
В Учи.ру мы стараемся даже небольшие улучшения выкатывать A/B-тестом, только за этот учебный год их было больше 250. A/B-тест — мощнейший инструмент тестирования изменений, без которого сложно представить нормальное развитие интернет-продукта. В то же время, несмотря на кажущуюся простоту, при проведении A/B-теста можно допустить серьёзные ошибки как на этапе дизайна эксперимента, так и при подведении итогов. В этой статье я расскажу о некоторых технических моментах проведения теста: как мы определяем срок тестирования, подводим итоги и как избегаем ошибочных результатов при досрочном завершении тестов и при тестировании сразу нескольких гипотез.

Типичная схема A/B-тестирования у нас (да и у многих) выглядит так:
- Разрабатываем фичу, но перед раскаткой на всю аудиторию хотим убедиться, что она улучшает целевую метрику, например, вовлечённость.
- Определяем срок, на который запускается тест.
- Случайно разбиваем пользователей на две группы.
- Одной группе показываем версию продукта с фичей (экспериментальная группа), другой — старую (контрольная).
- В процессе мониторим метрику, чтобы вовремя прекратить особо неудачный тест.
- По истечении срока теста сравниваем метрику в экспериментальной и контрольной группах.
- Если метрика в экспериментальной группе статистически значимо лучше, чем в контрольной, раскатываем протестированную фичу на всех. Если же статистической значимости нет, завершаем тест с отрицательным результатом.
Всё выглядит логично и просто, дьявол, как всегда, в деталях.
Статистическая значимость, критерии и ошибки
В любом A/B-тесте присутствует элемент случайности: метрики групп зависят не только от их функционала, но и от того, какие пользователи в них попали и как они себя ведут. Чтобы достоверно сделать выводы о превосходстве какой-то группы, нужно набрать достаточно наблюдений в тесте, но даже тогда вы не застрахованы от ошибок. Их различают два типа:
- Ошибка первого рода происходит, если мы фиксируем разницу между группами, хотя на самом деле её нет. В тексте также будет встречаться эквивалентный термин — ложноположительный результат. Статья посвящена именно таким ошибкам.
- Ошибка второго рода происходит, если мы фиксируем отсутствие разницы, хотя на самом деле она есть.
При большом количестве экспериментов важно, чтобы вероятность ошибки первого рода была мала. Её можно контролировать с помощью статистических методов. Например, мы хотим, чтобы в каждом эксперименте вероятность ошибки первого рода не превышала 5% (это просто удобное значение, для собственных нужд можно брать другое). Тогда мы будем принимать эксперименты на уровне значимости 0.05:
- Есть A/B-тест с контрольной группой A и экспериментальной — B. Цель — проверить, что группа B отличается от группы A по какой-то метрике.
- Формулируем нулевую статистическую гипотезу: группы A и B не отличаются, а наблюдаемые различия объясняются шумом. По умолчанию всегда считаем, что разницы нет, пока не доказано обратное.
- Проверяем гипотезу строгим математическим правилом — статистическим критерием, например, критерием Стьюдента.
- В результате получаем величину p-value. Она лежит в диапазоне от 0 до 1 и означает вероятность увидеть текущую или более экстремальную разницу между группами при условии верности нулевой гипотезы, то есть при отсутствии разницы между группами.
- Значение p-value сравнивается с уровнем значимости 0.05. Если оно больше, принимаем нулевую гипотезу о том, что различий нет, иначе считаем, что между группами есть статистически значимая разница.
Проверить гипотезу можно параметрическим или непараметрическим критерием. Параметрические опираются на параметры выборочного распределения случайной величины и обладают большей мощностью (реже допускают ошибки второго рода), но предъявляют требования к распределению исследуемой случайной величины.
Самый распространенный параметрический тест — критерий Стьюдента. Для двух независимых выборок (случай A/B-теста) его иногда называют критерием Уэлча. Этот критерий работает корректно, если исследуемые величины распределены нормально. Может показаться, что на реальных данных это требование почти никогда не удовлетворяется, однако на самом деле тест требует нормального распределения выборочных средних, а не самих выборок. На практике это означает, что критерий можно применять, если у вас в тесте достаточно много наблюдений (десятки-сотни) и в распределениях нет совсем уж длинных хвостов. При этом характер распределения исходных наблюдений неважен. Читатель самостоятельно может убедиться, что критерий Стьюдента работает корректно даже на выборках, сгенерированных из распределений Бернулли или экспоненциального.
Из непараметрических критериев популярен критерий Манна — Уитни. Его стоит применять, если ваши выборки очень малого размера или есть большие выбросы (метод сравнивает медианы, поэтому устойчив к выбросам). Также для корректной работы критерия в выборках должно быть мало совпадающих значений. На практике нам ни разу не приходилось применять непараметрические критерии, в своих тестах всегда пользуемся критерием Стьюдента.
Проблема множественного тестирования гипотез
Самая очевидная и простая проблема: если в тесте кроме контрольной группы есть несколько экспериментальных, то подведение итогов с уровнем значимости 0.05 приведёт к кратному росту доли ошибок первого рода. Так происходит, потому что при каждом применении статистического критерия вероятность ошибки первого рода будет 5%. При количестве групп
 и уровне значимости
и уровне значимости
 вероятность, что какая-то экспериментальная группа выиграет случайно, составляет:
вероятность, что какая-то экспериментальная группа выиграет случайно, составляет:

Например, для трёх экспериментальных групп получим 14.3% вместо ожидаемых 5%. Решается проблема поправкой Бонферрони на множественную проверку гипотез: нужно просто поделить уровень значимости на количество сравнений (то есть групп) и работать с ним. Для примера выше уровень значимости с учётом поправки составит 0.05/3 = 0.0167 и вероятность хотя бы одной ошибки первого рода составит приемлемые 4.9%.
Метод Холма — Бонферрони
Искушенный читатель знает и о методе Холма — Бонферрони, который всегда обладает большей мощностью, чем поправка Бонферрони, то есть реже совершает ошибки второго рода. В этом методе мы сортируем
гипотез по возрастанию значений p-value и начинаем их сравнивать по порядку с требуемым уровнем значимости, который увеличивается в зависимости от номера шага
 по формуле:
по формуле:

P-value первой гипотезы сравнивается с уровнем статистический значимости
 . Если гипотеза принимается, то переходим ко второй и сравниваем её p-value с уровнем статистической значимости
. Если гипотеза принимается, то переходим ко второй и сравниваем её p-value с уровнем статистической значимости
 , и так далее. Как только какая-то гипотеза отвергается, процесс останавливается и все оставшиеся гипотезы так же отвергаются. Самое жёсткое требование (и такое же, как в поправке Бонферрони) накладывается на гипотезу с наименьшим p-value, а большая мощность достигается за счёт менее жёстких условий для последующих гипотез. Цель A/B-теста — выбрать одного единственного победителя, поэтому методы Бонферрони и Холма — Бонферрони абсолютно идентичны в этом приложении.
, и так далее. Как только какая-то гипотеза отвергается, процесс останавливается и все оставшиеся гипотезы так же отвергаются. Самое жёсткое требование (и такое же, как в поправке Бонферрони) накладывается на гипотезу с наименьшим p-value, а большая мощность достигается за счёт менее жёстких условий для последующих гипотез. Цель A/B-теста — выбрать одного единственного победителя, поэтому методы Бонферрони и Холма — Бонферрони абсолютно идентичны в этом приложении.
Строго говоря, сравнения групп по разным метрикам или срезам аудитории тоже подвержены проблеме множественного тестирования. Формально учесть все проверки довольно сложно, потому что их количество сложно спрогнозировать заранее и подчас они не являются независимыми (особенно если речь идёт про разные метрики, а не срезы). Универсального рецепта нет, полагайтесь на здравый смысл и помните, что если проверить достаточно много срезов по разным метрикам, то в любом тесте можно увидеть якобы статистически значимый результат. А значит, надо с осторожностью относиться, например, к значимому приросту ретеншена пятого дня новых мобильных пользователей из крупных городов.
Проблема подглядывания
Частный случай множественного тестирования гипотез — проблема подглядывания (peeking problem). Смысл в том, что значение p-value по ходу теста может случайно опускаться ниже принятого уровня значимости. Если внимательно следить за экспериментом, то можно поймать такой момент и ошибочно сделать вывод о статистической значимости.
Предположим, что мы отошли от описанной в начале поста схемы проведения тестов и решили подводить итоги на уровне значимости 5% каждый день (или просто больше одного раза за время теста). Под подведением итогов я понимаю признание теста положительным, если p-value ниже 0.05, и его продолжение в противном случае. При такой стратегии доля ложноположительных результатов будет пропорциональна количеству проверок и уже за первый месяц достигнет 28%. Такая огромная разница кажется контринтуитивной, поэтому обратимся к методике A/A-тестов, незаменимой для разработки схем A/B-тестирования.
Идея A/A-теста проста: симулировать на исторических данных много A/B-тестов со случайным разбиением на группы. Разницы между группами заведомо нет, поэтому можно точно оценить долю ошибок первого рода в своей схеме A/B-тестирования. На гифке ниже показано, как изменяются значения p-value по дням для четырёх таких тестов. Равный 0.05 уровень значимости обозначен пунктирной линией. Когда p-value опускается ниже, мы окрашиваем график теста в красный. Если бы в этом время подводились итоги теста, он был бы признан успешным.
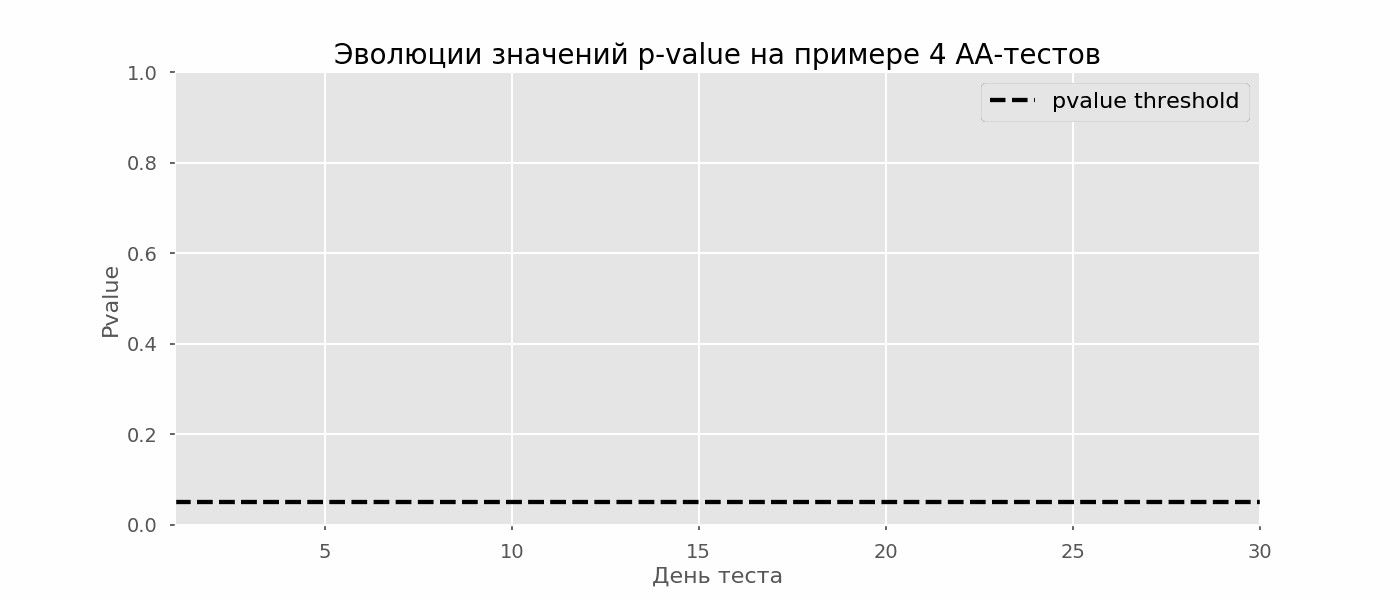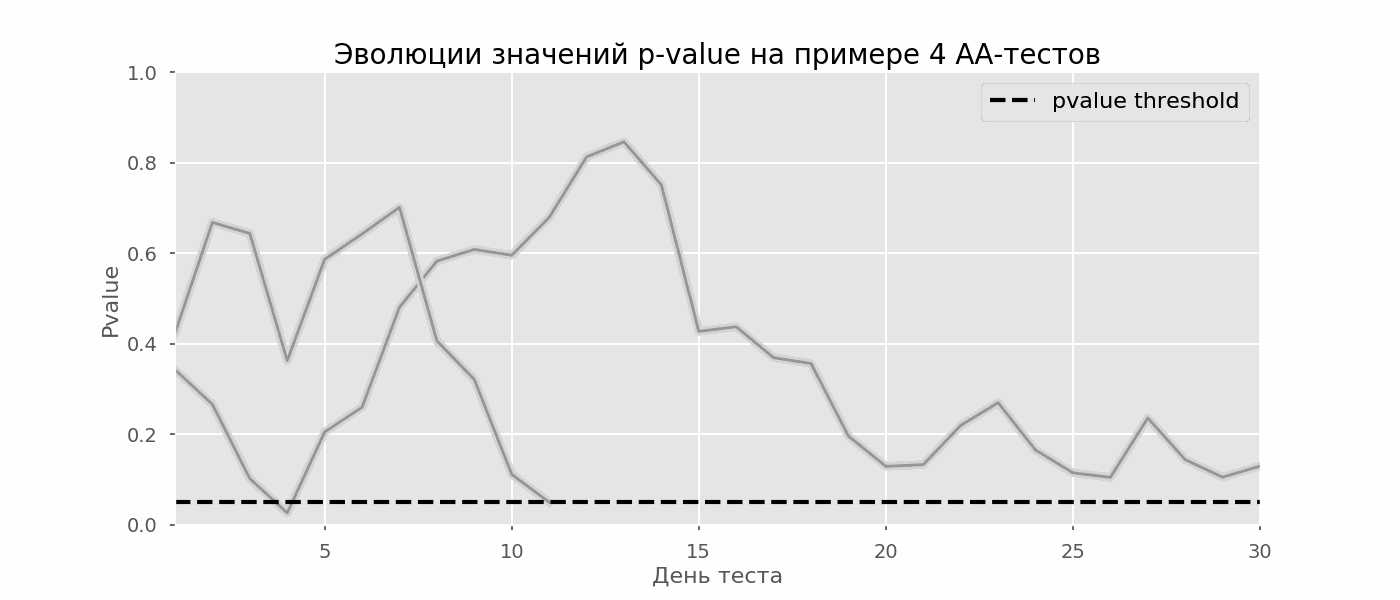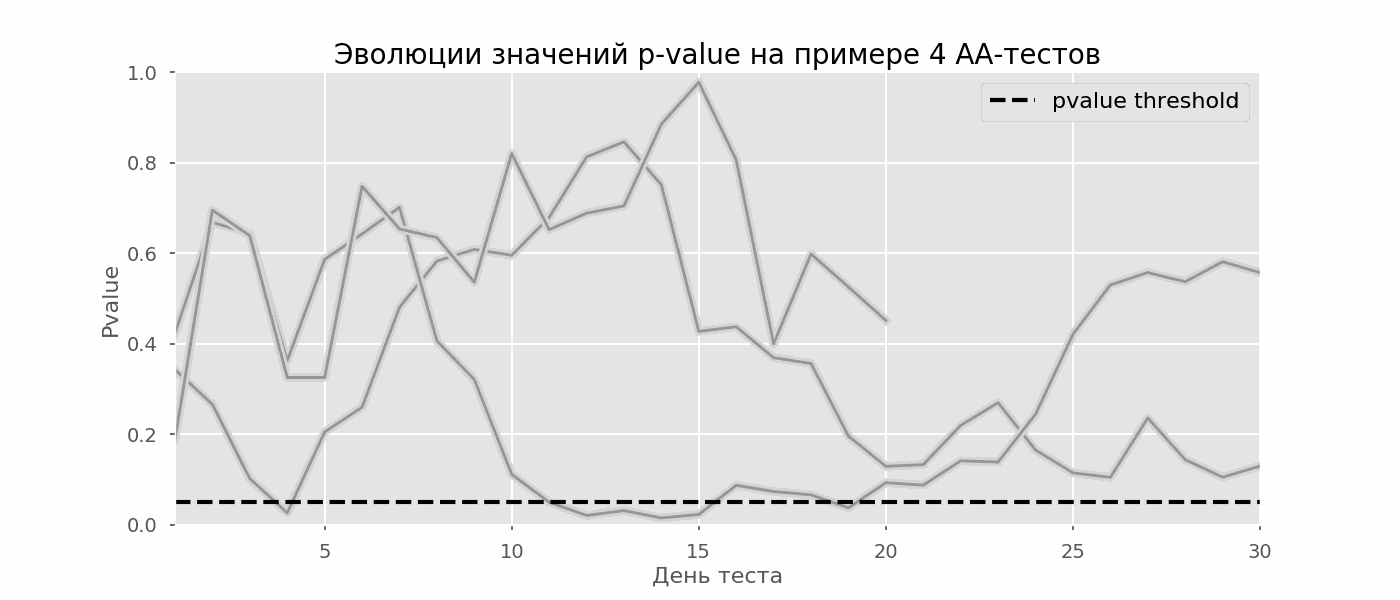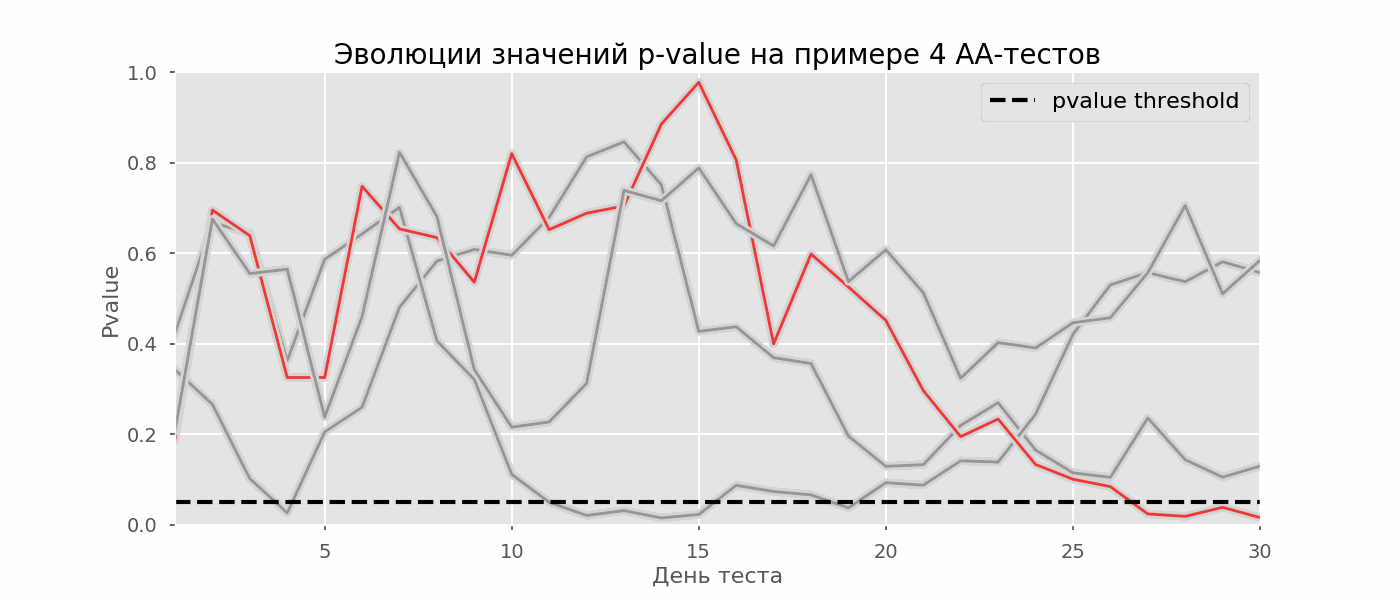
Рассчитаем аналогично 10 тысяч A/A-тестов продолжительностью в один месяц и сравним доли ложноположительных результатов в схеме с подведением итогов в конце срока и каждый день. Для наглядности приведём графики блуждания p-value по дням для первых 100 симуляций. Каждая линия — p-value одного теста, красным выделены траектории тестов, в итоге ошибочно признанных удачными (чем меньше, тем лучше), пунктирная линия — требуемое значение p-value для признания теста успешным.
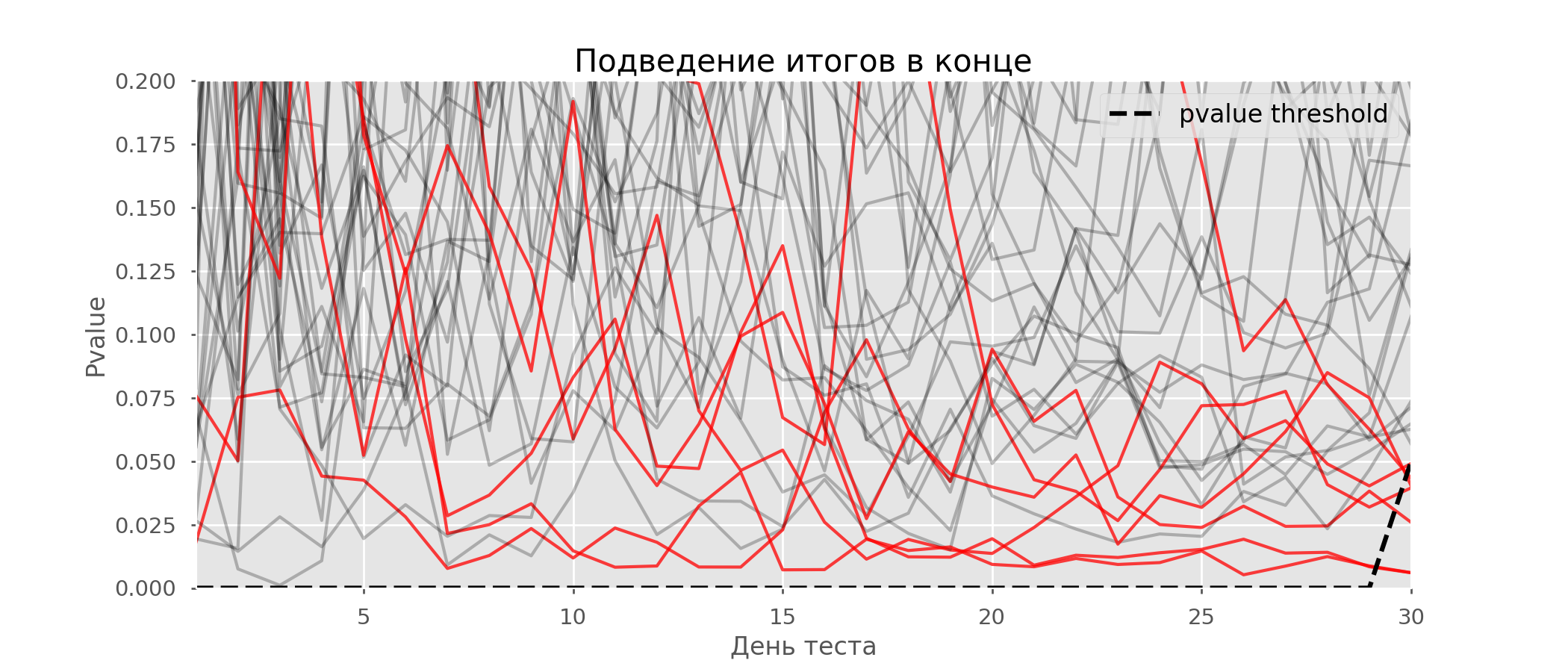
На графике можно насчитать 7 ложноположительных тестов, а всего среди 10 тысяч их было 502, или 5%. Хочется отметить, что p-value многих тестов по ходу наблюдений опускались ниже 0.05, но к концу наблюдений выходили за пределы уровня значимости. Теперь оценим схему тестирования с подведением итогов каждый день:

Красных линий настолько много, что уже ничего не понятно. Перерисуем, обрывая линии тестов, как только их p-value достигнут критического значения:
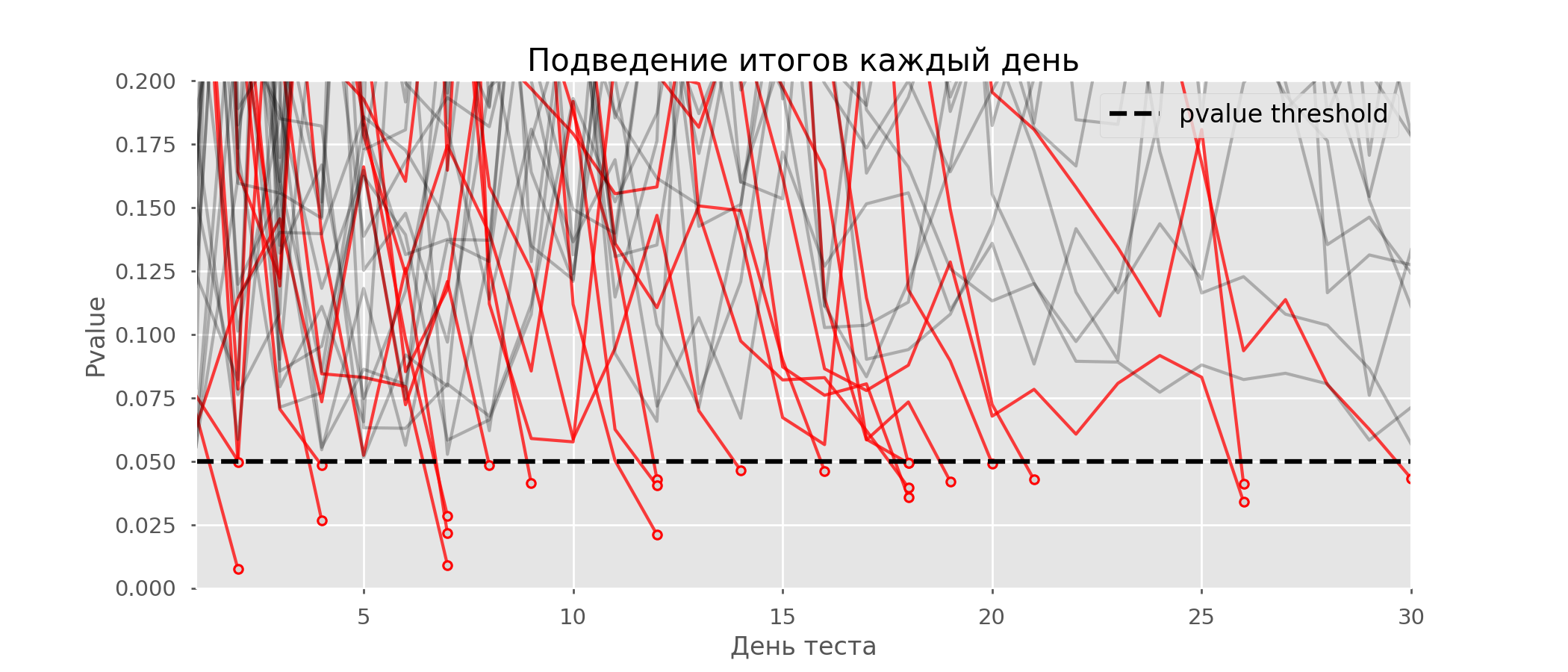
Всего будет 2813 ложноположительных тестов из 10 тысяч, или 28%. Понятно, что такая схема нежизнеспособна.
Хоть проблема подглядывания — это частный случай множественного тестирования, применять стандартные поправки (Бонферрони и другие) здесь не стоит, потому что они окажутся излишне консервативными. На графике ниже — доля ложноположительных результатов в зависимости от количества тестируемых групп (красная линия) и количества подглядываний (зелёная линия).
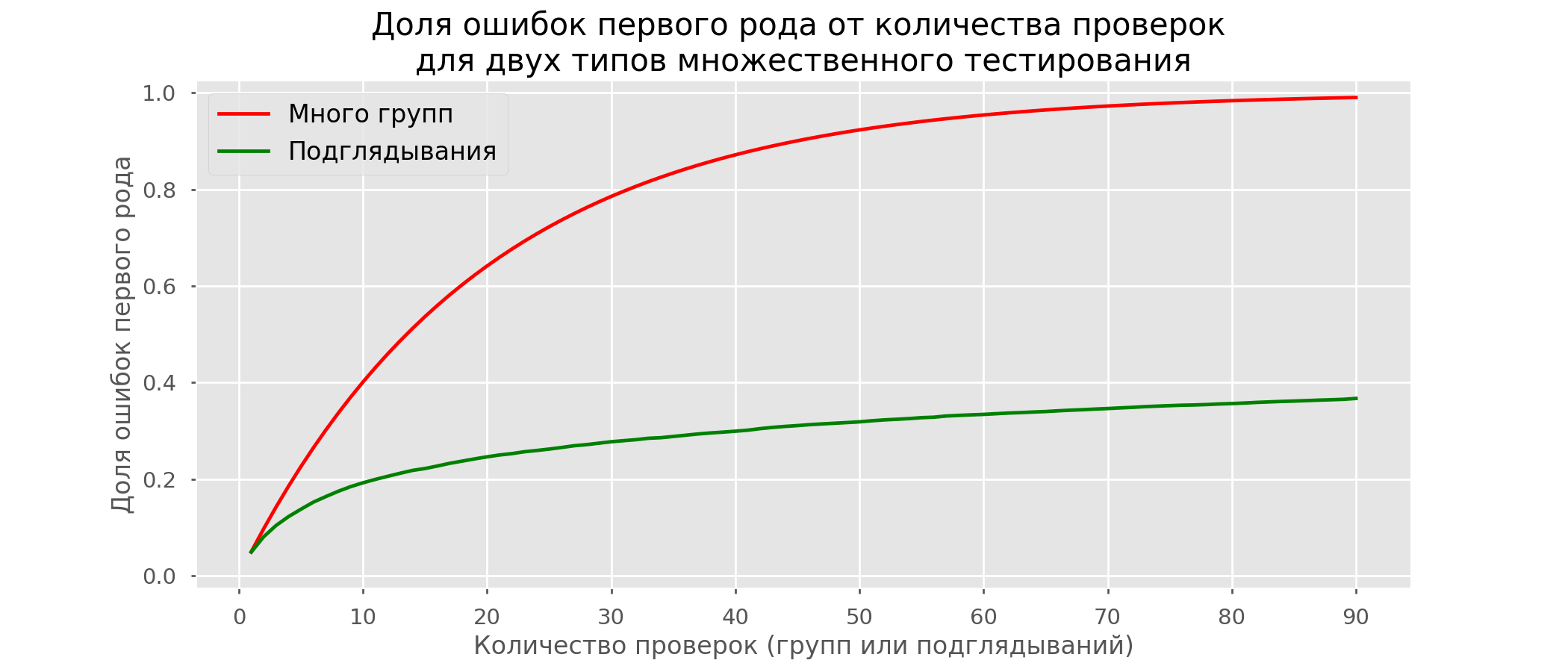
Хотя на бесконечности и в подглядываниях мы вплотную приблизимся к 1, доля ошибок растёт гораздо медленнее. Это объясняется тем, что сравнения в этом случае независимыми уже не являются.
Байесовский подход и проблема подглядывания
Можно встретить мнение, что Байесовский подход к анализу A/B-тестов избавляет от проблемы подглядывания. Это не так, хотя и его можно настроить соответствующим образом. Отличную статью с дополнительными материалами можно почитать здесь.
Методы досрочного завершения теста
Есть варианты тестирования, позволяющие досрочно принять тест. Расскажу о двух из них: с постоянным уровнем значимости (поправка Pocock’a) и зависимым от номера подглядывания (поправка O’Brien-Fleming’a). Строго говоря, для обеих поправок нужно заранее знать максимальный срок теста и количество проверок между запуском и окончанием теста. Причём проверки должны происходить примерно через равные промежутки времени (или через равные количества наблюдений).
Pocock
Метод заключается в том, что мы подводим итоги тестов каждый день, но при сниженном (более строгом) уровне значимости. Например, если мы знаем, что сделаем не больше 30 проверок, то уровень значимости надо выставить равным 0.006 (подбирается в зависимости от количества подглядываний методом Монте-Карло, то есть эмпирически). На нашей симуляции получим 4% ложноположительных исходов — видимо, порог можно было увеличить.

Несмотря на кажущуюся наивность, некоторые крупные компании пользуются именно этим способом. Он очень прост и надёжен, если вы принимаете решения по чувствительным метрикам и на большом трафике. Например, в «Авито» по умолчанию уровень значимости принят за 0.005.
O’Brien-Fleming
В этом методе уровень значимости изменяется в зависимости от номера проверки. Надо заранее определить количество шагов (или подглядываний) в тесте и рассчитать уровень значимости для каждого из них. Чем раньше мы пытаемся завершить тест, тем более жёсткий критерий будет применён. Пороговые значения статистики Стьюдента
 (в том числе значение на последнем шаге
(в том числе значение на последнем шаге
 ), соответствующие нужному уровню значимости, зависят от номера проверки
), соответствующие нужному уровню значимости, зависят от номера проверки
(принимает значения от 1 до общего количества проверок
 включительно) и рассчитываются по эмпирически полученной формуле:
включительно) и рассчитываются по эмпирически полученной формуле:

Код для воспроизведения коэффициентов
from sklearn.linear_model import LinearRegression
from sklearn.metrics import explained_variance_score
import matplotlib.pyplot as plt
# datapoints from https://www.aarondefazio.com/tangentially/?p=83
total_steps = [
2, 3, 4, 5, 6, 8, 10, 15, 20, 25, 30, 50, 60
]
last_z = [
1.969, 1.993, 2.014, 2.031, 2.045, 2.066, 2.081,
2.107, 2.123, 2.134, 2.143, 2.164, 2.17
]
features = [
[1/t, 1/t**0.5] for t in total_steps
]
lr = LinearRegression()
lr.fit(features, last_z)
print(lr.coef_) # [ 0.33729346, -0.63307934]
print(lr.intercept_) # 2.247105015502784
print(explained_variance_score(lr.predict(features), last_z)) # 0.999894
total_steps_extended = np.arange(2, 80)
features_extended = [ [1/t, 1/t**0.5] for t in total_steps_extended ]
plt.plot(total_steps_extended, lr.predict(features_extended))
plt.scatter(total_steps, last_z, s=30, color='black')
plt.show()
Соответствующие уровни значимости вычисляются через перцентиль
 стандартного распределения, соответствующий значению статистики Стьюдента
стандартного распределения, соответствующий значению статистики Стьюдента
 :
:
perc = scipy.stats.norm.cdf(Z)
pval_thresholds = (1 − perc) * 2
На тех же симуляциях это выглядит так:

Ложноположительных результатов получилось 501 из 10 тысяч, или ожидаемые 5%. Обратите внимание, что уровень значимости не достигает значения в 5% даже в конце, так как эти 5% должны «размазаться» по всем проверкам. В компании мы пользуемся именно этой поправкой, если запускаем тест с возможностью ранней остановки. Прочитать про эти же и другие поправки можно по ссылке.
Метод Optimizely
Метод Optimizely хорош тем, что позволяет вообще не фиксировать дату окончания теста, а требуемый уровень значимости рассчитывается на каждый момент времени как функция от количества наблюдений в тесте. Интуитивно лично мне их метод нравится меньше, так как в нём жёсткость критерия увеличивается по ходу теста. То есть она минимальна в первые дни, когда случайный шум оказывает наибольшее влияние на метрики. В методе O’Brien-Fleming’a ситуация противоположная.
Калькулятор A/B-тестов
Специфика нашего продукта такова, что распределение любой метрики очень сильно меняется в зависимости от аудитории теста (например, номера класса) и времени года. Поэтому не получится принять за дату окончания теста правила в духе «тест закончится, когда в каждой группе наберётся 1 млн пользователей» или «тест закончится, когда количество решённых заданий достигнет 100 млн». То есть получится, но на практике для этого надо будет учесть слишком много факторов:
- какие классы попадают в тест;
- тест раздаётся на учителей или учеников;
- время учебного года;
- тест на всех пользователей или только на новых.
Тем не менее, в наших схемах A/B-тестирования всегда нужно заранее фиксировать дату окончания. Для прогноза продолжительности теста мы разработали внутреннее приложение — калькулятор A/B-тестов. Основываясь на активности пользователей из выбранного сегмента за прошлый год, приложение рассчитывает срок, на который надо запустить тест, чтобы значимо зафиксировать аплифт в X% по выбранной метрике. Также автоматически учитывается поправка на множественную проверку и рассчитываются пороговые уровни значимости для досрочной остановки теста.
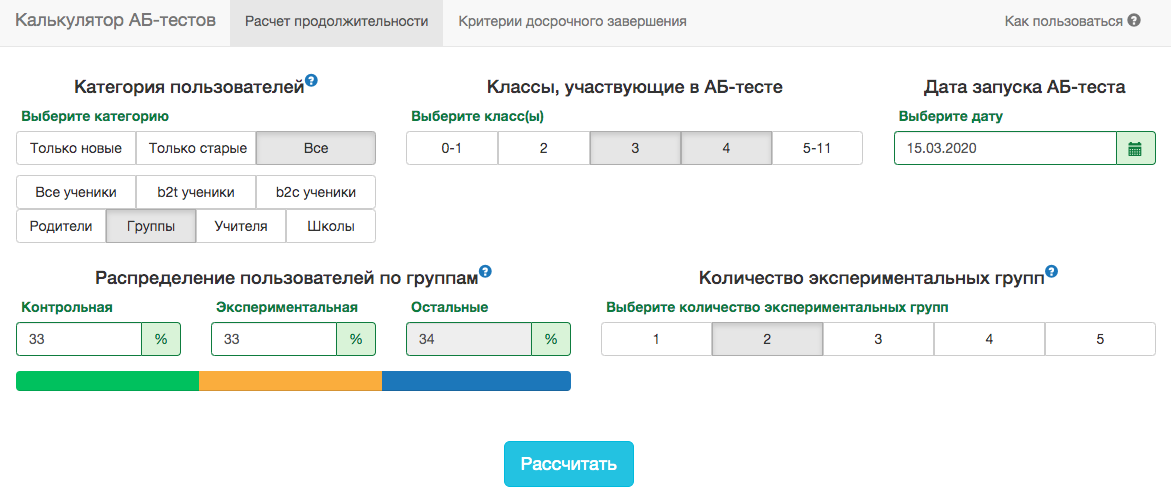
Все метрики у нас рассчитываются на уровне объектов теста. Если метрика — количество решённых задач, то в тесте на уровне учителей это будет сумма решённых задач его учениками. Так как мы пользуемся критерием Стьюдента, можно заранее рассчитать нужные калькулятору агрегаты по всем возможным срезам. Для каждого дня со старта теста нужно знать количество людей в тесте
 , среднее значение метрики
, среднее значение метрики
 и её дисперсию
и её дисперсию
 . Зафиксировав доли контрольной группы
. Зафиксировав доли контрольной группы
 , экспериментальной группы
, экспериментальной группы
 и ожидаемый прирост от теста
и ожидаемый прирост от теста
 в процентах, можно рассчитать ожидаемые значения статистики Стьюдента
в процентах, можно рассчитать ожидаемые значения статистики Стьюдента
 и соответствующее p-value на каждый день теста:
и соответствующее p-value на каждый день теста:

