
mistakeFrequency[ml.Item1].Add(ml.Item2, 0);
}
mistakeFrequency[ml.Item1][ml.Item2]++;
}
}
}
#endregion
Следующий код инициализирует модель и выполняет поиск правильных слов для слова «he;;o» (конечно подразумевается hello, точка-с-запятой находятся справа от l и легко было ошибиться при печати, в базе в списке ошибочных написания слова hello нет слова he;;o) на расстоянии не более 2, с засечением времени:
NoisyChannel nc = new NoisyChannel(words, wordFrequency, mistakeFrequency, 1);
Stopwatch timer = new Stopwatch();
timer.Start();
IDictionary<string, double> c = nc.GetCandidates("he;;o", 2);
timer.Stop();
TimeSpan ts = timer.Elapsed;
Console.WriteLine(ts.ToString());
У меня такое вычисление занимает в среднем чуть менее 1 секунды, хотя конечно процесс оптимизации не исчерпывается приведенными способами, а наоборот, только начинается с них. Взглянем на варианты замены и их вероятности:
Ссылки
- курс Natural Language Processing на курсере
- Natural Language Corpus Data: Beautiful Data
- годное описание алгоритмов Левенштейна и Домерау-Левенштейна
Архив с кодом можно слить от сюда.
По умолчанию Microsoft Word внесен в каталог как основной текстовый процессор, используемый в мире , благодаря своему замечательному историческому времени и большому количеству пользователей, которые он имеет в настоящее время. Принимая во внимание факт что он включен в знаменитый офисный пакет Microsoft .
В этом смысле Word относится к наиболее часто используемым программам для создавать, редактировать, персонализировать и управлять электронными письмами любого типа . Учитывая тот факт, что им управляют как студенты, так и профессионалы из разных сред, благодаря оптимальные инструменты, которые он предлагает для обогащения документов .
Один из них это средство проверки орфографии и грамматики, которое есть в этой программе для более легкого обнаружения слов с ошибками в тексте. Чтобы узнать больше об этой функции и как это использовать , читать дальше.
Прежде чем указывать некоторую интересующую информацию о том, что следует учитывать при использовании этой функции и как вы можете включить или настроить ее в текстовом процессоре, полезно указать в что конкретно делает проверка орфографии в Word .
В этом смысле компьютерную проверку орфографии можно определить как программное приложение, которое позволяет анализировать тексты, чтобы находить и обнаруживать орфографические ошибки , чтобы перейти к их ручному или автоматическому исправлению. Следовательно, в случае Word, это функция, встроенная в программу для облегчить управление документами .
Таким образом, проверка орфографии Microsoft Word служит в основном для того, чтобы помочь пользователю обогатить написание своего текста . Принимая это во внимание, это достигается путем сравнения слов текста со словами словаря и, следовательно, если их нет, они не будут приняты. Следовательно, вы немедленно предоставить аналогичные условия, чтобы заменить их в документе .
Это означает, что его основная функция — редактировать любой текст для убрать письменные ошибки, грамматические ошибки и лексические неточности , чтобы очистить его и убедиться, что читатель может понять весь открытый контент. Поскольку цель проверки орфографии — обеспечить заполнение документов без ошибок или несоответствий при печати .
О чем следует помнить при использовании средства проверки орфографии и грамматики Word?

Несмотря на то, что эта функция работает в Word почти автоматически, правда в том, что есть некоторые предпосылки, которые пользователь должен учитывать при активации и использовании проверки орфографии и грамматики в указанной программе. С, от них вы сможете быстро получить управление указанной утилитой .
Так что, в основном, это интересно ориентироваться на выбранный диалект . Что ж, если вы посмотрите на языковой раздел внизу главного окна Word, вы увидите, что они предлагаем несколько видов «испанского» , например: Аргентина, Колумбия, Испания, Мексика, Венесуэла и многие другие. Что полностью повлияет при проверке и исправлении слов в тексте. Поэтому важно, чтобы вы в этом случае выберите правильный регион .
К этому добавляются и другие аспекты, представляющие большой интерес, которые необходимо понять, прежде чем использовать добавленную грамматику и средство проверки орфографии в Word. Вот самый важный :
- Эта особенность не имеет возможности изменять или переписывать исходную историю, созданную автором , как полагают многие. С тех пор он сосредоточился исключительно на улучшении структуры письма и его представления по отношению к выражениям.
- Его задача — не только дать общую оценку аспектов, которые необходимо исправить в документе, но он также отвечает за предлагать рекомендации и руководить писателями по оптимизации их текстов .
- Проверка орфографии не диктует свой личный стиль , потому что он знает, как важно всегда иметь мнение автора. Следовательно, он не будет вносить никаких изменений в текст без вашего согласия и, что ж, он только предоставляет идеи для улучшения указанного письма на лексическом, грамматическом и синтаксическом уровнях.
Узнайте, как включить и настроить проверку орфографии и грамматики в Microsoft Word.
Ввиду превосходных преимуществ, предлагаемых этой утилитой Word, важно, чтобы все пользователи программы знать, как его активировать и настроить , в соответствии с их потребностями при управлении любой цифровой записью.
Поэтому ниже мы объясним каждый из Шаги по правильному использованию средства проверки орфографии и грамматики в Word :
комментарии
Первое, что вы можете сделать с помощью средства проверки орфографии этой программы для Windows, — это вносить исправления во всем документе . Либо текст в целом, либо только его выделенная часть, в зависимости от того, что вы хотите. Мы упоминаем здесь шаги, которые необходимо выполнить, чтобы активировать эту функцию :
- Для начала вы должны найдите и введите документ, который нужно отредактировать таким образом .
- Как только это будет сделано, перейдите на ленту Word и щелкните вкладку с надписью «Редакция» .
- Затем в группе «Редакция» нажмите на опцию «Орфография и грамматика» .
- Теперь, если программа обнаружит орфографические ошибки, она перейдут к их автоматическому выбору а с правой стороны появится диалоговое окно с первым словом с ошибкой, обнаруженным функцией проверки орфографии и грамматики.
- Наконец он вам просто нужно решить, как исправить эту ошибку , согласно предложенным альтернативам (опустить, изменить или добавить в словарь программы) и, таким образом, Word перейдет к следующему слову или ошибочному выражению.
С другой стороны, если вы хотите быстро запустить проверку орфографии и грамматики документа Microsoft Word, не выполняя все предыдущие шаги; Вы можете просто нажать клавишу F7 и автоматически программа отобразит первую обнаруженную неисправность.
исправления
Среди других альтернатив, связанных со средством проверки орфографии и грамматики в Word, возможно, что та же система мгновенно вносит исправления . Ввиду этого этот инструмент еще называют «автокоррекция» .
Эта функция, соответствующая грамматической проверке орфографии, позволяет вам устанавливать определенные ошибки, чтобы они по умолчанию изменяются средством проверки Word, если пользователь вводит их . Также можно проверить другие полезные функции автокоррекции.
Здесь мы покажем вам, как легко получить доступ к этому разделу, чтобы предусмотреть и записать исправления или «автоматические исправления» что ты хочешь Word автоматически выполняет:
- Находится в рассматриваемом документе, щелкните вкладку «Файл» в панель параметров программы.
- Затем на левой боковой панели нажмите «Параметры» и при этом откроется новое окно, содержащее различные варианты выбора.
- Позже, нажмите «Редакция» а точнее в раздел «Параметры автоматической коррекции» , нажмите кнопку с указанием этого имени, чтобы задать нужные вам термины.
- Enfin, нажмите на обе кнопки ОК , чтобы сохранить внесенные изменения, и при этом вы уже установили автоматическое исправление по умолчанию для Word.
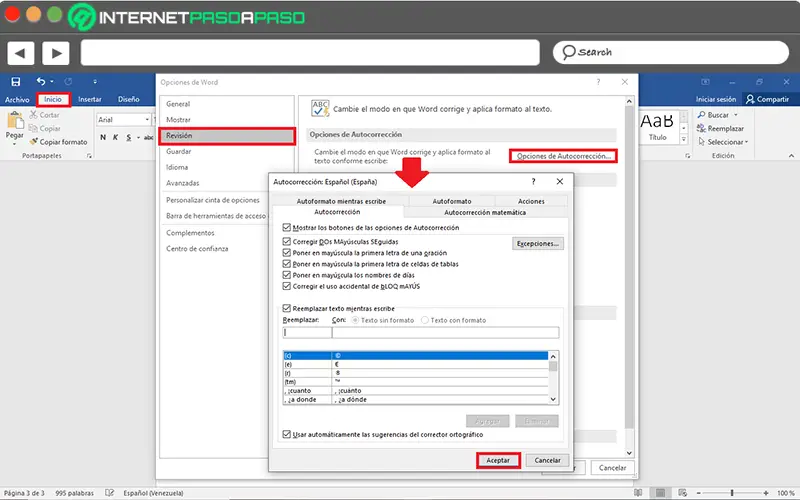
Уведомление на другом языке
Хотя это правда, испанский язык будет использоваться по умолчанию в вашем документе Microsoft Word. Но, если вам нужно написать текст на другом языке и правильно его исправить, есть возможность вносить правки на другом языке без каких-либо осложнений .
В этом случае пошагово следовать следующее :
- Как и в предыдущих случаях, начнем с найти и войти в документ Word в котором вы хотите выполнить проверку орфографии и грамматики на другом языке.
- Тогда пора выберите вкладку «Редакция» на панели параметров главного окна.
- Затем перейдите в поле «Язык» и нажмите стрелку вниз на опции «Язык» . Между двумя отображаемыми вариантами, нажмите «Языковые настройки …» .
- Наконец, откроется новое окно и в указанном разделе для выбора языков редактирования, добавить дополнительные языки, чтобы упростить пересмотр . Другими словами, если ваш текст, например, на немецком языке, вы должны добавить к нему этот язык.
Список лучших инструментов для исправления грамматики и орфографии вне Microsoft Word
«ОБНОВЛЕНИЕ ✅ Хотите узнать больше о программе проверки орфографии и грамматики Microsoft Word? ⭐ ВОЙДИТЕ ЗДЕСЬ ⭐ и узнайте все о SCRATCH! »
Если по какой-то причине вы предпочитаете использовать инструменты, отличные от средства проверки орфографии и грамматики Word, даже при создании текстов из этой программы; есть возможность их делать. С того времени, несколько внешних инструментов были созданы для этой программы, которая легко исправляет орфографию и грамматику .
Поэтому в заключение этой статьи мы остановимся на 5 абсолютно оптимальных бесплатных инструментов для улучшения орфографии и грамматики любого цифрового документа :
CorrectorOnline.es
В первую очередь мы размещаем этот онлайн-инструмент, который используется для находить и выделять основные, орфографические, грамматические и стилистические ошибки в любом цифровом тексте . Как только эти дефекты будут обнаружены, он предложит исправления, чтобы легко обогатить ваш документ. Который, помимо вспомогательных текстов на испанском языке, также имеет другие версии, позволяющие вносить изменения для других языков, например: Английский, португальский, французский, немецкий, итальянский и русский языки .
Со своей стороны, что касается его работы, мы ограничиваем то, что вы должны просто скопируйте и вставьте текст для изменения в указанное поле и если вы установите флажок «Автоматическое исправление», инструмент отобразит страницу результатов со списком, в котором будут указаны все обнаруженные ошибки. Это, когда-то вы нажали кнопку «Отправить» .
Copywritely.com
Еще одним из наиболее известных инструментов для проверки и исправления текстов на предмет возможных орфографических и грамматических ошибок является платформа, которая характеризуется тем, что является одним из наиболее полных для этого . Поскольку, помимо просмотра содержания и рекомендаций по качественному редактированию, он завод также как онлайн-редактор и средство проверки предложений .
К этому добавляется подробное описание процесса использования этого инструмента: вставьте текст, который хотите просмотреть, или его URL-адрес найти орфографические и грамматические ошибки. Позже вы получите рекомендации, как исправить найденные ошибки, а также выполнит переписать текст с помощью онлайн-редактора , затем вы получит обновленный текст .
languagetool.org
Он состоит из еще одной онлайн-проверки орфографии, которая отлично подходит для быстрой и простой проверки ошибок без использования Word и просто путем доступа к Интернету. Оценивая это, бесплатный инструмент (также с некоторыми планами платежей), в котором есть возможность редактировать тексты на нескольких языках (Испанский, английский, французский, немецкий и т. Д.) И не имеет ограничений по длине письма .
Со своей стороны допускает до 20000 знаков на каждую проверку, это оптимальный механизм для изменить стиль, грамматику и орфографию , в дополнение к способности обнаруживать до более чем 2500 XNUMX дополнительных ошибок за короткое время. Чтобы начать обзор, все, что вам нужно сделать, это вставить текст, выбрать правильный язык и нажмите «Проверить текст» . Следует отметить, что предлагает расширение для браузера Google Chrome .
Mystilus.com
Это платный онлайн-инструмент который предлагает своим пользователям два плана подписки и благодаря большому количеству инструментов в его распоряжении, это средство, используемое многими профессионалами при управлении своими цифровыми текстами. Итак, во всех самолетах Стилус обеспечивает чеки грамматика, орфография и стиль, лингвистические инструменты, аудиторские отчеты в различных форматах (PDF, TXT, DOC или HTML), а также гарантирует индивидуальные языковые настройки.
Кроме того, он имеет расширения для Word в Windows, а также для WordPress , учитывая, что он отлично интегрируется, чтобы упростить процесс редактирования. Среди прочего, это предлагает интерактивную коррекцию через Интернет , его лексическая база постоянно обновляется и имеет многоязычный пользовательский интерфейс. Il обеспечивает то же самое обновленные предложения с дидактическими пояснениями и библиографией .
Плагиат.net

Наконец, мы выделяем эту другую онлайн-проверку, которая, несмотря на непривлекательный дизайн страницы и менее известна, чем другие подробные альтернативы, считается хорошим инструментом для проверить орфографию и грамматику любого текста , особенно потому, что это поддерживает несколько языков и среди них кастильский / испанский. Кроме того, следует отметить, что бесплатно и легко использовать .
Как только вы зайдете на соответствующий веб-сайт, паста Simplement запись в соответствующее пустое поле , затем выберите язык указанного текста и нажмите кнопку «Правильное написание» , с помощью которого инструмент выполнит указанную коррекцию. Кроме того, у него есть несколько вариантов редактировать рассматриваемый документ (полужирный, курсив, подчеркивание, размер шрифта, размер и формат и т. д.).
Если у вас есть какие-либо вопросы, оставляйте их в комментариях, мы свяжемся с вами как можно скорее, и это будет большим подспорьем для большего числа участников сообщества. Je Vous remercie!

