
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.

Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:

Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:

Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:

Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:

Стандартное отклонение этих средних значений известно как стандартная ошибка.

Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.
Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:
Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:
Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:
Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:
Стандартное отклонение этих средних значений известно как стандартная ошибка.
Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
Стандартное отклонение (SD), измеряет количество изменчивости или дисперсии, из отдельных значений данных, к среднему значению, в то время как стандартная ошибка среднего (SEM) мер, как далеко образец среднее (среднее) данных, вероятно, будет от истинного среднего значения населения. SEM всегда меньше SD.
Ключевые выводы
- Стандартное отклонение (SD) измеряет разброс набора данных относительно его среднего значения.
- Стандартная ошибка среднего (SEM) измеряет, насколько вероятно расхождение между средним значением выборки по сравнению со средним значением генеральной совокупности.
- SEM берет SD и делит его на квадратный корень из размера выборки.
SEM против SD
Стандартное отклонение и стандартная ошибка используются во всех типах статистических исследований, включая исследования в области финансов, медицины, биологии, инженерии, психологии и т. Д. В этих исследованиях стандартное отклонение (SD) и расчетная стандартная ошибка среднего (SEM) ) используются для представления характеристик данных выборки и объяснения результатов статистического анализа. Однако некоторые исследователи иногда путают SD и SEM. Таким исследователям следует помнить, что расчеты SD и SEM включают разные статистические выводы, каждый из которых имеет свое значение. SD – это разброс отдельных значений данных.
Другими словами, SD указывает, насколько точно среднее значение представляет данные выборки. Однако значение SEM включает статистический вывод, основанный на распределении выборки. SEM – это стандартное отклонение теоретического распределения выборочных средних (выборочное распределение).
Расчет стандартного отклонения