Далее легко получить значения p-value на каждый день:
pvalue = (1 − scipy.stats.norm.cdf(ttest_stat_value)) * 2
Зная p-value и уровень значимости с учетом всех поправок на каждый день теста, для любой продолжительности теста можно рассчитать минимальный аплифт, который можно задетектировать (в англоязычной литературе — MDE, minimal detectable effect). После этого легко решить обратную задачу — определить количество дней, необходимое для выявления ожидаемого аплифта.
Заключение
В качестве заключения хочу напомнить основные посылы статьи:
- Если вы сравниваете средние значения метрики в группах, скорее всего, вам подойдёт критерий Стьюдента. Исключение — экстремально малые размеры выборки (десятки наблюдений) или аномальные распределения метрики (на практике я таких не встречал).
- Если в тесте несколько групп, пользуйтесь поправками на множественное тестирование гипотез. Подойдёт простейшая поправка Бонферрони.
- Сравнения по дополнительным метрикам или срезам групп тоже подвержены проблеме множественного тестирования.
- Выбирайте дату завершения теста заранее. Вместо даты также можно зафиксировать количество наблюдений в группе.
- Не подводите итоги теста раньше этой даты. Это можно делать, только если вы заранее решили пользоваться методами, подразумевающими досрочное завершение, например, методом O’Brien-Fleming.
- Когда вносите изменения в схему A/B-тестирования, всегда проверяйте её жизнеспособность A/A-тестами.
Несмотря на всё вышенаписанное, бизнес и здравый смысл не должны страдать в угоду математической строгости. Иногда можно выкатить на всех функционал, не показавший значимого прироста в тесте, какие-то изменения неизбежно происходят вообще без тестирования. Но если вы проводите сотни тестов в год, их аккуратный анализ особенно важен. Иначе есть риск, что количество ложноположительных тестов будет сравнимо с реально полезными.
A/B-тесты это основной способ решения споров об интерфейсах в команде. Но часто эти споры решаются неверно, потому что ключевая ошибка при анализе результатов A/B теста это сравнение двух средних, без подбора критерия, оценки выборки. Беглый визуальный анализ отчетов в GA по принципу «где график выше, та версия и лучше» приводит к ошибочным выводам и стоит бизнесу кучу денег. Если до этого момента вы обходились знаниями, что онлайн-калькуляторы должны показать «p < 0.05» и «нормальное распределение похоже на колокол», то в этой статье я постараюсь расширить ваш кругозор.
Все примеры будут продемонстрированы для R-Studio. Общий процесс анализа: экспериментальный дизайн → сырые данные → обработанные данные → выбор статистической модели → суммарная статистика → p value. С экспериментальным дизайном дизайнеры справляются, про остальные шаги давайте говорить подробнее.
Формируем гипотезу
При формировании гипотезы руководствоваться лучше простыми понятиями: цели бизнеса, как эти цели достигаются клиентами и как это можно измерить (Single A/B test или Multi A/B test). Не менее важно понимать, как данные будут собираться и валидироваться, и как будут вноситься изменения по результатам теста. При этом предполагается, что проблема репрезентативности и достаточности объёма выборки решена. По умолчанию в данном уроке мы будем считать, что стандартное отклонение (корень из дисперсии) не зависит от размера выборки, так как выборка репрезентативна.
Но будем честны, часто задача будет ставиться по принципу: «у нас упала прибыль, посмотри, че там такое». Или приходит продукт-менеджер или гейм-дизайнер, рассказывает про уже реализованную фичу на проде, и просит узнать эффективность этой фичи. При этом нет информации, на что эта фича была направлена, на каких данных ее исследовать, как ее операционализировать. В случае столь слабо формализованных задач нужно придумывать гипотезы самостоятельно и думать, откуда взять данные для формирования этих гипотез. Помогает консолидация данных из разных источников.
Либо, в качестве источника гипотезы банальный спор менеджеров продукта и проекта, результат коридорного опроса, желание оптимизировать CRO. Я не люблю тестировать фичи, которые очевидно улучшат конверсию, это достаточно бесполезная работа. Лучше тестировать фичи, у которых отдача бизнесу непредсказуема. В таких фичах обычно кроется рост всех ключевых метрик: CTR (Click Through Rate), конверсия, CPA, ROAS, CPI. Должен сказать, что при малом количестве данных очень сложно оценивать небинарные метрики (средний чек, выручка), результаты обычно очень шумные: работает принцип garbage in garbage out. А вот A/B тесты для бинарных задач проводить просто (выполнено/не выполнено). Но в любом случае самый первый шаг это определиться с целевой метрикой.
Далее мы должны определиться с математикой. Например, у нас частотный подход, а не Байес. Выбираем класс критериев. Если распределение нормальное, то параметрические критерии (Стьюдент, Anova для равенства средних; F-test, Бартлетта, Левана на равенство дисперсий; тест пропорций для биномиальных метрик; формальные тесты на принадлежность распределению). Они считают свою статистику на основе информации об оригинальной функции распределения, т.е. мы должны задать некие переменные. Если сравниваем средние и данных не много, то Bootstrap (траты внутри приложения). Последняя инстанция это непараметрические тесты, им нужна только информация из выборки. Есть подклассы: критерии случайности, симметрии, корреляции, сдвига и масштаба, сдвига. Они не такие мощные, но применимы везде. Так, Манна-Уитни и Краскала-Уоллисана наличие сдвига, для зависимых выборок тест Фридмана и «знаковый» критерий Уилкоксона, Bootstrap для сравнения распределения характеристик по квантилям и хи-квадрат Пирсона для изменения функций распределения.
Отличная практика для реальных данных со смещением влево, это сравнить две выборки непараметрикой, и сравнить эти же выборки после логарифма t-test’ом. Двойная проверка результата.
Хорошая гипотеза учитывает принципы индукции и фальсифицируемости. Индукция это отрицание гипотезы, возможность сформулировать негативного суждения. Древнегреческие боги были? Нет, не было. Фальсифицируемость же про попытки опровергнуть гипотезу, и если не получилось, тогда гипотезу можно принять. Докажи что не было Древнегреческих богов, а до тех пор считаем, что они были.
При проверке гипотезы помним, что нулевая гипотеза про отсутствие отличий, для ее доказательства нужна вся популяция, а не выборка. Альтернативная гипотеза говорит о значимости различий. Все отличия в выборках это всегда альтернативная гипотеза, а проверяется всегда нулевая. Ошибка первого рода (α, false positive) происходит, когда мы отклоняем нулевую гипотезу в пользу альтернативной гипотезы, при условии что справедлива нулевая гипотеза. H0 считается верной, пока не доказано обратное, и если она отвергается, значит нам пора бежать предпринимать действия. Это та самая альфа 0,05, которая говорит что в одном случае из 20 будет ошибка первого рода. Ошибка второго рода (false negative) происходит, когда верна альтернативная гипотеза, но было принято решение принять нулевую гипотезу. Другими словами, во время дизайна теста мы задаем уровень значимости. который показывает вероятность верности нулевой гипотезы. На основе significance level мы принимаем или отвергаем гипотезу с полученным p-value, это вероятность совершить ошибку первого рода. Вероятность ошибки второго рода это 1 — power, шанс не заметить значимые изменения. Поэтому нет смысла делать дизайна тестов базируясь только на ошибке первого рода. Низкое значение уровня значимости уменьшает шанс совершить ошибку первого рода, но растет шанс совершить ошибку второго рода, поэтому значение p-value подбирается исходя из критичности допуска ошибок. Например, нельзя допустить ошибку второго рода в таком кейсе: не сработать сигнализацией при попытке угона машины, это критично. При работе с калькуляторами вроде evanmiller для расчёта доверительных интервалов разницы мы не учитываем ошибку второго рода.
Возможно, некоторым будет проще понять так: p-value это соответствие площадей двух гипотез, дисперсии равны.
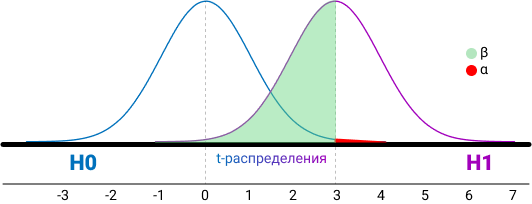
Доверительные интервалы всегда считаются по результатам теста и куда информативнее, чем размер выборки и мощность. Доверительные интервалы это способ смотреть на соответствие реальных и теоретических данных. Выборка из нормального распределения, и выборочное среднее не может быть равно мат. ожиданию. Поэтому нам нужно знать интервал, в который попадает значение оцениваемого параметра.
Итак, summary: если человек болен и мы это подтвердили — true positive (TP). Если человек не болен и мы это подтвердили — true negative (TN). Ошибка первого рода — здоровому человеку сказали, что он болен (FP). Или ошибка второго рода, сказали больному человеку что он здоров (FN).
Ошибки будут всегда, и для определения их существенности есть две метрики: полнота и точность (recall и precision), они про количество ошибок первого и второго рода. Recall = TP/(TP+FN), Precision = TP/(TP+FP). Метрики между собой конкурируют, поэтому надо учитывать обе метрики по интегральной характеристике.
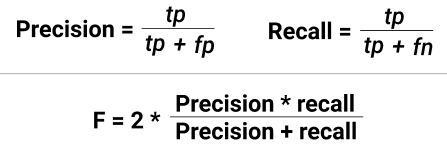
И вернемся к метрикам бизнеса, нельзя про них забывать в ходе погружения в техническую часть. Надо видеть картину целиком. Если игнорировать LTV (lifetime value или сколько денег принес клиент за свой жизненный цикл) и ROI (return on investment или окупилась ли сумма привлечения клиента), то в краткосрочной перспективе можно хорошо поднять метрики ARPU diary, ARPU month и процент платящих, чем часто пользуются продуктовые менеджеры, бегающие из компании в компанию. Для краткосрочного поднятия ARPU достаточно ввести дополнительные регулярные акции. Но в долгосрочной перспективе такой подход приведет к финансовым проблемам, так как каннибализирует остальные механики привлечения денег, и это будет видно на LTV 6 month. Еще можно выполнить краткосрочный KPI если uplift-нуть CTR одной кнопки, и каннибализировать CTR других кнопок. Или остановить трафик для мобильного приложения, очень краткосрочно подрастет ROI. В общем, любые временные изменения в базовой экономике всегда ведут к временному увеличению метрик с дальнейшей трагической просадкой. Можно привести более наглядный пример: промо-ловушка из продуктовых магазинов. Покупатель думает, что цены растут и доходы снижаются, значит нужно меньше тратить. Продавцы это видят и снижают цены в рамках акций, это увеличивает выручку на короткий промежуток времени. Покупатели привыкают к акциям и идут в магазин целенаправленно в поисках товаров по скидке, продавец вынужден еще раз снижать цену, и далее делать это постоянно. При чем тут тесты? Бизнес после запуска разовой акции видит, что прибыль пошла вверх, трафик увеличился, клиентов стало больше, но вы как аналитик должны сказать, что не смотря на это выгода/маржа/грязный вал в разрезе трех месяцев упали. Это вечная дилема: выполнить план и получить просадку по марже, или не выполнить план, разово увеличить прибыль, но просесть по выручке. Говорите бизнесу про положительную EBITDA, тогда они вас будут слушать
Я буду приводить p-value = 0,05, так как это общепринятое значение. В реальных проектах p-value куда меньше.
Либо вы идете к разработчику и он каким то образом все делает за вас, и при работе с мобилками это основной способ проведения A/B теста. Либо используете GTM или Google Optimize, где разделяем трафик, готовите визуальное представление гипотезы и задаете условия ее отображения (сегменты и тому подобное). В результате будет возможность менять не только цвет и тексты на странице, но и создавать новые функциональные сущности или развивать имеющиеся, а также успешно сегментировать гипотезы еще на этапе запуска. Это дает большое преимущество в условиях ограниченных технических и финансовых ресурсов крупного бизнеса.
С Optimize надо быть осторожным, нельзя полагаться на автоматику. Так, предположим что у вас есть два варианта страницы, но только второй вариант проходит через переадресацию. Тогда latency и частота отказов у второго варианта будет больше, как следствие, когорта меньше. Если смотреть более глобально на вопрос «в какой момент пользователь должен попасть в свою группу во время теста», то очевидным ответом будет «чем раньше, тем лучше». Тесты могут быть exposed и non-exposed, в первом случае мы сталкиваем пользователя с изменениями на сайте и тем самым уменьшаем дисперсию (не факт), во втором — глобально делим на когорты, тем самым экстраполируем эффект на весь трафик. Кейс из практики: мы устанавливаем виджет с такси только на главную страницу нашего сайта и только для пользователей, у кого накопилось более 20 000 баллов. Тогда используем exposed тест, считаем A2C, получаем бОльший эффект, чем при подсчете метрики глобально.
Вот как все происходит в подавляющем большинстве случаев: случайно делите весь новый трафик из новичков на тест и контроль. На основании опыта или теории получаем ожидаемый размер эффекта, и от него считаем выборку. Получив результаты, проверяем их на статистическую значимость. Дополнительно, можно провести АAB-тест, это позволит убедиться, что различия только на уровне поведения пользователей, а не на уровне багов системы, изменения погоды и прочих факторов. Аудиторию перед тестом можно раскидывать простым рандомом, а можно престратификацией (CUPED). Если почти все пользователи новые, то CUPED с дополнительной ковариатой.
В идеальном случае после запуска теста через определенное время тест проверяется, и делается переоценка кол-ва дней, нужных для сбора данных. Торопиться при сборе данных не надо, средний цикл оформления банковской услуги это 2 недели, значит, это минимальный срок для сбора данных. Данные влияют на качество валидации гипотез, обязательно проверяем стабильность данных (отсутствие шума), исходя из исторических данных.
Данные не обязательно собирать самостоятельно, основные источники данных это:
1. Данные из собственных приложений, сайтов, расширений и т.д (CRM, ERP, транзакции, метрика, Amplitude).
2. Снифферинг незашифрованного траффика на крупных узлах обмена данными.
3. Покупка данных сторонних поставщиков — создателей приложений, расширений, рекламных/баннерных сетей, малвари, червей и т.д., как легитимным, так и не очень образом.
4. Открытые данные рынка и исследования агентств (Росстат, GFK).
5. Сырые events из продукта.
6. Покупка данных о посещаемости каких-нибудь ресурсов, которые готовы продать данные.
7. Хантинг людей, опросы и исследования, фокус-группы.
Характеристика и нормализация данных
Предположим, данные готовы, они могут быть в формате csv или Excel. Их может быть много или мало, плотность распределения вероятностей среднего значения выборки может быть нормальной и ненормальной. Проверка на нормальность данных нужна, чтобы центральная предельная теорема выполнялась на малых выборках. Если выборки большие и наблюдения независимые, то предположение о нормальном распределении для теста Стьюдента не нужно (т.к. работает центральная предельная теорема). На 1000 пользователях не удастся отследить мелкие изменения (1-2%), но изменения в 20-30% можно. Проще говоря, при большой выборке результаты теста будут точные, при маленькой выборке не факт, что есть смысл проводить A/B тест.
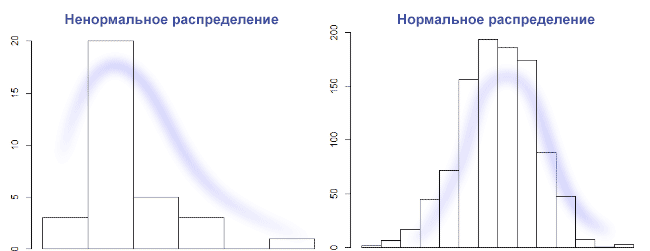
Предположим, что данных мало, значит, нужна проверка о типе распределения данных. Не факт, что удастся отличить равномерное распределение от нормального на очень маленькой выборке. В общем случае, нужно построить график столбчатой диаграммы и посмотреть его форму. Нормальное распределение выглядит как колокол с тремя сигмами с каждой стороны. Правило трех сигм: каждая сигма это одно стандартное отклонение, данные нормально распределены, и 99,7% выборки попадает влево по графику на три сигмы, и вправо по графику на 3 сигмы. Если выборки гомогенные и распределение нормальное, то наш выбор это t-Критерий Стьюдента. На Стьюденте сложно контролировать мощность, и значит, растет шанс совершить ошибку второго рода. Если же по графику видно, что распределение с отклонением на левую сторону графика, то используется хи-квадрат Пирсона, это непараметрический критерий. Он хорошо подходит для проверки равномерного налива трафика, но требует сгруппировать данные по бакетам (создать таблицу сопряженности). Если распределение отлично от нормального, то правило трех сигм — не лучший выбор, если наше распределение вырожденное. Но на картинке ниже слева распределение вполне может быть логнормальное, и можно отрезать по квантилям.
Встречается еще мультимодальное или бимодальное распределение, но чаще после ресемплинга. Если мы говорим про оценку средних, то при достаточном кол-ве наблюдений данные будут распределены нормально. Это большой плюс работы над крупным продуктом, в котором всегда много данных: при любом распределении исходных величин распределение выборочных средних будет стремиться к нормальному. Результат попросту зависит от мощности, т.е. от размера выборки. Идеально нормальных данных быть не может, если под реальной жизнью не понимать результат работы функции rnorm(). Да и данные в нашем случае дискретны и являются набором точек. Поэтому на большой выборке shapiro-wilk всегда будет значимым. А вот на выборках 10-15 значений он всегда незначимый из-за недостаточной мощности. В статистике мощность асимптотически стремится к 1.
Мощность это вероятность допустить ошибку первого рода, то есть отклонить нулевую гипотезу, хотя она верна.
Стратификация (выделение суб-группы из выборки и рандомом деллим на 2 группы) не плохо работает для однородности. Страта это группа наблюдений, подчиняющихся единому правилу. Стратифицированный метод предпочтителем, когда мы сначала делим людей по какому-то признаку (например, по полу), а затем берем людей из этих групп в равной пропорции. Если люди распределяются между двумя группами полностью случайно, то ни о какой статистической значимости речи быть не может.
Сегментация нужна. Хотя бы на уровне киты/планктон и рандомом, сверяясь на A/A-тесте. Или по странам, месяцу регистрации. Если нет параметрического критерия, тогда делим данные на две одинаковые группы, задаем α — уровень значимости, n — размер выборки, mde — эффект. Одну из групп сдвигаем на mde, применяем критерий и бутстрэп.
Итоговый процент принятия нулевых гипотез будет 1 — β. По завершению A/A-теста важно посмотреть на распределения p-value. Оно должно быть равномерным. Если наблюдается скос, то значит, есть сильные зависимости между данными и анализ делать нельзя. А вот для a/b такой подход не пойдёт.
И даже так выборки могут быть с нестабильным по времени и с дисбалансом. Поэтом важно выбрать подходящий критерий для таких выборок. Ресемплинг поможет для оценки, как и моральная подготовка к перезапуску теста при наличии скачков данных на ретроспективе.
Выбросы надо смотреть на box-plot и удалять ручками, как и дубли. Если мы работает с финансовыми метриками и удалять выбросы невозможно, то значит увеличивается разброс значений и доверительные интервалы также увеличиваются. Применяется правило трех сигм: убрать все значения, которые выходят за три стандартных отклонения и посмотреть, как изменятся наши данные. Но будет большая потеря данных, что может быть критично. Другой способ это метод трансформации по Боксу-Коксу. При этом надо понимать, что удаление выбросов только для применения того или иного критерия—не верный подход. Прагматичнее для начала посмотреть срезы, где явно будут видны различия.
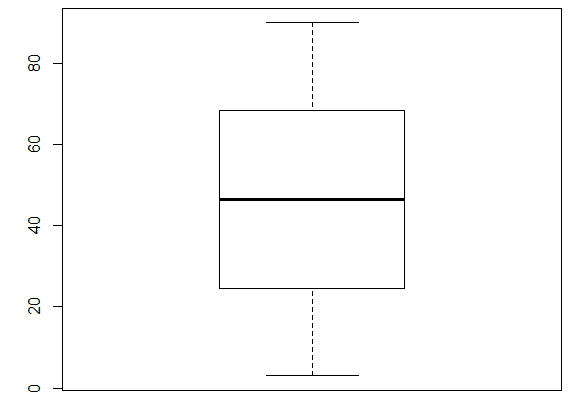
Давайте сгенерируем данные таким способом usersExport <- data.frame(n = 3:90) и построим график boxplot(usersExport). Мы получим практически идеальный график, на котором есть квантили.
Как читать график boxplot: точка или линия соответствуют средней арифметической, эту точку окружает квадрат, его длина соответствует точности оценки генерального параметра. Усы от квадрата соответствуют своей длиной одному из показателей разброса или точности. Для формирования boxplot нужно написать комманду boxplot(имя переменной). Можно для эксперимента создать дырки в данных usersExport <- usersExport[-sample(3:90, 23), ] и посмотреть, как изменится график boxplot.
Вот пример графика с выбросами:
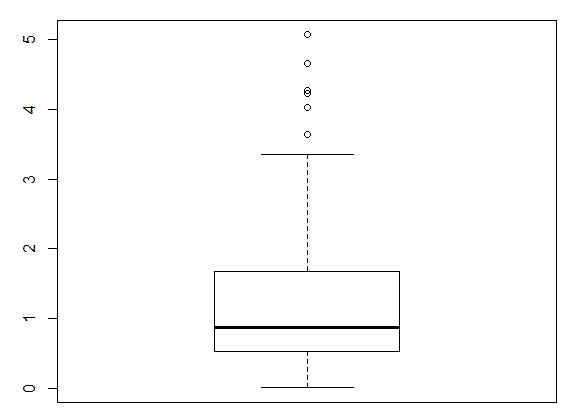
Проверить данные на нормальность можно простым взглядом по qqplot(). При больших объемах тесты практически всегда покажут отклонения от нормального распределения. Поэтому, если данные получились очень ненормальные, например у времени, проведенного за смартфоном или финансовых показателей всегда есть ограничение снизу, то нужна нормализация или хотя бы удаление выбросов. Переходя к цифрам, различие в 5% не такое уж и большое. На большой выборке будет совсем близко к 0,05. Кроме того, многие тесты устойчивы к умеренным отклонениям от нормального распределения. Даже очень небольшие отклонения от нормальности будут значимы на больших выборках, но это справедливо для всех стат. тестов.
qqplot(rt(a,df=3), x, main="t(3) Q-Q Plot") abline(0,1)
![]()
Мы видим, что R-Studio нарисовал график Q-Q (слева). На таком графике отображаются данные в отсортированном порядке по сравнению с квантилями из стандартного нормального распределения. За исключением выбросов, точки расположены более менее по прямой, хотя и скашиваются. Значит, наши данные искажены. На это также указывает, что точки расположены вдоль линии в середине графика, но отгибаются в конце. Такое поведение характеризует наличие в выборке более высокие значений, чем ожидалось от нормального распределения. Пример нормального распределения показан на графике Q-Q справа.
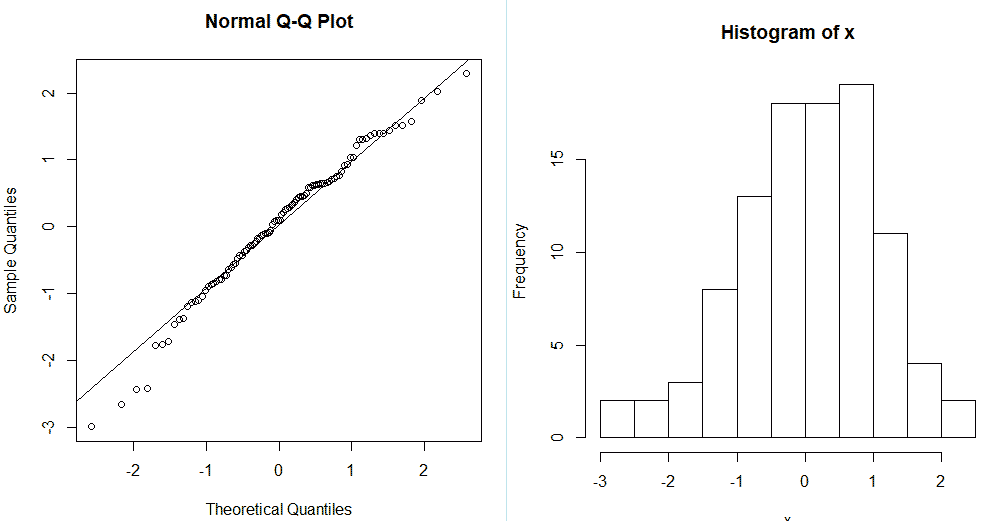
Еще один пример нормальных данных: вводим команду для генерирования данных x <- rnorm(100). Строим график с линией qqline(x), и добивает гистаграммой hist(x).
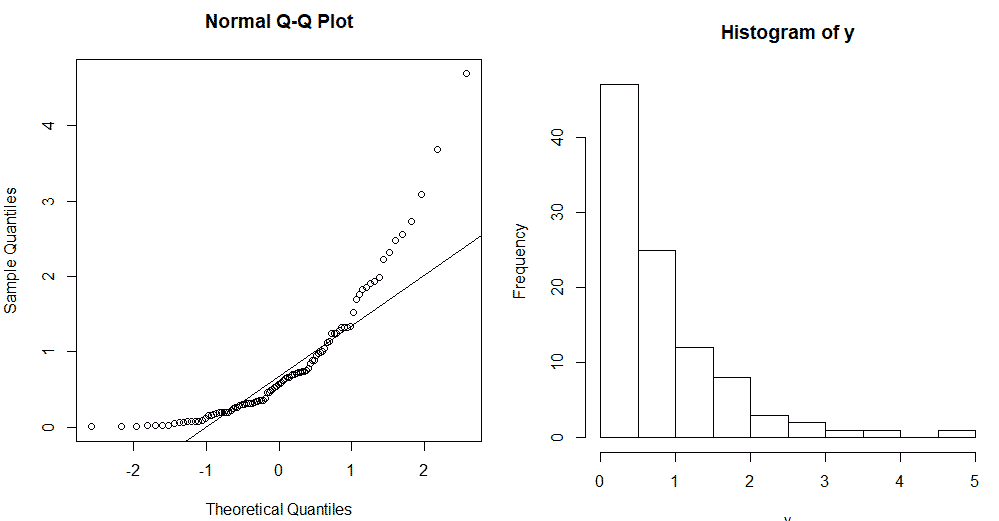
Пример ненормальных данных: y <- rgamma(100, 1), затем qqnorm(y); qqline(y), и гистограмма hist(y).
Выбираем победителя
В зависимости от количества и нормальности данных мы выбираем разные критерии для выявления победителя. Если данные нормально распределены, то используем бернулевский тест, гаусовские расчеты. Смотрим степени свободы, победил вариант, не победил вариант.
")
Для начала рассмотрим тест Шапиро-Уилка как критерий для определения нормальности, он очень мощный. Критерий Шапиро-Уилка это W-критерий, который также позволяет оценить нормальность. Если W=1, то выборка точно нормально распределена. Так, нулевая гипотеза = выборка принадлежит нормальному распределению. Если Шапиро-Уилка дает маленький p-value, то значит есть выбросы. Все, что выше 0,75, можно считать нормальным распределением. Для выполнения теста Шапиро-Уилка предназначена функция shapiro.test(x), принимающая на вход выборку x объема не меньше 3 и не больше 5000. Генерируем нормальные данные, x <- rnorm(4600), и используем тест shapiro.test(x). Мы видим следующий текст:
Shapiro-Wilk normality test data: x W = 0.99947, p-value = 0.222
Смотрим на p-value = 0.222 и принимаем нулевую гипотезу.
W это значение статистики теста, в данном случае это 0.99947, что считается отличным результатом, т.к. выборка изначально имеет нормально распределенные данные. Чтобы отклонить нулевую гипотезу, p-value должно быть не выше альфы 0,05 (максимум 0,1). Проверим на ненормальных данных: y <- rgamma(100, 1), shapiro.test(y).
Shapiro-Wilk normality test data: y W = 0.9829, p-value < 2.2e-16
P-value < 2.2e-16, что намного меньше 0.05, практически 0. И это при том, что R сообщает только значения p-value выше порога 2.2×10−16. Мы отклоняем нулевую гипотезу. Сначала смотрим, меньше ли 0.05, потом сравниваем средние или медианы. На несимметричных данных медиана значительно лучше отразит центральную тенденцию, чем обычное среднее. Если распределение одной из выборок заметно отличается от нормального, то в качестве центра берется медиана и соответственно, критерий Уилкоксона — Манна-Уитни, непараметрический и хорошая замена Хи-квадрату Пирсона. Если у данных положительный длинный хвост (прибыль) и ненормальное распределение, то это Манна-Уитни, перестановочные тесты или бутстреп. Перестановочные тесты про гипотезу о схожести распределений двух выборок.
Если же распределение всех выборок нормальное, то среднее арифметическое это наш выбор, и какой-либо из Стьюдентов (критерий сдвига).
Проблема это ограничение на 5000 наблюдений. Если наша выборка больше, то применяем Shapiro-francia w’ test. Или Anderson-Darling test, его попроще найти в готовом виде, он может проверить данные на любые распределения. Либо тест Колмогорова-Смирнова (критерий согласия), но для решения реальных задач лучше его не использовать.
A/B-тесты подразумевают два набора данных, поэтому тест нужно проводить для обоих выборок. Это не обязательно тест Шапиро-Уилка, это может быть и непараметрический ранговый U-критерий Уилкоксона — Манна-Уитни. Проверяет гипотезу сдвига, кушает любые выборки, но понятное дело, что обе выборки должны быть примерно схожи по распределению. Тест робастый, оперирует рангами. Сдвиг это не про проверку медианы, а про проверку «скошенности» данных относительно друг друга. Если в одной выборке у нас значения [2,3,4,5], а во второй [5,6,7,8], то это явно сдвиг.
Если данные непрерывные, то в простых случаях хорошо работают критерии Уилкоксона — Манна-Уитни/Краскела-Уоллиса, в которых нулевые гипотезы на сравнения распределений и медианы. Распределение 50 на 50 подразумевает использование формулы Бернулли, а может быть и Байесовский многорукий бандит. Если же использовалось сплит-тестирование, то нужно использовать непараметрический дисперсионный анализ — критерий Краскела-Уоллиса. Для сравнения дисперсий хороший вариант Fligner-Killeen и Brown–Forsythe. Рассмотрим с примерами.
Подход Байеса рекомендуется при большом количестве данных, альтернатива частотному подходу. Частотный подход про нулевую гипотезу и про частоту событий, Байес — про принятие нулевой гипотезы, позволяет работать с событиями и причинами. Нельзя применять Байеса и частотный подходы одновременно, это ведёт к «парадоксу Линди».
Частотный подход не позволяет сделать предположение заранее, предлагается полагаться на данные тестовой выборки. Мы повторяем эксперимент бесконечное количество раз для получения гистограммы объективной неопределенности. Сама гипотеза проверяется по классическому p-value. Важно зафиксировать размер выборки до эксперимента, вот две формулы для этого:
- В числителе находим дисперсию (α2), в знаменателе mde.
- z — стандартная ошибка, 1,96 при 95% уровне значимости.
- σ — стандартное отклонение.
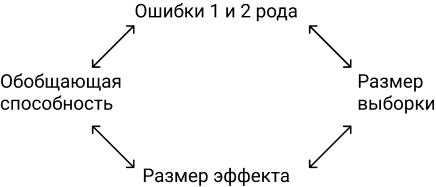
Обратите внимание, что практически все переменные взаимосвязаны. Чем меньше эффект, который мы хотим поймать, тем больше размер выборки.
Обобщающая способность. Если мы возьмем гомогенную выборку, то дисперсия будет меньше, функция плотности вероятности будет более сконцентрированная, чем при 100% доступных данных. Но и выводы по гомогенной выборке будутрелевантны выборке, а не всем данным. Вывод: меньше дисперсия = меньше обобщающая способность.
Давайте на примере. Нужно найти размер выборки для теста пропорции категориальных данных. α = 95%, mde = 0.05, p = 70%, z = 1.96. Так, n = 1.96^2 * 0.7 * (1 — 0.7) / 0.05^2 = 3.8416 * 0.7 * 0.3 / 0.0025 = 322.
Идея Байеса в получении 500 раз выпадение орла из 1000 бросаний монетки, и считается по формуле C500(1000) * 0.5^(500) * 0.5^(500), т.к. броски друг от друга никак не зависят. Если бы мы знали все возможные параметры монетки, мы могли бы предсказать результат. Но так как это невозможно, то проводим множество наблюдений. Байес позволяет ответить на задачу индукции, какой из вариантов лучше и на сколько. У Байаса всегда есть априорное распределение, а значит, нужно иметь свои представления о параметрах исследуемового процесса. Что, в принципе, является основой образа мышления дизайнера. Для Байеса можно не считать мощность и значимость, но пропадает понимание эффекта. Если по каким то причинам не нравится Байеc, то можно использовать Стьюдента или Бернулли для больших выборок. Если результаты 0 и 1, то точно Бернулли и биномиальное распределение. А с ним легко работать, интерпретировать, визуализировать.