Инструмент проверки текста на орфографические и грамматические ошибки онлайн, позволит исправить
самые громоздкие
ошибки, с высокой степенью точности и скорости, а
также улучшить свой письменный русский язык.
Если возможно несколько исправлений, вам будет предложено выбрать одно из них.
Слова в которых допущены ошибки выделяются разными цветами, можно кликнуть на подсвеченное слово,
посмотреть описание ошибки
и выбрать исправленный вариант.
Инструмент поддерживает 8 языков.
Символов в тексте
0
Без пробелов
0
Количество слов
0
Вставьте ваш текст для проверки
Ваш текст проверяется
Орфография
Написать текст без каких-либо орфографических или пунктуационных ошибок достаточно сложно даже
специалистам.
Наша автоматическая проверка
орфографии
может помочь профессионалам, студентам, владельцам веб-сайтов, блогерам и авторам получать текст
практически без ошибок. Это не только поможет им исправить текст, но и
получить информацию о том, почему использование слова неправильно в данном контексте.
Что входит в проверку текста?
- грамматические ошибки;
- стиль;
- логические ошибки;
- проверка заглавных/строчных букв;
- типографика;
- проверка пунктуации;
- общие правила правописания;
- дополнительные правила;
Грамматика
Для поиска грамматических ошибок инструмент содержит более 130 правил.
- Деепричастие и предлог
- Деепричастие и предлог
- «Не» с прилагательными/причастиями
- «Не» с наречиями
- Числительные «оба/обе»
- Согласование прилагательного с существительным
- Число глагола при однородных членах
- И другие
Грамматические ошибки вида: «Идя по улице, у меня развязался шнурок»
-
Грамматическая ошибка: Идя по улице, у меня…
-
Правильно выражаться: Когда я шёл по улице, у меня развязался шнурок.
Пунктуация
Чтобы найти пунктуационные ошибки и правильно расставить запятые в тексте, инструмент содержит более
60 самых важных правил.
- Пунктуация перед союзами
- Слова не являющиеся вводными
- Сложные союзы не разделяются «тогда как», «словно как»
- Союзы «а», «но»
- Устойчивое выражение
- Цельные выражения
- Пробелы перед знаками препинания
- И другие
Разберем предложение, где пропущена запятая «Парень понял как мальчик сделал эту модель»
-
Пунктуационная ошибка, пропущена запятая: Парень понял,
-
«Парень понял, как мальчик сделал эту модель»
Какие языки поддерживает инструмент?
Для поиска ошибок вы можете вводить текст не только на Русском
языке, инструмент поддерживает проверку орфографии на Английском, Немецком и Французском
Приложение доступно в Google Play
![]()

Никто не застрахован от всевозможных ошибок при написании текста. Более того, рано или поздно каждый сталкивается с ситуацией, когда необходимо создать грамотный текстовый документ для служебных целей. Есть ряд специальных программ, которые помогут с этой задачей, о которых пойдет речь в этой статье.
Содержание
- Key Switcher
- Punto Switcher
- LanguageTool
- AfterScan Express
- Orfo Switcher
- Spell Checker
- ОРФО
Key Switcher
Key Switcher — удобный и многофункциональный инструмент, предназначенный для автоматического обнаружения и исправления различных типов ошибок при наборе текста в любой программе, которая, в принципе, имеет поле ввода. Это приложение скрыто и может распознавать более 80 различных языков и диалектов. В список его функций также входит функция распознавания ошибочно включенного макета и его автоматическая модификация. Благодаря «Хранилищу паролей» вам не нужно беспокоиться о том, что при вводе приложение изменит макет и окажется некорректным.

В заключение хотелось бы отметить наличие функции «Автокоррекция», благодаря которой можно настроить автоматическую замену различных сокращений на нужный вариант. Правда, для этого пользователю придется предварительно заполнить эту базу своими словами. Так, например, нельзя изменить раскладку ввода «PS», а написать «shl», после чего Key Switcher автоматически выполнит замену. Это относится к любой другой замене, подобной этой.
Punto Switcher
Punto Switcher — программа, очень похожая по функциональности на предыдущую версию. Он также скрыт в трее и работает в фоновом режиме независимо от конкретного текстового редактора. Кроме того, Punto Switcher может автоматически изменять раскладку клавиатуры или исправлять пользователя, когда он делает опечатку в слове. Основные возможности — транслитерация, замена чисел текстом и изменение регистра орфографии. Punto Switcher также предоставляет функцию сохранения паролей и текстов шаблонов.

Что касается самого исправления ошибок, то здесь есть как общие правила (как исправлять сокращения, две заглавные буквы в начале слова), так и встроенный в базу словарь. Как и в предыдущем программном обеспечении, здесь есть функция «Автозамена», которая упрощает набор часто используемых фраз (например, набор «chd» будет автоматически заменен на «что необходимо доказать») и части предложения, требующие разные макеты. Кроме того, здесь вы можете настроить программы исключения, в рамках которых Punto Switcher не будет работать, а также включить дневник (сохранение набранных текстов в любом приложении), что поможет избежать потери важных писем и документов.
LanguageTool
LanguageTool отличается от других программ, упомянутых в этой статье, главным образом тем, что он предназначен для проверки орфографии уже созданного текста, который был скопирован в буфер обмена. Он содержит правила орфографии для более чем сорока языков, что, в свою очередь, позволяет выполнять проверки высокого качества. Если пользователь замечает отсутствие каких-либо правил, LanguageTool предлагает возможность загрузить их.

Его главная особенность — поддержка N-граммов, которые вычисляют вероятность повторения слов и фраз. Это также должно быть дополнено наличием морфологического анализа контролируемого текста. Также приятно, что программное обеспечение постоянно обновляется, улучшаются словари, что обеспечивает правильное написание не только на родном языке, но и на некоторых иностранных. Кстати, LanguageTool можно установить не только как отдельную программу, но и как надстройку для текстового редактора Microsoft Word, Libre Office, Open Office, Google Docs, расширений для Google Chrome и Mozilla Firefox. К недостаткам можно отнести большой размер дистрибутива (более 150 МБ) и необходимость установки Java для работы.
AfterScan Express
AfterScan Express был создан с целью автоматического исправления ошибок, допущенных при распознавании отсканированного текста сторонним программным обеспечением. Он предлагает пользователю несколько вариантов редактирования, предоставляет отчет о ходе работы и позволяет вносить окончательные исправления. Сам процесс сканирования OCR настраивается и состоит из трех этапов. Попутно вы сможете обрабатывать незнакомые слова, убирать знаки препинания, отступы, «барахло» в соответствии с правилами типографики. Полученный результат можно дополнительно скорректировать: неизвестные слова выделяются красным цветом, и для каждого из них предлагаются любые замены, которые можно вводить с помощью предложенной комбинации клавиш.

Кроме того, есть «Переформатирование», в результате которого будут удалены разрывы строк, сами строки будут склеены, лишние пробелы будут удалены, а другие параметры будут исправлены. Пользователь может настроить форматирование в соответствии со своими потребностями. Поддерживает пакетную обработку текстов, создание собственного словаря. Программа платная и, купив лицензию, пользователь получает дополнительные функции. К ним относятся пакетная обработка документов, настраиваемый словарь и возможность защиты файла от изменений.
Orfo Switcher
Orfo Switcher — еще одна программа, предназначенная для автоматического изменения текста при написании. Он полностью бесплатен, не привязан к конкретному редактору и после установки помещается в системный трей. Программа автоматически изменяет раскладку клавиатуры и предлагает варианты исправления слов с ошибками. Orfo Switcher также предоставляет пользователю возможность составлять словари неограниченного размера, которые содержат исключающие слова (например, пароль) и комбинации букв, необходимые для изменения раскладки клавиатуры. Как и в другом подобном программном обеспечении, здесь вы можете добавить определенные приложения в исключения, чтобы ввод текста в них не проверялся.

Spell Checker
Эта удобная маленькая программа сразу же предупреждает пользователя об опечатке одним словом. Он также может визуально отображать текст, скопированный в буфер обмена, и доступны расширенные параметры визуализации. Но при этом функциональность проверки орфографии распространяется только на английские и русские слова.

Среди дополнительных функций предлагается возможность указать, в каких процессах программа должна работать, а в каких — нет. Также вы можете скачать словари. Главный недостаток Sang Checker в том, что после его установки для работы также необходимо скачать словарь.
ОРФО
Последней в списке будет совсем не программа: ORFO — это надстройка для текстового редактора Microsoft Word. Тот, кто привык создавать документы в этом приложении, но не был удовлетворен базовыми правилами проверки орфографии, оценит возможности ORFO. Он выполняет не только грамматические, но и стилистические проверки, используя более 40 наборов правил и 23 000 шаблонов, которые включают проверку на разных уровнях: строгой, коммерческой или обычной переписке. У каждой найденной ошибки есть описание и объяснение того, почему следует применить то или иное исправление. Кроме того, здесь можно выполнить орфографию согласно стилю газеты и книги. Функция «Тезаурус» обеспечивает поиск и устранение тавтологии (повторения слов) путем поиска синонимов, соответствующих смыслу. Для этих целей в программе есть словарь, содержащий более 60 000 слов, некоторые из которых являются синонимами, антонимами и родственными им.

