
I have searched the forum and did not find where a solution was provided for this error so I am going for it again.
I have a fresh machine running win 10, 8GB of RAM, and a new install of acrobat DC.
the first PDF I am needing to open is 29 pages, it gets to page 4 before it says «out of memory» and does not show any more of the content, it will continue to scroll through the blank pages. it will open smaller files ok, it seems to be related to size but my machine has plenty of memory and HD space.
thank you in advance, I am held up on a project due to this.
Adobe Acrobat является одним из самых популярных инструментов для
просмотра и редактирования PDF-файлов, но он нередко выдает ошибки во время работы. Мы уже разбирали, что
делать при появлении надписи «Неверный параметр». Теперь
рассмотрим алгоритм действий, если при попытке открыть документы Reader или Acrobat показывает сообщение
«Недостаточно данных для изображения PDF». Что вызывает эту проблему, и как исправить ситуацию, вы узнаете
из этой статьи.
Устали от ошибок Adobe Reader?
Попробуйте более надёжный софт — PDF Commander
Содержание
- Почему возникает ошибка «Недостаточно данных для изображения» в
Adobe Reader - Решение проблемы
- Альтернативное решение проблемы
- Заключение
Почему возникает ошибка «Недостаточно данных для изображения» в Adobe Reader
Иногда при попытке открыть PDF-документ в программе Adobe Reader выскакивает табличка с надписью
«insufficient data for image», а содержимое страниц оказывается размытым или полностью отсутствует. Какие
могут быть причины:
- В документе используются поврежденные вложения или неправильно выставлены метаданные.
- Документ был создан в другом приложении и был сохранен с неправильными настройками.
- В программе произошел сбой.
- Вы используете устаревшую версию Reader.
Чтобы понять, что проблема действительно в программе, попробуйте открыть файл другим приложением,
поддерживающим чтение ПДФ. Если он не распознается, значит, вы работаете с поврежденным документом, сделать
тут ничего не возможно, только скачивать заново или искать рабочую версию. В ином случае проблема кроется в
Adobe Reader или Acrobat.
Решение проблемы
Самый простой вариант — для начала попробовать восстановить параметры отображения PDF-документов, чтобы
«воскресить» содержимое PDF-файла. Сделать это можно одним из следующих способов:
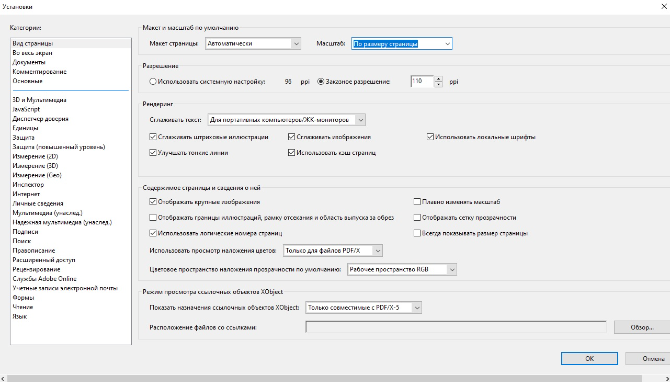
- Уменьшите отображение страницы через пункт «Масштаб», или воспользуйтесь опцией «Вписать целую страницу
в окно». - Установите правильное отображение содержимого по умолчанию. Для этого раскройте пункт меню
«Редактирование» и выберите инструмент «Установки». раскройте раздел «Вид страницы» и раскройте список
«Масштаб». Установите значение «По размеру страницы». Отныне все документы, открытые в Adobe Reader, будут
отображаться в выбранном масштабе.
Если этот вариант не помог, попробуйте пересохранить документ с нужными настройками.
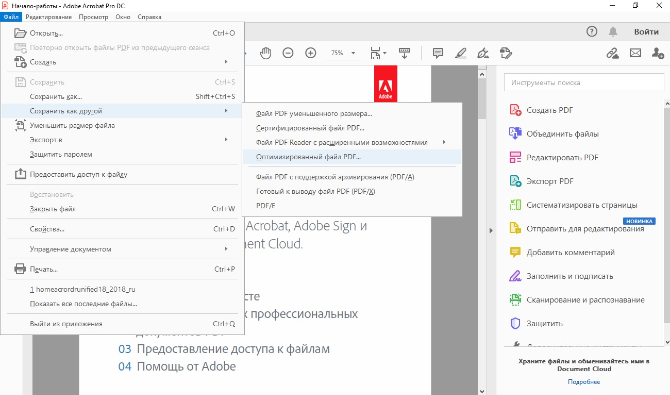
- В верхнем меню программы найдите пункт «Файл» и выберите «Сохранить как другой».
- Выберите «Файл PDF уменьшенного размера» или «Оптимизированный файл PDF».
- Попробуйте открыть переконвертированный документ. Этот способ должен решить ошибку неверных настроек.
Для этого варианта нужны премиум-функции, поэтому он не работает в бесплатной версии Adobe Reader.
Альтернативное решение проблемы
В последних обновлениях Adobe Reader была исправлена ошибка «Недостаточно данных для изображения…».
Поэтому проверьте, используете ли вы актуальную версию программы. Найти функцию обновления можно в пункте
меню «Справка».
Если ошибка связана с повреждением метаданных обрабатываемого файла, а вам требуется обработать его именно
в Adobe Reader, удалите неактуальную информацию. Для этого:
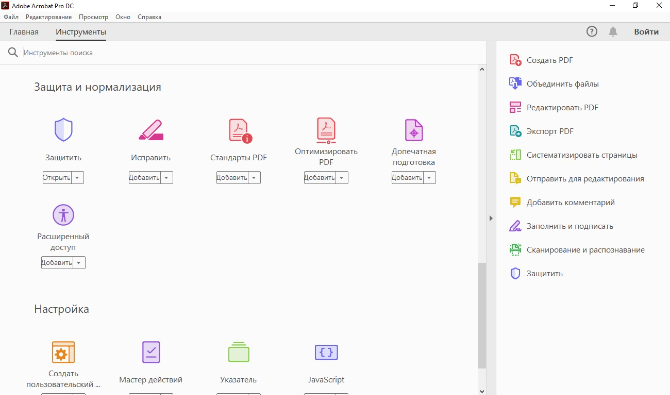
- В верхней панели программы откройте вкладку с инструментами.
- Найдите функцию «Защитить» и откройте документ.