Стьюдент. T-тест или определение t-критерия Стьюдента является простейшим способом проверки точности среднего значения для данных с естественными значениями. Выборки должны быть независимыми (не парными) и нормально распределенными (чем больше результатов, тем ближе распределение к нормальному). Это гарантирует концентрацию плотности значений вокруг среднего значения, что позволяет делать выводы о генеральной совокупности, имея только информацию о выборке. Провести тест легко: x = rnorm(1000000) и y = rnorm(1000000). Команда t.test(x,y). Получаем следующие данные:
data: x and y t = -1.1696, df = 2e+06, p-value = 0.2422 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -0.004424298 0.001117388 sample estimates: mean of x mean of y -0.0007571144 0.0008963404
И проверяем:
m = length(x); n = length(y) t = ( mean(x) - mean(y) ) / sqrt( var(x)/m + var(y)/n ); t
В обоих случаях получаем t = -1.1696, и p-value = 0.2422. Так как мы всегда обеспокоены тем, является ли p больше или меньше 0,05, то при 0.2422 > 0.05 есть основания не отвергать нулевую гипотезу. P-Value это достигнутый уровень значимости (пи-величина)—наименьшая величина уровня значимости, при которой нулевая гипотеза отвергается для данного значения статистики. По P-Value происходит проверки (и отклонения) «нулевой гипотезы». Чем меньше значение Р, найденное для набора результатов, тем меньше вероятность того, что результаты случайны. Результаты считаются «статистически значимыми», когда это значение ниже 0,05 (или 5%). Если удастся довести значение до 0,005, то уже хорошо, сильно уменьшится количество позитивных неправильных результатов. При 0,05 считается нормой 1/3 неправильных выводов. В идеальном мире даже 0,005 должно быть лишь приблизительной наводкой на финальное решение. В физике или при исследовании генов используется 0.0000003. Чем ниже значение p, тем выше перевес в пользу альтернативной гипотезы.
В примере ниже я визуализировал, как границы меняются в зависимости от входных данных, и в момент выхода за границы принимаем H1 о наличие различий. Различия могут быть на уровне среднего значения, медианы, и не только. Не обязательно делать динамические границы, можно и статичные.
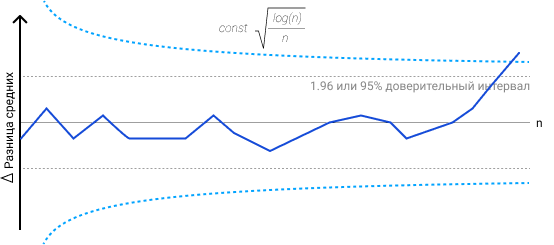
Нулевая гипотеза всегда про отсутствие статистической значимости в результатах, т.е. о равенстве значения генеральной совокупности относительно выбранного критерия. Она зовется нулевой, так как отрицание это ноль, а согласие это единица. Например, все пользователи видят баннер. Альтернативная гипотеза скажет, что не все пользователи видят баннер, т.е. нет утверждения о равенстве параметра генеральной совокупности заранее заданному значению.
Парный t-тест имеет уменьшенное количество степеней свободы, но при этом устраняется влияние индивидуальных различий. Нужен для сравнения зависимых выборок, он мощнее непарного t-теста. Зависимые выборки это когда элемент из контрольной группы имеет соответствующий ему элемент во второй группе. Например, при тесте одинаковой главной страницы в сентябре 2018 года и в сентябре 2019, или навыки дизайнеров до и после курсов. при зависимых выборках нас интересует, как изменения в одной группе повлияют на другую.
leftGroup <- c(12, 13, 11, 15, 19, 15, 17) rightGroup <- c(14, 14, 16, 16, 18, 14, 15) t.test(leftGroup, rightGroup, var.equal=TRUE) t.test(leftGroup, rightGroup, paired=TRUE)
Получаем p-value = 0.5648 в первом случае и p-value = 0.4539 во втором. Очевидно, что дискриминационная способность у парного теста больше.
Второй по популярности — z-тест пропорций. Это параметрический тест, проверяет равенство средних. Видим биномиальное распределение, применяем z-тест. Например, для метрик отношения/конверсии. Тестируется биномиальная случайная величина (орел или решка, 1 или 0, Да или Нет), значит, z-тест. Нужна независимость выборок. Если же задача в сравнении равенства дисперсий, то наш выбор это Levene, тест Бартлетта. Они параметрические, тест Бартлетта будет помощнее, но и требует более нормальное распределение, чем Levene.
Следующий критерий, Уилкоксона — Манна-Уитни, позволяет протестировать, что результаты случайных наблюдений из одной группы могут быть выше, чем в другой. Это непараметрический критерий, альтернатива t-test. Идея такая: для t-test нужны нормально распределенные данные (нормальность среднего распределения) и его результаты легко интерпретировать, но он чувствителен к выбросам. Если у нас нет информации о нормальности распределения, используем критерий Манна-Уитни, имея ввиду, что он не покажет тонких различий между выборками и его сложнее интерпретировать. Причина в том, что t-критерий работает на основе сравнения средних из фактических наблюдений, в то время как критерий Манна-Уитни использует сравнение рангов (номеров наблюдения в упорядоченной выборке), что позволяет ему быть устойчивым к выбросам. Но при этом критерий Манна-Уитни весьма чувствителен к различию дисперсий, и на больших выборках это становится очень заметно.
Поэтому на практике допускается использовать t-test для оценки средних на большой выборке, так как нормальность обеспечивается «сжиманием» крайних значений по ЦПД (чем больше элементов в выборке, тем меньше дисперсия среднего арифметического). Но при этом помним, что чем больше отклонения от нормальности, тем хуже тест сравнивает выборки. Так что t-test не подойдет для небольших выборок из ненормального распределения, но подойдет для большой выборки из ненормального распределения.
T-test чувствителен к выбросам, и если есть длинный хвост в данных (а он почти всегда есть на реальных финансовых данных), то такой хвост сильно скажется на среднем, и за счет большой дисперсии получим плохой результат работы критерия. Любые популярные метрики, вроде ARPU, количество сессий, время чего-либо, ARPPU, средний чек это не биномиальное распределения. И зачастую они не поддаются анализу параметрическими тестами, длинные хвосты и значит, большее количество денег мы получаем от небольшого кол-ва пользователей. Это можно решить за счет техники бакетов, но опять же, нужна большая выборка. Если маленькая выборка, тогда у нас выбор: либо U-критерий Манна-Уитни, считаем p-value внутри дней с поправкой на множественное сравнение, теряя в мощности. Если можно избежать применения поправок — лучше избежать. Либо накопительный p-value. Либо bootstrap как самое простое решение, получим распределение выборочного среднего и посмотрим на пересечение квантилей с заданным уровнем значимости. Либо CUPED преобразует данные в нормальные, уменьшив отклонения от среднего, и T-Test с поправкой Уэлча. Либо mood’s median test, но понадобится таблица сопряженности.
Используем команду wilcox.test(mpg ~ am, data=mtcars) получаем сообщение, “не могу подсчитать точное p-значение при наличии повторяющихся наблюдений”. Если вас смущает это сообщение, измените команду на wilcox.test(mpg ~ am, data=mtcars, exact=FALSE). Это объяснит программе, что мы все понимаем, и не ждем точного расчета p-value. Получилось W = 42, p-value = 0.001871. Напомню, P-Value должно быть не выше 0,05.
А теперь возьмем два набора наблюдений и протестируем:
a = c(123, 105, 147, 142, 119, 129, 130, 87 ,301, 92, 177, 141, 137, 112, 138, 128, 114, 197, 198, 210, 101, 125, 134, 214, 110, 100, 152, 122, 144, 148 ,153 ,212) b = c(154, 512, 120 ,131 ,124 ,118 ,178 ,140 ,136, 68, 162, 127, 78 ,106, 133, 655 ,155 ,169 ,199 ,108 ,143, 341 ,121 ,139, 166, 174, 184, 98, 135, 132, 146, 209)
wilcox.test(a,b)На выходе получаем:
data: a and b W = 455, p-value = 0.4507 alternative hypothesis: true location shift is not equal to 0
У нас есть наше любимое P-Value, которое куда больше, чем 0,05. Мы принимаем нулевую гипотезу. W является статистической статистикой Уилкоксона и, как следует из названия, является суммой рангов в одной из двух групп.
Если р < 0,05, то нулевая гипотеза про отсутствие отличий отвергается.
С Бернулли схожая история, берет два вида данных (орел/решка, мальчик/девочка, красное/черное). rbinom(200, size = 1, p = 0.68) где p это шанс получить 1. Грубо говоря, rbinom скажет, сколько будет орлов, если сыграть определенное кол-во раз в монетку. Пример показывает сразу 200 испытаний Бернулли. Посмотрим, как мы можем сравнить два испытания Бернулли, т.к. данные очень похоже на результат бинарного A/B теста:
varA <- rbinom(200, 20, 0.5)
varB <- rbinom(200, 20, 0.25)
И используем hist(varB, probability = TRUE, col = gray(0.9)) для двух наборов данных. На графиках мы видим 200 биномиально распределенных случайных чисел для испытаний размером = 20 и с разной вероятностью возникновения интересующего нас события p = 0,25 и 0,50.
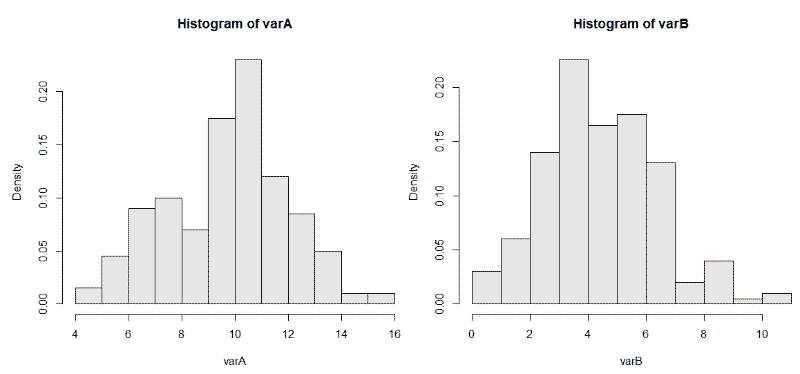
Биномиальные критерии это сравнение пропорций. Позволяют проверить гипотезу про коэффициент удаления приложения. Если выборка маленькая (100), конверсия в покупку 12%, то биномиальный тест лучший выбор. Стьюдент может быть применен к распределению Бернулли, но выборка маловата, должно быть > 200. В данном примере, с бутстрепом будет аналогичная история.
Говоря о типичных финансовых данных, где есть пик-скопление небольших платежей + длинный хвост, и нас не пугает работать с логарифмом от некой велечины (но не от 0), то методом Бокса-Кокса можно транформировать данные в нормально распределенные. Простой логарифм от числа, который тем не менее усложняет интерпретацию результатов. После этого берем привычный параметрический тест (t-критерий Стьюдента), смотрим p-value и оцениваем уровень значимости для закрытия эксперимента.
Процесс выглядит так: узнаем про выбросы с помощью boxplot, проверяем выборку на нормальность с помощью теста Шапиро Уилко, охарактеризовать распределение с помощью QQnorm, и выбрать метод анализа. Если данные нормальные, используем Бернулли, Гаусса, Стьюдента. Ненормальные (график сглажен по одной из сторон): Хи-квадрат, Байес, Пуассон. Обычно данные выглядят как диапазон от 0 до десятков в кучей выбросов до нескольких сотен, и это распределение Пуассона. Распределение Пуассона применяется в теории массового обслуживания. После этого оцениваем параметры, учитываем их при запуске теста хи-квадрат к выборке и распределению Пуассона, и получаем ответ про правильность гипотезы при распределение Пуассона.
Итак, тест прошёл. На что мы можем посмотреть? В первую очередь, нельзя подгонять новые гипотезы по факту завершения эксперимента под найденную разницу, хотя очень хочется. Называется это P-hacking, когда сначала идет сбор данных, проверяют множество разных гипотез, и те, которые соответствуют p<0.05, публикуют в научных журналах. Если вы работаете в науке и нужно собирать гранты на новые научные изыскания, то все на вашей совести. Но в бизнесе такой подход недопустим.
Могло показаться, что t-test это участь исключительно научной работы и он не применим для бизнес-задач. Но вот пример: возьмем метрику отношения (ratio metric), например CTR. Посчитаем соотношение суммы кликов и суммы просмотров, их отношение это конверсия в клик. В таком примере данные зависимы и не можем использовать t-test.
Другой тип метрик это поюзерная метрика. Смотрим на среднее значение, т.е. был ли открыт лутбокс, или нет. Здесь у нас одинаково распределенные, независимые случайные величины, и мы можем применить t-test. А теперь магия: мы можем использовать линеризацию для превращения метрик отношения в поюзерные метрики. При этом не теряется чувствительность и метрика сонаправлена с изначальной.
После теста проверяем, все ли пользователи завершили целевое действие. Например, среднее время жизни пользователя сервиса для генерации временных e-mail адресов составляет 5 дней. В выборке не должно быть тех, кто начал пользоваться сервисом за 5 дней до конца эксперимента.
Нельзя допускать аномальных всплесков в ходе эксперимента, они могут внести статистически значимый вклад в результат.
Если у нас биномиальная метрика, то надо смотреть на изменение мощности. Например, обе наблюдаемые группы резко скатились вниз, и это сказывается на мощности. Ближе к концу эксперимента можно пересчитать и сделать вывод, сильно ли отличается мощность в конце и начале эксперимента. Сильно отличается в худшую сторону? Продолжаем эксперимент, ждём нужную мощность.
P-value тоже имеет свой доверительный интервал. Если провести 10000 A/A-тестов при p-value=0.05, то мы ожидаем, что 500 прокрасится. Даже у этих 500 есть доверительный интервал, некий доверительный интервал доверительного интервала. Помогает вероятностный подход: классическая теорема Байеса.
Не только R
Сейчас любой аналитик (не важно, UX, бизнес, дашбордист, ресерчер, разработчик) должен уметь в R и Python. Но базовый навык работы в Excel по прежнему помогает быстро решать многие задачи. При работе над продуктом требуются быстрые выводы по популярным метрикам, dau/mau, конверсия в регистрацию, и показатели метрик часто меняются. Распространенная практика это использовать среднее для всех первичных KPI, если распределение нормальное. Это позволяет делать первичные выводы очень быстро. Понять тип распределение можно с помощью стандартного/среднеквадратичного отклонения. в Excel для этого используется функция =сроткл. Формула выглядит как STD=√[(∑(x-x)2)/n], и расшифровывается как корень из суммы квадратов разниц между элементами выборки и средним, деленной на количество элементов в выборке.
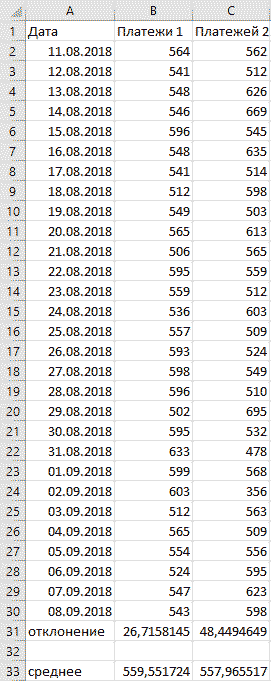
В примере выше видно, что, не смотря на практически одинаковые средние значения, видны огромные колебания данных вокруг среднего значения второго варианта. Первый вариант заслуживает больше доверия.
В Excel еще много замечательных способов визуализировать данные, особенно полезны сводные таблицы. Работают по принципу вирутальной группировки строчек с одинаковыми названиями товаров. Берется группа и считается для нее сумма, очень удобно. Такие таблицы используются для агрегирования данных и получения отчета.
Главное при проведении тестов это умение делать выводы из цифр, критически мыслить, делать выводы на основе исторических данных, генерировать гипотезы, рассуждать, чувство рациональности и нерациональности. Математический анализ лишь помогает не принять вымысел за правду, но окончательное бизнес-решение принимает по прежнему специалист.
В этом модуле вы узнаете:
• как бизнесу измерить реальный эффект от алгоритма по методу A/B-тестирования;
• как провести A/B-тест так, чтобы его результаты были максимально чистыми, и каких ошибок избегать при проведении эксперимента.
А заодно вы научитесь читать результаты таких сравнительных тестов.
Генеральная репетиция: модель машинного обучения против «как было раньше»
Итак, вы прогнали модель через дополнительные тестовые наборы данных, чтобы избежать переобучения и стабилизировать качество ее прогнозов. Кажется, она справилась отлично. Но это еще ничего не значит — модель должна начать работать на реальных данных и доказать свою эффективность на них. Настало время провести сравнительное тестирование в условиях, приближенных к боевым.
В этом нам поможет A/B-тест. Сегодня редкое изменение внедряется сразу без предварительной оценки его эффективности. Маркетологи и менеджеры цифровых продуктов в ИТ быстро пришли к тому, что не стоит тиражировать непроверенное улучшение на всех клиентов, ведь не все новшества одинаково полезны. Поэтому изменения сначала проверяют на части пользователей, а затем сравнивают ключевые метрики с показателями контрольной группы — теми людьми, кто в то же время взаимодействовал с продуктом «по старинке».
Такой подход, когда мы одновременно тестируем старый и новый вариант одной сущности, чтобы наши пользователи своими действиями подсказали нам лучший, и называется A/B-тест. Он применяется повсеместно: при изменении дизайна сайтов и приложений, для поиска оптимальных заголовков email-рассылок и так далее. A/B-тест позволит вам честно ответить на вопрос, работает ли модель лучше, чем обычная программа или человек, которые выполняли эти же задачи раньше.
Как проводят A/B-тесты для проверки моделей машинного обучения: реальные истории и советы
Лучше один раз увидеть, чем несколько раз прочитать, верно? Мы нашли для вас видео, в котором сотрудник проекта Yandex Data Factory (подразделение «Яндекса», которое разрабатывает модели машинного обучения для крупных внешних бизнес-заказчиков) рассказывает о трех реальных тестированиях: как они организовывались и с какими проблемами специалистам и их заказчикам пришлось столкнуться в процессе. Смотрите внимательно!
© «Яндекс»
Результаты A/B-теста легко измерить, но также легко исказить, если допускать ошибки. Мы собрали самые частые из них в одну подборку — пожалуйста, не повторяйте их, когда будете проверять модель.
Вредные советы от экспертов
Тестировать несколько изменений сразу
Представим, что вы решили тестировать новые рекомендации товаров. Меняется не только метод их подбора, а также дизайн и место блока на странице.
Смешав все изменения в кучу, вы не сможете увидеть чистый эффект от внедрения модели. Например, люди могут начать больше покупать потому, что сам блок рекомендаций стал заметнее и поднялся выше на странице. Но не факт, что они стали получать более качественные рекомендации. И, наоборот, если ваша модель стала давать рекомендации, которые действительно нравятся людям, но сам блок с ними стало трудно находить, скорее всего, общие продажи снизятся и модель просто назовут неэффективной, хотя это не так.
Поэтому при проведении A/B-теста рекомендуется вносить одно точечное изменение, чтобы избежать погрешностей и искажений.
Менять процесс целиком, а не встраивать модель в существующий
По факту это еще один вариант идеи «а давайте поменяем все и сразу, чтобы посмотреть, что будет». Часто модели машинного обучения внедряют, чтобы оптимизировать уже существующие процессы, которые раньше выполняли программы и люди. Бывает, что при таком внедрении возникает искушение произвести революцию: сильно перестроить процесс или вовсе заменить его на новый.
Конечно, ситуации бывают разными, но стоит отдавать себе отчет в том, что, возможно, новый процесс просто не будет работать и приносить ожидаемого результата сам по себе, а не потому, что модель плохая.
Поэтому лучше тестировать модель на существующем процессе, не меняя в нем ничего сверх необходимого — так вы точнее поймете, в чем она превосходит, а в чем уступает существующим решениям.
Останавливать тестирование слишком рано
Представьте ситуацию: вы показали изменение 1 000 человек и записали их реакцию, в то же время сайт без изменений просмотрели еще 1 200 посетителей. Новая версия показала лучший результат по дополнительным покупкам за счет рекомендаций — на целых 8%. Хочется зафиксировать победный счет и праздновать, но рано. Потому что затем сложно будет объяснить проседание до 0,3%, которое может случиться на отметке в 10 000 человек. Аналогично не стоит расстраиваться, если поначалу модель не проявит себя (время и статистически значимое число показов, реакций или иных взаимодействий все расставят по своим местам).
Поэтому сравнение двух версий в бою должно длиться до тех пор, пока вы не соберете статистически значимые показатели реакции людей на обе версии. Определить эти значения лучше заранее, как и метрики.
Анализировать результат по не тем показателям
Вы уже знаете о важности выбора метрик. Иногда изменение может положительно отразиться на сиюминутном показателе, но «обвалить» долгосрочный, и наоборот. Например, новая система рекомендаций может повлиять на размер чека покупателя — тот может набрать товаров на меньшую сумму, чем ожидалось. Но благодаря рекомендациям он может начать покупать чаще — и в перспективе сумма, которую компания получит, вырастет. Следом вырастет и выручка — значит, бизнес-цель будет решена, хотя по первым показателям модель справлялась «не очень».
Поэтому еще раз внимательно подумайте над четкими критериями оценки, исходя из решаемой бизнес-задачи. Изменения могут повлиять на несколько показателей — и сделать это как в лучшую, так и в худшую сторону, а вы должны принять взвешенное решение о том, использовать ли модель «в бою» дальше или отправить ее на доработку.
Сколько участников нужно для A/B-тестирования, чтобы мы могли верить его результатам
Мы упомянули статистическую значимость, без которой результаты теста нельзя будет считать надежными. Наверняка у вас возник вопрос: «А сколько человек в моем случае должны увидеть цифровой продукт без изменений и, наоборот, с изменениями, чтобы результаты исследования были достоверными и значимыми?» Давайте научимся оценивать объем выборки.
До старта эксперимента мы можем выдвинуть два предположения.
Первое: эффекта нет, и результаты вариантов А и B не будут различаться. Утверждение такого типа называют нулевой гипотезой.
Второе: изменение, которое мы внедряем, даст какой-то эффект. Утверждение этого типа называют альтернативной гипотезой.
В ходе A/B-теста мы проверим, какой гипотезе можно верить. А рассчитать, сколько наблюдений (сессий, открытий или других взаимодействий) нам нужно, поможет специальный калькулятор.
В интернете существует множество калькуляторов с готовыми формулами расчета для A/B-тестов, а также доступны описания методик из известных проектов. Найдите те, которые понравятся вам, а мы расскажем, как в принципе работать с любым сервисом. Как правило, вам потребуется указать 4 значения:
1. Среднее значение показателя, на который вы хотите повлиять
По сути, это результат до внедрения, с которым будет сравниваться эффект от изменений. Например, если вы внедряете новую систему рекомендаций, стоит указать, в скольких % случаев люди пользовались текущими рекомендациями. Если хотите улучшить процесс распознавания уходящих клиентов — укажите, какой % вам удавалось выявлять до внедрения модели. Эти цифры легко взять из исторических данных.
2. Размер эффекта (как должен измениться показатель)
Это ваше ожидание от внедрения модели — то, насколько вы хотите повлиять на текущий показатель. Эту цифру вы наверняка уже озвучивали, когда формулировали бизнес-цели проекта. Например, если вы говорили, что хотите увеличить конверсию на 2%, эти самые проценты и будут вашим размером эффекта.
Помните: чем меньший эффект вы хотите обнаружить, тем больший объем выборки вам нужен.
3. Вероятность ошибки первого рода (изменений по факту нет, но мы почему-то считаем, что они есть)
Выдавать желаемое за действительное — одна из особенностей человека. Например, по каким-то причинам мы можем посчитать, что конверсия страницы Б превышает конверсию страницы А, но на самом деле статистически две цифры не различаются.
Эта вероятность заложена в формулу расчета выборки и называется уровнем значимости и обозначается греческой буквой α. Вы сами определяете его значение (обычно это 0.1, 0.05 и 0.001 — чем меньше уровень значимости, тем реже ошибочно отвергается нулевая гипотеза).
Помните: чем меньше ошибок первого рода вы хотите допустить, тем больший объем выборки вам нужен.
4. Вероятность ошибки второго рода (изменения по факту есть, но мы их не заметили или проигнорировали)
Ошибка второго рода рассматривает обратную ситуацию. Обычно ее вероятность обозначают как мощность или 1-ß, а рекомендованное стандартное значение — 0.2.
Как A/B-тесты связаны с курсом статистики, который вы изучали в вузе
Мы рекомендуем изучать это видео, только если в институте у вас был курс статистического анализа. Если такого не было — смело переходите к тестам по итогам модуля.
На видео Элен подробнее расскажет о сравнительных тестах с точки зрения математика и их связи с законами распределения, которые вы проходили в вузе или старших классах.
Узнайте, насколько хорошо вы усвоили материал модуля:
ПРОВЕРИТЬ СЕБЯ
A/B-тестирование — это неотъемлемая часть процесса работы над продуктом. Это эксперимент, который позволяет сравнить две версии чего-либо, чтобы проверить гипотезы и определить, какая версия лучше. Должны ли кнопки быть черными или белыми, какая навигация лучше, какой порядок прохождения регистрации меньше всего отпугивает пользователей? Продуктовый дизайнер из Сан-Франциско Лиза Шу рассказывает о простой последовательности шагов, которые помогут провести базовое тестирование.
Кому нужно A/B-тестирование
— Продакт-менеджеры могут тестировать изменения ценовых моделей, направленные на повышение доходов, или оптимизацию части воронки продаж для увеличения конверсии.
— Маркетологи могут тестировать изображения, призывы к действию (call-to-action) или практически любые другие элементы маркетинговой кампании или рекламы с точки зрения улучшения метрик.
— Продуктовые дизайнеры могут тестировать дизайнерские решения (например, цвет кнопки оформления заказа) или использовать результаты тестирования для того, чтобы перед внедрением определить, будет ли удобно пользоваться новой функцией.
Вот шесть шагов, которые нужно пройти, чтобы провести тестирование. В некоторые из пунктов включены примеры тестирования страницы регистрации выдуманного стартапа.
1. Определите цели
Определите основные бизнес-задачи вашей компании и убедитесь, что цели A/B-тестирования с ними совпадают.
Пример: Допустим, вы менеджер продукта в «компании X» на стадии стартапа. Руководству нужно добиться роста количества пользователей. В частности, компания стремится к росту количества активных пользователей (метрика DAU), определяемых как среднее количество зарегистрированных пользователей сайта в день за последние 30 дней. Вы предполагаете, что этого можно добиться либо путем улучшения показателей удержания (процент пользователей, возвращающихся для повторного использования продукта), либо путем увеличения числа новых регистрирующихся пользователей.
В процессе исследования воронки вы замечаете, что 60% пользователей уходят до завершения регистрации. Это означает, что можно повысить количество регистраций, изменив страницу регистрации, что, в свою очередь, должно помочь увеличить количество активных пользователей.
2. Определите метрику
Затем вам нужно определить метрику, на которую вы будете смотреть, чтобы понять, является ли новая версия сайта более успешной, чем изначальная. Обычно в качестве такой метрики берут коэффициент конверсии, но можно выбрать и промежуточную метрику вроде показателя кликабельности (CTR).
Пример: В нашем примере в качестве метрики вы выбираете долю зарегистрированных пользователей (registration rate), определяемую как количество новых пользователей, которые регистрируются, поделенное на общее количество новых посетителей сайта.
3. Разработайте гипотезу
Затем нужно разработать гипотезу о том, что именно поменяется, и, соответственно, что вы хотите проверить. Нужно понять, каких результатов вы ожидаете и какие у них могут быть обоснования.
Пример: Допустим, на текущей странице регистрации есть баннер и форма регистрации. Есть несколько пунктов, которые вы можете протестировать: поля формы, позиционирование, размер текста, но баннер на главной странице визуально наиболее заметен, поэтому сначала надо узнать, увеличится ли доля регистраций, если изменить изображение на нём.
Общая гипотеза заключается в следующем: «Если изменить главную страницу регистрации, то больше новых пользователей будут регистрироваться внутри продукта, потому что новое изображение лучше передает его ценности».
Нужно определить две гипотезы, которые помогут понять, является ли наблюдаемая разница между версией A (изначальной) и версией B (новой, которую вы хотите проверить) случайностью или результатом изменений, которые вы произвели.
— Нулевая гипотеза предполагает, что результаты, А и В на самом деле не отличаются и что наблюдаемые различия случайны. Мы надеемся опровергнуть эту гипотезу.
— Альтернативная гипотеза — это гипотеза о том, что B отличается от A, и вы хотите сделать вывод об её истинности.
Решите, будет ли это односторонний или двусторонний тест. Односторонний тест позволяет обнаружить изменение в одном направлении, в то время как двусторонний тест позволяет обнаружить изменение по двум направлениям (как положительное, так и отрицательное).
4. Подготовьте эксперимент
Для того, чтобы тест выдавал корректные результаты сделайте следующее:
— Создайте новую версию (B), отражающую изменения, которые вы хотите протестировать.
— Определите контрольную и экспериментальную группы. Каких пользователей вы хотите протестировать: всех пользователей на всех платформах или только пользователей из одной страны? Определите группу испытуемых, отобрав их по типам пользователей, платформе, географическим показателям и т. п. Затем определите, какой процент исследуемой группы составляет контрольная группа (группа, видящая версию A), а какой процент — экспериментальная группа (группа, видящая версию B). Обычно эти группы одинакового размера.
— Убедитесь, что пользователи будут видеть версии A и B в случайном порядке. Это значит, у каждого пользователя будет равный шанс получить ту или иную версию.
— Определите уровень статистической значимости (α). Это уровень риска, который вы принимаете при ошибках первого рода (отклонение нулевой гипотезы, если она верна), обычно α = 0.05. Это означает, что в 5% случаев вы будете обнаруживать разницу между A и B, которая на самом деле обусловлена случайностью. Чем ниже выбранный вами уровень значимости, тем ниже риск того, что вы обнаружите разницу, вызванную случайностью.
— Определите минимальный размер выборки. Калькуляторы есть здесь и здесь, они рассчитывают размер выборки, необходимый для каждой версии. На размер выборки влияют разные параметры и ваши предпочтения. Наличие достаточно большого размера выборки важно для обеспечения статистически значимых результатов.
— Определите временные рамки. Возьмите общий размер выборки, необходимый вам для тестирования каждой версии, и разделите его на ваш ежедневный трафик, так вы получите количество дней, необходимое для проведения теста. Как правило, это одна или две недели.
Пример: На существующем сайте в разделе регистрации мы изменим главную страницу — это и будет нашей версией B. Мы решаем, что в эксперименте будут участвовать только новые пользователи, заходящие на страницу регистрации. Мы также обеспечиваем случайную выборку, то есть каждый пользователь будет иметь равные шансы получить A или B, распределенные случайным образом.
Важно определить временные рамки. Допустим, ежедневно на нашу страницу регистрации в среднем приходит трафик от 10 000 новых пользователей, это означает, что только 5000 пользователей могут увидеть каждую версию. Тогда минимальный размер выборки составляет около 100 000 просмотров каждой версии. 100 000/ 5000 = 20 дней — столько должен продлиться эксперимент.
5. Проведите эксперимент
Помните о важных шагах, которые необходимо выполнить:
— Обсудите параметры эксперимента с исполнителями.
— Выполните запрос на тестовой закрытой площадке, если она у вас есть. Это поможет проверить данные. Если ее нет, проверьте данные, полученные в первый день эксперимента.
— В самом начале проведения тестирования проверьте, действительно ли оно работает.
— И, наконец, не смотрите на результаты! Преждевременный просмотр результатов может испортить статистическую значимость. Почему? Читайте здесь.
6. Анализируйте результаты. Наконец-то самое интересное
Вам нужно получить данные и рассчитать значения выбранной ранее метрики успеха для обеих версий (A и B) и разницу между этими значениями. Если не было никакой разницы в целом, вы также можете сегментировать выборку по платформам, типам источников, географическим параметрам и т. п., если это применимо. Вы можете обнаружить, что версия B работает лучше или хуже для определенных сегментов.
Проверьте статистическую значимость. Статистическая теория, лежащая в основе этого подхода, объясняется здесь, но основная идея в том, чтобы выяснить, была ли разница в результатах между A и B связана с изменениями или это результат случайности или естественных изменений. Это определяется путем сравнения тестовых статистических данных (и полученного p-значения) с вашим уровнем значимости.
Если p-значение меньше уровня значимости, то можно отвергнуть нулевую гипотезу, имея доказательства для альтернативы.
Если p-значение больше или равно уровню значимости, мы не можем отвергнуть нулевую гипотезу о том, что A и B не отличаются друг от друга.
A/B-тестирование может дать следующие результаты:
— Контрольная версия, А выигрывает или между версиями нет разницы. Если исключить причины, которые могут привести к недействительному тестированию, то проигрыш новой версии может быть вызван, например, плохим сообщением и брендингом конкурентного предложения или плохим клиентским опытом.
В этом сценарии вы можете углубиться в данные или провести исследование пользователей, чтобы понять, почему новая версия не работает так, как ожидалось. Это, в свою очередь, поможет собрать информацию для следующих тестов.
— Версия B выигрывает. A/B-тест подтвердил вашу гипотезу о лучшей производительности версии B по сравнению с версией A. Отлично! Опубликовав результаты, вы можете провести эксперимент на всей аудитории и получить новые результаты.
Заключение
Независимо от того, был ли ваш тест успешным или нет, относитесь к каждому эксперименту как к возможности для обучения. Используйте то, чему вы научились, для выработки вашей следующей гипотезы. Вы можете, например, использовать предыдущий тест или сконцентрироваться на другой области, требующей оптимизации. Возможности бесконечны.
A/B тестирование — процесс интересный. Особенно если учесть, что сейчас огромное количество самых разных инструментов, и провести тест можно, не прилагая особых усилий. Однако далеко не все компании это делают. Кто-то не совсем понимает, как нужно проводить тест, кто-то недоволен первоначальными результатами и не хочет вновь в это «ввязываться», кто-то не знает, что делать дальше. Как правило, большая часть таких действий — последствия неправильных решений до, во время или после проведения теста. К счастью, их можно избежать.
1. Длительность теста слишком мала
Статистическая значимость — вот, что дает вам понять, что версия A лучше, чем версия В (при условии, что выборка достаточно большая). Если тест остановить, когда статистическая значимость равняется 50% — это все равно, как если бы мы вместо теста просто бросили монетку. И даже если мы получаем 80% — этого тоже недостаточно.
Как насчет 90%? Уже очень неплохо! Но можно и лучше.
Вы проводите научный эксперимент. И наверняка, вам важно, получить достоверные результаты. Но людям свойственно привязываться к своей гипотезе или варианту дизайна, и мысль о том, что лучшее предположение, оказывается, практически ничем не лучше текущего варианта, очень болезненна и воспринимается с трудом.
Но правда превыше всего — иначе все теряет смысл.
Часто бывает так, что компания целый год проводит тесты, один за другим, и по их результатам выкатывает нововведения, но конверсия не меняется. И так все время.
Почему так происходит? Потому что тесты прекратились очень рано или выборка была недостаточно большой. Вы не должны останавливать тест, пока не достигнете статистической значимости в 95% или выше. Показатель в 95% означает, что есть только 5%-ный шанс на то, что результаты — это чистая случайность.
Всегда остерегайтесь A/B тестов, которые заканчиваются слишком быстро, и всегда перепроверяйте данные. Самое худшее, что может быть, вы будете опираться на данные, которые в действительности не являются точными. Это ведет к потере денег и времени.
Насколько большой должна быть выборка?
Не стоит делать выводы, основываясь на небольшом количестве данных. Как минимум, для каждого тестируемого варианта нужно собрать 100 конверсий, прежде чем сделать какие либо заключения. Если трафика много — 250 конверсий.
Есть и особые случаи, когда вы можете прекратить эксперимент раньше времени — это если у вас уже есть высокий показатель конверсии и существенная разница между вариантами.
Что если уже есть 100 или даже 250 конверсий, а статистическая значимость не составляет 95%?
Это означает, что между вариантами нет существенной разницы. Проверьте результаты теста, продумайте еще раз гипотезу и запускайте новый тест.
2.Тесты не запускаются на полные недели
Давайте представим, что на сайт идет хороший трафик, и за три дня у нас получилось собрать 250 конверсий и 98% статистическую значимость. Тест окончен? Нет.
Вы начали тест в понедельник? Тогда и заканчиваем его в понедельник. Почему? Конверсия может колебаться в зависимости от дня недели.
Если эксперимент длится несколько дней, а не полную неделю, вы рискуете получить недостоверные результаты. Посмотрите в Google Analytics отчет по конверсиям в разные дни недели, колебания могут быть значительными. Пример:

Что мы тут видим? В четверг зафиксировано в 2 раза больше конверсий, чем в субботу и воскресенье, и показатель конверсии в четверг практически в два раза выше, чем в субботу.
Если мы не будем проводить эксперимент в течение полной недели, результаты будут некорректны. Итак, вот, что вы должны делать: запускать тесты как минимум на 7 дней. Если результаты не достигнуты за первые 7 дней, продлеваем тест еще на столько же. Если опять нет результата, еще на 7.
Единственный случай, когда можно сделать исключение — если данные показывают, что каждый день конверсия одинакова. Но даже в этом случае, все же лучше выбрать неделю.
Всегда уделяйте внимание внешним факторам, например, сезонность и праздники.
На дворе Рождество? Тест, который вы проводите в это время, может и не показать такие выдающиеся результаты в январе после праздников. Если вы запустили эксперимент в период высокого спроса, то непременно повторите его, когда он закончится. Проводите масштабную рекламную кампанию? Она также может исказить результаты. Внешние факторы всегда влияют на результаты экспериментов. Есть сомнения? Проведите еще один тест.
3.Сплит-тестирование проводится, даже если нет трафика и конверсий
Если у вас 1-2 продажи в месяц, и вы запускаете эксперимент, по результатам которого страница B конвертируется лучше, чем страница А, на 15% — как вы это узнаете? Ведь ничего не изменилось!
Не стоит использовать А/В тестирование для оптимизации конверсии, если у вас мало трафика. Причина заключается в том, что, даже если версия B намного лучше, чтобы получить заметные результаты потребуется много времени.
Вместо этого следует просто перейти на версию В. Без тестирования. Запускаете и смотрите результаты. Идея состоит в том, чтобы получить большой подъем — в 50-100%.
4.Тесты не всегда основаны на гипотезе
Идеи для эксперимента не появляются просто так. Они основываются на гипотезах.
Очень часто бывает так, что компания выбирает в качестве идеи для теста первое, что приходит в голову. И получается что-то вроде эксперимента со спагетти — мы бросаем их в стену, только ради того, чтобы узнать прилипнут они или нет. То есть мы просто тестируем случайную идею.
Случайные идеи обходятся недешево — на них тратится драгоценное время и трафик. Никогда так не делайте. У вас должна быть гипотеза. Что это такое, кстати?
Гипотеза — положение, выдвигаемое в качестве предварительного, условного объяснения некоторого явления или группы явлений; предположение о существовании некоторого явления.
И это не должна быть гипотеза в стиле «спагетти». Необходимо проанализировать и выяснить, какие проблемы могут быть и где, провести исследование, найти причину проблем, одновременно выстраивая гипотезу для их решения.
Если вы тестируете версию А против версии В, не имея четкой гипотезы, и версия В оказывается лучше на 15%, что вы узнаете из этого? Ничего.
 Ирина Чернова, руководитель отдела аналитики агентства i-Media:
Ирина Чернова, руководитель отдела аналитики агентства i-Media:
Поддерживаю пункт 4. Гипотеза эксперимента — это самый важный элемент. На начало эксперимента вы должны понимать, за счет чего вы хотите улучшить свою страницу.
Тестирование отвечает на вопрос: да, этот вариант лучше, чем предыдущий вариант. Если гипотеза построена верно, на основе статистики и знаний, то и эксперименты зачастую успешны.
Улучшайте ваши сайты и делайте их более удобными и понятными для пользователей.
5. Данные не отгружаются в Google Analytics
Усредненные цифры всегда врут, не забывайте об этом. Если версия А лучше, чем В на 10%, это далеко не полная картина. Необходимо сегментировать тестовые данные в Google Analytics — чтобы позволит найти важную информацию.

Встроенная сегментация также есть в инструменте Optimizely, но функционал гораздо скромнее, чем в Google Analytics. Visual Website Optimizer позволяет настроить автоматическую выгрузку данных в Google Analytics, которая будет происходить для каждого проводимого теста.
6.Время и трафик тратятся на глупые тесты
Вы тестируете цвета? Остановитесь. Не тратьте время и трафик на бессмысленные эксперименты только потому, что у кого-то это сработало. Тестируйте гипотезы, основанные на реальных данных.
7.Сдаваться после первой неудачной попытки
Мы провели тест, он не получился. Итак, попробуем провести тестирование другой страницы?
Не так быстро. Большинство «первых» тестов проваливаются. Но нужно повторять их. Мы запустили тест. Сделали соответствующий вывод, улучшили нашу гипотезу. Запускайте еще один тест следом, делайте выводы, и улучшайте гипотезу. Затем запустите еще один тест и т.д.
Вот пример компании, которая провела 6 тестов подряд с одной и той же страницей, чтобы получить результат, который их удовлетворит. Именно так и происходит в реальности.
Если думать, что первый тест превзойдет все ожидания, деньги будут потрачены зря и кто-то, возможно, потеряет работу. И это не должно быть так. Просто нужно запускать серию тестов.
8.Непонимание ошибок первого рода
Статистическая значимость — это не единственная вещь, которой нужно уделять внимание. Нужно также понимать ошибки первого рода. Нетерпеливые тестеры захотят пропустить А/В тестирование, и перейти к A/B/C/D/E/F/G/H — например, Google тестировал 41 оттенок синего цвета. Но это не самая хорошая идея. Чем больше вариантов вы тестируете, тем более высока вероятность ошибки первого рода. В случае 41 оттенка синего, даже при 95% статистической значимости шанс ошибки первого рода 88%.
Не тестируйте множество вариантов за 1 раз. Лучше делать простое А/В тестирование — вы быстрее получите результаты, сделаете вывод и улучшите гипотезу.
9.Проведение нескольких тестов одновременно с наложениями трафика
На своем ecommerce сайте вы решили запустить несколько тестов одновременно. Один на странице товара, другой на странице корзины, третий — на главной странице и т.д. Экономим время, не так ли?
Нет. Мы просто искажаем результаты. Если вы хотите тестировать новую версию сразу нескольких страниц — например, главную, страницу товара и чекаута — вы должны использовать многостраничные эксперименты, созданные специально для этого — функционал позволит им видеть либо новые версии для каждой страницы, либо старые варианты, но не чередовать их.
10.Игнорирование небольших достижений
Представим, что по результатам эксперимента тестовый вариант позволяет нам увеличить текущие показатели на 4%. Многие скажут: «Слишком небольшая выгода! Даже не буду напрягаться, чтобы внедрить обновление».
Но дело вот в чем — если сайт хороший, у вас не будет значительных результатов все время. По факту, они случаются очень редко. Если сайт не очень, может быть так, что большинство тестов позволит получать 50%-ное улучшение каждый раз. Но все равно это рано или поздно закончится.
Большинство успешных тестов получают небольшие результаты 1%, 5%, 8%. Иногда даже 1%-улучшение может привести в результате к миллионным доходам. Все зависит от цифр, с которыми мы имеем дело. Но главное вот что — на все нужно смотреть с годовой перспективы.
Один тест — это лишь один тест. Вы будете делать много тестов. Если вы будете увеличивать свою конверсию на 5% каждый месяц, через 12 месяцев первоначальный показатель конверсии вырастет уже на 80%.
Поэтому обращайте внимание на небольшие победы. В конце концов, вы в итоге получите больше.
11.Тесты не проводятся на постоянной основе
День без теста потрачен впустую. Тестирование — это обучение. Новые знания о вашей аудиторией, о том, что работает, а что — нет. Все это можно использовать в маркетинге, контексте и т.д.
Вы не узнаете, что работает, пока вы это не протестируете. Тестам нужны трафик и время.
Это вовсе не значит, что нужно запускать любые тесты, даже плохие. В любом случае нужно тщательное исследование, гипотеза и т.д.
 Наталья Чернецова, веб-аналитик агентства интернет-маркетинга SEO-Matik:
Наталья Чернецова, веб-аналитик агентства интернет-маркетинга SEO-Matik:
К перечисленным ошибкам я хочу добавить несколько базовых, от которых в принципе зависит возможность получения результатов.
Первая ошибка — неправильно поставленная задача. У заказчика и исполнителя нет понимания, для чего делать тестирование. В основе каждого тестирования должен находиться маркетинг. Я говорю о точной формулировке бизнес-задач. Улучшения ради улучшений не имеют смысла.
Вторая ошибка — отсутствие систематичности. Исследования проводятся от случая к случаю.
Третья ошибка — нет конверсии знаний в конкретные действия. Заказчик получает анализ, но либо не выполняет рекомендации, либо выполняет их не полностью.
Наконец, четвертая ошибка — тестирование одновременно нескольких элементов. Из-за этого сложно выявить, какое изменение повлияло на конверсию.
Могу сказать, что инструментов для тестирования много, но специалистов, которые способны его провести и обработать данные — мало.
По материалам conversionxl.com
Вчера мне в очередной раз пришлось объяснять почему DataScientist-ы не используют ошибки первого и второго рода и зачем же ввели полноту и точность. Вот прямо заняться нам нечем, лишь бы новые критерии вводить.
И если ошибка второго рода выражается просто:

где Π — это полнота;
то вот ошибка первого рода весьма нетривиально выражается через полноту и точность (см.ниже).
Но это лирика. Самый важный вопрос:
Почему в DataScience используют полноту и точность и почти никогда не говорят об ошибках первого и второго рода?
Кто не знает или забыл — прошу под кат.
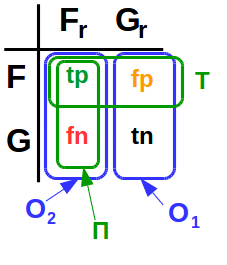
Бизнес-задача
Так как Хабр — это блог IT-шников, постараюсь по минимуму использовать мат.абстракции и рассказывать сразу на примере. Предположим, что мы решаем задачу Fraud-мониторинга в ДБО условного банка Roga & Copyta, сокращённо R&C.
Предположим, что у мы разработали некую автоматизированную экспертную систему (ЭС), определяющую для каждой платёжной транзакции: является ли данная транзакция мошеннической (fraud, F) или легитимной (genuine, G).
Необходимо определить «хорошие» критерии оценки качества системы и дать формулы расчета этих критериев.
Так как Roga & Copyta — это хоть и маленький, но всё же банк, то в нём работают люди меркантильные и ничего кроме денег их не интересует. Поэтому разрабатываемые критерии должны максимально прозрачно показывать: насколько выгодно им использовать нашу ЭС? Может быть выгодно установить ЭС конкурентов?
События и вероятности
Для каждой транзакции могут быть определены четыре события:
- Fr (fraud real) — событие того, что транзакция в действительности окажется мошеннической;
- Gr (genuine real) — событие того, что транзакция в действительности окажется легитимной;
- F — событие того, что ЭС «определит» транзакцию как мошенническую;
- G — событие того, что ЭС «определит» транзакцию как легитимную
Очевидно, что Fr и Gr — несовместные события; аналогично F и G — несовместные. По этой причине разумно рассматривать четыре вероятности:

Аббревиатуры читаются так:
- tn — true negative
- fn — false negative
- fp — false positive
- tp — true positive
Мы можем рассматривать условные вероятности:

Так же нам будут интересны и «обратные» условные вероятности:

Например вероятность  означает следующее:
означает следующее:
Какова вероятность того, что транзакция действительно окажется мошеннической, если ЭС «определила» это событие как мошенническое.
Не следует путать с  , которое можно определить словами:
, которое можно определить словами:
Какова вероятность того, что ЭС «назовёт» транзакцию мошеннической, если данная транзакция действительно мошенническая.
Аналогично можно определить словами и другие условные вероятности.
Вспомним определения
В статистике любят говорить о нулевой гипотезе (H0) и альтернативной (H1) гипотезе. Обычно под нулевой гипотезой определяют «естественное» состояние. В случае фрод-мониторинга «естественным» состоянием является то, что транзакция легитимная. Это действительно разумно, хотя бы по той причине, что количество мошеннических транзакций гораздо меньше количества легитимных.
Поэтому за нулевую гипотезу примем Gr, а за альтернативную Fr.
Ошибки первого (O1) и второго (O2) рода определяются так:

Словами
Ошибка первого рода (O1) — это вероятность того, что ЭС «определит» транзакцию как мошенническую, при условии, что она легитимная.
Ошибка второго рода (O2) — это вероятность того, что ЭС «определит» транзакцию как легитимную, при условии, что она мошенническая.
Замечание: часто ошибку первого рода называют false positives а ошибку второго рода как false negatives. В том числе, таковы определения в википедии. Это верно по сути. Но
и
 и
и  . Очень многие новички в DataScience делают такую ошибку и путаются.
. Очень многие новички в DataScience делают такую ошибку и путаются.Полнота (П) и точность (Т) по определению:

Т.е. полнота — это вероятность того, что ЭС «определит» транзакцию мошеннической, при условии, что она действительно мошенническая. А точность — это вероятность того, что транзакция действительно мошенническая, при условии, что ЭС «определила» транзакцию как мошенническую.
Полноту и точность можно выразить через tp, fp, fn следующим образом:

Вывод формул
Выводим тупо в лоб.
Для полноты:

Для точности:

Следует заметить, что именно эти формулы очень частно приводят в качестве определения полноты и точности. Тут вопрос во вкусе. Можно сказать, что квадрат — это прямоугольник, у которого все стороны равны и доказать, что ромб с прямым углом — это квадрат. А можно наоборот. Например, когда я учился в школе, у меня квадрат определяли как ромб с прямым углом и доказывали, что прямоугольник с равными сторонами — это квадрат.
Но все же определение полноты как  и точности как T
и точности как T  мне кажется более правильным. Сразу понятно в чем физический смысл этих величин. Понятно, зачем они нужны.
мне кажется более правильным. Сразу понятно в чем физический смысл этих величин. Понятно, зачем они нужны.
Бизнес-смысл полноты и точности
Предположим, что для Roga & Copyta мы создали систему с полнотой в 80% и точностью в 10%.
Предположим, что без ЭС банк теряет на мошенничестве 1 миллиард тугриков (₮) в год. Это значит, что благодаря ЭС они смогут предотвратить хищение на сумму в 800 миллионов ₮. Останется еще 200 миллионов ₮ — это ущерб банку (или клиентам банка), который не смогла предотвратить ЭС.
А что на счет точности в 10%? Данная величина значит, что из 100 сработок ЭС только 10 будут попадать по цели, а в остальных случаях мы приостановим легитимные транзакции. Хорошо это или плохо?
Во-первых при остановки транзакции банк совершает какие-либо действия. Например звонит клиентам с просьбой подтвердить операции.
Во-вторых заблокировать легитимные транзакции тоже не всегда хорошая идея. Представьте, что вы сидите с девушкой в ресторане, просите счёт, оплачиваете картой… А тут бах… ЭС ошибочно подсчитала что вы — мошенник… Наверное не очень удобно будет перед барышней… Но мы, чтобы не усложнять, пока опустим эту проблему.
Итак, предположим один звонок стоит 1000 ₮. Так же предположим что средний чек хакера у нас составляет 100 тысяч ₮.
Так как мы предотвращаем мошенничества на 800 миллионов ₮, то в среднем у нас будет 8000 правильных мошеннических сработок. Но 8000 — это, судя по точности, лишь 10%; следовательно всего мы позвоним 80000 раз. Умножаем эту цифру на стоимость одного звонка (1000 ₮) и получаем аж 80 миллионов ₮!
Итоговый ущерб в год для банка R&C равен: 200 + 80 = 280 миллионов ₮. Но без ЭС банк терял бы один один миллиард. Следовательно выгода R&C составляет 720 миллионов тугриков.
нюанс
Следует различать полноту и точность по количеству транзакций и по суммам. Это четыре разные величины. Здесь я «смешал все в кучу», что, конечно не верно! ;)) Будем считать что полнота и точность 80% и 10% как по количеству транзакций, так и по денежным суммам.
Бизнес-смысл ошибок первого и второго рода
Ошибка второго рода элементарно выводится через полноту:
Вывод формулы элементарен (см. следующий параграф)
Поэтому что считать — полноту или упущенный фрод (ошибка второго рода) особой разницы не представляет.
А что на счет ошибки первого рода?