ORFO состоит из нескольких словарей одновременно, которые вместе обеспечивают высочайший контроль слов и грамматики. Он поддерживает удобную замену определенного слова во всех его словоформах, отображая все доступные формы интересующего слова. Сразу стоит отметить, что расширение платное, но именно здесь программа действительно стоит своих денег. Для работы с ним необходимо установить Word 2016 и более поздние версии, а сама программа выбирается не только по ее версии (есть несколько наборов: Professional, Professional Plus, Maximum, 2 версии для Mac OS), но и в в соответствии с разрядностью самого слова (32/64 бит). В настоящее время разработчик готовит крупное обновление, и, несмотря на то, что сайт выглядит заброшенным, техническая поддержка по электронной почте продолжает активно работать.
В этой статье описаны программы проверки орфографии и пунктуации, которые избавят вас от неграмотного написания текста. После установки одного из них вы можете быть уверены, что все введенные вами слова будут правильными и предложения будут соответствовать правилам орфографии. Однако не забывайте, что даже самое умное программное обеспечение не сможет найти абсолютно все ошибки любого уровня сложности, поэтому не поленитесь перечитать свои тексты и прояснить спорные моменты вручную. Кроме того, отметим, что практически популярные текстовые редакторы имеют встроенную функцию проверки орфографии и пунктуации, а также существуют различные онлайн-сервисы, проверяющие не хуже многих приложений, перечисленных в материале.
Читайте также:
Текстовый редактор для Windows / Linux
Проверьте правописание онлайн
Программы для исправления ошибок бывают необходимы во многих случаях: когда нужно проверить документ большого объема или быстро устранить опечатки в тексте. Часто пользователи жалуются на то, что вычитывают текст по нескольку раз, но все равно пропускают ряд ошибок, списывая это на собственную невнимательность. В чем бы ни заключалась проблема, без программ для исправления ошибок работать действительно сложно — даже тем, у кого с внимательностью нет никаких проблем. В этой статье мы расскажем, какими программами для исправления ошибок пользуются юзеры сети и почему.
Навигация по статье
- ТОП-10 программ по исправлению ошибок в тексте
- Сравнение возможностей сервисов
ТОП-10 программ по исправлению ошибок в тексте
Мы сделали для вас подборку из десяти самых популярных программ и сервисов, которые проверяют текст на наличие ошибок и подсвечивают их, чтобы пользователь мог легко их обнаружить и устранить.
Orfogrammka.ru
Это платная платформа, которая дает возможность проверить до 1 млн символов текста в течение одного месяца. Данный сервис, помимо синтаксических и орфографических ошибок, дает возможность проверить:
- наличие тавтологии;
- водность текста;
- иностранные слова;
- замену символов.
Сервис работает по подписке, которая предоставляет доступ к полноценной работе на один месяц. Стоимость ее обойдется пользователю в 300 рублей. Здесь также есть возможность проверить 6 тысяч символов текста с пробелами в тестовом режиме. Это же касается и исправления ошибок.
Яндекс.Спеллер
Сервис от известной группы разработчиков Яндекс — “Спеллер”, был создан для тех, кто хочет быстро осуществить проверку текста и исправить ошибки в режиме онлайн. Как и в большинстве других программ и сервисов подобного типа, здесь в окно проверки текста помещается сам текст, после чего сервис осуществляет проверку последнего в порядке очередности на сервере. В нижнем окне представлены варианты исправления.
Text.ru
Эта программа проверки орфографии на наличие ошибок в русском языке пользуется большой популярностью. Сервис в своем роде уникален, т.к. выполняет одновременно проверку уникальности, ошибок и SEO-данных текста.
Advego
Адвего — пожалуй, самая распространенная программа проверки текста. Это высококачественный и удобный сервис, который удерживает высокие позиции уже довольно долгое время. Он получил широкую известность как у разработчиков и SEO-специалистов, так и у копирайтеров с редакторами. Помимо функции проверки текста на наличие ошибок, здесь представлена масса других полезных возможностей:
- расчет количества символов;
- выявление орфографических ошибок;
- количество вхождений слов;
- водность текста;
- тошнота текста (академ. и классическая);
- уникальность текста.
Орфограф
Студия Артемия Лебедева представила еще один свой сервис, на этот раз, касающийся проверки текста. Как и все остальные проекты этой группы, Орфограф имеет минимальный набор функций — а именно, проверяет текст на наличие ошибок. В сервисе представлен собственный уникальный словарь, и если какая-то часть текста не имеет совпадений с базой данных Орфографа, то неизвестные слова выделяются дополнительным цветом.
Onlinecorrector
У этой программы проверки текстов есть одна специфическая функция — она способна проверять Google-документы. Это расширение требует установки в браузере, после чего с сервисом можно работать в режиме онлайн.
Орфо
Для осуществления проверок программой на ошибки в текстах многие пользователи сети предпочитают Орфо. Программу можно скачать на сайте, а также воспользоваться сервисом в режиме онлайн. Помарки в тексте подсвечиваются зеленым и красным цветом, в зависимости от того, какой тип ошибки будет обнаружен. Офлайн-версия предлагает пользователям расширенный функционал — здесь можно создавать переносы или автоматически корректировать буквы.
LanguageTool
Сервис был разработан и создан с целью предоставить функцию автоматического исправления орфографии на русском языке. Разработчики побеспокоились о том, чтобы создать две версии — онлайн и стационарную, для работы с расширением в браузере. При анализе текста, все слова с ошибками подсвечиваются другим цветом. Данная функция работает по аналогии с другими сервисами, которые предоставляют те же функции. Однако, здесь присутствует одно ключевое отличие — при нажатии на подсвеченное слово с ошибкой выпадает дополнительное меню, в котором можно выбрать один из вариантов исправления. Премиум версия программы (платная) предоставляет расширенный функционал, который может оказаться полезным для профессиональных корректоров, а также частных редакций.
Мета.ua
Этот сервис подойдет пользователям, которые ищут бесплатный инструмент, способный не только подсветить слова с ошибками, но и предоставить варианты для замены. Помимо всего прочего, данный сервис представляет еще и функции автоматического перевода. Ошибки в словах выделяются пунктирной линией. При нажатии на подсвеченное слово, пользователь может увидеть список слов для замены и выбрать из них подходящее.
Главред
Сайт Главред предлагает интересную функцию — проверку не только орфографического, но и смыслового качества текста. Это позволяет оценить текст сразу по нескольким критериям. Все предлагаемые исправления в тексте подчеркиваются пунктиром.
Присоединяйтесь к
Rush-Analytics уже сегодня
7-ми дневный бесплатный доступ к полному функционалу. Без привязки карты.
Попробовать бесплатно
Сравнение возможностей сервисов
| Название сервиса / программы | Проприетарность | Версия | Автокоррекция |
| Orfogrammka.ru | Платная | Онлайн | Нет |
| Яндекс.Спеллер | Бесплатная | Онлайн | Нет |
| Text.ru | Платная и бесплатная | Онлайн | Нет |
| Advego | Платная и бесплатная | Онлайн и офлайн | Нет |
| Орфограф | Платная | Онлайн | Нет |
| Onlinecorrector | Платная и бесплатная | Онлайн и офлайн | Нет |
| Орфо | Платная и бесплатная | Онлайн и офлайн | Да |
| LanguageTool | Платная и бесплатная | Онлайн и офлайн | Да |
| Мета.ua | Бесплатная | Онлайн | Да |
| Главред | Бесплатная | Онлайн | Нет |
Рекомендуем протестировать каждый из этих инструментов, чтобы выбрать наиболее удобный и эффективный для ваших целей.
Во
время проверки орфографии Word просматривает
текст документа (или выделенную область)
и все слова сравнивает со словами,
содержащимися в нескольких встроенных
словарях. Если в тексте документа
содержится слово, отсутствующее в
словарях, Word помечает его как содержащее
орфографическую ошибку. Часто-густо
под такие слова попадают специфические
термины, фамилии людей, географические
названия и т.д. При желании такие слова
можно включать в словарь, при этом Word
будет их «запоминать» и в будущем
не будет помечать как ошибочные.
Существует
и обратная сторона медали. Word пропускает
слова, которые написаны правильно с
точки зрения орфографии, однако неверно
используются в контексте. Например,
«подоходный залог», вместо «подоходный
налог».
Функция
проверки орфографии выявляет и помечает
в документе одинаковые слова, следующие
одно за другим.
Проверка грамматики
Эта
функция проверяет текст на соответствие
грамматических и стилистических правил.
Проверка грамматических правил выявляет
такие ошибки, как неправильное
использование предлогов, согласование
слов в предложении и т.д.
Проверка
стилистики позволяет выявлять в документе
малоупотребительные, просторечные
слова и выражения.
По
большому счету не следует полностью
полагаться на возможности программы
по устранению ошибок, а по возможности,
делать проверку самому по окончании
набора текста документа.
Автоматическая проверка правописания
При
наборе текста Word подчеркивает красной
волнистой линией слова, содержащие
орфографические ошибки, и зеленой линией
— грамматические и стилистические
ошибки.
Чтобы
исправить орфографическую ошибку надо
щелкнуть правой кнопкой мыши на
подчеркнутом слове. При этом на экране
будет отображено контекстное меню.
Можно
выбрать правильное написание из числа
предлагаемых вариантов или открыть
окно диалога «Орфография…»,
Автозамена или Язык для дополнительных
параметров соответствующих функций.
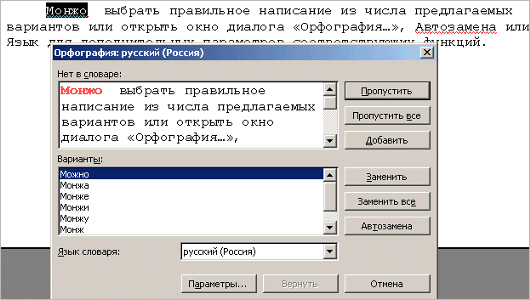
В
поле «Нет в словаре» отображается
фрагмент текста, содержащий слово с
ошибкой, а в поле «Варианты» — список
вариантов замены. Ошибку можно
отредактировать прямо в поле «Нет в
словаре» или выбрать один из предлагаемых
вариантов замены. После завершения
обработки текущей ошибки Word возобновляет
поиск и отображение следующей ошибки.
Кнопка
«Пропустить все» используется для
пропуска текущей ошибки и всех последующих
ее включений. Кнопка «Заменить»
позволяет заменить ошибку выбранным
вариантом замены или принять исправления,
выполненные в поле «Нет в словаре».
Кнопка
«Заменить все» позволяет заменить
все включения ошибочного слова выбранным
вариантом замены. При сброшенном флажке
«Грамматика» Word не производит
проверку текста на наличие грамматических
ошибок. Это позволяет сосредоточиться
исключительно на проверке орфографии.
Кнопка
«Параметры» обеспечивает доступ
к параметрам проверки правописания.
Кнопка
«Вернуть» отменяет последнее
выполненное исправление.
При
обнаружении в тексте документа
грамматической ли стилистической ошибки
Word отображает в окне диалога «Грамматика…»
следующее окно.
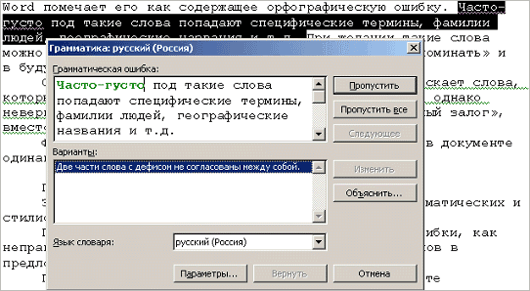
В
поле «Варианты» отображается
описание фрагмента, содержащего
грамматическую ошибку.
Как
и при исправлении орфографических
ошибок, при проверке грамматики можно
править текст непосредственно в поле
с ошибочным фрагментом или использовать
один из вариантов замены.
-
Кнопка
«Пропустить все» используется для
пропуска всех встречающихся в тексте
подобных ошибок. -
Кнопка
«Следующее» позволяет пропустить
текущую ошибку и перейти к следующему
проблемному фрагменту. -
Кнопка
«Объяснить» предлагает общие
рекомендации относительно устранения
грамматических ошибок подобного рода.
Надпись в
документе Word можно рассматривать как
контейнер, в котором размещаются
вложенные документы. Над всеми объектами,
находящимися в таком контейнере, можно
выполнять совместные операции: удаление,
перемещение, копирование и др.
Для
создания надписи в документе Word
выполняется команда Надпись меню
Вставка.
Положение
надписи в документе можно настраивать,
выделив ее и выбрав в контекстном меню,
вызванном на границе надписи, опцию
Формат надписи. Появляющееся диалоговое
окно содержит несколько вкладок, с
помощью которых можно изменять размер,
положение надписи относительно текста,
цветовое оформление надписи и др.
Страницы
документов Word могут содержать верхние
и нижние колонтитулы —
области, располагающиеся в верхней и
нижней части каждой страницы и содержащие
определенный текст. Простейший колонтитул
состоит из номера страницы. Однако в
него также может быть включена любая
информация, отражающаяся в верхней или
нижней части страницы. Создание
колонтитулов выполняется с помощью
команды Колонтитулы меню Вид.
При
выполнении этой команды на экран
выводится панель инструментов Колонтитулы,
кнопки которой позволяют создать и
отредактировать колонтитулы.
Области
верхнего и нижнего колонтитулов обычно
располагаются от левого до правого поля
страницы по горизонтали, а по вертикали
их положение определяется размерами
верхнего и нижнего поля и расстоянием
от края страницы до колонтитула, заданными
в окне диалога Параметры страницы. Если
вставленные в колонтитул данные требуют
больше места, то Word увеличивает размер
соответствующего поля страницы, чтобы
расширить область колонтитула. При этом
элементы колонтитула не накладываются
на основной текст. Однако часть колонтитула
можно расположить и за пределами области
колонтитулов. Для этого применяются
следующие приемы:
-
чтобы
изменить положение верхней или нижней
границы колонтитула, следует перетащить
маркер на вертикальной линейке. Кроме
того, можно отрегулировать положение
области колонтитула на вкладке Поля
окна диалога Параметры страницы; -
чтобы
сдвинуть текст колонтитула влево или
вправо от полей, следует задать для
одного или нескольких абзацев
колонтитулов отрицательное значение
левого или правого отступа. Для этого
используется горизонтальная линейка
или окно диалога Абзац; -
текст
колонтитула можно частично или полностью
вставить в надпись Word и перетащить его
в любое место страницы. Несмотря на
это, полученный кадр продолжает
оставаться частью колонтитула, поэтому
изменить его можно только выполнением
команды Колонтитулы меню Вид.
Обычно
на каждой странице документа выводится
один и тот же колонтитул. Тем не менее
существует несколько способов добиться
отображения в документе различных
колонтитулов. Прежде всего, можно создать
отличающийся колонтитул для первой
страницы документа или раздела. Можно
задавать разные колонтитулы для четных
и нечетных страниц документа. Указанные
действия задаются установкой
соответствующих флажков на вкладке
Макет диалогового окна Параметры
страницы меню Файл. Следует заметить,
что отличающийся колонтитул первой
страницы устанавливается для отдельного
раздела документа, но различия между
колонтитулами четных и нечетных страниц
устанавливаются для всего документа.
Наконец, если документ разбит на разделы,
их колонтитулы могут иметь разное
содержание. Изначально колонтитулы
каждого следующего раздела соединяются
с колонтитулами предыдущего раздела,
т. е. выглядят точно так же.
К
документу Word можно добавить оглавление,
в котором будут перечислены все заголовки
и номера страниц, на которых они находится.
Для создания оглавления следует выполнить
следующие действия:
-
убедиться
в том, что каждому заголовку, включаемому
в оглавление, назначен стиль. Проще
всего воспользоваться встроенными
стилями Заголовок 1 — Заголовок 9, -
установить
курсор в том месте документа, где будет
вставлено оглавление; -
выполнить
команду Оглавление и указатели меню
Вставка; -
выбрать
вкладку Оглавление; -
если
требуется вместо встроенных стилей
заголовков воспользоваться другими,
нажать кнопку Параметры, чтобы открыть
окно диалога Параметры оглавления. В
этом окне можно выбрать стили, включаемые
в оглавление, и связать с ними определенные
уровни в оглавлении; -
для
изменения внешнего вида оглавления
подбирать значения параметров до тех
пор, пока примерный вид оглавления в
поле Образец не будет соответствовать
желаемому. Можно задать формат оглавления,
способ выравнивания номеров страниц,
число уровней и символ-заполнитель.
Также можно разрешить или запретить
показ номеров страниц.
Определенные
места в документе могут быть помечены
для быстрого возврата к ним в дальнейшем.
Чтобы пометить какое-либо место документа,
надо создать закладку. Создание закладки
осуществляется с помощью команды
Закладка меню Вставка. В диалоговом
окне команды следует ввести имя
создаваемой закладки. Этот способ может
применяться для пометки любого количества
мест в документе. Закладки можно сделать
видимыми, выполнив команду Параметры
меню Сервис и установив на вкладке Вид
флажок Закладки.
Чтобы
быстро переместить курсор в место,
помеченное закладкой, следует выполнить
команду Закладка меню Вставка или нажать
комбинацию клавиш Ctrl+Shift+F5, в открывшемся
диалоговом окне Закладка выбрать ее
имя, присвоенное при пометке текста, и
нажать кнопку Церейти. Word переместит
курсор в помеченную позицию. К аналогичному
результату приведет выполнение команды
Перейти меню Правка. В диалоговом окне
команды в списке Объект перехода следует
выбрать Закладка.
Пакет
MS Office. Текстовый редактор Word. Функции
поиска и замены символов. Поиск и замена
специальных символов (непечатных).
Автозамена при вводе. Пользовательские
настройки автозамены вводимых символов.
При
создании новых документов могут также
использоваться специальные шаблоны —
мастера, обеспечивающие настройку
создаваемых документов в процессе
диалога с пользователем.
В
текстовом процессоре Word существуют три
способа быстрой вставки часто используемой
текстовой или графической информации
в документ, основанные на
использованииАвтотекста,
Автозамены и Копилки.
С
помощью команды Автозамена меню Сервис
ранее созданные элементы (фрагменты
текста, рисунки, таблицы и т. д.) могут
быть многократно автоматически вставлены
в документ. По этой команде также может
производиться расшифровка аббревиатур
и автоматическое исправление наиболее
типичных опечаток. В диалоговом окне
команды можно:
-
создать,
применить, удалить элемент автозамены; -
использовать
автозамену в процессе набора текста; -
выполнить
общую настройку преобразования текста,
используя соответствующие флажки в
верхней части диалогового окна.
С
помощью команды Автотекст меню
Вставка (или вкладка Автотекст в
диалоговом окне команды Автозамена меню
Сервис) ранее созданные элементы
(фрагменты текста, рисунки, таблицы и
т. д.) могут быть многократно вставлены
в документ по команде пользователя. С
помощью диалогового окна команды можно
создавать и удалять элементы автотекста.
Копилка —
это инструмент для накопления и
объединения различных блоков информации
из разных частей документов и вставки
их в документ как единого целого. Копилка
создается на основе автотекста. Выделенный
фрагмент документа переносится в копилку
при нажатии комбинации клавиш Ctrl+F3.
Лодобное действие может быть выполнено
для одного или нескольких документов,
открытых в разных окнах. Просмотреть
содержимое копилки можно с помощью
команды Автотекст меню Вставка, выделив
в списке имен Копилка. Для вставки
содержимого копилки в текст вводится
слово копилка и нажимается комбинация
клавиш Ctrl+Shift+F3 для переноса содержимого
копилки или клавиша F3 для копирования
содержимого.
Текст
документа Word может быть проверен на
правильность правописания на нескольких
десятках языков. Перечень языков
устанавливается командой Язык меню
Сервис. Имеется возможность проверять
тексты на наличие в них орфографических
и грамматических ошибок. Проверку
правописания можно производить
непосредственно при вводе текста или
в ранее введенных текстах. Для
автоматической проверки правописания
при вводе текста следует настроить
вкладку Правописание диалогового окна
команды Параметры меню Сервис. Проверка
правописания в выделенном фрагменте
ранее введенного текста выполняется
командой Правописание меню Сервис или
при нажатии на соответствующую кнопку
на панели инструментов.
При
проверке правописания Word подчеркивает
красной волнистой линией возможную
орфографическую ошибку, зеленой волнистой
линией — возможную грамматическую
ошибку.
Основная
работа ведется в диалоговом окне команды
Правописание с помощью кнопок. Пользователь
может пропустить слово, заменить его
одним из слов, содержащихся в поле
Варианты, добавить это слово в
пользовательский словарь, добавить его
в список автозамены для автоматического
исправления ошибок и т. д.
Настройка
параметров проверки правописания
(установка нужных флажков в диалоговом
окне, вызываемом нажатием кнопки
Параметры в окне Правописание, и нажатием
кнопки Настройка) позволяет добиться
оптимального соотношения между строгостью
и скоростью проверки.
В
процессе редактирования иногда требуется
выполнить поиск текста. Поиск текста
часто выполняется затем, чтобы заменить
его. Для поиска текста щелкните
ссылку Найти
в документе на
панели Поиск в
области задач или выберите команду Найти в
меню Правка или
щелкните клавиши Ctrl+F.
В поле Найти введите
искомый текст и нажмите кнопку «Найти
далее».
После этого будет выполняться поиск.
Чтобы прервать поиск, нажмите клавишу Esc.
Примечание.
Для отображения в окне дополнительных
возможностей поиска щелкните кнопку
«Больше». После этого в окне поиска
будут отображены поля, в которых вы
можете задать направление поиска,
включить учет регистра, задать формат.
Щелкнув кнопку «Специальный», вы можете
задать поиск специальных символов. Если
вам для описания образа поиска не
требуется задавать дополнительные
параметры, то щелкните кнопку «Меньше»
для уменьшения окна, чтобы скрыть
ненужные поля.
Для
замены текста выберите в
меню Правка команду Заменить.
В поле Найти введите
искомый текст, а в поле Заменить па
введите текст для замены. Щелкните
кнопку «Найти
далее».
Если данный текст будет найден, то поиск
будет остановлен, искомый текст будет
выделен жирным начертанием. Щелкните
кнопку «Заменить»
для замены текста. Если вы хотите заменить
все вхождения искомого текста, то
щелкните кнопку «Заменить
все».
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание
- Key Switcher
- Punto Switcher
- LanguageTool
- AfterScan Express
- Orfo Switcher
- Spell Checker
- ОРФО
- Вопросы и ответы