Формула SD требует нескольких шагов:
- Во-первых, возьмите квадрат разницы между каждой точкой данных и средним значением выборки, найдя сумму этих значений.
- Затем разделите эту сумму на размер выборки минус один, который представляет собой дисперсию.
- Наконец, извлеките квадратный корень из дисперсии, чтобы получить стандартное отклонение.
Стандартная ошибка среднего
SEM рассчитывается путем деления стандартного отклонения на квадратный корень из размера выборки.
Стандартная ошибка дает точность выборочного среднего путем измерения изменчивости выборочного среднего от образца к образцу. SEM описывает, насколько точное среднее значение выборки является оценкой истинного среднего значения совокупности. По мере увеличения размера выборки данных SEM уменьшается по сравнению с SD; следовательно, по мере увеличения размера выборки среднее значение выборки оценивает истинное среднее значение генеральной совокупности с большей точностью. Напротив, увеличение размера выборки не обязательно делает SD больше или меньше, это просто становится более точной оценкой SD населения.
Стандартная ошибка и стандартное отклонение в финансах
В финансах стандартная ошибка средней дневной доходности актива измеряет точность выборочного среднего как оценки долгосрочной (постоянной) средней дневной доходности актива.
С другой стороны, стандартное отклонение доходности измеряет отклонения индивидуальных доходов от среднего значения. Таким образом, SD является мерой волатильности и может использоваться в качестве меры риска для инвестиций. Активы с более высокими ежедневными движениями цен имеют более высокое SD, чем активы с меньшими ежедневными движениями. Предполагая нормальное распределение, около 68% дневных изменений цен находятся в пределах одного стандартного отклонения от среднего, при этом около 95% дневных изменений цен находятся в пределах двух стандартных значений среднего.
Вступление
стандарт D (SD) а также S tandard Е rror (SE) по-видимому, аналогичные терминологии; однако они концептуально настолько разнообразны, что они используются почти взаимозаменяемо в статистической литературе. Каждому термину обычно предшествует символ плюс-минус (+/-), который указывает на то, что они определяют симметричное значение или представляют диапазон значений. Неизменно оба выражения появляются со средним (средним) набором измеренных значений.
Интересно, что SE не имеет ничего общего со стандартами, с ошибками или с сообщением научных данных.
Подробный взгляд на происхождение и объяснение SD и SE покажет, почему профессиональные статистики и те, кто использует это сдержанно, оба склонны ошибаться.
Стандартное отклонение (SD)
SD является описательный статистика, описывающая распространение распределения. Как метрика, это полезно, когда данные обычно распределяются. Однако это менее полезно, когда данные сильно искажены или бимодальны, потому что они не очень хорошо описывают форму распределения. Как правило, мы используем SD при представлении характеристик образца, поскольку мы намерены описывать насколько данные изменяются по среднему значению. Другая полезная статистика для описания распространения данных — это межквартильный диапазон, 25-й и 75-й процентили и диапазон данных.
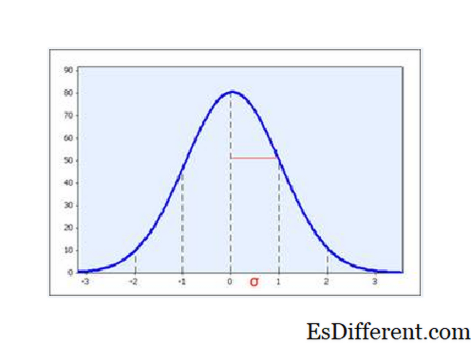
Рисунок 1. SD является мерой распространения данных. Когда данные являются образцом из нормально распределенного распределения, тогда ожидается, что две трети данных будут находиться в пределах 1 стандартного отклонения среднего значения.
Разница заключается в описательный статистика также, и она определяется как квадрат стандартного отклонения. Обычно это не сообщается при описании результатов, но это более математически приемлемая формула (a.k.a. сумма квадратов отклонений) и играет роль в вычислении статистики.
Например, если у нас есть две статистики п & Q с известными отклонениями вар (П) & вар (Q) , то дисперсия суммы Р + Q равна сумме дисперсий: вар (P) + вар (Q) , Теперь очевидно, почему статистикам нравится говорить об отклонениях.
Но стандартные отклонения имеют важное значение для распространения, особенно когда данные обычно распределяются: среднее значение интервала +/- 1 SD можно ожидать захвата 2/3 образца, а среднее значение интервала + — 2 SD можно ожидать захвата 95% образца.
SD дает представление о том, насколько индивидуальные ответы на вопрос меняются или «отклоняются» от среднего. SD рассказывает исследователю, насколько распространены ответы: сосредоточены ли они вокруг среднего или разбросаны по всему миру? Все ваши респонденты оценили ваш продукт в середине шкалы, или кто-то одобрил его, а некоторые отклонили его?
Рассмотрим эксперимент, в котором респондентам предлагается оценивать продукт по ряду атрибутов по 5-балльной шкале. Среднее значение для группы из десяти респондентов (обозначаемое «A» через «J» ниже) для «хорошей стоимости за деньги» составляло 3,2 с SD 0,4, а среднее значение для «надежности продукта» составляло 3,4 с SD 2,1.
На первый взгляд (смотря только на средства), казалось бы, надежность была оценена выше стоимости. Но более высокий SD для надежности может указывать (как показано ниже в распределении), что ответы были очень поляризованы, где большинство респондентов не имели проблем с надежностью (с оценкой атрибута «5»), но меньший, но важный сегмент респондентов, проблема надежности и оценили атрибут «1». Однако, глядя на среднее значение, он говорит только часть истории, однако чаще всего это то, на что ориентируются исследователи. Распределение ответов важно учитывать, и SD обеспечивает ценную описательную меру этого.
| ответчик | Хорошая ценность для денег | Надежность продукта |
| 3 | 1 | |
| В | 3 | 1 |
| С | 3 | 1 |
| D | 3 | 1 |
| Е | 4 | 5 |
| F | 4 | 5 |
| г | 3 | 5 |
| ЧАС | 3 | 5 |
| я | 3 | 5 |
| J | 3 | 5 |
| Имею в виду | 3.2 | 3.4 |
| Std. Девиация | 0.4 | 2.1 |
Первый опрос: респонденты оценивают продукт по пятибалльной шкале
Два очень разных распределения ответов на 5-балльную рейтинговую шкалу могут дать одно и то же значение. Рассмотрим следующий пример, показывающий значения ответа для двух разных оценок.
В первом примере (Рейтинг «A») SD равен нулю, потому что ВСЕ ответы были точно средним значением. Индивидуальные ответы не отклонялись от среднего.
В рейтинге «B», хотя среднее значение группы одинаково (3.0) в качестве первого распределения, стандартное отклонение выше. Стандартное отклонение 1.15 показывает, что индивидуальные ответы в среднем * были чуть более 1 балла от среднего.
| ответчик | Рейтинг «A» | Рейтинг «B» |
| 3 | 1 | |
| В | 3 | 2 |
| С | 3 | 2 |
| D | 3 | 3 |
| Е | 3 | 3 |
| F | 3 | 3 |
| г | 3 | 3 |
| ЧАС | 3 | 4 |
| я | 3 | 4 |
| J | 3 | 5 |
| Имею в виду | 3.0 | 3.0 |
| Std. Девиация | 0.00 | 1.15 |
Второй опрос: респонденты оценивают продукт по пятибалльной шкале
Другой способ взглянуть на SD — это построить распределение как гистограмму ответов. Распределение с низким SD будет отображаться как высокая узкая форма, в то время как большая SD будет обозначаться более широкой формой.
SD обычно не указывает «правильно или неправильно» или «лучше или хуже» — более низкая SD не обязательно более желательна. Он используется исключительно как описательная статистика. Он описывает распределение по отношению к среднему.
T echnical disclaimer, относящийся к SD
Думая о том, что SD как «отклонение» — это отличный способ концептуально понять его смысл. Тем не менее, он фактически не рассчитывается как среднее (если бы это было так, мы бы назвали это «отклонениями»). Вместо этого он «стандартизирован» — несколько сложный метод вычисления значения с использованием суммы квадратов.
Для практических целей вычисление не имеет значения. Большинство программ табуляции, электронных таблиц или других инструментов управления данными будут вычислять SD для вас. Более важно понять, что передает статистика.
Стандартная ошибка
Стандартная ошибка — это выведенный статистика, которая используется при сравнении выборочных средств (средних) по группам населения. Это мера точность от среднего значения выборки. Среднее значение выборки — это статистическая информация, полученная из данных, имеющих базовое распределение. Мы не можем визуализировать его так же, как и данные, поскольку мы выполнили один эксперимент и имеем только одно значение. Статистическая теория говорит нам о том, что среднее значение выборки (для большого, более выбранного образца и в нескольких условиях регулярности) приблизительно нормально распределено. Стандартное отклонение этого нормального распределения — это то, что мы называем стандартной ошибкой.