Это вероятность того, что ЭС назовёт мошеннической операцией транзакцию, при условии что она легитимная. Проблема в том, что легитимных транзакций существенно больше мошеннических. Есть банки, в которых более 50 платёжных транзакций в секунду… И это совсем не предел.
R&C — банк небольшой, там всего пять платёжных транзакций в секунду. Давайте посчитаем, сколько это в сутки:

В прошлом параграфе мы узнали, что в R&C 80000 сработок в год, это значит что в сутки в среднем 80000 / 365 = 219,17 сработок. Из них только 10% попали в цель (такова точность), то есть 22. Значит остальные — подлинные: 432000 — 22 = 431978.
Так как полнота 80%, то из этих 22 мы только 4.4 будем упускать.
Значит ошибка первого рода:

Слишком маленькая величина! Бизнес не любит такие числа. Так же сложнее, чем для точности высчитать пользу и ущерб для бизнеса. И есть еще одна проблема:
через ошибку первого рода, можно косвенно понять об объемах платёжных операций в банке!
Что касается точности, то такой проблемы нет. Специалисты из отдела безопасности R&C знают об объемах мошенничества. Они узнают о допустимой нагрузке на контактный центр у самой главной девочки + спрашивают руководство банка о желаемой полноте. Зная абсолютную нагрузку, желаемую полноту и объем фрода можно без труда вычислить приемлемую точность. Эти две цифры вписываются в техническое задание (или тендер).
Разработчику выдают выборку из мошеннических транзакций и легитимных. Если выборка репрезентативна, этих данных достаточно.
«Неправильность» точности с точки зрения чистой математики
Если объем транзакций увеличится в два раза, то точность уменьшится. Если объем мошенничества увеличится в два раза, то точность так же будет больше… С ошибкой первого рода такой проблемы нет, поэтому с точки зрения «чистой математики», эта величина гораздо более «правильная»…
Но на практике, если и резко увеличивается объем мошенничества, то как правило это фрод нового типа и ЭС просто не обучена его ловить… Точность останется той же (а вот полнота уменьшиться, т.к. появится фрод, который мы не умеем ловить). Что касается увеличения количества легитимных транзакций — то это увеличение постепенное и никаких «рывков» не будет.
Поэтому на практике точность — замечательный, понятный для бизнеса критерий оценки качества ЭС.
Вывод ошибок первого рода и второго рода из полноты и точности
Но может быть существует изящная формула вывода ошибки первого рода через точность?
Вот с ошибкой второго рода как все красиво:
Вывод формулы

К сожалению с O1 так изящно не получится. Вот отношение через точность (Т) и полноту (П):

Вывод формулы
Эй! Ты что такой ленивый! А ну давай сам попробуй!
Я сегодня плохо спал, Павел! Ну покажи!
Из  и
и
 можно составить выражение:
можно составить выражение:

Откуда следует:

Уже из этого отношения легко получить формулу для O1
Заключение
Точность и полнота «не хуже» и «не лучше» чем ошибки первого и второго рода. Всё зависит от задачи. Мы же не едим столовой ложкой торт, а чайной борщ? Хотя это возможно.
Точность и полнота более понятные критерии качества. Ими легче оперировать. С помощью них просто вычислить предотвращённый ущерб в задаче фрод-мониторинга.
Если вы обнаружили описку или грамматическую ошибку — прошу написать в личку.
В машинном обучении различают оценки качества для задачи классификации и регрессии. Причем оценка задачи классификации часто значительно сложнее, чем оценка регрессии.
Содержание
- 1 Оценки качества классификации
- 1.1 Матрица ошибок (англ. Сonfusion matrix)
- 1.2 Аккуратность (англ. Accuracy)
- 1.3 Точность (англ. Precision)
- 1.4 Полнота (англ. Recall)
- 1.5 F-мера (англ. F-score)
- 1.6 ROC-кривая
- 1.7 Precison-recall кривая
- 2 Оценки качества регрессии
- 2.1 Средняя квадратичная ошибка (англ. Mean Squared Error, MSE)
- 2.2 Cредняя абсолютная ошибка (англ. Mean Absolute Error, MAE)
- 2.3 Коэффициент детерминации
- 2.4 Средняя абсолютная процентная ошибка (англ. Mean Absolute Percentage Error, MAPE)
- 2.5 Корень из средней квадратичной ошибки (англ. Root Mean Squared Error, RMSE)
- 2.6 Cимметричная MAPE (англ. Symmetric MAPE, SMAPE)
- 2.7 Средняя абсолютная масштабированная ошибка (англ. Mean absolute scaled error, MASE)
- 3 Кросс-валидация
- 4 Примечания
- 5 См. также
- 6 Источники информации
Оценки качества классификации
Матрица ошибок (англ. Сonfusion matrix)
Перед переходом к самим метрикам необходимо ввести важную концепцию для описания этих метрик в терминах ошибок классификации — confusion matrix (матрица ошибок).
Допустим, что у нас есть два класса и алгоритм, предсказывающий принадлежность каждого объекта одному из классов.
Рассмотрим пример. Пусть банк использует систему классификации заёмщиков на кредитоспособных и некредитоспособных. При этом первым кредит выдаётся, а вторые получат отказ. Таким образом, обнаружение некредитоспособного заёмщика () можно рассматривать как «сигнал тревоги», сообщающий о возможных рисках.
Любой реальный классификатор совершает ошибки. В нашем случае таких ошибок может быть две:
- Кредитоспособный заёмщик распознается моделью как некредитоспособный и ему отказывается в кредите. Данный случай можно трактовать как «ложную тревогу».
- Некредитоспособный заёмщик распознаётся как кредитоспособный и ему ошибочно выдаётся кредит. Данный случай можно рассматривать как «пропуск цели».
Несложно увидеть, что эти ошибки неравноценны по связанным с ними проблемам. В случае «ложной тревоги» потери банка составят только проценты по невыданному кредиту (только упущенная выгода). В случае «пропуска цели» можно потерять всю сумму выданного кредита. Поэтому системе важнее не допустить «пропуск цели», чем «ложную тревогу».
Поскольку с точки зрения логики задачи нам важнее правильно распознать некредитоспособного заёмщика с меткой , чем ошибиться в распознавании кредитоспособного, будем называть соответствующий исход классификации положительным (заёмщик некредитоспособен), а противоположный — отрицательным (заемщик кредитоспособен ). Тогда возможны следующие исходы классификации:
- Некредитоспособный заёмщик классифицирован как некредитоспособный, т.е. положительный класс распознан как положительный. Наблюдения, для которых это имеет место называются истинно-положительными (True Positive — TP).
- Кредитоспособный заёмщик классифицирован как кредитоспособный, т.е. отрицательный класс распознан как отрицательный. Наблюдения, которых это имеет место, называются истинно отрицательными (True Negative — TN).
- Кредитоспособный заёмщик классифицирован как некредитоспособный, т.е. имела место ошибка, в результате которой отрицательный класс был распознан как положительный. Наблюдения, для которых был получен такой исход классификации, называются ложно-положительными (False Positive — FP), а ошибка классификации называется ошибкой I рода.
- Некредитоспособный заёмщик распознан как кредитоспособный, т.е. имела место ошибка, в результате которой положительный класс был распознан как отрицательный. Наблюдения, для которых был получен такой исход классификации, называются ложно-отрицательными (False Negative — FN), а ошибка классификации называется ошибкой II рода.
Таким образом, ошибка I рода, или ложно-положительный исход классификации, имеет место, когда отрицательное наблюдение распознано моделью как положительное. Ошибкой II рода, или ложно-отрицательным исходом классификации, называют случай, когда положительное наблюдение распознано как отрицательное. Поясним это с помощью матрицы ошибок классификации:
-
Истинно-положительный (True Positive — TP) Ложно-положительный (False Positive — FP) Ложно-отрицательный (False Negative — FN) Истинно-отрицательный (True Negative — TN)
Здесь — это ответ алгоритма на объекте, а — истинная метка класса на этом объекте.
Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP).
P означает что классификатор определяет класс объекта как положительный (N — отрицательный). T значит что класс предсказан правильно (соответственно F — неправильно). Каждая строка в матрице ошибок представляет спрогнозированный класс, а каждый столбец — фактический класс.
# код для матрицы ошибок # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import confusion_matrix from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (англ. Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе # Для расчета матрицы ошибок сначала понадобится иметь набор прогнозов, чтобы их можно было сравнивать с фактическими целями y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687], # [ 1891, 3530]])
Безупречный классификатор имел бы только истинно-положительные и истинно отрицательные классификации, так что его матрица ошибок содержала бы ненулевые значения только на своей главной диагонали (от левого верхнего до правого нижнего угла):
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.metrics import confusion_matrix
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist["data"], mnist["target"]
y = y.astype(np.uint8)
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки
y_test_5 = (y_test == 5)
y_train_perfect_predictions = y_train_5 # притворись, что мы достигли совершенства
print(confusion_matrix(y_train_5, y_train_perfect_predictions))
# array([[54579, 0],
# [ 0, 5421]])
Аккуратность (англ. Accuracy)
Интуитивно понятной, очевидной и почти неиспользуемой метрикой является accuracy — доля правильных ответов алгоритма:
Эта метрика бесполезна в задачах с неравными классами, что как вариант можно исправить с помощью алгоритмов сэмплирования и это легко показать на примере.
Допустим, мы хотим оценить работу спам-фильтра почты. У нас есть 100 не-спам писем, 90 из которых наш классификатор определил верно (True Negative = 90, False Positive = 10), и 10 спам-писем, 5 из которых классификатор также определил верно (True Positive = 5, False Negative = 5).
Тогда accuracy:
Однако если мы просто будем предсказывать все письма как не-спам, то получим более высокую аккуратность:
При этом, наша модель совершенно не обладает никакой предсказательной силой, так как изначально мы хотели определять письма со спамом. Преодолеть это нам поможет переход с общей для всех классов метрики к отдельным показателям качества классов.
# код для для подсчета аккуратности: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import accuracy_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(accuracy_score(y_train_5, y_train_pred)) # == (53892 + 3530) / (53892 + 3530 + 1891 +687) # 0.9570333333333333
Точность (англ. Precision)
Точностью (precision) называется доля правильных ответов модели в пределах класса — это доля объектов действительно принадлежащих данному классу относительно всех объектов которые система отнесла к этому классу.
Именно введение precision не позволяет нам записывать все объекты в один класс, так как в этом случае мы получаем рост уровня False Positive.
Полнота (англ. Recall)
Полнота — это доля истинно положительных классификаций. Полнота показывает, какую долю объектов, реально относящихся к положительному классу, мы предсказали верно.
Полнота (recall) демонстрирует способность алгоритма обнаруживать данный класс вообще.
Имея матрицу ошибок, очень просто можно вычислить точность и полноту для каждого класса. Точность (precision) равняется отношению соответствующего диагонального элемента матрицы и суммы всей строки класса. Полнота (recall) — отношению диагонального элемента матрицы и суммы всего столбца класса. Формально:
Результирующая точность классификатора рассчитывается как арифметическое среднее его точности по всем классам. То же самое с полнотой. Технически этот подход называется macro-averaging.
# код для для подсчета точности и полноты: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import precision_score, recall_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(precision_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 687) print(recall_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 1891) # 0.8370879772350012 # 0.6511713705958311
F-мера (англ. F-score)
Precision и recall не зависят, в отличие от accuracy, от соотношения классов и потому применимы в условиях несбалансированных выборок.
Часто в реальной практике стоит задача найти оптимальный (для заказчика) баланс между этими двумя метриками. Понятно что чем выше точность и полнота, тем лучше. Но в реальной жизни максимальная точность и полнота не достижимы одновременно и приходится искать некий баланс. Поэтому, хотелось бы иметь некую метрику которая объединяла бы в себе информацию о точности и полноте нашего алгоритма. В этом случае нам будет проще принимать решение о том какую реализацию запускать в производство (у кого больше тот и круче). Именно такой метрикой является F-мера.
F-мера представляет собой гармоническое среднее между точностью и полнотой. Она стремится к нулю, если точность или полнота стремится к нулю.
Данная формула придает одинаковый вес точности и полноте, поэтому F-мера будет падать одинаково при уменьшении и точности и полноты. Возможно рассчитать F-меру придав различный вес точности и полноте, если вы осознанно отдаете приоритет одной из этих метрик при разработке алгоритма:
где принимает значения в диапазоне если вы хотите отдать приоритет точности, а при приоритет отдается полноте. При формула сводится к предыдущей и вы получаете сбалансированную F-меру (также ее называют ).
-

Рис.1 Сбалансированная F-мера,
-

Рис.2 F-мера c приоритетом точности,
-

Рис.3 F-мера c приоритетом полноты,
F-мера достигает максимума при максимальной полноте и точности, и близка к нулю, если один из аргументов близок к нулю.
F-мера является хорошим кандидатом на формальную метрику оценки качества классификатора. Она сводит к одному числу две других основополагающих метрики: точность и полноту. Имея «F-меру» гораздо проще ответить на вопрос: «поменялся алгоритм в лучшую сторону или нет?»
# код для подсчета метрики F-mera: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier from sklearn.metrics import f1_score mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распознавать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(f1_score(y_train_5, y_train_pred)) # 0.7325171197343846
ROC-кривая
Кривая рабочих характеристик (англ. Receiver Operating Characteristics curve).
Используется для анализа поведения классификаторов при различных пороговых значениях.
Позволяет рассмотреть все пороговые значения для данного классификатора.
Показывает долю ложно положительных примеров (англ. false positive rate, FPR) в сравнении с долей истинно положительных примеров (англ. true positive rate, TPR).
Доля FPR — это пропорция отрицательных образцов, которые были некорректно классифицированы как положительные.
- ,
где TNR — доля истинно отрицательных классификаций (англ. Тrие Negative Rate), представляющая собой пропорцию отрицательных образцов, которые были корректно классифицированы как отрицательные.
Доля TNR также называется специфичностью (англ. specificity). Следовательно, ROC-кривая изображает чувствительность (англ. seпsitivity), т.е. полноту, в сравнении с разностью 1 — specificity.
Прямая линия по диагонали представляет ROC-кривую чисто случайного классификатора. Хороший классификатор держится от указанной линии настолько далеко, насколько это
возможно (стремясь к левому верхнему углу).
Один из способов сравнения классификаторов предусматривает измерение площади под кривой (англ. Area Under the Curve — AUC). Безупречный классификатор будет иметь площадь под ROC-кривой (ROC-AUC), равную 1, тогда как чисто случайный классификатор — площадь 0.5.
# Код отрисовки ROC-кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import roc_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") fpr, tpr, thresholds = roc_curve(y_train_5, y_scores) def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0, 1], [0, 1], 'k--') # dashed diagonal plt.xlabel('False Positive Rate, FPR (1 - specificity)') plt.ylabel('True Positive Rate, TPR (Recall)') plt.title('ROC curve') plt.savefig("ROC.png") plot_roc_curve(fpr, tpr) plt.show()
Precison-recall кривая
Чувствительность к соотношению классов.
Рассмотрим задачу выделения математических статей из множества научных статей. Допустим, что всего имеется 1.000.100 статей, из которых лишь 100 относятся к математике. Если нам удастся построить алгоритм , идеально решающий задачу, то его TPR будет равен единице, а FPR — нулю. Рассмотрим теперь плохой алгоритм, дающий положительный ответ на 95 математических и 50.000 нематематических статьях. Такой алгоритм совершенно бесполезен, но при этом имеет TPR = 0.95 и FPR = 0.05, что крайне близко к показателям идеального алгоритма.
Таким образом, если положительный класс существенно меньше по размеру, то AUC-ROC может давать неадекватную оценку качества работы алгоритма, поскольку измеряет долю неверно принятых объектов относительно общего числа отрицательных. Так, алгоритм , помещающий 100 релевантных документов на позиции с 50.001-й по 50.101-ю, будет иметь AUC-ROC 0.95.
Precison-recall (PR) кривая. Избавиться от указанной проблемы с несбалансированными классами можно, перейдя от ROC-кривой к PR-кривой. Она определяется аналогично ROC-кривой, только по осям откладываются не FPR и TPR, а полнота (по оси абсцисс) и точность (по оси ординат). Критерием качества семейства алгоритмов выступает площадь под PR-кривой (англ. Area Under the Curve — AUC-PR)
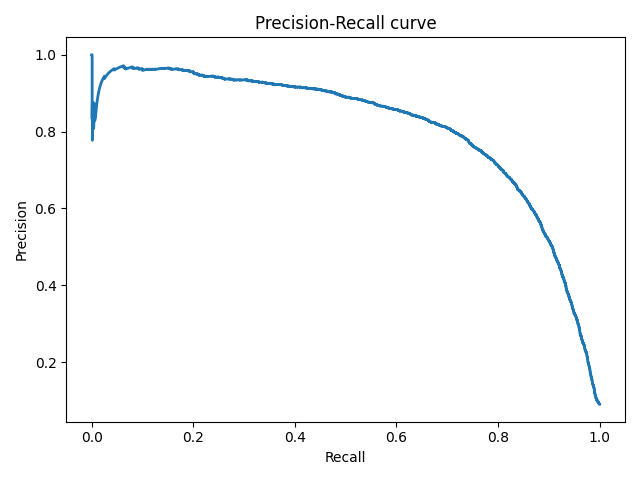
# Код отрисовки Precison-recall кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import precision_recall_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores) def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(recalls, precisions, linewidth=2) plt.xlabel('Recall') plt.ylabel('Precision') plt.title('Precision-Recall curve') plt.savefig("Precision_Recall_curve.png") plot_precision_recall_vs_threshold(precisions, recalls, thresholds) plt.show()
Оценки качества регрессии
Наиболее типичными мерами качества в задачах регрессии являются
Средняя квадратичная ошибка (англ. Mean Squared Error, MSE)
MSE применяется в ситуациях, когда нам надо подчеркнуть большие ошибки и выбрать модель, которая дает меньше больших ошибок прогноза. Грубые ошибки становятся заметнее за счет того, что ошибку прогноза мы возводим в квадрат. И модель, которая дает нам меньшее значение среднеквадратической ошибки, можно сказать, что что у этой модели меньше грубых ошибок.
- и
Cредняя абсолютная ошибка (англ. Mean Absolute Error, MAE)
Среднеквадратичный функционал сильнее штрафует за большие отклонения по сравнению со среднеабсолютным, и поэтому более чувствителен к выбросам. При использовании любого из этих двух функционалов может быть полезно проанализировать, какие объекты вносят наибольший вклад в общую ошибку — не исключено, что на этих объектах была допущена ошибка при вычислении признаков или целевой величины.
Среднеквадратичная ошибка подходит для сравнения двух моделей или для контроля качества во время обучения, но не позволяет сделать выводов о том, на сколько хорошо данная модель решает задачу. Например, MSE = 10 является очень плохим показателем, если целевая переменная принимает значения от 0 до 1, и очень хорошим, если целевая переменная лежит в интервале (10000, 100000). В таких ситуациях вместо среднеквадратичной ошибки полезно использовать коэффициент детерминации —
Коэффициент детерминации
Коэффициент детерминации измеряет долю дисперсии, объясненную моделью, в общей дисперсии целевой переменной. Фактически, данная мера качества — это нормированная среднеквадратичная ошибка. Если она близка к единице, то модель хорошо объясняет данные, если же она близка к нулю, то прогнозы сопоставимы по качеству с константным предсказанием.
Средняя абсолютная процентная ошибка (англ. Mean Absolute Percentage Error, MAPE)
Это коэффициент, не имеющий размерности, с очень простой интерпретацией. Его можно измерять в долях или процентах. Если у вас получилось, например, что MAPE=11.4%, то это говорит о том, что ошибка составила 11,4% от фактических значений.
Основная проблема данной ошибки — нестабильность.
Корень из средней квадратичной ошибки (англ. Root Mean Squared Error, RMSE)
Примерно такая же проблема, как и в MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня.
Cимметричная MAPE (англ. Symmetric MAPE, SMAPE)
Средняя абсолютная масштабированная ошибка (англ. Mean absolute scaled error, MASE)
MASE является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Обратите внимание, что в MASE мы имеем дело с двумя суммами: та, что в числителе, соответствует тестовой выборке, та, что в знаменателе — обучающей. Вторая фактически представляет собой среднюю абсолютную ошибку прогноза. Она же соответствует среднему абсолютному отклонению ряда в первых разностях. Эта величина, по сути, показывает, насколько обучающая выборка предсказуема. Она может быть равна нулю только в том случае, когда все значения в обучающей выборке равны друг другу, что соответствует отсутствию каких-либо изменений в ряде данных, ситуации на практике почти невозможной. Кроме того, если ряд имеет тенденцию к росту либо снижению, его первые разности будут колебаться около некоторого фиксированного уровня. В результате этого по разным рядам с разной структурой, знаменатели будут более-менее сопоставимыми. Всё это, конечно же, является очевидными плюсами MASE, так как позволяет складывать разные значения по разным рядам и получать несмещённые оценки.
Недостаток MASE в том, что её тяжело интерпретировать. Например, MASE=1.21 ни о чём, по сути, не говорит. Это просто означает, что ошибка прогноза оказалась в 1.21 раза выше среднего абсолютного отклонения ряда в первых разностях, и ничего более.
Кросс-валидация
Хороший способ оценки модели предусматривает применение кросс-валидации (cкользящего контроля или перекрестной проверки).
В этом случае фиксируется некоторое множество разбиений исходной выборки на две подвыборки: обучающую и контрольную. Для каждого разбиения выполняется настройка алгоритма по обучающей подвыборке, затем оценивается его средняя ошибка на объектах контрольной подвыборки. Оценкой скользящего контроля называется средняя по всем разбиениям величина ошибки на контрольных подвыборках.
Примечания
- [1] Лекция «Оценивание качества» на www.coursera.org
- [2] Лекция на www.stepik.org о кросвалидации
- [3] Лекция на www.stepik.org о метриках качества, Precison и Recall
- [4] Лекция на www.stepik.org о метриках качества, F-мера
- [5] Лекция на www.stepik.org о метриках качества, примеры
См. также
- Оценка качества в задаче кластеризации
- Кросс-валидация
Источники информации
- [6] Соколов Е.А. Лекция линейная регрессия
- [7] — Дьяконов А. Функции ошибки / функционалы качества
- [8] — Оценка качества прогнозных моделей
- [9] — HeinzBr Ошибка прогнозирования: виды, формулы, примеры
- [10] — egor_labintcev Метрики в задачах машинного обучения
- [11] — grossu Методы оценки качества прогноза
- [12] — К.В.Воронцов, Классификация
- [13] — К.В.Воронцов, Скользящий контроль
Ошибки первого рода (англ. type I errors, α errors, false positives) и ошибки второго рода (англ. type II errors, β errors, false negatives) в математической статистике — это ключевые понятия задач проверки статистических гипотез. Тем не менее, данные понятия часто используются и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.
Содержание
- 1 Определения
- 2 О смысле ошибок первого и второго рода
- 3 Вероятности ошибок (уровень значимости и мощность)
- 4 Примеры использования
- 4.1 Радиолокация
- 4.2 Компьютеры
- 4.2.1 Компьютерная безопасность
- 4.2.2 Фильтрация спама
- 4.2.3 Вредоносное программное обеспечение
- 4.2.4 Поиск в компьютерных базах данных
- 4.2.5 Оптическое распознавание текстов (OCR)
- 4.2.6 Досмотр пассажиров и багажа
- 4.2.7 Биометрия
- 4.3 Массовая медицинская диагностика (скрининг)
- 4.4 Медицинское тестирование
- 4.5 Исследования сверхъестественных явлений
- 5 См. также
- 6 Примечания
Определения
Пусть дана выборка  из неизвестного совместного распределения
из неизвестного совместного распределения  , и поставлена бинарная задача проверки статистических гипотез:
, и поставлена бинарная задача проверки статистических гипотез:

где  — нулевая гипотеза, а
— нулевая гипотеза, а  — альтернативная гипотеза. Предположим, что задан статистический критерий
— альтернативная гипотеза. Предположим, что задан статистический критерий
- ,
 ,
,сопоставляющий каждой реализации выборки  одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
- Распределение выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть .
 соответствует гипотезе
соответствует гипотезе  .
. .
.Во втором и четвертом случае говорят, что произошла статистическая ошибка, и её называют ошибкой первого и второго рода соответственно. [1][2]
| Верная гипотеза | |||
|---|---|---|---|
| |
|
||
| Результат применения критерия |
|
верно принята |
неверно принята (Ошибка второго рода) |
| |
неверно отвергнута (Ошибка первого рода) |
верно отвергнута |
О смысле ошибок первого и второго рода
Как видно из вышеприведённого определения, ошибки первого и второго рода являются взаимно-симметричными, то есть если поменять местами гипотезы и , то ошибки первого рода превратятся в ошибки второго рода и наоборот. Тем не менее, в большинстве практических ситуаций путаницы не происходит, поскольку принято считать, что нулевая гипотеза соответствует состоянию «по умолчанию» (естественному, наиболее ожидаемому положению вещей) — например, что обследуемый человек здоров, или что проходящий через рамку металлодетектора пассажир не имеет запрещённых металлических предметов. Соответственно, альтернативная гипотеза обозначает противоположную ситуацию, которая обычно трактуется как менее вероятная, неординарная, требующая какой-либо реакции.
С учётом этого ошибку первого рода часто называют ложной тревогой, ложным срабатыванием или ложноположительным срабатыванием — например, анализ крови показал наличие заболевания, хотя на самом деле человек здоров, или металлодетектор выдал сигнал тревоги, сработав на металлическую пряжку ремня. Слово «положительный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают положительный результат (т.е. показывают наличие заболевания у пациента), когда на самом деле пациент этим заболеванием не страдает. Такой результат называется ложноположительным.
В других областях обычно используют словосочетания со схожим смыслом, например, «ложное срабатывание», «ложная тревога» и т.п. В информационных технологиях часто используют английский термин false positive без перевода.
Из-за возможности ложных срабатываний не удаётся полностью автоматизировать борьбу со многими видами угроз. Как правило, вероятность ложного срабатывания коррелирует с вероятностью пропуска события (ошибки второго рода). То есть: чем более чувствительна система, тем больше опасных событий она детектирует и, следовательно, предотвращает. Но при повышении чувствительности неизбежно вырастает и вероятность ложных срабатываний. Поэтому чересчур чувствительно (параноидально) настроенная система защиты может выродиться в свою противоположность и привести к тому, что побочный вред от неё будет превышать пользу.
Соответственно, ошибку второго рода иногда называют пропуском события или ложноотрицательным срабатыванием — человек болен, но анализ крови этого не показал, или у пассажира имеется холодное оружие, но рамка металлодетектора его не обнаружила (например, из-за того, что чувствительность рамки отрегулирована на обнаружение только очень массивных металлических предметов).
Слово «отрицательный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают отрицательный результат (т.е. показывают отсутствие заболевания у пациента), когда на самом деле пациент страдает этим заболеванием. Такой результат называется ложноотрицательным.
В других областях обычно используют словосочетания со схожим смыслом, например, «пропуск события», и т.п. В информационных технологиях часто используют английский термин false negative без перевода.
Степень чувствительности системы защиты должна представлять собой компромисс между вероятностью ошибок первого и второго рода. Где именно находится точка баланса, зависит от оценки рисков обоих видов ошибок.
Вероятности ошибок (уровень значимости и мощность)
Вероятность ошибки первого рода при проверке статистических гипотез называют уровнем значимости и обычно обозначают греческой буквой  (отсюда название -errors).
(отсюда название -errors).
Вероятность ошибки второго рода не имеет какого-то особого общепринятого названия, на письме обозначается греческой буквой  (отсюда -errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле
(отсюда -errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле  . Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
. Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
Обе эти характеристики обычно вычисляются с помощью так называемой функции мощности критерия. В частности, вероятность ошибки первого рода есть функция мощности, вычисленная при нулевой гипотезе. Для критериев, основанных на выборке фиксированного объема, вероятность ошибки второго рода есть единица минус функция мощности, вычисленная в предположении, что распределение наблюдений соответствует альтернативной гипотезе. Для последовательных критериев это также верно, если критерий останавливается с вероятностью единица (при данном распределении из альтернативы).
В статистических тестах обычно приходится идти на компромисс между приемлемым уровнем ошибок первого и второго рода. Зачастую для принятия решения используется пороговое значение, которое может варьироваться с целью сделать тест более строгим или, наоборот, более мягким. Этим пороговым значением является уровень значимости, которым задаются при проверке статистических гипотез. Например, в случае металлодетектора повышение чувствительности прибора приведёт к увеличению риска ошибки первого рода (ложная тревога), а понижение чувствительности — к увеличению риска ошибки второго рода (пропуск запрещённого предмета).
Примеры использования
Радиолокация
В задаче радиолокационного обнаружения воздушных целей, прежде всего, в системе ПВО ошибки первого и второго рода, с формулировкой «ложная тревога» и «пропуск цели» являются одним из основных элементов как теории, так и практики построения радиолокационных станций. Вероятно, это первый пример последовательного применения статистических методов в целой технической области.
Компьютеры
Понятия ошибок первого и второго рода широко используются в области компьютеров и программного обеспечения.
Компьютерная безопасность
Наличие уязвимостей в вычислительных системах приводит к тому, что приходится, с одной стороны, решать задачу сохранения целостности компьютерных данных, а с другой стороны — обеспечивать нормальный доступ легальных пользователей к этим данным (см. компьютерная безопасность). Moulton (1983, с.125) отмечает, что в данном контексте возможны следующие нежелательные ситуации:
- когда нарушители классифицируются как авторизованные пользователи (ошибки первого рода)
- когда авторизованные пользователи классифицируются как нарушители (ошибки второго рода)
Фильтрация спама
Ошибка первого рода происходит, когда механизм блокировки/фильтрации спама ошибочно классифицирует легитимное email-сообщение как спам и препятствует его нормальной доставке. В то время как большинство «антиспам»-алгоритмов способны блокировать/фильтровать большой процент нежелательных email-сообщений, гораздо более важной задачей является минимизировать число «ложных тревог» (ошибочных блокировок нужных сообщений).
Ошибка второго рода происходит, когда антиспам-система ошибочно пропускает нежелательное сообщение, классифицируя его как «не спам». Низкий уровень таких ошибок является индикатором эффективности антиспам-алгоритма.
Пока не удалось создать антиспамовую систему без корреляции между вероятностью ошибок первого и второго рода. Вероятность пропустить спам у современных систем колеблется в пределах от 1% до 30%. Вероятность ошибочно отвергнуть валидное сообщение — от 0,001 % до 3 %. Выбор системы и её настроек зависит от условий конкретного получателя: для одних получателей риск потерять 1% хорошей почты оценивается как незначительный, для других же потеря даже 0,1% является недопустимой.
Вредоносное программное обеспечение
Понятие ошибки первого рода также используется, когда антивирусное программное обеспечение ошибочно классифицирует безвредный файл как вирус. Неверное обнаружение может быть вызвано особенностями эвристики, либо неправильной сигнатурой вируса в базе данных. Подобные проблемы могут происходить также и с антитроянскими и антишпионскими программами.
Поиск в компьютерных базах данных
При поиске в базе данных к ошибкам первого рода можно отнести документы, которые выдаются поиском, несмотря на их иррелевантность (несоответствие) поисковому запросу. Ошибочные срабатывания характерны для полнотекстового поиска, когда поисковый алгоритм анализирует полные тексты всех хранимых в базе данных документов и пытается найти соответствия одному или нескольким терминам, заданным пользователем в запросе.
Большинство ложных срабатываний обусловлены сложностью естественных языков, многозначностью слов: например, «home» может обозначать как «место проживания человека», так и «корневую страницу веб-сайта». Число подобных ошибок может быть снижено за счёт использования специального словаря. Однако это решение относительно дорогое, поскольку подобный словарь и разметка документов (индексирование) должны создаваться экспертом.
Оптическое распознавание текстов (OCR)
Разнообразные детектирующие алгоритмы нередко выдают ошибки первого рода. Программное обеспечение оптического распознавания текстов может распознать букву «a» в ситуации, когда на самом деле изображены несколько точек, которые используемый алгоритм расценил как «a».
Досмотр пассажиров и багажа
Ошибки первого рода регулярно встречаются каждый день в компьютерных системах предварительного досмотра пассажиров в аэропортах. Установленные в них детекторы предназначены для предотвращения проноса оружия на борт самолёта; тем не менее, уровень чувствительности в них зачастую настраивается настолько высоко, что много раз за день они срабатывают на незначительные предметы, такие как ключи, пряжки ремней, монеты, мобильные телефоны, гвозди в подошвах обуви и т.п. (см. обнаружение взрывчатых веществ, металлодетекторы).
Таким образом, соотношение числа ложных тревог (идентифицикация благопристойного пассажира как правонарушителя) к числу правильных срабатываний (обнаружение действительно запрещённых предметов) очень велико.
Биометрия
Ошибки первого и второго рода являются большой проблемой в системах биометрического сканирования, использующих распознавание радужной оболочки или сетчатки глаза, черт лица и т.д. Такие сканирующие системы могут ошибочно отождествить кого-то с другим, «известным» системе человеком, информация о котором хранится в базе данных (к примеру, это может быть лицо, имеющее право входа в систему, или подозреваемый преступник и т.п.). Противоположной ошибкой будет неспособность системы распознать легитимного зарегистрированного пользователя, или опознать подозреваемого в преступлении.[3]
Массовая медицинская диагностика (скрининг)
В медицинской практике есть существенное различие между скринингом и тестированием:
- Скрининг включает в себя относительно дешёвые тесты, которые проводятся для большой группы людей при отсутствии каких-либо клинических признаков болезни (например, мазок Папаниколау).
- Тестирование подразумевает гораздо более дорогие, зачастую инвазивные, процедуры, которые проводятся только для тех, у кого проявляются клинические признаки заболевания, и которые, в основном, применяются для подтверждения предполагаемого диагноза.
К примеру, в большинстве штатов в США обязательно прохождение новорожденными процедуры скрининга на оксифенилкетонурию и гипотиреоз, помимо других врождённых аномалий. Несмотря на высокий уровень ошибок первого рода, эти процедуры скрининга считаются целесообразными, поскольку они существенно увеличивают вероятность обнаружения этих расстройств на самой ранней стадии.[4]
Простые анализы крови, используемые для скрининга потенциальных доноров на ВИЧ и гепатит, имеют существенный уровень ошибок первого рода; однако в арсенале врачей есть гораздо более точные (и, соответственно, дорогие) тесты для проверки, действительно ли человек инфицирован каким-либо из этих вирусов.
Возможно, наиболее широкие дискуссии вызывают ошибки первого рода в процедурах скрининга на рак груди (маммография). В США уровень ошибок первого рода в маммограммах достигает 15%, это самый высокий показатель в мире.[5] Самый низкий уровень наблюдается в Нидерландах, 1%.[6]
Медицинское тестирование
Ошибки второго рода являются существенной проблемой в медицинском тестировании. Они дают пациенту и врачу ложное убеждение, что заболевание отсутствует, в то время как в действительности оно есть. Это зачастую приводит к неуместному или неадекватному лечению. Типичным примером является доверие результатам кардиотестирования при выявлении коронарного атеросклероза, хотя известно, что кардиотестирование выявляет только те затруднения кровотока в коронарной артерии, которые вызваны стенозом.
Ошибки второго рода вызывают серьёзные и трудные для понимания проблемы, особенно когда искомое условие является широкораспространённым. Если тест с 10%-ным уровнем ошибок второго рода используется для обследования группы, где вероятность «истинно-положительных» случаев составляет 70%, то многие отрицательные результаты теста окажутся ложными. (См. Теорему Байеса).
Ошибки первого рода также могут вызывать серьёзные и трудные для понимания проблемы. Это происходит, когда искомое условие является редким. Если уровень ошибок первого рода у теста составляет один случай на десять тысяч, но в тестируемой группе образцов (или людей) вероятность «истинно-положительных» случаев составляет в среднем один случай на миллион, то большинство положительных результатов этого теста будут ложными.[7]
Исследования сверхъестественных явлений
Термин ошибка первого рода был взят на вооружение исследователями в области паранормальных явлений и привидений для описания фотографии или записи или какого-либо другого свидетельства, которое ошибочно трактуется как имеющее паранормальное происхождение — в данном контексте ошибка первого рода — это какое-либо несостоятельное «медиасвидетельство» (изображение, видеозапись, аудиозапись и т.д.), которое имеет обычное объяснение.[8]
См. также
- Статистическая значимость
- Ложноположительный
- Атака второго рода
- Случаи ложного срабатывания систем предупреждения о ракетном нападении
- Receiver_operating_characteristic
Примечания
- ↑ ГОСТ Р 50779.10-2000. «Статистические методы. Вероятность и основы статистики. Термины и определения.». Стр. 26
- ↑ Valerie J. Easton, John H. McColl. Statistics Glossary: Hypothesis Testing.
- ↑ Данный пример как раз характеризует случай, когда классификация ошибок будет зависеть от назначения системы: если биометрическое сканирование используется для допуска сотрудников (нулевая гипотеза: «проходящий сканирование человек действительно является сотрудником»), то ошибочное отождествление будет ошибкой второго рода, а «неузнавание» — ошибкой первого рода; если же сканирование используется для опознания преступников (нулевая гипотеза: «проходящий сканирование человек не является преступником»), то ошибочное отождествление будет ошибкой первого рода, а «неузнавание» — ошибкой второго рода.
- ↑ Относительно скрининга новорожденных, последние исследования показали, что количество ошибок первого рода в 12 раз больше, чем количество верных обнаружений (Gambrill, 2006. [1])
- ↑ Одним из последствий такого высокого уровня ошибок первого рода в США является то, что за произвольный 10-летний период половина обследуемых американских женщин получают как минимум одну ложноположительную маммограмму. Такие ошибочные маммограммы обходятся дорого, приводя к ежегодным расходам в 100 миллионов долларов на последующее (ненужное) лечение. Кроме того, они вызывают излишнюю тревогу у женщин. В результате высокого уровня подобных ошибок первого рода в США, примерно у 90-95% женщин, получивших хотя бы раз в жизни положительную маммограмму, на самом деле заболевание отсутствует.
- ↑ Наиболее низкие уровни этих ошибок наблюдаются в северной Европе, где маммографические плёнки считываются дважды, и для дополнительного тестирования устанавливается повышенное пороговое значение (высокий порог снижает статистическую эффективность теста).
- ↑ Вероятность того, что выдаваемый тестом результат окажется ошибкой первого рода, может быть вычислена при помощи Теоремы Байеса.
- ↑ На некоторых сайтах приведены примеры ошибок первого рода, например: Атлантическое Сообщество Паранормальных явлений (The Atlantic Paranormal Society, TAPS) и Морстаунская организация по Исследованию Привидений (Moorestown Ghost Research).
Оши́бка пе́рвого ро́да (α-ошибка, ложноположительное заключение) — ситуация, когда отвергнута верная нулевая гипотеза (b) (об отсутствии связи между явлениями или искомого эффекта).
Оши́бка второ́го ро́да (β-ошибка, ложноотрицательное заключение) — ситуация, когда принята неверная нулевая гипотеза.
В математической статистике (b) это ключевые понятия задач проверки статистических гипотез (b) . Данные понятия часто используются и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.
Определения
Пусть дана выборка из неизвестного совместного распределения , и поставлена бинарная задача проверки статистических гипотез:
где — нулевая гипотеза (b) , а — альтернативная гипотеза (b) . Предположим, что задан статистический критерий
- ,
сопоставляющий каждой реализации выборки одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
- Распределение выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть .
Во втором и четвёртом случае говорят, что произошла статистическая ошибка, и её называют ошибкой первого и второго рода соответственно[1][2].
| Верная гипотеза | |||
|---|---|---|---|
| Результат применения критерия |
верно принята | неверно принята (Ошибка второго рода) |
|
| неверно отвергнута (Ошибка первого рода) |
верно отвергнута |
О смысле ошибок первого и второго рода
Из определения выше видно, что ошибки первого и второго рода являются взаимно-симметричными, то есть если поменять местами гипотезы и , то ошибки первого рода превратятся в ошибки второго рода и наоборот. Тем не менее, в большинстве практических ситуаций путаницы не происходит, поскольку принято считать, что нулевая гипотеза соответствует состоянию «по умолчанию» (естественному, наиболее ожидаемому положению вещей) — например, что обследуемый человек здоров, или что проходящий через рамку металлодетектора пассажир не имеет запрещённых металлических предметов. Соответственно, альтернативная гипотеза обозначает противоположную ситуацию, которая обычно трактуется как менее вероятная, неординарная, требующая какой-либо реакции.
С учётом вышесказанного, ошибку первого рода часто называют ложной тревогой, ложным срабатыванием или ложноположительным срабатыванием. Если, например, анализ крови показал наличие заболевания, хотя на самом деле человек здоров, или металлодетектор выдал сигнал тревоги, сработав на металлическую пряжку ремня, то принятая гипотеза не верна, а следовательно совершена ошибка первого рода. Слово «ложноположительный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают положительный результат (то есть показывают наличие заболевания у пациента), когда на самом деле пациент этим заболеванием не страдает. Такой результат называется ложноположительным.
В других областях обычно используют словосочетания со схожим смыслом, например, «ложное срабатывание», «ложная тревога» и т. п. В информационных технологиях часто используют английский термин false positive без перевода.
Из-за возможности ложных срабатываний не удаётся полностью автоматизировать борьбу со многими видами угроз. Как правило, вероятность ложного срабатывания коррелирует с вероятностью пропуска события (ошибки второго рода). То есть: чем более чувствительна система, тем больше опасных событий она детектирует и, следовательно, предотвращает. Но при повышении чувствительности неизбежно вырастает и вероятность ложных срабатываний. Поэтому чересчур чувствительно (параноидально) настроенная система защиты может выродиться в свою противоположность и привести к тому, что побочный вред от неё будет превышать пользу.
Соответственно, ошибку второго рода иногда называют пропуском события или ложноотрицательным срабатыванием. Человек болен, но анализ крови этого не показал, или у пассажира имеется холодное оружие, но рамка металлодетектора его не обнаружила (например, из-за того, что чувствительность рамки отрегулирована на обнаружение только очень массивных металлических предметов). Данные примеры указывают на совершение ошибки второго рода. Слово «ложноотрицательный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают отрицательный результат (то есть показывают отсутствие заболевания у пациента), когда на самом деле пациент страдает этим заболеванием. Такой результат называется ложноотрицательным.
В других областях обычно используют словосочетания со схожим смыслом, например, «пропуск события», и т. п.
Так как с ростом вероятности ошибки первого рода обычно уменьшается вероятность ошибки второго рода, и наоборот, настройка принимающей решение системы должна представлять собой компромисс. Где именно находится точка получаемого такой настройкой баланса, зависит от оценки последствий при совершении обоих видов ошибок.
Вероятности ошибок (уровень значимости и мощность)
Вероятность ошибки первого рода при проверке статистических гипотез (b) называют уровнем значимости (b) и обычно обозначают греческой буквой (отсюда название -ошибка).
Вероятность ошибки второго рода не имеет какого-то особого общепринятого названия, она обозначается греческой буквой (отсюда название -ошибка). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле Таким образом, чем выше мощность критерия, тем меньше вероятность совершить ошибку второго рода.
Обе эти характеристики обычно вычисляются с помощью так называемой функции мощности (b) критерия. В частности, вероятность ошибки первого рода есть функция мощности, вычисленная при нулевой гипотезе. Для критериев, основанных на выборке фиксированного объёма, вероятность ошибки второго рода есть единица минус функция мощности, вычисленная в предположении, что распределение наблюдений соответствует альтернативной гипотезе. Для последовательных критериев (b) это также верно, если критерий останавливается с вероятностью единица (при данном распределении из альтернативы).
В статистических тестах обычно приходится идти на компромисс между приемлемым уровнем ошибок первого и второго рода. Зачастую для принятия решения используется пороговое значение, которое может варьироваться с целью сделать тест более строгим или, наоборот, более мягким. Этим пороговым значением является уровень значимости (b) , которым задаются при проверке статистических гипотез (b) . Например, в случае металлодетектора повышение чувствительности прибора приведёт к увеличению риска ошибки первого рода (ложная тревога), а понижение чувствительности — к увеличению риска ошибки второго рода (пропуск запрещённого предмета).
Примеры использования
Радиолокация (b)
В задаче радиолокационного обнаружения воздушных целей, прежде всего, в системе ПВО ошибки первого и второго рода, с формулировкой «ложная тревога» и «пропуск цели» являются одним из основных элементов как теории, так и практики построения радиолокационных станций (b) . Вероятно, это первый пример последовательного применения статистических методов в целой технической области.
Компьютеры
Понятия ошибок первого и второго рода широко используются в области компьютеров и программного обеспечения.
Компьютерная безопасность
Наличие уязвимостей в вычислительных системах приводит к тому, что приходится, с одной стороны, решать задачу сохранения целостности компьютерных данных, а с другой стороны — обеспечивать нормальный доступ легальных пользователей к этим данным (см. компьютерная безопасность (b) ). В данном контексте возможны следующие нежелательные ситуации[3]:
- когда авторизованные пользователи классифицируются как нарушители (ошибки первого рода);
- когда нарушители классифицируются как авторизованные пользователи (ошибки второго рода).
Фильтрация спама
Ошибка первого рода происходит, когда механизм блокировки/фильтрации спама (b) ошибочно классифицирует легитимное email (b) -сообщение как спам и препятствует его нормальной доставке. В то время как большинство «антиспам»-алгоритмов способны блокировать/фильтровать большой процент нежелательных email-сообщений, гораздо более важной задачей является минимизировать число «ложных тревог» (ошибочных блокировок нужных сообщений).
Ошибка второго рода происходит, когда антиспам-система ошибочно пропускает нежелательное сообщение, классифицируя его как «не спам». Низкий уровень таких ошибок является индикатором эффективности антиспам-алгоритма.
Пока не удалось создать антиспамовую систему без корреляции между вероятностью ошибок первого и второго рода. Вероятность пропустить спам у современных систем колеблется в пределах от 1 % до 30 %. Вероятность ошибочно отвергнуть валидное сообщение — от 0,001 % до 3 %. Выбор системы и её настроек зависит от условий конкретного получателя: для одних получателей риск потерять 1 % хорошей почты оценивается как незначительный, для других же потеря даже 0,1 % является недопустимой.
Вредоносное программное обеспечение
Понятие ошибки первого рода также используется, когда антивирусное (b) программное обеспечение ошибочно классифицирует безвредный файл как вирус (b) . Неверное обнаружение может быть вызвано особенностями эвристики (b) , либо неправильной сигнатурой вируса (b) в базе данных. Подобные проблемы могут происходить также и с антитроянскими (b) и антишпионскими (b) программами.
Поиск в компьютерных базах данных
При поиске в базе данных к ошибкам первого рода можно отнести документы, которые выдаются поиском, несмотря на их иррелевантность (b) (несоответствие) поисковому запросу. Ошибочные срабатывания характерны для полнотекстового поиска (b) , когда поисковый алгоритм (b) анализирует полные тексты всех хранимых в базе данных документов и пытается найти соответствия одному или нескольким терминам, заданным пользователем в запросе.
Большинство ложных срабатываний обусловлены сложностью естественных языков (b) , многозначностью слов: например, «home» может обозначать как «место проживания человека», так и «корневую страницу веб-сайта». Число подобных ошибок может быть снижено за счёт использования специального словаря (b) . Однако это решение относительно дорогое, поскольку подобный словарь и разметка документов (индексирование (b) ) должны создаваться экспертом.
Оптическое распознавание текстов (OCR)
Разнообразные детектирующие алгоритмы нередко выдают ошибки первого рода. Программное обеспечение оптического распознавания текстов (b) может распознать букву «a» в ситуации, когда на самом деле изображены несколько точек.
Досмотр пассажиров и багажа
Ошибки первого рода регулярно встречаются каждый день в компьютерных системах предварительного досмотра пассажиров в аэропортах. Установленные в них детекторы предназначены для предотвращения проноса оружия на борт самолёта; тем не менее, уровень чувствительности (b) в них зачастую настраивается настолько высоко, что много раз за день они срабатывают на незначительные предметы, такие как ключи, пряжки ремней, монеты, мобильные телефоны, гвозди в подошвах обуви и т. п. (см. обнаружение взрывчатых веществ (англ.) (рус. (b) , металлодетекторы (b) ).
Таким образом, соотношение числа ложных тревог (идентифицикация благопристойного пассажира как правонарушителя) к числу правильных срабатываний (обнаружение действительно запрещённых предметов) очень велико.
Биометрия
Ошибки первого и второго рода являются большой проблемой в системах биометрического (b) сканирования, использующих распознавание радужной оболочки (b) или сетчатки (b) глаза, черт лица (b) и т. д. Такие сканирующие системы могут ошибочно отождествить кого-то с другим, «известным» системе человеком, информация о котором хранится в базе данных (к примеру, это может быть лицо, имеющее право входа в систему, или подозреваемый преступник и т. п.). Противоположной ошибкой будет неспособность системы распознать легитимного зарегистрированного пользователя, или опознать подозреваемого в преступлении[4].
Массовая медицинская диагностика (скрининг)
В медицинской практике есть существенное различие между скринингом (b) и тестированием (b) :
- Скрининг включает в себя относительно дешёвые тесты, которые проводятся для большой группы людей при отсутствии каких-либо клинических признаков болезни (например, мазок Папаниколау (b) ).
- Тестирование подразумевает гораздо более дорогие, зачастую инвазивные, процедуры, которые проводятся только для тех, у кого проявляются клинические признаки заболевания, и которые, в основном, применяются для подтверждения предполагаемого диагноза.
К примеру, в большинстве штатов в США обязательно прохождение новорожденными процедуры скрининга на оксифенилкетонурию (b) и гипотиреоз (b) , помимо других врождённых аномалий (b) . Несмотря на высокий уровень ошибок первого рода, эти процедуры скрининга считаются целесообразными, поскольку они существенно увеличивают вероятность обнаружения этих расстройств на самой ранней стадии[5].
Простые анализы крови, используемые для скрининга потенциальных доноров (b) на ВИЧ (b) и гепатит (b) , имеют существенный уровень ошибок первого рода; однако в арсенале врачей есть гораздо более точные (и, соответственно, дорогие) тесты для проверки, действительно ли человек инфицирован каким-либо из этих вирусов.
Возможно, наиболее широкие дискуссии вызывают ошибки первого рода в процедурах скрининга на рак груди (маммография (b) ). В США уровень ошибок первого рода в маммограммах достигает 15 %, это самый высокий показатель в мире[6]. Самый низкий уровень наблюдается в Нидерландах (b) , 1 %[7].
Медицинское тестирование
Ошибки второго рода являются существенной проблемой в медицинском тестировании (b) . Они дают пациенту и врачу ложное убеждение, что заболевание отсутствует, в то время как в действительности оно есть. Это зачастую приводит к неуместному или неадекватному лечению. Типичным примером является доверие результатам велоэргометрии (b) при выявлении коронарного атеросклероза (b) , хотя известно, что велоэргометрия выявляет только те затруднения кровотока в коронарной артерии (b) , которые вызваны стенозом (b) .
Ошибки второго рода вызывают серьёзные и трудные для понимания проблемы, особенно когда искомое условие является широкораспространённым. Если тест с 10%-ным уровнем ошибок второго рода используется для обследования группы, где вероятность «истинно-положительных» случаев составляет 70 %, то многие отрицательные результаты теста окажутся ложными. (См. теорему Байеса).
Ошибки первого рода также могут вызывать серьёзные и трудные для понимания проблемы. Это происходит, когда искомое условие является редким. Если уровень ошибок первого рода у теста составляет один случай на десять тысяч, но в тестируемой группе образцов (или людей) вероятность «истинно-положительных» случаев составляет в среднем один случай на миллион, то большинство положительных результатов этого теста будут ложными[8].
Исследования сверхъестественных явлений
Термин ошибка первого рода был взят на вооружение исследователями в области паранормальных явлений (b) и привидений (b) для описания фотографии или записи или какого-либо другого свидетельства, которое ошибочно трактуется как имеющее паранормальное происхождение — в данном контексте ошибка первого рода — это какое-либо несостоятельное «медиасвидетельство» (изображение, видеозапись, аудиозапись и т. д.), которое имеет обычное объяснение.[9]
См. также
- Статистическая значимость (b)
- Атака второго рода (b)
- Случаи ложного срабатывания систем предупреждения о ракетном нападении (b)
- ROC-кривая (b)
- Коррекция на множественное тестирование (b)
Примечания
- ↑ ГОСТ Р 50779.10-2000. «Статистические методы. Вероятность и основы статистики. Термины и определения». — С. 26Архивная копия от 9 ноября 2018 на Wayback Machine (b)
- ↑ Easton V. J., McColl J. H.Statistics Glossary: Hypothesis Testing.Архивная копия от 24 сентября 2011 на Wayback Machine (b)
- ↑ Moulton R. T. Network Security (англ.) // Datamation. — 1983. — Vol. 29, iss. 7. — P. 121—127.
- ↑ Данный пример как раз характеризует случай, когда классификация ошибок будет зависеть от назначения системы: если биометрическое сканирование используется для допуска сотрудников (нулевая гипотеза: «проходящий сканирование человек действительно является сотрудником»), то ошибочное отождествление будет ошибкой второго рода, а «неузнавание» — ошибкой первого рода; если же сканирование используется для опознания преступников (нулевая гипотеза: «проходящий сканирование человек не является преступником»), то ошибочное отождествление будет ошибкой первого рода, а «неузнавание» — ошибкой второго рода.
- ↑ Относительно скрининга новорожденных, последние исследования показали, что количество ошибок первого рода в 12 раз больше, чем количество верных обнаружений (Gambrill, 2006. )
- ↑ Одним из последствий такого высокого уровня ошибок первого рода в США является то, что за произвольный 10-летний период половина обследуемых американских женщин получают как минимум одну ложноположительную (b) маммограмму. Такие ошибочные маммограммы обходятся дорого, приводя к ежегодным расходам в 100 миллионов долларов на последующее (ненужное) лечение. Кроме того, они вызывают излишнюю тревогу у женщин. В результате высокого уровня подобных ошибок первого рода в США, примерно у 90—95 % женщин, получивших хотя бы раз в жизни положительную маммограмму, на самом деле заболевание отсутствует.
- ↑ Наиболее низкие уровни этих ошибок наблюдаются в северной Европе, где маммографические плёнки считываются дважды, и для дополнительного тестирования устанавливается повышенное пороговое значение (b) (высокий порог снижает статистическую эффективность (b) теста).
- ↑ Вероятность того, что выдаваемый тестом результат окажется ошибкой первого рода, может быть вычислена при помощи теоремы Байеса.
- ↑ На некоторых сайтах приведены примеры ошибок первого рода, например: Атлантическое Сообщество Паранормальных явлений (The Atlantic Paranormal Society, TAPS)Архивировано 28 марта 2005 года. (недоступная ссылка с 13-05-2013 [3546 дней]) и Морстаунская организация по Исследованию Привидений (Moorestown Ghost Research)Архивировано 14 июня 2006 года. (недоступная ссылка с 13-05-2013 [3546 дней] — история).
This article is about erroneous outcomes of statistical tests. For closely related concepts in binary classification and testing generally, see false positives and false negatives.
In statistical hypothesis testing, a type I error is the mistaken rejection of an actually true null hypothesis (also known as a «false positive» finding or conclusion; example: «an innocent person is convicted»), while a type II error is the failure to reject a null hypothesis that is actually false (also known as a «false negative» finding or conclusion; example: «a guilty person is not convicted»).[1] Much of statistical theory revolves around the minimization of one or both of these errors, though the complete elimination of either is a statistical impossibility if the outcome is not determined by a known, observable causal process.
By selecting a low threshold (cut-off) value and modifying the alpha (α) level, the quality of the hypothesis test can be increased.[2] The knowledge of type I errors and type II errors is widely used in medical science, biometrics and computer science.[clarification needed]
Intuitively, type I errors can be thought of as errors of commission, i.e. the researcher unluckily concludes that something is the fact. For instance, consider a study where researchers compare a drug with a placebo. If the patients who are given the drug get better than the patients given the placebo by chance, it may appear that the drug is effective, but in fact the conclusion is incorrect.
In reverse, type II errors are errors of omission. In the example above, if the patients who got the drug did not get better at a higher rate than the ones who got the placebo, but this was a random fluke, that would be a type II error. The consequence of a type II error depends on the size and direction of the missed determination and the circumstances. An expensive cure for one in a million patients may be inconsequential even if it truly is a cure.
Definition[edit]
Statistical background[edit]
In statistical test theory, the notion of a statistical error is an integral part of hypothesis testing. The test goes about choosing about two competing propositions called null hypothesis, denoted by H0 and alternative hypothesis, denoted by H1. This is conceptually similar to the judgement in a court trial. The null hypothesis corresponds to the position of the defendant: just as he is presumed to be innocent until proven guilty, so is the null hypothesis presumed to be true until the data provide convincing evidence against it. The alternative hypothesis corresponds to the position against the defendant. Specifically, the null hypothesis also involves the absence of a difference or the absence of an association. Thus, the null hypothesis can never be that there is a difference or an association.
If the result of the test corresponds with reality, then a correct decision has been made. However, if the result of the test does not correspond with reality, then an error has occurred. There are two situations in which the decision is wrong. The null hypothesis may be true, whereas we reject H0. On the other hand, the alternative hypothesis H1 may be true, whereas we do not reject H0. Two types of error are distinguished: type I error and type II error.[3]
Type I error[edit]
The first kind of error is the mistaken rejection of a null hypothesis as the result of a test procedure. This kind of error is called a type I error (false positive) and is sometimes called an error of the first kind. In terms of the courtroom example, a type I error corresponds to convicting an innocent defendant.
Type II error[edit]
The second kind of error is the mistaken failure to reject the null hypothesis as the result of a test procedure. This sort of error is called a type II error (false negative) and is also referred to as an error of the second kind. In terms of the courtroom example, a type II error corresponds to acquitting a criminal.[4]
Crossover error rate[edit]
The crossover error rate (CER) is the point at which type I errors and type II errors are equal. A system with a lower CER value provides more accuracy than a system with a higher CER value.
False positive and false negative[edit]
In terms of false positives and false negatives, a positive result corresponds to rejecting the null hypothesis, while a negative result corresponds to failing to reject the null hypothesis; «false» means the conclusion drawn is incorrect. Thus, a type I error is equivalent to a false positive, and a type II error is equivalent to a false negative.
Table of error types[edit]
Tabularised relations between truth/falseness of the null hypothesis and outcomes of the test:[5]
| Table of error types | Null hypothesis (H0) is |
||
|---|---|---|---|
| True | False | ||
| Decision about null hypothesis (H0) |
Don’t reject |
Correct inference (true negative) (probability = 1−α) |
Type II error (false negative) (probability = β) |
| Reject | Type I error (false positive) (probability = α) |
Correct inference (true positive) (probability = 1−β) |
Error rate[edit]

The results obtained from negative sample (left curve) overlap with the results obtained from positive samples (right curve). By moving the result cutoff value (vertical bar), the rate of false positives (FP) can be decreased, at the cost of raising the number of false negatives (FN), or vice versa (TP = True Positives, TPR = True Positive Rate, FPR = False Positive Rate, TN = True Negatives).
A perfect test would have zero false positives and zero false negatives. However, statistical methods are probabilistic, and it cannot be known for certain whether statistical conclusions are correct. Whenever there is uncertainty, there is the possibility of making an error. Considering this nature of statistics science, all statistical hypothesis tests have a probability of making type I and type II errors.[6]
- The type I error rate is the probability of rejecting the null hypothesis given that it is true. The test is designed to keep the type I error rate below a prespecified bound called the significance level, usually denoted by the Greek letter α (alpha) and is also called the alpha level. Usually, the significance level is set to 0.05 (5%), implying that it is acceptable to have a 5% probability of incorrectly rejecting the true null hypothesis.[7]
- The rate of the type II error is denoted by the Greek letter β (beta) and related to the power of a test, which equals 1−β.[8]
These two types of error rates are traded off against each other: for any given sample set, the effort to reduce one type of error generally results in increasing the other type of error.[9]
The quality of hypothesis test[edit]
The same idea can be expressed in terms of the rate of correct results and therefore used to minimize error rates and improve the quality of hypothesis test. To reduce the probability of committing a type I error, making the alpha value more stringent is quite simple and efficient. To decrease the probability of committing a type II error, which is closely associated with analyses’ power, either increasing the test’s sample size or relaxing the alpha level could increase the analyses’ power.[10] A test statistic is robust if the type I error rate is controlled.
Varying different threshold (cut-off) value could also be used to make the test either more specific or more sensitive, which in turn elevates the test quality. For example, imagine a medical test, in which an experimenter might measure the concentration of a certain protein in the blood sample. The experimenter could adjust the threshold (black vertical line in the figure) and people would be diagnosed as having diseases if any number is detected above this certain threshold. According to the image, changing the threshold would result in changes in false positives and false negatives, corresponding to movement on the curve.[11]
Example[edit]
Since in a real experiment it is impossible to avoid all type I and type II errors, it is important to consider the amount of risk one is willing to take to falsely reject H0 or accept H0. The solution to this question would be to report the p-value or significance level α of the statistic. For example, if the p-value of a test statistic result is estimated at 0.0596, then there is a probability of 5.96% that we falsely reject H0. Or, if we say, the statistic is performed at level α, like 0.05, then we allow to falsely reject H0 at 5%. A significance level α of 0.05 is relatively common, but there is no general rule that fits all scenarios.
Vehicle speed measuring[edit]
The speed limit of a freeway in the United States is 120 kilometers per hour. A device is set to measure the speed of passing vehicles. Suppose that the device will conduct three measurements of the speed of a passing vehicle, recording as a random sample X1, X2, X3. The traffic police will or will not fine the drivers depending on the average speed  . That is to say, the test statistic
. That is to say, the test statistic

In addition, we suppose that the measurements X1, X2, X3 are modeled as normal distribution N(μ,4). Then, T should follow N(μ,4/3) and the parameter μ represents the true speed of passing vehicle. In this experiment, the null hypothesis H0 and the alternative hypothesis H1 should be
H0: μ=120 against H1: μ1>120.
If we perform the statistic level at α=0.05, then a critical value c should be calculated to solve

According to change-of-units rule for the normal distribution. Referring to Z-table, we can get

Here, the critical region. That is to say, if the recorded speed of a vehicle is greater than critical value 121.9, the driver will be fined. However, there are still 5% of the drivers are falsely fined since the recorded average speed is greater than 121.9 but the true speed does not pass 120, which we say, a type I error.
The type II error corresponds to the case that the true speed of a vehicle is over 120 kilometers per hour but the driver is not fined. For example, if the true speed of a vehicle μ=125, the probability that the driver is not fined can be calculated as