Никто не застрахован от допущения разного рода ошибок при написании текста. При этом каждый рано или поздно сталкивается с ситуацией, когда требуется создать грамотный текстовый документ для официальных целей. Специально для помощи при выполнении этой задачи существует ряд программ, о которых и будет рассказано в этой статье.
Key Switcher
Key Switcher — удобный и многофункциональный инструмент, предназначенный для выявления и автоматического исправления разного рода ошибок при наборе текста в любой программе, которая в принципе имеет поле ввода. Это приложение работает скрыто, и может распознать более 80 разных языков и наречий. В списке ее функций также присутствует функция распознавания неправильно включенной раскладки и ее автоматическое изменение. Благодаря «Хранилищу паролей» не нужно будет переживать о том, что во время ввода приложение переключит раскладку, и он окажется неверным.
В завершение хочется упомянуть и о наличии функции «Автозамена», благодаря которой можно настроить автоматическую замену различных сокращений на нужный вариант. Правда, пользователю для этого понадобится предварительно пополнить эту базу собственными словами. Так, например, можно не переключать раскладку для ввода «P.S.», а писать «зы», после чего Key Switcher автоматически выполнит замену. Это касается любых других замен, аналогичных этой.
Скачать Key Switcher
Punto Switcher
Punto Switcher — программа, которая очень схожа по функциональности с предыдущим вариантом. Она так же скрыта в трее и работает в фоновом режиме, не завися от конкретного текстового редактора. Кроме того, Пунто Свитчер может автоматически изменять раскладку клавиатуры или поправлять пользователя, когда тот сделает опечатку в слове. Ключевыми особенностями стали транслитерация, замена цифр на текст и смена регистра правописания. Punto Switcher также предоставляет функция сохранения паролей и шаблонных текстов.
Что касается самого исправления ошибок, то здесь есть как общие правила (типа исправления аббревиатур, двух заглавных букв в начале слова), так и заложенный в базу словарь. Как и в предыдущем софте, здесь имеется «Автозамена», упрощающая набор часто употребляемых оборотов (к примеру, набор «чтд» автоматически заменится на «что и требовалось доказать») и частей предложения, требующих разной раскладки. Дополнительно тут можно настроить программы-исключения, внутри которых Пунто Свитчер не будет срабатывать, а также включить ведение дневника (сохранение набранных текстов в любых приложениях), что поможет избежать потери важных писем и документов.
Скачать Punto Switcher
LanguageTool
LanguageTool отличается от других указанных в этой статье программ в первую очередь тем, что она предназначена для проверки правописания уже созданного текста, который был скопирован в буфер обмена. Содержит в себе правила правописания для более чем сорока языков, что в свою очередь позволяет выполнять качественную проверку. Если же юзер заметит отсутствие какого-либо правила, LanguageTool предоставляет возможность загрузить его.
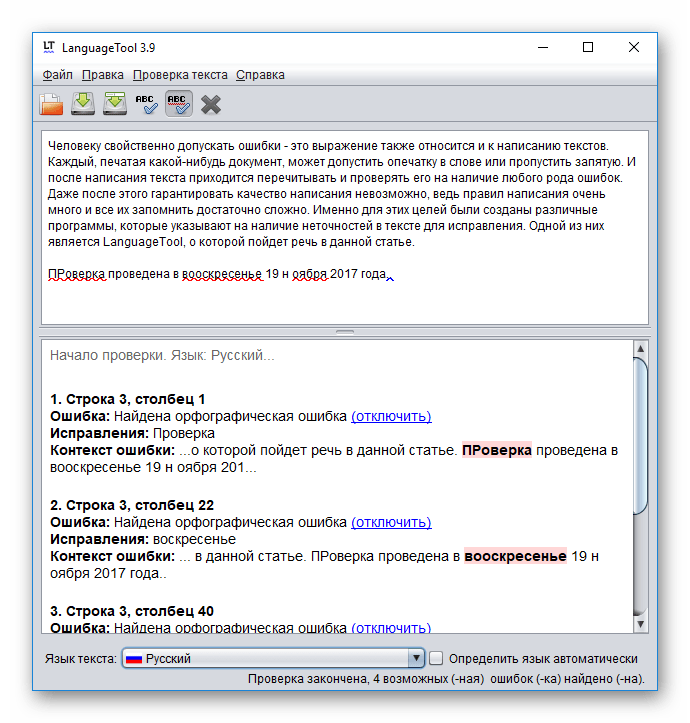
Главной ее особенностью является поддержка N-грамм, которые рассчитывают вероятность повторения слов и словосочетаний. Сюда также следует добавить наличие морфологического разбора проверяемого текста. Приятно и то, что софт постоянно обновляется, улучшая словари, что обеспечивает грамотное написание не только на родном языке, но и на каком-то из иностранных. К слову, LanguageTool можно установить не только как отдельную программу, но и в качестве надстройки для текстового редактора Microsoft Word, Libre Office, Open Office, Google Docs, расширения для Google Chrome и Mozilla Firefox. Из недостатков следует указать большой размер дистрибутива (более 150 МБ) и необходимость установки Java для работы.
Скачать LanguageTool
AfterScan Express
AfterScan Express создана с целью автоматического исправления ошибок, которые были допущены во время распознавания сканированного текста сторонним софтом. Она предлагает пользователю несколько вариантов редактирования, предоставляет отчет о проделанной работе и позволяет выполнить окончательное исправление. Сам процесс OCR-сканирования настраиваемый и состоит из трех шагов. По ходу дела можно управлять незнакомыми словами, убирать пунктуацию, отступы, «мусор» в соответствии с нормами типографии. Полученный результат дополнительно можно откорректировать: незнакомые слова выделены красным цветом, и для каждого из них предлагаются возможные замены, вставлять которые можно предложенной горячей клавишей.