Фигура 2. Распределение в нижней части распределяет данные, тогда как распределение сверху — это теоретическое распределение среднего значения выборки. SD 20 является мерой распространения данных, тогда как SE of 5 является мерой неопределенности вокруг среднего значения выборки.
Когда мы хотим сравнить средства исходов от эксперимента с двумя образцами Лечения A против лечения B, нам нужно оценить, насколько точно мы измерили средства.
На самом деле нас интересует, насколько точно мы измерили разницу между этими двумя средствами. Мы называем эту меру стандартной ошибкой разности. Вы не можете быть удивлены, узнав, что стандартная ошибка разницы в средствах выборки является функцией стандартных ошибок средств:

Теперь, когда вы поняли, что стандартная ошибка среднего (SE) и стандартное отклонение распределения (SD) — это два разных зверя, вам может быть интересно, как они запутались в первую очередь. Хотя они принципиально отличаются друг от друга, они имеют математическую форму:

, где n — количество точек данных.
Обратите внимание, что стандартная ошибка зависит от двух компонентов: стандартного отклонения выборки и размера выборки N , Это делает интуитивный смысл: чем больше стандартное отклонение выборки, тем менее точным может быть наша оценка истинного среднего.
Кроме того, большой размер выборки, чем больше информации мы имеем о населении, тем точнее мы можем оценить истинное значение.
SE является показателем надежности среднего значения. Небольшой SE является показателем того, что среднее значение выборки является более точным отражением фактического значения популяции. Более большой размер выборки обычно приводит к меньшему SE (тогда как SD не зависит напрямую от размера выборки).
Большинство исследовательских исследований включает в себя выборку из населения. Затем мы делаем выводы о популяции из результатов, полученных из этого образца. Если был сделан второй образец, результаты, вероятно, были бы точно совпадают с первым образцом. Если среднее значение для атрибута рейтинга составляло 3,2 для одного образца, это может быть 3,4 для второго образца того же размера. Если бы мы собирали бесконечное количество выборок (равного размера) из нашей популяции, мы могли бы отображать наблюдаемые средства как распределение. Затем мы могли бы вычислить среднее значение всех наших образцов. Это означало бы равное истинное значение популяции. Мы также можем рассчитать SD распределения средств выборки. SD этого распределения средств выборки является SE каждого отдельного образца.
Таким образом, мы имеем самое значительное наблюдение: SE является SD среднего значения.
| Образец | Имею в виду |
| первый | 3.2 |
| второй | 3.4 |
| третий | 3.3 |
| четвёртая | 3.2 |
| пятые | 3.1 |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| Имею в виду | 3.3 |
| Std. Девиация | 0.13 |
Таблица, иллюстрирующая взаимосвязь между SD и SE
Теперь ясно, что если SD этого распределения помогает нам понять, насколько далека среднее значение выборки от истинной совокупности, то мы можем использовать это, чтобы понять, насколько точна какая-либо индивидуальная выборка по отношению к истинному среднему значению. В этом суть SE.
На самом деле, мы набрали только один образец из нашего населения, но мы можем использовать этот результат для оценки надежности нашего наблюдаемого образца.
На самом деле, SE говорит нам, что мы можем быть на 95% уверены, что наше наблюдаемое среднее значение выборки плюс или минус примерно 2 (на самом деле 1,96). Стандартные ошибки от населения.
В приведенной ниже таблице показано распределение ответов от нашей первой (и единственной) выборки, используемой для наших исследований. SE 0,13, будучи относительно небольшим, дает нам указание на то, что наше среднее значение относительно близко к истинному среднему для нашей общей популяции. Предел погрешности (с доверием 95%) для нашего среднего значения (примерно) в два раза превышает это значение (+/- 0,26), сообщая нам, что истинное среднее значение, скорее всего, составляет от 2,94 до 3,46.
| ответчик | Рейтинг |
| 3 | |
| В | 3 |
| С | 3 |
| D | 3 |
| Е | 4 |
| F | 4 |
| г | 3 |
| ЧАС | 3 |
| я | 3 |
| J | 3 |
| Имею в виду | 3.2 |
| Std. заблуждаться | 0.13 |
Резюме
Многие исследователи не понимают различия между стандартным отклонением и стандартной ошибкой, хотя они обычно включаются в анализ данных. Хотя фактические расчеты для стандартного отклонения и стандартной ошибки выглядят очень схожими, они представляют собой две очень разные, но взаимодополняющие меры. SD рассказывает нам о форме нашего распределения, насколько близки значения отдельных данных от среднего значения. SE рассказывает нам, насколько близка наша выборка к истинному средству общей популяции.Вместе они помогают обеспечить более полную картину, чем может сказать нам только одно значащее.
Представление результатов исследования
В научных публикациях важно представление результатов исследования. Очень часто окончательный результат приводится в следующем виде: M±m, где M – среднее арифметическое, m –ошибка среднего арифметического. Например, 163,7±0,9 см.