which means, if the true speed of a vehicle is 125, the driver has the probability of 0.36% to avoid the fine when the statistic is performed at level 125 since the recorded average speed is lower than 121.9. If the true speed is closer to 121.9 than 125, then the probability of avoiding the fine will also be higher.
The tradeoffs between type I error and type II error should also be considered. That is, in this case, if the traffic police do not want to falsely fine innocent drivers, the level α can be set to a smaller value, like 0.01. However, if that is the case, more drivers whose true speed is over 120 kilometers per hour, like 125, would be more likely to avoid the fine.
Etymology[edit]
In 1928, Jerzy Neyman (1894–1981) and Egon Pearson (1895–1980), both eminent statisticians, discussed the problems associated with «deciding whether or not a particular sample may be judged as likely to have been randomly drawn from a certain population»:[12] and, as Florence Nightingale David remarked, «it is necessary to remember the adjective ‘random’ [in the term ‘random sample’] should apply to the method of drawing the sample and not to the sample itself».[13]
They identified «two sources of error», namely:
- (a) the error of rejecting a hypothesis that should have not been rejected, and
- (b) the error of failing to reject a hypothesis that should have been rejected.
In 1930, they elaborated on these two sources of error, remarking that:
…in testing hypotheses two considerations must be kept in view, we must be able to reduce the chance of rejecting a true hypothesis to as low a value as desired; the test must be so devised that it will reject the hypothesis tested when it is likely to be false.
In 1933, they observed that these «problems are rarely presented in such a form that we can discriminate with certainty between the true and false hypothesis» . They also noted that, in deciding whether to fail to reject, or reject a particular hypothesis amongst a «set of alternative hypotheses», H1, H2…, it was easy to make an error:
…[and] these errors will be of two kinds:
- (I) we reject H0 [i.e., the hypothesis to be tested] when it is true,[14]
- (II) we fail to reject H0 when some alternative hypothesis HA or H1 is true. (There are various notations for the alternative).
In all of the papers co-written by Neyman and Pearson the expression H0 always signifies «the hypothesis to be tested».
In the same paper they call these two sources of error, errors of type I and errors of type II respectively.[15]
[edit]
Null hypothesis[edit]
It is standard practice for statisticians to conduct tests in order to determine whether or not a «speculative hypothesis» concerning the observed phenomena of the world (or its inhabitants) can be supported. The results of such testing determine whether a particular set of results agrees reasonably (or does not agree) with the speculated hypothesis.
On the basis that it is always assumed, by statistical convention, that the speculated hypothesis is wrong, and the so-called «null hypothesis» that the observed phenomena simply occur by chance (and that, as a consequence, the speculated agent has no effect) – the test will determine whether this hypothesis is right or wrong. This is why the hypothesis under test is often called the null hypothesis (most likely, coined by Fisher (1935, p. 19)), because it is this hypothesis that is to be either nullified or not nullified by the test. When the null hypothesis is nullified, it is possible to conclude that data support the «alternative hypothesis» (which is the original speculated one).
The consistent application by statisticians of Neyman and Pearson’s convention of representing «the hypothesis to be tested» (or «the hypothesis to be nullified») with the expression H0 has led to circumstances where many understand the term «the null hypothesis» as meaning «the nil hypothesis» – a statement that the results in question have arisen through chance. This is not necessarily the case – the key restriction, as per Fisher (1966), is that «the null hypothesis must be exact, that is free from vagueness and ambiguity, because it must supply the basis of the ‘problem of distribution,’ of which the test of significance is the solution.»[16] As a consequence of this, in experimental science the null hypothesis is generally a statement that a particular treatment has no effect; in observational science, it is that there is no difference between the value of a particular measured variable, and that of an experimental prediction.[citation needed]
Statistical significance[edit]
If the probability of obtaining a result as extreme as the one obtained, supposing that the null hypothesis were true, is lower than a pre-specified cut-off probability (for example, 5%), then the result is said to be statistically significant and the null hypothesis is rejected.
British statistician Sir Ronald Aylmer Fisher (1890–1962) stressed that the «null hypothesis»:
… is never proved or established, but is possibly disproved, in the course of experimentation. Every experiment may be said to exist only in order to give the facts a chance of disproving the null hypothesis.
— Fisher, 1935, p.19
Application domains[edit]
Medicine[edit]
In the practice of medicine, the differences between the applications of screening and testing are considerable.
Medical screening[edit]
Screening involves relatively cheap tests that are given to large populations, none of whom manifest any clinical indication of disease (e.g., Pap smears).
Testing involves far more expensive, often invasive, procedures that are given only to those who manifest some clinical indication of disease, and are most often applied to confirm a suspected diagnosis.
For example, most states in the USA require newborns to be screened for phenylketonuria and hypothyroidism, among other congenital disorders.
Hypothesis: «The newborns have phenylketonuria and hypothyroidism»
Null Hypothesis (H0): «The newborns do not have phenylketonuria and hypothyroidism»,
Type I error (false positive): The true fact is that the newborns do not have phenylketonuria and hypothyroidism but we consider they have the disorders according to the data.
Type II error (false negative): The true fact is that the newborns have phenylketonuria and hypothyroidism but we consider they do not have the disorders according to the data.
Although they display a high rate of false positives, the screening tests are considered valuable because they greatly increase the likelihood of detecting these disorders at a far earlier stage.
The simple blood tests used to screen possible blood donors for HIV and hepatitis have a significant rate of false positives; however, physicians use much more expensive and far more precise tests to determine whether a person is actually infected with either of these viruses.
Perhaps the most widely discussed false positives in medical screening come from the breast cancer screening procedure mammography. The US rate of false positive mammograms is up to 15%, the highest in world. One consequence of the high false positive rate in the US is that, in any 10-year period, half of the American women screened receive a false positive mammogram. False positive mammograms are costly, with over $100 million spent annually in the U.S. on follow-up testing and treatment. They also cause women unneeded anxiety. As a result of the high false positive rate in the US, as many as 90–95% of women who get a positive mammogram do not have the condition. The lowest rate in the world is in the Netherlands, 1%. The lowest rates are generally in Northern Europe where mammography films are read twice and a high threshold for additional testing is set (the high threshold decreases the power of the test).
The ideal population screening test would be cheap, easy to administer, and produce zero false-negatives, if possible. Such tests usually produce more false-positives, which can subsequently be sorted out by more sophisticated (and expensive) testing.
Medical testing[edit]
False negatives and false positives are significant issues in medical testing.
Hypothesis: «The patients have the specific disease».
Null hypothesis (H0): «The patients do not have the specific disease».
Type I error (false positive): «The true fact is that the patients do not have a specific disease but the physicians judges the patients was ill according to the test reports».
False positives can also produce serious and counter-intuitive problems when the condition being searched for is rare, as in screening. If a test has a false positive rate of one in ten thousand, but only one in a million samples (or people) is a true positive, most of the positives detected by that test will be false. The probability that an observed positive result is a false positive may be calculated using Bayes’ theorem.
Type II error (false negative): «The true fact is that the disease is actually present but the test reports provide a falsely reassuring message to patients and physicians that the disease is absent».
False negatives produce serious and counter-intuitive problems, especially when the condition being searched for is common. If a test with a false negative rate of only 10% is used to test a population with a true occurrence rate of 70%, many of the negatives detected by the test will be false.
This sometimes leads to inappropriate or inadequate treatment of both the patient and their disease. A common example is relying on cardiac stress tests to detect coronary atherosclerosis, even though cardiac stress tests are known to only detect limitations of coronary artery blood flow due to advanced stenosis.
Biometrics[edit]
Biometric matching, such as for fingerprint recognition, facial recognition or iris recognition, is susceptible to type I and type II errors.
Hypothesis: «The input does not identify someone in the searched list of people»
Null hypothesis: «The input does identify someone in the searched list of people»
Type I error (false reject rate): «The true fact is that the person is someone in the searched list but the system concludes that the person is not according to the data».
Type II error (false match rate): «The true fact is that the person is not someone in the searched list but the system concludes that the person is someone whom we are looking for according to the data».
The probability of type I errors is called the «false reject rate» (FRR) or false non-match rate (FNMR), while the probability of type II errors is called the «false accept rate» (FAR) or false match rate (FMR).
If the system is designed to rarely match suspects then the probability of type II errors can be called the «false alarm rate». On the other hand, if the system is used for validation (and acceptance is the norm) then the FAR is a measure of system security, while the FRR measures user inconvenience level.
Security screening[edit]
False positives are routinely found every day in airport security screening, which are ultimately visual inspection systems. The installed security alarms are intended to prevent weapons being brought onto aircraft; yet they are often set to such high sensitivity that they alarm many times a day for minor items, such as keys, belt buckles, loose change, mobile phones, and tacks in shoes.
Here, the null hypothesis is that the item is not a weapon, while the alternative hypothesis is that the item is a weapon.
A type I error (false positive): «The true fact is that the item is not a weapon but the system still alarms».
Type II error (false negative) «The true fact is that the item is a weapon but the system keeps silent at this time».
The ratio of false positives (identifying an innocent traveler as a terrorist) to true positives (detecting a would-be terrorist) is, therefore, very high; and because almost every alarm is a false positive, the positive predictive value of these screening tests is very low.
The relative cost of false results determines the likelihood that test creators allow these events to occur. As the cost of a false negative in this scenario is extremely high (not detecting a bomb being brought onto a plane could result in hundreds of deaths) whilst the cost of a false positive is relatively low (a reasonably simple further inspection) the most appropriate test is one with a low statistical specificity but high statistical sensitivity (one that allows a high rate of false positives in return for minimal false negatives).
Computers[edit]
The notions of false positives and false negatives have a wide currency in the realm of computers and computer applications, including computer security, spam filtering, Malware, Optical character recognition and many others.
For example, in the case of spam filtering the hypothesis here is that the message is a spam.
Thus, null hypothesis: «The message is not a spam».
Type I error (false positive): «Spam filtering or spam blocking techniques wrongly classify a legitimate email message as spam and, as a result, interferes with its delivery».
While most anti-spam tactics can block or filter a high percentage of unwanted emails, doing so without creating significant false-positive results is a much more demanding task.
Type II error (false negative): «Spam email is not detected as spam, but is classified as non-spam». A low number of false negatives is an indicator of the efficiency of spam filtering.
See also[edit]
- Binary classification
- Detection theory
- Egon Pearson
- Ethics in mathematics
- False positive paradox
- False discovery rate
- Family-wise error rate
- Information retrieval performance measures
- Neyman–Pearson lemma
- Null hypothesis
- Probability of a hypothesis for Bayesian inference
- Precision and recall
- Prosecutor’s fallacy
- Prozone phenomenon
- Receiver operating characteristic
- Sensitivity and specificity
- Statisticians’ and engineers’ cross-reference of statistical terms
- Testing hypotheses suggested by the data
- Type III error
References[edit]
- ^ «Type I Error and Type II Error». explorable.com. Retrieved 14 December 2019.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Sheskin, David (2004). Handbook of Parametric and Nonparametric Statistical Procedures. CRC Press. p. 54. ISBN 1584884401.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Lindenmayer, David. (2005). Practical conservation biology. Burgman, Mark A. Collingwood, Vic.: CSIRO Pub. ISBN 0-643-09310-9. OCLC 65216357.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Moroi, K.; Sato, T. (15 August 1975). «Comparison between procaine and isocarboxazid metabolism in vitro by a liver microsomal amidase-esterase». Biochemical Pharmacology. 24 (16): 1517–1521. doi:10.1016/0006-2952(75)90029-5. ISSN 1873-2968. PMID 8.
- ^ NEYMAN, J.; PEARSON, E. S. (1928). «On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference Part I». Biometrika. 20A (1–2): 175–240. doi:10.1093/biomet/20a.1-2.175. ISSN 0006-3444.
- ^ C.I.K.F. (July 1951). «Probability Theory for Statistical Methods. By F. N. David. [Pp. ix + 230. Cambridge University Press. 1949. Price 155.]». Journal of the Staple Inn Actuarial Society. 10 (3): 243–244. doi:10.1017/s0020269x00004564. ISSN 0020-269X.
- ^ Note that the subscript in the expression H0 is a zero (indicating null), and is not an «O» (indicating original).
- ^ Neyman, J.; Pearson, E. S. (30 October 1933). «The testing of statistical hypotheses in relation to probabilities a priori». Mathematical Proceedings of the Cambridge Philosophical Society. 29 (4): 492–510. Bibcode:1933PCPS…29..492N. doi:10.1017/s030500410001152x. ISSN 0305-0041. S2CID 119855116.
- ^ Fisher, R.A. (1966). The design of experiments. 8th edition. Hafner:Edinburgh.
Bibliography[edit]
- Betz, M.A. & Gabriel, K.R., «Type IV Errors and Analysis of Simple Effects», Journal of Educational Statistics, Vol.3, No.2, (Summer 1978), pp. 121–144.
- David, F.N., «A Power Function for Tests of Randomness in a Sequence of Alternatives», Biometrika, Vol.34, Nos.3/4, (December 1947), pp. 335–339.
- Fisher, R.A., The Design of Experiments, Oliver & Boyd (Edinburgh), 1935.
- Gambrill, W., «False Positives on Newborns’ Disease Tests Worry Parents», Health Day, (5 June 2006). [1] Archived 17 May 2018 at the Wayback Machine
- Kaiser, H.F., «Directional Statistical Decisions», Psychological Review, Vol.67, No.3, (May 1960), pp. 160–167.
- Kimball, A.W., «Errors of the Third Kind in Statistical Consulting», Journal of the American Statistical Association, Vol.52, No.278, (June 1957), pp. 133–142.
- Lubin, A., «The Interpretation of Significant Interaction», Educational and Psychological Measurement, Vol.21, No.4, (Winter 1961), pp. 807–817.
- Marascuilo, L.A. & Levin, J.R., «Appropriate Post Hoc Comparisons for Interaction and nested Hypotheses in Analysis of Variance Designs: The Elimination of Type-IV Errors», American Educational Research Journal, Vol.7., No.3, (May 1970), pp. 397–421.
- Mitroff, I.I. & Featheringham, T.R., «On Systemic Problem Solving and the Error of the Third Kind», Behavioral Science, Vol.19, No.6, (November 1974), pp. 383–393.
- Mosteller, F., «A k-Sample Slippage Test for an Extreme Population», The Annals of Mathematical Statistics, Vol.19, No.1, (March 1948), pp. 58–65.
- Moulton, R.T., «Network Security», Datamation, Vol.29, No.7, (July 1983), pp. 121–127.
- Raiffa, H., Decision Analysis: Introductory Lectures on Choices Under Uncertainty, Addison–Wesley, (Reading), 1968.
External links[edit]
- Bias and Confounding – presentation by Nigel Paneth, Graduate School of Public Health, University of Pittsburgh
This article is about erroneous outcomes of statistical tests. For closely related concepts in binary classification and testing generally, see false positives and false negatives.
In statistical hypothesis testing, a type I error is the mistaken rejection of an actually true null hypothesis (also known as a «false positive» finding or conclusion; example: «an innocent person is convicted»), while a type II error is the failure to reject a null hypothesis that is actually false (also known as a «false negative» finding or conclusion; example: «a guilty person is not convicted»).[1] Much of statistical theory revolves around the minimization of one or both of these errors, though the complete elimination of either is a statistical impossibility if the outcome is not determined by a known, observable causal process.
By selecting a low threshold (cut-off) value and modifying the alpha (α) level, the quality of the hypothesis test can be increased.[2] The knowledge of type I errors and type II errors is widely used in medical science, biometrics and computer science.[clarification needed]
Intuitively, type I errors can be thought of as errors of commission, i.e. the researcher unluckily concludes that something is the fact. For instance, consider a study where researchers compare a drug with a placebo. If the patients who are given the drug get better than the patients given the placebo by chance, it may appear that the drug is effective, but in fact the conclusion is incorrect.
In reverse, type II errors are errors of omission. In the example above, if the patients who got the drug did not get better at a higher rate than the ones who got the placebo, but this was a random fluke, that would be a type II error. The consequence of a type II error depends on the size and direction of the missed determination and the circumstances. An expensive cure for one in a million patients may be inconsequential even if it truly is a cure.
Definition[edit]
Statistical background[edit]
In statistical test theory, the notion of a statistical error is an integral part of hypothesis testing. The test goes about choosing about two competing propositions called null hypothesis, denoted by H0 and alternative hypothesis, denoted by H1. This is conceptually similar to the judgement in a court trial. The null hypothesis corresponds to the position of the defendant: just as he is presumed to be innocent until proven guilty, so is the null hypothesis presumed to be true until the data provide convincing evidence against it. The alternative hypothesis corresponds to the position against the defendant. Specifically, the null hypothesis also involves the absence of a difference or the absence of an association. Thus, the null hypothesis can never be that there is a difference or an association.
If the result of the test corresponds with reality, then a correct decision has been made. However, if the result of the test does not correspond with reality, then an error has occurred. There are two situations in which the decision is wrong. The null hypothesis may be true, whereas we reject H0. On the other hand, the alternative hypothesis H1 may be true, whereas we do not reject H0. Two types of error are distinguished: type I error and type II error.[3]
Type I error[edit]
The first kind of error is the mistaken rejection of a null hypothesis as the result of a test procedure. This kind of error is called a type I error (false positive) and is sometimes called an error of the first kind. In terms of the courtroom example, a type I error corresponds to convicting an innocent defendant.
Type II error[edit]
The second kind of error is the mistaken failure to reject the null hypothesis as the result of a test procedure. This sort of error is called a type II error (false negative) and is also referred to as an error of the second kind. In terms of the courtroom example, a type II error corresponds to acquitting a criminal.[4]
Crossover error rate[edit]
The crossover error rate (CER) is the point at which type I errors and type II errors are equal. A system with a lower CER value provides more accuracy than a system with a higher CER value.
False positive and false negative[edit]
In terms of false positives and false negatives, a positive result corresponds to rejecting the null hypothesis, while a negative result corresponds to failing to reject the null hypothesis; «false» means the conclusion drawn is incorrect. Thus, a type I error is equivalent to a false positive, and a type II error is equivalent to a false negative.
Table of error types[edit]
Tabularised relations between truth/falseness of the null hypothesis and outcomes of the test:[5]
| Table of error types | Null hypothesis (H0) is |
||
|---|---|---|---|
| True | False | ||
| Decision about null hypothesis (H0) |
Don’t reject |
Correct inference (true negative) (probability = 1−α) |
Type II error (false negative) (probability = β) |
| Reject | Type I error (false positive) (probability = α) |
Correct inference (true positive) (probability = 1−β) |
Error rate[edit]
The results obtained from negative sample (left curve) overlap with the results obtained from positive samples (right curve). By moving the result cutoff value (vertical bar), the rate of false positives (FP) can be decreased, at the cost of raising the number of false negatives (FN), or vice versa (TP = True Positives, TPR = True Positive Rate, FPR = False Positive Rate, TN = True Negatives).
A perfect test would have zero false positives and zero false negatives. However, statistical methods are probabilistic, and it cannot be known for certain whether statistical conclusions are correct. Whenever there is uncertainty, there is the possibility of making an error. Considering this nature of statistics science, all statistical hypothesis tests have a probability of making type I and type II errors.[6]
- The type I error rate is the probability of rejecting the null hypothesis given that it is true. The test is designed to keep the type I error rate below a prespecified bound called the significance level, usually denoted by the Greek letter α (alpha) and is also called the alpha level. Usually, the significance level is set to 0.05 (5%), implying that it is acceptable to have a 5% probability of incorrectly rejecting the true null hypothesis.[7]
- The rate of the type II error is denoted by the Greek letter β (beta) and related to the power of a test, which equals 1−β.[8]
These two types of error rates are traded off against each other: for any given sample set, the effort to reduce one type of error generally results in increasing the other type of error.[9]
The quality of hypothesis test[edit]
The same idea can be expressed in terms of the rate of correct results and therefore used to minimize error rates and improve the quality of hypothesis test. To reduce the probability of committing a type I error, making the alpha value more stringent is quite simple and efficient. To decrease the probability of committing a type II error, which is closely associated with analyses’ power, either increasing the test’s sample size or relaxing the alpha level could increase the analyses’ power.[10] A test statistic is robust if the type I error rate is controlled.
Varying different threshold (cut-off) value could also be used to make the test either more specific or more sensitive, which in turn elevates the test quality. For example, imagine a medical test, in which an experimenter might measure the concentration of a certain protein in the blood sample. The experimenter could adjust the threshold (black vertical line in the figure) and people would be diagnosed as having diseases if any number is detected above this certain threshold. According to the image, changing the threshold would result in changes in false positives and false negatives, corresponding to movement on the curve.[11]
Example[edit]
Since in a real experiment it is impossible to avoid all type I and type II errors, it is important to consider the amount of risk one is willing to take to falsely reject H0 or accept H0. The solution to this question would be to report the p-value or significance level α of the statistic. For example, if the p-value of a test statistic result is estimated at 0.0596, then there is a probability of 5.96% that we falsely reject H0. Or, if we say, the statistic is performed at level α, like 0.05, then we allow to falsely reject H0 at 5%. A significance level α of 0.05 is relatively common, but there is no general rule that fits all scenarios.
Vehicle speed measuring[edit]
The speed limit of a freeway in the United States is 120 kilometers per hour. A device is set to measure the speed of passing vehicles. Suppose that the device will conduct three measurements of the speed of a passing vehicle, recording as a random sample X1, X2, X3. The traffic police will or will not fine the drivers depending on the average speed . That is to say, the test statistic
In addition, we suppose that the measurements X1, X2, X3 are modeled as normal distribution N(μ,4). Then, T should follow N(μ,4/3) and the parameter μ represents the true speed of passing vehicle. In this experiment, the null hypothesis H0 and the alternative hypothesis H1 should be
H0: μ=120 against H1: μ1>120.
If we perform the statistic level at α=0.05, then a critical value c should be calculated to solve
According to change-of-units rule for the normal distribution. Referring to Z-table, we can get
Here, the critical region. That is to say, if the recorded speed of a vehicle is greater than critical value 121.9, the driver will be fined. However, there are still 5% of the drivers are falsely fined since the recorded average speed is greater than 121.9 but the true speed does not pass 120, which we say, a type I error.
The type II error corresponds to the case that the true speed of a vehicle is over 120 kilometers per hour but the driver is not fined. For example, if the true speed of a vehicle μ=125, the probability that the driver is not fined can be calculated as
which means, if the true speed of a vehicle is 125, the driver has the probability of 0.36% to avoid the fine when the statistic is performed at level 125 since the recorded average speed is lower than 121.9. If the true speed is closer to 121.9 than 125, then the probability of avoiding the fine will also be higher.
The tradeoffs between type I error and type II error should also be considered. That is, in this case, if the traffic police do not want to falsely fine innocent drivers, the level α can be set to a smaller value, like 0.01. However, if that is the case, more drivers whose true speed is over 120 kilometers per hour, like 125, would be more likely to avoid the fine.
Etymology[edit]
In 1928, Jerzy Neyman (1894–1981) and Egon Pearson (1895–1980), both eminent statisticians, discussed the problems associated with «deciding whether or not a particular sample may be judged as likely to have been randomly drawn from a certain population»:[12] and, as Florence Nightingale David remarked, «it is necessary to remember the adjective ‘random’ [in the term ‘random sample’] should apply to the method of drawing the sample and not to the sample itself».[13]
They identified «two sources of error», namely:
- (a) the error of rejecting a hypothesis that should have not been rejected, and
- (b) the error of failing to reject a hypothesis that should have been rejected.
In 1930, they elaborated on these two sources of error, remarking that:
…in testing hypotheses two considerations must be kept in view, we must be able to reduce the chance of rejecting a true hypothesis to as low a value as desired; the test must be so devised that it will reject the hypothesis tested when it is likely to be false.
In 1933, they observed that these «problems are rarely presented in such a form that we can discriminate with certainty between the true and false hypothesis» . They also noted that, in deciding whether to fail to reject, or reject a particular hypothesis amongst a «set of alternative hypotheses», H1, H2…, it was easy to make an error:
…[and] these errors will be of two kinds:
- (I) we reject H0 [i.e., the hypothesis to be tested] when it is true,[14]
- (II) we fail to reject H0 when some alternative hypothesis HA or H1 is true. (There are various notations for the alternative).
In all of the papers co-written by Neyman and Pearson the expression H0 always signifies «the hypothesis to be tested».
In the same paper they call these two sources of error, errors of type I and errors of type II respectively.[15]
[edit]
Null hypothesis[edit]
It is standard practice for statisticians to conduct tests in order to determine whether or not a «speculative hypothesis» concerning the observed phenomena of the world (or its inhabitants) can be supported. The results of such testing determine whether a particular set of results agrees reasonably (or does not agree) with the speculated hypothesis.
On the basis that it is always assumed, by statistical convention, that the speculated hypothesis is wrong, and the so-called «null hypothesis» that the observed phenomena simply occur by chance (and that, as a consequence, the speculated agent has no effect) – the test will determine whether this hypothesis is right or wrong. This is why the hypothesis under test is often called the null hypothesis (most likely, coined by Fisher (1935, p. 19)), because it is this hypothesis that is to be either nullified or not nullified by the test. When the null hypothesis is nullified, it is possible to conclude that data support the «alternative hypothesis» (which is the original speculated one).
The consistent application by statisticians of Neyman and Pearson’s convention of representing «the hypothesis to be tested» (or «the hypothesis to be nullified») with the expression H0 has led to circumstances where many understand the term «the null hypothesis» as meaning «the nil hypothesis» – a statement that the results in question have arisen through chance. This is not necessarily the case – the key restriction, as per Fisher (1966), is that «the null hypothesis must be exact, that is free from vagueness and ambiguity, because it must supply the basis of the ‘problem of distribution,’ of which the test of significance is the solution.»[16] As a consequence of this, in experimental science the null hypothesis is generally a statement that a particular treatment has no effect; in observational science, it is that there is no difference between the value of a particular measured variable, and that of an experimental prediction.[citation needed]
Statistical significance[edit]
If the probability of obtaining a result as extreme as the one obtained, supposing that the null hypothesis were true, is lower than a pre-specified cut-off probability (for example, 5%), then the result is said to be statistically significant and the null hypothesis is rejected.
British statistician Sir Ronald Aylmer Fisher (1890–1962) stressed that the «null hypothesis»:
… is never proved or established, but is possibly disproved, in the course of experimentation. Every experiment may be said to exist only in order to give the facts a chance of disproving the null hypothesis.
— Fisher, 1935, p.19
Application domains[edit]
Medicine[edit]
In the practice of medicine, the differences between the applications of screening and testing are considerable.
Medical screening[edit]
Screening involves relatively cheap tests that are given to large populations, none of whom manifest any clinical indication of disease (e.g., Pap smears).
Testing involves far more expensive, often invasive, procedures that are given only to those who manifest some clinical indication of disease, and are most often applied to confirm a suspected diagnosis.
For example, most states in the USA require newborns to be screened for phenylketonuria and hypothyroidism, among other congenital disorders.
Hypothesis: «The newborns have phenylketonuria and hypothyroidism»
Null Hypothesis (H0): «The newborns do not have phenylketonuria and hypothyroidism»,
Type I error (false positive): The true fact is that the newborns do not have phenylketonuria and hypothyroidism but we consider they have the disorders according to the data.
Type II error (false negative): The true fact is that the newborns have phenylketonuria and hypothyroidism but we consider they do not have the disorders according to the data.
Although they display a high rate of false positives, the screening tests are considered valuable because they greatly increase the likelihood of detecting these disorders at a far earlier stage.
The simple blood tests used to screen possible blood donors for HIV and hepatitis have a significant rate of false positives; however, physicians use much more expensive and far more precise tests to determine whether a person is actually infected with either of these viruses.
Perhaps the most widely discussed false positives in medical screening come from the breast cancer screening procedure mammography. The US rate of false positive mammograms is up to 15%, the highest in world. One consequence of the high false positive rate in the US is that, in any 10-year period, half of the American women screened receive a false positive mammogram. False positive mammograms are costly, with over $100 million spent annually in the U.S. on follow-up testing and treatment. They also cause women unneeded anxiety. As a result of the high false positive rate in the US, as many as 90–95% of women who get a positive mammogram do not have the condition. The lowest rate in the world is in the Netherlands, 1%. The lowest rates are generally in Northern Europe where mammography films are read twice and a high threshold for additional testing is set (the high threshold decreases the power of the test).
The ideal population screening test would be cheap, easy to administer, and produce zero false-negatives, if possible. Such tests usually produce more false-positives, which can subsequently be sorted out by more sophisticated (and expensive) testing.
Medical testing[edit]
False negatives and false positives are significant issues in medical testing.
Hypothesis: «The patients have the specific disease».
Null hypothesis (H0): «The patients do not have the specific disease».
Type I error (false positive): «The true fact is that the patients do not have a specific disease but the physicians judges the patients was ill according to the test reports».
False positives can also produce serious and counter-intuitive problems when the condition being searched for is rare, as in screening. If a test has a false positive rate of one in ten thousand, but only one in a million samples (or people) is a true positive, most of the positives detected by that test will be false. The probability that an observed positive result is a false positive may be calculated using Bayes’ theorem.
Type II error (false negative): «The true fact is that the disease is actually present but the test reports provide a falsely reassuring message to patients and physicians that the disease is absent».
False negatives produce serious and counter-intuitive problems, especially when the condition being searched for is common. If a test with a false negative rate of only 10% is used to test a population with a true occurrence rate of 70%, many of the negatives detected by the test will be false.
This sometimes leads to inappropriate or inadequate treatment of both the patient and their disease. A common example is relying on cardiac stress tests to detect coronary atherosclerosis, even though cardiac stress tests are known to only detect limitations of coronary artery blood flow due to advanced stenosis.
Biometrics[edit]
Biometric matching, such as for fingerprint recognition, facial recognition or iris recognition, is susceptible to type I and type II errors.
Hypothesis: «The input does not identify someone in the searched list of people»
Null hypothesis: «The input does identify someone in the searched list of people»
Type I error (false reject rate): «The true fact is that the person is someone in the searched list but the system concludes that the person is not according to the data».
Type II error (false match rate): «The true fact is that the person is not someone in the searched list but the system concludes that the person is someone whom we are looking for according to the data».
The probability of type I errors is called the «false reject rate» (FRR) or false non-match rate (FNMR), while the probability of type II errors is called the «false accept rate» (FAR) or false match rate (FMR).
If the system is designed to rarely match suspects then the probability of type II errors can be called the «false alarm rate». On the other hand, if the system is used for validation (and acceptance is the norm) then the FAR is a measure of system security, while the FRR measures user inconvenience level.
Security screening[edit]
False positives are routinely found every day in airport security screening, which are ultimately visual inspection systems. The installed security alarms are intended to prevent weapons being brought onto aircraft; yet they are often set to such high sensitivity that they alarm many times a day for minor items, such as keys, belt buckles, loose change, mobile phones, and tacks in shoes.
Here, the null hypothesis is that the item is not a weapon, while the alternative hypothesis is that the item is a weapon.
A type I error (false positive): «The true fact is that the item is not a weapon but the system still alarms».
Type II error (false negative) «The true fact is that the item is a weapon but the system keeps silent at this time».
The ratio of false positives (identifying an innocent traveler as a terrorist) to true positives (detecting a would-be terrorist) is, therefore, very high; and because almost every alarm is a false positive, the positive predictive value of these screening tests is very low.
The relative cost of false results determines the likelihood that test creators allow these events to occur. As the cost of a false negative in this scenario is extremely high (not detecting a bomb being brought onto a plane could result in hundreds of deaths) whilst the cost of a false positive is relatively low (a reasonably simple further inspection) the most appropriate test is one with a low statistical specificity but high statistical sensitivity (one that allows a high rate of false positives in return for minimal false negatives).
Computers[edit]
The notions of false positives and false negatives have a wide currency in the realm of computers and computer applications, including computer security, spam filtering, Malware, Optical character recognition and many others.
For example, in the case of spam filtering the hypothesis here is that the message is a spam.
Thus, null hypothesis: «The message is not a spam».
Type I error (false positive): «Spam filtering or spam blocking techniques wrongly classify a legitimate email message as spam and, as a result, interferes with its delivery».
While most anti-spam tactics can block or filter a high percentage of unwanted emails, doing so without creating significant false-positive results is a much more demanding task.
Type II error (false negative): «Spam email is not detected as spam, but is classified as non-spam». A low number of false negatives is an indicator of the efficiency of spam filtering.
See also[edit]
- Binary classification
- Detection theory
- Egon Pearson
- Ethics in mathematics
- False positive paradox
- False discovery rate
- Family-wise error rate
- Information retrieval performance measures
- Neyman–Pearson lemma
- Null hypothesis
- Probability of a hypothesis for Bayesian inference
- Precision and recall
- Prosecutor’s fallacy
- Prozone phenomenon
- Receiver operating characteristic
- Sensitivity and specificity
- Statisticians’ and engineers’ cross-reference of statistical terms
- Testing hypotheses suggested by the data
- Type III error
References[edit]
- ^ «Type I Error and Type II Error». explorable.com. Retrieved 14 December 2019.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Sheskin, David (2004). Handbook of Parametric and Nonparametric Statistical Procedures. CRC Press. p. 54. ISBN 1584884401.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Lindenmayer, David. (2005). Practical conservation biology. Burgman, Mark A. Collingwood, Vic.: CSIRO Pub. ISBN 0-643-09310-9. OCLC 65216357.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Moroi, K.; Sato, T. (15 August 1975). «Comparison between procaine and isocarboxazid metabolism in vitro by a liver microsomal amidase-esterase». Biochemical Pharmacology. 24 (16): 1517–1521. doi:10.1016/0006-2952(75)90029-5. ISSN 1873-2968. PMID 8.
- ^ NEYMAN, J.; PEARSON, E. S. (1928). «On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference Part I». Biometrika. 20A (1–2): 175–240. doi:10.1093/biomet/20a.1-2.175. ISSN 0006-3444.
- ^ C.I.K.F. (July 1951). «Probability Theory for Statistical Methods. By F. N. David. [Pp. ix + 230. Cambridge University Press. 1949. Price 155.]». Journal of the Staple Inn Actuarial Society. 10 (3): 243–244. doi:10.1017/s0020269x00004564. ISSN 0020-269X.
- ^ Note that the subscript in the expression H0 is a zero (indicating null), and is not an «O» (indicating original).
- ^ Neyman, J.; Pearson, E. S. (30 October 1933). «The testing of statistical hypotheses in relation to probabilities a priori». Mathematical Proceedings of the Cambridge Philosophical Society. 29 (4): 492–510. Bibcode:1933PCPS…29..492N. doi:10.1017/s030500410001152x. ISSN 0305-0041. S2CID 119855116.
- ^ Fisher, R.A. (1966). The design of experiments. 8th edition. Hafner:Edinburgh.
Bibliography[edit]
- Betz, M.A. & Gabriel, K.R., «Type IV Errors and Analysis of Simple Effects», Journal of Educational Statistics, Vol.3, No.2, (Summer 1978), pp. 121–144.
- David, F.N., «A Power Function for Tests of Randomness in a Sequence of Alternatives», Biometrika, Vol.34, Nos.3/4, (December 1947), pp. 335–339.
- Fisher, R.A., The Design of Experiments, Oliver & Boyd (Edinburgh), 1935.
- Gambrill, W., «False Positives on Newborns’ Disease Tests Worry Parents», Health Day, (5 June 2006). [1] Archived 17 May 2018 at the Wayback Machine
- Kaiser, H.F., «Directional Statistical Decisions», Psychological Review, Vol.67, No.3, (May 1960), pp. 160–167.
- Kimball, A.W., «Errors of the Third Kind in Statistical Consulting», Journal of the American Statistical Association, Vol.52, No.278, (June 1957), pp. 133–142.
- Lubin, A., «The Interpretation of Significant Interaction», Educational and Psychological Measurement, Vol.21, No.4, (Winter 1961), pp. 807–817.
- Marascuilo, L.A. & Levin, J.R., «Appropriate Post Hoc Comparisons for Interaction and nested Hypotheses in Analysis of Variance Designs: The Elimination of Type-IV Errors», American Educational Research Journal, Vol.7., No.3, (May 1970), pp. 397–421.
- Mitroff, I.I. & Featheringham, T.R., «On Systemic Problem Solving and the Error of the Third Kind», Behavioral Science, Vol.19, No.6, (November 1974), pp. 383–393.
- Mosteller, F., «A k-Sample Slippage Test for an Extreme Population», The Annals of Mathematical Statistics, Vol.19, No.1, (March 1948), pp. 58–65.
- Moulton, R.T., «Network Security», Datamation, Vol.29, No.7, (July 1983), pp. 121–127.
- Raiffa, H., Decision Analysis: Introductory Lectures on Choices Under Uncertainty, Addison–Wesley, (Reading), 1968.
External links[edit]
- Bias and Confounding – presentation by Nigel Paneth, Graduate School of Public Health, University of Pittsburgh
Ошибки первого и второго рода
Ошибки первого рода (false positives) и ошибки второго рода (false negatives) — ключевые понятия задач проверки статистических гипотез. Они используются также и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет).
Ошибку первого рода часто называют ложной тревогой, ложным срабатыванием или ложноположительным результатом — например, анализ крови показал наличие заболевания, хотя на самом деле человек здоров, или металлодетектор выдал сигнал тревоги, сработав на металлическую пряжку ремня. В информационных технологиях часто используют английский термин false positive без перевода.
Из-за возможности ложных срабатываний не удаётся полностью автоматизировать борьбу со многими видами угроз. Как правило, вероятность ложного срабатывания коррелирует с вероятностью пропуска события (ошибки второго рода). То есть: чем более чувствительна система, тем больше опасных событий она детектирует и, следовательно, предотвращает. Но при повышении чувствительности неизбежно вырастает и вероятность ложных срабатываний. Поэтому чересчур чувствительно (параноидально) настроенная система защиты может выродиться в свою противоположность и привести к тому, что побочный вред от неё будет превышать пользу.
Соответственно, ошибку второго рода иногда называют пропуском события или ложноотрицательным срабатыванием — человек болен, но анализ крови этого не показал, или у пассажира имеется холодное оружие, но рамка металлодетектора его не обнаружила (например, из-за того, что чувствительность рамки отрегулирована на обнаружение только очень массивных металлических предметов).
Степень чувствительности системы защиты должна представлять собой компромисс между вероятностью ошибок первого и второго рода. Где именно находится точка баланса, зависит от оценки рисков обоих видов ошибок.
Радиолокация
В задаче радиолокационного обнаружения воздушных целей, прежде всего, в системе ПВО ошибки первого и второго рода, с формулировкой «ложная тревога» и «пропуск цели» являются одним из основных элементов как теории, так и практики построения радиолокационных станций. Вероятно, это первый пример последовательного применения статистических методов в целой технической области.
Компьютерная безопасность
Наличие уязвимостей в вычислительных системах приводит к тому, что приходится, с одной стороны, решать задачу сохранности данных, а с другой стороны — обеспечивать доступ пользователей к этим данным. В этом контексте возможны следующие нежелательные ситуации:
когда авторизованные пользователи классифицируются как нарушители (ошибки первого рода)
когда нарушители классифицируются как авторизованные пользователи (ошибки второго рода)
Вредоносное программное обеспечение
Понятие ошибки первого рода также используется, когда антивирусное программное обеспечение ошибочно классифицирует безвредный файл как вирус.
Неверное обнаружение может быть вызвано особенностями эвристики, либо неправильной сигнатурой вируса в базе данных. Подобные проблемы могут происходить также и с антитроянскими и антишпионскими программами.
Досмотр пассажиров и багажа
Ошибки первого рода регулярно встречаются каждый день в компьютерных системах предварительного досмотра пассажиров в аэропортах. Установленные в них детекторы предназначены для предотвращения проноса оружия на борт самолёта; тем не менее, уровень чувствительности в них зачастую настраивается настолько высоко, что много раз за день они срабатывают на незначительные предметы, такие как ключи, пряжки ремней, монеты, мобильные телефоны, гвозди в подошвах обуви и т.п.
Таким образом, соотношение числа ложных тревог (идентифицикация благопристойного пассажира как правонарушителя) к числу правильных срабатываний (обнаружение действительно запрещённых предметов) очень велико.
Медицинское тестирование
Ошибки второго рода являются существенной проблемой в медицинском тестировании. Они дают пациенту и врачу ложное убеждение, что заболевание отсутствует, в то время как в действительности оно есть. Это зачастую приводит к неуместному или неадекватному лечению. Типичным примером является доверие результатам кардиотестирования при выявлении коронарного атеросклероза, хотя известно, что кардиотестирование выявляет только те затруднения кровотока в коронарной артерии, которые вызваны стенозом.
Ошибки второго рода вызывают серьёзные и трудные для понимания проблемы, особенно когда искомое условие является широкораспространённым. Если тест с 10%-ным уровнем ошибок второго рода используется для обследования группы, где вероятность «истинно-положительных» случаев составляет 70%, то многие отрицательные результаты теста окажутся ложными. (См. Теорему Байеса).
Ошибки первого рода также могут вызывать серьёзные и трудные для понимания проблемы. Это происходит, когда искомое условие является редким. Если уровень ошибок первого рода у теста составляет один случай на десять тысяч, но в тестируемой группе образцов (или людей) вероятность «истинно-положительных» случаев составляет в среднем один случай на миллион, то большинство положительных результатов этого теста будут ложными.
Исследования сверхъестественных явлений
Термин ошибка первого рода был взят на вооружение исследователями в области паранормальных явлений и привидений для описания фотографии или записи или какого-либо другого свидетельства, которое ошибочно трактуется как имеющее паранормальное происхождение — в данном контексте ошибка первого рода — это какое-либо несостоятельное «медиасвидетельство» (изображение, видеозапись, аудиозапись и т.д.), которое имеет обычное объяснение
Источник: https://ru.wikipedia.org/wiki/Ошибки_первого_и_второго_рода

18

766
-
Ошибки первого и второго рода при проверке гипотез.
шибки первого рода (англ. type
I
errors,
α
errors,
false
positives)
и ошибки
второго рода (англ. type
II
errors,
β
errors,
false
negatives)
в математической
статистике —
это ключевые понятия задач проверки
статистических гипотез. Тем не менее,
данные понятия часто используются и в
других областях, когда речь идёт о
принятии «бинарного» решения (да/нет)
на основе некоего критерия (теста,
проверки, измерения), который с некоторой
вероятностью может давать ложный
результат.
[Править]Определения
Пусть дана выборка ![]()
из
неизвестного совместного распределения ![]()
,
и поставлена бинарная задача проверки
статистических гипотез:
![]()
где ![]()
— нулевая
гипотеза,
а ![]()
— альтернативная
гипотеза.
Предположим, что задан статистический
критерий
![]()
,
сопоставляющий каждой
реализации выборки ![]()
одну
из имеющихся гипотез. Тогда возможны
следующие четыре ситуации:
-
Распределение
выборки
соответствует
гипотезе
,
и она точно определена статистическим
критерием, то есть
. -
Распределение
выборки
соответствует
гипотезе
,
но она неверно отвергнута статистическим
критерием, то есть
. -
Распределение
выборки
соответствует
гипотезе
,
и она точно определена статистическим
критерием, то есть
. -
Распределение
выборки
соответствует
гипотезе
,
но она неверно отвергнута статистическим
критерием, то есть
.
Во втором и четвертом случае
говорят, что произошла статистическая
ошибка, и её называют ошибкой
первого и второго рода соответственно. [1][2]
|
Верная гипотеза |
|||
|
Результат
применения
критерия |
верно |
(Ошибка второго рода) |
|
|
(Ошибка первого рода) |
верно |
[Править]о смысле ошибок первого и второго рода
Как видно из вышеприведённого
определения, ошибки
первого и второго рода являются
взаимно-симметричными, то есть если
поменять местами гипотезы
и
,
то ошибки
первого рода превратятся
в ошибки
второго рода и
наоборот. Тем не менее, в большинстве
практических ситуаций путаницы не
происходит, поскольку принято считать,
что нулевая
гипотеза
соответствует
состоянию «по умолчанию» (естественному,
наиболее ожидаемому положению вещей) —
например, что обследумый человек здоров,
или что проходящий через рамку
металлодетектора пассажир не имеет
запрещённых металлических предметов.
Соответственно, альтернативная
гипотеза
обозначает
противоположную ситуацию, которая
обычно трактуется как менее вероятная,
неординарная, требующая какой-либо
реакции.
С учётом этого ошибку
первого рода часто
называют ложной
тревогой, ложным
срабатыванием илиложноположительным срабатыванием —
например, анализ крови показал наличие
заболевания, хотя на самом деле человек
здоров, или металлодетектор выдал сигнал
тревоги, сработав на металлическую
пряжку ремня. Слово «положительный» в
данном случае не имеет отношения к
желательности или нежелательности
самого события.
Термин широко используется в медицине.
Например, тесты, предназначенные для
диагностики заболеваний, иногда дают
положительный результат (т. е. показывают
наличие заболевания у пациента), когда,
на самом деле пациент этим заболеванием
не страдает. Такой результат называется
ложноположительным.
В других областях, обычно, используют
словосочетания со схожим смыслом,
например, «ложное срабатывание», «ложная
тревога» и т. п. В информационных
технологиях часто используют английский
термин false positive без перевода.
Из-за возможности ложных срабатываний
не удаётся полностью автоматизировать
борьбу со многими видами угроз. Как
правило, вероятность ложного срабатывания
коррелирует с вероятностью пропуска
события (ошибки второго рода). То есть,
чем более чувствительна система, тем
больше опасных событий она детектирует
и, следовательно, предотвращает. Но при
повышении чувствительности неизбежно
вырастает и вероятность ложных
срабатываний. Поэтому чересчур
чувствительно (параноидально) настроенная
система защиты может выродиться в свою
противоположность и привести к тому,
что побочный вред от неё будет превышать
пользу.
Соответственно, ошибку
второго рода иногда
называют пропуском
события или ложноотрицательным срабатыванием —
человек болен, но анализ крови этого не
показал, или у пассажира имеется холодное
оружие, но рамка металлодетектора его
не обнаружила (например, из-за того, что
чувствительность рамки отрегулирована
на обнаружение только очень массивных
металлических предметов).
Слово «отрицательный» в данном случае
не имеет отношения к желательности или
нежелательности самого события.
Термин широко используется в медицине.
Например, тесты, предназначенные для
диагностики заболеваний иногда дают
отрицательный результат (т. е. показывают
отсутствие заболевания у пациента),
когда, на самом деле пациент страдает
этим заболеванием. Такой результат
называется ложноотрицательным.
В других областях, обычно, используют
словосочетания со схожим смыслом,
например, «пропуск события», и т. п. В
информационных технологиях часто
используют английский термин false negative
без перевода.
Степень чувствительности системы защиты
должна представлять собой компромисс
между вероятностью ошибок первого и
второго рода. Где именно находится точка
баланса, зависит от оценки рисков обоих
видов ошибок.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Развитие бизнеса и продвижение продуктов в Интернете неразрывно связано с тестированием разных концепций и идей. Отслеживание реакций аудитории позволяет выбирать и использовать именно те креативы, которые больше всего нравятся аудитории, привлекают внимание людей, вызывают нужные ассоциации и эмоции. Помогает в этом A/B тестирование, без которого не обходится развитие ни одного серьезного проекта.
![]()
![]()

В сегодняшней статье читайте, что такое A/B-тест, кому и зачем он нужен, что возможно исследовать с его помощью, на какие показатели и метрики нужно смотреть. Разберем виды А/В-тестирования и процесс его проведения по шагам, а также расскажем, как интерпретировать результаты и что делать после теста. Интересно? Поехали!
Что такое A/B-тестирование
A/B тест – это метод маркетингового исследования, который предполагает тестирование двух или более вариантов одного и того же маркетингового элемента, чтобы узнать, какой из них лучше по эффективности.
Например, кнопки на лендинге имеют остроугольную форму, но есть предположение, что закругленная форма будет больше привлекать посетителей. В таком случае создается еще одни идентичный лендинг. Единственное отличие двух вариантов друг от друга – форма кнопок. Трафик равномерно делится между двумя вариантами, и запускается A/B тест, который позволяет протестировать, может ли форма кнопок повлиять на конверсию.
A/B тестирование – отличный способ проверить, дадут ли вносимые изменения нужный результат до того, как они будут внедрены в конечный продукт.

В русскоязычном интернет-пространстве A/B тест и сплит-тестирование трактуются одинаково и употребляются как синонимы. Но если копнуть вглубь этих терминов, можно увидеть, что это совершенно разные исследования.
- A/B-тест предполагает пошаговое повышение эффективности сайта, рекламы или пользовательского интерфейса, которое по мере внесения мелких изменений приводит к идеальному результату.
- Сплит-тест – это сравнение двух кардинально отличающихся вариантов (страниц сайта, рекламных баннеров и т. д.).
История появления
Многие считают, что А/Б тестирование появилось после популяризации Интернета. Однако математик Вильям Госсет использовал его еще в начале XX века на пивном заводе Guinness. При варке пива использовался ячмень разных видов. Готовый продукт предлагали потребителям и таким образом определяли, какое сочетание ингредиентов нравится им больше всего.