Дополнительно имеется «Переформатирование», по итогам которого будут убраны жесткие переносы строки, сами строки склеятся, уберутся лишние пробелы и исправятся другие параметры. Настройку переформатирования юзер осуществляет под свои нужды. Поддерживается пакетная обработка текстов, создание собственного словаря. Программа платная, и приобретая лицензию, пользователь получает дополнительные функции. В их список входит пакетная обработка документов, пользовательский словарь и возможность защиты файла от редактирования.
Скачать AfterScan Express
Orfo Switcher
Orfo Switcher — это еще одна программа, которая предназначена для автоматического редактирования текста в момент его написания. Она полностью бесплатная, не привязана к конкретному редактору и после установки размещается в системном трее. ПО выполняет автоматическое переключение раскладки клавиатуры и предлагает варианты исправления неправильно написанных слов. Orfo Switcher также предоставляет пользователю возможность составления словарей неограниченного объема, которые содержат слова-исключения (например, пароли) и сочетания букв, обязательные к смене раскладки клавиатуры. Как и в другом аналогичном софте, тут можно внести определенные приложения в исключения, чтобы внутри них не происходила проверка ввода текста.
Скачать Orfo Switcher
Spell Checker
Это небольшое и удобное ПО моментально предупреждает пользователя о допущенной им опечатке в слове. Оно также может визуально отображать текст, который был скопирован в буфер обмена, при этом есть расширенные настройки визуализации. Но при этом функциональность Spell Checker распространяется только на англо- и русскоязычные слова.
Среди дополнительных функций предлагается возможность указания, в каких процессах программа должна работать, а в каких — нет. Дополнительно доступна загрузка словарей. Главным недостатком Спел Чекер является то, что после ее установки нужно дополнительно загрузить словарь для работы.
Скачать Spell Checker
ОРФО
Последней в списке будет не совсем программа — ОРФО представляет собой надстройку для текстового процессора Microsoft Word. Все те, кто привык создавать документы в этом приложении, но оказался не удовлетворен базовыми правилами проверки правописания, оценят возможности ОРФО. Она занимается не только грамматической, но и стилистической проверкой, используя более 40 групп правил и 23 тысяч шаблонов, что обеспечивает проверку на разных уровнях: строгая, деловая или обычная переписка. К каждой найденной ошибке есть описание и пояснение, почему нужно применить то или иное исправление. Помимо этого, здесь можно расставлять переносы в соответствии с газетной и книжной стилистикой. Функция «Тезаурус» обеспечивает поиск и устранение тавтологии (повторения слов) путем поиска подходящих по смыслу синонимов. Для этих целей в программе есть словарь с более чем 60 000 слов, часть из которых является синонимами, антонимами и родственными.
ОРФО состоит сразу из нескольких словарей, что вкупе обеспечивает максимально качественную проверку слов, грамматики. Поддерживается удобная замена конкретного слова во всех его словоформах, отображение всех доступных форм интересующего слова. Сразу стоит отметить, что расширение платное, но этот тот случай, когда софт действительно стоит своих денег. Для работы с ним вам требуется установленный Word 2016 и выше, а сама программа подбирается не только исходя из своей версии (есть несколько комплектов: Профессиональная, Профессиональная Плюс, Максимальная, 2 версии для Mac OS), но и в соответствии с разрядностью самого Ворд (32/64 бит). Сейчас разработчик готовит крупное обновление и, несмотря на то, что сайт выглядит заброшенным, техническая поддержка по email продолжает активно работать.
Перейти на официальный сайт ОРФО
В этой статье описаны программы для проверки орфографии и пунктуации, которые избавят юзера от неграмотно написанных текстов. Установив любую из них, можно быть уверенным в том, что любое напечатанное слово будет правильным, а предложения будут соответствовать правилам правописания. Однако не стоит забывать и о том, что даже самое умное программное обеспечение не сможет отыскать абсолютно всех ошибок любого уровня сложности, поэтому не ленитесь перечитывать свои тексты и уточнять спорные моменты вручную. Дополнительно отметим, что практически популярные текстовые редакторы имеют встроенную функцию проверки орфографии и пунктуации, а также существуют разнообразные онлайн-сервисы, проверяющие не хуже, чем многие перечисленные в материале приложения.
Читайте также:
Текстовые редакторы для Windows / Linux
Проверка правописания онлайн
Программы для исправления ошибок бывают необходимы во многих случаях: когда нужно проверить документ большого объема или быстро устранить опечатки в тексте. Часто пользователи жалуются на то, что вычитывают текст по нескольку раз, но все равно пропускают ряд ошибок, списывая это на собственную невнимательность. В чем бы ни заключалась проблема, без программ для исправления ошибок работать действительно сложно — даже тем, у кого с внимательностью нет никаких проблем. В этой статье мы расскажем, какими программами для исправления ошибок пользуются юзеры сети и почему.
Навигация по статье
- ТОП-10 программ по исправлению ошибок в тексте
- Сравнение возможностей сервисов
ТОП-10 программ по исправлению ошибок в тексте
Мы сделали для вас подборку из десяти самых популярных программ и сервисов, которые проверяют текст на наличие ошибок и подсвечивают их, чтобы пользователь мог легко их обнаружить и устранить.
Orfogrammka.ru
Это платная платформа, которая дает возможность проверить до 1 млн символов текста в течение одного месяца. Данный сервис, помимо синтаксических и орфографических ошибок, дает возможность проверить:
- наличие тавтологии;
- водность текста;
- иностранные слова;
- замену символов.
Сервис работает по подписке, которая предоставляет доступ к полноценной работе на один месяц. Стоимость ее обойдется пользователю в 300 рублей. Здесь также есть возможность проверить 6 тысяч символов текста с пробелами в тестовом режиме. Это же касается и исправления ошибок.
Яндекс.Спеллер
Сервис от известной группы разработчиков Яндекс — “Спеллер”, был создан для тех, кто хочет быстро осуществить проверку текста и исправить ошибки в режиме онлайн. Как и в большинстве других программ и сервисов подобного типа, здесь в окно проверки текста помещается сам текст, после чего сервис осуществляет проверку последнего в порядке очередности на сервере. В нижнем окне представлены варианты исправления.
Text.ru
Эта программа проверки орфографии на наличие ошибок в русском языке пользуется большой популярностью. Сервис в своем роде уникален, т.к. выполняет одновременно проверку уникальности, ошибок и SEO-данных текста.
Advego
Адвего — пожалуй, самая распространенная программа проверки текста. Это высококачественный и удобный сервис, который удерживает высокие позиции уже довольно долгое время. Он получил широкую известность как у разработчиков и SEO-специалистов, так и у копирайтеров с редакторами. Помимо функции проверки текста на наличие ошибок, здесь представлена масса других полезных возможностей:
- расчет количества символов;
- выявление орфографических ошибок;
- количество вхождений слов;
- водность текста;
- тошнота текста (академ. и классическая);
- уникальность текста.
Орфограф
Студия Артемия Лебедева представила еще один свой сервис, на этот раз, касающийся проверки текста. Как и все остальные проекты этой группы, Орфограф имеет минимальный набор функций — а именно, проверяет текст на наличие ошибок. В сервисе представлен собственный уникальный словарь, и если какая-то часть текста не имеет совпадений с базой данных Орфографа, то неизвестные слова выделяются дополнительным цветом.
Onlinecorrector
У этой программы проверки текстов есть одна специфическая функция — она способна проверять Google-документы. Это расширение требует установки в браузере, после чего с сервисом можно работать в режиме онлайн.
Орфо
Для осуществления проверок программой на ошибки в текстах многие пользователи сети предпочитают Орфо. Программу можно скачать на сайте, а также воспользоваться сервисом в режиме онлайн. Помарки в тексте подсвечиваются зеленым и красным цветом, в зависимости от того, какой тип ошибки будет обнаружен. Офлайн-версия предлагает пользователям расширенный функционал — здесь можно создавать переносы или автоматически корректировать буквы.
LanguageTool
Сервис был разработан и создан с целью предоставить функцию автоматического исправления орфографии на русском языке. Разработчики побеспокоились о том, чтобы создать две версии — онлайн и стационарную, для работы с расширением в браузере. При анализе текста, все слова с ошибками подсвечиваются другим цветом. Данная функция работает по аналогии с другими сервисами, которые предоставляют те же функции. Однако, здесь присутствует одно ключевое отличие — при нажатии на подсвеченное слово с ошибкой выпадает дополнительное меню, в котором можно выбрать один из вариантов исправления. Премиум версия программы (платная) предоставляет расширенный функционал, который может оказаться полезным для профессиональных корректоров, а также частных редакций.
Мета.ua
Этот сервис подойдет пользователям, которые ищут бесплатный инструмент, способный не только подсветить слова с ошибками, но и предоставить варианты для замены. Помимо всего прочего, данный сервис представляет еще и функции автоматического перевода. Ошибки в словах выделяются пунктирной линией. При нажатии на подсвеченное слово, пользователь может увидеть список слов для замены и выбрать из них подходящее.
Главред
Сайт Главред предлагает интересную функцию — проверку не только орфографического, но и смыслового качества текста. Это позволяет оценить текст сразу по нескольким критериям. Все предлагаемые исправления в тексте подчеркиваются пунктиром.
Присоединяйтесь к
Rush-Analytics уже сегодня
7-ми дневный бесплатный доступ к полному функционалу. Без привязки карты.
Попробовать бесплатно
Сравнение возможностей сервисов
| Название сервиса / программы | Проприетарность | Версия | Автокоррекция |
| Orfogrammka.ru | Платная | Онлайн | Нет |
| Яндекс.Спеллер | Бесплатная | Онлайн | Нет |
| Text.ru | Платная и бесплатная | Онлайн | Нет |
| Advego | Платная и бесплатная | Онлайн и офлайн | Нет |
| Орфограф | Платная | Онлайн | Нет |
| Onlinecorrector | Платная и бесплатная | Онлайн и офлайн | Нет |
| Орфо | Платная и бесплатная | Онлайн и офлайн | Да |
| LanguageTool | Платная и бесплатная | Онлайн и офлайн | Да |
| Мета.ua | Бесплатная | Онлайн | Да |
| Главред | Бесплатная | Онлайн | Нет |
Рекомендуем протестировать каждый из этих инструментов, чтобы выбрать наиболее удобный и эффективный для ваших целей.
Никто не застрахован от всевозможных ошибок при написании текста. Более того, рано или поздно каждый сталкивается с ситуацией, когда необходимо создать грамотный текстовый документ для служебных целей. Есть ряд специальных программ, которые помогут с этой задачей, о которых пойдет речь в этой статье.
Содержание
- Key Switcher
- Punto Switcher
- LanguageTool
- AfterScan Express
- Orfo Switcher
- Spell Checker
- ОРФО
Key Switcher
Key Switcher — удобный и многофункциональный инструмент, предназначенный для автоматического обнаружения и исправления различных типов ошибок при наборе текста в любой программе, которая, в принципе, имеет поле ввода. Это приложение скрыто и может распознавать более 80 различных языков и диалектов. В список его функций также входит функция распознавания ошибочно включенного макета и его автоматическая модификация. Благодаря «Хранилищу паролей» вам не нужно беспокоиться о том, что при вводе приложение изменит макет и окажется некорректным.
В заключение хотелось бы отметить наличие функции «Автокоррекция», благодаря которой можно настроить автоматическую замену различных сокращений на нужный вариант. Правда, для этого пользователю придется предварительно заполнить эту базу своими словами. Так, например, нельзя изменить раскладку ввода «PS», а написать «shl», после чего Key Switcher автоматически выполнит замену. Это относится к любой другой замене, подобной этой.
Punto Switcher
Punto Switcher — программа, очень похожая по функциональности на предыдущую версию. Он также скрыт в трее и работает в фоновом режиме независимо от конкретного текстового редактора. Кроме того, Punto Switcher может автоматически изменять раскладку клавиатуры или исправлять пользователя, когда он делает опечатку в слове. Основные возможности — транслитерация, замена чисел текстом и изменение регистра орфографии. Punto Switcher также предоставляет функцию сохранения паролей и текстов шаблонов.
Что касается самого исправления ошибок, то здесь есть как общие правила (как исправлять сокращения, две заглавные буквы в начале слова), так и встроенный в базу словарь. Как и в предыдущем программном обеспечении, здесь есть функция «Автозамена», которая упрощает набор часто используемых фраз (например, набор «chd» будет автоматически заменен на «что необходимо доказать») и части предложения, требующие разные макеты. Кроме того, здесь вы можете настроить программы исключения, в рамках которых Punto Switcher не будет работать, а также включить дневник (сохранение набранных текстов в любом приложении), что поможет избежать потери важных писем и документов.
LanguageTool
LanguageTool отличается от других программ, упомянутых в этой статье, главным образом тем, что он предназначен для проверки орфографии уже созданного текста, который был скопирован в буфер обмена. Он содержит правила орфографии для более чем сорока языков, что, в свою очередь, позволяет выполнять проверки высокого качества. Если пользователь замечает отсутствие каких-либо правил, LanguageTool предлагает возможность загрузить их.
Его главная особенность — поддержка N-граммов, которые вычисляют вероятность повторения слов и фраз. Это также должно быть дополнено наличием морфологического анализа контролируемого текста. Также приятно, что программное обеспечение постоянно обновляется, улучшаются словари, что обеспечивает правильное написание не только на родном языке, но и на некоторых иностранных. Кстати, LanguageTool можно установить не только как отдельную программу, но и как надстройку для текстового редактора Microsoft Word, Libre Office, Open Office, Google Docs, расширений для Google Chrome и Mozilla Firefox. К недостаткам можно отнести большой размер дистрибутива (более 150 МБ) и необходимость установки Java для работы.
AfterScan Express
AfterScan Express был создан с целью автоматического исправления ошибок, допущенных при распознавании отсканированного текста сторонним программным обеспечением. Он предлагает пользователю несколько вариантов редактирования, предоставляет отчет о ходе работы и позволяет вносить окончательные исправления. Сам процесс сканирования OCR настраивается и состоит из трех этапов. Попутно вы сможете обрабатывать незнакомые слова, убирать знаки препинания, отступы, «барахло» в соответствии с правилами типографики. Полученный результат можно дополнительно скорректировать: неизвестные слова выделяются красным цветом, и для каждого из них предлагаются любые замены, которые можно вводить с помощью предложенной комбинации клавиш.
Кроме того, есть «Переформатирование», в результате которого будут удалены разрывы строк, сами строки будут склеены, лишние пробелы будут удалены, а другие параметры будут исправлены. Пользователь может настроить форматирование в соответствии со своими потребностями. Поддерживает пакетную обработку текстов, создание собственного словаря. Программа платная и, купив лицензию, пользователь получает дополнительные функции. К ним относятся пакетная обработка документов, настраиваемый словарь и возможность защиты файла от изменений.
Orfo Switcher
Orfo Switcher — еще одна программа, предназначенная для автоматического изменения текста при написании. Он полностью бесплатен, не привязан к конкретному редактору и после установки помещается в системный трей. Программа автоматически изменяет раскладку клавиатуры и предлагает варианты исправления слов с ошибками. Orfo Switcher также предоставляет пользователю возможность составлять словари неограниченного размера, которые содержат исключающие слова (например, пароль) и комбинации букв, необходимые для изменения раскладки клавиатуры. Как и в другом подобном программном обеспечении, здесь вы можете добавить определенные приложения в исключения, чтобы ввод текста в них не проверялся.
Spell Checker
Эта удобная маленькая программа сразу же предупреждает пользователя об опечатке одним словом. Он также может визуально отображать текст, скопированный в буфер обмена, и доступны расширенные параметры визуализации. Но при этом функциональность проверки орфографии распространяется только на английские и русские слова.
Среди дополнительных функций предлагается возможность указать, в каких процессах программа должна работать, а в каких — нет. Также вы можете скачать словари. Главный недостаток Sang Checker в том, что после его установки для работы также необходимо скачать словарь.
ОРФО
Последней в списке будет совсем не программа: ORFO — это надстройка для текстового редактора Microsoft Word. Тот, кто привык создавать документы в этом приложении, но не был удовлетворен базовыми правилами проверки орфографии, оценит возможности ORFO. Он выполняет не только грамматические, но и стилистические проверки, используя более 40 наборов правил и 23 000 шаблонов, которые включают проверку на разных уровнях: строгой, коммерческой или обычной переписке. У каждой найденной ошибки есть описание и объяснение того, почему следует применить то или иное исправление. Кроме того, здесь можно выполнить орфографию согласно стилю газеты и книги. Функция «Тезаурус» обеспечивает поиск и устранение тавтологии (повторения слов) путем поиска синонимов, соответствующих смыслу. Для этих целей в программе есть словарь, содержащий более 60 000 слов, некоторые из которых являются синонимами, антонимами и родственными им.