- Для полного удаления тегов, метаданных и комментариев нажмите на верхней панели «Удалить скрытую
информацию». - Подождите, пока программа проведет анализ, затем в боковой колонке кликните «Удалить»
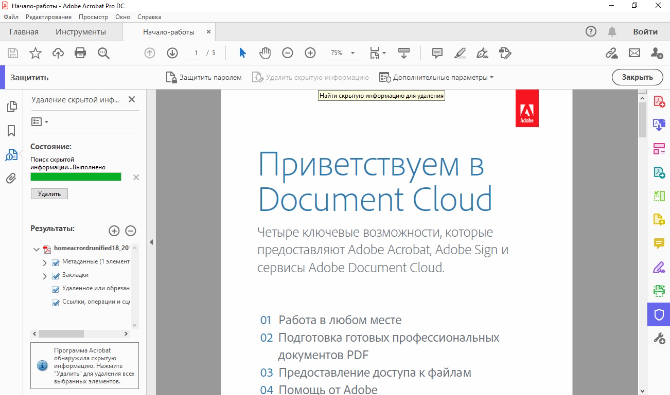
Имейте в виду, что выбранная информация стирается из документа полностью без возможности восстановления.
Заключение
Если вы столкнулись с ошибкой Adobe Reader «Недостаточно данных для изображения…», один из перечисленных
способов поможет вам справиться с проблемой. Однако стоит иметь в виду, что программа не всегда «дружит» с
файлами, созданными в других приложениях, и может отказываться читать документацию, полученную от других
пользователей или из интернета. Если вы не хотите в дальнейшем получать подобные ошибки, советуем вам
использовать более универсальный редактор ПДФ.
PDF Commander – качественное приложение для Windows, которое позволяет редактировать, конвертировать и
создавать с нуля многостраничные документы. Он более удобен в управлении, чем Adobe Reader, позволяет
накладывать защиту, вручную сортировать страницы, объединять несколько ПДФ-файлов в один или собирать
документ из изображений. А главное — он не подвержен типичным ошибкам Адоб Акробат и легко читает
электронную документацию из других программ. Скачайте PDF Commander и
убедитесь, насколько легко и быстро с его помощью можно обрабатывать крупные многостраничные документы.
Похожие приложения
Актуальные статьи
Проблемы с установкой Adobe
Acrobat?
Скачайте 100% рабочую версию PDF редактора

-
#1
Столкнулся с такой проблемой. При распознавании файла PDF (https://yadi.sk/d/9ZZiKc7GctAe7) ClearScan вываливается с ошибкой нехватки памяти:

Если я выбираю распознавание Searchable Image, то получаю
Непонятно, какой памяти не хватает, оперативной или памяти на жестком диске? Вроде и то и другое присутствует в достаточном количестве. Скриншот Диспетчера устройств прилагаю. На всех разделах по несколько десятков гигабайт свободно. ОС Win 7 Pro SP1 64-bit. Acrobat Pro Version 11.0.06. Переустанавливал на 10-ку — не помогло. Менял расположение каталога Temp в переменных среды — не помогло. Сколько же памяти ему надо и почему это нигде не описывается в системных требованиях к ПО — непонятно.
-

procman.jpg
134.1 КБ
· Просм.: 825

-
#3
Ну это грязный хак, памятуя о сканировании 2400…
-
#4
Увеличивал файл подкачки до 16 Гб, ставил и по выбору системы… Да не в этом дело, при импорте и распознавании память-то не расходуется особо, ну вместо 2,5 системных тратится 2,8-3 Гб и еще 5 остается свободных, при этом акробат жалуется на нехватку памяти.
Навскидку моя текущая конфигурация:
Процессор Intel Core i5-3xxx серии
Память 8ГБ DDR3
Видеокарта GT630x2 (шт.)
ЖД 500 Seaagate 500 Гб, из которых на системном разделе 100, при этом половина дискового пространства свободна.
Даже если бы у меня был 8-ядерный сервер Dell на Xeon 26xx-v3 с 32 Гб набортной памяти, сомневаюсь, что это бы мне помогло. У кого распознается мой файл, отзовитесь. Попробую проверить на второй машине.
-
#5
Вы имеете ввиду, если я распознаю этот файл, у меня получится? А чем он отличается от моего?
Ну это грязный хак, памятуя о сканировании 2400…
Да, только пока грязный хак 2400 — 600 — 2400 не прокатывает — ругается на память.


-
#7
У кого распознается мой файл, отзовитесь.
Ау.
-
#8
Последнее редактирование: 24.11.2014
-
#9
300 dpi? Спасибо, но качество распознавания будет не очень, к сожалению.
OS X 10.10.1, Acrobat 10.1.12. Настройки распознавания такие:
Посмотреть вложение 67253
Результат такой: http://forum.rudtp.ru/resources/ocr-pdf.602/
Вроде бы проблем нет.
Попробовал на другой машине с Win XP SP3 32-bit с Acrobat ver. 10.1.4 — проблема осталась. Что-ж, придется обновиться, да и прикупить еще Mac Pro  :)") … не радужная перспектива…
… не радужная перспектива…
Тогда еще вот до кучи ZIP Flate. Распознает или нет? Все таки большой размер. И второй файл ZIP Flate A3:
https://yadi.sk/d/9ZZiKc7GctAe7
https://yadi.sk/d/ADMaFAEwcuT85
Мне просто очень интересно знать, проглотит Acrobat эти сканы или нет.
) А у вас какая конфигурация аппаратного и ПО? 2. Это Searchable Image? Меня интересует ClearScan.
Последнее редактирование: 24.11.2014
-
#10
А у вас какая конфигурация аппаратного и ПО?
OS X 10.8.5, Acrobat 11.0.9.29
-
#11
Ну насколько я понял, здесь речь идет об ошибке «Unable to locate the paper Capture recognition service. …» и решается она копированием «Copy C:ProgramFiles (x86)adobeacrobat 9.0acrobatplug-insPaperCapture*» в parent directory «C:ProgramFiles (x86)adobeacrobat 9.0acrobatplug-ins», а точнее. файла drs32.dll. Здесь же доступ к сервису распознавания имеется, сервис распознавания начинает работу, но Acrobat не хватает памяти для распознавания и распознавание прекращается, как-то так.
-
#12
Если не помогает, тогда только в техподдержку или сменить платформу.
-
#13
Да, у пользователей OS X проблемы пока не вижу, но окончательно в этом убежусь, если вам удастся распознать те два крупных файла, ссылки на которые я указал в комментарии выше.
-
#14
у пользователей OS X проблемы пока не вижу
Есть проблема на этих крупных файлах.
При открытии 300М файла после этапа Postprocessing image появляется такое сообщение об ошибке:

При открытии 600М файла процесс не начинается, сразу появляется такое сообщение:
![]()
PS. Должен сказать, что если 300М файл открыть в Photoshop, тут же сохранить как TIFF с LZW-компрессией и этот TIFF открыть в Акробате, то процесс проходит без ошибок.