С массовым появлением Интернета A/B-тесты приобрели особую популярность. Все владельцы сайтов экспериментировали с заменой элементов страниц, стараясь сделать их наиболее привлекательными для посетителей и добиться максимальной конверсии.
Провести А/Б-тестирование тогда было очень просто. Добавляли тег Google Optimize и настраивали тестируемые элементы в визуальном редакторе. После этого запускали тест, в ходе которого пользователи делились на две равные части и равномерно (рандомно) распределялись по двум версиям страницы.
Время шло, A/B тесты стали более сложными и совершенными. С появлением смартфонов появилась потребность в тестировании интерфейсов мобильных приложений, которую инструмент полностью покрывал. Однако многие разработчики до сих пор не хотят использовать тесты для своих продуктов, считая, что это трудоемко, долго и дорого.
Для чего нужны A/B-тесты и какие задачи решают
Когда идет речь о создании хорошего, эффективного инструмента, который обеспечит хороший трафик на сайт или рост продаж, изначально неизвестно, каким должен быть этот инструмент.
Нужно сформулировать оффер так или иначе, сделать кнопки больше или меньше, оформить интерфейс в светлых или темных тонах – даже самый опытный маркетолог не даст однозначные ответы на эти вопросы, а порекомендует провести A/B-тестирование, и это будет самым хорошим решением.
Дело в том, что пользователи разного возраста и пола из разных регионов в разное время года и даже дня могут вести себя по-разному. Факторов, влияющих на поведение людей, тысячи. Проведение исследования позволяет учесть большинство из них и выбрать наиболее привлекательный для посетителей вариант.
А/В тест позволяет решать следующие задачи:
- создавать продукт, соответствующий потребностям, привычкам и поведению клиентов;
- делать персонализированными коммуникации с пользователями;
- получать объективное мнение посетителей о качестве изменений;
- избегать принятия решений, основанных на субъективных факторах влияния;
- обеспечивать стабильную окупаемость инвестиций (ROI);
- увеличивать конверсию;
- повышать вовлеченность и снижать показатель отказов;
- улучшать дизайн, юзабилити, текстовое наполнение, УТП, визуальные материалы;
- минимизировать риски при внесении изменений;
- внедрять только статистически значимые улучшения;
- экономить время и ресурсы.
Основная цель, ради которой используют A/B-тестирование – повышение прибыльности сайта. Принятие решений о любых изменениях основывается на том, чтобы получить самые хорошие результаты и выйти на максимальный уровень дохода.
Кому нужно A/B-тестирование
Сплит-тесты используют в своей практике многие узкие специалисты. Этот инструмент есть в арсенале:
- маркетологов;
- продакт-менеджеров;
- дизайнеров;
- вебмастеров;
- SEO-специалистов;
- аналитиков;
- администраторов сайтов;
- UX-исследователей;
- UX-писателей.
A/B-тестирование не требует специальных знаний и навыков, поэтому использовать этот инструмент для решения своих задач может любой специалист, который работает над продуктом.
Особую роль в A/B-тестировании играет аналитик, поскольку решение в данном случае принимается на основе статистики. Задача специалиста – найти, собрать в отчетах и проанализировать все данные, полученные в процессе тестов, после чего попробовать сделать оптимальный прогноз по внедрению новшеств.
В ходе работы аналитикам важно не делать следующих ошибок:
- ошибки первого рода – когда кажется, что есть эффект там, где его нет;
- ошибки второго рода – когда незаметен эффект там, где он есть.
Еще одна важная функция аналитики – расчет статистической значимости, которая показывает, есть ли связь результатов исследования с изменениями продукта.
Что можно исследовать при помощи тестов
Предположения по улучшению существующего сайта или приложения могут касаться различных его элементов, и A/B-тест позволяет проверить абсолютно любые гипотезы.
Чаще всего с помощью A/B-тестирования проверяют:

- заголовки, подзаголовки, офферы, призывы к действию, текстовые описания, темы писем;
- внешний вид, размер, расположение кнопок CTA и их текст;
- расположение, количество полей, текст конверсионных форм;
- размер текста и глубина содержания;
- изображения, аудио, видео, анимации;
- дизайн и макет, размещение блоков и разделов;
- скидки, акционные предложения, пробные периоды;
- упоминания в СМИ;
- социальные доказательства: ссылки, цитаты, отзывы;
- лид-магниты;
- функционал;
- УТП, цены и бизнес-элементы;
- каналы коммуникации;
- email-рассылки;
- рекламные объявления: тексты, заголовки, баннеры;
Золотое правило классического A/B тестирования: один тест – одно изменение. Если внести несколько изменений на одной странице и запустить простое тестирование, невозможно будет понять, что именно привело к конкретному итогу.
Какие показатели улучшают за счет A/B-тестирования

Выбор показателей, которые будут улучшаться с помощью сплит-тестирования не такой большой, определяется он целями и задачами проекта. В интернет-маркетинге чаще всего оценивают конверсию, экономические метрики и поведенческие факторы. Рассмотрим их подробнее.
Конверсия
Это доля посетителей, которые совершили нужное целевое действие на странице сайта, сервиса или в приложении. Измерение конверсии после внесения изменений актуально не только для коммерческих проектов, но и для информационных сайтов, блогов. В данном случае тестируют:
- заполнение формы на сайте;
- совершение покупки (оформление заказа и его оплата);
- использование какого-либо инструмента (например, калькулятор расчета с запросом ответов на почту, форма заказа обратного звонка);
- оформление подписки;
- регистрация на сайте, для участия в обучающем курсе, в вебинаре, акции;
- сбор подписей;
- клик по рекламе Яндекс Директ / Google Ads или по ссылке.
Экономические метрики
Они актуальны преимущественно для интернет-магазинов и других коммерческих сайтов, работа которых связана с финансами. Чем более дружественен интерфейс, тем активнее пользователи будут совершать покупки или оставлять донаты.
Среди финансовых метрик с помощью A/B-тестов отслеживают:
- средний чек;
- число продаж определенной группы услуг или товаров;
- стоимость привлечения клиентов (CAC);
- возврат инвестиций в маркетинг (ROMI);
- перераспределение методов оплаты.
Поведенческие факторы
Это все методы взаимодействия посетителей с ресурсом или приложением. Отслеживая эти метрики, можно понять степень заинтересованности посетителей и их готовность делать покупки или совершать другие целевые действия.
Чаще всего оценивают:
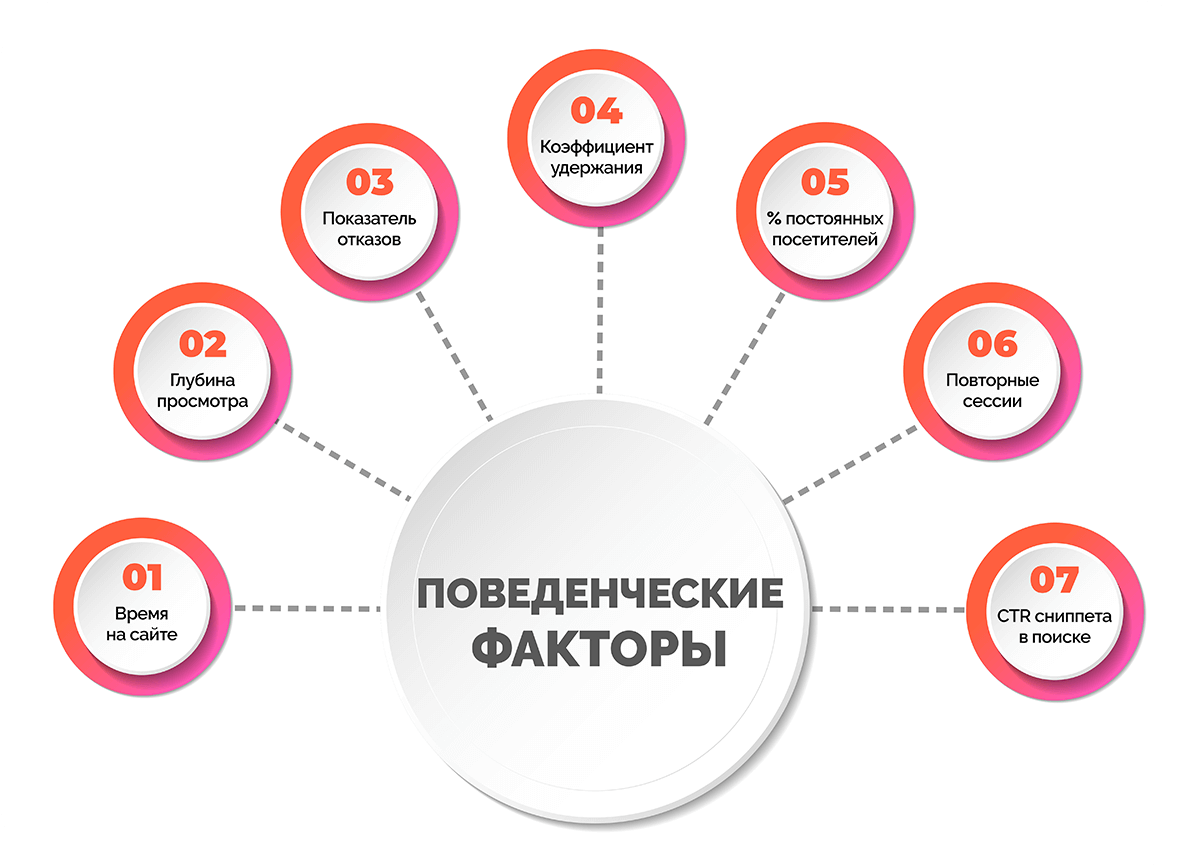
- время на сайте;
- глубину просмотра;
- показатель отказов;
- коэффициент удержания;
- процент постоянных посетителей;
- повторные сессии;
- CTR сниппета в поиске.
Виды A/B-тестирования
Когда говорят об A/B-тестировании, как правило, речь идет о простом тесте. На самом же деле существует несколько видов исследования, о которых далее в статье мы расскажем чуть подробнее.
- Простое A/B-тестирование (сплит-тестирование) – предполагает сравнение двух вариантов страницы или интерфейса – контрольного (исходного) и тестового (измененного). При этом отличаются они всего одним элементом. Простой тест подходит для точечных изменений, не влияющих на работу сайта в целом.
Пример: тестируются посадочные страницы – первая с красной CTA-кнопкой, вторая с оранжевой. - A/B/n-тест – его суть в том, что вы сможете запустить тестирование одного или нескольких изменений одновременно на одной странице. Результат учитывает коэффициенты конверсий среди разных вариантов на базе одного изменения, а в итоге можно выбрать одно решение из нескольких вариантов, которое стало наиболее успешным.
Пример: сравнение лендинга с прямоугольной, закругленной, овальной и фигурной кнопкой действия. - Многовариантное (многовариативное или мультивариативное) тестирование – позволяет сравнивать несколько исследуемых элементов, комбинируя их по-разному на одной странице. Сайтам с небольшим трафиком рекомендуется ограничиться 2-3 тестируемыми элементами, в противном случае можно получить статистически незначимые данные, и тест придется повторять заново.
Пример: тест формы кнопки и расположения текста описания в карточке товара. - Байесовский многорукий бандит – это тесты, в которых происходят реальные обновления онлайн на основе эффективности вариации. Самый хороший вариант получает наибольшую долю. Таким образом, происходит автооптимизация.
Этапы А/Б тестирования
Весь процесс A/Б теста можно условно разделить на несколько шагов. Далее в статье рассмотрим основные этапы исследования:

- Оценка объективной потребности в тестировании. Нужно понимать, действительно ли есть достаточные условия, чтобы провести исследование: хороший трафик на сайт, регулярные конверсии, налажена система аналитики, а не хочется провести тест чисто ради собственного интереса.
- Формулировка гипотезы. A/B-тест эффективен, когда есть четкая проблема, и в процессе исследования удается получить вероятное ее решение. Просто так сравнивать рандомные варианты интересно, но в этом нет смысла.
- Определение критерия исследования. Исследуемый параметр основывается на проблеме, которую нужно решить по итогам теста. Это может быть показатель отказов, время на сайте, средний чек, число покупок и другие метрики.
Важно, чтобы к сайту была подключена аналитика и настроена статистика, которая будет фиксировать изменения показателей.
- Выбор единственного элемента тестирования. В одном тесте должно быть только одно изменение, например, только заголовок или только форма кнопки, или только слова на кнопке.
- Определение выборки. Важно заранее просчитать, какое количество человек должны просмотреть первую и вторую тестируемую страницу, чтобы получить статистически значимый (положительный) результат, которому можно доверять.
- Определение длительности исследования. Даже если нужное количество посетителей набралось за день, A/B-тестирование стоит проводить минимум в течение недели, чтобы посмотреть и учесть разницу в поведении пользователей в разные дни. По умолчанию средняя продолжительность теста составляет 10-14 дней.
Чтобы получить достоверные результаты не рекомендуется останавливать тест раньше предопределенного времени, даже если четко вырисовывается лидер среди вариантов.
- Проверка однородности аудитории. При распределении посетителей между двумя альтернативными вариантами важно обеспечить их похожесть и однородность.
- Учет внешних факторов влияния. Проведение эксперимента в период резкого скачка курса валюты, летних отпусков или новогодних праздников может существенно исказить итоговые значения.
- Проверка работоспособности. Если отличия в результатах теста аномальные (например, на контрольной странице конверсия 7%, а на исследуемой 0%), нужно убедиться, что все ссылки и кнопки работают, как положено.
- Сбор результатов и повтор теста. После завершения исследования стоит подсчитать статистическую значимость результатов. Но даже при условии, что с данными все в порядке, эксперимент не был завершен досрочно, и был выявлен победивший вариант, никогда не помешает провести новый тест повторно.
- Анализ данных и принятие решения. Результаты исследования нужно проанализировать и решить, стоит ли сразу начать вносить изменения в текущую версию или лучше оставить все, как есть.
Формулировка устойчивой гипотезы для A/B-теста
A/B тестирование проводится для решения какой-либо проблемы или изменения некоего поведения людей. Зная конкретную проблему или задачу, формируется гипотеза или предположение, которое в конце эксперимента будет подтверждено или опровергнуто. Без гипотезы исследование не имеет смысла.
Правильно сформулировать гипотезу помогает список, состоящий из 5 приоритетов. Именно он сможет показать, какие предположения важно тестировать в первую очередь.

|
Приоритет |
Что показывает |
|
Цель |
Теснота связи гипотезы с KPI. |
|
Предмет |
Важность анализируемой функции или страницы для бизнеса. |
|
Положение |
Будет ли наблюдаться рост конверсии вследствие изменений и в какой степени это будет заметно. |
|
Ценность |
Станет ли предложение более ценным для клиента после внесения новых изменений или это лишь «косметическое» улучшение. |
|
Доказательства |
Существуют ли хорошие примеры подобных изменений с высокой эффективностью. |
Оценка каждой метрики по шкале от 1 до 5 поможет понять, имеет ли предположение шансы стать статистически значимым по итогам теста. Общий балл 20 и более говорит в пользу предложенной гипотезы.
Как сделать сплит-тестирование объективным
При A/B-тесте пользователи делятся на две одинаковые группы случайным образом. Одна группа видит текущую версию, другой показывается страница с изменениями. Чтобы в ходе тестирования минимизировать влияние различных факторов и рассчитывать на объективность, стоит придерживаться нескольких правил:
- тест обеих версий проводится одновременно, поочередное тестирование с последующим сравнением результатов не допускается;
- фильтрация сотрудников компании, они не должны войти в фокус-группы, чтобы не исказить общую картину эксперимента;
- репрезентативность выборки, т. е. каждая группа должна включать достаточное количество людей, чтобы сократить риск влияния случайных действий. Кроме этого, группы не должны пересекаться – необходимо исключить вероятность того, что пользователь зайдет на одну версию сайта (например, на главной странице), а после обновления увидит измененный вариант.

Результат эксперимента зависит от целого ряда внутренних и внешних факторов.
Внутренние факторы
- Маркетологи.
- Разработчики.
- Сотрудники call-центра.
- Менеджеры по продажам.
- Специалисты службы техподдержки и другие.
Эти специалисты взаимодействуют с сайтом большую часть рабочего времени, поэтому их трафик не должен учитываться при тестировании.
Внешние факторы
- Сезонность.
- Погодные условия.
- День недели.
- Время суток.
- Рекламные кампании.
- Активность конкурентов и т. д.
Все это может указать на то, что любая ситуация требует проверить результаты с участием контрольной группы. Отследить колебания показателей в связи с влиянием внешних факторов можно с помощью сквозной аналитики и корпоративной CRM-системы.
Как анализировать результаты и что делать дальше
Итак, сплит-тестирование завершено в установленный срок, необходимая статистика набрана. Теперь необходимо отделить показания с высокой статистической значимостью от изменений метрик случайного характера. Это значит, предстоит перейти в отчеты и оценивать значимость результатов.
Случайные величины сравниваются путем проверки статистических гипотез, которых в A/B-тестировании всего две: нулевая и альтернативная. Согласно первой, наблюдается незначительное различие между средними величинами показателя. Согласно второй, эта разница существенная.

Проверка гипотез осуществляется с применением ряда статистических тестов, выбор которых определяется характером измеряемого показателя. Наиболее универсальным является тест Стьюдента, который подходит для измерения различных количественных показателей и позволяет работать с небольшими массивами данных.
Убедившись, что результаты исследования имеют высокую статистическую значимость и не случайны, необходимо принять решение о запуске лучшего варианта в работу или оставить страницу без изменений.
После того, как тест завершен, результаты проанализированы, изменения вступили в силу, стоит заняться поиском новых предполагаемых точек роста, сформулировать новые гипотезы и приступить к следующему тесту с целью улучшения и повышения эффективности ресурса.
В поиске наиболее перспективных ступеней воронки продаж продукта имеет смысл использовать методы юнит-экономики. С ее помощью можно определить доходность бизнес-модели по выручке от одного клиента или товара. Если продукт – мобильное приложение, то доходом выступают деньги от подписки, продажи приложения, а также прибыль с рекламы.
Ошибки при оценке статистической значимости
- Вера в то, что одна страница лучше другой. На самом деле значения лишь отражают вероятность, что полученный результат не случайный.
- Результат подтверждает, что первая версия тестируемой страницы может оказаться лучше второй или наоборот. На деле это не так. А/Б-тестирование не позволяет это доказать, а лишь показывает, что одна версия получила больше целевых показателей в сравнении с другой.
- Пользователи выбрали одну из версий. Фактически люди не могут самостоятельно сравнить два варианта, оценить преимущества и предпочесть один из них. Измерения показывают, как определенное изменение или разработка влияет на поведение людей.
Сегментация аудитории
Если в результате сплит-тестирования не было выявлено существенной разницы между сравниваемыми вариантами, можно попытаться их сегментировать по различным признакам:
- по демографии (примеры: пол и возраст, страна);
- по старым и новым пользователям (желательно включать в фокус-группы только новых посетителей);
- по плательщикам;
- по источнику трафика и платформе.
Один из вариантов может в целом проиграть другому, но обойти его по некоторым отдельным параметрам.

Если вы хотите провести правильную сегментацию аудитории, следует придерживаться двух полезных правил:
- В каждом сегменте должен быть достаточно большой объем выборки, которые стоит рассчитать заранее. Минимальное количество конверсий на один тестируемый вариант в каждом сегменте – 250-350.
- В слишком маленьких и статистически незначимых сегментах проводить A/B тест бессмысленно.
Калькулятор достоверности AB-тестирования
Чтобы получить максимально достоверные результаты теста и сделать объективные выводы, стоит обратить внимание на правильность определения размера выборки перед началом исследования, а затем определить статистическую значимость полученной информации. В обоих случаях для удобства расчетов можно пользоваться онлайн-калькуляторами. Ниже в статье предлагаем два удобных онлайн-сервиса, которые помогут быстрее сделать расчеты и получить нужные значения, нажимая на кнопку вычисления.
Калькулятор размера выборки для А/Б-теста
Для проведения A/B-теста важно правильно рассчитать размер выборки. Поможет в этом калькулятор, однако потребуется сделать дополнительные расчеты, которые предстоит провести вручную.
Коэффициент конверсии (CR) = (Конверсия / Трафик) × 100%
Предположим, что у исследуемой страницы трафик 1200 пользователей, конверсия – 18%. Тогда CR = 1,5. Заносим данные в калькулятор и считаем.

Теперь вы знаете, что размер выборки для каждого варианта составит 14 496 человек.
Калькулятор статистической значимости А/Б-теста
Чтобы успешно закончить A/B-тест, необходимо убедиться, что результаты были интерпретированы верно и не являются случайными. Для этого можно воспользоваться калькулятором статистической значимости.
Рассмотрим простой пример. Предположим, что по итогу А/Б-тестирования двух страниц сайта были получены такие данные:
- страница 1: трафик – 1500 пользователей, конверсия – 6;
- страница 2: трафик – 1200 пользователей, конверсия – 18.
Для проверки статистической значимости можно добавить эти данные в соответствующие поля калькулятора.
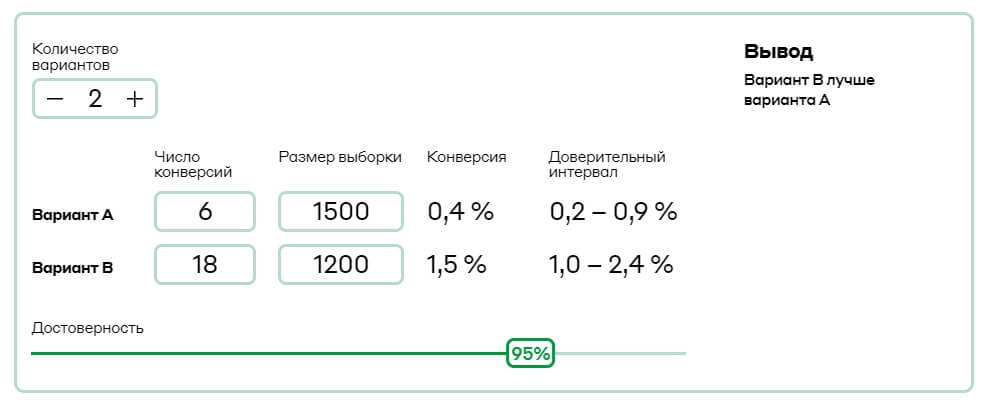
Для повышения статистической значимости результатов исследования стоит придерживаться следующих рекомендаций:
- использовать максимально согласованные данные с минимальными отклонениями;
- обеспечивать значительное повышение коэффициента конверсии, сравнивая две страницы;
- увеличивать размер выборки.
Инструменты для работы с A/B тестами
Для упрощения работы маркетологов, аналитиков и других исследователей предназначены специальные программы. Их можно использовать, не только чтобы работать с тестами, но, и чтобы разделять пользователей на фокус-группы, отслеживать эффективность различных тестируемых вариантов. В статье рассмотрим основные их них.

- Калькулятор А/Б-тестирований от Яндекса. Позволяет сравнивать результаты исследования в разных рекламных кампаниях с учетом привлеченных лидов. Учитывает показатели CPA, CPC, CTR.
- Google Optimize или Google Marketing Platform. Наиболее популярный бесплатный сервис с возможностью одновременной проверки 5 вариантов одной страницы для теста нескольких гипотез. Для подключения нужен аккаунт Google Analytics.
- Optimizely.com. Простой сервис, который можно использовать для A/B-тестирования, с удобными визуальными редакторами и понятным интерфейсом.
- Changeagain.me. Алгоритмы платформы позволяют ей интегрироваться с Google Analytics и дают возможность формировать цели, которые загружаются в систему автоматически.
- ABtasty.com. Хороший сервис, который позволяет проводить сплит-тестирование, мультивариантные тестирования, имеет 7 параметров настройки таргетинга и интегрируется с Google Analytics.
- Realroi.ru. Удобный и простой российский аналог зарубежных программ для A/B-тестирования.
- Vwo.com или Visual Website Optimizer. Еще один иностранный сервис с большими возможностями, тем не менее, требует навыков работы с html.
- Convert. Платформа поддерживает самый большой набор параметров для настройки таргетинга среди известных сервисов, способна работать с трафиком до 1,2 млрд пользователей.
- Flexbe. Штатный инструмент для A/B-тестирования страниц, созданных с помощью одноименного конструктора.
- LPGenerator. Сервис имеет шаблоны и удобный визуальный редактор, но способен работать только с теми лендингами, которые были созданы с помощью данного конструктора.
- Unbounce. Приложение для теста и оптимизации внутренних одностраничных сайтов.
- Facebook. Социальная сеть позволяет удобно и бесплатно сделать сплит-тестирование креативов. Например, у ВКонтакте такого инструмента нет.
- MyTarget. Здесь доступно А/Б тестирование рекламных кампаний, а также сегментирование аудитории.
Как настроить Google Optimize
Это один из наиболее популярных сервисов, поэтому в данной статье мы разберем, как с его помощью провести A/B-тестирование.
- Заходим на сайт и авторизуемся под Google аккаунтом.
- Создаем проект оптимизации, указываем название эксперимента, URL страницы, выбираем «Эксперимент А/Б».
- Указываем настройки таргетинга.
- Для настройки целей подключаем аналитику.
- Создаем страницы с изменениями и прописываем цели, которые вы ожидаете достичь.
- Прописываем адреса веб-страниц с изменениями.
- Задаем аудиторию для просмотра тестируемых страниц и элементов.
- Указываем процент аудитории, который будет принимать участие в исследовании.
- Генерируем код эксперимента и добавляем его в html-файл сайта.
- Запускаем эксперимент. Для этого нажмите кнопку ОК в личном кабинете. Здесь же будет отображаться статистика.
Если в Google Analytics еще не заданы цели, их нужно создавать. Для этого:
- Зайдите в Google Analytics и авторизуйтесь в аккаунте.
- Нажмите «Создать цель».
- Выберите подходящую цель из стандартных или отметьте «Выбрать» и кликните «Далее».
- Напишите название цели, определите ее тип.
- В поле Цель пропишите путь к странице, которая подтверждает, что цель достигнута.
- Кликните «Создать цель».
Как настроить Яндекс Метрику для A/B-тестирования
Яндекс Метрика тоже может помочь провести сплит-тест двух разных страниц сайта. Настройка предполагает два этапа работы.
- На первом этапе создайте две страницы, которые будет видеть аудитория и где отличаться будет только один элемент, например, кнопка. Вместо этого можно настроить посадочную страницу так, чтобы целевой аудитории показывались два ее варианта: оригинальный и альтернативный.
- Второй шаг – настройте передачу данных в Метрику о том, какая версия сайта была показана посетителю. Для этого нужно создать параметр, которому будет присвоено требуемое значение, и передать его в Метрику. На основе этого будет формироваться отчет с данными. Как это сделать, читайте подробнее в справке Яндекса.
А/В-тестирование в Яндекс.Директ
Яндекс Директ позволяет проводить A/B-тестирование серии рекламных материалов с целю выбрать наиболее эффективные и организовать показ только самых кликабельных объявлений. Сделать это можно с помощью инструмента «Группы объявлений».
Все рекламные объявления в одной группе имеют идентичные настройки: ключи, минус-слова, геотергетинг, ставки за клик и т. д., что делает группы идеальным инструментом для сплит-тестирования контекстной рекламы.
Перед тем, как создавать группу, распределите ключевые слова по категориям товаров или услуг в рамках рекламной кампании. Для каждой подгруппы ключей предстоит сделать какое-то количество объявлений, которые и будут показываться аудитории в ходе тестирования.
Например, сплит-тестирование позволяет сравнивать, как влияет на поведение аудитории:
- ограничение длительности акции;
- упоминание в тексте о скидке;
- конкретизирование текста объявления;
- различные вариации изображений;
- разные формулировки предложений;
- наличие быстрых ссылок.
При этом объявления в группе могут быть как для одной посадочной страницы, так и для разных. То же самое касается контактов.
Обязательно нужно соблюдать правило тестирования одного элемента. В противном случае будет невозможно определить, как может повлиять на реакцию аудитории то или иное изменение.
Поначалу все объявления из группы будут показываться равномерно, но с течением времени, когда система накопит достаточно статистики, предпочтение будет отдаваться более эффективной рекламе с наивысшим CTR.
Воспользоваться инструментом легко. Достаточно включить функцию «Начать работать с группами» в личном кабинете Яндекс Директ.
Создать группу объявлений можно несколькими способами:
- задайте параметры группы на специальной вкладке в интерфейсе Директ Коммандер;
- воспользуйтесь csv- или xls-файлами;
- воспользуйтесь API Директа, которая поддерживает группы в работе с объявлениями (версия API Live 4).
Более подробно о работе с группами объявлений в Директ можно почитать в документации Яндекса.
Советы для эффективного проведения A/B-теста
Бывает, что вы проверяете все гипотезы, но это не приводит к улучшению результата. В таком случае стоит прибегнуть к следующим рекомендациям.
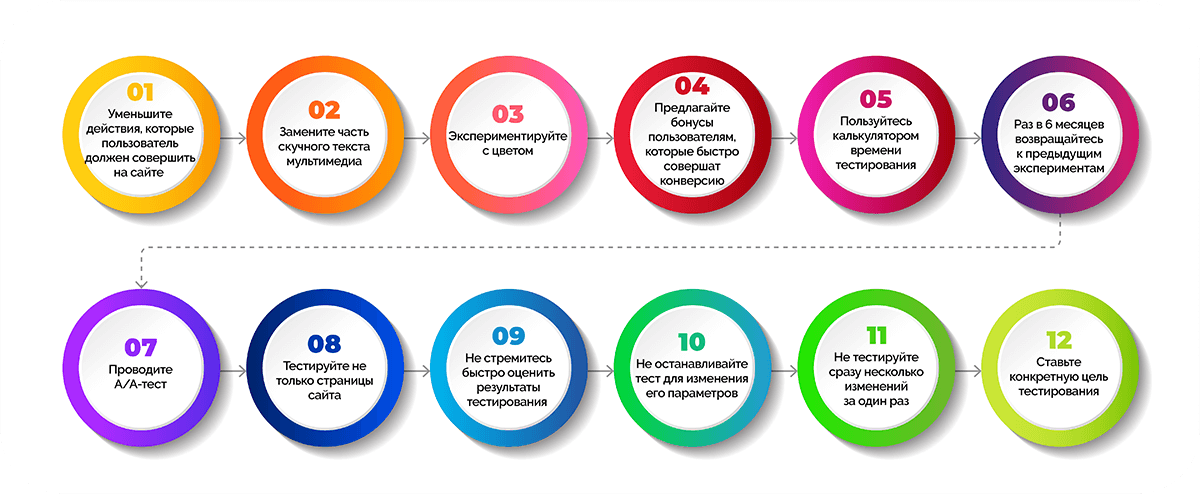
- Минимизируйте действия, которые пользователь должен совершить на сайте для достижения цели.
- Замените часть скучного текста в статье интересными и информативными мультимедиа (видео, инфографика).
- Экспериментируйте с цветом. Опыт говорит о том, что со временем некоторые цвета и выходят из моды или приедаются и начинают раздражать.
- Предлагайте бонусы пользователям, которые быстро совершат конверсию.
- Пользуйтесь калькулятором времени теста, чтобы правильно определить длительность исследования.
- Минимум раз в 6 месяцев возвращайтесь к предыдущим экспериментам, чтобы пересмотреть их результаты на текущий момент с учетом прошедшего времени.
- Проводите А/А-тест, чтобы проверить корректность исследования и избежать отклонения значений более чем на 10%.
- Тестируйте не только страницы сайта, но и всплывающие окна, карточки товаров, электронные рассылки, новости.
- Не стремитесь оценить результаты теста до того, как пройдет нужное время и наберется достаточное количество посетителей на сайте.
- Не останавливайте тест для изменения каких-либо его параметров или элементов.
- Избегайте тестирования одновременно нескольких изменений на сайте за один раз.
- Ставьте конкретную цель теста.
Примеры A/B-тестов
Компания специализируется на мониторинге серверов. Основная задача – повышение цен ради увеличения выручки. Было выдвинуто две гипотезы:
- С ростом цен количество бесплатных регистраций уменьшится.
- С ростом цен выручка повысится несмотря на уменьшение числа регистраций.
Среднее число подключаемых серверов составляло 8, при этом за обслуживание одного сервера клиентам приходилось платить 1100 руб. Пользователи жаловались на слишком высокую цену. Однако фирма решила продавать новый пакет услуг: обслуживание 10 серверов по цене 9 900 руб.
По старой цене обслуживание 10 машин обошлось бы в 11 000 руб. Так, компания повысила цену одного заказа, но при заказе большого количества услуг общая цена снизилась и стала выгодной для клиентов. При этом средний чек повысился, что положительно сказалось на общем доходе предприятия.
Продавец женской одежды ранее запускал рекламную кампанию под каждую категорию товара (юбки, платья, блузки, брюки и т. д.). При этом было подобрано соответствующее семантическое ядро.
В ходе A/B-тестирования было принято решение создать одну масштабную рекламную кампанию, в которой будут объединены все ранее созданные мелкие. В рамках одной крупной РК планировалось разделение товаров по категориям. Это позволило максимально укрупнить семантику, которая до этого приносила конверсии.
В этом примере в результате теста стало понятно, что новая РК приносит где-то на 25% конверсий больше, позволяет увеличить приток клиентов на сайт и прибыль.
В каких случаях А/Б тесты не нужны
Несмотря на полезность и универсальность А/Б тестов они не всегда актуальны и уместны. Разберем примеры случаев, когда лучше воздержаться от экспериментов.
- Отсутствие понимания принципов сплит-тестирования. Если вы «не в теме», как работает тест, лучше поручить эту работу профессионалу или хотя бы предварительно хорошо изучить теорию и чужие кейсы.
- Недостаток конверсий. При отсутствии стабильных продаж и потока заявок вы не получите достоверных результатов теста.
- Размытые предположения или их отсутствие. Гипотеза должна быть четкой, иначе ее тестирование ничего не даст.
- Продукт рассчитан на премиум-сегмент потребителей или сегменты B2B / B2G. В данном случае каждый клиент имеет высокую ценность. Любое «сырое» решение может отпугнуть и сорвать сделку на крупную сумму.
Частые ошибки при А/Б тестировании
- Тестирование страниц с несколькими изменениями.
- Использование заимствованных гипотез и чужих результатов.
- Неверно выбранная продолжительность исследования.
- Однократное тестирование.
- Игнорирование влияния внешних факторов на эксперимент.
- Неправильно выбранный инструментарий.
- Минимальное отслеживание метрик.
- Принятие решения до того, как завершится тест (проблема подглядывания).
- Тестирование в два, три и более этапов – поочередно.
- Ожидание значительных результатов при минимальных изменениях.
- Запуск нескольких тестов одновременно.
- Замеры микроконверсий.
- Игнорирование автором статистики в пользу личных ощущений.
Часто задаваемые вопросы
Если стоит задача повысить прибыль компании, какие-то ключевые показатели или менять маркетинговые инструменты взаимодействия с клиентами (сайт, лендинг, рассылку, креатив и пр.), A/B-тестирование является обязательным.
Приступать к A/B тестированию можно, если:
- подключена аналитика на сайт или трекинг к мобильному приложению;
- ведутся подсчеты расходов и доходов, есть понимание, сколько будет стоит привлечение одного пользователя, и возможность масштабирования;
- есть ресурсы для проведения системных проверок гипотез.
Продолжительность тестирования должна быть такой, чтобы результаты приобрели статистическую значимость и могли использоваться в качестве основы для принятия решений. Останавливать эксперимент можно тогда, когда становится ясно, что в итогах нет конвергенции. Минимально допустимый период – неделя. В большинстве сервисов пол умолчанию установлен рекомендуемый срок тестирования – от 10 до 14 дней.
Кроме A/B-тестов, в некоторых случаях проверять, сработала ли гипотеза, можно и другими методами:
- юзабилити-тестирование – подходит для проверки удобства интерфейса;
- fake door тест – позволяет проверить, нужна ли конкретная опция пользователям (устанавливается «пустая» кнопка и отслеживаются клики по ней);
- релиз на ограниченную ЦА – метод позволяет запустить продукт на выделенную часть аудитории, определенный район или город;
- unbounce – сервис, с помощью которого можно создать несколько вариантов страниц, а аудиторию для каждого типа страницы подберет искусственный интеллект.
Существует риск снижения рейтинга сайта в поисковых системах из-за того, что альтернативные страницы могут быть восприняты как дубли. Однако на практике к этому приводят только длительные эксперименты.
Для такого случая существует A/B/n тестирование, которое имеет аналогичный принцип, что и сплит-тест, но может сравнивать одновременно больше двух альтернативных изменений одного объекта.
Определить примерное количество пользователей для участия в эксперименте можно с помощь специальных калькуляторов. Но в любом случае, чем больше будет выборка, тем выше шансы получить точные результаты.
Это допускается, но есть ограничения. При параллельных тестах выборки не должны пересекаться, иначе одно изменение может изменить восприятие другого.
Заключение
Сплит-тестирование – неотъемлемый инструмент работы маркетологов, аналитиков, разработчиков, дизайнеров и других специалистов, которые непосредственно связаны с созданием и продвижением продукта или бренда. A/B-тест помогает улучшить показатели компании и повысить доходность бизнеса. Если вы стремитесь уверенно продвигаться на рынке и обходить конкурентов, данный механизм должен стать верным спутником в процессе всей работы.

Олег Вершинин
Специалист по продукту
Все статьи автора
Нашли ошибку в тексте? Выделите нужный фрагмент и нажмите
ctrl
+
enter
Время на прочтение
24 мин
Количество просмотров 14K
Всем привет! Меня зовут Дима Лунин, и я аналитик в Авито. Как и в большинстве компаний, наш основной инструмент для принятия решений — это A/B-тесты. Мы уделяем им большое внимание: проверяем на корректность все используемые критерии, пытаемся сделать результаты более интерпретируемыми, а также увеличиваем мощность критериев. Про это всё мы уже написали две статьи на Хабр, вот первая часть, а вот — вторая.
В текущем посте я хочу рассказать, как ещё сильнее увеличить мощность критериев для A/B-тестирования, используя машинное обучение. В некоторых моментах буду ссылаться на две предыдущие статьи, так что если вы их ещё не читали, самое время это исправить.

Кратко, о чём я собираюсь рассказать:
-
Что такое CUPED-метод.
-
Как улучшить CUPED-алгоритм. CUPAC, CUNOPAC и CUMPED — подробно про каждый из них.
-
Как использовать Uplift-модель в качестве статистического критерия. Здесь я продемонстрирую все прелести bootstrap-технологий.
-
Как использовать все модели сразу для достижения лучшей мощности.
-
Насколько эти методы вместе с парной стратификацией лучше, чем обычный CUPED.
Отдельно отмечу, что такие методы, как CUNOPAC, CUMPED, критерий на основе Uplift-модели и критерий, объединяющий несколько критериев, были разработаны и придуманы нашей командой.
Задачи для проверки критериев
Прежде чем приступить к рассказу о критериях, хочу показать, для каких задач годятся описанные далее алгоритмы.
Поюзерные A/B-тесты. Здесь вы одним пользователям показываете новый дизайн, новые фишки и так далее, а в другой группе оставляете всё как было. Ждёте какой-то срок и смотрите с помощью статистического критерия, прокрашен тест или нет.
Конечно, в таких экспериментах хочется иметь наиболее мощный критерий: так мы сможем проверить больше гипотез за меньшее время. Ещё примеры, зачем может потребоваться большая мощность у критерия, можно найти в статьях выше.
Но бывают случаи, когда такое не получается сделать. Например, вы тестируете новую рекламу на билбордах или телевидении. Тогда вы не можете одним пользователям в Москве показывать новую рекламу, а вторым в этот момент завязать глаза.
То же самое с новыми продуктами. Мы в Авито тестировали в своё время новые услуги продвижения. Если бы мы проводили обычный поюзерный A/B-тест, то в поисковой выдаче были бы два типа объявлений: с новыми услугами продвижения и со старыми. И это нарушило бы чистоту эксперимента: при раскатке у нас все объявления будут с новыми услугами в поисковой выдаче, а результаты A/B мы получили на смешанной поисковой выдаче. Здесь поможет другой тип экспериментов.
Региональные A/B-тесты. Давайте перейдём к новой статистической единице — региону. Например, будем показывать нашу рекламу или введём новые услуги только в половине регионов России. Тогда всё честно: рекламу в одном регионе не увидят пользователи из других регионов (а точнее число тех, кто увидит, будет пренебрежимо мало). И выдача объявлений не пересекается по регионам. Так что пользователям Ростовской области можно разрешить купить новые услуги продвижения, а в Краснодарском крае — нет, они друг на друга не влияют.
С точки зрения математики это означает, что вместо гигантского количества пользователей в A/B-тесте у нас будет примерно 85 элементов-регионов: 42 из них — в тесте и 43 — в контроле. В этом случае мы также можем применять статкритерии, которые используются для поюзерных экспериментов. Но элементов всего 85, нормально ли они себя покажут? Не будут ли критерии строить некорректный доверительный интервал?

Главный минус таких тестов — они слишком шумные. Чтобы задетектировать хоть какой-то эффект, надо, чтобы он был огромным. Поэтому если будет алгоритм, который сможет очень сильно увеличить мощность критерия, или, что эквивалентно, сократить доверительный интервал для эффекта, это будет мегаполезно для бизнеса.
На этих двух задачах я и буду тестировать все представленные далее критерии и на них же покажу результаты. Теперь предлагаю перейти к сути статьи. Начнём с CUPED-алгоритма.
CUPED

CUPED (Controlled-experiment Using Pre-Experiment Data) — очень популярный в последнее время метод уменьшения вариации. Чтобы понять, как он работает, рассмотрим искусственный пример.
Пусть ваша метрика — выручка, и эксперимент длится месяц. Вы собрали данные во время эксперимента, какая выручка от пользователей в тесте и в контроле:

В итоге метрики очень шумные: в тесте даже на трёх точках видно, что значения разнятся от 50 до 150, а в контроле — от 20 до 200 рублей. С помощью T-test получились следующие результаты: +10±20 ₽ на одного пользователя, результат не статзначим. Как это исправить?
Давайте добавим информацию с предпериода: сколько эти пользователи тратили в среднем в месяц до начала эксперимента. При правильном сетапе теста матожидание этой величины одинаково в тесте и в контроле. Тогда:

Будем теперь смотреть на дельту. Это разница выручки на экспериментальном периоде минус средняя выручка на предпериоде в месяц.
Во-первых, почему так можно? В тесте и в контроле мы вычитаем с точки зрения матожидания одно и то же, потому что в правильно проведённом A/B-тесте контроль и тест ничем не отличаются на предпериоде. Поэтому, когда мы смотрим на разницу, эти вычитаемые величины нивелируются.
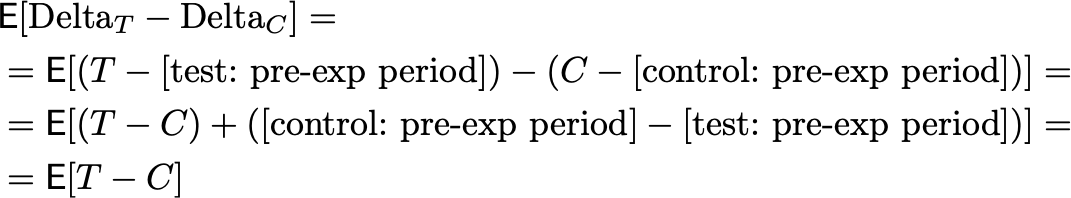
Здесь:
-
T — экспериментальная метрика в тесте.
-
C — экспериментальная метрика в контроле.
Во-вторых, зачем нам всё это?
Посмотрим на разброс значений в delta: в контроле от -10 до 6 рублей, а в тесте от -10 до 20 рублей. Это намного меньше того разброса, что мы видели ранее. Поэтому и доверительный интервал сократится: результат станет +15±5 ₽ для одного пользователя, и он уже статзначим! Почему дисперсия уменьшилась? Потому что мы смогли объяснить часть данных в эксперименте с помощью предпериода.
А теперь посмотрим на CUPED более формально.
Основная идея CUPED-метода: давайте вычтем что-то из теста и из контроля так, чтобы матожидание разницы новых величин осталось таким же, как и было. Но дисперсия при этом уменьшилась бы:

Где A и B — некоторые случайные величины (ковариаты). Тогда утверждается, что если θ будет такой, как указано в формулах далее, то дисперсия будет минимально возможной для таких статистик.

В примере выше θ я взял равной 1, но на самом деле, лучше было подобрать значение по этой формуле. Тогда формула для дисперсии получается такой:
![]()
![]()
Поэтому, чем больше корреляция по модулю, тем меньше будет дисперсия.
Также важно помнить: чтобы метод работал корректно, достаточно, чтобы матожидания A и B совпадали:
![]()
Ещё больше интересных и нетривиальных моментов про CUPED расписано в прошлой статье. В частности, там есть информация о том, как построить относительный CUPED-критерий.
Осталось понять, что брать в роли A и B. Чаще всего для них берут значения той же метрики, но на предэкспериментальном периоде. В примере выше мы брали среднюю выручку за месяц. Чем хорош такой способ:
-
Матожидание метрики на предпериоде будет одним и тем же в тесте и в контроле — иначе у вас некорректно поставлен A/B-тест. А значит, CUPED даст правильный результат.
-
В большинстве случаев метрика на предпериоде сильно коррелирует с экспериментальным периодом. Отсюда получается, что и дисперсия сильно уменьшится.
Но кроме значения метрики на предпериоде можно использовать результаты ML-модели, обученной предсказывать истинные значения метрик без влияния тритмента. С хорошей моделью можно достичь большего уменьшения дисперсии. Давайте поговорим о том, как это сделать.
CUPAC

CUPAC (Controlled-experiment Using Prediction As Covariate) — первая вариация на тему CUPED с ML. Как я уже писал выше, давайте попробуем использовать предсказание в качестве ковариаты. Распишу сам предлагаемый алгоритм на примере определённой задачи. Для ваших задач вы сможете переиспользовать алгоритм по аналогии.
Пусть у нас есть A/B-тест, где:
-
Дата начала — 1 июня.
-
Длительность теста составляет 1 месяц.
-
Наша ключевая метрика — выручка.
-
1 месяц уже прошёл.
Чтобы оценить такой тест, мы проделаем следующую операцию из трёх основных шагов:
-
Соберём датасет для предсказания (или «экспериментальный датасет») и обучения.
-
На обучающем датасете обучим нашу модель, подберём гиперпараметры, а на экспериментальном будем предсказывать таргет, используя фичи с предпериода.
-
Мы получили новую ковариату и запускаем обычный CUPED-алгоритм.
На схеме это можно изобразить так:

Как собрать экспериментальный и обучающий датасеты?