ORFO состоит из нескольких словарей одновременно, которые вместе обеспечивают высочайший контроль слов и грамматики. Он поддерживает удобную замену определенного слова во всех его словоформах, отображая все доступные формы интересующего слова. Сразу стоит отметить, что расширение платное, но именно здесь программа действительно стоит своих денег. Для работы с ним необходимо установить Word 2016 и более поздние версии, а сама программа выбирается не только по ее версии (есть несколько наборов: Professional, Professional Plus, Maximum, 2 версии для Mac OS), но и в в соответствии с разрядностью самого слова (32/64 бит). В настоящее время разработчик готовит крупное обновление, и, несмотря на то, что сайт выглядит заброшенным, техническая поддержка по электронной почте продолжает активно работать.
В этой статье описаны программы проверки орфографии и пунктуации, которые избавят вас от неграмотного написания текста. После установки одного из них вы можете быть уверены, что все введенные вами слова будут правильными и предложения будут соответствовать правилам орфографии. Однако не забывайте, что даже самое умное программное обеспечение не сможет найти абсолютно все ошибки любого уровня сложности, поэтому не поленитесь перечитать свои тексты и прояснить спорные моменты вручную. Кроме того, отметим, что практически популярные текстовые редакторы имеют встроенную функцию проверки орфографии и пунктуации, а также существуют различные онлайн-сервисы, проверяющие не хуже многих приложений, перечисленных в материале.
Читайте также:
Текстовый редактор для Windows / Linux
Проверьте правописание онлайн
Создание коммерческих текстов плотно связано с объёмными статьями и необходимостью выдавать максимально грамотные и лаконичные статьи. Наличие ошибок в словах и пунктуации – признак плохого качества работы автора, будь то блогер, копирайтер или журналист. Поэтому возникает необходимость автоматической проверки крупных текстов. Причём анализировать готовую работу необходимо не только конечным исполнителям, но и их редакторам и владельцам коммерческих сайтов.
Оценивая качество статьи, можно составить объективное представление о профессионализме сотрудников. Предлагаем вашему вниманию топ программных решений, позволяющих закрывать такие задачи наиболее быстро и эффективно.
Топ-10 онлайн-сервисов для проверки правописания
Популярный софт, предназначенный для работы с текстом, оценивает не только его грамотность, но и другие параметры. Например, тошнотность – этот показатель характеризует плотность размещения ключевых вхождений в теле статьи. И, разумеется, уникальность – чем более уникальна работа автора, тем выше её будут ценить поисковые алгоритмы. Никому не интересны тексты, которые полностью или частично повторяют уже ранее опубликованные работы.
Orfogrammka.ru
Скриншот главной страницы Орфограммка
Веб-сайт: orfogrammka.ru
Онлайн сервис для проверки орфографии. Изначально он был полностью бесплатным, но владельцы решили перейти к его активной монетизации и разработали платные подписки.
Инструменты сервиса позволяют не только анализировать орфографию и пунктуацию, но также отслеживают разнообразные опечатки, помогают в подборе синонимов и эпитетов. Вы можете ознакомиться с функционалом в пробный период, который позволяет в полной мере испытать на практике все возможности программного обеспечения.
Плюсы:
-
Простой и интуитивно понятный интерфейс не вызывает проблем с освоением сервиса. Он включает два различных раздела с анализом грамотности проверяемого текста и его красотой. Сегодня софт позволяет оценить даже слог автора, а не только его техническое соответствие правилам языка.
-
Широкие возможности по распознаванию слов – это касается всевозможных омонимов и других ситуаций, когда ошибка в написании не привела к тому, что были нарушены правила орфографии.
-
Помощь в расстановке знаков препинания – сегодня далеко не все сервисы позволяют работать с пунктуацией. Она бывает запутанной и неоднозначной. Сложносоставные предложения, с большим числом знаков препинания, тяжело анализировать и исправлять. Ведь каждая запятая может изменить общий смысл предложенной информации.
-
Проверка на синонимы – никто не любит частые повторы. Даже если речь идёт об использовании синонимов. Таким образом вы сможете ещё раз оценить красоту и качество текста, а также слог его автора.
-
Целевой аудиторией программного продукта являются не только копирайтеры и редакторы. Он создавался с учётом потребностей студентов и преподавателей. Поэтому его функционал достаточно обширный, чтобы проводить практически любые работы с текстами.
-
Ограничения в сервисе связаны не с количеством текстов, а с общим объёмом символов. Поэтому вы вполне можете работать одновременно с несколькими статьями. Самое главное, чтобы они не превышали максимально допустимый объём знаков.
Минусы:
-
Платная подписка – далеко не все готовы платить за подобные инструменты. Тем не менее, если речь идёт о профессионалах, работающих с текстами каждый день, стоит задуматься о том, чтобы сразу прикупить себе подобное программное обеспечение. Это позволит существенно сэкономить ваше время и силы, которые можно будет потратить на более сложные и полезные задачи.
-
Ограниченный словарь – количество слов в языке столь велико, что собрать их все в одном справочнике крайне сложно. Язык растёт и развивается, какие-то выражения теряют свою актуальность, а другие – напротив, появляются и прочно входят в обиход. Непрекращающаяся эволюция языка вызывает определённые сложности в работе с текстами. Потому что некоторые современные слова в него могут и не попадать.
-
Определённые ограничения касаются и инструмента подбора словоформ – он не всегда правильно подбирает варианты в качестве рекомендаций. Не забывайте проверять результаты его работы.
-
Ограниченность итогового отчёта об анализе текста – не так много параметров попадают в заключительную оценку. Дополнительная информация о работе никогда не бывает лишней, а здесь её несколько недостаточно.
-
Нет никаких систем индикации и пояснений для работы с улучшением грамотности и красоты статей. Такие простые и понятные инструменты мотивируют к более тщательной работе и вносят ясность, когда текст перестаёт быть ширпотребом и становится действительно полезным и интересным для чтения.
Сервис доступен бесплатно для преподавателей. А ученики и студенты могут претендовать на скидку в 50% от стоимости платной подписки. Поэтому спрос на него достаточно большой. Стоимость тарифа во много зависит от количества ежедневных проверок, которые вам требуются.
Яндекс.Спеллер
Скриншот главной страницы Яндекс.Спеллер
Веб-сайт: yandex.ru
Когда речь идёт о работе с поисковыми алгоритмами и настройке статей именно под них, нельзя не упомянуть разработку компании Яндекс.
Спеллер отличается не только широкими возможностями по проверки орфографии, но также самым обширным словарём русских слов, который насчитывает более трёх миллионов словоформ.
Возможности отечественного поисковика позволяют ему привлекать для анализа статей библиотеки машинного обучения – CatBoost. Это технически сложное программное обеспечение, которое очень глубоко оценивает тексты. Оно способно выявлять искажённые слова, учитывать контекст, отслеживать опечатки и вообще, проводит практически все возможные манипуляции, нацеленные на улучшение качества.
Спеллер работает в качестве плагина, который вшивается в сайты на WordPress. Поэтому применять его можно прямо из окна вашей админки. Даже переходить никуда не потребуется. Самая главная проблема, не позволяющая полностью передать бразды правления грамотностью на сайте этому плагину – отсутствие возможности проверить пунктуацию.
Плюсы:
-
Нет формы регистрации или авторизации – просто установите плагин и пользуйтесь себе на здоровье. В современной Глобальной сети количество учётных записей рядового пользователя и так уже превосходит все разумные пределы. Поэтому бесконтрольно плодить их определённо не стоит.
-
Возможность предварительной настройки параметров анализа текста – то есть вы можете самостоятельно решать, какие показатели попадут в итоговый отчёт.
-
Отсутствие платной подписки – Яндекс предоставляет свои возможности на безвозмездной основе. Поэтому Спеллер заслуживает самого пристального внимания.
-
Интуитивный интерфейс – он очень похож на функционал Microsoft Word или Google Doc, который знаком практически всем. Времени на освоение, в общем-то, и не надо. Устанавливайте и сразу же начинайте пользоваться.
-
Возможность прямой интеграции на сайт – система плагинов вообще очень удобная. Ведь вам не приходится постоянно переключаться между различными вкладками с внешними сервисами. А значит вы можете найти все необходимые инструменты в одном окне, где и производите работу над текстами.
-
Постоянное обновление и сопровождение – вероятность того, что Яндекс перестанет заниматься активной разработкой Спеллера, практически равна нулю. Это полезный и эффективный сервис, который должен быть в арсенале любого вебмастера или копирайтера.
Минусы:
-
Он не работает с пунктуацией – на настоящий момент знаки препинания Спеллер практически не понимает. Но Яндекс не стоит на месте и, возможно, в скором времени этот пробел будет заполнен.
-
Необходимость установки стороннего программного обеспечения – разумеется, перегружать админку тоже не следует. Если у вас и без того уже обширный диапазон разнообразных плагинов, следует несколько раз подумать, прежде чем добавлять в него новые.
Спеллер намного активнее используется владельцами сайтов. Тогда как копирайтеры к его помощи прибегают намного реже. Хотя, возможно, и стоило бы.
Advego
Скриншот главной страницы Advego
Веб-сайт: advego.com
Хотя это и полноценная биржа контента, а не специализированное программное обеспечение, Advego располагает собственными инструментами для проверки качества текстов и проведения семантического анализа. Допустимый объём статей для проверки составляет 100 000 знаков. Так что все задачи сайтостроения этот сервис закрывает в полной мере.
Полюсы:
-
Инструменты доступны совершенно бесплатно. Достаточно пройти регистрацию и вы сможете использовать их в полной мере. Они находятся в разделе: «Сервис» – «Инструменты вебмастера» – «Проверка орфографии».
-
Мультиязычность – вы можете проверять тексты, написанные на одном из двадцати поддерживаемых словарей.
-
Рекомендации по правильному написанию – всегда удобно, когда программное обеспечение само предлагает вам вариант исправления в местах ошибок, а не только указывает на их наличие.
Минусы:
-
Разумеется, пунктуация не входит в число проверяемых элементов текста.
-
Работает только в рамках отечественного сегмента Глобальной сети. Заграничные проекты сервис обрабатывать отказывается или делает это некорректно.
-
Проверка уникальности занимает определённое время. И оно куда больше, чем хотелось бы, когда речь заходит о проведении регулярного анализа.
В итоге получается, что Advego подходит для проверки грамотности написанного текста, однако его недостатки вынуждают совмещать сервис с другими вариантами анализа.
Text.ru
Скриншот интерфейса Text.ru
Веб-сайт: text.ru
Пожалуй, один из наиболее востребованных сервисов для проверки уникальности и грамотности текстов. Будучи одним из первых, он работает ещё с 2007 года и за свою многолетнюю историю Text.ru претерпел немало различных изменений и улучшений. Поэтому сегодня сервис предлагает вам наилучшие варианты анализа качества статей.
Здесь нет никаких регистраций, авторизаций или установок. Вы просто переходите на сайт сервиса и помещаете в открывшееся окно текст для анализа. Сервис проверяет орфографию, уникальность и проводит SEO-анализ. Причём он и знаки препинания неплохо исправляет. Указывает на недостающие запятые, лишние скобки и тому подобные недостатки.
А ещё Text.ru отлично справляется с проверкой уникальности. Потому что он анализирует статью и выявляет совпадения, независимо от порядка слов в предложениях, их положения в теле статьи или какие-либо другие ухищрения, на которые могут пойти нечистые на руку копирайтеры.
Плюсы:
-
Бесплатная проверка текстов общим объёмом до 15 тысяч знаков.
-
Успешное выявление фактов плагиата или некачественного рерайта.
-
В итоговом анализе вы увидите не только недостатки орфографии и пунктуации. Сервис оценивает уровень тошнотности и водности, а также работает с SEO-составляющей текста.
-
Вы можете проверять и уникальности внешних страниц или документов.
-
Анализ включает указания на исходные источники информации. В тех случаях, когда речь идёт о наличии плагиата. Просматривая исходные материалы, вы сможете самостоятельно оценить степень качества рерайта. И решить, стоит ли подобная работа вашего внимания.
-
За свою многолетнюю историю, Text.ru обзавёлся крайне эргономичным и понятным интерфейсом. Все инструменты находятся под рукой и не нуждаются в поиске или разъяснениях.
Минусы:
-
Проверка уникальности не всегда происходит корректно. Это связано с ощутимой зависимостью от структуры статьи.
-
Анализ текстов и объявление результатов занимает достаточно длительное время. Разумеется, всё зависит от количества знаков, но если говорить о полноценной работе с наполнением сайтов и регулярных проверках, то ждать приходится слишком долго.
-
А проверка объёмных текстов требует дополнительной регистрации. Так что вам придётся добавить ещё одну учётную запись в собственный профиль.
Есть возможность перехода на платную подписку, которая позволяет работать быстрее и снимает ограничения. Но это необходимо только для профессиональных редакторов, ежедневно работающих с крупными статьями. А в целом, даже бесплатный вариант работы с сервисом позволяет закрыть большинство основных задач.
Скриншот главной страницы Language Tool
Веб-сайт: languagetool.org
Простая и доступная программа для проверки орфографии. Доступна она в виде расширения для браузеров. В качестве варианта есть установка десктопной версии программного обеспечения. Она была разработана ещё в 2003 году и по праву может считаться одной из наиболее ранних в своём роде.
Плюсы:
-
Проверка происходит не только по части орфографии и пунктуации. Она также затрагивает общий стиль и качество текста, его уникальность и лаконичность.
-
Это мультиязычное программное обеспечение. Оно позволяет работать с различными языками.
-
Автоматизированные инструменты самостоятельно определят язык текста и проанализируют его качество.
-
Большинство исправлений, которые предлагаются сервисом, включают в себя и варианты исправлений. Поэтому вы сможете вносить правки максимально оперативно.
-
В случае необходимости, вы можете вносить собственные правки в работу сервиса, отмечая их, как единичный случай или в качестве постоянного правила.
-
Практичный и эргономичный интерфейс интуитивно понятен и не вызывает вопросов даже у неподготовленных пользователей.
Минусы:
-
Существует ряд ограничений на внесение правок. Они затрагивают длинное и короткое тире, кавычки, буквы «е» и «ё».
-
Проверка не всегда предоставляет корректные результаты. В некоторых случаях, технически сложные тексты вполне могут неправильно оцениваться инструментом.
LanguageTool предоставляет своим клиентам как платную, так и бесплатную версии. Так что вы сможете в полной мере оценить качество и инструментарий сервиса до того, как решитесь на приобретение подписки. Орфографию и пунктуацию можно проверять совершенно бесплатно.
Главред
Скриншот интерфейса Главред
Веб-сайт: glvrd.ru
Несколько более специализированный сервис. Он нацелен на работу с текстом для выявления несоответствий конкретному стилю изложения, рекламных штампов и других признаков некачественной работы автора. Также Главред проверяет орфографию и пунктуацию.
Плюсы:
-
Сервис полностью бесплатный. Вам не придётся приобретать расширенную версию программного обеспечения для получения доступа к более специфическим инструментам. Всё доступно сразу и без каких-либо дополнительных расходов.
-
Удобный и понятный интерфейс позволяет оперативно включить его в рабочие процессы без дополнительного времени на освоение.
-
Наглядно демонстрирует слабые места в анализируемом тексте. Наличие чрезмерной тошнотности или водности.
-
Быстро выявляет наличие словесного мусора. Многие нерадивые копирайтеры пичкают свои работы лишними словами, растягивая итоговый текст только ради количества символов. В итоге они становятся трудночитаемыми и неэффективными.
Минусы:
-
Этот сервис весьма своеобразно оценивает статьи. Даже качественные материалы он может посчитать за ширпотреб, потому что неверно истолковал те или иные посылы. Предлагая изменить смысл в предложениях, зачастую, он советует изменить идею, заложенную в тексте, а это, как правило, просто неприемлемо.
-
Не подходит для любых ситуаций из-за ограниченности функционала. Здесь иногда попросту недостаточно инструментов для полноценного редактирования текста.
-
Сервис пытается «учить» писать тексты. Далеко не каждый исполнитель готов пойти на подобные уступки, особенно, если они базируются на неверных посылах.
Главред – это весьма популярный сервис. Он позволяет взглянуть на качество текстов по-новому. Нельзя однозначно сказать, хорошо это или плохо. В большинстве случаев всё зависит от конкретного текста. Тем не менее, интересные рекомендации он дать вполне в состоянии.
Сервис идеально подходит для изменения стиля подачи деловой переписки. Мотивирует специалистов сокращать свои сообщения и придавать им более компактный и информативный вид.
Key Switcher
Скриншот сайта KeySwitcher
Разносторонний и максимально автоматизированный инструмент. Он предназначен для быстрого выявления и исправления всех грамматических ошибок при наборе текста. Может быть интегрирован практически в любую программу ввода, самое главное, чтобы она имела это самое поле ввода.
Работает в фоновом режиме и способно распознавать более 80 языков. Дополнительный бонус для всех пользователей – автоматическое определение неправильно включённой раскладки клавиатуры и быстрая смена языка ввода.