-
#15
FineReader сильно дешевле макпро. Качество распознавания очень высокое.
-
#16
И второй файл ZIP Flate A3
Ежели А3, то voila.
-
#17
Извините, я ошибся, имел ввиду как есть, А1, без уменьшения размера.
FineReader сильно дешевле макпро. Качество распознавания очень высокое.
Finereader не интересен, нужен ClearScan.
Последнее редактирование: 25.11.2014
-
#18
Не по теме:
Будем искать…
-
#19
если 300М файл открыть в Photoshop, тут же сохранить как TIFF с LZW-компрессией и этот TIFF открыть в Акробате, то процесс проходит без ошибок.
М-да, странно, как же это так получается, ведь LZW компрессия не влияет на процесс распознавания, ведь при импорте в PDF TIFF-файл конвертируется в соответствии с настройками, заданными в Adobe PDF settings, а для цветных изображений там либо ZIP, либо JPEG/JPEG2000. У меня настройки такие:

По крайней мере Quite a box of tricks показывает тип компрессии ZIP:

Получается на входе может быть TIFF файл с любой компрессией или без нее, все равно он будет сжат/пересжат по методу ZIP.
При открытии 600М файла процесс не начинается, сразу появляется такое сообщение:
Эх, понадеялся я на Max Wyss, который написал, что подобное ограничение срабатывает только при размере страницы 45 дюйма, а она всего 33 дюйма. At the desired resolution the image is too wide… Интересно, о чем думали программисты Adobe и I.R.I.S. S.A., когда создавали движок ClearScan? Как вообще такой баг могли допустить? Это даже не баг, а намеренное ограничение. Я уже молчу про поддержку режимов с более высоким разрешением.
Последнее редактирование: 25.11.2014
-
#20
А1, без уменьшения размера.
Разницу практически незаметно, что А1, что смасштабить в А3.

При открытии файла PDF в Acrobat или Acrobat Reader отображается следующее сообщение об ошибке: «Недостаточно данных для изображения». При открытии документа PDF его содержимое размыто или отсутствует.
Решение
Выполните одно из следующих действий в Acrobat или Acrobat Reader.
- Измените параметры масштабирования, чтобы можно было увидеть содержимое документа. Попробуйте уменьшить коэффициент масштабирования или нажмите «Подогнать по размеру одной страницы». (Вы можете сделать эту настройку постоянной, чтобы избежать ее изменения для каждого документа:
выберите Редактирование > Установки > Вид страницы, а затем выберите По размеру страницы в раскрывающемся списке «Масштаб» в верхней части страницы.) - Заново сохраните файл PDF в Acrobat в качестве оптимизированного. Выберите Файл > Уменьшить размер файла или Сжать PDF. Выберите местоположение для сохранения файла и нажмите Сохранить.
Альтернативное решение
Повреждение структуры файла PDF или неправильные теги, изображения, метаданные также могут привести к ошибке. Выполните следующие действия, чтобы удалить информацию из файла PDF.
-
В Acrobat перейдите в меню Инструменты > Исправить.
-
На панели инструментов «Исправить» выберите Удалить конфиденциальную информацию.
-
В диалоговом окне «Удалить конфиденциальную информацию» выполните одно из следующих действий.
- Чтобы навсегда удалить такие элементы, как метаданные, комментарии и файлы вложений, нажмите OК.
- Чтобы выборочно удалить скрытую информацию и получить больше возможностей для удаления, нажмите на ссылку Нажмите здесь.
Выберите, какую информацию необходимо удалить из файла PDF, нажмите Удалить, а затем нажмите ОК.
-
Введите имя файла и расположение и нажмите Сохранить.
После удаления конфиденциальной информации из файла PDF и его сохранения выбранный контент удаляется без возможности восстановления.
Go to sysadmin
Adobe Acrobat — Out of Memory?
Got a few users on different kinds of Adobe Acrobat (and different OS’ Win7 and Win10).
Some of them are on old Pro XI and one of them is on the newest Acrobat Pro DC.
Seems to only happen in Adobe, but I’m getting reports on launch and if the PDF opens it pops up after a bit of time.
For some reason I’m thinking fonts or something but they all have the same default fonts.
There’s nothing really different with the PDF’s that trigger Out of Memory errors. Other people are able open the PDFs..
Does anyone have a good idea of where to start?
Temp folder is cleared.
Archived post. New comments cannot be posted and votes cannot be cast.