На иллюстрации сине-красный датасет — экспериментальный, а бирюзовый — обучающий, собранный до 1 июня. Одним цветом отмечено, что пользователи друг от друга в среднем ничем не отличаются, разными цветами — между ними есть разница.
Теперь опишем сам алгоритм в тексте. Повторим в цикле, пока не жалко:
-
Вычитаем из текущей даты длительность эксперимента. Начинаем с 1 июня, потом получим дату 1 мая, потом — 1 апреля и так далее.
-
Теперь собираем таргет. Для каждого юзера сохраняем его суммарные траты у нас на сайте за этот месяц. Для 1 июня это экспериментальная выручка за июнь (и уже за июнь вся выручка известна), для мая это выручка за май, когда ещё не было никаких отличий между тестом и контролем, и так далее.
-
Тут у нас получатся один сине-красный датасет с экспериментальной выручкой (и она отлична у теста с контролем) и много бирюзовых датасетов, где пользователи в среднем неразличимы.
-
-
И теперь собираем датасет фичей. Главная особенность состоит в том, что фичи должны быть собраны до текущей рассматриваемой даты. То есть для 1 июня все фичи должны быть собраны по данным до 1 июня, аналогично для остальных дат.
-
Например, количество заходов на сайт за N месяцев до рассматриваемой даты (за 2 месяца до 1 июня; за 2 месяца до 1 мая и так далее).
-
Выручка от пользователя за разные промежутки времени (за 1 месяц, за 2 месяца и так далее).
-
Сколько месяцев назад зарегистрировался пользователь.
-
-
Ни в одном из датасетов нет фичи тестовая или контрольная группа. Важно, чтобы пользователи по обучающим фичам в тесте и в контроле были полностью идентичны.
Что важно проверить: нужно, чтобы матожидания новых ковариат совпадали. А для этого достаточно, чтобы признаки ML-модели в среднем не отличались в тесте и в контроле. Далее идёт теоретическое пояснение этому факту.
Теоретическое пояснение
Обозначим X и Y — фичи пользователей в тесте и в контроле. То есть наша случайная величина — это вектор фичей. Тогда, если тест и контроль подобраны корректно (случайно или с помощью парной стратификации):
![]()
Что произойдет, когда мы обучим модель? Она просто преобразует вектор признаков одного пользователя в число с помощью некоторой функции F. Тогда:
![]()
Обозначим A := F(X), B := F(Y). Тогда, как я писал выше в CUPED, метод будет корректен.
Вот и всё! Это полный пайплайн работы CUPAC-алгоритма. Теперь я попытаюсь объяснить, зачем нужен тот или иной шаг.
Вопросы и ответы к методу
Зачем нужен обучающий датасет?
Чтобы не было переобучения. Если объяснять простыми словами, то это приводит к тому, что доверительный интервал заужается и становится некорректным. И ошибка первого рода будет не 5, а, например, 15%. А теперь поподробней.
Допустим, мы бы обучались прямо на экспериментальном датасете и на нём же предсказывали. Рассмотрим пример:

Пусть у нас есть один признак для обучения, и функция выручки пользователя зависит от признака рыжей линией на рисунке. Допустим, мы возьмём какую-то легко переобучаемую модель: например, полином 10-й степени. Обучим её на синих точках-примерах (экспериментальном датасете в терминах CUPAC). В таком случае текущая модель практически идеально предскажет их значения.
Подставим в CUPED предсказание, получим эффект 0 и дисперсию 0, потому что модель везде всё верно предсказала. Имеет ли это какое-то отношение к реальной картине? Нет! Видно даже, что в реальности синие точки не лежат на рыжей линии, а значит, некоторый шум в данных точно есть.
Мы видим, что в других точках, где модель не обучалась, она ведёт себя совершенно не так, как истинная функция выручки. Это значит, что если бы мы насемплировали другую выборку пользователей, то эффект и дисперсия в CUPED были бы другими! Итого, мы обучились не на генеральную совокупность, а на частичный, увиденный в обучении, пример. Это и есть проблема переобучения.
Почему нельзя собирать обучающие фичи на том же периоде, на котором мы и предсказываем?
Во время эксперимента так делать нельзя, потому что мы могли повлиять на этот признак тестируемым тритментом. И тогда фичи в тесте и в контроле будут различны в этих группах, а полученные на таких данных ковариаты будут иметь разное матожидание в зависимости от группы. А значит, CUPED применять нельзя.
На обучающем датасете мы тоже не можем использовать такие признаки, потому что тогда обучающий и экспериментальный датасеты будут различны по структуре.
Зачем лезть так далеко в историю? Не достаточно ли для обучающего датасета взять датасет, собранный, например, для 1 мая?
В принципе, такой вариант подойдёт, но чем больше обучающий датасет, тем лучше обучится модель. Плюс мы можем добавить временные признаки в качестве обучающих фичей: номер года, категорийную фичу месяца, сезон.
А что, если наша метрика — конверсия?
Так вместо задачи регрессии у нас задача классификации. И можно использовать вероятность модели в качестве ковариаты. При этом можно точно также оставить регрессионную модель.
Как обучать модель?
Об этом я расскажу дальше.
Про результаты работы критерия: как и ранее, я буду сравнивать алгоритмы по метрике «ширина доверительного интервала». Чем она меньше, тем лучше.
-
На поюзерных тестах: уменьшение доверительного интервала на 1000 A/A-тестах в среднем на 4% относительно CUPED.
-
На региональных тестах: уменьшение доверительного интервала на 1000 A/A-тестах в среднем на 22% относительно CUPED.
Если вы решите реализовать этот или любой другой алгоритм из статьи, то обязательно проверьте его корректность!
Это всё, что здесь можно рассказать. Теперь перейдём к «нечестному» CUPAC и избавимся от большинства шагов в алгоритме.
CUNOPAC

CUNOPAC (Controlled-experiment Using Not Overfitted Prediction As Covariate) — чуть более простая, чуть менее корректная и чуть более мощная модель, чем CUPAC. В вопросах к CUPAC я писал, что обучающий датасет нам нужен, ведь иначе может возникнуть проблема переобучения. Но я предлагаю забыть про эту проблему!
Главное, о чём надо помнить в таком случае — вы можете построить некорректный критерий! Он будет строить зауженный доверительный интервал, и вместо 95% случаев будет покрывать лишь 85%. Но об этом я расскажу далее.
Алгоритм работы критерия такой:
-
Соберём экспериментальный датасет для предсказания.
-
На нём обучим нашу модель, подберём гиперпараметры, и на нём будем предсказывать таргет, используя фичи с предпериода. Обучаемся на всем датасете сразу! И предсказываем весь датасет. Ничего не откладываем на валидацию (да, метод рискованный).
-
Мы получили новую ковариату и запускаем обычный CUPED-алгоритм.
На схеме это можно изобразить так:
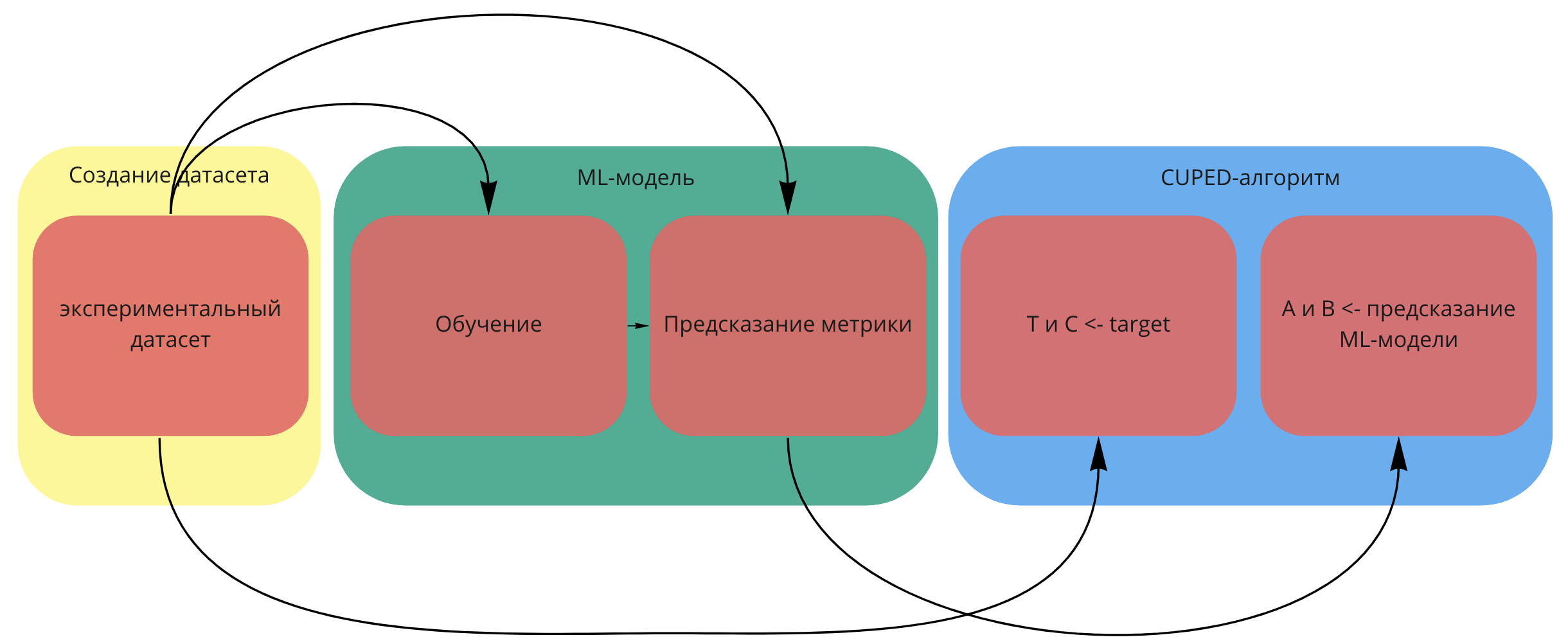
Датасет собираем также, как и в CUPAC-алгоритме, только обучающий датасет больше не нужен:

Теперь вопрос: как подобрать модель, которая не переобучится? Мы решили этот вопрос так: отбираем небольшое количество фичей и используем только линейные модели.
Рассмотрим пример: что, если взять CatBoost-алгоритм или линейную регрессию в качестве ML-алгоритма внутри критерия? Посмотрим на реальный уровень значимости (или False Positive Rate), полученный при проверке метода на 1000 А/А-тестах:
-
Линейные модели: 0.055 (при alpha=0.05), результат статзначимо не отличается от теоретического alpha.
-
CatBoost: 0.14 (при alpha=0.05), результат статзначимо отличается от теоретического alpha!
То есть CatBoost ошибается примерно в 3 раза чаще, чем должен был! Он переобучается, заужает доверительный интервал и поэтому критерий некорректен. Что это значит на практике? Что вы в 3 раза чаще будете катить изменение, которое на самом деле не имеет никакого эффекта. Поэтому CatBoost нельзя использовать внутри CUNOPAC, а линейные модели можно. При этом я не говорю, что CatBoost плохой алгоритм! Он отличный, просто он легче переобучается.
Есть ли переобучение у линейной модели? Наверняка есть, но оно настолько мало, что не влияет на эффект.
А почему качество CUNOPAC лучше, чем у CUPAC?
Возникает вопрос: а почему качество может стать лучше, чем у CUPAC?
-
В предыдущей модели CUNOPAC мы обучаемся на исторических данных, и в этот момент не учитываем текущие тренды и сезонность, а в текущей CUNOPAC эти недостатки убраны.
-
Наша цель — найти наиболее скоррелированную метрику с T-C, ведь в таком случае дисперсия уменьшится максимально возможным способом. А так как в CUPAC при обучении вообще никак не участвует метрика T (а лишь значения метрики без какого-либо тритмента), то результат вполне ожидаемо будет менее скоррелирован, чем у модели, которая обучалась в том числе и на значениях метрики T. Поэтому, качество у CUNOPAC должно быть лучше, чем у CUPAC.
-
Ну и наконец, как показали наши эксперименты, в CUPAC лучше всего также сработали линейные модели (что было для нас удивительно, бустинги и деревья показали себя хуже). CUNOPAC дал буст по качеству, так как тоже использует линейные модели.
Что ещё хочется отметить: это очень опасная модель! Если модель переобучиться, вы будете заужать доверительный интервал и ошибка будет больше заявленной. Поэтому снова предупреждаю: обязательно проверьте ваш критерий!
Результаты работы критерия:
-
На поюзерных тестах: уменьшение доверительного интервала на 9% относительно CUPED.
-
На региональных тестах: не удалось использовать, реальный уровень значимости сильно больше тестируемых 5%, слишком мало регионов. Модель просто всегда переобучается.
Проверено на 1000 A/А-тестах.
А теперь обсудим, как построить пайплайн обучения модели для этих двух критериев.
Автоматизация ML-части критериев
Поговорим про основную часть алгоритмов. Что у нас есть: обучающий и экспериментальный датасеты, которые мы будем скармливать модели. В случае CUNOPAC это один и тот же датасет. Расскажу, как я воплотил ML-часть алгоритмов, но это не значит, что у меня получилась идеальная автоматизация: возможно, вы сможете придумать лучше. При этом, если вы плохо понимаете идеи и алгоритмы машинного обучения, то можете пропустить эту часть. Она никак не повлияет на осознание всех алгоритмов далее.
Краткая иллюстрация:
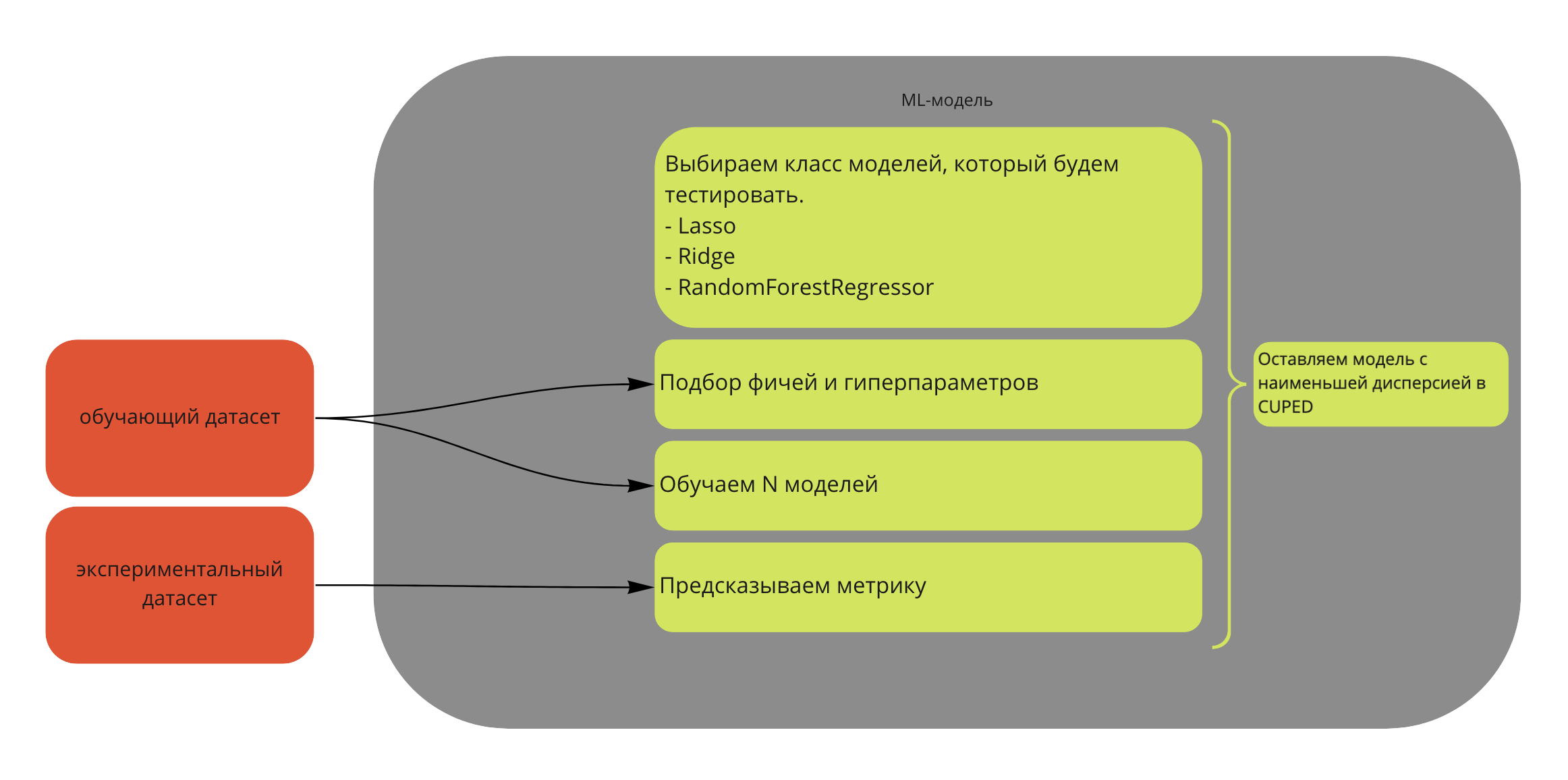
Шаг 1. Выбираем класс моделей, который будем тестировать. Например, я использовал:
Для CUPAC: Lasso, Ridge, ARDRegression, CatBoostRegressor, RandomForestRegressor, SGD, XGBRegressor.
Для CUNOPAC: Lasso, ARDRegression, Ridge.
Дополнительно: для адекватности я нормирую все признаки с помощью StandardScaler.
Шаг 2. Выбираем фичи для обучения. Ограничим сверху количество используемых фичей и воспользуемся одним из алгоритмов подбора признаков:
-
Жадный алгоритм добавления/удаления признаков (например, SequentialFeatureSelector из библиотеки scikit-learn на Python).
-
Алгоритм на основе feature_importance параметра фичей у модели (SelectFromModel из библиотеки scikit-learn на Python). Самый быстрый из алгоритмов.
-
Add-del алгоритм (добавляем фичи, пока качество улучшается, потом выкидываем фичи, пока качество улучшается, повторим процедуру снова, пока не сойдёмся).
-
Всё, что ещё найдёте или придумаете.
Единственное замечание: если у алгоритма отбора фичей можно задать функцию оценки для качества модели, то стоит использовать специальную функцию-скоррер:
def cuped_std_loss_func(y_true, y_pred):
theta = np.cov(y_true, y_pred)[0, 1] / (np.var(y_pred) + 1e-5)
cuped_metric = y_true - theta * y_pred
return np.std(cuped_metric)Так вы будете оценивать ровно ту величину, которую вы хотите оптимизировать — ширину доверительного интервала у CUPED-метрики.
Шаг 3. Следующая остановка — выбор гиперпараметров. Мы считаем в этот момент, что все обучающие признаки уже выбраны. Есть следующие варианты:
-
Перебор по GridSearchCV.
-
Перебор по RandomizedSearchCV.
-
Жадный перебор по одному параметру:
-
сначала подбираем по функции cuped_std_loss_func первый в списке гиперпараметр;
-
потом подбираем второй в списке, при учёте выбранного первого гиперпараметра и т.д. Пример с кодом:
-
start_params = {
'random_state': [0, 2, 5, 7, 229, 13],
'loss': ['squared_loss', 'huber'],
'alpha': np.logspace(-4, 2, 200),
'l1_ratio': np.linspace(0, 1, 20),
} # Пример перебора параметров для SGD
def create_best_model_with_grid_search(pipeline, start_params, X, y):
final_params = {}
params = []
for param in start_params.items():
params_dict = {}
params_dict[param[0]] = param[1]
params.append(params_dict)
score = make_scorer(cuped_std_loss_func, greater_is_better=False)
for param in params:
search_model = GridSearchCV(pipeline, param, cv = 2, n_jobs = -1,
scoring = score)
search_model.fit(X, y)
final_params = {**final_params, **search_model.best_params_}
pipeline.set_params(**final_params)
return pipeline, final_paramsПлюс такого метода: скорость по сравнению с первым методом. Вместо всех возможных комбинаций здесь перебирается линейное количество вариантов. Все значения гиперпараметров будут рассмотрены по сравнению со вторым методом.
Минус: GridSearchCV даст лучшее качество, но работать будет сильно дольше.
Ещё, конечно, можно объединить предыдущий шаг с этим: для каждого набора фичей подобрать гиперпараметры и измерять качество по cuped_std_loss_func. Но это работает очень долго. Можно также устроить сходящуюся процедуру из этих двух шагов: выбираем признаки, выбираем гиперпараметры, снова выбираем признаки с подобранными значениями гиперпараметра и так далее.
Шаг 4. Отлично, после обучения у нас есть N моделей с первого шага с подобранными гиперпараметрами и обучающими признаками для каждой из них. Отберём из них одну модель, которая даёт наилучшее качество на экспериментальном датасете по cuped_std_loss_func. Почему так можно сделать, я расскажу, когда буду описывать Frankenstein-критерий.
А пока перейдём к третьему критерию, который, грубо говоря, не является ML-критерием.
CUMPED

Почему нам вообще нужна только одна ковариата? Почему нельзя использовать сразу N ковариат? Именно на этой идее построен алгоритм CUMPED (Controlled-experiment Using Multiple Pre-Experiment Data).
Ранее в CUPED было так:

А теперь в CUMPED будет так:

При этом не обязательно использовать только две ковариаты, их может быть сколько угодно!

Зачем нам вообще может потребоваться N ковариат? Почему одной недостаточно?
Как я писал в CUPED-алгоритме, из-за того, что часть метрик T и C описывается данными из ковараиты, мы и сокращаем дисперсию. А если признаков будет не один, а сразу несколько, то мы лучше опишем нашу метрику T и C, а значит сильнее сократим дисперсию. Это то же самое, что и в машинном обучении: что лучше, использовать один признак для обучения или несколько различных фичей? Обычно выбирают второе.
Теперь опишем первую версию предлагаемого алгоритма CUMPED:
-
Соберём один экспериментальный датасет, как сделали это в CUNOPAC.
-
В цикле по всем признакам, которые использовались ранее для предсказания метрики:
-
Образуем CUPED-метрику T’, С’, используя в качестве ковариат текущие признаки в цикле.
-
В следующий раз в качестве изначальных метрик будут использоваться новые CUPED-метрики. То есть на следующей итерации цикла вместо текущих метрик T и C будут использоваться полученные сейчас T’, C’.
-
Если расписать формулами, то:

Где наша итоговая CUMPED-метрика это T^N, C^N, а A_i, B_i — это признаки пользователя, собранные на предпериоде. Раньше мы на них обучали модель, а сейчас используем в качестве ковариат. Коэффициенты тета подбираются следующим образом:

Вот и весь алгоритм. Но! Если бы вы его реализовали, то он, вероятно, показал бы себя хуже, чем обычный CUPED-алгоритм. Почему?
В этом алгоритме есть одна беда:
![]()
Порядок применения ковариат важен! Если сначала вычесть ковариату A_1, а потом ковариату А_2, то дисперсия может быть больше, нежели в случае, когда вы сначала вычтете A_2, а потом A_1. Вы можете сами расписать формулы, и увидеть, что две эти случайные величины будут иметь разную дисперсию.
Поэтому предлагается применять ковариаты в «жадном» порядке: сначала ищем наилучшую ковариату, уменьшающую дисперсию сильнее всего, потом следующую ковариату, уменьшающую дисперсию лучше всего для T^1, C^1 и т. д. То есть в первой версии алгоритма мы берём не случайную ковариату, а ту, которая на текущий момент сильнее всего уменьшает доверительный интервал.
На рисунке представлен итоговый алгоритм CUMPED:

Иллюстрация подбора наилучшей ковариаты:

Можно ли подобрать коэффициенты theta_1, theta_2, … theta_N в алгоритме неким другим способом, чтобы дисперсия была меньше?
Да, можно. Текущий алгоритм не является оптимальным, потому что если решать задачу,
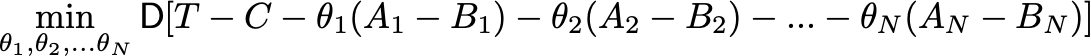
то оптимум у коэффициентов будет другим! Но для этого надо взять производную N раз по каждой theta, приравнять производные к 0 и решить N уравнений относительно N неизвестных. Не самая приятная задача, хотя есть методы, которые могут численно найти ответ для неё. Также я не считаю, что дисперсия в таком решении сильно уменьшится относительно того, что я получил описанным жадным алгоритмом. Я не реализовывал такой вариант, так что буду рад, если кто-то решит сравнить эти два алгоритма.
А алгоритм может остановиться? Если признаков в обучающем датасете будет бесконечно много, то как понять, что пора остановиться?
Никак. Если посмотреть на CUPED-алгоритм, то дисперсия в новых CUPED-метриках не больше изначальной дисперсии. Поэтому в теории можно использовать бесконечно много ковариат, просто большинство из них будут иметь нулевой коэффициент theta.
На практике всё не так радужно: к сожалению, мы не знаем истинной ковариаты, а лишь её состоятельную оценку, полученную на текущих данных. А оценка, как известно, практически всегда отличается от настоящего значения. Поэтому в реальности посчитанный коэффициент theta в алгоритме всегда будет не нулём, и мы всё время будем уменьшать выборочную дисперсию, даже если метрика и ковариата не скоррелированны. А это может привести к тому, что мы заузим доверительный интервал. А значит и ошибка первого рода будет больше заявленной.
В качестве примера рассмотрим на искусственных данных первый шаг алгоритма: насколько он уменьшит дисперсию. Пример будет показан на одновыборочном CUPED-критерии.
import scipy.stats as sps
import numpy as np
import seaborn as sns
sample_size = 100
sample = sps.norm(scale=10).rvs(sample_size)
cumpled_std_samples = []
# генерируем эксперимент 100 раз, чтобы получить какое-то распределение для оценки дисперсии
for _ in range(100):
# истинная оценка стандартного отклонения
estimated_mean_sample_std = np.std(sample) / np.sqrt(sample_size)
# признаки-ковариаты в CUMPED, никак не скоррелированны с sample
feature_matrix = sps.norm().rvs((5000, sample_size))
# 1 шаг алгоритма
for covariate in feature_matrix:
# CUPED part
theta = np.cov(sample, covariate)[0, 1] / np.var(covariate)
sample_std = np.std(sample - theta * covariate) / np.sqrt(sample_size)
# Выбор наилучшей ковариаты по уменьшению std у CUPED-метрики. Первый шаг алгоритма.
if sample_std < estimated_mean_sample_std:
estimated_mean_sample_std = sample_std
cumpled_std_samples.append(estimated_mean_sample_std)
sns.distplot(cumpled_std_samples)
Получилось, что оценка алгоритмом стандартного отклонения в каждом случае из 100 была меньше теоретического значения 1 — стандартное отклонение равно 10, а размер выборки равен 100, значит стандартное отклонение для среднего равно 1. А это лишь первый шаг алгоритма!
А теперь хорошие новости: чем больше выборка, тем меньше будет это различие. Рассмотрим на примере, когда размер выборки равен 10000. В этом случае мы всё также будем заужать дисперсию, но в процентном соотношении сильно меньше: например в случае, когда выборка была размера 100, средний процент заужения доверительного интервала составлял 8%. А когда выборка стала размером 10000, то процент заужения относительно истинного стандартного отклонения составил 0,1%!
Поэтому во втором случае заужением доверительного интервала можно пренебречь: ничего плохо не произойдёт. Да, возможно ошибка первого рода будет не 5%, а 5,1%, но это и не страшно. Плюс в реальности размеры выборок чаще всего ещё больше.
Итого, исходя из вышесказанного, CUMPED отлично работает в случае, если выборка большого размера: и с точки зрения теории, и на проведенных 1000 A/A-тестах. То есть на поюзерных тестах его можно использовать. Но на региональных тестах с ним надо быть осторожным: в нашем случае он заработал только тогда, когда мы ограничили количество шагов алгоритма до 1.
Результаты работы критерия:
-
На поюзерных тестах: уменьшение доверительного интервала на 14% относительно CUPED. Это наилучший результат среди всех представленных здесь алгоритмов.
-
На региональных тестах: уменьшение доверительного интервала на 21% относительно CUPED. Но можно использовать лишь одну ковариату! Почему так, я ответил в скрытом разделе с вопросами.
Проверено на 1000 A/А-тестах.
Uplift-критерий

Всё, забыли про CUPED и всё, что с ним связано. В этом разделе я покажу, как из Uplift-модели сделать настоящий критерий. Но для начала о том, что такое Uplift-модель.
Давайте соберём датасет так же, как ранее это делали в CUNOPAC и в CUMPED, но в этот раз добавим фичу: какая группа пользователя. 1 — пользователь в тесте, 0 — в контроле.

Теперь посмотрим, как работает алгоритм:
-
Разделим датасет на K частей.
-
Будем в цикле размера K выбирать часть пользователей, которым будем предсказывать их метрику. На оставшейся части обучим ML-алгоритм. Эти два шага в ML зовутся кросс-валидацией.
-
Теперь для каждого пользователя на тестовой части предскажем его выручку, если бы он был в тесте и если бы он был в контроле. Как мы это сделаем? Поменяем в датасете фичу группы пользователя: на 1, если предсказываем выручку от него в тесте, и на 0, если предсказываем его выручку в контроле. Обозначим эти значения T_p и C_p. Теперь оценка Uplift для пользователя — это предсказанная выручка, если пользователь в тесте минус предсказанная выручка, если пользователь в контроле.
-
Повторим K раз и получим Uplift для всех пользователей.
На рисунке я кратко описал то же самое. Возможно, так будет понятней:

Мы смогли получить численную оценку эффекта для каждого пользователя. Однако есть несколько «но»:
-
Как из оценки построить доверительный интервал?
-
А если модель смещённая или некорректная? Например, она никак не учитывает группу пользователя внутри себя: тогда Uplift будет равен 0, что может быть не так. А если для тестовых юзеров он постоянно занижает предсказание, а для контрольных юзеров завышает?
Чтобы решить обе проблемы, введём ошибку предсказания:

Тогда:
![]()
То есть наш Uplift будет равен разнице предсказаний + разнице ошибок предсказаний в тесте и в контроле. Отличие по сравнению со старой формулой в том, что теперь мы добавляем ошибку предсказания: если мы занижаем предсказание на тестовых юзерах, то ошибка предсказания на тесте будет положительной. То же самое для контрольных юзеров.
Тогда численную оценку Uplift можно представить следующим образом:

Но и здесь есть проблема: размер выборок у трёх слагаемых разный! Давайте посмотрим, а что мы вообще можем посчитать для каждого пользователя.
Для пользователя в тесте:
-
Значение метрики в тесте (или T в формулах выше).
-
Предсказание модели, если пользователь в тесте (или T_p в формулах выше).
-
Предсказание модели, если пользователь в контроле (или C_p в формулах выше).
-
Ошибку предсказания модели, если пользователь в тесте (или ε_T в формулах выше).
Для пользователя в контроле:
-
Значение метрики в контроле (или C в формулах выше).
-
Предсказание модели, если пользователь в тесте (или T_p в формулах выше).
-
Предсказание модели, если пользователь в контроле (или C_p в формулах выше).
-
Ошибку предсказания модели, если пользователь в контроле (или ε_C в формулах выше).
Поэтому, размер выборок на самом деле будет таким:
-
T_p, С_p: их размер равен количеству пользователей в тесте и в контроле, или |T| + |C| .
-
ε_C: размер этой выборки равен количеству пользователей в контроле, или |C|.
-
ε_T: размер выборки равен количеству пользователей в тесте, или |T|.
Вкратце это выглядит так:

Выпишем формулу Uplift с учётом всех вводных:

Так, а теперь вопрос. Как для такой статистики построить доверительный интервал? Ведь T_p, C_p, ε_T, ε_C ещё и коррелируют между собой? Как я упоминал в предыдущих статьях, если не знаете, как что-то посчитать теоретически, то используйте bootstrap. В данном случае достаточно забутстрапить каждого пользователя в тесте и в контроле по отдельности, а точнее их метрики T_p, С_p, ε_C, ε_T. Далее на каждой итерации внутри бутстрапа посчитаем оценку Uplift для них по формуле выше, и по этим данным построим доверительный интервал.
Замечание
В предложении выше есть небольшой подвох: на самом деле, мы должны не просто забутсрапить пользователей, но и каждый раз заново обучать модель. Когда мы обучаем модель, наши предсказания на тесте становятся зависимыми от пользователей в обучении. Если мы обучимся на одних пользователях, то предсказание будет одно, а если на других, то предсказание изменится.
Поэтому, по логике работы бутстрапа, когда мы бутстрапим пользователей для построения доверительного интервала, мы должны использовать не те значения, которые были посчитаны в первый раз на изначальном датасете, а заново обучить модель K раз (K — параметр кросс-валидации) и использовать новые метрики.
Но на практике работает и описанный выше алгоритм, поэтому можете провести обучение один раз и не заморачиваться.
Результаты работы критерия:
-
На поюзерных тестах: уменьшение доверительного интервала на 4% относительно CUPED.
-
На региональных тестах: уменьшение доверительного интервала на 40% относительно CUPED. Это наилучший результат — обыгрывает CUPAC, CUMPED в 2 раза.
Почему произошло столь сильное сокращение на региональных тестах? Потому что на самом деле мы увеличили датасет в 2 раза. Если ранее размер выборки был примерно 42 на 43 (если регионов 85), то сейчас, так как модель предсказывает значения в тесте и в контроле для каждого региона, размер датасета стал 85 на 85. Есть, конечно, оговорка, что мы так увеличили только T_p и C_p, но как видим, это отлично работает.
Проверено на 1000 A/А-тестах.
Frankenstein-критерий

Вот у нас есть четыре критерия, а когда какой стоит использовать? Ранее я писал, что CUMPED лучше всего работает для поюзерных тестов, а Uplift — для региональных. А зачем я рассказывал про все остальные? Но ведь они лучше всего работают в среднем, а не всегда. На самом деле когда-то лучше может сработать CUPED, а когда-то — CUPAC или CUNOPAC. И как в каждом A/B-тесте выбрать, какой критерий сейчас лучше всего использовать?
Для ответа на этот вопрос был придуман критерий-Франкенштейн. Посмотрим на следующую схему:

Суть метода проста: берём N критериев и из них выбираем тот, который на текущий момент даёт наименьший доверительный интервал.
Какие критерии использовать внутри? У нас получилась следующая картина.
Для поюзерных тестов стоит использовать:
-
CUNOPAC.
-
CUMPED.
-
CUPED.
CUPAC и Uplift-критерий не стоит использовать, так как они всегда работают хуже, чем CUNOPAC и CUMPED.
А для региональных тестов стоит использовать:
-
Uplift-критерий.
-
CUPAC.
-
CUMPED.
-
CUPED.
Почему критерий валиден?
Вопрос 1. Почему нет проблемы множественной проверки гипотез? Мы же провели на самом деле N тестов, и по-хорошему должны применить поправку Бонферрони/Холма. Ведь когда мы выбираем критерий с наиболее узким доверительным интервалом, мы можем как-то влиять на эффект.
Ответа два. Во-первых, проверено на 1000 А/А-тестах. Реальный уровень значимости (или ошибка первого рода) всегда был равен заданному теоретическому значению. Во-вторых, есть теоретическое объяснение. Если совсем просто, то мы смотрим не на p-value, а на ширину доверительного интервала, поэтому множественную проверку гипотез применять не надо. А теперь чуть более формально:
-
Выборочное среднее и выборочная дисперсия независимы (в предположении, что CUPED-выборка из нормального распределения). Когда мы выбираем какой-то критерий, то мы выбираем его на самом деле по выборочной дисперсии. И в этот момент, если наша метрика была бы из нормального распределения, то можно было бы утверждать, что оценка эффекта никак не зависит от выборочной дисперсии. А значит, выбирая критерий по выборочной дисперсии, мы никак не влияем на оценённый эффект, то есть применять множественную проверку гипотез не надо. Можно считать, что на самом деле мы проверили результаты только одним критерием. Единственное «но»: всё это верно, если данные из нормального распределения, что на самом деле не так.
-
В общем случае можно утверждать, что корреляция между выборочным средним и выборочной дисперсией стремится к 0 при увеличении размера выборки. Зависимость может и есть, но здесь играют роль три фактора: если даже она и есть, то нелинейная. Поэтому сложно придумать адекватную ситуацию на практике, когда при наиболее узком доверительном интервале будет наибольший/наименьший эффект. Хотя с точки зрения теории это вполне возможно. Далее, для нормальных случайных величин выборочное среднее и дисперсия независимы, отсюда есть шанс полагать, что и на ваших данных нет зависимости. Ну и в-третьих, у нас всё было проверено. Вы также можете проверить критерий у себя на данных и удостовериться, что всё хорошо.
Вопрос 2. Не заужаем ли мы доверительный интервал?
Для начала допустим, что на самом деле все критерии описывают одно и то же распределение, но полученное из разных семплирований. Например, пусть CUPAC и CUNOPAC строят ковариату из одного и того же распределения, просто она получилась разной в двух алгоритмах (получились разные выборки из одного распределения).
И вот здесь ответ неутешительный: да, мы можем заузить доверительный интервал. Представьте себе, что у нас N критериев, которые оперируют с нормальным распределением Norm(0, 1). Каждый из них как-то оценивает его дисперсию, и из всех этих оценок мы берём не любую, а наименьшую! Если среди этих N критериев хотя бы один критерий оценил дисперсию меньше, чем она есть на самом деле, то мы заузили доверительный интервал. При этом очевидно, что чем больше критериев, тем более вероятно, что хотя бы раз мы получим оценку дисперсии меньше реальной и ошибёмся. В качестве примера приведу код:
import scipy.stats as sps
import numpy as np
import matplotlib.pyplot as plt
small_number_of_criteria_std = []
large_number_of_criteria_std = []
# генерируем эксперимент 1000 раз, чтобы получить какое-то распределение для оценки дисперсии
for i in range(1000):
# small_number_of_criteria, 5 критериев внутри критерия Франкенштейна
current_std_array = []
for i in range(5):
# текущий критерий
sample = sps.norm().rvs(100)
# сохраняем std, полученное от критерия
current_std_array.append(np.std(sample))
# сохраняем текущее std, полученное от критерия Франкенштейна
small_number_of_criteria_std.append(min(current_std_array))
# large_number_of_criteria_std, 500 критериев внутри критерия Франкенштейна
current_std_array = []
for i in range(500):
# текущий критерий
sample = sps.norm().rvs(100)
# сохраняем std, полученное от критерия
current_std_array.append(np.std(sample))
# сохраняем текущее std, полученное от критерия Франкенштейна
large_number_of_criteria_std.append(min(current_std_array))
plt.hist(small_number_of_criteria_std, label='small number of criteria', bins='auto')
plt.hist(large_number_of_criteria_std, label='large number of criteria', bins='auto')
plt.xlabel('std')
plt.legend()
plt.show()
Мы видим, что чем больше критериев, тем сильнее дисперсия смещена в меньшую сторону. Так что если использовать очень много критериев, мы можем заузить доверительный интервал и создать некорректный критерий.
Но на практике, во-первых, во всех критериях распределения всё же разные, во-вторых, у нас всего 3 или 4 критерия. При этом, на наших проверках, реальный уровень значимости каждый раз был заявленные alpha%. Мы проверили критерий на 1000 А/А- и A/B-тестах, как поюзерных, так и региональных, везде всё было корректно. Так что предложенный Frankenstein-критерий корректен. Но когда будете реализовывать его у себя, не забудьте дополнительно его проверить!
Результаты
Поюзерные тесты:
-
Сокращение доверительного интервала на 14% относительно CUPED.
-
С использованием парной стратификации: на 21%.
Региональные тесты:
-
Сокращение доверительного интервала в 1,5 раза относительно CUPED.
-
С использованием парной стратификации: в 2 раза .
Получились отличные результаты! Особенно для региональных тестов.
Итого, в данной статье я постарался рассказать про такие методы, как:
-
CUPED.
-
CUPAC, CUNOPAC, CUNOPAC — три вариации на тему CUPED.
-
Uplift-критерий — как из Uplift-модели сделать критерий.
-
Frankenstein-критерий — как из нескольких критериев сделать один.
Если у вас остались вопросы, обязательно пишите. Постараюсь ответить. Также мне можно писать в соц. сетях:
-
тг: @dimon2016
-
linkedin