Плюсы:
-
Способна исправлять популярные опечатки и явные грамматические ошибки.
-
Отслеживает и правит слова, напечатанные с двумя заглавными буквами. При ежедневной работе, копирайтеры достаточно часто сталкиваются с подобными ошибками, особенно когда речь идёт о действительно быстрой печати.
-
Исправно работает с различными суффиксами. Например, она корректно понимает указание суффикса для чисел.
-
Автоматически правит неверный регистр. Особенно актуально, если вы случайно задели клавишу «Caps Lock», вместо «Shift».
Минусы:
-
Это стороннее программное обеспечение. Со всеми вытекающими сложностями. Предоставляя доступ таким программам к собственному компьютеру, вы соглашаетесь с определёнными рисками, связанными с их эксплуатацией.
-
Далеко не все версии поддерживаются современными операционными системами. Поэтому озаботьтесь поиском наиболее свежего патча.
Это старое и проверенное решение в сфере редактирования больших текстов. Оно обладает собственной преданной аудиторией, которая устанавливает его на все свои компьютеры и, зачастую, даже отказывается от части встроенных в операционную систему функций, потому что они дублируются в Key Switcher. Тем не менее, для молодой аудитории такой вариант может стать слишком сложным, как технически, так и функционально.
Punto Switcher
Скриншот сайта Punto Switcher
Веб-сайт: yandex.ru
Ещё один вариант работы со сторонним программным обеспечением, которое устанавливается на компьютер и функционирует в фоновом режиме.
Работая из трея, Punto Switcher способен распознавать текст практически в любом редакторе. Он автоматически переключает раскладки, вносит изменения, в случаях опечаток, заменяет цифры на слова и вообще способен в существенной степени упростить жизнь копирайтеров и редакторов.
Плюсы:
-
Работа в фоновом режиме, которая не требует от вас никаких переключений между окнами и чего бы то ни было подобного. Он просто интегрируется в любое окно ввода текста и помогает не допускать никаких ошибок или опечаток.
-
Автоматически правит большинство, часто встречающихся, ошибок.
-
Самостоятельно меняет выбранный регистр, в случае необходимости.
-
Способен транслитерировать все цифровые элементы, заменяя их текстовыми.
-
Включает функцию сохранения паролей и шаблонных текстов.
Минусы:
-
Иногда вам может понадобиться неверно ввести те или иные слова, а программное обеспечение постарается помешать это сделать. В таких случаях чрезмерно умный софт может показаться вам слишком навязчивым.
-
Потребляет системные ресурсы – хоть и в малом количестве, но всё же потребляет. Так что, если решили использовать это программное обеспечение, придётся смириться с тем, что оно съест часть вычислительных мощностей.
Подобные разработки были очень популярными десять или даже двадцать лет назад. Но сегодня нечасто можно встретить поклонников таких решений для работы с орфографией и пунктуацией. Решение, так сказать, для специалистов старой школы.
Spell-Checker
Отличное решение для проверки уже опубликованных текстов. Разумеется, Spell-Checker может работать и с текстами на этапе внесения правок. Тем не менее, возможность проанализировать целый сайт и предоставить отчёт о найденных ошибках и неточностях выглядит крайне привлекательно.
Плюсы:
-
Позволяет работать с текстами в любых редакторах.
-
Отслеживая ошибки в набираемых текстах, Spell-Checker помечает их красными полупрозрачными флажками, появляющимися в верхнем левом углу вашего рабочего стола.
-
Мультиязычность – вы можете работать практически с любыми языковыми группами, правда придётся вручную добавить их словари.
Минусы:
-
Возможность работы с различными языками требует предустановки словарей. Более того, их базы необходимо постоянно обновлять и актуализировать.
-
Необходимость установки стороннего софта изначально отталкивает значительную часть аудитории. Далеко не все пользователи готовы предоставлять доступ к своему компьютеру неизвестному программному обеспечению.
-
На сегодняшний день может считаться устаревшей.
Орфограф
Скриншот интерфейса Орфограф
Веб-сайт: artlebedev.ru
Программный продукт студии Лебедева. Он может успешно работать с русскоязычными и англоязычными текстами. Основное достоинство – возможность практически мгновенной проверки текстов в режиме онлайн. Достаточно просто скопировать его в рабочее поле сервиса и он подсветит все ошибки и неточности.
Плюсы:
-
Нет системы платных подписок – сервис полностью доступен на безвозмездной основе.
-
Разработки студии Лебедева вообще весьма удобны и эргономичны. Не исключением стал и Орфограф. Он позволяет даже неподготовленной аудитории легко справляться с различными задачами по редактуре и корректировке статей.
-
Высокая скорость работы – особенно на фоне аналогичных инструментов. Вам вообще не нужно будет ждать результатов анализа. Всё происходит практически мгновенно.
-
Возможность работы не только с текстами, но и с полноценными веб страницами. То есть провести проверку можно и уже опубликованных статей, а не только тех, которые находятся в разработке.
-
Наличие разнообразных визуальных элементов и вариантов их настройки.
Минусы:
-
Орфограф не может работать с пунктуацией. То есть проверяет только правильность написания слов, но никак не оценивает знаки препинания.
-
Ограничения по объёму текста – вы можете проверить за раз только одну тысячу слов.
-
Нет встроенных подсказок по исправлениям – так что вам придётся самостоятельно искать верные варианты написания тех или иных слов. Зачастую, эта часть может вызывать некоторые затруднения и чрезмерные потери времени.
правописание, статьи
Как открыть файл
Особенности файла SIG: как открыть онлайн и на компьютере
18 Февраль 2019
Настройка
Гугл хром не открывает страницы
04 Июнь 2022
Настройка
Не работает микрофон в Дискорде
16 Май 2019
Игры
Инструкции
Где в папке Стим находятся игры
06 Июнь 2022
103
103 people found this article helpful
The 5 Best Spelling and Grammar Check Apps of 2023
Let your browser or phone check your work
We independently research, test, review, and recommend the best
products—learn more about
our process. If you buy something through our links, we may earn a commission.
Lifewire / Design by Amelia Manley
The Rundown
- Best All-Around Spelling and Grammar Check App: Grammarly
- Best Grammar Checker for Translations: WhiteSmoke
- Best In-Browser Companion: Ginger
- Best Spell Check App for Creative Projects: CorrectMe
- Best for Fast Spell Checks: Speller
Whether you’re typing an email to your boss or writing a novel, grammar and spelling are critical. Luckily, there are spelling and grammar apps that will check your work, improving clarity and fixing any mistakes.
Here are the best spelling and grammar check apps for multiple platforms and devices.
Best All-Around Spelling and Grammar Check App: Grammarly
Grammarly is best known for being an all-around great app for documents, social media posts, and any other text. The app is available online through Grammarly’s website and also includes extensions for various browsers. If you use Microsoft Word, or another Microsoft Office application, Grammarly connects directly through the software. (Grammarly for Microsoft Office isn’t currently supported on the Mac, however.)
Grammarly Keyboard is the app’s mobile keyboard extension that works with both iOS and Android devices.
If you’re using Grammarly for basic grammar checking, you’ll benefit the most from the free version. However, for heavy editing, vocabulary enhancement suggestions, and genre-specific writing checks, Grammarly Premium is for you; it’s available for $29.95 a month, with lower monthly rates on quarterly and annual subscriptions.
What We Like
-
Fast, accurate, and extremely simple to use.
-
Integrates anywhere you need it, ensuring your grammar is spot-on no matter what you’re typing.
What We Don’t Like
-
For Mac users who also use Microsoft Word, Grammarly currently doesn’t support Word on Mac. You’ll have to use the online app or a browser extension.
Best Grammar Checker for Translations: WhiteSmoke
WhiteSmoke is a complete grammar checker built for all devices, integrating with Mac, Windows, and most browsers. The mobile app is available for both iOS and Android devices.
WhiteSmoke includes a grammar, spelling, style, and punctuation checker, as well as a unique translation feature. With full-text translation to and from more than 50 different languages, WhiteSmoke makes it easy to communicate no matter your location.
WhiteSmoke features three different pricing plans for one-year or three-year billing periods: Web, Premium, and Business. The Web plan costs $59.95 for a year (about $5/month) or less if you subscribe for the three year plan.
What We Like
-
WhiteSmoke’s accessibility makes it easy to use on any device at any time.
-
Built-in translation makes writing communication in another language simpler.
What We Don’t Like
-
The mobile app interface could use some improvement.
Best In-Browser Companion: Ginger
Your emails, Google Docs, and social media posts should all be error-free. That’s where Ginger comes in. Ginger works on Windows and Mac, as well as on iOS devices via the Ginger Page app. For Android users, Ginger offers the Ginger Android Keyboard as an additional tool.
Adding the Ginger extension to Chrome or Safari is simple, and the grammar check starts immediately. You can also copy and paste your text into the companion window to get started.
Ginger’s tools include a grammar checker, sentence rephraser, word prediction, and more. The app is free to use unless you wish to unlock all of its capabilities by purchasing the Premium version, which can be paid monthly, annually, or every two years with the monthly cost being $19.99 and the annual prices reducing that further when payed in full.
What We Like
-
The in-browser window makes it easy to test your text before you place it into an email, a document, or on social media.
What We Don’t Like
-
To take full advantage of what Ginger has to offer, Premium is a must.
Best Spell Check App for Creative Projects: CorrectMe
Sometimes, you need a more creative and flavorful word beyond the basic message. For those moments, CorrectMe is there as an all-in-one spell checker and thesaurus. Use the app to correct your text and the built-in synonym checker to find different words for your search term.
CorrectMe is free on iOS devices. The app offers a Pro version that removes ads and unlocks more features, such as smart recommendations and grammar explanations.
What We Like
-
CorrectMe is fast, simple, and great for finding the perfect word for any project.
What We Don’t Like
-
To take advantage of the advanced features, you need the Pro version.
Best for Fast Spell Checks: Speller
Have you ever needed a spell check on the go? Speller is an app that combines various sources into one app, making for easy spelling on the go.
Speller checks the spelling of both English and Spanish words in one easy-to-use interface. Simply search for a word and Speller will tell you if it’s correct. You’ll also receive dictionary definitions from the internet as well as spelling suggestions.
Speller is available for iOS devices only and is free to download and use.
What We Like
-
Speller is fast and fun to use.
-
Spanish spelling makes it easy to translate words as needed.
What We Don’t Like
-
Because the app searches Google and other domains, search results take some time to load.
Thanks for letting us know!
Get the Latest Tech News Delivered Every Day
Subscribe
103
103 people found this article helpful
The 5 Best Spelling and Grammar Check Apps of 2023
Let your browser or phone check your work
We independently research, test, review, and recommend the best
products—learn more about
our process. If you buy something through our links, we may earn a commission.
Lifewire / Design by Amelia Manley
The Rundown
- Best All-Around Spelling and Grammar Check App: Grammarly
- Best Grammar Checker for Translations: WhiteSmoke
- Best In-Browser Companion: Ginger
- Best Spell Check App for Creative Projects: CorrectMe
- Best for Fast Spell Checks: Speller
Whether you’re typing an email to your boss or writing a novel, grammar and spelling are critical. Luckily, there are spelling and grammar apps that will check your work, improving clarity and fixing any mistakes.
Here are the best spelling and grammar check apps for multiple platforms and devices.
Best All-Around Spelling and Grammar Check App: Grammarly
Grammarly is best known for being an all-around great app for documents, social media posts, and any other text. The app is available online through Grammarly’s website and also includes extensions for various browsers. If you use Microsoft Word, or another Microsoft Office application, Grammarly connects directly through the software. (Grammarly for Microsoft Office isn’t currently supported on the Mac, however.)
Grammarly Keyboard is the app’s mobile keyboard extension that works with both iOS and Android devices.
If you’re using Grammarly for basic grammar checking, you’ll benefit the most from the free version. However, for heavy editing, vocabulary enhancement suggestions, and genre-specific writing checks, Grammarly Premium is for you; it’s available for $29.95 a month, with lower monthly rates on quarterly and annual subscriptions.
What We Like
-
Fast, accurate, and extremely simple to use.
-
Integrates anywhere you need it, ensuring your grammar is spot-on no matter what you’re typing.
What We Don’t Like
-
For Mac users who also use Microsoft Word, Grammarly currently doesn’t support Word on Mac. You’ll have to use the online app or a browser extension.
Best Grammar Checker for Translations: WhiteSmoke
WhiteSmoke is a complete grammar checker built for all devices, integrating with Mac, Windows, and most browsers. The mobile app is available for both iOS and Android devices.
WhiteSmoke includes a grammar, spelling, style, and punctuation checker, as well as a unique translation feature. With full-text translation to and from more than 50 different languages, WhiteSmoke makes it easy to communicate no matter your location.
WhiteSmoke features three different pricing plans for one-year or three-year billing periods: Web, Premium, and Business. The Web plan costs $59.95 for a year (about $5/month) or less if you subscribe for the three year plan.
What We Like
-
WhiteSmoke’s accessibility makes it easy to use on any device at any time.
-
Built-in translation makes writing communication in another language simpler.
What We Don’t Like
-
The mobile app interface could use some improvement.
Best In-Browser Companion: Ginger
Your emails, Google Docs, and social media posts should all be error-free. That’s where Ginger comes in. Ginger works on Windows and Mac, as well as on iOS devices via the Ginger Page app. For Android users, Ginger offers the Ginger Android Keyboard as an additional tool.
Adding the Ginger extension to Chrome or Safari is simple, and the grammar check starts immediately. You can also copy and paste your text into the companion window to get started.
Ginger’s tools include a grammar checker, sentence rephraser, word prediction, and more. The app is free to use unless you wish to unlock all of its capabilities by purchasing the Premium version, which can be paid monthly, annually, or every two years with the monthly cost being $19.99 and the annual prices reducing that further when payed in full.
What We Like
-
The in-browser window makes it easy to test your text before you place it into an email, a document, or on social media.
What We Don’t Like
-
To take full advantage of what Ginger has to offer, Premium is a must.
Best Spell Check App for Creative Projects: CorrectMe
Sometimes, you need a more creative and flavorful word beyond the basic message. For those moments, CorrectMe is there as an all-in-one spell checker and thesaurus. Use the app to correct your text and the built-in synonym checker to find different words for your search term.
CorrectMe is free on iOS devices. The app offers a Pro version that removes ads and unlocks more features, such as smart recommendations and grammar explanations.
What We Like
-
CorrectMe is fast, simple, and great for finding the perfect word for any project.
What We Don’t Like
-
To take advantage of the advanced features, you need the Pro version.
Best for Fast Spell Checks: Speller
Have you ever needed a spell check on the go? Speller is an app that combines various sources into one app, making for easy spelling on the go.
Speller checks the spelling of both English and Spanish words in one easy-to-use interface. Simply search for a word and Speller will tell you if it’s correct. You’ll also receive dictionary definitions from the internet as well as spelling suggestions.
Speller is available for iOS devices only and is free to download and use.
What We Like
-
Speller is fast and fun to use.
-
Spanish spelling makes it easy to translate words as needed.
What We Don’t Like
-
Because the app searches Google and other domains, search results take some time to load.
Thanks for letting us know!
Get the Latest Tech News Delivered Every Day
Subscribe
Беспокоитесь, что можете ошибиться, когда набираете текст? Не стоит. Word предоставляет вам несколько функций проверки правописания, которые помогут вам создавать профессиональные без ошибок документы. В этом уроке вы узнаете о различных функциях проверки правописания, включая инструмент проверки орфографии и грамматики.
Чтобы ваш документ выглядел профессионально, вы должны быть уверены, что в нем нет орфографических и грамматических ошибок. Для этого вы можете запустить проверку орфографии и грамматики, или можете позволить Word проверять правописание автоматически при вводе текста.
Чтобы запустить проверку орфографии и грамматики:
- Перейдите на вкладку Рецензирование.
- Кликните по команде Правописание.