Прежде чем разбираться в правилах представления результатов исследования, давайте точно усвоим, что же такое ошибка среднего арифметического.
Ошибка среднего арифметического
Среднее арифметическое, вычисленное на основе выборочных данных (выборочное среднее), как правило, не совпадает с генеральным средним (средним арифметическим генеральной совокупности). Экспериментально проверить это утверждение невозможно, потому что нам неизвестно генеральное среднее. Но если из одной и той же генеральной совокупности брать повторные выборки и вычислять среднее арифметическое, то окажется, что для разных выборок среднее арифметическое будет разным.
Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности.
Ошибка среднего арифметического обозначается как m или ![]()
Формула SD требует нескольких шагов:
- Во-первых, возьмите квадрат разницы между каждой точкой данных и средним значением выборки, найдя сумму этих значений.
- Затем разделите эту сумму на размер выборки минус один, который представляет собой дисперсию.
- Наконец, извлеките квадратный корень из дисперсии, чтобы получить стандартное отклонение.
Стандартная ошибка среднего
SEM рассчитывается путем деления стандартного отклонения на квадратный корень из размера выборки.
Стандартная ошибка дает точность выборочного среднего путем измерения изменчивости выборочного среднего от образца к образцу. SEM описывает, насколько точное среднее значение выборки является оценкой истинного среднего значения совокупности. По мере увеличения размера выборки данных SEM уменьшается по сравнению с SD; следовательно, по мере увеличения размера выборки среднее значение выборки оценивает истинное среднее значение генеральной совокупности с большей точностью. Напротив, увеличение размера выборки не обязательно делает SD больше или меньше, это просто становится более точной оценкой SD населения.
Стандартная ошибка и стандартное отклонение в финансах
В финансах стандартная ошибка средней дневной доходности актива измеряет точность выборочного среднего как оценки долгосрочной (постоянной) средней дневной доходности актива.
С другой стороны, стандартное отклонение доходности измеряет отклонения индивидуальных доходов от среднего значения. Таким образом, SD является мерой волатильности и может использоваться в качестве меры риска для инвестиций. Активы с более высокими ежедневными движениями цен имеют более высокое SD, чем активы с меньшими ежедневными движениями. Предполагая нормальное распределение, около 68% дневных изменений цен находятся в пределах одного стандартного отклонения от среднего, при этом около 95% дневных изменений цен находятся в пределах двух стандартных значений среднего.
Вступление
стандарт D (SD) а также S tandard Е rror (SE) по-видимому, аналогичные терминологии; однако они концептуально настолько разнообразны, что они используются почти взаимозаменяемо в статистической литературе. Каждому термину обычно предшествует символ плюс-минус (+/-), который указывает на то, что они определяют симметричное значение или представляют диапазон значений. Неизменно оба выражения появляются со средним (средним) набором измеренных значений.
Интересно, что SE не имеет ничего общего со стандартами, с ошибками или с сообщением научных данных.
Подробный взгляд на происхождение и объяснение SD и SE покажет, почему профессиональные статистики и те, кто использует это сдержанно, оба склонны ошибаться.
Стандартное отклонение (SD)
SD является описательный статистика, описывающая распространение распределения. Как метрика, это полезно, когда данные обычно распределяются. Однако это менее полезно, когда данные сильно искажены или бимодальны, потому что они не очень хорошо описывают форму распределения. Как правило, мы используем SD при представлении характеристик образца, поскольку мы намерены описывать насколько данные изменяются по среднему значению. Другая полезная статистика для описания распространения данных — это межквартильный диапазон, 25-й и 75-й процентили и диапазон данных.
Рисунок 1. SD является мерой распространения данных. Когда данные являются образцом из нормально распределенного распределения, тогда ожидается, что две трети данных будут находиться в пределах 1 стандартного отклонения среднего значения.
Разница заключается в описательный статистика также, и она определяется как квадрат стандартного отклонения. Обычно это не сообщается при описании результатов, но это более математически приемлемая формула (a.k.a. сумма квадратов отклонений) и играет роль в вычислении статистики.
Например, если у нас есть две статистики п & Q с известными отклонениями вар (П) & вар (Q) , то дисперсия суммы Р + Q равна сумме дисперсий: вар (P) + вар (Q) , Теперь очевидно, почему статистикам нравится говорить об отклонениях.
Но стандартные отклонения имеют важное значение для распространения, особенно когда данные обычно распределяются: среднее значение интервала +/- 1 SD можно ожидать захвата 2/3 образца, а среднее значение интервала + — 2 SD можно ожидать захвата 95% образца.