- Откроется диалоговое окно Правописание. Для каждой из ошибок в вашем документе Word попытается предложить один или несколько вариантов замены. Вы можете выбрать приемлемый вариант, а затем нажать Заменить для исправления ошибки.

- Если вариантов замены нет, то вы можете самостоятельно ввести правильное написание.




Пропуск «Ошибок»
Проверка правописания не всегда верно работает. Особенно это касается грамматики. Многих ошибок, Word просто не заметит. Также бывает, что проверка правописания говорит, что что-то содержит ошибку, хотя на самом деле это не так. Такое часто случается с именами людей, которых может не быть в словаре.
Если Word говорит, что что-то содержит ошибку, вы можете ничего не изменять. В зависимости от того, какая перед вами ошибка, орфографическая или грамматическая, вы можете выбрать из нескольких параметров:
Для орфографических «ошибок»:
- Пропустить: Пропустить слово, не изменяя его.
- Пропустить все: Пропустить слово, не изменяя его. Также пропустить это слово во всем документе.
- Добавить в словарь: Добавляет слово в словарь, так что оно не будет восприниматься программой как ошибочно написанное. Убедитесь, что слово написано правильно, прежде чем выбирать этот параметр.
Для грамматических «ошибок»:
- Пропустить: Пропустить «ошибку» без изменений.
- Пропустить все: Пропустить «ошибку» без изменений, а также применить это со всеми другими случаями, которые относятся к этому же правилу.
- Следующее: Пропустить предложение без изменений и оставить его с пометкой об ошибке. Это означает, что запущенная позже проверка Правописания снова укажет на это предложение.
Если вы не уверены верно ли Word указал на грамматическую ошибку, вы можете нажать на кнопку Объяснить, чтобы прочитать, почему программа так думает. Это может помочь вам решить, хотите ли вы вносить изменения.
Автоматическая проверка орфографии и грамматики
По умолчанию Word автоматически проверяет ваш документ на наличие орфографических и грамматических ошибок, поэтому вам может быть даже не нужно отдельно запускать проверку Правописания. Найденные ошибки подчеркиваются цветными волнистыми линиями.
- Красная линия означает, что слово написано неправильно.
- Зеленая линия означает грамматическую ошибку.
- Синяя линия означает контекстную ошибку. Эта функция по умолчанию отключена.

Контекстная ошибка – это употребление неподходящего для заданного контекста слова. Само слово при этом написано верно. Например, если я напишу предложение «В каждую эпоху формируются свои ценные ориентиры», то ценные является контекстной ошибкой, так как я должен был использовать слово ценностные. Ценные написано верно, но использовано не в том контексте.
Чтобы исправить орфографическую ошибку:
- Кликните правой кнопкой мыши по подчеркнутому слову. Появится контекстное меню.
- Кликните по корректному написанию слова в списке замен.
- Правильное слово появится в документе.

Вы также можете выбрать пропустить подчеркнутое слово и добавить его в словарь, или можете кликнуть Орфография и откроется диалоговое окне с другими вариантами.
Чтобы исправить грамматическую ошибку:
- Кликните правой кнопкой мыши по подчеркнутому слову или фразе. Появится контекстное меню.
- Кликните по корректной фразе в списке замен (или вместо корректной фразы будет объяснение грамматической ошибки).

Вы также можете пропустить подчеркнутую фразу, открыть диалоговое окно Грамматика, или кликнуть по пункту «Об этом предложении», чтобы узнать нарушенное правило грамматики.
Чтобы изменить настройки автоматической проверки орфографии и грамматики:
- Во всплывающем меню Файл, выберите команду Параметры.

- Выберите Правописание. В открывшемся окне можно будет выбрать из нескольких опций:
- Если вы не хотите, чтобы Word автоматически проверял орфографию, уберите отметку у пункта «Проверять орфографию в процессе набора текста».
- Если вы не хотите, чтобы отмечались грамматические ошибки, уберите отметку у пункта «Отмечать ошибки грамматики в процессе набора текста».
- Для проверки на наличие контекстуальных ошибок отметьте пункт «Использовать контекстную проверку орфографии».


Если вы выключите автоматическую проверку грамматических и орфографических ошибок, вы все равно сможете запустить ее вручную, выбрав команду Правописание, на вкладке Рецензирование.
Чтобы скрыть орфографические и грамматические ошибки в документе:
Если вы делитесь документом с кем-либо, то можете захотеть, чтобы этот человек не видел раздражающих красных, зеленых и синих линий. Выключение автоматической проверки орфографии и грамматики будет работать только на вашем компьютере, так что линии снова появятся при открытии документа на другом компьютере. К счастью, вы можете скрыть ошибки в документе так, чтобы линии не отображались ни на одном компьютере.
- Во всплывающем меню Файл, выберите команду Параметры.
- Выберите Правописание.
- Для пункта «Исключения для файла:» выберите нужный документ (если у вас открыто больше одного документа).

- Отметьте галочкой пункты «Скрыть орфографические ошибки только в этом документе» и «Скрыть грамматические ошибки только в этом документе».
- Нажмите OK.