SD дает представление о том, насколько индивидуальные ответы на вопрос меняются или «отклоняются» от среднего. SD рассказывает исследователю, насколько распространены ответы: сосредоточены ли они вокруг среднего или разбросаны по всему миру? Все ваши респонденты оценили ваш продукт в середине шкалы, или кто-то одобрил его, а некоторые отклонили его?
Рассмотрим эксперимент, в котором респондентам предлагается оценивать продукт по ряду атрибутов по 5-балльной шкале. Среднее значение для группы из десяти респондентов (обозначаемое «A» через «J» ниже) для «хорошей стоимости за деньги» составляло 3,2 с SD 0,4, а среднее значение для «надежности продукта» составляло 3,4 с SD 2,1.
На первый взгляд (смотря только на средства), казалось бы, надежность была оценена выше стоимости. Но более высокий SD для надежности может указывать (как показано ниже в распределении), что ответы были очень поляризованы, где большинство респондентов не имели проблем с надежностью (с оценкой атрибута «5»), но меньший, но важный сегмент респондентов, проблема надежности и оценили атрибут «1». Однако, глядя на среднее значение, он говорит только часть истории, однако чаще всего это то, на что ориентируются исследователи. Распределение ответов важно учитывать, и SD обеспечивает ценную описательную меру этого.
| ответчик | Хорошая ценность для денег | Надежность продукта |
| 3 | 1 | |
| В | 3 | 1 |
| С | 3 | 1 |
| D | 3 | 1 |
| Е | 4 | 5 |
| F | 4 | 5 |
| г | 3 | 5 |
| ЧАС | 3 | 5 |
| я | 3 | 5 |
| J | 3 | 5 |
| Имею в виду | 3.2 | 3.4 |
| Std. Девиация | 0.4 | 2.1 |
Первый опрос: респонденты оценивают продукт по пятибалльной шкале
Два очень разных распределения ответов на 5-балльную рейтинговую шкалу могут дать одно и то же значение. Рассмотрим следующий пример, показывающий значения ответа для двух разных оценок.
В первом примере (Рейтинг «A») SD равен нулю, потому что ВСЕ ответы были точно средним значением. Индивидуальные ответы не отклонялись от среднего.
В рейтинге «B», хотя среднее значение группы одинаково (3.0) в качестве первого распределения, стандартное отклонение выше. Стандартное отклонение 1.15 показывает, что индивидуальные ответы в среднем * были чуть более 1 балла от среднего.
| ответчик | Рейтинг «A» | Рейтинг «B» |
| 3 | 1 | |
| В | 3 | 2 |
| С | 3 | 2 |
| D | 3 | 3 |
| Е | 3 | 3 |
| F | 3 | 3 |
| г | 3 | 3 |
| ЧАС | 3 | 4 |
| я | 3 | 4 |
| J | 3 | 5 |
| Имею в виду | 3.0 | 3.0 |
| Std. Девиация | 0.00 | 1.15 |
Второй опрос: респонденты оценивают продукт по пятибалльной шкале
Другой способ взглянуть на SD — это построить распределение как гистограмму ответов. Распределение с низким SD будет отображаться как высокая узкая форма, в то время как большая SD будет обозначаться более широкой формой.
SD обычно не указывает «правильно или неправильно» или «лучше или хуже» — более низкая SD не обязательно более желательна. Он используется исключительно как описательная статистика. Он описывает распределение по отношению к среднему.
T echnical disclaimer, относящийся к SD
Думая о том, что SD как «отклонение» — это отличный способ концептуально понять его смысл. Тем не менее, он фактически не рассчитывается как среднее (если бы это было так, мы бы назвали это «отклонениями»). Вместо этого он «стандартизирован» — несколько сложный метод вычисления значения с использованием суммы квадратов.
Для практических целей вычисление не имеет значения. Большинство программ табуляции, электронных таблиц или других инструментов управления данными будут вычислять SD для вас. Более важно понять, что передает статистика.
Стандартная ошибка
Стандартная ошибка — это выведенный статистика, которая используется при сравнении выборочных средств (средних) по группам населения. Это мера точность от среднего значения выборки. Среднее значение выборки — это статистическая информация, полученная из данных, имеющих базовое распределение. Мы не можем визуализировать его так же, как и данные, поскольку мы выполнили один эксперимент и имеем только одно значение. Статистическая теория говорит нам о том, что среднее значение выборки (для большого, более выбранного образца и в нескольких условиях регулярности) приблизительно нормально распределено. Стандартное отклонение этого нормального распределения — это то, что мы называем стандартной ошибкой.
Фигура 2. Распределение в нижней части распределяет данные, тогда как распределение сверху — это теоретическое распределение среднего значения выборки. SD 20 является мерой распространения данных, тогда как SE of 5 является мерой неопределенности вокруг среднего значения выборки.
Когда мы хотим сравнить средства исходов от эксперимента с двумя образцами Лечения A против лечения B, нам нужно оценить, насколько точно мы измерили средства.
На самом деле нас интересует, насколько точно мы измерили разницу между этими двумя средствами. Мы называем эту меру стандартной ошибкой разности. Вы не можете быть удивлены, узнав, что стандартная ошибка разницы в средствах выборки является функцией стандартных ошибок средств:
Теперь, когда вы поняли, что стандартная ошибка среднего (SE) и стандартное отклонение распределения (SD) — это два разных зверя, вам может быть интересно, как они запутались в первую очередь. Хотя они принципиально отличаются друг от друга, они имеют математическую форму:
, где n — количество точек данных.
Обратите внимание, что стандартная ошибка зависит от двух компонентов: стандартного отклонения выборки и размера выборки N , Это делает интуитивный смысл: чем больше стандартное отклонение выборки, тем менее точным может быть наша оценка истинного среднего.
Кроме того, большой размер выборки, чем больше информации мы имеем о населении, тем точнее мы можем оценить истинное значение.
SE является показателем надежности среднего значения. Небольшой SE является показателем того, что среднее значение выборки является более точным отражением фактического значения популяции. Более большой размер выборки обычно приводит к меньшему SE (тогда как SD не зависит напрямую от размера выборки).
Большинство исследовательских исследований включает в себя выборку из населения. Затем мы делаем выводы о популяции из результатов, полученных из этого образца. Если был сделан второй образец, результаты, вероятно, были бы точно совпадают с первым образцом. Если среднее значение для атрибута рейтинга составляло 3,2 для одного образца, это может быть 3,4 для второго образца того же размера. Если бы мы собирали бесконечное количество выборок (равного размера) из нашей популяции, мы могли бы отображать наблюдаемые средства как распределение. Затем мы могли бы вычислить среднее значение всех наших образцов. Это означало бы равное истинное значение популяции. Мы также можем рассчитать SD распределения средств выборки. SD этого распределения средств выборки является SE каждого отдельного образца.
Таким образом, мы имеем самое значительное наблюдение: SE является SD среднего значения.
| Образец | Имею в виду |
| первый | 3.2 |
| второй | 3.4 |
| третий | 3.3 |
| четвёртая | 3.2 |
| пятые | 3.1 |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| Имею в виду | 3.3 |
| Std. Девиация | 0.13 |
Таблица, иллюстрирующая взаимосвязь между SD и SE
Теперь ясно, что если SD этого распределения помогает нам понять, насколько далека среднее значение выборки от истинной совокупности, то мы можем использовать это, чтобы понять, насколько точна какая-либо индивидуальная выборка по отношению к истинному среднему значению. В этом суть SE.
На самом деле, мы набрали только один образец из нашего населения, но мы можем использовать этот результат для оценки надежности нашего наблюдаемого образца.
На самом деле, SE говорит нам, что мы можем быть на 95% уверены, что наше наблюдаемое среднее значение выборки плюс или минус примерно 2 (на самом деле 1,96). Стандартные ошибки от населения.
В приведенной ниже таблице показано распределение ответов от нашей первой (и единственной) выборки, используемой для наших исследований. SE 0,13, будучи относительно небольшим, дает нам указание на то, что наше среднее значение относительно близко к истинному среднему для нашей общей популяции. Предел погрешности (с доверием 95%) для нашего среднего значения (примерно) в два раза превышает это значение (+/- 0,26), сообщая нам, что истинное среднее значение, скорее всего, составляет от 2,94 до 3,46.
| ответчик | Рейтинг |
| 3 | |
| В | 3 |
| С | 3 |
| D | 3 |
| Е | 4 |
| F | 4 |
| г | 3 |
| ЧАС | 3 |
| я | 3 |
| J | 3 |
| Имею в виду | 3.2 |
| Std. заблуждаться | 0.13 |
Резюме
Многие исследователи не понимают различия между стандартным отклонением и стандартной ошибкой, хотя они обычно включаются в анализ данных. Хотя фактические расчеты для стандартного отклонения и стандартной ошибки выглядят очень схожими, они представляют собой две очень разные, но взаимодополняющие меры. SD рассказывает нам о форме нашего распределения, насколько близки значения отдельных данных от среднего значения. SE рассказывает нам, насколько близка наша выборка к истинному средству общей популяции.Вместе они помогают обеспечить более полную картину, чем может сказать нам только одно значащее.
Представление результатов исследования
В научных публикациях важно представление результатов исследования. Очень часто окончательный результат приводится в следующем виде: M±m, где M – среднее арифметическое, m –ошибка среднего арифметического. Например, 163,7±0,9 см.
Прежде чем разбираться в правилах представления результатов исследования, давайте точно усвоим, что же такое ошибка среднего арифметического.
Ошибка среднего арифметического
Среднее арифметическое, вычисленное на основе выборочных данных (выборочное среднее), как правило, не совпадает с генеральным средним (средним арифметическим генеральной совокупности). Экспериментально проверить это утверждение невозможно, потому что нам неизвестно генеральное среднее. Но если из одной и той же генеральной совокупности брать повторные выборки и вычислять среднее арифметическое, то окажется, что для разных выборок среднее арифметическое будет разным.
Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности.
Ошибка среднего арифметического обозначается как m или ![]()
Ошибка среднего арифметического рассчитывается по формуле:

где: S — стандартное отклонение, n – объем выборки; Например, если стандартное отклонение равно S=5 см, объем выборки n=36 человек, то ошибка среднего арифметического равна: m=5/6 = 0,833.
Ошибка среднего арифметического показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего выборочное среднее.
Так как при небольшом объеме выборки истинное значение генерального среднего не может быть определено сколь угодно точно, поэтому при вычислении выборочного среднего арифметического нет смысла оставлять большое число значащих цифр.
Правила записи результатов исследования
- В записи ошибки среднего арифметического оставляем две значащие цифры, если первые цифры в ошибке «1» или «2».
- В остальных случаях в записи ошибки среднего арифметического оставляем одну значащую цифру.
- В записи среднего арифметического положение последней значащей цифры должно соответствовать положению первой значащей цифры в записи ошибки среднего арифметического.
Представление результатов научных исследований
В своей статье «Осторожно, статистика!», опубликованной в 1989 году В.М. Зациорский указал, какие числовые характеристики должны быть представлены в публикации, чтобы она имела научную ценность. Он писал, что исследователь «…должен назвать: 1) среднюю величину (или другой так называемый показатель положения); 2) среднее квадратическое отклонение (или другой показатель рассеяния) и 3) число испытуемых. Без них его публикация научной ценности иметь не будет “с. 52
В научных публикациях в области физической культуры и спорта очень часто окончательный результат приводится в виде: (М±m) (табл.1).
Таблица 1 — Изменение механических свойств латеральной широкой мышцы бедра под воздействием физической нагрузки (n=34)
| Эффективный модуль
упругости (Е), кПа |
Эффективный модуль
вязкости (V), Па с |
|||
| Этап
эксперимента |
Рассл. | Напряж. | Рассл. | Напряж. |
| До ФН | 7,0±0,3 | 17,1±1,4 | 29,7±1,7 | 46±4 |
| После ФН | 7,7±0,3 | 18,7±1,4 | 30,9±2,0 | 53±6 |
Литература
- Высшая математика и математическая статистика: учебное пособие для вузов / Под общ. ред. Г. И. Попова. – М. Физическая культура, 2007.– 368 с.
- Гласс Дж., Стэнли Дж. Статистические методы в педагогике и психологии. М.: Прогресс. 1976.- 495 с.
- Зациорский В.М. Осторожно — статистика! // Теория и практика физической культуры, 1989.- №2.
- Катранов А.Г. Компьютерная обработка данных экспериментальных исследований: Учебное пособие/ А. Г. Катранов, А. В. Самсонова; СПб ГУФК им. П.Ф. Лесгафта. – СПб.: изд-во СПб ГУФК им. П.Ф. Лесгафта, 2005. – 131 с.
- Основы математической статистики: Учебное пособие для ин-тов физ. культ / Под ред. В.С. Иванова.– М.: Физкультура и спорт, 1990. 176 с.
Стандартное отклонение (SD), измеряет количество изменчивости или дисперсии, из отдельных значений данных, к среднему значению, в то время как стандартная ошибка среднего (SEM) мер, как далеко образец среднее (среднее) данных, вероятно, будет от истинного среднего значения населения. SEM всегда меньше SD.
Ключевые выводы
- Стандартное отклонение (SD) измеряет разброс набора данных относительно его среднего значения.
- Стандартная ошибка среднего (SEM) измеряет, насколько вероятно расхождение между средним значением выборки по сравнению со средним значением генеральной совокупности.
- SEM берет SD и делит его на квадратный корень из размера выборки.
SEM против SD
Стандартное отклонение и стандартная ошибка используются во всех типах статистических исследований, включая исследования в области финансов, медицины, биологии, инженерии, психологии и т. Д. В этих исследованиях стандартное отклонение (SD) и расчетная стандартная ошибка среднего (SEM) ) используются для представления характеристик данных выборки и объяснения результатов статистического анализа. Однако некоторые исследователи иногда путают SD и SEM. Таким исследователям следует помнить, что расчеты SD и SEM включают разные статистические выводы, каждый из которых имеет свое значение. SD — это разброс отдельных значений данных.
Другими словами, SD указывает, насколько точно среднее значение представляет данные выборки. Однако значение SEM включает статистический вывод, основанный на распределении выборки. SEM — это стандартное отклонение теоретического распределения выборочных средних (выборочное распределение).
Расчет стандартного отклонения
Формула SD требует нескольких шагов:
- Во-первых, возьмите квадрат разницы между каждой точкой данных и средним значением выборки, найдя сумму этих значений.
- Затем разделите эту сумму на размер выборки минус один, который представляет собой дисперсию.
- Наконец, извлеките квадратный корень из дисперсии, чтобы получить стандартное отклонение.
Стандартная ошибка среднего
SEM рассчитывается путем деления стандартного отклонения на квадратный корень из размера выборки.
Стандартная ошибка дает точность выборочного среднего путем измерения изменчивости выборочного среднего от образца к образцу. SEM описывает, насколько точное среднее значение выборки является оценкой истинного среднего значения совокупности. По мере увеличения размера выборки данных SEM уменьшается по сравнению с SD; следовательно, по мере увеличения размера выборки среднее значение выборки оценивает истинное среднее значение генеральной совокупности с большей точностью. Напротив, увеличение размера выборки не обязательно делает SD больше или меньше, это просто становится более точной оценкой SD населения.
Стандартная ошибка и стандартное отклонение в финансах
В финансах стандартная ошибка средней дневной доходности актива измеряет точность выборочного среднего как оценки долгосрочной (постоянной) средней дневной доходности актива.
С другой стороны, стандартное отклонение доходности измеряет отклонения индивидуальных доходов от среднего значения. Таким образом, SD является мерой волатильности и может использоваться в качестве меры риска для инвестиций. Активы с более высокими ежедневными движениями цен имеют более высокое SD, чем активы с меньшими ежедневными движениями. Предполагая нормальное распределение, около 68% дневных изменений цен находятся в пределах одного стандартного отклонения от среднего, при этом около 95% дневных изменений цен находятся в пределах двух стандартных значений среднего.
![]()
Формула SD требует нескольких шагов:
- Во-первых, возьмите квадрат разницы между каждой точкой данных и средним значением выборки, найдя сумму этих значений.
- Затем разделите эту сумму на размер выборки минус один, который представляет собой дисперсию.
- Наконец, извлеките квадратный корень из дисперсии, чтобы получить стандартное отклонение.
Стандартная ошибка среднего
SEM рассчитывается путем деления стандартного отклонения на квадратный корень из размера выборки.
Стандартная ошибка дает точность выборочного среднего путем измерения изменчивости выборочного среднего от образца к образцу. SEM описывает, насколько точное среднее значение выборки является оценкой истинного среднего значения совокупности. По мере увеличения размера выборки данных SEM уменьшается по сравнению с SD; следовательно, по мере увеличения размера выборки среднее значение выборки оценивает истинное среднее значение генеральной совокупности с большей точностью. Напротив, увеличение размера выборки не обязательно делает SD больше или меньше, это просто становится более точной оценкой SD населения.
Стандартная ошибка и стандартное отклонение в финансах
В финансах стандартная ошибка средней дневной доходности актива измеряет точность выборочного среднего как оценки долгосрочной (постоянной) средней дневной доходности актива.
С другой стороны, стандартное отклонение доходности измеряет отклонения индивидуальных доходов от среднего значения. Таким образом, SD является мерой волатильности и может использоваться в качестве меры риска для инвестиций. Активы с более высокими ежедневными движениями цен имеют более высокое SD, чем активы с меньшими ежедневными движениями. Предполагая нормальное распределение, около 68% дневных изменений цен находятся в пределах одного стандартного отклонения от среднего, при этом около 95% дневных изменений цен находятся в пределах двух стандартных значений среднего.
![]() Download Article
Download Article
![]() Download Article
Download Article
After collecting data, oftentimes the first thing you need to do is analyze it. This usually entails finding the mean, the standard deviation, and the standard error of the data. This article will show you how it’s done.
Cheat Sheets
-

1
Obtain a set of numbers you wish to analyze. This information is referred to as a sample.
- For example, a test was given to a class of 5 students, and the test results are 12, 55, 74, 79 and 90.

Advertisement
-
1
Calculate the mean. Add up all the numbers and divide by the population size:[1]
- Mean (μ) = ΣX/N, where Σ is the summation (addition) sign, xi is each individual number, and N is the population size.
- In the case above, the mean μ is simply (12+55+74+79+90)/5 = 62.

-
1
Calculate the standard deviation. This represents the spread of the population.
Standard deviation = σ = sq rt [(Σ((X-μ)^2))/(N)].[2]
- For the example given, the standard deviation is sqrt[((12-62)^2 + (55-62)^2 + (74-62)^2 + (79-62)^2 + (90-62)^2)/(5)] = 27.4. (Note that if this was the sample standard deviation, you would divide by n-1, the sample size minus 1.)

Advertisement
-
1
Calculate the standard error (of the mean). This represents how well the sample mean approximates the population mean. The larger the sample, the smaller the standard error, and the closer the sample mean approximates the population mean. Do this by dividing the standard deviation by the square root of N, the sample size.[3]
Standard error = σ/sqrt(n)[4]
- So for the example above, if this were a sampling of 5 students from a class of 50 and the 50 students had a standard deviation of 17 (σ = 21), the standard error = 17/sqrt(5) = 7.6.

Add New Question
-
Question
How do you find the mean given number of observations?

To find the mean, add all the numbers together and divide by how many numbers there are. e.g to find the mean of 1,7,8,4,2: 1+7+8+4+2 = 22/5 = 4.4.
-
Question
The standard error is calculated as 0.2 and the standard deviation of a sample is 5kg. Can it be said to be smaller or larger than the standard deviation?
The standard error (SE) must be smaller than the standard deviation (SD), because the SE is calculating by dividing the SD by something — i.e. making it smaller.
-
Question
How can I find out the standard deviation of 50 samples?
The results of all your figures (number plus number plus number etc.) divided by quantity of samples 50 =SD.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
-
Calculations of the mean, standard deviation, and standard error are most useful for analysis of normally distributed data. One standard deviation about the central tendency covers approximately 68 percent of the data, 2 standard deviation 95 percent of the data, and 3 standard deviation 99.7 percent of the data. The standard error gets smaller (narrower spread) as the sample size increases.
Thanks for submitting a tip for review!
Advertisement
-
Check your math carefully. It is very easy to make mistakes or enter numbers incorrectly.
Advertisement
References
About This Article
Article SummaryX
The mean is simply the average of a set of numbers. You can work it out by adding up all the numbers and dividing the total by the amount of numbers. For example, if you wanted to find the average test score of 3 students who scored 74, 79, and 90, you’d add the 3 numbers together to get 243, then divide it by 3 to get 81. The standard error represents how well the sample mean approximates the population mean. All you need to do is divide the standard deviation by the square root of the sample size. For instance, if you were sampling 5 students from a class of 50 and the 50 students had a standard deviation of 17, you’d divide 17 by the square root of 5 to get 7.6. For more tips, including how to calculate the standard deviation, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 1,003,352 times.